1. Introduction
Object detection is widely employed in remote sensing imaging technology applications such as urban planning, resource and environmental surveys, traffic control, mapping, communication and navigation [
1,
2,
3,
4], and it has received constant attention from many scholars. Machine learning technology is constantly updating and evolving, and it has been used in various image processing applications, such as pose estimation [
5,
6], image reconstruction [
7,
8], target tracking [
9,
10], and so on. Recognition methods utilizing deep learning have achieved ideal detection results. Motivated by the great successes of convolutional neural networks (CNNs), many researchers have introduced deep networks for measuring large-scale natural image datasets such as ImageNet [
11] and MSCOCO [
12] in the remote sensing identification field. The direct transfer of models from natural scene images to optical aerial images does not achieve the ideal detection effect. Object identification in aerial images also faces multiple difficulties, such as illumination, weather, multiscale settings, partially obscured, and so on. In addition, aerial images are obtained from vertical views, and the feature information of the target is obviously different from that contained in natural scene images, which usually capture information from an approximately horizontal perspective. Remote sensing images have lower spatial resolutions since they are acquired from substantial distances. Objects in aerial images such as ships and vehicles usually occupy fewer pixels and are densely packed, resulting in intercategory feature crosstalk and intracategory feature boundary blurring. Therefore, it is necessary to improve such networks according to the characteristics of remote sensing images.
Due to the image acquisition mode of vertical views, objects in optical aerial images usually appear arbitrarily oriented, which requires the utilized bounding box to be rotatable to match the characteristics of the target. Many excellent arbitrarily oriented detectors have been proposed and applied in remote sensing and scene text detection [
13,
14,
15]. The differences between horizontal bounding box (HBB) detection and oriented bounding box (OBB) detection are shown in
Figure 1. An HBB can be denoted by four parameters
, where
represent the coordinates of the center point and
indicate the width and height of the bounding box. OBB introduces an additional parameter
θ to describe the rotation angle of the objects. Compared with OBB, HBB detection has three disadvantages: (1) an HBB does not reflect the size and shape information of the target, especially for a target with a high aspect ratio; (2) an HBB is less enveloping than an OBB, and it contains many background pixels; (3) objects that are densely packed are hard to distinguish from each other. Therefore, the OBB method is more suitable for object detection in aerial images. However, experiments have shown that the discontinuity during the angle regression affects the model performance, so it is necessary to investigate effective solutions to eliminate the boundary discontinuity caused by angular periodicity.
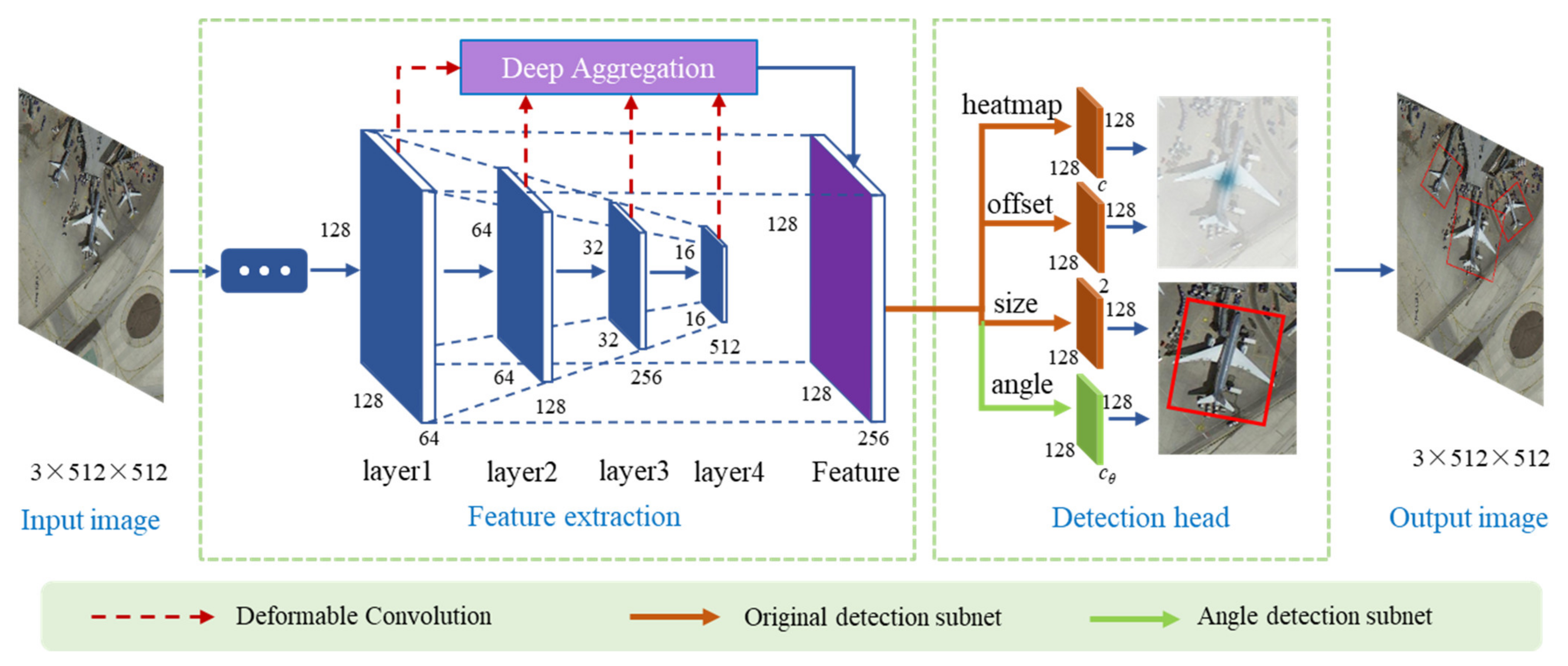
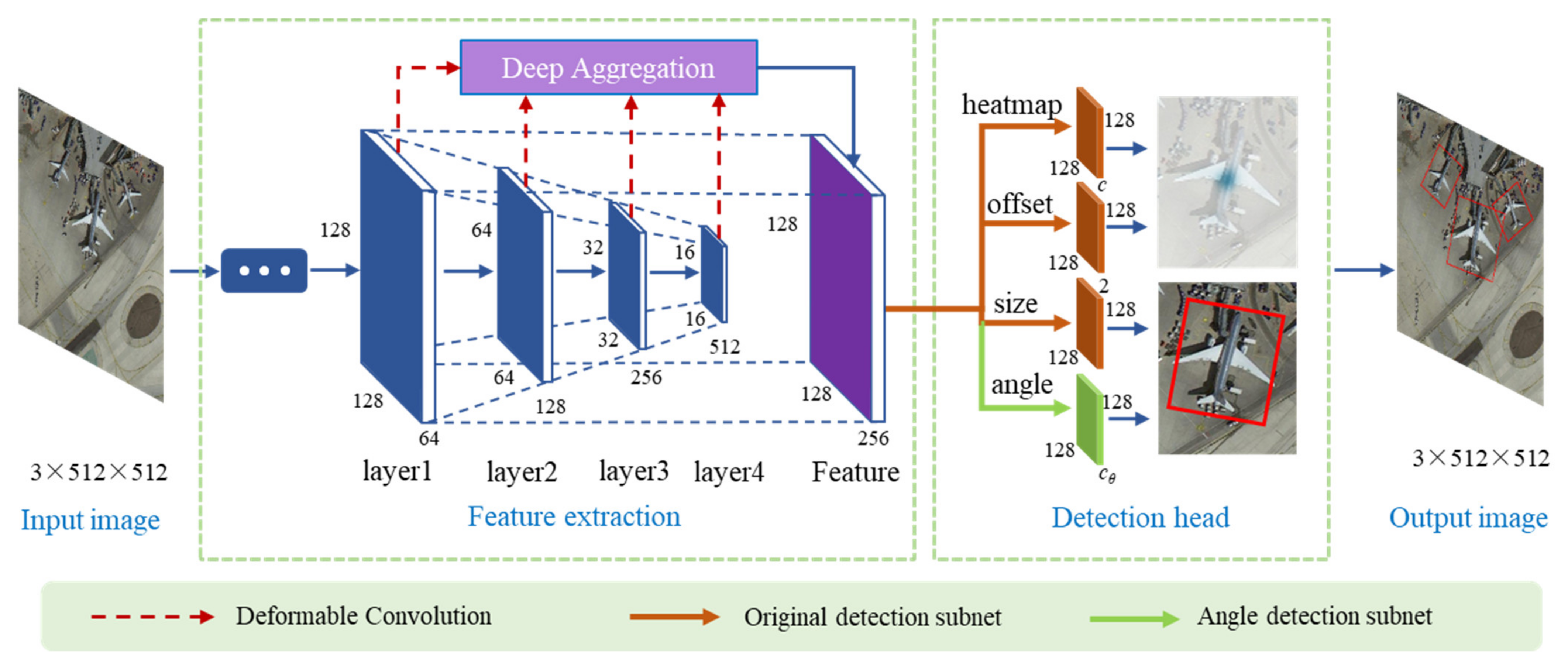
We adopt an anchor-free approach to realize the detection of arbitrarily oriented objects. The detector is based on CenterNet [
16], which regards the given object as a point and then directly predicts its width and height values. This method designs an additional angle prediction branch to extract the angle information of the object. To handle the problem of angle periodicity, we introduce a smooth labeling method to convert the issue into a classification task. This method transforms a single truth value into a sequence, which effectively improves the angle prediction accuracy.
In addition, the sample quantity imbalance problem restricts the performance of the classifier. In aerial images, positive examples occupy only a fraction of an image, and most of them are easily identifiable examples. The quantity variance between positive and negative examples and hard and easy examples harms the accuracy of the classification task. Focusing on the problem, online hard example mining (OHEM) [
17] is proposed to increase the contribution of hard examples to the loss function, but the screening process for hard samples causes more training time. Focal loss [
18] modifies the cross-entropy loss to pay more attention to hard examples. However, hard examples contain some discrete targets that are difficult to be recognize by eyes, and it will harm model convergence by increasing the weight of those discrete targets.
To improve the learning efficiency of the network for obtaining effective features, a gradient harmonizing mechanism (GHM) [
19] is introduced to suppress the disequilibrium between examples. This method focuses on weakening the influence of the very hard examples. Aiming at improving the detection accuracy of the model, we propose a more effective example dynamic equalization method on the basis of the GHM. First, a weight coefficient is incorporated into the harmonization module to address the quantity imbalance between positive and negative examples. Second, gradient adjustment mechanism is embedded into the classification function [
18,
20] to dynamically adjust the weighing factor of easy examples and hard examples.
Besides, independent regression of object distribution parameters raises several problems. First, this will introduce more hyper-parameters in the optimization function. Second, its inconsistency to the evaluation metric, i.e., Intersection over Union (IoU). Generalized IoU (GIoU) loss [
21] and complete IoU (CIoU) loss [
22] can overcome such issues in HBB task. But they cannot be applied directly in OBB task. Pixes IoU (PIoU) loss [
23] realizes it by counting the number of pixels in the intersection area, but its accuracy is not satisfactory. We propose a rotated CIoU (RCIoU) loss which incorporates angle information in CIoU, and adopts it to achieve the union regression of rotation objects.
In this article, we propose a novel framework for the high-precision detection of rotating objects in remote sensing images. Our approach aims to eliminate the limitations of angle discontinuity, sample quantity imbalance, and parameter separation regression on model performance. The experimental results show that our method achieves state-of-the-art performance in remote sensing datasets. The major contributions of this article include the following.
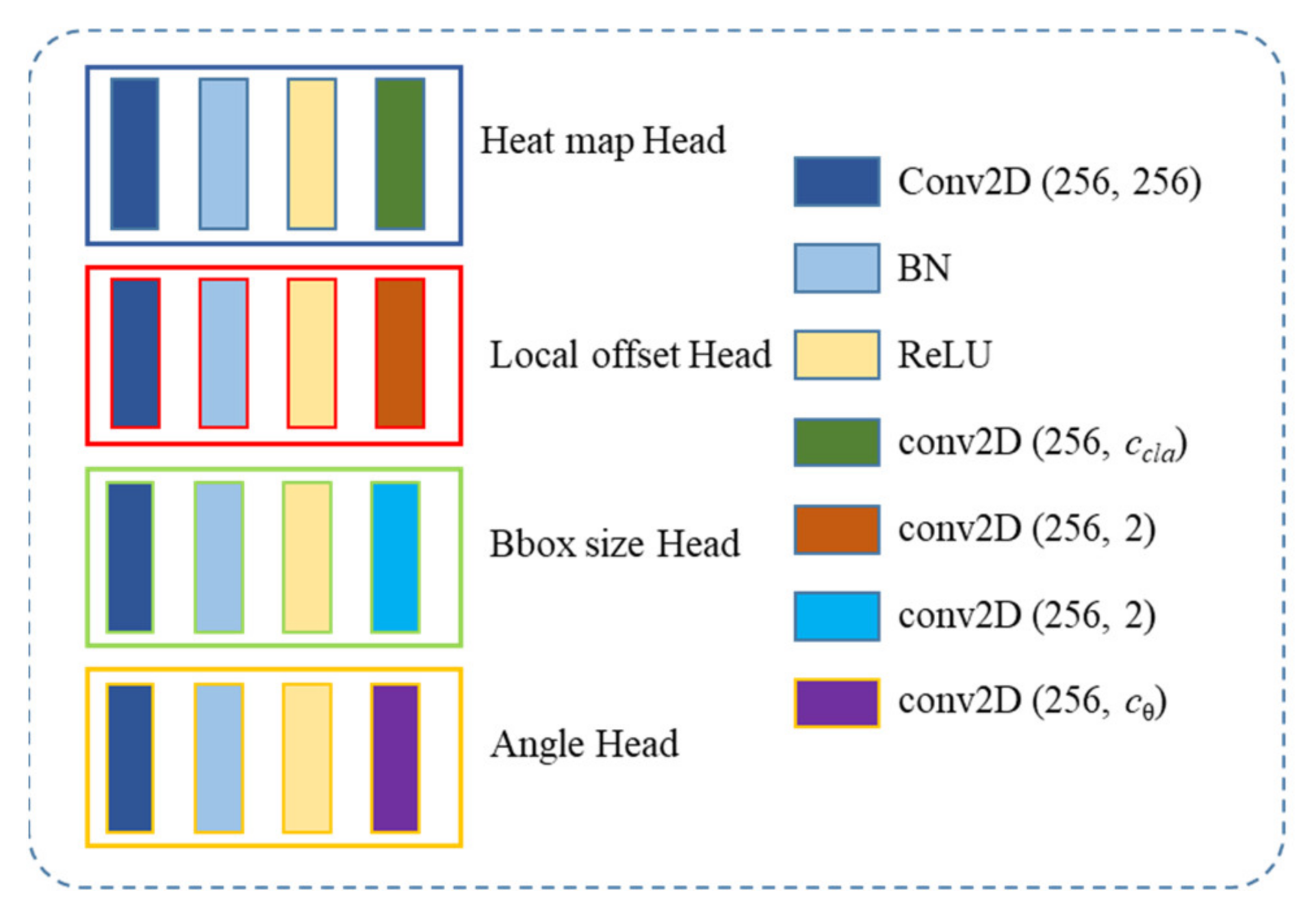
We propose a unified paradigm for arbitrarily oriented object detection in remote sensing imaging. The detector is built based on the anchor-free CenterNet, and an angle-sensitive subnet is added to the network to realize rotated object detection. The periodic smooth label is introduced to transform the one-hot value of the rotated angle into a category label sequence. This transformation method can eliminate the discontinuity of the rotated boundary, which is caused by the periodicity of the angle.
A dynamic gradient adjustment method is embedded into the angle classification loss function to harmonize the quantity imbalance between easy and hard examples. This method is transplanted into the angle loss function to further improve the angle identification accuracy.
We proposed an RCIoU loss for oriented bounding box regression, which achieves a faster convergence rate and higher detection accuracy than independent regression of distribution parameters.
The structure of this paper is designed as follows.
Section 2 outlines relevant deep convolutional networks in remote sensing object detection and describes arbitrarily oriented object detection methods. We elaborate on the detection principle of our proposed method in
Section 3. The superiority of the proposed approach is verified, and a quantitative comparison with the existing methods is conducted in
Section 4. Finally,
Section 5 gives the conclusion of this article.
4. Experiment and Discussion
We perform a series of ablation experiments to verify the validity of the designed network in aerial images. First, we introduce the datasets for experimentation and the metrics for evaluating the performance of the detector. Second, multiple sets of comparative experiments are performed to verify the impacts of the proposed modules on performance, and we carry out a detailed comparative analysis. Finally, we compare the proposed method with published advanced approaches on public datasets. The numeral results indicate that our detector is a competitive paradigm in terms of object identification.
4.1. Datasets
UCAS-AOD: We conduct ablation experiments on the UCAS-AOD dataset [
51], which contains two categories: cars and planes. All remote images are taken from aerial and satellite platforms. The dataset contains 1510 images with 14,596 items annotated by HBBs and OBBs. Among them, the car dataset is composed of 510 images, and the plane dataset is composed of 1000 images. The dataset is randomly divided into a training set and a test set, and the proportion of the former is 80%. The input images are cropped into 512 × 512 during the training process.
DOTA: The DOTA dataset [
52] consists of 15 kinds of categories: plane (PL), baseball diamond (BD), ship (SH), tennis court (TC), storage tank (ST), bridge (BR), basketball court (BC), ground field track (GTF), harbor (HA), small vehicle (SV), large vehicle (LV), roundabout (RA), helicopter (HC), swimming pool (SP), and soccer ball field (SBF). It contains 2806 images obtained from different scenes and includes 188,282 instances in total. The size of the image ranges from about 800 × 800 to 4000 × 4000 pixels and contains a large number of objects with diverse orientations and sizes. We divide these images into 500 × 500 with an overlap of 200 pixels. We obtain about 20,000 subimages for training and 7000 subimages for validation after the cropping operation.
HRSC2016: Ship detection in aerial images is widely applied in many scenarios. The HRSC2016 dataset [
53] contains 1070 remote sensing images with ships in various backgrounds, and the images are all collected from the internet (Google Earth). The ships in the dataset have large aspect ratios, and their angles are randomly distributed. The training dataset is composed of 626 images, while the test set contains 444 images with 1228 ship samples. The resolutions of the images range from 2 to 0.4 m. The test set is used to measure the detector.
4.2. Evaluation Metrics
We select two common metrics to measure the accuracy of the tested networks: mean average precision (mAP) and mean recall (mRecall). In addition, we use the error of angle (EoA) to describe the accuracy of the angle recognition results. The evaluation methods [
12] are described as follows.
IoU: This parametric measure is applied to describe the matching degree between the predicted box and ground-truth box, and they are considered to be matched if their IoU is greater than the threshold. A true positive (TP) indicates that there is a ground-truth box to match this prediction; otherwise, the predicted sample is marked as a false positive (FP). A false negative (FN) indicates that a ground-truth box is not matched by any predicted box. The precision can be calculated by , while the recall is defined as .
mAP: Average precision (AP) is used to characterize the accuracy of a single category, and it is calculated by the mean value of precision under a series of recall values. The mAP denotes the average value across all categories. Furthermore, the mRecall is the mean recall value for all classes. mAP50 means that the results are computed when the IoU threshold is 0.5, and mAP75 indicates that the threshold is set to 0.75. We compute the mRecall at the IoU threshold of 0.5 to evaluate the recall performance of the detector.
EoA: To evaluate the angle prediction performance of the model for rotated objects, we define the EoA to quantitatively describe the deviation between the predicted angle and the ground truth. We adopt the mean absolute error to measure the deviation, and EoA is defined as , N is the number of predicted boxes that meet the IoU requirement (larger than 0.5), indicates the predicted angle, and indicates the ground truth angle.
4.3. Ablation Experiments
In this subsection, we present comparative results to demonstrate the validity of our method. All networks are implemented on our laptop with an Intel single-core i7-9750H CPU and an NVIDIA RTX 2070 GPU (8 GB of memory). The software version of our platform is Python 3.6, PyTorch 1.2.0, CUDA10.0, and CUDNN 7.6.1. The model crops the input image randomly to 512 × 512; then, it downsamples to generate a 128 × 128 × 3 feature map. The initial learning rate of the model is set to 1.25 × 10−4, and it will be reduced to 1.25 × 10−5 after 50 epochs. During the training process, our detector will randomly flip the input image. In the test session, the image maintains its original size without cropping.
4.3.1. Angle Branch Evaluation
We conduct a series of comparison experiments on the UCAS-AOD dataset to verify the effectiveness of our method. On the basis of the original network, we add an angle prediction branch to realize the detection of rotating targets in aerial images. A comparison of the results between horizontal detection and rotation detection for vehicles is shown in
Figure 6, and the quantitative comparison results are listed in the first and fourth rows of
Table 1.
By comparing the detection results between HBB detection and OBB detection, we can see that rotated detection allows for the effective distinction of dense objects and the number of background pixels in the bounding box is significantly reduced than HBB. However, the accuracy of the model slightly decreases, and some of the predicted boxes have significant offsets. The results show that the accuracy of angle prediction is unsatisfactory, with a mean deviation of 14.7°. The model performance needs to be further improved.
4.3.2. Evaluation of DGA
Focal loss acts as the center point loss function in the baseline framework, but the sample imbalance problem cannot be effectively harmonized. DGA is proposed to improve the detection performance of our network. We conduct many experiments to determine the optimal loss function for target identification, and the HBB and OBB detection results are listed in
Table 1. In accordance with the comparison results, the experiments demonstrate that the DGA method can suppress the angle deviation and improve the model detection accuracy. The mAP of horizontal detection increases by 2.4%, while that of rotary detection increases by 1.0%. In addition, the EoA decreases from 14.72° to 13.01°. These results confirm the validity of the GHM method in complex backgrounds.
4.3.3. Evaluation of PSL
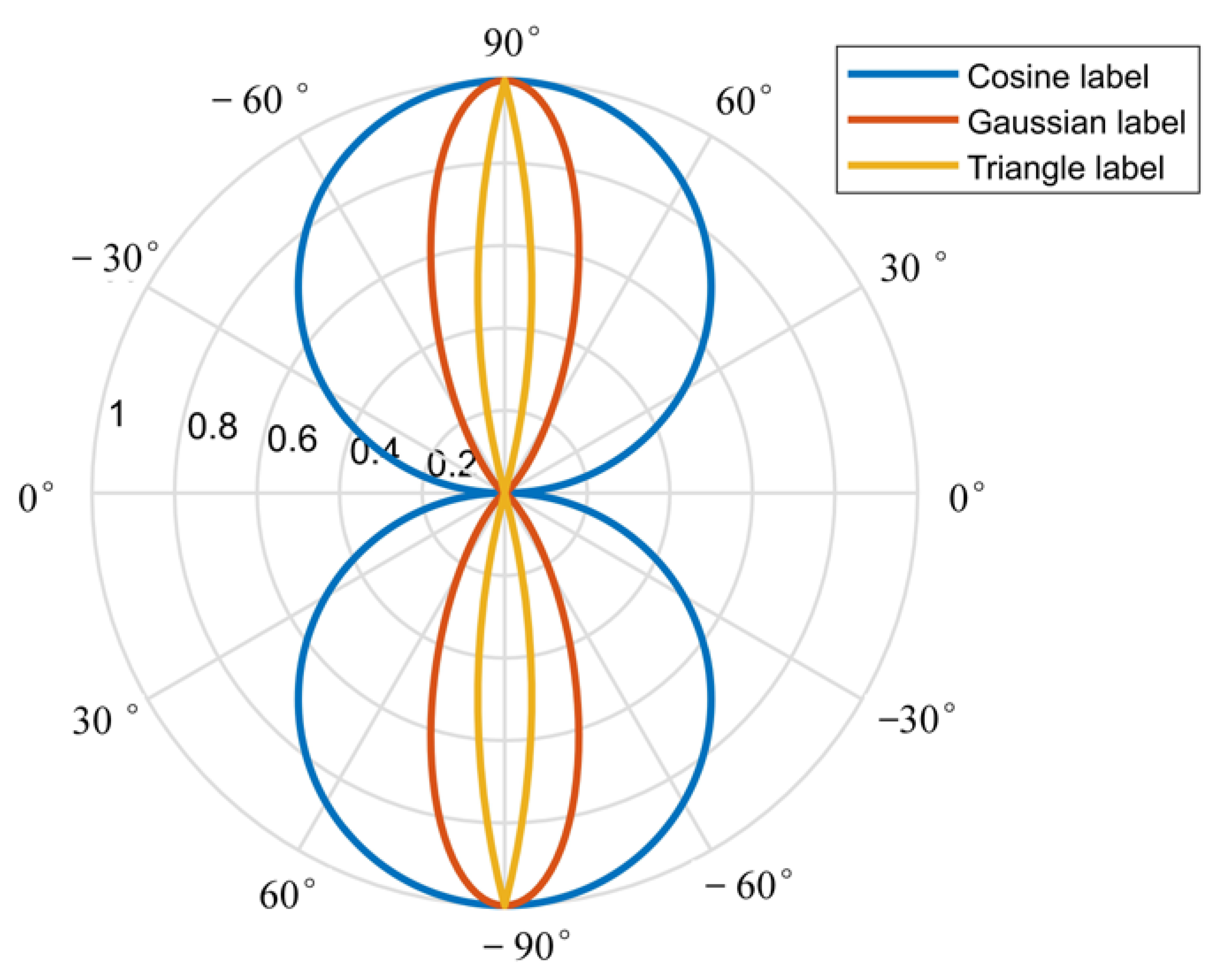
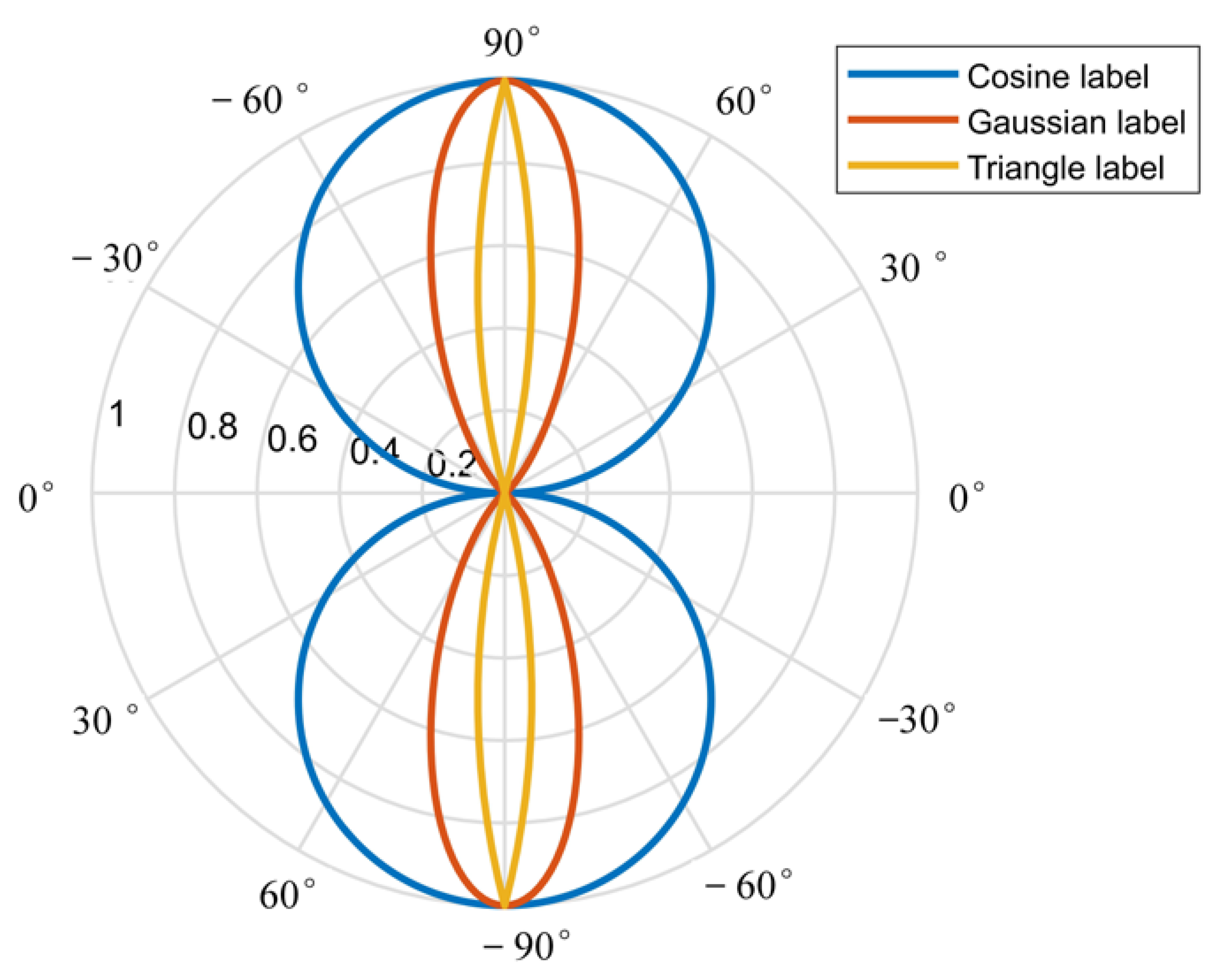
We also evaluate the proposed periodic smooth label module on the UCAS-AOD dataset. The differences among the three window functions are revealed in
Table 2. An inspection of the data indicates that the proposed PSL module can effectively improve the ability of the network to identify objects’ rotation angles.
A closer observation indicates that the Gaussian window function performs best, while the triangle function is the worst. Compared with the baseline network, the detector with the DGA and PSL modules improves the mAP by approximately 3% to 0.956, and the angle recognition error is effectively suppressed and reduced by 56%.
Figure 7 shows the partial prediction results of the three window functions. The prediction result of the Gaussian window function is closer to the ground truth than the results of the other two functions.
Aiming at further improving the accuracy of angle recognition, we optimize the loss function of the angle recognition network. The results of an experimental comparison are presented in
Table 3. We apply the DGA strategy to the angle regression branch to improve the learning efficiency of the network. The DGAA method achieves the highest mAP (96.4%), which is a 0.8% improvement over that of the L1 method. In addition, the angle recognition accuracy of the detector is significantly improved, the EoA is reduced from 5.71° to 3.17°, and the performance is improved by 44.5%.
4.3.4. Evaluation of United Regression
The RCIoU function realizes the united regression of distribution parameters, making it easier and faster for the detector to converge to the optimal value. The new loss improves the accuracy to 0.969, and the EoA is further suppressed to 2.96° with a 6.6% improvement. This method increases the mAP
75 from 0.513 to 0.530, which shows that the coincidence degree of predicted OBB and true OBB is obviously improved.
Figure 8 exhibits the detection results before and after adding the RCIoU loss function.
As can be seen from the figure, the bounding box envelops the object more compactly after adding the RCIoU loss. RCIoU loss further improves the prediction accuracy of the angle. The predicted bounding boxes of this method are closer to the ground truth, which also confirms the significant improvement in mAP75.
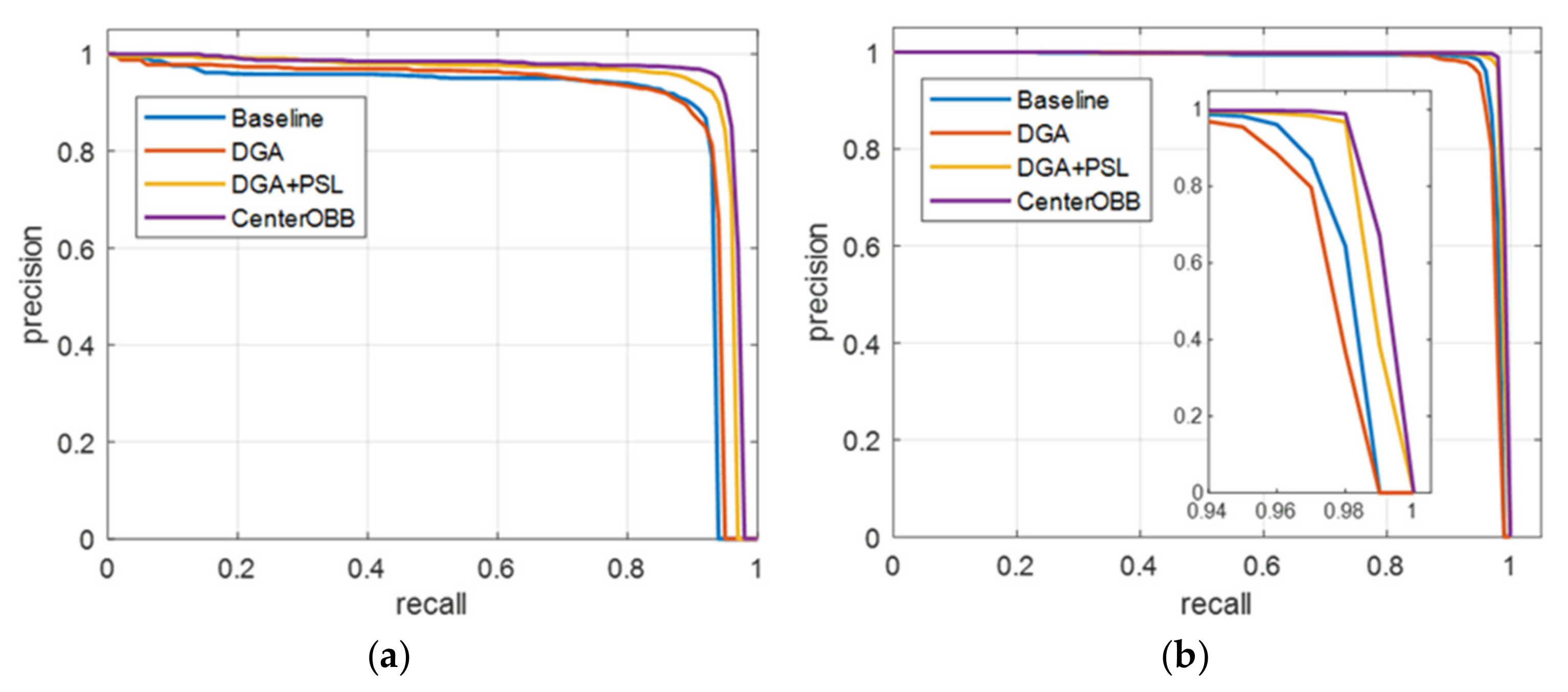
In addition, we plot the PR curves of models with different improvements, and the results are illustrated in
Figure 9.
CenterOBB in
Figure 9 represents the combination of improvements DGA, PSL, and RCIoU loss. The results of the PR curve also prove the effectiveness of our improvement modules. In the UCAS-AOD dataset, car samples are more difficult to identify than aircraft samples due to their small size and complex background. It can be seen that our approach improves the recognition of cars more significantly.
4.4. Comparison with Other Popular Frameworks
The baseline model achieves great success in object detection when using a horizontal box, and we design the DGA mechanism to further enhance the performance of the model. When the PSL, DGAA, and RCIoU are applied to rotation angle detection, a substantial improvement is still achieved, which confirms the effectiveness of our method. In the following, contrast tests with other representative frameworks are conducted on different datasets.
Results for UCAS-AOD. We enumerate the detection results obtained by our detector and other published methods on the UCAS-AOD dataset in
Table 4. In terms of HBB detection, we achieve an mAP of 0.966, outperforming the baseline model by 2.4%. In addition, we embed an angle classification branch into our approach, and OBB detection also achieves SOTA performance. The AP for the car and plane categories reaches 0.952 and 0.987, respectively. The mAP reaches 0.969, which is the best result among those of the published models.
Figure 10 shows some visualization of detection results among several typical rotated detection methods. The comparison detectors we have chosen include RoI-Trans, FPN-CSL, R
3Det-GWD, and our approach, and the first column is the ground truth. The first picture contains a car instance partially obscured by trees and two samples of the car close to the background color. All the other methods have missed alarms, while our approach accurately identifies all instances. The second picture reflects the scene where objects are dense and cluttered parked. There are two missed instances and a false prediction for RoI-Trans. The angle recognition performances of RoI-Trans and FPN-CSL are reduced. R
3Det-GWD performs well in angle detection, but it misses a car instance in the shadow. The prediction of our model is closest to the ground truth. The third image of
Figure 10 is for plane detection in an airport environment. FPN-CSL misses a plane, while RoI-Trans and R
3Det-GWD have inaccurate predictions. R
3Det-GWD is insensitive to the angles of near-square targets, resulting in a large deviation in the angle prediction of plane instances.
The performance of the four models is listed in
Table 5. We also give the performance of these four detectors with an IoU threshold of 0.75 (mAP
75). RoI-trans transforms a horizontal region of interest (RoI) into a rotated one, but it suffers from the problem of angle discontinuity. R
3Det-GWD adopts the rotated Gaussian function to describe the object distribution, which overcomes the problem of angular discontinuity, but when the target is a square. However, when the object is a square, its Gaussian distribution will correspond to multiple rotated bounding boxes. This leads to an unsatisfactory accuracy on mAP
75. FPN-CSL adopts the angle classification method, which performs well with an EoA of 3.42°. Our method suppresses both the angular boundary problem and the sample quantity imbalance problem; its mAP
75 reaches 0.53 and the EoA is limited to 2.96°. Experimental results verify the validity of our approach.
Results for DOTA. We compare our approach with other state-of-the-art detectors for the OBB detection on the DOTA dataset. The comparison result is listed in
Table 6; our anchor-free detector with DLA-34 obtains a precision of 0.7785. Our method achieves the best performance overall compared to the other methods.
Figure 11 shows several prediction results obtained on the dataset, and there are a large number of small and densely parked objects in images. The accurate prediction results show that our approach performs well under complex backgrounds.
Results for HRSC2016. Aiming to verify the universality of the proposed approach for different objectives, we perform tests on the HRSC2016 ship dataset. During the test process, all methods predict on the original images without cropping operation.
Table 7 summarizes the experimental results obtained by the SOTA networks, and the size in the table stands for the pixels of the input image in the training phase. Our method reaches the highest AP of 0.901, which is comparable to that of many current advanced methods. Some detection results are exhibited in the second row of
Figure 11.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}