
Run-Length-Based River Skeleton Line Extraction from High-Resolution Remote Sensed Image



Abstract
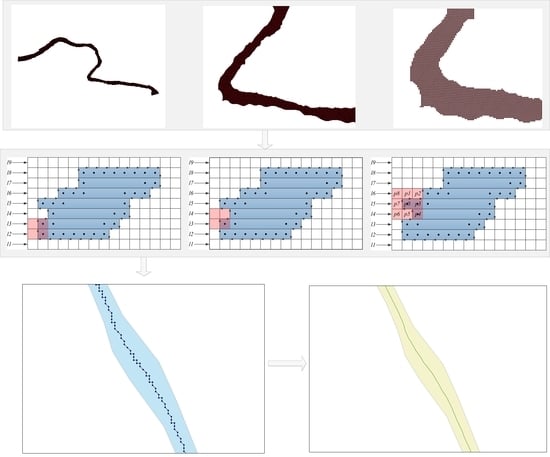
1. Introduction
2. Methods
2.1. Extraction of Raster Data for a River System from an RS Image
2.2. Conversion of Raster Data to Run-Length-Encoded Data for Rivers
2.3. River Skeleton Line Generation Based on RLE
2.3.1. Rules for Determining Redundant Pixels
2.3.2. Run-Length Boundary Tracing and Redundant Pixel Removal
2.3.3. Design of Boundary Tracing Direction Templates
2.4. Vectorization of River Skeleton Lines
3. Study Area and Data Set
4. Results and Analysis
4.1. Analysis of the Extracted Skeleton Lines
4.2. Skeleton Line Extraction Performance Analysis
- (1)
- Computational efficiency. It is evident from Table 3 that the run-length method was superior in terms of computational efficiency. At a grid cell size of 1 m, the run-length method still took only approximately 3 min to complete the computation, compared to more than 30 min for Zhang and Suen’s method. A data comparison revealed that the ratio of the time consumed by Zhang and Suen’s method to the time consumed by the run-length method increased rapidly as the grid cell size decreased. As the grid cell size was refined to 0.1 m, the number of rows and columns in the grid reached the order of hundreds of thousands. Under this condition, the proposed method still exhibited excellent stability.
- (2)
- Memory consumption. In the extraction of the skeleton lines of a bifurcated river, the memory to be allocated is related to the complexity of the bifurcated river in addition to the raster resolution. The more complexly the river is bifurcated, the more run lengths there are in the raster rows, and the more memory is required. However, the run-length method can completely deal with all types of complex river data, with almost no requirement to consider memory limitations. As seen in Table 3, even if the spatial resolution was set to 0.1 m, which increased the number of rows and columns in the grid to 300,000, less than 20 MB of memory was used to store the run-length data. At a resolution of 0.1 m, Zhang and Suen’s method required 215 GB of memory. The run-length method is hugely advantageous in terms of memory consumption and can theoretically handle terabyte-scale raster data.
5. Discussion
6. Conclusions
- (1)
- An RLE structure for storing large-scale river raster data is proposed, which can compress the amount of raster data to less than 1%. The link list structure is particularly suitable for representing complex river systems with islands.
- (2)
- A river boundary pixel deletion strategy based on RLE data is designed, which is implemented by using run length boundary tracing iteration operation and provides a template for judging the direction of boundary tracing.
- (3)
- A method of vectorizing skeleton lines from RLE data with skeleton line pixels only reserved is designed. By identifying endpoints, junctions, and bifurcation, skeleton lines are automatically reorganized.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| remote-sensing | RS |
| deep-learning | DL |
| run-length encoding | RLE |
References
- ZIHE & ZRRWCMC (Zhejiang Institute of Hydraulics & Estuary & Zhejiang River-Lake and Rural Water Conservancy Management Center). Technical Guidelines for Water Area Survey in Zhejiang Province. 2019; Available online: https://zrzyt.zj.gov.cn/art/2019/7/15/art_1289924_35720739.html; https://zjjcmspublic.oss-cn-hangzhou-zwynet-d01-a.internet.cloud.zj.gov.cn/jcms_files/jcms1/web1568/site/attach/0/ec12d18a4f2c42ba9c03c23674403408.pdf; (accessed on 5 October 2022). [Google Scholar]
- Liu, Y.; Guo, Q.; Sun, Y.; Lin, Q.; Zheng, C. An Algorithm for Skeleton Extraction between Map Objects. Geomat. Inf. Sci. Wuhan Univ. 2015, 40, 264–268. (In Chinese) [Google Scholar]
- Dey, A.; Bhattacharya, R.K. Monitoring of River Center Line and Width-a Study on River Brahmaputra. J. Indian Soc. Remote Sens. 2014, 42, 475–482. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, Y.; Liu, C.; Gong, S.; Ji, Y. Bankline Extraction in Remote Sensing Images Using Principal Curves. J. Commun. 2016, 37, 80–89. (In Chinese) [Google Scholar]
- Zhao, W.; Ma, Y.; Zheng, J. Extraction Scheme for River Skeleton Line Based on DWT-SVD. Mine Surv. 2019, 47, 121–123. (In Chinese) [Google Scholar]
- Meng, L.; Li, J.; Wang, R.; Zhang, W. Single River Skeleton Extraction Method Based on Mathematical Morphology and Topology Constraints. J. Remote Sens. 2017, 21, 785–795. (In Chinese) [Google Scholar]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Lu, Z.; Wang, D.; Deng, Z.; Shi, Y.; Ding, Z.; Ning, D.; Zhao, H.; Zhao, J.; Xu, H.; Zhao, X. Application of red edge band in remote sensing extraction of surface water body: A case study based on GF-6 WFV data in arid area. Hydrol. Res. 2021, 52, 1526–1541. [Google Scholar] [CrossRef]
- Mohammadreza, S.; Masoud, M.; Hamid, G. Support Vector Machine Versus Random Forest for Remote Sensing Image Classification: A Meta-Analysis and Systematic Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6308–6325. [Google Scholar]
- Perkel, J.F.; Cottam, A.; Gorelick, N.; Belward, A.S. High-resolution Mapping of Global Surface Water and Its Long-term Changes. Nature 2016, 540, 418–422. [Google Scholar] [CrossRef]
- Wang, G.; Wu, M.; Wei, X.; Song, H. Water Identification from High Resolution Remote Sensing Images Based on Multidimentional Densely Connected Convolutional Neural Networks. Remote Sens. 2020, 12, 795. [Google Scholar] [CrossRef]
- Hu, B.; Yang, X. GPU-Accelerated Parallel 3D Image Thinning. In Proceedings of the 2013 IEEE 10th International Conference on High Performance Computing and Communications & 2013 IEEE 10th International Conference on Embedded and Ubiquitous Computing, Zhangjiajie, China, 13–15 November 2013. [Google Scholar]
- Jiang, W.; Xu, K.; Cheng, Z.; Martin, R.R.; Dang, G. Curve Skeleton Extraction by Coupled Graph Contraction and Surface Clustering. Graph. Models 2013, 75, 137–148. [Google Scholar] [CrossRef]
- Gao, F.; Wei, G.; Xin, S.; Gao, S.; Zhou, Y. 2D Skeleton Extraction Based on Heat Equation. Comput. Graph. 2018, 74, 99–108. [Google Scholar] [CrossRef]
- Shukla, A.P.; Chauhan, S.; Agarwal, S.; Garg, H. Training cellular automata for image thinning and thickening. In Proceedings of the Confluence 2013: The Next Generation Information Technology Summit (4th International Conference), Noida, India, 26–27 September 2013. [Google Scholar]
- Ji, L.; Yi, Z.; Shang, L.; Pu, X. Binary Fingerprint Image Thinning Using Template-Based PCNNs. IEEE Trans. Syst. Man Cybern. Part B 2007, 37, 1407–1413. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Suen, C. A Fast Parallel Algorithm for Thinning Digital Patterns. Commun. ACM 1984, 27, 236–239. [Google Scholar] [CrossRef]
- Padole, G.V.; Pokle, S.B. New Iterative Algorithms for Thinning Binary Images. In Proceedings of the Third International Conference on Emerging Trends in Engineering & Technology (ICETET), Goa, India, 19–21 November 2010; Volume 1, pp. 166–171. [Google Scholar]
- Tarabek, P. A Robust Parallel Thinning Algorithm for Pattern Recognition. In Proceedings of the 7th IEEE International Symposium on Applied Computational Intelligence and Informatics, Timisoara, Romania, 24–26 May 2012; pp. 75–79. [Google Scholar]
- Boudaoud, L.B.; Sider, A.; Tari, A.K. A New Thinning Algorithm for Binary Images. In Proceedings of the Third International Conference on Control, Engineering & Information Technology, Tlemcen, Algeria, 25–27 May 2015; pp. 1–6. [Google Scholar]
- Hermanto, L.; Sudiro, S.A.; Wibowo, E.P. Hardware implementation of fingerprint image thinning algorithm in FPGA device. In Proceedings of the 2010 International Conference on Networking and Information Technology, Manila, Philippines, 11–12 June 2010. [Google Scholar]
- Wang, M.; Li, Z.; Si, F.; Guan, L. An Improved Image Thinning Algorithm and Its Application in Chinese Character Image Refining. In Proceedings of the 2019 IEEE 3rd Information Technology Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019. [Google Scholar]
- Bai, X.; Ye, L.; Zhu, J.; Komura, T. Skeleton Filter: A Self-Symmetric Filter for Skeletonization in Noisy Text Images. IEEE Trans. Image Process. 2020, 29, 1815–1826. [Google Scholar] [CrossRef]
- Mahmoudi, R.; Akil, M.; Matas, P. Parallel image thinning through topological operators on shared memory parallel machines. In Proceedings of the 2009 Conference Record of the Forty-Third Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 1–4 November 2009. [Google Scholar]
- Li, C.; Dai, Z.; Yin, Y.; Wu, P. A Method for The Extraction of Partition Lines from Long and Narrow Paths That Account for Structural Features. Trans. GIS 2019, 23, 349–364. [Google Scholar] [CrossRef]
- Stefanelli, R.; Rosenfeld, A. Some Parallel Thinning Algorithms for Digital Pictures. J. ACM 1971, 18, 255–264. [Google Scholar] [CrossRef]
- Chen, Q.; Zheng, L.; Li, X.; Xu, C.; Wu, Y.; Xie, D.; Liu, L. Water Body Extraction from High-Resolution Satellite Remote Sensing Images Based on Deep Learning. Geogr. Geo-Inf. Sci. 2019, 35, 43–49. (In Chinese) [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Sematic Image Segmentation. In Proceedings of the European Conference on Computer Vision, ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Shen, D.; Rui, Y.; Wang, J.; Zhang, Y.; Cheng, L. Flood Inundation Extent Mapping Based on Block Compressed Tracing. Comput. Geosci. 2015, 80, 74–83. [Google Scholar] [CrossRef]
- He, Z.; Sun, W.; Lu, W.; Lu, H. Digital image splicing detection based on approximate run length. Pattern Recognit. Lett. 2011, 32, 1591–1597. [Google Scholar] [CrossRef]
- Hwang, S.S.; Kim, H.; Jang, T.Y.; Yoo, J.; Kim, S.; Paeng, K.; Kim, S.D. Image-based object reconstruction using run-length representation. Signal Process. Image Commun. 2017, 51, 1–12. [Google Scholar] [CrossRef]
- Qin, Y.; Wang, Z.; Wang, H.; Gong, Q. Binary image encryption in a joint transform correlator scheme by aid of run-length encoding and QR code. Opt. Laser Technol. 2018, 103, 93–98. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Z.; Cheng, L.; Li, M.; Wang, J. Parallel scanline algorithm for rapid rasterization of vector geographic data. Comput. Geosci. 2013, 59, 31–40. [Google Scholar] [CrossRef]
- Zhou, C.; Chen, Z.; Liu, Y.; Li, F.; Cheng, L.; Zhu, A.; Li, M. Data decomposition method for parallel polygon rasterization considering load balancing. Comput. Geosci. 2015, 85, 196–209. [Google Scholar] [CrossRef]
- Yuan, W.; Xu, W. GapLoss: A Loss Function for Semantic Segmentation of Roads in Remote Sensing Images. Remote Sens. 2022, 14, 2422. [Google Scholar] [CrossRef]
- Lewandowicz, E.; Flisek, P. Base Point Split Algorithm for Generating Polygon Skeleton Lines on the Example of Lakes. ISPRS Int. J. Geo-Inf. 2020, 9, 680. [Google Scholar] [CrossRef]
- Li, C.; Yin, Y.; Wu, P.; Wu, W. Skeleton Line Extraction Method in Areas with Dense Junctions Considering Stroke Features. ISPRS Int. J. Geo-Inf. 2019, 8, 303. [Google Scholar] [CrossRef]
- Li, C.; Yin, Y.; Wu, P.; Liu, X.; Guo, P. Improved Jitter Elimination and Topology Correction Method for the Split Line of Narrow and Long Patches. ISPRS Int. J. Geo-Inf. 2018, 7, 402. [Google Scholar] [CrossRef]
- Chen, G.; Qian, H. Extracting Skeleton Lines from Building Footprints by Integration of Vector and Raster Data. ISPRS Int. J. Geo-Inf. 2022, 11, 480. [Google Scholar] [CrossRef]
- ESRI (Environmental Systems Research Institute). Collapse Dual Lines to Centerline. 2021. Available online: https://desktop.arcgis.com/en/arcmap/latest/tools/coverage-toolbox/collapse-dual-lines-to-centerline.htm (accessed on 1 September 2021).






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Struct Runlength{ int StartColNo, EndColNo; Runlength *Next Runlength; } | Struct RunlengthLIST{ int RunlengthNum; Runlength *First Runlength; } |
| IoU for Non-Water Bodies | IoU for Water Bodies | ACC |
|---|---|---|
| 0.9725 | 0.6013 | 0.9736 |
| Cell Size | Zhang and Suen’s Method | Run-Length Method | ||||
|---|---|---|---|---|---|---|
| (m) | Lines × Columns | Time (s) | Total Memory (MB) | Lines × Columns | Time (s) | Total Memory (MB) |
| 10 | 3718 × 2922 | 4 | 21 | 3718 × 2922 | 2 | 0.18 |
| 8 | 4646 × 3650 | 7 | 33 | 4646 × 3650 | 3 | 0.23 |
| 6 | 6191 × 4863 | 15 | 60 | 6191 × 4863 | 5 | 0.31 |
| 4 | 9281 × 7289 | 45 | 135 | 9281 × 7289 | 11 | 0.47 |
| 2 | 18,552 × 14,568 | 283 | 540 | 18,552 × 14,568 | 43 | 0.95 |
| 1 | 37,095 × 29,127 | 2333 | 2160 | 37,095 × 29,127 | 193 | 1.9 |
| 0.8 | 46,366 × 36,406 | 6944 | 3376 | 46,366 × 36,406 | 283 | 2.38 |
| 0.6 | 61,808 × 48,528 | 551 | 3.17 | |||
| 0.4 | 92,712 × 72,792 | 1199 | 4.76 | |||
| 0.2 | 185,425 × 145,594 | 4944 | 9.5 | |||
| 0.1 | 370,850 × 291,168 | 20,615 | 19.08 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Shen, D.; Chen, W.; Liu, Y.; Xu, Y.; Tan, D. Run-Length-Based River Skeleton Line Extraction from High-Resolution Remote Sensed Image. Remote Sens. 2022, 14, 5852. https://doi.org/10.3390/rs14225852
Wang H, Shen D, Chen W, Liu Y, Xu Y, Tan D. Run-Length-Based River Skeleton Line Extraction from High-Resolution Remote Sensed Image. Remote Sensing. 2022; 14(22):5852. https://doi.org/10.3390/rs14225852
Chicago/Turabian StyleWang, Helong, Dingtao Shen, Wenlong Chen, Yiheng Liu, Yueping Xu, and Debao Tan. 2022. "Run-Length-Based River Skeleton Line Extraction from High-Resolution Remote Sensed Image" Remote Sensing 14, no. 22: 5852. https://doi.org/10.3390/rs14225852
APA StyleWang, H., Shen, D., Chen, W., Liu, Y., Xu, Y., & Tan, D. (2022). Run-Length-Based River Skeleton Line Extraction from High-Resolution Remote Sensed Image. Remote Sensing, 14(22), 5852. https://doi.org/10.3390/rs14225852