Abstract
Matching aerial and satellite optical images with large dip angles is a core technology and is essential for target positioning and dynamic monitoring in sensitive areas. However, due to the long distances and large dip angle observations of the aerial platform, there are significant perspective, radiation, and scale differences between heterologous space-sky images, which seriously affect the accuracy and robustness of feature matching. In this paper, a multiview satellite and unmanned aerial vehicle (UAV) image matching method based on deep learning is proposed to solve this problem. The main innovation of this approach is to propose a joint descriptor consisting of soft descriptions and hard descriptions. Hard descriptions are used as the main description to ensure matching accuracy. Soft descriptions are used not only as auxiliary descriptions but also for the process of network training. Experiments on several problems show that the proposed method ensures matching efficiency and achieves better matching accuracy for multiview satellite and UAV images than other traditional methods. In addition, the matching accuracy of our method in optical satellite and UAV images is within 3 pixels, and can nearly reach 2 pixels, which meets the requirements of relevant UAV missions.
1. Introduction
Aviation and space-based remote sensing technology has been applied in many fields due to its advantages of macroscopic, rapid, and accurate object recognition [1]. Therefore, it has important theoretical significance and practical value for mining and is associated with different sensors (not simultaneously), different angles, and different resolutions of image information (space and sky images) to achieve high precision and high efficiency in regional dynamic monitoring, change detection, target recognition, positioning, and other visual tasks [2,3,4,5]. Space images mean the images captured by the airborne platform and sky images mean the images captured by the spaceborne platform. Among them, image matching is the key core technology, and the resulting matching effect directly affects and restricts the success or failure of the subsequent follow-up tasks.
Image matching technology refers to mapping an image to other images obtained under different conditions, such as different time phases, angles, and levels of illumination, through spatial transformation and the establishment of spatial correspondence relations among these images. It is the key technology of image processing and analysis and provides technical support for medical image analysis, industrial image detection, remote sensing image processing, and other fields [6]. Remote sensing image matching connects the subregions of different images that correspond to the same landform scene, which lays a foundation for follow-up operations such as remote sensing image registration, mosaic procedures, and fusion and can also provide supervisory information for scene analyses of remote sensing images [7]. Due to the observation of large aviation platform dip angles, there are significant differences between the viewing angles and scales of satellite and unmanned aerial vehicle (UAV) images, which brings great difficulties to the feature matching process for the satellite and UAV images. This is shown in Figure 1.

Figure 1.
The UAV image is on the left and the satellite image is on the right. (a,b) show the difference in view between UAV images and satellite images. (c) shows the scale difference between UAV images and satellite images.
Due to differences in imaging mechanisms, illumination levels, time phases, and viewing angles, there are obvious nonlinear radiation distortions between UAV images and satellite images. Therefore, it is difficult to achieve reliable matching with multiview heterogeneous images by using only traditional artificial image-gradient-based operators (such as the scale-invariant feature transform (SIFT)) [8]. With the development of deep learning, convolutional neural networks (CNNs) have achieved great success in the field of image processing [9,10,11]. The convolutional layer in a CNN has strong feature extraction ability. Compared with artificially designed feature descriptors, CNN features can be trained by a network model to enable a deep network to find the most appropriate feature extraction process and representation form. Therefore, CNNs can be used for image matching to better solve the influence of nonlinear radiation distortion between images, which cannot be solved by the underlying gradient feature. During the process of network training, the parameters of the network layer are updated by monitoring information and a back-propagation function so that the CNN also has good robustness to deformation and noise. This paper proposes a joint description neural network specifically designed to match multiview satellite and UAV images. Compared with some traditional methods, the proposed method can achieve better results in the multiview satellite image and remote sensing image matching. First, the proposed method extracts features and filters them through a CNN. Second, the extracted features are expressed by hard and soft descriptions. Then, the loss function of the neural network is designed with a soft descriptor for neural network training. Finally, the hard description and soft description are combined as the final feature description, and the final matching result is obtained. The main contributions of this paper can be summarized as follows:
- (1)
- A soft description method is designed for network training and auxiliary description.
- (2)
- A high-dimensional hard description method is designed to ensure the matching accuracy of the model.
- (3)
- The joint descriptor supplements the hard descriptor to highlight the differences between different features.
The rest of this article is organized as follows. In Section 2, the related works of image matching are briefly discussed. In Section 3, a neural network matching method is presented that includes feature detection, hard and soft descriptors, joint descriptors, multiscale models, and a training loss. In Section 4, the experimental results for this model are discussed. Finally, the conclusion is presented in Section 5.
2. Related Works
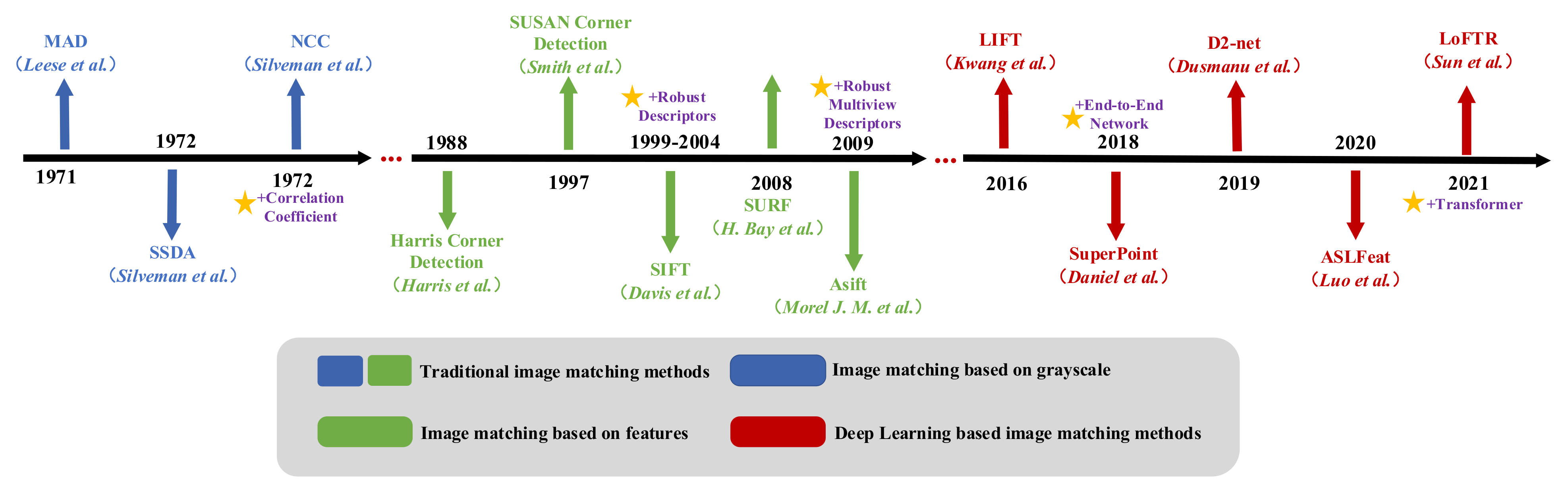
The existing image matching methods can be divided into gray-based matching methods and feature-based matching methods. These two kinds of methods as well as the image matching method based on deep learning and the improved method of multiperspective image matching will be reviewed and analyzed in the following sections. The practical image matching method is based on grayscale at the beginning. Due to the limitations of the method based on grayscale, the feature-based image matching method was proposed later, which greatly improves the applicability of image matching technology. In recent years, with the rapid development of deep learning technology, image matching methods based on deep learning are becoming more and more popular, which has brought the image matching technology to a new level. Its development is shown in Figure 2.
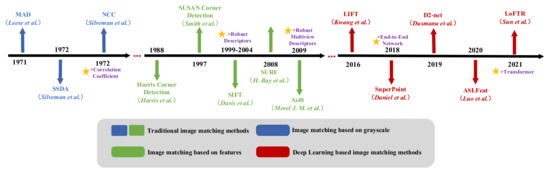
Figure 2.
Image matching development history map. In the 1970s and 1980s, the main method of image matching was based on grayscale. By the end of the last century, feature-based image matching methods became popular. In recent years, with the development of deep learning technology, more and more image matching methods based on deep learning have been emerging.
2.1. Matching Method Based on Grayscale
The basic idea of image matching algorithms based on grayscale is to directly compare the grayscale values of image pixels one by one; this is the most basic type of matching method. Such an approach compares the similarity of all gray values of all pixels in the image and then uses a certain algorithm to search for the transformation model parameter value that maximizes or minimizes the similarity to judge the whole image. The similarity measurement functions commonly used in this kind of matching algorithm include the sum of squares, correlation, covariance, cross-correlation, and phase correlation functions of the gray difference between two images.
Image matching methods based on grayscale are most suitable for image pairs with only the rotation and scaling geometric relations. Leese [12] first proposed the multivariate alteration detection (MAD) algorithm in 1971, which is the basic image matching algorithm based on image gray levels. Subsequently, Silverman and Barnea [13] proposed the sequential similarity detection algorithm (SSDA) based on the MAD algorithm and then proposed the normalized cross-correlation (NCC) algorithm. Compared with other image matching algorithms based on the grayscale, the NCC algorithm has been proven to be the best approach for similarity evaluation, so the NCC algorithm has also been widely used. However, because the NCC algorithm uses the gray information of the whole input image for image matching, it consumes considerable time, thus reflecting its limitations in some applications requiring high real-time performance. Gray-based matching methods are sensitive to the grayscale differences between images, and they can only match images with linear positive grayscale characteristic correlations. In cases with large geometric disparities between images, this method often fails and it is difficult to use it to match multiview images [14].
Matching methods based on grayscale contain the information of all pixel points in the input image, so their matching accuracy rates are very high, but they also have many shortcomings and problems. (1) Because this type of method uses all image pixel points, the algorithmic complexity is high, and the matching speed is very slow. However, most matching algorithms require high real-time performance, which limits the application scope of this approach. (2) Because this class of algorithms is sensitive to brightness changes, its matching performance is greatly reduced for two images that are in the same scene but under different lighting conditions. (3) For two images with only rigid body transformations and affine transformations, the matching effects of these algorithms are good, but for images with serious deformation and occlusion issues, the matching performance is poor. (4) The algorithms exhibit poor antinoise performance.
2.2. Matching Method Based on Features
Feature-based image matching algorithms make up for the deficiencies of grayscale matching algorithms and have good effects on the matching results of image pairs with affine transformations and projection transformations. At the same time, because feature-based matching algorithms do not match the whole input image but rather extract a series of representative features from the image and then match the features between two images, the algorithmic complexity is greatly reduced, and the matching rate is faster. Feature-based image matching algorithms are typically used in applications requiring high real-time performance. Therefore, this type of algorithm has become a research hotspot in recent years. In 1988, Harris [15] proposed the Harris corner detection algorithm, and it was proven that the Harris corner is rotation invariant and robust to noise and brightness changes to a certain extent. In 1997, Smith and Brady [16] proposed Susan’s corner detection method. In 1999, Davis Lowe et al. [17] proposed a SIFT descriptor-based detection method and improved the algorithm in 2004. The SIFT algorithm has been a hot research topic because of its high robustness and invariance to scaling, rotation, and other transformations. Bosch et al. [18] proposed the hue/saturation/value-SIFT (HSV-SIFT) algorithm due to the lack of color information in existing algorithms. The algorithm extracts feature points in each channel of the HSV color space and then connects the feature points in an end-to-end manner in three channels to form a 3 × 128-dimensional descriptor. Yan et al. [19] proposed reducing the dimensionality of the SIFT algorithm by using principal component analysis (PCA) to solve the problems regarding high SIFT dimensions and long matching times and formed the PCA-SIFT algorithm with low dimensions. Aiming at the sensitivity of the SIFT algorithm to affine transformation, Morel J M et al. [20] proposed the affine SIFT (ASIFT) algorithm with full affine invariance, which improved the matching accuracy of the algorithm for images with multiple perspectives. To improve remote sensing image registration technology, Pouriya and Hassan [21] proposed a sample consistency-based feature matching method built on sparse coding. This method can greatly improve the matching results of two images via SCSC through a joint checkpoint. In addition, the method exhibits excellent performance when many feature points are present or noise is observed. San J et al. [22] proposed a feature-based image matching method by taking advantage of the Delaunay triangulation. First, the Delaunay triangulation result and its corresponding map were used to form adjacent structures containing the randomly distributed feature points of an input image, and the image plane was divided into nearly equilateral triangle patches. Second, photometric and geometric constraints were implemented based on the constructed adjacent structures, and the influence of outliers on the algorithm’s decision-making regarding the embedded lines was transmitted by combining hierarchical culling and left-right checking strategies to ensure the accuracy of the final matching results. Li et al. [23] proposed a method based on the concepts of local barycentric coordinates (LBCs) and matching coordinate matrices (MCMs) called locality affine-invariant feature matching (LAM). The LAM method first establishes a mathematical model based on LBCs to extract a good match-preserving local neighborhood structure. LAM then uses the extracted reliable communication to construct local MCMs and identifies the correctness of the residual match by minimizing the ranks of the MCMs. This method achieves excellent performance when matching real images with rigid and nonrigid images. Yu et al. [24] proposed an improved nonlinear SIFT framework algorithm, which combines spatial feature detection with local frequency domain description for synthetic aperture radar (SAR) image registration and optical image registration.
2.3. Multiview Space-Sky Image Matching Method
Under the condition of a large dip angle, the resulting image deformation is serious and traditional feature detection and description methods are often not applicable; especially in scenarios with extreme viewing angles, it is difficult to achieve reliable matching results. Gao et al. [25] proposed that there are two main methods for space-sky image matching at present. The first is the direct matching method, which directly calculates a feature descriptor for the input ground image and then realizes feature matching according to the similarity measure of the feature descriptor. The other approach is the matching method based on the geometric correction. This method first uses prior information to perform geometric correction on a vacant image, then generates composite images, eliminates or reduces the geometric deformation of the input space-sky image, and finally carries out feature matching between the composite images. In the field of photogrammetry, to overcome the matching problems of perspective and dimension changes, Hu et al. [26] proposed the use of a priori information, such as high-precision POS data, as auxiliary information and then performed geometric corrections on the obtained global image, which eliminated or reduced the effects of geometric deformation. Finally, traditional feature description and matching methods are used to match feature points. This kind of method can improve the image matching effect to some extent, but it relies on prior information, and the improvement yielded is limited because the global correction step has difficulty accurately describing the local geometric deformation between the compared images. Jiang et al. [27] proposed the idea that a certain number of matching points could be obtained through initial matching to calculate a geometric transformation model between pairs of stereo images in the absence of high-precision POS data, and then geometric correction could be carried out for these images. However, such methods rely on the initial matching results. In cases with more significant viewing angle and image scale differences with large dip angles from the sky to space, it is difficult for the existing methods to obtain reliable initial matching results for the subsequent geometric correction of the images and thus to ensure the reliability of the final matching results for points with the same labels.
2.4. Matching Method Based on Deep Learning
With the rise of artificial intelligence, methods based on deep learning have been introduced into the field of image feature matching. Kwang et al. [28] proposed a method called learned invariant feature transform (LIFT). This method is a pioneering approach in this field that combines three CNNs (corresponding to key point detection, direction estimation, and feature description) to perform image matching. Balntas et al. [29] proposed PN-Net, which adopts triplet network training. An image block triad T = {P1, P2, n} includes a positive sample pair (P1, P2) and negative sample pairs (P1, n) and (P2, n). A soft PN loss function is used to calculate the similarity between output network descriptors to ensure that the minimum negative sample pair distance is greater than the positive sample pair distance. Compared with other feature descriptors, PN-Net exhibits more efficient descriptor extraction and matching performance and can significantly reduce the time costs of training and execution. Daniel et al. [30] proposed a method called Super Point to train a full CNN consisting of an encoder and two decoders. The two decoders correspond to key point detection and key point feature description. Bhowmik et al. [31] proposed a new training method in which feature detectors were embedded in a complete visual pipeline, and learnable parameters were trained in an end-to-end manner. They used the principle of reinforcement learning to overcome the discrepancies of key point selection and descriptor matching. This training method has very few restrictions on learning tasks and can be used to predict any key point heat map and key point position descriptor architecture. Yuki et al. [32] proposed a novel end-to-end network structure, loss function, and training method to learn image matching (LF-Net). LF-Net uses the ideas of twin networks and Q-learning for reference; one branch generates samples and then trains the parameters of another branch. The network inputs a quarter video graphics array (QVGA) image, outputs a multiscale response distribution, and then processes the response distribution to predict the locations, scales, and directions of key points. Finally, it intercepts the local image input network to extract features. Jiamin S. et al. [33] proposed a method of local image feature matching based on the Transformer model, which operates under the idea that intensive pixel-level matching should be established at the coarse level first, and then fine matching should be refined at the fine level, rather than executing image feature detection, description, and matching first. The global acceptance fields provided by Transformer enable our approach to produce dense matches in low-texture areas where feature detectors typically have difficulty producing repeatable points of interest. Deep learning is also used for specific image matching. Lloyd et al. [34] proposed a three-step framework for the sparse matching of SAR and optical images, where a deep neural network encoded each step. Dusmanu et al. [35] proposed a method called D2Net, which uses more than 300,000 prematched stereo images for training. This method has made important progress in solving the problem of image matching in changing scenes and has shown great potential. However, the main purpose of these algorithmic models is to match close-up visible light ground images with light and visual angle changes, and they are mostly used for the three-dimensional reconstruction of buildings and visual navigation for vehicles. This paper attempts to propose a dense multiview feature extraction neural network specifically for multiview remote sensing image matching based on the idea of D2Net feature extraction.
In summary, the advantages and disadvantages of various type matching methods are compared in Table 1.

Table 1.
Comparison of matching methods.
3. Proposed Method
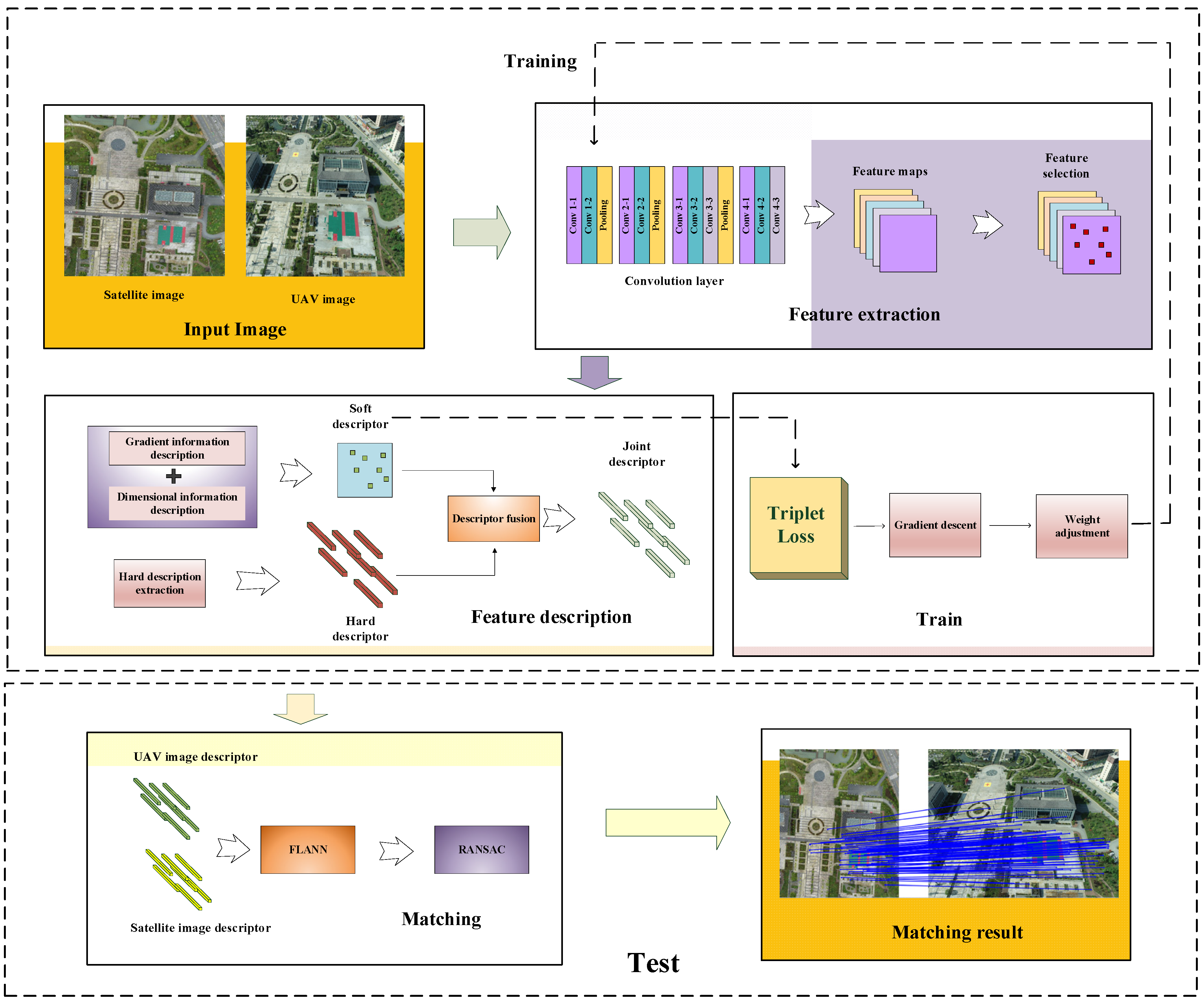
In this section, a dense multiview feature extraction neural network is proposed to solve the matching problem between space and sky images. Firstly, CNN is used to extract high-dimensional feature maps for heterologous images with large space and sky dip angles. Secondly, the salient feature points and feature vectors are selected from the obtained feature map, and the feature vector is used as the hard descriptor of the feature points. Meanwhile, based on the gradient information around the feature points and their multiscale information, soft descriptors for the feature points are constructed, which are also used in the neural network training process. Then, by combining the hard and soft descriptors, a joint feature point descriptor is obtained. Finally, the fast nearest neighbor search method (FLANN) [36] is used to match the feature points, and random sample consensus (RANSAC) [37] is used to screen out false matches. Figure 3 shows the structure of the proposed method.
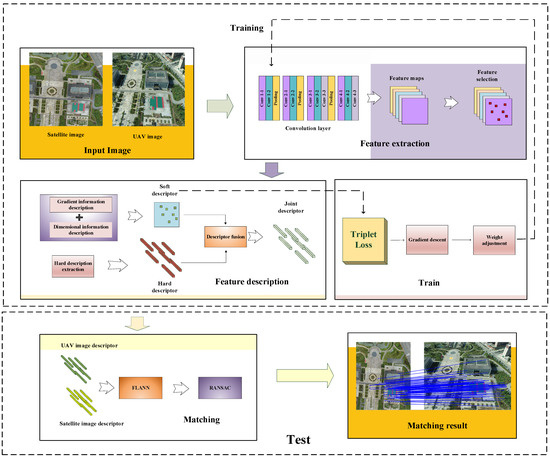
Figure 3.
Flow chart of histogram of the proposed image matching method. After the input image is passed through the convolutional network, the feature map is obtained. Then, the salient feature points are screened from the feature map and the hard description is extracted. At the same time, a soft description is made for the salient feature points, which is also used in the loss function. Finally, the final descriptor is obtained by combining hard description and soft description.
3.1. Feature Detection and Hard Descriptor
In this section, the aim is to extract salient feature points and obtain their hard descriptor. In the first step, the proposed method uses the fast nearest neighbor search method (FLANN) [36] to match the feature points and uses random sample consensus (RANSAC) [37] to screen out false matches. We use a CNN to convolve the input image and obtain a 3D depth feature map . The form of is shown in Equation (1).
where is the height of the convoluted image, is the width of the convoluted image, and is the number of channels in the convolution output. The two-dimensional array of the output of the two-dimensional convolution layer can be regarded as a representation of the input at a certain level of spatial dimension (width and height). Therefore, is equivalent to a 2D feature map that represents a feature in a certain direction.
To screen out more significant feature points in , the feature point screening strategy adopted by the method in this paper is as follows: (1) The feature point is the most prominent in the channel direction of the high-dimensional feature map. (2) The feature point is also the most prominent feature point on the local plane of the feature map. So, is required to be a local maximum in and is derived from Equation (2).
is the feature value at point of . For a point to be selected, the channel with the maximum response value is firstly selected from n channel feature maps. Then, is verified to be locally maximum. If the above two conditions are met, it means that is obtained as the significant feature point through screening.
Then, the channel row vector at is extracted from the feature map as the hard descriptor of , and we apply L2 normalization on the hard descriptor, as shown in Equation (3).
However, the extrema of discrete space are not real extreme points. To obtain more accurate key point positions, the proposed method uses the SIFT algorithm for reference and adopts the method of local feature map interpolation and encryption to accurately perform subpixel-level positioning. Some points are removed by considering eliminating edge response and eliminating points with low contrast, and then the subpixel extreme points are accurately located by curve fitting. Finally, the precise coordinates of feature points are obtained. Additionally, the hard descriptor is also obtained by bilinear interpolation in the neighborhood.
3.2. Soft Descriptor
In this section, we attempt to introduce a soft descriptor for training and auxiliary description. During the training process, the descriptor is designed as a one-dimensional vector to be amenable for neural network backpropagation.
First, the proposed method extracts the gradient information of the salient feature points. A 3 × 3 matrix is constructed with the point as the center. The gradient information of the feature point is calculated according to the pixel values of the nine points in the matrix in the dimension. Therefore, the gradient scores of these feature points are calculated. The gradient score containing the simple gradient information of point can be obtained by Equation (4).
Then, the proposed method extracts the dimensional difference information of the salient feature points. Since the extracted salient feature points are relatively significant in some dimensions but not so significant in other dimensions, the differences among the salient feature points are highlighted according to these different pieces of information. Thus, the dimension scores of these feature points are calculated by Equations (5) and (6).
where is the average pixel value of the feature point in each dimension. The dimension score contains the dimension difference information of the feature point .
Finally, the proposed method constructs a soft descriptor from the gradient score and dimension score of point . This is because the product rule is well adaptable to input data of different scales. Since the above two feature scores are one-dimensional values, the final soft descriptor is obtained by multiplying the above two feature scores to highlight the differences among the significant feature points. Soft descriptor is derived from Equation (7).
Soft descriptors have two functions. On the one hand, they are used as the evaluation basis for the training of neural networks; on the other hand, they are used as auxiliary parts of hard descriptors to make the subsequent descriptions more accurate.
3.3. Joint Descriptors
In this section, we attempt to introduce a way to combine hard and soft descriptions, as well as ways to adapt models to multiple scales.
Usually, the first few layers of the network have small receptive domains, and the features obtained are edges, corners, and other local features relative to the bottom layer, but the positioning accuracy is high. The deeper the network layers, the more abstract the extracted features are and the more global the information is. The more resistant the interference caused by geometric deformation and scale difference is, the worse the positioning accuracy is. Therefore, the use of a hard description as the main description results in deeper feature expression ability and ensures a certain positioning accuracy. At the same time, the use of soft descriptions as auxiliary descriptions strengthens the antijamming ability of joint descriptors.
Regarding the fusion of hard descriptors and soft descriptors, there are several strategies for combining them, such as the sum, product, and maximum rules. In this paper, we employ the product rule for similar reasons as those in Yang et al. [38]. First, utilizing the product rule to integrate hard descriptions and soft descriptions can better amplify the differences between the descriptions. Second, the product rule adapts well to input data with different scales and does not require heavy normalization of the data. The joint descriptor is calculated as Equation (8).
3.4. Multiscale Models
The CNN model uses training samples with different scales for training, and the feature descriptor can learn scale invariance to a certain extent, but it is also difficult to deal with situations involving large-scale changes. Therefore, this paper adopts the discrete image pyramid model to cope with large-scale changes.
Given an input image , an image pyramid containing four different resolutions is used to accommodate drastic changes in the resolutions of the two images. Each layer of the pyramid extracts the of the feature map and then accumulates the fusion results according to Equation (9).
The feature descriptions of key points are extracted through the fusion feature graph obtained by accumulation. Due to the different resolutions of pyramids, the low-resolution feature maps need to be linearly interpolated to the same size as that of the high-resolution feature maps before they can be accumulated. In addition, to prevent the detection of repetitive features at different levels, this paper starts from the coarsest scale and marks the detected positions. These positions are unsampled into a feature map with a higher scale as a template. To ensure the number of key points extracted from the feature map at low resolution, if the key points extracted from the feature map at a higher resolution fall into the template, they are discarded.
3.5. Training Loss
The purpose of the loss function is to judge the quality of the neural network through its output value so that the parameters of the neural network can be adjusted adaptively. Furthermore, the feature detector and feature descriptions can be optimized so that the next output result of the neural network is improved.
In this paper, the triple margin ranking loss (TMRL) is used as the loss function. During the process of feature detection, the feature points should have some uniqueness that allows them to adapt to the effects of environmental light and geometric differences. However, at the same time, during the process of feature description, we want the feature vector to be as unique as possible to find the homonymic image point. To address this problem, the triple distance sorting loss function enhances the uniqueness of the correlation descriptor by penalizing any uncorrelated descriptor that leads to a false match. Similar to D2Net, first, images and are given, and a pair of the corresponding feature points A and B are in and , respectively, where and . The distance between the soft descriptors of A and B is derived from Equation (10).
and are soft descriptor values of A and B, respectively. At the same time, a pair of points and can be found, which are the point structures most similar to A and B, respectively. is derived from Equation (11).
represents the pixel coordinate distance from the point to point. The distance should be greater than K to prevent from being adjacent to point A. is also obtained as in Equation (11). Then, the distances between points A and B and their unrelated approximate points are calculated by Equation (12).
Finally, the triplet loss is derived from Equation (13).
where M is the margin parameter, and the function of the margin parameter is to widen the gap between the matched point pair and the unmatched point pair. The smaller it is set, the more easily the loss value approaches zero, but it is difficult to distinguish between similar images. The larger it is set, the more difficult it is for the loss value to approach zero, which even leads to network nonconvergence.
In Equation (13), C is the set of corresponding points including A and B in image pair and . The smaller the loss value is, the closer the value of the corresponding point descriptor is, and the greater the difference between it and the value of an irrelevant point descriptor. Therefore, the evolution of the neural network towards the direction of a smaller loss value means that it evolves towards the direction of more accurate matching.
For the CNN model to learn a pixel-level feature similarity expression under radiation and geometric differences, the training data must satisfy the following two conditions in addition to containing a sufficient quantity of points. First, the training images must have great radiometric and geometric differences. Then, the training images must have pixel-level correspondence. Similar to D2Net, we use the MegaDepth data set consisting of 196 different scenes reconstructed from more than a million internet photos using COLMAP.
3.6. Feature Matching Method
After the feature points and feature descriptors of the image are extracted in the third section, FLANN [36] method is used for feature matching. FLANN uses KDTree or Kmeans to conduct clustering modelling for features so that the nearest neighbor point can be found quickly. By comparing, screening the feature points and corresponding feature vectors of the input target images, FLANN finally establishes a mapping set to matching points. Since the proposed method extracts as many features as possible, a large number of mismatched point pairs are generated. Therefore, RANSAC [37] is used to screen out the mismatched point pairs. RANSAC randomly selects at least four samples from the matched data set and ensures that the four samples are not collinear to calculate the homography matrix. Then, RANSAC uses this model to test all the data and calculate the number of data points and the projection error (the cost function) that satisfy this model. If this model is optimal, the corresponding cost function is minimum.
3.7. Model Training Methods and Environment
The proposed method uses a VGG16 model pretrained on the ImageNet data set. The last dense feature extractor Conv4_3 in the network model is trained using the migration learning fine-tuning training method. The initial learning rate was set to 10−3, and then reduced by half for every 10 epochs. For each pair of homonymous image points, a random image region of 256 × 256 pixels centered on the homonymous image point is selected and fed into the network for training.
In the experimental process, the proposed method is implemented in the PyTorch framework. The computer used for the experiments has a CPU of i9-10900X, a graphics card of NVIDIA TITAN RTX (24 GB video memory), and 32 GB of memory. The implementation language is Python, and the operating system is Windows 10.
4. Experiment and Results
4.1. Data
Here, four sets of experiments (see Figure 4 and Table 2) are designed to evaluate the proposed approach and compare it with previously developed methods. The areas where the images are taken are a square, school, gas station, and park, each with its own characteristics and representativeness. Finally, all sets are analyzed to provide comparative results.

Figure 4.
These are UAV images and the corresponding satellite remote sensing images. The left side of each group of images is UAV image, and the right side is the satellite remote sensing image. Each pair of images has obvious scale differences and perspective differences. In group (a) and group (b), the UAV images are low-altitude UAV images. In groups (c) and (d), the UAV images are high-altitude UAV images.
Table 2.
Test data.
4.2. Comparison of Image Matching Methods
To demonstrate the effectiveness of our approach, we use the proposed method, D2Net [35] (a mainstream deep learning image matching method) and ASIFT [20] (a classical multiview image matching method) to conduct control experiments on these four groups of data, as shown in Table 3.
Table 3.
Test image matching.
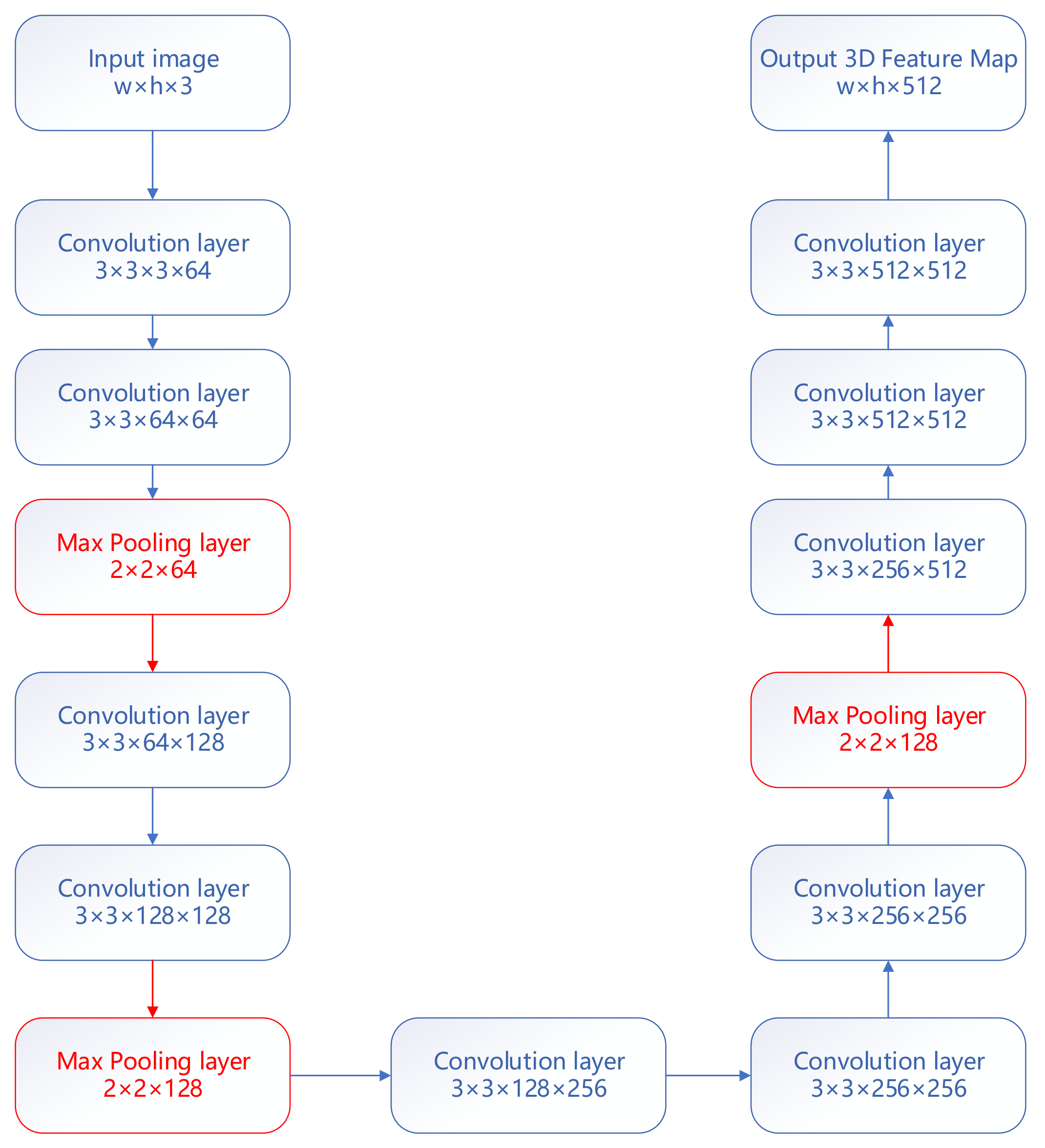
The convolutional network layer of the proposed method mainly refers to the convolutional layer settings of Visual Geometry Group 16 (VGG16), as shown in Figure 5. In addition, the size of the feature extraction frame is 7 × 7. The D2Net parameter is set as its default parameter. The algorithm feature extraction and feature description components of ASIFT use the VLFeat library.
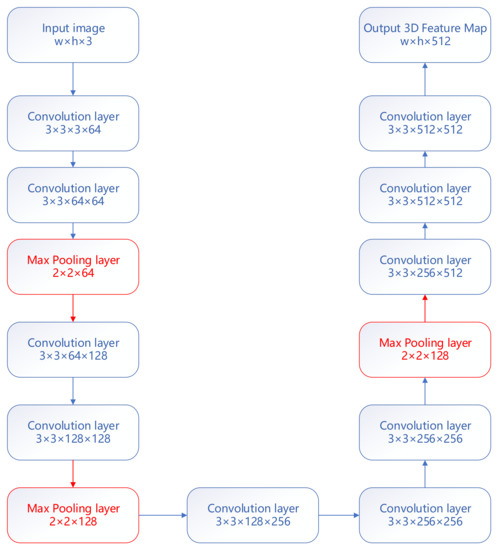
Figure 5.
Configuration of the convolutional network layer in our joint description neural network for multiview satellite and UAV image matching.
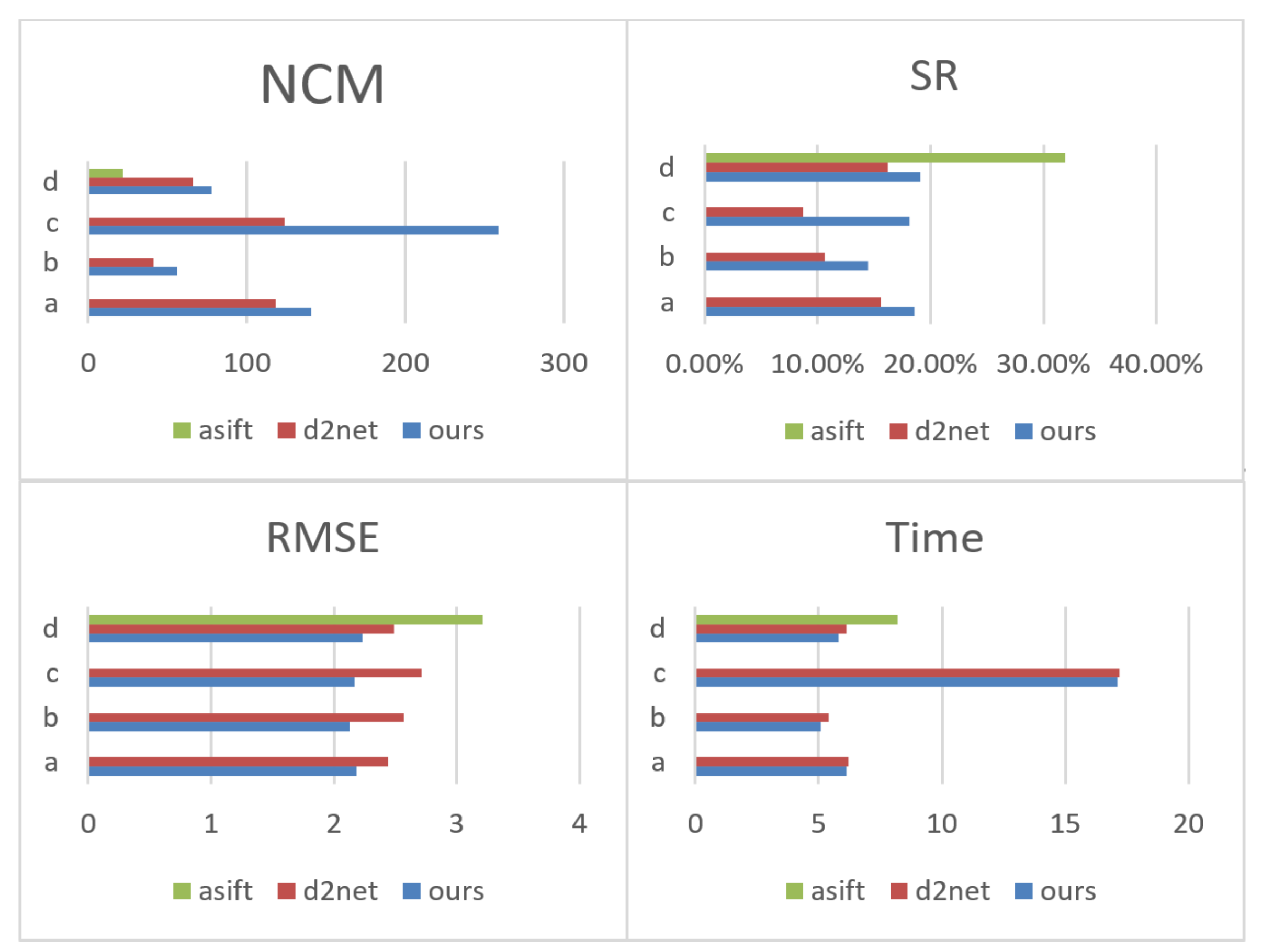
The number of correct matching points (NCM), matching accuracy (SR), root mean square error (RMSE), and matching consumption time (MT) were used to evaluate the performance of these algorithms, as shown in Figure 6.

Figure 6.
The matching effects of the proposed method and D2Net on groups (a–d).
NCM: NCM is the number of matched pairs on the whole image that satisfy Equation (14). This metric can reflect the performance of the matching algorithm.
where , denote the matching feature points to be judged, respectively. is the reprojection error between the image corresponding matched point pairs and is the true transformation parameter between the image pairs.
SR: SR is the percentage of NCM to all initial match points.
RMSE: RMSE can reflect the accuracy of the matching point, which is calculated by the following Equation (15).
This indicator reflects the position offset error of the matching point on the pixel.
MT: MT indicates the matching consumption time, reflecting the efficiency of the method.
Figure 6 and Figure 7 intuitively show the matching effects of the proposed method and D2Net on the images in groups A, B, C, and D. Notably, compared with the D2Net results, the matching points obtained by the proposed method are more widely distributed. It can be intuitively seen from C that, in a case with large perspective, scale, and time phase differences, the proposed method yields a better matching effect than D2Net.
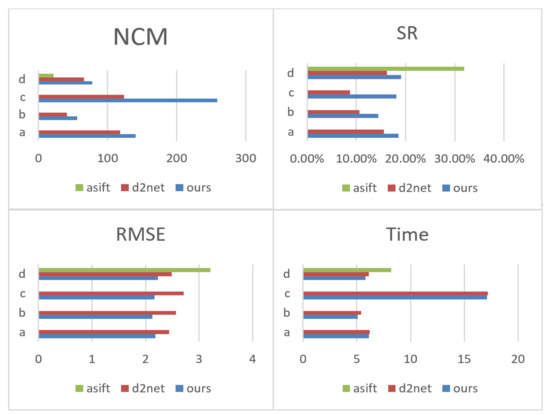
Figure 7.
Quantitative comparisons of the proposed method, D2Net, and ASIFT on groups (a–d). The higher the NCM and SR, the better the matching performance. A smaller RMSE means higher matching accuracy. The smaller MT is, the higher the matching efficiency is. Based on the graph analysis, the proposed method has better matching performance and accuracy than the other two methods.
For ASIFT [20] method, due to the radiation differences and the fuzziness of the UAV images, it cannot work well in the image groups A, B, and C, and there are no matching points to be found. However, our method can effectively eliminate the influence of radiation difference; thus, good results can be achieved for these images, which highlights the effectiveness of matching UAV and remote sensing images from multiple perspectives. For the image group D, the radiation difference is not obvious, and ASIFT method is superior to our method on SR. However, based on the comparison of NCM, our method shows better and more stable matching performance.
Compared with D2Net, for image groups A, B, and D, a slight improvement can be achieved by the proposed method. However, for the image group C, there are more significant scale and perspective differences; thus, the advantages of our method are more obvious.
As can be seen from Figure 7, compared with the other two methods, our method has better matching accuracy and matching performance. This reflects the superiority of the joint description method. Hard description ensures a certain matching performance. Soft description and hard description complement each other, which makes the joint descriptor more specifically reflect the uniqueness of features.
In general, the proposed method can provide certain numbers of correctly matched points for all test image pairs, and the RMSEs of the matched points are approximately 2 to 3 pixels, which is a partial accuracy improvement over that of D2Net. Moreover, the ASIFT algorithm has difficulty matching the correct points for images with large perspective and scale differences. This shows that the proposed method has better adaptability for multiview satellite and UAV image matching.
4.3. Angle Adaptability Experiment
Notably, as the visual angle differences between the images increase, the matching difficulty becomes greater. To verify the feasibility of the proposed method for matching multiview UAV images and satellite images, we conducted experiments on UAV images and satellite images taken from different angles at the same location. The experimental results are shown in Figure 8.


Figure 8.
The results of experiments with UAV images and satellite images taken from different angles at the same locations. (a) The angle degree difference between this group of images is about 5°. (b) The angle degree difference between this group of images is about 10–15°. (c) The angle degree difference between this group of images is about 20–25°. (d) The angle degree difference between this group of images is about 30°.
Four sets of multi-angle experiments are shown in Figure 8. There are scale, phase, and viewing angle differences in each group of experimental images. These four sets of experimental images are well matched. It can be seen from these four experimental image pairs that although the viewing angle increases, the matching effect does not fail. In brief, the algorithm proposed in this paper is applicable to UAV image matching with satellite images when the tilt degree is less than or equal to 30 degrees.
4.4. Application in Image Geometric Correction
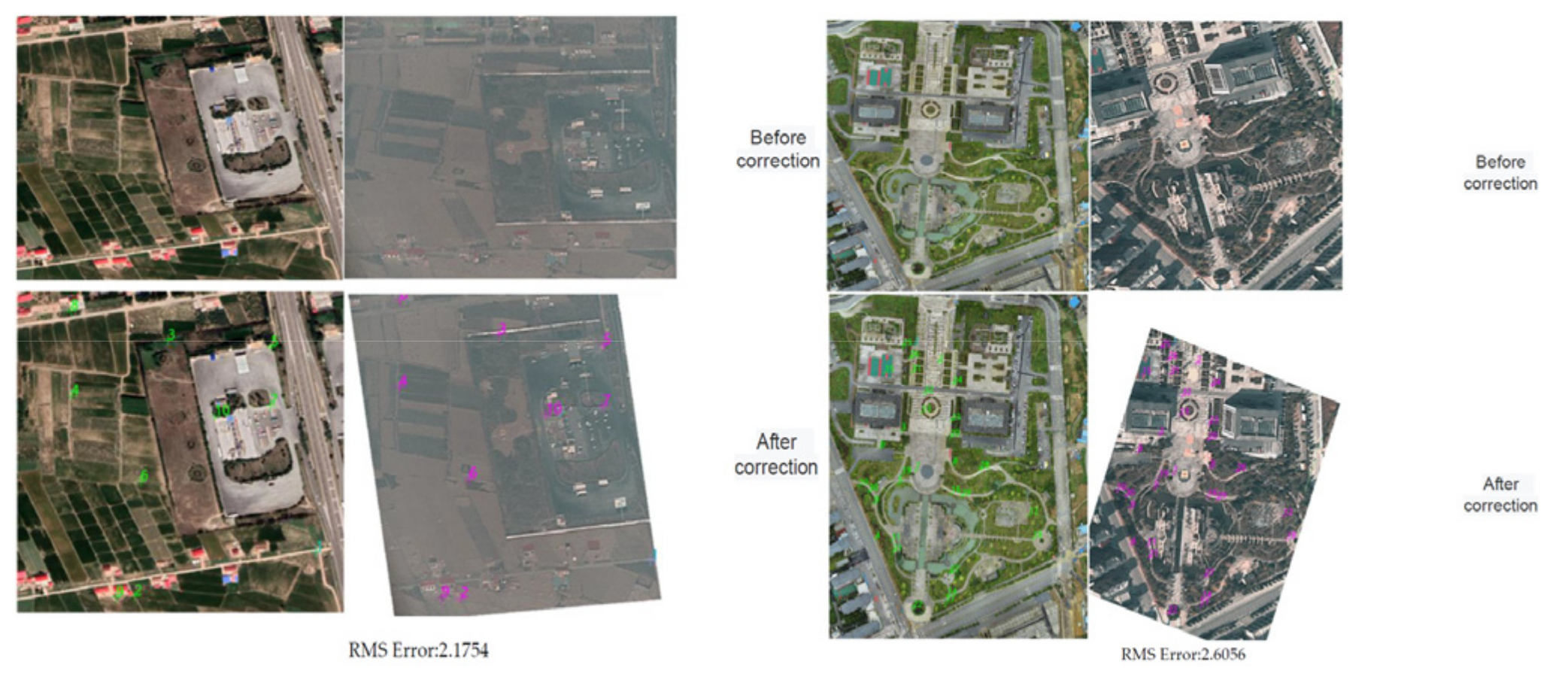
One of the main purposes of matching UAV images with remote sensing images is to correct UAV images and provide geographic information. Based on the correctly matched points determined in the previous section, a homographic transformation matrix is estimated, and then this matrix is used to correct the input UAV image. Figure 9 shows the results of correcting UAV images and assigning geographic information after matching them with the proposed method.
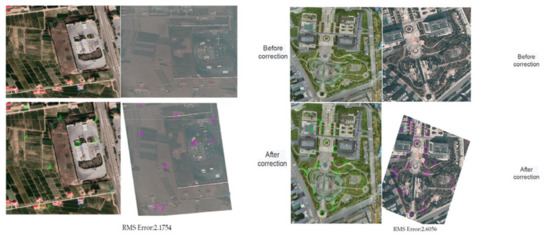
Figure 9.
These are the results of selecting evenly distributed points from satellite images and corrected UAV images, and calculating the errors among them.
From the registration results, the registration effect for UAV and satellite images is improved due to the good matching correspondence. The registration accuracy nearly reaches 2 pixels, which can meet the needs of UAV reconnaissance target positioning.
5. Discussion
The method presented in this paper exhibits a good matching effect for multiview UAV and satellite images from the matching results. A certain number of relatively uniform distributions of correctly matched points were obtained by the proposed method, which can support the registration of UAV images. In addition, the proposed method exhibits good adaptability to viewing angle, scale, and time phase differences among multiview images. This shows that our designed joint descriptor makes our algorithm more robust for multiview, multiscale, and multitemporal images. However, due to the large number of convolutional computations required by deep feature learning, despite the use of GPU acceleration, the efficiency of feature extraction is not greatly improved relative to that of traditional feature extraction algorithms.
It is difficult to match multiview satellite images with UAV images due to the large time phase, perspective, and scale differences between these images. The method proposed in this paper uses joint description to make the resulting features more prominent, solving the situation in which the features are difficult to match due to the above problems. Experiments show that the proposed method is better than the traditional method in solving these matching difficulties. However, the proposed method also has the problem of a long matching time requirement, which makes it impossible to carry out real-time positioning and registration for UAV images. Thus, in the future, it will be important to accurately screen out the significant feature points to reduce the matching time. With the development of deep learning technology, image matching technology of multiview satellites and UAV should also make continuous progress from its development trend.
6. Conclusions
In this paper, an algorithm for multiview UAV and satellite image matching is proposed. This method is based on a joint description network. The developed joint descriptor includes a specifically designed hard descriptor and soft descriptor, among which the hard descriptor ensures the matching accuracy of the network, and the soft descriptor is used for network training and auxiliary description. According to experiments, the algorithm proposed in this paper can achieve good matching effects for multiview satellite images and UAV images in comparison with some popular methods. Moreover, the matching accuracy of the proposed method in optical satellite and UAV images nearly reaches 2 pixels, which meets the requirements of relevant UAV missions.
Author Contributions
Conceptualization, C.X.; methodology, C.L.; software, C.L.; validation, H.L., Z.Y. and H.S.; formal analysis, W.Y.; data curation, H.L.; writing—original draft preparation, C.L.; writing—review and editing, C.X.; visualization, C.X.; supervision, Z.Y.; project administration, C.X.; funding acquisition, C.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China, grant number 41601443 and 41771457, Scientific Research Foundation for Doctoral Program of Hubei University of Technology (Grant No. BSQD2020056).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The raw/processed data required to reproduce these findings cannot be shared at this time as the data also forms part of an ongoing study.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Li, Y.; Chen, W.; Zhang, Y.; Tao, C.; Xiao, R.; Tan, Y. Accurate cloud detection in high-resolution remote sensing imagery by weakly supervised deep learning. Remote Sens. Environ. 2020, 250, 112045. [Google Scholar] [CrossRef]
- Dou, P.; Chen, Y. Dynamic monitoring of land-use/land-cover change and urban expansion in Shenzhen using Landsat imagery from 1988 to 2015. Int. J. Remote Sens. 2017, 38, 5388–5407. [Google Scholar] [CrossRef]
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change detection based on artificial intelligence: State-of-the-art and challenges. Remote Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- Guo, Y.; Du, L.; Wei, D.; Li, C. Robust SAR Automatic Target Recognition via Adversarial Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 716–729. [Google Scholar] [CrossRef]
- Guerra, E.; Munguía, R.; Grau, A. UAV visual and laser sensors fusion for detection and positioning in industrial applications. Sensors 2018, 18, 2071. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image matching from handcrafted to deep features: A survey. Int. J. Comput. Vis. 2021, 129, 23–79. [Google Scholar] [CrossRef]
- Ye, Y.; Shan, J.; Hao, S.; Bruzzone, L.; Qin, Y. A local phase based invariant feature for remote sensing image matching. ISPRS J. Photogramm. Remote Sens. 2018, 142, 205–221. [Google Scholar] [CrossRef]
- Manzo, M. Attributed relational sift-based regions graph: Concepts and applications. Mach. Learn. Knowl. Extr. 2020, 2, 13. [Google Scholar] [CrossRef]
- Zhao, X.; Li, H.; Wang, P.; Jing, L. An Image Registration Method Using Deep Residual Network Features for Multisource High-Resolution Remote Sensing Images. Remote Sens. 2021, 13, 3425. [Google Scholar] [CrossRef]
- Zeng, L.; Du, Y.; Lin, H.; Wang, J.; Yin, J.; Yang, J. A Novel Region-Based Image Registration Method for Multisource Remote Sensing Images via CNN. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1821–1831. [Google Scholar] [CrossRef]
- Wang, S.; Quan, D.; Liang, X.; Ning, M.; Guo, Y.; Jiao, L. A deep learning framework for remote sensing image registration. ISPRS J. Photogramm. Remote Sens. 2018, 145, 148–164. [Google Scholar] [CrossRef]
- Leese, J.A.; Novak, C.S.; Clark, B.B. An automated technique for obtaining cloud motion from geosynchronous satellite data using cross correlation. J. Appl. Meteorol. Climatol. 1971, 10, 118–132. [Google Scholar] [CrossRef]
- Barnea, D.I.; Silverman, H.F. A class of algorithms for fast digital image registration. IEEE Trans. Comput. 1972, 100, 179–186. [Google Scholar] [CrossRef]
- Zitova, B.; Flusser, J. Image registration methods: A survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar] [CrossRef] [Green Version]
- Harris, C.G.; Stephens, M. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; Volume 15, p. 10-5244. [Google Scholar]
- Smith, S.M.; Brady, J.M. SUSAN—A new approach to low level image processing. Int. J. Comput. Vis. 1997, 23, 45–78. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Corfu, Greece, 20–25 September 1999; IEEE: Piscataway, NJ, USA, 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Bosch, A.; Zisserman, A.; Munoz, X. Scene classification using a hybrid generative/discriminative approach. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 712–727. [Google Scholar] [CrossRef] [Green Version]
- Ke, Y.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 2, p. 2. [Google Scholar]
- Morel, J.M.; Yu, G. ASIFT: A new framework for fully affine invariant image comparison. SIAM J. Imaging Sci. 2009, 2, 438–469. [Google Scholar] [CrossRef]
- Etezadifar, P.; Farsi, H. A New Sample Consensus Based on Sparse Coding for Improved Matching of SIFT Features on Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5254–5263. [Google Scholar] [CrossRef]
- Jiang, S.; Jiang, W. Reliable image matching via photometric and geometric constraints structured by Delaunay triangulation. ISPRS J. Photogramm. Remote Sens. 2019, 153, 1–20. [Google Scholar] [CrossRef]
- Li, J.; Hu, Q.; Ai, M. LAM: Locality affine-invariant feature matching. ISPRS J. Photogramm. Remote Sens. 2019, 154, 28–40. [Google Scholar] [CrossRef]
- Yu, Q.; Ni, D.; Jiang, Y.; Yan, Y.; An, J.; Sun, T. Universal SAR and optical image registration via a novel SIFT framework based on nonlinear diffusion and a polar spatial-frequency descriptor. ISPRS J. Photogramm. Remote Sens. 2021, 171, 1–17. [Google Scholar] [CrossRef]
- Gao, X.; Shen, S.; Zhou, Y.; Cui, H.; Zhu, L.; Hu, Z. Ancient Chinese Architecture 3D Preservation by Merging Ground and Aerial Point Clouds. ISPRS J. Photogramm. Remote Sens. 2018, 143, 72–84. [Google Scholar] [CrossRef]
- Hu, H.; Zhu, Q.; Du, Z.; Zhang, Y.; Ding, Y. Reliable spatial relationship constrained feature point matching of oblique aerial images. Photogramm. Eng. Remote Sens. 2015, 81, 49–58. [Google Scholar] [CrossRef]
- Jiang, S.; Jiang, W. On-Board GNSS/IMU Assisted Feature Extraction and Matching for Oblique UAV Images. Remote Sens. 2017, 9, 813. [Google Scholar] [CrossRef] [Green Version]
- Yi, K.M.; Trulls, E.; Lepetit, V.; Fua, P. Lift: Learned invariant feature transform. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 467–483. [Google Scholar]
- Balntas, V.; Johns, E.; Tang, L.; Mikolajczyk, K. PN-Net: Conjoined triple deep network for learning local image descriptors. arXiv 2016, arXiv:1601.05030. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 224–236. [Google Scholar]
- Bhowmik, A.; Gumhold, S.; Rother, C.; Brachmann, E. Reinforced Feature Points: Optimizing Feature Detection and Description for a High-Level Task. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Ono, Y.; Trulls, E.; Fua, P.; Yi, K.M. LF-Net: Learning local features from images. arXiv 2018, arXiv:1805.09662. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 8922–8931. [Google Scholar]
- Lhh, A.; Dm, B.; Slb, C.; Dtb, D.; Msa, E. A deep learning framework for matching of SAR and optical imagery. ISPRS J. Photogramm. Remote Sens. 2020, 169, 166–179. [Google Scholar]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-net: A trainable cnn for joint description and detection of local features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8092–8101. [Google Scholar]
- Megalingam, R.K.; Sriteja, G.; Kashyap, A.; Apuroop, K.G.S.; Gedala, V.V.; Badhyopadhyay, S. Performance Evaluation of SIFT & FLANN and HAAR Cascade Image Processing Algorithms for Object Identification in Robotic Applications. Int. J. Pure Appl. Math. 2018, 118, 2605–2612. [Google Scholar]
- Li, H.; Qin, J.; Xiang, X.; Pan, L.; Ma, W.; Xiong, N.N. An efficient image matching algorithm based on adaptive threshold and RANSAC. IEEE Access 2018, 6, 66963–66971. [Google Scholar] [CrossRef]
- Yang, T.Y.; Hsu, J.H.; Lin, Y.Y.; Chuang, Y.Y. Deepcd: Learning deep complementary descriptors for patch representations. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3314–3332. [Google Scholar]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).