
SAR Target Recognition Using cGAN-Based SAR-to-Optical Image Translation


Abstract
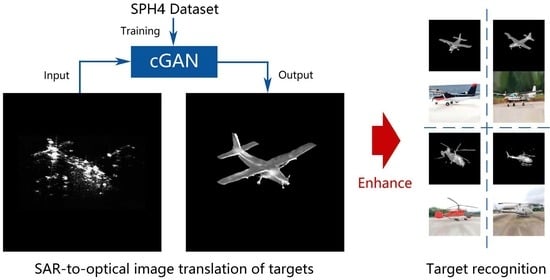
:
1. Introduction
- A novel SAR target recognition system is proposed and developed, using SAR-to-optical translation to enhance target recognition for improving the accuracy of recognition.
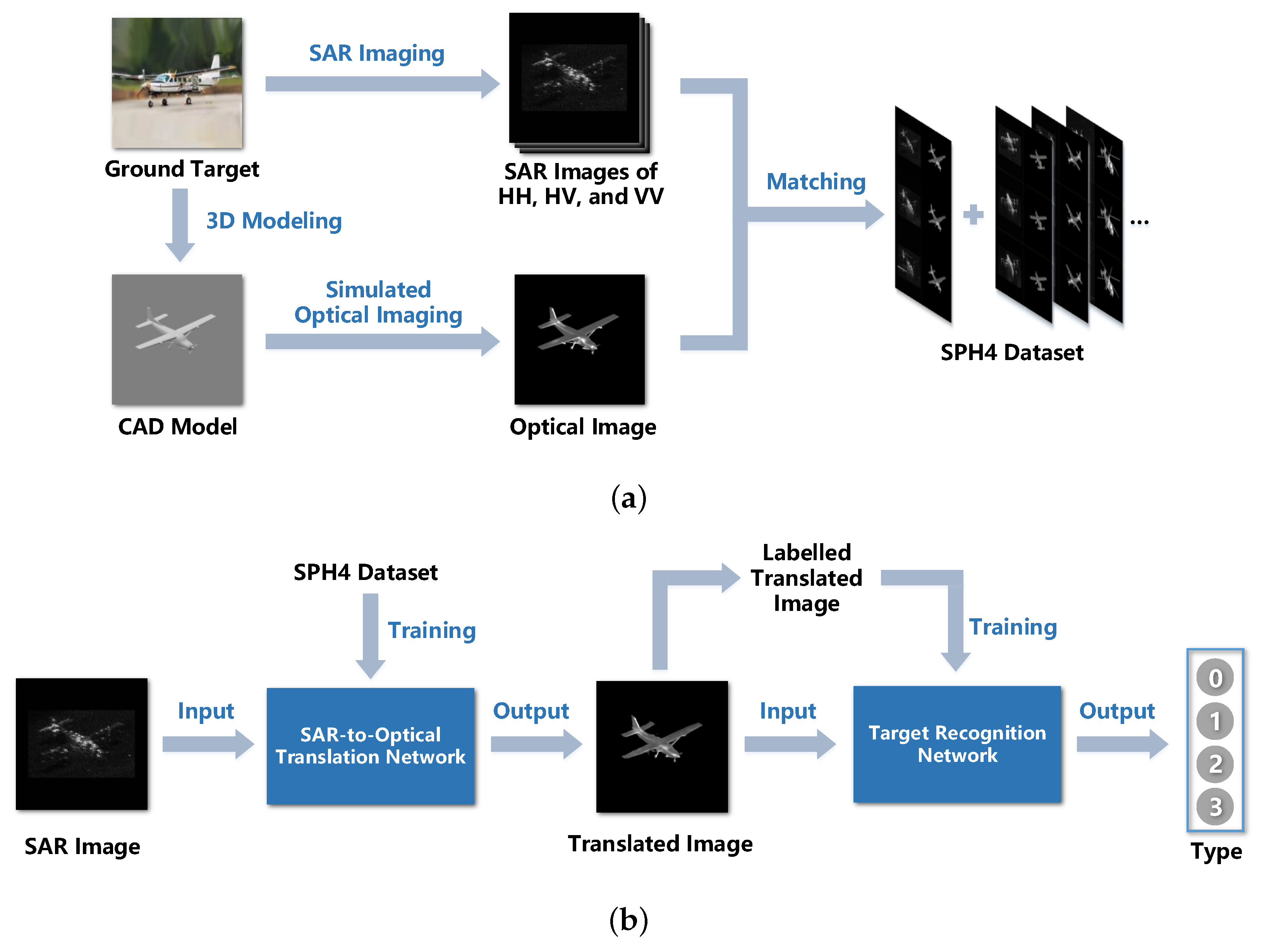
- A new approach to creating the matched SAR-optical dataset is presented by simulating optical images corresponding to SAR target images for SAR-to-optical translation, SAR target recognition, and other following research.
- A modified cGAN network with a new generator architecture is explored, which can be competent for the SAR-to-optical translation of aircraft targets.
- Experiments of noise addition and aircraft type extension are designed and implemented to demonstrate good robustness and extensibility of the proposed recognition system.
2. Related Works
2.1. SAR ATR
2.2. Image-to-Image Translation Based on cGAN
2.3. Model-Based Data Generation
3. Methods
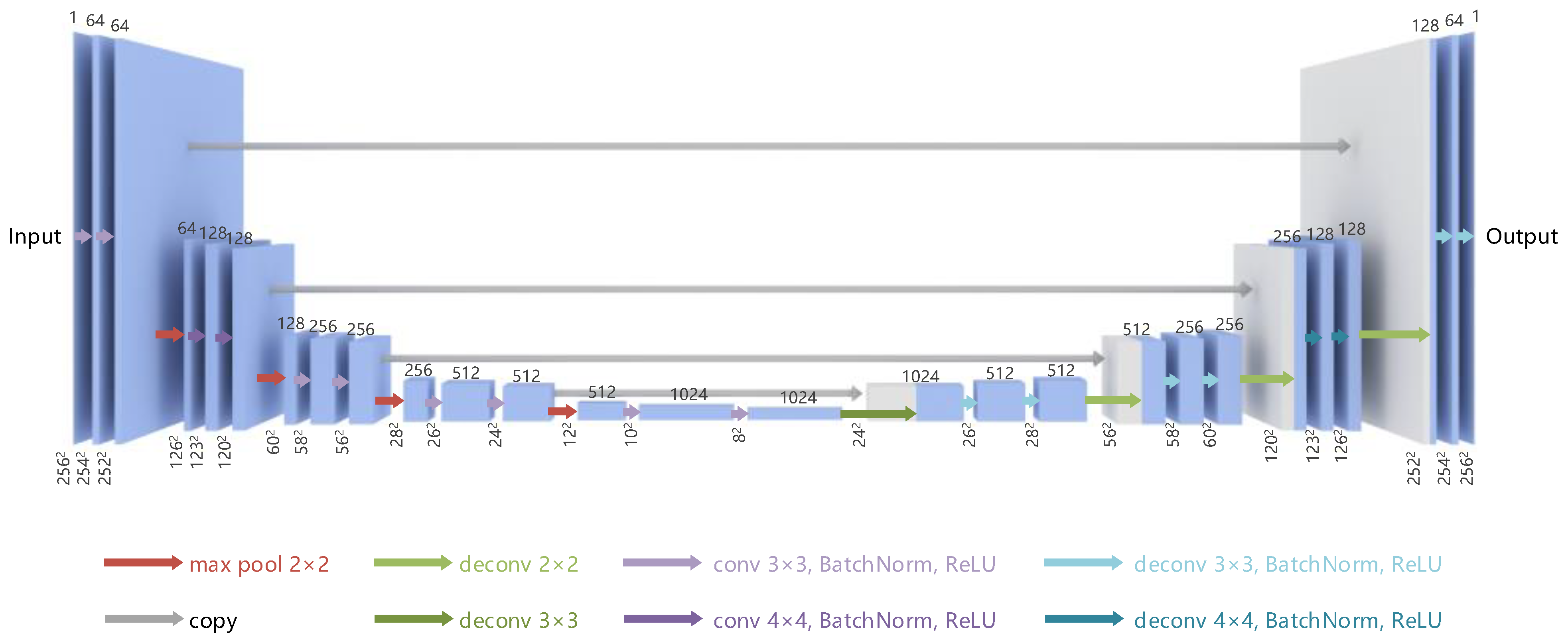
3.1. Translation Network
3.2. Recognition Network
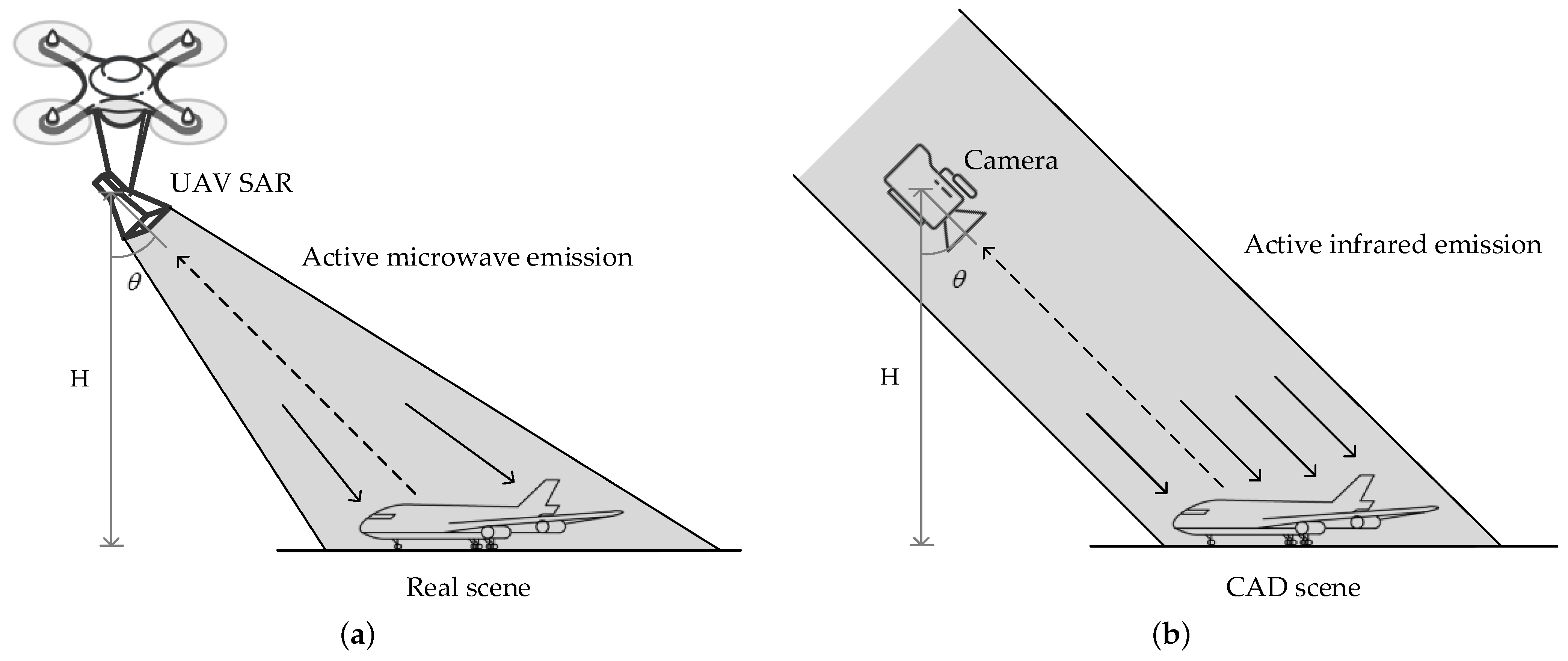
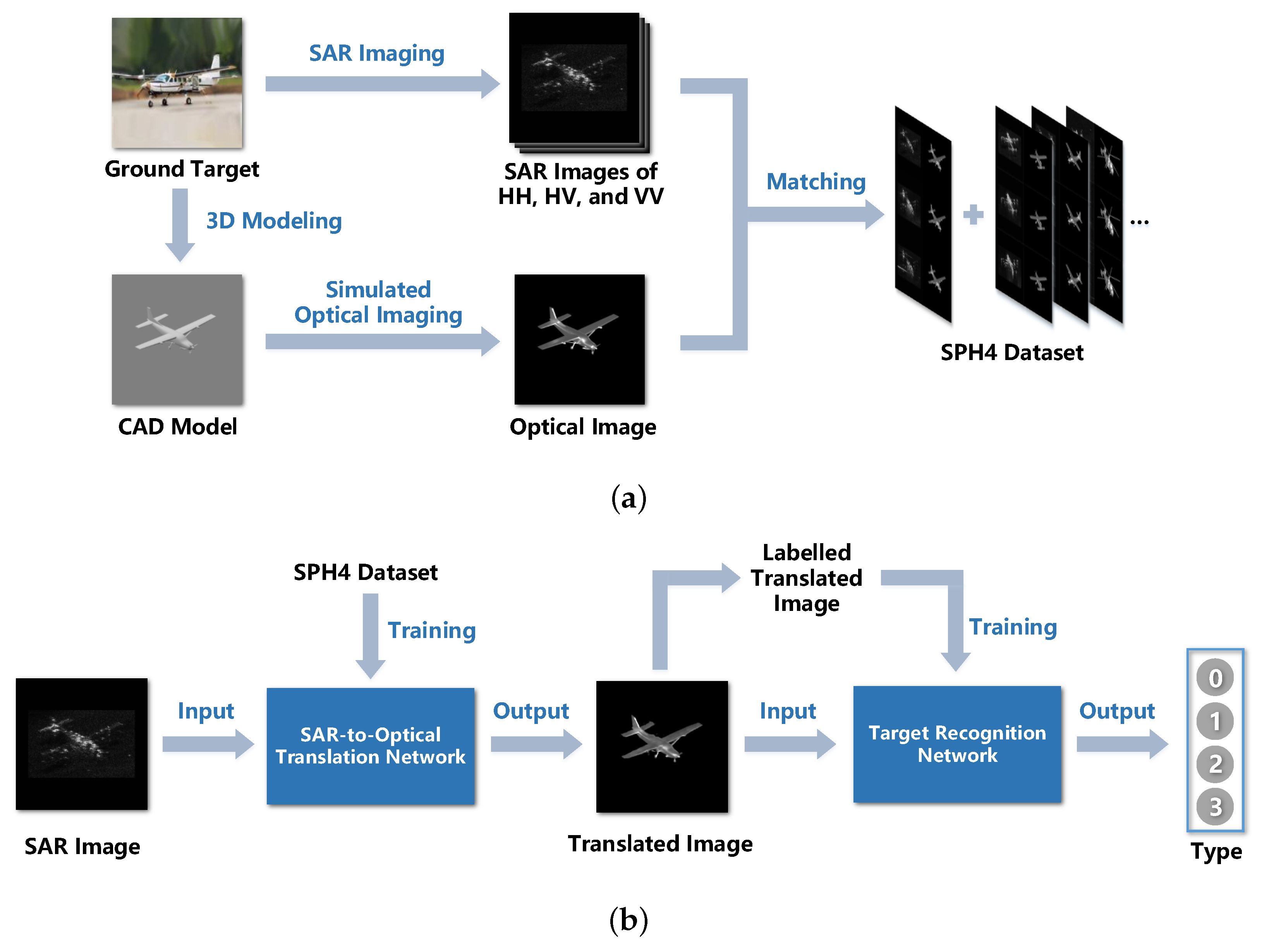
3.3. Optical Imaging Simulation
4. Experiments and Results
4.1. SPH4 Dataset
4.2. Implement Details
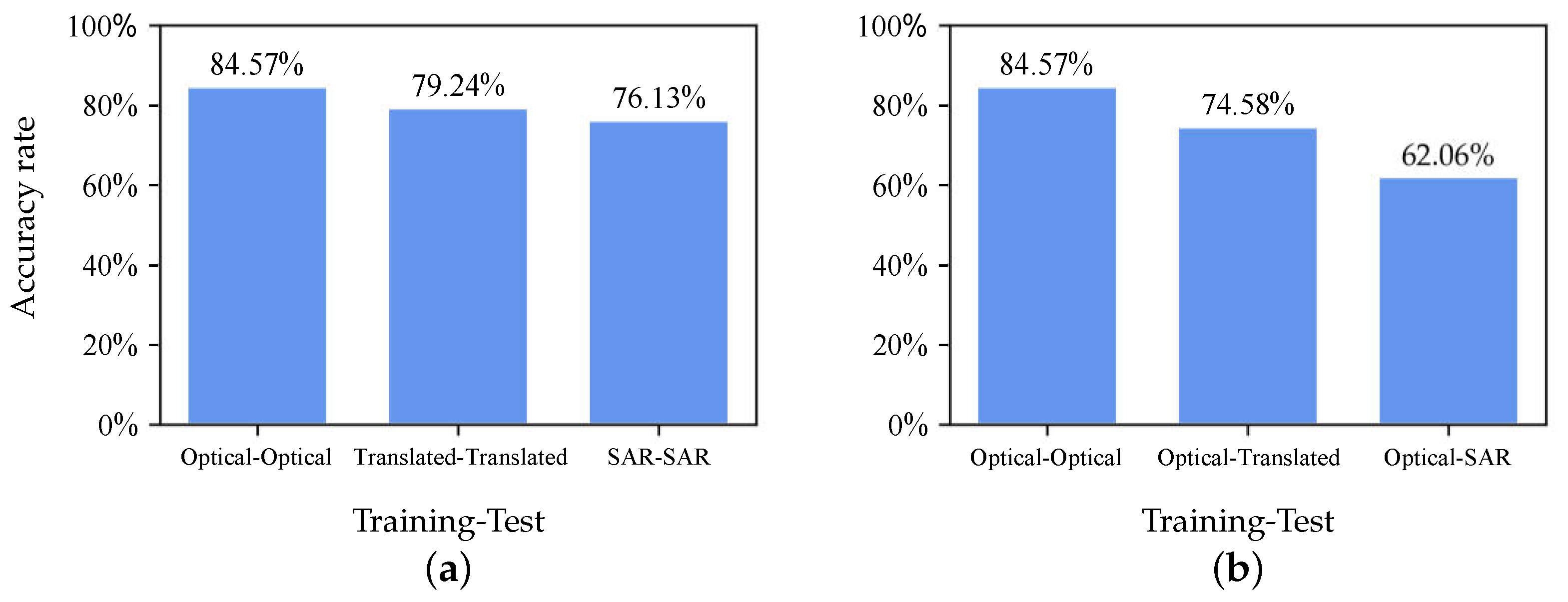
4.3. Results
4.3.1. Translation Results
4.3.2. Recognition Results
5. Discussion
5.1. Expending Experiments
5.1.1. Noise Resistance
5.1.2. Type Extension
5.2. Failed Cases
6. Conclusions and Outlook
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Manual Target Recognition Experiment

References
- Huang, Z.; Pan, Z.; Lei, B. What, Where, and How to Transfer in SAR Target Recognition Based on Deep CNNs. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2324–2336. [Google Scholar] [CrossRef] [Green Version]
- Goodman, J.W. Some fundamental properties of speckle. JOSA 1976, 66, 1145–1150. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, H.; Patel, V.M. SAR Image Despeckling Using a Convolutional Neural Network. IEEE Signal Process. Lett. 2017, 24, 1763–1767. [Google Scholar] [CrossRef] [Green Version]
- Chierchia, G.; Cozzolino, D.; Poggi, G.; Verdoliva, L. SAR image despeckling through convolutional neural networks. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Schmitt, M.; Hughes, L.H.; Zhu, X.X. The SEN1-2 Dataset for Deep Learning in SAR-Optical Data Fusion. arXiv 2018, arXiv:1807.01569. [Google Scholar] [CrossRef] [Green Version]
- Fuentes Reyes, M.; Auer, S.; Merkle, N.; Henry, C.; Schmitt, M. SAR-to-Optical Image Translation Based on Conditional Generative Adversarial Networks—Optimization, Opportunities and Limits. Remote Sens. 2019, 11, 2067. [Google Scholar] [CrossRef] [Green Version]
- Hughes, L.H.; Schmitt, M.; Mou, L.; Wang, Y.; Zhu, X.X. Identifying Corresponding Patches in SAR and Optical Images with a Pseudo-Siamese CNN. IEEE Geosci. Remote Sens. Lett. 2018, 15, 784–788. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Liu, J.; Xu, F. Ship Detection in Optical Remote Sensing Images Based on Saliency and a Rotation-Invariant Descriptor. Remote Sens. 2018, 10, 400. [Google Scholar] [CrossRef] [Green Version]
- Ren, Y.; Zhu, C.; Xiao, S. Small Object Detection in Optical Remote Sensing Images via Modified Faster R-CNN. Appl. Sci. 2018, 8, 813. [Google Scholar] [CrossRef] [Green Version]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Bermudez, J.D.; Happ, P.N.; Feitosa, R.Q.; Oliveira, D.A.B. Synthesis of Multispectral Optical Images From SAR/Optical Multitemporal Data Using Conditional Generative Adversarial Networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1220–1224. [Google Scholar] [CrossRef]
- Turnes, J.N.; Castro, J.D.B.; Torres, D.L.; Vega, P.J.S.; Feitosa, R.Q.; Happ, P.N. Atrous cGAN for SAR to Optical Image Translation. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Darbaghshahi, F.N.; Mohammadi, M.R.; Soryani, M. Cloud removal in remote sensing images using generative adversarial networks and SAR-to-optical image translation. arXiv 2020, arXiv:2012.12180. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, J.; Li, M.; Zhou, H.; Yu, T. Quality Assessment of SAR-to-Optical Image Translation. Remote Sens. 2020, 12, 3472. [Google Scholar] [CrossRef]
- Wang, L.; Xu, X.; Yu, Y.; Yang, R.; Gui, R.; Xu, Z.; Pu, F. SAR-to-Optical Image Translation Using Supervised Cycle-Consistent Adversarial Networks. IEEE Access 2019, 7, 129136–129149. [Google Scholar] [CrossRef]
- Keydel, E.R.; Lee, S.W.; Moore, J.T. MSTAR extended operating conditions: A tutorial. In Algorithms for Synthetic Aperture Radar Imagery III; SPIE: Bellingham, WA, USA, 1996; Volume 2757, pp. 228–242. [Google Scholar]
- Pohl, C.; Van Genderen, J. Remote Sensing Image Fusion; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y.Q. Target Classification Using the Deep Convolutional Networks for SAR Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Novak, L.M.; Owirka, G.J.; Weaver, A.L. Automatic target recognition using enhanced resolution SAR data. IEEE Trans. Aerosp. Electron. Syst. 1999, 35, 157–175. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, Z.; Todorovic, S.; Li, J. Adaptive boosting for SAR automatic target recognition. IEEE Trans. Aerosp. Electron. Syst. 2007, 1, 112–125. [Google Scholar] [CrossRef]
- Yuan, X.; Tang, T.; Xiang, D.; Li, Y.; Su, Y. Target recognition in SAR imagery based on local gradient ratio pattern. Int. J. Remote Sens. 2014, 35, 857–870. [Google Scholar] [CrossRef]
- Zhu, H.; Lin, N.; Leung, H.; Leung, R.; Theodoidis, S. Target Classification from SAR Imagery Based on the Pixel Grayscale Decline by Graph Convolutional Neural Network. IEEE Sens. Lett. 2020, 4, 1–4. [Google Scholar] [CrossRef]
- Mishra, A.K.; Motaung, T. Application of linear and nonlinear PCA to SAR ATR. In Proceedings of the 2015 25th International Conference Radioelektronika (RADIOELEKTRONIKA), Pardubice, Czech Republic, 21–22 April 2015; pp. 349–354. [Google Scholar]
- Zhao, Q.; Principe, J.C. Support vector machines for SAR automatic target recognition. IEEE Trans. Aerosp. Electron. Syst. 2001, 37, 643–654. [Google Scholar] [CrossRef] [Green Version]
- Bhanu, B.; Lin, Y. Genetic algorithm based feature selection for target detection in SAR images. Image Vis. Comput. 2003, 21, 591–608. [Google Scholar] [CrossRef]
- Majumder, U.; Christiansen, E.; Wu, Q.; Inkawhich, N.; Blasch, E.; Nehrbass, J. High-performance computing for automatic target recognition in synthetic aperture radar imagery. In Cyber Sensing 2017; International Society for Optics and Photonics: Bellingham, WA, USA, 2017; Volume 10185, p. 1018508. [Google Scholar]
- Wagner, S.A. SAR ATR by a combination of convolutional neural network and support vector machines. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 2861–2872. [Google Scholar] [CrossRef]
- Qu, Y.; Chen, Y.; Huang, J.; Xie, Y. Enhanced pix2pix dehazing network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8160–8168. [Google Scholar]
- Wang, X.; Yan, H.; Huo, C.; Yu, J.; Pant, C. Enhancing Pix2Pix for remote sensing image classification. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2332–2336. [Google Scholar]
- Li, Y.; Fu, R.; Meng, X.; Jin, W.; Shao, F. A SAR-to-Optical Image Translation Method Based on Conditional Generation Adversarial Network (cGAN). IEEE Access 2020, 8, 60338–60343. [Google Scholar] [CrossRef]
- Yuan, Y.; Liu, S.; Zhang, J.; Zhang, Y.; Dong, C.; Lin, L. Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 701–710. [Google Scholar]
- Sato, M.; Hotta, K.; Imanishi, A.; Matsuda, M.; Terai, K. Segmentation of Cell Membrane and Nucleus by Improving Pix2pix. In Proceedings of the 11th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2018), Funchal, Portugal, 19–21 January 2018; pp. 216–220. [Google Scholar]
- Liebelt, J.; Schmid, C. Multi-view object class detection with a 3d geometric model. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1688–1695. [Google Scholar]
- Sun, B.; Saenko, K. From Virtual to Reality: Fast Adaptation of Virtual Object Detectors to Real Domains. In Proceedings of the BMVC 2014, Nottingham, UK, 1–5 September 2014; Volume 1, p. 3. [Google Scholar]
- Peng, X.; Sun, B.; Ali, K.; Saenko, K. Learning deep object detectors from 3d models. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1278–1286. [Google Scholar]
- Malmgren-Hansen, D.; Kusk, A.; Dall, J.; Nielsen, A.A.; Engholm, R.; Skriver, H. Improving SAR Automatic Target Recognition Models With Transfer Learning From Simulated Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1484–1488. [Google Scholar] [CrossRef] [Green Version]
- Lewis, B.; Scarnati, T.; Sudkamp, E.; Nehrbass, J.; Rosencrantz, S.; Zelnio, E. A SAR dataset for ATR development: The Synthetic and Measured Paired Labeled Experiment (SAMPLE). In Algorithms for Synthetic Aperture Radar Imagery XXVI; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 10987, p. 109870H. [Google Scholar]
- Lewis, B.; Liu, J.; Wong, A. Generative adversarial networks for SAR image realism. In Algorithms for Synthetic Aperture Radar Imagery XXV; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10647, p. 1064709. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2017, arXiv:1608.03983. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Boyat, A.K.; Joshi, B.K. A review paper: Noise models in digital image processing. arXiv 2015, arXiv:1505.03489. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Type | PSNR | SSIM |
|---|---|---|
| SAR | 18.7729 | 0.4685 |
| Translated | 21.4738 | 0.7420 |
| Name | Type Accuracy | Orientation Accuracy | ||
|---|---|---|---|---|
| SAR | Translated | SAR | Translated | |
| K.F. | 0.6854 | 0.7508 | 0.9221 | 0.9533 |
| J.H | 0.6106 | 0.7445 | 0.8847 | 0.9533 |
| J.L. | 0.6791 | 0.6916 | 0.9159 | 0.9408 |
| R.W. | 0.7975 | 0.8723 | 0.9470 | 0.9626 |
| Q.X. | 0.6667 | 0.7165 | 0.9252 | 0.9626 |
| J.Y. | 0.7788 | 0.9003 | 0.9470 | 0.9657 |
| Average | 0.7030 | 0.7797 | 0.9237 | 0.9564 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Jiang, W.; Yang, J.; Li, W. SAR Target Recognition Using cGAN-Based SAR-to-Optical Image Translation. Remote Sens. 2022, 14, 1793. https://doi.org/10.3390/rs14081793
Sun Y, Jiang W, Yang J, Li W. SAR Target Recognition Using cGAN-Based SAR-to-Optical Image Translation. Remote Sensing. 2022; 14(8):1793. https://doi.org/10.3390/rs14081793
Chicago/Turabian StyleSun, Yuchuang, Wen Jiang, Jiyao Yang, and Wangzhe Li. 2022. "SAR Target Recognition Using cGAN-Based SAR-to-Optical Image Translation" Remote Sensing 14, no. 8: 1793. https://doi.org/10.3390/rs14081793
APA StyleSun, Y., Jiang, W., Yang, J., & Li, W. (2022). SAR Target Recognition Using cGAN-Based SAR-to-Optical Image Translation. Remote Sensing, 14(8), 1793. https://doi.org/10.3390/rs14081793