
Bi-HRNet: A Road Extraction Framework from Satellite Imagery Based on Node Heatmap and Bidirectional Connectivity



Abstract
:1. Introduction
1.1. Heuristic Road Extraction Algorithm
1.2. Deep-Learning-Based Road Automatic Extraction Algorithm
- We propose a new way of predicting the direction of road networks, which classifies the importance of road topology connectivity according to different road nodes and converts the regression of the direction and angle into a regional classification problem to enhance the network on direction learning.
- To improve the accuracy of node connectivity prediction, we propose a bidirectional connectivity prediction strategy, which is based on a “top-to-down” and “down-to-top” strategy.
- We propose a framework for predicting key points of road networks based on a multiresolution road node heatmap, which can improve the precision of key nodes.
2. Materials and Methods
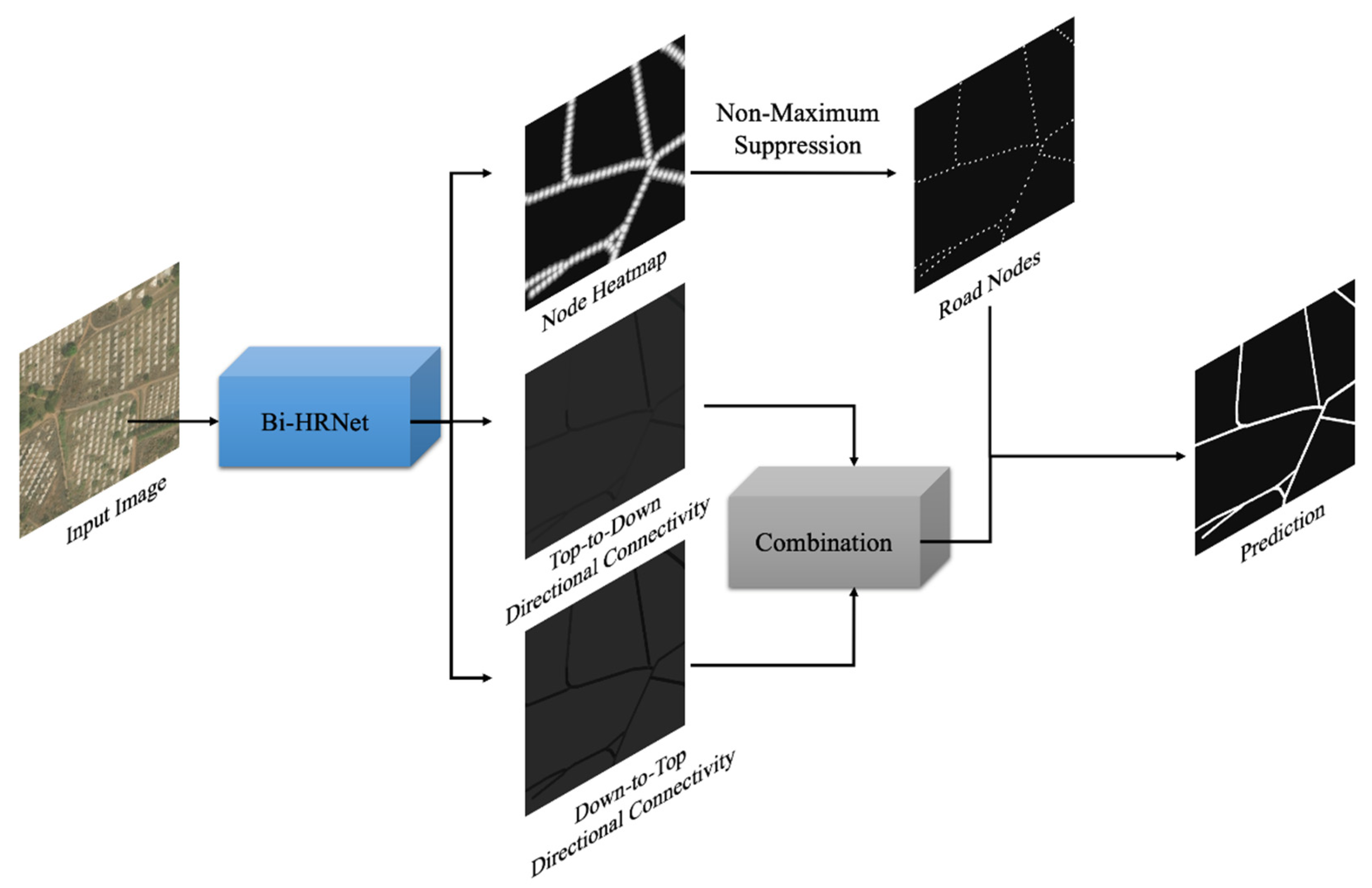
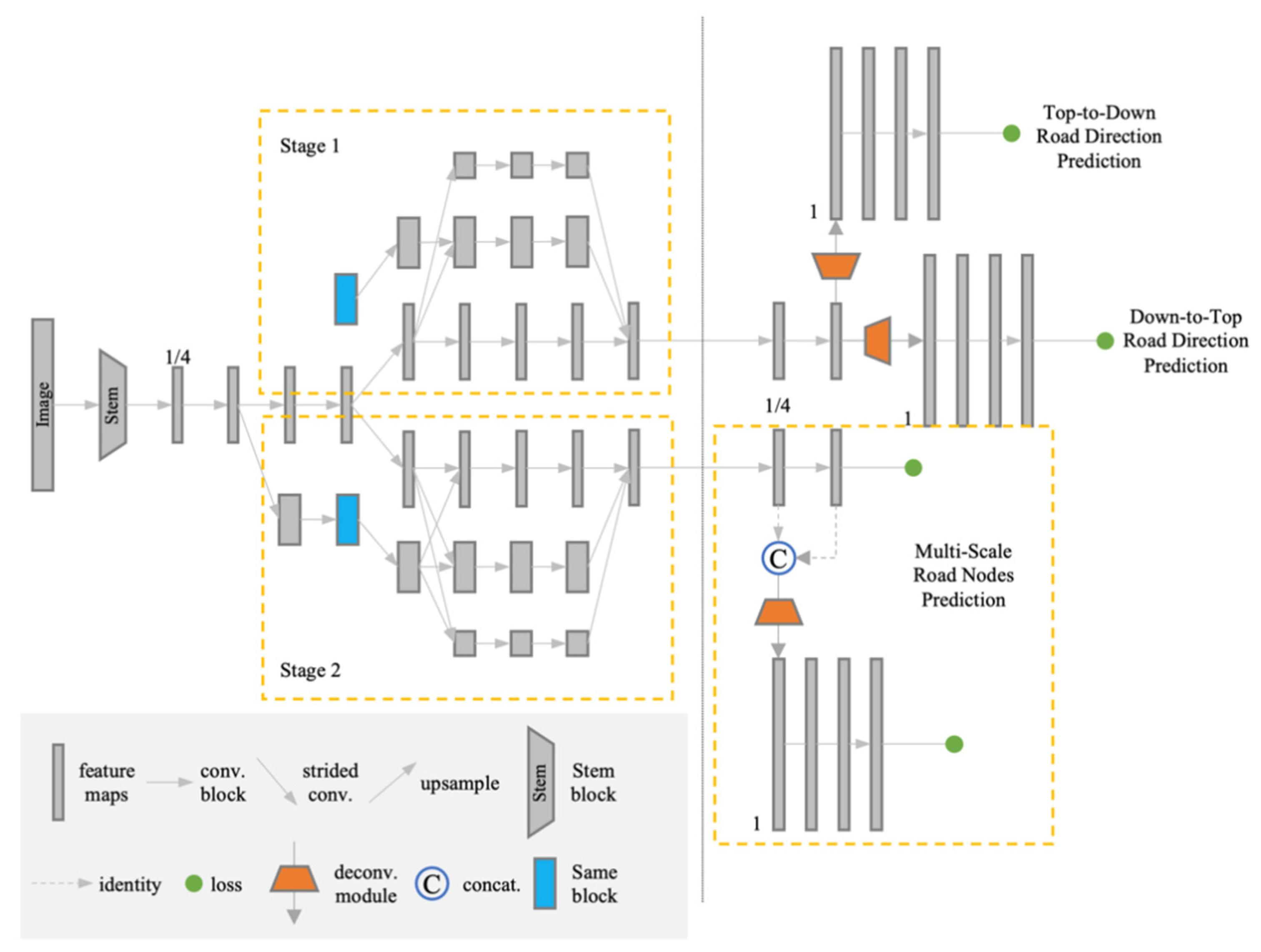
2.1. Overview of the Proposed Framework
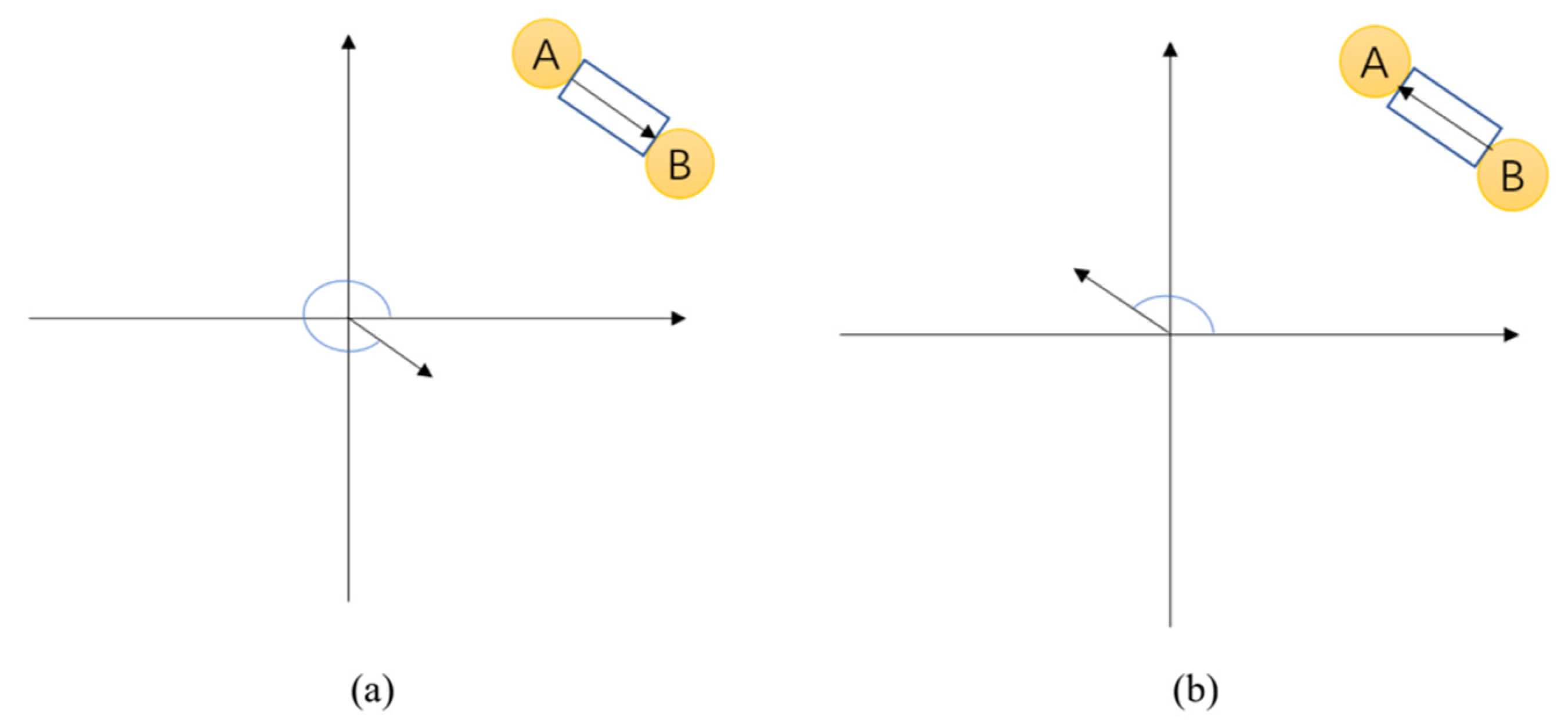
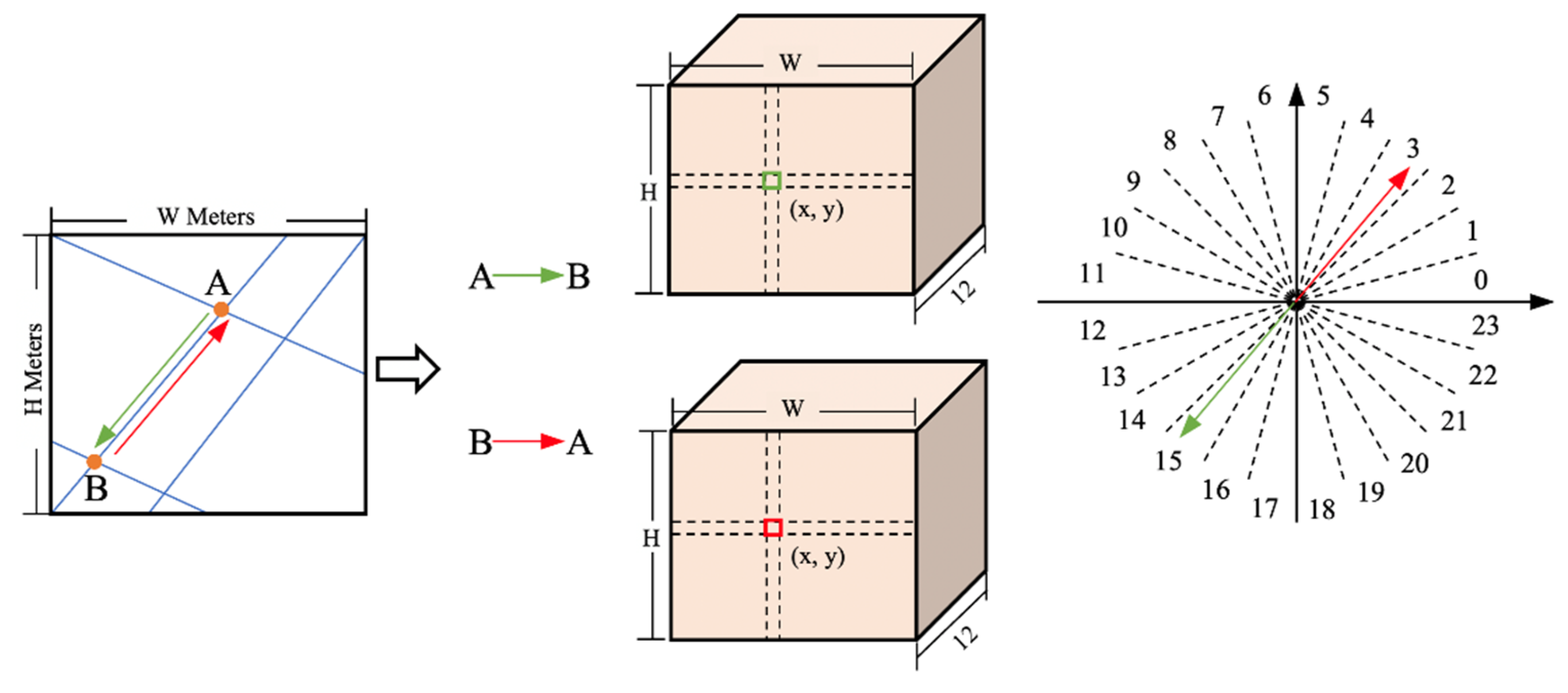
2.2. Bidirectional Road Graph Prediction
2.3. Road Node Prediction
2.4. Training Bi-HRNet
2.5. Implementation Details
3. Experimental Results
3.1. Experimental Datasets
3.2. Metrics
3.3. Experimental Results on DeepGlobe Dataset
3.4. Experimental Results on RoadTracer Dataset
3.5. Experimental Results on Google Dataset
4. Discussion
4.1. Main Goals of the Study
4.2. Ablation Experiment
4.3. Extended Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bucha, V.; Uchida, S.; Ablameyko, S. Interactive road extraction with pixel force fields. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 829–832. [Google Scholar] [CrossRef]
- Trinder, J.C.; Wang, Y. Automatic Road Extraction from Aerial Images. Digit. Signal Process. 1998, 8, 215–224. [Google Scholar] [CrossRef]
- Doucette, P.; Agouris, P.; Stefanidis, A.; Musavi, M. Self-organised clustering for road extraction in classified imagery. ISPRS J. Photogramm. Remote Sens. 2001, 55, 347–358. [Google Scholar] [CrossRef]
- Maurya, R.; Gupta, P.; Shukla, A.S. Road extraction using K-Means clustering and morphological operations. In Proceedings of the 2011 International Conference on Image Information Processing, Shimla, India, 3–5 November 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Niu, X. A geometric active contour model for highway extraction. In Proceedings of the ASPRS 2006 Annual Conference, Reno, NV, USA, 1–5 May 2006. [Google Scholar]
- Gruen, A.; Li, H. Road extraction from aerial and satellite images by dynamic programming. ISPRS J. Photogramm. Remote Sens. 1995, 50, 11–20. [Google Scholar] [CrossRef]
- Herumurti, D.; Uchimura, K.; Koutaki, G.; Uemura, T. Urban road extraction based on hough transform and region growing. In Proceedings of the 19th Korea-Japan Joint Workshop on Frontiers of Computer Vision, Incheon, Korea, 30 January–1 February 2013; pp. 220–224. [Google Scholar] [CrossRef]
- Jia, C.L.; Ji, K.F.; Jiang, Y.M.; Kuang, G.-Y. Road extraction from high-resolution SAR imagery using Hough transform. In Proceedings of the 2005 IEEE International Geoscience and Remote Sensing Symposium, IGARSS ‘05, Seoul, Korea, 29 July 2005. [Google Scholar] [CrossRef]
- Alvarez, J.M.; Lopez, A.; Baldrich, R. Illuminant-invariant model-based road segmentation. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008. [Google Scholar] [CrossRef]
- Shi, W.; Miao, Z.; Debayle, J. An Integrated Method for Urban Main-Road Centerline Extraction from Optical Remotely Sensed Imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3359–3372. [Google Scholar] [CrossRef]
- Amini, J.; Saradjian, M.R.; Blais, J.; Lucas, C.; Azizi, A. Automatic road-side extraction from large scale imagemaps. Int. J. Appl. Earth Obs. Geoinf. 2003, 4, 95–107. [Google Scholar] [CrossRef]
- Tang, I.; Breckon, T.P. Automatic Road Environment Classification. IEEE Trans. Intell. Transp. Syst. 2010, 12, 476–484. [Google Scholar] [CrossRef] [Green Version]
- Kass, M.; Witkin, A.; Terzopoulos, D. Snakes: Active contour models. Int. J. Comput. Vis. 1988, 1, 321–331. [Google Scholar] [CrossRef]
- Anil, P.N.; Natarajan, S. A Novel Approach Using Active Contour Model for Semi-Automatic Road Extraction from High Resolution Satellite Imagery. In Proceedings of the 2010 Second International Conference on Machine Learning and Computing, Bangalore, India, 9–11 February 2010; pp. 263–266. [Google Scholar] [CrossRef]
- Maarir, A.; Bouikhalene, B. Roads Detection from Satellite Images Based on Active Contour Model and Distance Transform. In Proceedings of the 2016 13th International Conference on Computer Graphics, Imaging and Visualization (CGiV), Beni Mellal, Morocco, 29 March–1 April 2016; pp. 94–98. [Google Scholar] [CrossRef]
- Park, S.R.; Kim, T. Semi-automatic road extraction algorithm from IKONOS images using template matching. In Proceedings of the 22nd Asian Conference on Remote Sensing, Singapore, 5–9 November 2001. [Google Scholar]
- Lin, X.; Shen, J.; Liang, Y. Semi-automatic road tracking using parallel angular texture signature. Intell. Autom. Soft Comput. 2012, 18, 1009–1021. [Google Scholar] [CrossRef]
- Yager, N.; Sowmya, A. Support Vector Machines for Road Extraction from Remotely Sensed Images. In Computer Analysis of Images and Patterns. CAIP 2003; Petkov, N., Westenberg, M.A., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2756, pp. 285–292. [Google Scholar] [CrossRef]
- Song, M.; Civco, D. Road extraction using SVM and image segmentation. Photogramm. Eng. Remote Sens. 2004, 70, 1365–1371. [Google Scholar] [CrossRef] [Green Version]
- Abdollahi, A.; Bakhtiari, H.R.R.; Nejad, M.P. Investigation of SVM and Level Set Interactive Methods for Road Extraction from Google Earth Images. J. Indian Soc. Remote Sens. 2018, 46, 423–430. [Google Scholar] [CrossRef]
- Storvik, G.; Fjortoft, R.; Solberg, A. A bayesian approach to classification of multiresolution remote sensing data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 539–547. [Google Scholar] [CrossRef]
- Qundong, Q.; Hu, Z.; Wu, Z. A Regional Adaptive Segmentation Algorithm for Remote Sensing Image; Geomatics and Information Science of Wuhan University: Wuhan, China, 2011; Volume 3. [Google Scholar]
- Li, L.; Zhang, X. A quickly automatic road extraction method for high-resolution remote sensing images. Geomat. Sci. Technol. 2015, 3, 27–33. [Google Scholar] [CrossRef]
- Shao, Y.; Guo, B.; Hu, X.; Di, L. Application of a Fast Linear Feature Detector to Road Extraction from Remotely Sensed Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2010, 4, 626–631. [Google Scholar] [CrossRef]
- Bakhtiari, H.R.R.; Abdollahi, A.; Rezaeian, H. Semi automatic road extraction from digital images. Egypt. J. Remote Sens. Space Sci. 2017, 20, 117–123. [Google Scholar] [CrossRef]
- Panteras, G.; Cervone, G. Enhancing the temporal resolution of satellite-based flood extent generation using crowdsourced data for disaster monitoring. Int. J. Remote Sens. 2018, 39, 1459–1474. [Google Scholar] [CrossRef]
- Zhu, Z.; Yang, S.; Xu, G.; Lin, X.; Shi, D. Fast road classification and orientation estimation using omni-view images and neural networks. IEEE Trans. Image Process. 1998, 7, 1182–1197. [Google Scholar] [CrossRef]
- Mokhtarzade, M.; Zoej, M.V. Road detection from high-resolution satellite images using artificial neural networks. Int. J. Appl. Earth Obs. Geoinf. 2007, 9, 32–40. [Google Scholar] [CrossRef] [Green Version]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–189. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Hinton, G.E. Learning to Detect Roads in High-Resolution Aerial Images. In Computer Vision—ECCV 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 210–223. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling; University of Toronto: Toronto, ON, Canada, 2013. [Google Scholar]
- Saito, S.; Yamashita, T.; Aoki, Y. Multiple Object Extraction from Aerial Imagery with Convolutional Neural Networks. Electron. Imaging 2016, 28, art00004. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Cui, W.; Jiang, H. Fully convolutional networks for building and road extraction: Preliminary results. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1591–1594. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Wei, Y.; Wang, Z.; Xu, M. Road Structure Refined CNN for Road Extraction in Aerial Image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Panboonyuen, T.; Vateekul, P.; Jitkajornwanich, K.; Lawawirojwong, S. An Enhanced Deep Convolutional Encoder-Decoder Network for Road Segmentation on Aerial Imagery. In International Conference on Computing and Information Technology; Springer: Berlin/Heidelberg, Germany, 2017; pp. 191–201. [Google Scholar] [CrossRef]
- Máttyus, G.; Luo, W.; Urtasun, R. DeepRoadMapper: Extracting Road Topology from Aerial Images. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3458–3466. [Google Scholar]
- Mosinska, A.; Marquez-Neila, P.; Kozinski, M.; Fua, P. Beyond the Pixel-Wise Loss for Topology-Aware Delineation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3136–3145. [Google Scholar]
- Gao, X.; Sun, X.; Zhang, Y.; Yan, M.; Xu, G.; Sun, H.; Jiao, J.; Fu, K. An End-to-End Neural Network for Road Extraction from Remote Sensing Imagery by Multiple Feature Pyramid Network. IEEE Access 2018, 6, 39401–39414. [Google Scholar] [CrossRef]
- Jegou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The one hundred layers tiramisu: Fully convolutional DenseNets for semantic segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1175–1183. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road Extraction from High-Resolution Remote Sensing Imagery Using Deep Learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef] [Green Version]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Batra, A.; Singh, S.; Pang, G.; Basu, S.; Jawahar, C.; Paluri, M. Improved road connectivity by joint learning of orientation and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10385–10393. [Google Scholar]
- Van Etten, A.; Lindenbaum, D.; Bacastow, T.M. Spacenet: A remote sensing dataset and challenge series. arXiv 2018, arXiv:1807.01232. [Google Scholar]
- Bastani, F.; He, S.; Abbar, S.; Alizadeh, M.; Balakrishnan, H.; Chawla, S.; Madden, S.; DeWitt, D. Roadtracer: Automatic extraction of road networks from aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4720–4728. [Google Scholar]
- Li, Z.; Wegner, J.D.; Lucchi, A. Topological map extraction from overhead images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1715–1724. [Google Scholar]
- Wan, J.; Xie, Z.; Xu, Y.; Chen, S.; Qiu, Q. DA-RoadNet: A Dual-Attention Network for Road Extraction from High Resolution Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6302–6315. [Google Scholar] [CrossRef]
- Zhou, K.; Xie, Y.; Gao, Z.; Miao, F.; Zhang, L. FuNet: A Novel Road Extraction Network with Fusion of Location Data and Remote Sensing Imagery. ISPRS Int. J. Geo-Inf. 2021, 10, 39. [Google Scholar] [CrossRef]
- Zhou, G.; Chen, W.; Gui, Q.; Li, X.; Wang, L. Split Depth-Wise Separable Graph-Convolution Network for Road Extraction in Complex Environments from High-Resolution Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5614115. [Google Scholar] [CrossRef]
- Wang, S.; Mu, X.; Yang, D.; He, H.; Zhao, P. Road Extraction from Remote Sensing Images Using the Inner Convolution Integrated Encoder-Decoder Network and Directional Conditional Random Fields. Remote Sens. 2021, 13, 465. [Google Scholar] [CrossRef]
- Mei, J.; Li, R.-J.; Gao, W.; Cheng, M.-M. CoANet: Connectivity Attention Network for Road Extraction from Satellite Imagery. IEEE Trans. Image Process. 2021, 30, 8540–8552. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Lin, D.; Wei, W.; Wozniak, M.; Damasevicius, R. Road Detection Based on Shearlet for GF-3 Synthetic Aperture Radar Images. IEEE Access 2020, 8, 28133–28141. [Google Scholar] [CrossRef]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–17209. [Google Scholar]
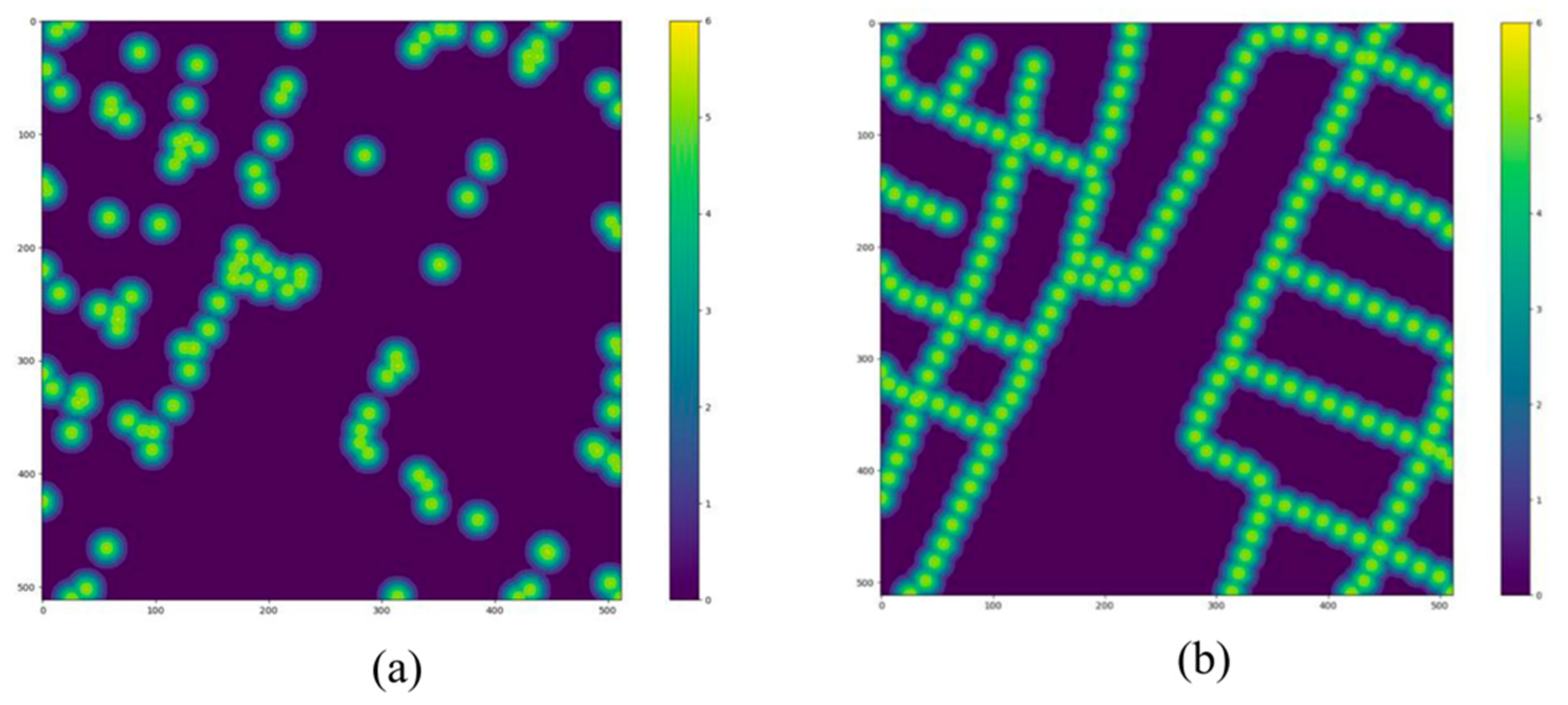




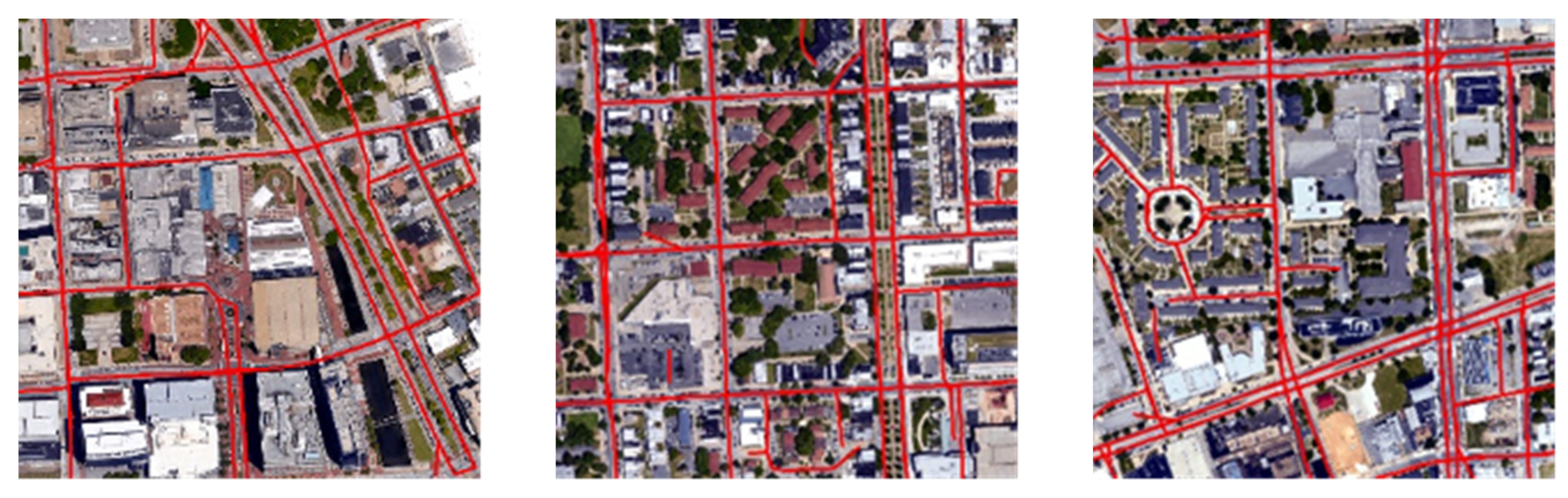


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | ||||
|---|---|---|---|---|
| LinkNet | 0.8076 | 0.8574 | 0.8318 | 0.5089 |
| D-LinkNet | 0.8177 | 0.8786 | 0.8471 | 0.5143 |
| RoadTracer | 0.8345 | 0.8721 | 0.8529 | 0.5324 |
| Bi-HRNet | 0.8439 | 0.8878 | 0.8651 | 0.5478 |
| Methods | ||||
|---|---|---|---|---|
| LinkNet | 0.6143 | 0.6523 | 0.6327 | 0.5021 |
| D-LinkNet | 0.6038 | 0.6789 | 0.6392 | 0.5067 |
| RoadTracer | 0.6356 | 0.6612 | 0.6481 | 0.5203 |
| Bi-HRNet | 0.6337 | 0.6634 | 0.6482 | 0.5317 |
| Methods | ||||
|---|---|---|---|---|
| LinkNet | 0.8421 | 0.8648 | 0.8533 | 0.5418 |
| D-LinkNet | 0.8539 | 0.8802 | 0.8669 | 0.5523 |
| RoadTracer | 0.8650 | 0.8957 | 0.8801 | 0.5582 |
| Bi-HRNet | 0.8671 | 0.9017 | 0.8841 | 0.5615 |
| Top-to-Down Directional Connectivity | Down-to-Top Directional Connectivity | Multi-Scale Road Nodes Prediction | ||||
|---|---|---|---|---|---|---|
| 0.8211 | 0.8572 | 0.8388 | 0.5382 | |||
| 0.8389 | 0.8781 | 0.8581 | 0.5449 | |||
| 0.8439 | 0.8878 | 0.8651 | 0.5478 |
| Methods | ||||
|---|---|---|---|---|
| Bi-HRNet | 0.8163 | 0.8626 | 0.8388 | 0.5170 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Z.; Zhang, J.; Zhang, L.; Liu, X.; Qiao, H. Bi-HRNet: A Road Extraction Framework from Satellite Imagery Based on Node Heatmap and Bidirectional Connectivity. Remote Sens. 2022, 14, 1732. https://doi.org/10.3390/rs14071732
Wu Z, Zhang J, Zhang L, Liu X, Qiao H. Bi-HRNet: A Road Extraction Framework from Satellite Imagery Based on Node Heatmap and Bidirectional Connectivity. Remote Sensing. 2022; 14(7):1732. https://doi.org/10.3390/rs14071732
Chicago/Turabian StyleWu, Ziyun, Jinming Zhang, Lili Zhang, Xiongfei Liu, and Hailang Qiao. 2022. "Bi-HRNet: A Road Extraction Framework from Satellite Imagery Based on Node Heatmap and Bidirectional Connectivity" Remote Sensing 14, no. 7: 1732. https://doi.org/10.3390/rs14071732
APA StyleWu, Z., Zhang, J., Zhang, L., Liu, X., & Qiao, H. (2022). Bi-HRNet: A Road Extraction Framework from Satellite Imagery Based on Node Heatmap and Bidirectional Connectivity. Remote Sensing, 14(7), 1732. https://doi.org/10.3390/rs14071732