
A Serverless-Based, On-the-Fly Computing Framework for Remote Sensing Image Collection



Abstract
:1. Introduction
- (1)
- Proposing a definition for the on-the-fly cloud computing paradigm for remote sensing image collections, including some empirical or descriptive characteristics and a formal definition.
- (2)
- Designing an entirely serverless architecture based on the serverless commodities of a public cloud, which consists of a data model, a programming model, and a series of key implementing technologies for remote sensing image collection analysis.
- (3)
- Providing some concrete, proof-of-concept experiments suggesting that on-the-fly cloud computing for remote sensing images can effectively run on the serverless cloud platform.
2. On-the-Fly Cloud Computing
2.1. Cloud Computing vs. HPC
2.2. Characteristics
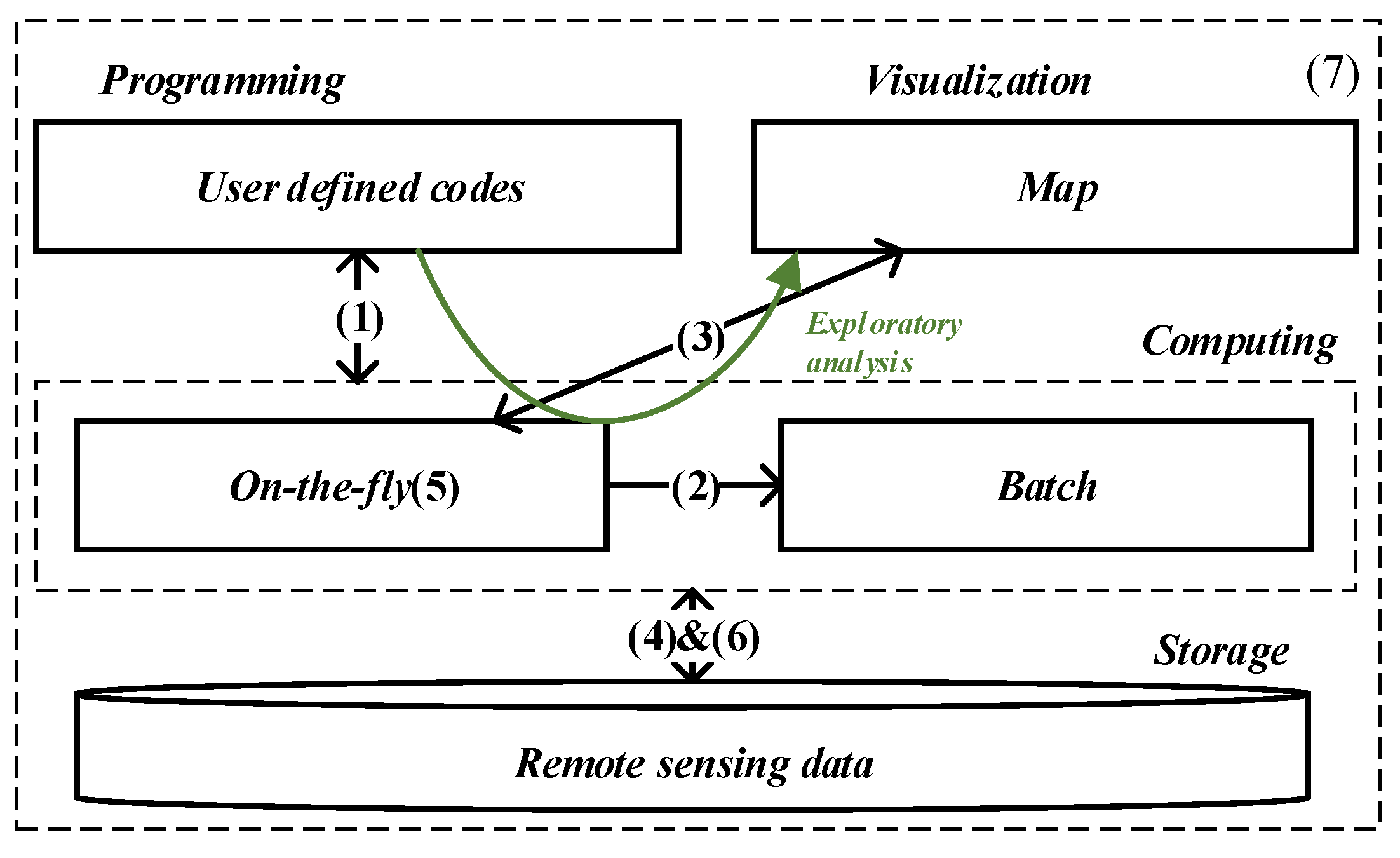
- (1)
- Shipping code to the remote sensing images persisted in the cloud storage instead of downloading the data locally for analysis.
- (2)
- Seamlessly switching to batch processing without code modification, which requires the data abstraction and operators to be the same.
- (3)
- Implicitly triggering the execution implied in specific operators, such as visualization and data export.
- (4)
- Dynamically determining the spatial scope of remote sensing images to be processed based on the tiles visualized on the map.
- (5)
- Responding as rapidly as possible when the user needs to evaluate without queueing of workloads.
- (6)
- Executing user-defined codes based on the overviews of remote sensing images without explicitly provisioning and managing data allocation.
- (7)
- Paying in proportion to remote sensing data used instead of paying for the computing resources allocated.
2.3. Formal Definition
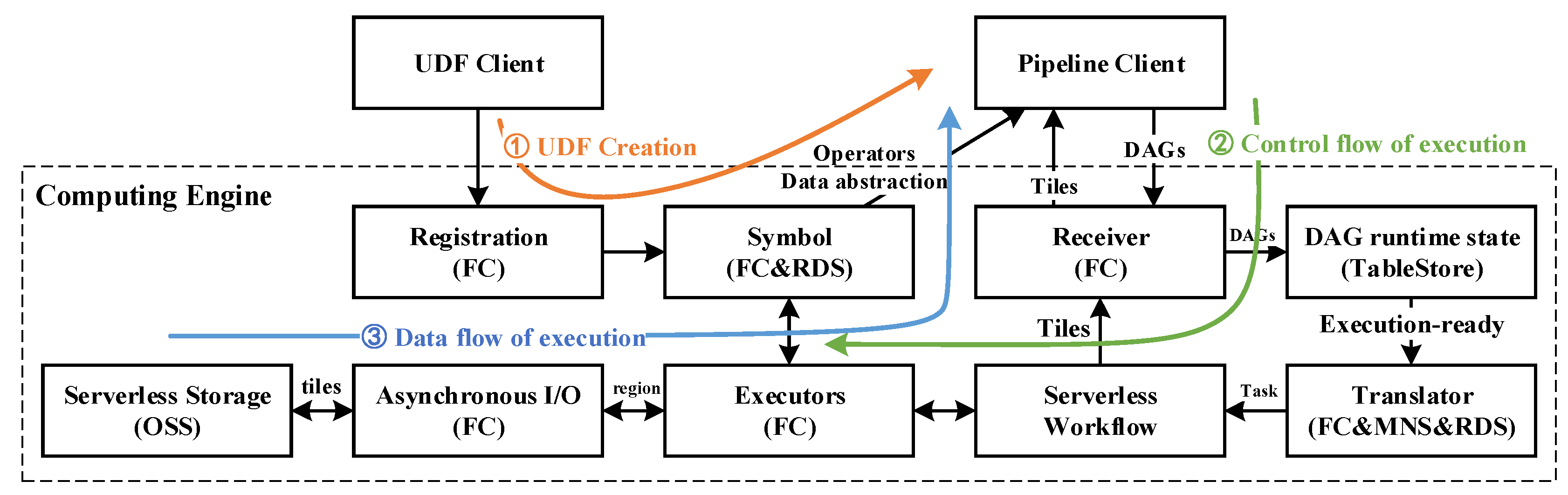
2.4. Serverless Architecture
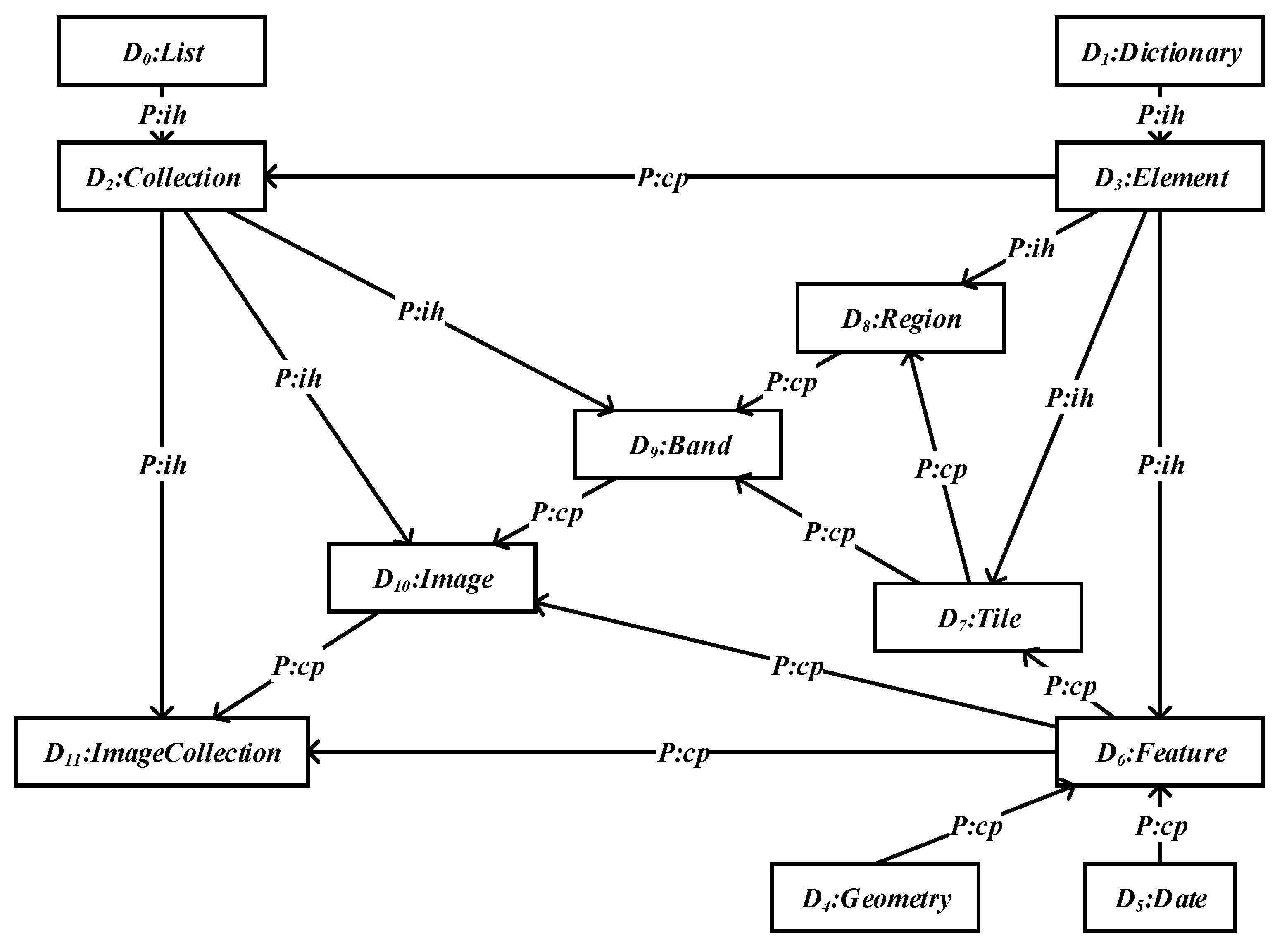
3. Data Model
3.1. Tiling
3.2. Logical Region
3.3. Datatypes
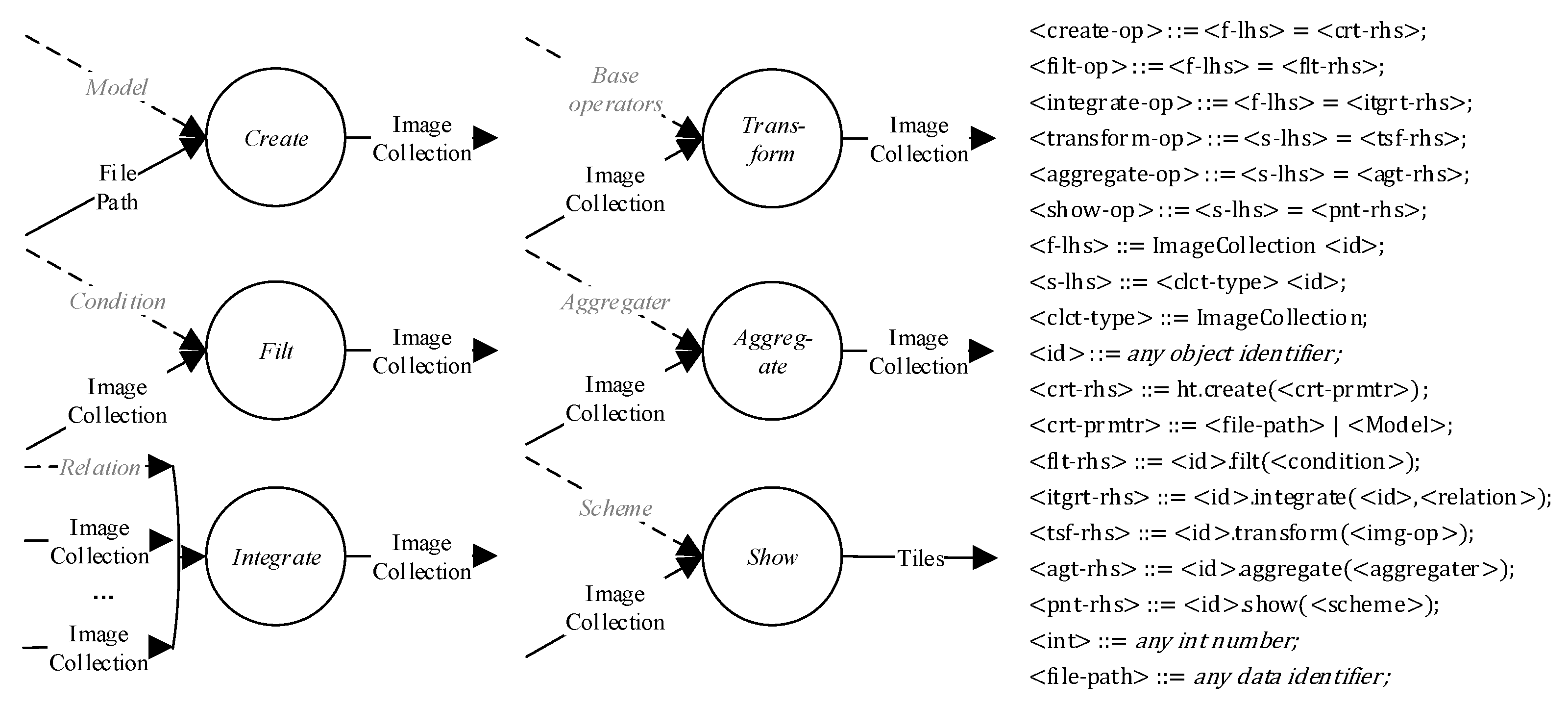
4. Programming Model
4.1. Workflow
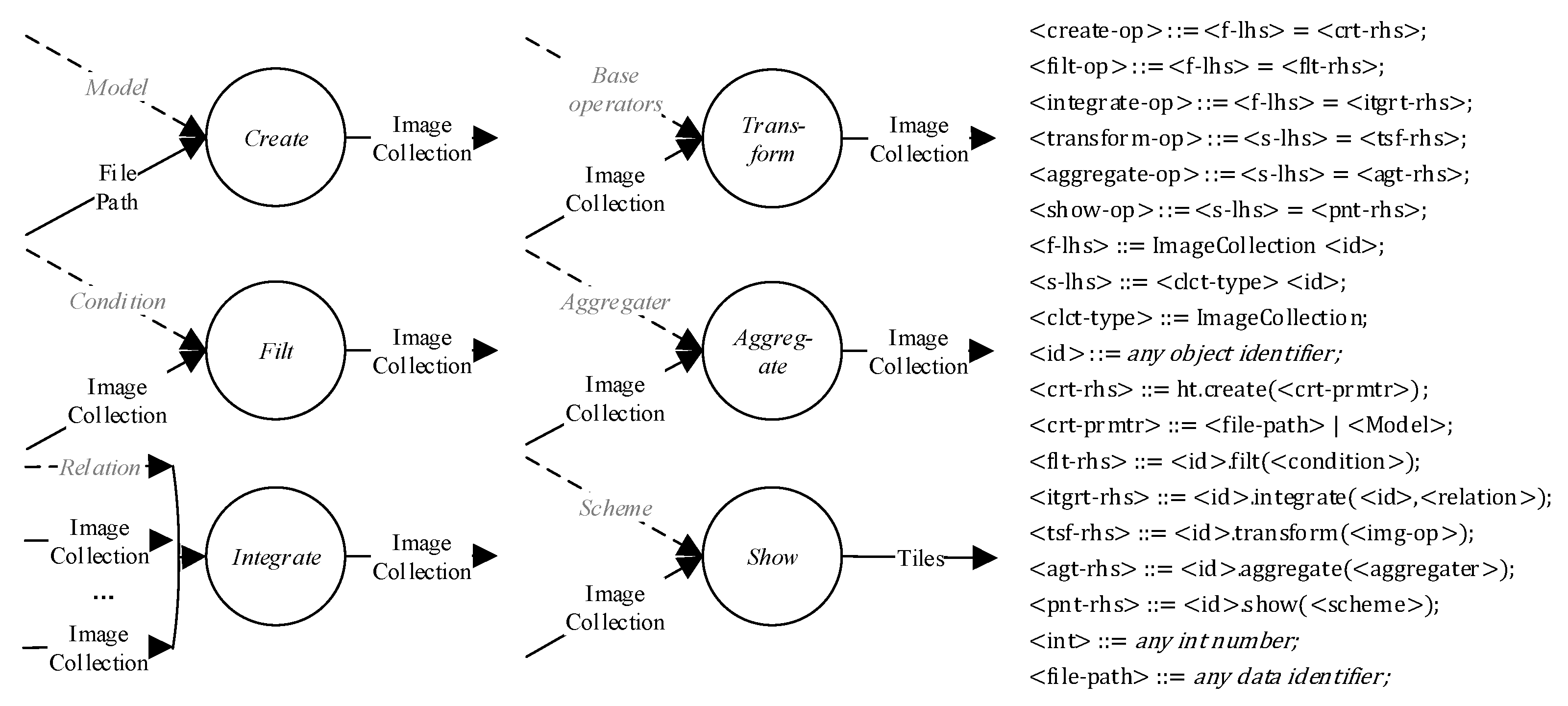
- (1)
- . The composite datatypes are the user-visible components of data abstraction, defined in Section 3.3, except and . In the construction of workflow, is the most common datatype.
- (2)
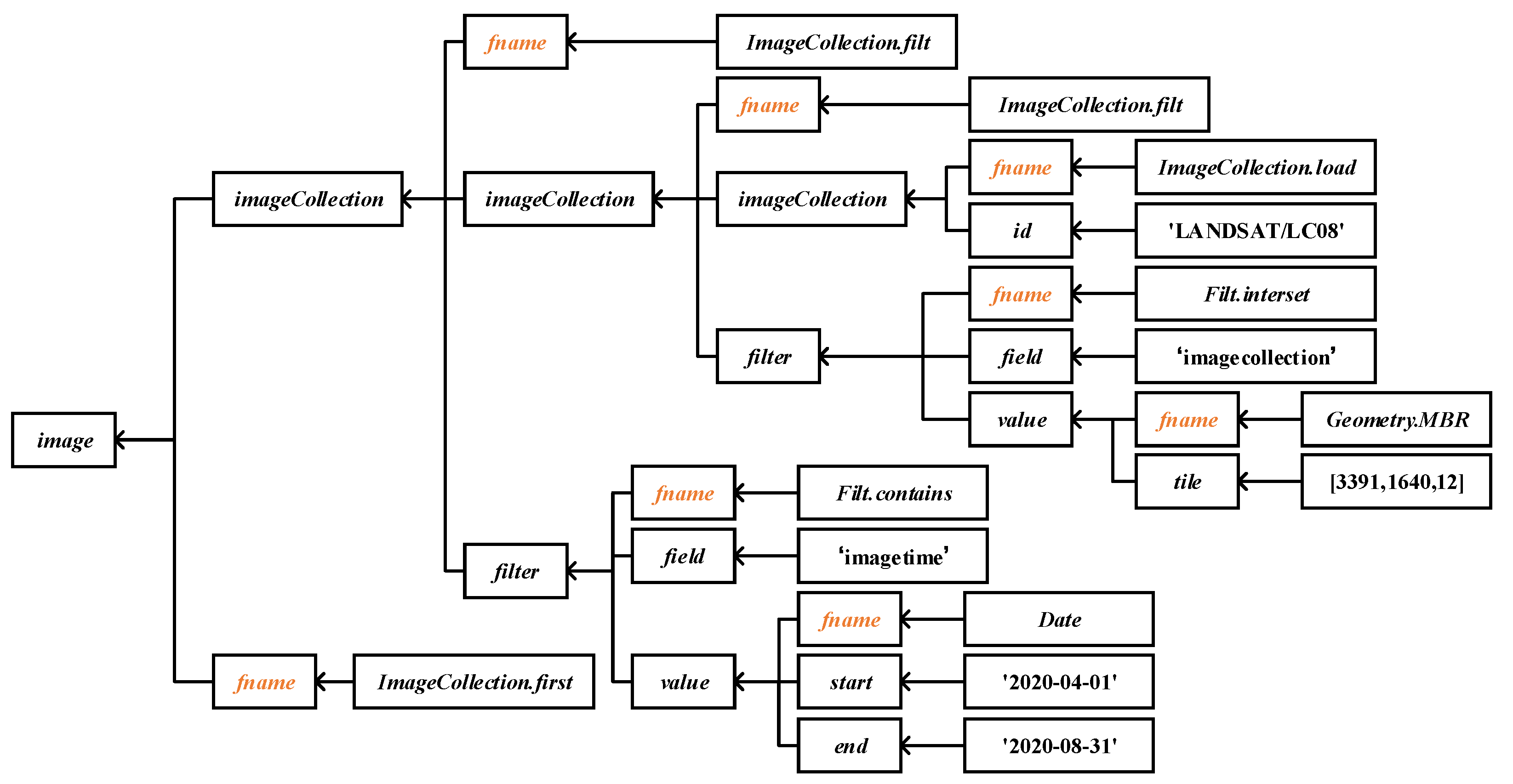
- . Workflow skeletons are high-level operators representing the basic workflow semantics. There are six operators related to workflow construction, including , , , , , and . These skeletons are functions mapping from one image collection to another., , , , , , and are kinds of user-defined functions, defined in Section 4.2. The definition is shown in Figure 5.
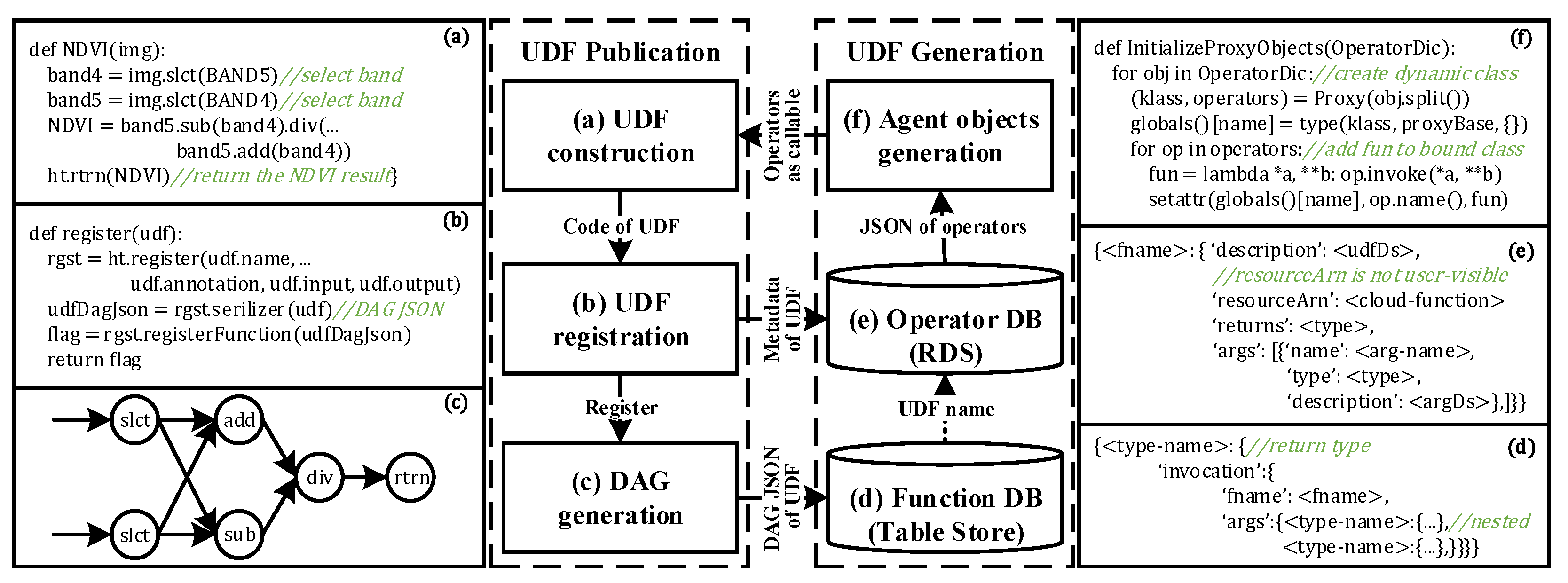
4.2. User-Defined Function
4.3. Operator Publication
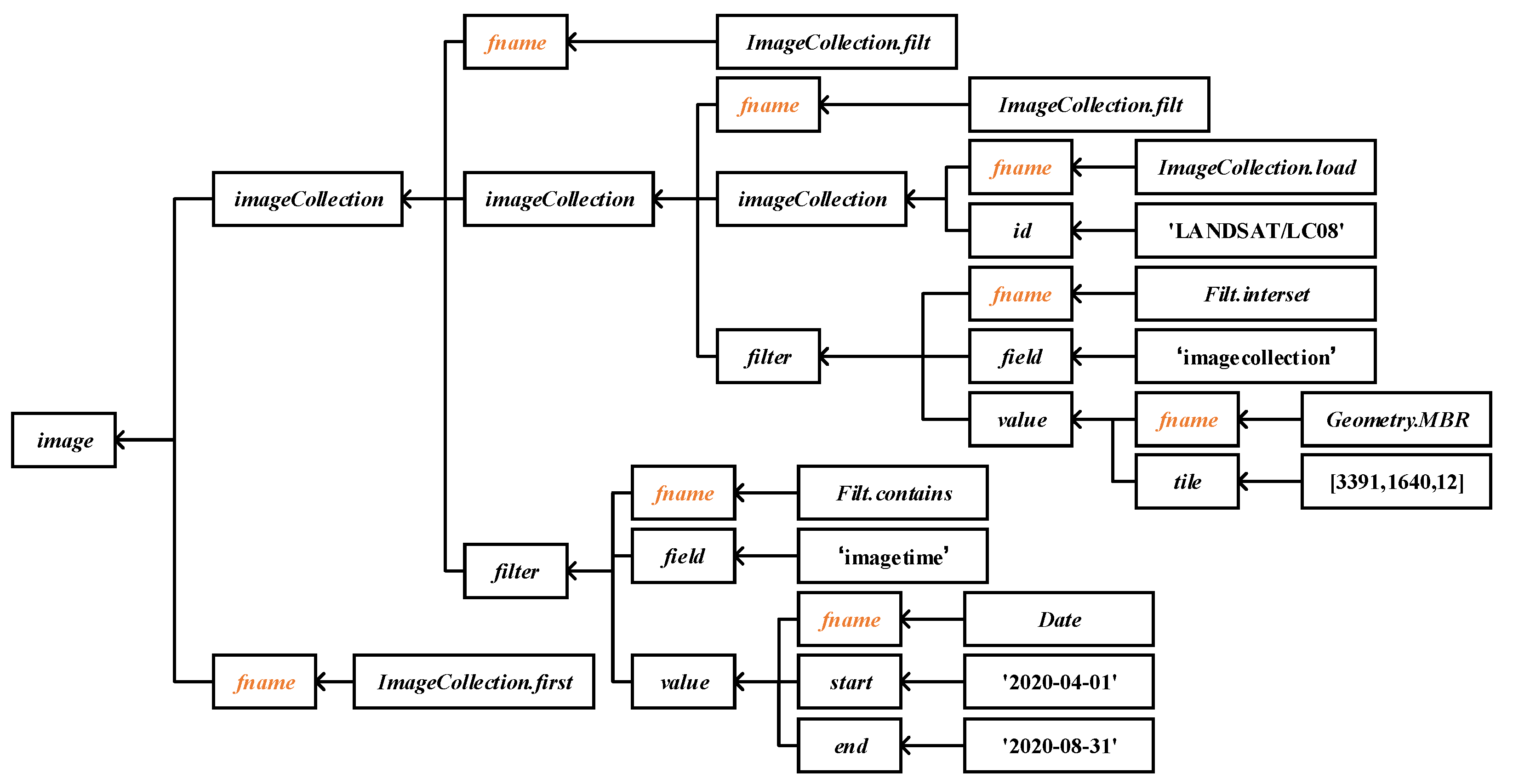
4.4. DAG Generation
4.5. Trigger of Execution
5. DAG Execution
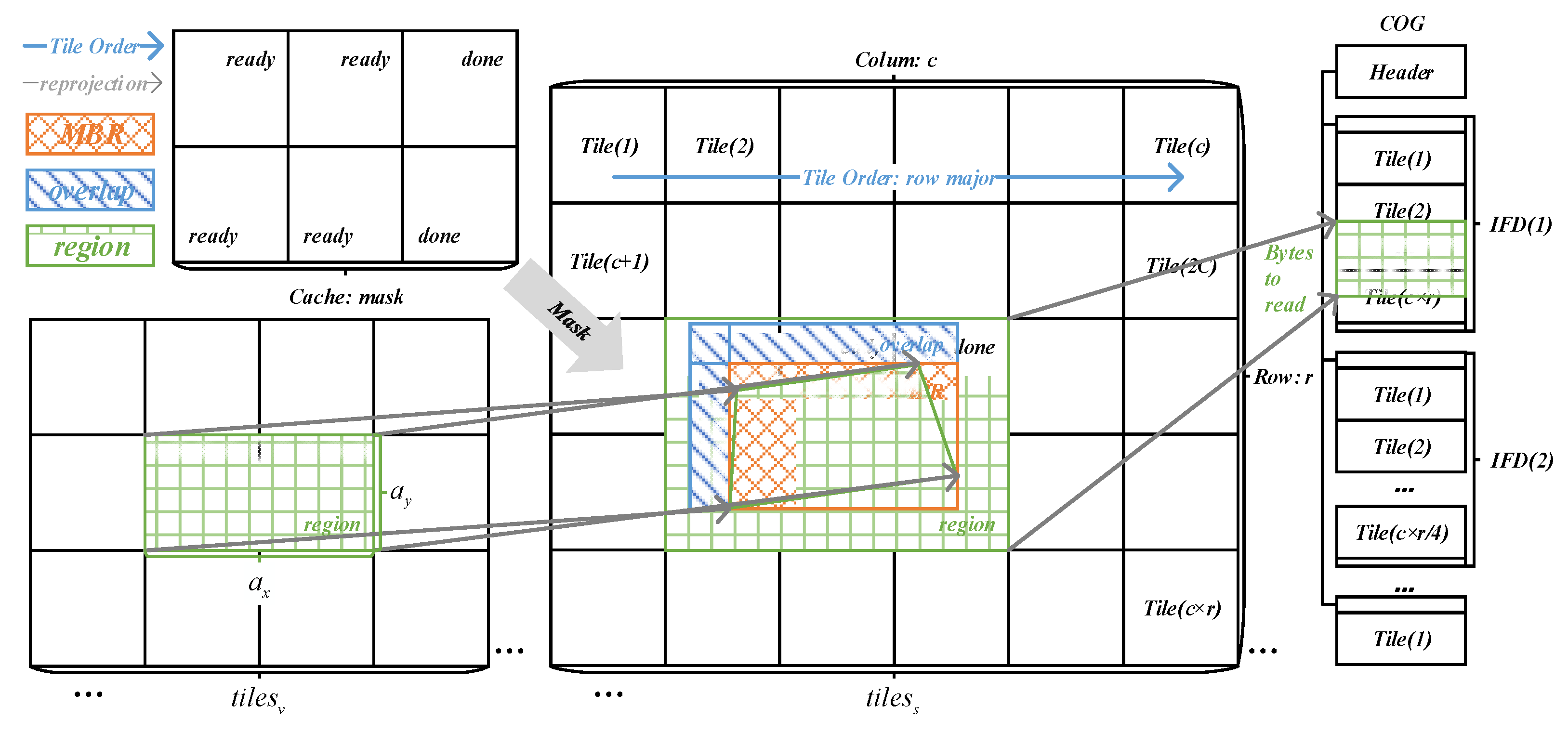
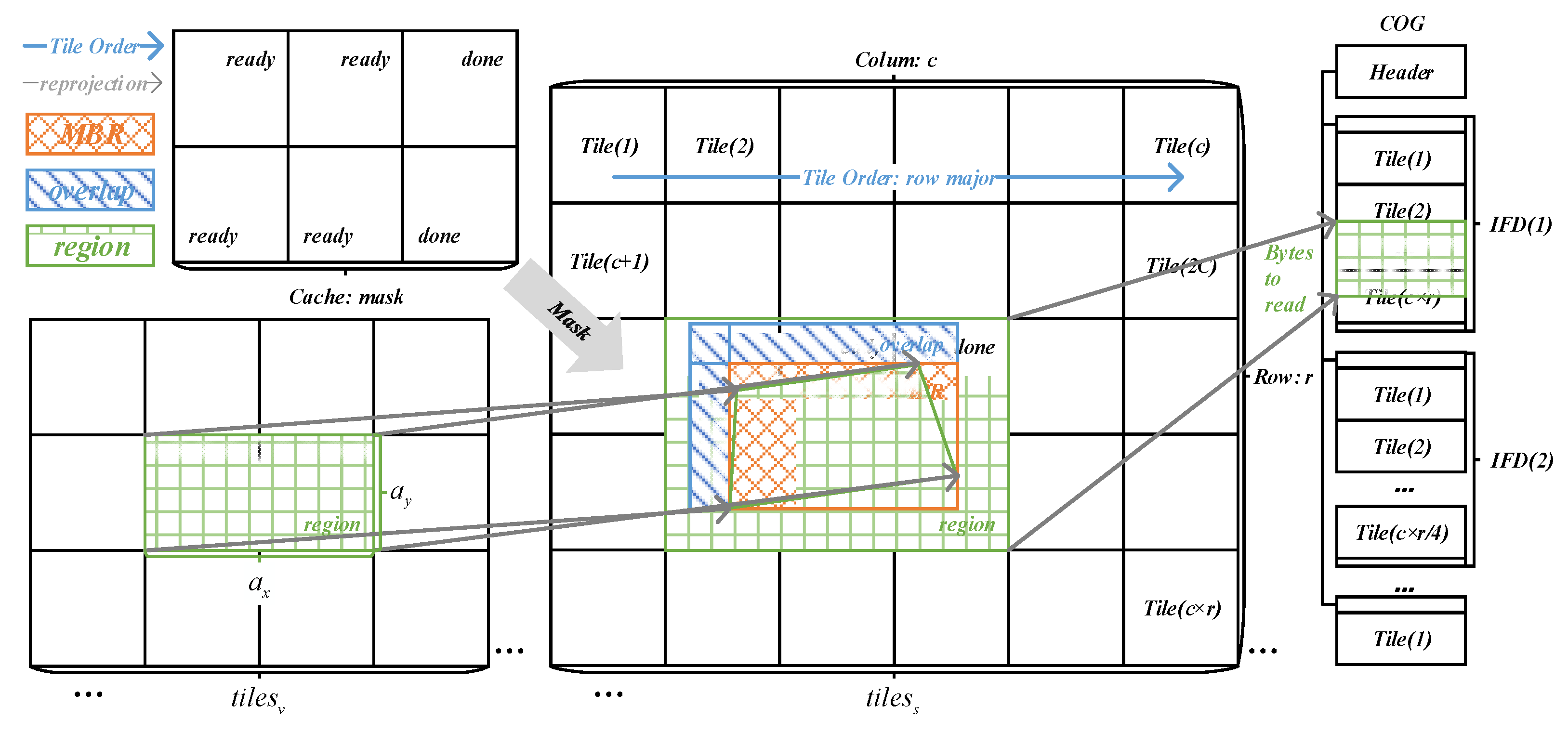
5.1. Data Partition
5.2. Execution
| Algorithm 1 Data-Parallel DAG Execution |
 |
5.3. Cache
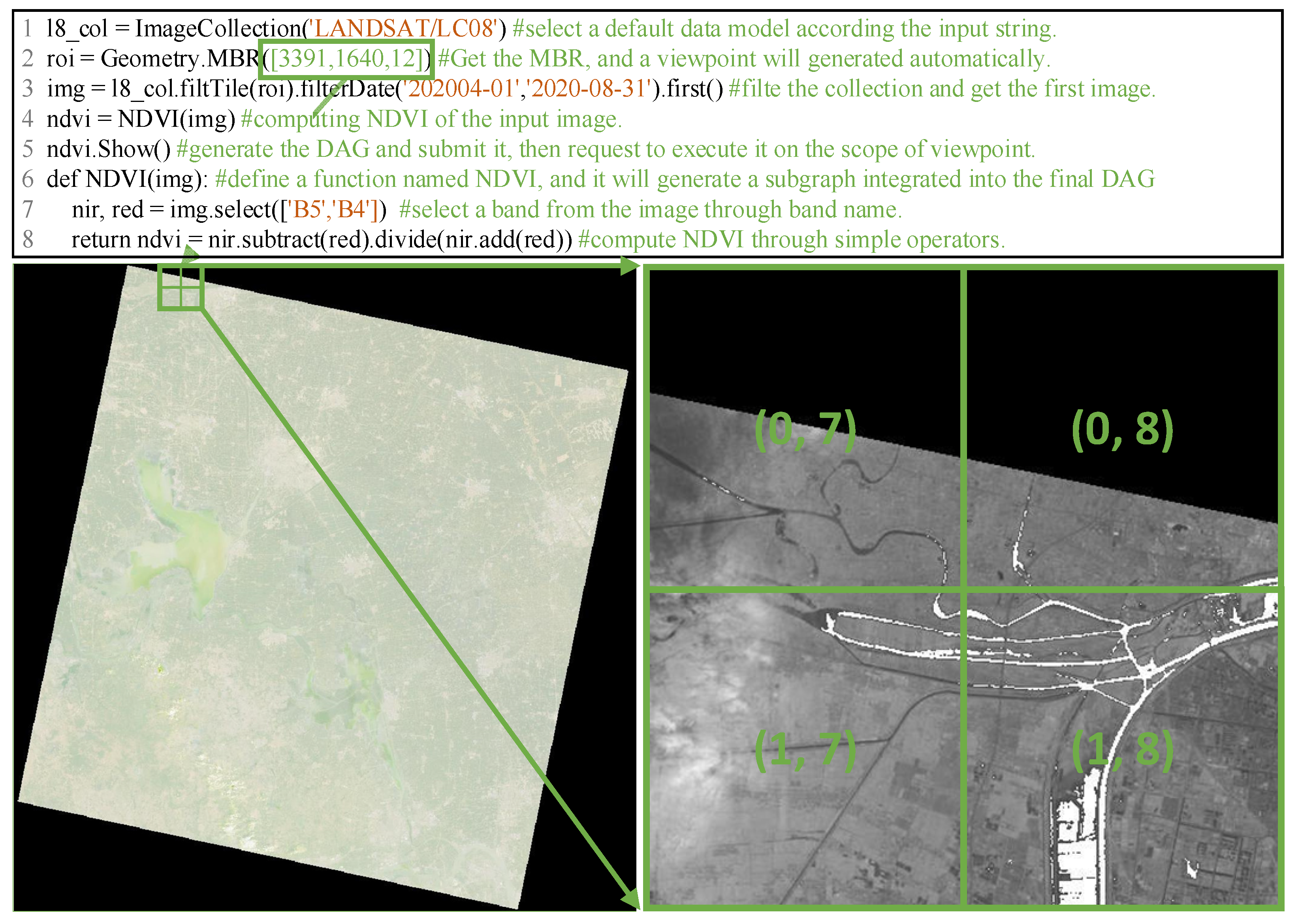
6. Case Study
6.1. Data and Result
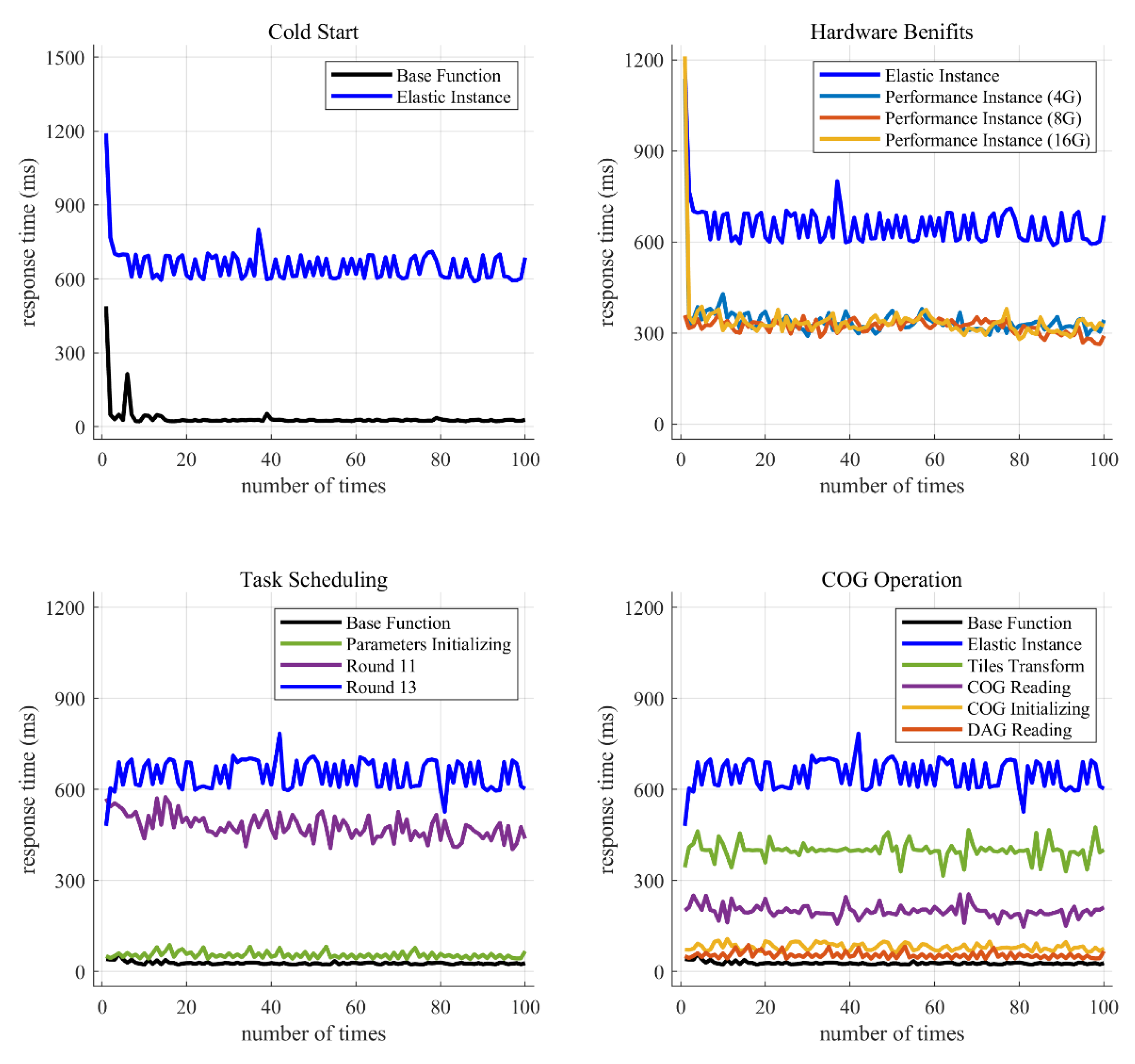
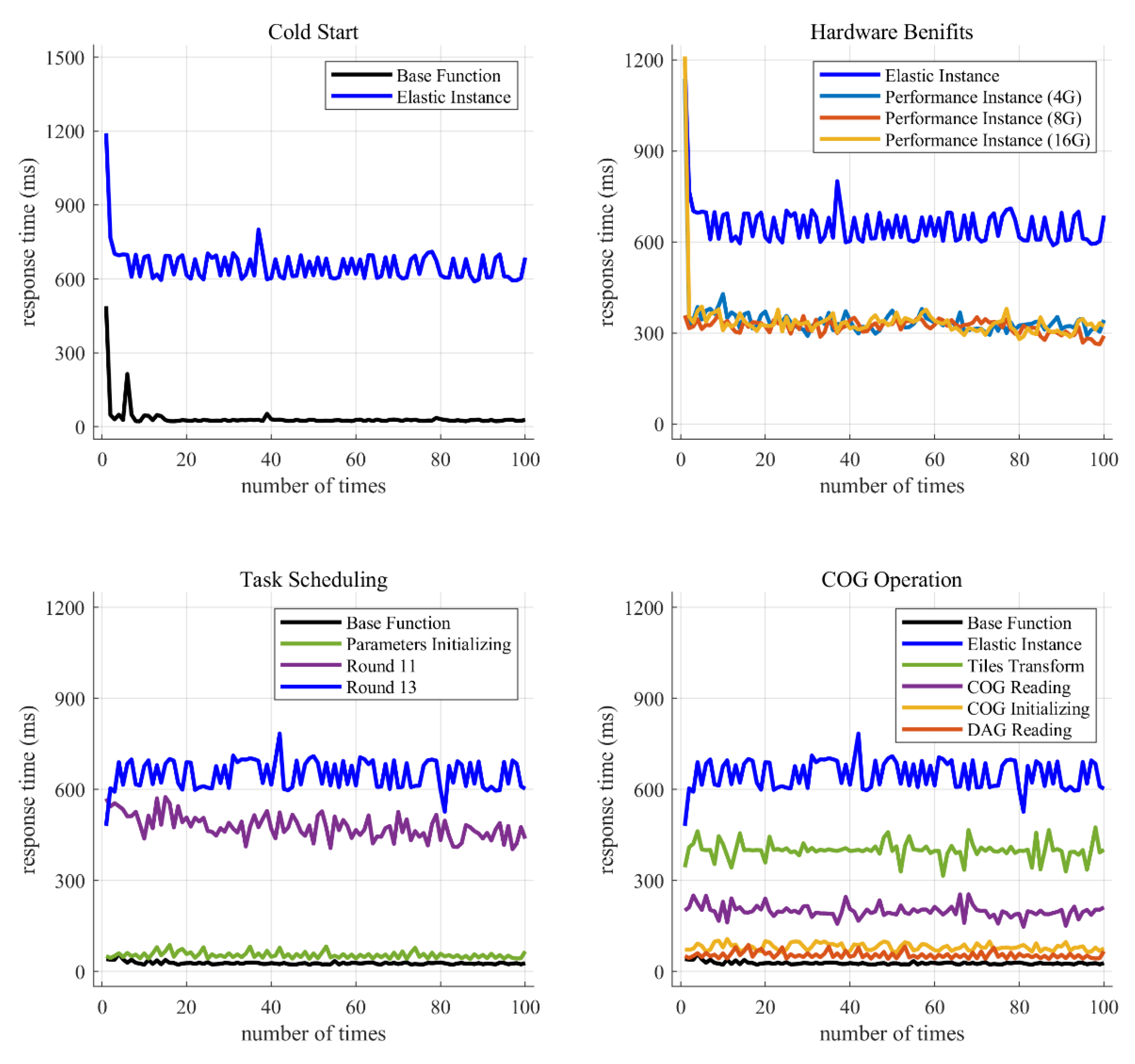
6.2. Response Time
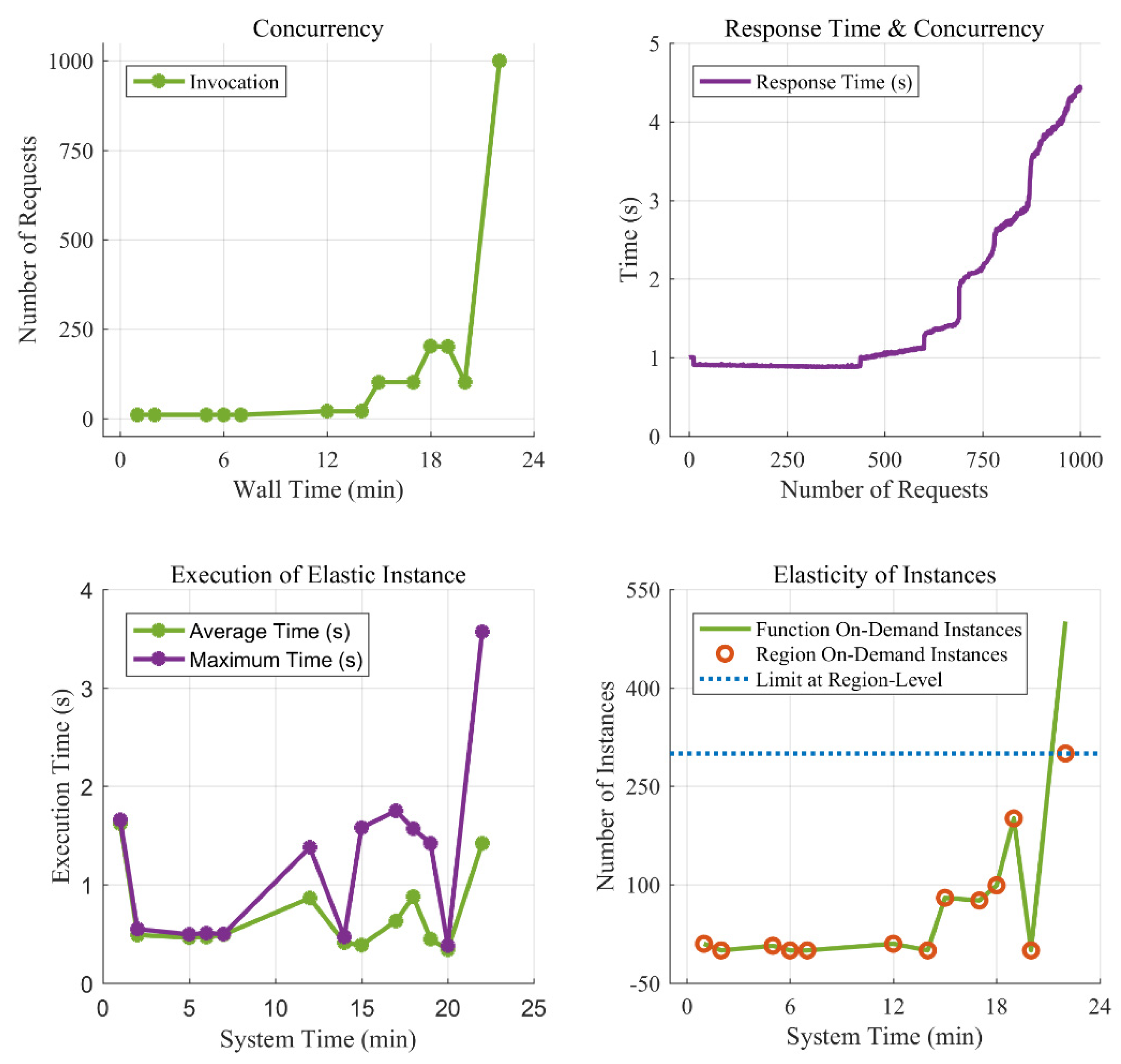
6.3. Concurrency
7. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alam, M.M.; Torgo, L.; Bifet, A. A Survey on Spatio-temporal Data Analytics Systems. arXiv 2021, arXiv:2103.09883. [Google Scholar] [CrossRef]
- Gomes, V.; Queiroz, G.; Ferreira, K. An Overview of Platforms for Big Earth Observation Data Management and Analysis. Remote Sens. 2020, 12, 1253. [Google Scholar] [CrossRef] [Green Version]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J. Apache spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- White, T. Hadoop: The Definitive Guide; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- Rocklin, M. Dask: Parallel computation with blocked algorithms and task scheduling. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015. [Google Scholar]
- Han, S.; Egi, N.; Panda, A.; Ratnasamy, S.; Shi, G.; Shenker, S. Network support for resource disaggregation in next-generation datacenters. In Proceedings of the Twelfth ACM Workshop on Hot Topics in Networks, College Park, MD, USA, 21–22 November 2013; pp. 1–7. [Google Scholar]
- Jonas, E.; Schleier-Smith, J.; Sreekanti, V.; Tsai, C.-C.; Khandelwal, A.; Pu, Q.; Shankar, V.; Carreira, J.; Krauth, K.; Yadwadkar, N. Cloud programming simplified: A berkeley view on serverless computing. arXiv 2019, arXiv:1902.03383. [Google Scholar]
- Ozturk, D.; Chaudhary, A.; Votava, P.; Kotfila, C. GeoNotebook: Browser based Interactive analysis and visualization workflow for very large climate and geospatial datasets. AGU Fall Meet. Abstr. 2016, 2016, IN53A-1876. [Google Scholar]
- Jangda, A.; Pinckney, D.; Brun, Y.; Guha, A. Formal foundations of serverless computing. Proc. ACM Program. Lang. 2019, 3, 1–26. [Google Scholar] [CrossRef] [Green Version]
- AlibabaCloud. Function Computing. Available online: https://help.aliyun.com/product/50980.html (accessed on 3 April 2022).
- AlibabaCloud. Serverless Workflow. Available online: https://help.aliyun.com/product/113549.html (accessed on 3 April 2022).
- AlibabaCloud. TableStore. Available online: https://help.aliyun.com/product/27278.html (accessed on 3 April 2022).
- AlibabaCloud. Message Service. Available online: https://help.aliyun.com/product/27412.html (accessed on 3 April 2022).
- AlibabaCloud. Relation Database System. Available online: https://help.aliyun.com/product/26090.html (accessed on 3 April 2022).
- AlibabaCloud. Object Storage Service. Available online: https://help.aliyun.com/product/31815.html (accessed on 3 April 2022).
- COG. Cloud Optimized GeoTIFF. Available online: https://www.cogeo.org/ (accessed on 3 April 2022).
- STAC. SpatioTemporal Asset Catalogs. Available online: http://stacspec.org/ (accessed on 3 April 2022).
- Hennessy, J.; Patterson, D. A New Golden Age for Computer Architecture: Domain-Specific Hardware/Software Co-Design, Enhanced Security, Open Instruction Sets, and Agile Chip Development. In Proceedings of the Turing Lecture Given at ISCA’18, Los Angeles, CA, USA, 2–6 June 2018; Volume 10. [Google Scholar]
- Crocker, D.; Overell, P. Augmented BNF for Syntax Specifications: ABNF; RFC 2234; HKU Sandy Bay RFC Ltd.: Pok Fu Lam, China, 1997. [Google Scholar]
- Dong, B.; Wu, K.; Byna, S.; Liu, J.; Zhao, W.; Rusu, F. ArrayUDF: User-defined scientific data analysis on arrays. In Proceedings of the 26th International Symposium on High-Performance Parallel and Distributed Computing, Washington, DC, USA, 26–30 June 2017; pp. 53–64. [Google Scholar]
- Lewis, A.; Oliver, S.; Lymburner, L.; Evans, B.; Wyborn, L.; Mueller, N.; Raevksi, G.; Hooke, J.; Woodcock, R.; Sixsmith, J.; et al. The Australian Geoscience Data Cube—Foundations and lessons learned. Remote Sens. Environ. 2017, 202, 276–292. [Google Scholar] [CrossRef]
- Hoyer, S.; Hamman, J. xarray: ND labeled arrays and datasets in Python. J. Open Res. Softw. 2017, 5, 10. [Google Scholar] [CrossRef] [Green Version]
- Eldawy, A.; Mokbel, M.F. The era of big spatial data: A survey. Foundations and Trends in Databases 2016, 6, 163–273. [Google Scholar] [CrossRef]
- Geotrellis. GeoTrellis is a Geographic Data Processing Engine for High Performance Applications. Available online: https://geotrellis.io/ (accessed on 3 April 2022).
- Yu, J.; Wu, J.; Sarwat, M. Geospark: A cluster computing framework for processing large-scale spatial data. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2015; pp. 1–4. [Google Scholar]
- Chambers, C.; Raniwala, A.; Perry, F.; Adams, S.; Henry, R.R.; Bradshaw, R.; Weizenbaum, N. FlumeJava: Easy, efficient data-parallel pipelines. ACM Sigplan Not. 2010, 45, 363–375. [Google Scholar] [CrossRef]
- Zaharia, M.; Chowdhury, M.; Das, T.; Dave, A.; Ma, J.; McCauly, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In Proceedings of the 9th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 12), San Jose, CA, USA, 25–27 April 2012; pp. 15–28. [Google Scholar]
- Hamman, J.; Rocklin, M.; Abernathy, R. Pangeo: A big-data ecosystem for scalable earth system science. In Proceedings of the EGU General Assembly Conference Abstracts, Vienna, Austria, 8–13 April 2018; p. 12146. [Google Scholar]
- Taibi, D.; El Ioini, N.; Pahl, C.; Niederkofler, J.R.S. Serverless cloud computing (function-as-a-service) patterns: A multivocal literature review. In Proceedings of the 10th International Conference on Cloud Computing and Services Science (CLOSER 2020), Prague, Czech Republic, 7–9 May 2020. [Google Scholar]
- Shankar, V.; Krauth, K.; Vodrahalli, K.; Pu, Q.; Recht, B.; Stoica, I.; Ragan-Kelley, J.; Jonas, E.; Venkataraman, S. Serverless linear algebra. In Proceedings of the 11th ACM Symposium on Cloud Computing, Seattle, WA, USA, 19–21 October 2020; pp. 281–295. [Google Scholar]
- Wu, C.; Faleiro, J.; Lin, Y.; Hellerstein, J. Anna: A kvs for any scale. IEEE Trans. Knowl. Data Eng. 2019, 33, 344–358. [Google Scholar] [CrossRef]
- Zhang, H.; Tang, Y.; Khandelwal, A.; Chen, J.; Stoica, I. Caerus:{NIMBLE} Task Scheduling for Serverless Analytics. In Proceedings of the 18th USENIX Symposium on Networked Systems Design and Implementation (NSDI 21), Boston, MA, USA, 12–14 April 2021; pp. 653–669. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Description | Example |
|---|---|---|
| <> | Denotes an operator or variable in programming; | <img-clct> |
| [] | Indicates creating a data structure of numeric array; | [[…]…[…]] |
| {} | Body of the UDF or a data structure of dictionary; | {<metadata>*} |
| () | Indicates the inputs of the UDF; | (<img-lhs>) |
| | | Choice operator for two candidate expressions; | EQ | NE |
| * | Zero or more occurrences of the preceding element; | <img-op>* |
| + | One or more occurrences of the preceding element; | <img-op>+ |
| . | Denotes the attribute or method of an object; | <id>.apply(…) |
| ; | Indicates end of a BNF statement; | Image <id>; |
| // | Annotation of the production rules; | //annotation |
| ::= | Means being defined as the right-hand expressions; | <l-op> ::= or; |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Wu, M.; Li, H.; Li, L.; Li, L. A Serverless-Based, On-the-Fly Computing Framework for Remote Sensing Image Collection. Remote Sens. 2022, 14, 1728. https://doi.org/10.3390/rs14071728
Wu J, Wu M, Li H, Li L, Li L. A Serverless-Based, On-the-Fly Computing Framework for Remote Sensing Image Collection. Remote Sensing. 2022; 14(7):1728. https://doi.org/10.3390/rs14071728
Chicago/Turabian StyleWu, Jin, Mingbo Wu, Haiyan Li, Lijuan Li, and Leilei Li. 2022. "A Serverless-Based, On-the-Fly Computing Framework for Remote Sensing Image Collection" Remote Sensing 14, no. 7: 1728. https://doi.org/10.3390/rs14071728
APA StyleWu, J., Wu, M., Li, H., Li, L., & Li, L. (2022). A Serverless-Based, On-the-Fly Computing Framework for Remote Sensing Image Collection. Remote Sensing, 14(7), 1728. https://doi.org/10.3390/rs14071728