
SDTGAN: Generation Adversarial Network for Spectral Domain Translation of Remote Sensing Images of the Earth Background Based on Shared Latent Domain


Abstract
:1. Introduction
- The location accuracy of the surface area: The cloud and water vapor will shield the earth’s surface in the remote sensing image and affect the transmittance of the atmospheric radiation, resulting in the incompleteness of the surface boundary and misjudgment of features in the image. Based on a single source of remote sensing spectral data, it is difficult to deduce the true surface under cloud cover and atmospheric transmittance fluctuations.
- Limitations of spectral characterization information: The physical characteristics expressed by each spectrum are different. For example, the band of 3.5~4.0 microns can filter water vapor to observe the surface, while the band of 7 microns can only show water vapor and clouds. Due to the differences in the information of different spectral images, even with spatio-temporal matching datasets, datasets, it is difficult to realize the information migration or speculation between the bands with significant differences.
- Spectral translation accuracy: Computational vision tasks often focus on the similarity of image styles in different domains and encourage the diversity of synthesis effects. However, spectral translation tasks require the conversion of pixels under the same input conditions between different spectral images. The result is unique and conforms to physical characteristics.
- The introduction of shared latent domain: Through cross domain translation and within domain self-reconstruction training, the shared latent domain fits the joint probability distribution of the multi-spectral domain, and can parse and store diversity and the characteristics of each spectral domain. It is the end of encoders and the beginning of the decoders of all spectral domains. In this way, the parameter expansion problem of many-to-many translation is avoided.
- The introduction of multimodal feature map: By introducing discrete feature (e.g., surface type and cloud map type), and numerical feature maps (e.g., surface temperature), the location accuracy of the surface area is improved, and the limitations of spectral characterization information are overcome.
- The training is conducted on the supervised spatio-temporal matching data sets, combined with cycle consistency loss and perceptual loss, to ensure the uniqueness of the output result and improve spectral translation accuracy.
2. Materials and Methods
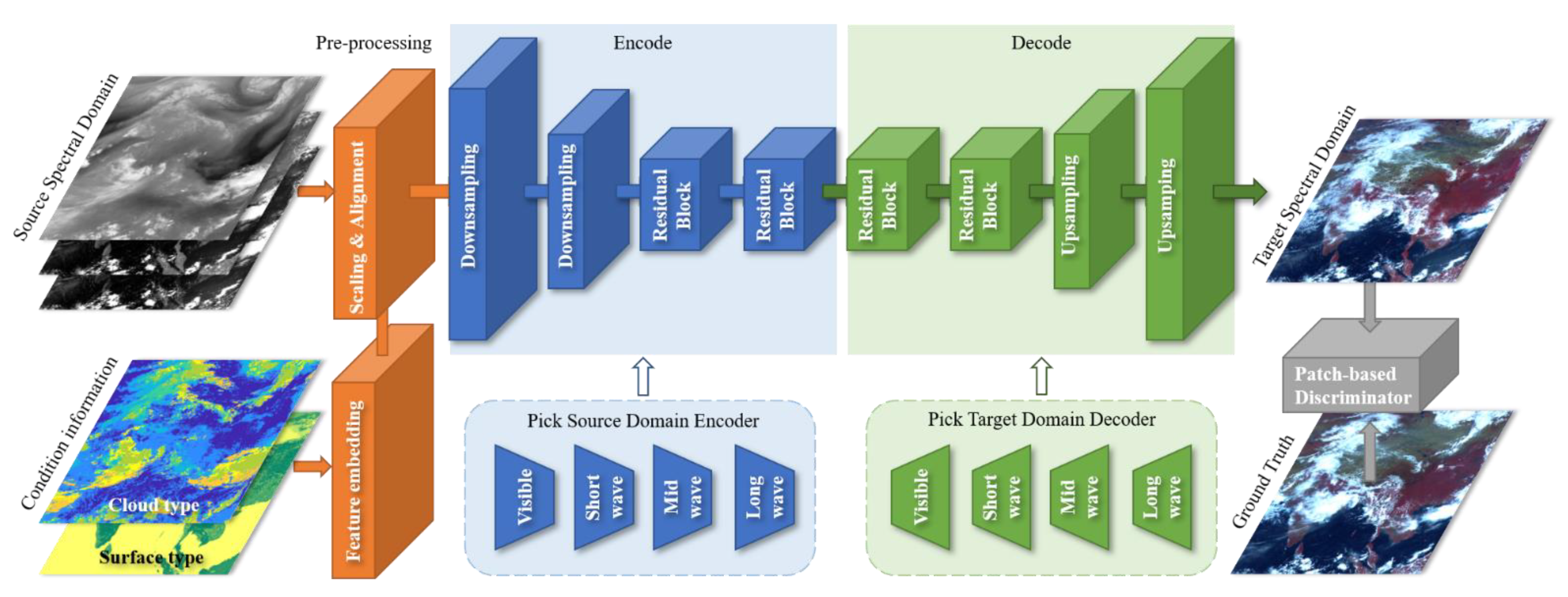
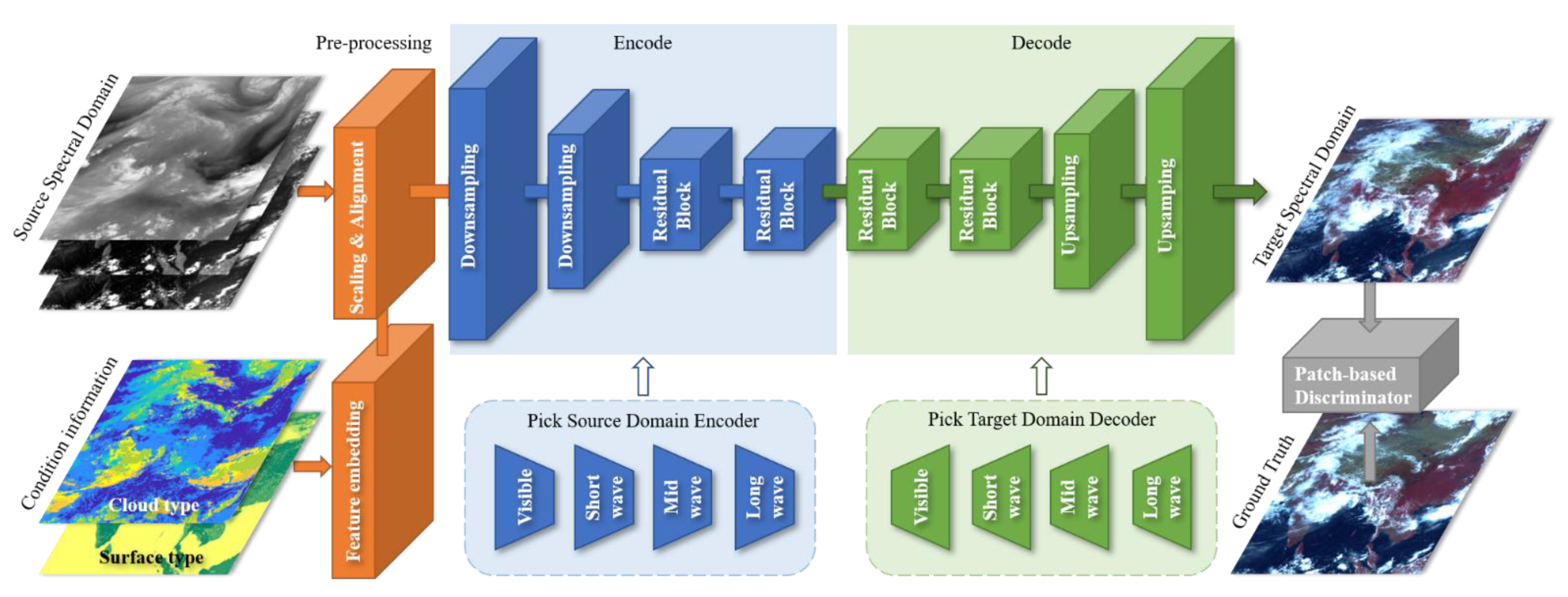
2.1. Overview of the Method
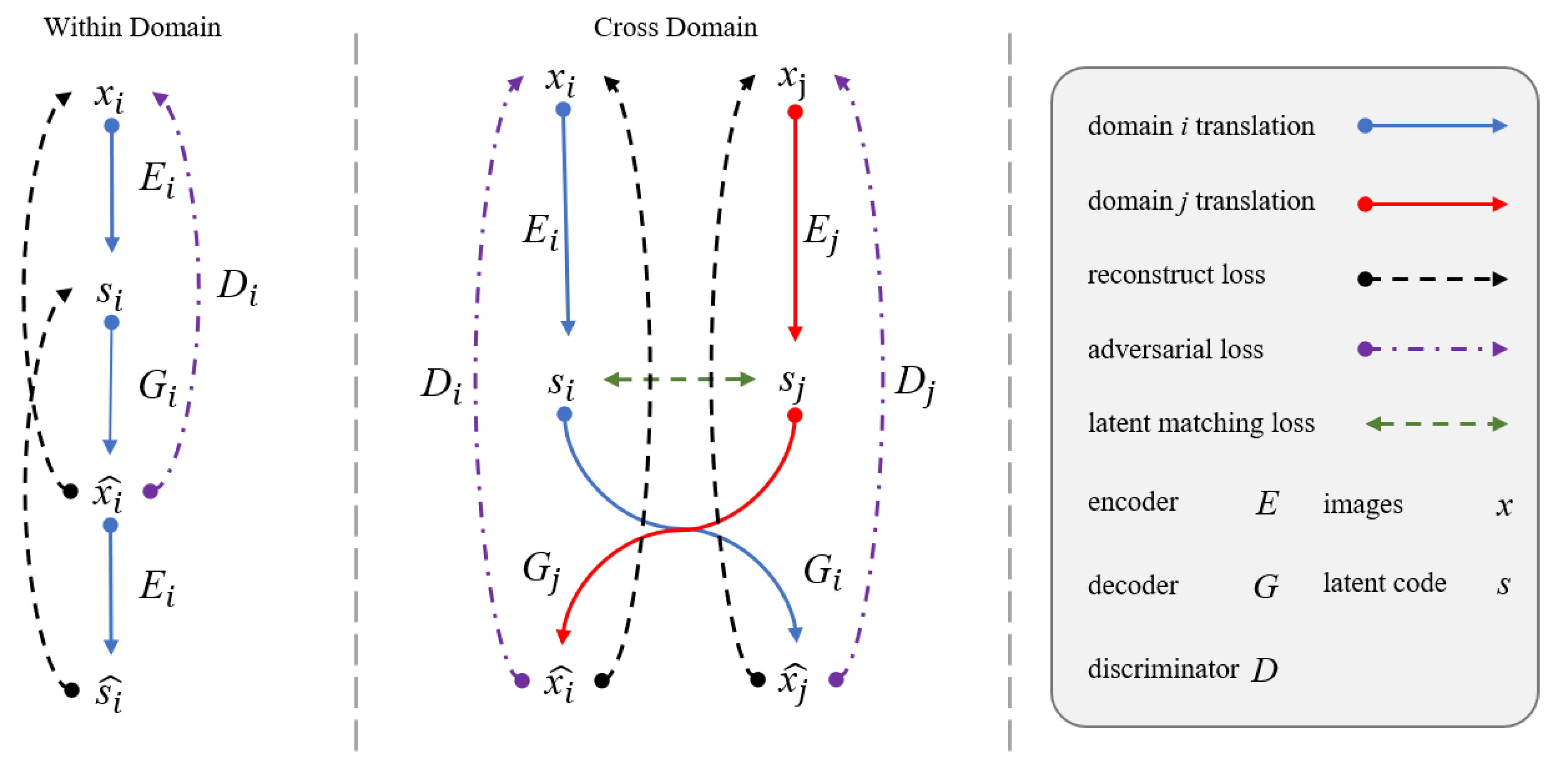
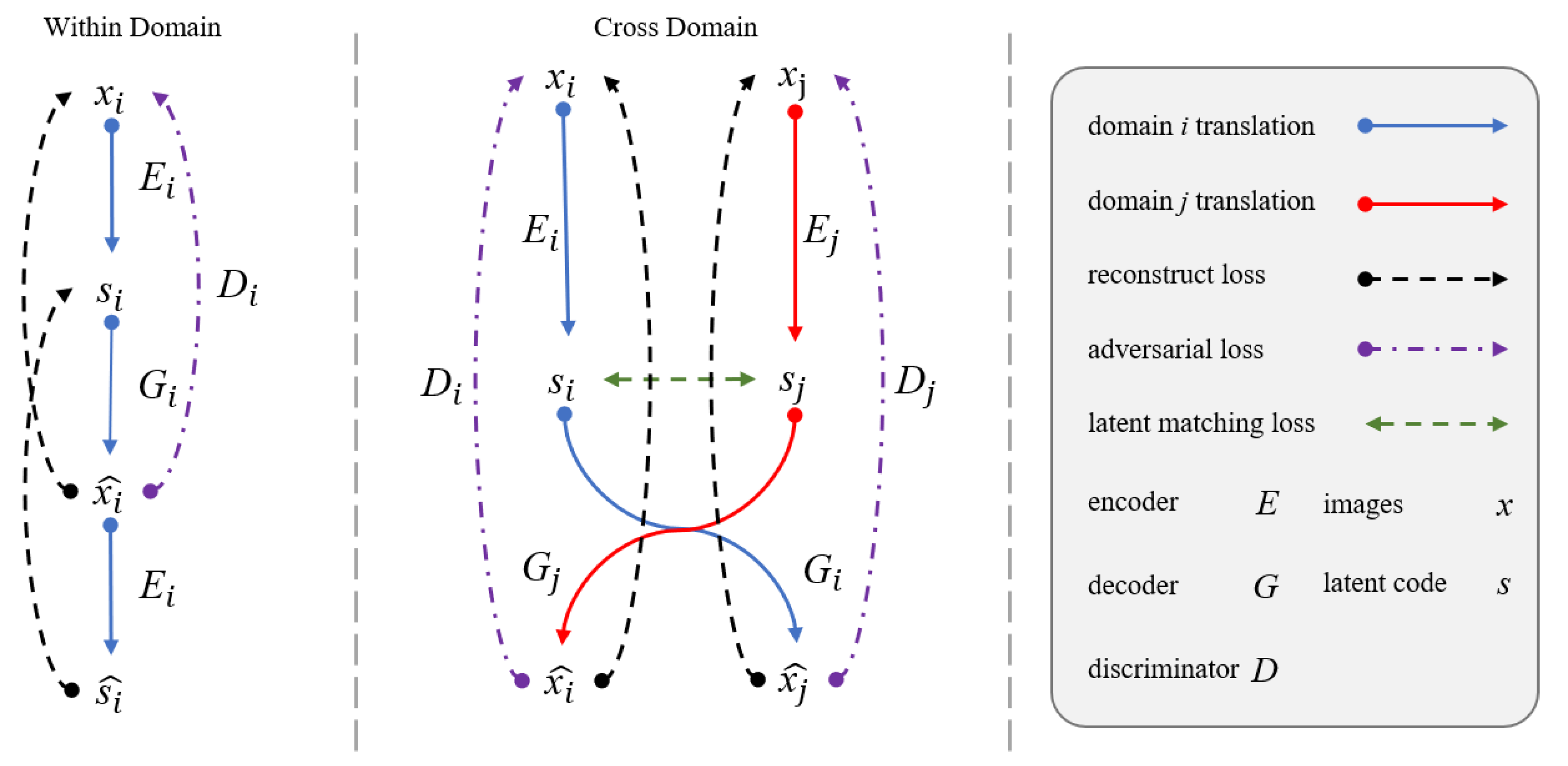
2.2. Shared Latent Domain Assumption
2.3. Architecture
2.3.1. Generative Network
2.3.2. Patch Based Discriminator Network
2.3.3. Feature Embedding
2.4. Loss Function
2.4.1. Reconstruction loss
- Within domain reconstruction loss
- 2.
- Cross domain reconstruction loss
2.4.2. Latent Matching loss
2.4.3. Adversarial loss
2.4.4. Total Loss
2.5. Traning Process
| Algorithm 1. Generators training process in a single iteration |
| for i = 1 to N |
| for j = i + 1 to N |
| update |
| Backward gradient decent |
| Optimizer update |
| end for |
| end for |
3. Experiment
3.1. Datasets
3.1.1. Remote sensing Datasets
3.1.2. Condition Information Dataset
- (1)
- Earth surface type
- (2)
- Cloud type
3.2. Implementation Details
3.3. Visual Comparison
3.4. Digital Comparison
3.5. Ablation Study
3.6. Limitation
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Srivastava, A.; Oza, N.; Stroeve, J. Virtual sensors: Using data mining techniques to efficiently estimate remote sensing spectra. IEEE Trans. Geosci. Remote Sens. 2005, 43, 590–600. [Google Scholar] [CrossRef]
- Miller, S.W.; Bergen, W.R.; Huang, H.; Bloom, H.J. End-to-end simulation for support of remote sensing systems design. Proc. SPIE-Int. Soc. Opt. Eng. 2004, 5548, 380–390. [Google Scholar]
- Börner, A.; Wiest, L.; Keller, P.; Reulke, R.; Richter, R.; Schaepman, M.; Schläpfer, D. SENSOR: A tool for the simulation of hyperspectral remote sensing systems. ISPRS J. Photogramm. Remote Sens. 2001, 55, 299–312. [Google Scholar] [CrossRef]
- Gastellu-Etchegorry, J.P.; Martin, E.; Gascon, F. DART: A 3D model for simulating satellite images and studying surface radiation budget. Int. J. Remote Sens. 2004, 25, 73–96. [Google Scholar] [CrossRef]
- Gascon, F.; Gastellu-Etchegorry, J.P.; Lefevre, M.-J. Radiative transfer model for simulating high-resolution satellite images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 1922–1926. [Google Scholar] [CrossRef]
- Ambeau, B.L.; Gerace, A.D.; Montanaro, M.; McCorkel, J. The characterization of a DIRSIG simulation environment to support the inter-calibration of spaceborne sensors. In Proceedings of the Earth Observing Systems XXI, San Diego, CA, USA, 19 September 2016; p. 99720M. [Google Scholar]
- Tiwari, V.; Kumar, V.; Pandey, K.; Ranade, R.; Agrawal, S. Simulation of the hyperspectral data using Multispectral data. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 6157–6160. [Google Scholar]
- Rengarajan, R.; Goodenough, A.A.; Schott, J.R. Simulating the directional, spectral and textural properties of a large-scale scene at high resolution using a MODIS BRDF product. In Proceedings of the Sensors, Systems, and Next-Generation Satellites XX, Edinburgh, UK, 19 October 2016; p. 100000Y. [Google Scholar]
- Cheng, X.; Shen, Z.-F.; Luo, J.-C.; Shen, J.-X.; Hu, X.-D.; Zhu, C.-M. Method on simulating remote sensing image band by using groundobject spectral features study. J. Infrared Millim. WAVES 2010, 29, 45–48. [Google Scholar] [CrossRef]
- Geng, Y.; Mei, S.; Tian, J.; Zhang, Y.; Du, Q. Spatial Constrained Hyperspectral Reconstruction from RGB Inputs Using Dictionary Representation. In Proceedings of the IGARSS 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3169–3172. [Google Scholar]
- Han, X.; Yu, J.; Luo, J.; Sun, W. Reconstruction from Multispectral to Hyperspectral Image Using Spectral Library-Based Dictionary Learning. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1325–1335. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.-C.; Liu, M.-Y.; Zhu, J.-Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Xiong, F.; Wang, Q.; Gao, Q. Consistent Embedded GAN for Image-to-Image Translation. IEEE Access 2019, 7, 126651–126661. [Google Scholar] [CrossRef]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Cambridge, MA, USA, 20–23 June 2017; pp. 2849–2857. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.-Y.; Isola, P.; Saenko, K.; Efros, A.A.; Darrell, T. CyCADA: Cycle-Consistent Adversarial Domain Adaptation. In Proceedings of the ICML, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Chen, S.; Liao, D.; Qian, Y. Spectral Image Visualization Using Generative Adversarial Networks. In Proceedings of the Swarm, Evolutionary, and Memetic Computing; Springer Science and Business Media LLC: Secaucus, NJ, USA, 2018; pp. 388–401. [Google Scholar]
- Shi, Z.; Chen, C.; Xiong, Z.; Liu, D.; Wu, F. HSCNN+: Advanced CNN-Based Hyperspectral Recovery from RGB Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 939–947. [Google Scholar] [CrossRef]
- Wu, J.; Aeschbacher, J.; Timofte, R. In Defense of Shallow Learned Spectral Reconstruction from RGB Images. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 471–479. [Google Scholar]
- Zhao, Y.; Fu, G.; Wang, H.; Zhang, S. The Fusion of Unmatched Infrared and Visible Images Based on Generative Adversarial Networks. Math. Probl. Eng. 2020, 2020, 1–12. [Google Scholar] [CrossRef]
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Tang, R.; Liu, H.; Wei, J. Visualizing Near Infrared Hyperspectral Images with Generative Adversarial Networks. Remote Sens. 2020, 12, 3848. [Google Scholar] [CrossRef]
- Cheng, W. Creating synthetic meteorology satellite visible light images during night based on GAN method. arXiv 2021, arXiv:2108.04330. [Google Scholar]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Arad, B.; Ben-Shahar, O. Sparse Recovery of Hyperspectral Signal from Natural RGB Images. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 11–14. [Google Scholar]
- Liu, P.; Zhao, H. Adversarial Networks for Scale Feature-Attention Spectral Image Reconstruction from a Single RGB. Sensors 2020, 20, 2426. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Liu, M.-Y.; Belongie, S.; Kautz, J. Multimodal Unsupervised Image-to-Image Translation; Springer Science and Business Media LLC: Secaucus, NJ, USA, 2018; pp. 179–196. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherland, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. Available online: https://arxiv.org/abs/1605.06211 (accessed on 1 March 2022).
- Durugkar, I.; Gemp, I.M.; Mahadevan, S. Generative Multi-Adversarial Networks. arXiv 2017, arXiv:1611.01673. [Google Scholar]
- Rosca, M.; Lakshminarayanan, B.; Warde-Farley, D.; Mohamed, S. Variational Approaches for Auto-Encoding Generative Adversarial Networks. arXiv 2017, arXiv:1706.04987. [Google Scholar]
- Zhang, P.; Zhu, L.; Tang, S.; Gao, L.; Chen, L.; Zheng, W.; Han, X.; Chen, J.; Shao, J. General Comparison of FY-4A/AGRI with Other GEO/LEO Instruments and Its Potential and Challenges in Non-meteorological Applications. Front. Earth Sci. 2019, 6, 6. [Google Scholar] [CrossRef] [Green Version]
- Zhang, P.; Lu, Q.; Hu, X.; Gu, S. Latest Progress of the Chinese Meteorological Satellite Program and Core Data Processing Technologies. Adv. Atmos. Sci. 2019, 36, 1027–1045. [Google Scholar] [CrossRef]
- Congalton, R.G.; Gu, J.; Yadav, K.; Thenkabail, P.S.; Ozdogan, M. Global Land Cover Mapping: A Review and Uncertainty Analysis. Remote Sens. 2014, 6, 12070–12093. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V.S. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Setiadi, D.R.I.M. PSNR vs. SSIM: Imperceptibility quality assessment for image steganography. Multimedia Tools Appl. 2021, 80, 8423–8444. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Channel ID | Description | Band (μm) | Spatial Resolution (km) | Main Application |
|---|---|---|---|---|
| CH01 | Visible & Near-Infrared | 0.45~0.49 | 1 | Aerosol |
| CH02 | 0.55~0.75 | 0.5~1 | Fog, Cloud | |
| CH03 | 0.75~0.90 | 1 | Vegetation | |
| CH04 | Short-Wave Infrared | 1.36~1.39 | 2 | Cirrus |
| CH05 | 1.58~1.64 | 2 | Cloud, Snow | |
| CH06 | 2.1~2.35 | 2~4 | Cirrus, Aerosol | |
| CH07 | Mid-Wave Infrared | 3.5~4.0 (High) | 2 | Fire |
| CH08 | 3.5~4.0 (Low) | 4 | Land Surface | |
| CH09 | Water Vapor | 5.8~6.7 | 4 | Water Vapor |
| CH10 | 6.9~7.3 | 4 | Water Vapor | |
| CH11 | Long-Wave Infrared | 8.0~9.0 | 4 | Water Vapor, |
| CH12 | 10.3~11.3 | 4 | Cloud | |
| CH13 | 11.5~12.5 | 4 | Surface Temperature | |
| CH14 | 13.2~13.8 | 4 | Surface Temperature |
| Label | Type |
|---|---|
| 0 | Post-flooding or irrigated croplands |
| 1 | Rainfed croplands |
| 2 | Mosaic Cropland (50–70%)/Vegetation (grassland, shrubland, forest) (20–50%) |
| 3 | Mosaic Vegetation (grassland, shrubland, forest) (50–70%)/Cropland |
| 4 | Closed to open (>15%) broadleaved evergreen and/or semi-deciduous forest (>5 m) |
| 5 | Closed (>40%) broad leaved deciduous forest (>5 m) |
| 6 | Open (15–40%) broad leaved deciduous forest (>5 m) |
| 7 | Closed (>40%) needle leaved evergreen forest (>5 m) |
| 8 | Open (15–40%) needle leaved deciduous or evergreen forest (>5 m) |
| 9 | Closed to open (>15%) mixed broadleaved and needle leaved forest (>5 m) |
| 10 | Mosaic Forest/Shrubland (50–70%)/Grassland (20–50%) |
| 11 | Mosaic Grassland (50–70%)/Forest/Shrubland (20–50%) |
| 12 | Closed to open (>15%) shrubland (<5 m) |
| 13 | Closed to open (>15%) grassland |
| 14 | Sparse (>15%) vegetation (woody vegetation, shrubs, grassland) |
| 15 | Closed (>40%) broadleaved forest regularly flooded-Fresh water |
| 16 | Closed (>40%) broadleaved semi-deciduous and/or evergreen forest regularly flooded-Saline water |
| 17 | Closed to open (>15%) vegetation (grassland, shrubland, woody vegetation) on regularly flooded or waterlogged soil-Fresh, brackish or saline water |
| 18 | Artificial surfaces and associated areas (urban areas >50%) |
| 19 | Bare areas |
| 20 | Water bodies |
| 21 | Permanent snow and ice |
| 22 | No data |
| Label | Type |
|---|---|
| 0 | Clear |
| 1 | Water Type |
| 2 | Super Cooled Type |
| 3 | Mixed Type |
| 4 | Ice Type |
| 5 | Cirrus Type |
| 6 | Overlap Type |
| 7 | Uncertain |
| 8 | Space |
| 9 | Fill Number |
| Method | MSE | PSNR | SSIM |
|---|---|---|---|
| CycleGAN | 0.0979 | 10.1333 | 0.347 |
| UNIT | 0.0931 | 10.3951 | 0.3841 |
| Pix2pixHD | 0.0663 | 11.8969 | 0.4846 |
| SDTGAN with Surface Label | 0.0361 | 14.5794 | 0.6246 |
| SDTGAN with Surface and Cloud Label | 0.0237 | 16.4055 | 0.7018 |
| Method | MSE | PSNR | SSIM |
|---|---|---|---|
| CycleGAN | 0.0521 | 13.014 | 0.7148 |
| UNIT | 0.1592 | 8.1298 | 0.5055 |
| Pix2pixHD | 0.0105 | 19.9687 | 0.775 |
| SDTGAN with Surface Label | 0.0017 | 27.9227 | 0.8695 |
| SDTGAN with Surface and Cloud Label | 0.0019 | 27.6883 | 0.9031 |
| Method | MSE | PSNR | SSIM |
|---|---|---|---|
| Basic | 0.0393 | 14.1868 | 0.5986 |
| Basic + within Domain Reconstruction Loss | 0.0382 | 14.2955 | 0.5867 |
| Basic + cross Domain Reconstruction Loss | 0.0251 | 16.0984 | 0.6801 |
| Basic + Latent Matching Loss | 0.0326 | 14.9459 | 0.6195 |
| Method | MSE | PSNR | SSIM |
|---|---|---|---|
| Basic | 0.0037 | 24.4947 | 0.5256 |
| Basic + within Domain Reconstruction Loss | 0.0048 | 23.3879 | 0.8383 |
| Basic + cross Domain Reconstruction Loss | 0.0019 | 27.6244 | 0.898 |
| Basic + Latent Matching Loss | 0.0032 | 25.083 | 0.56 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, B.; Zhu, L.; Guo, X.; Wang, X.; Wu, J. SDTGAN: Generation Adversarial Network for Spectral Domain Translation of Remote Sensing Images of the Earth Background Based on Shared Latent Domain. Remote Sens. 2022, 14, 1359. https://doi.org/10.3390/rs14061359
Wang B, Zhu L, Guo X, Wang X, Wu J. SDTGAN: Generation Adversarial Network for Spectral Domain Translation of Remote Sensing Images of the Earth Background Based on Shared Latent Domain. Remote Sensing. 2022; 14(6):1359. https://doi.org/10.3390/rs14061359
Chicago/Turabian StyleWang, Biao, Lingxuan Zhu, Xing Guo, Xiaobing Wang, and Jiaji Wu. 2022. "SDTGAN: Generation Adversarial Network for Spectral Domain Translation of Remote Sensing Images of the Earth Background Based on Shared Latent Domain" Remote Sensing 14, no. 6: 1359. https://doi.org/10.3390/rs14061359
APA StyleWang, B., Zhu, L., Guo, X., Wang, X., & Wu, J. (2022). SDTGAN: Generation Adversarial Network for Spectral Domain Translation of Remote Sensing Images of the Earth Background Based on Shared Latent Domain. Remote Sensing, 14(6), 1359. https://doi.org/10.3390/rs14061359