
Hyperspectral Monitoring Driven by Machine Learning Methods for Grassland Above-Ground Biomass



Abstract
:1. Introduction
2. Materials and Methods
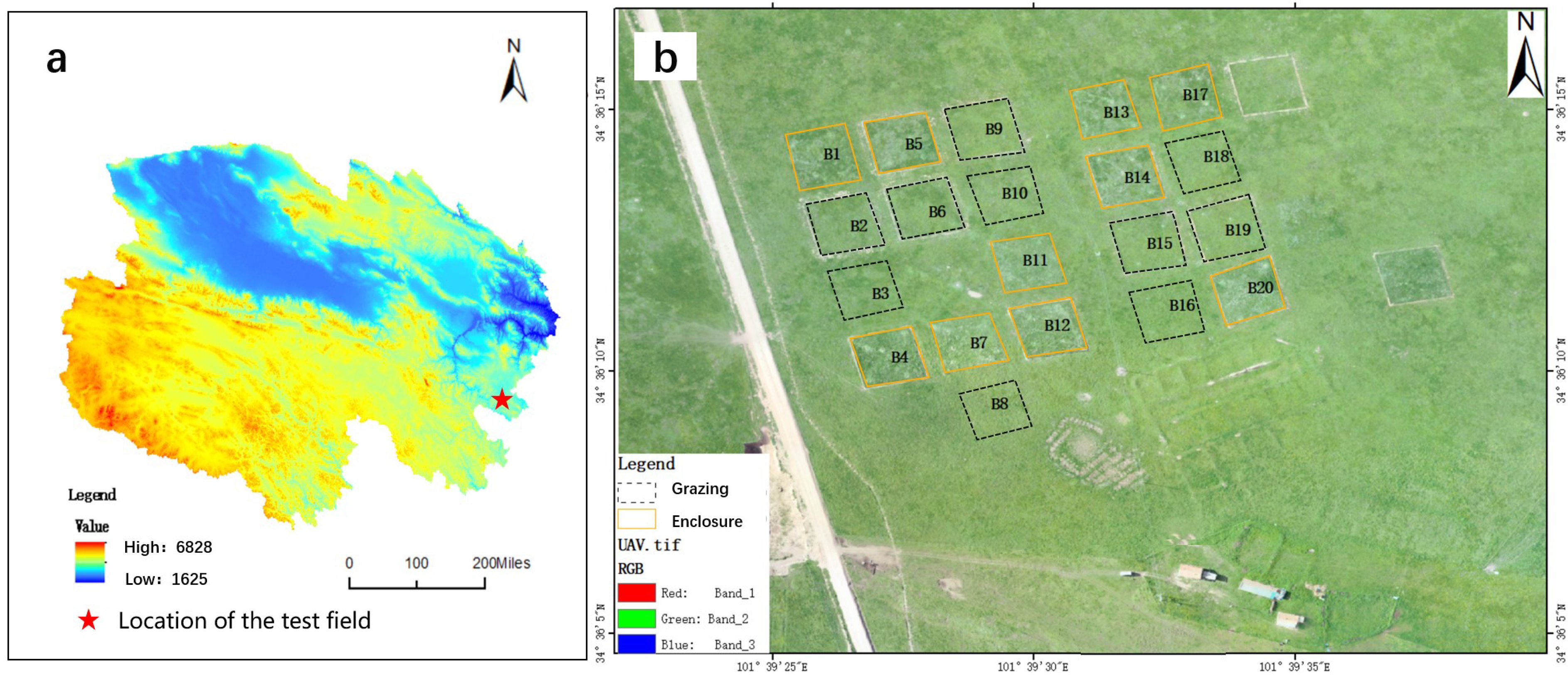
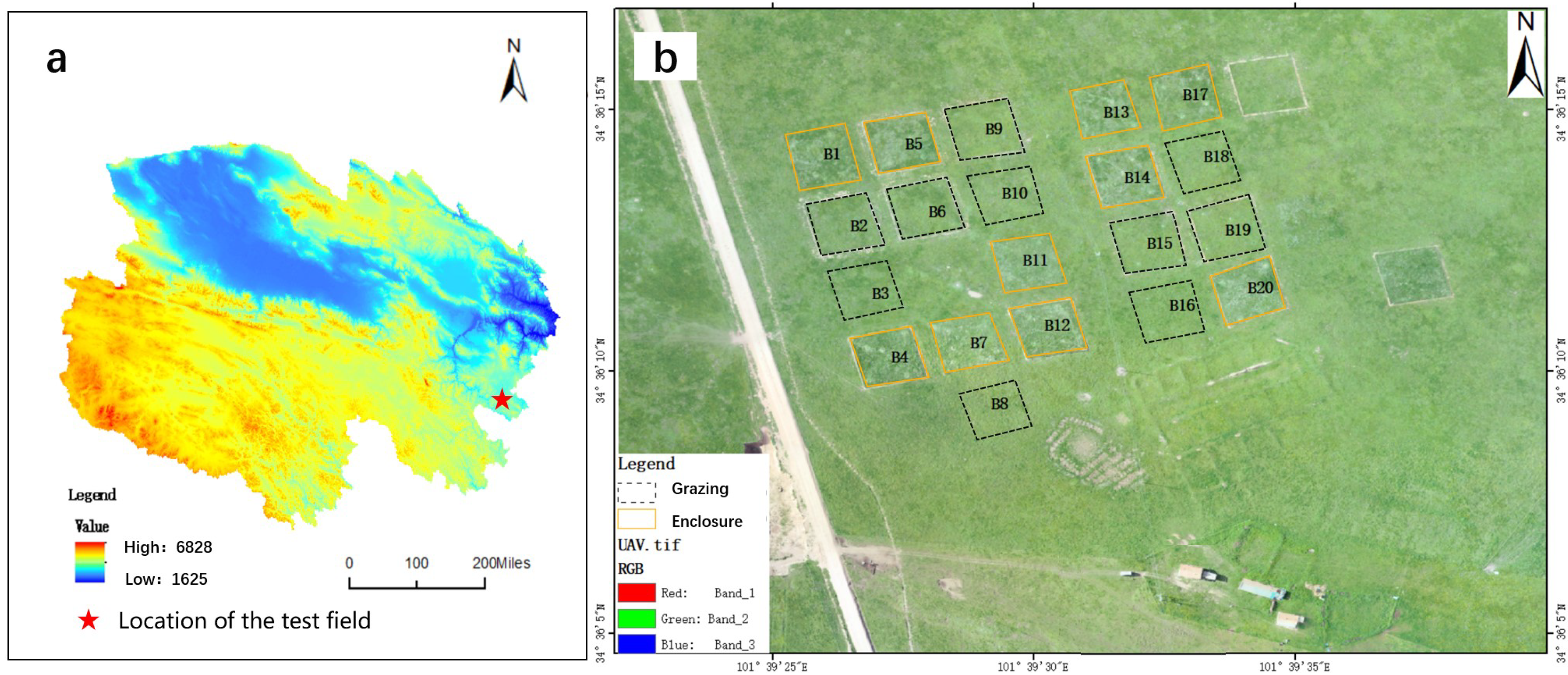
2.1. Study Area
2.2. Collection of Data
2.3. Methods and Flow of Data Processing
2.3.1. Pre-Processing of Data
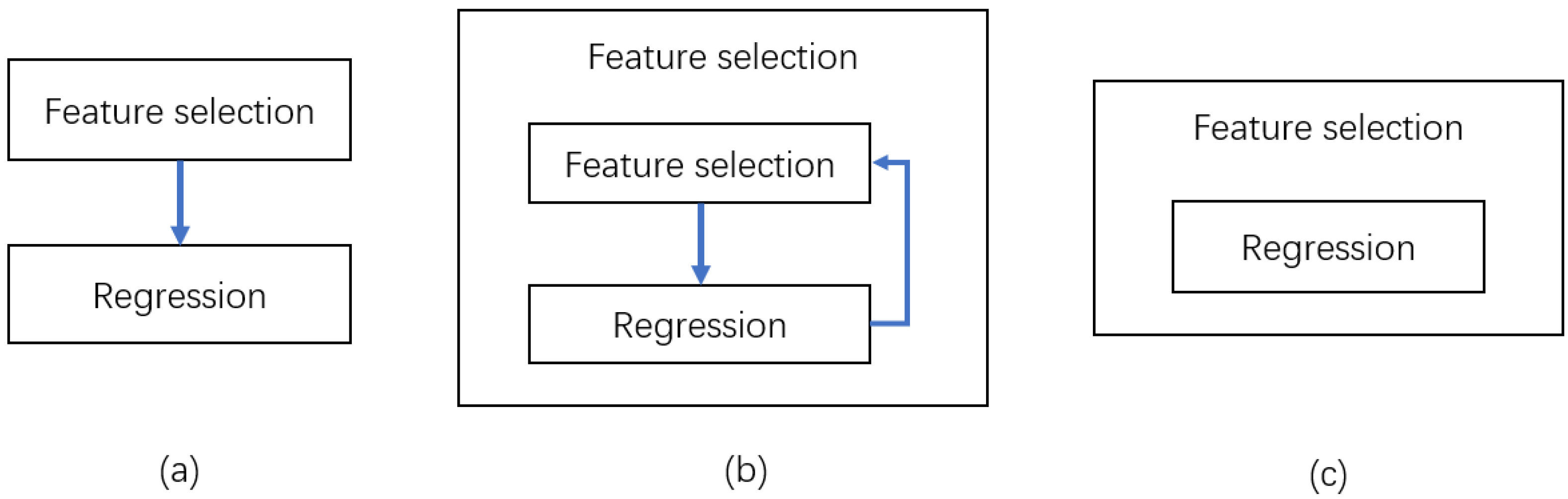
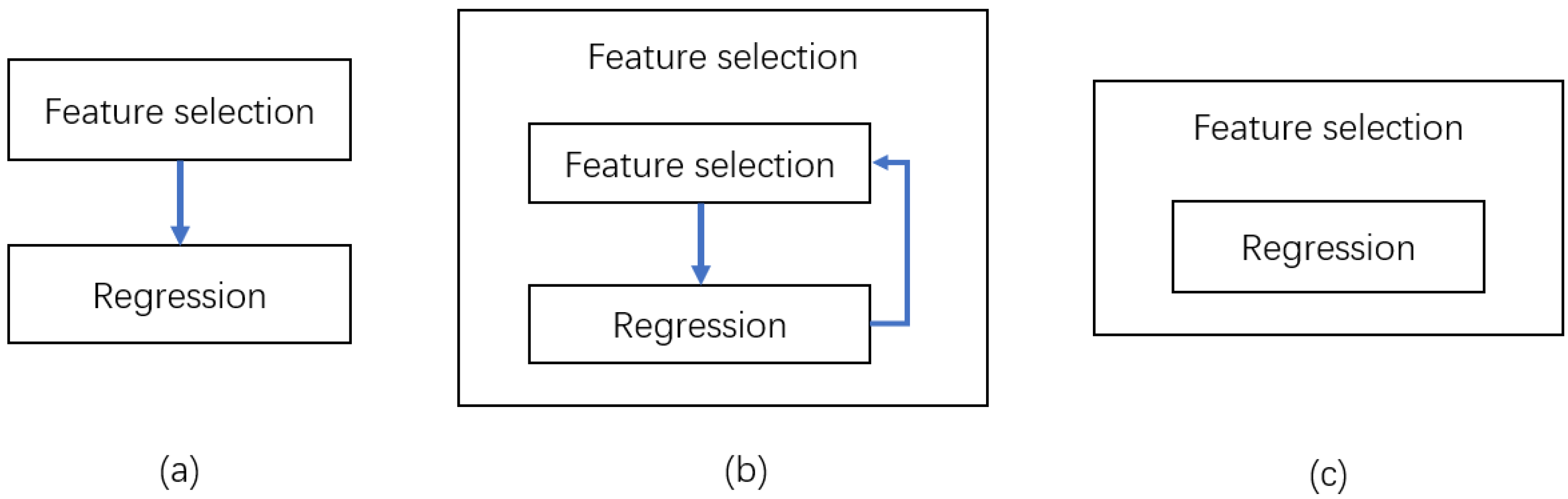
2.3.2. Feature Selection
- Filter feature selection
- Wrapped feature selection
- Embedded feature selection
- (1)
- Construct the training sample set: parts of the samples are randomly selected from the original sample set to form the training sample set (Bootstrap method). N training sample sets could be obtained after repeating N times.
- (2)
- Establish N CART decision trees: Based on the samples in the training sample set, firstly M features are randomly selected from all input features M (node random splitting method), and then M features are constructed according to the variance impurity index. The calculation formula is as follows:
- (3)
- Overall planning of decision tree results. All the constructed decision trees are formed into a random forest, the random forest regressor is used to predict, and finally the result is determined by voting.
2.3.3. Methods of Model Construction
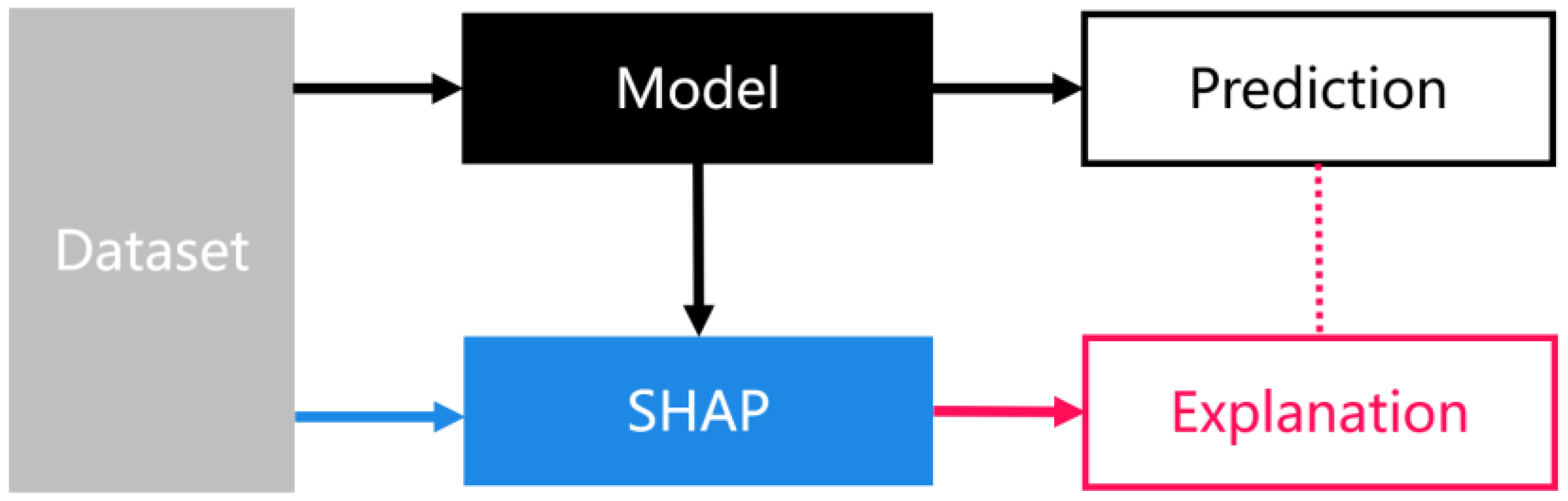
2.3.4. Interpretability Based on SHAP Values
3. Results
3.1. Data Exploration and Analysis
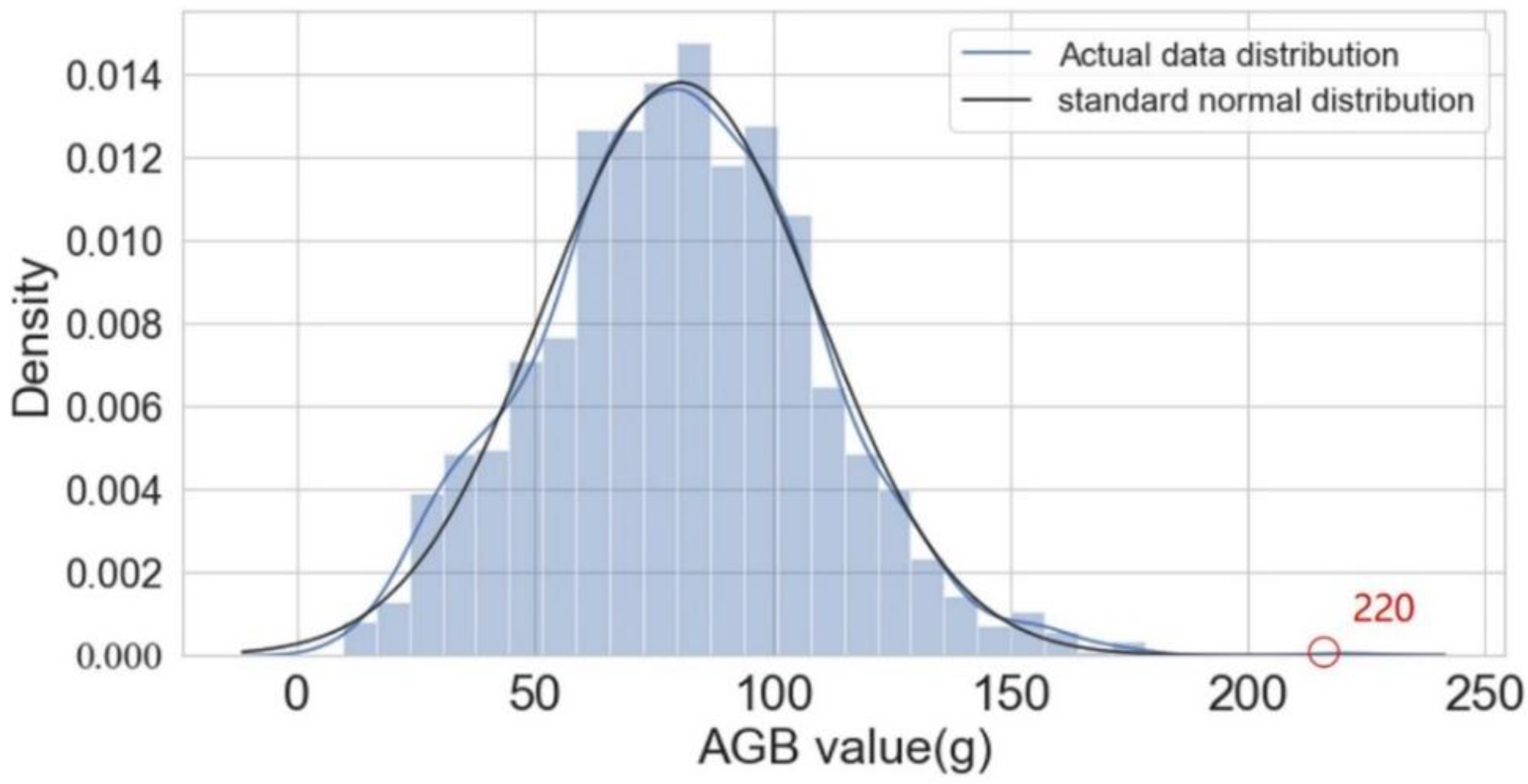
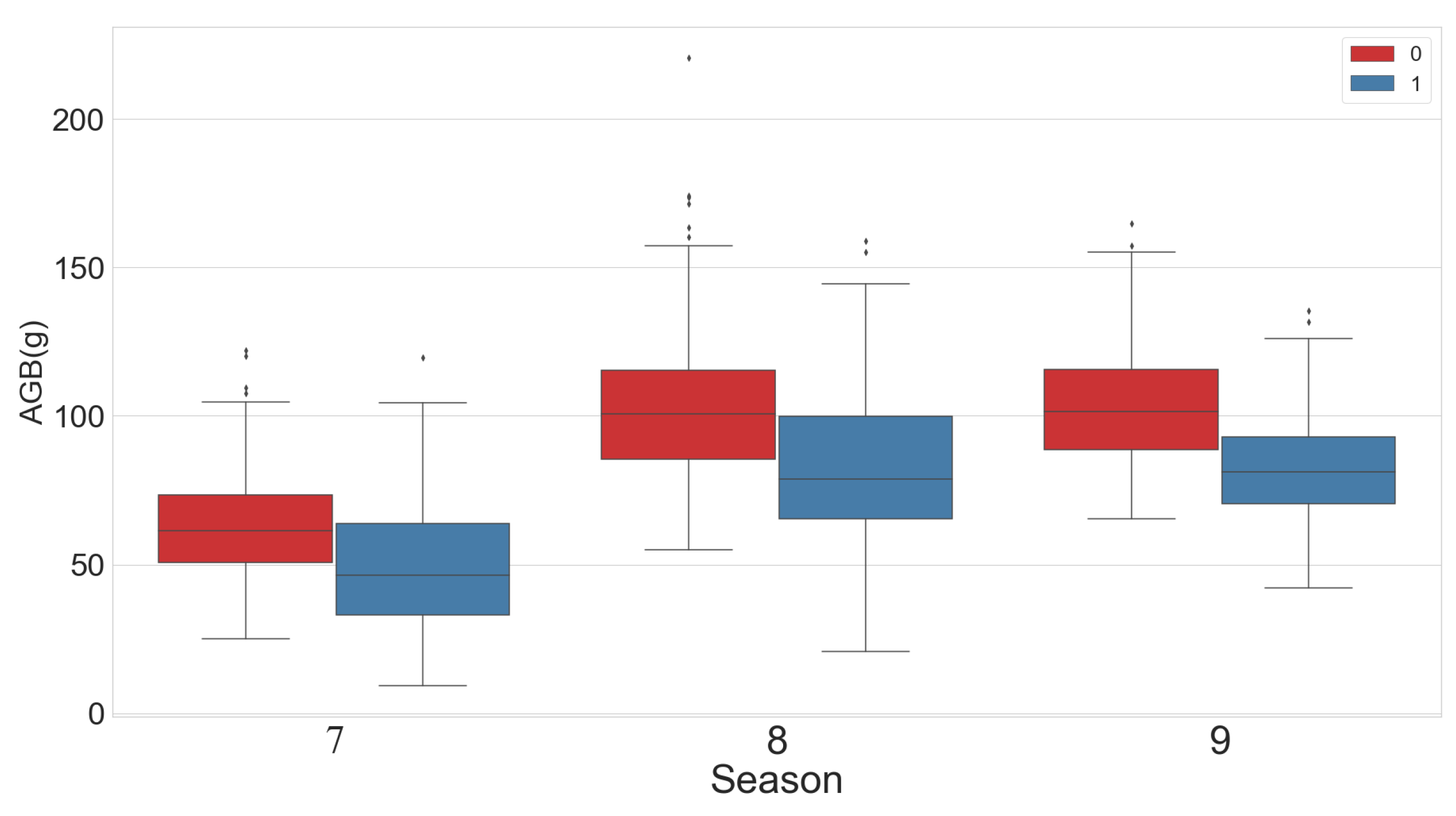
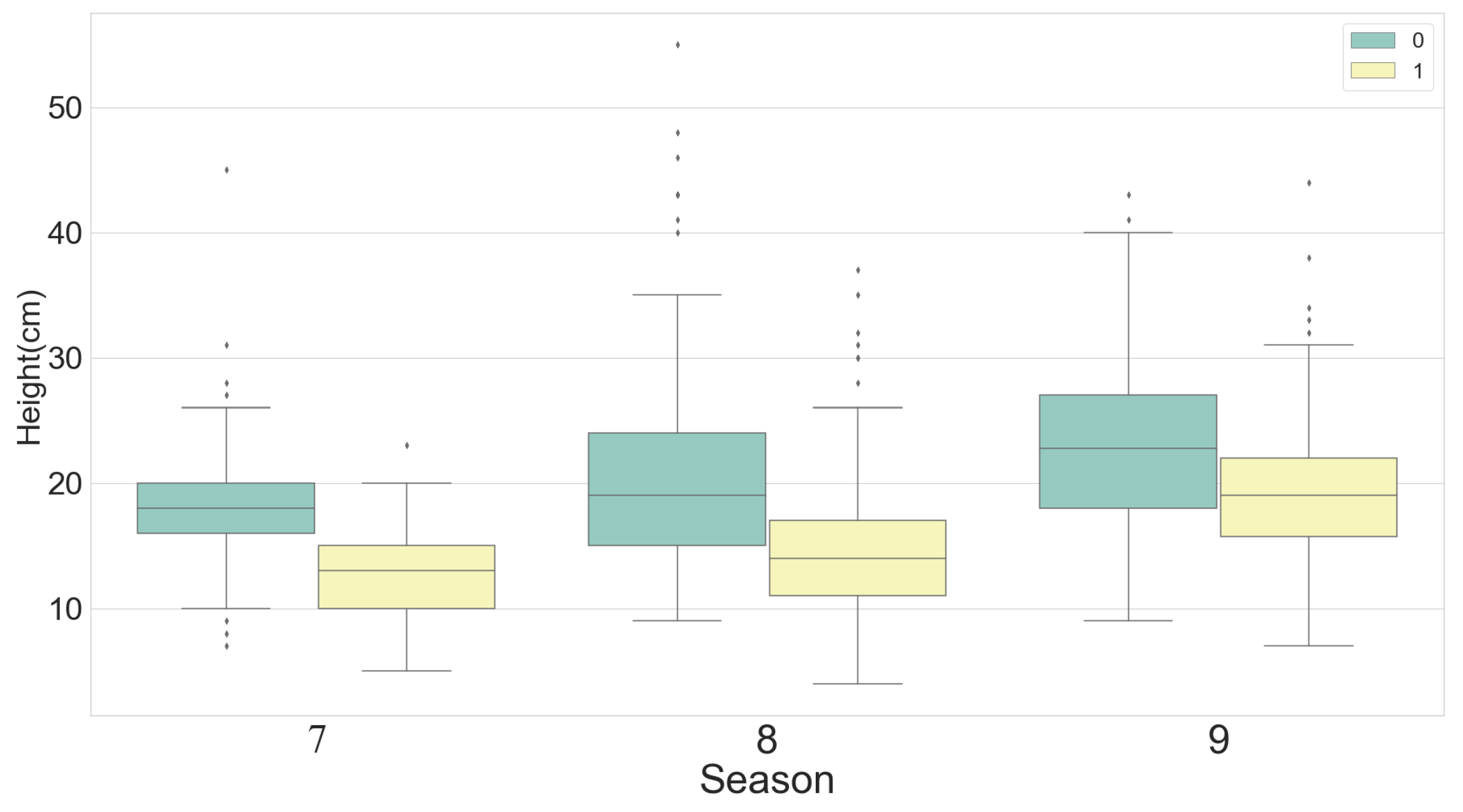
3.1.1. Statistical Analysis of Ecological Data
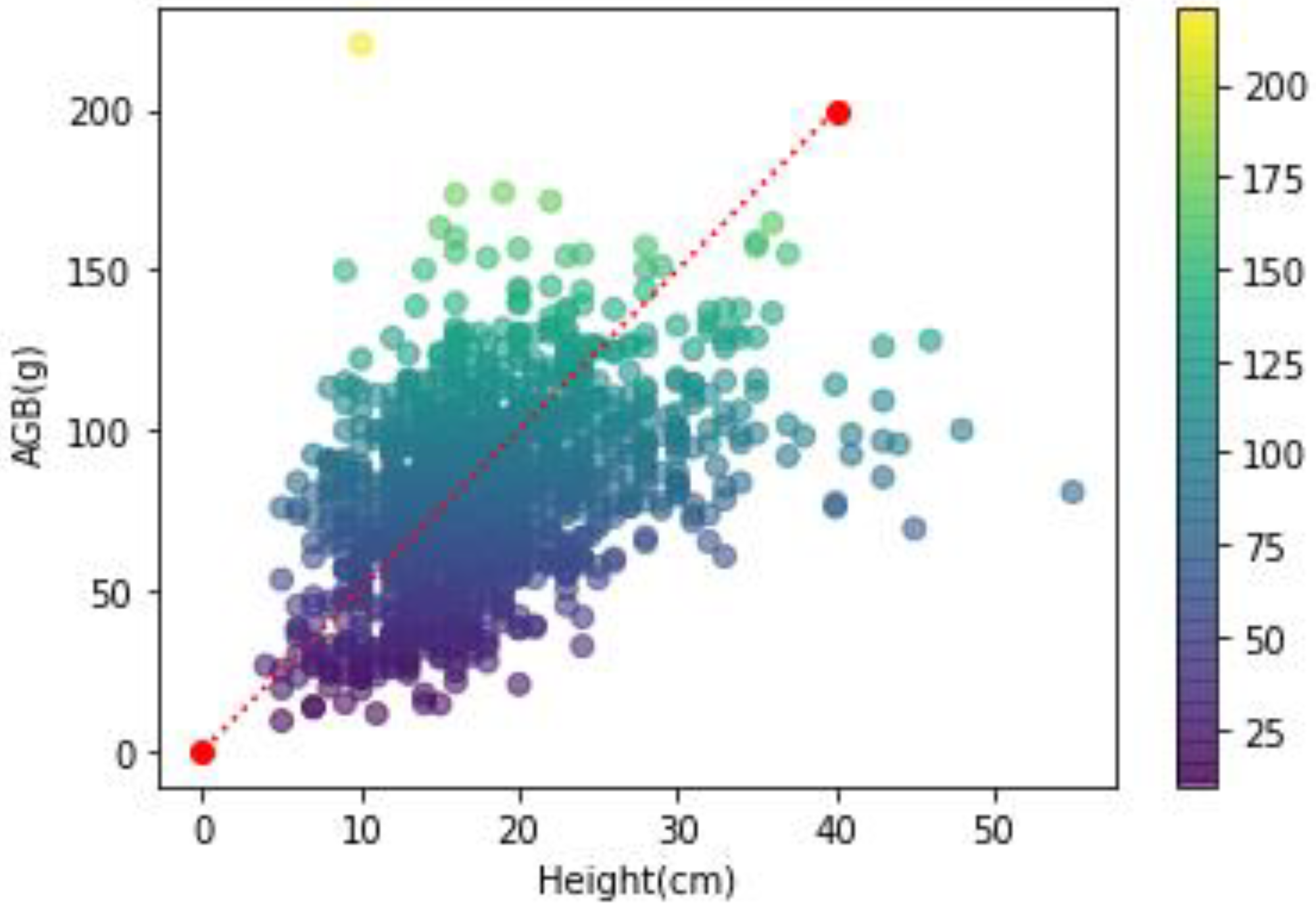
3.1.2. Correlation Analysis of Ecological Data
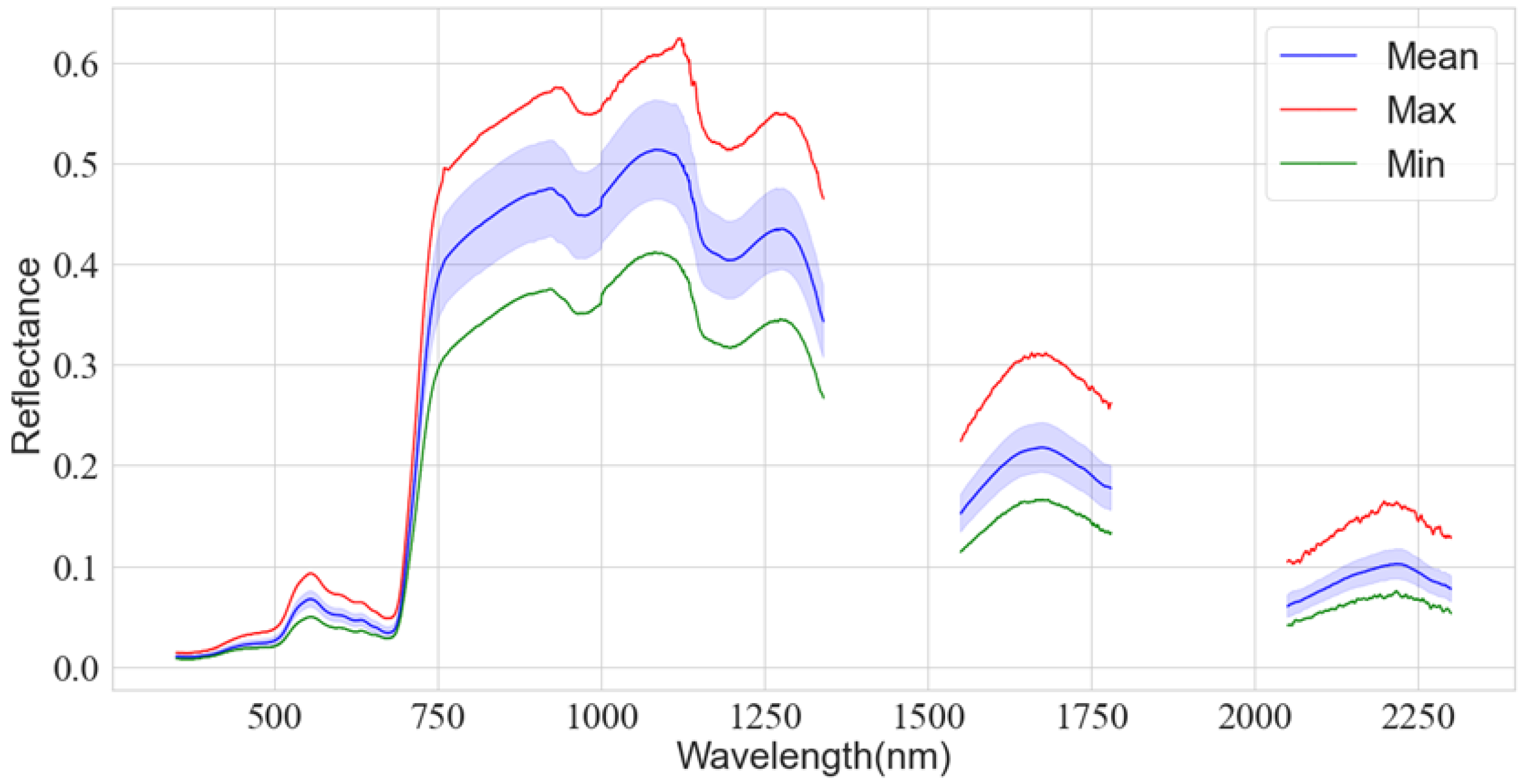
3.1.3. Spectral Data Analysis
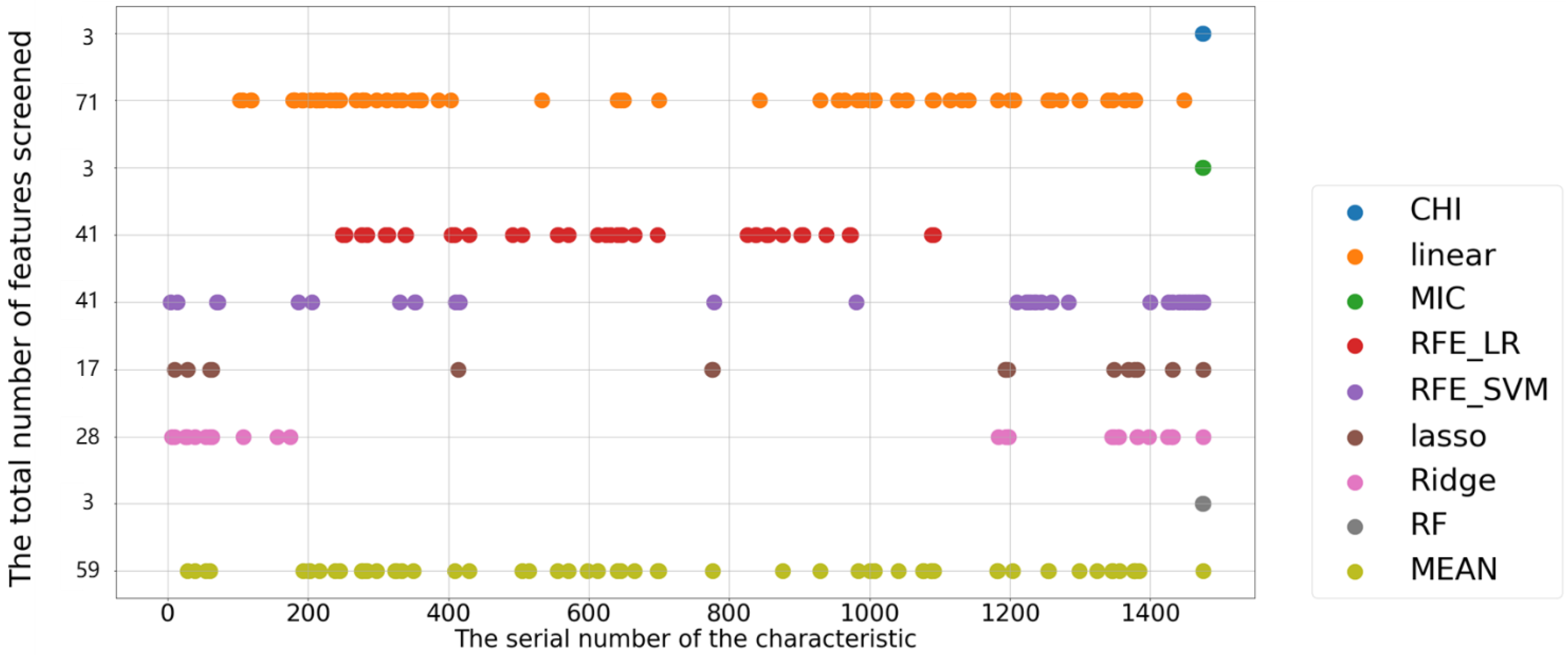
3.2. Feature Selection
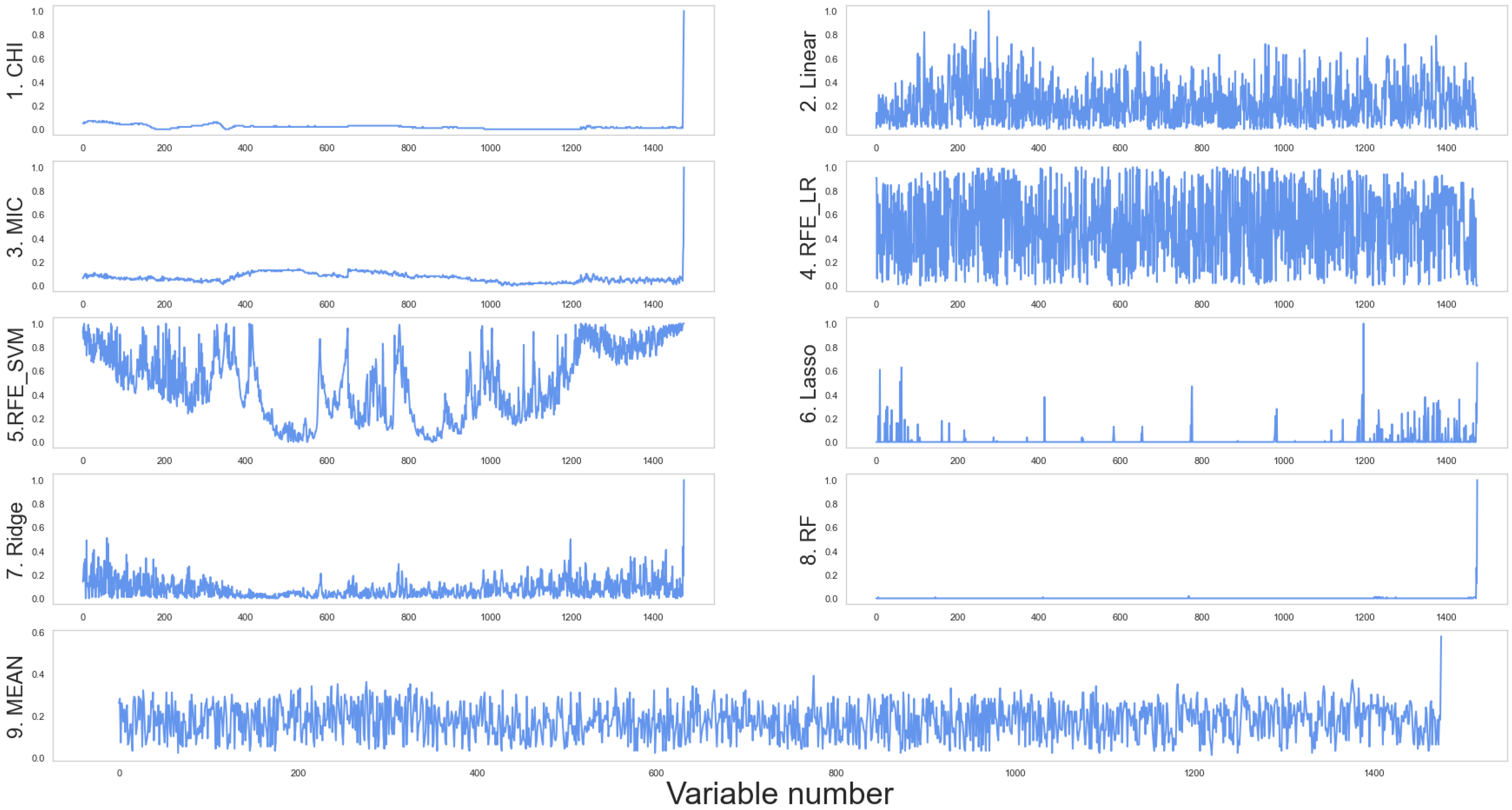
3.2.1. Spectral Data-Based Feature Selection
- Scoring of features based on pure spectral data
- 2.
- Selection of features based on pure spectral data
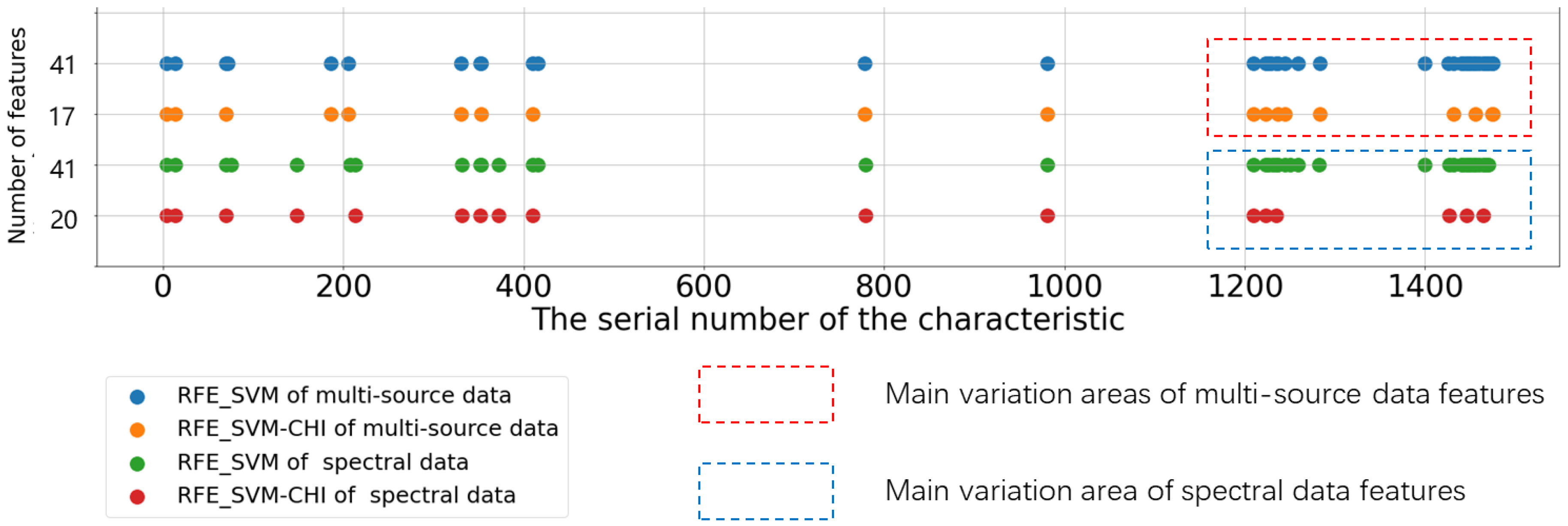
3.2.2. Multi-Source Data-Based Variable Score Analysis
- (1)
- Multi-source data-based feature scoring
- (2)
- Feature screening based on pure multi-source data
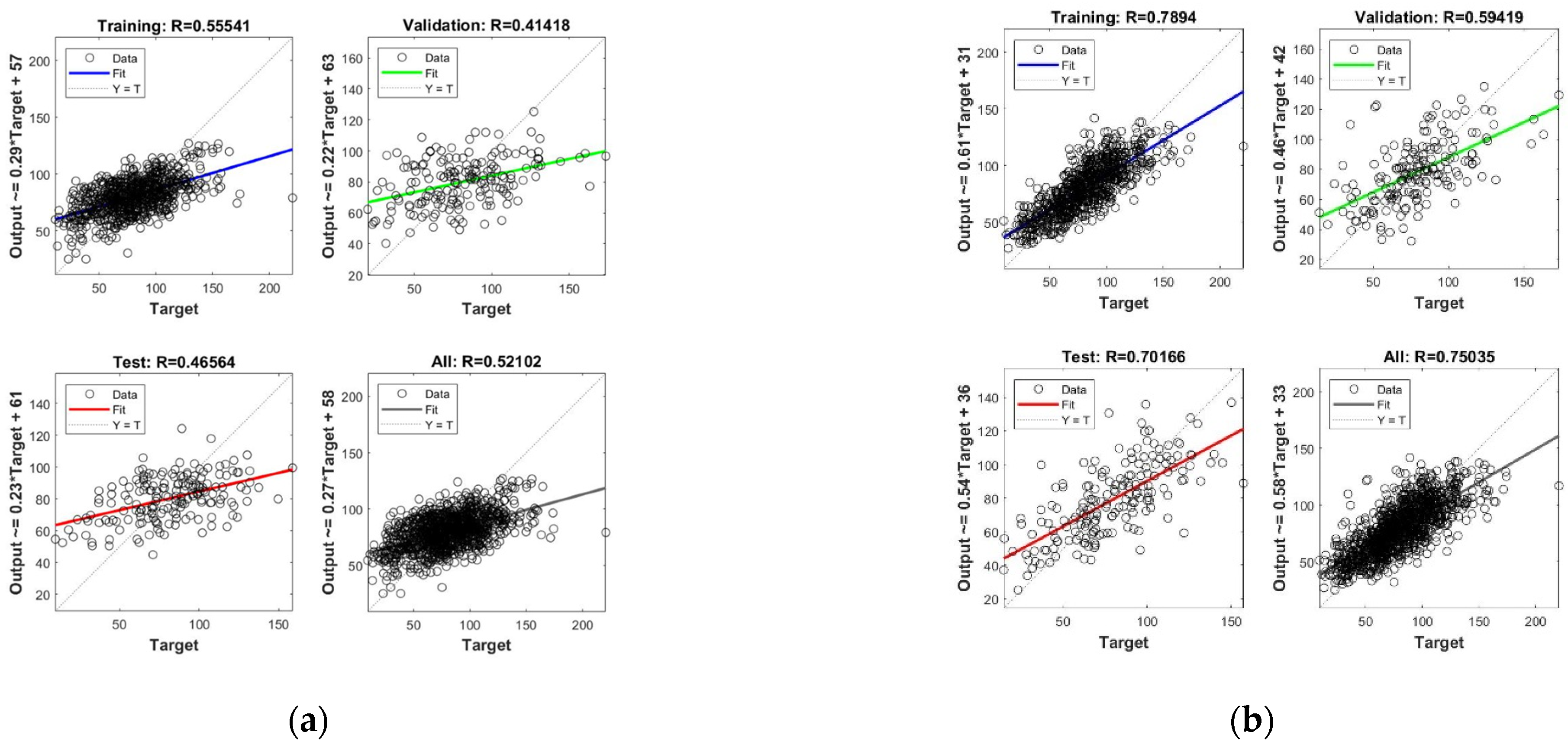
3.3. Model Construction and Evaluation
3.3.1. AGB Inversion Model Based on Machine Learning
3.3.2. AGB Inversion Model Based on Deep Learning Neural Networks
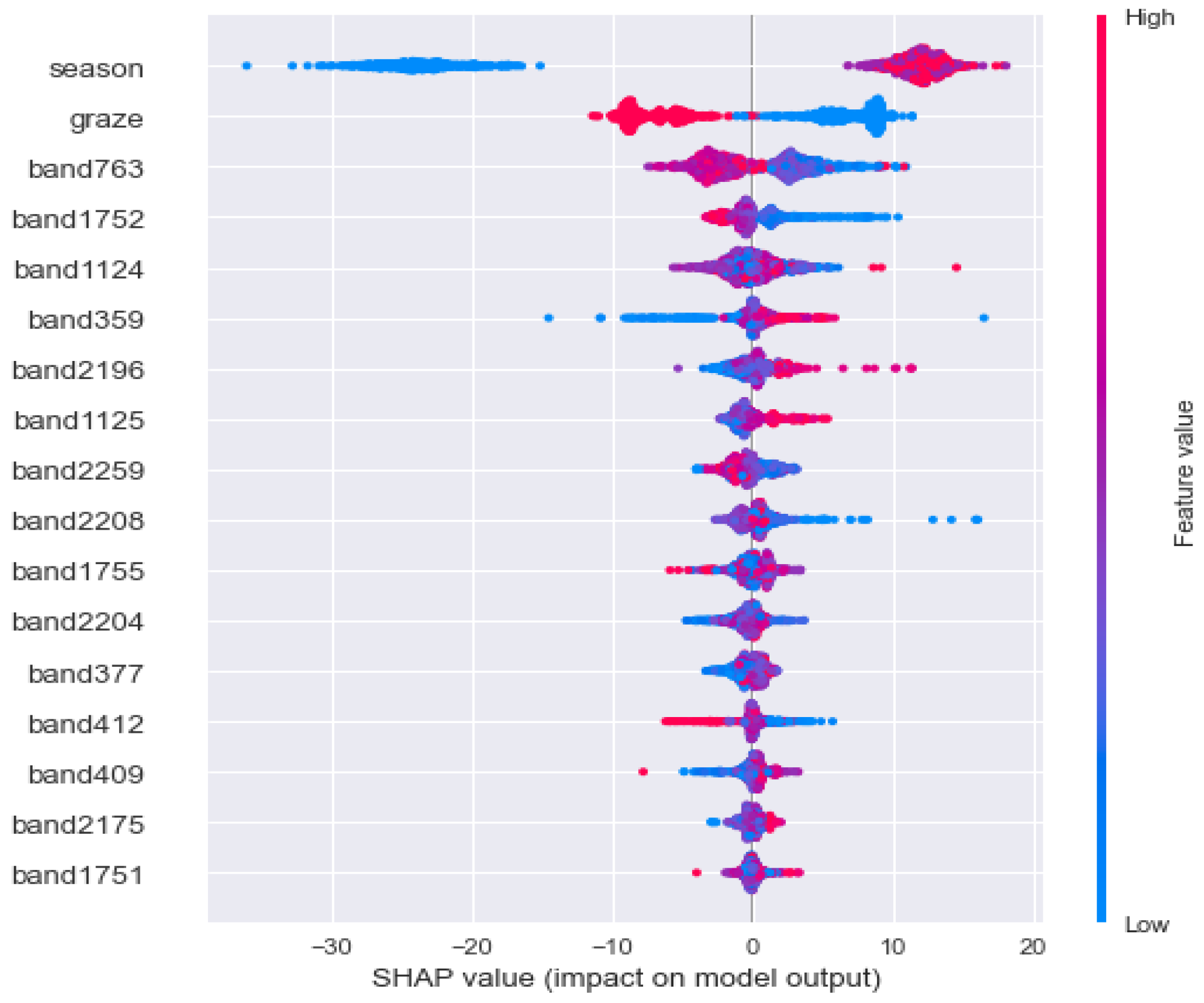
3.3.3. Interpretability of AGB Inversion Model Based on SHAP
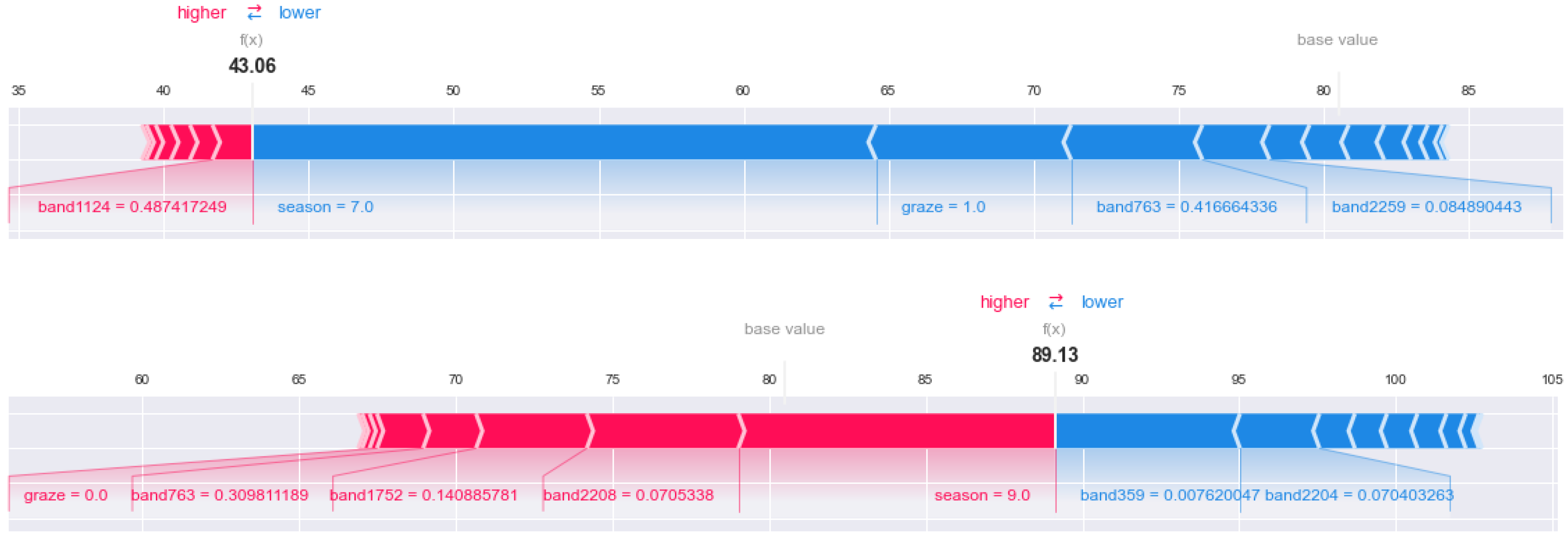
- (1)
- The effect of features on AGB in aggregate data
- (2)
- The influence of features on AGB in single data
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, Y.; Feng, J.; Yuan, X.; Zhu, B. Effects of warming on carbon and nitrogen cycling in alpine grassland ecosystems on the Tibetan Plateau: A meta-analysis. Geoderma 2020, 370, 114363. [Google Scholar] [CrossRef]
- Chen, B.X.; Zhang, X.Z.; Tao, J.; Wu, J.S.; Wang, J.S.; Shi, P.L.; Zhang, Y.J.; Yu, C.Q. The impact of climate change and anthropogenic activities on alpine grassland over the Qinghai-Tibet Plateau. Agric. For. Meteorol. 2014, 189, 11–18. [Google Scholar] [CrossRef]
- Conant, R.T.; Cerri, C.E.P.; Osborne, B.B.; Paustian, K. Grassland management impacts on soil carbon stocks: A new synthesis. Ecol. Appl. 2017, 27, 662–668. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fayiah, M.; Dong, S.K.; Khomera, S.W.; Rehman, S.A.U.; Yang, M.Y.; Xiao, J.N. Status and Challenges of Qinghai-Tibet Plateau’s Grasslands: An Analysis of Causes, Mitigation Measures, and Way Forward. Sustainability 2020, 12, 1099. [Google Scholar] [CrossRef] [Green Version]
- Xiao, J.F.; Chevallier, F.; Gomez, C.; Guanter, L.; Hicke, J.A.; Huete, A.R.; Ichii, K.; Ni, W.J.; Pang, Y.; Rahman, A.F.; et al. Remote sensing of the terrestrial carbon cycle: A review of advances over 50 years. Remote Sens. Environ. 2019, 233, 37. [Google Scholar] [CrossRef]
- Craven, D.; Eisenhauer, N.; Pearse, W.D.; Hautier, Y.; Isbell, F.; Roscher, C.; Bahn, M.; Beierkuhnlein, C.; Bonisch, G.; Buchmann, N.; et al. Multiple facets of biodiversity drive the diversity-stability relationship. Nat. Ecol. Evol. 2018, 2, 1579–1587. [Google Scholar] [CrossRef] [Green Version]
- Isbell, F.; Calcagno, V.; Hector, A.; Connolly, J.; Harpole, W.S.; Reich, P.B.; Scherer-Lorenzen, M.; Schmid, B.; Tilman, D.; van Ruijven, J.; et al. High plant diversity is needed to maintain ecosystem services. Nature 2011, 477, 199–202. [Google Scholar] [CrossRef]
- de Vries, F.T.; Griffiths, R.I.; Bailey, M.; Craig, H.; Girlanda, M.; Gweon, H.S.; Hallin, S.; Kaisermann, A.; Keith, A.M.; Kretzschmar, M.; et al. Soil bacterial networks are less stable under drought than fungal networks. Nat. Commun. 2018, 9, 12. [Google Scholar] [CrossRef] [Green Version]
- Wagg, C.; Schlaeppi, K.; Banerjee, S.; Kuramae, E.E.; van der Heijden, M.G.A. Fungal-bacterial diversity and microbiome complexity predict ecosystem functioning. Nat. Commun. 2019, 10, 10. [Google Scholar] [CrossRef]
- Morgan, J.A.; LeCain, D.R.; Pendall, E.; Blumenthal, D.M.; Kimball, B.A.; Carrillo, Y.; Williams, D.G.; Heisler-White, J.; Dijkstra, F.A.; West, M. C-4 grasses prosper as carbon dioxide eliminates desiccation in warmed semi-arid grassland. Nature 2011, 476, 202–205. [Google Scholar] [CrossRef]
- Dong, S.K.; Shang, Z.H.; Gao, J.X.; Boone, R.B. Enhancing sustainability of grassland ecosystems through ecological restoration and grazing management in an era of climate change on Qinghai-Tibetan Plateau. Agric. Ecosyst. Environ. 2020, 287, 16. [Google Scholar] [CrossRef]
- Wang, G.X.; Li, Y.S.; Wang, Y.B.; Wu, Q.B. Effects of permafrost thawing on vegetation and soil carbon pool losses on the Qinghai-Tibet Plateau, China. Geoderma 2008, 143, 143–152. [Google Scholar] [CrossRef]
- Yang, Y.; Tilman, D.; Furey, G.; Lehman, C. Soil carbon sequestration accelerated by restoration of grassland biodiversity. Nat. Commun. 2019, 10, 7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bosch, A.; Dorfer, C.; He, J.S.; Schmidt, K.; Scholten, T. Predicting soil respiration for the Qinghai-Tibet Plateau: An empirical comparison of regression models. Pedobiologia 2016, 59, 41–49. [Google Scholar] [CrossRef]
- Veldhuis, M.P.; Ritchie, M.E.; Ogutu, J.O.; Morrison, T.A.; Beale, C.M.; Estes, A.B.; Mwakilema, W.; Ojwang, G.O.; Parr, C.L.; Probert, J.; et al. Cross-boundary human impacts compromise the Serengeti-Mara ecosystem. Science 2019, 363, 1424–1428. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, L.; Delgado-Baquerizo, M.; Wang, D.L.; Isbell, F.; Liu, J.; Feng, C.; Liu, J.S.; Zhong, Z.W.; Zhu, H.; Yuan, X.; et al. Diversifying livestock promotes multidiversity and multifunctionality in managed grasslands. Proc. Natl. Acad. Sci. USA 2019, 116, 6187–6192. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.Y.; Mi, Z.R.; Lin, L.; Wang, Y.H.; Zhang, Z.H.; Zhang, F.W.; Wang, H.; Liu, L.L.; Zhu, B.A.; Cao, G.M.; et al. Shifting plant species composition in response to climate change stabilizes grassland primary production. Proc. Natl. Acad. Sci. USA 2018, 115, 4051–4056. [Google Scholar] [CrossRef] [Green Version]
- Miehe, G.; Schleuss, P.M.; Seeber, E.; Babel, W.; Biermann, T.; Braendle, M.; Chen, F.H.; Coners, H.; Foken, T.; Gerken, T.; et al. The Kobresia pygmaea ecosystem of the Tibetan highlands—Origin, functioning and degradation of the world’s largest pastoral alpine ecosystem Kobresia pastures of Tibet. Sci. Total Environ. 2019, 648, 754–771. [Google Scholar] [CrossRef]
- Lemaire, G.; Franzluebbers, A.; Carvalho, P.C.D.; Dedieu, B. Integrated crop-livestock systems: Strategies to achieve synergy between agricultural production and environmental quality. Agric. Ecosyst. Environ. 2014, 190, 4–8. [Google Scholar] [CrossRef]
- Reinermann, S.; Asam, S.; Kuenzer, C. Remote Sensing of Grassland Production and Management-A Review. Remote Sens. 2020, 12, 1949. [Google Scholar] [CrossRef]
- Kumar, L.; Sinha, P.; Taylor, S.; Alqurashi, A.F. Review of the use of remote sensing for biomass estimation to support renewable energy generation. J. Appl. Remote Sens. 2015, 9, 28. [Google Scholar] [CrossRef]
- Eisfelder, C.; Kuenzer, C.; Dech, S. Derivation of biomass information for semi-arid areas using remote-sensing data. Int. J. Remote Sens. 2012, 33, 2937–2984. [Google Scholar] [CrossRef]
- Wachendorf, M.; Fricke, T.; Moeckel, T. Remote sensing as a tool to assess botanical composition, structure, quantity and quality of temperate grasslands. Grass Forage Sci. 2018, 73, 1–14. [Google Scholar] [CrossRef]
- Liang, T.; Yang, S.; Feng, Q.; Liu, B.; Zhang, R.; Huang, X.; Xie, H. Multi-factor modeling of above-ground biomass in alpine grassland: A case study in the Three-River Headwaters Region, China. Remote Sens. Environ. 2016, 186, 164–172. [Google Scholar] [CrossRef]
- Pang, H.; Zhang, A.; Kang, X.; He, N.; Dong, G. Estimation of the Grassland Aboveground Biomass of the Inner Mongolia Plateau Using the Simulated Spectra of Sentinel-2 Images. Remote Sens. 2020, 12, 4155. [Google Scholar] [CrossRef]
- Sun, S.; Wang, C.; Yin, X.; Wang, W.; Liu, W.; Zhang, Y.; Zhao, Q.Z. Estimating aboveground biomass of natural grassland based on multispectral images of Unmanned Aerial Vehicles. J. Remote Sens. 2018, 22, 848–856. [Google Scholar] [CrossRef]
- Khaliq, A.; Comba, L.; Biglia, A.; Aimonino, D.R.; Chiaberge, M.; Gay, P. Comparison of Satellite and UAV-Based Multispectral Imagery for Vineyard Variability Assessment. Remote Sens. 2019, 11, 436. [Google Scholar] [CrossRef] [Green Version]
- Tattaris, M.; Reynolds, M.P.; Chapman, S.C. A Direct Comparison of Remote Sensing Approaches for High-Throughput Phenotyping in Plant Breeding. Front. Plant Sci. 2016, 7, 1131. [Google Scholar] [CrossRef]
- Transon, J.; d’Andrimont, R.; Maugnard, A.; Defourny, P. Survey of Hyperspectral Earth Observation Applications from Space in the Sentinel-2 Context. Remote Sens. 2018, 10, 157. [Google Scholar] [CrossRef] [Green Version]
- van der Meer, F.D.; van der Werff, H.M.A.; van Ruitenbeek, F.J.A.; Hecker, C.A.; Bakker, W.H.; Noomen, M.F.; van der Meijde, M.; Carranza, E.J.M.; de Smeth, J.B.; Woldai, T. Multi- and hyperspectral geologic remote sensing: A review. Int. J. Appl. Earth Obs. Geoinf. 2012, 14, 112–128. [Google Scholar] [CrossRef]
- Shi, Y.; Gao, J.; Li, X.; Li, J.; dela Torre, D.M.G.; Brierley, G.J. Improved Estimation of Aboveground Biomass of Disturbed Grassland through Including Bare Ground and Grazing Intensity. Remote Sens. 2021, 13, 2015. [Google Scholar] [CrossRef]
- Melville, B.; Lucieer, A.; Aryal, J. Assessing the Impact of Spectral Resolution on Classification of Lowland Native Grassland Communities Based on Field Spectroscopy in Tasmania, Australia. Remote Sens. 2018, 10, 308. [Google Scholar] [CrossRef] [Green Version]
- Oberrneier, W.A.; Lehnert, L.W.; Pohl, M.J.; Gianonni, S.M.; Silva, B.; Seibert, R.; Laser, H.; Moser, G.; Muller, C.; Luterbacher, J.; et al. Grassland ecosystem services in a changing environment: The potential of hyperspectral monitoring. Remote Sens. Environ. 2019, 232, 16. [Google Scholar] [CrossRef]
- Wang, J.; Brown, D.G.; Bai, Y.F. Investigating the spectral and ecological characteristics of grassland communities across an ecological gradient of the Inner Mongolian grasslands with in situ hyperspectral data. Int. J. Remote Sens. 2014, 35, 7179–7198. [Google Scholar] [CrossRef]
- Shahshahani, B.M.; Landgrebe, D.A. The effect of unlabeled samples in reducing the small sample-size problem and mitigating the hughes phenomenon. IEEE Trans. Geosci. Remote Sens. 1994, 32, 1087–1095. [Google Scholar] [CrossRef] [Green Version]
- Taskin, G.; Kaya, H.; Bruzzone, L. Feature Selection Based on High Dimensional Model Representation for Hyperspectral Images. IEEE Trans. Image Process. 2017, 26, 2918–2928. [Google Scholar] [CrossRef]
- Fava, F.; Parolo, G.; Colombo, R.; Gusmeroli, F.; Della Marianna, G.; Monteiro, A.T.; Bocchi, S. Fine-scale assessment of hay meadow productivity and plant diversity in the European Alps using field spectrometric data. Agric. Ecosyst. Environ. 2010, 137, 151–157. [Google Scholar] [CrossRef]
- Marabel, M.; Alvarez-Taboada, F. Spectroscopic Determination of Aboveground Biomass in Grasslands Using Spectral Transformations, Support Vector Machine and Partial Least Squares Regression. Sensors 2013, 13, 10027–10051. [Google Scholar] [CrossRef] [Green Version]
- Bratsch, S.; Epstein, H.; Buchhorn, M.; Walker, D.; Landes, H. Relationships between hyperspectral data and components of vegetation biomass in Low Arctic tundra communities at Ivotuk, Alaska. Environ. Res. Lett. 2017, 12, 14. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Brown, L.G. A SURVEY OF Image registration techniques. Comput. Surv. 1992, 24, 325–376. [Google Scholar] [CrossRef]
- Shen, M.; Tang, Y.; Klein, J.; Zhang, P.; Gu, S.; Shimono, A.; Chen, J. Estimation of aboveground biomass using in situ hyperspectral measurements in five major grassland ecosystems on the Tibetan Plateau. J. Plant Ecol. 2008, 1, 247–257. [Google Scholar] [CrossRef] [Green Version]
- Gao, J.X.; Chen, Y.M.; Lu, S.H.; Feng, C.Y.; Chang, X.L.; Ye, S.X.; Liu, J.D. A ground spectral model for estimating biomass at the peak of the growing season in Hulunbeier grassland, Inner Mongolia, China. Int. J. Remote Sens. 2012, 33, 4029–4043. [Google Scholar] [CrossRef]
- Ali, I.; Greifeneder, F.; Stamenkovic, J.; Neumann, M.; Notarnicola, C. Review of Machine Learning Approaches for Biomass and Soil Moisture Retrievals from Remote Sensing Data. Remote Sens. 2015, 7, 16398–16421. [Google Scholar] [CrossRef] [Green Version]
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A Survey of Deep Learning and Its Applications: A New Paradigm to Machine Learning. Arch. Comput. Method Eng. 2020, 27, 1071–1092. [Google Scholar] [CrossRef]
- Su, J.W.; Vargas, D.V.; Sakurai, K. One Pixel Attack for Fooling Deep Neural Networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef] [Green Version]
- Arrieta, A.B.; Diaz-Rodriguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- McGovern, A.; Lagerquist, R.; Gagne, D.J.; Jergensen, G.E.; Elmore, K.L.; Homeyer, C.R.; Smith, T. Making the Black Box More Transparent: Understanding the Physical Implications of Machine Learning. Bull. Amer. Meteorol. Soc. 2019, 100, 2175–2199. [Google Scholar] [CrossRef]
- ASD Inc. FieldSpec®4 UserManual. Available online: http://support.asdi.com/Document/FileGet.aspx?f=600000.PDF (accessed on 10 December 2015).
- Curra, A.; Gasbarrone, R.; Cardillo, A.; Trompetto, C.; Fattapposta, F.; Pierelli, F.; Missori, P.; Bonifazi, G.; Serranti, S. Near-infrared spectroscopy as a tool for in vivo analysis of human muscles. Sci Rep 2019, 9, 14. [Google Scholar] [CrossRef]
- Steinier, J.; Termonia, Y.; Deltour, J. Smoothing and differentiation of data by simplified least square procedure. Anal. Chem. 1972, 44, 1906–1909. [Google Scholar] [CrossRef]
- Li, J.D.; Cheng, K.W.; Wang, S.H.; Morstatter, F.; Trevino, R.P.; Tang, J.L.; Liu, H. Feature Selection: A Data Perspective. ACM Comput. Surv. 2018, 50, 45. [Google Scholar] [CrossRef] [Green Version]
- Gui, J.; Sun, Z.N.; Ji, S.W.; Tao, D.C.; Tan, T.N. Feature Selection Based on Structured Sparsity: A Comprehensive Study. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 1490–1507. [Google Scholar] [CrossRef] [PubMed]
- Cai, J.; Luo, J.W.; Wang, S.L.; Yang, S. Feature selection in machine learning: A new perspective. Neurocomputing 2018, 300, 70–79. [Google Scholar] [CrossRef]
- Lazar, C.; Taminau, J.; Meganck, S.; Steenhoff, D.; Coletta, A.; Molter, C.; de Schaetzen, V.; Duque, R.; Bersini, H.; Nowe, A. A Survey on Filter Techniques for Feature Selection in Gene Expression Microarray Analysis. IEEE-ACM Trans. Comput. Biol. Bioinform. 2012, 9, 1106–1119. [Google Scholar] [CrossRef] [PubMed]
- McHugh, M.L. The Chi-square test of independence. Biochem. Medica. 2013, 23, 143–149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Austin, P.C.; Steyerberg, E.W. The number of subjects per variable required in linear regression analyses. J. Clin. Epidemiol. 2015, 68, 627–636. [Google Scholar] [CrossRef] [Green Version]
- Chu, F.C.; Fan, Z.P.; Guo, B.H.; Zhi, D.; Yin, Z.J.; Zhao, W.J. Variable Selection based on Maximum Information Coefficient for Data Modeling. In Proceedings of the 2nd IEEE Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 25–26 March 2017; pp. 1714–1717. [Google Scholar]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef] [Green Version]
- Mao, Y.; Pi, D.Y.; Liu, Y.M.; Sun, Y.X. Accelerated recursive feature elimination based on support vector machine for key variable identification. Chin. J. Chem. Eng. 2006, 14, 65–72. [Google Scholar] [CrossRef]
- Zhang, R.; Ma, J.W.; Chen, X.; Tong, Q.X. Feature selection for hyperspectral data based on modified recursive support vector machines. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Cape Town, South Africa, 12–17 July 2009; pp. II-847–II-850. [Google Scholar]
- Zhang, X.C.; Zhao, Z.X.; Zheng, Y.; Li, J.Y. Prediction of Taxi Destinations Using a Novel Data Embedding Method and Ensemble Learning. IEEE Trans. Intell. Transp. Syst. 2020, 21, 68–78. [Google Scholar] [CrossRef]
- Xia, J.N.; Sun, D.Y.; Xiao, F. Summary of lasso and relative methods. In Proceedings of the 13th International Conference on Enterprise Information Systems (ICEIS 2011), Beijing, China, 8–11 June 2011; Beijing Jiaotong University, Sch Econ & Management: Beijing, China, 2011; pp. 131–134. [Google Scholar]
- Jain, R.H.; Xu, W. HDSI: High dimensional selection with interactions algorithm on feature selection and testing. PLoS ONE 2021, 16, 17. [Google Scholar] [CrossRef]
- Dormann, C.F.; Elith, J.; Bacher, S.; Buchmann, C.; Carl, G.; Carre, G.; Marquez, J.R.G.; Gruber, B.; Lafourcade, B.; Leitao, P.J.; et al. Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography 2013, 36, 27–46. [Google Scholar] [CrossRef]
- Muthukrishnan, R.; Rohini, R. LASSO: A Feature Selection Technique In Predictive Modeling For Machine Learning. In Proceedings of the IEEE International Conference on Advances in Computer Applications (ICACA), Coimbatore, India, 24 October 2016; pp. 18–20. [Google Scholar]
- Verikas, A.; Gelzinis, A.; Bacauskiene, M. Mining data with random forests: A survey and results of new tests. Pattern Recognit. 2011, 44, 330–349. [Google Scholar] [CrossRef]
- Belgiu, M.; Dragut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS-J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Hearst, M.A. Support vector machines. IEEE Intell. Syst. Appl. 1998, 13, 18–21. [Google Scholar] [CrossRef] [Green Version]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS-J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Schulz, E.; Speekenbrink, M.; Krause, A. A tutorial on Gaussian process regression: Modelling, exploring, and exploiting functions. J. Math. Psychol. 2018, 85, 1–16. [Google Scholar] [CrossRef]
- Williams, C.; Rasmussen, C. Gaussian processes for regression. In Proceedings of the Advances in Neural Information Processing Systems 8, Denver, CO, USA, 27–30 November 1995. [Google Scholar]
- Liu, H.T.; Ong, Y.S.; Shen, X.B.; Cai, J.F. When Gaussian Process Meets Big Data: A Review of Scalable GPs. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4405–4423. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ambikasaran, S.; Foreman-Mackey, D.; Greengard, L.; Hogg, D.W.; O’Neil, M. Fast Direct Methods for Gaussian Processes. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 252–265. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Spring: New York, NY, USA, 2008. [Google Scholar]
- Abu-Taieh, E.M. Artificial neural networks: Enhanced Back Propagation in character recognition. In Proceedings of the International Conference of the Information-Resources-Management-Association, Philadelphia, PA, USA, 18–21 May 2003; pp. 263–265. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J.J.N. Learning Representations by Back Propagating Errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Sharma, P.; Mirzan, S.R.; Bhandari, A.; Pimpley, A.; Eswaran, A.; Srinivasan, S.; Shao, L.Q. Evaluating Tree Explanation Methods for Anomaly Reasoning: A Case Study of SHAP TreeExplainer and TreeInterpreter. In Proceedings of the 39th International Conference on Conceptual Modeling (ER), Vienna, Austria, 3–6 November 2020; pp. 35–45. [Google Scholar]
- Nohara, Y.; Matsumoto, K.; Soejima, H.; Nakashima, N. Explanation of machine learning models using shapley additive explanation and application for real data in hospital. Comput. Meth. Progr. Biomed. 2022, 214, 6. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.M.; Zhang, Q.; Du, X.Y.; Ma, Y.F.; Wang, S.H. Social media rumor refutation effectiveness: Evaluation, modelling and enhancement. Inf. Processing Manag. 2021, 58, 102420. [Google Scholar] [CrossRef]
- Zhiqin, L. Summary of feature selection methods. Comput. Eng. Appl. 2019, 55, 10–19. [Google Scholar] [CrossRef]
- Chaofang, L. The Research on Causal Feature Selection Algorithm Based on AD-Tree; Hefei University of Technology: Hefei, China, 2021; pp. 7–9. [Google Scholar] [CrossRef]
- Ruiqi, J. Research on Interpretable Prediction Model of Traumatic Hemorrhagic Shock Based on Improved ANN; Beijing Jiaotong University: Beijing, China, 2021; pp. 13–16. [Google Scholar] [CrossRef]
- Wu, J.; Peng, D.L. Advances in Researches on Hyperspectral Remote Sensing Forestry Information-Extracting Technology. Spectrosc. Spectr. Anal. 2011, 31, 2305–2312. [Google Scholar] [CrossRef]
- Smith, W.K.; Dannenberg, M.P.; Yan, D.; Herrmann, S.; Barnes, M.L.; Barron-Gafford, G.A.; Biederman, J.A.; Ferrenberg, S.; Fox, A.M.; Hudson, A.; et al. Remote sensing of dryland ecosystem structure and function: Progress, challenges, and opportunities. Remote Sens. Environ. 2019, 233, 23. [Google Scholar] [CrossRef]
- Long, W.; Lu, Z.C.; Cui, L.X. Deep learning-based feature engineering for stock price movement prediction. Knowl.-Based Syst. 2019, 164, 163–173. [Google Scholar] [CrossRef]
- Sagheer, A.; Kotb, M. Time series forecasting of petroleum production using deep LSTM recurrent networks. Neurocomputing 2019, 323, 203–213. [Google Scholar] [CrossRef]
- Li, T.Y.; Fong, S.M.; Siu, S.W.I.; Yang, X.S.; Liu, L.S.; Mohammed, S. White learning methodology: A case study of cancer-related disease factors analysis in real-time PACS environment. Comput. Meth. Programs Biomed. 2020, 197, 18. [Google Scholar] [CrossRef]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.L.; Tian, H.M.; Tao, Y.D.; Reyes, M.P.; Shyu, M.L.; Chen, S.C.; Iyengar, S.S. A Survey on Deep Learning: Algorithms, Techniques, and Applications. ACM Comput. Surv. 2019, 51, 36. [Google Scholar] [CrossRef]
- Kalaba, R.E.; Johnson, J.; Natsuyama, H.H. Statistical measures for least squares using the alpha Q beta R algorithm. J. Optim. Theory Appl. 2005, 127, 515–522. [Google Scholar] [CrossRef]
- Wu, X.D.; Zhu, X.Q.; Wu, G.Q.; Ding, W. Data Mining with Big Data. IEEE Trans. Knowl. Data Eng. 2014, 26, 97–107. [Google Scholar] [CrossRef]
- Wang, Y.Q.; Yao, Q.M.; Kwok, J.T.; Ni, L.M. Generalizing from a Few Examples: A Survey on Few-shot Learning. ACM Comput. Surv. 2020, 53, 34. [Google Scholar] [CrossRef]
- Aasen, H.; Honkavaara, E.; Lucieer, A.; Zarco-Tejada, P.J. Quantitative Remote Sensing at Ultra-High Resolution with UAV Spectroscopy: A Review of Sensor Technology, Measurement Procedures, and Data Correction Workflows. Remote Sens. 2018, 10, 1091. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Unit | N | Min | Max | Mean | SD | CV |
|---|---|---|---|---|---|---|---|
| AGB | gram | 1200 | 9.35 | 220.54 | 80.5779 | 28.884 | 0.358 |
| Height | centimeter | 1200 | 4 | 55 | 18.578 | 6.702 | 0.372 |
| Factor | CHI | Linear | MIC | RFE_LR | RFE_SVM | Lasso | Ridge | RF | Mean |
|---|---|---|---|---|---|---|---|---|---|
| Grazing conditions | 0.32 | 0 | 0.28 | 0 | 1 | 0.33 | 0.44 | 0.26 | 0.2 |
| Height | 0.59 | 0 | 0.34 | 0 | 1 | 0.16 | 0.19 | 0.16 | 0.18 |
| Season | 1 | 0 | 1 | 0 | 1 | 0.67 | 1 | 0.67 | 0.58 |
| Feature Selection | Evaluation Index | Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| Spectral Data | Multi-Source Data | |||||||
| SVM | GPR | LSB | SVM | GPR | LSB | |||
| Filter | CHI | R2 | 0.04 | 0.02 | −0.06 | 0.38 | 0.48 | 0.46 |
| RMSE | 28.267 | 28.615 | 29.744 | 22.748 | 20.909 | 21.323 | ||
| Linear | R2 | 0.07 | 0.07 | −0.05 | 0.09 | 0.08 | −0.03 | |
| RMSE | 27.798 | 27.887 | 29.542 | 27.554 | 27.707 | 29.337 | ||
| MIC | R2 | 0.02 | 0.04 | −0.05 | 0.38 | 0.48 | 0.47 | |
| RMSE | 28.554 | 28.554 | 29.552 | 22.75 | 20.811 | 21.058 | ||
| Wrapper | RFE_LR | R2 | 0.07 | 0.05 | −0.03 | 0.08 | 0.06 | −0.03 |
| RMSE | 27.799 | 28.206 | 29.552 | 22.750 | 20.811 | 21.058 | ||
| RFE_SVM | R2 | 0.09 | 0.10 | −0.01 | 0.38 | 0.47 | 0.48 | |
| RMSE | 27.536 | 27.416 | 29.07 | 22.667 | 20.96 | 20.832 | ||
| RFE_SVM-CHI | R2 | 0.06 | 0.08 | 0 | 0.38 | 0.53 | 0.49 | |
| RMSE | 27.987 | 27.699 | 28.938 | 22.748 | 19.878 | 20.665 | ||
| Embedded | Lasso | R2 | 0.17 | 0.18 | −0.01 | 0.39 | 0.53 | 0.46 |
| RMSE | 26.39 | 26.132 | 29.049 | 22.597 | 19.837 | 21.153 | ||
| Ridge | R2 | 0.09 | 0.07 | −0.03 | 0.39 | 0.48 | 0.45 | |
| RMSE | 27.562 | 27.91 | 29.285 | 22.603 | 20.88 | 21.358 | ||
| RF | R2 | 0.07 | 0.1 | 0 | 0.38 | 0.48 | 0.47 | |
| RMSE | 27.835 | 27.41 | 28.97 | 22.745 | 20.778 | 21.111 | ||
| Models | Advantages | Disadvantages |
|---|---|---|
| Filter | Fast | Ignores interaction with the regression |
| Scalable | ||
| Wrapper | Simple | Risk of overfitting |
| Interacts with the regression | Model dependent | |
| Computationally intensive | ||
| Embedded | Interacts with the regression | |
| Less complexity than Wrapper | Model dependent |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, W.; Li, W.; Xu, J.; Ma, X.; Li, C.; Liu, C. Hyperspectral Monitoring Driven by Machine Learning Methods for Grassland Above-Ground Biomass. Remote Sens. 2022, 14, 2086. https://doi.org/10.3390/rs14092086
Huang W, Li W, Xu J, Ma X, Li C, Liu C. Hyperspectral Monitoring Driven by Machine Learning Methods for Grassland Above-Ground Biomass. Remote Sensing. 2022; 14(9):2086. https://doi.org/10.3390/rs14092086
Chicago/Turabian StyleHuang, Weiye, Wenlong Li, Jing Xu, Xuanlong Ma, Changhui Li, and Chenli Liu. 2022. "Hyperspectral Monitoring Driven by Machine Learning Methods for Grassland Above-Ground Biomass" Remote Sensing 14, no. 9: 2086. https://doi.org/10.3390/rs14092086
APA StyleHuang, W., Li, W., Xu, J., Ma, X., Li, C., & Liu, C. (2022). Hyperspectral Monitoring Driven by Machine Learning Methods for Grassland Above-Ground Biomass. Remote Sensing, 14(9), 2086. https://doi.org/10.3390/rs14092086