
A Swin Transformer-Based Encoding Booster Integrated in U-Shaped Network for Building Extraction



Abstract
:
1. Introduction
2. Methodology
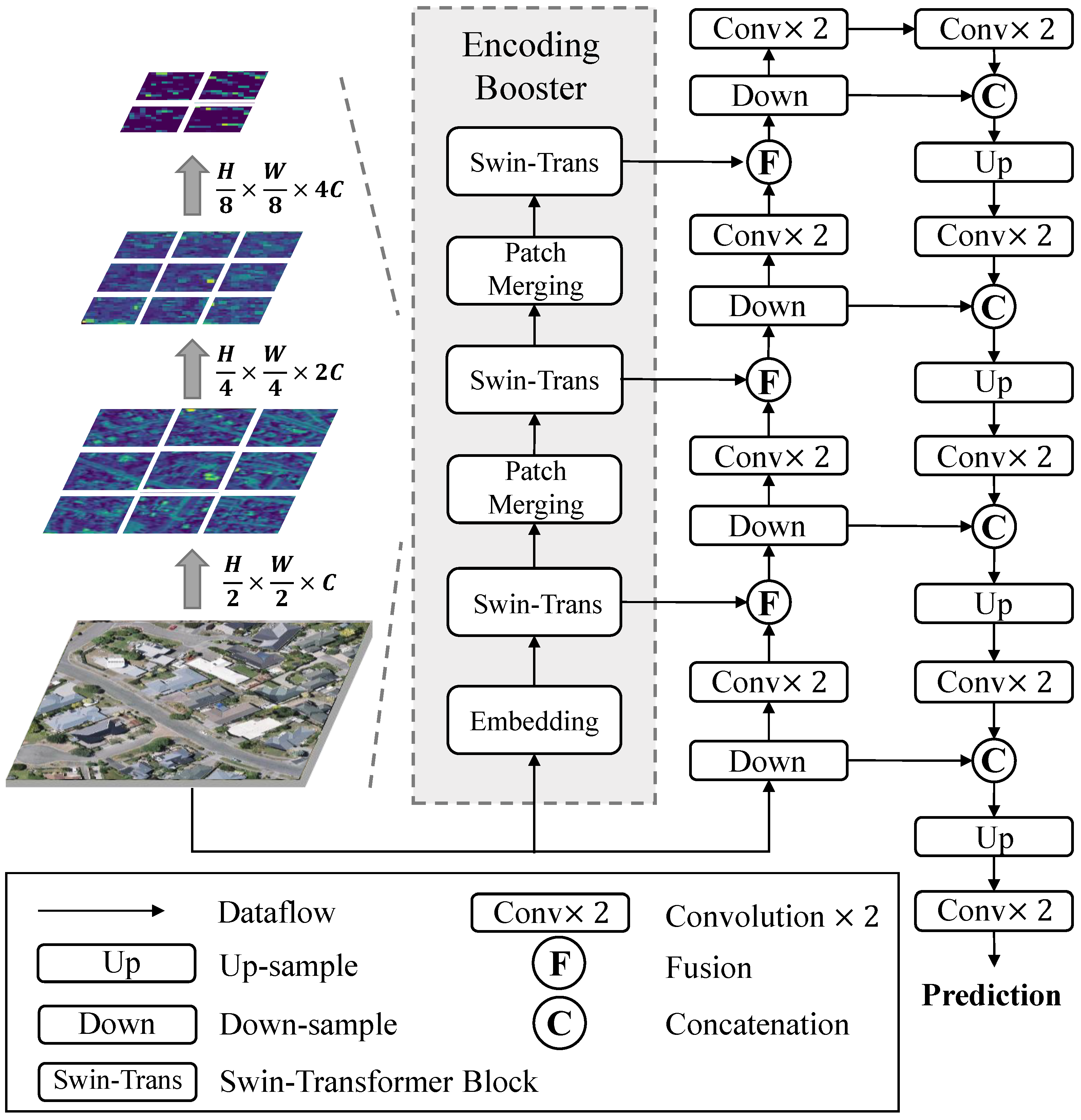
2.1. Overall Architecture
2.2. Transformer and Shifted-Window Design
2.3. Swin Transformer-Based Encoding Booster
2.4. U-Shaped Network with Feature Fusion
2.5. Loss Function
3. Experiments and Results
3.1. Experiment Dataset
3.2. Evaluation Metrics
3.3. Experimental Setting
3.4. Comparison Network
3.5. Experimental Result and Analysis
3.6. Generalization Testing
4. Discussion
4.1. Loss Function
4.2. Resource Requirement Analysis
4.3. Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Enemark, S.; Williamson, I.; Wallace, J. Building modern land administration systems in developed economies. J. Spat. Sci. 2005, 50, 51–68. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Li, Z.; Yang, J.; Liu, Y.; Fu, B.; Qi, W.; Fan, X. Spatiotemporal characteristics of earthquake disaster losses in China from 1993 to 2016. Nat. Hazards 2018, 94, 843–865. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Z.; Wei, B.; Li, X.; Fu, B. Seismic vulnerability assessment at urban scale using data mining and GIScience technology: Application to Urumqi (China). Geomat. Nat. Hazards Risk 2019, 10, 958–985. [Google Scholar] [CrossRef] [Green Version]
- Zhang, B.; Chen, Z.; Peng, D.; Benediktsson, J.A.; Liu, B.; Zou, L.; Li, J.; Plaza, A. Remotely sensed big data: Evolution in model development for information extraction [point of view]. Proc. IEEE 2019, 107, 2294–2301. [Google Scholar] [CrossRef]
- Saeedi, P.; Zwick, H. Automatic building detection in aerial and satellite images. In Proceedings of the 2008 10th International Conference on Control, Automation, Robotics and Vision, Hanoi, Vietnam, 17–20 December 2008; pp. 623–629. [Google Scholar]
- Huang, X.; Zhang, L. Morphological building/shadow index for building extraction from high-resolution imagery over urban areas. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 5, 161–172. [Google Scholar] [CrossRef]
- Ok, A.O.; Senaras, C.; Yuksel, B. Automated detection of arbitrarily shaped buildings in complex environments from monocular VHR optical satellite imagery. IEEE Trans. Geosci. Remote Sens. 2012, 51, 1701–1717. [Google Scholar] [CrossRef]
- Manno-Kovács, A.; Ok, A.O. Building detection from monocular VHR images by integrated urban area knowledge. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2140–2144. [Google Scholar] [CrossRef]
- Femiani, J.; Li, E.; Razdan, A.; Wonka, P. Shadow-based rooftop segmentation in visible band images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 8, 2063–2077. [Google Scholar] [CrossRef]
- Li, E.; Xu, S.; Meng, W.; Zhang, X. Building extraction from remotely sensed images by integrating saliency cue. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 906–919. [Google Scholar] [CrossRef]
- Manno-Kovacs, A.; Sziranyi, T. Orientation-selective building detection in aerial images. ISPRS J. Photogramm. Remote Sens. 2015, 108, 94–112. [Google Scholar] [CrossRef]
- Inglada, J. Automatic recognition of man-made objects in high resolution optical remote sensing images by SVM classification of geometric image features. ISPRS J. Photogramm. Remote Sens. 2007, 62, 236–248. [Google Scholar] [CrossRef]
- Turker, M.; Koc-San, D. Building extraction from high-resolution optical spaceborne images using the integration of support vector machine (SVM) classification, Hough transformation and perceptual grouping. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 58–69. [Google Scholar] [CrossRef]
- Du, S.; Zhang, F.; Zhang, X. Semantic classification of urban buildings combining VHR image and GIS data: An improved random forest approach. ISPRS J. Photogramm. Remote Sens. 2015, 105, 107–119. [Google Scholar] [CrossRef]
- Katartzis, A.; Sahli, H. A stochastic framework for the identification of building rooftops using a single remote sensing image. IEEE Trans. Geosci. Remote Sens. 2007, 46, 259–271. [Google Scholar] [CrossRef]
- Sirmacek, B.; Unsalan, C. Urban-area and building detection using SIFT keypoints and graph theory. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1156–1167. [Google Scholar] [CrossRef]
- Liu, Z.; Cui, S.; Yan, Q. Building extraction from high resolution satellite imagery based on multi-scale image segmentation and model matching. In Proceedings of the 2008 International Workshop on Earth Observation and Remote Sensing Applications, Beijing, China, 30 June–2 July 2008; pp. 1–7. [Google Scholar]
- Huang, X.; Zhang, L. A multidirectional and multiscale morphological index for automatic building extraction from multispectral GeoEye-1 imagery. Photogramm. Eng. Remote Sens. 2011, 77, 721–732. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Liu, Y.; Piramanayagam, S.; Monteiro, S.T.; Saber, E. Dense semantic labeling of very-high-resolution aerial imagery and lidar with fully-convolutional neural networks and higher-order CRFs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 76–85. [Google Scholar]
- Li, L.; Liang, J.; Weng, M.; Zhu, H. A multiple-feature reuse network to extract buildings from remote sensing imagery. Remote Sens. 2018, 10, 1350. [Google Scholar] [CrossRef] [Green Version]
- Kang, W.; Xiang, Y.; Wang, F.; You, H. EU-Net: An efficient fully convolutional network for building extraction from optical remote sensing images. Remote Sens. 2019, 11, 2813. [Google Scholar] [CrossRef] [Green Version]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic segmentation of urban buildings from VHR remote sensing imagery using a deep convolutional neural network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef] [Green Version]
- Ye, Z.; Fu, Y.; Gan, M.; Deng, J.; Comber, A.; Wang, K. Building extraction from very high resolution aerial imagery using joint attention deep neural network. Remote Sens. 2019, 11, 2970. [Google Scholar] [CrossRef] [Green Version]
- Guo, M.; Liu, H.; Xu, Y.; Huang, Y. Building extraction based on U-Net with an attention block and multiple losses. Remote Sens. 2020, 12, 1400. [Google Scholar] [CrossRef]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. BRRNet: A fully convolutional neural network for automatic building extraction from high-resolution remote sensing images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef] [Green Version]
- Chen, M.; Wu, J.; Liu, L.; Zhao, W.; Tian, F.; Shen, Q.; Zhao, B.; Du, R. DR-Net: An improved network for building extraction from high resolution remote sensing image. Remote Sens. 2021, 13, 294. [Google Scholar] [CrossRef]
- Jin, Y.; Xu, W.; Zhang, C.; Luo, X.; Jia, H. Boundary-aware refined network for automatic building extraction in very high-resolution urban aerial images. Remote Sens. 2021, 13, 692. [Google Scholar] [CrossRef]
- Chen, D.Y.; Peng, L.; Li, W.C.; Wang, Y.D. Building Extraction and Number Statistics in WUI Areas Based on UNet Structure and Ensemble Learning. Remote Sens. 2021, 13, 1172. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2022; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Pan, X.; Gao, L.; Marinoni, A.; Zhang, B.; Yang, F.; Gamba, P. Semantic labeling of high resolution aerial imagery and LiDAR data with fine segmentation network. Remote Sens. 2018, 10, 743. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. A scale robust convolutional neural network for automatic building extraction from aerial and satellite imagery. Int. J. Remote Sens. 2019, 40, 3308–3322. [Google Scholar] [CrossRef]
- Ma, J.; Wu, L.; Tang, X.; Liu, F.; Zhang, X.; Jiao, L. Building extraction of aerial images by a global and multi-scale encoder-decoder network. Remote Sens. 2020, 12, 2350. [Google Scholar] [CrossRef]
- Wierzbicki, D.; Matuk, O.; Bielecka, E. Polish cadastre modernization with remotely extracted buildings from high-resolution aerial orthoimagery and airborne LiDAR. Remote Sens. 2021, 13, 611. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Yuan, W.; Xu, W. MSST-Net: A Multi-Scale Adaptive Network for Building Extraction from Remote Sensing Images Based on Swin Transformer. Remote Sens. 2021, 13, 4743. [Google Scholar] [CrossRef]
- Chen, X.; Qiu, C.; Guo, W.; Yu, A.; Tong, X.; Schmitt, M. Multiscale feature learning by transformer for building extraction from satellite images. IEEE Geosci. Remote. Sens. Lett. 2022, 19, 2503605. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Petit, O.; Thome, N.; Rambour, C.; Themyr, L.; Collins, T.; Soler, L. U-net transformer: Self and cross attention for medical image segmentation. In Proceedings of the International Workshop on Machine Learning in Medical Imaging; Springer: Berlin/Heidelberg, Germany, 2021; pp. 267–276. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling; University of Toronto: Toronto, ON, Canada, 2013. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Valanarasu, J.M.J.; Oza, P.; Hacihaliloglu, I.; Patel, V.M. Medical transformer: Gated axial-attention for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 36–46. [Google Scholar]
- Zhang, Y.; Liu, H.; Hu, Q. Transfuse: Fusing transformers and cnns for medical image segmentation. arXiv 2021, arXiv:2102.08005. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Input Size | Batch Size | Optimizer | Parameter Setting |
|---|---|---|---|---|
| STEB-UNet | 32 | Adam | lr = 0.001, betas = (0.9, 0.999), eps =1 × 10−8, weight decay = 0 | |
| U-Net [34] | 32 | RMSProp | lr = 0.001, momentum = 0.9, weight decay =1 × 10−8 | |
| -Net [51] | 32 | Adam | lr = 0.001, betas = (0.9, 0.999), eps = 1 × 10−8, weight decay = 0 | |
| SETR-Naïve [52] | 2 | Adam | lr = 0.0001, betas = (0.9, 0.999), eps = 1 × 10−8, weight decay = 0 | |
| BRRNet [30] (reported) | 8 | Adam | lr = 0.001 | |
| RFA-UNet [28] (reported) | (WHU) (Mass) | 8 | Adam | lr = 0.001 |
| TEB-UNet | 4 | Adam | lr = 0.0001, betas = (0.9, 0.999), eps = 1 × 10−8, weight decay = 0 |
| Massachusetts [53] | WHU [36] | |||
|---|---|---|---|---|
| Score ↑ | IOU ↑ | Score ↑ | IOU ↑ | |
| U-Net [34] | 82.81% | 73.34% | 85.45% | 87.98% |
| BRRNet [30] (report) | 85.36% | 74.46% | 92.40% | 85.90% |
| U2-Net [51] | 85.91% | 80.56% | 92.47% | 91.34% |
| RFA-UNet [28] (report) | 85.65% | 74.91% | 94.75% | 90.02% |
| SETR-Naïve [52] | 87.05% | 77.39% | 93.41% | 88.47% |
| TEB-UNet | 89.74% | 76.91% | 94.55% | 88.63% |
| STEB-UNet | 89.90% | 81.66% | 96.85% | 93.89% |
| Massachusetts [53] | WHU [36] | |||
|---|---|---|---|---|
| Score ↑ | IOU ↑ | Score ↑ | IOU ↑ | |
| U-Net [34] | 74.20% | 72.45% | 81.01% | 78.49% |
| U2-Net [51] | 81.83% | 74.54% | 84.13% | 80.92% |
| SETR-Naïve [52] | 85.74% | 74.51% | 85.84% | 81.43% |
| TEB-UNet | 85.11% | 75.80% | 87.11% | 84.87% |
| STEB-UNet | 87.08% | 78.95% | 87.64% | 85.22% |
| Loss Function | Score | IOU |
|---|---|---|
| BCE | 96.74% | 93.62% |
| Dice | 96.85% | 93.89% |
| Combine ( = 0.4) | 96.76% | 93.61% |
| Combine ( = 0.5) | 96.79% | 93.65% |
| Combine ( = 0.6) | 96.79% | 93.64% |
| Model | Parameter (M) | Memory (MB) | Training Time/Epoch |
|---|---|---|---|
| SETR-Naive [52] | 51.95 | 22165 | 1769.4 s |
| TEB-UNet | 25.86 | 16579 | 1385.8 s |
| STEB-UNet | 21.14 | 2465 | 807.3 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, X.; Guo, W.; Chen, R.; Hui, Y.; Wang, J.; Zhao, H. A Swin Transformer-Based Encoding Booster Integrated in U-Shaped Network for Building Extraction. Remote Sens. 2022, 14, 2611. https://doi.org/10.3390/rs14112611
Xiao X, Guo W, Chen R, Hui Y, Wang J, Zhao H. A Swin Transformer-Based Encoding Booster Integrated in U-Shaped Network for Building Extraction. Remote Sensing. 2022; 14(11):2611. https://doi.org/10.3390/rs14112611
Chicago/Turabian StyleXiao, Xiao, Wenliang Guo, Rui Chen, Yilong Hui, Jianing Wang, and Hongyu Zhao. 2022. "A Swin Transformer-Based Encoding Booster Integrated in U-Shaped Network for Building Extraction" Remote Sensing 14, no. 11: 2611. https://doi.org/10.3390/rs14112611
APA StyleXiao, X., Guo, W., Chen, R., Hui, Y., Wang, J., & Zhao, H. (2022). A Swin Transformer-Based Encoding Booster Integrated in U-Shaped Network for Building Extraction. Remote Sensing, 14(11), 2611. https://doi.org/10.3390/rs14112611