1. Introduction
Positional accuracy has always been considered a defining and essential element of the quality of any geospatial data [
1], as it affects factors such as geometry, topology, and thematic quality; it is directly related to the interoperability of spatial data [
2]. Considering the widespread use of geospatial information and the interoperability requirements of different geomatics applications and spatial data infrastructures (SDIs), it is crucial to ensure information quality, as this is the only means of guaranteeing reliable solutions when making decisions [
3]. A particular case of geospatial data is that of digital elevation models (DEMs). Currently, there are numerous technologies (GNSS, LiDAR, InSAR, etc.) [
3,
4], which allow the generation of DEM data products with very diverse characteristics (numerical precision, spacing, grid storage, etc.) [
3,
5]. DEMs are a key data type for many applications domains because they provide the height component in GIS analysis, the geomorphological description of the land [
6], which is a reference surface for all hydrological applications (water cycle, erosion, floods, etc). In [
7], the basis for the development of forestry models [
8] and the base for agricultural parcel rating [
9] is useful in every analysis task related to civil engineering [
10]. DEMs are part of the information infrastructure to achieve the Sustainable Development Goals and are considered as Global Fundamental Geospatial Themes by the United Nations [
11]; they are also included in the list of geospatial themes of the European Spatial Infrastructure [
12]. The data model most used in the case of DEMs is the grid [
13,
14]. Usually, in the case of gridded DEMs, the evaluation of positional accuracy is limited to the errors in the altimetric component (elevation/height) (Case 1D). This 1D perspective is of interest in this document, since, without loss of generality, it allows a simpler approach to the proposed method. The positional accuracy in DEMs has a direct influence on elevation derivatives such as slope, aspect and curvature, and generates erroneous drainage network or watershed delineation [
15,
16]. Vertical positional accuracy requirements depend on the scale and specific use case; in this line, [
15,
17] present indicative accuracy values for some usual DEM applications.
Positional accuracy assessment methods (PAAMs) are standardized processes to either estimate or control the positional quality [
18] of geospatial data. The PAAMs understand the quality of the data product as the presence of errors with a limited size (e.g., lesser than a tolerance value for the bias or for the dispersion). The accuracy estimation consists of determining a reliable value of the property of interest (e.g., mean bias, standard deviation, proportion, etc.), in the data product. These methods provide a value and its corresponding confidence interval as a result (e.g., a mean value and its deviation such as 5.27 m ± 0.15 m). On the other hand, quality control involves deciding whether or not the property of interest in that data product reaches a certain quality level. These are intended to provide a statistical basis for making an acceptance/rejection decision as a consequence of compliance/noncompliance with a specification (e.g., given the specification that no more than 5% of the elements present 1D-positional errors greater than 1 m, a decision is made to accept/reject according to the evidence found in the sample). In this sense, specific recommendations for the positional assessment of DEM can be observed in [
18].
Acquisition technologies used in the positional accuracy assessment, such as Global Navigation Satellite Systems (GNSS) and LiDAR systems, enable the collection of coordinates in the field with high accuracy, which increases the possibility of more accurate positional accuracy assessments. Moreover, PAAMs have evolved over time, from the National Map Accuracy Standard (NMAS) [
19] to the more recent by the American Society for Photogrammetry and Remote Sensing, called the Positional Accuracy Standards for Digital Geospatial Data [
20], in which the statistics are based on the National Standard for Spatial Accuracy (NSSDA) [
21]. It should be noted that these PAAMs apply to both planimetric control (2D-error data) and altimetric control (1D-error data). It is interesting to analyze these three PAAMs, as they present different and complementary perspectives. The NMAS can be considered a method with capabilities to work with free-distributed data [
21]. This standard sets out a method of positional accuracy control that establishes an acceptance/rejection rule in a very simple manner, and is based on the binomial distribution applied to error counts. This standard is outdated, however, as it refers to tolerances defined on paper, that is, to the representation scale, but its conceptual basis can be applied to any tolerance value. The Engineering Map Accuracy Standards [
22] assumes that positional errors are normally distributed and proposes a set of statistical hypothesis tests that must be overcome for the product to be accepted. Specifically, it establishes two statistical tests per component, one focused on the detection of biases (Student’s
t-test) and the other on the behavior of dispersion (Chi square test). Finally, the NSSDA assumes the normality of the error data and is not a positional accuracy control method, as it does not establish acceptance or rejection; the result is a value and, therefore, is an estimation method.
The normal distribution function remains the theoretical base model for some widely used PAAMs (e.g., for the EMAS and the NSSDA) because it is a suitable distribution for representing real-valued random variables generated purely at random. In fact, what is desirable when working with measurement errors is their normal distribution, as this implies that there are no other unknown causes—which are therefore uncontrollable—that affect the measurement result. But, in practice, it is hard to find error data sets that, strictly, could be adequately modeled with one normal distribution. This circumstance has been highlighted specially for the case of DEM [
23,
24]. This can be due to various causes that can appear alone or together (e.g., many extreme values, overlap of several processes, elimination of data, distribution of values closes to zero or the natural limit, and so on). For these reasons, alternatives based on robust statistics [
25]), nonparametric models such as the observed distribution [
26], on error counting [
27] or percentiles [
28], among others, have been proposed. Therefore, we have chosen the case applied to DEMs because it offers a situation where the non-normality of the errors has already been indicated in previous studies and because dealing with 1D errors is a simpler situation than the case of 2D errors, which makes it easy to explain.
In this paper, we explore the case when, even assuming underlying normality, errors come from different normal distributions, that is to say, normal distributions with different parameters. In this case, an approach based on the use of Gaussian finite mixture models (FMM) is adequate for obtaining a whole parametric model that reproduces the empirical distribution of observed data [
29,
30,
31,
32]. This approach to the problem is chosen because the FMMs are nothing more than the extension of the traditional model based on a one-single normal distribution. This offers the user a familiar framework with the advantages of a parametric model for statistical inference questions. In addition, FMMs offer enough robustness and adaptability to particular distributions that can demonstrate the very varied possible use cases.
In this work, a double objective is pursued. Firstly, to study the distribution of the estimators in the sampling under the FMM, which allows proposing specific hypothesis tests for the fitted model, and secondly, to apply this study to various positional accuracy standards (specifically NMAS, EMAS and NSSDA) , for which the theoretical framework is defined, the procedure is developed and it is verified how its use improves the results obtained under the assumption of a single normal distribution. Therefore, our ultimate goal is just to propose a parametric model that can replace the normal univariate statistical model (widely accepted and applied) and that can be used in all cases that are required, but not to develop a new model (theoretical or empirical) for the uncertainty or new specific indices for the evaluation of positional accuracy.
After this section, the conceptual bases of the finite mixture model are presented. In
Section 3, an overview of the methods is presented, which includes the adjustment process of the FMM and the simulation process to analyse the behavior when applied to the selected PAAMs.
Section 4 presents the data; these are altimetric discrepancies from two digital terrain models.
Section 5 shows the results obtained and the application to the different standards.It is long because it presents the results of the FMM adjustment process and also of the simulation process for the three PAAMs under analysis. The
Section 6 and
Section 7 are devoted to presenting the discussions and conclusions.
2. Finite Mixture Models
This article proposes the application of the finite Gaussian mixture model methodology to fit a set of measurement errors. A detailed analysis can be observed in [
29,
30,
31,
32] and may be summarized as follows:
Let the vector of observed errors
, a random sample that comes from a mixture of
distributions
, in the way that each of which appears with a proportion
in the mixture,
. Then, the value of the density function of each
is given by:
Which implies estimating the vector of parameters
of dimension
.
The estimation of
(
2) is made with the
algorithm [
30,
33,
34,
35], which is obtained iteratively through the operator
where
,
is the value of the iteration
t and the expectation refers to the distribution of
of
c given
x for the value
of the parameter.
In this way,
g groups are calculated. The posterior probability of pertaining to the group
is given by
and each sample point
is assigned to the group where
is maximum.
The final density function is:
where
are obtained in (
4).
In order to determine the best value of
g (the final number of mixing distributions), the use of some information criteria to choose the best fitted model is proposed. In this case, they are the Akaike Information Criteria,
and the Bayesian Information Criteria,
(see for instance [
36,
37]):
where
is the log-likelihood value in the estimation with
g groups and
is the number of estimated parameters (
2). In both cases, the best value of
g corresponds to the one in which the value obtained by
or
is the minimum. The difference between both measures is the presence in the
of the sampling size
n in order to correct the criterion value. This criterion penalizes models with a greater number of estimated parameters by replacing the term “
” by “
”, thus obtaining models of lower order than those obtained by the
, which allows for correcting the tendency to overestimate. To implement the calculations, the package
mixtools of R [
38,
39] has been employed.
Once selected, the theoretical model provides a whole description about the population where data come from, and all population probabilities and parameters can be calculated. In this case:
Variance:
and, in consequence,
4. Discrepancy Data for the Application Case
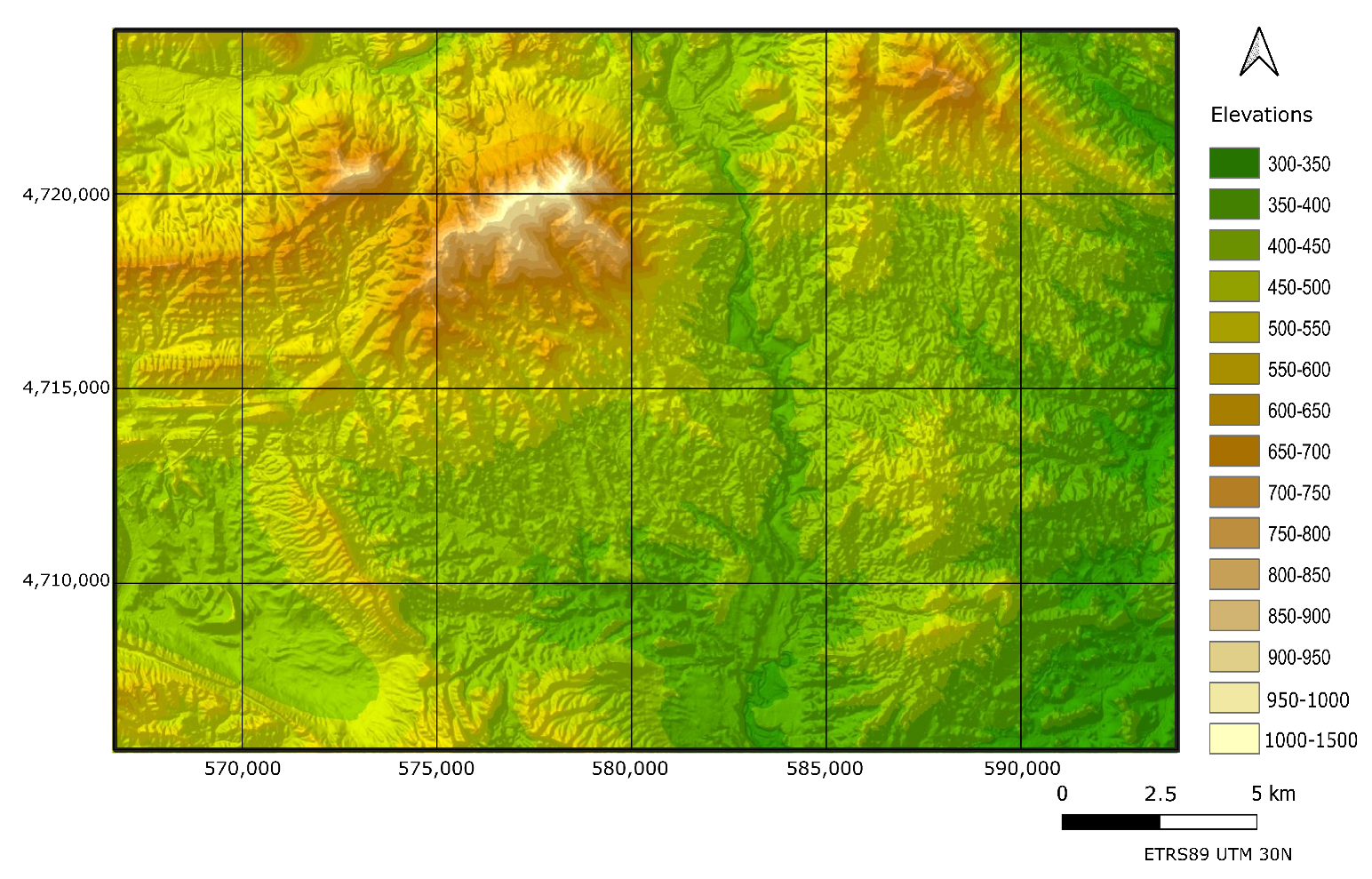
In order to simplify the example case,
-positional-error data are used. In any case, the process shown here is valid for all PAAMs that consider the components of the horizontal positional error (
and
) as one-dimensional normal variables. In this study case, the errors are vertical and the
and
models will be applied to discrepancy data (errors) obtained in a study area around Allo (Navarra, Spain). It is a mid-mountain area of 504 km
, where the elevation varies between 316 and 1046 m; the average elevation is 468 m and the standard deviation of elevations is 92.8 m. A map of the studied area appears on
Figure 2.
Discrepancy is derived as the difference between two DEMs:
where
: elevation in position i of a DEM product;
: elevation in position i of a reference;
: discrepancy in elevation in position i.
In this study, the DEM data sets are:
(Reference): DEM02. In this case, it is a gridded DEM (
m resolution). Its primary data source is an aerial LiDAR survey obtained in 2017 (second coverage of the PNOA-LiDAR project
https://pnoa.ign.es/estado-del-proyecto-lidar/segunda-cobertura, accessed on 28 March 2022). The informed positional accuracies for the DEM are
cm and
cm.
(Product): DEM05 is a gridded DEM (
m resolution) that comes from an aerial LiDAR survey obtained in 2012 (first coverage of the PNOA-LiDAR project
https://pnoa.ign.es/estado-del-proyecto-lidar/primera-cobertura, accessed on 28 March 2022). The informed positional accuracies for the DEM are
cm and
cm.
Both data sets can be considered independent in their generation. However, the one used as a reference (DEM02) does not meet the criteria of being a true reference because its accuracy is not at least three times better than that of the product to be evaluated (DEM05). However, this circumstance does not invalidate the proposed procedure and the results obtained from its application.
Both DEM data sets are freely available on the webpage,
http://www.ign.es, (accessed on 30 March 2022) of the National Geographic Institute of Spain (IGN), and have the same spatial reference system ETRS89 UTM Zone 30N.
To ensure the overlap of the two grids, and not degrade the quality of the reference (DEM02), the DEM05 data set was interpolated with a 2 × 2 mesh step by means of a bilinear interpolation. Following the variance prediction model for the case of bilinear interpolation developed by [
4], considering the equality of all the variances of the four positions that intervene in the bilinear interpolation, and the case of a high altimetric correlation; the average variance of the predictor of an altimetric value over any position is equivalent to the variance of the positions involved in the interpolation. In our case, according to the information provided by the metadata, it can be considered to be of the order of 50 cm.
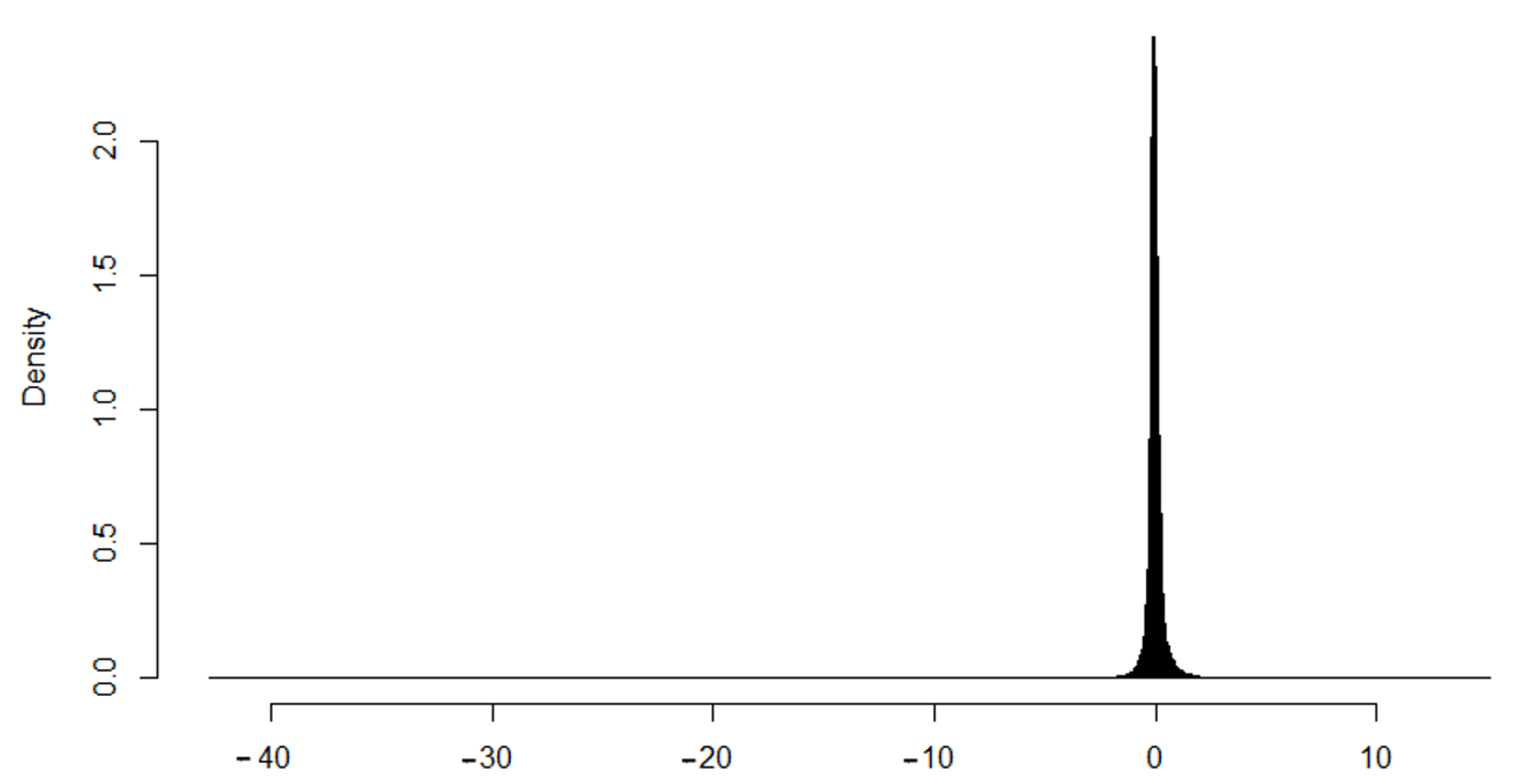
The points analyzed have been obtained through a systematic sampling, for which a grid of 578 rows and 853 columns was generated, which provides a sample size of
n = 493,034. The discrepancies are in the interval (
) m; the mean value of the discrepancies is 0.00062 m and the standard deviation 0.41835 m. A general spatial vision of discrepancies appears in
Figure 3. Usually, the values assumed for the discrepancies between a product and a reference must be close to zero, but in this case, the above-mentioned observed interval means the presence of extreme values (outliers). Therefore, these data present some extreme points, both on the left and the right. Moreover, the Fisher asymmetry coefficient is
and the Fisher coefficient of kurtosis is 1009.753; both of them are very high in respect to the normal distribution.
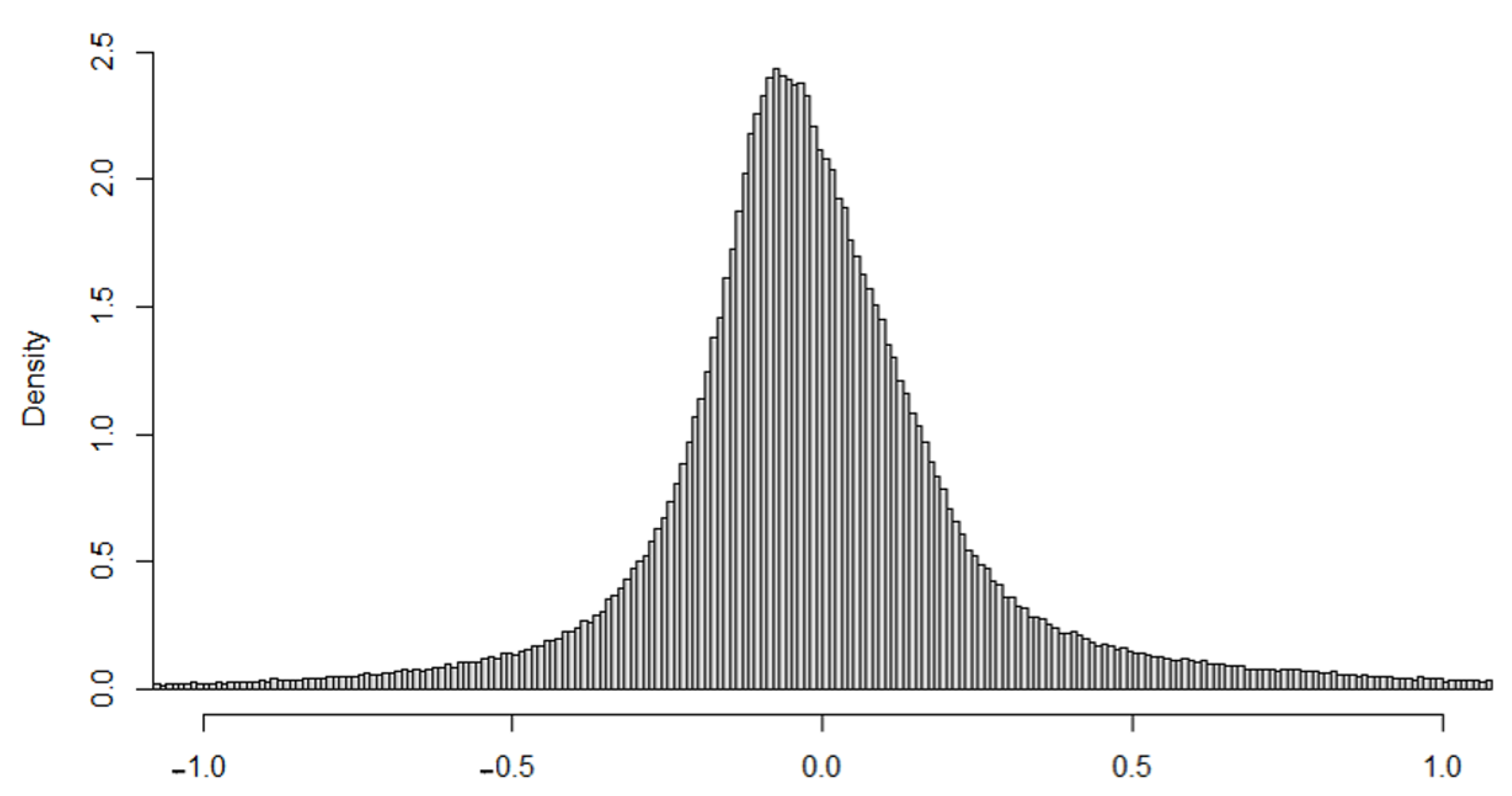
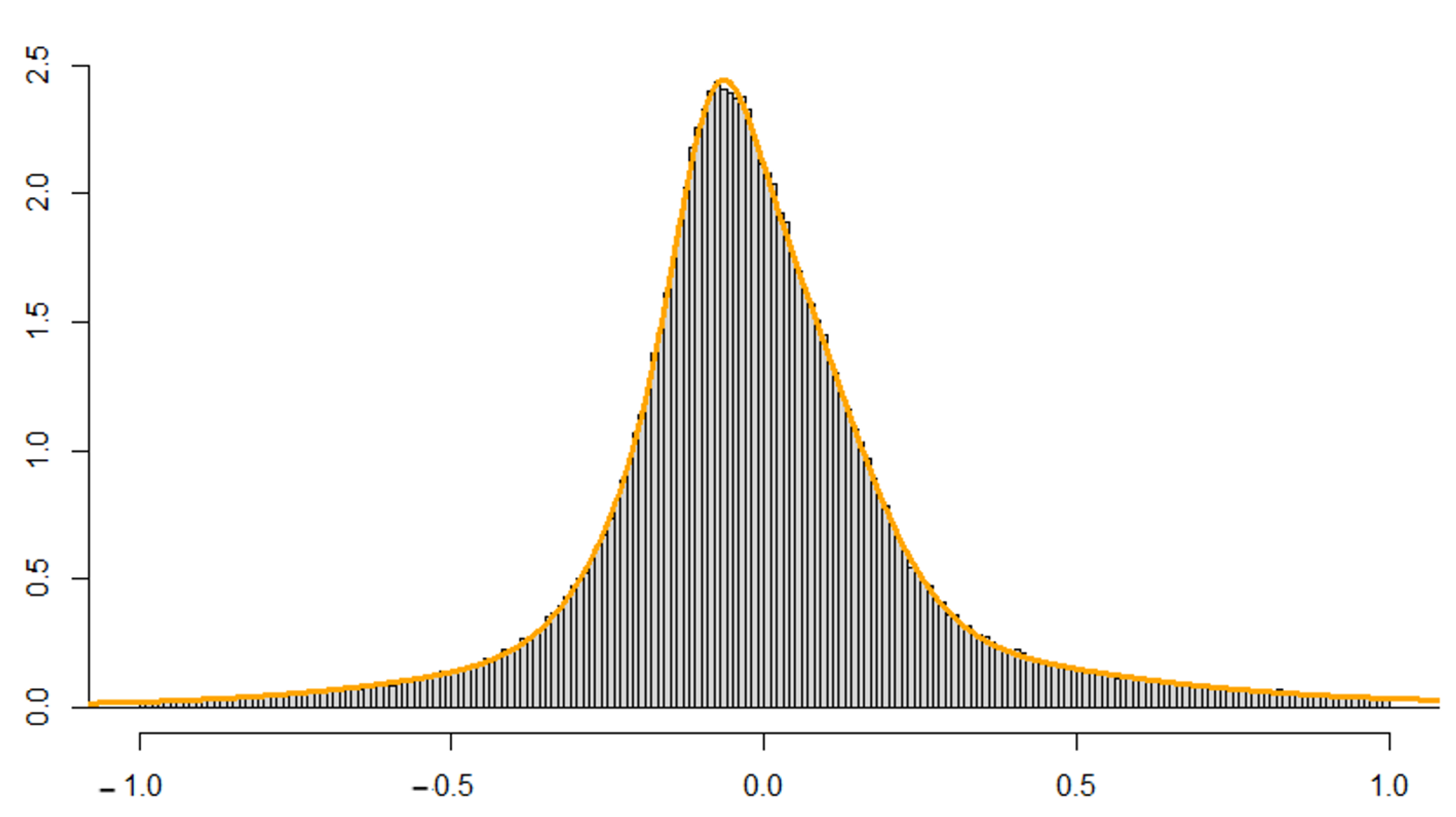
Figure 4 shows the data histogram of the complete data set. Due to the presence of a relatively small number of extreme values, and the histogram showing the distribution concentrated around 0, and due to the effect of the scale of the
x axis, the values farthest from 0 are not visible. In order to see the shape of the histogram in more detail,
Figure 5 shows the histogram constrained to the interval
, which contains 97.69% of observed discrepancies.
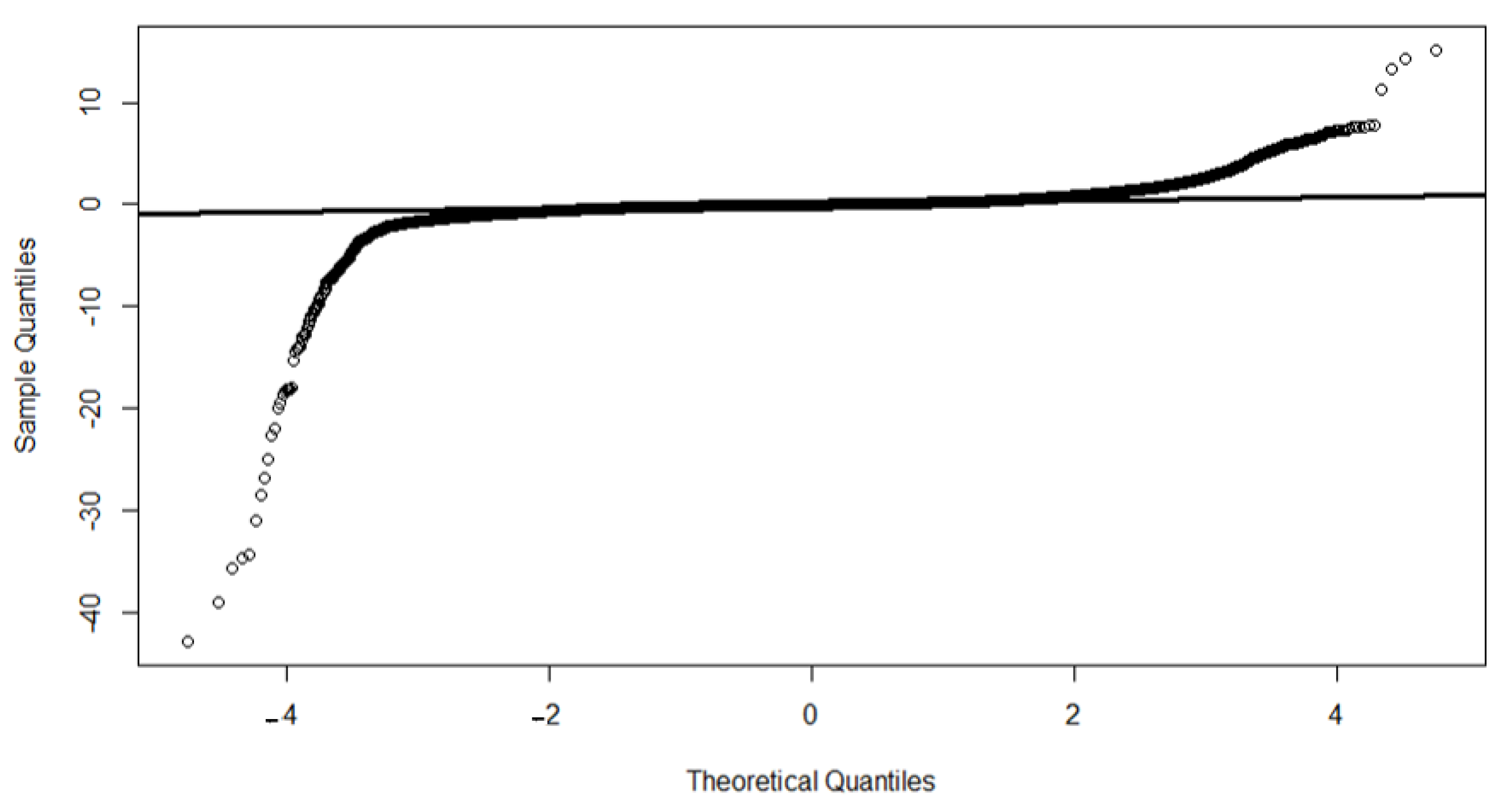
Finally, the overall non-normality of discrepancy data may be also observed in
Figure 6, where the QQ-plot is shown together with the expected normal line. These graphics suggest a great deviation of expected normality. This situation opens the possibility that the underlying discrepancy data model comes from a finite mixture of normal distributions.
6. Discussion
In relation to the , we can highlight that they are a fully developed and applied statistical tools in other fields; however, we do not have knowledge of their application to the case of spatial data, and even less on the subject of positional accuracy. The application of is not complex, as has been evidenced in the work; in addition, to show a simpler case we have only worked in 1D (elevation discrepancies). However, the model is directly applicable to 2D and 3D cases if the coordinates and their associated errors are considered independently. Since the tools to fit the model exist, and the selection criteria are common (e.g., AIC, BIC), the most critical aspect is the sample size to make a good fit. This size will depend a lot on the data to be adjusted (informational structure); thus, there is no possibility of offering quantitative recommendations. Obviously, the bigger the sampling size is, more accurate the estimation is, especially if the hypothesis of a mixture is true. As a first idea, the sample size should be as big as possible, but an important limitation is given by the obtention cost of the sample.
In any case, it is best to proceed with empirical testing; for instance, by some simulation procedures, we found that sample sizes greater than 2000 produce acceptable results regarding the distance between the obtained model (the fitted
) and the real data (the
). An interesting aspect that has not been explored in this work is that once the MMF has been obtained, its results may have other applications. For example, through the estimated model, a grouping can be provided, which is intrinsic to the data and that, unlike the cluster analysis, does not need additional explanatory variables, since it is produced by the ascription of each discrepancy case to that one mixing distribution to which it is most likely to belong. These groups can also try to be interpreted using multivariate statistical techniques such as discriminant analysis, logistic regression, etc. In addition, if other variables are available (e.g., slope, aspect, type of terrain and so on), this situation can help to better understand the nature of the mixing distributions (see, for instance, [
31,
32,
43,
44,
45]). The BIC criterion has led us to select a model with seven components. This model offers a majority component (fifth component with 52% of the weight), three components with weights between 5% and 20% and other very minor components, two of them linked to extreme values (atypical/outlier values in the
case). We really do not know if a model with fewer components would work pretty much the same as this seven component model; however, this is not really a problem, because once it is decided to use an
type adjustment, its dimension (number of components) is easily managed by means of any statistical tool. For this reason, we consider that the following selection criteria based on BIC offers the same solution, impartial and objective, to anyone who performs the same process on the same data, which allows the method to be standardized.
In relation to the discrepancy data values used in this paper, the analysis carried out comparing the results of the
with the
and the observed data (
) clearly show that the
offers much more consistent results with the real population than the
. Thus, the difference in values between the
and the MMF is very small in all the cases presented in
Table 3,
Table 4 and
Table 12. Moreover, if the
is compared with the MMF and the
, it can be observed that the difference in quantile distance has reached 23% in the case of 90% quantile (
Table 3). In the case of probabilities (
Table 4), the probability difference between
, the MMF and the
in the analyzed intervals has reached 0.3 (case
), which means 30% of discrepancy. The above two examples are cases of maximum difference, but on average, the difference is also quite a lot. This clearly demonstrates that the
model is not suitable for modeling data such as those used in this paper.
Finally, we will pay attention to the results when considering commonly used standards for positional accuracy assessment. In this case, the most important thing is the adjustment to the level of significance, as it is the risk of the producer that is assumed in a statistical process of control. As shown by
Table 8 for the NMAS, the
performs statistically much better than the
when considering all the tolerance values and sample sizes used in the analysis. In the case of the
, the values are usually less than 5%, which indicates that its statistical behavior is not “as expected”.
Table 11 presents the main results for the case of the EMAS. The first conclusion is the need of a Bonferroni correction when applying the EMAS. For both significance levels (0.05 and 0.1), the rejection level by the
is a little less than the prescribed level; the differences are in the order [2.1, 1.5]% (always less). The contrary occurs for the
; the differences are in the order [5.6, 7.4]% (always more). We consider that these differences with respect to the consigned value are really high. In this case, there exists an excess of rejection that harms the producer, with the consequent problems that this can also generate for the user. The NSSDA is not a statistical test, although it can be understood that it considers a process of acceptance/rejection by the user, as the latter must ask himself whether the result of the estimation seems adequate or not for his application. If we consider that this process is based on the simple comparison of values (estimated by the sample versus the theoretical),
Table 12 indicates the acceptance for all sample sizes and models, and a very similar behavior of the three approaches is under consideration.
7. Conclusions
We consider that statistical models based on finite mixtures of normal distributions allow a better approximation to actual altimetric errors, as shown by its ability to fit the observed data. The method and the tools for the application of this alternative are already developed, and its application is quite direct. The main limitation of the use of s is the need for large sample sizes to fit the parameters of the mixing distributions. Furthermore, no simple rule can be offered to establish this size. For the application phase of the FMMs using PAAMs, larger sample sizes will be needed, but, in any case, in the order of the previous recommendations for these standards.
The use of the s as the statistical models for the application of the PAAMs analyzed (NMAS, EMAS and NSSDA), generates improvements in the behavior of the results for those standards based on statistical hypotheses tests (e.g., NMAS and EMAS). In this case, the s application offers results with a better approximation to the levels of significance. If the PAAM is not based on a statistical process, as it is here analyzed for the NSSDA, it does not have such a clear advantage.
Since FMM is a statistical model obtained from the numerical values of the errors, it does not necessarily have to be associated, a priori, with an underlying physical model of the soil. Therefore it can be considered as a black box system, which is common for PAAMs of this type. However, a posteriori, the FMM could be used to analyze the spatial distribution of the mixing distributions in order to get a more ground-based interpretation of the error distribution and the reason of its allocation to each component of the FMM. We believe that this could be of great interest if some relationship is achieved with variables that have traditionally been considered to explain the altimetry error (e.g., slope, vegetation cover). We consider this to be a future line of research that could help establish the use of FMMs for DEM error assessment and analysis.
In this paper, the application has been developed for the case of 1D errors, and for this reason we worked with DEMs, but the method is directly applicable to the case of 2D errors, if the X and Y components are considered independently. Let us bear in mind that the proposed method provides a parametric statistical model, which, once estimated, allows us to work through population values. Therefore, its use is not limited to the case of altimetry errors, which is what has been developed here; it is also useful for obtaining probabilistic models in any set of quantitative measurements, such as slopes or the values of heights themselves. This would allow them to be used, for example, to compare between different areas, or even in the same area in different periods of time. Likewise, knowledge of the theoretical model allows its use when proposing more precise and exact contrasts appropriate to the nature of the data.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}