
A Methodology to Generate Integrated Land Cover Data for Land Surface Model by Improving Dempster-Shafer Theory



Abstract
1. Introduction
2. Materials and Methods
2.1. Land Cover Data
2.1.1. CNLULC
2.1.2. MODIS LC
2.1.3. FROM-GLC
2.1.4. China Vegetation Map
2.2. Atmospheric Forcing Data
2.3. Validation Data
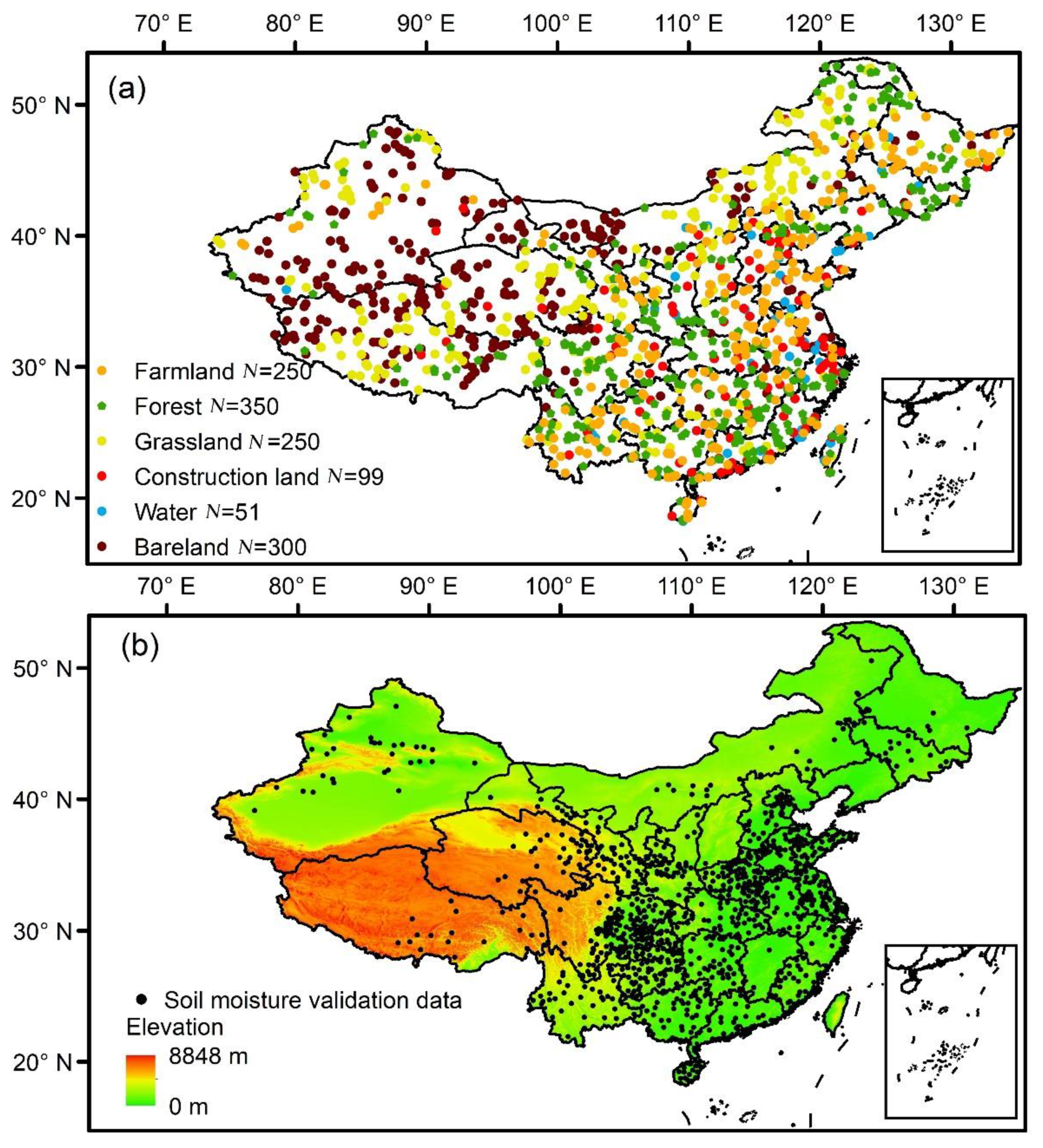
2.3.1. Land Cover Validation Data
2.3.2. Soil Moisture Validation Data
2.4. Fusion Method Construction
2.4.1. Improving D-S Evidence Theory
2.4.2. Construction of the Frame of Discernment
2.4.3. Construction of BPA Based on Knowledge Rules Optimization
- (1)
- If A and B have no relationship in definition, such as “Water bodies” and “Urban and built-up land”, then the affinity score between A and B is 0.
- (2)
- If A and B are partly related, such as “evergreen mixed forest” and “evergreen green forest”, then the affinity score between A and B is 50.
- (3)
- If A and B are completely matched in definition, such as “evergreen mixed forest” and “mixed forest”, then the affinity score between A and B is 100.
- (4)
- If A and B are little or mostly related, then the affinity score between A and B is 25 or 75.
2.4.4. Establishment of Decision Rules Based on Degree of Belief
2.5. Soil Moisture Simulation Based on Noah-MP LSM
3. Results
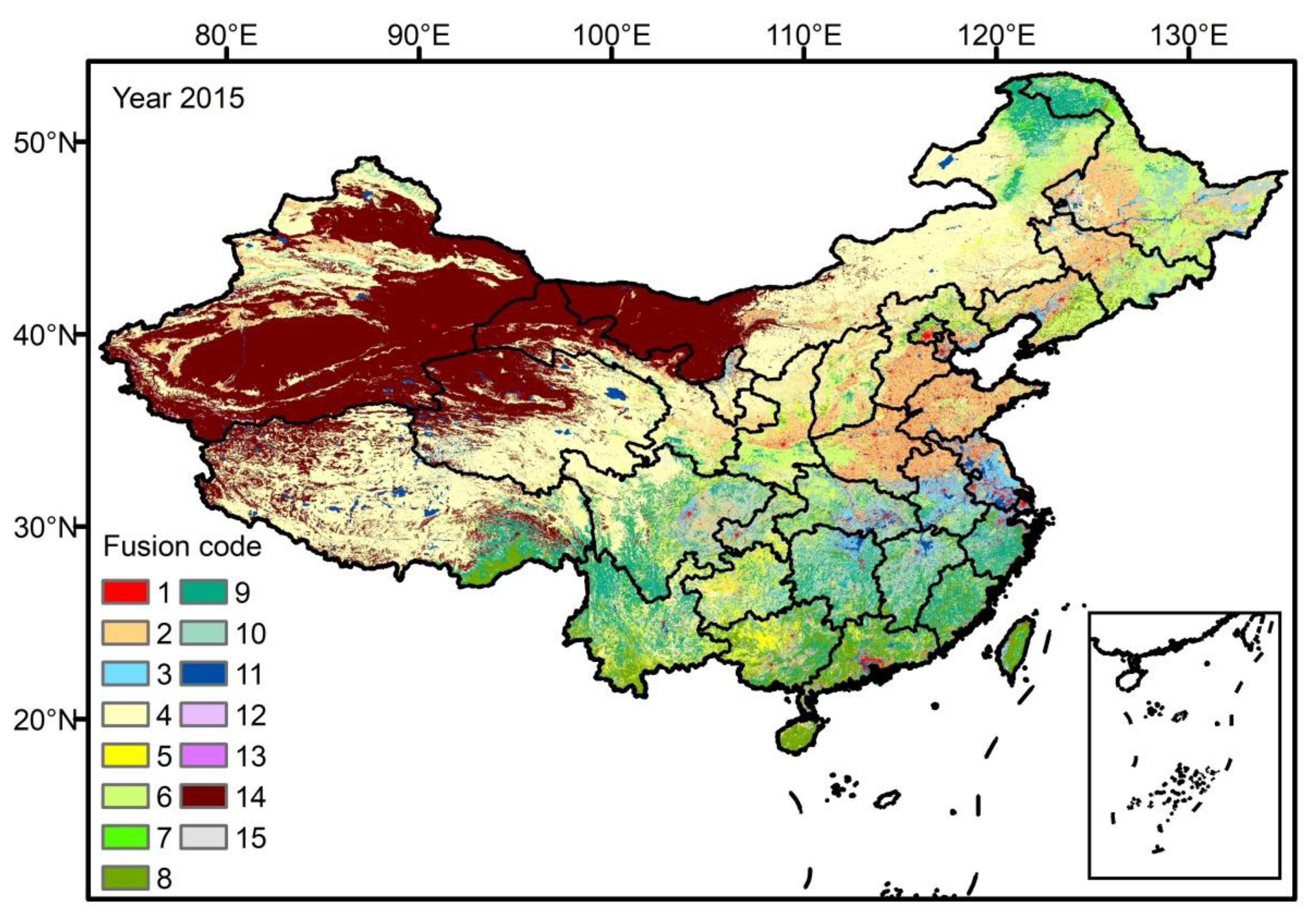
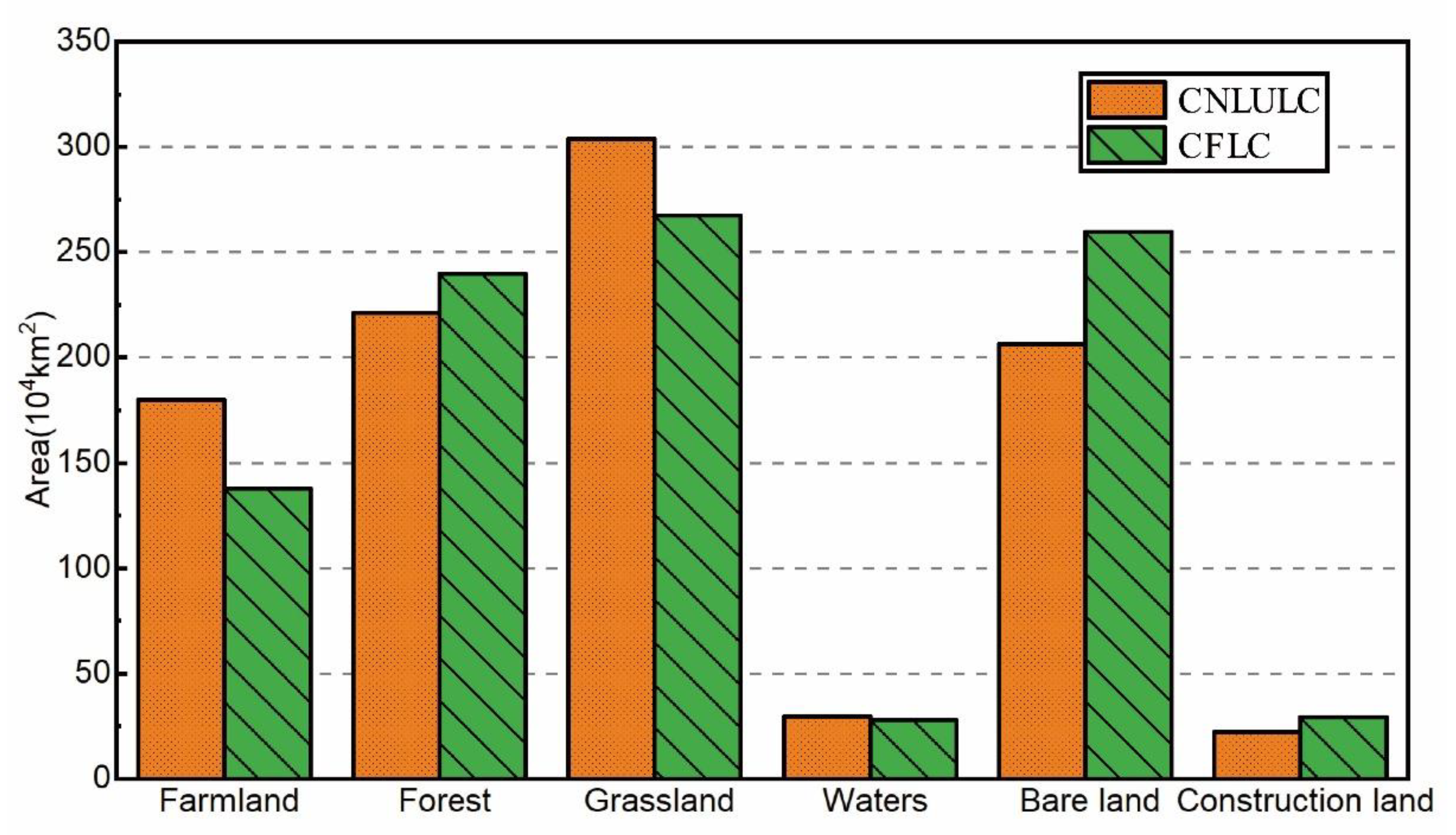
3.1. Comparison of CFLC and CNLULC
3.2. Comparison of CFLC and Global Remote Sensing Land Cover Data
3.2.1. Comparison of Classification Accuracy Based on Geo-Wiki
3.2.2. Cross-Validation Based on Multiple Land Cover Data
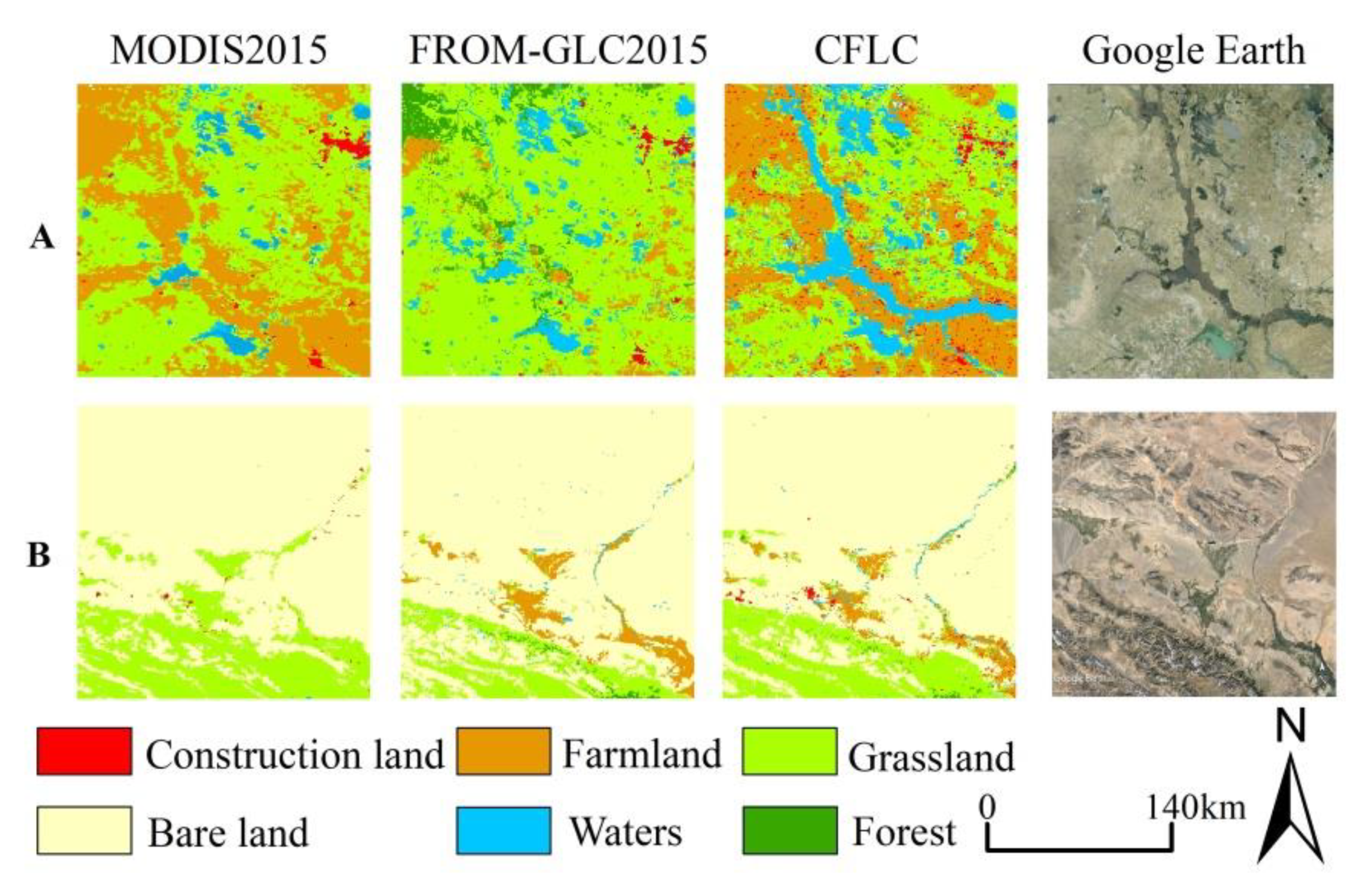
3.2.3. Comparison of Typical Areas
3.3. Uncertainty Analysis
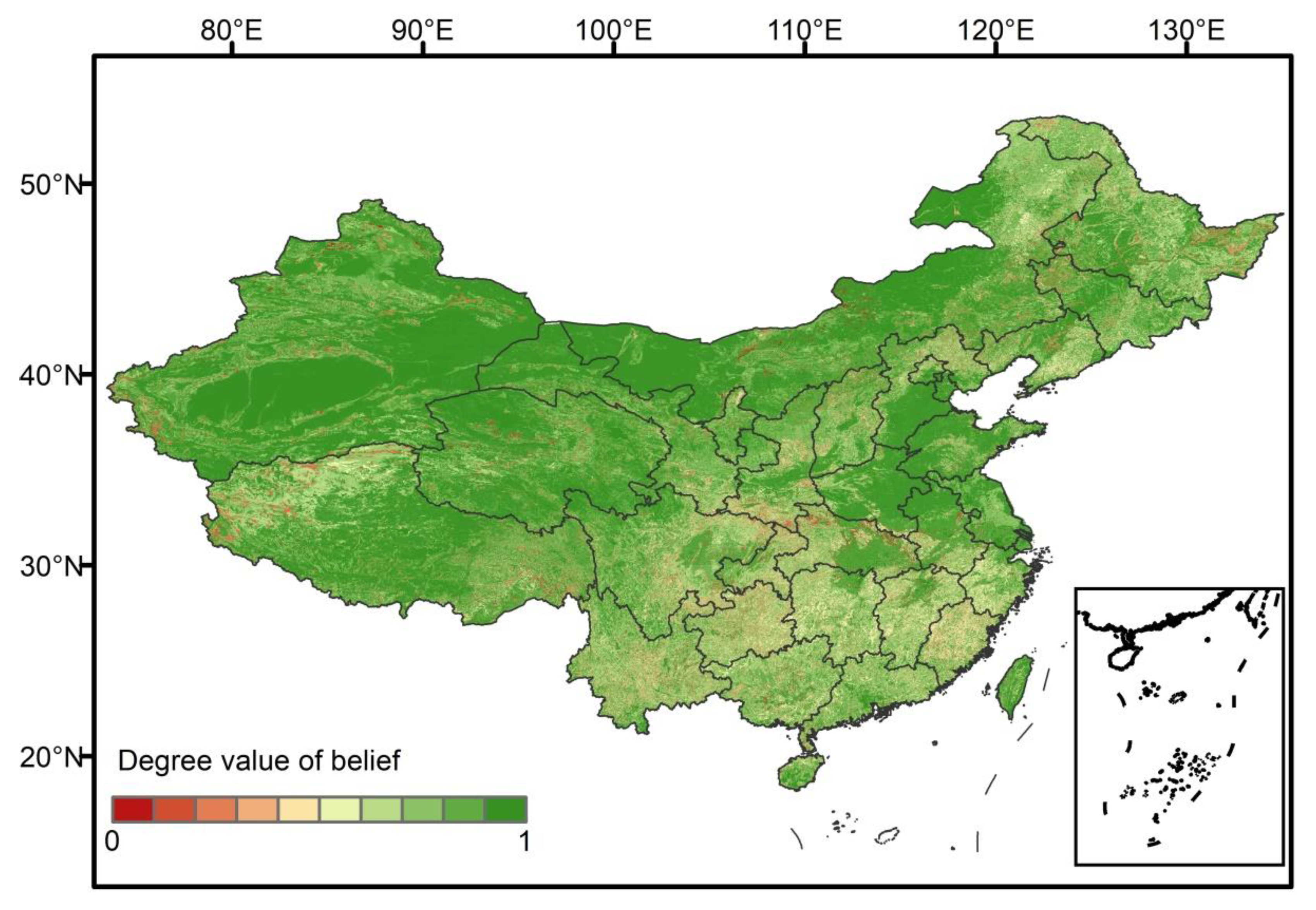
3.3.1. The Spatial Distribution of Certainty
3.3.2. The Certainty of Different Land Cover Types
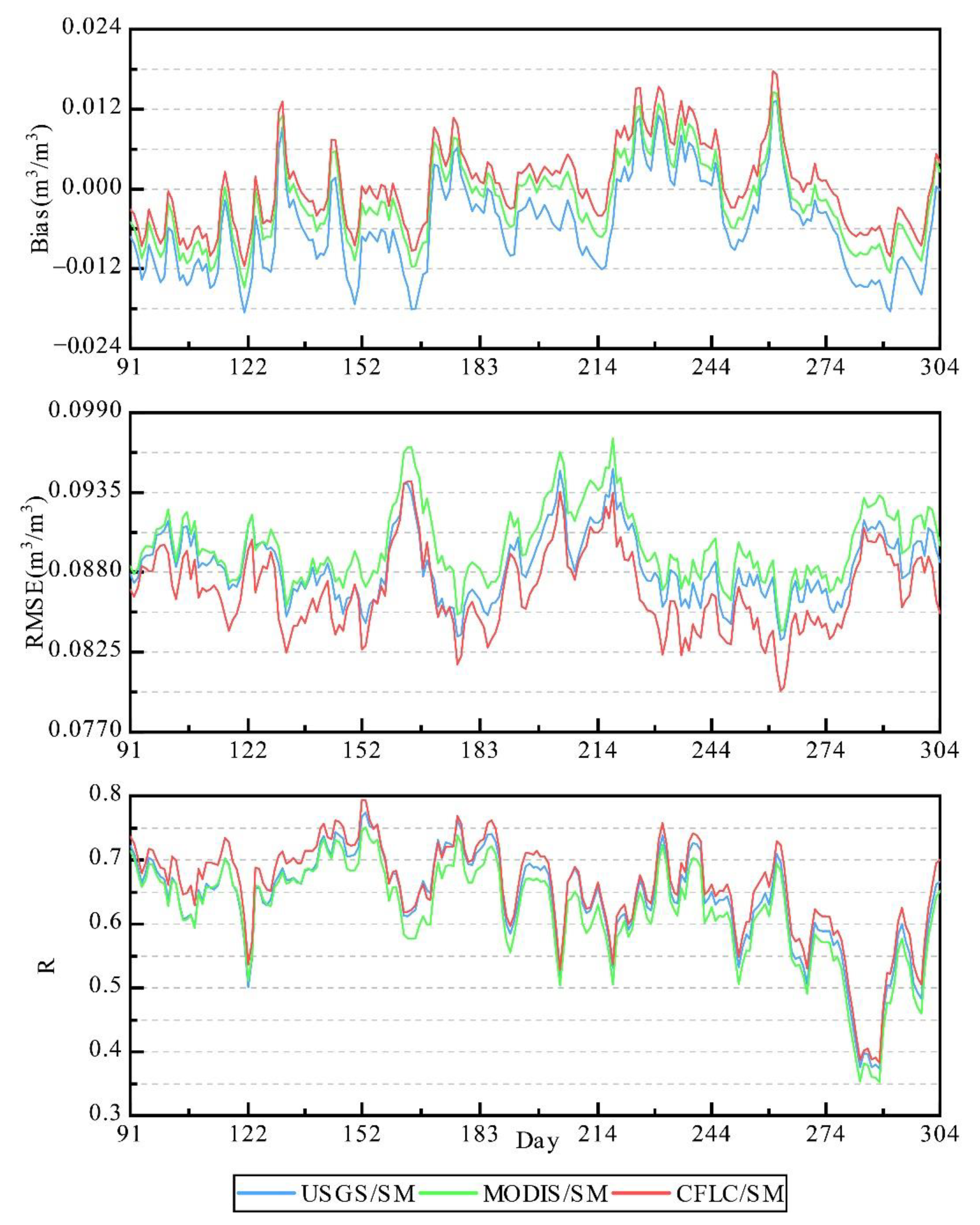
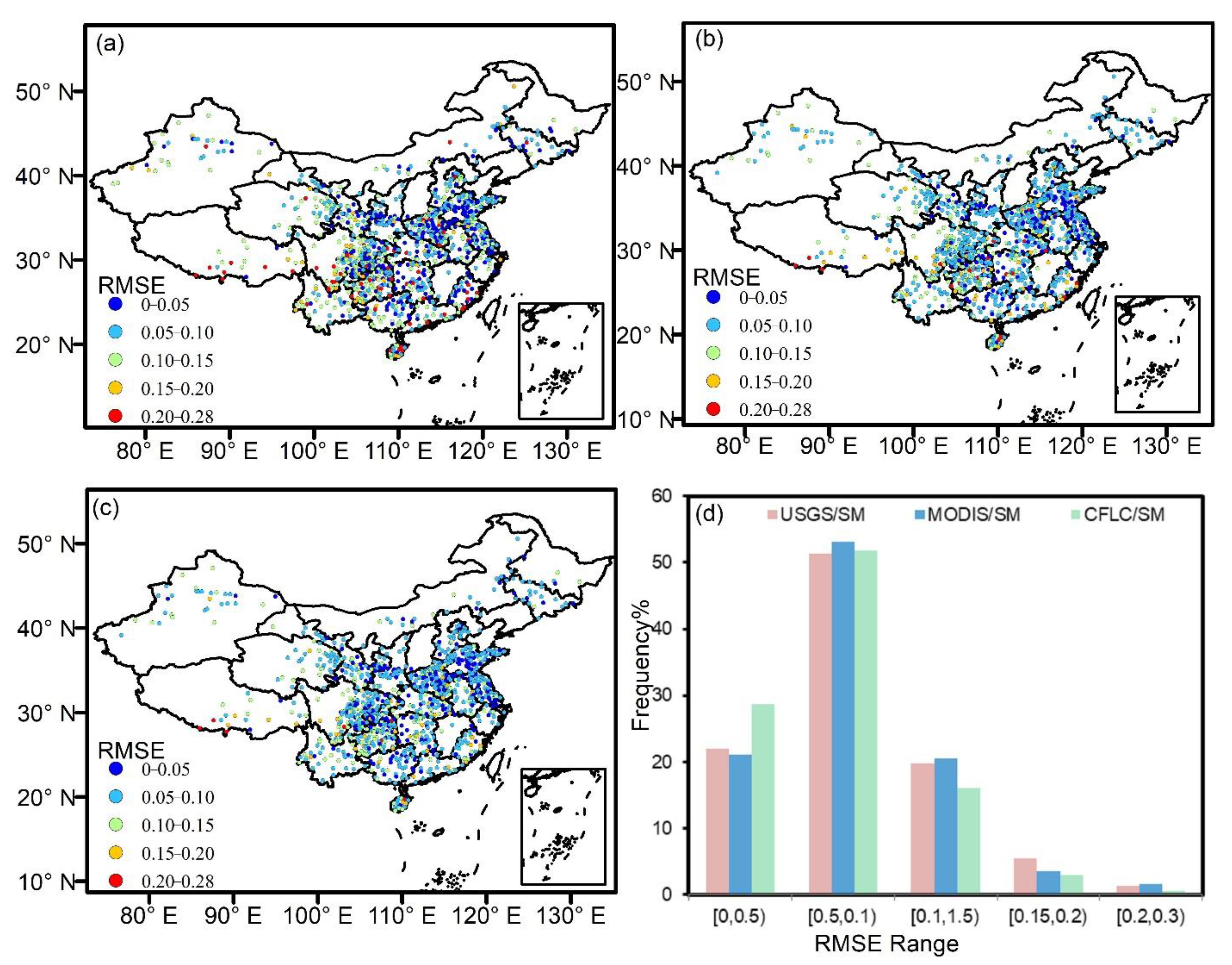
3.4. Analysis of Soil Moisture Simulation Based on Noah-MP LSM
4. Discussion
5. Conclusions
- (1)
- A new land cover data fusion method was established by improving D-S evidence theory with mathematical models and knowledge rules optimization. The new method can reduce the contradiction between input data and realize the conversion of multiple land cover classification systems to the Noah-MP classification system.
- (2)
- Measured data verification and visual comparisons showed that China Fusion Land Cover data (CFLC) in 2015 generated by new method had more abundant land cover classes than visual interpretation-based CNLULC data and higher accuracy relative to two global land cover data (MODIS LC and FROM-GLC). Compared with Geo-Wiki observations in 2015, the overall accuracy for CFLC is 71.4% relative to other two global land cover data (58.2% for FROM-GLC and 52.7% for MODIS).
- (3)
- The site-based evaluation results showed that the new integrated land cover data improved the simulation accuracy of soil moisture at the depth of 10 cm in Noah-MP LSM relative to the initial land cover data in the model and widely used MODIS land cover data. The underestimation rate was reduced by 23.5% and 14.1% relative to initial land cover data and MODIS land cover data, respectively, while the correlation coefficient and the root mean square error of the soil moisture simulated by the CFLC were all better than that simulated by the initial land cover data in the model and widely used MODIS land cover data.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sellers, P.J.; Tucker, C.J.; Collatz, G.J.; Los, S.O.; Justice, C.O.; Dazlich, D.A.; Randall, D.A. A revised land surface parameterization (SiB2) for atmospheric GCMs. Part II: The generation of global fields of terrestrial biophysical parameters from satellite data. J. Clim. 1996, 9, 706–737. [Google Scholar] [CrossRef]
- Dai, Y.; Zeng, X.; Dickinson, R.E.; Baker, I.; Bonan, G.B.; Bosilovich, M.G.; Denning, A.S.; Dirmeyer, P.A.; Houser, P.R.; Niu, G. The common land model. Bull. Am. Meteorol. Soc. 2003, 84, 1013–1024. [Google Scholar] [CrossRef]
- Yang, Z.L.; Niu, G.Y.; Mitchell, K.E.; Chen, F.; Ek, M.B.; Barlage, M.; Longuevergne, L.; Manning, K.; Niyogi, D.; Tewari, M. The community Noah land surface model with multiparameterization options (Noah-MP): 2. Evaluation over global river basins. J. Geophys. Res. Atmos. 2011, 116, D12. [Google Scholar] [CrossRef]
- Niraula, R.; Meixner, T.; Norman, L.M. Determining the importance of model calibration for forecasting absolute/relative changes in streamflow from LULC and climate changes. J. Hydrol. 2015, 522, 439–451. [Google Scholar] [CrossRef]
- Chen, C.; Li, D.; Li, Y.; Piao, S.; Wang, X.; Huang, M.; Gentine, P.; Nemani, R.R.; Myneni, R.B. Biophysical impacts of Earth greening largely controlled by aerodynamic resistance. Sci. Adv. 2020, 6, eabb1981. [Google Scholar] [CrossRef]
- Ge, J.; Pitman, A.J.; Guo, W.; Wang, S.; Fu, C. Do uncertainties in the reconstruction of land cover affect the simulation of air temperature and rainfall in the CORDEX region of East Asia? J. Geophys. Res. Atmos. 2019, 124, 3647–3670. [Google Scholar] [CrossRef]
- Hansen, M.C.; Reed, B. A comparison of the IGBP DISCover and University of Maryland 1 km global land cover products. Int. J. Remote Sens. 2000, 21, 1365–1373. [Google Scholar] [CrossRef]
- Sulla-Menashe, D.; Gray, J.M.; Abercrombie, S.P.; Friedl, M.A. Hierarchical mapping of annual global land cover 2001 to present: The MODIS Collection 6 Land Cover product. Remote Sens. Environ. 2019, 222, 183–194. [Google Scholar] [CrossRef]
- Arino, O.; Gross, D.; Ranera, F.; Leroy, M.; Bicheron, P.; Brockman, C.; Defourny, P.; Vancutsem, C.; Achard, F.; Durieux, L. GlobCover: ESA service for global land cover from MERIS. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–27 July 2007; pp. 2412–2415. [Google Scholar]
- Chirachawala, C.; Shrestha, S.; Babel, M.S.; Virdis, S.G.; Wichakul, S. Evaluation of global land use/land cover products for hydrologic simulation in the Upper Yom River Basin, Thailand. Sci. Total Environ. 2020, 708, 135148. [Google Scholar] [CrossRef]
- Liang, L.; Liu, Q.; Liu, G.; Li, H.; Huang, C. Accuracy evaluation and consistency analysis of four global land cover products in the Arctic region. Remote Sens. 2019, 11, 1396. [Google Scholar] [CrossRef]
- Shi, W.; Zhang, X.; Hao, M.; Shao, P.; Cai, L.; Lyu, X. Validation of land cover products using reliability evaluation methods. Remote Sens. 2015, 7, 7846–7864. [Google Scholar] [CrossRef]
- Chen, B.; Huang, B.; Xu, B. Multi-source remotely sensed data fusion for improving land cover classification. ISPRS J. Photogramm. Remote Sens. 2017, 124, 27–39. [Google Scholar] [CrossRef]
- Ghassemian, H. A review of remote sensing image fusion methods. Inf. Fusion 2016, 32, 75–89. [Google Scholar] [CrossRef]
- Zhang, J. Multi-source remote sensing data fusion: Status and trends. Int. J. Image Data Fusion 2010, 1, 5–24. [Google Scholar] [CrossRef]
- Pérez-Hoyos, A.; García-Haro, F.J.; San-Miguel-Ayanz, J. A methodology to generate a synergetic land-cover map by fusion of different land-cover products. Int. J. Appl. Earth Obs. Geoinf. 2012, 19, 72–87. [Google Scholar] [CrossRef]
- Jung, M.; Henkel, K.; Herold, M.; Churkina, G. Exploiting synergies of global land cover products for carbon cycle modeling. Remote Sens. Environ. 2006, 101, 534–553. [Google Scholar] [CrossRef]
- See, L.; Schepaschenko, D.; Lesiv, M.; McCallum, I.; Fritz, S.; Comber, A.; Perger, C.; Schill, C.; Zhao, Y.; Maus, V. Building a hybrid land cover map with crowdsourcing and geographically weighted regression. ISPRS J. Photogramm. Remote Sens. 2015, 103, 48–56. [Google Scholar] [CrossRef]
- Gao, H.; Jia, G.; Fu, Y. Generate Integrated Land Cover Product for Regional Climate Model by Fusing Different Land Cover Products. In Proceedings of the International Conference on Collaborative Computing: Networking, Applications and Worksharing, Beijing, China, 16–17 October 2016; pp. 665–675. [Google Scholar]
- Liu, K.; Xu, E. Fusion and Correction of Multi-Source Land Cover Products Based on Spatial Detection and Uncertainty Reasoning Methods in Central Asia. Remote Sens. 2021, 13, 244. [Google Scholar] [CrossRef]
- Feng, M.; Bai, Y. A global land cover map produced through integrating multi-source datasets. Big Earth Data 2019, 3, 191–219. [Google Scholar] [CrossRef]
- Lesiv, M.; Moltchanova, E.; Schepaschenko, D.; See, L.; Shvidenko, A.; Comber, A.; Fritz, S. Comparison of data fusion methods using crowdsourced data in creating a hybrid forest cover map. Remote Sens. 2016, 8, 261. [Google Scholar] [CrossRef]
- Clinton, N.; Yu, L.; Gong, P. Geographic stacking: Decision fusion to increase global land cover map accuracy. ISPRS J. Photogramm. Remote Sens. 2015, 103, 57–65. [Google Scholar] [CrossRef]
- Kussul, N.; Shelestov, A.; Lavreniuk, M.; Butko, I.; Skakun, S. Deep learning approach for large scale land cover mapping based on remote sensing data fusion. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 198–201. [Google Scholar]
- Song, X.-P.; Huang, C.; Townshend, J.R. Improving global land cover characterization through data fusion. Geo-Spat. Inf. Sci. 2017, 20, 141–150. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Wang, Z.; Wang, Z.J.; Ward, R.K.; Wang, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef] [PubMed]
- Han, S.; Shi, C.; Xu, B.; Sun, S.; Zhang, T.; Jiang, L.; Liang, X. Development and evaluation of hourly and kilometer resolution retrospective and real-time surface meteorological blended forcing dataset (smbfd) in china. J. Meteorol. Res. 2019, 33, 1168–1181. [Google Scholar] [CrossRef]
- Liu, J.; Liu, M.; Tian, H.; Zhuang, D.; Zhang, Z.; Zhang, W.; Tang, X.; Deng, X. Spatial and temporal patterns of China’s cropland during 1990–2000: An analysis based on Landsat TM data. Remote Sens. Environ. 2005, 98, 442–456. [Google Scholar] [CrossRef]
- Ran, Y.; Li, X.; Lu, L.; Li, Z. Large-scale land cover mapping with the integration of multi-source information based on the Dempster–Shafer theory. Int. J. Geogr. Inf. Sci. 2012, 26, 169–191. [Google Scholar] [CrossRef]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef]
- Shi, C.; Xie, Z.; Qian, H.; Liang, M.; Yang, X. China land soil moisture EnKF data assimilation based on satellite remote sensing data. Sci. China Earth Sci. 2011, 54, 1430–1440. [Google Scholar] [CrossRef]
- Liu, J.; Shi, C.; Sun, S.; Liang, J.; Yang, Z.-L. Improving land surface hydrological simulations in China using CLDAS meteorological forcing data. J. Meteorol. Res. 2019, 33, 1194–1206. [Google Scholar] [CrossRef]
- Fritz, S.; McCallum, I.; Schill, C.; Perger, C.; See, L.; Schepaschenko, D.; Van der Velde, M.; Kraxner, F.; Obersteiner, M. Geo-Wiki: An online platform for improving global land cover. Environ. Model. Softw. 2012, 31, 110–123. [Google Scholar] [CrossRef]
- Jiang, W.; Zhan, J. A modified combination rule in generalized evidence theory. Appl. Intell. 2017, 46, 630–640. [Google Scholar] [CrossRef]
- Zhao, J.; Liu, S.; Wan, J.; Yasir, M.; Li, H. Change Detection Method of High Resolution Remote Sensing Image Based on DS Evidence Theory Feature Fusion. IEEE Access 2020, 9, 4673–4687. [Google Scholar] [CrossRef]
- Shafer, G. A betting interpretation for probabilities and Dempster-Shafer degrees of belief. arXiv 2010, arXiv:1001.1653. [Google Scholar] [CrossRef]
- Chang, M.; Liao, W.; Wang, X.; Zhang, Q.; Chen, W.; Wu, Z.; Hu, Z. An optimal ensemble of the Noah-MP land surface model for simulating surface heat fluxes over a typical subtropical forest in South China. Agric. For. Meteorol. 2020, 281, 107815. [Google Scholar] [CrossRef]
- Niu, G.Y.; Yang, Z.L.; Mitchell, K.E.; Chen, F.; Ek, M.B.; Barlage, M.; Kumar, A.; Manning, K.; Niyogi, D.; Rosero, E. The community Noah land surface model with multiparameterization options (Noah-MP): 1. Model description and evaluation with local-scale measurements. J. Geophys. Res. Atmos. 2011, 116, D12. [Google Scholar] [CrossRef]
- Hagan, D.F.T.; Parinussa, R.M.; Wang, G.; Draper, C.S. An Evaluation of Soil Moisture Anomalies from Global Model-Based Datasets over the People’s Republic of China. Water 2020, 12, 117. [Google Scholar] [CrossRef]
- Li, H.; Wolter, M.; Wang, X.; Sodoudi, S. Impact of land cover data on the simulation of urban heat island for Berlin using WRF coupled with bulk approach of Noah-LSM. Theor. Appl. Climatol. 2018, 134, 67–81. [Google Scholar] [CrossRef]
- Li, J.; Chen, F.; Zhang, G.; Barlage, M.; Gan, Y.; Xin, Y.; Wang, C. Impacts of land cover and soil texture uncertainty on land model simulations over the central Tibetan Plateau. J. Adv. Modeling Earth Syst. 2018, 10, 2121–2146. [Google Scholar] [CrossRef]
- Duveiller, G.; Caporaso, L.; Abad-Viñas, R.; Perugini, L.; Grassi, G.; Arneth, A.; Cescatti, A. Local biophysical effects of land use and land cover change: Towards an assessment tool for policy makers. Land Use Policy 2020, 91, 104382. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
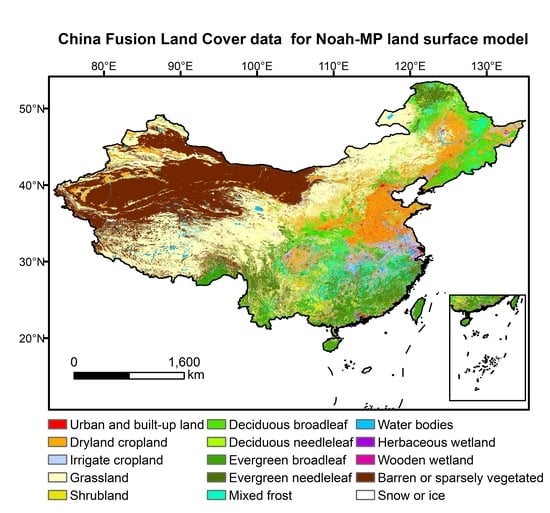
| Fusion Code | USGS Code | Land Cover Type |
|---|---|---|
| 1 | 1 | Urban and built-up land |
| 2 | 2 | Dryland cropland and pasture |
| 3 | 3 | Irrigated cropland and pasture |
| - | 4 | Mixed Dryland/Irrigated Cropland and Pasture |
| - | 5 | Cropland/Grassland Mosaic |
| - | 6 | Cropland/Woodland Mosaic |
| 4 | 7 | Grassland |
| 5 | 8 | Shrubland |
| - | 9 | Mixed Shrubland/Grassland |
| - | 10 | Savanna |
| 6 | 11 | Deciduous broadleaf forest |
| 7 | 12 | Deciduous needleleaf forest |
| 8 | 13 | Evergreen broadleaf forest |
| 9 | 14 | Evergreen needleleaf forest |
| 10 | 15 | Mixed forest |
| 11 | 16 | Water bodies |
| 12 | 17 | Herbaceous wetland |
| 13 | 18 | Wooden wetland |
| 14 | 19 | Barren or sparsely vegetable |
| - | 20 | Herbaceous Tundra |
| - | 21 | Wooded Tundra |
| - | 22 | Mixed Tundra |
| - | 23 | Bare Ground Tundra |
| 15 | 24 | Snow or ice |
| Initial Type | Semantic Rule | Score | Target Type |
|---|---|---|---|
| FROM-GLC Mixed leaf, leaf-on | Is not | 0 | Water bodies |
| little related | 25 | Shrubland | |
| partly related | 50 | Evergreen needle/broadleaf | |
| mostly related | 75 | - | |
| Is | 100 | Mixed forest | |
| MODIS LC Savannas | Is not | 0 | Water bodies |
| little related | 25 | Various types of forest | |
| partly related | 50 | - | |
| mostly related | 75 | Grassland | |
| Is | 100 | - |
| CFLC | CNLULC | |||||
|---|---|---|---|---|---|---|
| Farmland | Forest | Grassland | Waters | Construction Land | Bare Land | |
| Farmland | 0.801 | 0.022 | 0.015 | 0.038 | 0.005 | 0.003 |
| Forest | 0.102 | 0.904 | 0.050 | 0.037 | 0 | 0.005 |
| Grassland | 0.091 | 0.068 | 0.790 | 0.152 | 0 | 0.090 |
| Waters | 0.003 | 0.002 | 0.002 | 0.750 | 0 | 0.002 |
| Construction land | 0 | 0 | 0 | 0 | 0.994 | 0 |
| Bare land | 0.003 | 0.004 | 0.143 | 0.023 | 0.001 | 0.900 |
| Data | Farmland | Forest | Grassland | Waters | Construction Land | Bare Land | |
|---|---|---|---|---|---|---|---|
| Producer’s accuracy | CFLC | 0.844 | 0.774 | 0.808 | 0.510 | 0.707 | 0.687 |
| FROM-GLC | 0.768 | 0.634 | 0.576 | 0.235 | 0.131 | 0.607 | |
| MODIS | 0.568 | 0.377 | 0.476 | 0.608 | 0.393 | 0.483 | |
| User’s accuracy | CFLC | 0.818 | 0.853 | 0.659 | 0.266 | 0.766 | 0.950 |
| FROM-GLC | 0.644 | 0.685 | 0.589 | 0.381 | 0.350 | 0.744 | |
| MODIS | 0.543 | 0.585 | 0.478 | 0.724 | 0.506 | 0.662 |
| Pair of Datasets | The Relative Consistency |
|---|---|
| MODIS-FROMGLC | 0.648 |
| MODIS-CNLULC | 0.587 |
| MODIS-CFLC | 0.710 |
| FROMGLC-CNLULC | 0.637 |
| FROMGLC-CFLC | 0.756 |
| CFLC-CNLULC | 0.845 |
| Land Cover Type | Min | Max | Range | Mean |
|---|---|---|---|---|
| Urban and built-up land | 0.211 | 0.996 | 0.785 | 0.955 |
| Dryland cropland and pasture | 0.111 | 0.991 | 0.880 | 0.774 |
| Irrigated cropland and pasture | 0.185 | 0.954 | 0.769 | 0.669 |
| Grassland | 0.117 | 0.990 | 0.873 | 0.811 |
| Shrubland | 0.129 | 0.986 | 0.857 | 0.538 |
| Deciduous broadleaf forest | 0.110 | 0.989 | 0.879 | 0.676 |
| Deciduous needleleaf forest | 0.149 | 0.955 | 0.806 | 0.658 |
| Evergreen broadleaf forest | 0.154 | 0.989 | 0.835 | 0.620 |
| Evergreen needleleaf forest | 0.175 | 0.989 | 0.814 | 0.608 |
| Mixed forest | 0.167 | 0.974 | 0.807 | 0.642 |
| Water bodies | 0.125 | 0.986 | 0.861 | 0.965 |
| Herbaceous wetland | 0.115 | 0.831 | 0.716 | 0.557 |
| Wooden wetland | 0.124 | 0.436 | 0.312 | 0.306 |
| Barren or sparsely vegetable | 0.129 | 0.995 | 0.866 | 0.889 |
| Snow or ice | 0.165 | 0.980 | 0.815 | 0.771 |
| Farmland | Forest | Grassland | Waters | Construction Land | Bare Land | |
|---|---|---|---|---|---|---|
| USGS | 26.2% | 29.4% | 25.0% | 1.0% | 0. 1% | 18.3% |
| MODIS | 15.7% | 11.4% | 46.1% | 1.1% | 1.2% | 24.5% |
| CFLC | 14.3% | 24.9% | 27.8% | 2.9% | 3.0% | 27.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, A.; Shen, R.; Li, Y.; Han, H.; Di, W.; Hagan, D.F.T. A Methodology to Generate Integrated Land Cover Data for Land Surface Model by Improving Dempster-Shafer Theory. Remote Sens. 2022, 14, 972. https://doi.org/10.3390/rs14040972
Huang A, Shen R, Li Y, Han H, Di W, Hagan DFT. A Methodology to Generate Integrated Land Cover Data for Land Surface Model by Improving Dempster-Shafer Theory. Remote Sensing. 2022; 14(4):972. https://doi.org/10.3390/rs14040972
Chicago/Turabian StyleHuang, Anqi, Runping Shen, Yeqing Li, Huimin Han, Wenli Di, and Daniel Fiifi Tawia Hagan. 2022. "A Methodology to Generate Integrated Land Cover Data for Land Surface Model by Improving Dempster-Shafer Theory" Remote Sensing 14, no. 4: 972. https://doi.org/10.3390/rs14040972
APA StyleHuang, A., Shen, R., Li, Y., Han, H., Di, W., & Hagan, D. F. T. (2022). A Methodology to Generate Integrated Land Cover Data for Land Surface Model by Improving Dempster-Shafer Theory. Remote Sensing, 14(4), 972. https://doi.org/10.3390/rs14040972