
Correcting the Results of CHM-Based Individual Tree Detection Algorithms to Improve Their Accuracy and Reliability





Abstract
1. Introduction
2. Materials and Methods
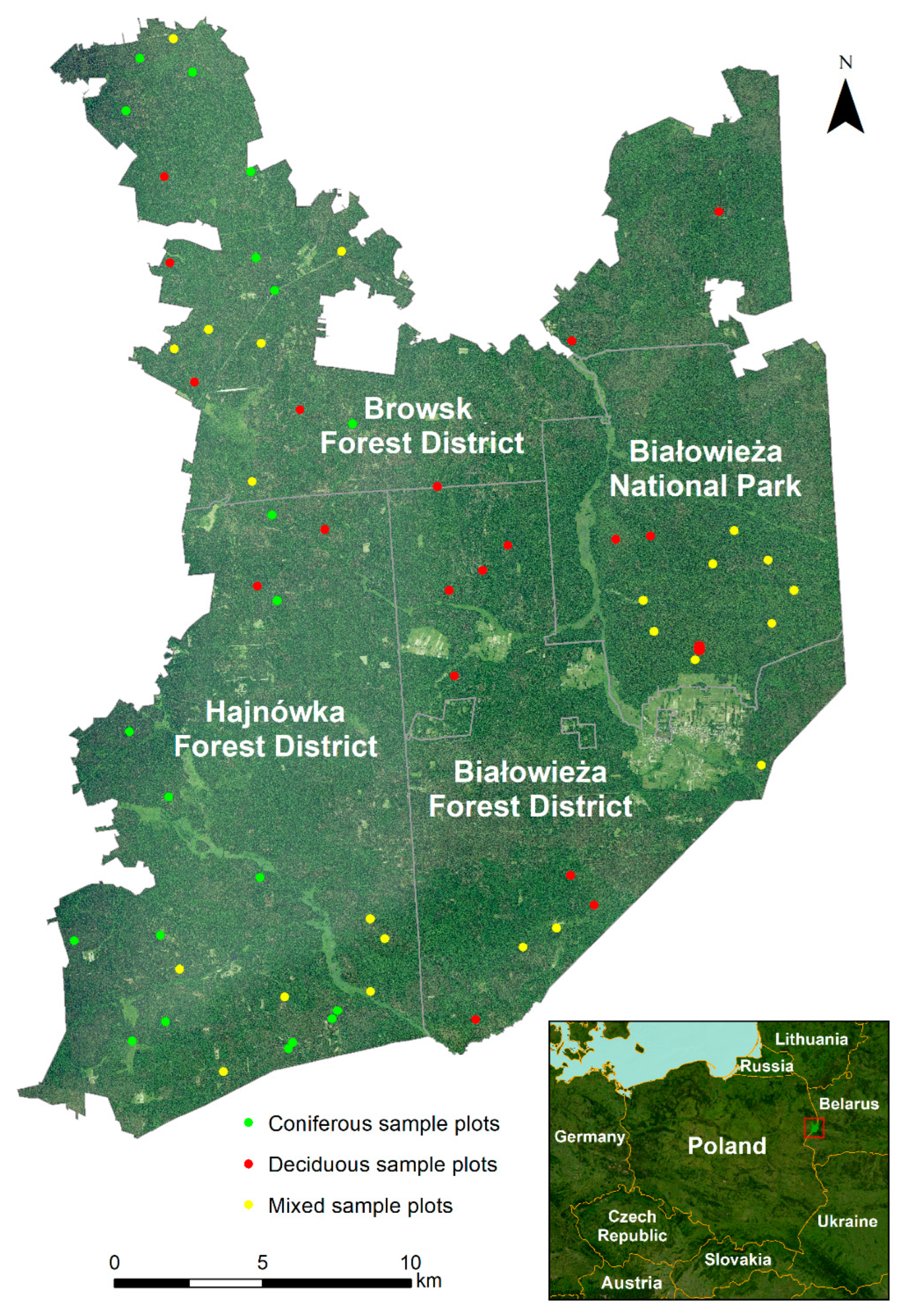
2.1. Study Area
2.2. Field Measurement
- -
- Coniferous—the proportion of spruce and/or pine is over 90%;
- -
- Deciduous—the proportion of deciduous trees is over 90%;
- -
- Mixed stands—the proportion of deciduous and coniferous trees is about 50% in each forest type.
2.3. ALS Dataset
2.4. Segmentation Algorithms
2.4.1. Local Method
2.4.2. MCWS 3 × 3 Method
2.4.3. MCWS 5 × 5 Method
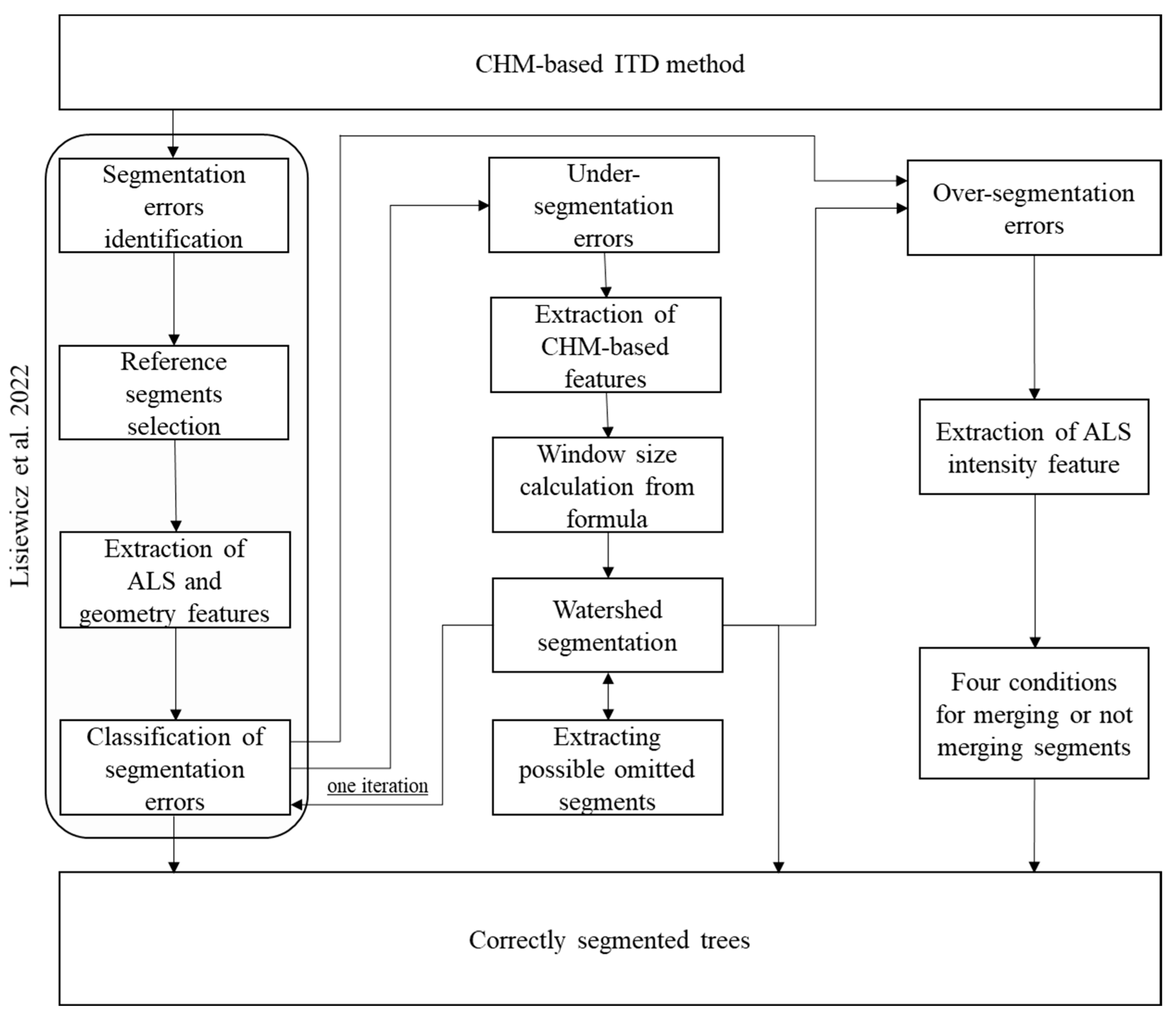
2.5. Correction Method
2.5.1. Recognition and Classification of Segmentation Errors
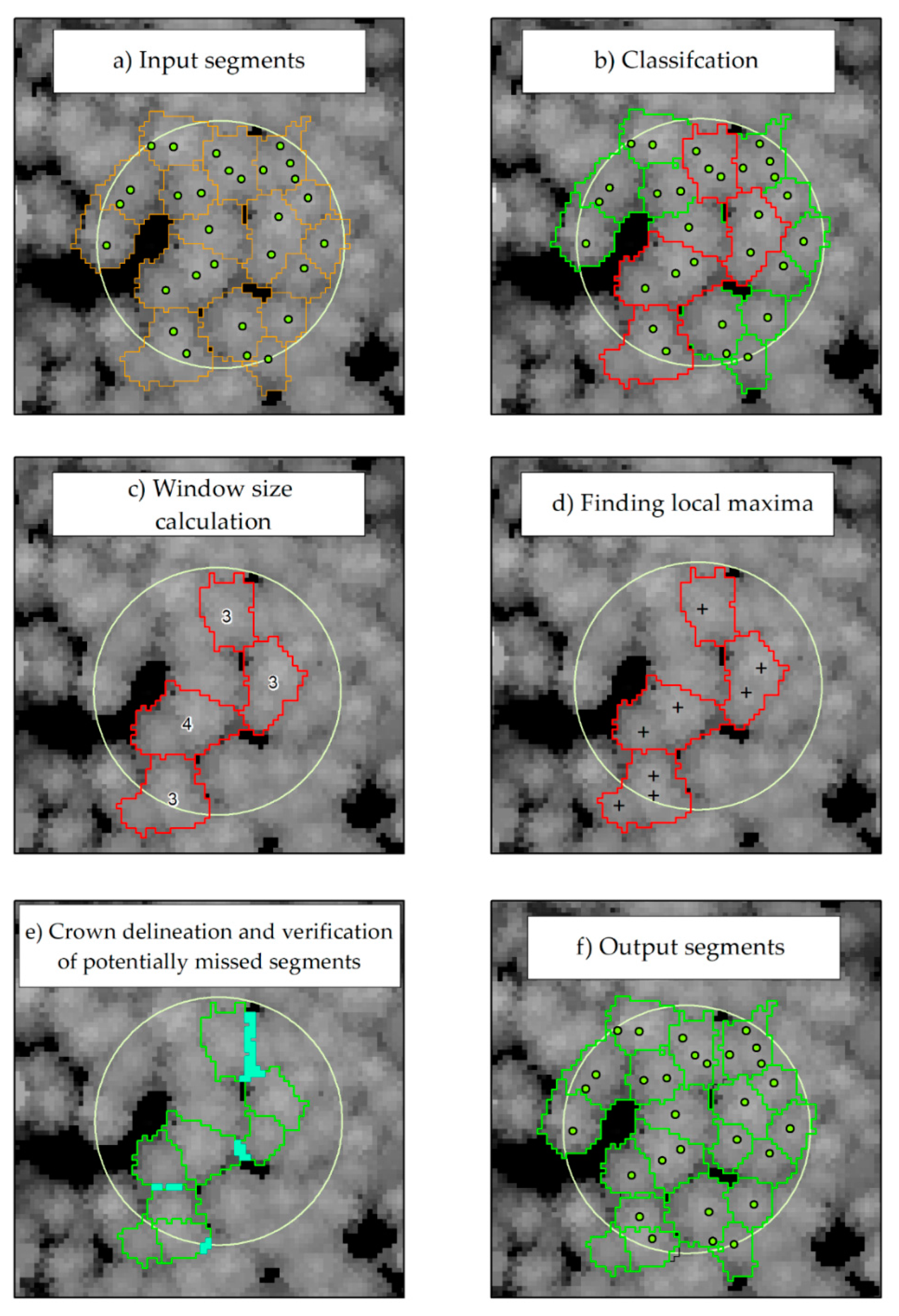
2.5.2. Refine Under-Segmentation Errors
2.5.3. Refine Over-Segmentation Errors
- ▪
- It has been checked how many of them are correct-segmentation. If only one, then the term from condition 2 was executed. If more than one is correct-segmentation and both segments have an int_cv difference of 15% or less, the segment with the longest common boundary was merged (Figure 3C).
- ▪
- In other cases, i.e., if there was more than one segment from the over-segmentation class, the same condition as above was executed.
2.5.4. Segmentation Methods and Correction Validation
3. Results
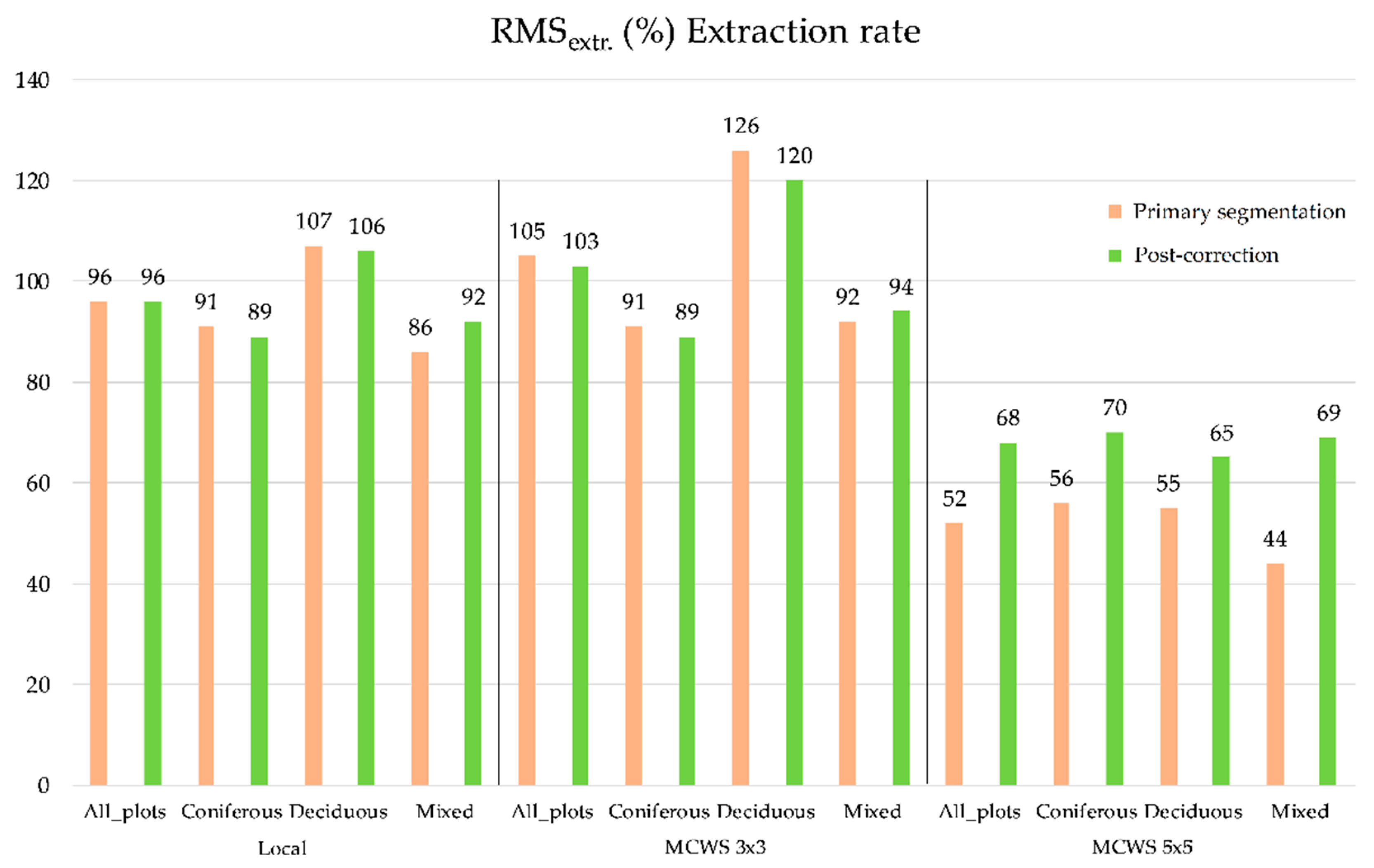
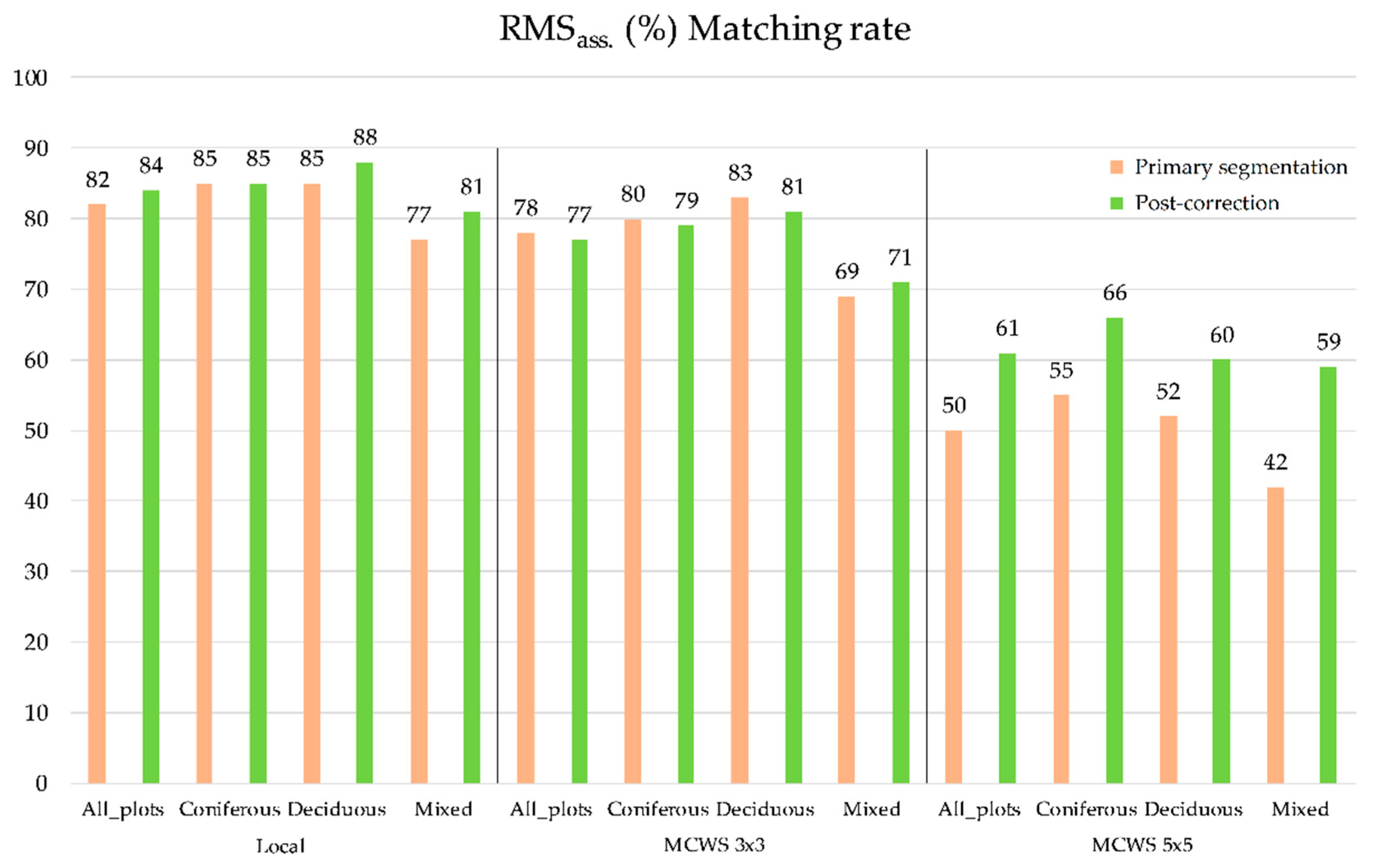
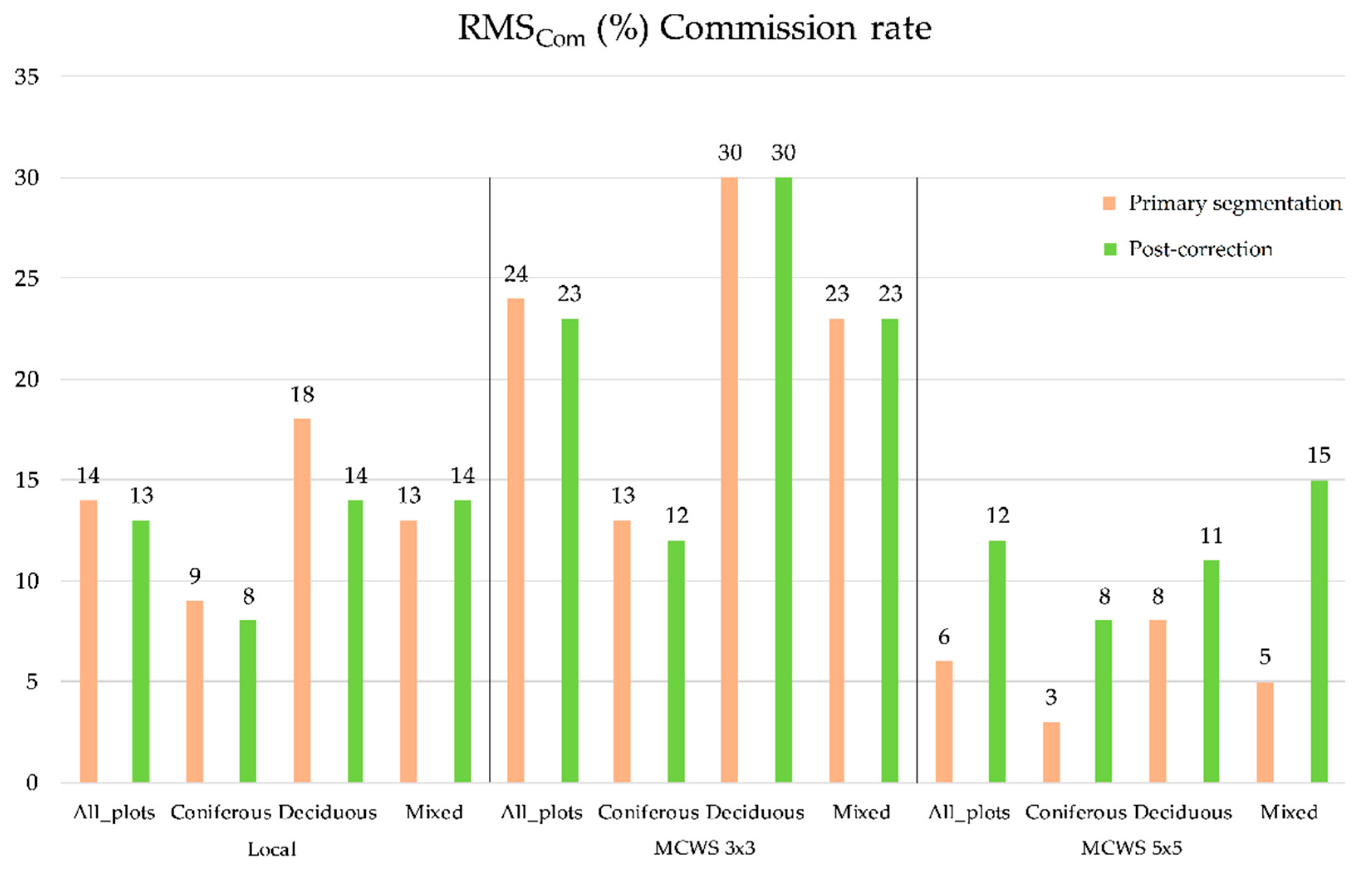
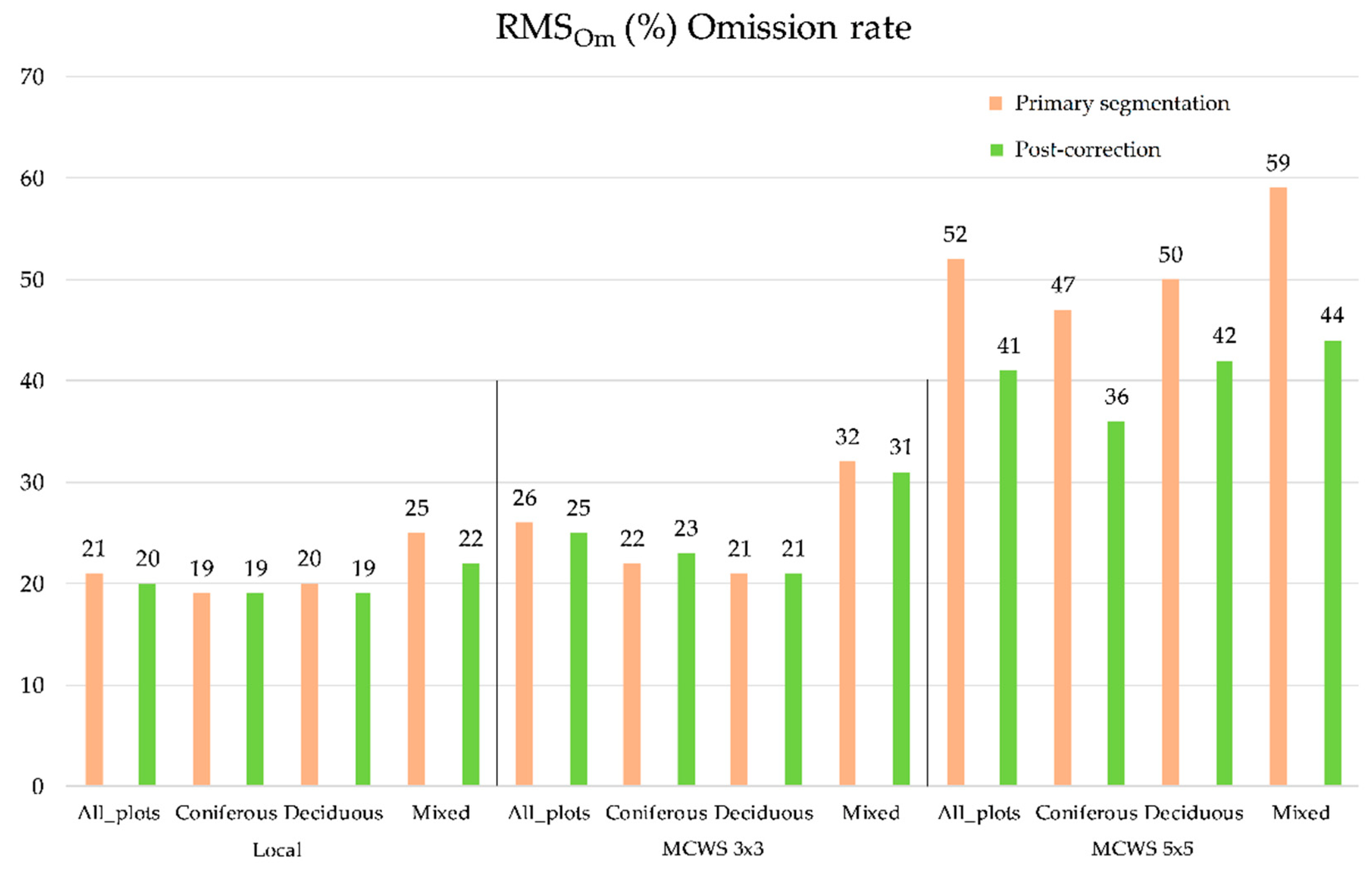
3.1. Overall Matching and Correction Results
3.2. Matching and Correction Results with Various Height Subgroups
3.3. Matching and Correction Results with Various Coefficient of Variation of Height Subgroups
4. Discussion
4.1. Overall Matching and Correction Results
4.2. Matching and Correction Results with Various Height Subgroups
4.3. Matching and Correction Results with Various Coefficient of Variation of Height Subgroups
4.4. Outlook
5. Conclusions
- -
- The correction method allows refinement of many segmentation errors.
- -
- Local ITD methods largely solve many of the potential problems causing errors at the initial stage, so the proposed method is often more effective in improving the results of commonly available methods.
- -
- In general, the correction method is most efficient for mixed stands, for which the lowest segmentation accuracy is initially obtained. According to the literature, mixed stands have the highest error rate and are the most difficult to parameterise.
- -
- Using standardised variables for the classification process and refining the over-segmentation errors allows for easier implementation of the method in other study areas without having to adjust the variables.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gallo, R.; Grigolato, S.; Cavalli, R.; Mazzetto, F. GNSS-based operational monitoring devices for forest logging operation chains. J. Agric. Eng. 2013, 44. [Google Scholar] [CrossRef]
- Fardusi, M.J.; Chianucci, F.; Barbati, A. Concept to practices of geospatial information tools to assist forest management & planning under precision forestry framework: A review. Ann. Silvic. Res. 2017, 41, 3–14. [Google Scholar] [CrossRef]
- Panagiotidis, D.; Abdollahnejad, A.; Slavík, M. Assessment of stem volume on plots using terrestrial laser scanner: A precision forestry application. Sensors 2021, 21, 301. [Google Scholar] [CrossRef] [PubMed]
- McRoberts, R.E.; Cohen, W.B.; Erik, N.; Stehman, S.V.; Tomppo, E.O. Using remotely sensed data to construct and assess forest attribute maps and related spatial products. Scand. J. For. Res. 2010, 25, 340–367. [Google Scholar] [CrossRef]
- Dash, J.; Pont, D.; Watt, M.S.; Dash, J.; Pont, D.; Brownlie, R.; Dunningham, A.; Watt, M.S.; Pearse, G. Remote sensing for precision forestry. N. Z. J. For. 2016, 60, 15–24. [Google Scholar]
- Mielcarek, M.; Kamińska, A.; Stereńczak, K. Digital aerial photogrammetry (DAP) and airborne laser scanning (ALS) as sources of information about tree height: Comparisons of the accuracy of remote sensing methods for tree height estimation. Remote Sens. 2020, 12, 1808. [Google Scholar] [CrossRef]
- Popescu, S.C.; Wynne, R.H.; Nelson, R.F. Estimating plot-level tree heights with lidar: Local filtering with a canopy-height based variable window size. Comput. Electron. Agric. 2002, 37, 71–95. [Google Scholar] [CrossRef]
- Błaszczak-Bąk, W.; Janicka, J.; Kozakiewicz, T.; Chudzikiewicz, K.; Bąk, G. Methodology of Calculating the Number of Trees Based on ALS Data for Forestry Applications for the Area of Samławki Forest District. Remote Sens. 2022, 14, 16. [Google Scholar] [CrossRef]
- Luo, L.; Zhai, Q.; Su, Y.; Ma, Q.; Kelly, M.; Guo, Q. Simple method for direct crown base height estimation of individual conifer trees using airborne LiDAR data. Opt. Express 2018, 26, A562–A578. [Google Scholar] [CrossRef]
- Korhonen, L.; Vauhkonen, J.; Virolainen, A.; Hovi, A.; Korpela, I. Estimation of tree crown volume from airborne lidar data using computational geometry. Int. J. Remote Sens. 2013, 34, 7236–7248. [Google Scholar] [CrossRef]
- Lindberg, E.; Hollaus, M. Comparison of Methods for Estimation of Stem Volume, Stem Number and Basal Area from Airborne Laser Scanning Data in a Hemi-Boreal Forest. Remote Sens. 2012, 4, 1004–1023. [Google Scholar] [CrossRef]
- Yu, X.; Hyyppä, J.; Vastaranta, M.; Holopainen, M.; Viitala, R. Predicting individual tree attributes from airborne laser point clouds based on the random forests technique. ISPRS J. Photogramm. Remote Sens. 2011, 66, 28–37. [Google Scholar] [CrossRef]
- Magdon, P.; González-Ferreiro, E.; Pérez-Cruzado, C.; Purnama, E.S.; Sarodja, D.; Kleinn, C. Evaluating the Potential of ALS Data to Increase the Efficiency of Aboveground Biomass Estimates in Tropical Peat–Swamp Forests. Remote Sens. 2018, 10, 1344. [Google Scholar] [CrossRef]
- Koch, B.; Heyder, U.; Welnacker, H. Detection of individual tree crowns in airborne lidar data. Photogramm. Eng. Remote. Sens. 2006, 72, 357–363. [Google Scholar] [CrossRef]
- Zhen, Z.; Quackenbush, L.J.; Zhang, L. Trends in automatic individual tree crown detection and delineation-evolution of LiDAR data. Remote Sens. 2016, 8, 333. [Google Scholar] [CrossRef]
- Koch, B.; Kattenborn, T.; Straub, C.; Vauhkonen, J. Segmentation of forest to tree objects. In Forestry Applications of Airborne Laser Scanning: Concepts and Case Studies; Maltamo, M., Næsset, E., Vauhkonen, J., Eds.; Springer: Dordrecht, The Netherlands, 2014; pp. 89–112. ISBN 978-94-017-8663-8. [Google Scholar]
- Shamsoddini, A.; Turner, R.; Trinder, J.C. Improving lidar-based forest structure mapping with crown-level pit removal. J. Spat. Sci. 2013, 58, 29–51. [Google Scholar] [CrossRef]
- Zhao, D.; Pang, Y.; Li, Z.; Sun, G. Filling invalid values in a lidar-derived canopy height model with morphological crown control. Int. J. Remote Sens. 2013, 34, 4636–4654. [Google Scholar] [CrossRef]
- Eysn, L.; Hollaus, M.; Lindberg, E.; Berger, F.; Monnet, J.M.; Dalponte, M.; Kobal, M.; Pellegrini, M.; Lingua, E.; Mongus, D.; et al. A benchmark of lidar-based single tree detection methods using heterogeneous forest data from the Alpine Space. Forests 2015, 6, 1721–1747. [Google Scholar] [CrossRef]
- Wang, Y.; Hyyppa, J.; Liang, X.; Kaartinen, H.; Yu, X.; Lindberg, E.; Holmgren, J.; Qin, Y.; Mallet, C.; Ferraz, A.; et al. International Benchmarking of the Individual Tree Detection Methods for Modeling 3-D Canopy Structure for Silviculture and Forest Ecology Using Airborne Laser Scanning. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5011–5027. [Google Scholar] [CrossRef]
- Stereńczak, K. Factors influencing individual tree crowns detection based on airborne laser scanning data. For. Res. Pap. 2013, 74, 323–333. [Google Scholar] [CrossRef][Green Version]
- Hyyppä, J.; Kelle, O.; Lehikoinen, M.; Inkinen, M. A segmentation-based method to retrieve stem volume estimates from 3-D tree height models produced by laser scanners. IEEE Trans. Geosci. Remote Sens. 2001, 39, 969–975. [Google Scholar] [CrossRef]
- Persson, Å.; Holmgren, J.; Söderman, U. Detecting and measuring individual trees using an airborne laser scanner. Photogramm. Eng. Remote. Sens. 2002, 68, 925–932. [Google Scholar]
- Hyyppä, J.; Inkinen, M. Detecting and estimating attribute for single trees using laser scanner. Photogramnetric J. Finl. 1999, 16, 27–42. [Google Scholar]
- Larsen, M.; Eriksson, M.; Descombes, X.; Perrin, G.; Brandtberg, T.; Gougeon, F.A. Comparison of six individual tree crown detection algorithms evaluated under varying forest conditions. Int. J. Remote Sens. 2011, 32, 5827–5852. [Google Scholar] [CrossRef]
- Wang, X.H.; Zhang, Y.Z.; Xu, M.M. A multi-threshold segmentation for tree-level parameter extraction in a deciduous forest using small-footprint airborne LiDAR data. Remote Sens. 2019, 11, 2109. [Google Scholar] [CrossRef]
- Stereńczak, K.; Kraszewski, B.; Mielcarek, M.; Piasecka, Ż.; Lisiewicz, M.; Heurich, M. Mapping individual trees with airborne laser scanning data in an European lowland forest using a self-calibration algorithm. Int. J. Appl. Earth Obs. Geoinf. 2020, 93, 102191. [Google Scholar] [CrossRef]
- Jing, L.; Hu, B.; Li, J.; Noland, T. Automated delineation of individual tree crowns from lidar data by multi-scale analysis and segmentation. Photogramm. Eng. Remote. Sens. 2012, 78, 1275–1284. [Google Scholar] [CrossRef]
- Hamraz, H.; Contreras, M.A.; Zhang, J. A robust approach for tree segmentation in deciduous forests using small-footprint airborne LiDAR data. Int. J. Appl. Earth Obs. Geoinf. 2016, 52, 532–541. [Google Scholar] [CrossRef]
- Vauhkonen, J.; Ene, L.; Gupta, S.; Heinzel, J.; Holmgren, J.; Pitkänen, J.; Solberg, S.; Wang, Y.; Weinacker, H.; Hauglin, K.M.; et al. Comparative testing of single-tree detection algorithms under different types of forest. Forestry 2012, 85, 27–40. [Google Scholar] [CrossRef]
- Yang, Q.; Su, Y.; Jin, S.; Kelly, M.; Hu, T.; Ma, Q.; Li, Y.; Song, S.; Zhang, J.; Xu, G.; et al. The influence of vegetation characteristics on individual tree segmentation methods with airborne LiDAR data. Remote Sens. 2019, 11, 2880. [Google Scholar] [CrossRef]
- Hastings, J.H.; Ollinger, S.V.; Ouimette, A.P.; Sanders-DeMott, R.; Palace, M.W.; Ducey, M.J.; Sullivan, F.B.; Basler, D.; Orwig, D.A. Tree Species Traits Determine the Success of LiDAR-Based Crown Mapping in a Mixed Temperate Forest. Remote Sens. 2020, 12, 309. [Google Scholar] [CrossRef]
- Lisiewicz, M.; Kamińska, A.; Stereńczak, K. Recognition of specified errors of Individual Tree Detection methods based on Canopy Height Model. Remote Sens. Appl. Soc. Environ. 2022, 25, 100690. [Google Scholar] [CrossRef]
- Kankare, V.; Räty, M.; Yu, X.; Holopainen, M.; Vastaranta, M.; Kantola, T.; Hyyppä, J.; Hyyppä, H.; Alho, P.; Viitala, R. Single tree biomass modelling using airborne laser scanning. ISPRS J. Photogramm. Remote Sens. 2013, 85, 66–73. [Google Scholar] [CrossRef]
- Wolf, B.M.; Heipke, C. Automatic extraction and delineation of single trees from remote sensing data. Mach. Vis. Appl. 2007, 18, 317–330. [Google Scholar] [CrossRef]
- Dai, W.; Yang, B.; Dong, Z.; Shaker, A. A new method for 3D individual tree extraction using multispectral airborne LiDAR point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 144, 400–411. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, Y.; Luo, Z. Combining Trunk Detection with Canopy Segmentation to Delineate Single Deciduous Trees Using Airborne LiDAR Data. IEEE Access 2020, 8, 99783–99796. [Google Scholar] [CrossRef]
- Dersch, S.; Heurich, M.; Krueger, N.; Krzystek, P. Combining graph-cut clustering with object-based stem detection for tree segmentation in highly dense airborne lidar point clouds. ISPRS J. Photogramm. Remote Sens. 2021, 172, 207–222. [Google Scholar] [CrossRef]
- Stereńczak, K.; Kraszewski, B.; Mielcarek, M.; Kamińska, A.; Lisiewicz, M.; Modzelewska, A.; Sadkowski, R.; Białczak, M.; Piasecka, Ż.; Wilkowska, R. The Białowieża Forest monitoring with the use of remote sensing data. In Zimowa Szkoła Leśna XI Sesja-Zastosowanie Geoinformatyki w Leśnictwie; Instytut Badawczy Leśnictwa: Sękocin Stary, Poland, 2020; pp. 99–107. (In Polish) [Google Scholar]
- Axelsson, P. DEM generation from laser scanner data using adaptive TIN models. Int. Arch. Photogramm. Remote Sens. 2000, 33, 110–117. [Google Scholar]
- Erfanifard, Y.; Stereńczak, K.; Kraszewski, B.; Kamińska, A. Development of a robust canopy height model derived from ALS point clouds for predicting individual crown attributes at the species level. Int. J. Remote Sens. 2018, 39, 9206–9227. [Google Scholar] [CrossRef]
- Soille, P. Morphological Image Analysis: Principles and Applications; Springer: Berlin/Heidelberg, Germany, 1999; ISBN 978-3-662-03941-0. [Google Scholar]
- Popescu, S.C.; Wynne, R.H. Seeing the Trees in the Forest: Using Lidar and Multispectral Data Fusion with Local Filtering and Variable Window Size for Estimating Tree Height. Photogramm. Eng. Remote Sens. 2004, 70, 589–604. [Google Scholar] [CrossRef]
- Meyer, F.; Beucher, S. Morphological segmentation. J. Vis. Commun. Image Represent. 1990, 1, 21–46. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees, 1st ed.; Routledge: Boca Raton, FL, USA, 1984. [Google Scholar]
- Reock, E.C. A Note: Measuring Compactness as a Requirement of Legislative Apportionment. Midwest J. Polit. Sci. 1961, 5, 70–74. [Google Scholar] [CrossRef]
- Kamińska, A.; Lisiewicz, M.; Stereńczak, K.; Kraszewski, B.; Sadkowski, R. Species-related single dead tree detection using multi-temporal ALS data and CIR imagery. Remote Sens. Environ. 2018, 219, 31–43. [Google Scholar] [CrossRef]
- R Foundation for Statistical Computing. R Development Core Team R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: https://www.r-project.org/ (accessed on 20 February 2022).
- Hijmans, R.J. Raster: Geographic Data Analysis and Modeling; Version 3.5-15; R Core Team: Vienna, Austria, 2022. [Google Scholar]
- Bivand, R.; Keitt, T.; Rowlingson, B. Rgdal: Bindings for the “Geospatial” Data Abstraction Library; Version 1.5-29; R Core Team: Vienna, Austria, 2022. [Google Scholar]
- Bivand, R.; Rundel, C. Rgeos: Interface to Geometry Engine-Open Source (‘GEOS’) Version 0.5-9; R Core Team: Vienna, Austria, 2021. [Google Scholar]
- Roussel, J.R.; Auty, D.; Coops, N.C.; Tompalski, P.; Goodbody, T.R.H.; Meador, A.S.; Bourdon, J.F.; de Boissieu, F.; Achim, A. lidR: An R package for analysis of Airborne Laser Scanning (ALS) data. Remote Sens. Environ. 2020, 251, 112061. [Google Scholar] [CrossRef]
- Plowright, A.; Roussel, J.R. ForestTools: Analyzing Remotely Sensed Forest Data; Version 0.2.5; R Core Team: Vienna, Austria, 2021. [Google Scholar]
- Pebesma, E. Simple Features for R: Standardized Support for Spatial Vector Data. R J. 2018, 10, 439–446. [Google Scholar] [CrossRef]
- Pang, Y.; Wang, W.; Du, L.; Zhang, Z.; Liang, X.; Li, Y.; Wang, Z. Nyström-based spectral clustering using airborne LiDAR point cloud data for individual tree segmentation. Int. J. Digit. Earth 2021, 14, 1452–1476. [Google Scholar] [CrossRef]
- Peuhkurinen, J.; Mehtätalo, L.; Maltamo, M. Comparing individual tree detection and the areabased statistical approach for the retrieval of forest stand characteristics using airborne laser scanning in Scots pine stands. Can. J. For. Res. 2011, 41, 583–598. [Google Scholar] [CrossRef]
- Falkowski, M.J.; Smith, A.M.S.; Gessler, P.E.; Hudak, A.T.; Vierling, L.A.; Evans, J.S. The influence of conifer forest canopy cover on the accuracy of two individual tree measurement algorithms using lidar data. Can. J. Remote Sens. 2008, 34, 338–350. [Google Scholar] [CrossRef]
- Magnussen, S.; Eggermont, P.; LaRiccia, V.N. Recovering Tree Heights from Airborne Laser Scanner Data. For. Sci. 1999, 45, 407–422. [Google Scholar] [CrossRef]
- Forzieri, G.; Guarnieri, L.; Vivoni, E.R.; Castelli, F.; Preti, F. Multiple attribute decision making for individual tree detection using high-resolution laser scanning. For. Ecol. Manag. 2009, 258, 2501–2510. [Google Scholar] [CrossRef]
- Jakubowski, M.; Li, W.; Guo, Q.; Kelly, M. Delineating Individual Trees from Lidar Data: A Comparison of Vector- and Raster-based Segmentation Approaches. Remote Sens. 2013, 5, 4163–4186. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Species | n | H_Range (m) | DBH_Range (cm) |
|---|---|---|---|
| Coniferous (20 plots) | |||
| Pine | 270 | 16.8–41.0 | 14.6–75.6 |
| Spruce | 131 | 9.0–44.3 | 7.5–66.8 |
| Deciduous | 21 | 13.8–32.3 | 10.9–58.8 |
| Deciduous (26 plots) | |||
| Birch | 16 | 20.7–31.1 | 14.6–36.6 |
| Hornbeam | 79 | 9.1–31.8 | 8.0–63.0 |
| Lime | 55 | 5.1–34.5 | 7.6–117 |
| Maple | 17 | 16.8–36.8 | 13.5–98 |
| Oak | 50 | 17.2–38.7 | 15.5–117.4 |
| Spruce | 20 | 19.8–37.5 | 17.9–68.7 |
| Other | 14 | 16.4–34.2 | 14.9–56.8 |
| Mixed (23 plots) | |||
| Alder | 55 | 9.9–36.5 | 7.4–62.8 |
| Birch | 47 | 9.1–38.0 | 7.1–66.2 |
| Hornbeam | 40 | 7.9–24.8 | 7.0–51.0 |
| Lime | 10 | 13.9–28.6 | 13.3–45.7 |
| Oak | 22 | 17.0–40.2 | 12.2–111.7 |
| Pine | 32 | 12.1–35.6 | 15.3–82.2 |
| Poplar | 12 | 21.5–36.7 | 23–56.1 |
| Spruce | 121 | 8.0–39.0 | 7.6–71.6 |
| Other | 3 | 18.4–30.6 | 15.1–50.4 |
| Method | Group | RMSextr. (%) | RMSass. (%) | RMSCom (%) | RMSOm (%) |
|---|---|---|---|---|---|
| Extraction Rate | Matching Rate | Commission Rate | Omission Rate | ||
| Local method | All_plots | 86|86 | 80|80 | 8|9 | 22|22 |
| Coniferous | 91|89 | 85|86 | 9|5 | 20|18 | |
| Deciduous | 88|87 | 82|81 | 9|9 | 20|21 | |
| Mixed | 81|83 | 76|77 | 7|10 | 25|24 | |
| MCWS 3 × 3 | All_plots | 90|92 | 74|76 | 18|18 | 29|27 |
| Coniferous | 81|82 | 78|80 | 5|3 | 22|22 | |
| Deciduous | 99|100 | 79|79 | 21|21 | 24|23 | |
| Mixed | 78|84 | 66|70 | 17|17 | 35|32 | |
| MCWS 5 × 5 | All_plots | 48|69 | 47|62 | 5|12 | 55|40 |
| Coniferous | 47|71 | 47|68 | 0|5 | 54|33 | |
| Deciduous | 51|64 | 50|61 | 5|9 | 52|41 | |
| Mixed | 43|74 | 42|63 | 5|16 | 59|39 |
| Method | Group | RMSextr. (%) | RMSass. (%) | RMSCom (%) | RMSOm (%) |
|---|---|---|---|---|---|
| Extraction Rate | Matching Rate | Commission Rate | Omission Rate | ||
| Local method | All_plots | 103|104 | 84|87 | 17|15 | 21|19 |
| Coniferous | 91|89 | 85|84 | 9|8 | 19|19 | |
| Deciduous | 130|124 | 86|92 | 28|20 | 20|15 | |
| Mixed | 90|92 | 77|81 | 16|14 | 24|22 | |
| MCWS 3 × 3 | All_plots | 117|111 | 80|79 | 27|26 | 23|24 |
| Coniferous | 92|90 | 80|79 | 14|12 | 23|23 | |
| Deciduous | 163|150 | 90|85 | 42|40 | 14|18 | |
| Mixed | 105|104 | 72|72 | 28|27 | 29|30 | |
| MCWS 5 × 5 | All_plots | 53|67 | 52|61 | 5|12 | 51|42 |
| Coniferous | 58|70 | 57|66 | 4|8 | 46|37 | |
| Deciduous | 61|67 | 56|59 | 11|15 | 47|43 | |
| Mixed | 45|63 | 43|55 | 6|14 | 59|49 |
| Method | Group | RMSextr. (%) | RMSass. (%) | RMSCom (%) | RMSOm (%) |
|---|---|---|---|---|---|
| Extraction Rate | Matching Rate | Commission Rate | Omission Rate | ||
| Local method | All_plots | 102|101 | 84|87 | 16|13 | 20|19 |
| Coniferous | 89|88 | 83|83 | 9|9 | 21|20 | |
| Deciduous | 117|114 | 87|93 | 21|15 | 18|17 | |
| Mixed | 93|102 | 80|88 | 17|15 | 21|17 | |
| MCWS 3 × 3 | All_plots | 116|112 | 81|80 | 26|25 | 22|22 |
| Coniferous | 90|86 | 80|79 | 13|11 | 22|23 | |
| Deciduous | 137|129 | 85|83 | 33|32 | 19|20 | |
| Mixed | 114|120 | 75|77 | 30|31 | 26|24 | |
| MCWS 5 × 5 | All_plots | 57|70 | 54|64 | 6|11 | 48|37 |
| Coniferous | 57|67 | 56|64 | 4|7 | 47|37 | |
| Deciduous | 58|68 | 55|62 | 8|11 | 47|39 | |
| Mixed | 52|79 | 49|67 | 7|15 | 52|35 |
| Method | Group | RMSextr. (%) | RMSass. (%) | RMSCom (%) | RMSOm (%) |
|---|---|---|---|---|---|
| Extraction Rate | Matching Rate | Commission Rate | Omission Rate | ||
| Local method | All_plots | 86|90 | 79|81 | 10|12 | 23|22 |
| Coniferous | 100|92 | 94|92 | 9|0 | 11|13 | |
| Deciduous | 84|90 | 79|81 | 9|12 | 22|22 | |
| Mixed | 83|89 | 75|78 | 11|13 | 26|23 | |
| MCWS 3 × 3 | All_plots | 90|92 | 73|74 | 20|20 | 30|29 |
| Coniferous | 91|96 | 79|83 | 14|15 | 23|20 | |
| Deciduous | 103|103 | 80|78 | 24|25 | 24|24 | |
| Mixed | 82|84 | 67|68 | 19|19 | 34|33 | |
| MCWS 5 × 5 | All_plots | 45|66 | 44|58 | 5|13 | 57|45 |
| Coniferous | 54|79 | 54|72 | 0|10 | 47|32 | |
| Deciduous | 49|60 | 47|55 | 7|11 | 55|46 | |
| Mixed | 41|64 | 40|56 | 5|15 | 61|47 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lisiewicz, M.; Kamińska, A.; Kraszewski, B.; Stereńczak, K. Correcting the Results of CHM-Based Individual Tree Detection Algorithms to Improve Their Accuracy and Reliability. Remote Sens. 2022, 14, 1822. https://doi.org/10.3390/rs14081822
Lisiewicz M, Kamińska A, Kraszewski B, Stereńczak K. Correcting the Results of CHM-Based Individual Tree Detection Algorithms to Improve Their Accuracy and Reliability. Remote Sensing. 2022; 14(8):1822. https://doi.org/10.3390/rs14081822
Chicago/Turabian StyleLisiewicz, Maciej, Agnieszka Kamińska, Bartłomiej Kraszewski, and Krzysztof Stereńczak. 2022. "Correcting the Results of CHM-Based Individual Tree Detection Algorithms to Improve Their Accuracy and Reliability" Remote Sensing 14, no. 8: 1822. https://doi.org/10.3390/rs14081822
APA StyleLisiewicz, M., Kamińska, A., Kraszewski, B., & Stereńczak, K. (2022). Correcting the Results of CHM-Based Individual Tree Detection Algorithms to Improve Their Accuracy and Reliability. Remote Sensing, 14(8), 1822. https://doi.org/10.3390/rs14081822