1. Introduction
Hyperspectral sensors can capture images in hundreds of narrow and continuous bands which provide fine spectral details for different ground objects, and hyperspectral image (HSI) has been widely used for various research fields, such as environmental science, geological science, urban planning, and precision agriculture [
1,
2,
3,
4]. In recent years, the analysis of HSI data has gained substantial attention and become an increasingly active research topic [
5,
6,
7,
8]. In real applications, it is a key task to classify each pixel in hyperspectral data [
9,
10,
11]. However, the high dimensionality of HSI data generally leads to a problem named curse-of-dimensionality. While dimensionality reduction (DR) is an effective tool that can tackle this problem, it explores the transformation process from high-dimensional space to low-dimensional space to obtain embedding features [
12,
13].
In general, the DR methods can be categorized as feature selection (FS) and feature extraction (FE) [
14,
15]. The former is tried to search a subset of original variables for removing irrelevant or redundant features, while the latter projects data into low-dimensional embedding space and preserves most intrinsic information [
16,
17,
18,
19]. This paper mainly focuses on FE algorithms for dimensionality reduction of HSI.
The FE methods are divided into unsupervised, supervised, and semi-supervised ones [
20,
21]. Unsupervised FE algorithms learn low-dimensional features without exploring label information of training sets [
22,
23]. A number of unsupervised approaches have been proposed; such methods include principal component analysis (PCA) [
24], locality preserving projections (LPP) [
25,
26], locally linear embedding (LLE) [
27], neighborhood preserving embedding (NPE) [
28], Laplacian eigenmaps (LE) [
29], and local tangent space alignment (LTSA) [
30]. However, the unsupervised nature limits the discriminant capability of embedding features for classification [
31]. Supervised FE methods exploit prior knowledge of training samples to obtain discriminant features in low-dimensional space for classification [
32,
33], such as linear discriminant analysis (LDA) [
34], locality sensitive discriminant analysis (LSDA) [
35], local geometric structure Fisher analysis (LGSFA) [
36], and marginal Fisher analysis (MFA) [
37]. Although the aforementioned FE approaches may achieve good performance in some scenes, they heavily depend on shallow-based descriptors, which will limit the applicability of those methods in difficult scenes. The shallow features usually cannot deal with the nonlinear relationship between collected spectral information and corresponding land covers [
38,
39]. Therefore, extracting deep discriminant features is considered to be of great significance in HSI classification.
Recently, deep learning (DL) has been explored as an effective FE strategy to address nonlinear problems and it has shown the advantages in different fields such as natural language processing and computer vision [
40,
41,
42,
43]. Motivated by these encouraging applications, DL has been introduced into the classification of HSI [
44,
45,
46,
47]. Compared with the traditional shallow descriptors-based FE method, DL techniques can obtain discriminant information from original spectral features with hierarchical layers [
48,
49,
50,
51]. Chen et al. [
52] designed a stacked autoencoder (SAE)-based method to classify the hyperspectral data by directly using spectral information in the DL model, and then learned features are classified by logistic regression. Chen et al. [
53] extracted the deep features of HSI using convolutional neural network (CNN), and obtained high classification performance by spatial–spectral feature extraction. Li et al. [
54] developed the manifold-based maximization margin discriminant network (M
DNet) to enhance the feature extraction ability of DL models. Although aforementioned deep models effectively explore deep features to enhance classification performance, they fail to consider the intrinsic manifold structure of HSI when constructing network models, which limits the discriminant ability of extracted features.
To address the above issues, a novel FE method termed manifold-based multi-deep belief network (MMDBN) is proposed by fusing deep network and manifold learning. MMDBN developed a new network initialization method based on local geometric structure among samples, and then built a multi-DBN model by training multiple DBNs with samples from each class to learn intrinsic information in different classes. After that, deep features extracted from the multi-DBN model are exploited to construct a discrimination manifold layer. In the manifold layer, a penalty graph and an intrinsic graph are explored to reveal the manifold structure of deep features for HSI data, which can further enhance the interclass separability and intraclass compactness in low-dimensional embedding space.
The contributions of the proposed approach are concluded as follows:
A hierarchical initialization strategy is designed to utilize the local geometric structure to initialize the network;
A multi-DBN structure is proposed to learn deep features from samples in each class, and the extracted abstract features are conducive to representing the deep information in hyperspectral data;
A discrimination manifold layer is constructed by using the prior knowledge of training samples, and this will reveal the intrinsic manifold structure of deep features and bring the benefit to improve the discriminant capability of embedding features.
The remainder of this paper is organized as follows: A brief description of RBM, DBN, and graph embedding framework are presented in
Section 2.
Section 3 describes the proposed algorithm in detail.
Section 4 gives experimental results to demonstrate the effectiveness of the MMDBN. We summarize this paper and provide recommendations for future work in
Section 5.
2. Related Works
Let us denote a hyperspectral dataset by , where N is the number of pixels and D indicates the number of spectral bands. The class label of is denoted by , and c is the class number of land covers. The purpose of FE is to learn a low-dimensional space , where d is the dimension of embedding features.
2.1. Restricted Boltzmann Machine (RBM)
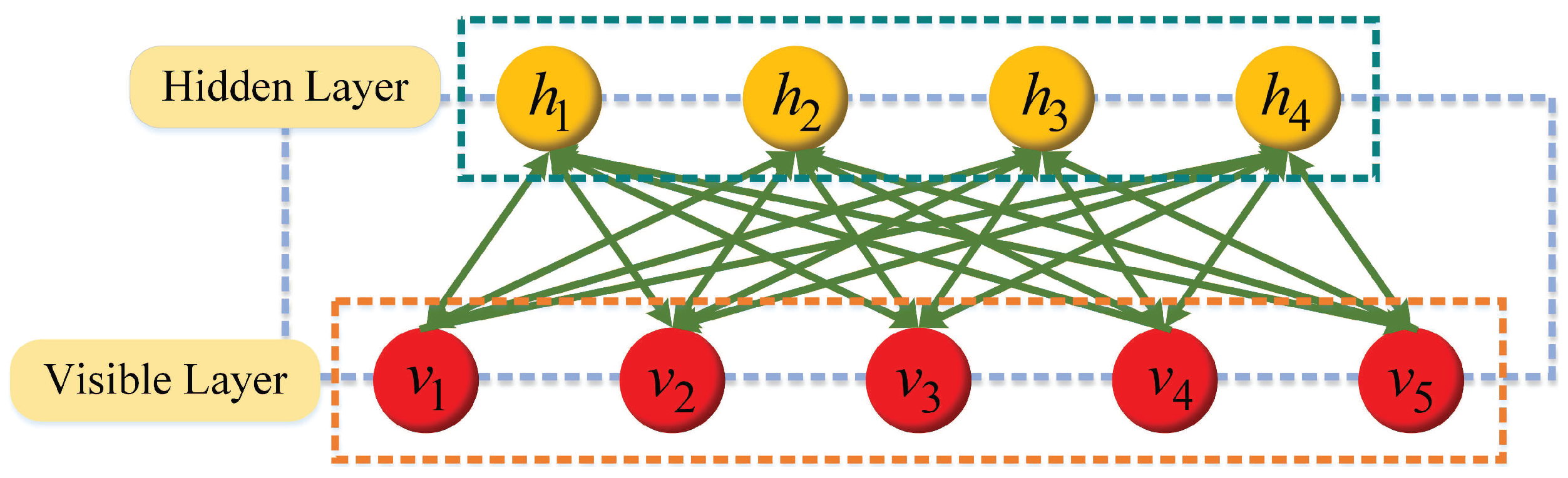
RBM consists of visible a layer and a hidden layer. The visible layer is responsible for input, and the hidden layer learns high-level semantic features from input data. The visible unit and hidden unit are binary variables whose state is 1 or 0. The whole network is a bipartite graph, and there is no joining edge inside the visible layer or hidden layer, which exists between the visible unit
and the hidden unit
.
Figure 1 displays the network structure of RBM.
As an energy-based model, the joint configuration energy of visible unit
v and hidden unit
h for RBM is defined as follows:
where
is the parameter of RBM,
and
define the bias vectors of the hidden unit and visible unit, respectively, and
is the weight between visible unit
and hidden unit
.
The joint probability distribution of
v and
h is calculated by
in which
is the normalization factor.
The likelihood function of
v and
h are given as
where
is the logistic function.
The RBM model is trained by iteration, and the parameter
can be obtained through the following gradient descent algorithm:
where
is a learning rate. With high-dimensional data, the gradient descent method is difficult to solve the model expectation. However, the training efficiency of RBM can greatly improve by using the contrastive divergence (CD) algorithm [
55] as
where
indicates the mathematical expectation of training data, and
represents the expectation of the reconstructed model. Then, the updated criteria for obtaining the DBN weight and bias are defined as follows:
After that, the parameters of RBM can be adjusted to the appropriate values to avoid the local optimal solution. RBM has a strong feature learning ability, and it can be used for information extraction. However, the performance of RBM for FE is limited when it is applied to complex nonlinear data.
2.2. Deep Belief Network (DBN)
To improve the representation ability of a single RBM, a DBN model is established by stacking multiple RBMs together. Thus, the DBN can explore a deep hierarchical representation of training samples.
Figure 2 shows the structure of DBN.
As in
Figure 2, the two adjacent layers of DBN can be considered as a single RBM. Every RBM is trained by the greedy layer-wise unsupervised learning, and an RBM does not consider other RBMs during its learning process [
56].
2.3. Graph Embedding (GE)
The GE framework is designed to unify most classical DR approaches [
37]. GE explores the desirable geometrical or statistical properties through an intrinsic graph
and avoids undesirable characteristics by a penalty graph
, where
X represents the vertex set of a graph. Both
G and
are undirected weighted graphs,
W and
are the weight matrices of two graphs, in which
measures the similarity between vertices
and
in intrinsic graph, and
calculates the dissimilarity of vertices
and
in penalty graph.
The similarity relationship between vertex pairs should be preserved in low-dimensional embedding space, and the objective function can be designed as
where
h is a constant,
D is a diagonal matrix, and
,
L and
H are Laplacian matrices of graph
G and
.
H is a constraint matrix for scale normalization, i.e.,
,
.
3. Proposed Method
In this section, a manifold-based multi-deep belief network (MMDBN) is proposed to extract deep discriminant features for HSI classification. represents the hyperspectral dataset, where indicates the samples from the i-th class, and is the number of samples in it. represents the deep features extracted by multi-DBN structure, and represents the features of corresponding class, where is the dimension of deep features. The output of MMDBN can be denoted as , where is the projection matrix and d is the dimension of low-dimensional features.
At first, MMDBN develops a local geometric structure-based initialization method and constructs a multi-DBN structure to train a DBN model for each class, then the deep features of different classes will be extracted with the corresponding DBN model. To further analyze the deep features extracted from the
-th layer, we designed a discrimination manifold layer as the last layer of the whole network. In this layer, the label information of each pixel is introduced as the prior knowledge to discover the manifold structure contained within hyperspectral data, and the layer separates the intermanifold samples while compacting the intramanifold samples, which increases the margins among different manifolds.
Figure 3 displays the process of the MMDBN.
3.1. Local Geometric Structure-Based Network Initialization
Different from traditional DBN that initializes the network by random initialization, MMDBN develops a hierarchical initialization strategy based on the manifold structure in HSI.
Assume a DBN model consists of
L layers, for
i-th training labeled sample at
l-th (
) layer, the output and input are
and
, respectively. MMDBN builds a neighbor graph
in each layer,
is connected to samples from the same class, and the weights
are represented as
where
is determined by the spectral Euclidean distance between the
j-th and
i-th training samples, and
is the heat kernel parameter.
Given that
and
are neighbor points, we expect that the relationship can be maintained between
and
. The corresponding objective function is represented by
where
is the network parameters matrix of layer
l.
By some algebraic operations, Equation (
12) can be reformulated as
in which
,
.
To reduce the influence of scaling factors in the projection, a constraint
is imposed on the following objective function:
By introducing the Lagrange multiplier method, the optimization program of Equation (
14) is transformed to tackle a generalized eigenvalue issue:
where
consists of
d smallest eigenvalues of Equation (
15) corresponding to eigenvectors.
3.2. Multi-DBN Structure
In order to extract deep features for each class in hyperspectral image, we designed a multi-DBN structure to fully extract the information in each class. As illustrated in
Figure 3, the 1st to
-th layers in MMDBN belong to a multi-DBN structure. According to the properties of HSI, Gaussian distribution is introduced to model the input data, which realizes real-valued RBM instead of binary RBM [
57,
58]. The energy function and conditional probability distributions are defined as follows:
where
is the standard deviation of Gaussian visible units, and
is the Gaussian distribution with mean
and variance
.
The multi-DBN structure extracts features from the perspective of deep learning, and the features obtained from the -th layer contain deep abstract information for hyperspectral data. To improve the discriminative capability of extracted features, MMDBN explores the manifold structure in HSI using label information.
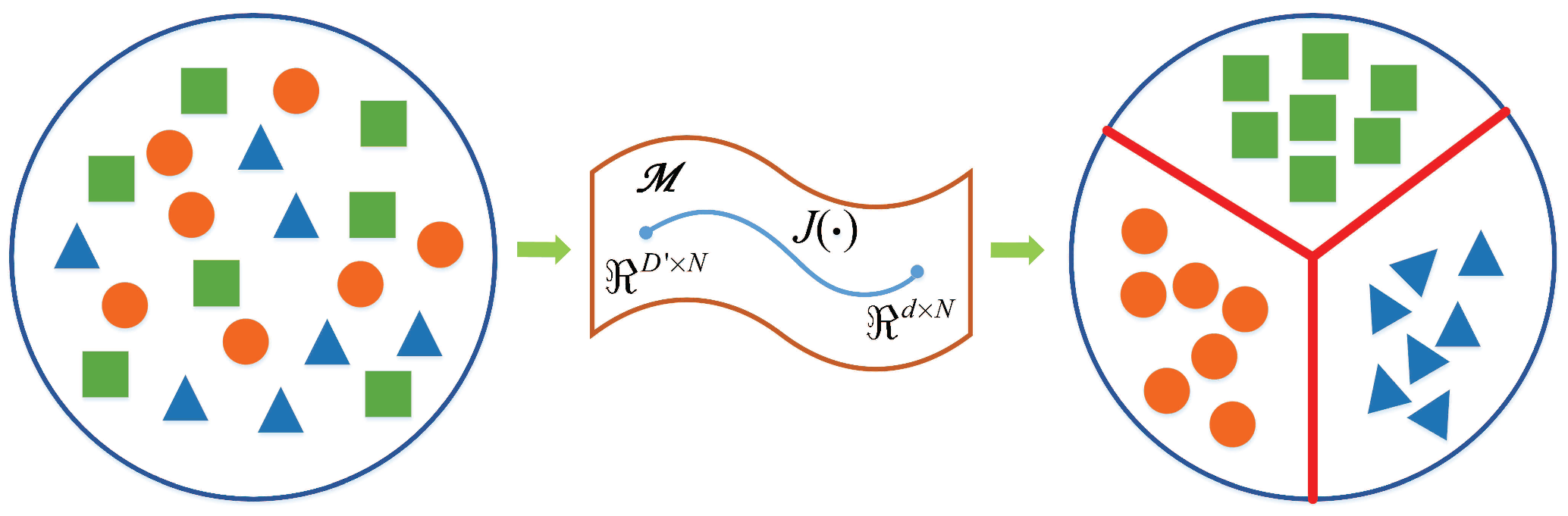
3.3. Discrimination Manifold Layer
The discrimination manifold layer allows the proposed method to discover the manifold structure in deep features, so that the extracted features can maintain large margins between different manifolds in low-dimensional embedding space.
Figure 4 displays the illustration of the discrimination manifold layer.
The motivation of designing the discrimination manifold layer is to keep local geometric neighboring relation and label information in low-dimensional embedded space. To achieve this goal, it constructs the intra-DBN graph
and the inter-DBN graph
to explore the discriminant manifold structure from deep features. The weights between
and
for
is represented by
For graph
, the weight is defined as
where
is the
intra-DBN neighbors of
and
indicates the
inter-DBN neighbors of
.
The purpose of the discrimination manifold layer is to separate deep features extracted from different DBNs and compact features learned from the same DBN. The objective functions are represented as
With some mathematical operations, Equations (
21) and (
22) can be reduced as
where
,
,
,
.
As discussed above, the discriminant manifold layer not only preserves the local geometric structure of HSI, but also maximizes the margins between different manifolds. Therefore, it possesses a discriminant capability at low-dimensional space, and the optimization of the following objective functions is an acceptable criterion for selecting an appropriate projection matrix:
The optimization problem of the multi-objective function in Equation (
25) can be equivalent to
Then, the optimization solution can be formulated by Lagrange multiplier method into the following form:
Based on the above mathematical transformation, Equation (
27) can be further simplified as
where the optimal projection matrix
consists of
d eigenvectors corresponding to the
d minimum eigenvalues of Equation (
28). The low-dimensional embedding features are given as
4. Experimental Results and Analysis
In this section, three real HSI datasets, Indian Pines, Salinas, and Botswana, are introduced to evaluate the effectiveness of the proposed MMDBN.
4.1. Experiment Datasets
Indian Pines dataset [
59]: This dataset is a scene of Northwest Indiana acquired by the AVIRIS sensor. It contains 684 × 453 pixels with 220 bands, and its spatial resolution is 20 m. There are 200 radiance channels remaining after removing water vapor and atmospheric effect. It has 16 classes of land covers in total, and its false-color image and ground truth with detailed type information are given in
Figure 5. Brackets list the sample size of each class.
Salinas dataset [
59]: The second dataset was captured in Salinas Valley, Southern California through the AVIRIS sensor. The set is composed of 224 spectral channels after the 20 bands were removed due to the noise and water absorption. The spatial size of this dataset is up to 512 × 217 pixels, and its geometric resolution is 3.7 m. There are sixteen land cover types and the ground truth with corresponding classes are displayed in
Figure 6.
Botswana dataset [
59]: This dataset is a scene of Botswana Okavango Delta, South Africa collected by the Hyperion sensor on NASA EO-1 satellite on 31 May 2001. The size of the image is 1476 × 256 pixels and the spatial resolution is 30 m. A total of 145 spectral bands are utilized for the experiments after removing 20 channels seriously affected by noise.
Figure 7 exhibits its false-color image and ground truth.
4.2. Experimental Setup
In all experiments, each HSI dataset was randomly divided into training and test set. Meanwhile, we set 10 training samples per class for small classes such as , , and in Indian Pines dataset. A low-dimensional embedding space was constructed through DR method with the training samples, while the test set was mapped into the embedding space. Then, the K-nearest neighborhood (KNN) classifier with Euclidean distance was employed for classification. After that, coefficient (), average accuracy (AA), overall accuracy (OA), and classification accuracy for each class (CA) were introduced to investigate the performance of different DR approaches. Under each condition, the experiment was repeated 10 times to obtain a result with mean and standard deviation (STD). Experiments in this paper were completed on a computer with MATLAB 2014b, 32 GB memory, and i7-7800X CPU. The deep learning toolbox in MATLAB was used as a toolkit to develop the code of MMDBN.
4.3. Parameter Sensitivity Analysis
To evaluate the influence of parameters on the performance for MMDBN, 10%, 2%, and 10% samples in Indian Pines, Salinas, and Botswana datasets were randomly selected in each class of ground object for training, and the remaining samples were utilized for test.
4.3.1. Evaluation of the Model with Embedding Dimension
In this subsection, a series of experiments were designed to analyze the influence of embedding dimension for all FE algorithms.
Figure 8 displays the OAs with different embedding dimensions.
As shown in
Figure 8, the OAs of all algorithms first improve with the increase of embedding dimension, because there is more information that can be used for classification. However, the classification results for most algorithms tend to be stable or even reduced when the dimension reaches a certain degree, for the reason that valuable information contained in embedding features is close to saturation. Compared with other approaches, MMDBN achieved the best performance on all datasets, because it fuses multi-DBN structure and discrimination manifold layer to extract deep manifold features, which possesses a good discriminant ability for HSI classification. Based on the above analysis, we chose 30 as the feature dimension to achieve satisfactory performance. For LDA, the embedding dimension was set to
, in which
c is the class number in HSI dataset.
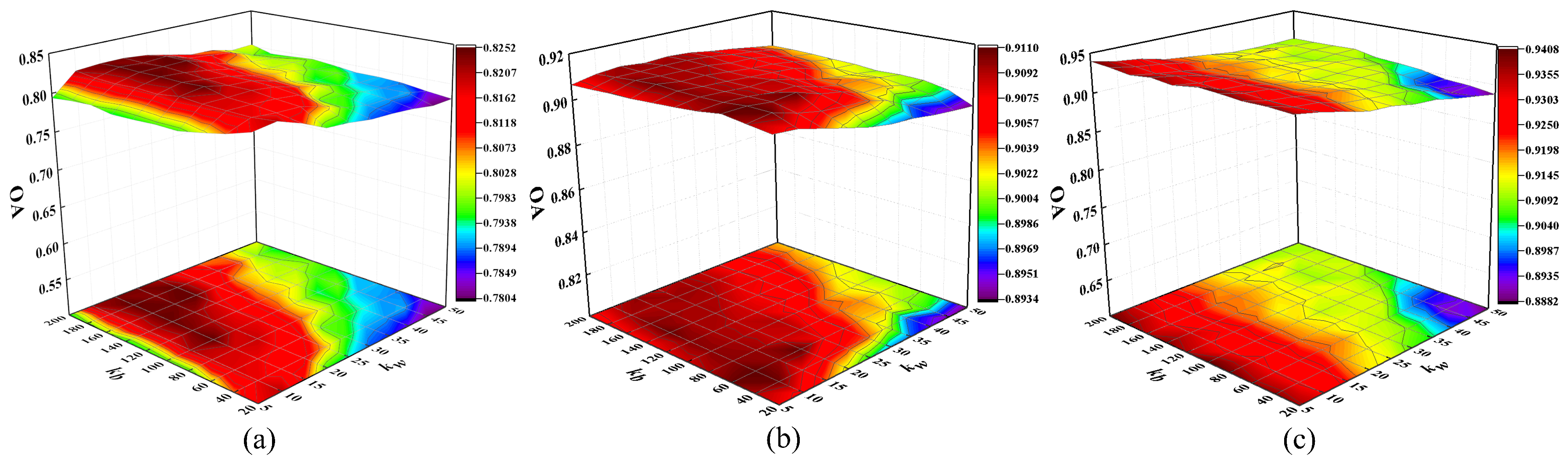
4.3.2. Evaluation of the Model with Different Value of Neighbors in Discrimination Manifold Layer
This subsection investigates the relationship between different number of interclass and intraclass neighbors and classification performance for the MMDBN method. In the experiment, parameters
and
are tuned with
and
, respectively. The OAs with different values of
and
are shown in
Figure 9.
From
Figure 9, the OA improves and then stabilizes with the increase of
, because a large number of interclass neighbor points are conduciveto explore the discriminative structure for maximizing the manifold margins of HSI data. Meanwhile, an appropriate size of
can discover the local manifold structure and compact samples from the same class. For three HSI datasets, we set the parameters
and
to 10 and 100, respectively.
4.3.3. Evaluation of the Model with Different Number of Model Layers
To analyze the impact with the number of layers on the performance of MMDBN, experiments were repeated ten times to obtain a result of OA with mean and standard deviation at each condition, and the relationship between the number of layers and the OAs on three HSI datasets are displayed in
Figure 10.
As illustrated in
Figure 10, the number of hidden layers within the multi-DBN structure plays a significant role in feature extraction of hyperspectral data. It can be easily observed that when the value of
L is 3 or 4, the proposed approach will achieve better classification performance. This is because the parameter number in MMDBN increases dramatically with the increase of layer number, which easily leads to overfitting of limited training data. To obtain better classification results, the number of layers in MMDBN algorithm was set to 4 in three datasets.
4.3.4. Evaluation of the Model with Different Number of Nodes
To set a proper number of hidden nodes for the proposed model, we investigated the performance of MMDBN with a different number of nodes, and the nodes within each layer were tuned with
.
Figure 11 shows the relationship between the node number in each layer and the classification accuracies.
According to
Figure 11, nodes number has a considerable impact on the classification results of MMDBN. It can be easily observed that the OA first raises and then reduces. This indicates that too many nodes will bring negative effects for classification, and a high number of nodes will make the model redundant or even cause overlearning when limited training samples are available. Based on the above analysis, the optimal number of nodes is 60 for the three HSI datasets.
4.4. Comparisons with Other State-of-the-Art DR Methods
To evaluate the effectiveness of MMDBN, we compared it with several state-of-the-art DR approaches; such methods include Baseline, PCA [
24], LDA [
29], LPP [
26], NPE [
28], LGSFA [
36], and MFA [
37], and Baseline denotes that the test set is classified through KNN classifier without the process of DR. The cross-validation was adopted to obtain the optimal parameters for all methods. The number of neighbor points for LPP and NPE was chosen as 9. The numbers of intraclass and interclass neighbor points for LGSFA and MFA were set to 9 and 180, respectively.
In order to analyze the classification performance of each method with different size of training set, we selected
samples in each class for training, and the rest of the samples were set for test samples.
Table 1,
Table 2 and
Table 3 report the mean OA with STD for different DR approaches on three HSI datasets.
As shown in
Table 1,
Table 2 and
Table 3, the OAs of all methods raise with the increase in the sample size of the training set. The experiment results of supervised learning methods outperform unsupervised learning methods in most conditions, the reason is that prior knowledge of training data brings benefits to improve the discriminative ability of extracted features. The proposed approach produces the best classification results among all DR methods, especially when there are a few available training samples. This is because the MMDBN not only extracts deep abstract features, but also explores a discrimination manifold layer to reveal the manifold structure within HSI.
To investigate the classification performance of MMDBN on different types of land covers, 10%, 2%, and 10% samples in each class were randomly selected from three datasets for training.
Table 4,
Table 5 and
Table 6 list the classification accuracy of each class for different methods on HSI datasets, and corresponding classification maps are shown in
Figure 12,
Figure 13 and
Figure 14, respectively.
As illustrated in
Table 4,
Table 5 and
Table 6, the proposed approach achieves better classification results on most classes of three datasets, especially for the Indian Pines dataset. Compared with other methods without a multi-manifold model, MMDBN needs longer FE time because it learns the intrinsic information of each type of land cover by constructing a multi-DBN structure. However, it is acceptable owing to the competitive results of MMDBN. As displayed in
Figure 12,
Figure 13 and
Figure 14, it is clear that the proposed approach generated more homogenous regions in classification maps than comparison methods. The results show that the MMDBN extracts the deep discriminant features of each class, and maximizes the manifold margins among different classes.
4.5. Comparisons with Some Deep Learning Methods
To further compare the performance of MMDBN with deep learning models, ANN [
43], CNN [
53], SAE [
52], M
DNet [
54], and MDBN were introduced as compared algorithms. MDBN means the multi-DBN structure without the discrimination manifold layer, and we set the parameters of each model empirically to achieve the best performance in each condition.
In experiments, the training set contained
samples randomly selected in each class, and the test set consisted of the remaining samples. The average OA with STD for different methods is given in
Table 7.
From
Table 7, the classification accuracies of different deep learning models on three datasets are improved as the training samples increased, because a larger size of the training set can bring rich discriminant information for extracted features. Different from traditional deep learning methods, MMDBN initializes the network by exploring the local geometric structure. Meanwhile, it designs a multi-DBN structure to learn intrinsic information of different classes, and then improves the separability of features by constructing a discrimination manifold layer. As a result, the proposed approach achieves the best results in most cases. Compared with MDBN, the competitive performance of MMDBN shows the effectiveness of the discrimination manifold layer, and it can compact samples for the same class and separate samples for different classes; this is conducive to extracting discriminant features for land cover classification.
To investigate the running time of different deep learning methods, we randomly selected 10%, 2%, and 10% samples per class from three datasets for training and the rest of the data were chosen as a test set.
Table 8 lists Kappas, OAs, and running times for different methods on three datasets.
The running times of MDBN and MMDBN are significantly less than other deep learning models under the training phase. While in the test phase, the subsequent classification process of MMDBN needs to explore the k-nearest neighbors of extracted features, so it takes a longer time than some comparison methods.
5. Conclusions
The deep belief network (DBN) model is an unsupervised deep learning method and it fails to discover manifold structure in HSI. This paper proposes a novel FE method called MMDBN, which combines manifold learning and deep learning to address these issues. MMDBN extracts the deep abstract features contained in various land covers by constructing a multi-DBN structure. Then, under the GE framework, it designs the discrimination manifold layer for supervised learning, which can separate interclass samples while compactingintraclass samples. As a result, the proposed approach effectively extracts discriminant features and significantly improves classification accuracy for hyperspectral data. Experiment results on Indian Pines, Salinas, and Botswana HSI datasets show that the proposed MMDBN has a better ability for feature extraction than some state-of-the-art DR methods.
In the future, we are interested in exploring the spatial information of hyperspectral data to solve the limitation of MMDBN only considering spectral information, and designing the spectral–spatial combined deep manifold networks to further improve the classification performance of the MMDBN model.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}