
Spatial Transferability of Random Forest Models for Crop Type Classification Using Sentinel-1 and Sentinel-2


Abstract
:1. Introduction
2. Study Sites and Data
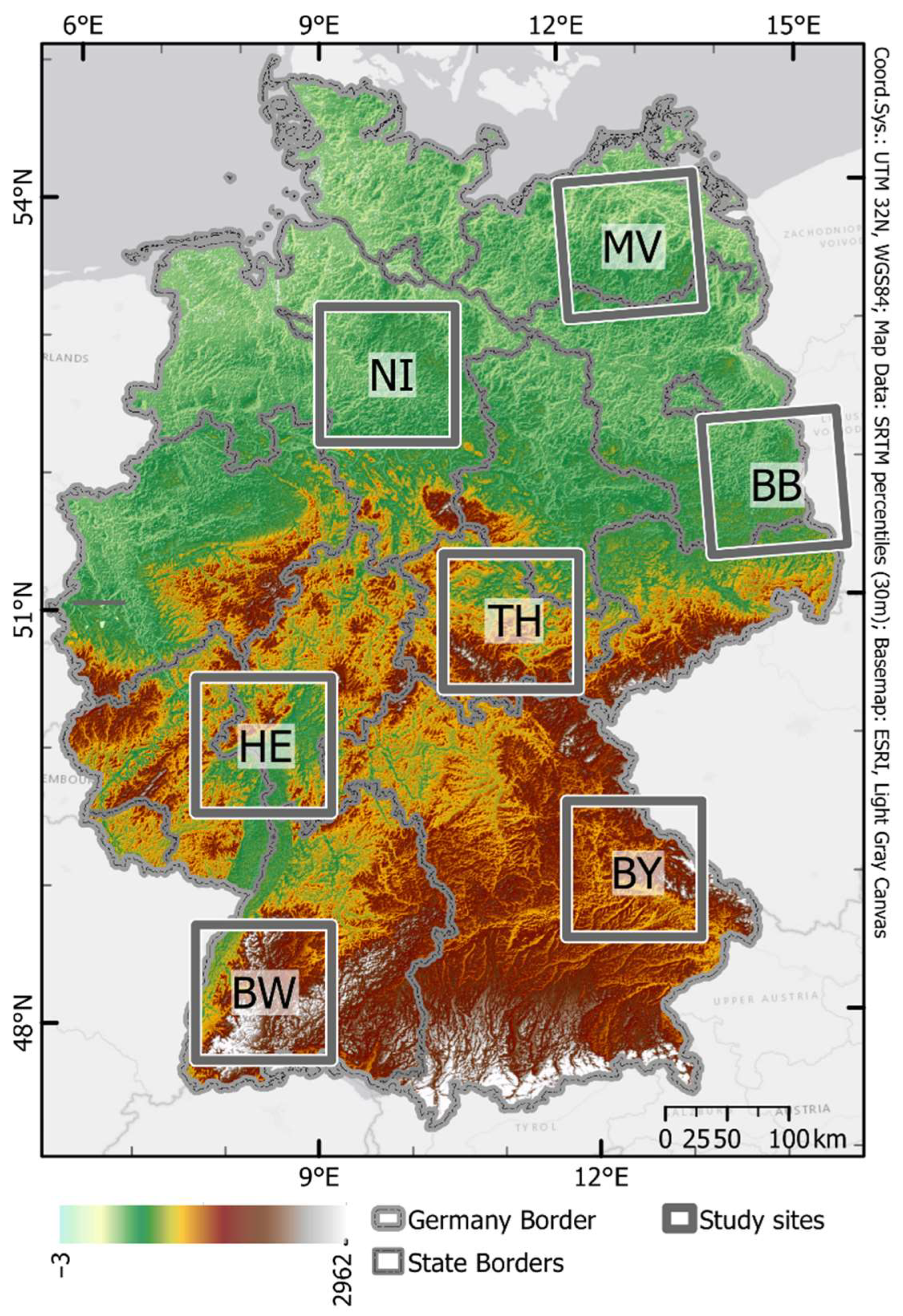
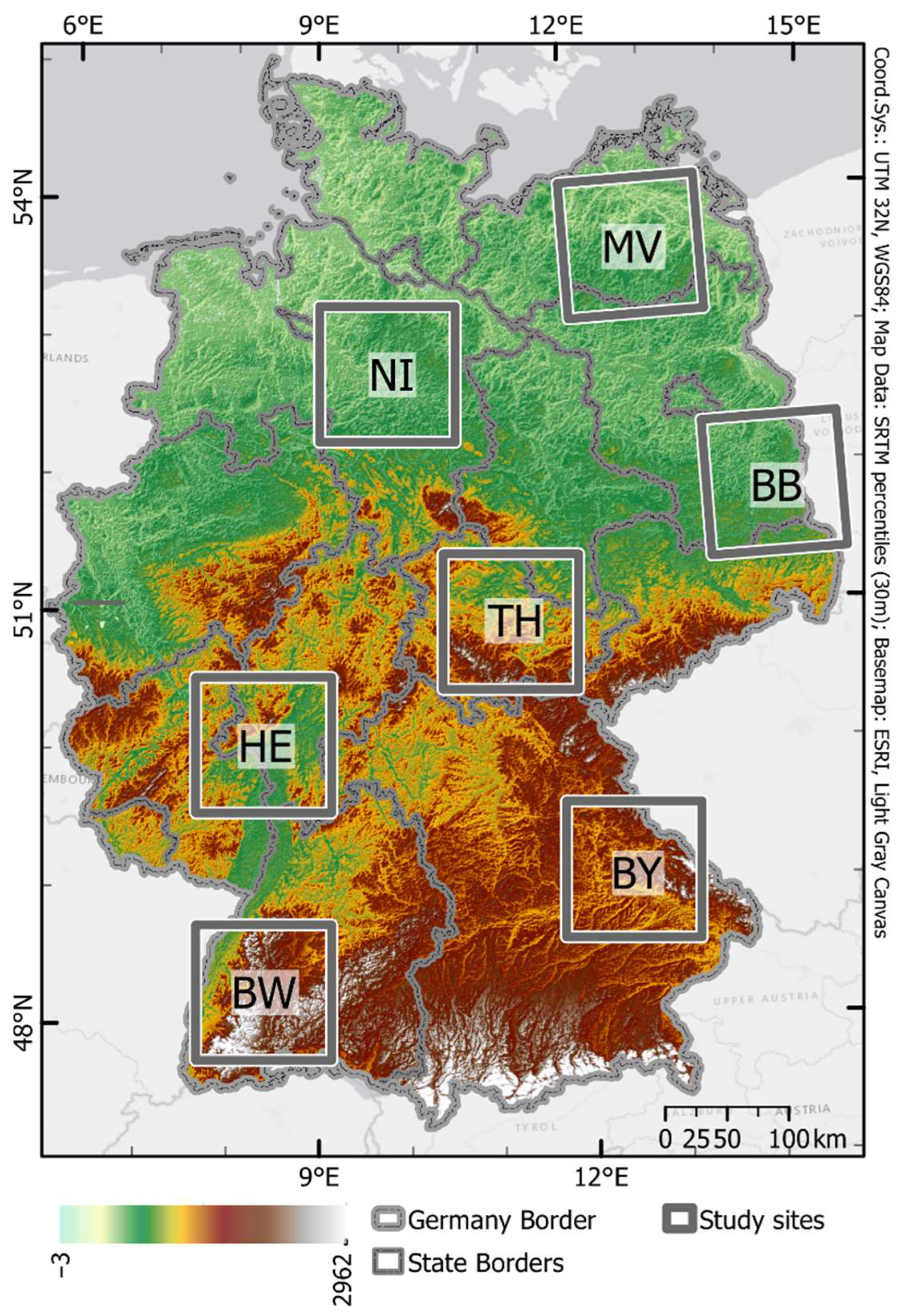
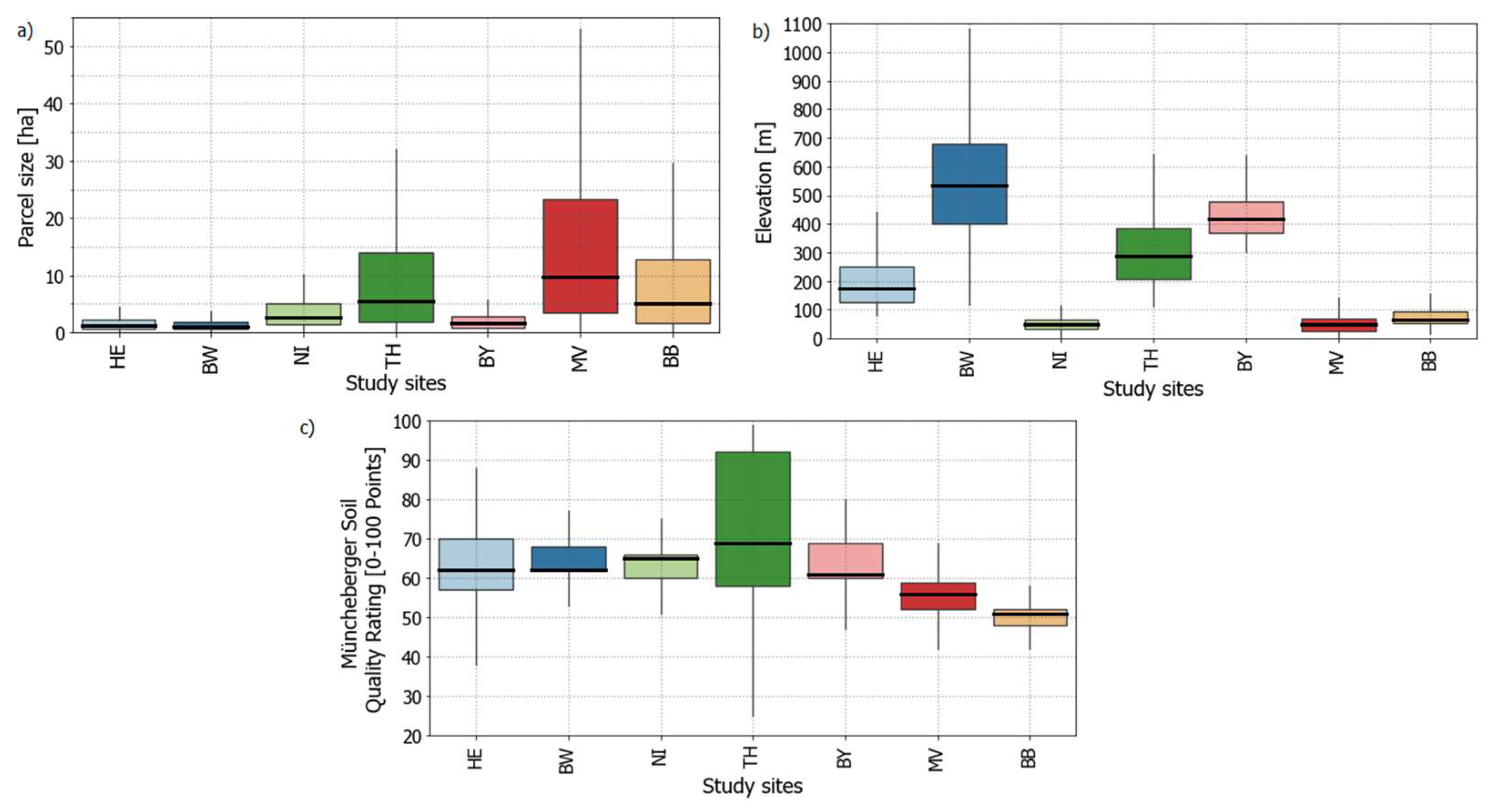
2.1. Study Sites
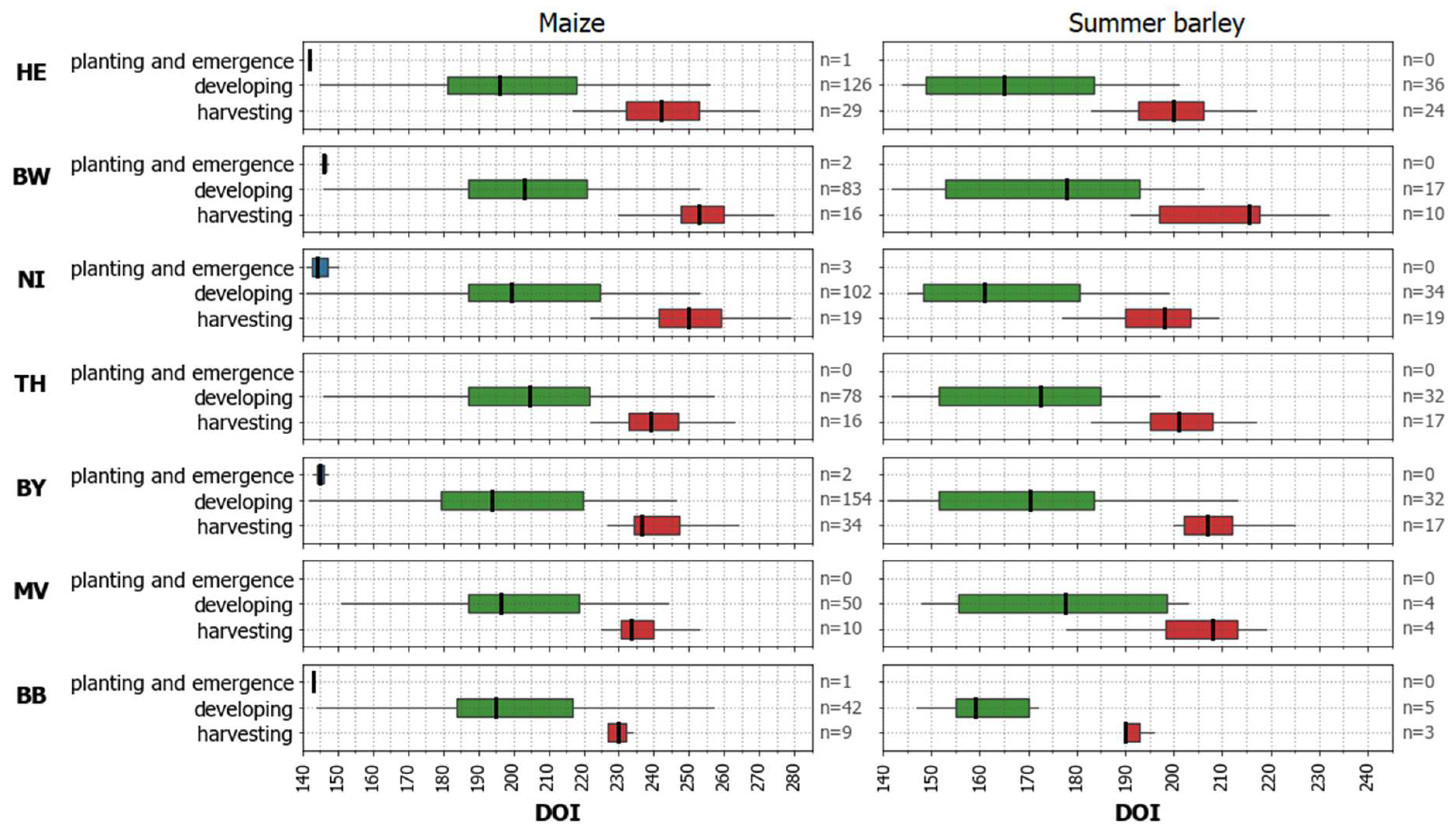
2.2. Reference Data
2.3. Remote Sensing Data and Pre-Processing
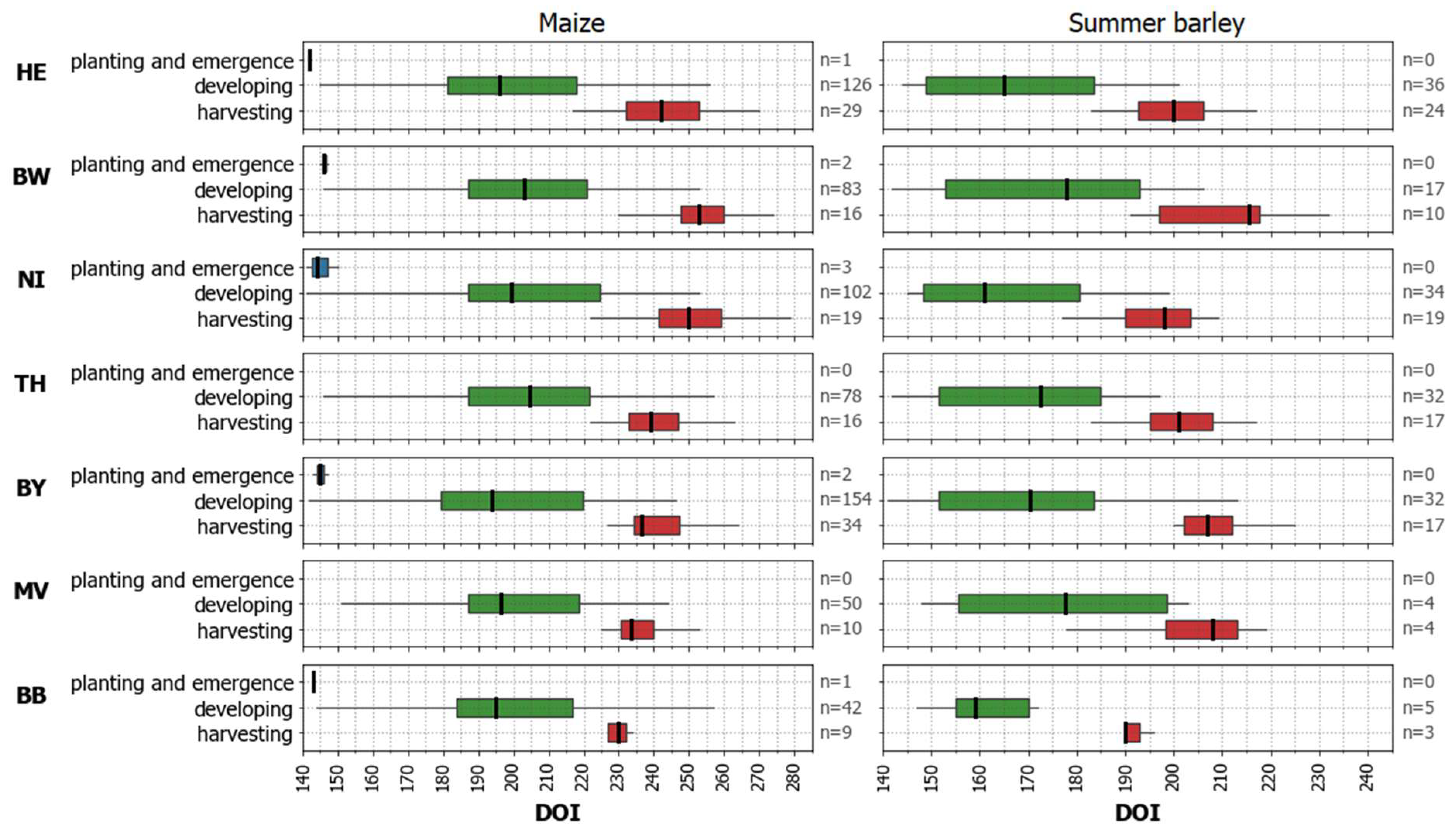
2.4. Auxiliary Data
3. Methodology
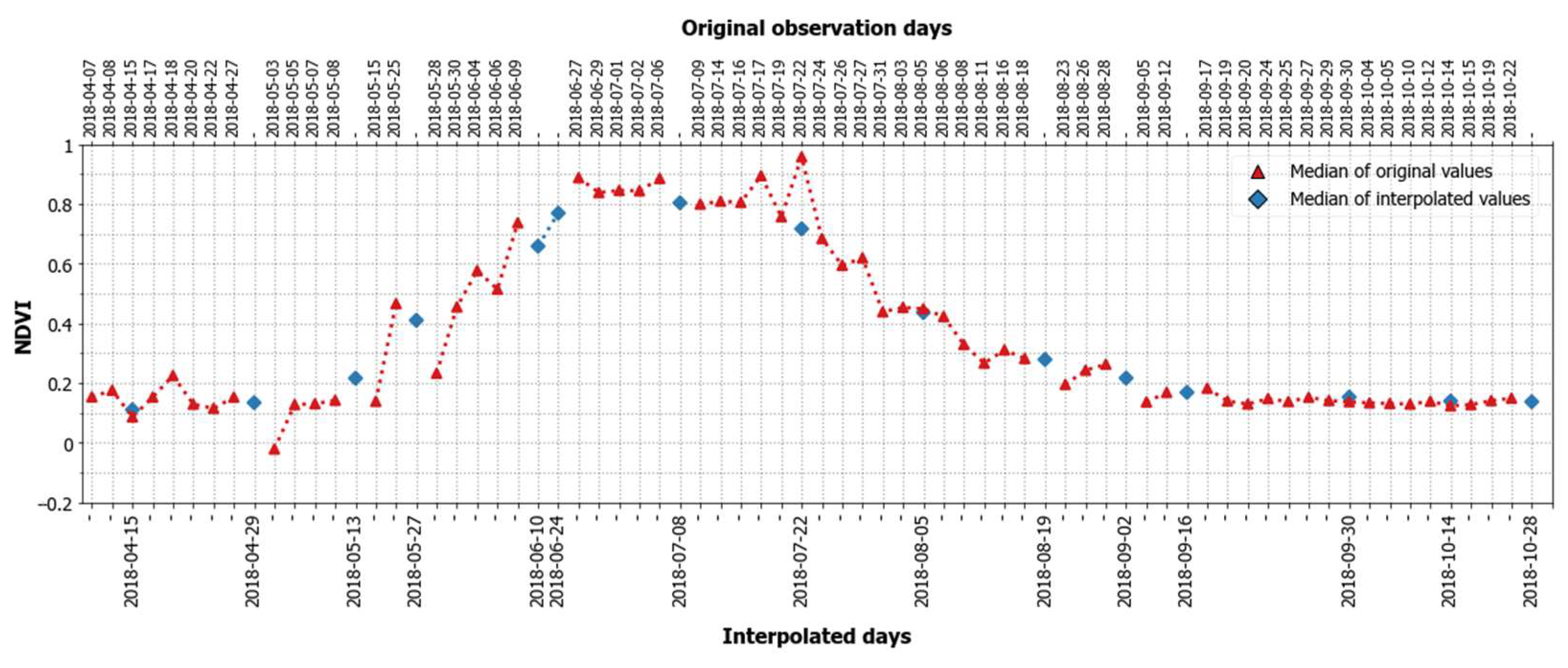
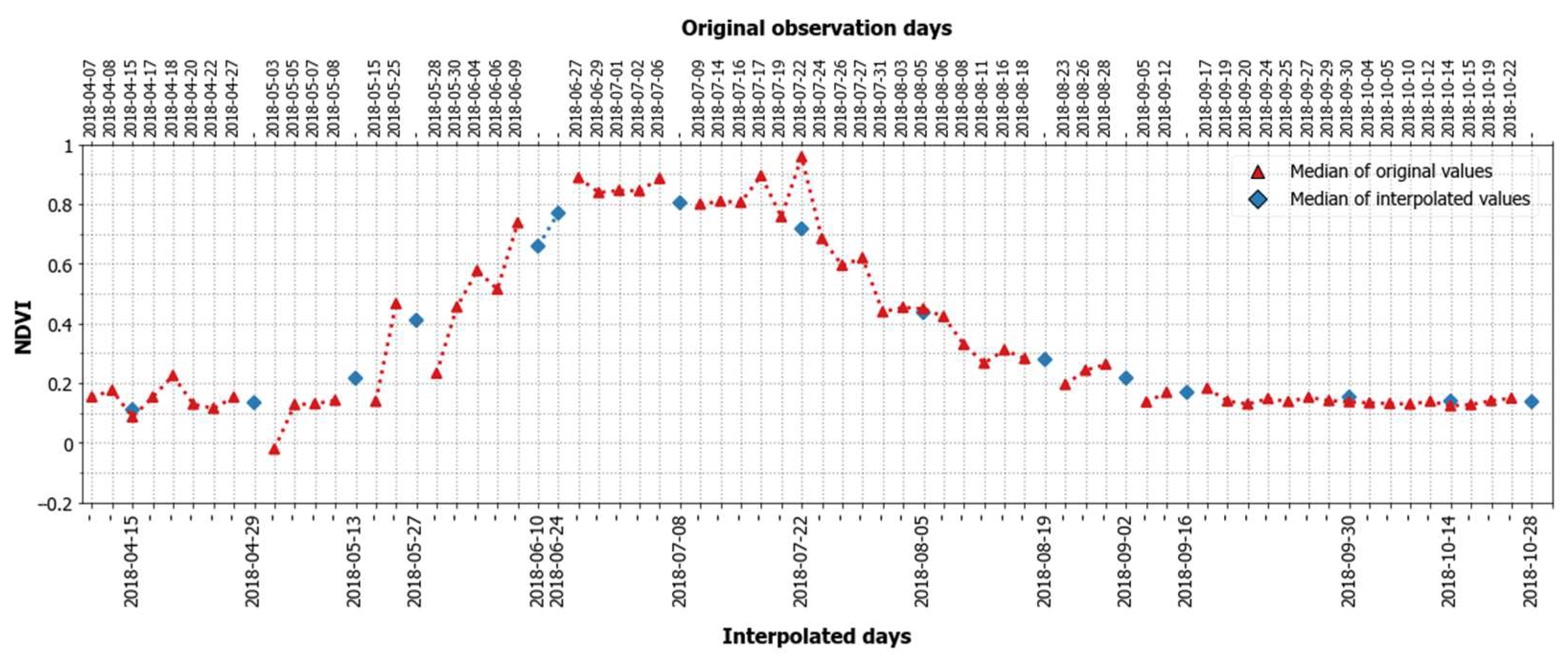
3.1. Generation of Dense Time Series Features
3.2. Training and Testing Samples
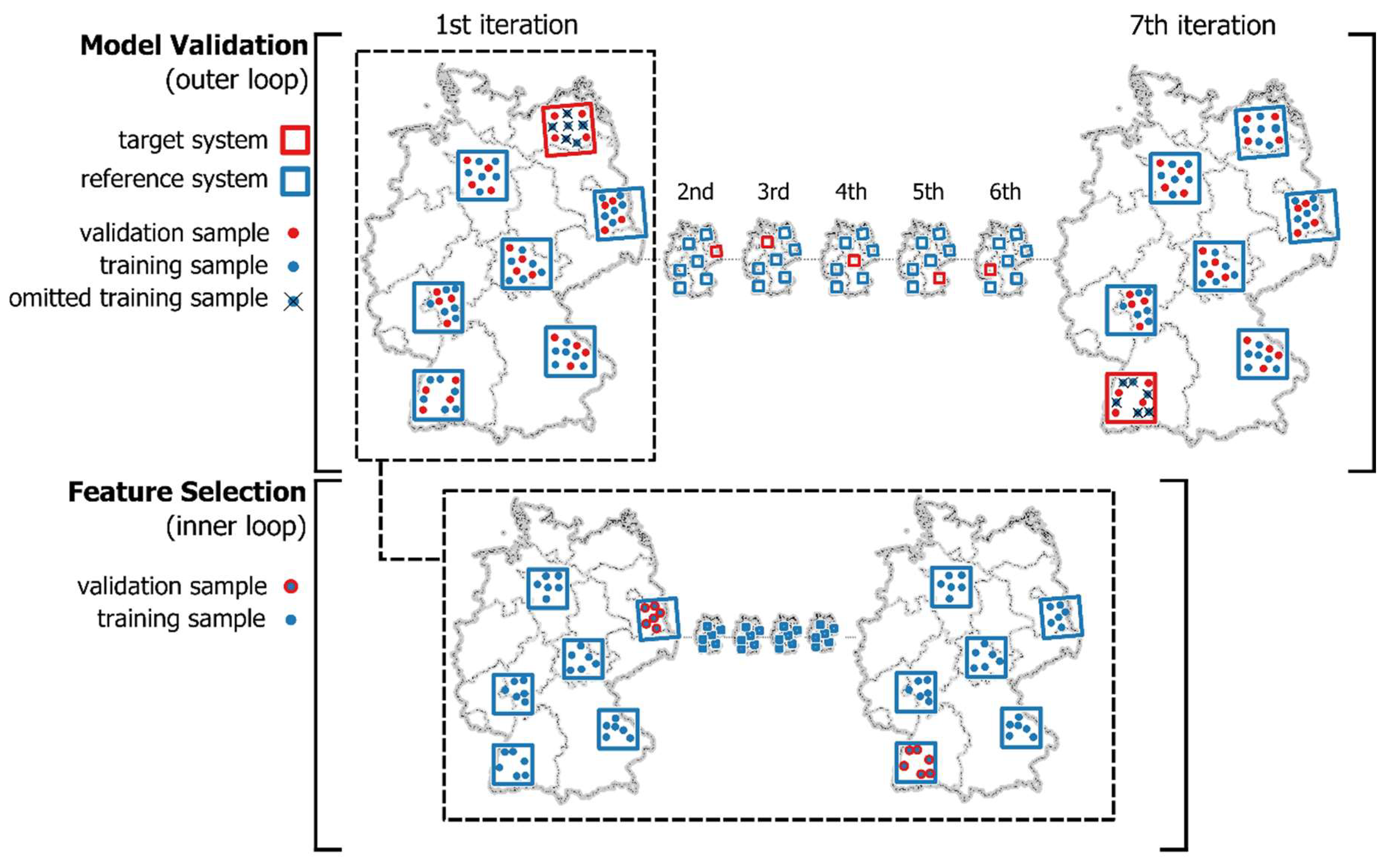
3.3. Model Performance Estimation Using Spatial Cross-Validation
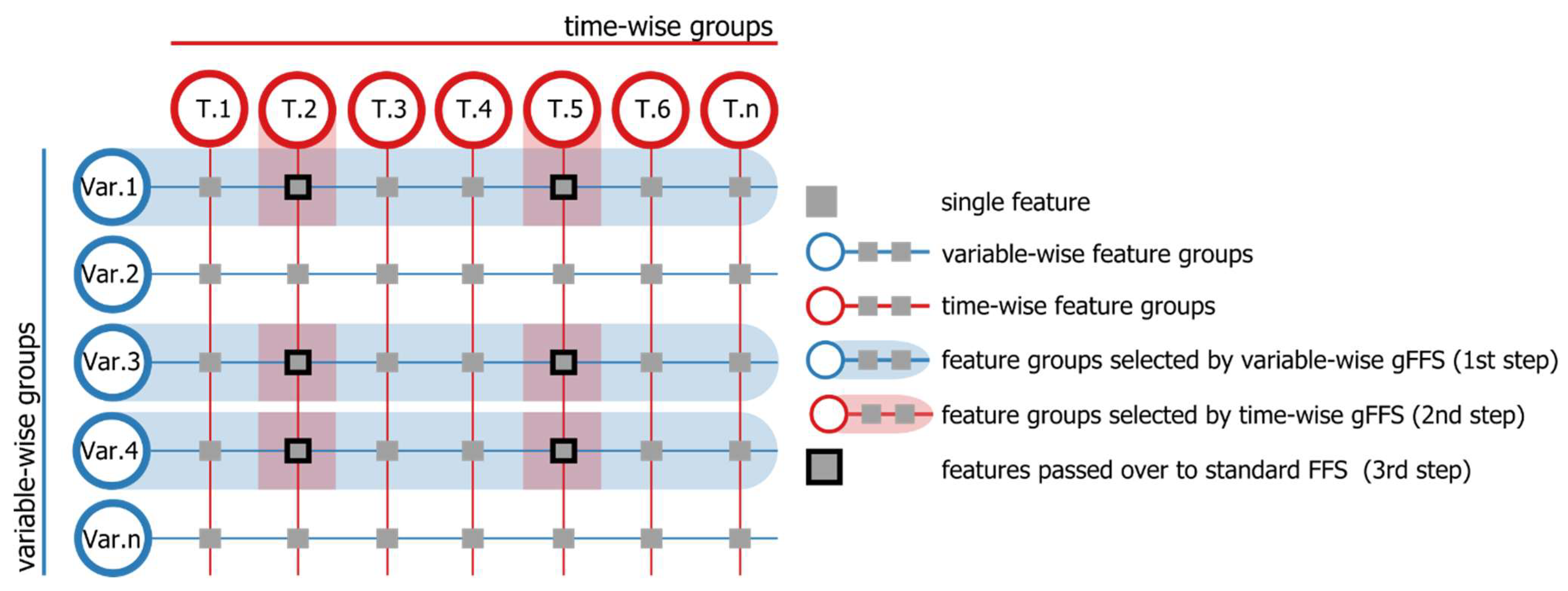
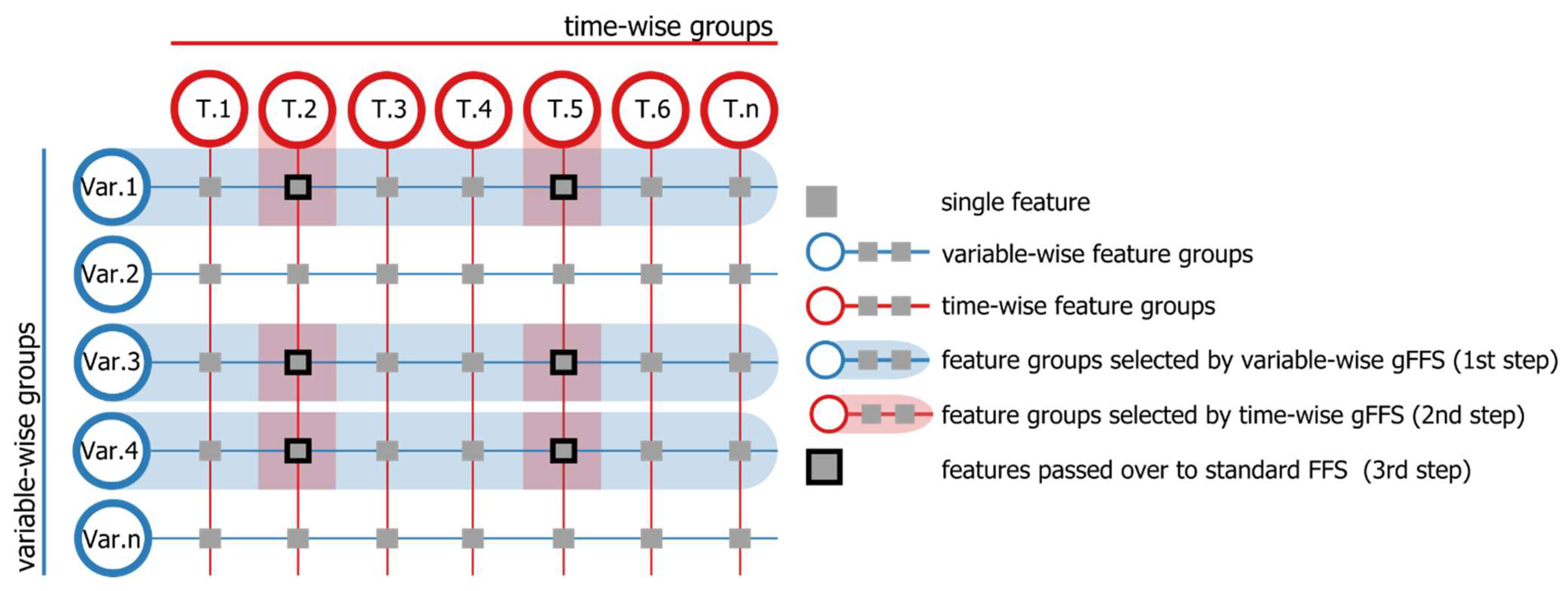
3.4. Feature Selection and Model Building
4. Results
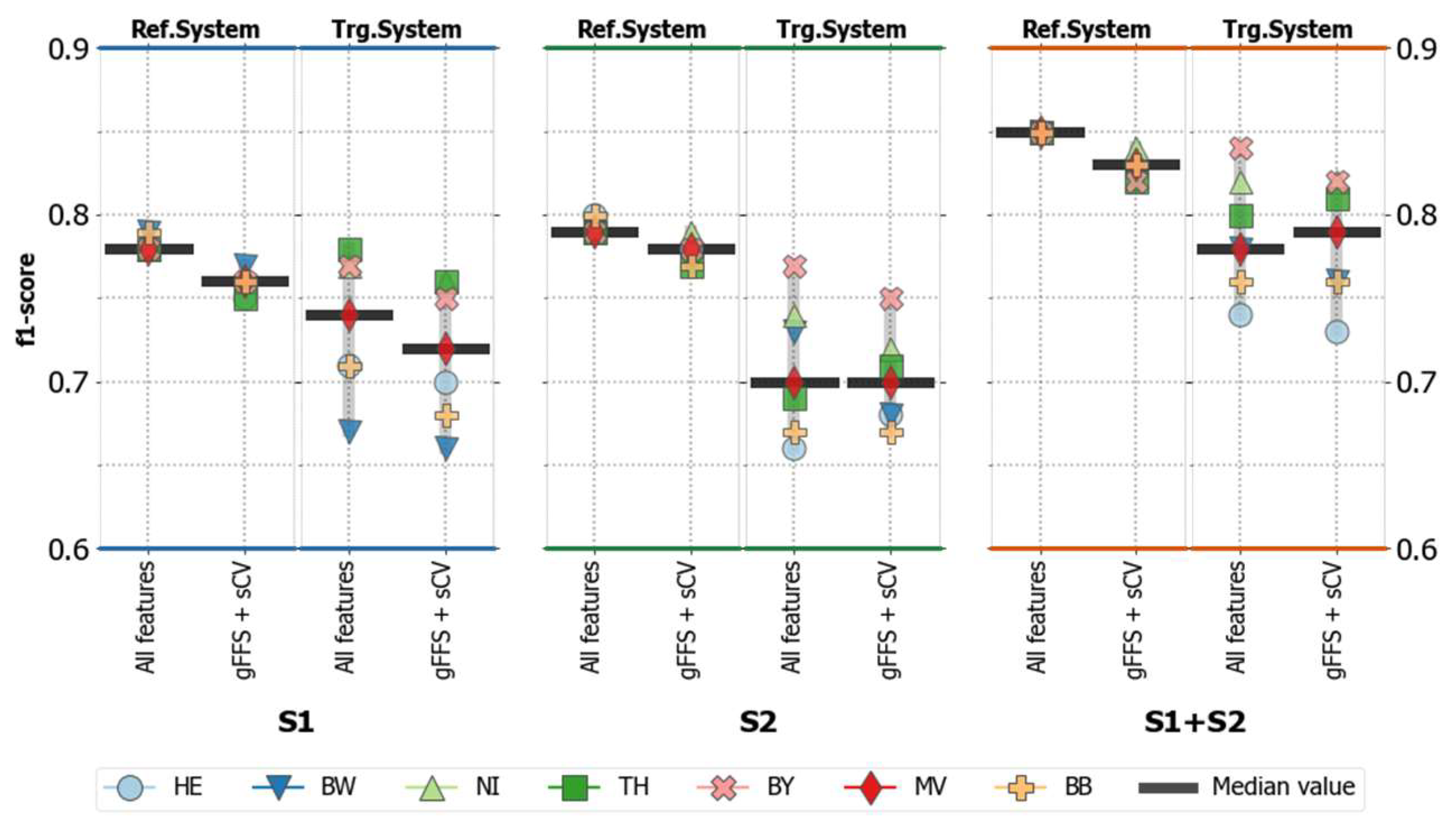
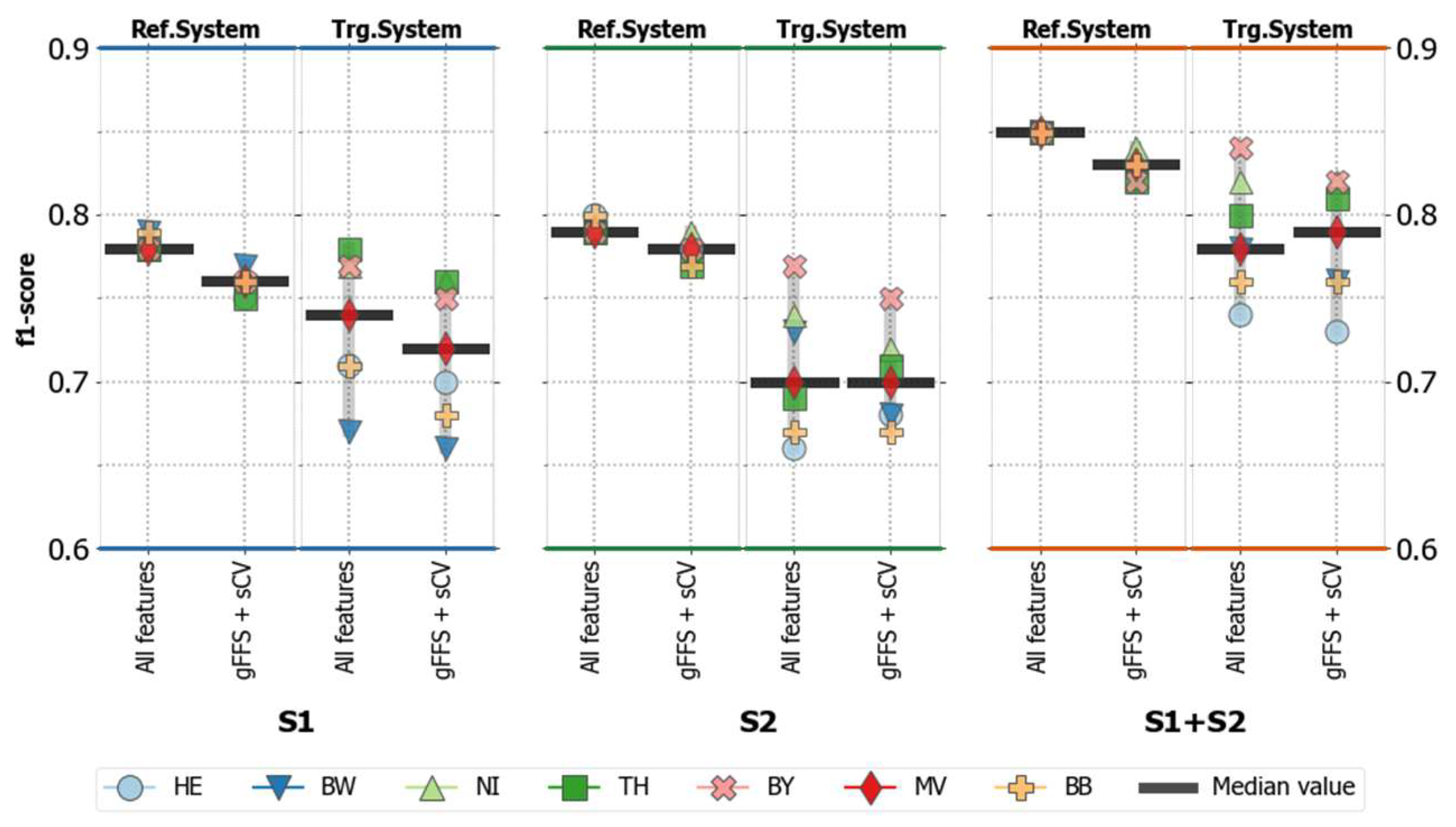
4.1. Overall Classification Accuracies
4.1.1. Accuracies without Spatial Transfer (Reference Systems)
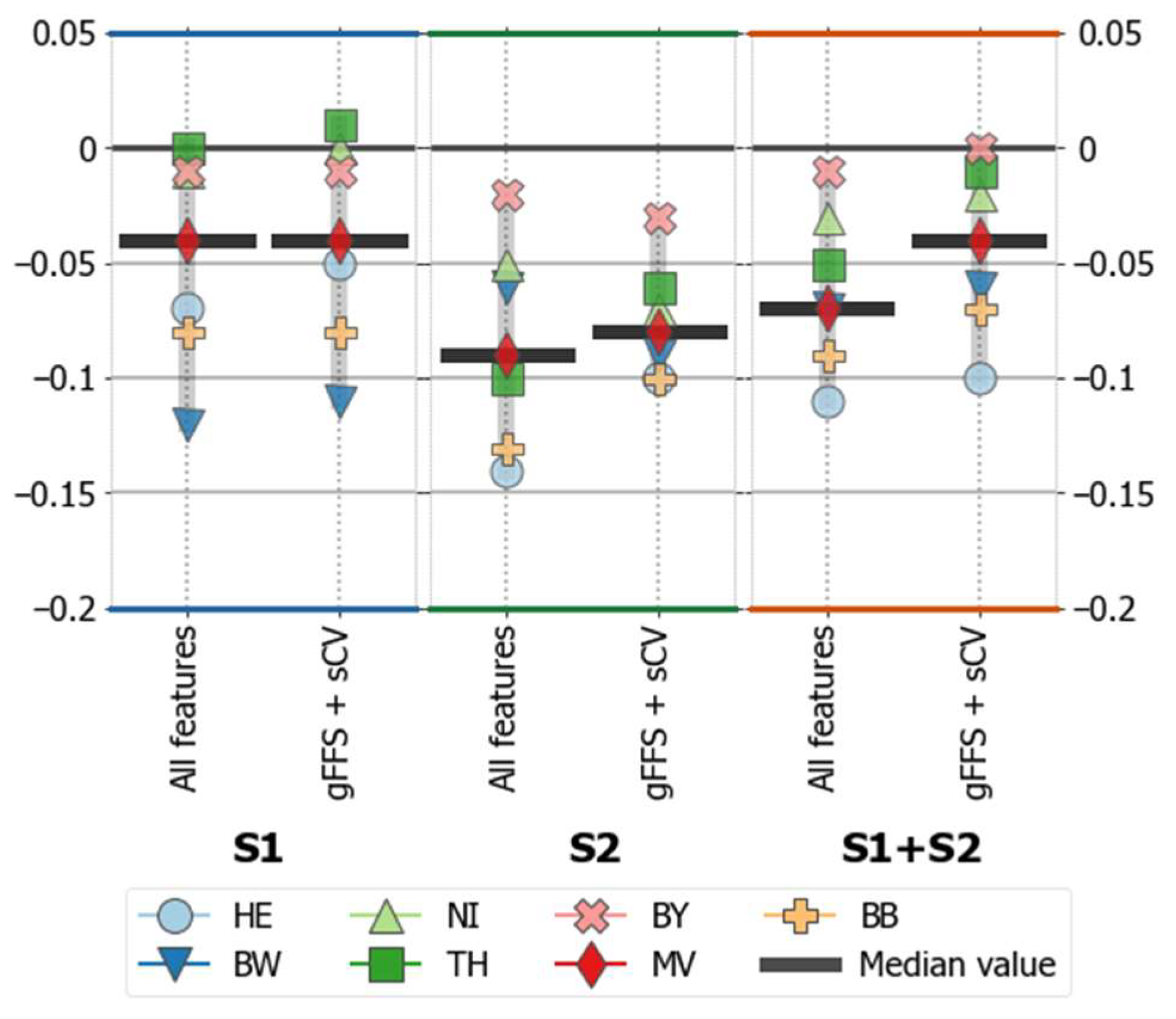
4.1.2. Accuracies for Spatially Transferred Models (Target Systems)
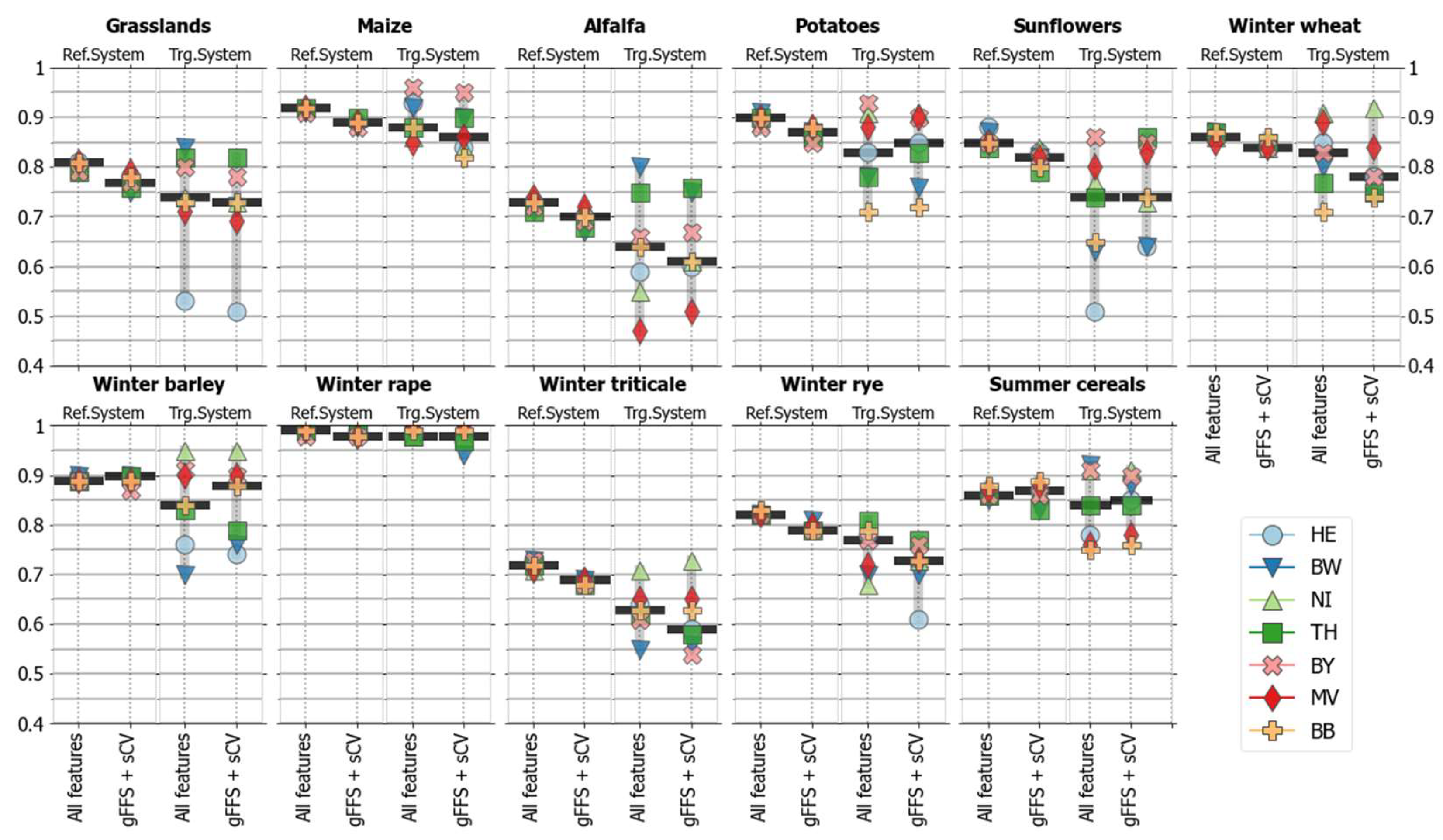
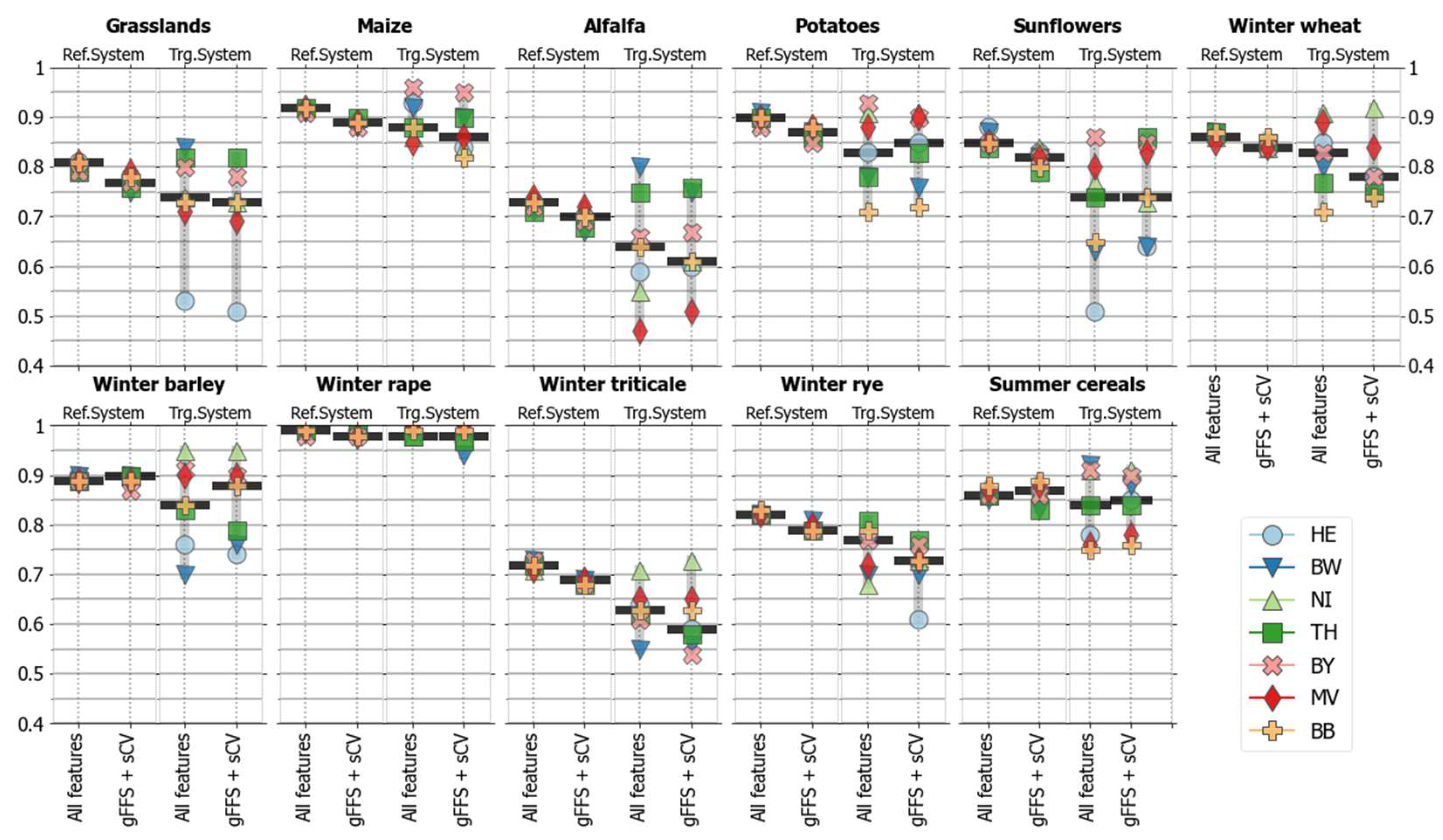
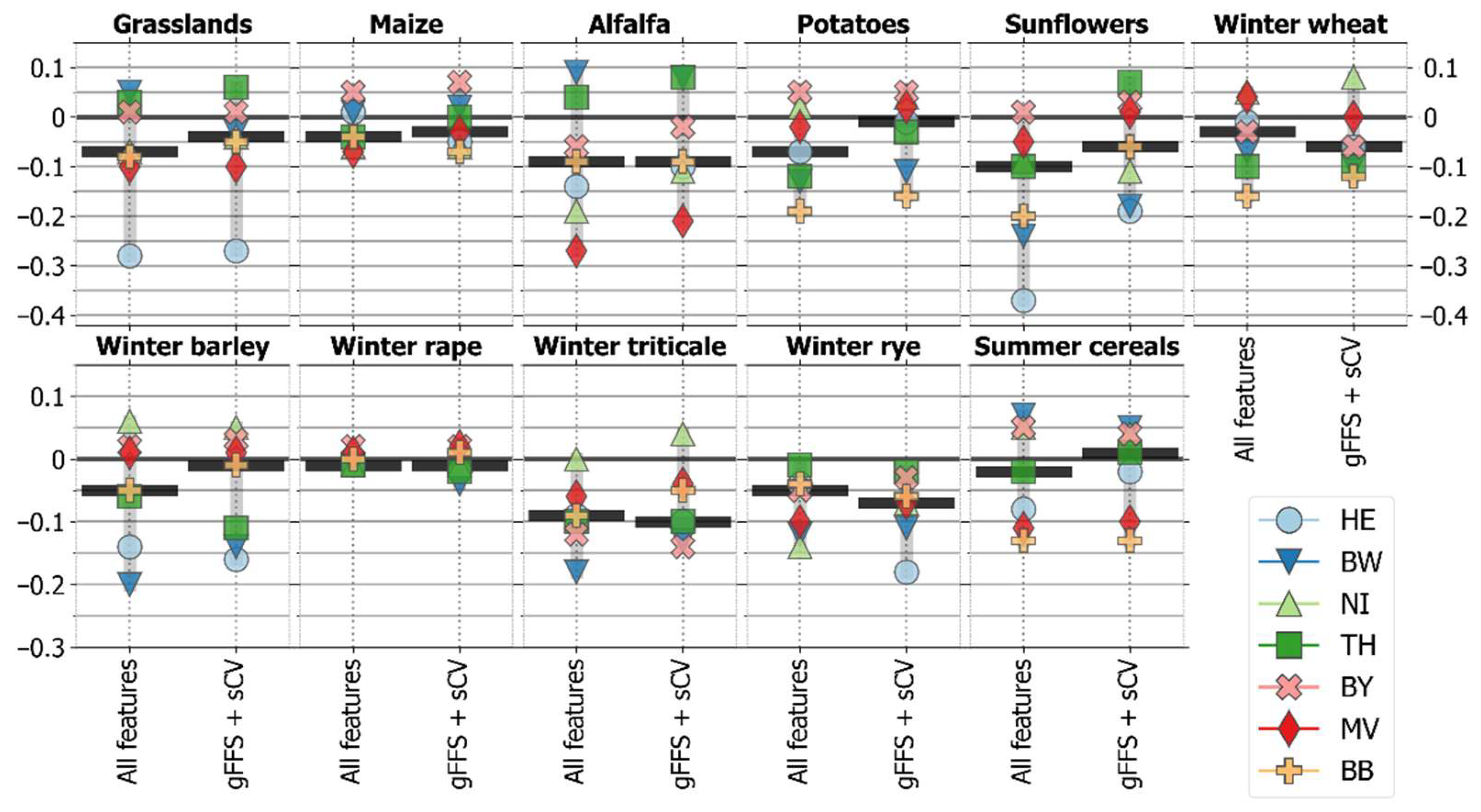
4.2. Class-Specific Classification Accuracies
4.2.1. Accuracies without Spatial Transfer (Reference Systems)
4.2.2. Accuracies for Spatially Transferred Models (Target Systems)
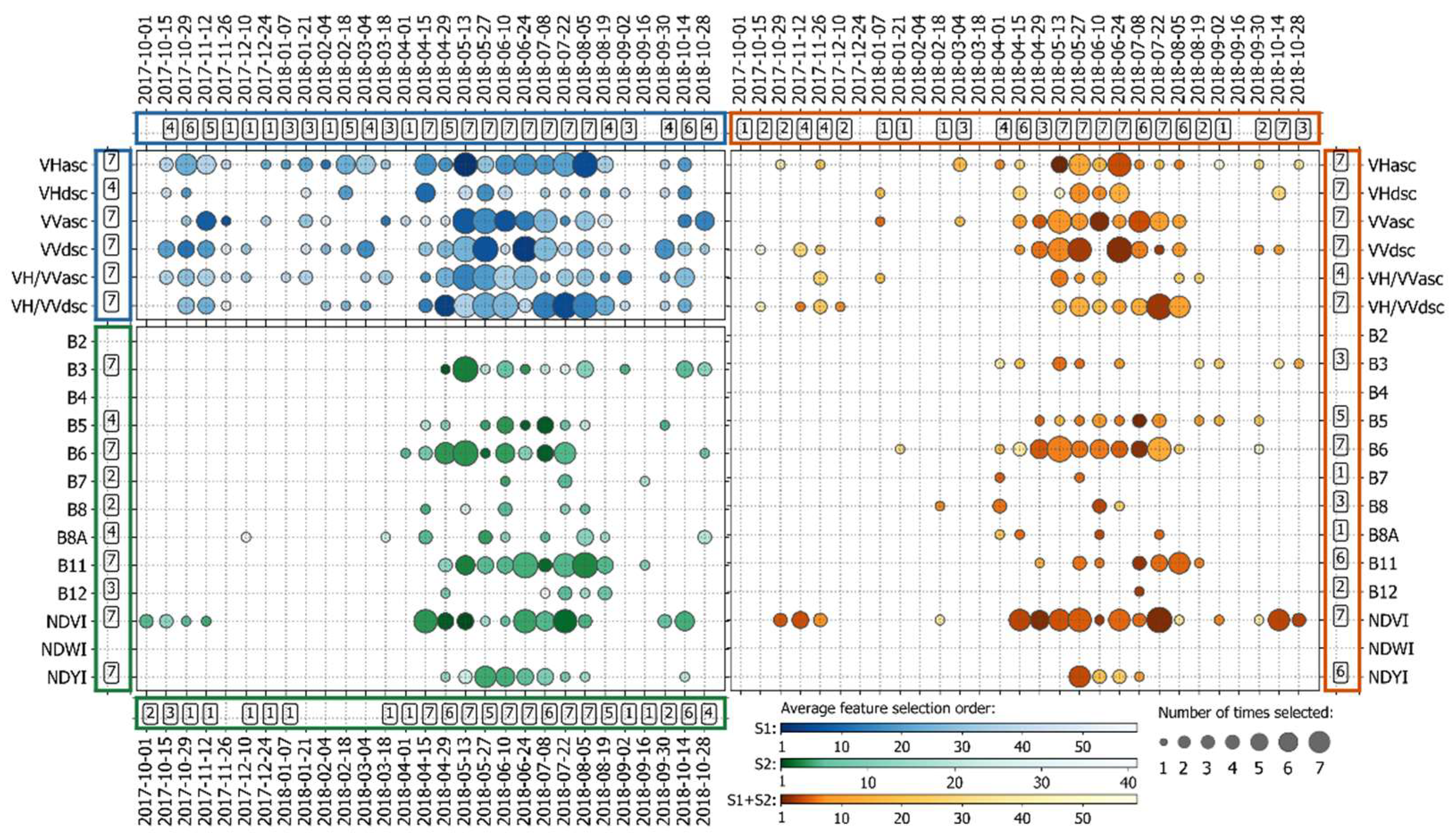
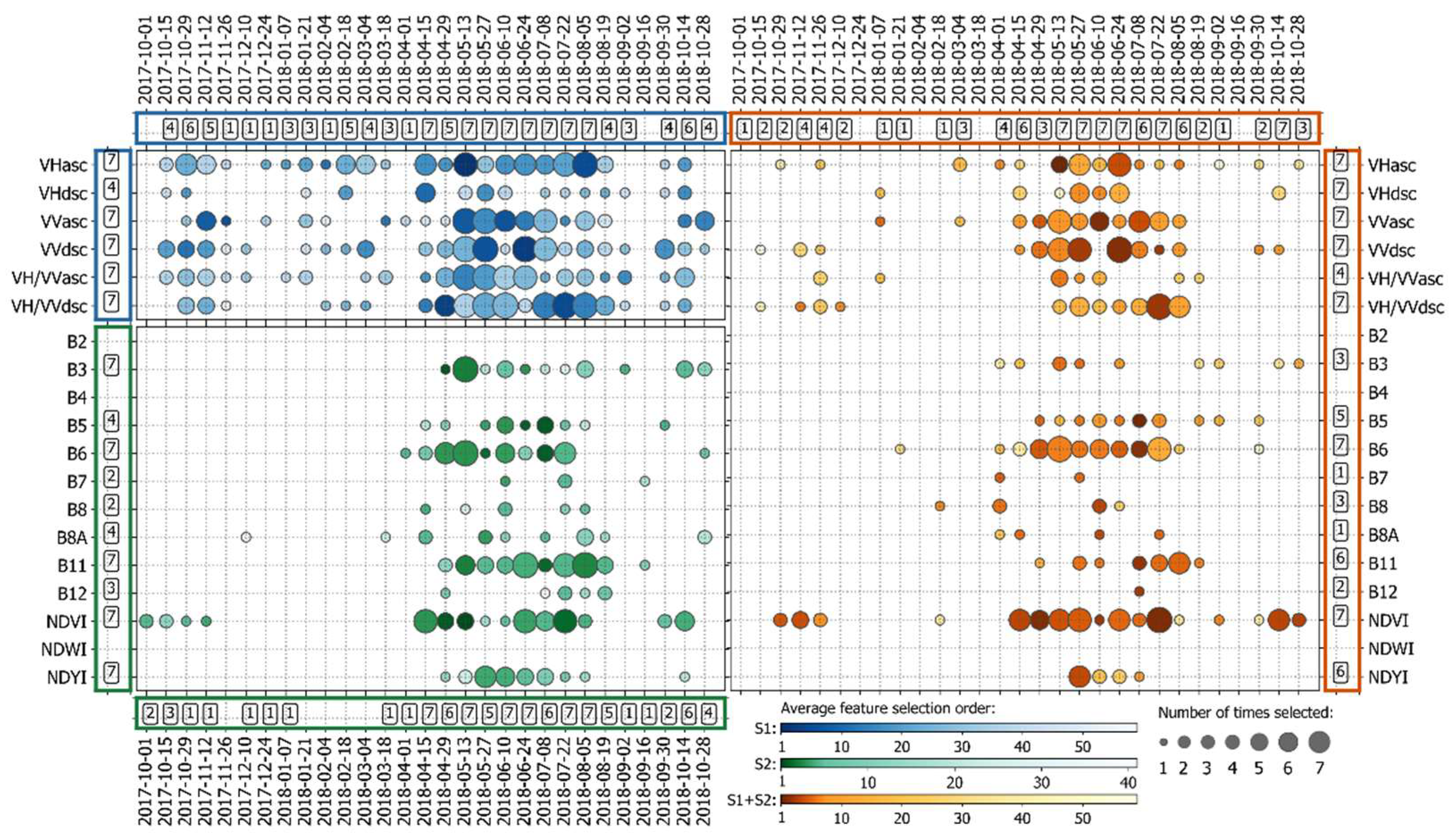
4.3. Features Selected with Spatial gFFS
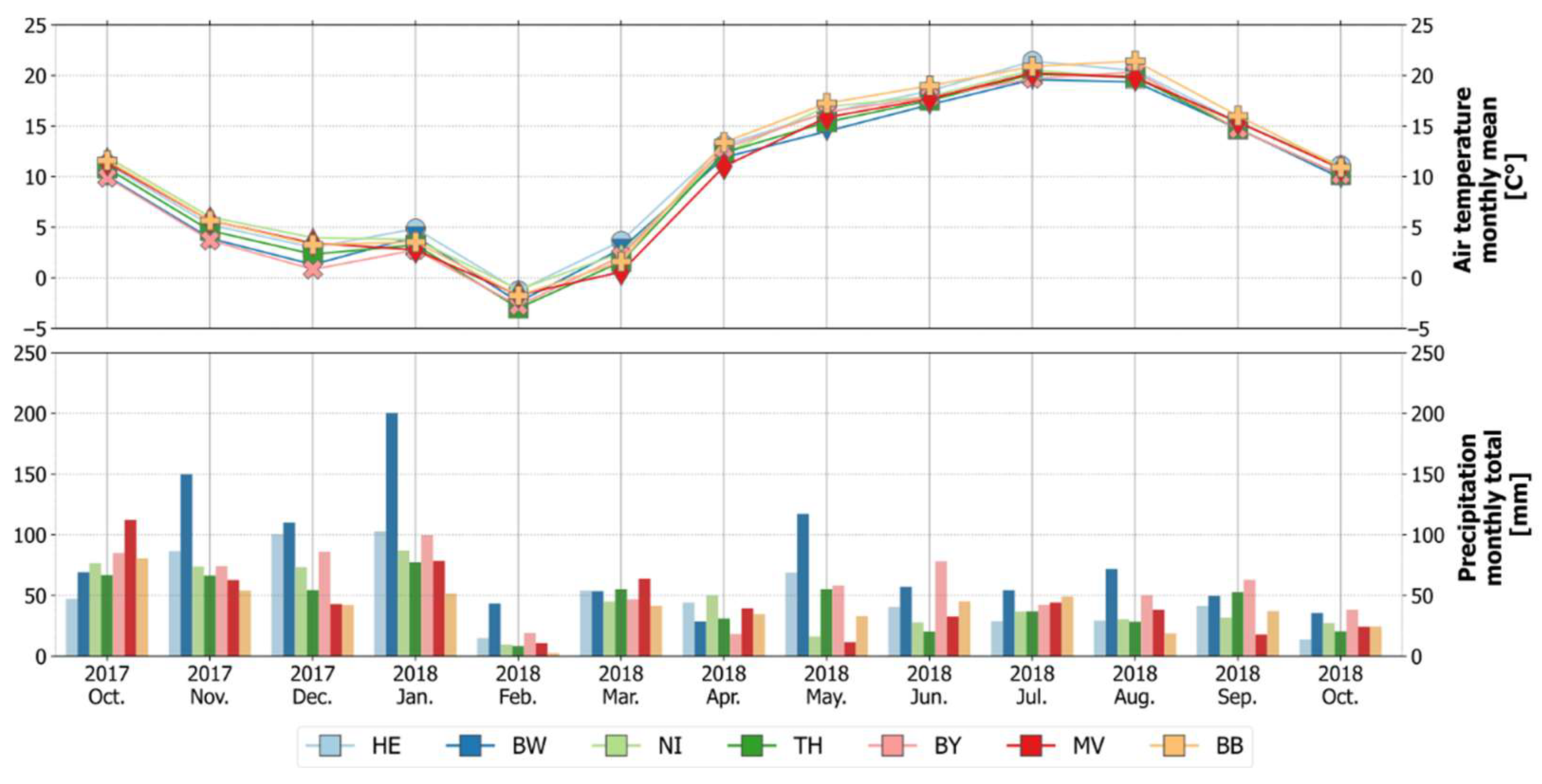
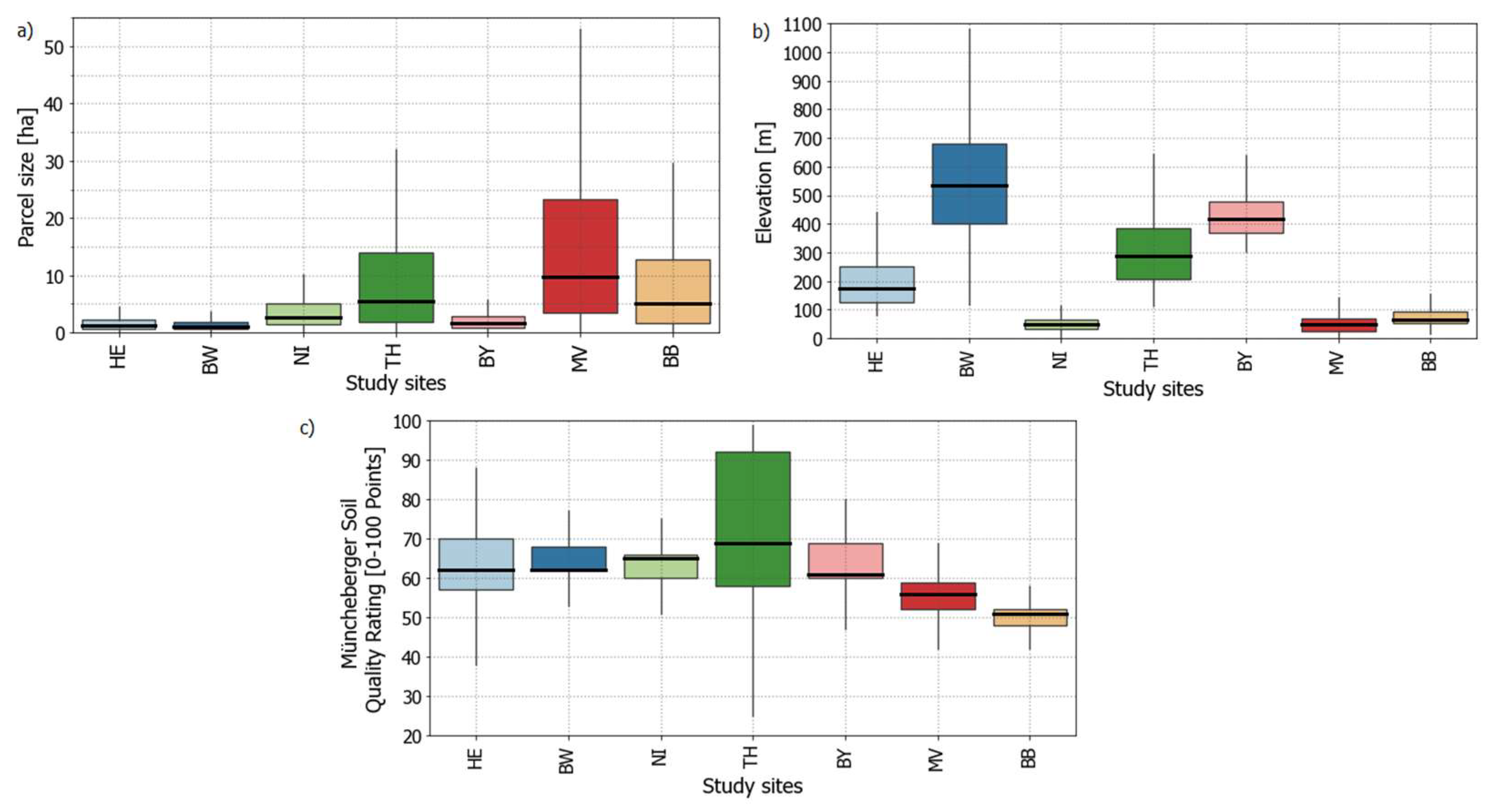
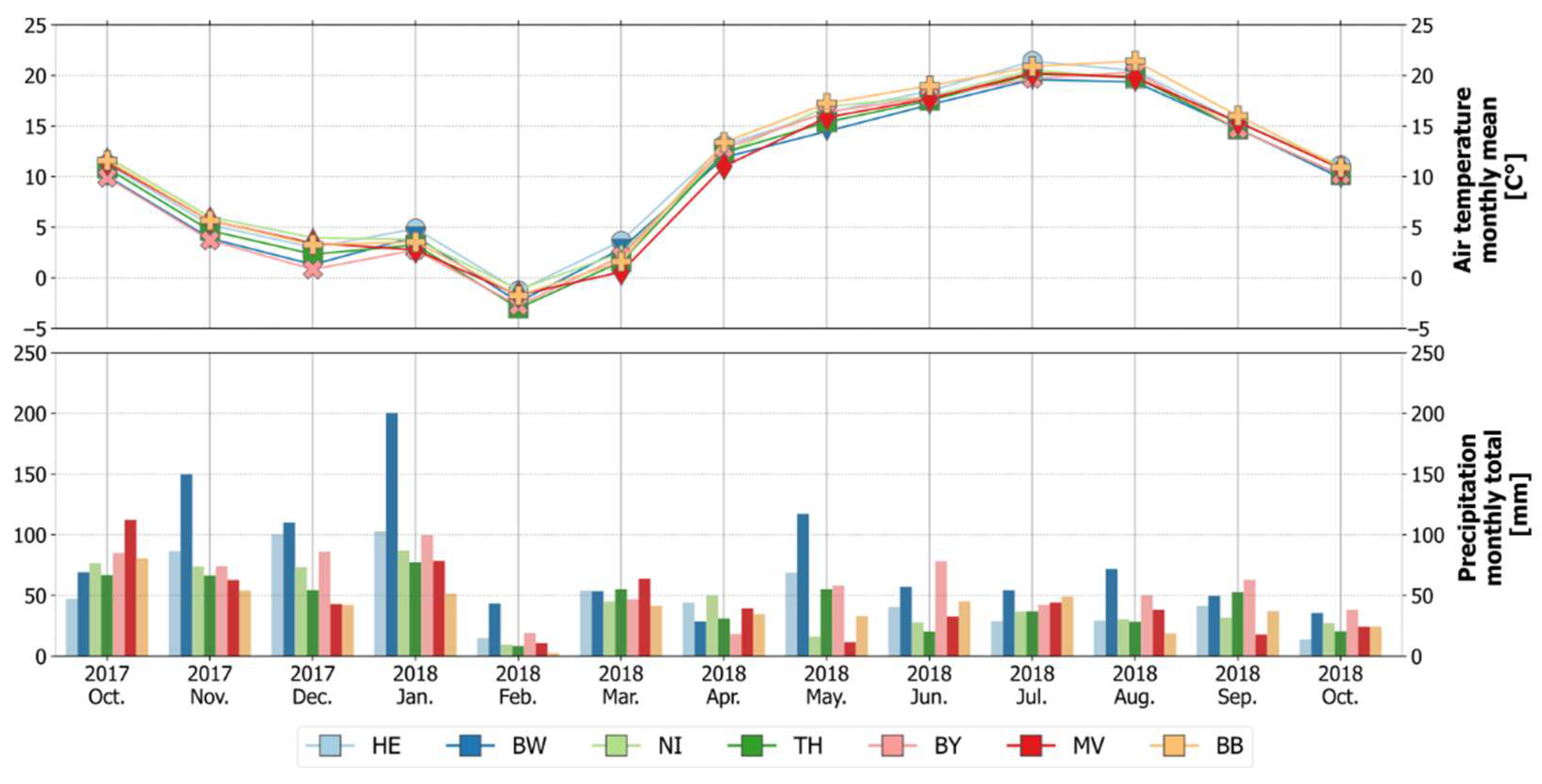
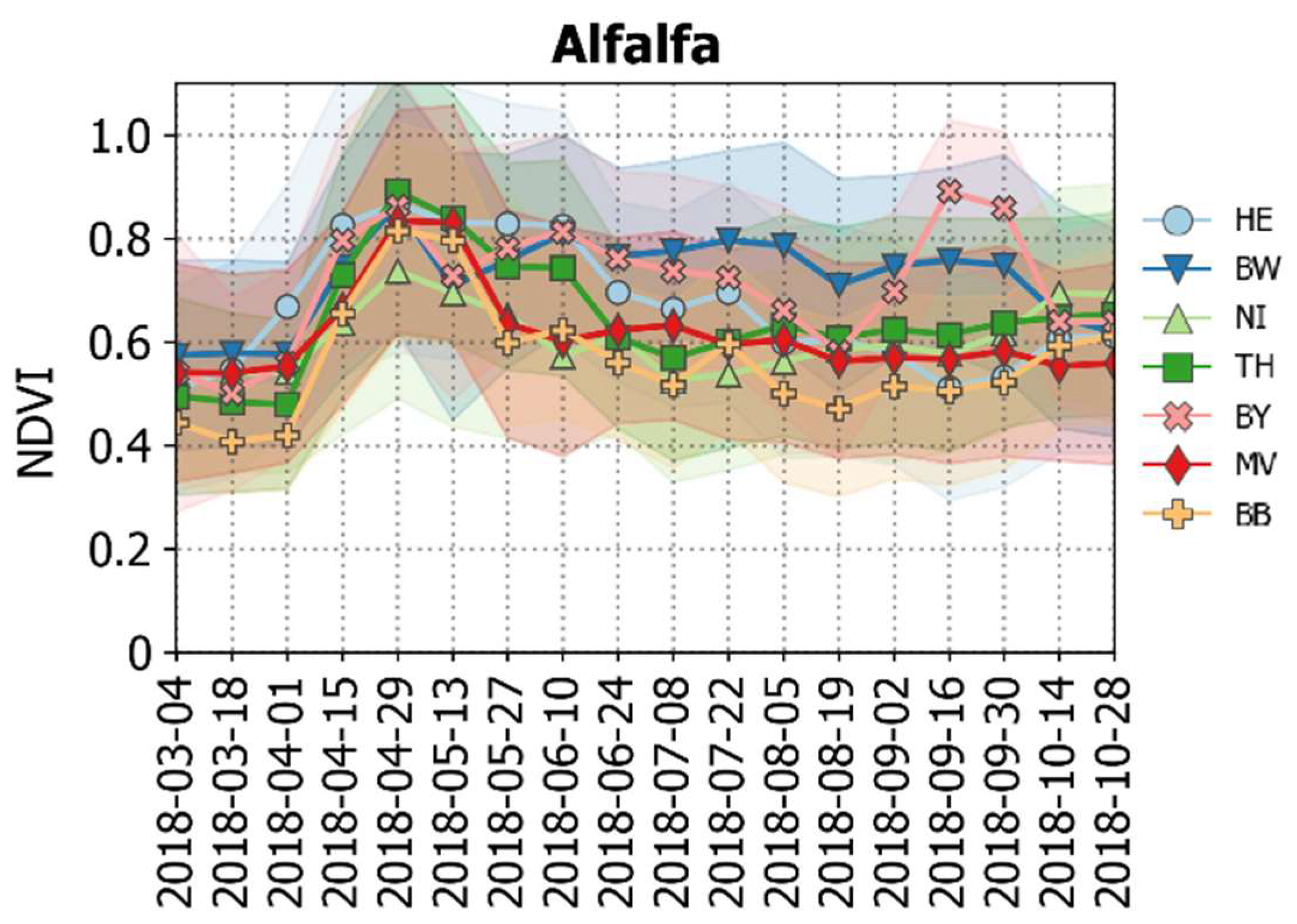
4.4. (Potential) Influences of Environmental Settings
5. Discussion
6. Conclusions
- Random Forest models based on optical-SAR combinations outperform models based on single sensor data in training sites and geographic spaces unseen by the model;
- SAR-based models show the lowest accuracy losses when transferred to an area outside the training regions;
- Performing spatial feature selection on feature sets with only optical data and optical-SAR combination reduces classification accuracy losses in areas where the models were not trained;
- Small classes, grasslands, and alfalfa show high accuracy losses in areas outside the training regions;
- Environmental and geographic variables could aid in explaining or anticipating poor spatial transferability for specific regions.
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Inglada, J.; Vincent, A.; Arias, M.; Tardy, B.; Morin, D.; Rodes, I. Operational High Resolution Land Cover Map Production at the Country Scale Using Satellite Image Time Series. Remote Sens. 2017, 9, 95. [Google Scholar] [CrossRef] [Green Version]
- Griffiths, P.; Nendel, C.; Hostert, P. Intra-annual reflectance composites from Sentinel-2 and Landsat for national-scale crop and land cover mapping. Remote Sens. Environ. 2019, 220, 135–151. [Google Scholar] [CrossRef]
- Preidl, S.; Lange, M.; Doktor, D. Introducing APiC for regionalised land cover mapping on the national scale using Sentinel-2A imagery. Remote Sens. Environ. 2020, 240, 111673. [Google Scholar] [CrossRef]
- Lucas, B.; Pelletier, C.; Schmidt, D.; Webb, G.I. Unsupervised domain adaptation techniques for classification of satellite image time series. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020. [Google Scholar]
- Schratz, P.; Muenchow, J.; Iturritxa, E.; Richter, J.; Brenning, A. Performance evaluation and hyperparameter tuning of statistical and machine-learning models using spatial data. Ecol. Model. 2019, 406, 109–120. [Google Scholar] [CrossRef] [Green Version]
- Nowakowski, A.; Mrziglod, J.; Spiller, D.; Bonifacio, R.; Ferrari, I.; Mathieu, P.P.; Garcia-Herranz, M.; Kim, D.-H. Crop type mapping by using transfer learning. Int. J. Appl. Earth Obs. Geoinf. 2021, 98, 102313. [Google Scholar] [CrossRef]
- Gadiraju, K.K.; Vatsavai, R.R. Comparative analysis of deep transfer learning performance on crop classification. In Proceedings of the 9th ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data, Seattle, WA, USA, 3 November 2020; Association for Computing Machinery: New York, NY, USA, 2020; Volume 1, ISBN 9781450381628. [Google Scholar]
- Ajadi, O.A.; Barr, J.; Liang, S.-Z.; Ferreira, R.; Kumpatla, S.P.; Patel, R.; Swatantran, A. Large-scale crop type and crop area mapping across Brazil using synthetic aperture radar and optical imagery. Int. J. Appl. Earth Obs. Geoinf. 2021, 97, 102294. [Google Scholar] [CrossRef]
- Bazzi, H.; Ienco, D.; Baghdadi, N.; Zribi, M.; Demarez, V. Distilling Before Refine: Spatio-Temporal Transfer Learning for Mapping Irrigated Areas Using Sentinel-1 Time Series. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1909–1913. [Google Scholar] [CrossRef]
- Lucas, B.; Pelletier, C.; Schmidt, D.; Webb, G.I.; Petitjean, F. A Bayesian-Inspired, Deep Learning-Based, Semi-Supervised Domain Adaptation Technique for Land Cover Mapping. Mach. Learn. 2021, 1–33. [Google Scholar] [CrossRef]
- Gilcher, M.; Udelhoven, T. Field Geometry and the Spatial and Temporal Generalization of Crop Classification Algorithms—A Randomized Approach to Compare Pixel Based and Convolution Based Methods. Remote Sens. 2021, 13, 775. [Google Scholar] [CrossRef]
- Hao, P.; Di, L.; Zhang, C.; Guo, L. Transfer Learning for Crop classification with Cropland Data Layer data (CDL) as training samples. Sci. Total Environ. 2020, 733, 138869. [Google Scholar] [CrossRef]
- Wenger, S.J.; Olden, J.D. Assessing transferability of ecological models: An underappreciated aspect of statistical validation. Methods Ecol. Evol. 2012, 3, 260–267. [Google Scholar] [CrossRef]
- Meyer, H.; Reudenbach, C.; Hengl, T.; Katurji, M.; Nauss, T. Improving performance of spatio-temporal machine learning models using forward feature selection and target-oriented validation. Environ. Model. Softw. 2018, 101, 1–9. [Google Scholar] [CrossRef]
- Roberts, D.R.; Bahn, V.; Ciuti, S.; Boyce, M.; Elith, J.; Guillera-Arroita, G.; Hauenstein, S.; Lahoz-Monfort, J.J.; Schroder, B.; Thuiller, W.; et al. Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography 2017, 40, 913–929. [Google Scholar] [CrossRef]
- Meyer, H.; Reudenbach, C.; Wöllauer, S.; Nauss, T. Importance of spatial predictor variable selection in machine learning applications—Moving from data reproduction to spatial prediction. Ecol. Model. 2019, 411, 108815. [Google Scholar] [CrossRef] [Green Version]
- Tuia, D.; Persello, C.; Bruzzone, L. Domain Adaptation for the Classification of Remote Sensing Data: An Overview of Recent Advances. IEEE Geosci. Remote Sens. Mag. 2016, 4, 41–57. [Google Scholar] [CrossRef]
- Orynbaikyzy, A.; Gessner, U.; Conrad, C. Crop type classification using a combination of optical and radar remote sensing data: A review. Int. J. Remote Sens. 2019, 40, 6553–6595. [Google Scholar] [CrossRef]
- Inglada, J.; Vincent, A.; Arias, M.; Marais-Sicre, C. Improved Early Crop Type Identification By Joint Use of High Temporal Resolution SAR And Optical Image Time Series. Remote Sens. 2016, 8, 362. [Google Scholar] [CrossRef] [Green Version]
- Orynbaikyzy, A.; Gessner, U.; Mack, B.; Conrad, C. Crop Type Classification Using Fusion of Sentinel-1 and Sentinel-2 Data: Assessing the Impact of Feature Selection, Optical Data Availability, and Parcel Sizes on the Accuracies. Remote Sens. 2020, 12, 2779. [Google Scholar] [CrossRef]
- Van Tricht, K.; Gobin, A.; Gilliams, S.; Piccard, I. Synergistic Use of Radar Sentinel-1 and Optical Sentinel-2 Imagery for Crop Mapping: A Case Study for Belgium. Remote Sens. 2018, 10, 1642. [Google Scholar] [CrossRef] [Green Version]
- Veloso, A.; Mermoz, S.; Bouvet, A.; Le Toan, T.; Planells, M.; Dejoux, J.-F.; Ceschia, E. Understanding the temporal behavior of crops using Sentinel-1 and Sentinel-2-like data for agricultural applications. Remote Sens. Environ. 2017, 199, 415–426. [Google Scholar] [CrossRef]
- Beck, H.E.; Zimmermann, N.E.; McVicar, T.R.; Vergopolan, N.; Berg, A.; Wood, E.F. Present and future Köppen-Geiger climate classification maps at 1-km resolution. Sci. Data 2018, 5, 180214. [Google Scholar] [CrossRef] [Green Version]
- DWD. DWD Climate Data Center (CDC): Grids of Monthly Averaged Daily Air Temperature (2 m) over Germany, Version v 1.0. Available online: ftp://opendata.dwd.de/climate_environment/CDC/grids_germany/monthly/air_temperature_mean/ (accessed on 21 December 2020).
- DWD. DWD Climate Data Center (CDC): Grids of Monthly Total Precipitation over Germany, Version v1.0. Available online: ftp://opendata.dwd.de/climate_environment/CDC/grids_germany/monthly/precipitation/ (accessed on 21 December 2020).
- DWD The Weather in Germany in 2018. 2018, pp. 12–13. Available online: https://www.dwd.de/EN/press/press_release/EN/2018/20181228_the_weather_in_germany_2018.pdf%3F__blob%3DpublicationFile%26v%3D2 (accessed on 21 December 2020).
- Reinermann, S.; Gessner, U.; Asam, S.; Kuenzer, C.; Dech, S. The Effect of Droughts on Vegetation Condition in Germany: An Analysis Based on Two Decades of Satellite Earth Observation Time Series and Crop Yield Statistics. Remote Sens. 2019, 11, 1783. [Google Scholar] [CrossRef] [Green Version]
- Klages, S.; Heidecke, C.; Osterburg, B. The Impact of Agricultural Production and Policy on Water Quality during the Dry Year 2018, a Case Study from Germany. Water 2020, 12, 1519. [Google Scholar] [CrossRef]
- Gerstmann, H.; Doktor, D.; Gläßer, C.; Möller, M. PHASE: A geostatistical model for the Kriging-based spatial prediction of crop phenology using public phenological and climatological observations. Comput. Electron. Agric. 2016, 127, 726–738. [Google Scholar] [CrossRef]
- Hagolle, O.; Huc, M.; Desjardins, C.; Auer, S.; Richter, R. MAJA ATBD Algorithm Theoretical Basis Document. pp. 1–29. Available online: http://tully.ups-tlse.fr/olivier/maja_atbd/raw/master/atbd_maja.pdf (accessed on 21 December 2020).
- Tardy, B.; Inglada, J.; Michel, J. Fusion Approaches for Land Cover Map Production Using High Resolution Image Time Series without Reference Data of the Corresponding Period. Remote Sens. 2017, 9, 1151. [Google Scholar] [CrossRef] [Green Version]
- D’Andrimont, R.; Taymans, M.; Lemoine, G.; Ceglar, A.; Yordanov, M.; van der Velde, M. Detecting flowering phenology in oil seed rape parcels with Sentinel-1 and -2 time series. Remote Sens. Environ. 2020, 239, 111660. [Google Scholar] [CrossRef] [PubMed]
- NASA. JPL NASA Shuttle Radar Topography Mission Global 1 Arc Second. 2013, Distributed by NASA EOSDIS Land Processes DAAC. 2013. Available online: https://lpdaac.usgs.gov/products/srtmgl1v003/ (accessed on 7 July 2021). [CrossRef]
- BGR. The Product Center of the Federal Institute for Geosciences and Natural Resources (BGR). Available online: https://produktcenter.bgr.de/terraCatalog/Start.do (accessed on 9 June 2021).
- Mueller, L.; Schindler, U.; Shepherd, T.G.; Ball, B.C.; Smolentseva, E.; Pachikin, K.; Hu, C.; Hennings, V.; Sheudshen, A.K.; Behrendt, A.; et al. The muencheberg soil quality rating for assessing the quality of global farmland. In Environmental Science and Engineering; Springer: Cham, Switzerland, 2014; pp. 235–248. [Google Scholar] [CrossRef]
- DWD. Climate Data Center (CDC): Phenological Observations of Crops from Sowing to Harvest (Annual Reporters, Recent), Version v006. Available online: https://opendata.dwd.de/climate_environment/CDC/observations_germany/phenology/annual_reporters/crops/recent (accessed on 26 May 2021).
- Tetteh, G.O.; Gocht, A.; Erasmi, S.; Schwieder, M.; Conrad, C. Evaluation of Sentinel-1 and Sentinel-2 Feature Sets for Delineating Agricultural Fields in Heterogeneous Landscapes. IEEE Access 2021, 9, 116702–116719. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Forkuor, G.; Conrad, C.; Thiel, M.; Ullmann, T.; Zoungrana, E. Integration of Optical and Synthetic Aperture Radar Imagery for Improving Crop Mapping in Northwestern Benin, West Africa. Remote Sens. 2014, 6, 6472–6499. [Google Scholar] [CrossRef] [Green Version]
- Zhong, L.; Gong, P.; Biging, G.S. Efficient corn and soybean mapping with temporal extendability: A multi-year experiment using Landsat imagery. Remote Sens. Environ. 2014, 140, 1–13. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Blickensdörfer, L.; Schwieder, M.; Pflugmacher, D.; Nendel, C.; Erasmi, S.; Hostert, P. Mapping of crop types and crop sequences with combined time series of Sentinel-1, Sentinel-2 and Landsat 8 data for Germany. Remote Sens. Environ. 2022, 269, 112831. [Google Scholar] [CrossRef]
- Saeys, Y.; Inza, I.; Larrañaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Defourny, P.; Moreau, I.; Wolter, J.; Khalil, E.; Gallaun, H.; Miletich, P.; Puhm, M.; Villerot, S.; Pennec, A.; Lhernould, A.; et al. D33.1b-Time Series Analysis for Thematic Classification (Issue 2). Available online: https://www.ecolass.eu/project-deliverables (accessed on 19 February 2021).
- Raschka, S. MLxtend: Providing machine learning and data science utilities and extensions to Python’s scientific computing stack. J. Open Source Softw. 2018, 3. [Google Scholar] [CrossRef]
- Mack, B. EO-BOX: Open Source Python Package. Available online: https://github.com/benmack/eo-box (accessed on 8 June 2021).
- McKinney, W. Data Structures for Statistical Computing In Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 11–17 July 2010; pp. 51–56. [Google Scholar]
- Oliphant, T.E. A Guide to NumPy; Trelgol Publishing: Spanish Fork, UT, USA, 2006. [Google Scholar]
- Bargiel, D. A new method for crop classification combining time series of radar images and crop phenology information. Remote Sens. Environ. 2017, 198, 369–383. [Google Scholar] [CrossRef]
- Woźniak, E.; Rybicki, M.; Kofman, W.; Aleksandrowicz, S.; Wojtkowski, C.; Lewiński, S.; Bojanowski, J.; Musiał, J.; Milewski, T.; Slesiński, P.; et al. Multi-temporal phenological indices derived from time series Sentinel-1 images to country-wide crop classification. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102683. [Google Scholar] [CrossRef]
- D’Andrimont, R.; Verhegghen, A.; Lemoine, G.; Kempeneers, P.; Meroni, M.; van der Velde, M. From parcel to continental scale—A first European crop type map based on Sentinel-1 and LUCAS Copernicus in-situ observations. Remote Sens. Environ. 2021, 266, 112708. [Google Scholar] [CrossRef]
- Ghassemi, B.; Dujakovic, A.; Żółtak, M.; Immitzer, M.; Atzberger, C.; Vuolo, F. Designing a European-Wide Crop Type Mapping Approach Based on Machine Learning Algorithms Using LUCAS Field Survey and Sentinel-2 Data. Remote Sens. 2022, 14, 541. [Google Scholar] [CrossRef]
- Ferraciolli, M.A.; Bocca, F.F.; Rodrigues, L.H.A. Neglecting spatial autocorrelation causes underestimation of the error of sugarcane yield models. Comput. Electron. Agric. 2019, 161, 233–240. [Google Scholar] [CrossRef]
- Macholdt, J.; Honermeier, B. Yield Stability in Winter Wheat Production: A Survey on German Farmers’ and Advisors’ Views. Agronomy 2017, 7, 45. [Google Scholar] [CrossRef] [Green Version]
- Sun, W.; Heidt, V.; Gong, P.; Xu, G. Information fusion for rural land-use classification with high-resolution satellite imagery. IEEE Trans. Geosci. Remote Sens. 2003, 41, 883–890. [Google Scholar] [CrossRef] [Green Version]
- Bajocco, S.; Vanino, S.; Bascietto, M.; Napoli, R. Exploring the Drivers of Sentinel-2-Derived Crop Phenology: The Joint Role of Climate, Soil, and Land Use. Land 2021, 10, 656. [Google Scholar] [CrossRef]
- Wizemann, H.-D.; Ingwersen, J.; Högy, P.; Warrach-Sagi, K.; Streck, T.; Wulfmeyer, V. Three year observations of water vapor and energy fluxes over agricultural crops in two regional climates of Southwest Germany. Meteorol. Z. 2015, 24, 39–59. [Google Scholar] [CrossRef]
- Meyer, H.; Pebesma, E. Predicting into unknown space? Estimating the area of applicability of spatial prediction models. Methods Ecol. Evol. 2021, 12, 1620–1633. [Google Scholar] [CrossRef]
- Stoian, A.; Poulain, V.; Inglada, J.; Poughon, V.; Derksen, D. Land Cover Maps Production with High Resolution Satellite Image Time Series and Convolutional Neural Networks: Adaptations and Limits for Operational Systems. Remote Sens. 2019, 11, 1986. [Google Scholar] [CrossRef] [Green Version]
- Arias, M.; Campo-Bescós, M.; Álvarez-Mozos, J. Crop Classification Based on Temporal Signatures of Sentinel-1 Observations over Navarre Province, Spain. Remote Sens. 2020, 12, 278. [Google Scholar] [CrossRef] [Green Version]
- Löw, F.; Duveiller, G. Defining the Spatial Resolution Requirements for Crop Identification Using Optical Remote Sensing. Remote Sens. 2014, 6, 9034–9063. [Google Scholar] [CrossRef] [Green Version]
- Bichler, B.; Lippert, C.; Häring, A.M.; Dabbert, S. The determinants of the spatial distribution of organic farming in Germany. Ber. Uber Landwirtsch. 2005, 83, 50–75. [Google Scholar]
- Lüttger, A.B.; Feike, T. Development of heat and drought related extreme weather events and their effect on winter wheat yields in Germany. Theor. Appl. Climatol. 2018, 132, 15–29. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| HE | BW | NI | TH | BY | MV | BB | Sum | |
|---|---|---|---|---|---|---|---|---|
| Grasslands | 2563 | 124,977 | 55,511 | 25,233 | 95,925 | 22,766 | 19,615 | 346,590 |
| Maize | 9837 | 28,756 | 26,486 | 2762 | 37,947 | 4165 | 2383 | 112,336 |
| Alfalfa | 486 | 942 | 46 | 1007 | 532 | 103 | 516 | 3632 |
| Potatoes | 1390 | 561 | 6023 | 159 | 4551 | 360 | 206 | 13,250 |
| Sunflowers | 43 | 69 | 20 | 31 | 32 | 83 | 406 | 684 |
| Winter wheat | 29,547 | 22,397 | 13,149 | 10,495 | 32,742 | 5585 | 1259 | 115,174 |
| Winter barley | 8741 | 7959 | 6356 | 3418 | 17,511 | 2513 | 1065 | 47,563 |
| Winter rape | 9392 | 5433 | 5273 | 5327 | 5694 | 3746 | 860 | 35,725 |
| Winter triticale | 1721 | 4585 | 3293 | 839 | 5137 | 386 | 717 | 16,678 |
| Winter rye | 2497 | 846 | 9944 | 468 | 2069 | 1902 | 4195 | 21,921 |
| Summer cereals | 7017 | 11,399 | 10,065 | 3272 | 6001 | 1519 | 1176 | 40,449 |
| Sum | 73,234 | 207,924 | 136,166 | 53,011 | 208,141 | 43,128 | 32,398 | 754,002 |
| Input Dataset | ||||
|---|---|---|---|---|
| S1 1 | S2 2 | S1+S2 3 | ||
| Feature Selection Method | All features 4 | Ref. System 6 and Trg. System 7 | Ref. System 6 and Trg. System 7 | Ref. System 6 and Trg. System 7 |
| gFFS+sCV 5 | Ref. System 6 and Trg. System 7 | Ref. System 6 and Trg. System 7 | Ref. System 6 and Trg. System 7 | |
| Sensors | Feature Selection Approach | Avg. Number of Selected Variable Groups | Avg. Number of Selected Time Groups | Avg. Number of Selected Single Variables | Total Number of Model Evaluation Runs | Number of Needed Runs If Standard FFS Applied |
|---|---|---|---|---|---|---|
| S1 | All features | - | - | 174 | - | - |
| gFFS+sCV | 6 | 17 | 53 | 4474 | 7965 | |
| S2 | All features | - | - | 377 | - | - |
| gFFS+sCV | 7 | 13 | 31 | 2807 | 11,568 | |
| S1 + S2 | All features | - | - | 551 | - | - |
| gFFS+sCV | 11 | 14 | 46 | 6649 | 24,816 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Orynbaikyzy, A.; Gessner, U.; Conrad, C. Spatial Transferability of Random Forest Models for Crop Type Classification Using Sentinel-1 and Sentinel-2. Remote Sens. 2022, 14, 1493. https://doi.org/10.3390/rs14061493
Orynbaikyzy A, Gessner U, Conrad C. Spatial Transferability of Random Forest Models for Crop Type Classification Using Sentinel-1 and Sentinel-2. Remote Sensing. 2022; 14(6):1493. https://doi.org/10.3390/rs14061493
Chicago/Turabian StyleOrynbaikyzy, Aiym, Ursula Gessner, and Christopher Conrad. 2022. "Spatial Transferability of Random Forest Models for Crop Type Classification Using Sentinel-1 and Sentinel-2" Remote Sensing 14, no. 6: 1493. https://doi.org/10.3390/rs14061493
APA StyleOrynbaikyzy, A., Gessner, U., & Conrad, C. (2022). Spatial Transferability of Random Forest Models for Crop Type Classification Using Sentinel-1 and Sentinel-2. Remote Sensing, 14(6), 1493. https://doi.org/10.3390/rs14061493