
A Visual Compass Based on Point and Line Features for UAV High-Altitude Orientation Estimation


Abstract
:
1. Introduction
- Global Navigation Satellite Systems (GNSS) is a type of fundamental localization method in outdoor environments. Besides position and velocity, it can also provide the attitude of an agent. However, this can only be achieved when the agent is moving, which is unavailable when the UAV is hovering in the sky. Double-antenna GPS can ignore the limitation of velocity, but it can get high precision only with a wide baseline [2].
- Inertial Measurement Unit (IMU) is a kind of autonomous sensor with high frequency. However, the severe drifts over a long period of runtime and the unobservable orientation angle mean it cannot be used alone [3].
- Magnetic compass has been applied to direct the orientation and compensate the orientation angle estimation of IMU for a long time, whereas it can be influenced seriously by magnetic variations, which usually appear in an urban environment, electric transmission lines, and even the vehicle itself.
- Poor features. There is little useful information within the front-view. Moreover, in most cases, the quality of the high-altitude remote sensing image deteriorates because of the long-distance and UAVs’ inevitable jitters.
- Viewpoints switch primarily. The scenes observed by a UAV switch so fast in most cases, especially when the UAV is hovering in the sky, which means it rotates nearly purely.
- Hard to calibrate the camera. In order to get images as clearly as possible, cameras with a long focal length are generally used. Nevertheless, they are challenging to be calibrated.
- Coarse-to-fine tracking method. Design a coarse-to-fine method to track the cluster centers so that the influence of noises is reduced to a large extent.
- LK-ZNCC for line matching. Propose a new strategy LK-ZNCC using photometric and geometric characters to describe and match line segments, which accelerates the algorithm essentially.
- Hierarchical fusion. Fuse point and line features hierarchically to expand the scope of the usage. Marginalize unreliable features to eliminate the influences of the noises and dynamic objects.
- Geometric computation approach. Compute the orientation angle by including angles of matched line vectors rather than the projective geometry method to avoid calibration, which is very tough for a long focal length camera.
2. Related Works
2.1. VC for Omnidirectional or Panorama Cameras
- The enormous expenses on feature extraction and tracking.
- The severe sensitivity to outliers and illumination changes.
- The strong assumption of the structure of the 3D environment [12].
- Using this kind of camera or mounting them on a robotic platform is challengeable [4].
- The number of the observed features is larger than other cameras, which results in expensive computation.
- These algorithms will fail in dynamic situations. Because they compare the images in reference and current positions, extracting the information is computationally expensive and complex in hardware [19].
2.2. VC for Pinhole Cameras
3. Methods
3.1. Overview
3.1.1. Decoupling the Attitude Angles
- (1)
- When the camera rotates around axis, ’s direction will change to (Figure 1(2)). Then, we can project both and in the imaging plane to get and , it is easy to conclude that the changed orientation angle of camera equals to included angle of and , which is also equivalent to the included angle of and .
- (2)
- In general, the rotation axis of the camera is not parallel with the axis, which means not only the yaw angle, but the roll and pitch angle will change. In this case, the projected line can be derived by decoupling the three attitude angles (Figure 1(3)), and the increment yaw angle of the camera equals the included angle of and ( in Figure 1(4)), which is also the intersection angle of and in the plane (Figure 1(3)).
- (3)
- No matter how the camera translates during rotation, it will not influence the conclusion above according to the axiom: corresponding angles are equal.
3.1.2. Pipeline Overview
- (1)
- Cluster the ORB [25] feature points by density. Choose a typical and robust point for each cluster to represent it (in Section 3.2). Then, match these representative points and as the first part of point features in the current frame and the keyframe, named as clustered keypoints;
- (2)
- Detect line features by EDlines [26,27] and match line features in the current frame and the keyframe by the proposed method LK-ZNCC to get line pairs (in Section 3.3);
- (3)
- Compute the first kind of orientation angle increments from line pairs (see the Equations (12) and (13) in Section 3.4 for details);
- (4)
- The global keypoints consist of clustered keypoints and the midpoints of line pairs;
- (5)
- Another kind of orientation angle increments are computed from global keypoints;
- (6)
- Filter and fuse and to get the incremental orientation angle with respect to the keyframe ;
- (7)
- Obtain the relative orientation angle with respect to the first frame by means of incremental method and the keyframe mechanism, denoted as ;
- (8)
- Output the absolute orientation angle of the current frame with the aid of an extra sensor like GPS.
3.2. Coarse-to-Fine Mechanism for Clustered Keypoints
- Strengthen the raw keypoints. The raw keypoints are chosen from initial ORB keypoints with a great Harris response [29].
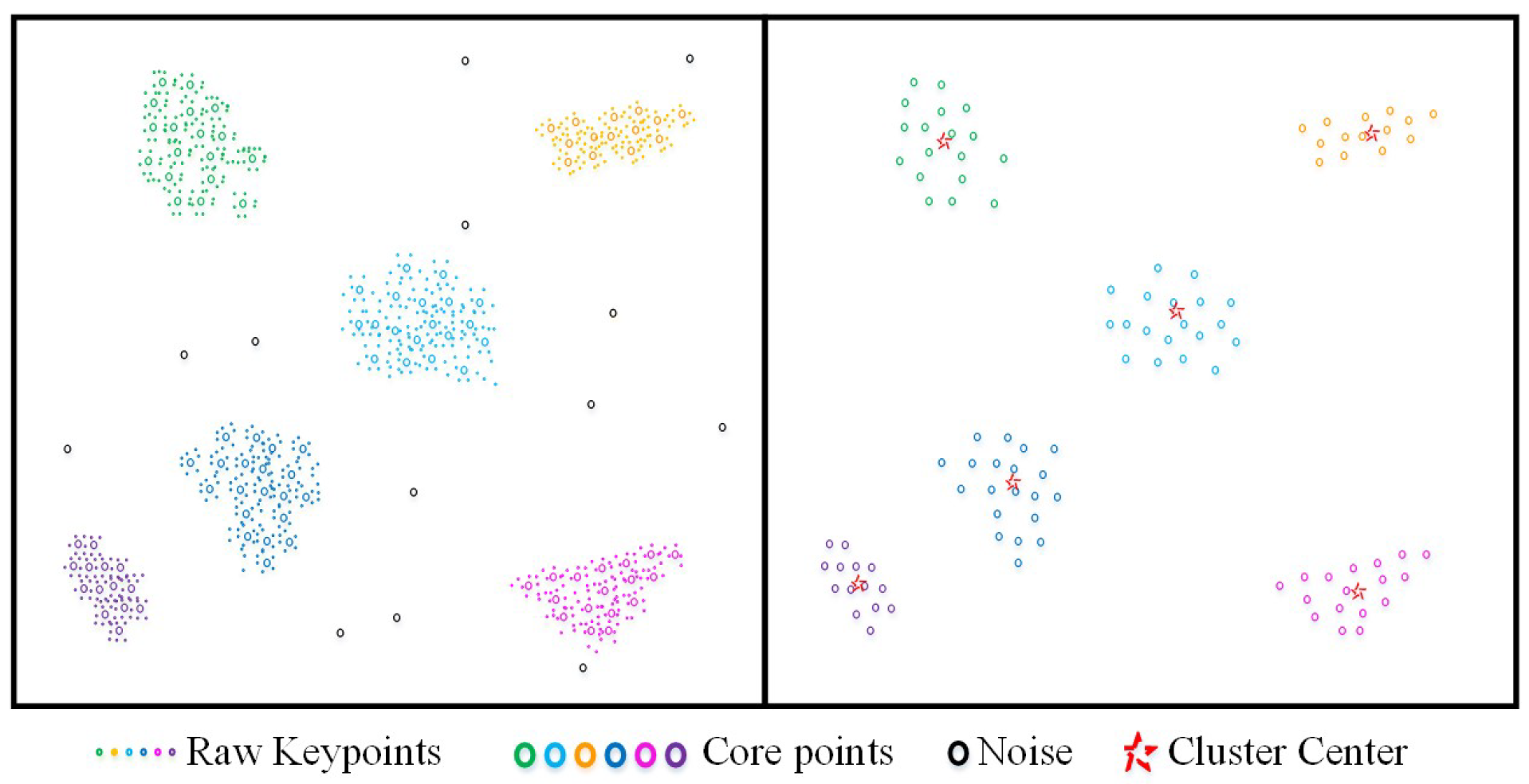
- Make the cluster smaller but more robust. Only use the core points to compute the cluster center as the initial representative points so that the points without sufficient neighbors will be ignored (Figure 5).
- Find more precise representative points for the keyframes. Considering the keypoints which are closest to the cluster centers as the clustered keypoints of the keyframes (Figure 6).
3.3. Line Pairs from LK-ZNCC
3.4. Computation of the Orientation Angle
3.4.1. Hierarchical Fusion of Point and Line Features
Feature Fusion: Creating New Features
Application Fusion: Loosely Couple Different Orientation Angles
3.4.2. Update the Keyframe
4. Results and Discussion
4.1. The Matching Result
4.2. Outdoor Datasets
- ScSe: static UAV (camera) in static environment.
- ScDe: static UAV (camera) in dynamic environment.
- RcSe: rotating UAV (camera) in static environment.
- RcDe: rotating UAV (camera) in dynamic environment.
4.3. Outdoor Experiments
4.4. Supplementary Indoor Experiments
- XSENS: A kind of high-accuracy IMU whose product model is MTi-300. Although the orientation angle is unobservable for IMU, XSENS is considered as an excellent state estimation sensor because of the fused magnetic compass and the precise state estimation algorithm. The estimation accuracy of the orientation angle can reach 1 degree. However, it needs a few minutes to set up the sensors and converge the fusing algorithm inside when it powers on.
- Magnetic Compass: A high-precision magnetic compass DCM260B whose estimation error is 0.8 degree. Though this magnetic compass is seen as precise as the ground truth, the changes of the surrounding magnetic field influence it.
- GPS-denied multi-sensors system: As presented before, PIXHAWK works well with GPS and the flight data is considered as ground truth. Nevertheless, how the multi-sensors system performs in GPS-denied cases needs to be certified.
- Converge Time: These three sensors are compared just after power on and three minutes later to test the converge time for XSENS.
- Changes of Magnetic Fields: The sensors are used in the metallic and non-metallic environment to test the influence of magnetic field for a magnetic compass.
- GPS-denied or Not: The magnetic compass is replaced by the flight controller we used in outdoor experiments, but the GPS is invalid in the internal environment. So, the influence of GPS can be displayed.
4.4.1. Testing the Converge Time
4.4.2. Testing the Changes of Magnetic Fields
4.4.3. Testing the Effect of GPS
5. Conclusions
6. Patents
- Yu Zhang, Ying Liu, Ping Li. Zhejiang University. A directional downward-looking compass based on the visual and inertial information: China, ZL2018101196741, 27 May 2020.
- Yu Zhang, Ying Liu, Ping Li. Zhejiang University. A downward-looking visual compass based on the point and line features: China, ZL2018106233944, 30 April 2021.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Karantanellis, E.; Marinos, V.; Vassilakis, E.; Christaras, B. Object-based analysis using unmanned aerial vehicles (UAVs) for site-specific landslide assessment. Remote Sens. 2020, 12, 1711. [Google Scholar] [CrossRef]
- Xu, J.; Zhu, T.; Bian, H. Review on gps attitude determination. J. Nav. Univ. Eng. 2003, 36, 17–22. [Google Scholar]
- Li, Y.; Zahran, S.; Zhuang, Y.; Gao, Z.; Luo, Y.; He, Z.; Pei, L.; Chen, R.; El-Sheimy, N. IMU/magnetometer/barometer/mass-flow sensor integrated indoor quadrotor UAV localization with robust velocity updates. Remote Sens. 2019, 11, 838. [Google Scholar] [CrossRef] [Green Version]
- Mariottini, G.L.; Scheggi, S.; Morbidi, F.; Prattichizzo, D. An accurate and robust visual-compass algorithm for robot-mounted omnidirectional cameras. Robot. Auton. Syst. 2012, 60, 1179–1190. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Y.; Li, P.; Xu, B. Uncalibrated downward-looking UAV visual compass based on clustered point features. Sci. China Inf. Sci. 2019, 62, 199202. [Google Scholar] [CrossRef] [Green Version]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef]
- Teed, Z.; Deng, J. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras. arXiv 2021, arXiv:2108.10869. [Google Scholar]
- Xu, W.; Zhong, S.; Zhang, W.; Wang, J.; Yan, L. A New Orientation Estimation Method Based on Rotation Invariant Gradient for Feature Points. IEEE Geosci. Remote Sens. Lett. 2020, 18, 791–795. [Google Scholar] [CrossRef]
- Mariottini, G.L.; Scheggi, S.; Morbidi, F.; Prattichizzo, D. A robust uncalibrated visual compass algorithm from paracatadioptric line images. In First Workshop on Omnidirectional Robot Vision, Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Morbidi, F.; Caron, G. Phase correlation for dense visual compass from omnidirectional camera-robot images. IEEE Robot. Autom. Lett. 2017, 2, 688–695. [Google Scholar] [CrossRef] [Green Version]
- Montiel, J.M.; Davison, A.J. A visual compass based on SLAM. In Proceedings of the 2006 IEEE International Conference on Robotics and Automation, Orlando, FL, USA, 15–19 May 2006; ICRA 2006. pp. 1917–1922. [Google Scholar]
- Pajdla, T.; Hlaváč, V. Zero phase representation of panoramic images for image based localization. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Ljubljana, Slovenia, 1–3 September 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 550–557. [Google Scholar]
- Menegatti, E.; Maeda, T.; Ishiguro, H. Image-based memory for robot navigation using properties of omnidirectional images. Robot. Auton. Syst. 2004, 47, 251–267. [Google Scholar] [CrossRef] [Green Version]
- Stürzl, W.; Mallot, H.A. Efficient visual homing based on Fourier transformed panoramic images. Robot. Auton. Syst. 2006, 54, 300–313. [Google Scholar] [CrossRef]
- Differt, D. Real-time rotational image registration. In Proceedings of the 2017 18th International Conference on Advanced Robotics (ICAR), Hong Kong, China, 10–12 July 2017; pp. 1–6. [Google Scholar]
- Makadia, A.; Geyer, C.; Sastry, S.; Daniilidis, K. Radon-based structure from motion without correspondences. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 796–803. [Google Scholar]
- Sturm, J.; Visser, A. An appearance-based visual compass for mobile robots. Robot. Auton. Syst. 2009, 57, 536–545. [Google Scholar] [CrossRef] [Green Version]
- Lv, W.; Kang, Y.; Zhao, Y.B. FVC: A novel nonmagnetic compass. IEEE Trans. Ind. Electron. 2018, 66, 7810–7820. [Google Scholar] [CrossRef]
- Kim, P.; Li, H.; Joo, K. Quasi-globally Optimal and Real-time Visual Compass in Manhattan Structured Environments. IEEE Robot. Autom. Lett. 2022, 7, 2613–2620. [Google Scholar] [CrossRef]
- Sabnis, A.; Vachhani, L. A multiple camera based visual compass for a mobile robot in dynamic environment. In Proceedings of the 2013 IEEE International Conference on Control Applications (CCA), Hyderabad, India, 28–30 August 2013; pp. 611–616. [Google Scholar]
- Sturzl, W. A lightweight single-camera polarization compass with covariance estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5353–5361. [Google Scholar]
- Di Stefano, L.; Mattoccia, S. Fast template matching using bounded partial correlation. Mach. Vis. Appl. 2003, 13, 213–221. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Washington, DC, USA, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Akinlar, C.; Topal, C. Edlines: Real-time line segment detection by edge drawing (ed). In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 2837–2840. [Google Scholar]
- Akinlar, C.; Topal, C. EDLines: A real-time line segment detector with a false detection control. Pattern Recognit. Lett. 2011, 32, 1633–1642. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. KDD 1996, 96, 226–231. [Google Scholar]
- Harris, C.G.; Stephens, M.J. A combined corner and edge detector. Alvey Vis. Conf. 1988, 2, 147–151. [Google Scholar]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence, IJCAI ’81, Vancouver, BC, Canada, 24–28 August 1981. [Google Scholar]
- He, Y.; Zhao, J.; Guo, Y.; He, W.; Yuan, K. Pl-vio: Tightly-coupled monocular visual–inertial odometry using point and line features. Sensors 2018, 18, 1159. [Google Scholar] [CrossRef] [Green Version]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Hough, P.V. Method and Means for Recognizing Complex Patterns. U.S. Patent 3,069,654, 18 December 1962. [Google Scholar]
- Xu, L.; Oja, E.; Kultanen, P. A new curve detection method: Randomized Hough transform (RHT). Pattern Recognit. Lett. 1990, 11, 331–338. [Google Scholar] [CrossRef]
- Kiryati, N.; Eldar, Y.; Bruckstein, A.M. A probabilistic Hough transform. Pattern Recognit. 1991, 24, 303–316. [Google Scholar] [CrossRef]
- Galambos, C.; Kittler, J.; Matas, J. Gradient based progressive probabilistic Hough transform. IEEE Proc.-Vis. Image Signal Process. 2001, 148, 158–165. [Google Scholar] [CrossRef] [Green Version]
- Fernandes, L.A.; Oliveira, M.M. Real-time line detection through an improved Hough transform voting scheme. Pattern Recognit. 2008, 41, 299–314. [Google Scholar] [CrossRef]
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.M.; Randall, G. LSD: A line segment detector. Image Process. Online 2012, 2, 35–55. [Google Scholar] [CrossRef] [Green Version]
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.M.; Randall, G. LSD: A fast line segment detector with a false detection control. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 32, 722–732. [Google Scholar] [CrossRef]
- Fan, B.; Wu, F.; Hu, Z. Line matching leveraged by point correspondences. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 390–397. [Google Scholar]
- Wang, Z.; Wu, F.; Hu, Z. MSLD: A robust descriptor for line matching. Pattern Recognit. 2009, 42, 941–953. [Google Scholar] [CrossRef]
- Zhang, L.; Koch, R. An efficient and robust line segment matching approach based on LBD descriptor and pairwise geometric consistency. J. Vis. Commun. Image Represent. 2013, 24, 794–805. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario Settings | Illumination | Test1 | Test2 | Test3 | |||
|---|---|---|---|---|---|---|---|
| Mean (deg) | Cov (deg) | Mean (deg) | Cov (deg) | Mean (deg) | Cov (deg) | ||
| ScSe | +++ | −0.1663 | 0.2327 | 0.3634 | −0.3315 | 0.0835 | 0.5367 |
| ++ | −0.1149 | 0.3189 | −0.0034 | 0.5267 | 3.949 × 10 | 0.1750 | |
| + | 0.1567 | 0.1640 | 0.4337 | 0.1750 | 0.5647 | 0.3762 | |
| ScDe | +++ | −0.5073 | 0.3809 | 0.9909 | −0.5451 | 1.0718 | −0.1028 |
| ++ | −0.1125 | 0.1526 | 0.6468 | −0.0238 | −3.99 × 10 | −0.1484 | |
| + | −0.4643 | 0.3766 | 1.0183 | −0.0068 | 1.0718 | −0.1028 | |
| RcSe | +++ | −0.1070 | 0.7295 | 1.8363 | 0.6339 | 1.6050 | 0.6339 |
| ++ | 0.9365 | 0.7783 | −0.2505 | 2.4579 | 0.0728 | 1.0686 | |
| + | −0.6674 | 1.0272 | −0.2760 | 1.0686 | 1.7573 | 1.4529 | |
| RcDe | +++ | 0.1567 | 0.1640 | −0.3626 | 0.6875 | −0.2506 | 0.6875 |
| ++ | −1.4292 | 1.3539 | −0.2369 | 0.9934 | −0.1330 | 0.9934 | |
| + | −0.1071 | 0.8869 | −1.0427 | 0.7606 | −0.0193 | 0.7606 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Tao, J.; Kong, D.; Zhang, Y.; Li, P. A Visual Compass Based on Point and Line Features for UAV High-Altitude Orientation Estimation. Remote Sens. 2022, 14, 1430. https://doi.org/10.3390/rs14061430
Liu Y, Tao J, Kong D, Zhang Y, Li P. A Visual Compass Based on Point and Line Features for UAV High-Altitude Orientation Estimation. Remote Sensing. 2022; 14(6):1430. https://doi.org/10.3390/rs14061430
Chicago/Turabian StyleLiu, Ying, Junyi Tao, Da Kong, Yu Zhang, and Ping Li. 2022. "A Visual Compass Based on Point and Line Features for UAV High-Altitude Orientation Estimation" Remote Sensing 14, no. 6: 1430. https://doi.org/10.3390/rs14061430
APA StyleLiu, Y., Tao, J., Kong, D., Zhang, Y., & Li, P. (2022). A Visual Compass Based on Point and Line Features for UAV High-Altitude Orientation Estimation. Remote Sensing, 14(6), 1430. https://doi.org/10.3390/rs14061430