Effectiveness of Semi-Supervised Learning and Multi-Source Data in Detailed Urban Landuse Mapping with a Few Labeled Samples




Abstract
:1. Introduction
2. Related Work
2.1. Urban Landuse Classification Methods
2.2. Classification Stability with Small Sample Size
3. Materials and Methods
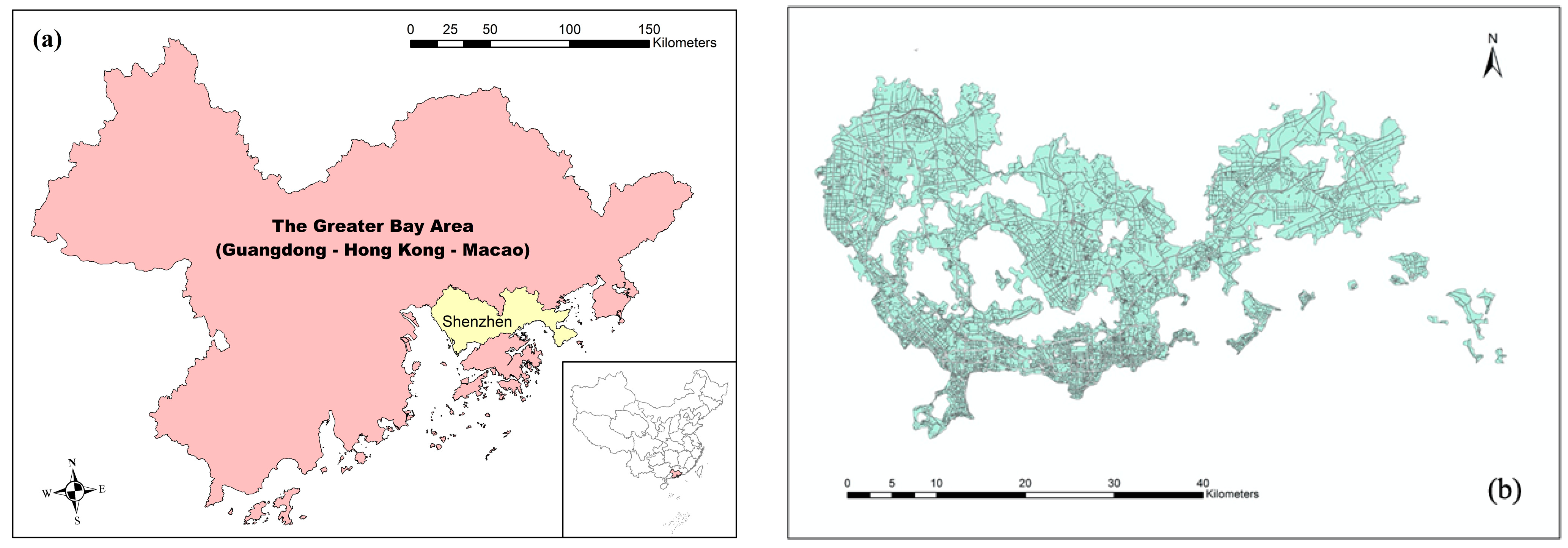
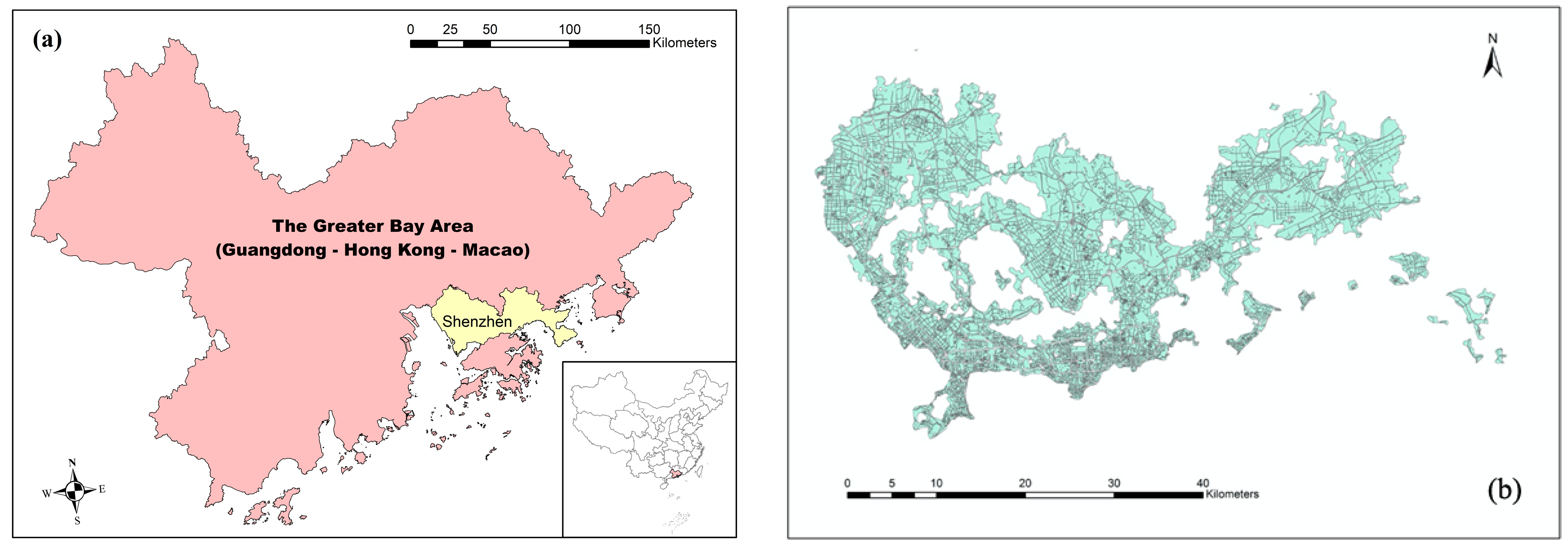
3.1. Study Area
3.2. Road Segmentation for Land Parcels
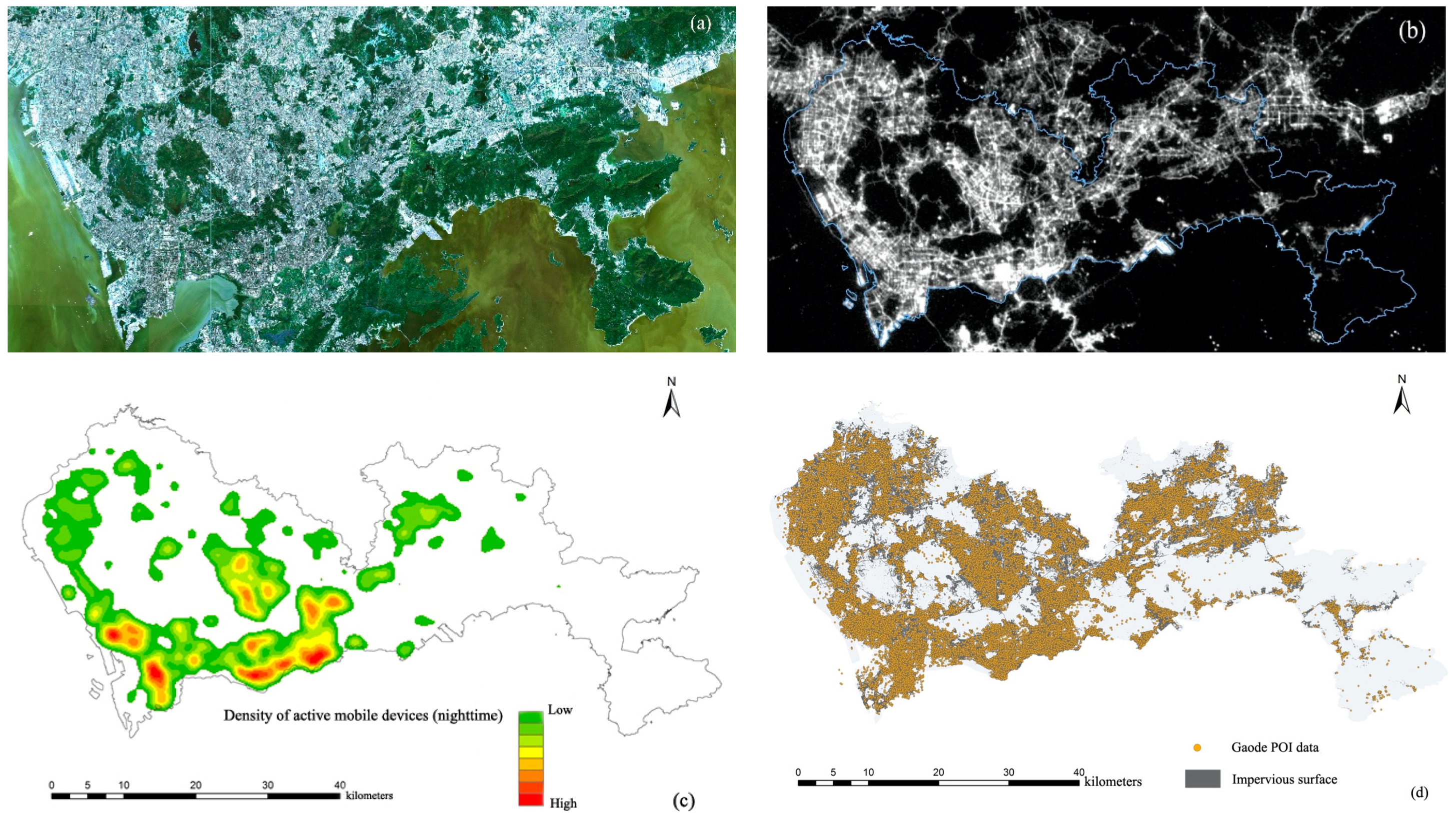
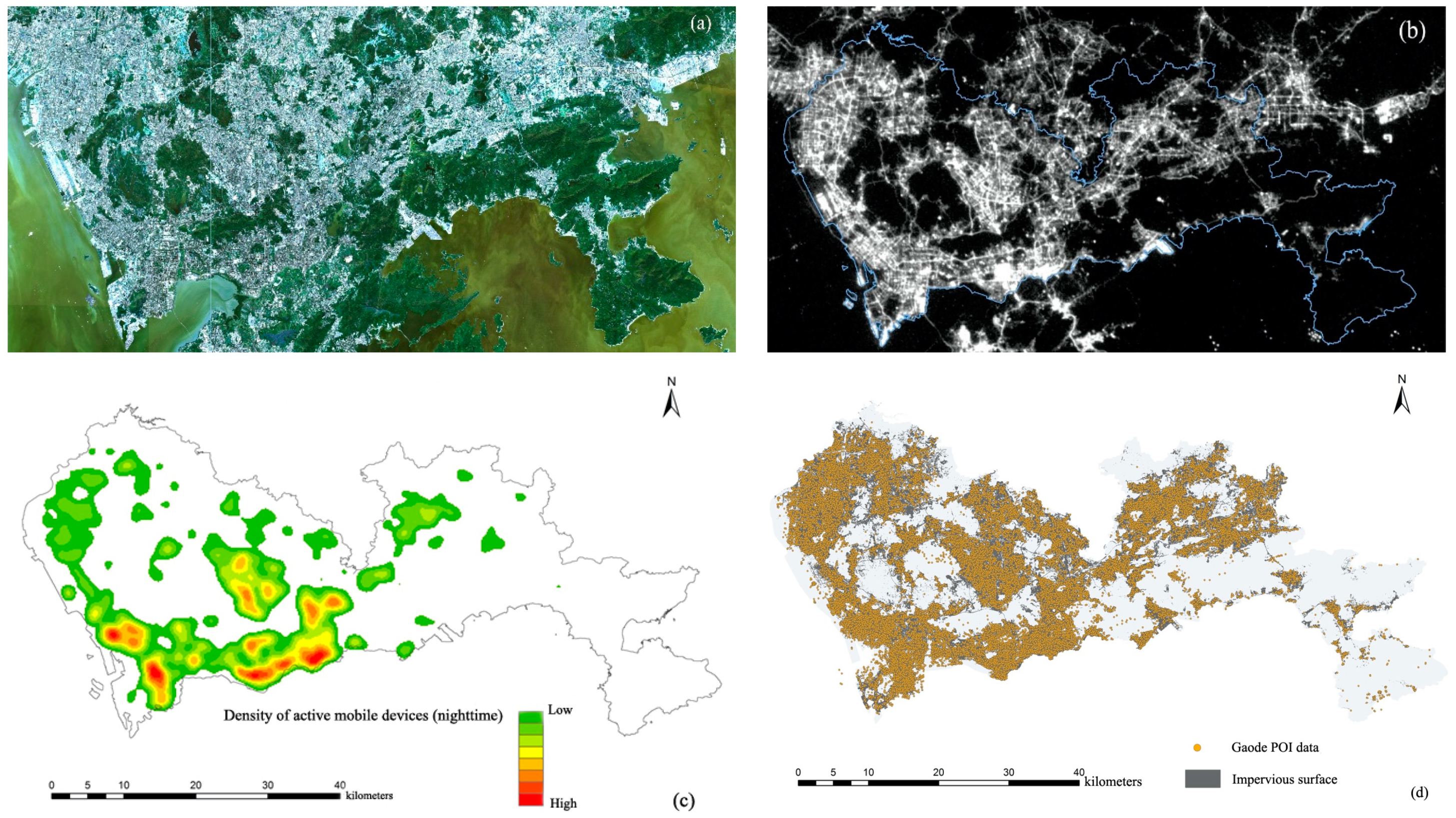
3.3. Data and Data Pre-Processing
3.4. Feature Selection and Dimension Reduction
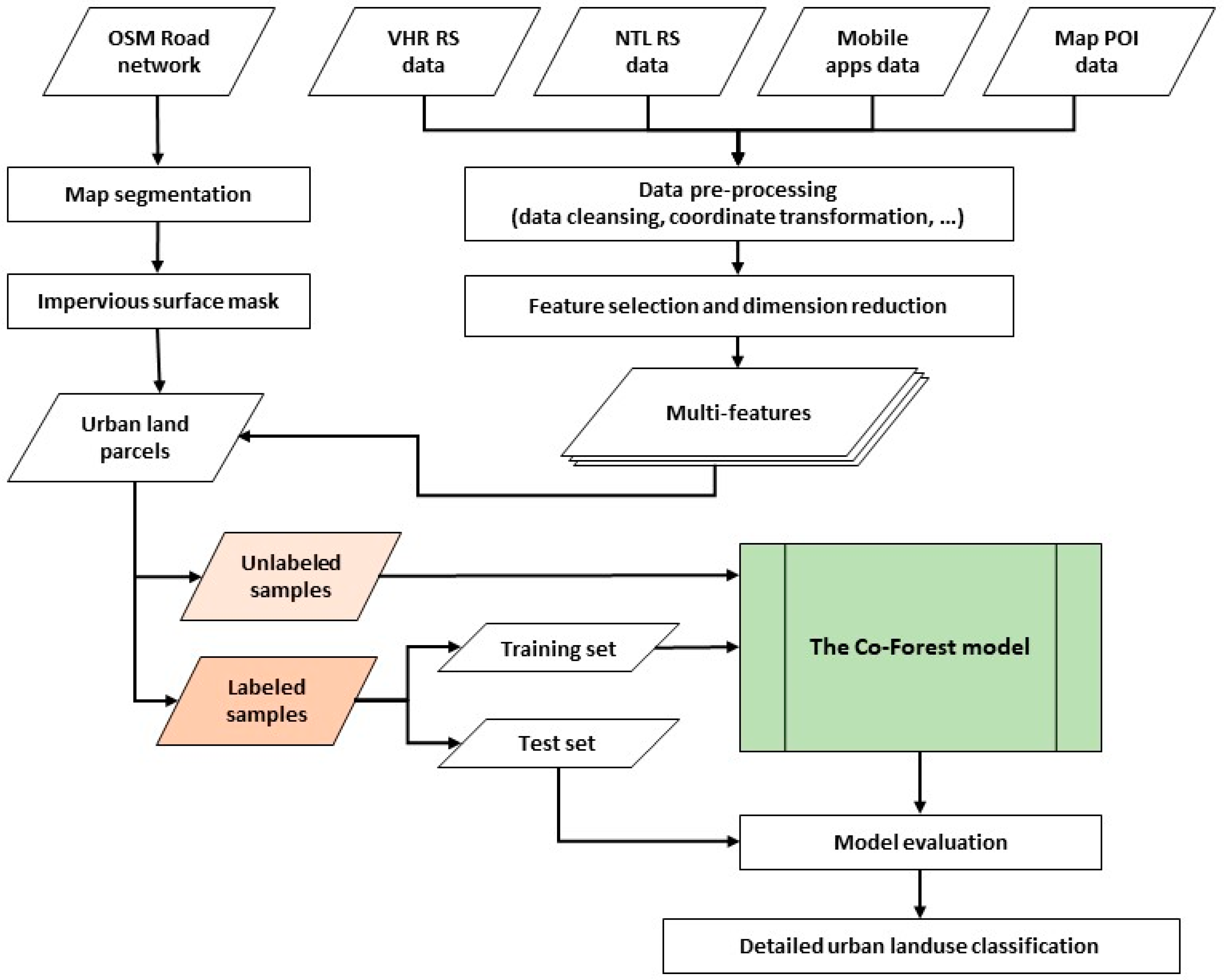
3.5. Semi-Supervised Multi-Feature Classification Framework
3.6. Model Adjustment and Improvement
3.7. Model Evaluation and Accuracy Assessment
3.8. Impact Analysis of Small Sample Size
4. Experiments
4.1. Subset of Features
4.2. Urban Landuse Classification System
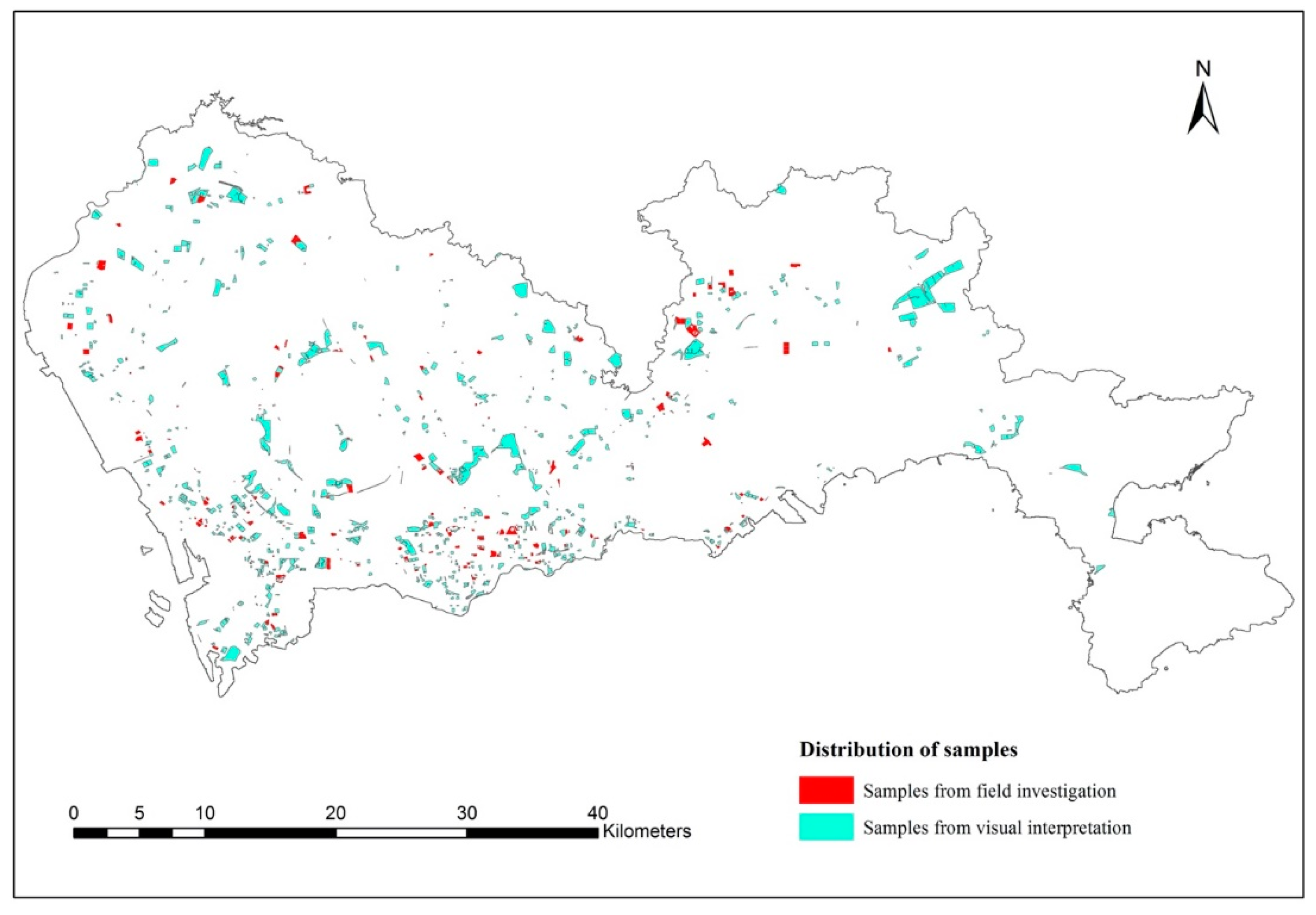
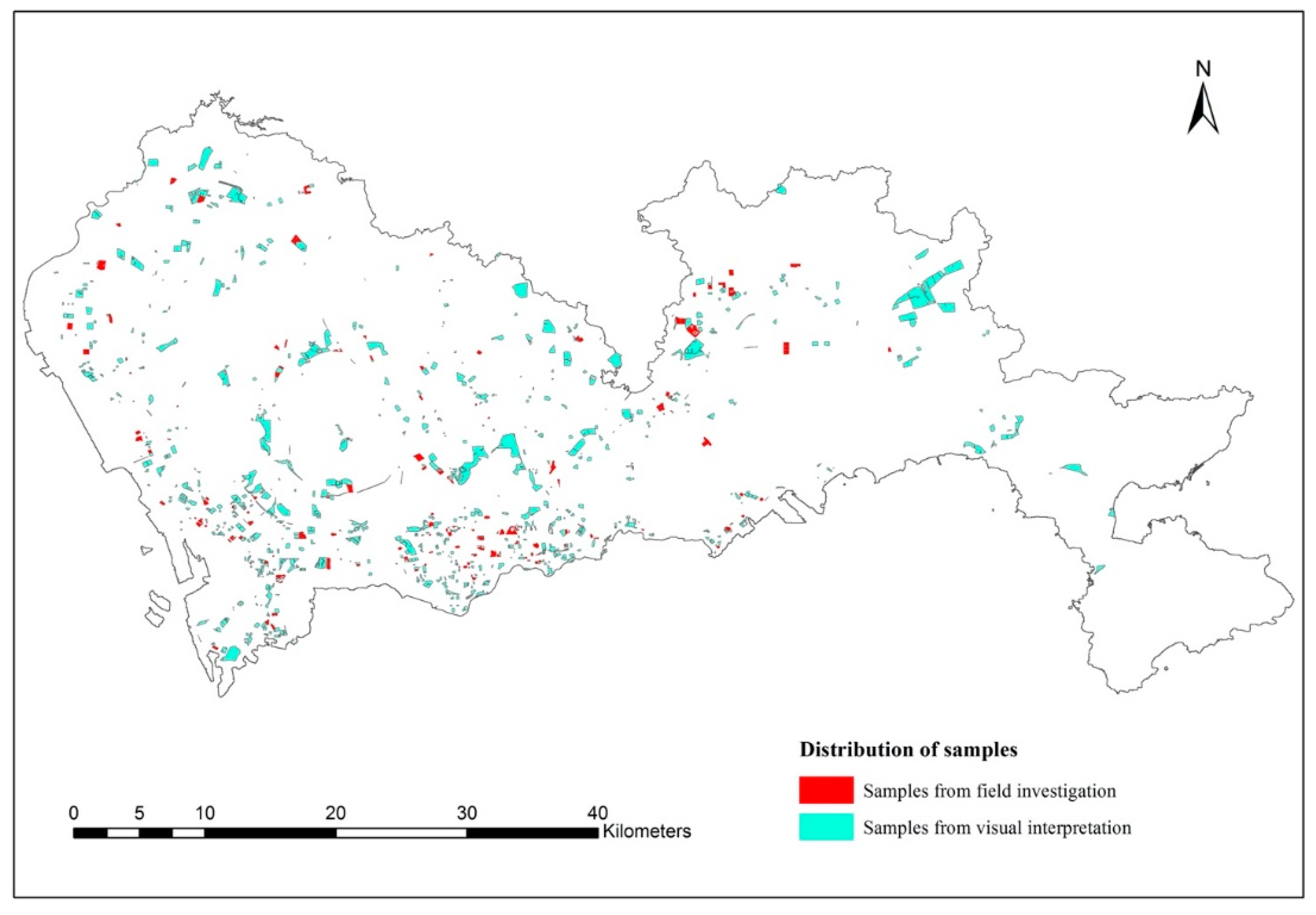
4.3. Labeling and Train/Test Split
4.4. Experimental Environment and Parameters
5. Results and Analysis
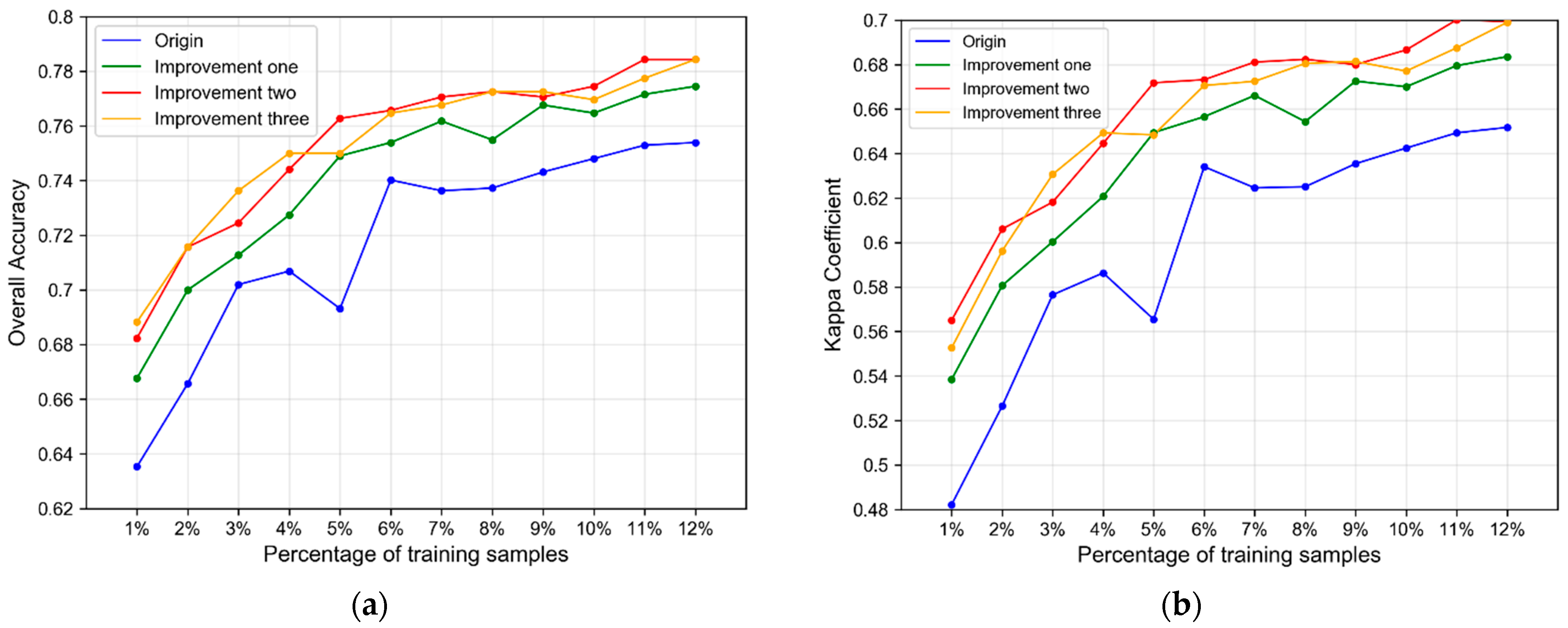
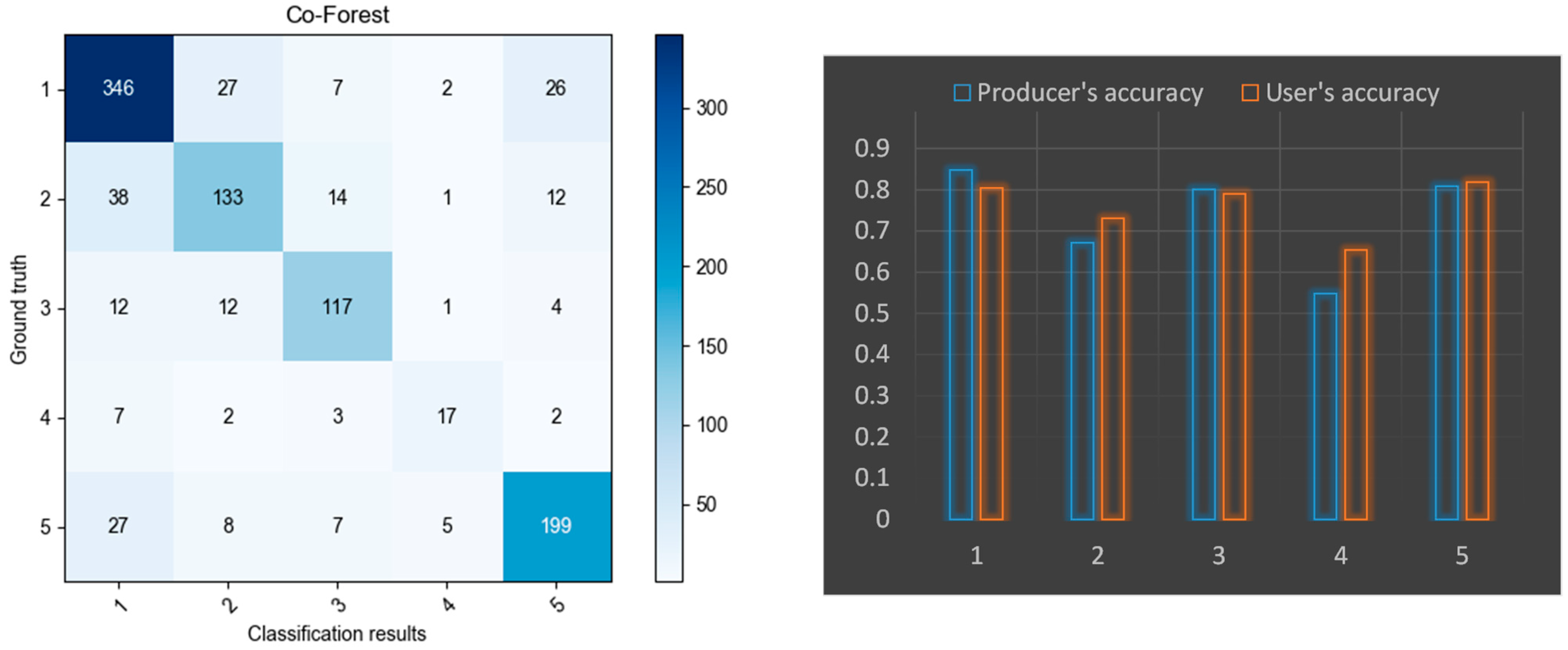
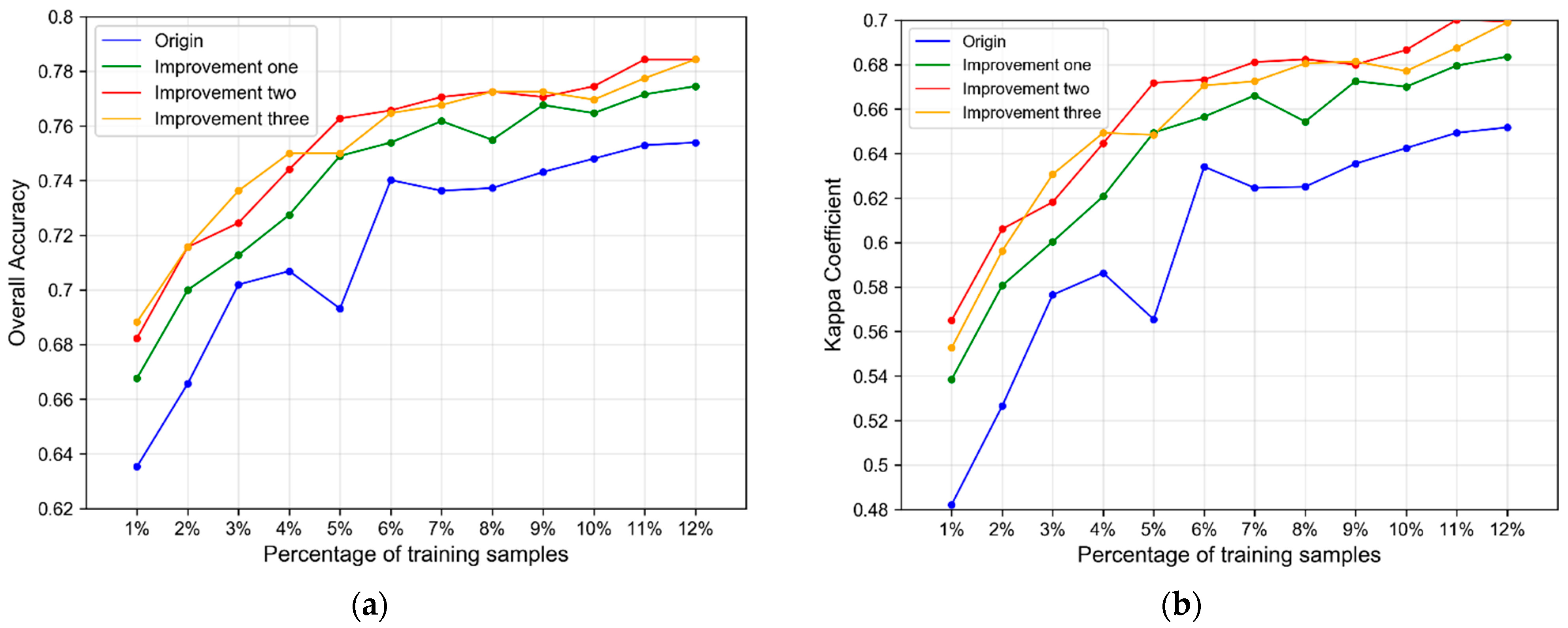
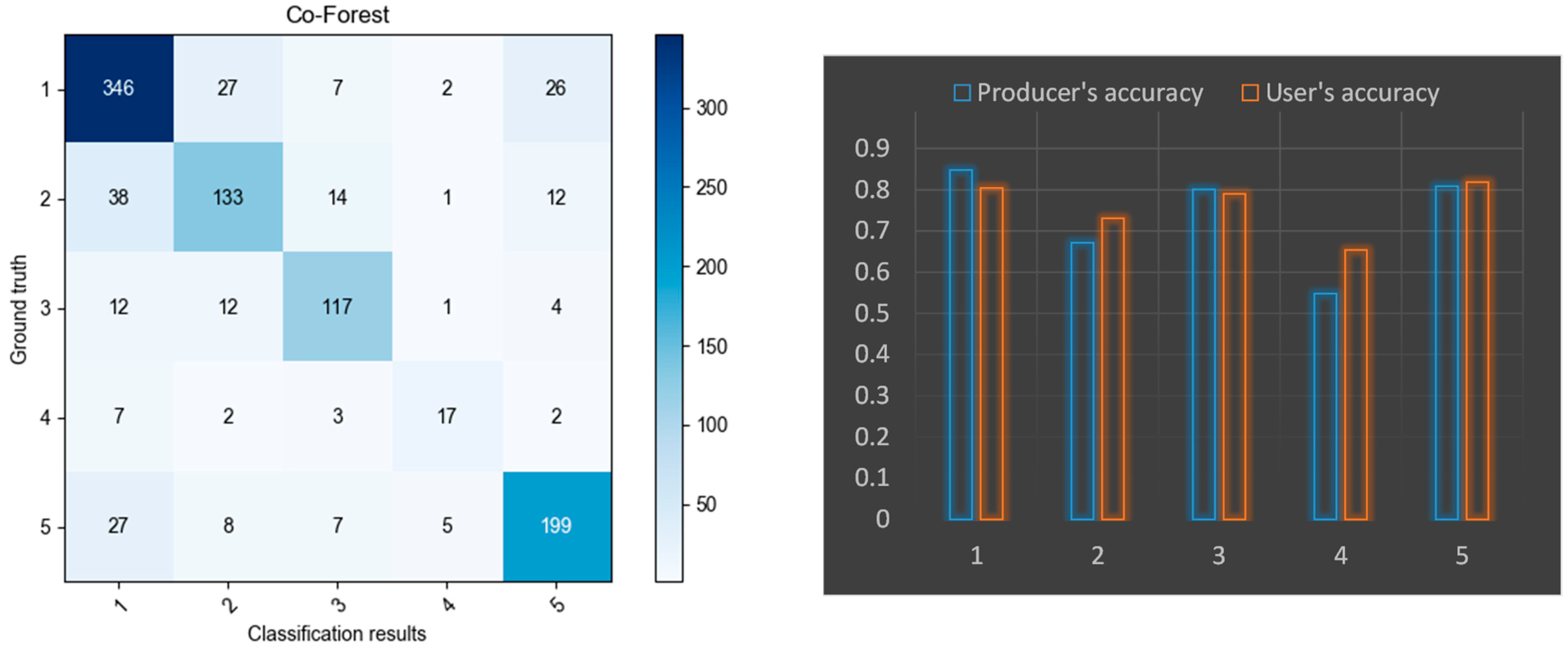
5.1. Performance of Algorithm Improvement of the Co-Forest
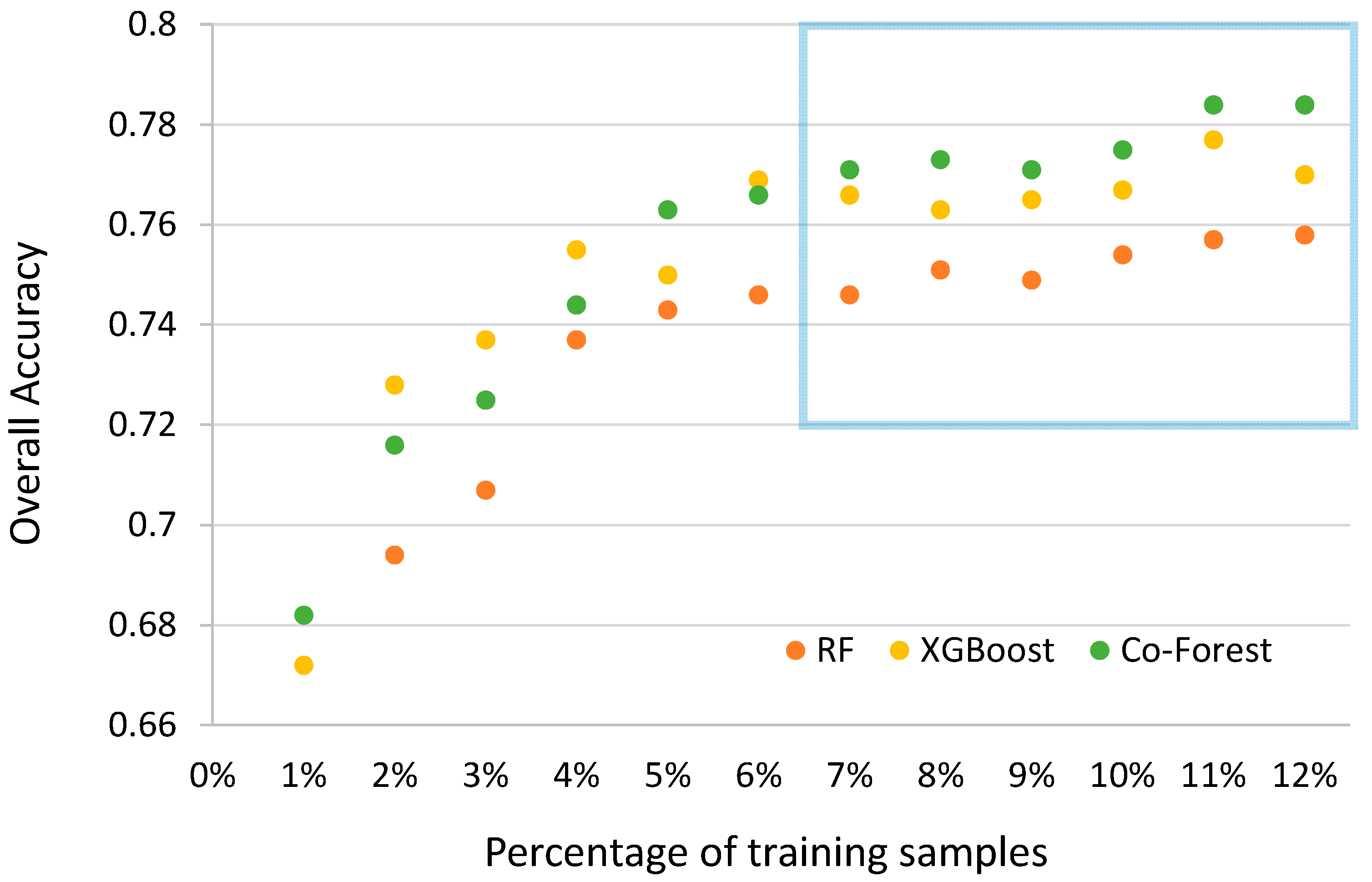
5.2. Comparison with Traditional Supervised Algorithms
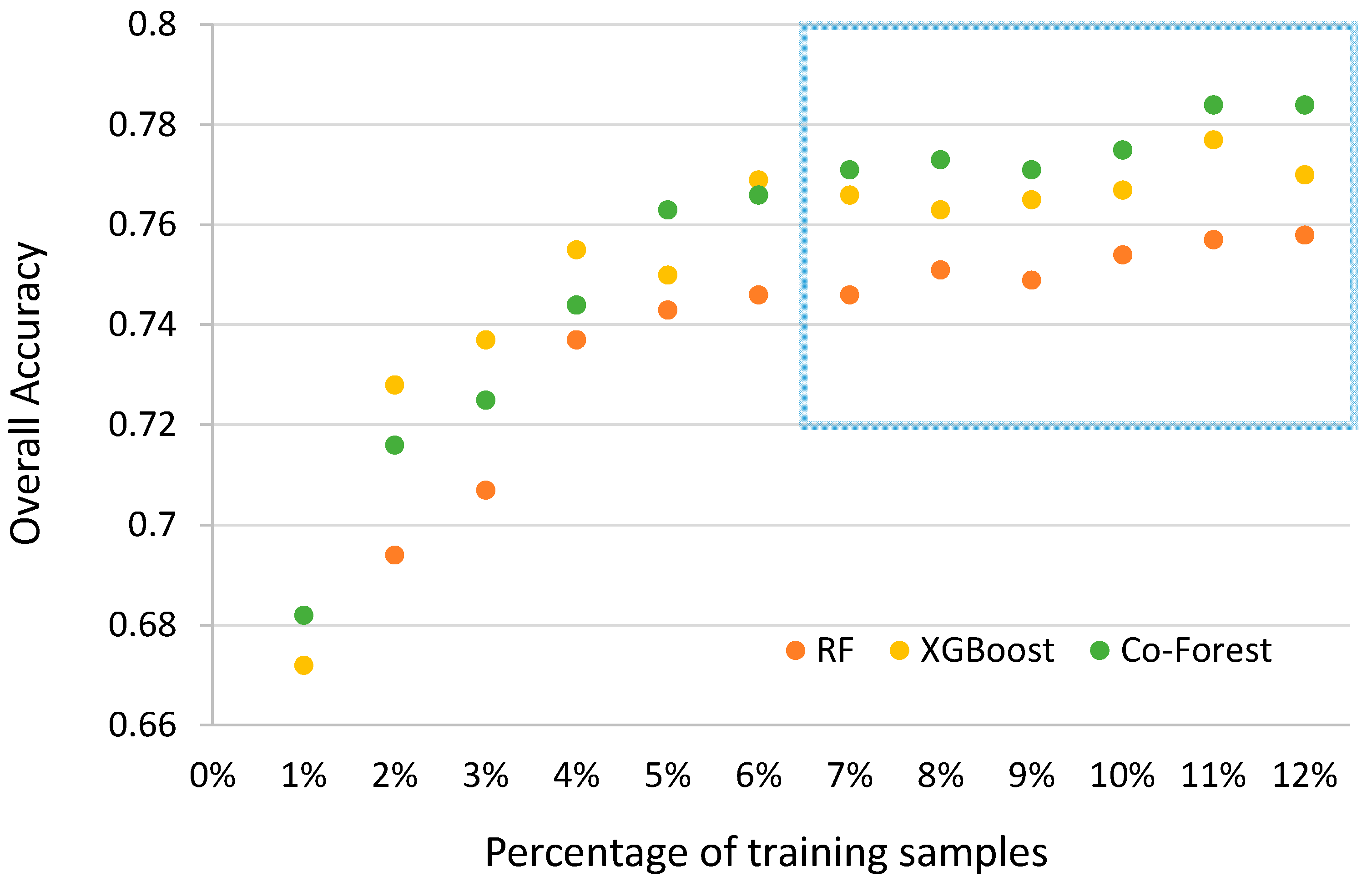
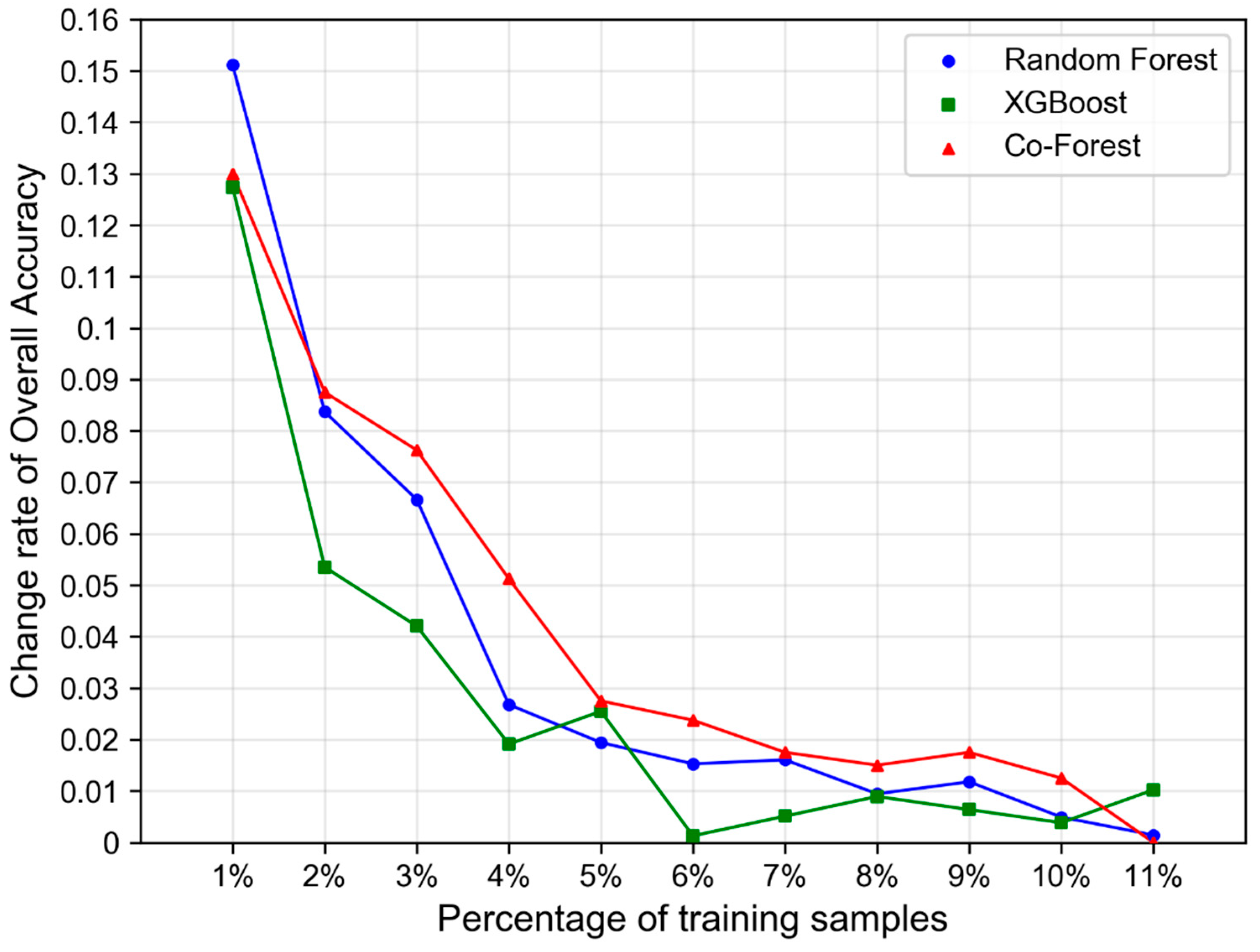
5.3. Impact of Training Sample Size
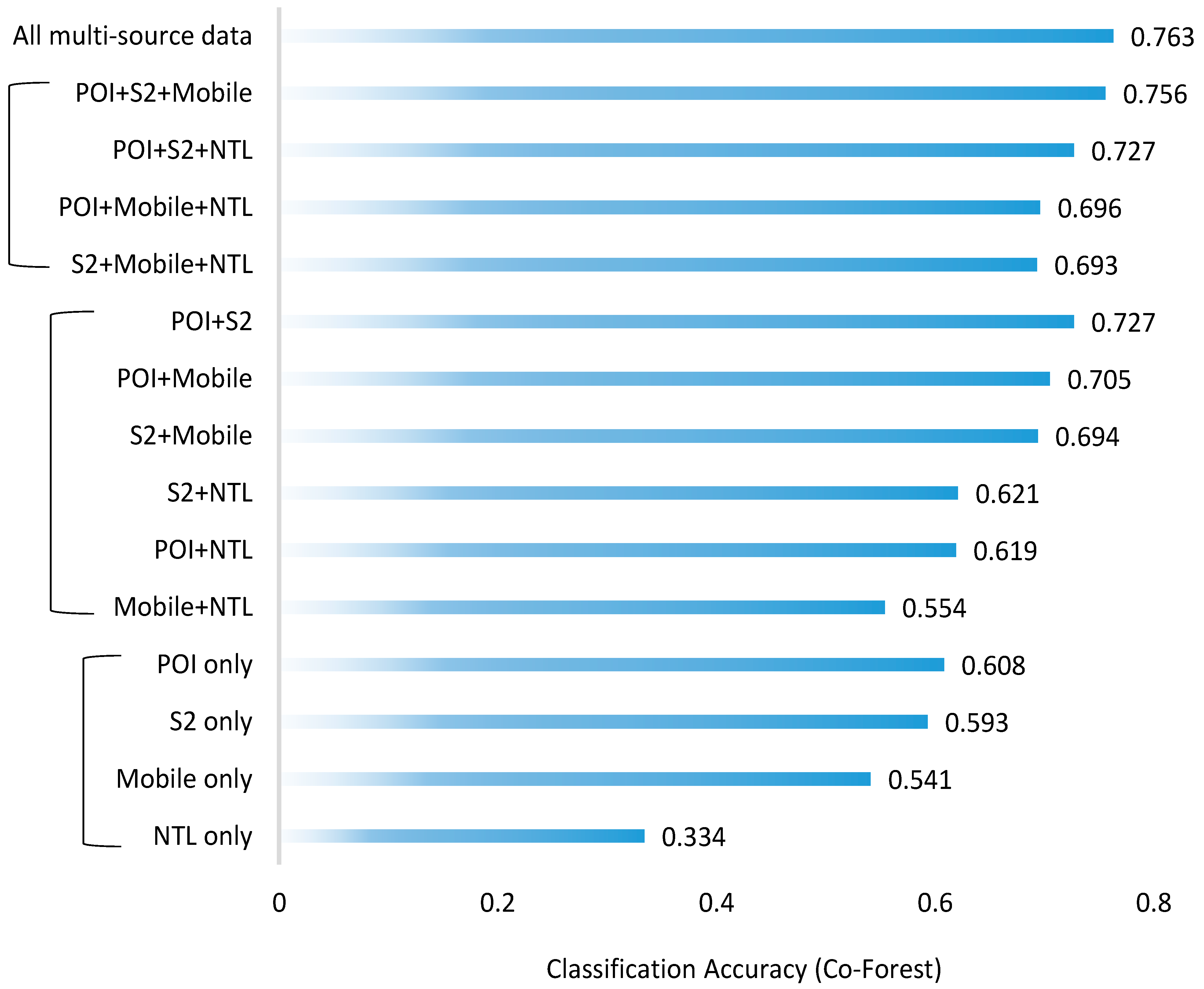
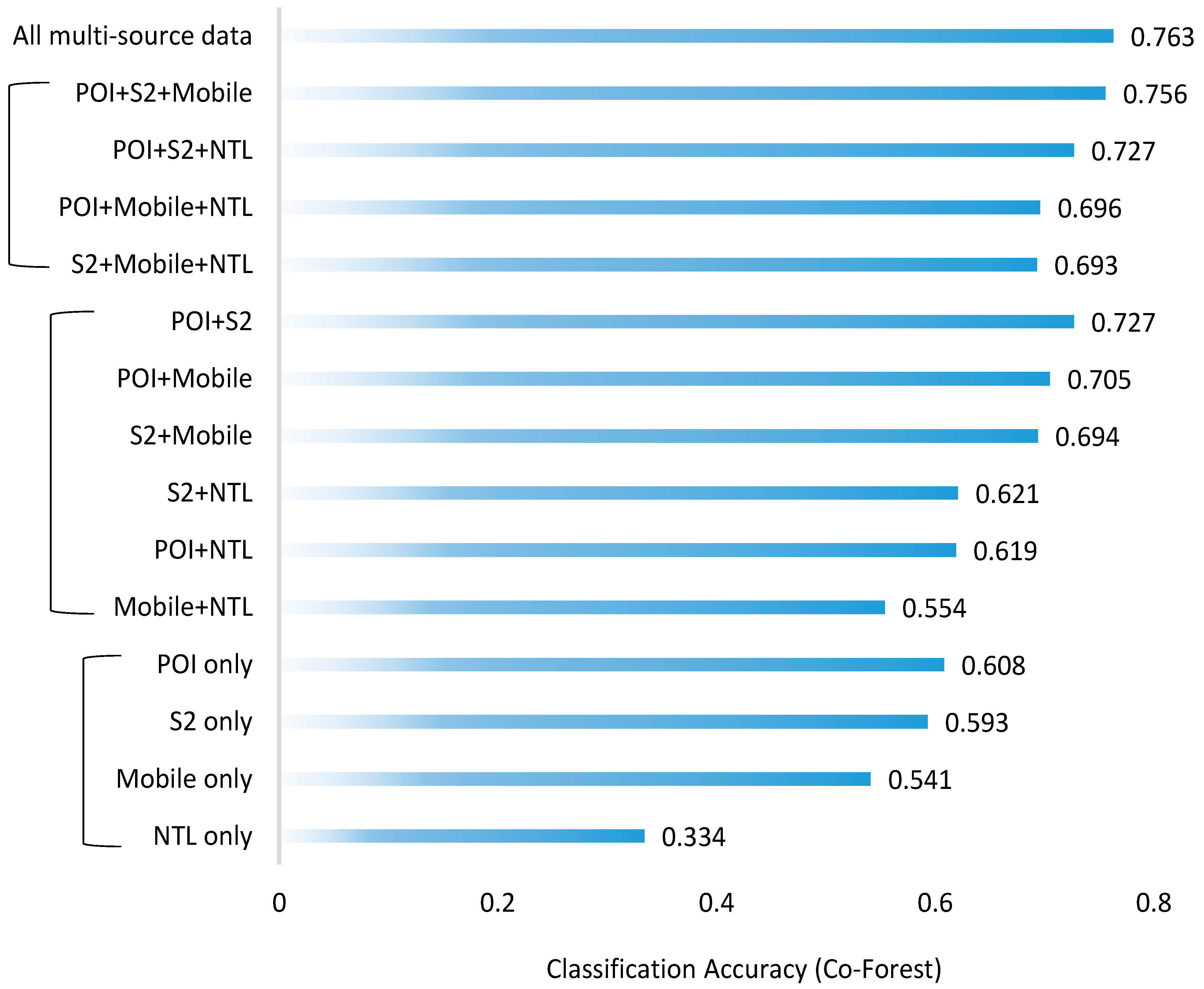
5.4. Importance of Multi-Source Geospatial Data
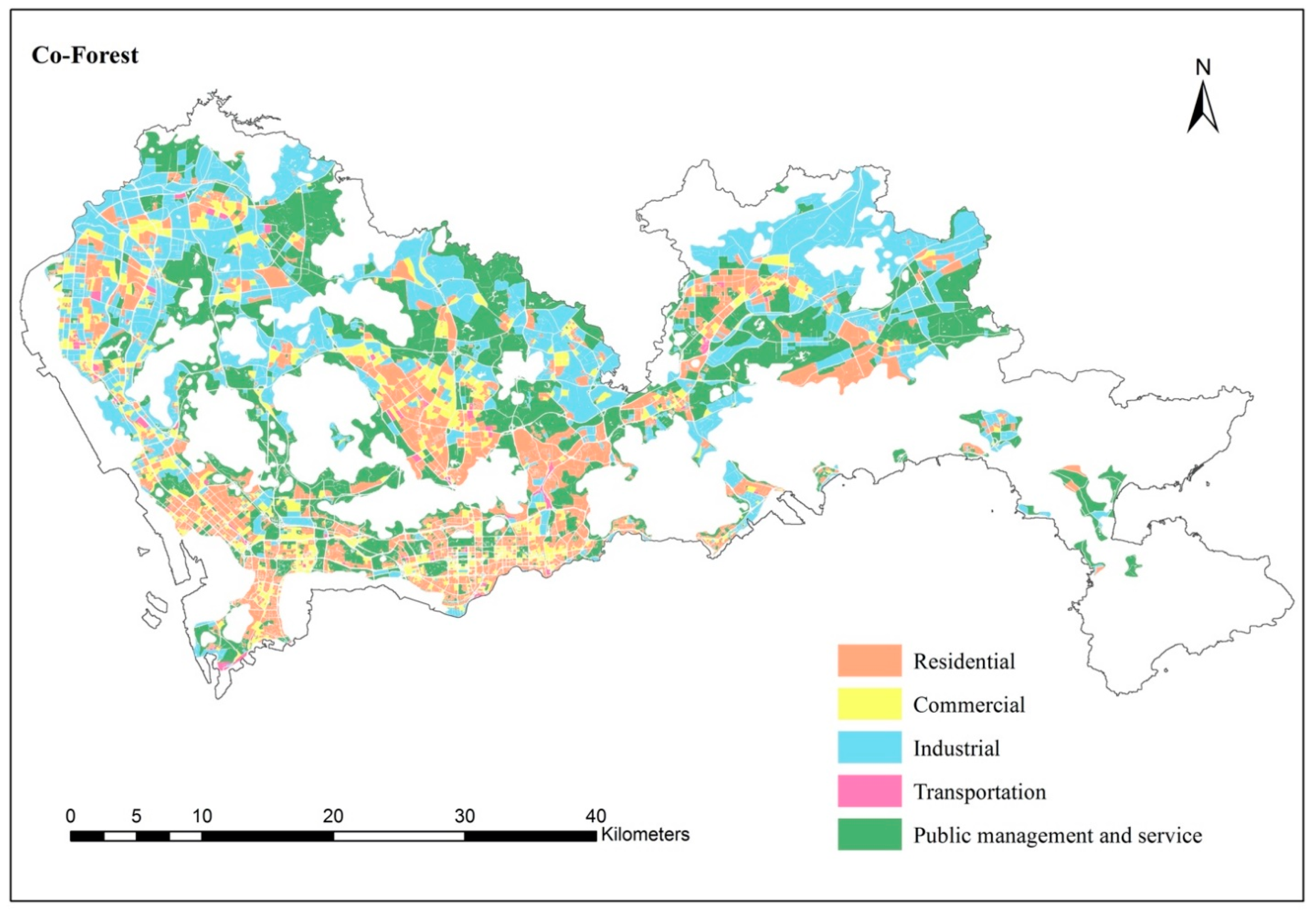
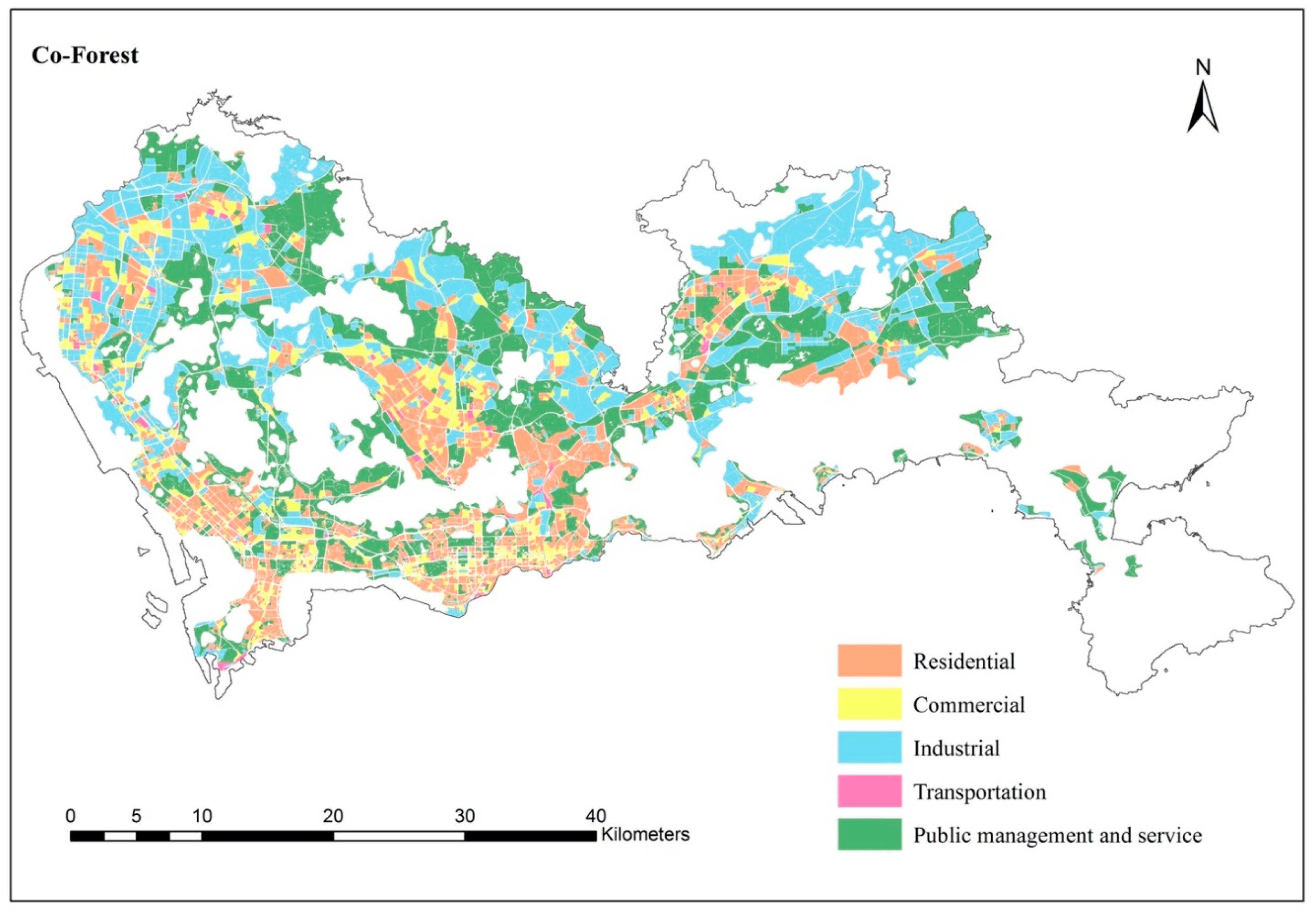
5.5. Detailed Urban Landuse Mapping with Few Samples
6. Discussion
6.1. Small Sample Learning in Urban Landuse Classification
6.2. Classification Stability under Small Size of Training Samples
6.3. Limitations and Uncertainties
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lu, D.; Weng, Q. Use of impervious surface in urban land-use classification. Remote Sens. Environ. 2006, 102, 146–160. [Google Scholar] [CrossRef]
- Zhou, Q.; Sun, B. Analysis of spatio-temporal pattern and driving force of land cover change using multi-temporal remote sensing images. Sci. China Ser.-Technol. Sci. 2010, 53, 111–119. [Google Scholar] [CrossRef]
- Hu, S.; Wang, L. Automated urban land-use classification with remote sensing. Int. J. Remote Sens. 2013, 34, 790–803. [Google Scholar] [CrossRef]
- Liu, X.; Hu, G.; Chen, Y.; Li, X.; Xu, X.; Li, S.; Pei, F.; Wang, S. High-resolution multi-temporal mapping of global urban land using Landsat images based on the Google Earth Engine Platform. Remote Sens. Environ. 2018, 209, 227–239. [Google Scholar] [CrossRef]
- Herold, M.; Liu, X.; Clarke, K.C. Spatial metrics and image texture for mapping urban land use. Photogramm. Eng. Remote Sens. 2003, 69, 991–1001. [Google Scholar] [CrossRef] [Green Version]
- Carleer, A.P.; Wolff, E. Urban land cover multi-level region-based classification of VHR data by selecting relevant features. Int. J. Remote Sens. 2006, 27, 1035–1051. [Google Scholar] [CrossRef]
- Pacifici, F.; Chini, M.; Emery, W. A neural network approach using multi-scale textural metrics from very high-resolution panchromatic imagery for urban land-use classification. Remote Sens. Environ. 2009, 113, 1276–1292. [Google Scholar] [CrossRef]
- Liu, X.; Tian, Y.; Zhang, X.; Wan, Z. Identification of urban functional regions in chengdu based on taxi trajectory time series data. ISPRS Int. J. Geo-Inf. 2020, 9, 158. [Google Scholar] [CrossRef] [Green Version]
- Yao, Y.; Li, X.; Liu, X.; Liu, P.; Liang, Z.; Zhang, J.; Mai, K. Sensing spatial distribution of urban land use by integrating points-of-interest and Google Word2Vec model. Int. J. Geogr. Inf. Sci. 2017, 31, 825–848. [Google Scholar] [CrossRef]
- Andrade, R.; Alves, A.; Bento, C. POI Mining for Land Use Classification: A Case Study. ISPRS Int. J. Geo-Inf. 2020, 9, 493. [Google Scholar] [CrossRef]
- Fang, F.; Yuan, X.; Wang, L.; Liu, Y.; Luo, Z. Urban Land-Use Classification From Photographs. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1927–1931. [Google Scholar] [CrossRef]
- Liu, X.; He, J.; Yao, Y.; Zhang, J.; Liang, H.; Wang, H.; Hong, Y. Classifying urban land use by integrating remote sensing and social media data. Int. J. Geogr. Inf. Sci. 2017, 31, 1675–1696. [Google Scholar] [CrossRef]
- Shi, Y.; Qi, Z.; Liu, X.; Niu, N.; Zhang, H. Urban land use and land cover classification using multisource remote sensing images and social media data. Remote Sens. 2019, 11, 2719. [Google Scholar] [CrossRef] [Green Version]
- Pei, T.; Sobolevsky, S.; Ratti, C.; Shaw, S.-L.; Li, T.; Zhou, C. A new insight into land use classification based on aggregated mobile phone data. Int. J. Geogr. Inf. Sci. 2014, 28, 1988–2007. [Google Scholar] [CrossRef] [Green Version]
- Jia, Y.; Ge, Y.; Ling, F.; Guo, X.; Wang, J.; Wang, L.; Chen, Y.; Li, X. Urban land use mapping by combining remote sensing imagery and mobile phone positioning data. Remote Sens. 2018, 10, 446. [Google Scholar] [CrossRef] [Green Version]
- Wieland, W.; Pittore, M. Performance evaluation of machine learning algorithms for urban pattern recognition from multi-spectral satellite images. Remote Sens. 2014, 6, 2912–2939. [Google Scholar] [CrossRef] [Green Version]
- Sun, L.; Tang, L.; Shao, G.; Qiu, Q.; Lan, T.; Shao, J. A machine learning-based classification system for urban built-up areas using multiple classifiers and data sources. Remote Sens. 2019, 12, 91. [Google Scholar] [CrossRef] [Green Version]
- Cao, K.; Guo, H.; Zhang, Y. Comparison of approaches for urban functional zones classification based on multi-source geospatial data: A case study in Yuzhong District, Chongqing, China. Sustainability 2019, 11, 660. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Li, Q.; Huang, H.; Wu, W.; Du, X.; Wang, H. The combined use of remote sensing and social sensing data in fine-grained urban land use mapping: A case study in Beijing, China. Remote Sens. 2017, 9, 865. [Google Scholar] [CrossRef] [Green Version]
- Li, W. Mapping urban land use by combining multi-source social sensing data and remote sensing images. Earth Sci. Inform. 2021, 14, 1537–1545. [Google Scholar] [CrossRef]
- Hong, D.; Yokoya, N.; Ge, N.; Chanussot, J.; Zhu, X.X. Learnable manifold alignment (LeMA): A semi-supervised cross-modality learning framework for land cover and land use classification. ISPRS J. Photogramm. Remote Sens. 2019, 147, 193–205. [Google Scholar] [CrossRef] [PubMed]
- Ligthart, A.; Catal, C.; Tekinerdogan, B. Analyzing the effectiveness of semi-supervised learning approaches for opinion spam classification. Appl. Soft Comput. 2021, 101, 107023. [Google Scholar] [CrossRef]
- Yin, J.; Dong, J.; Hamm, N.A.; Li, Z.; Wang, J.; Xing, H.; Fu, P. Integrating remote sensing and geospatial big data for urban land use mapping: A review. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102514. [Google Scholar] [CrossRef]
- Cao, R.; Tu, W.; Yang, C.; Li, Q.; Liu, J.; Zhu, J.; Zhang, Q.; Li, Q.; Qiu, G. Deep learning-based remote and social sensing data fusion for urban region function recognition. ISPRS J. Photogramm. Remote Sens. 2020, 163, 82–97. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Yang, C.; Wu, G.; Ding, K.; Shi, T.; Li, Q.; Wang, J. Improving land use/land cover classification by integrating pixel unmixing and decision tree methods. Remote Sens. 2017, 9, 1222. [Google Scholar] [CrossRef] [Green Version]
- Talukdar, S.; Singha, P.; Mahato, S.; Pal, S.; Liou, Y.-A.; Rahman, A. Land-use land-cover classification by machine learning classifiers for satellite observations—A review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Sun, Y.; Zheng, A.; Wang, Y. A New Approach to refining land use types: Predicting point-of-interest categories using weibo check-in data. ISPRS Int. J. Geo-Inf. 2020, 9, 124. [Google Scholar] [CrossRef] [Green Version]
- Xu, S.; Qing, L.; Han, L.; Liu, M.; Peng, Y.; Shen, L. A new remote sensing images and point-of-interest fused (rpf) model for sensing urban functional regions. Remote Sens. 2020, 12, 1032. [Google Scholar] [CrossRef] [Green Version]
- Jozdani, S.E.; Johnson, B.A.; Chen, D. comparing deep neural networks, ensemble classifiers, and support vector machine algorithms for object-based urban land use/land cover classification. Remote Sens. 2019, 11, 1713. [Google Scholar] [CrossRef] [Green Version]
- Tu, W.; Hu, Z.; Li, L.; Cao, J.; Jiang, J.; Li, Q.; Li, Q. Portraying urban functional zones by coupling remote sensing imagery and human sensing data. Remote Sens. 2018, 10, 141. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Yan, X. Discovering the relationship between travel behavior and land use: A case study of Beijing, China. In Proceedings of the 2019 4th International Conference on Electromechanical Control Technology and Transportation (ICECTT 2019), Guilin, China, 26–28 April 2019. [Google Scholar]
- Zhao, K.; Jin, X.; Wang, Y. Survey on few-shot learning. J. Softw. 2021, 32, 349–369. (In Chinese) [Google Scholar]
- Li, C.; Wang, J.; Wang, L.; Hu, L.; Gong, P. Comparison of classification algorithms and training sample sizes in urban land classification with Landsat Thematic Mapper imagery. Remote Sens. 2014, 6, 964–983. [Google Scholar] [CrossRef] [Green Version]
- Su, M.; Guo, R.; Chen, B.; Hong, W.; Wang, J.; Feng, Y.; Xu, B. Sampling strategy for detailed urban land use classification: A systematic analysis in Shenzhen. Remote Sens. 2020, 12, 1497. [Google Scholar] [CrossRef]
- Gong, P.; Chen, B.; Li, X.; Liu, H.; Wang, J.; Bai, Y.; Chen, J.; Chen, X.; Fang, L.; Feng, S.; et al. Mapping essential urban land use categories in China (EULUC-China): Preliminary results for 2018. Sci. Bull. 2019, 65, 182–187. [Google Scholar] [CrossRef] [Green Version]
- Hartmann, W.M. Dimension Reduction vs. Variable Selection. In Applied Parallel Computing. State of the Art in Scientific Computing. PARA 2004; Dongarra, J., Madsen, K., Waśniewski, J., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3732. [Google Scholar] [CrossRef]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory-COLT’ 98, Madison, WI, USA, 24–26 July 1998. [Google Scholar] [CrossRef]
- Zhou, Z.-H.; Li, M. Semi-supervised learning by disagreement. Knowl. Inf. Syst. 2009, 24, 415–439. [Google Scholar] [CrossRef]
- Tanha, J.; Van Someren, M.; Afsarmanesh, H. Semi-supervised self-training for decision tree classifiers. Int. J. Mach. Learn. Cybern. 2017, 8, 355–370. [Google Scholar] [CrossRef] [Green Version]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a Few Examples. ACM Comput. Surv. 2021, 53, 1–34. [Google Scholar] [CrossRef]
- Chen, B.; Xu, B.; Gong, P. Mapping essential urban land use categories (EULUC) using geospatial big data: Progress, challenges, and opportunities. Big Earth Data 2021, 5, 410–441. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, H.; Yang, H. Urban functional zone recognition integrating multisource geographic data. Remote Sens. 2021, 13, 4732. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Data | Source | Spatial Resolution | Acquisition Time |
|---|---|---|---|
| Optical remote sensing | Sentinel-2 | 10 m | 2019 |
| NTL remote sensing | Luojia-1 | 130 m | November 2018 to March 2019 |
| Mobile big data | Apps with GPS location sharing | 140 m (approx.) | October 2018 to February 2019 |
| Map POI | Gaode map POI | / | June 2020 |
| Type | Selected Features |
|---|---|
| Optical remote sensing imagery | mean and standard deviation of NDVI, NDBI, MNDWI, band 4 (red), band 8 (NIR), band 7 (red edge), band 11 (SWIR) |
| NTL remote sensing imagery | DN value (or brightness) in November 2018, January 2019, and March 2019, mean brightness |
| Mobile apps data | average number of mobile devices, no. at daytime and nighttime |
| Map POI data | no. of POI, no. and ratio of POI by landuse category (5 categories) |
| Code | Category | Descriptions |
|---|---|---|
| 1 | Residential (R) | Residential area including village-in-city (urban village specific to China). |
| 2 | Commercial (C) | Commercial area including business districts, shopping areas, etc. |
| 3 | Industrial (I) | Industrial area including manufacturing districts, storage areas, etc. |
| 4 | Transportation (T) | Roads * and transportation hubs (e.g., station, airport, harbor, etc.). |
| 5 | Public management and service (P) | Governmental office zone, medical and health services, sports and cultural facilities. |
| The Level of Accuracy (by OA) | Training Sample Size Requirement (% in Total) | * Training Samples Saved (%) | ||
|---|---|---|---|---|
| RF | XGBoost | Co-Forest | ||
| 0.74 | 5% | 4% | 4% | 20% |
| 0.76 | / | 6% | 5% | 17% |
| 0.78 | / | / | 11% | / |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, B.; Zhang, Y.; Zhou, Q.; Zhang, X. Effectiveness of Semi-Supervised Learning and Multi-Source Data in Detailed Urban Landuse Mapping with a Few Labeled Samples. Remote Sens. 2022, 14, 648. https://doi.org/10.3390/rs14030648
Sun B, Zhang Y, Zhou Q, Zhang X. Effectiveness of Semi-Supervised Learning and Multi-Source Data in Detailed Urban Landuse Mapping with a Few Labeled Samples. Remote Sensing. 2022; 14(3):648. https://doi.org/10.3390/rs14030648
Chicago/Turabian StyleSun, Bo, Yang Zhang, Qiming Zhou, and Xinchang Zhang. 2022. "Effectiveness of Semi-Supervised Learning and Multi-Source Data in Detailed Urban Landuse Mapping with a Few Labeled Samples" Remote Sensing 14, no. 3: 648. https://doi.org/10.3390/rs14030648
APA StyleSun, B., Zhang, Y., Zhou, Q., & Zhang, X. (2022). Effectiveness of Semi-Supervised Learning and Multi-Source Data in Detailed Urban Landuse Mapping with a Few Labeled Samples. Remote Sensing, 14(3), 648. https://doi.org/10.3390/rs14030648