


Comparison of Model-Assisted Endogenous Poststratification Methods for Estimation of Above-Ground Biomass Change in Oregon, USA

 ,
,  ,
, 
Abstract
1. Introduction
Objective
- A GREG estimator, GREG-EPS, based on the interactions of multiple categorical variables [13].
- An EPS estimator using the method proposed by Breidt and Opsomer [11] that uses a generalized linear model to form strata, GL-EPS.
- An EPS estimator using McConville and Toth’s [14] method based on recursive partitioning trees, TREE-EPS.
2. Material and Methods
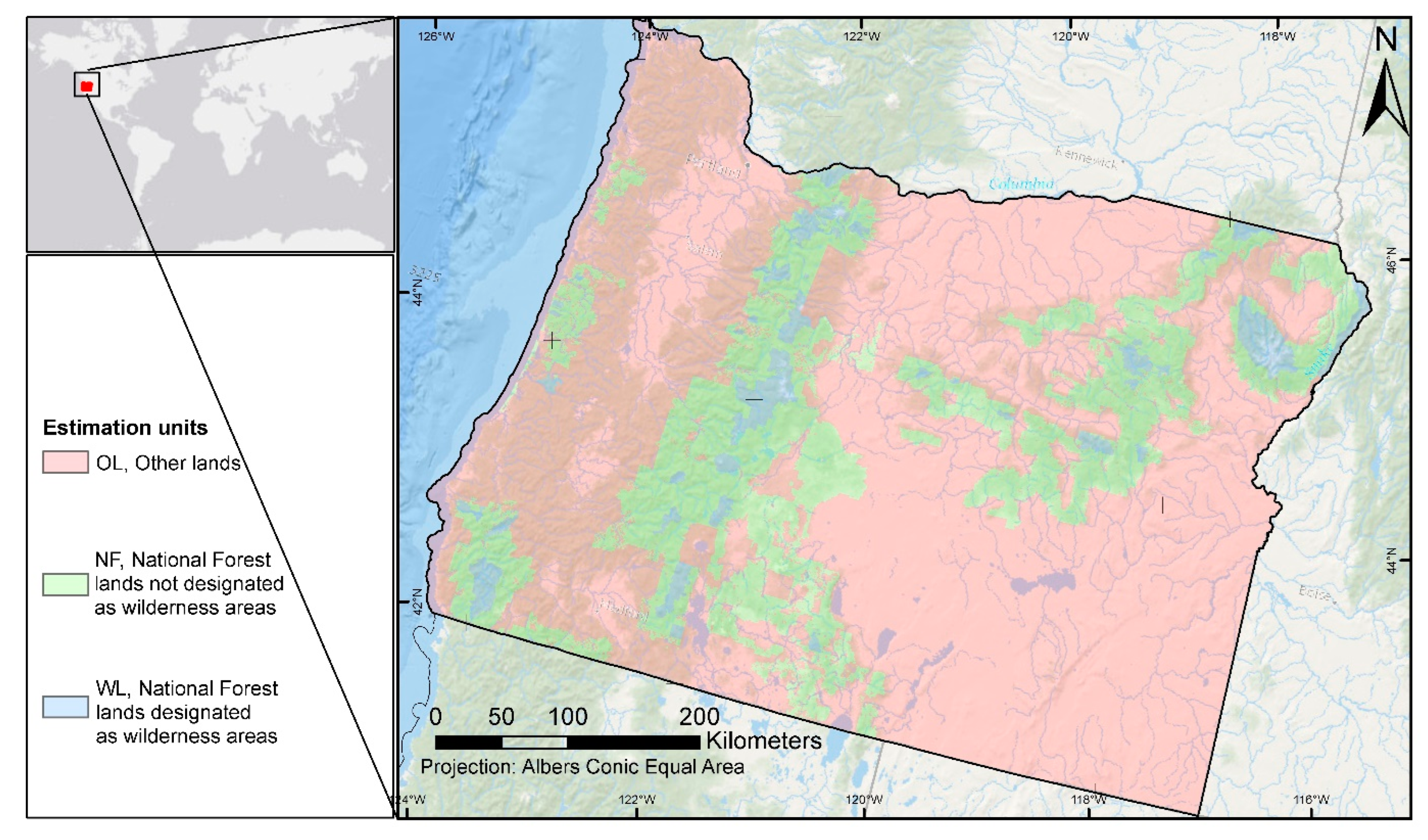
2.1. Study Area
2.2. Auxiliary Information
2.3. Estimation Framework
2.3.1. Population
2.3.2. Target Parameter
2.3.3. PNW-FIA Sampling Design and Sample
2.4. Development of Models for EPS
2.4.1. General Model Selection Considerations
2.4.2. GREG-EPS
- First, arranged all combinations on a tree that was constructed using the variables , and . Branches in the first level of the tree were defined using , and branches for the second and third levels were based on and respectively. Each combination of ,,, , , , and , resulted in a leaf that was placed in its corresponding branch depending on , and .
- Leaves with four plots per year or more were set as fixed leaves. The remaining leaves were merged with other leaves (fixed or not) in the same branch. The merging process ran separately in each branch and started with the leaf with a smaller area in the branch. The selected leaf was merged with the closest leaf in the same branch. The Gower distance [21], computed with all categorical variables, was used to determine which leaf was the closest to the selected leaf. This distance was selected because it allows treating differently categorical variables with an implicit ordering (i.e., all categorical variables derived from a continuous one) and categorical variables without an implicit ordering (e.g., . The two leaves were merged into a single leaf, and the expected number of plots per year was recomputed based on the area of the group resulting from the merge. If the expected number of plots per year of the resulting leaf was four or more, or if the small leaf was merged to a fixed leaf, the result was tagged as fixed, and it was not considered as a target for further merging steps.
- Step 2 was repeated until all the resulting leaves in a branch had an expected number of four plots per year or all leaves in one branch were merged into a single leaf.
- When merging all leaves in one branch did not yield an area from which to expect four plots per year, the merging process continued but considered merging groups from branches of the previous level of the tree (i.e., the algorithm continued with branches defined by and first, and then with branches defined by only).
2.4.3. GL-EPS
- The maximum value of reported by [16] was 8.75 Mg ha−1 year−1. Based on this value, we defined the following five positive intervals and .
- For disturbances causing losses in forest AGB with magnitudes comparable to growth, we used the thresholds used for growth but with negative signs. The last interval accommodates large and negative values of occurring after stand-replacing disturbances such as clear cuts.
2.4.4. TREE-EPS
2.5. Estimators of and Variance Estimators
2.5.1. Approximation to Sampling Design Weights and Point and Variance Estimators
2.5.2. Point and Variance Estimators
2.5.3. Comparison to Current PNW-FIA Estimators and Horvitz-Thompson Estimators
3. Results
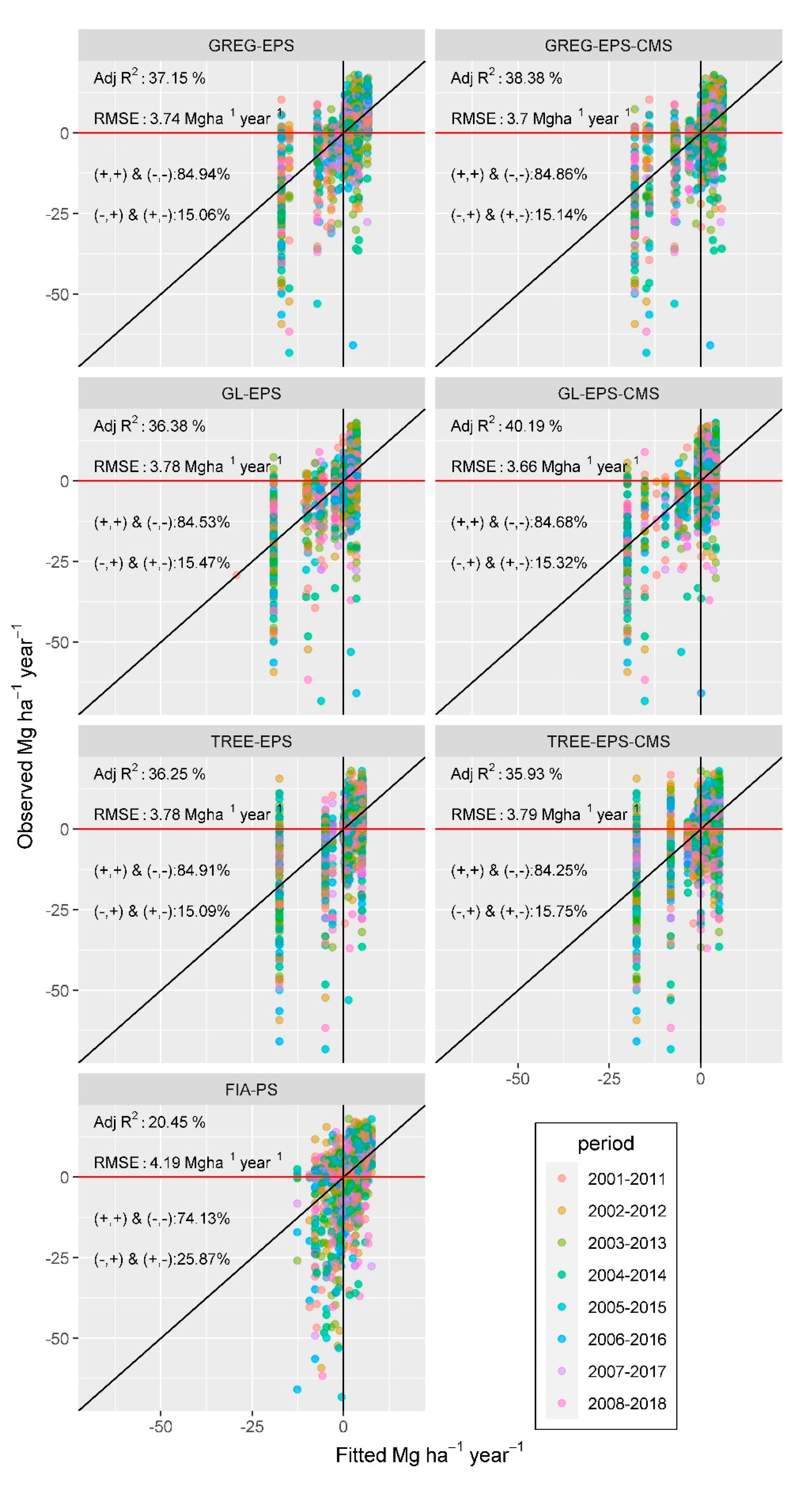
3.1. EPS and PS Assisting Models and Summaries
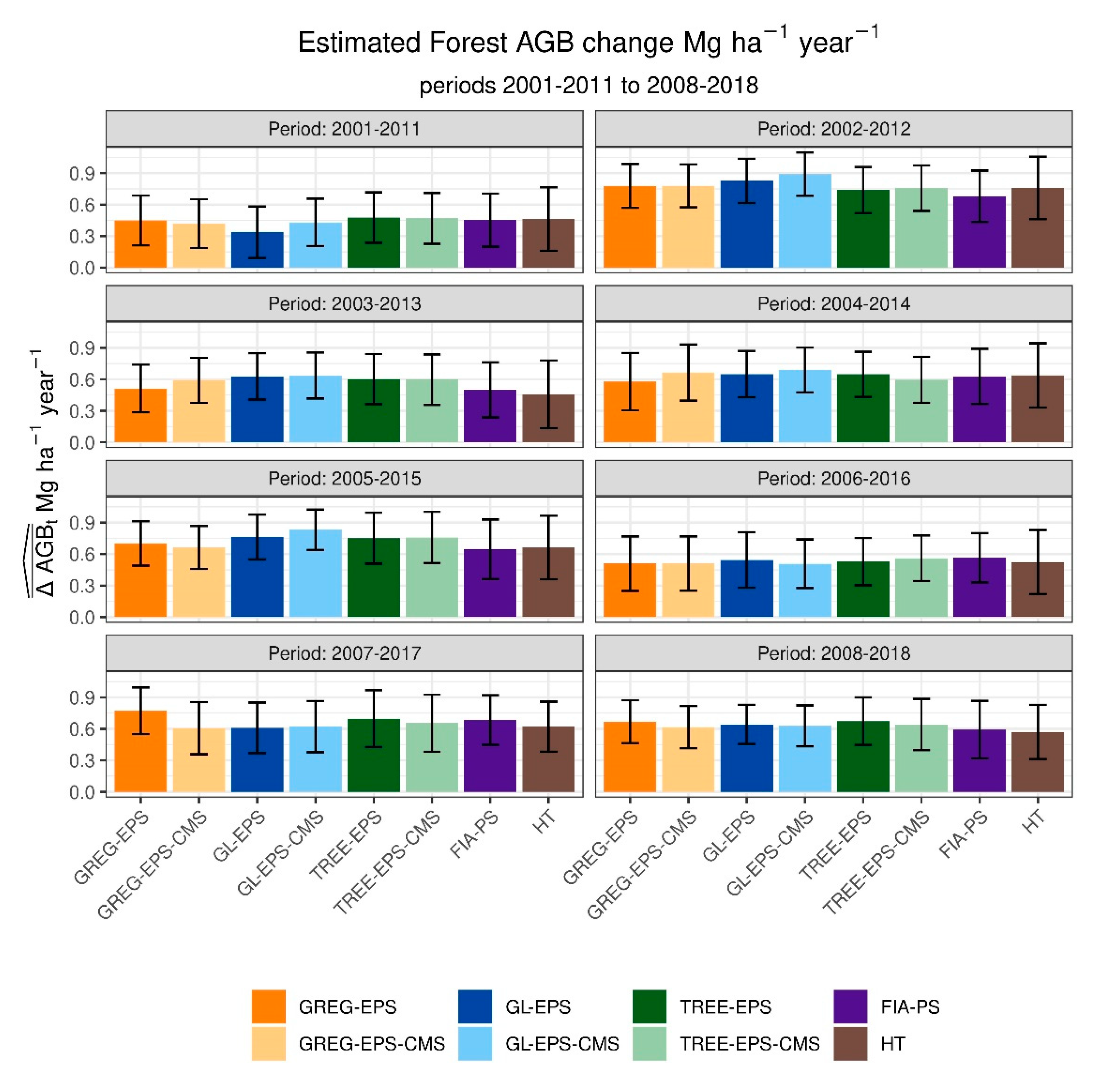
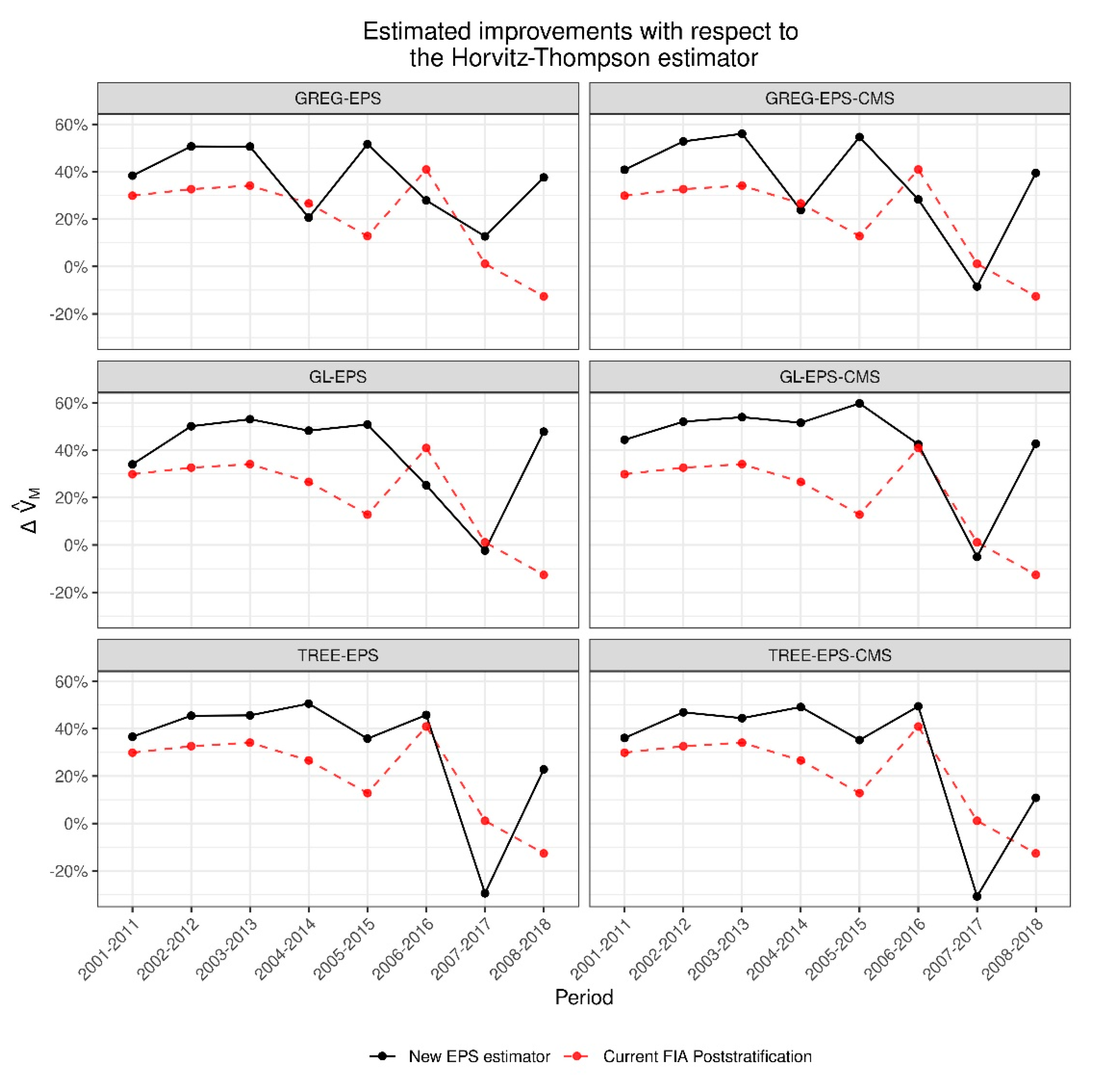
3.2. Estimates of Changes for the State for Specific 10-Year Periods
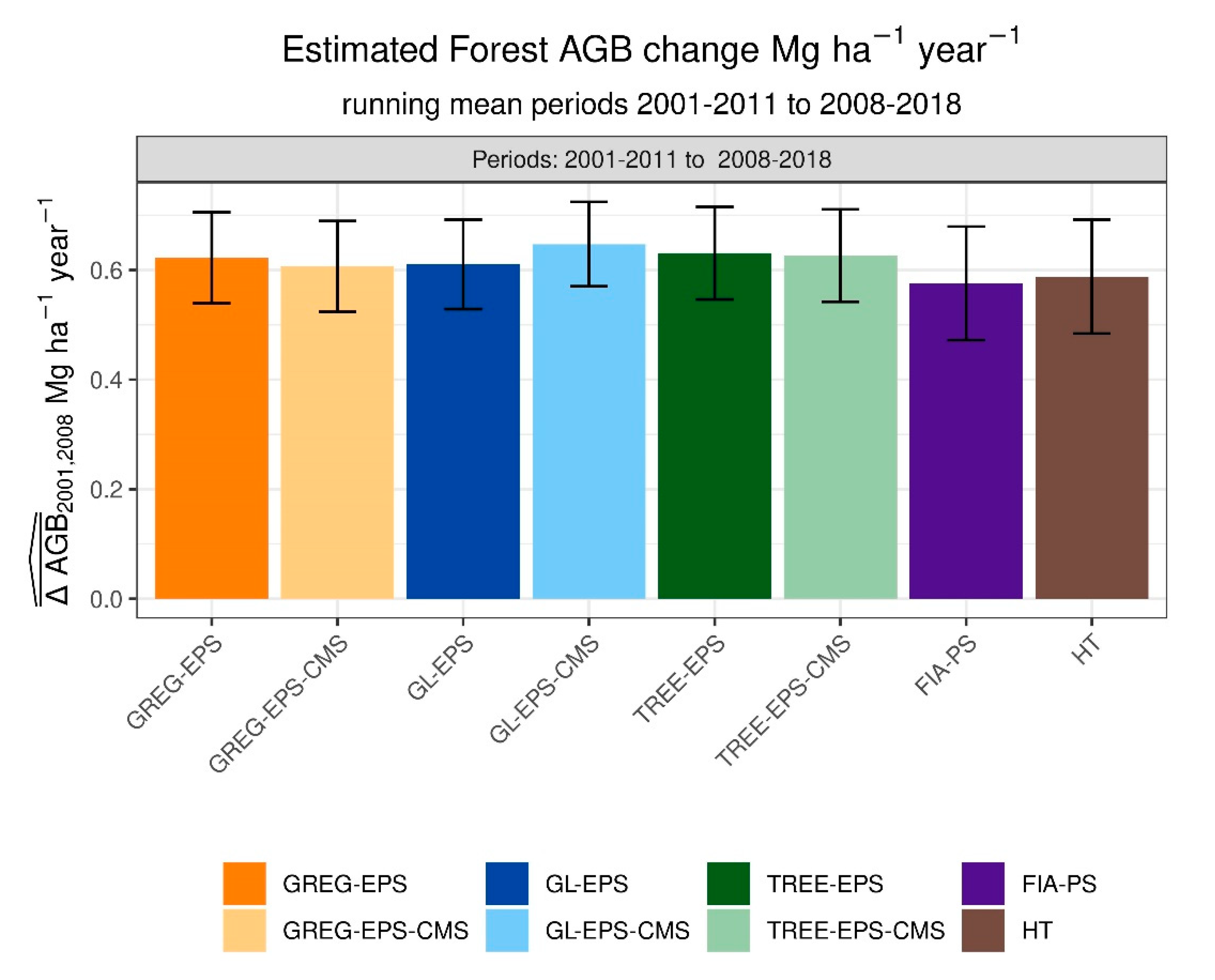
3.3. Estimators of Running Means
4. Discussion
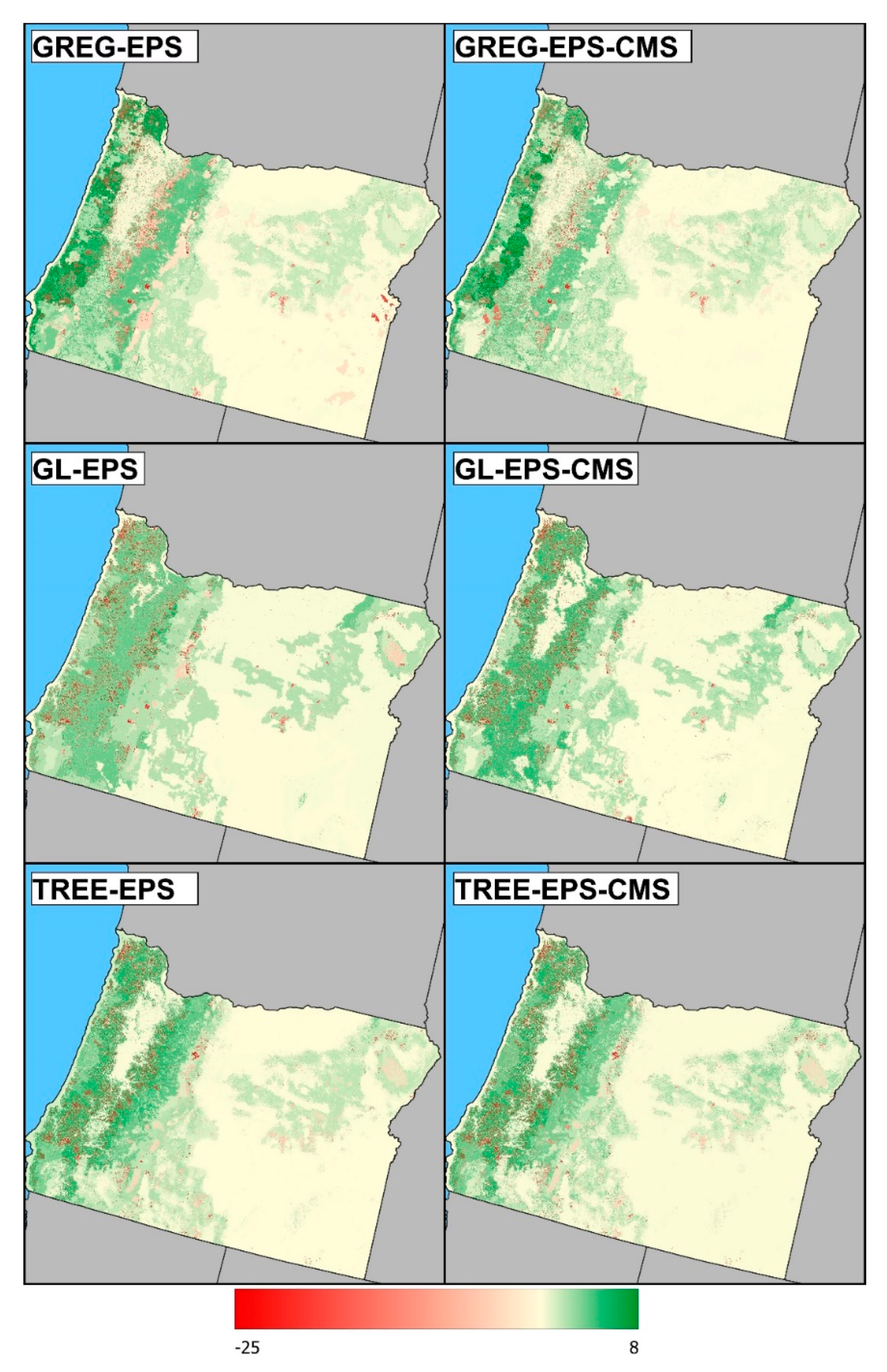
4.1. Similarities between Model-Assisted Estimators
4.2. Model Selection
4.3. Differences between Model-Assisted Estimators
4.4. Other Considerations of Practical Importance
4.4.1. Estimation of Variance and Estimation of Change for Periods Not Matching the PNW-FIA Panel Frequency
4.4.2. Auxiliary Variables
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Breidenbach, J.; Granhus, A.; Hylen, G.; Eriksen, R.; Astrup, R. A Century of National Forest Inventory in Norway–Informing Past, Present, and Future Decisions. For. Ecosyst. 2020, 7, 46. [Google Scholar] [CrossRef] [PubMed]
- Kovac, M.; Gasparini, P.; Notarangelo, M.; Rizzo, M.; Cañellas, I.; Fernández-de-Uña, L.; Alberdi, I. Towards a Set of National Forest Inventory Indicators to Be Used for Assessing the Conservation Status of the Habitats Directive Forest Habitat Types. J. Nat. Conserv. 2020, 53, 125747. [Google Scholar] [CrossRef]
- Tomppo, E.; Gschwantner, T.; Lawrence, M.; McRoberts, R.E.; Gabler, K.; Schadauer, K.; Vidal, C.; Lanz, A.; Ståhl, G.; Cienciala, E. National Forest Inventories. Pathw. Common Report. Eur. Sci. Found. 2010, 1, 541–553. [Google Scholar]
- McConville, K.S.; Moisen, G.G.; Frescino, T.S. A Tutorial on Model-Assisted Estimation with Application to Forest Inventory. Forests 2020, 11, 244. [Google Scholar] [CrossRef]
- Lawrence, M.; McRoberts, R.E.; Tomppo, E.; Gschwantner, T.; Gabler, K. Comparisons of National Forest Inventories. In National Forest Inventories; Springer: Berlin/Heidelberg, Germany, 2010; pp. 19–32. [Google Scholar]
- Breidenbach, J.; Astrup, R. Small Area Estimation of Forest Attributes in the Norwegian National Forest Inventory. Eur. J. For. Res. 2012, 131, 1255–1267. [Google Scholar] [CrossRef]
- Särndal, C.-E.; Swensson, B.; Wretman, J. Model Assisted Survey Sampling (Springer Series in Statistics); Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Fekety, P.A.; Hudak, A.T. Annual Aboveground Biomass Maps for Forests in the Northwestern USA, 2000–2016; ORNL DAAC: Oak Ridge, TN, USA, 2019. [Google Scholar] [CrossRef]
- Hudak, A.T.; Fekety, P.A.; Kane, V.R.; Kennedy, R.E.; Filippelli, S.K.; Falkowski, M.J.; Tinkham, W.T.; Smith, A.M.S.; Crookston, N.L.; Domke, G.M.; et al. A Carbon Monitoring System for Mapping Regional, Annual Aboveground Biomass across the Northwestern USA. Environ. Res. Lett. 2020, 15, 095003. [Google Scholar] [CrossRef]
- Stanke, H.; Finley, A.O.; Weed, A.S.; Walters, B.F.; Domke, G.M. RFIA: An R Package for Estimation of Forest Attributes with the US Forest Inventory and Analysis Database. Environ. Model. Softw. 2020, 127, 104664. [Google Scholar] [CrossRef]
- Breidt, F.J.; Opsomer, J.D. Endogenous Post-Stratification in Surveys: Classifying with a Sample-Fitted Model. Ann. Stat. 2008, 36, 403–427. [Google Scholar] [CrossRef]
- Dahlke, M.; Breidt, F.J.; Opsomer, J.D.; Van Keilegom, I. Nonparametric endogenous post-stratification estimation. Stat. Sin. 2013, 23, 189–211. [Google Scholar] [CrossRef]
- McConville, K.S.; Breidt, F.J.; Lee, T.C.M.; Moisen, G. Model-Assisted Survey Regression Estimation with the Lasso. J. Surv. Stat. Methodol. 2017, 5, 131–158. [Google Scholar] [CrossRef]
- McConville, K.S.; Toth, D. Automated Selection of Post-strata Using a Model-assisted Regression Tree Estimator. Scand. J. Stat. 2019, 46, 389–413. [Google Scholar] [CrossRef]
- Palmer, M.; Christensen, G.; Kuegler, O.; Chase, J.; Fried, J.; Jovan, S.; Mercer, K.; Gray, D.; Loreno, S.; Morgan, T. Oregon’s Forest Resources, 2006–2015: Ten-Year Forest Inventory and Analysis Report; U.S. Department of Agriculture, Forest Service, Pacific Northwest Research Station: Portland, OR, USA, 2018.
- Poudel, P.K.; Flewelling, J.W.; Temesgen, H. Predicting Volume and Biomass Change from Multi-Temporal Lidar Sampling and Remeasured Field Inventory Data in Panther Creek Watershed, Oregon, USA. Forests 2018, 9, 28. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Hansen, M.H.; Smith, W.B. United States of America (USA). In National Forest Inventories; Springer: Berlin/Heidelberg, Germany, 2010; pp. 185–206. [Google Scholar]
- Bechtold, W.A.; Patterson, P.L. The Enhanced Forest Inventory and Analysis Program: National Sampling Design and Estimation Procedures; U.S. Department of Agriculture Forest Service, Southern Research Station Asheville, North Carolina: Asheville, NC, USA, 2005; p. 85.
- Blackard, J.A.; Patterson, P.L. National FIA plot intensification procedure report. In General Technical Report (GTR) RMRS-GTR-329; US Department of Agriculture, Forest Service, Rocky Mountain Research Station: Fort Collins, CO, USA, 2014; 63p. [Google Scholar]
- Puliti, S.; Breidenbach, J.; Schumacher, J.; Hauglin, M.; Klingenberg, T.F.; Astrup, R. Above-Ground Biomass Change Estimation Using National Forest Inventory Data with Sentinel-2 and Landsat. Remote Sens. Environ. 2021, 265, 112644. [Google Scholar] [CrossRef]
- Gower, J.C. A General Coefficient of Similarity and Some of Its Properties. Biometrics 1971, 27, 857–871. [Google Scholar] [CrossRef]
- Friedman, J.H.; Hastie, T.; Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Softw. Artic. 2010, 33, 1–22. [Google Scholar] [CrossRef]
- Toth, D. Rpms: Recursive Partitioning for Modeling Survey Data. 2019. Available online: https://cran.r-project.org/web/packages/rpms/index.html (accessed on 13 October 2022).
- Toth, D.; Eltinge, J.L. Building Consistent Regression Trees From Complex Sample Data. J. Am. Stat. Assoc. 2011, 106, 1626–1636. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Næsset, E.; Gobakken, T.; Bollandsås, O.M. Indirect and Direct Estimation of Forest Biomass Change Using Forest Inventory and Airborne Laser Scanning Data. Remote Sens. Environ. 2015, 164, 36–42. [Google Scholar] [CrossRef]
- Bollandsås, O.M.; Gregoire, T.G.; Næsset, E.; Øyen, B.-H. Detection of Biomass Change in a Norwegian Mountain Forest Area Using Small Footprint Airborne Laser Scanner Data. Stat. Methods Appl. 2013, 22, 113–129. [Google Scholar] [CrossRef]
- Skowronski, N.S.; Clark, K.L.; Gallagher, M.; Birdsey, R.A.; Hom, J.L. Airborne Laser Scanner-Assisted Estimation of Aboveground Biomass Change in a Temperate Oak–Pine Forest. Remote Sens. Environ. 2014, 151, 166–174. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Næsset, E.; Gobakken, T. Comparing the Stock-Change and Gain–Loss Approaches for Estimating Forest Carbon Emissions for the Aboveground Biomass Pool. Can. J. For. Res. 2018, 48, 1535–1542. [Google Scholar] [CrossRef]
- Babcock, C.; Finley, A.O.; Gregoire, T.G.; Andersen, H.-E. Remote Sensing to Reduce the Effects of Spatial Autocorrelation on Design-Based Inference for Forest Inventory Using Systematic Samples. arXiv 2018, arXiv:1810.08588. [Google Scholar]
- Fuller, W.A. Probability Sampling from a Finite Universe. In Sampling Statistics; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2009; pp. 1–93. ISBN 978-0-470-52355-1. [Google Scholar]
- D’Orazio, M. Estimating the Variance of the Sample Mean in Two-Dimensional Systematic Sampling. J. Agric. Biol. Environ. Stat. 2003, 8, 280. [Google Scholar] [CrossRef]
- Stevens Jr, D.L.; Olsen, A.R. Variance Estimation for Spatially Balanced Samples of Environmental Resources. Environmetrics 2003, 14, 593–610. [Google Scholar] [CrossRef]
- Matérn, B. Spatial Variation, 2nd ed.; Lecture Notes in Statistics; Springer: New York, NY, USA, 1986; ISBN 978-0-387-96365-5. [Google Scholar]
- Frank, B.; Monleon, V.J. Comparison of Variance Estimators for Systematic Environmental Sample Surveys: Considerations for Post-Stratified Estimation. Forests 2021, 12, 772. [Google Scholar] [CrossRef]
- Zhao, X.; Grafström, A. A Sample Coordination Method to Monitor Totals of Environmental Variables. Environmetrics 2020, 31, e2625. [Google Scholar] [CrossRef]
- Grafström, A.; Matei, A. Spatially Balanced Sampling of Continuous Populations. Scand. J. Stat. 2018, 45, 792–805. [Google Scholar] [CrossRef]
- PRISM Climate Group, Oregon State University Parameter-Elevation Regressions on Independent Slopes Model, PRISM, 800m Resolution 30-Year Normals. 2019. Available online: https://prism.oregonstate.edu/ (accessed on 13 October 2022).
- McNab, W.H.; Cleland, D.T.; Freeouf, J.A.; Keys, J.; Nowacki, G.; Carpenter, C. Description of Ecological Subregions: Sections of the Conterminous United States; General Technical Report WO-76B 76; U.S. Department of Agriculture, Forest Service: Washington, DC, USA, 2007; Volume 76, pp. 1–82.
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-Scale Geospatial Analysis for Everyone. Remote Sens. Environ. 2017, 255. [Google Scholar] [CrossRef]
- Rodman, H. Forest Soils and Topography: Decoding the Influence of Physical Site Characteristics on Soil Water and Forest Productivity in Oregon’s Coast Ranges; Oregon State University: Corvallis, OR, USA, 2016; Available online: https://ir.library.oregonstate.edu/concern/graduate_thesis_or_dissertations/p2677094w (accessed on 13 October 2022).
- Stage, A.R. An Expression for the Effect of Aspect, Slope, and Habitat Type on Tree Growth. For. Sci. 1976, 22, 457–460. [Google Scholar]
- Benavides, R.; Roig, S.; Osoro, K. Potential Productivity of Forested Areas Based on a Biophysical Model. A Case Study of a Mountainous Region in Northern Spain. Ann. For. Sci. 2009, 66, 108. [Google Scholar] [CrossRef]
- Körner, C. Treelines Will Be Understood Once the Functional Difference between a Tree and a Shrub Is. Ambio 2012, 41 (Suppl. 3), 197–206. [Google Scholar] [CrossRef]
- ESRI ArcGIS Desktop: Release 10.6; Environmental Systems Research Institute: Redlands, CA, USA, 2017.
- Cleland, D.T.; Freeouf, J.A.; Keys, J.E.; Nowacki, G.J.; Carpenter, C.A.; McNab, W.H. Ecological268 Subregions: Sections and Subsections for the Conterminous United States; General Technical Report WO-76B; U.S. Department of Agriculture, Forest Service: Washington, DC, USA, 2007; Volume 76.
- McCarley, T.R.; Hudak, A.T.; Sparks, A.M.; Vaillant, N.M.; Meddens, A.J.H.; Trader, L.; Mauro, F.; Kreitler, J.; Boschetti, L. Estimating Wildfire Fuel Consumption with Multitemporal Airborne Laser Scanning Data and Demonstrating Linkage with MODIS-Derived Fire Radiative Energy. Remote Sens. Environ. 2020, 251, 112114. [Google Scholar] [CrossRef]
- Picotte, J.J.; Bhattarai, K.; Howard, D.; Lecker, J.; Epting, J.; Quayle, B.; Benson, N.; Nelson, K. Changes to the Monitoring Trends in Burn Severity Program Mapping Production Procedures and Data Products. Fire Ecol. 2020, 16, 16. [Google Scholar] [CrossRef]
- Freeman, E.A.; Moisen, G. PresenceAbsence: An R Package for Presence Absence Analysis. J. Stat. Softw. 2008, 23, 1–31. [Google Scholar] [CrossRef]
- Jin, S.; Homer, C.; Yang, L.; Danielson, P.; Dewitz, J.; Li, C.; Zhu, Z.; Xian, G.; Howard, D. Overall280 Methodology Design for the United States National Land Cover Database 2016 Products. Remote Sens. 2019, 11, 2971. [Google Scholar] [CrossRef]
- Fekety, P.A.; Hudak, A.T.; Bright, B.C. Tree and Stand Attributes for “A Carbon Monitoring System for Mapping Regional, Annual Aboveground Biomass across the Northwestern USA”. For. Serv. Res. Data Arch. 2020. Available online: https://www.fs.usda.gov/rds/archive/catalog/RDS-2020-0026 (accessed on 13 October 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Source | Variables, Acronym | Pre-Processing | Variable Type | Temporal |
|---|---|---|---|---|---|
| Proxies for potential forest AGB productivity | 1 Arc second Shuttle Radar Topography Mission, SRTM, Google earth engine | Elevation, | Resampling bilinear interpolation | Co | Static |
| Elevation categories, | Division in 3 elevation categories of equal area | *Ca | |||
| Slope, | Computed from | Co | |||
| Heat load index, | Computed from | Co | |||
| 800 m resolution PRISM 30-year normals & Sun hours from SRTM | Paterson climate productivity index, | Resampling bilinear interpolation.Solar radiation ArcGIS tool | Co | ||
| Categories Paterson climate productivity index, | Division in 3 categories of equal area | *Ca | |||
| US Forest Service | Cleland’s level 3 ecoregions, | Rasterization | Ca | ||
| Ownership | Bureau of land management, BLM | Ownership, | Rasterization & reclassification | Ca | |
| Proxies for disturbance | Monitoring trends in burn severity, MTBS. | Fire severity, | Maximum fire severity for 10-year periods. Resampling nearest neighbors | Ca | Dynamic |
| Landscape Change Monitoring System, LCMS. | Disturbances, | Computation of accumulated disturbances for 10-year periods | Co | ||
| MTBS- LCMS | Disturbance-categories, | Reclassification of and thresholds for | *Ca | ||
| MRLC National Land Cover Database, NLCD. | Land cover change, | Resampling nearest-neighbor. Reclassification and computation of change | Ca | ||
| Change in multi-year CMS AGB map | Fekety and Hudak, (2019) & Hudak et al., (2020) [8,9] | Independent prediction of derived from Fekety and Hudak, (2019) [8] predictions of AGB for multiple years, | Resampling with bilinear interpolation. Computation of differences in predicted forest AGB between years. | Co | |
| Categories of change derived from independent predictions of AGB for multiple years, | Reclassification of based on intervals defined from values reported by [16] | *Ca |
| Period | Total Number of Plots | Number of Plots by EU | Excluded Plots | ||
|---|---|---|---|---|---|
| NF | OL | WL | |||
| 2001–2011 | 1310 | 675 | 592 | 28 | 15 |
| 2002–2012 | 1412 | 681 | 682 | 29 | 20 |
| 2003–2013 | 1402 | 687 | 656 | 29 | 30 |
| 2004–2014 | 1418 | 703 | 671 | 29 | 15 |
| 2005–2015 | 1420 | 704 | 662 | 33 | 21 |
| 2006–2016 | 1348 | 680 | 623 | 22 | 23 |
| 2007–2017 | 1331 | 650 | 645 | 18 | 18 |
| 2008–2018 | 1340 | 674 | 616 | 25 | 25 |
| 2001–2011 | 2002–2012 | 2003–2013 | 2004–2014 | 2005–2015 | 2006–2016 | 2007–2017 | 2008–2018 | All Periods | ||
|---|---|---|---|---|---|---|---|---|---|---|
| GREG-EPS | Total # of strata | 84 | ||||||||
| Sampled strata | 84 | 84 | 83 | 84 | 83 | 84 | 84 | 84 | 84 | |
| % area sampled | 100.00 | 100.00 | 99.89 | 100.00 | 99.80 | 100.00 | 100.00 | 100.00 | 100.00 | |
| GREG-EPS-CMS | Total # of strata | 97 | ||||||||
| Sampled strata | 95 | 97 | 97 | 97 | 97 | 97 | 94 | 95 | 97 | |
| % area sampled | 99.47 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 99.07 | 99.51 | 100.00 | |
| GL-EPS | Total # of strata | 30 | ||||||||
| Sampled strata | 21 | 20 | 19 | 21 | 20 | 18 | 18 | 20 | 27 | |
| % area sampled | 99.75 | 99.87 | 99.80 | 99.85 | 99.74 | 99.83 | 99.56 | 99.78 | 100.00 | |
| GL-EPS-CMS | Total # of strata | 30 | ||||||||
| Sampled strata | 27 | 23 | 24 | 24 | 23 | 21 | 23 | 25 | 30 | |
| % area sampled | 99.65 | 99.30 | 99.60 | 99.76 | 99.60 | 99.77 | 99.53 | 99.71 | 100.00 | |
| TREE-EPS | Total # of strata | 44 | ||||||||
| Sampled strata | 44 | 44 | 44 | 44 | 44 | 44 | 44 | 44 | 44 | |
| % area sampled | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| TREE-EPS-CMS | Total # of strata | 34 | ||||||||
| Sampled strata | 34 | 34 | 34 | 34 | 34 | 34 | 34 | 34 | 34 | |
| % area sampled | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| FIA-PS | Total # of strata | 191 | ||||||||
| Sampled strata | 167 | 173 | 175 | 177 | 171 | 166 | 163 | 167 | 191 | |
| % area sampled | 96.79 | 97.68 | 97.64 | 97.43 | 97.50 | 96.61 | 95.40 | 96.92 | 100.00 | |
| Method | for 10-Year Periods | for 10-Year Periods |
|---|---|---|
| GREG-EPS | 37.95% | 36.25% |
| GREG-EPS-CMS | 40.13% | 35.91% |
| GL-EPS | 48.02% | 38.36% |
| GL-EPS-CMS | 47.99% | 42.27% |
| TREE-EPS | 41.05% | 31.66% |
| TREE-EPS-CMS | 40.27% | 30.16% |
| FIA-PS | 28.24% | 20.68% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mauro, F.; Monleon, V.J.; Gray, A.N.; Kuegler, O.; Temesgen, H.; Hudak, A.T.; Fekety, P.A.; Yang, Z. Comparison of Model-Assisted Endogenous Poststratification Methods for Estimation of Above-Ground Biomass Change in Oregon, USA. Remote Sens. 2022, 14, 6024. https://doi.org/10.3390/rs14236024
Mauro F, Monleon VJ, Gray AN, Kuegler O, Temesgen H, Hudak AT, Fekety PA, Yang Z. Comparison of Model-Assisted Endogenous Poststratification Methods for Estimation of Above-Ground Biomass Change in Oregon, USA. Remote Sensing. 2022; 14(23):6024. https://doi.org/10.3390/rs14236024
Chicago/Turabian StyleMauro, Francisco, Vicente J. Monleon, Andrew N. Gray, Olaf Kuegler, Hailemariam Temesgen, Andrew T. Hudak, Patrick A. Fekety, and Zhiqiang Yang. 2022. "Comparison of Model-Assisted Endogenous Poststratification Methods for Estimation of Above-Ground Biomass Change in Oregon, USA" Remote Sensing 14, no. 23: 6024. https://doi.org/10.3390/rs14236024
APA StyleMauro, F., Monleon, V. J., Gray, A. N., Kuegler, O., Temesgen, H., Hudak, A. T., Fekety, P. A., & Yang, Z. (2022). Comparison of Model-Assisted Endogenous Poststratification Methods for Estimation of Above-Ground Biomass Change in Oregon, USA. Remote Sensing, 14(23), 6024. https://doi.org/10.3390/rs14236024