RelationRS: Relationship Representation Network for Object Detection in Aerial Images


Abstract
:
1. Introduction
2. Related Work
2.1. Object Detection of Aerial Images
2.2. Multi-Scale Feature Representations
2.3. Conditional Convolution Mechanism
3. Proposed Method
3.1. Dual Relationship Module (DRM)
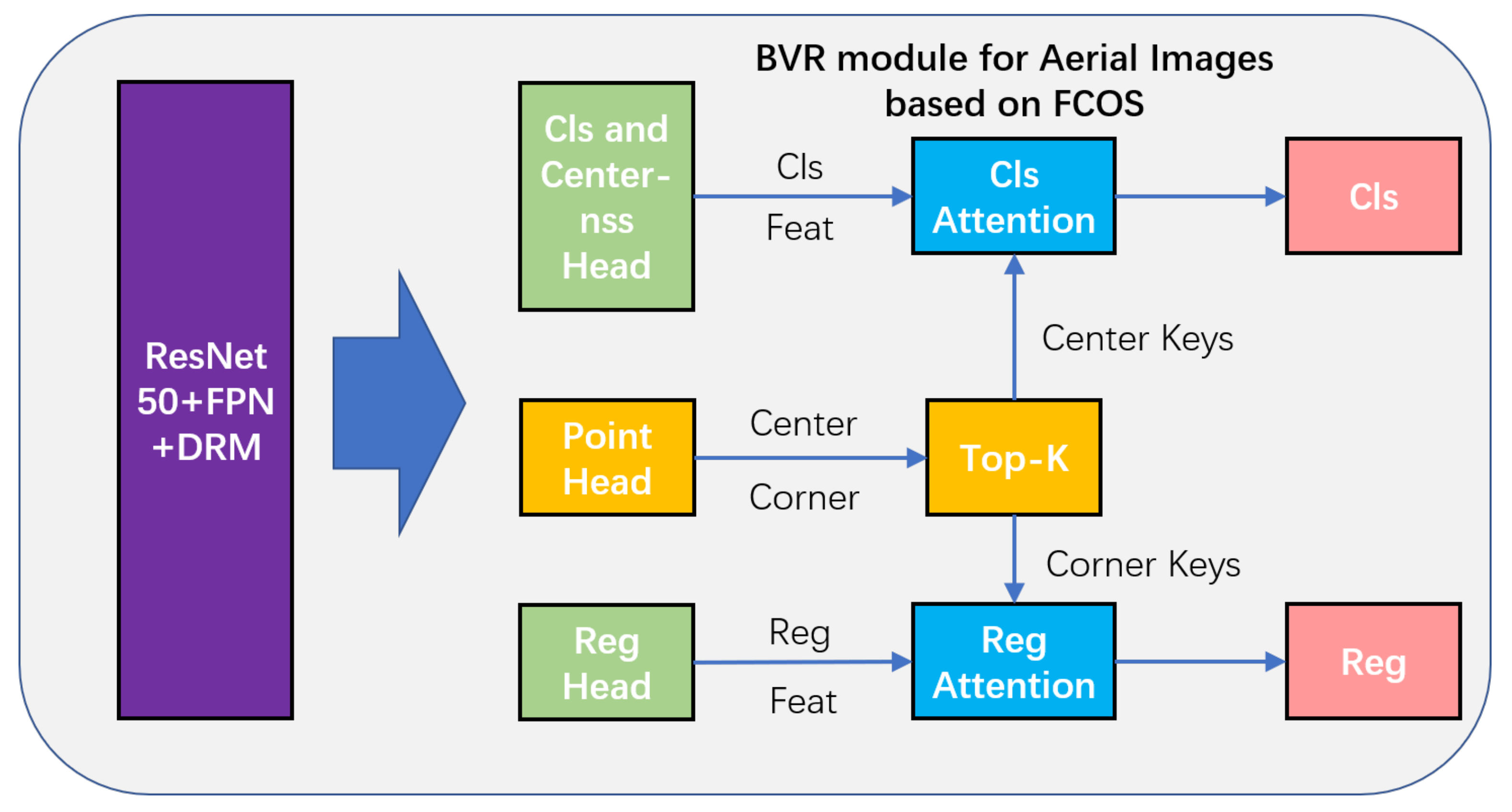
3.2. Bridging Visual Representations for Object Detection in Aerial Images
4. Experiments and Results
4.1. Dataset
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Ablation Experiments
4.4.1. Dual Relationship Module
4.4.2. Bridging Visual Representations for Object Detection in Aerial Images
4.5. Comparison with the State-of-the-Art
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xia, G.S.; Bai, X.; Zhang, L.P.; Serge, B.; Marcello, P. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Li, C.; Luo, B.; Hong, H.; Su, X.; Wang, Y.; Liu, J.; Wang, C.; Zhang, J.; Wei, L. Object Detection Based on Global-Local Saliency Constraint in Aerial Images. Remote Sens. 2020, 12, 1435. [Google Scholar] [CrossRef]
- Li, C.; Liu, J.; Hong, H.; Mao, W.; Wang, C.; Hu, C.; Su, X.; Luo, B. Object Detection based on OcSaFPN in Aerial Images with Noise. arXiv 2020, arXiv:2012.09859. [Google Scholar]
- Huyan, L.; Bai, Y.; Li, Y.; Jiang, D.; Zhang, Y.; Zhou, Q.; Wei, J.; Liu, J.; Zhang, Y.; Cui, T. A Lightweight Object Detection Framework for Remote Sensing Images. Remote Sens. 2021, 13, 683. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship Rotated Bounding Box Space for Ship Extraction From High-Resolution Optical Satellite Images With Complex Backgrounds. IEEE Geosci. Remote Sens. Lett. 2017, 13, 1074–1078. [Google Scholar] [CrossRef]
- Yang, F.; Xu, Q.; Li, B. Ship Detection From Optical Satellite Images Based on Saliency Segmentation and Structure-LBP Feature. IEEE Geosci. Remote Sens. Lett. 2017, 14, 602–606. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A Survey on Object Detection in Optical Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; Lecun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–26 April 2014. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9627–9636. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Law, H.; Teng, Y.; Russakovsky, O.; Deng, J. CornerNet-Lite: Efficient Keypoint Based Object Detection. arXiv 2019, arXiv:1904.08900. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Shi, J. FoveaBox: Beyond Anchor-based Object Detector. arXiv 2019, arXiv:1904.03797. [Google Scholar]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Dong, Y.; Chen, F.; Han, S.; Liu, H. Ship Object Detection of Remote Sensing Image Based on Visual Attention. Remote Sens. 2021, 13, 3192. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A context-aware detection network for objects in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef] [Green Version]
- Cheng, C.; Wei, F.; Hu, H. Relationnet++: Bridging visual representations for object detection via transformer decoder. arXiv 2020, arXiv:2010.15831. [Google Scholar]
- Zou, Z.; Shi, Z. Ship detection in spaceborne optical image with SVD networks. IEEE Trans. Geosci. Remote Sens. 2017, 54, 5832–5845. [Google Scholar] [CrossRef]
- Van de Sande, K.E.; Uijlings, J.R.; Gevers, T.; Smeulders, A.W. Segmentation as selective search for object recognition. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–11 November 2011; p. 7. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Dong, R.; Xu, D.; Zhao, J.; Jiao, L.; An, J. Sig-NMS-Based Faster R-CNN Combining Transfer Learning for Small Target Detection in VHR Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8534–8545. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Zou, H. Toward fast and accurate vehicle detection in aerial images using coupled region-based convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3652–3664. [Google Scholar] [CrossRef]
- Xiao, Z.; Gong, Y.; Long, Y.; Li, D.; Wang, X.; Liu, H. Airport detection based on a multiscale fusion feature for optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1469–1473. [Google Scholar] [CrossRef]
- Xu, Z.; Xu, X.; Wang, L.; Yang, R.; Pu, F. Deformable convnet with aspect ratio constrained nms for object detection in remote sensing imagery. Remote Sens. 2017, 9, 1312. [Google Scholar] [CrossRef] [Green Version]
- Ren, Y.; Zhu, C.; Xiao, S. Small object detection in optical remote sensing images via modified faster R-CNN. Appl. Sci. 2018, 8, 813. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Hamaguchi, R.; Fujita, A.; Nemoto, K.; Imaizumi, T.; Hikosaka, S. Effective use of dilated convolutions for segmenting small object instances in remote sensing imagery. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1442–1450. [Google Scholar]
- Yu, F.; Vladlen, K. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Wu, Y.; Zhang, K.; Wang, J.; Wang, Y.; Wang, Q.; Li, Q. CDD-Net: A Context-Driven Detection Network for Multiclass Object Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Qiu, H.; Li, H.; Wu, Q.; Meng, F.; Ngan, K.N.; Shi, H. A2RMNet: Adaptively Aspect Ratio Multi-Scale Network for Object Detection in Remote Sensing Images. Remote Sens. 2019, 11, 1594. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Ma, J.Q.; Shao, W.Y.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.B.; Xue, X.Y. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimedia 2018, 20, 3111–3122. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-insensitive and context-augmented object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2337–2348. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.X.; Lu, Q.K. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2844–2853. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8232–8241. [Google Scholar]
- Fang, Y.; Ding, G.; Li, J.; Fang, Z. Deep3DSaliency: Deep Stereoscopic Video Saliency Detection Model by 3D Convolutional Networks. IEEE Trans. Image Process. 2019, 28, 2305–2318. [Google Scholar] [CrossRef] [PubMed]
- Jian, M.; Wang, J.; Yu, H.; Wang, G.; Meng, X.; Yang, L.; Dong, J.; Yin, Y. Visual saliency detection by integrating spatial position prior of object with background cues. Expert Syst. Appl. 2021, 168, 114219. [Google Scholar] [CrossRef]
- Li, Y.; Huang, Q.; Pei, X.; Jiao, L.; Shang, R. RADet: Refine Feature Pyramid Network and Multi-Layer Attention Network for Arbitrary-Oriented Object Detection of Remote Sensing Images. Remote Sens. 2020, 12, 389. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Ding, J.; Guo, H.; Cheng, W.; Pan, T.; Yang, W. Mask OBB: A Semantic Attention-Based Mask Oriented Bounding Box Representation for Multi-Category Object Detection in Aerial Images. Remote Sens. 2019, 11, 2930. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Li, C.; Xu, C.; Cui, Z.; Wang, D.; Jie, Z.; Zhang, T.; Yang, J. Learning object-wise semantic representation for detection in remote sensing imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 20–27. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Du, J.; Wu, X. Adaptive period embedding for representing oriented objects in aerial images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7247–7257. [Google Scholar] [CrossRef] [Green Version]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-aware and multi-scale convolutional neural network for object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Xue, N.; Xia, G. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 2786–2795. [Google Scholar]
- Van Etten, A. You only look twice: Rapid multi-scale object detection in satellite imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Wang, P.; Sun, X.; Diao, W.; Fu, K. FMSSD: Feature-merged single-shot detection for multiscale objects in large-scale remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3377–3390. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Random access memories: A new paradigm for target detection in high resolution aerial remote sensing images. IEEE Trans. Image Process. 2017, 27, 1100–1111. [Google Scholar] [CrossRef]
- Yang, X.; Liu, Q.; Yan, J.; Li, A.; Zhang, Z.; Yu, G. R3det: Refined single-stage detector with feature refinement for rotating object. arXiv 2019, arXiv:1908.05612. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Zhou, P.; Ni, B.; Geng, C.; Hu, J.; Xu, Y. Scale-Transferrable Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 528–537. [Google Scholar]
- Kong, T.; Sun, F.; Tan, C.; Liu, H.; Huang, W. Deep feature pyramid reconfiguration for object detection. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 169–185. [Google Scholar]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. Augfpn: Improving multi-scale feature learning for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 14–29 June 2020; pp. 12595–12604. [Google Scholar]
- Wang, C.; Li, C.; Liu, J.; Luo, B.; Su, X.; Wang, Y.; Gao, Y. U2-ONet: A Two-Level Nested Octave U-Structure Network with a Multi-Scale Attention Mechanism for Moving Object Segmentation. Remote Sens. 2021, 13, 60. [Google Scholar] [CrossRef]
- Ghiasi, G.; Lin, T.; Le, Q. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7036–7045. [Google Scholar]
- Chen, B.; Ghiasi, G.; Liu, H.; Lin, T.; Kalenichenko, D.; Adam, H.; Le, Q. Mnasfpn: Learning latency-aware pyramid architecture for object detection on mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 14–29 June 2020; pp. 13607–13616. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 14–29 June 2020; pp. 10781–10790. [Google Scholar]
- Jia, X.; De Brabandere, B.; Tuytelaars, T.; Gool, L. Dynamic filter networks. Adv. Neural Inf. Process Syst. 2016, 29, 667–675. [Google Scholar]
- Ha, D.; Dai, A.; Le, Q. Hypernetworks. arXiv 2016, arXiv:1609.09106. [Google Scholar]
- Shen, F.; Yan, S.; Zeng, G. Neural style transfer via meta networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8061–8069. [Google Scholar]
- Jo, Y.; Oh, S.W.; Kang, J.; Kim, S. Deep video super-resolution network using dynamic upsampling filters without explicit motion compensation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3224–3232. [Google Scholar]
- Hu, X.; Mu, H.; Zhang, X.; Wang, Z.; Tan, T.; Sun, J. Meta-SR: A magnification-arbitrary network for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1575–1584. [Google Scholar]
- Yang, B.; Bender, G.; Le, Q.; Ngiam, J. Condconv: Conditionally parameterized convolutions for efficient inference. arXiv 2019, arXiv:1904.04971. [Google Scholar]
- Wu, J.; Li, D.; Yang, Y.; Bajaj, C.; Ji, X. Dynamic filtering with large sampling field for convnets. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 185–200. [Google Scholar]
- Harley, A.; Derpanis, K.; Kokkinos, I. Segmentation-aware convolutional networks using local attention masks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5038–5047. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H. Conditional convolutions for instance segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2018; pp. 282–298. [Google Scholar]
- Xue, T.; Wu, J.; Bouman, K.L.; Freeman, W. Visual dynamics: Probabilistic future frame synthesis via cross convolutional networks. arXiv 2016, arXiv:1607.02586. [Google Scholar]
- Sagong, M.; Shin, Y.; Yeo, Y.; Park, S.; Ko, S. cGANs with Conditional Convolution Layer. arXiv 2019, arXiv:1906.00709. [Google Scholar]
- Liu, X.; Yin, G.; Shao, J.; Wang, X.; Li, H. Learning to predict layout-to-image conditional convolutions for semantic image synthesis. arXiv 2019, arXiv:1910.06809. [Google Scholar]
- Liu, L.; Chen, X.; Zhu, S.; Tan, P. CondLaneNet: A Top-to-down Lane Detection Framework Based on Conditional Convolution. arXiv 2021, arXiv:2105.05003. [Google Scholar]
- Yang, K.; Yi, J.; Chen, A.; Liu, J.; Chen, W. ConDinet++: Full-Scale Fusion Network Based on Conditional Dilated Convolution to Extract Roads From Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Sutskever, I.; Hinton, G.E.; Krizhevsky, A. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 60, 1097–1105. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the International Conferenceon Neural Information Processing Systems, Lake Tahoe, ND, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Sun, P.; Chen, G.; Luke, G.; Shang, Y. Salience biased loss for object detection in aerial images. arXiv 2018, arXiv:1810.08103. [Google Scholar]
- Wang, P.; Sun, X.; Diao, W.; Fu, K. Mergenet: Feature-merged network for multi-scale object detection in remote sensing images. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28–2 July–August 2019; pp. 238–241. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Plane | BD | Bridge | GTF | SV | LV | Ship | TC | mAP(%) |
|---|---|---|---|---|---|---|---|---|---|
| BC | ST | SBF | RA | Harbor | SP | HC | |||
| baseline | 88.12 | 70.77 | 44.04 | 47.46 | 76.36 | 65.34 | 77.96 | 90.83 | 64.25 |
| 74.31 | 78.37 | 48.3 | 52.62 | 72.25 | 42.77 | 34.27 | |||
| +DRM | 87.95 | 71.66 | 44.1 | 52.48 | 78.02 | 68.41 | 82.93 | 90.83 | 65.63 |
| 68.91 | 84.85 | 44.09 | 53.6 | 72.44 | 43.42 | 40.73 |
| Method | Plane | BD | Bridge | GTF | SV | LV | Ship | TC | mAP(%) |
|---|---|---|---|---|---|---|---|---|---|
| BC | ST | SBF | RA | Harbor | SP | HC | |||
| baseline | 88.12 | 70.77 | 44.04 | 47.46 | 76.36 | 65.34 | 77.96 | 90.83 | 64.25 |
| 74.31 | 78.37 | 48.3 | 52.62 | 72.25 | 42.77 | 34.27 | |||
| +BVR | 89.32 | 72.75 | 45.21 | 53.01 | 78.36 | 65.65 | 78.74 | 90.83 | 65.92 |
| 72.88 | 80.27 | 45.42 | 52.36 | 72.12 | 47.78 | 44.07 |
| Method | Plane | BD | Bridge | GTF | SV | LV | Ship | TC | mAP(%) |
|---|---|---|---|---|---|---|---|---|---|
| BC | ST | SBF | RA | Harbor | SP | HC | |||
| YOLOv3-tiny [18] | 61.48 | 24.35 | 4.3 | 15.49 | 20.27 | 30.22 | 26.96 | 72 | 25.73 |
| 26.21 | 22.91 | 14.05 | 7.27 | 28.78 | 27.07 | 4.55 | |||
| SSD [21] | 57.85 | 32.79 | 16.14 | 18.67 | 0.05 | 36.93 | 24.74 | 81.16 | 29.86 |
| 25.1 | 47.47 | 11.22 | 31.53 | 14.12 | 9.09 | 0 | |||
| YOLOv2 [17] | 76.9 | 33.87 | 22.73 | 34.88 | 38.73 | 32.02 | 52.37 | 61.65 | 39.2 |
| 48.54 | 33.91 | 29.27 | 36.83 | 36.44 | 38.26 | 11.61 | |||
| RetinaNet [23] | 78.22 | 53.41 | 26.38 | 42.27 | 63.64 | 52.63 | 73.19 | 87.17 | 50.39 |
| 44.64 | 57.99 | 18.03 | 51 | 43.39 | 56.56 | 7.44 | |||
| YOLOv3 [18] | 79 | 77.1 | 33.9 | 68.1 | 52.8 | 52.2 | 49.8 | 89.9 | 60 |
| 74.8 | 59.2 | 55.5 | 49 | 61.5 | 55.9 | 41.7 | |||
| SBL [91] | 89.15 | 66.04 | 46.79 | 52.56 | 73.06 | 66.13 | 78.66 | 90.85 | 64.77 |
| 67.4 | 72.22 | 39.88 | 56.89 | 69.58 | 67.73 | 34.74 | |||
| [92] | 88.1 | 82.4 | 47.7 | 72.9 | 45.9 | 73.5 | 64.4 | 90.4 | 66.3 |
| 66.7 | 50.1 | 54 | 60.1 | 77.8 | 51.7 | 69.5 | |||
| baseline [22] | 88.12 | 70.77 | 44.04 | 47.46 | 76.36 | 65.34 | 77.96 | 90.83 | 64.25 |
| 74.31 | 78.37 | 48.3 | 52.62 | 72.25 | 42.77 | 34.27 | |||
| +DRM | 87.95 | 71.66 | 44.1 | 52.48 | 78.02 | 68.41 | 82.93 | 90.83 | 65.63 |
| 68.91 | 84.85 | 44.09 | 53.6 | 72.44 | 43.42 | 40.73 | |||
| +BVR | 89.32 | 72.75 | 45.21 | 53.01 | 78.36 | 65.65 | 78.74 | 90.83 | 65.92 |
| 72.88 | 80.27 | 45.42 | 52.36 | 72.12 | 47.78 | 44.07 | |||
| RelationRS | 88.27 | 72.96 | 45.47 | 53.7 | 79.73 | 70.98 | 82.38 | 90.83 | 66.81 |
| 69.86 | 83.29 | 45.26 | 54.61 | 72.79 | 47.85 | 44.18 |
| Method | FPS (fps) | Memory (MByte) |
|---|---|---|
| baseline | 11.65 | 1691 |
| +BVR | 7.97 | 2081 |
| RelationRS | 7.67 | 2157 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Zhang, X.; Liu, C.; Wang, H.; Sun, C.; Li, B.; Huang, P.; Li, Q.; Liu, Y.; Kuang, H.; et al. RelationRS: Relationship Representation Network for Object Detection in Aerial Images. Remote Sens. 2022, 14, 1862. https://doi.org/10.3390/rs14081862
Liu Z, Zhang X, Liu C, Wang H, Sun C, Li B, Huang P, Li Q, Liu Y, Kuang H, et al. RelationRS: Relationship Representation Network for Object Detection in Aerial Images. Remote Sensing. 2022; 14(8):1862. https://doi.org/10.3390/rs14081862
Chicago/Turabian StyleLiu, Zhiming, Xuefei Zhang, Chongyang Liu, Hao Wang, Chao Sun, Bin Li, Pu Huang, Qingjun Li, Yu Liu, Haipeng Kuang, and et al. 2022. "RelationRS: Relationship Representation Network for Object Detection in Aerial Images" Remote Sensing 14, no. 8: 1862. https://doi.org/10.3390/rs14081862
APA StyleLiu, Z., Zhang, X., Liu, C., Wang, H., Sun, C., Li, B., Huang, P., Li, Q., Liu, Y., Kuang, H., & Xiu, J. (2022). RelationRS: Relationship Representation Network for Object Detection in Aerial Images. Remote Sensing, 14(8), 1862. https://doi.org/10.3390/rs14081862