
Few-Shot Learning for Radar Emitter Signal Recognition Based on Improved Prototypical Network


Abstract
:1. Introduction
- An approach based on PN belonging to meta-learning is proposed to realize few-shot signals recognition of known classes and signals distinguishment of unknown classes simultaneously for the first time in radar emitter signal recognition.
- RepVGG net is adopted instead of the original structure which limits the performance of the model seriously to increase the recognition performance.
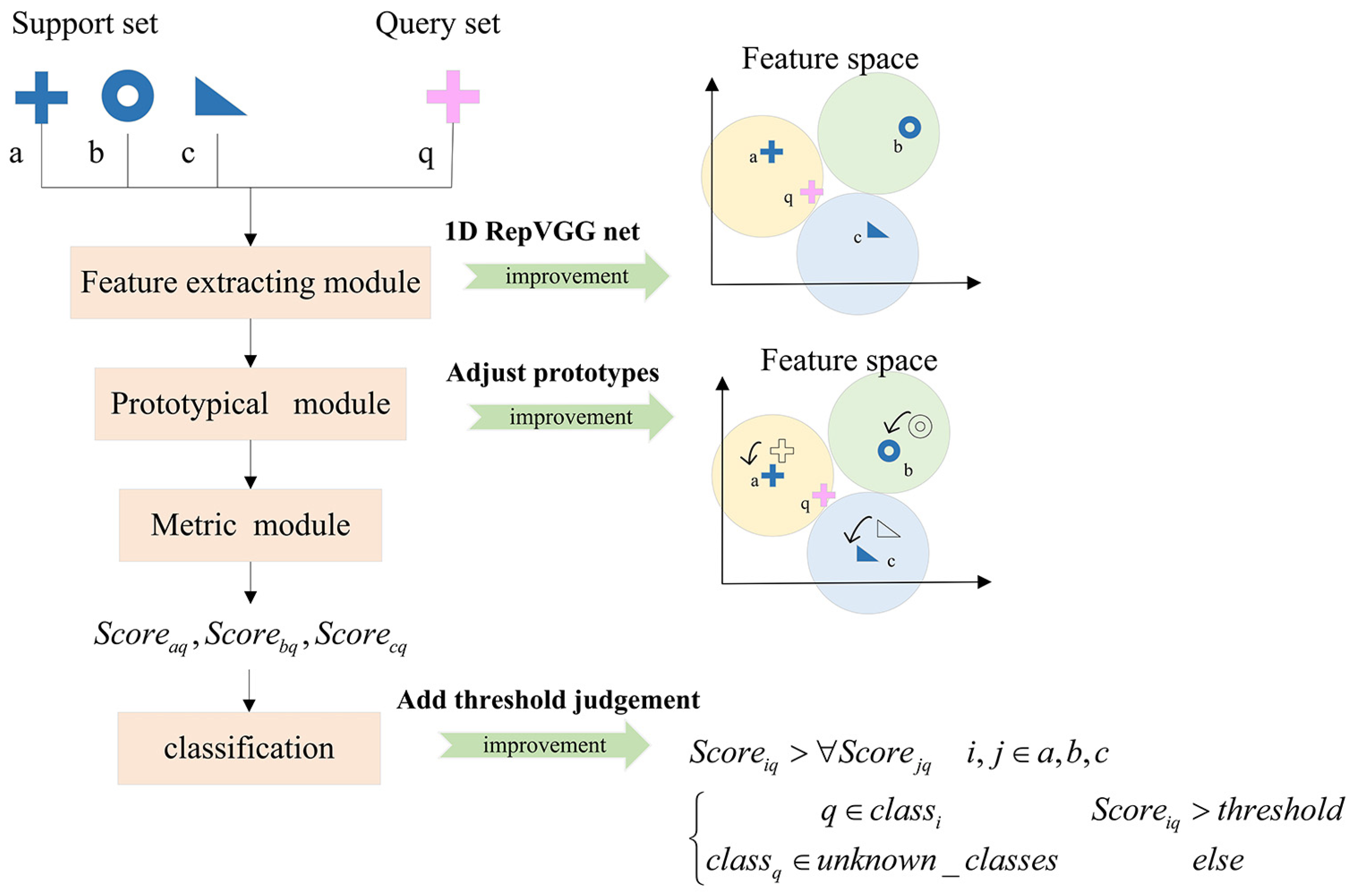
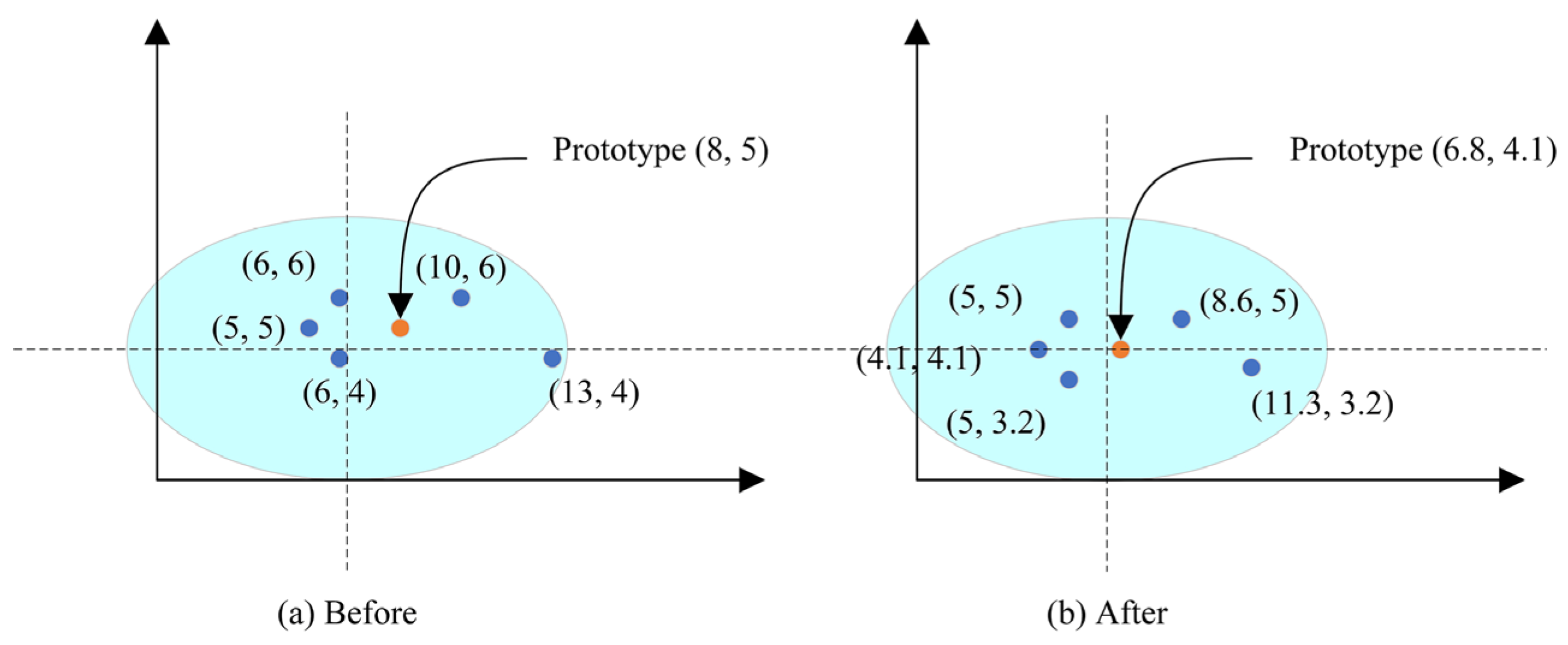
- The way of obtaining prototypes in IPN is designed to avoid extreme samples affecting the prototypes by adding two trainable vectors to adjust the feature embedding vectors before average operation.
- The function of metric-based meta-learning that distinguishes samples of unknown classes is activated by setting a threshold in our method to verify whether samples belong to known classes or not.
2. Related Work
2.1. Radar Emitter Signal Recognition
2.2. Few-Shot Learning
3. Methods
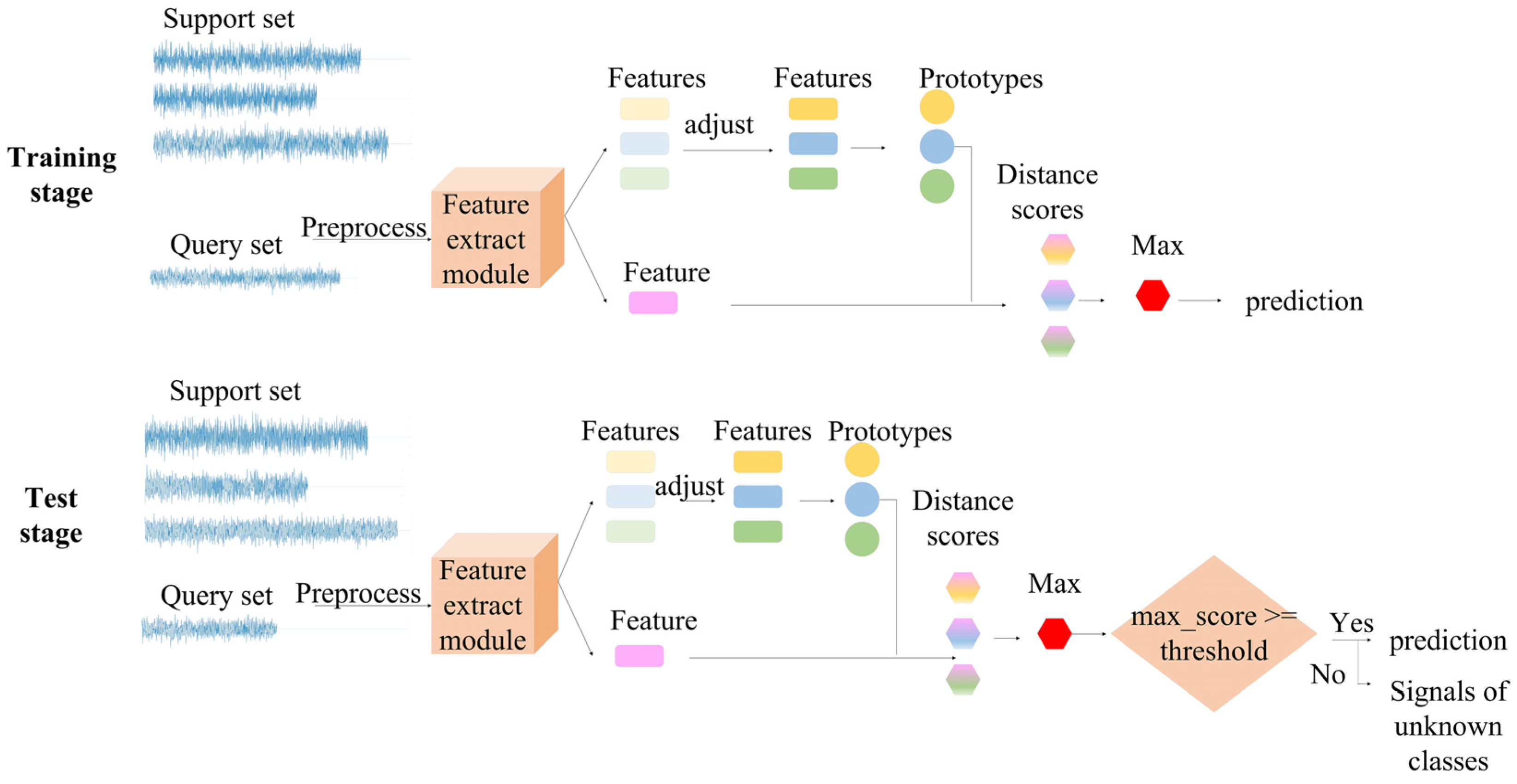
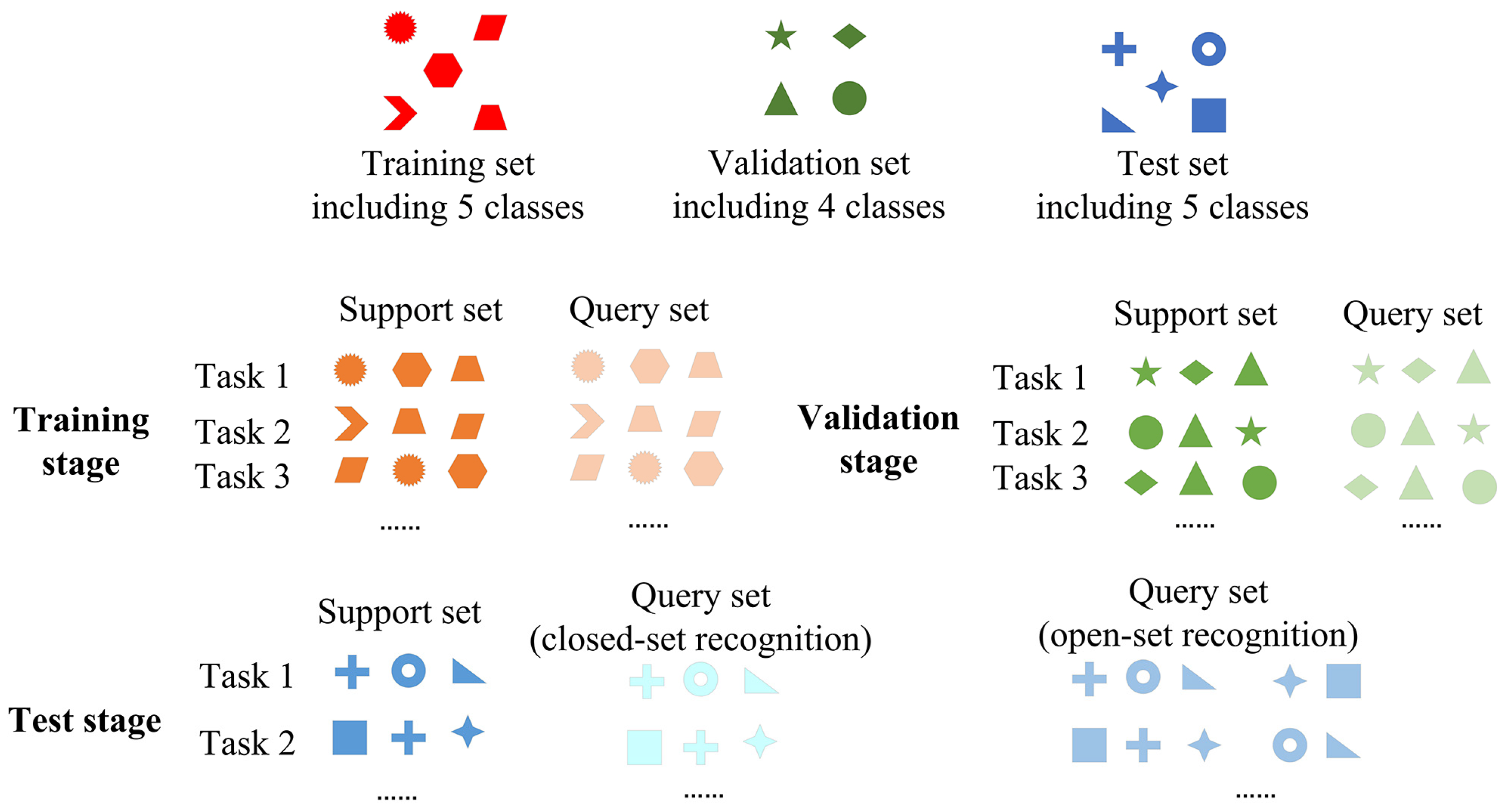
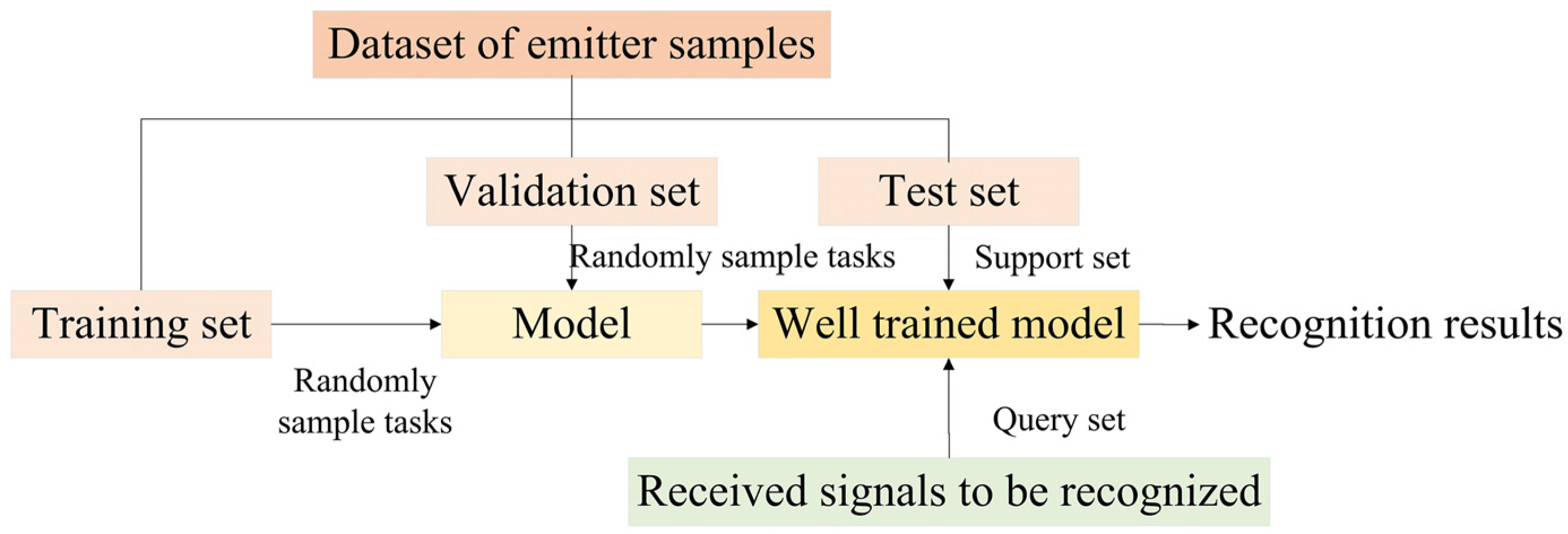
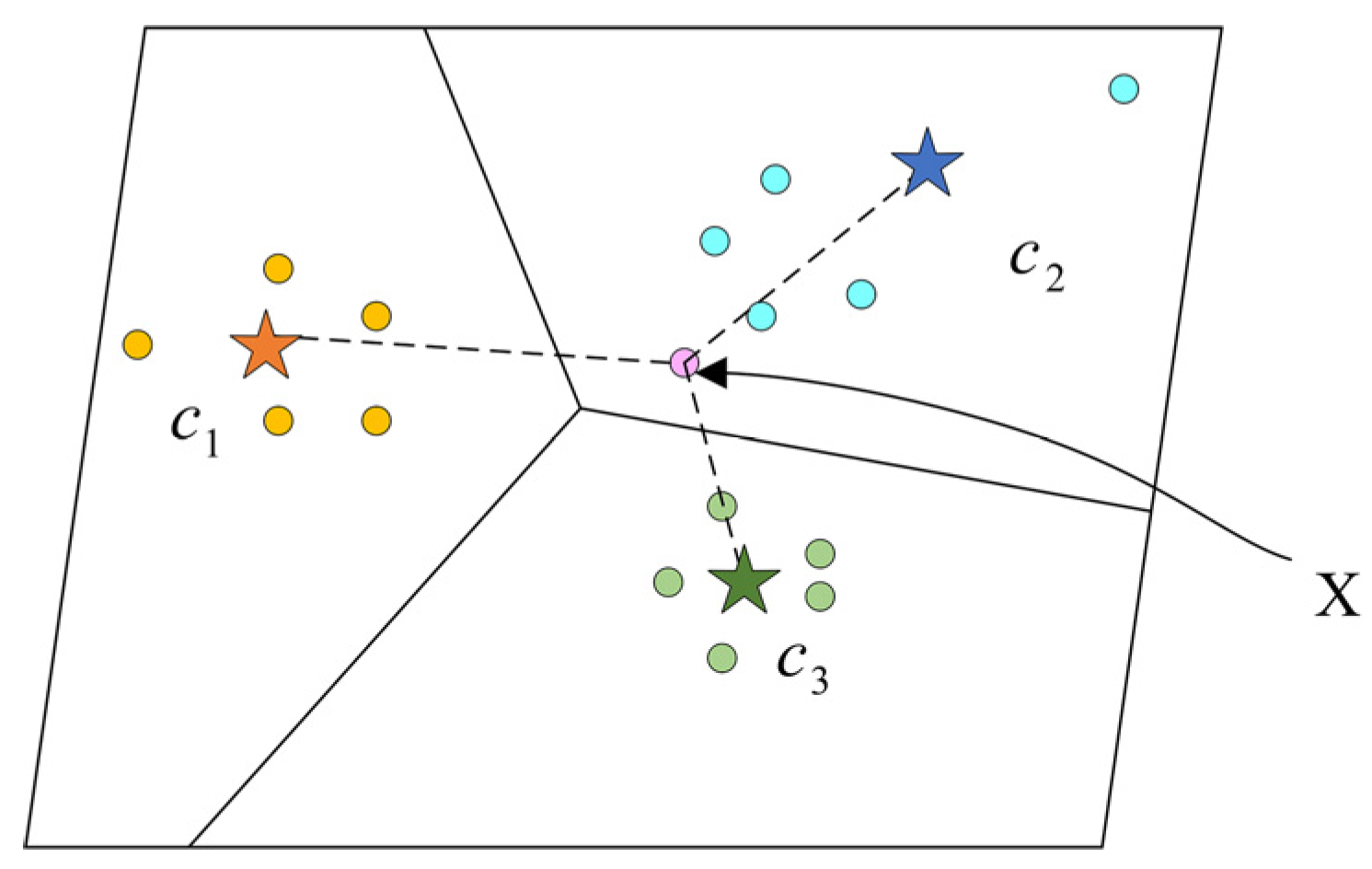
3.1. Task Description
3.2. Improved Prototypical Network
3.2.1. Feature Extracting Module
3.2.2. Prototypical Module
3.2.3. Metric Module
| Algorithm 1: Episode-based training for IPN |
| Input: the training set |
| , and learning rate α |
| For i = 1: episode number |
| Randomly sample N classes from the training dataset |
| Randomly extract K samples from each of the N classes |
| End while |
| Output: Model parameters ϕ, γ, β |
4. Experiments
4.1. Dataset
- (1)
- First, we generated 14 types of radar emitter signals with different values of SNR. The SNR for each type of signal ranged from 0 to 9 dB with 1 dB step, containing a total of 10 values. The number of samples for each type of signal with each value SNR was 200;
- (2)
- Second, we utilized 2000 points FFT to process signals processed in (1). To ensure different data samples under the same distribution scale, z-score standardization is adopted to process input data, which is also beneficial to network optimization and training-time reduction. Assuming the sample sequence of a radar emitter signal is , where U is the number of sample points. The value of each point of this sequence after standardizing is detailed below:
- (3)
- Third, we divided the dataset into a training set, a validation set, and a test set as described in Section 3.1. In order to avoid the accident caused by different ways of dividing the dataset, three experiments were done to examine the networks’ performance. The different classifications of the dataset in experiments are described in Table 2.
4.2. Results
5. Discussion
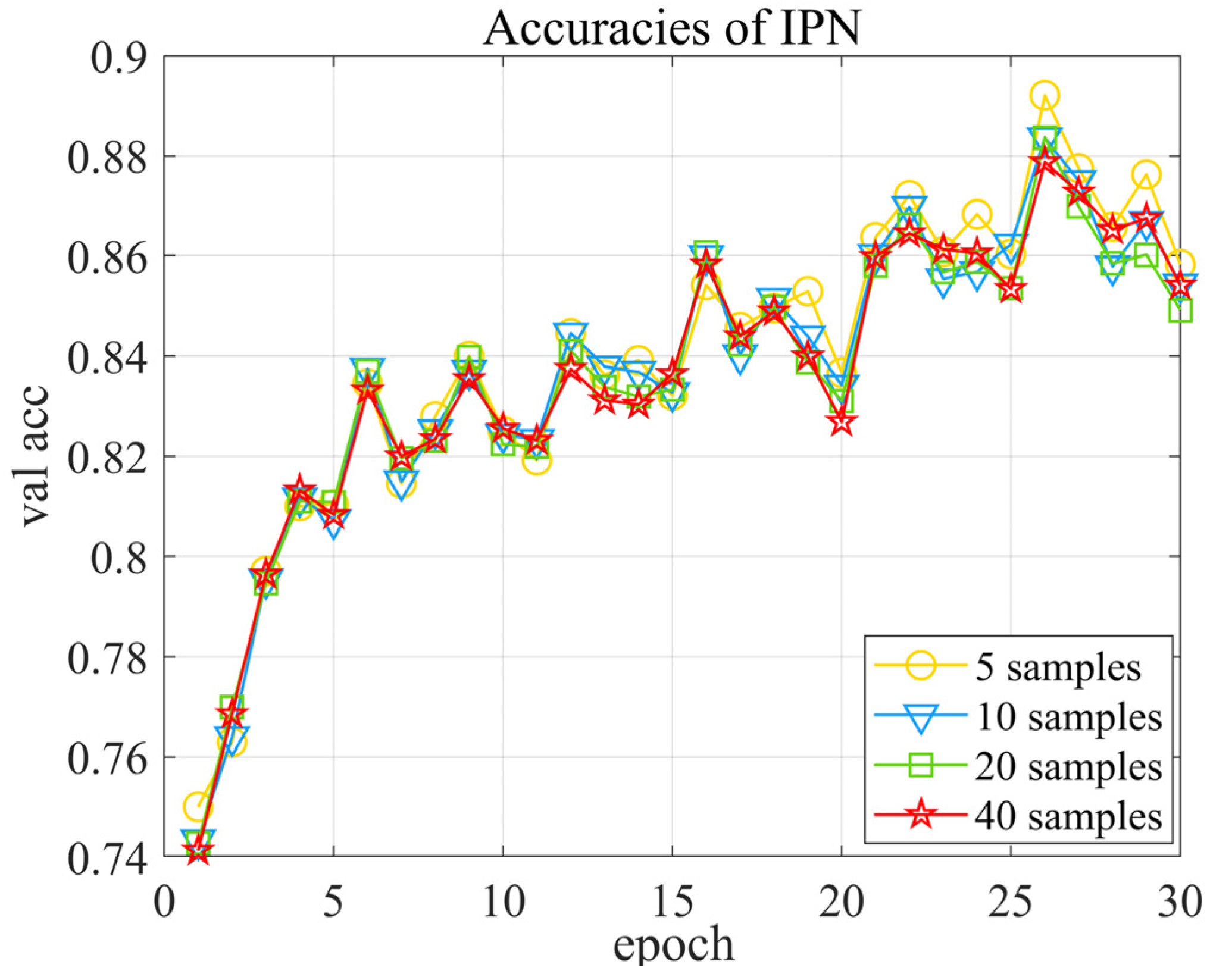
5.1. Influence of the Number of Support Samples on Recognition Accuracy
5.2. Influence of Query Samples on Recognition Accuracy
5.3. Influence of Mismatching Condition
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Jin, Q.; Wang, H.Y.; Ma, F.F. An Overview of Radar Emitter Classification and Identification Methods. Telecommun. Eng. 2019, 59, 360–368. [Google Scholar]
- Li, F.Z.; Liu, Y.; Wu, P.X. A Survey on Recent Advances in Meta-Learning. Chin. J. Comput. 2021, 44, 422–446. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In International Conference on Machine Learning; PMLR: Long Beach, CA, USA, 2017. [Google Scholar]
- Chen, Y.; Hoffman, M.W.; Colmenarejo, S.G.; Denil, M.; Lillicrap, T.P.; Botvinick, M.; Freitas, N. Learning to Learn without Gradient Descent by Gradient Descent; PMLR: Long Beach, CA, USA, 2017. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Processing Syst. 2016, 29, 3630–3638. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical Networks for Few-shot Learning. Adv. Neural Inf. Processing Syst. 2017, 30, 4077–4087. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Fort, S. Gaussian prototypical networks for few-shot learning on omniglot. arXiv 2017, arXiv:1708.02735. [Google Scholar]
- Zhang, X.; Qiang, Y.; Sung, F.; Yang, Y.; Hospedales, T. RelationNet2: Deep comparison network for few-shot learning. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Yang, N.; Zhang, B.; Ding, G.; Wei, Y.; Wei, G.; Wang, J.; Guo, D. Specific Emitter Identification with Limited Samples: A Model-Agnostic Meta-Learning Approach. IEEE Commun. Lett. 2021, 26, 345–349. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style ConvNets Great Again. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13728–13737. [Google Scholar]
- Liu, Z.; Shi, Y.; Zeng, Y.; Gong, Y. Radar Emitter Signal Detection with Convolutional Neural Network. In Proceedings of the 2019 IEEE 11th International Conference on Advanced Infocom Technology (ICAIT), Jinan, China, 18–20 October 2019; pp. 48–51. [Google Scholar]
- Pan, Y.; Yang, S.; Peng, H.; Li, T.; Wang, W. Specific Emitter Identification Based on Deep Residual Networks. IEEE Access 2019, 7, 54425–54434. [Google Scholar] [CrossRef]
- Wu, B.; Yuan, S.; Li, P.; Jing, Z.; Huang, S.; Zhao, Y. Radar Emitter Signal Recognition Based on One-Dimensional Convolutional Neural Network with Attention Mechanism. Sensors 2020, 20, 6350. [Google Scholar] [CrossRef] [PubMed]
- Yuan, S.; Wu, B.; Li, P. Intra-Pulse Modulation Classification of Radar Emitter Signals Based on a 1-D Selective Kernel Convolutional Neural Network. Remote Sens. 2021, 13, 2799. [Google Scholar] [CrossRef]
- Wong, L.J.; Headley, W.C.; Michaels, A.J. Specific Emitter Identification Using Convolutional Neural Network-Based IQ Imbalance Estimators. IEEE Access 2019, 7, 33544–33555. [Google Scholar] [CrossRef]
- Nguyen, H.P.K.; Do, V.L.; Dong, Q.T. A Parallel Neural Network-based Scheme for Radar Emitter Recognition. In Proceedings of the 14th International Conference on Ubiquitous Information Management and Communication (IMCOM) Viettel High Technology Industries Corporation Viettel Group Hanoi Vietnam, Taichung, Taiwan, 3–5 January 2020. [Google Scholar]
- Wang, F.; Yang, C.; Huang, S.; Wang, H. Automatic modulation classification based on joint feature map and convolutional neural network. IET Radar Sonar Navig. 2019, 13, 998–1003. [Google Scholar] [CrossRef]
- Shao, G.; Chen, Y.; Wei, Y. Deep Fusion for Radar Jamming Signal Classification Based on CNN. IEEE Access 2020, 8, 117236–117244. [Google Scholar] [CrossRef]
- Qu, Z.; Mao, X.; Deng, Z. Radar Signal Intra-Pulse Modulation Recognition Based on Convolutional Neural Network. IEEE Access 2018, 6, 43874–43884. [Google Scholar] [CrossRef]
- Ding, J.; Chen, B.; Liu, H.; Huang, M. Convolutional Neural Network With Data Augmentation for SAR Target Recognition. IEEE Geosci. Remote Sens. Lett. 2016, 13, 364–368. [Google Scholar] [CrossRef]
- Guo, Q.; Yu, X.; Ruan, G. LPI Radar Waveform Recognition Based on Deep Convolutional Neural Network Transfer Learning. Symmetry 2019, 11, 540. [Google Scholar] [CrossRef] [Green Version]
- Peng, Y.; Zhang, Y.; Chen, C.; Yang, L.; Li, Y.; Yu, Z. Radar Emitter Identification Based on Co-clustering and Transfer Learning. In Proceedings of the 2021 IEEE 16th Conference on Industrial Electronics and Applications (ICIEA), Chengdu, China, 1–4 August 2021; pp. 1685–1690. [Google Scholar]
- Ran, X.; Zhu, W. Radar emitter identification based on discriminant joint distribution adaptation. In Proceedings of the 2019 IEEE 3rd Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 11–13 October 2019; pp. 1169–1173. [Google Scholar]
- Li, Y.; Ding, Z.; Zhang, C.; Wang, Y.; Chen, J. SAR Ship Detection Based on Resnet and Transfer Learning. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1188–1191. [Google Scholar] [CrossRef]
- Shang, R.; Wang, J.; Jiao, L.; Stolkin, R.; Hou, B.; Li, Y. SAR Targets Classification Based on Deep Memory Convolution Neural Networks and Transfer Parameters. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2834–2846. [Google Scholar] [CrossRef]
- Pahde, F.; Puscas, M.; Klein, T.; Nabi, M. Multimodal Prototypical Networks for Few-shot Learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 2643–2652. [Google Scholar] [CrossRef]
- Lopez-Martin, M.; Sanchez-Esguevillas, A.; Arribas, J.I.; Carro, B. Supervised contrastive learning over prototype-label embeddings for network intrusion detec-tion—ScienceDirect. Inf. Fusion 2022, 79, 200–228. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Signal Type | Carrier Frequency | Parameter | |
|---|---|---|---|
| Emitter 1 | CW | 200~250 MHz | None |
| Emitter 2 | LFM | 200~250 MHz | Frequency bandwidth: 30–32 MHz |
| Emitter 3 | NLFM | 200~250 MHz | Frequency of modulation signal ranges from 10 to 11 MHz |
| Emitter 4 | MLFM | 100~120 MHz 140~160 MHz | Frequency bandwidth: 30–32 MHz |
| Emitter 5 | DLFM | 200~250 MHz | Frequency bandwidth: 30–32 MHz |
| Emitter 6 | EQFM | 200~250 MHz | Frequency bandwidth: 30–32 MHz |
| Emitter 7 | BPSK | 200~250 MHz | 13-bit Barker code |
| Emitter 8 | BFSK | 100~120 MHz 140~160 MHz | 13-bit Barker code |
| Emitter 9 | QPSK | 200~250 MHz | 16-bit Frank code |
| Emitter 10 | QFSK | 100~120 MHz 140~160 MHz 180~200 MHz 220~240 MHz | 16-bit Frank code |
| Emitter 11 | BPSK-LFM | 200~250 MHz | Frequency bandwidth: 30–32 MHz 13-bit Barker code |
| Emitter 12 | BFSK-BPSK | 100~120 MHz 140~160 MHz | 13-bit Barker code |
| Emitter 13 | BFSK-QPSK | 100~120 MHz 140~160 MHz | 16-bit Frank code |
| Emitter 14 | QFSK-BPSK | 100~120 MHz 140~160 MHz 180~200 MHz 220~240 MHz | 16-bit Frank code 13-bit Barker code |
| Dataset 1 | Dataset 2 | Dataset 3 | |
|---|---|---|---|
| Training set (5 types) | CW, LFM, NLFM, MLFM, EQFM | CW, BPSK, BFSK, QPSK, BFSK-QPSK | BPSK, QPSK, QFSK, BFSK-BPSK, QFSK-BPSK |
| Validation set (4 types) | BPSK, BFSK, QPSK, QFSK | NLFM, MLFM, BPSK-LFM, QFSK-BPSK | LFM, DLFM, EQFM, BFSK-QPSK |
| Test set (5 types) | DLFM, BPSK-LFM, BFSK-BPSK, BFSK-QPSK, QFSK-BPSK | LFM, EQFM, DLFM, QFSK, BFSK-BPSK | CW, NLFM, MLFM, BFSK, BPSK-LFM |
| Model | 3-Way 1-Shot | 3-Way 5-Shot | |
|---|---|---|---|
| Experiment 1 | MAML [11] | 81.045% | 92.233% |
| MN [6] | 81.331% | 81.842% | |
| RN [8] | 89.885% | 92. 652% | |
| PN [7] | 88.826% | 94.232% | |
| OURS | 91.827% | 95.157% | |
| Experiment 2 | MAML [11] | 78.769% | 92.581% |
| MN [6] | 79.876% | 79.825% | |
| RN [8] | 85.020% | 87.111% | |
| PN [7] | 90.724% | 95.727% | |
| OURS | 96.568% | 98.178% | |
| Experiment 3 | MAML [11] | 91.238% | 97.528% |
| MN [6] | 87.835% | 88.005% | |
| RN [8] | 87.146% | 85.682% | |
| PN [7] | 99.397% | 99.919% | |
| OURS | 99.997% | 100% |
| Model | 3-Way 1-Shot | 3-Way 5-Shot | |||
|---|---|---|---|---|---|
| Acc1 * | Acc2 | Acc1 | Acc2 | ||
| Experiment 1 | PN [7] | 65.231% | 71.437% | 78.278% | 80.840% |
| OURS | 75.325% | 79.564% | 81.795% | 84.671% | |
| Experiment 2 | PN [7] | 73.655% | 77.995% | 81.279% | 82.985% |
| OURS | 87.375% | 88.123% | 87.509% | 88.085% | |
| Experiment 3 | PN [7] | 76.014% | 76.258% | 83.144% | 83.178% |
| OURS | 81.717% | 81.717% | 87.754% | 87.754% | |
| Model | 3-Way 1-Shot | 3-Way 5-Shot |
|---|---|---|
| PN [7] | 22.160 s | 33.963 s |
| OURS | 33.309 s | 53.063 s |
| Model | 3-Way 1-Shot | 3-Way 5-Shot |
|---|---|---|
| PN [7] | 23.000 s | 31.408 s |
| OURS | 14.018 s | 19.787 s |
| Model | 3-Way 1-Shot | 3-Way 5-Shot | 3-Way 10-Shot | 3-Way 20-Shot | 3-Way 40-Shot |
|---|---|---|---|---|---|
| PN | 88.826% | 94.232% | 94.824% | 95.302% | 95.248% |
| OURS | 91.827% | 95.157% | 95.592% | 95.771% | 95.746% |
| Model | 3-Way 1-Shot | 3-Way 5-Shot | 3-Way 10-Shot | 3-Way 20-Shot | 3-Way 40-Shot | |
|---|---|---|---|---|---|---|
| Acc1 | PN [7] | 65.231% | 78.278% | 78.848% | 77.830% | 78.153% |
| OURS | 75.325% | 81.795% | 86.345% | 86.571% | 85.482% | |
| Acc2 | PN [7] | 71.437% | 80.840% | 81.564% | 80.457% | 80.421% |
| OURS | 79.564% | 84.671% | 88.945% | 89.045% | 87.916% |
| Task Settings for the Train Stage | Task Settings for the Test Stage | ||||
|---|---|---|---|---|---|
| 3-Way 1-Shot | 3-Way 5-Shot | 3-Way 10-Shot | 3-Way 20-Shot | 3-Way 40-Shot | |
| 3-Way 1-Shot | 91.827% | 94.956% | 95.529% | 95.702% | 95.854% |
| 3-Way 5-shot | 92.299% | 95.157% | 95.618% | 95.850% | 95.968% |
| 3-Way 10-shot | 92.158% | 95.101% | 95.592% | 95.840% | 95.943% |
| 3-Way 20-shot | 92.059% | 95.072% | 95.564% | 95.771% | 95.932% |
| 3-Way 40-shot | 91.478% | 94.785% | 95.320% | 95.593% | 95.746% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, J.; Wu, B.; Li, P.; Li, X.; Wang, J. Few-Shot Learning for Radar Emitter Signal Recognition Based on Improved Prototypical Network. Remote Sens. 2022, 14, 1681. https://doi.org/10.3390/rs14071681
Huang J, Wu B, Li P, Li X, Wang J. Few-Shot Learning for Radar Emitter Signal Recognition Based on Improved Prototypical Network. Remote Sensing. 2022; 14(7):1681. https://doi.org/10.3390/rs14071681
Chicago/Turabian StyleHuang, Jing, Bin Wu, Peng Li, Xiao Li, and Jie Wang. 2022. "Few-Shot Learning for Radar Emitter Signal Recognition Based on Improved Prototypical Network" Remote Sensing 14, no. 7: 1681. https://doi.org/10.3390/rs14071681
APA StyleHuang, J., Wu, B., Li, P., Li, X., & Wang, J. (2022). Few-Shot Learning for Radar Emitter Signal Recognition Based on Improved Prototypical Network. Remote Sensing, 14(7), 1681. https://doi.org/10.3390/rs14071681