


Hyperspectral Video Target Tracking Based on Deep Edge Convolution Feature and Improved Context Filter
 , ,
, , 
Abstract
:1. Introduction
- We propose a 3D edge feature-extraction method. The three directional edge features are fused with directional adaptive weights to extract a 3D matrix, which enhances the edge information and contains spatial-spectral features.
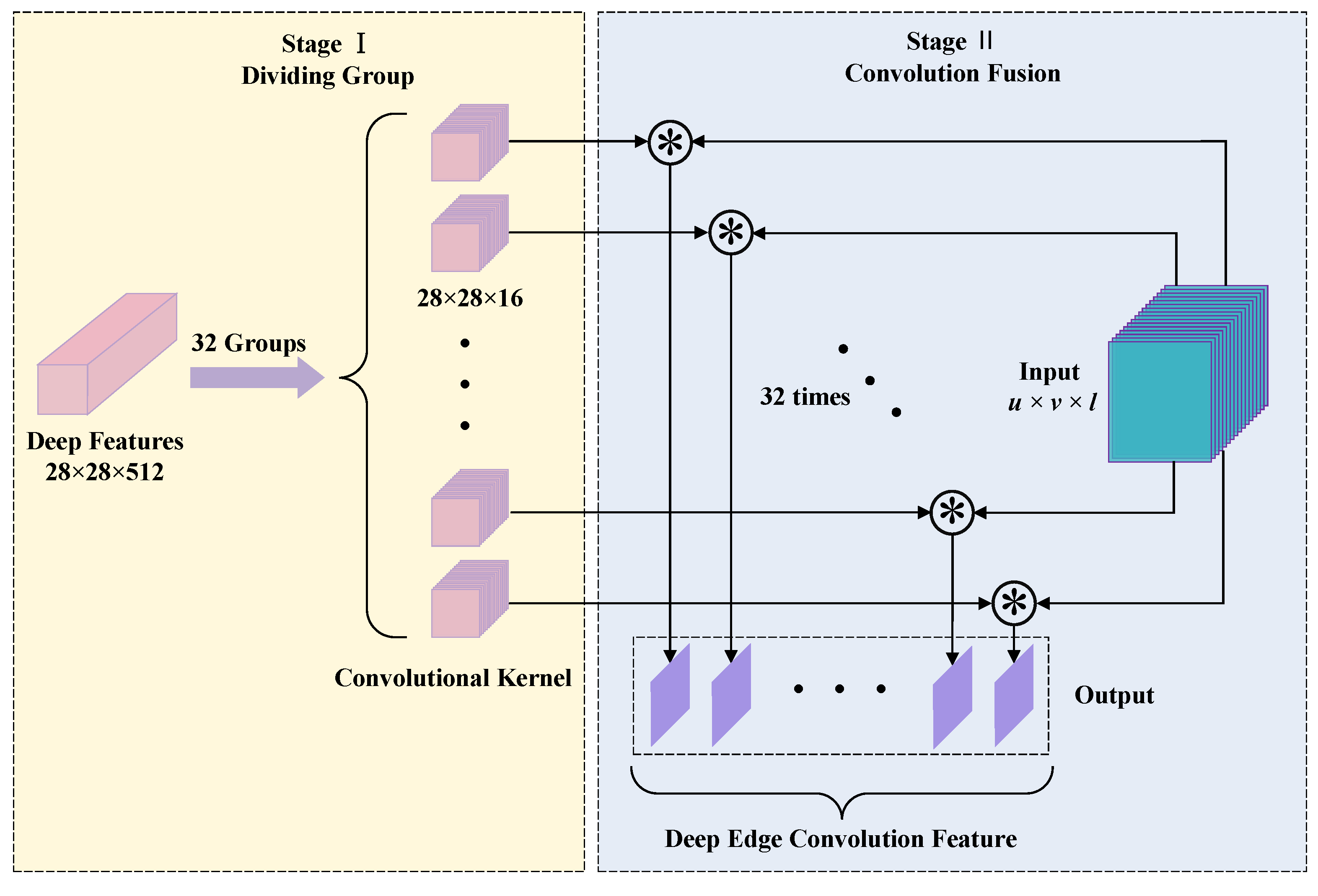
- We first used a novel convolution fusion feature named DECF, which is obtained by convolving the grouped depth features with the 3D edge features. DECF greatly preserves semantic and spatial-spectral information and makes the target more discriminative.
- An ICF is first proposed. First, eight influence factors are calculated in the context areas. Secondly, four areas corresponding to the first four influence factors are regarded as negative samples to train context filter. At last, adaptive weights calculated by four influence factors are used to suppress background clutter.
- Inspired by the region proposal network (RPN), this paper proposes a new adaptive scale estimation method named RPM. The estimation of the target box is achieved by adjusting the length and width of the target box by using RPM.
2. Related Work
2.1. Feature Extraction
2.2. CF Trackers
2.3. Scale Estimation
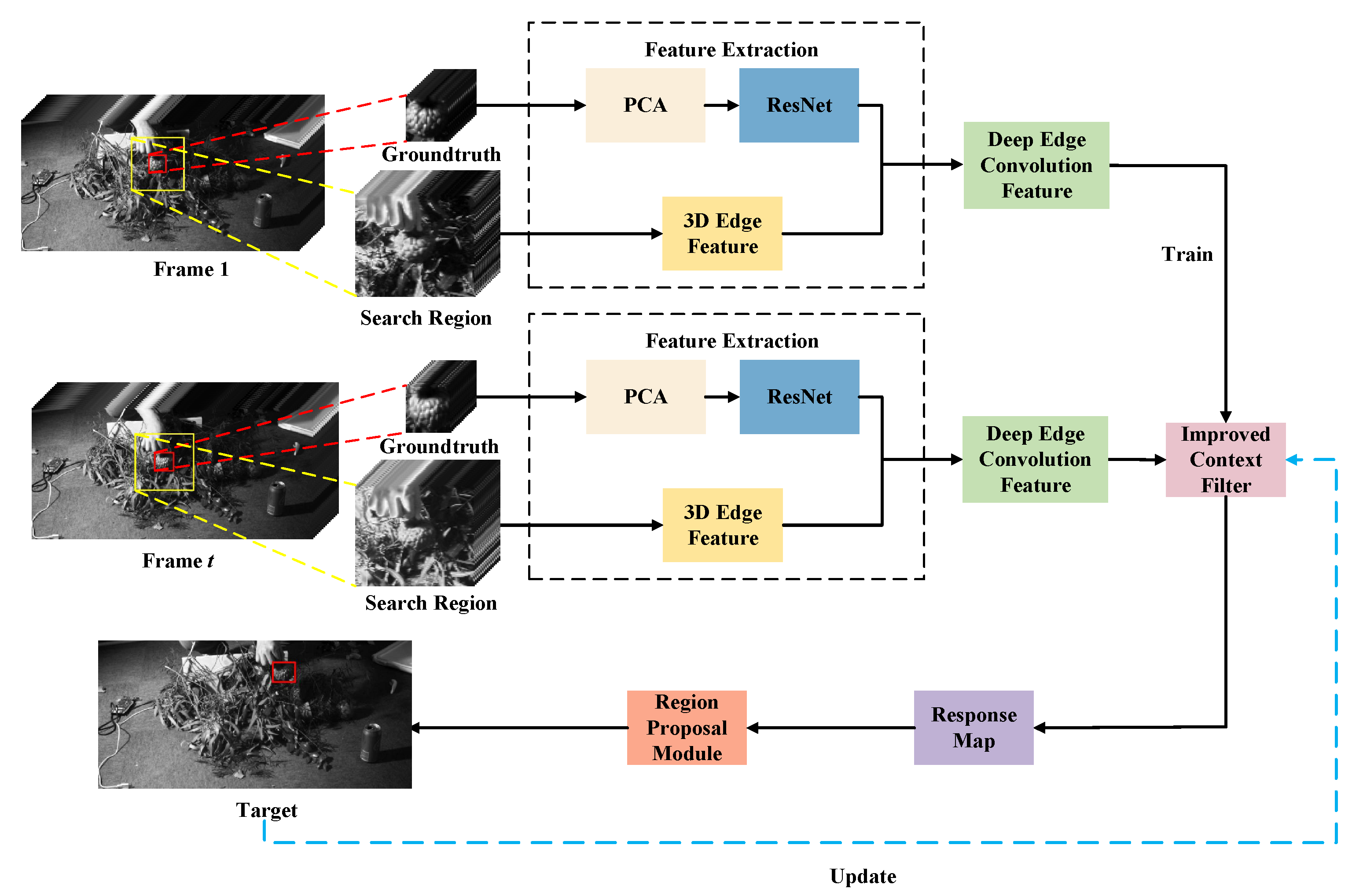
3. Proposed Approach
3.1. PCA Dimensionality Reduction
3.2. Deep Features
3.3. 3D Edge Features
3.4. Deep Edge Convolution Feature
3.5. Improved Context Filter
3.6. Adaptive Scale Estimation
4. Experimental Results and Analysis
4.1. Experimental Setting
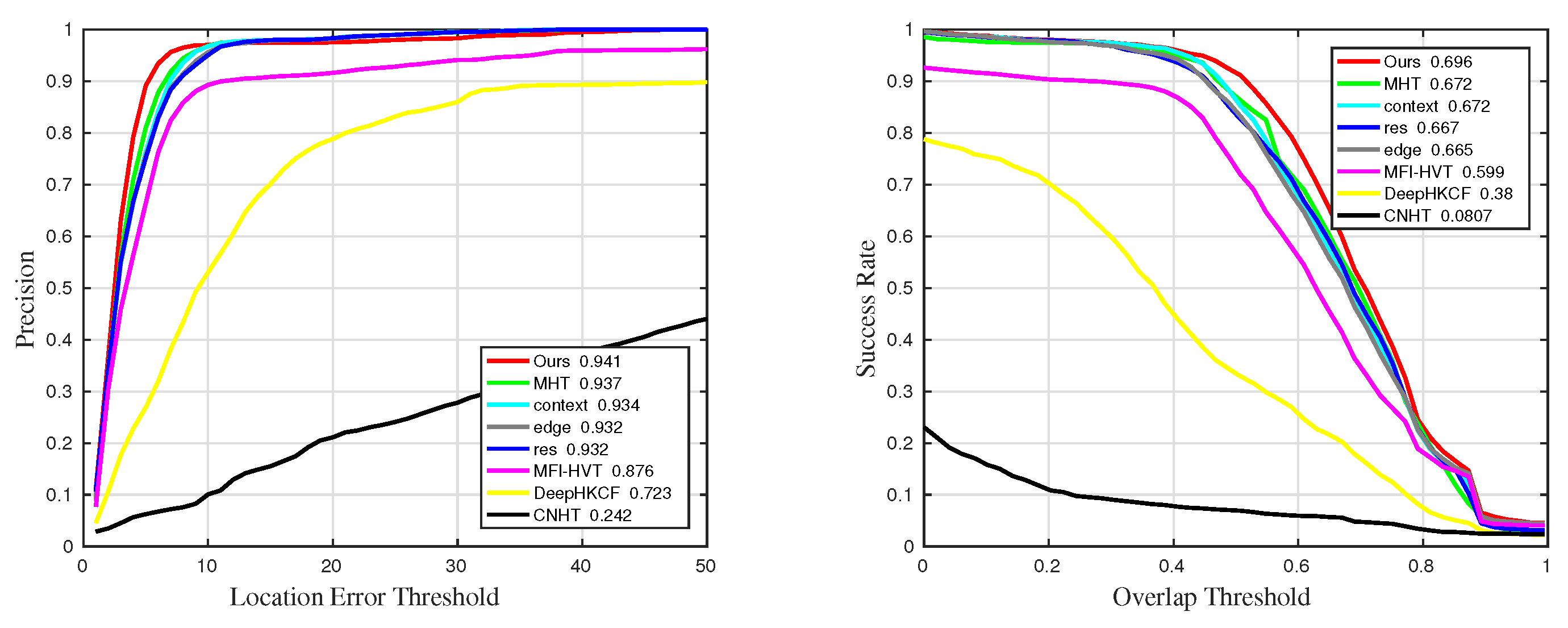
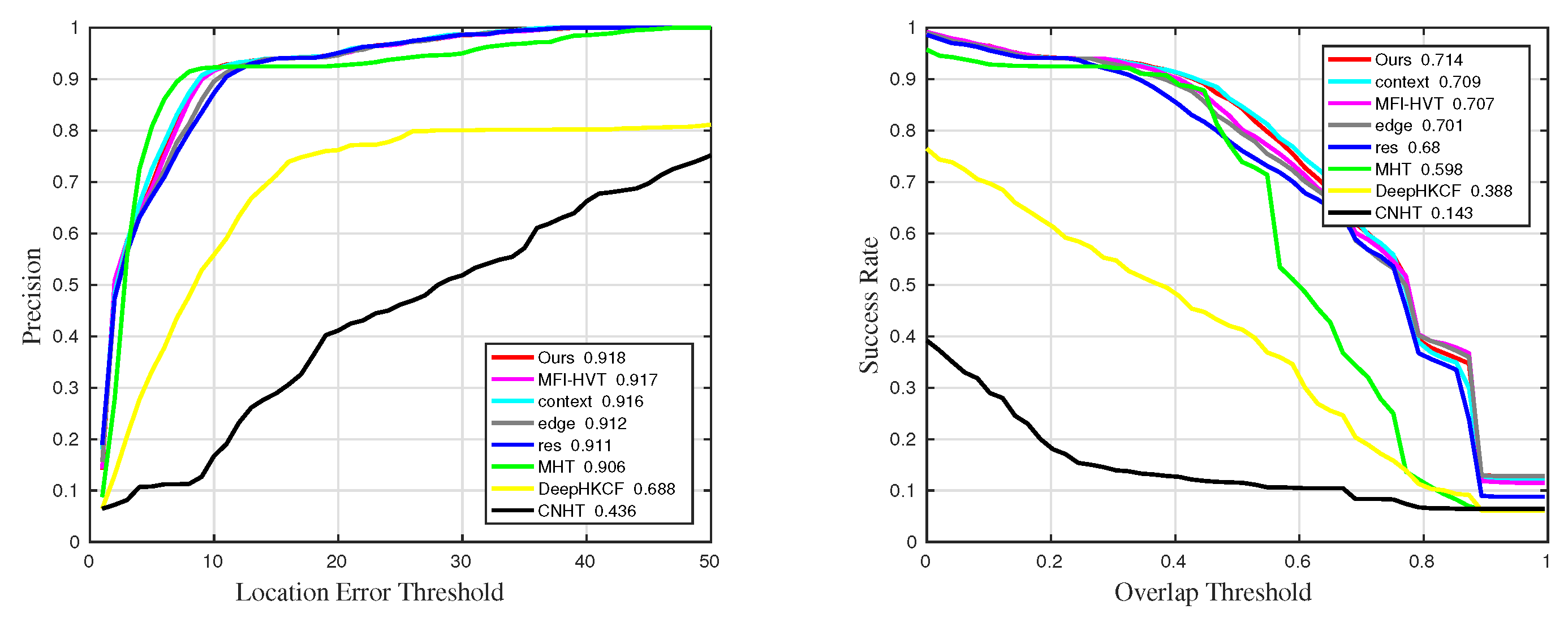
4.2. Qualitative Comparison
4.3. Quantitative Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, Z.P.; Liu, Y.H.; Wang, X.; Li, B. Learn to Match: Automatic Matching Network Design for Visual Tracking. In Proceedings of the International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Wang, X.; Shu, X.; Zhang, Z.; Jiang, B.; Wang, Y.; Tian, Y.; Wu, F. Towards More Flexible and Accurate Object Tracking with Natural Language: Algorithms and Benchmark. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Zhao, D.; Gu, L.; Qian, K.; Zhou, H.; Cheng, K. Target tracking from infrared imagery via an improved appearance model. Infrared Phys. Technol. 2019, 104, 103–116. [Google Scholar] [CrossRef]
- Bhat, G.; Danelljan, M.; Gool, L.V.; Timofte, R. Learning Discriminative Model Prediction for Tracking. In Proceedings of the International Conference on Computer Vision, Chongqing, China, 23–28 August 2020. [Google Scholar]
- Marques, J.S.; Jorge, P.M.; Abrantes, A.J.; Lemos, J.M. Tracking Groups of Pedestrians in Video Sequences. In Proceedings of the Computer Vision and Pattern Recognition Workshop, Madison, MI, USA, 16–22 June 2003. [Google Scholar]
- Li, D.; Zhang, Z.; Chen, X.; Huang, K. A Richly Annotated Pedestrian Dataset for Person Retrieval in Real Surveillance Scenarios. IEEE Trans. Image Process. 2019, 28, 1575–1590. [Google Scholar] [CrossRef] [PubMed]
- Xiang, Y.; Alahi, A.; Savarese, S. Learning to Track: Online Multi-object Tracking by Decision Making. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Ravankar, A.; Ravankar, A.A.; Kobayashi, Y.; Hoshino, Y. Path Smoothing Techniques in Robot Navigation: State-of-the-Art, Current and Future Challenges. Sensors 2018, 18, 3170. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ojha, S.; Sakhare, S. Image processing techniques for object tracking in video surveillance—A survey. In Proceedings of the International Conference on Pervasive Computing, St. Louis, MO, USA, 23–27 March 2015. [Google Scholar]
- Dorfler, F.; Jovanovic, M.R.; Chertkov, M.; Bullo, F. Sparsity-Promoting Optimal Wide-Area Control of Power Networks. IEEE Trans. Power Syst. 2013, 29, 2281–2291. [Google Scholar] [CrossRef] [Green Version]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking Hyperspectral Image Classification with Transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Uzair, M.; Mahmood, A.; Mian, A. Hyperspectral Face Recognition With Spatiospectral Information Fusion and PLS Regression. IEEE Trans. Image Process. 2015, 24, 1127–1137. [Google Scholar] [CrossRef]
- Prasad, S.; Bruce, L.M. Decision fusion with confidence-based weight assignment for hyperspectral target recognition. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1448–1456. [Google Scholar] [CrossRef]
- Naoto, Y.; Jonathan, C.; Karl, S. Potential of Resolution-Enhanced Hyperspectral Data for Mineral Mapping Using Simulated EnMAP and Sentinel-2 Images. Remote Sens. 2016, 8, 172. [Google Scholar] [CrossRef] [Green Version]
- Uzkent, B.; Rangnekar, A.; Hoffman, M.J. Tracking in Aerial Hyperspectral Videos Using Deep Kernelized Correlation Filters. IEEE Trans. Geosci. Remote Sens. 2018, 57, 449–461. [Google Scholar] [CrossRef] [Green Version]
- Qian, K.; Zhou, J.; Xiong, F.; Zhou, H.; Du, J. Object Tracking in Hyperspectral Videos with Convolutional Features and Kernelized Correlation Filter. Int. Conf. Smart Multimed. 2018, 11010, 308–319. [Google Scholar]
- Xiong, F.; Zhou, J.; Qian, Y. Material Based Object Tracking in Hyperspectral Videos. IEEE Trans. Image Process. 2020, 29, 3719–3733. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Qian, K.; Du, J.; Zhou, H. Multi-Features Integration Based Hyperspectral Videos Tracker. In Proceedings of the IEEE Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing, Amsterdam, The Netherlands, 24–26 March 2021. [Google Scholar]
- Martinez, A.M.; Kak, A.C. PCA versus LDA. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 23, 228–233. [Google Scholar] [CrossRef] [Green Version]
- Jian, Y.; David, Z.; Frangi, A.F.; Jing, Y. Two-dimensional PCA: A new approach to appearance-based face representation and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 131–137. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Clausi, D.A.; Jernigan, M.E. Designing Gabor filters for optimal texture separability. Pattern Recognit. 2000, 33, 1835–1849. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, L.; Zhang, D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar]
- Benediktsson, J.A.; Palmason, J.A.; Sveinsson, J.R. Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 2005, 43, 480–491. [Google Scholar] [CrossRef]
- Zhu, J.; Hu, J.; Jia, S.; Jia, X.; Li, Q. Multiple 3-D feature fusion framework for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1873–1886. [Google Scholar] [CrossRef]
- Li, W.; Chen, C.; Su, H.; Du, Q. Local binary patterns and extreme learning machine for hyperspectral imagery classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3681–3693. [Google Scholar] [CrossRef]
- Tu, B.; Kuang, W.; Zhao, G.; He, D.; Liao, Z.; Ma, W. Hyperspectral image classification by combining local binary pattern and joint sparse representation. Int. J. Remote Sens. 2019, 40, 9484–9500. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Zhao, X.; Jia, X. Spectral–spatial classification of hyperspectral data based on deep belief network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- He, M.; Li, B.; Chen, H. Multi-scale 3D deep convolutional neural network for hyperspectral image classification. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3904–3908. [Google Scholar]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Henriques, J.F.; Rui, C.; Martins, P.; Batista, J. Exploiting the Circulant Structure of Tracking-by-Detection with Kernels. Eur. Conf. Comput. Vis. 2012, 7575, 702–715. [Google Scholar]
- Tappen, M.F.; Freeman, W.T.; Adelson, E.H. Recovering Intrinsic Images from a Single Image. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1459–1472. [Google Scholar] [CrossRef] [PubMed]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [Green Version]
- Kiani Galoogahi, H.; Fagg, A.; Lucey, S. Learning background-aware correlation filters for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1135–1143. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning spatially regularized correlation filters for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 4310–4318. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. Context-Aware Correlation Filter Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1396–1404. [Google Scholar]
- Li, Y.; Zhu, J. A scale adaptive kernel correlation filter tracker with feature integration. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 254–265. [Google Scholar]
- Martin, D.L.; Häger, G.; Fahad, S.; Michael, F. Accurate Scale Estimation for Robust Visual Tracking. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Discriminative scale space tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1561–1575. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P. Fully-Convolutional Siamese Networks for Object Tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 850–865. [Google Scholar]
- Li, B.; Yan, J.; Wei, W.; Zheng, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking With Very Deep Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Skurikhin, A.N.; Garrity, S.R.; McDowell, N.G. Automated tree crown detection and size estimation usingmulti-scale analysis of high-resolution satellite imagery. Remote Sens. Lett. 2013, 4, 465–474. [Google Scholar] [CrossRef]
- Witkin, A.P. Scale-space filtering: A new approach to multi-scale description. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, San Diego, CA, USA, 19–21 March 1984. [Google Scholar]
- Lowe, D. Distinctive image features from scale-invariant key points. Int. J. Comput. Vis. 2003, 20, 91–110. [Google Scholar]
- Cheng, X.; Chen, Y.; Tao, Y.; Wang, C.; Kim, M.; Lefcourt, A. A novel integrated PCA and FLD method on hyperspectral image feature extraction for cucumber chilling damage inspection. Trans. ASAE 2004, 47, 1313. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Gang, W. Recent Advances in Convolutional Neural Networks. Pattern Recognit. 2015, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Martins, V.S.; Kaleita, A.L.; Gelder, B.K.; da Silveira, H.L.; Abe, C.A. Exploring multiscale object-based convolutional neural network (multi-OCNN) for remote sensing image classification at high spatial resolution. ISPRS J. Photogramm. Remote Sens. 2020, 168, 56–73. [Google Scholar] [CrossRef]
- Vincent, O.R.; Folorunso, O. A descriptive algorithm for sobel image edge detection. In Proceedings of the Informing Science & IT Education Conference (InSITE), Macon, GA, USA, 12–15 June 2009; Volume 40, pp. 97–107. [Google Scholar]
- Kanopoulos, N.; Vasanthavada, N.; Baker, R.L. Design of an image edge detection filter using the Sobel operator. IEEE J. Solid-State Circuits 1988, 23, 358–367. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequences | Coin | Fruit | Pedestrain | Kangaroo | Drive | Forest |
|---|---|---|---|---|---|---|
| Frames | 149 | 552 | 306 | 117 | 725 | 530 |
| Resolution | ||||||
| Initial Size | ||||||
| Challenges | BC, MB | BC, OCC | SV, IV | OPR, SV | SV, BC | OCC, BC |
| Sequences | Precision | Precision_BC | Precision_OCC | Precision_SV | Precision_OPR |
|---|---|---|---|---|---|
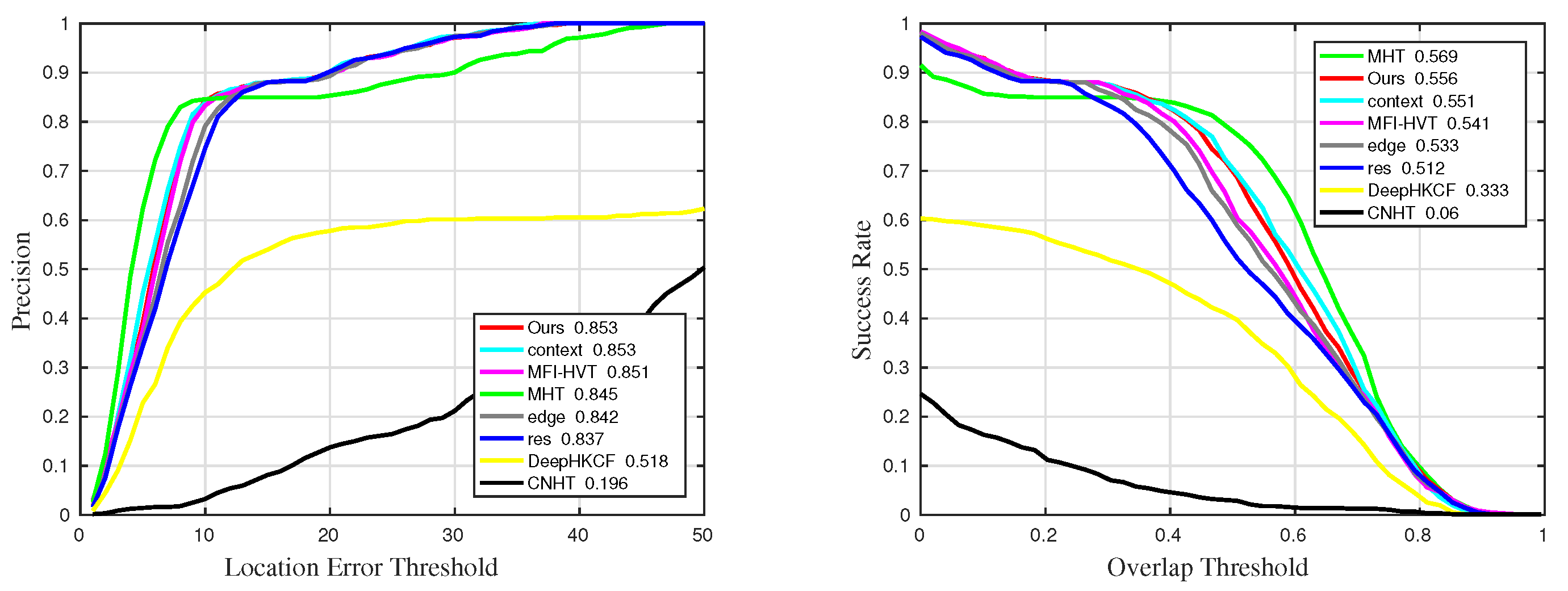
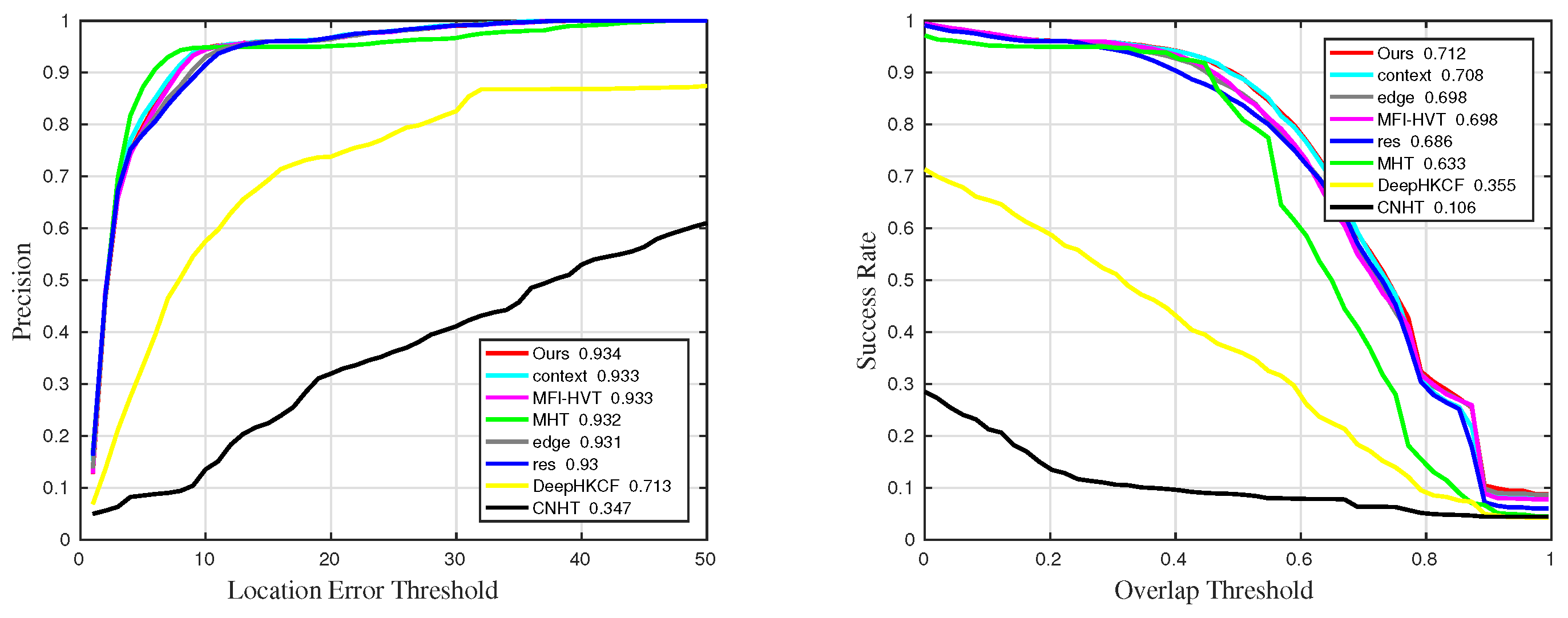
| Ours | 0.941 | 0.918 | 0.853 | 0.934 | 0.946 |
| MHT | 0.937 | 0.906 | 0.845 | 0.932 | 0.958 |
| RES | 0.932 | 0.911 | 0.837 | 0.93 | 0.947 |
| context | 0.934 | 0.916 | 0.853 | 0.933 | 0.943 |
| edge | 0.932 | 0.912 | 0.842 | 0.931 | 0.945 |
| MFI-HVT | 0.876 | 0.917 | 0.851 | 0.933 | 0.775 |
| DeepHKCF | 0.723 | 0.688 | 0.518 | 0.713 | 0.683 |
| CNHT | 0.242 | 0.436 | 0.196 | 0.347 | 0.138 |
| Sequences | Success | Success_BC | Success_OCC | Success_SV | Success_OPR |
|---|---|---|---|---|---|
| Ours | 0.696 | 0.714 | 0.556 | 0.712 | 0.712 |
| MHT | 0.672 | 0.598 | 0.569 | 0.633 | 0.755 |
| RES | 0.667 | 0.68 | 0.512 | 0.686 | 0.695 |
| context | 0.672 | 0.709 | 0.551 | 0.708 | 0.674 |
| edge | 0.665 | 0.701 | 0.533 | 0.698 | 0.675 |
| MFI-HVT | 0.599 | 0.707 | 0.541 | 0.698 | 0.474 |
| DeepHKCF | 0.38 | 0.388 | 0.333 | 0.355 | 0.417 |
| CNHT | 0.0807 | 0.143 | 0.06 | 0.106 | 0.0551 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, D.; Cao, J.; Zhu, X.; Zhang, Z.; Arun, P.V.; Guo, Y.; Qian, K.; Zhang, L.; Zhou, H.; Hu, J. Hyperspectral Video Target Tracking Based on Deep Edge Convolution Feature and Improved Context Filter. Remote Sens. 2022, 14, 6219. https://doi.org/10.3390/rs14246219
Zhao D, Cao J, Zhu X, Zhang Z, Arun PV, Guo Y, Qian K, Zhang L, Zhou H, Hu J. Hyperspectral Video Target Tracking Based on Deep Edge Convolution Feature and Improved Context Filter. Remote Sensing. 2022; 14(24):6219. https://doi.org/10.3390/rs14246219
Chicago/Turabian StyleZhao, Dong, Jialu Cao, Xuguang Zhu, Zhe Zhang, Pattathal V. Arun, Yecai Guo, Kun Qian, Like Zhang, Huixin Zhou, and Jianling Hu. 2022. "Hyperspectral Video Target Tracking Based on Deep Edge Convolution Feature and Improved Context Filter" Remote Sensing 14, no. 24: 6219. https://doi.org/10.3390/rs14246219
APA StyleZhao, D., Cao, J., Zhu, X., Zhang, Z., Arun, P. V., Guo, Y., Qian, K., Zhang, L., Zhou, H., & Hu, J. (2022). Hyperspectral Video Target Tracking Based on Deep Edge Convolution Feature and Improved Context Filter. Remote Sensing, 14(24), 6219. https://doi.org/10.3390/rs14246219