3.1. Network Mode
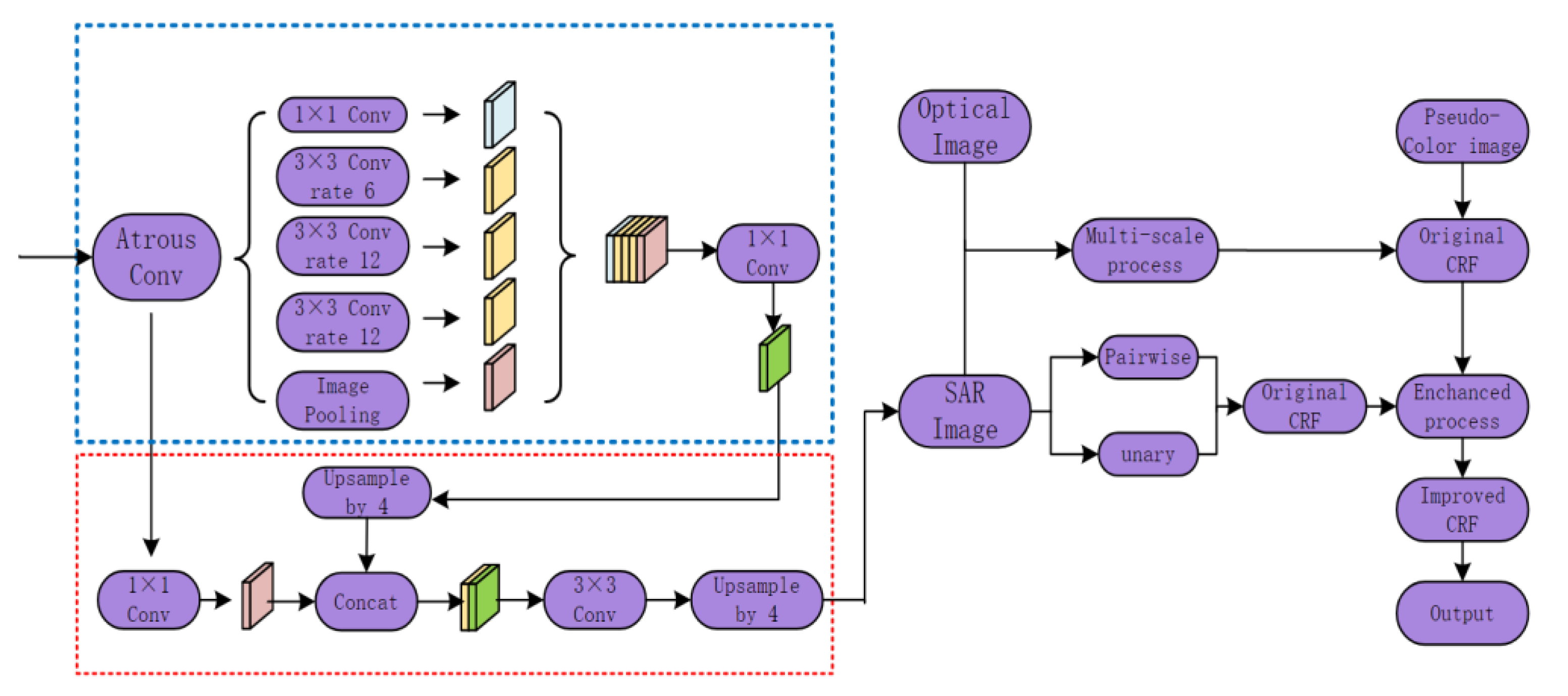
In this paper, the polarimetric SAR image and the corresponding optical image are simultaneously input into the fully connected random field model. The structure of the entire model is shown in
Figure 1. As can be seen from the figure, the unary potential function of the fully connected conditional random field still models the semantic segmentation results of polarimetric SAR image outputs by the previous DCNN. Through the input of optical image, more abundant feature information is introduced into the energy function, such as the spatial feature and spectral feature of pixels. More context exists between adjacent pixel categories in the image can be captured during the overall conditional random field modeling process—semantic dependencies.
According to the fully connected conditional random field model, for the convenience of reading and writing, the condition X is omitted, and the unary potential function and the binary potential function are respectively expressed as:
where
represents the predicted probability value of the
ith pixel category output by DCNN,
represents the label compatibility function, and
represents the feature vector of the ith pixel category. It can be seen that the unary potential function is based on the semantic segmentation results of polarimetric SAR images output by the previous deep convolutional neural network. In contrast, the binary potential function utilizes the spectral feature information of optical images, which can further improve the semantic segmentation effect. The fully polarimetric pseudocolor SAR image can further display the image features of the polarimetric SAR image. Using it as the auxiliary input of the optical image in the dual-channel model can significantly expand the detailed information of the image. The binary potential function expression of the polarimetric SAR image and the optical image is:
, and represent the potential binary functions established by the optical image, polarimetric SAR image, and full polarimetric pseudo-color SAR image, respectively, and represent the corresponding weighting coefficients.
The binary potential function corresponding to the optical image is composed of the feature
and the position
:
The first term indicates that two pixels closer together are more likely to belong to the same pixel label, and the second term indicates that two pixels with similar locations and features are more likely to belong to the same class. Feature I of the optical image consists of two aspects: (1) The R, G, and B channels are the three features of the spectral feature; and (2) based on the gray value of the image, the potential spatial relationship information is converted into texture information, such as variance, energy, and other features.
The binary potential function corresponding to the polarimetric SAR image is composed of the feature
and the position
:
The feature of the polarimetric SAR image is extracted by Pauli decomposition, Freeman decomposition, Yamaguchi decomposition, and correlation feature decomposition of polarimetric features.
The label compatibility function
represents the probability of two different superpixel categories appearing simultaneously in adjacent positions. One of the most straightforward label compatibility functions is the Potts model:
The Potts model imposes the same penalty on all inconsistent pixel labels in the image, but in practice, the network should implement different penalties. This section uses the method of [
13] to implement the label compatibility function in the model inference process of learning.
In summary, the two-channel multi-scale fully connected convolutional conditional random field is expressed as the weighted sum of the input CRF output results of different resolution images:
Among them, represents the weight value corresponding to the input of polarimetric SAR images of different sizes.
3.2. Polarimetric SAR Image and Optical Image Weight Parameter Estimation
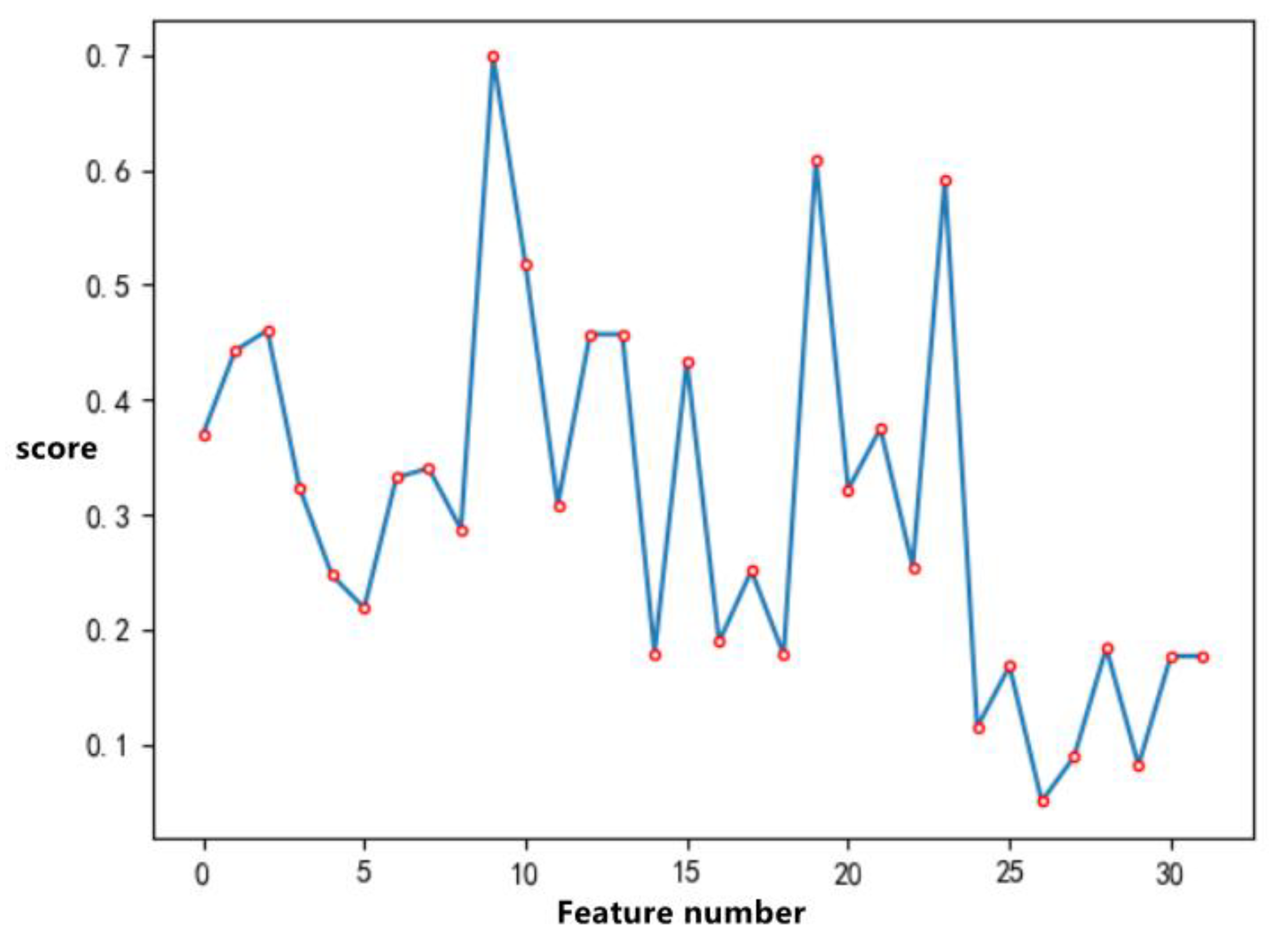
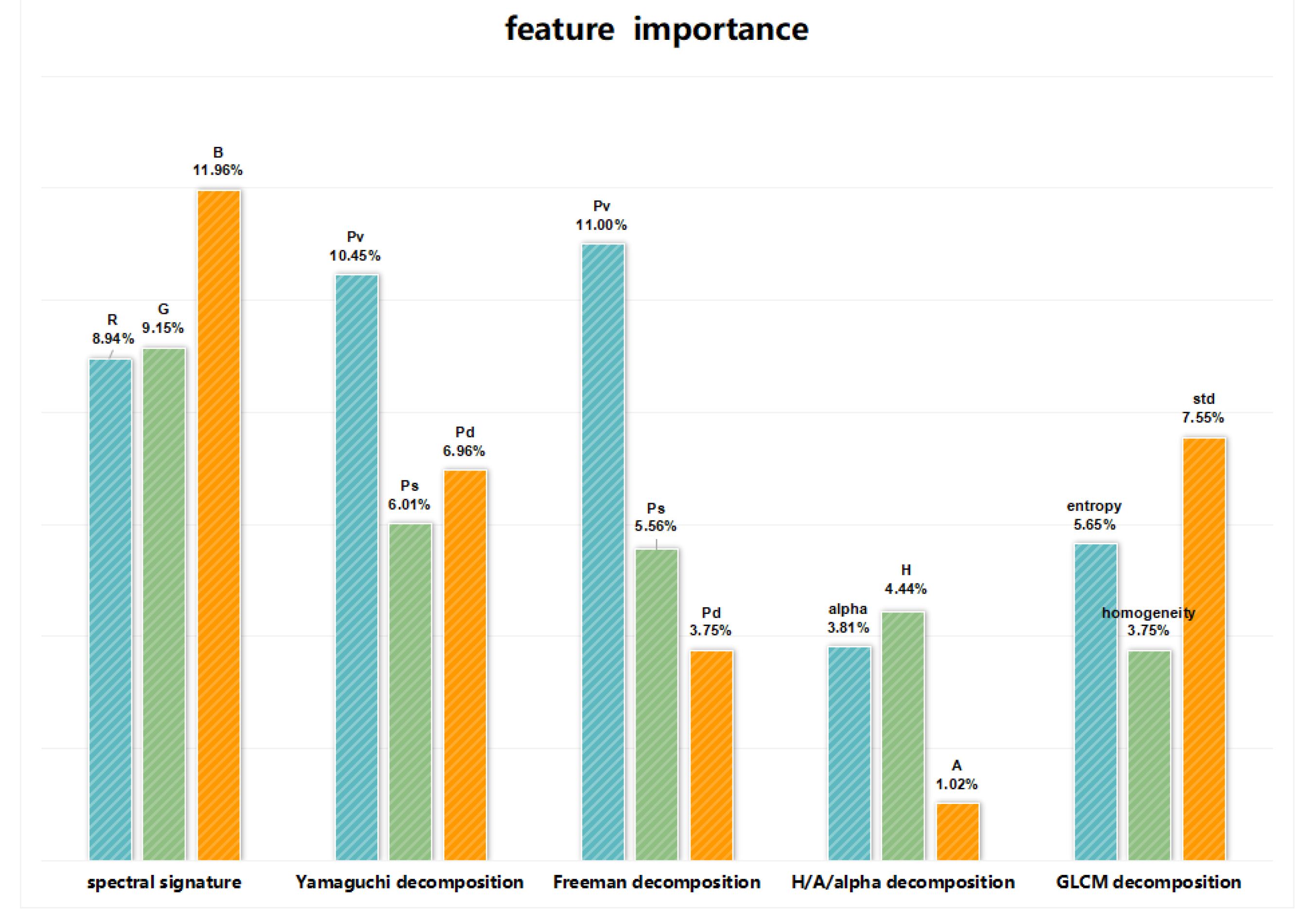
Feature screening experiments are performed. This experiment determines the importance of different features of polarimetric SAR images and optical images for the final processing results. The weighting coefficients and of the polarimetric SAR image and the optical image in the binary potential function are determined according to the proportion of feature importance. For this reason, this section takes polarimetric SAR images and optical images as research data and studies the importance of features, and obtains the results. In order to find the optimal value of the weighting coefficients and of the binary potential functions and of the polarimetric SAR image and the optical image in Formula (9), this section uses the support vector machine feature recursive elimination (SVM-RFE) method. In this section, a total of 32 optical image features and polarimetric SAR image features are extracted first, and then the SVM-RFE method is used to screen and sort the 32 features.
The first step is optical image feature extraction. The optical image mainly adopts the technology of spectral feature and texture feature extraction, in which the spectral feature uses the
R, G, B channels of the optical image as the three vectors of the spectral feature, and the texture feature is based on the gray value of the image. The relationship information is converted into texture information, and the mean, variance, energy, etc., are all commonly used feature indicators. First of all, this paper uses the
R, G, B channels of the optical image as the three eigenvectors of the spectral features, which are expressed as:
Secondly, the co-occurrence grayscale matrix is used to extract features. This paper extracts eight kinds of texture information as feature vectors, namely: mean, energy, variance, homogeneity, entropy, correlation, contrast, and dissimilarity, are expressed as:
The second step is feature extraction of polarimetric SAR images. Polarimetric SAR images mainly use polarimetric decomposition algorithms, such as Pauli decomposition, H/A/α decomposition, Freeman decomposition, Yamaguchi decomposition, and polarimetric feature correlation feature decomposition.
Pauli decomposition principle is relatively basic, based on a polarization scattering matrix, which is the sum of certain scattering mechanism matrices, and can be expressed as:
The
H/A/α decomposition is the eigendecomposition of the scattering correlation matrix and three eigenvectors, the average scattering angle
α, the scattering entropy
H, and the anisotropy
A, are extracted. Where
A is anisotropy, which can provide information about the distribution of eigenvalues, when the H value is significant, it can indicate the degree of influence of the second and third largest scattering mechanism eigenvalues on the results. The three extracted feature vectors are:
Freeman decomposition is a commonly used incoherent target decomposition method in this paper to obtain three distinct polarization components of plane scattering power, dihedral angle scattering power, and volume scattering power. The main idea of Freeman decomposition is based on the assumption of reflection symmetry. The correlation coefficient between co-polarization and cross-polarization is 0, and each pixel is composed of three types of scattering; that is, a first-order Bragg surface scattering. The surface scattering component of the even reflection component was obtained from the dihedral corner reflector, and the volume scattering component was obtained from a series of directional dipole scattering from the vegetation canopy [
14]. Freeman decomposition is based on the C matrix, and three eigenvectors of even scattering, volume scattering, and surface scattering are extracted by calculation, respectively expressed as:
The Yamaguchi decomposition can generally be cited not only in the case of asymmetric reflection, but also in the case of reflection symmetry. Compared with the Freeman decomposition based on reflection symmetry, Yamaguchi is more universal and used in a broader range [
15]. The Yamaguchi decomposition extends the Freeman decomposition as it used the same even and surface scattering components. It modifies the bulk scattering component by changing the probability density function of the associated azimuth while adding a new component, the helix scattering component, which is suitable for more complex areas in urban buildings. The four feature vectors extracted by Yamaguchi decomposition can be expressed as:
Surface objects generally appear as complex mixtures of different standard scatterers or standard targets, and the polarization characteristics of standard targets should be used as a reference for classification. The polarization characteristic map reflects the change of the radar received power of the target under different polarization modes to a certain extent and can be used to analyze the polarization characteristics of different targets so different types of ground objects can be distinguished. Usually, the characteristic polarization map can be used to analyze and describe the effect of calibration accuracy on the polarization scattering characteristics of the target. In this paper, PSCF decomposition mainly extracts four kinds of radar polarization features of dihedral angle, flat plate, horizontal dipole, and vertical dipole and calculates the correlation coefficient:
Among them, represents the standard deviation of the polarization characteristics of the observed image pixels, represents the standard deviation of the polarization characteristics of the standard target, and represents the covariance between the standard target and the image pixels.
Using the above formula, the feature correlation coefficient between a single target and four standard target tables can be established, and a total of 8 feature vectors can be obtained, which are
co_DI,
co_FP,
co_HD,
co_VD,
cross_DI,
cross_FP,
cross_HD,
cross_VD, and
co is the same polarity, the cross is cross-polarized:
The third step is feature screening. In terms of feature screening, this section adopts sensitivity analysis. First, the sensitivity is calculated for each feature through measurement indicators, and the cross-validation method is used to analyze its impact on subsequent processing. Then, using SVM-RFE to train the filtered feature set, calculating the importance of each feature and sorting them, deleting the features with the minor importance, obtains the optimal feature subset, and calculating the accuracy rate through the training model ensures the accuracy of deletion. It is the least important feature. Feature sensitivity mainly refers to the effect and influence of each feature value on the system to different degrees. The main sensitivity measures used are: input the extracted high-dimensional feature vector set, combine the cross-validation method to calculate the sensitivity of each feature according to the sensitivity measurement standard, and delete the feature vector with less contribution or less impact.
Calculate the variation range
of the system response when the eigenvalue changes. The nth eigenvalue is
, and its value range is divided into M equals, where the
ith value is
, and the response is
, then the variation range
of the nth feature is:
Calculate the change
at the output when the eigenvalues of the input change:
where
is the average value.
Calculate the gradient value
of all adjacent points:
By calculating the sensitivity of the eigenvalues, the eigenvectors with less contribution or less influence are deleted.
SVM is a further developed classification algorithm based on statistical learning and optimization theories. Its operation process is shown in
Figure 2. It can only be applied to deal with classification and regression problems in nonlinear, high-level data modes with small samples [
13]. Assuming that
and
are the
ith samples in the training set, N is the sample size, and D is the number of sample features. SVM seeks the optimal classification hyperplane:
Among them, w is the weight vector,
x is the input feature vector, b is the deviation value, and the purpose is to make the variable target minimum; that is, the maximum geometric interval. The original problem can be transformed into a dual problem:
Among them,
is the Lagrange multiplier, and the final solution is:
Then the optimal decision can be expressed as:
The formula for calculating the importance of the
ith feature is:
Finally, the weighting coefficients
and
of the binary potential function of the polarimetric SAR image and the optical image are obtained as:
In each round of training, the extracted 32 features are selected for training, and then the classification hyperplane is obtained. For 32 features, SVM-RFE will delete the corresponding feature of the sequence number with the smallest square value of the component in w; in the second round, the number of features will be reduced by one, and continue to use the remaining features to train the same, removing the least important feature.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}