1. Introduction
The individual image taken by IR or VI cannot extract all features due to the limitation of sensor systems. In particular, the IR images can extract thermal information about the foreground, such as hidden targets, camouflage identification, movement of objects, and so on [
1]. Nonetheless, it cannot extract background information such as vegetation and soil due to different spectrums, resulting in the loss of spatial features [
2]. In contrast, the VI images extract the background information, such as details of objects and edges, but they cannot provide information about thermal targets. The primary objective of image fusion is to acquire desired characteristics so that composite images can simultaneously produce background information and thermal targets perceptually. The IR and VI image fusion is a process of amalgamating both images to provide one final fused image that extracts all substantial features from both images without adding artifacts or noise. Recently, the fusion of IR and VI images has garnered a lot of attention as it has played a vital role in understanding image recognition and classification. It has opened a new path for many real-world applications, including object detection such as surveillance, remote sensing [
3], vehicular ad hoc network (VANET), navigation, and so on [
4,
5,
6]. Based on different applications, the fusion of images can be performed using pixel-level-, feature-level-, or decision-level-based fusion schemes [
7]. In a pixel-based scheme, the pixels of both images are merged directly to obtain a final fused image, whereas a feature-based scheme first extracts the features from given images and then combines the extracted features [
8]. On the contrary, the decision-based scheme extracts all the features from given images and makes decisions based on specific criteria to fuse the desired features [
9].
For decades, numerous signal processing algorithms have been contemplated in image fusion to extract features such as multi-scale transform-based methods [
10,
11], sparse-representation-based [
12,
13], edge-preserving filtering [
14,
15], neural network [
16], subspace-based [
17] and hybrid-based methods [
3]. During the last five years, deep learning (DL)-based [
18] methods have received painstaking attention in image fusion due to their outstanding feature extraction from source images.
The PCA-based fusion method is employed in [
17], which preserves energy features in the fused image. This scheme calculates the eigenvalues and eigenvectors for source images that use the highest eigenvector. Then, principal components are obtained from eigenvectors corresponding to the highest eigenvalues. This method helps to eliminate the redundant information with a robust operation. However, this method fails to extract detailed features such as edges, boundaries, and textures. The discrete cosine transform (DCT)-based image fusion algorithm is inferred by [
18]. This method employs a correlation coefficient to calculate the change in the resultant image after passing from a low-pass filter. This method is unable to capture smooth contours and textures from source images. The improved discrete wavelet transform (DWT)-based fusion scheme is exploited in [
19], which preserves high-frequency features with fast computation. This method decomposes the source image into one low-frequency sub-band and three high-frequency sub-bands (low-high sub-band, high-low sub-band, and high-high sub-band). Nevertheless, this method introduces artifacts and noise because it uses down sampling that causes shift variance, which degrades fused image quality. The author in [
20] used the hybrid method using DWT and PCA, wherein DWT decomposes the source images and then decomposed images are fused by the PCA method. Although this method can preserve energy features and high-frequency features, it fails to capture sharp edges and boundaries due to limited directional information. Authors in [
21] have used discrete stationary wavelet transform (DSWT) that decomposes the source images into one low-frequency sub-band and three high-frequency sub-bands (low-high sub-band, high-low sub-band, and high-high sub-band) without using down sampling. The resultant image produces better results for spectral information but fails to capture spatial features.
The contourlet transform-based method is applied in [
22], which overcomes the issue of directional information. The edges and textures are captured precisely, but Gibb’s effect is introduced due to the property of shift variance. The non-sub-sampled contourlet transform (NSCT) is pinpointed in [
11] that uses non-subsampled pyramid filter banks (NSPFB) and non-subsampled directional filter banks (NSDFB). It has a shift-invariant property and flexible frequency selectivity with fast computation. This method addresses the aforementioned issues, but the fused image suffers from uneven illumination, and the noise is generated due to the environment. The median average filter-based fusion scheme using hybrid DSWT and PCA is highlighted by Tian et al. in [
23]. The combined filter is used to eliminate the noise, and then DSWT is applied that decomposes the images into sub-frequency bands. The sub-frequency bands are then fed to PCA for fusion. Nevertheless, this method has limited directional information, and it cannot preserve sharp edges and boundaries. The author in [
24] has used a morphology-hat transform (MT) using a hybrid contourlet and PCA algorithm. The morphological processing top–bottom operation removes noise, while the energy features are preserved by principal component analysis (PCA), and edges are precisely obtained by contourlet transform. However, the fused image suffers due to the shift variance property that introduces Gibb’s effect, and hence the final image quality is degraded. The spatial frequency (SF)-based non-subsampled shearlet transform (NSST) along with pulse code neural network (PCNN) is designed by authors in [
16]. The images are decomposed by NSST and these decomposed images are fed into a spatial frequency pulse code neural network (SF-PCNN) for fusion. This method produces better results due to shift-invariant and flexible frequency selectivity, but its image quality is affected due to uneven illumination. Hence, the fused image loses some energy information and edges are not captured smoothly.
The sparse representation (SR) has been employed in many applications in the last decade. This method learns an over-complete dictionary (OCD) from many high-quality images, and then the learned dictionary sparsely represents input images. The sparse-based schemes use the sliding window method to divide input images into various overlapping patches that help to reduce artifacts. The author in [
12] constructed a fixed over complete discrete cosine transform dictionary to fuse IR and VI images. Kim et al. in [
25] designed a scheme for learning a dictionary based on image patch clustering and the PCA. This scheme reduces the dimensions due to the robust operation of the PCA without affecting the fusion performance. The author in [
26] applied an SR method and a histogram of gradient (HOG). The features obtained from the HOG are taken for classifying the image patches to learn various sub-dictionaries. The author in [
27] applied a convolutional sparse representation (CSR) scheme. It decomposes the input images into base and detail layers. The detailed parts are fused by sparse coefficients obtained by utilizing the CSR model, and base parts are fused using the choose-max selection fusion rule. The final fused image is reconstructed by combining the base and detailed parts. This method has more ability to preserve detailed features than simple SR-based methods; however, this method uses a window-based averaging strategy that leads to the loss of essential features due to the value of the window size. The latent low-rank representation (LatLRR)-based fusion method is used in [
28]. The source images are firstly decomposed into low rank and saliency parts by LatLRR. After that, a weighted averaging scheme fuses low-rank parts, while the sum strategy fuses the saliency parts. Finally, the fused image is acquired by merging the low-rank and saliency parts. This method captures smooth edges but fails to capture more energy information because it uses a weighted-averaging strategy that leads to losing some energy information.
Edge-preserving-based filtering methods have become an active research tool for many image fusion applications in the last two decades. The given images are decomposed by filtering into one base layer and more detailed layers. The base layer is acquired by an edge-preserving filter that accurately gets foremost changes in intensity. In contrast, the detail layers consist of a series of different images that acquire coarse resolution at fine scales. These filtering-based approaches retain spatial consistency and reduce the halo effects around textures and edges. The cross bilateral filtering (CBF) method is applied in [
15]. This scheme calculates the weights by measuring the strength of the image by subtracting the CBF from the source images. After that, these weights are directly multiplied with source images using the normalization of weights. This direct multiplication leads to introducing artifacts and noise. The author in [
29] designed an image decomposition filtering-based scheme based on L1 fidelity with L0 gradient. This method retains the features of the base layer, and it obtains good edges, textures, and boundaries around the objects. Zhou et al. in [
30] used a new scheme using Gaussian and bilateral filters capable of decomposing the image multi-scale edges and retaining fine texture details.
The role of deep learning (DL) has received considerable attention in the last five years, and it has been employed in the field of image fusion [
31,
32,
33]. The convolutional neural network (CNN)-based image fusion scheme is proposed in [
34]. This method employs image patches consisting of various blur copies of the original image for training their network to acquire a decision map. The fused image is obtained using that decision map and the input images. A new fully CNN-based IR and VI fusion-based method is proposed in [
35] that uses local non-subsampled shearlet transform (LNSST) to decompose the given images into low-frequency and high-frequency sub-bands. The high-frequency coefficients are fed into CNN to obtain the weight map. After that, the average gradient fusion strategy is used for these coefficients, while the local energy fusion scheme is used for low-frequency coefficients.
Table 1 presents the overall summary of related work.
In a nutshell, the main motive of any fusion method is to extract all useful features from given images to produce a composite image that comprises all salient features from both individual images without introducing artifacts or noise. Though various fusion algorithms fulfill the vital motive of image fusion by producing one final fused image with the aid of combining the features from individual images, the quality of the final fused image is still not up to the mark. As a result, the quality of the final fused image is still degraded due to contrast variation in the background, uneven illumination, environments with fog, dust, haze, and dense smoke, the presence of noise, and improper fusion strategy. In such a context, this work bridges the technological gap of recent works by proposing an improved image fusion scheme, thereby overcoming the aforementioned shortcomings. To the best of our knowledge, this is the first time that an image fusion scheme using an adaptive fuzzy-based enhancement method and a deep convolutional network model through the guidance of transfer learning with multiple fusion strategies is employed. The proposed hybrid method outperforms the traditional and recent fusion methods in subjective evaluation and objective quality assessments.
The main contributions of this paper are outlined as:
The robust and adaptive fuzzy set-based image enhancement method is applied as a preprocessing task that automatically enhances the contrast of IR and VI images for better visualization with adaptive parameter calculation. The enhanced images are then decomposed into base and detail layers using an anisotropic diffusion-based method.
The resultant detailed parts are fed to four convolutional layers of the VGG-19 network through transfer learning to extract the multi-layer features. Afterward, and averaging-based fusion strategies along with the max selection rule are applied to obtain the fused detail contents.
The base parts are fused by the principal component analysis (PCA) method to preserve the local energy from base parts. At last, the final fused image is obtained by a linear combination of base and detailed parts.
The outline of this paper is as follows.
Section 2 presents the materials and methods. The results are summarized in
Section 3. The discussion is elaborated in
Section 4. Finally,
Section 5 draws the conclusion and future work.
2. Materials and Methods
The main motive of any image fusion method is to acquire a final fused image that extracts all the useful features from individual source images by eliminating the redundant information without introducing artifacts and noise. Many recent image fusion methods have been proposed so far, and they achieve satisfactory results compared with traditional fusion schemes. Nevertheless, the fused image suffers from contrast variation, uneven illumination, blurring effects, noise, and improper fusion strategies. Moreover, the input images taken in environments with dense fog, haze, dust, cloud, and improper illumination affect the quality of the final fused image. We propose an effective image fusion method that circumvents the mentioned shortcomings.
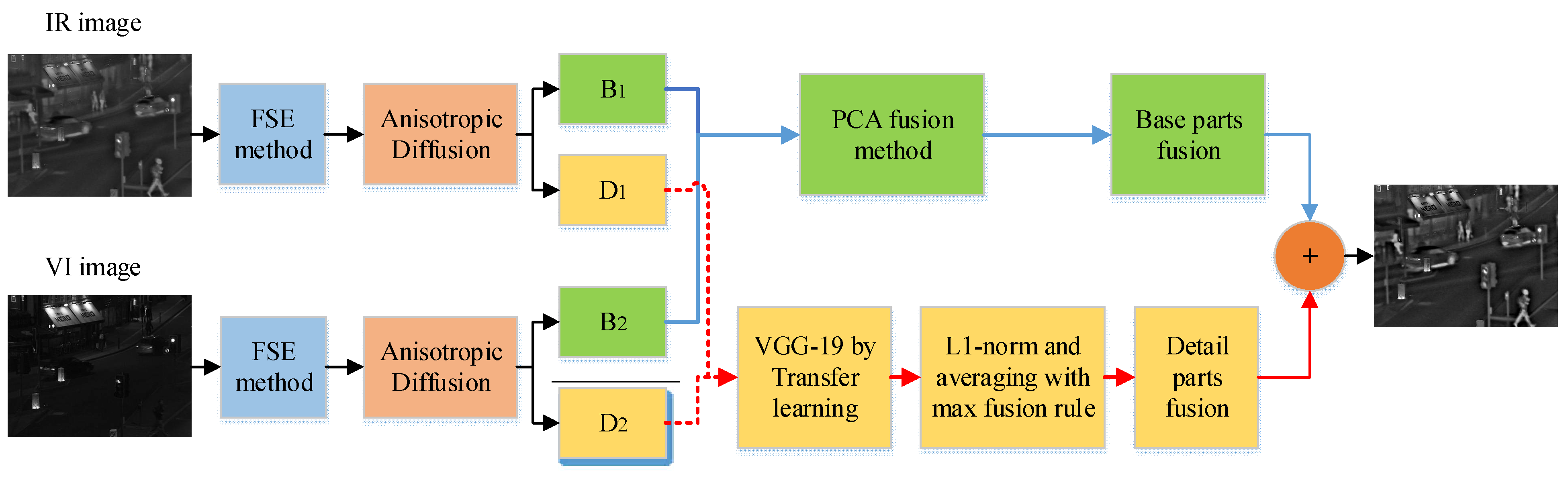
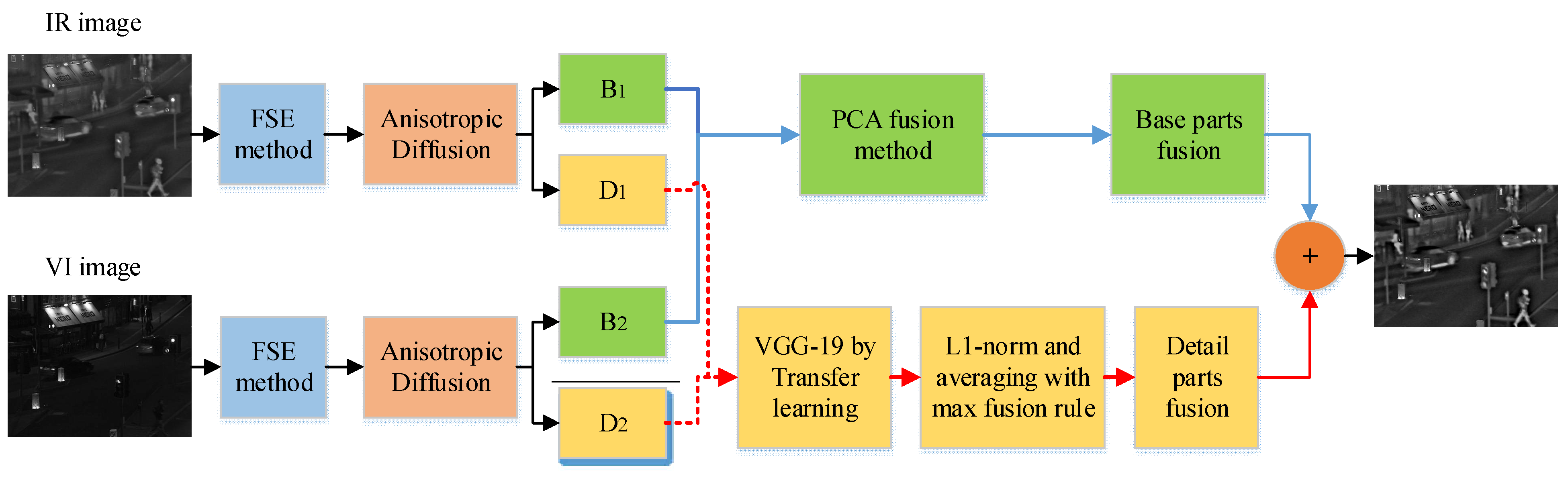
The proposed method first uses a preprocessing contrast enhancement technique named adaptive fuzzy set-based enhancement (FSE). This method automatically enhances the contrast of IR and VI images for better visualization with adaptive parameter calculation. These enhanced images are decomposed into base and detail parts by the anisotropic diffusion method using the partial differential equation. This method prevents diffusion across the edges; it removes the noise and preserves the edges. The PCA method is employed for a fusion of base parts. It can preserve the local energy information while eliminating the redundant data with its robust operation. The four convolution layers of the VGG-19 network through the guidance of transfer learning are applied to detailed parts. This model extracts all the useful salient features with better visual perception, while it saves time and resources during the training without requiring a lot of data. Furthermore, the averaging fusion strategy and choose-max selection rule removes the noise in smooth regions while restoring the edges precisely.
The proposed method consists of a series of sequential steps presented in
Figure 1. Each step in the proposed method performs a specific task to improve the fused image quality. We will elaborate on each step in detail in sub-sections.
2.1. Fuzzy Set-Based Enhancement (FSE) Method
Capturing the IR and VI image is quite a simple task; however, it is challenging for the human visual system (HVS) to obtain all information due to environments with dense fog, haze, cloud, poor illumination, and noise. In addition, IR and the visible images taken at night vision have low contrast, and they have more ambiguity and uncertainty in the pixel values that arise during the sampling and quantization process. The pixel intensity evaluation needs to be carried out if the image has low contrast. The fuzzy domain is the best approach to alleviate the above-mentioned shortcomings. We have used the FSE method that improves the visualization of IR and VI automatically. This method is adaptive and robust for the parameter calculation of image enhancement.
The fuzzy set for an image I of
size with L gray levels each having membership value is given as:
where,
represents the membership function for each value of intensity at
, and
is the intensity value of each pixel. The membership function typifies the appropriate property of images such as edges, brightness, darkness, and textural that can be described globally for the whole image. The block diagram for FSE is given in
Figure 2.
We will discuss each step that is involved in FSE in detail as follows:
2.1.1. Fuzzification
The IR or VI images are fed as input I. Then, the image is transformed from spatial domain to fuzzy domain by Equation (2).
where,
indicates the maximum intensity level in an image I, whereas
and
represent the fuzzifier dominator and exponential.
The importance of fuzzifiers given in Equation (2) is to reduce the ambiguity and uncertainty in a given image. Many of the researchers have chosen the value of exponential fuzzifier as 2. Instead of selecting a static value for
, we have determined the adaptive calculation. As we used IR and the VI images (VI taken at night) that have a poor resolution, the general trials using the static value of
cannot acquire good results. Therefore, keeping the above considerations, we compute the value of
using the sigmoid [
41] function that is calculated by Equation (3):
where, m indicates the mean value of an image.
The dominator fuzzifier
is obtained as:
2.1.2. Modification of Membership Function
The contrast intensification operator (CIO) is applied to
to modify the membership function value that is computed by Equation (5):
The is the cross-over point that ascertains the value of . There is a monotonical increment in the value because of the incremental value from 0 to 1 due to CIO, and we have set 0.5 as the value for .
2.1.3. Defuzzification
It is a phenomenon of transforming modified fuzzification data from fuzzy domain to spatial domain using Equation (6):
where
indicates the modified member function.
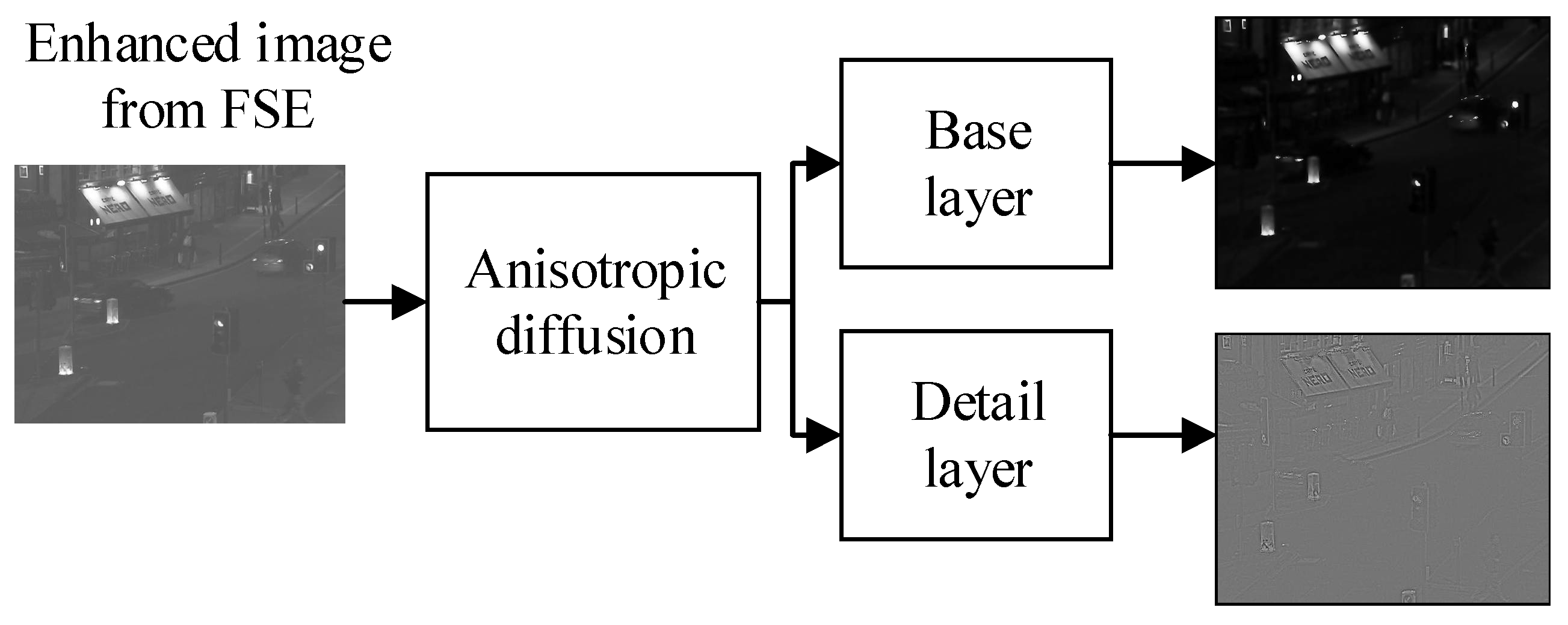
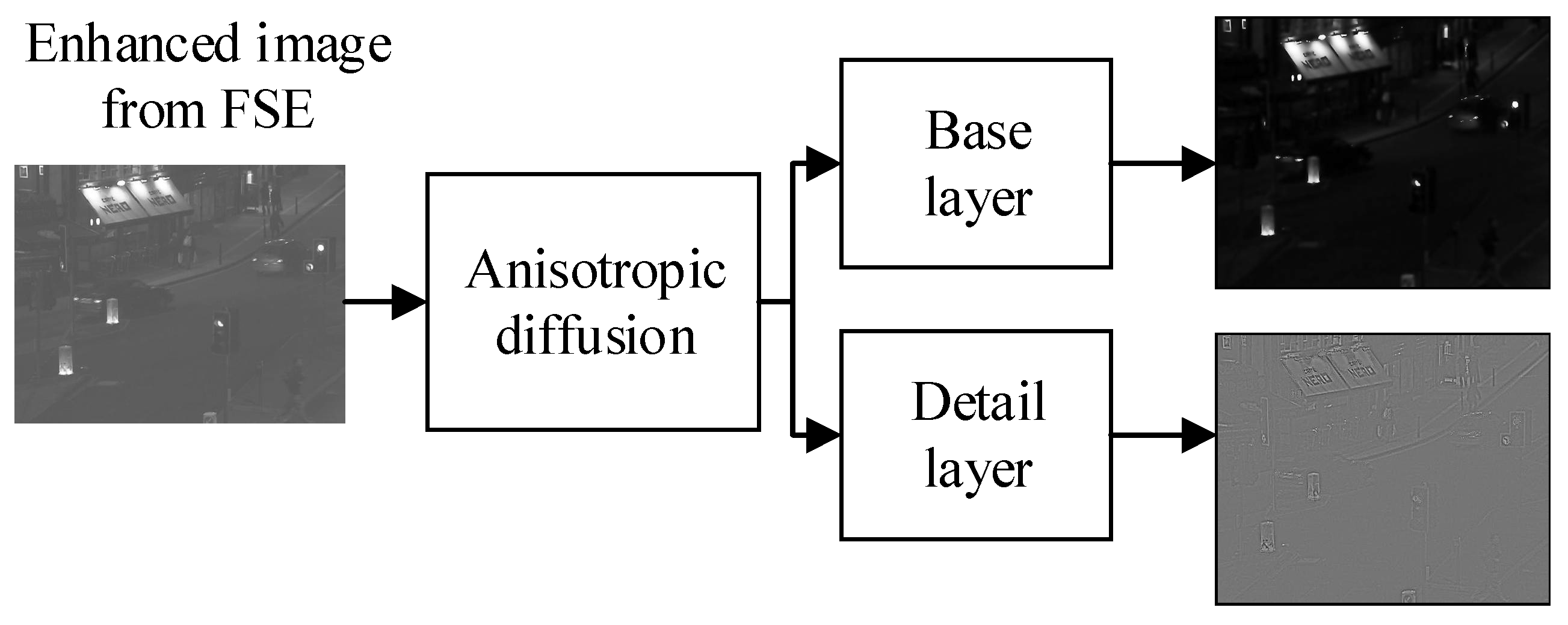
2.2. Anisotropic Diffusion
The anisotropic diffusion (AD) is a way to decompose the source image into a base layer and detailed layer used for image fusion in this paper. This method employs the intra region smoothing procedure to obtain coarse resolution images; hence, the edges are sharper at each coarse resolution. This scheme will acquire the sharp edges while smoothing the homogenous areas more precisely by employing partial differential equations (PDE). An AD employs flux function to ascend the image diffusion that can be computed by Equation (7):
where
represents the image diffusion,
= rate of diffusion,
= gradient operator,
= Laplacian operator, and
is iteration.
We will use forward time central space (FTCS) to solve the PDE. The reason to use FTCS is to maintain diffusion stability, which can be assured by the maximum principle [
42]. The equation to resolve the PDE can be computed by Equation (8) as:
where
represents the stability constant in the range
,
indicates the image coarse resolution in forward time at
iteration that relies on former
. The
, and
show the neighboring differences in the north, south, east, and west directions, and it can be computed by Equation (9):
Similarly, the flux functions
, and
will be updated at each iteration in all four directions as:
The
in Equation (10) is the monotonical decrement function with
, and can be computed as:
where p represents a free parameter used to determine the validity of the region boundary based on its edge intensity level.
Equation (11) is more useful if a given image contains wide regions instead of narrow regions. Wherein, Equation (12) is more flexible if an image has high-edge resolution than poor-edge resolution; however, the parameter p is fixed.
Let the input images
having
size be fed into AD that are well-aligned and co-registered. These images are infiltrated into the edge-preserving smoothing AD process for acquiring the base layer, and it is computed as Equation (13):
where
indicates the AD process for the n-th base layer, while
is the acquired n-th base layer. After acquiring the base layer, the detail layer is computed by subtracting the base layer from the source image as given in Equation (14):
It can be seen in
Figure 3 that AD is employed in an enhanced image obtained from the FSE scheme. The AD decomposes the image into the base layer and detail layer, and their base and detail images are shown in
Figure 3. We have applied AD to only one enhanced image of FSE, and we will apply the AD to another image in the same pattern to obtain a base and detail layer for another image.
2.3. Fusion Strategy of Base Layers
The base layers contain the energy information, and it is vital to preserve the energy information from both base layers to extract more features. Though the average fusion scheme can be applied, it cannot preserve the complete information. The PCA is utilized for the fusion of low-frequency images that is a dimension reduction technique that minimizes the complexity of a model and avoids overfitting. This method compresses a dataset into a lower-dimensional feature subspace while preserving relevant information at a high level of detail. It takes a subset of the original features and uses that knowledge to create a new feature subspace. It locates the most elevated variance directions in high-dimensional data and projects them onto a new subspace with the same or fewer dimensions as the original. The PCA transforms correlated variables into uncorrelated forms that choose features with significant values of eigenvalues and eigenvectors . After that, the principal components and are computed from these highest eigenvalues and eigenvectors . All the principal components are orthogonal to each other, which helps to eliminate redundant information and makes fast computation. The PCA method used for the fusion of base layers is discussed below.
1. The proposed method is applicable for a fusion of two, or more than two, base layers; however, we consider only two base layers for simplicity. Let and be the two base layers obtained after decomposition from the AD process. The first step is to acquire a column matrix, Z, from these two base layers.
2. Obtain the variance V and covariance
matrix
from column matrix Z for both base layers
and
. The V and
is calculated by Equation (15):
In Equations (15) and (16), indicates the variance and covariance, whereas T represents the number of iterations.
3. After obtaining the variance and co-variance, the next step is to obtain the eigen values
and eigen vectors
. The
is computed by Equation (17):
Now we compute the
by Equation (19):
4. The next step is to determine if the uncorrelated components
and
match the highest eigenvalues
. Let
represent the eigenvector corresponding to
, then
and
are computed as:
5. The final fused base layer can be calculated by Equation (21) as:
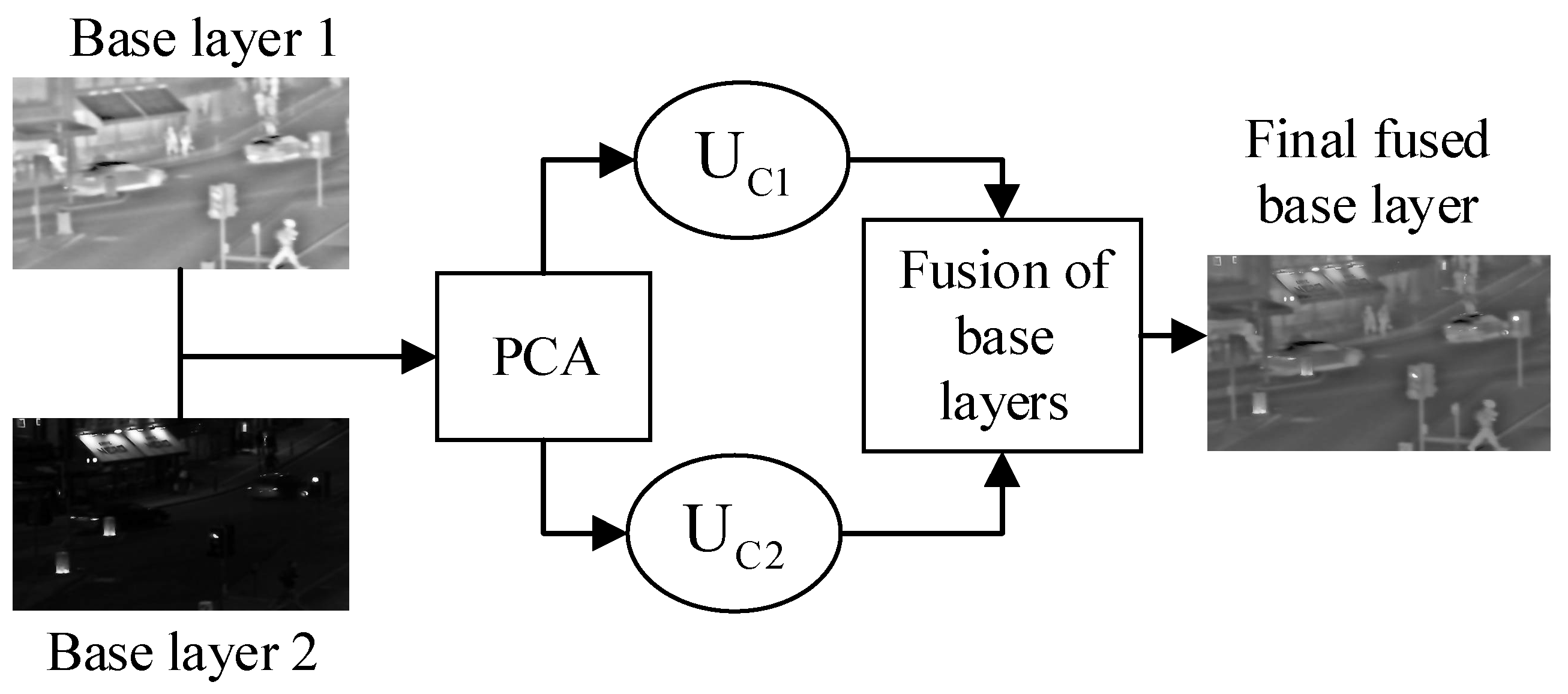
The block diagram for a fusion of base layers by PCA method is shown in
Figure 4. The two base layers that are decomposed by AD are fed to PCA and the final fused base layer is obtained after the fusion process of PCA. The symbols
and
in
Figure 4 represent the uncorrelated components for both base layers. These uncorrelated components are obtained from the highest eigenvalues and eigenvectors that are orthogonal to each other, and its computation would be fast due to the elimination of redundant data.
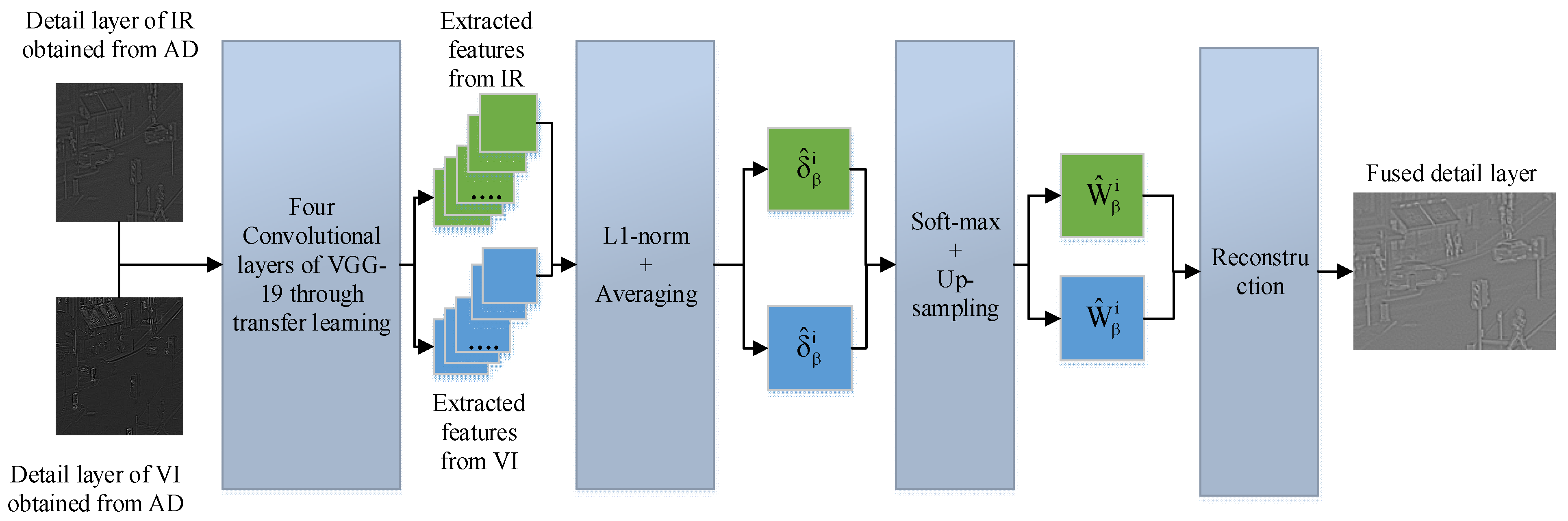
2.4. Fusion Strategy for Detail Layers
Most traditional methods use the choose-maximum fusion rule to extract the deep features. Nonetheless, this fusion scheme significantly loses detailed information that affects the overall fused image quality. In this paper, we extract the deep features by four convolutional layers of VGG-19 through the guidance of transfer learning. The activity level maps are acquired from desired extracted deep features by
and the averaging method. Then, soft-max and up-sampling are employed to these activity level maps to generate the weight maps. After that, these weight maps are convolved with IR and VI images to obtain the four candidates. Finally, the maximum strategy is applied to these four candidates to obtain the final fused detailed layer. The whole phenomena for a fusion of detailed layers are shown in
Figure 5.
We will discuss each step more precisely in sub-sections.
2.4.1. Feature Extraction by VGG-19 through Transfer Learning
We have used a VGG-19 network that consists of convolution layers, ReLU (rectified linear unit) layers, pooling layers, and fully connected layers [
43]. The main purpose for using the VGG-19 network is its feasibility which has a
receptive field for each convolution layer with a fixed stride of 1 pixel and spatial padding of 1 pixel. We took only four convolution layers from VGG-19 through the guidance of transfer learning. Transfer learning helps to reduce the training effort. We took four convolution layers (conv1-1, conv2-1, conv3-1, and conv4-1) and chose the first convolution layer from each convolution group because the first convolution layer contains complete significant information.
Let
represent the number of detailed images, and we took two detailed images that are
and
. Assume that
represents the feature map of the
detailed layer at
convolution layer, and m shows the number of channels of the
layer, so
. The M is the maximum number of channels, and it can be calculated as
by Equation (22).
Each represents a layer in VGG-19, and we chose four layers, i.e., conv1-1, conv2-1, conv3-1, and conv4-1.
Suppose
indicate the contents of
at
position, and
is an M-dimensional vector. Consequently, the phenomena of our fusion strategy is elaborated in the next section, which is also shown in
Figure 5.
2.4.2. Feature Processing by Multiple Fusion Strategies
Inspired by [
44], we employ the
method to quantify the amount of information in the detailed images, which is called the activity level measurement of detailed images. After acquiring the feature maps
, the next step is to find the initial and final activity level maps. The initial activity level map
is obtained by using the
scheme that is computed as given in Equation (23) and depicted in
Figure 5:
The next step is to find the final activity level map
. The
is computed by Equation (24):
where r represents the size of the block, which helps our fusion method avoid misregistration. The larger value of r makes fusion more robust to prevent misregistration. Though some detail could be lost by choosing a higher value of r, we need to determine the value of r carefully. In our case, we have selected
because it preserves all information at this value while it also avoids misregistration.
It can be seen in
Figure 5 that we have applied a soft-max that is used for computing the weight map
from
. The
is calculated by Equation (25):
where
indicates the number of activity level maps. As we have taken two source images, therefore,
in our case, we will obtain four pairs of initial weight maps to distinguish scales because we have chosen four convolutional layers through transfer learning.
The pooling layer is used in the VGG-19 network that acts as a sub-sampling; hence, it reduces the size of feature maps. Therefore, after every pooling layer, the feature maps are resized to
times where s denotes the pooling stride, and the stride of the pooling operator is 2. Thus, the size of the feature maps would be
for each different layer of the convolution group, so
for the first, second, third, and fourth convolution layer in each convolution group. Therefore, after obtaining the initial weight maps, we use the up-sampling operator to resize the weight map size that equals the size of detail content. The final weight maps using the up-sampling operator can be computed by Equation (26):
Now, the four weight maps that are acquired by the up-sampling operator are convolved with the detail layer of IR and VI images to obtain the candidates, and it is computed by Equation (27):
The fused detail content
is finally computed by employing a choose-max value from four candidate fused images, as shown in
Figure 5 and Equation (28).
2.5. Reconstruction
The reconstruction of the final fused image is obtained by simple linear superposition of the fused base image and the fused detailed image as given in Equation (29).
4. Discussion
Implementing the image fusion method that extracts all salient features from individual source images into one composite fused image is the hot research topic of future development in IR and VI applications. This proposed work is one of the attempts in the IR and IV image fusion research area. Our method not only emphasizes the crucial objects by eliminating the noise but also preserves the essential and rich detailed information that is helpful for many applications such as target detection, recognition, tracking, and other computer vision applications.
Various hybrid fusion methods amalgamate the advantages of different schemes to enhance the image fusion quality. In our hybrid method, each stage improves the image quality, which can be observed in
Figure 2,
Figure 3,
Figure 4 and
Figure 5, respectively. Our hybrid method extensively uses the fuzzy set-based enhancement, anisotropic diffusion, and VGG-19 network through transfer learning with multiple fusion strategies and PCA. The FSE method automatically enhances the contrast of IR and IV with its adaptive parameter calculation. In addition, this method is robust in environments with fog, dust, haze, rain, and cloud. The AD method using PDE is applied that decomposes the enhanced images of FSE into the base and detailed images. It has the attribute of removing noise from smooth regions while retaining sharp edges. The PCA method is employed in the fusion of the base parts that restrain the distinction between the background and targets since it can restore the energy information. Besides, it eliminates redundant information with its robust operation. The VGG-19 network using transfer learning is adapted as it has a significant ability to extract specific salient features. In addition, we have used four convolution layers of VGG-19 through transfer learning that efficiently saves time and resources during the training without requiring a lot of data. At last, the
and averaging fusion strategy along with the choose-max selection fusion rule is applied, which efficiently removes the noise and retains the sharp edges.
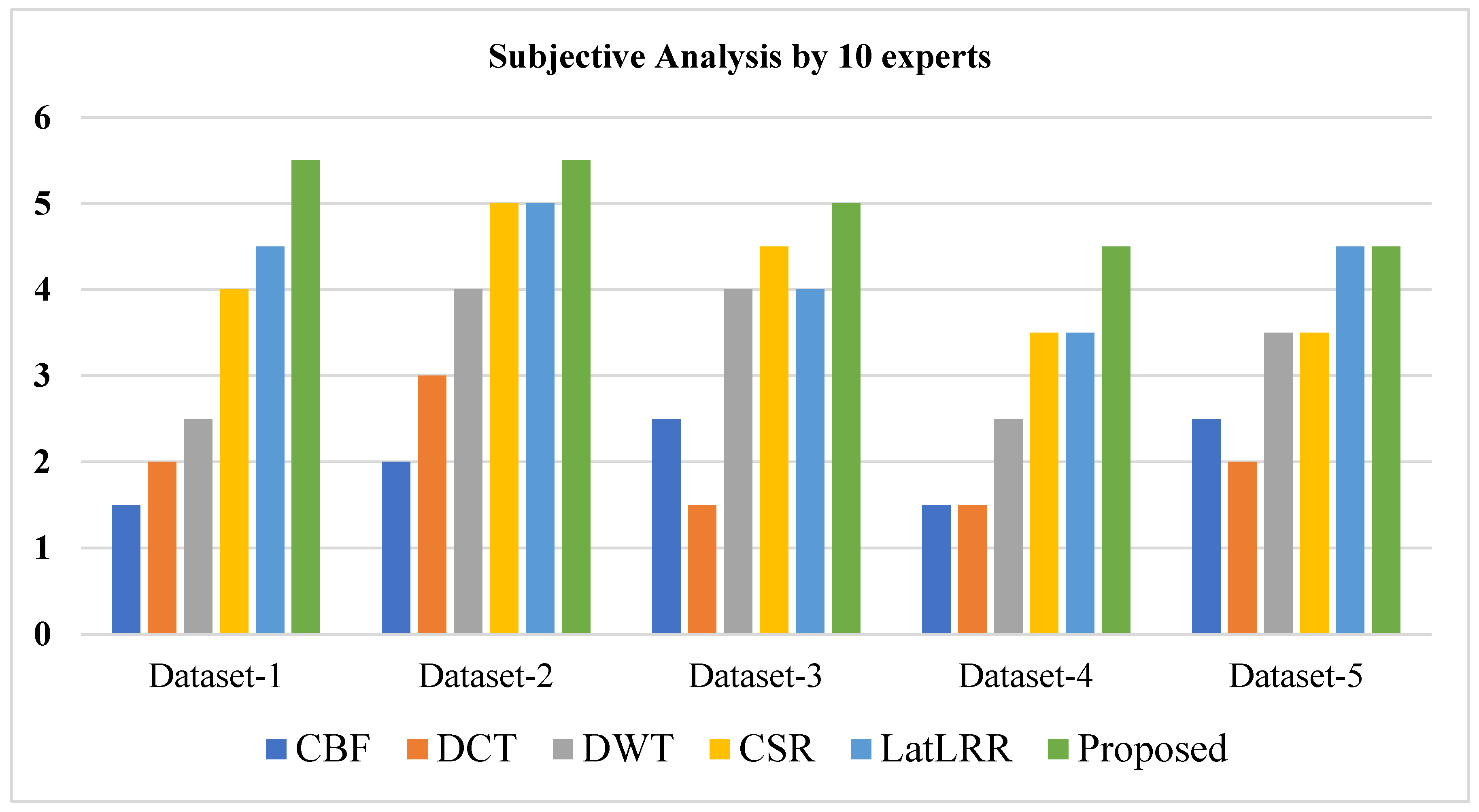
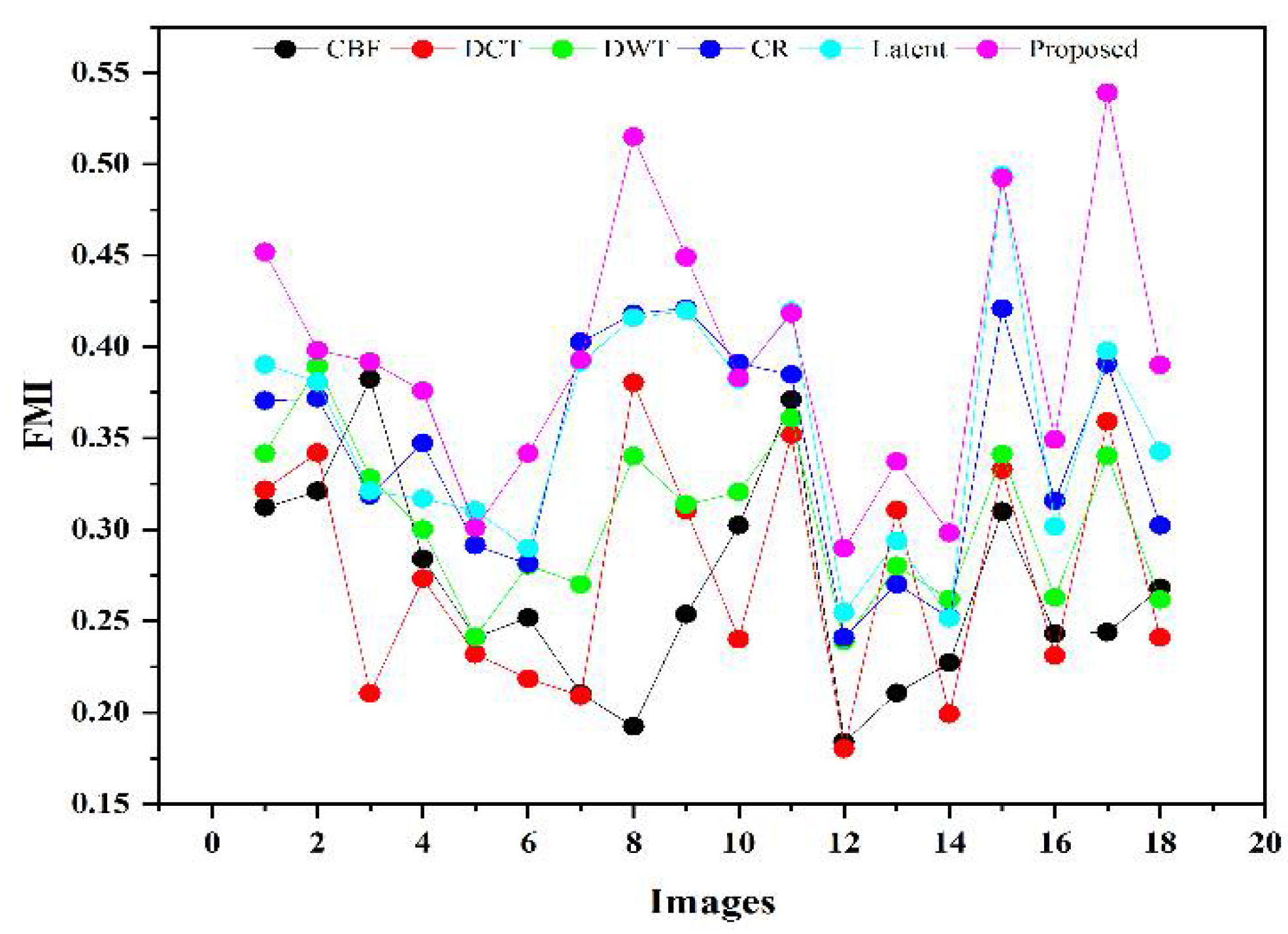
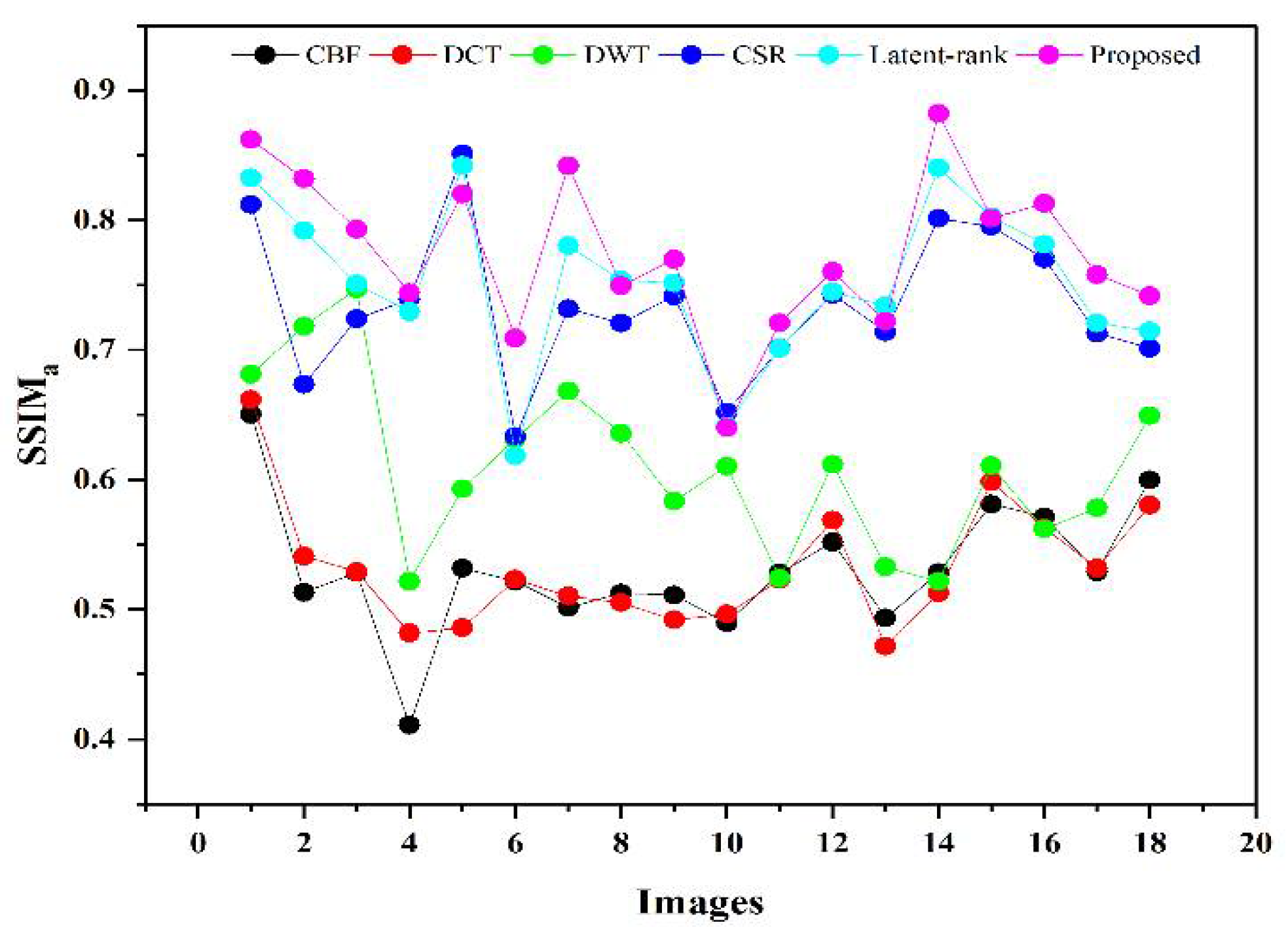
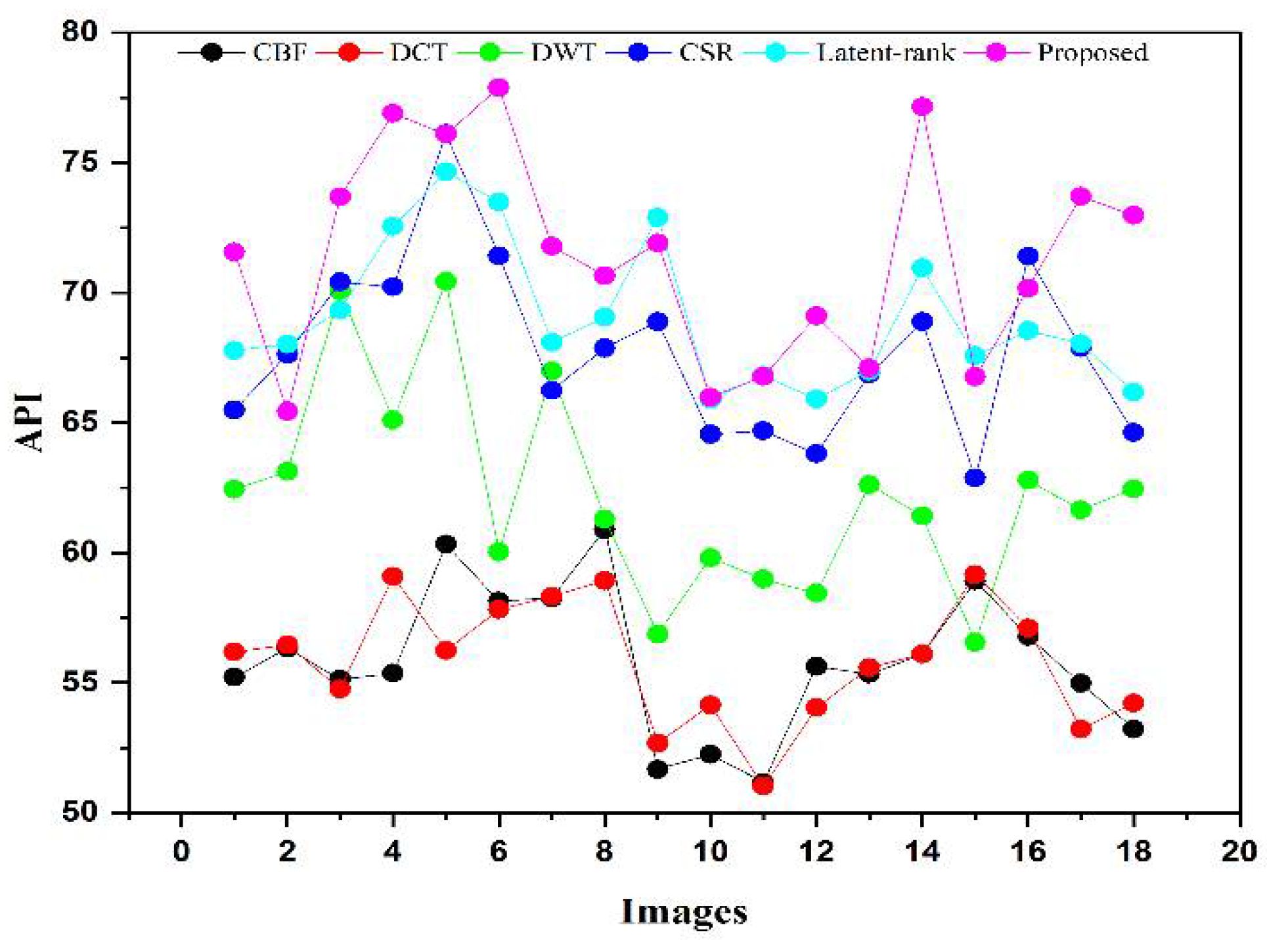
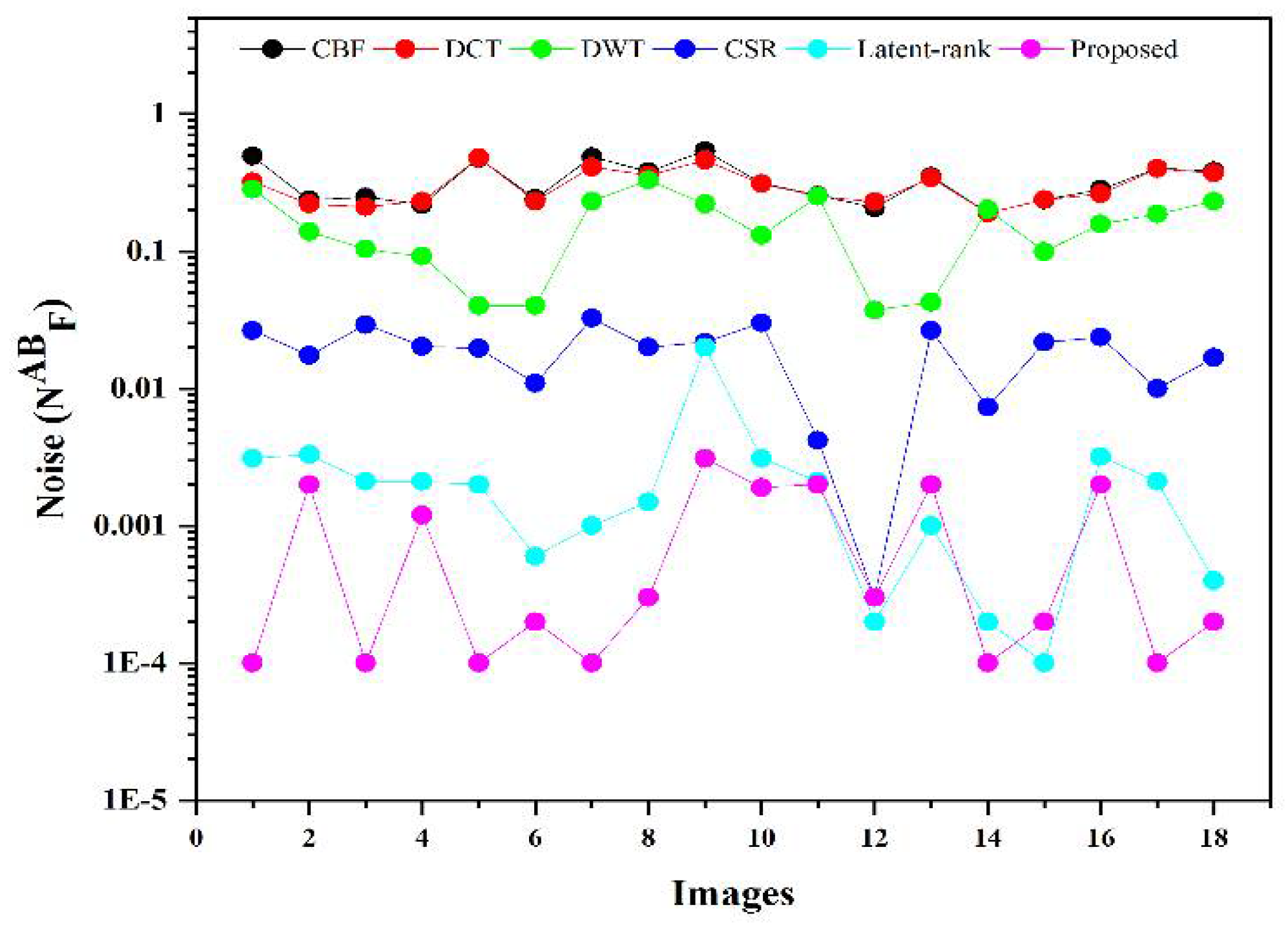
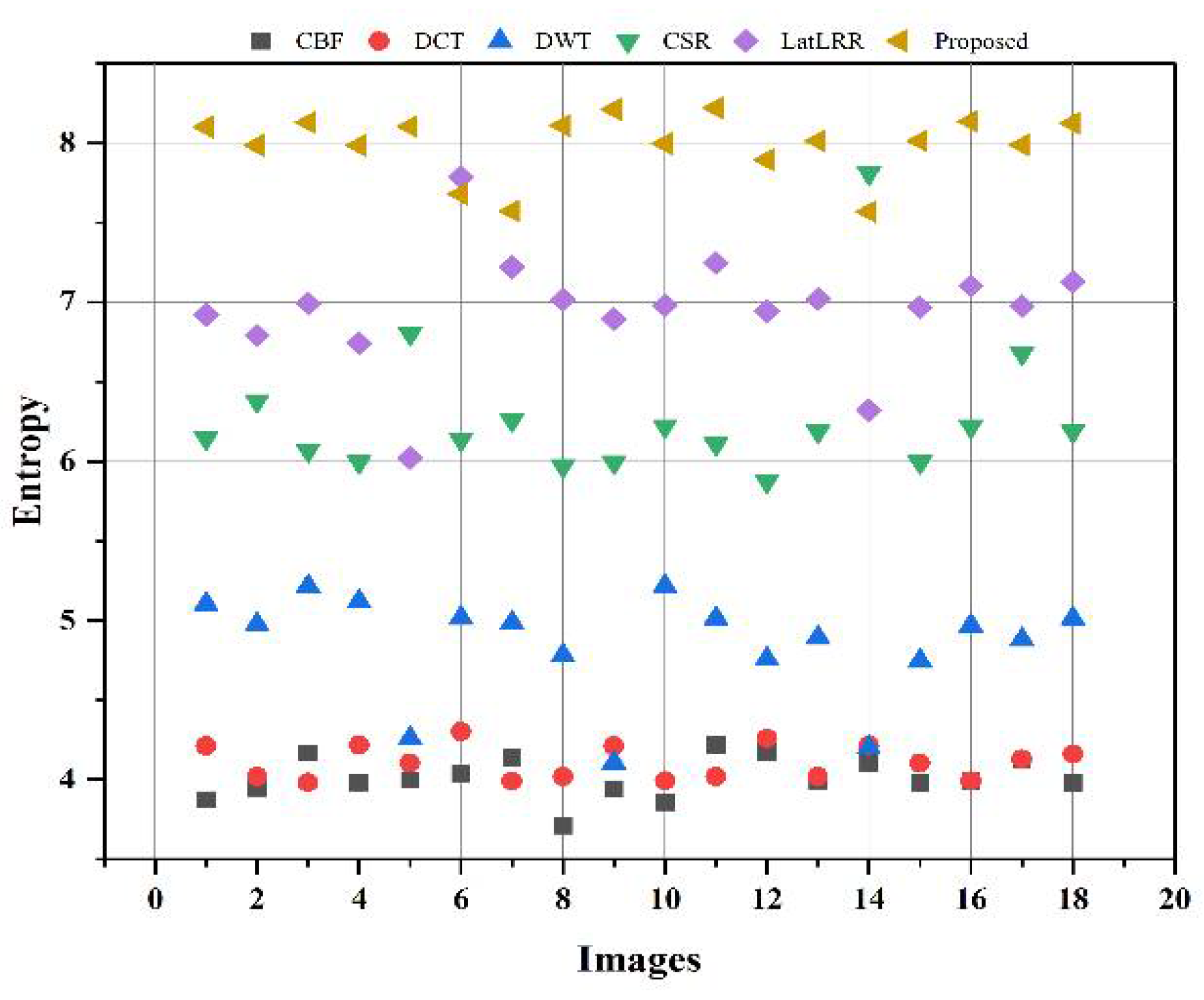
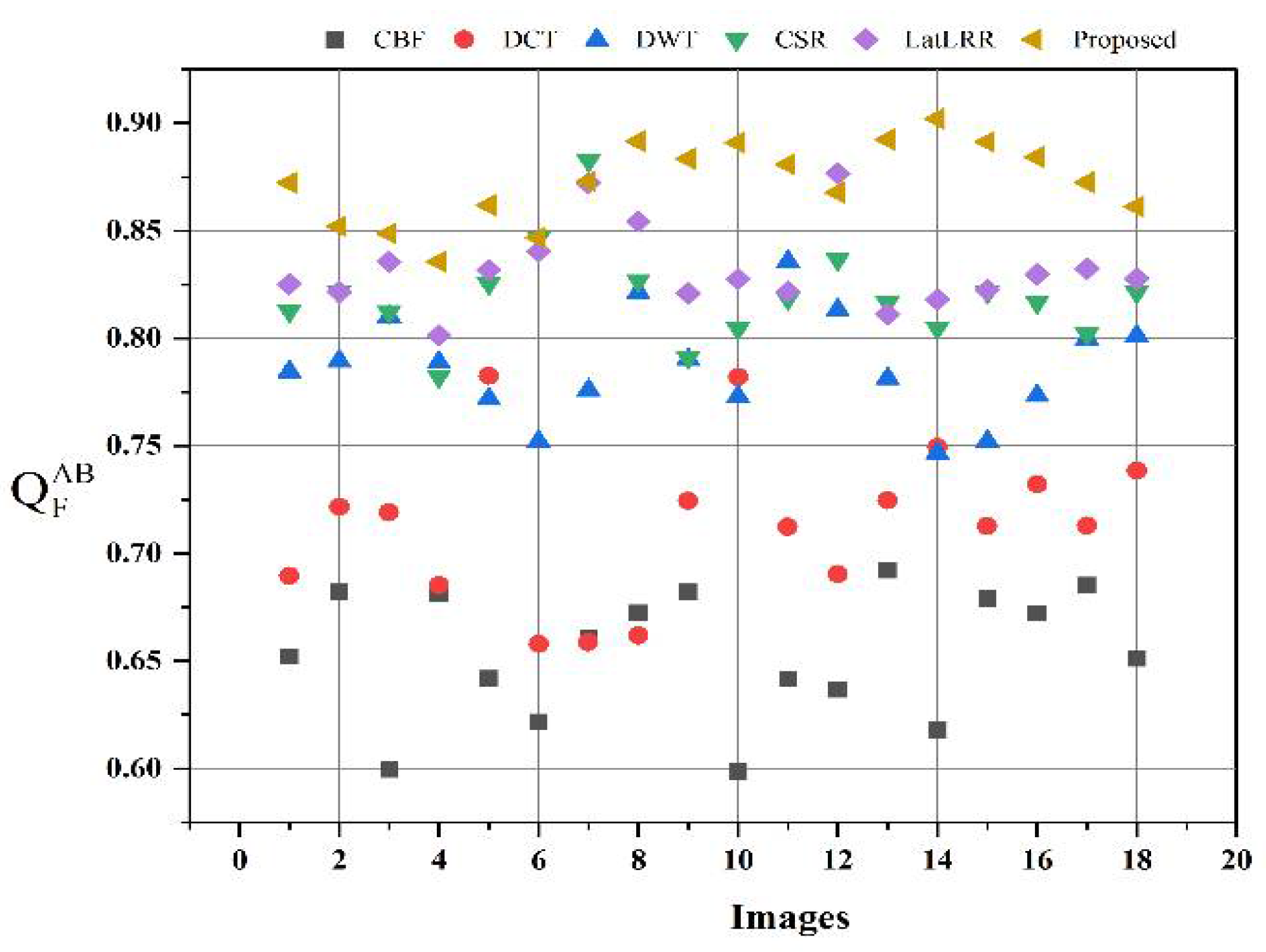
All in all, from a visual perspective, it can be observed from
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10 and
Figure 11, and experts ranking in
Table 2 and
Figure 12, that the proposed method produced a better quality fused image than the other fusion methods, demonstrating the supremacy of our method. Similarly, the proposed method has better values in the indexes of
,
,
, EN,
, and
objective evaluation assessment that further justify the dominancy of the proposed work.
Although the proposed work shows supremacy over recent fusion methods, this work still has limitations. The proposed work is implemented for the general IR and VI image fusion framework. However, the IR and VI image fusion for a specific application needs particular details based on that application. Therefore, we will extend this work for specific applications such as night vision and surveillance. The computation time of the proposed method is not very favorable. In future research, we will emphasize reducing the consumption time while sustaining the improved quality of a fused image.
5. Conclusions
A novel IR and VI image fusion method is proposed in this work. This work contains several stages of novel techniques. We use fuzzy set-based contrast enhancement to automatically adjust the contrast of images with its adaptive calculation and an anisotropic diffusion to remove noise from smooth regions while capturing sharp edges. Moreover, a deep learning network based on four convolutional layers named VGG-19 through transfer learning is exploited to detail images to restore substantial features. Concurrently, it saves time and resources during training and restores spectral information. The extracted detailed features are fed into and the averaging fusion scheme with a max selection rule that helps to remove the noise in smooth regions, thereby resulting in sharp edges. The PCA method is applied to base parts to preserve the essential energy information by eliminating the redundant information with its robust operation. Finally, a fused image is obtained by the superposition of base and detail parts containing substantial rich and detailed features with negligible noise. The proposed method is compared with other methods on subjective and objective assessments. The subjective analysis is performed by statistical tests (Wilcoxon signed-rank and Friedman) and experts’ visual experience. In contrast, the objective evaluation is conducted by computing the quality parameters (FMI, , API, EN, , and ). The proposed method exhibits superiority by obtaining a smaller value for statistical tests than other methods from a subjective perspective. Besides, experts also prefer the average results produced by the proposed method. In addition, the proposed method further justifies its efficacy for objective parameters by achieving 0.2651 to 0.3951, 0.5827 to 0.8469, 56.3710 to 71.9081, 4.0117 to 7.9907, 0.6538 to 0.8727 gain for , , , , and respectively
Intuitively, it can be concluded that the proposed method achieves optimal fusion performance. Our next research direction is to implement a framework for other image fusion tasks such as multimodal remote sensing, medical imaging, and multi-focus. In addition, we can apply transfer learning to other deep convolutional networks in image fusion to improve the fusion quality.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}