1. Introduction
The increasing availability of satellite images alongside computational improvements makes the remote sensing field conducive to using deep learning (DL) techniques [
1]. Unlike traditional machine learning (ML) methods for image classification that rely on a per-pixel analysis [
2,
3], DL enables the understanding of shapes, contours, textures, among other characteristics, resulting in better classification and predictive performance. In this regard, convolutional neural networks (CNNs) were a game-changing method in DL and pattern recognition because of its ability to process multi-dimensional arrays [
4]. CNNs apply convolutional kernels throughout the image resulting in feature maps, enabling low, medium, and high-level feature recognition (e.g., corners, parts of an object, and full objects, respectively) [
5]. Besides, the development of new CNN architectures is a fast-growing field with novel and better architectures year after year, such as VGGnet [
6], ResNet [
7], AlexNet [
8], ResNeXt [
9], Efficient-net [
10], among others.
There are endless applications with CNN architectures, varying from single image classification to keypoint detection [
11]. Nevertheless, there are three main approaches for image segmentation [
1,
12,
13,
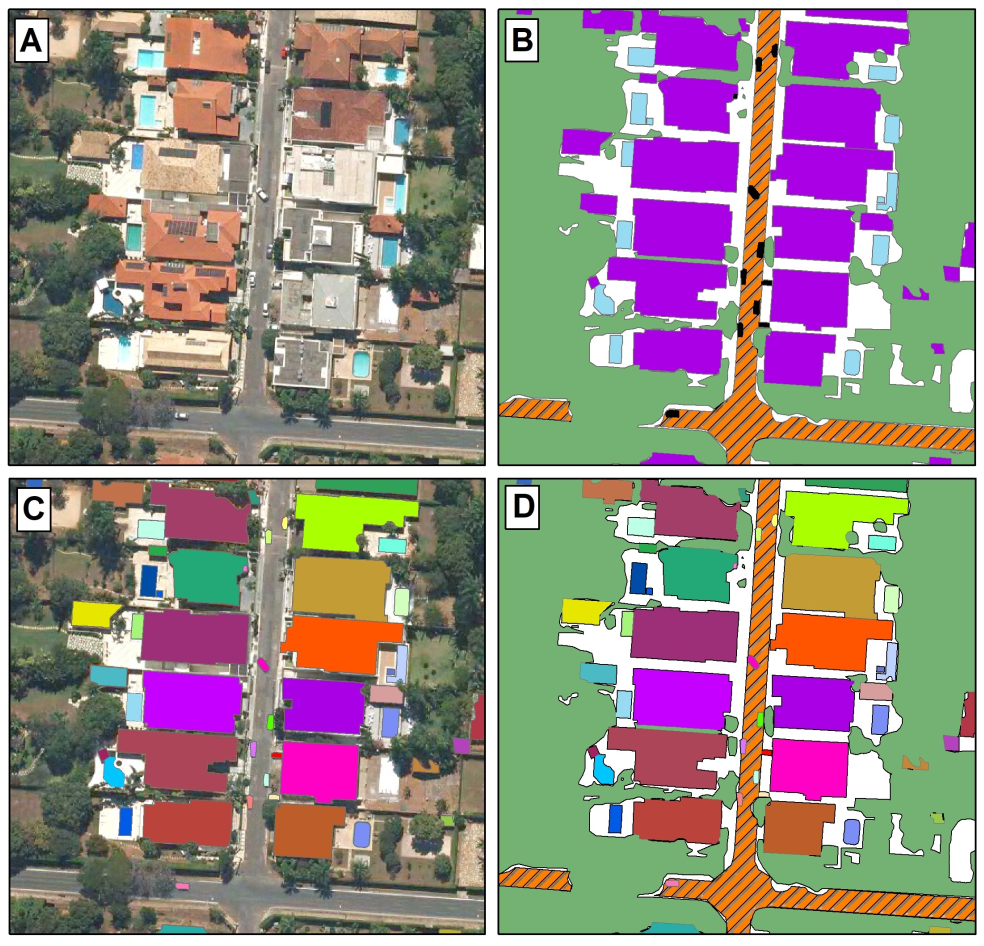
14] (
Figure 1: (1) semantic segmentation; (2) instance segmentation; and (3) panoptic segmentation. For a given input image (
Figure 1A), semantic segmentation models perform a pixel-wise classification [
15] (
Figure 1B), in which all elements belonging to the same class receive the same label. However, this method presents limitations for the recognition of individual elements, especially in crowded areas. On the other hand, instance segmentation generates bounding boxes (i.e., a set of four coordinates that delimits the object’s boundaries) and performs a binary segmentation mask for each element, enabling a distinct identification [
16]. Nonetheless, instance segmentation approaches are restricted to objects (
Figure 1B), not covering background elements (e.g., lake, grass, roads). Most datasets adopt a terminology of “thing” and “stuff” categories to differentiate objects and backgrounds [
17,
18,
19,
20,
21]. The “thing” categories are often countable and present characteristic shapes, similar sizes, and identifiable parts (e.g., buildings, houses, swimming pools). Oppositely, “stuff” categories are usually not countable and amorphous (e.g., lake, grass, roads) [
22]. Thus, panoptic segmentation [
23] aims to simultaneously combine instance and semantic predictions for classifying things and stuff categories, providing a more informative scene understanding (
Figure 1D).
Although panoptic segmentation has excellent potential in remote sensing data, a crucial step for its expansion is the image annotation that varies according to the segmentation task. Semantic segmentation is the most straightforward approach, requiring the original image and their corresponding ground truth images. The instance segmentation has a more complicated annotation style, which requires the bounding box information, the class identification, and the polygons that constitute each object. A standard approach is to store all of this information in the Common Objects in Context (COCO) annotation format [
20]. Panoptic segmentation has the most complex and laborious format, requiring instance and semantic annotations. Therefore, the high complexity of panoptic annotations leads to a lack of remote sensing databases. Currently, panoptic segmentation algorithms are compatible with the standard COCO annotation format [
23]. A significant advantage of using the COCO annotation format is compatibility with state-of-the-art software. Nowadays, Detectron2 [
24] is one of the most advanced algorithms for instance and panoptic segmentation, and most research advances involve changes in the backbone structures, e.g., MobileNetV3 [
25], EfficientPS [
26], Res2Net [
27]. Therefore, this format enables vast methodological advances. However, a big challenge in the application of remote sensing is the adaptation of algorithms to its peculiarities, which include the image format (e.g., GeoTIFF and TIFF) and the multiple channels (e.g., multispectral and time series), which differ from the traditional Red, Green, and Blue (RGB) images used in other fields of computer vision [
28].
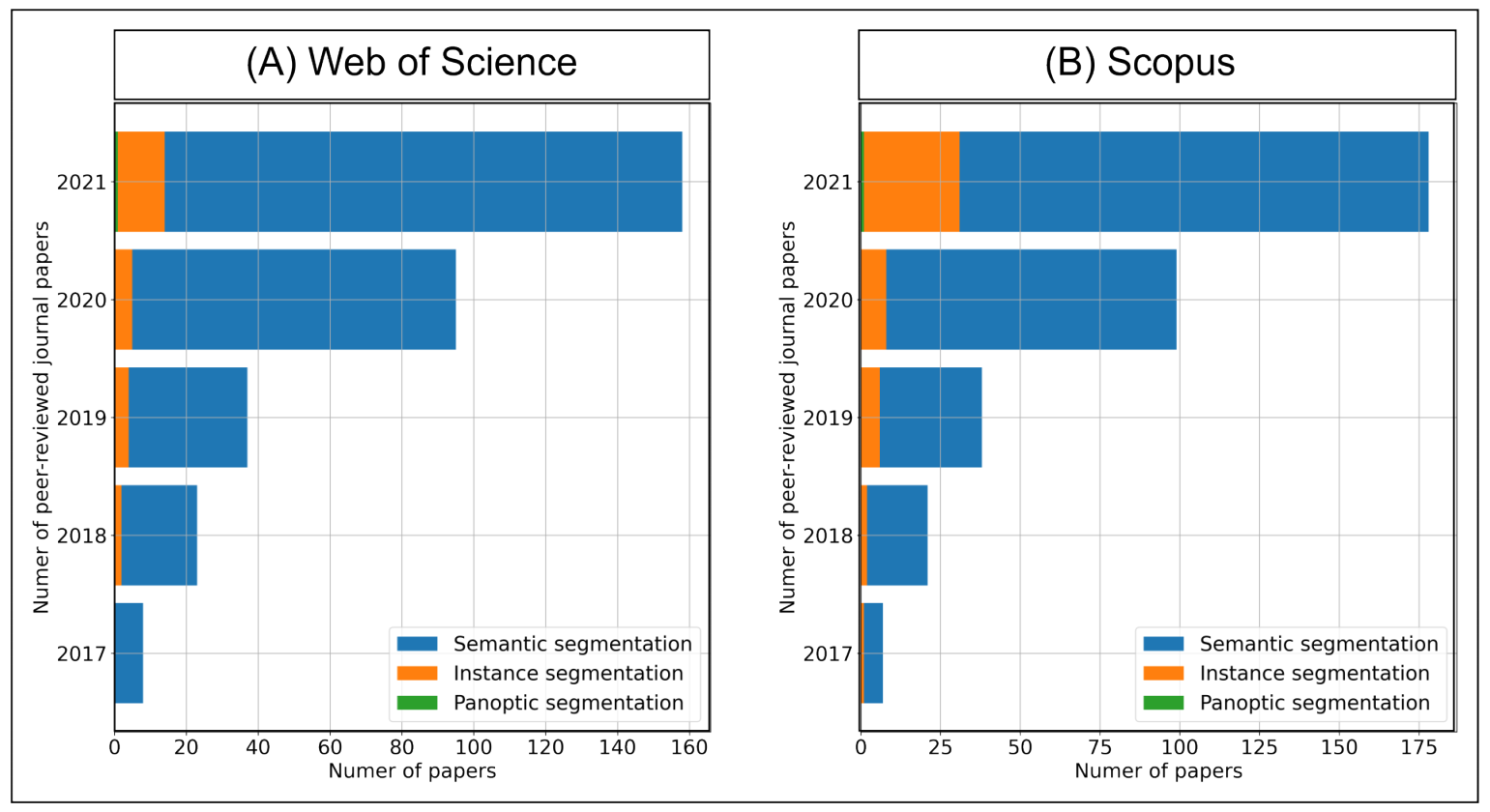
The increase in complexity among DL methods (panoptic segmentation > instance segmentation > semantic segmentation) reflects the frequency of peer-reviewed articles across each DL approach (
Figure 2). On the web of science and scopus databases considering articles up to 1 January 2022, we evaluated four searches filtering by topic and only considering journal papers: (1) “remote sensing” AND “semantic segmentation” AND “deep learning”; (2) “remote sensing” AND “instance segmentation” AND “deep learning”; (3) “remote sensing” AND “panoptic segmentation” AND “deep learning” and (4) “panoptic segmentation”. Semantic segmentation is the most common approach using DL in remote sensing, while instance segmentation has significantly fewer papers. On the other hand, panoptic segmentation has only one research published in remote sensing [
29], in which the authors used the DOTA [
30], UCAS-AOD [
31], and ISPRS-2D (
https://www2.isprs.org/commissions/comm2/wg4/benchmark/semantic-labeling/, accessed on 25 January 2021) datasets, none of which are made for the panoptic segmentation task. Moreover, we found two other studies. The first focuses on change detection in building footprints using bi-temporal images [
32], and the second use for different crops [
33]. Although both studies implement panoptic models, it does not use “stuff” categories apart from the background, being very similar to an instance segmentation approach.
Even though the panoptic task is laborious, tools for easing the panoptic data preparation and integration with remote sensing peculiarities may present a significant breakthrough. The panoptic predictions retrieve countable objects and different backgrounds, guiding public policies and decision-making with complete information. The absence of remote sensing panoptic segmentation research alongside databases for this task represents a substantial gap. Moreover, One of the notable drawbacks in the computer vision community regarding traditional images is the inference time, which exalts models like YOLACT and YOLACT++ [
34,
35] due to the ability to handle real data time, even compromising the accuracy metrics a little. This problem is less significant in remote sensing as the image acquisition frequency is days, weeks, or even months, making it preferable to use methods that return more information and higher accuracy rather than speed performance.
Moreover, the advancements of DL tasks are strictly related to the disposition of large publicly available datasets, being the case in most computer vision problems, mainly after the ImageNet dataset [
36]. These publicly available datasets encourage researchers to develop new methods to achieve ever-increasing accuracy and, consequently, new strategies that drive scientific progress. This phenomenon occurs in all tasks, shown by progressively better accuracy results in benchmarked datasets. What makes the COCO and other large datasets attractive to test new algorithms is: (1) an extensive number of images; (2) a high number of classes; and (3) the variety of annotations for different tasks. However, up until now, the publicly available datasets for remote sensing are insufficient. First, there are no panoptic segmentation datasets. Second, the instance segmentation databases are usually monothematic, as many building footprints datasets such as the SpaceNet competition [
37].
A good starting point for a large remote sensing dataset would include widely used and researched targets, and the urban setting and its components is a very hot topic with many applications: road extraction [
38,
39,
40,
41,
42,
43,
44,
45], building extraction [
46,
47,
48,
49,
50,
51,
52], lake water bodies [
53,
54,
55], vehicle detection [
56,
57,
58], slum detection [
59], plastic detection [
60], among others. Most studies address a single target at a time (e.g., road extraction, buildings), and panoptic segmentation would enable vast semantic information of images.
This study aims to solve these issues in panoptic segmentation for remote sensing images from data preparation up to implementation, presenting the following contributions:
BSB Aerial Dataset: a novel dataset with a high amount of data and commonly used thing and stuff classes in the remote sensing community, suitable for semantic, instance, and panoptic segmentation tasks.
Data preparation pipeline and annotation software: a method for preparing the ground truth data using commonly used Geographic Information Systems (GIS) tools (e.g., ArcMap) and an annotation converter software to store panoptic, instance, and semantic annotations in the COCO annotation format, that other researchers can apply in other datasets.
Urban setting evaluation: evaluation of semantic, instance, and panoptic segmentation metrics and evaluation of difficulties in the urban setting.
The remainder of this paper is organized as follows.
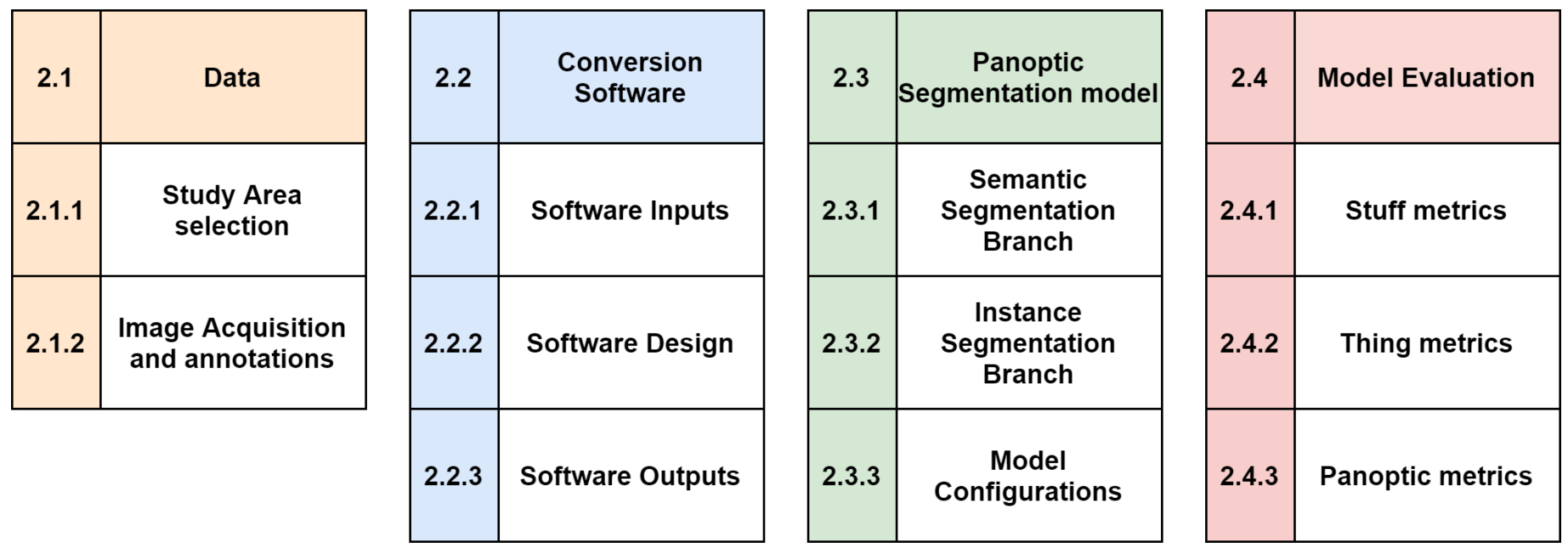
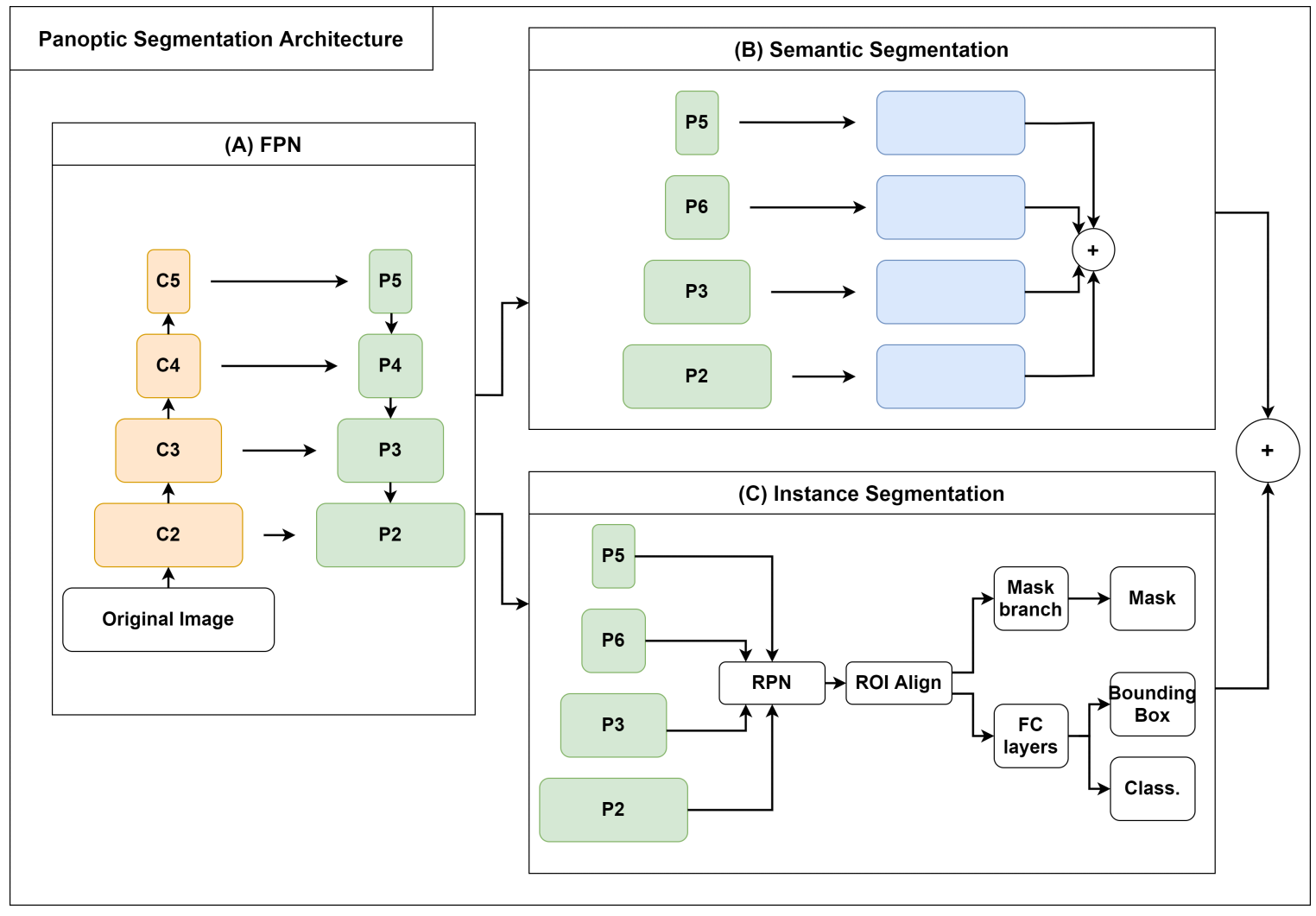
Section 2 describe the study area, how the annotations were made, our proposed software, the Panoptic-Feature Pyramid Network (FPN) architecture, and the metrics used for evaluation. Next,
Section 3 shows the outcomes and visual results. In
Section 4, we present four topics of discussion retrieving the main contributions from this study (annotation tools, remote sensing datasets, difficulties in the urban setting, an overview of the panoptic segmentation task, and limitations and future works. Finally, we present the conclusions in
Section 5.
4. Discussion
The panoptic segmentation task imposes new challenges in the formulation of algorithms and database structures, covering particularities of both object detection and semantic segmentation. Therefore, panoptic segmentation establishes a unified image segmentation approach, which changes digital image processing and requires new annotation tools and extensive and adapted datasets. In this context, this research innovates by developing a panoptic data annotation tool, establishing a panoptic remote sensing dataset, and being one of the first evaluations of the use of panoptic segmentation in urban aerial images.
4.1. Annotation Tools for Remote Sensing
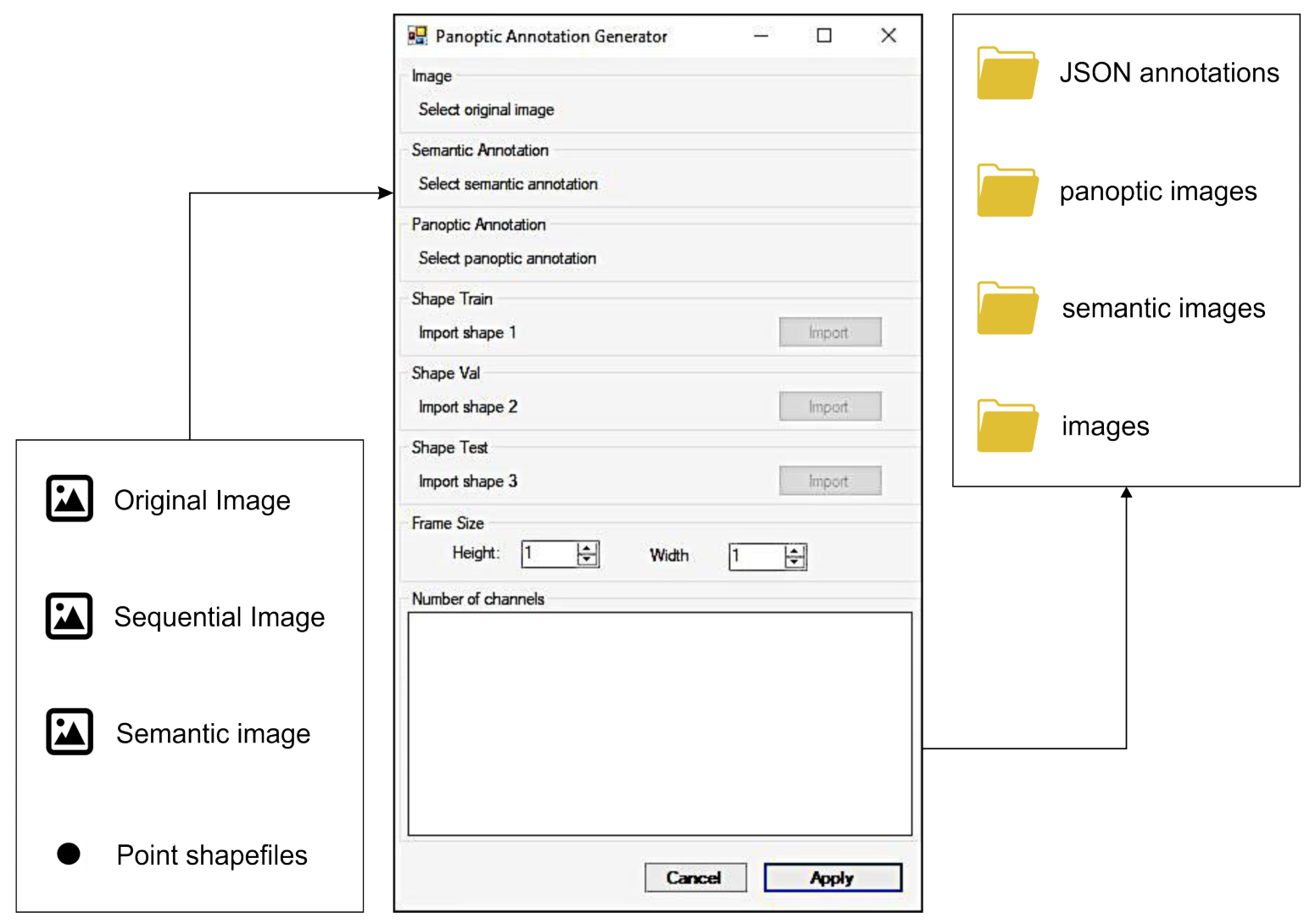
Many software annotation tools are available online, e.g., LabelMe [
62]. Nevertheless, those tools have problems with satellite image data because of large sizes and other singularities that are uncommon in the traditional computer vision tasks: (a) image format (i.e., satellite imagery is often in GeoTIFF, whereas traditional computer vision uses PNG or JPEG images), (b) georeferencing, and (c) compatibility with polygon GIS data. The remote sensing field made use of GIS software long before the rise of DL. With that said, there are extensive collections of GIS data (urban, agriculture, change detection) that other researchers could apply DL models. However, vector-based GIS data requires modifications to use DL models. Thus, we proposed a conversion tool from GIS data that automatically crops image tiles with their corresponding polygon vector data stored in shapefile format to panoptic, instance, and semantic annotations. The proposed tool is open access and works independently, without the need to use proprietary programs such as LabelRS developed by ArcPy and dependent on ArcGis [
65]. Besides, our proposed pipeline and software enable the users to choose many samples for training, validation, and testing in strategic areas using point shapefiles. This method of choosing samples presents a huge benefit compared to methods such as sliding windows for image generation. Finally, our software enables the generation of the three segmentation tasks (instance, semantic, and panoptic), allowing other researchers to exploit the field of desire.
4.2. Datasets
Most transfer learning applications use trained models from extensive databases such as the COCO dataset. Nevertheless, remote sensing images present characteristics that may not yield the most optimal results using traditional images. These images contain diverse targets and landscapes, with different geometric shapes, patterns, and textural attributes, representing a challenge for automatic interpretation. Therefore, the effectiveness of training and testing depends on accurately annotated ground truth datasets, which requires much effort into building large remote sensing databases with a significant variety of classes. Furthermore, the availability of open access encourages new methods and applications, as seen in other computer vision tasks.
Long et al. [
72] performed a complete review of remote sensing image datasets for DL methods, including tasks of scene classification, object detection, semantic segmentation, and change detection. In this recent review, there is no database for panoptic segmentation, which demonstrates a knowledge gap. Most datasets consider limited semantic categories or target a specific element, such as building [
37,
73,
74], vehicle [
75,
76,
77], ship [
78,
79,
80], road [
81,
82], among others. Regarding available remote sensing datasets for various urban categories, one of the main is the iSAID [
83], with 2806 aerial images distributed in 15 different classes, for instance segmentation and object detection tasks.
The scarcity of remote sensing databases with all cityscape elements makes mapping difficult due to highly complex classes, numerous instances, and mainly intraclass and interclass elements commonly neglected. Adopting the panoptic approach allows us to relate the content of interest and the surrounding environment, which is still little explored. Therefore, organizing large datasets into panoptic categories is a key alternative to mapping complex environments such as urban systems that are not reached even with enriched semantic categories.
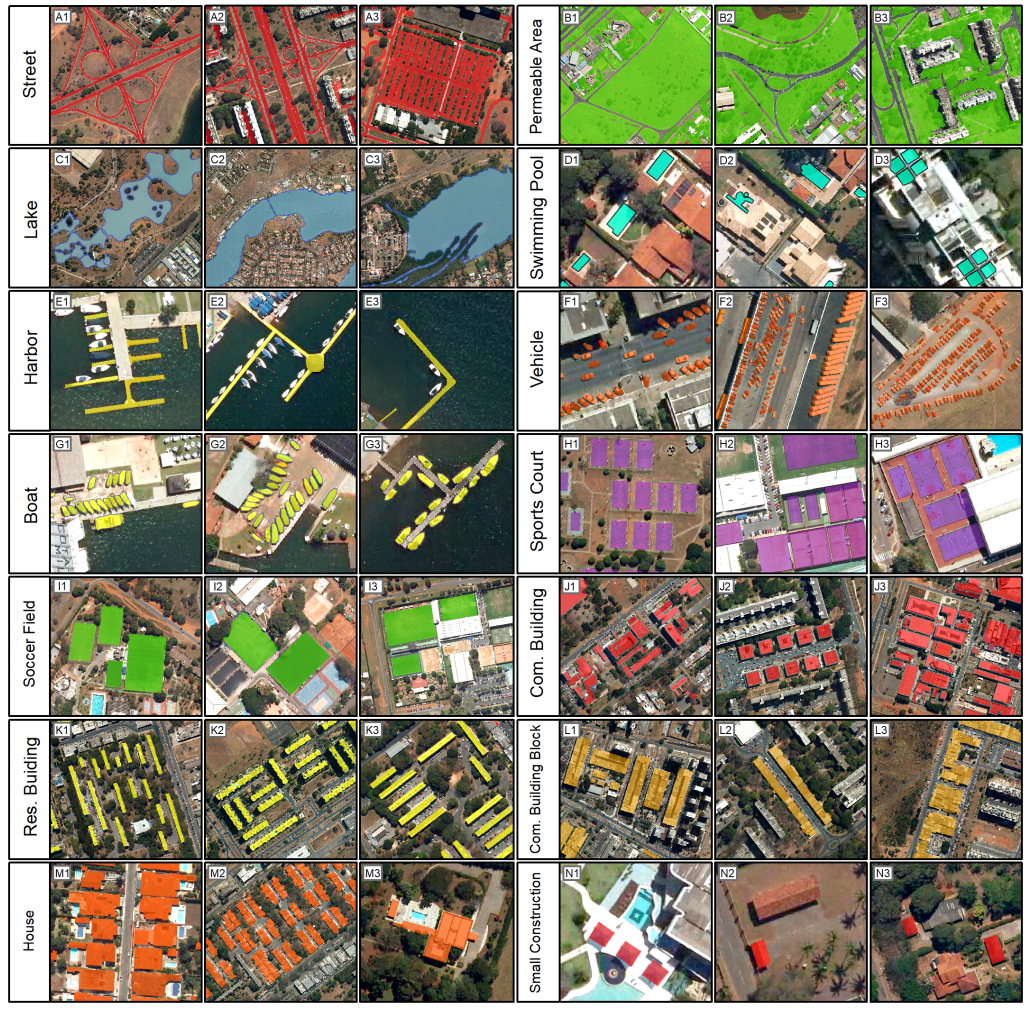
The proposed BSB Aerial Dataset contains 3400 images (3000 for training, 200 for validation, and 200 for testing) with 512 × 512 dimensions containing fourteen common urban classes. This dataset simplified some urban classes, such as sports courts instead of tennis courts, soccer fields, and basketball courts. Moreover, our dataset considers three “stuff” classes, widely represented in the urban setting, such as roads. The availability of data and the need for periodic mapping of urban infrastructure by the government allows for the constant improvement of this database. Besides, the dataset aims to trigger other researchers to exploit this task thoroughly.
4.3. Difficulties in the Urban Setting
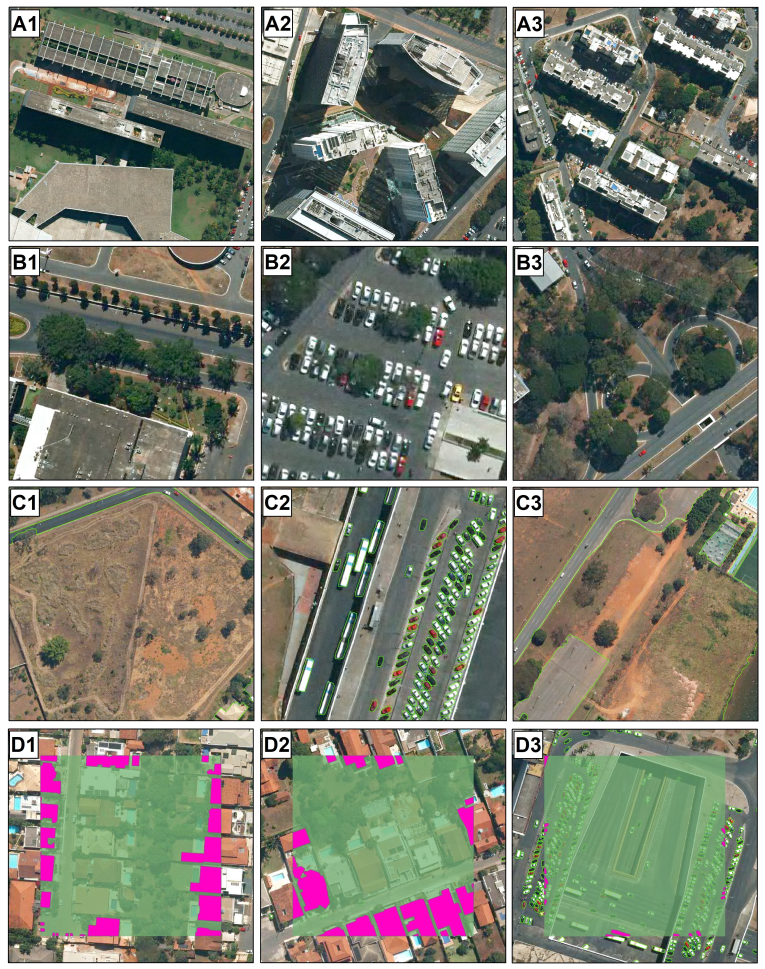
Although this study shows a promising field in remote sensing with a good capability of identifying “thing” and “stuff” categories simultaneously, we observed four main difficulties in image annotation and possible results in the urban setting (
Figure 10): (1) shadows, (2) occlusion objects, (3) class categorization, and (4) edge problem on the image tiles. Shadows entirely or partially obstruct the light and occur under diverse conditions from the different objects (e.g., cloud, building, mountain, and trees), requiring well-established ground rules to obtain consistent annotations. Therefore, the shadow presence is a source of confusion and misclassification, reducing image quality for visual interpretation and segmentation and, consequently, negatively impacting the accuracy metrics [
84] (
Figure 10(A1–A3)). Specifically, urban landscapes have a high proportion of areas covered by shadows due to the high density of tall objects. Therefore, urban zones aggravate the interference of shadows, causing semantic ambiguity and incorrect labeling, which is a challenge in remote sensing studies [
72,
85]. DL methods tend to minimize shading effects, but errors occur in very low light locations. Another fundamental problem in computer vision is the occlusion that impedes object recognition in satellite images. Commonly, there are many object occlusions in the urban landscape, such as vehicles partially covered by trees and buildings, making their identification difficult even for humans (
Figure 10(B1–B3)).
Like the occlusion problem, the objects that rely on the tile edges may present an insufficient representation. In monothematic studies, the authors may design the dataset to avoid this problem. However, for the panoptic segmentation task, which aims for an entire scene pixel-wise classification, some objects will be partial representation no matter how large we choose the image tile (
Figure 10(D1–D3)). Our proposed annotation tool enables the authors to select each tile’s exact point, which gives data generation autonomy to avoid very few representations (even though the problem will still be present). By choosing large image tiles, the percentual representation of edge objects will be lower and tends to have a smaller impact on the model and accuracy metrics but increasing the image tile also requires more computational power.
Finally, the improvement of urban classes in the database is ongoing work. This research sought to establish general and representative classes, but the advent of new categories will allow for more detailed analysis according to research interests. For example, our vehicle class encompasses buses, small cars, and trucks, and our permeable area class contains bare ground, grass, and trees as shown in
Figure 10(C1–C3).
4.4. Panoptic Segmentation Task
The remote sensing field is prone to using panoptic segmentation, mainly when referring to satellite and aerial images that do not require real-time processing. Most images have a frequency of at least days apart from each other, making some widely studied metrics such as inference time much less relevant. In remote sensing, the more information we can get simultaneously, the better. However, panoptic segmentation presents some non-trivial data generation mechanisms that require information for both instance and semantic segmentation. Besides, the existing panoptic segmentation studies that develop novel remote sensing datasets do not fully embrace the “stuff” classes [
32,
33].
The panoptic segmentation may represent a breakthrough in the remote sensing field for the ability to gather countable objects and background elements using a single framework, surpassing some difficulties of semantic and instance segmentation. Nonetheless, the data generation process and configuration of the models are much less straightforward than other methods, highlighting the importance of shortening this gap.
4.5. Limitations and Future Work
The high diversity of properties in remote sensing images (different spatial, spectral, and temporal resolutions) and the different landscapes of the Earth’s surface make it a challenge to formulate a generalized DL dataset. In this sense, our proposed annotation tool is suitable for creating datasets considering different image types. Future research on panoptic segmentation in remote sensing should progress to include images from various sensors, allowing faster advances in its application.
Furthermore, an important advance for panoptic segmentation is to include occlusion scenarios. Currently, the panoptic segmentation and its subsequent metrics (PQ, SQ, and RQ) require no overlapping segments, i.e., it considers only the visible pixels of the images. The usage of top-view images is very susceptible to classifying non-visible areas (occluded targets). Those changes would require adaptations in the models and metrics.
Practical remote sensing applications also require mechanisms for classifying large regions. Those methods usually use sliding windows, which have different peculiarities for pixel-based (e.g., semantic segmentation) and box-based methods (e.g., instance segmentation). The semantic segmentation approach use sliding windows with overlapping pixels, in which overlapped pixels are averaged. This averaging procedure attenuates the borders and enhances the metrics [
86,
87,
88]. The instance segmentation proposals use sliding windows with a half-frame stride value, which allows identifying the elements as a whole and eliminating partial predictions [
28,
89]. There is no specific method for using a panoptic segmentation framework using sliding windows.
5. Conclusions
The application of panoptic, instance and semantic segmentation often depends on the desired outcome of a research or industry application. Nevertheless, a research gap in the remote sensing community is the lack of studies addressing panoptic segmentation, one of the most powerful techniques. The present research proposed an effective solution for using this unexplored and powerful method in remote sensing by: (a) providing a large dataset (BSB aerial dataset) containing 3400 images with 512 × 512 pixel dimensions in the COCO annotation format and fourteen classes (eleven “thing” and three “stuff” categories), being suitable for testing new DL models, (b) providing a novel pipeline and software for easily generating panoptic segmentation datasets in a format that is compatible with state-of-the-art software (e.g., Detectron2), and (c) leveraging and modifying structures in the DL models for remote sensing applicability, and (d) making a complete analysis of different metrics and evaluating difficulties of this task in the urban setting. One of the main challenges for preparing a panoptic segmentation model is the image format, which is still not well documented. Thus, we proposed an automatic converter from GIS data to panoptic, instance, and semantic segmentation formats. GIS data was widespread even before the DL rise, and the number of datasets that could benefit from our method is enormous. Besides, our tool allows the users to choose the exact points in large images to generate the DL samples using point shapefiles, which brings more autonomy to the studies and allows better data choosing. We believe that this work may increase other studies on the panoptic segmentation task with the BSB Aerial Dataset and the annotation tool and the baselines comparisons using well-documented software (Detectron2). Moreover, we evaluated the Panoptic-FPN model using two backbones (ResNet-101 and ResNet-50), showing promising metrics for this method’s usage in the urban setting. Therefore, this research shows an effective annotation tool, a large dataset for multiple tasks, and their application on some non-trivial models. Regarding future studies, we discussed three major problems to be addressed: (1) augmenting the dataset with images with different spectral bands and spatial resolution, (2) expand the panoptic idea for occlusion scenarios in remote sensing, and (3) adapt methods for classifying large images.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}