1. Introduction
In the 21st century, the population is increasing, and the rapid growth of human society has consumed numerous natural resources and seriously contaminated the environment. In order to coordinate the relationship between the strikingly rapid development rate and environmental resources of farming areas, and to continuously improve human living standards and carry out sustainable development, we must monitor and protect the environmental resources of farming areas at four levels: (1) Arable land—ensuring the quantity and quality of arable land is of primary importance for maintaining sustainable agricultural development [
1]. (2) Grassland [
2]—grassland is a renewable natural resource that covers about 1/2 of the total global land area, and is the most fundamental means of production and base for developing grassland livestock farming. (3) Woodland—woodland is an integral component of forest resource assets, and the source of forest material production and ecological services [
3], whose area and value are mainly evaluated when conducting economic benefits assessment. (4) Water—human economic flourishment and agricultural production, including hydroelectric power generation, irrigation, shipping, fisheries, also rely on water. Each of these four levels can be monitored and protected with the assistance of computer technology.
Thanks to the prosperous trends in computer technology in the remote sensing field, enormous technical support has been provided for remote monitoring and protection of farming areas in the field of computer vision. M. H. Elagouz et al. [
4] used satellite data and remote sensing techniques to detect and supervise the transformation of land use or cover in the Egyptian Nile Delta. Willians Ribeiro Mendes et al. [
5] intended to create an intelligent fuzzy inference system underlying precise irrigation knowledge. They ultimately established a system aiming to construct particular maps to manipulate the rotation speed of the central pivot, and satellite images were employed. Karim Ennouri et al. [
6] suggested that due to the evolution of remote sensing technologies, satellite information has been regarded as the primary data source to monitor high-dimension crop growth conditions. In addition, the emergence of digital image processing methods have also made crop condition observation and decision-making straightforward.
Among the above techniques, aerial image segmentation is of particular interest in the agricultural research space. Previous scholars in this field have laid a solid foundation and achieved remarkable breakthroughs. To perform a fig plant segmentation in top-view RGB (red, green, blue) images, Jorge Fuentes-Pacheco et al. [
7] proposed an encoder–decoder convolutional neural network (CNN) that classifies each pixel as crop or non-crop. They introduced the approach to the research institution and performed it on an aerial image dataset. The new network achieved an average accuracy of 93.85%. A manual ground truth segmentation with pixel precision was adopted to compare different algorithms. Satoki Tsuichihara et al. [
8] created a farm management system that used aerial images of grass to detect weeds and precisely determine the quantity and location for applying fertilizers. Broad-leaved weeds may be detected with an accuracy of roughly 80% using a region segmentation method based on deep learning. Cow groups and locations can be located with higher volumes of cow manure by comparing the GPS data from the overall sensors. Maximilian Johenneken et al. [
9] suggested an autonomous system to detect and categorize the cause of damage to grasslands. The strategy entailed using CNN for the semantic segmentation of grasslands. They constructed an RGB baseline and evaluated multimodal architectures, resulting in a joint representation of elevation information and spectrum. Experimental results demonstrate that incorporating late fusion with elevation features enriches the network’s all-around performance over the RGB baselines. Weitao Wang, Qin Ma et al. [
10] validated the merits of combining multi-spectral (MS) and synthetic aperture radar (SAR) data to enhance classification accuracy, particularly in fog and cloud obscured areas. Additionally, they proposed an adaptive feature fusion method based on an attention mechanism and experimented with two patch construction methodologies. Experiments revealed that the suggested method with single-size patches produced the most favorable outcomes—a 0.91 average f1-score and 93.12% accuracy, to be exact. These outcomes suggested that by incorporating MS and SAR data with appropriate feature fusion methods, full-time and all-weather remote sensing monitoring of grassland resources is conceivable, effectively enhancing the self-adjusting capability of grasslands.
Even though the merits of progress and relatively high efficiency by current aerial image segmentation strategies are noticeable, they tend to be restricted to ideal circumstances, such as the desired premise with high-qualified aerial images. In other words, there are still various obstacles in this field.
- 1.
Multi-scale problem: one object in the image may occupy different frame sizes caused by the distance between the camera and the shooting object. The problem of multiple poses (or multiple perspectives) of the object is caused by the different shooting angles. External lighting conditions and weather would cause poor image quality and illuminance.
- 2.
Adjacent pixels are too similar to the image information in the receptive field (adjacent pixels are just on the boundary of the desired segmentation area), resulting in oscillation and distortion of the edges of the corresponding segmentation area.
- 3.
Pixel imbalance in different categories or instances in the same image is another barrier. The difficulty of segmenting different objects is not the same.
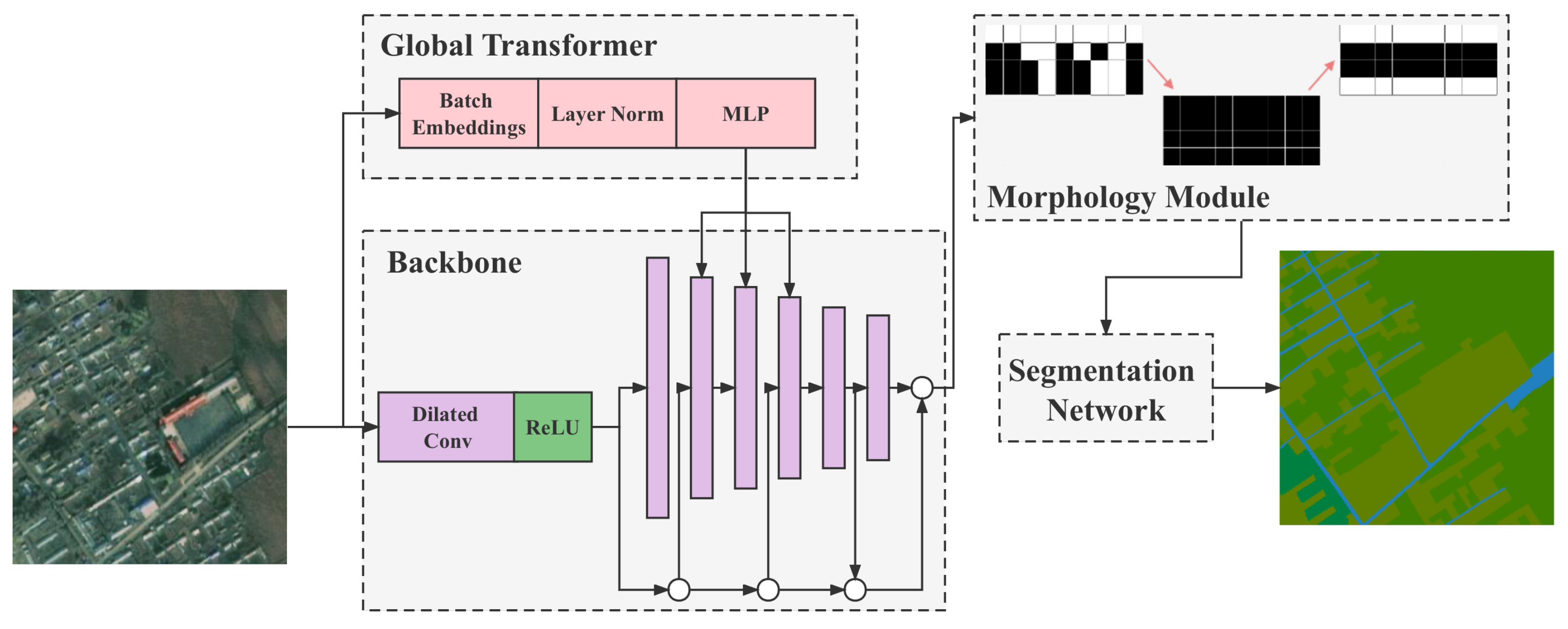
Driven by these preliminary requirements and relevant research in this area, this paper proposes a global farming area segmentation network using a morphological method to perform segmentation of farming areas (such as arable land, grasslands, woodlands, etc.) in aerial images, thereby resolving the aforementioned issues in the management of farming area resources. The principal contributions in this paper are as follows:
- 1.
The global-transformer structure was proposed to simplify the number of transformer parameters while retaining its core ability to extract global features.
- 2.
Applying dilated convolutional layers to the backbone further improves the segmentation capability of small-scale objects.
- 3.
A morphological method was used to reduce the number of connected domains for segmenting water bodies and roads in farming areas, so the segmentation effect could be as smooth and coherent as possible, with reduced noise.
Apart from these prominent contributions, limitations also exist in this study. (1) The road category—which retains comparatively the worst segmentation effect in the dataset—has a narrow shape in images, resulting in comprehensive model performance degradation. (2) The optimized segmentation performance of road categories is still insufficient, even though a separate model was selected. (3) Superior segmentation outcomes are based on an exceptional recognition rate. These limitations are future difficulties that the authors of this paper will strive to break through, and are the focus of subsequent research.
The subsequent sections of this paper are organized as follows: (1) The Related Work section demonstrates the preliminary theories and knowledge in the relative research field. (2) The Materials and Methods section describes the dataset and methods we employed, including the data pre-processing. (3) Important metrics, functions, settings, and training strategies are discussed in the Experiment section. (4) The Results and Discussion section illustrates the experimental results and provides a comparison. (5) The Conclusions section summarizes this study.
2. Related Work
Deep convolutional neural networks have been evolving, bringing continuous breakthroughs in image classification tasks. These models can integrate low, medium, or high-level features and then perform end-to-end classification, and the level of features can be enriched by applying deeper models. It is universally acknowledged that the effectiveness of a neural network is strongly related to the number of layers. In general, taking AlexNet [
11,
12] and VGG [
13,
14] as examples, the deeper the network, the better the results and the more difficult it is to train.
In contrast, the network’s training cost grows drastically as the depth rises further, while the results do not improve or even degrade. To resolve this issue, the deep residual learning framework ResNet [
15] was proposed, with deeper network layers, more straightforward optimization, and more excellent training results corresponding to the depth.
However, training a deep model is much more complicated than designing a deep model, such as the gradient instability problems. Fortunately, these issues have been tackled to some extent by regularization, allowing networks with tens of layers to converge by stochastic gradient descent (SGD) [
16] and backward propagation (BP) algorithms.
Another problem is that when deeper layers are able to converge, the accuracy of the network starts to plunge substantially. This degradation is not related to overfitting and brings about a more significant training error. This obstacle indicates that not all models are easy to train, and that shallow models may work better than deeper models that simply repeat the model’s layer.
Based on these excellent backbones, multiple segmentation networks were presented. We refer to the task with only one label (merely distinguishing categories) as semantic segmentation [
17]. With regard to distinguishing different individuals of the same category, we refer to this as instance segmentation [
18]. Since instance segmentation often only discriminates countable targets, the concept of panoptic segmentation was proposed by Alexander Kirillov et al. [
19] in 2019 to realize both instance segmentation and semantic segmentation. Currently, the majority of the successful algorithms in image segmentation derive from the same pioneer: the fully convolutional network (FCN) suggested by Long et al. [
20]. The FCN converts classification networks into a network structure for segmentation tasks and demonstrates that the segmentation problem can be implemented end-to-end in network training. For instance, the structure of UNet [
21] is a U-shaped structure for encoding (downsampling) and then decoding (upsampling), keeping the input and output sizes the same. SegNet [
22] is somewhat similar to UNet. It adopts an encoding–decoding structure. Such a structure mainly utilizes deconvolution and up-pooling. The decoder achieves nonlinear upsampling by pooling index, calculated by the maximum pooling operation of the encoder corresponding to the decoder.
The parameters in the backbones and segmentation networks are adjusted and optimized by the loss function. In regard to the different sorts of loss functions, softmax loss (cross-entropy loss with softmax) is the most common loss function in deep learning, which consists of three components: a fully connected layer, softmax function, and cross-entropy loss. The pipeline of softmax loss is as follows: first, an encoder is used to learn the features of the data, followed by the use of a fully connected layer, the softmax function, and finally cross-entropy is used to calculate the loss. More loss functions were proposed for different research areas and particular problems. For instance, the DIC loss function, an ensemble similarity measure function, is popularly used in medical image segmentation. Moreover, the BCE loss function creates a criterion that measures the binary cross entropy between the target and the input probabilities. In this study, we incorporated the Lovasz softmax loss and softmax loss and employed this combination.
4. Experiment
4.1. Evaluation Metrics
The semantic segmentation task is essentially a classification task, where the object of classification is each pixel in the input image. Therefore, when evaluating the performance of a semantic segmentation task, the relevant performance metric of the classification task is frequently utilized. More specifically, depending on the combination of the actual and predicted categories of the classification objects, four classification results will be obtained. Each of these four combinations yields
(True Positive), when the predicted result is the same as the true label, and others,
(False Positive),
(False Negative) and
(True Negative), as shown in
Table 3. This table is only used to indicate how the above four parameters are defined, not to indicate the specific values of these parameters.
where Positive represents the positive sample, while Negative represents the negative sample. denotes that the actual category of the sample is positive, and the predicted category is also positive, alleged “True Positive”. denotes that the actual category of the sample is negative, whereas the predicted category is positive, entitled “False Positive”. indicates that the actual category of the sample is positive, but the predicted category is negative, alleged “False Negative”. means that the actual category of the sample is negative; meanwhile, the predicted category is also negative, which is called “True Negative”.
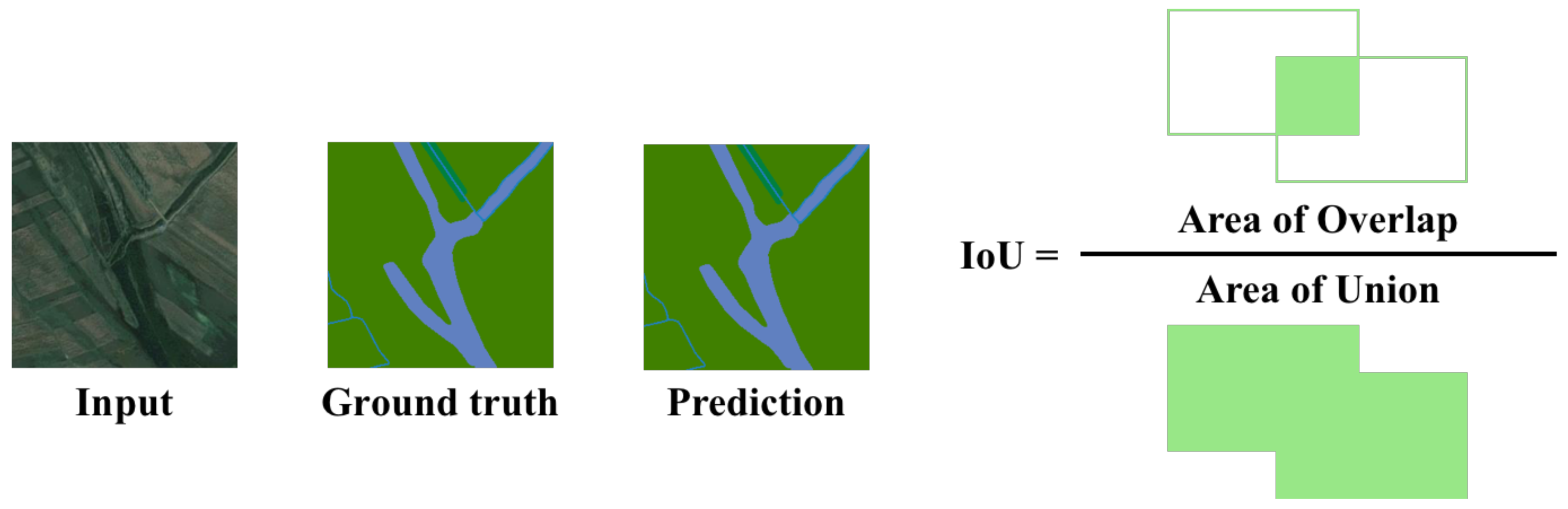
On this basis,
is the most commonly used performance metric in semantic segmentation to measure the degree of overlap between the predicted and actual regions, as portrayed in
Figure 7.
Equation (
3) provides the explicit computation process:
Apart from calculating
, we undertook the evaluation in terms of continuity metrics of the region based on the combination of characteristics of remote sensing tasks and evaluation metrics of the tournament where the dataset originated from. This metric is calculated as shown in Equation (
4).
where
p represents the number of valid images,
c denotes the number of valid categories in the
ith graph,
m denotes the number of connected domains in the
jth category of ground truth in the
ith graph, and
n denotes the
kth connected domain in the
jth category of the
ith graph, divided into
n parts.
4.2. Rebalance the Class-Imbalance
The “hard balance” and “soft balance” are two strategies to cope with the category imbalance problem. The intuitive manifestation of category imbalance is the conspicuous gap between the amount of positive and negative samples. Automatically, the solution is to diminish the quantity difference, including expanding the positive samples and lowering the number of negative samples. Solving category imbalance by adjusting the number of categories is the idea of “hard balance”. Generally, it is always challenging to obtain additional new samples, so “hard balance” is performed by growing the number of positive samples (oversampling) or decreasing the number of negative samples (undersampling). The rudimentary effect of category imbalance is that it causes the model to focus too much on counterexamples during training, resulting in a model that is biased against counterexamples. Therefore, “soft balance” (also called rebalance in the category) ensures that the model focuses less on counterexamples by assigning smaller weights to the loss values of counterexamples; meanwhile, giving larger weights to the loss values of positive samples. Since the samples for semantic segmentation are pixels, it is hard to undertake “oversampling” and “undersampling” of the pixels in the image, so this paper chooses the “rebalance” method to address the imbalance issue.
The weights used for “rebalance” are usually negatively related to the actual number of categories. In other words, the larger the number of categories, the smaller the weights; meanwhile, the smaller the number of categories, the larger the weights. A typical median rebalance weight is calculated by taking the median
of the sample size of all categories as the numerator, and the actual sample size of each category
as the denominator, as shown in Equation (
5).
i represents the category, and
m indicates the total number of categories. Equation (
5) is brought into the loss function equation to obtain the weighted and rebalanced loss function, as shown in Equation (
6).
The model performance comparison before and after rebalancing is shown in
Table 4, and the experimental results show that this method can effectively improve the model performance on this dataset.
4.3. Experiment Settings
This subsection presents the relevant parameter settings for the final training underlying the previous content. After analyzing the above, due to the exceptionally unbalanced distribution of categories in the dataset, this paper eventually adopted median rebalanced weights for processing, and the weights are presented in
Table 5.
The platform configuration for model training and prediction in this paper is displayed in
Table 6.
4.4. Training Strategies
Regarding the selection of loss functions, due to the existence of category imbalance, this study tested the softmax loss, weighted softmax loss, and Lovasz softmax loss. Each loss function has its own merits and drawbacks, which leads to the use of a single loss function for model training that may fail to help the model achieve acceptable performance. Therefore, this paper incorporated Lovasz softmax loss and softmax loss and applied this combined loss function.
For each method model that was compared, we trained and tested on the dataset to find the most suitable method for the farming area.
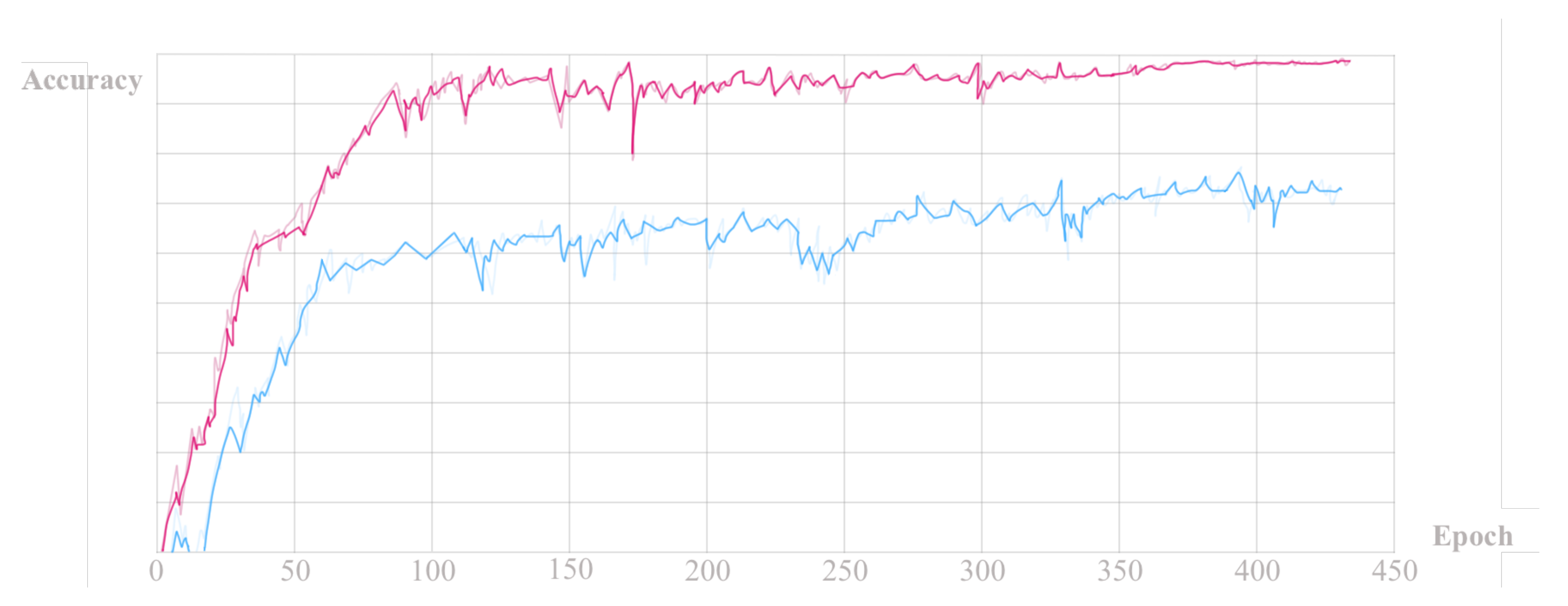
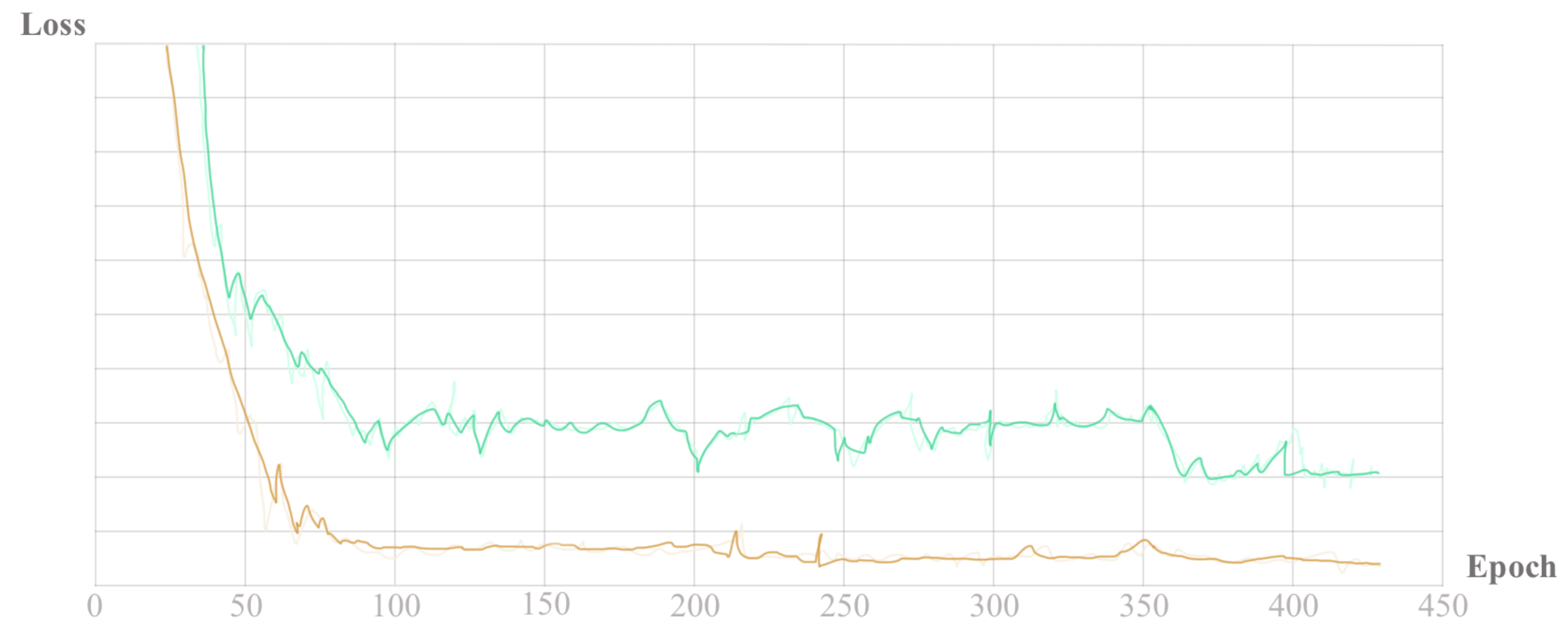
Figure 8 and
Figure 9 display the trend in accuracy and loss during the training process.
The model parameters used in this paper are selected as the optimal parameters when the loss function converges on the training set in
Figure 9.
6. Discussion
6.1. Validation of Backbone
In addition to the dilated convolution and transformer structures used in this paper, other structures are used in different CNN models to extract features, such as the block idea in ResNet and the attention module. Therefore, this section will show the comparison experiments after replacing the backbone of the model with these two modules’ representative networks: SENet and ResNet.
Table 10 indicates that the backbone using the combination of dilated convolution and transformer has a superior ability to extract features compared to SENet and ResNet. To be more specific, it has higher Precision and Recall scores. Hence, it can be concluded that the improved method proposed in this paper has better feature extraction capability.
6.2. Weakly Class Processing
As demonstrated in
Section 3.1.1, the accuracy of the model is shallow for identifying roads and grasslands categories, resulting in a comprehensively deficient performance of the model. Therefore, in this paper, some additional work was done to train the model for these two categories:
- 1.
For the road category, we first extracted a binary dataset from the original training set and then performed a separate binary training; here, we operated a combination of U-Net+Dice loss training to obtain the predicted road binary results. Eventually, a straightforward judgment condition, such as the matching degree of road class on two labels, was applied to override the overall prediction outcome.
- 2.
The prediction results revealed that the grassland category is prone to be mispredicted as arable lands. Therefore, the separate training for grassland was conducted by extracting the two categories of arable lands and grasslands for triple classification. Afterward, the same network training as that of the main model was applied. Eventually, grassland coverage in the total prediction results only occurred between the two grassland and arable land categories.
6.3. Connectivity Metrics Optimization
The connectivity metrics are particularly prominent only for the water body and road categories, and there are two principal optimization strategies:
- 1.
Accuracy: To start with, we must guarantee a high classification accuracy for these two categories. The accuracy of the water body category is high enough, but the accuracy of the road category is still particularly low. Therefore, the recognition accuracy of the road category needs to be improved.
- 2.
Connectivity: The consideration of connectivity can start from two aspects, one is from the model, selecting or improving the model to improve the connectivity integrity of the prediction results, and the other is the post-processing step to optimize the connectivity.
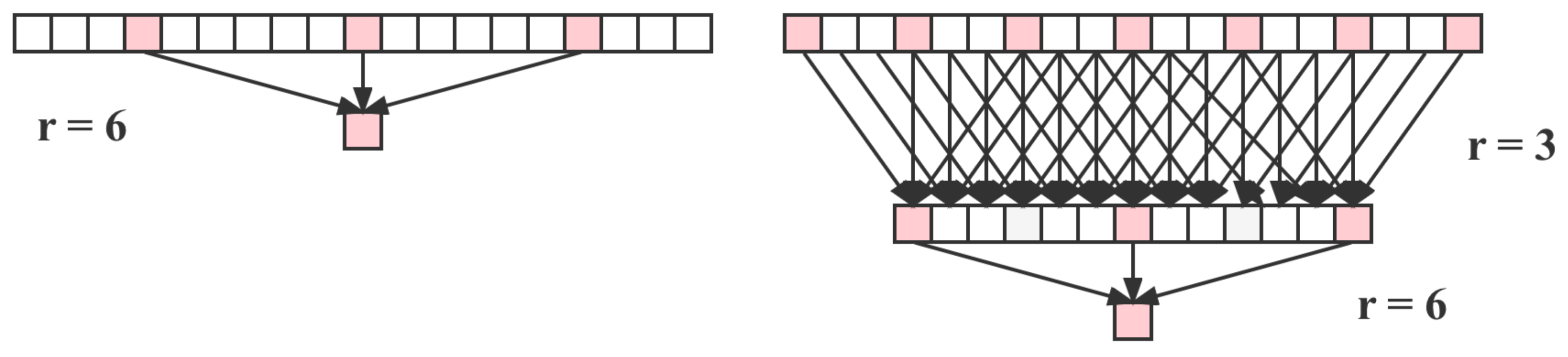
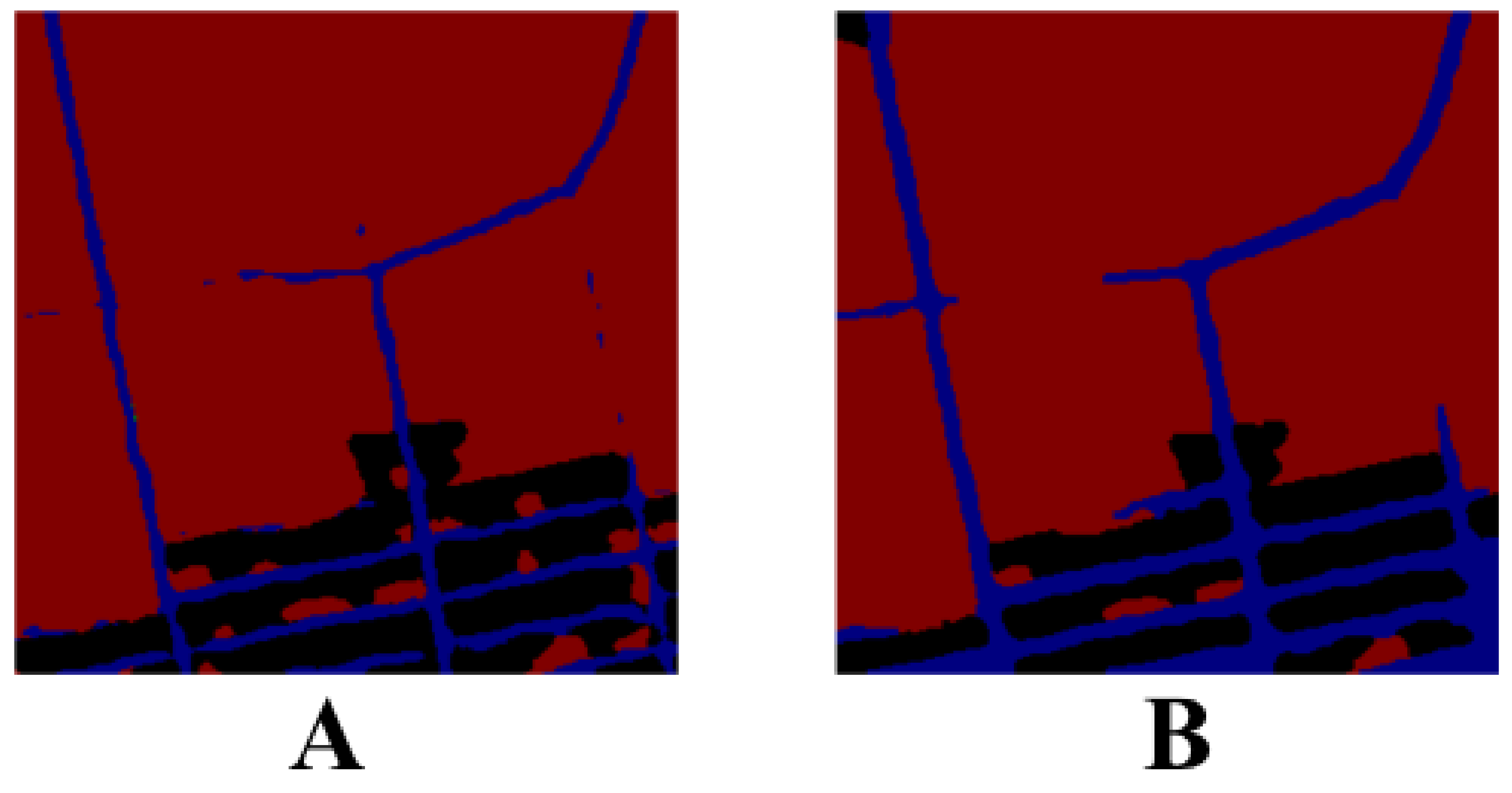
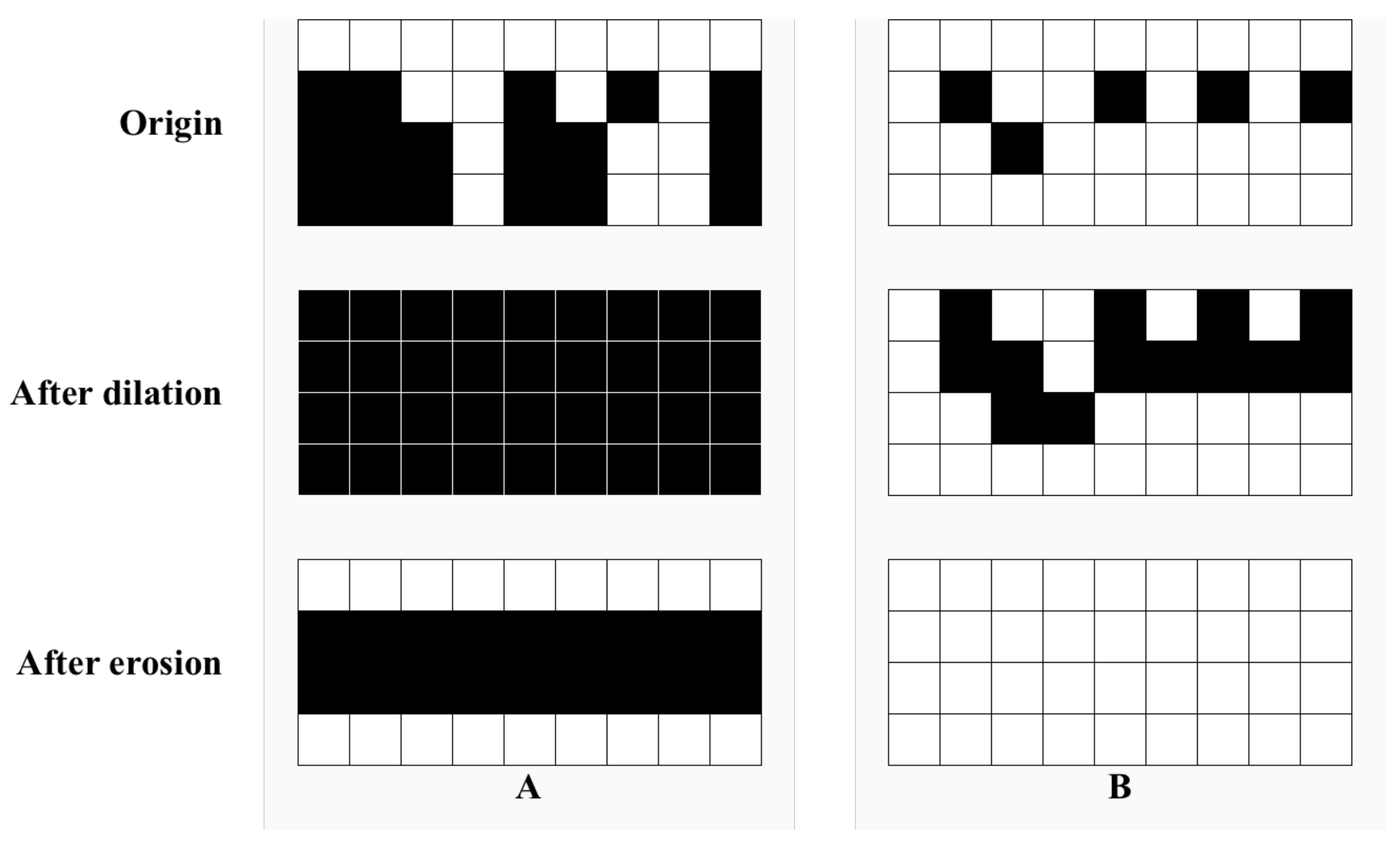
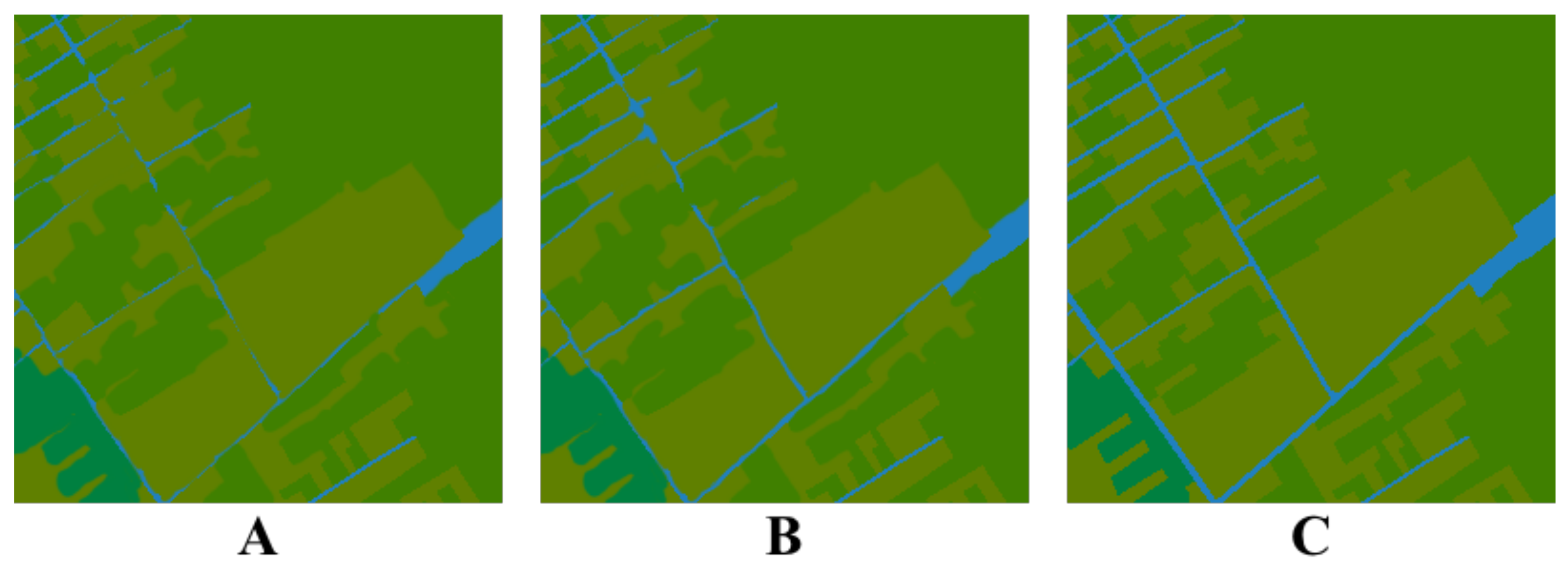
In this paper, we co-opted image morphology to improve the connectivity. The same treatment was carried out for both water bodies and roads. Firstly, the morphology was closed, and the dilation and erosion coefficients were set differently to improve the connectivity effect. Subsequently, the slight area noise was eliminated.
As illustrated in
Figure 12, the road category is shown in blue, the left one is the unprocessed image, and the middle one is the morphological processed image.
6.4. Model Enhancement
6.4.1. Single Model Enhancement
Prediction enhancements for a single model typically include multi-scale prediction and flipping prediction. In order to control the prediction time, this paper only performed the prediction enhancement by flipping left and right, and flipping up and down once, i.e., flipping before prediction and then flipping back after getting the labels. Single model enhancement mainly improves prediction stability, so performing it too many times is unnecessary.
6.4.2. Model Combination Enhancement
Model combination enhancement is a model integration method, and the commonly used model integration methods include bagging, boosting, and stacking. This paper ultimately employed the hard voting method for multi-model prediction results, mainly aiming for reasoning time optimization. Multi-model enhancement mainly relies on the independence between models, so the lower the correlation between models, the better the integration effect.
6.5. Validation of Data Enhancement Methods
In addition to the fundamental data enhancement methods, such as flipping, folding, mirroring, etc., this paper also used advanced enhancement methods requiring a certain amount of computations. These methods invoke more computations, so this section discusses whether it is reasonable to use these enhancement methods. We have done many ablation experiments, and the results are given in
Table 11.
Table 11 indicates that the model’s performance decreases significantly when only utilizing the basic augmentation method, compared to the previous experimental results in this paper. Moreover, all of these enhancement methods have improved the model’s performance. Stockade Mask has the most significant effect on the model, improving by 4.9%, 3.4%, 3.7%, and 2.0% in precision, recall,
, and continuity, respectively.
6.6. Limitation
The worst segmentation effect in this dataset is the road category, resulting in the degradation of the overall model performance. To be more precise, this category has the traits of slimness and length in the image. Although this paper has selected a separate model for the road category for training, the outcome is unsatisfactory. To optimize the segmentation effect of this category, the focus is on improving its connectivity metrics. Although the segmentation effect has been improved by morphological processing, the prerequisite—a favorable recognition rate—is required. Achieving superior segmentation results in the case of a low recognition rate is difficult. Therefore, to further improve the segmentation of these images, optimizations of the recognition rate should be considered in future work.
7. Conclusions
Farming areas have substantial socio-economic value in terms of farmer livelihoods, societal prosperity, and agricultural research. Detecting crops (such as wheat and corn) in farming areas permits the supervision of farming area production, and is significant for managing agricultural resources. Motivated by this practical significance, this paper proposed a global-transformer segmentation network based on the morphological correction method. The suggested model tackled the drawbacks of current image segmentation methods—their homogeneity and insufficiency in segmenting multiple objects in farming areas, as well as small-scale objects such as corn and wheat. Moreover, unlike traditional models, our model incorporated the dilated convolution technique and the transformer technique in the backbone and the branches, respectively. Because this innovation improved the feature extraction capability of the model’s backbone, the backbone enhanced by this method was applied to an object detection network on a corn and wheat ear dataset. Experimentally, our model can satisfactorily detect wheat ears in a complicated environment.
The proposed method can improve the global feature extraction ability of the model while simplifying the model structure and reducing the number of parameters, which can satisfactorily enhance the segmentation effect of small-scale objects. The morphological correction method can process the initial segmentation results, effectively minimizing the number of connected domains of narrow objects such as water bodies and roads, making the segmentation results smooth and coherent. The method finally reached 0.903 in and 13 for continuity, implying that the proposed scheme is as effective as expected, and is superior to other comparison models. More precisely, the continuity has risen by 408%. These outcomes reveal that the proposed method is superior and validated on diverse datasets, demonstrating its fine generalizability. This method can provide rudimentary preparations and viable strategies for detecting crops and managing farming area resources.
As described in
Section 5, the effect of morphological correction is based on the segmentation effect. Therefore, further enhancing the segmentation accuracy of remote sensing images, especially in small-scale objects, will be the future work and subsequent research interest of the authors in this paper.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}