
Efficient and Robust Feature Matching for High-Resolution Satellite Stereos


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Methodology
2.1. Workflow
2.2. Formulation
2.2.1. Global Energy Function
2.2.2. Cost Term
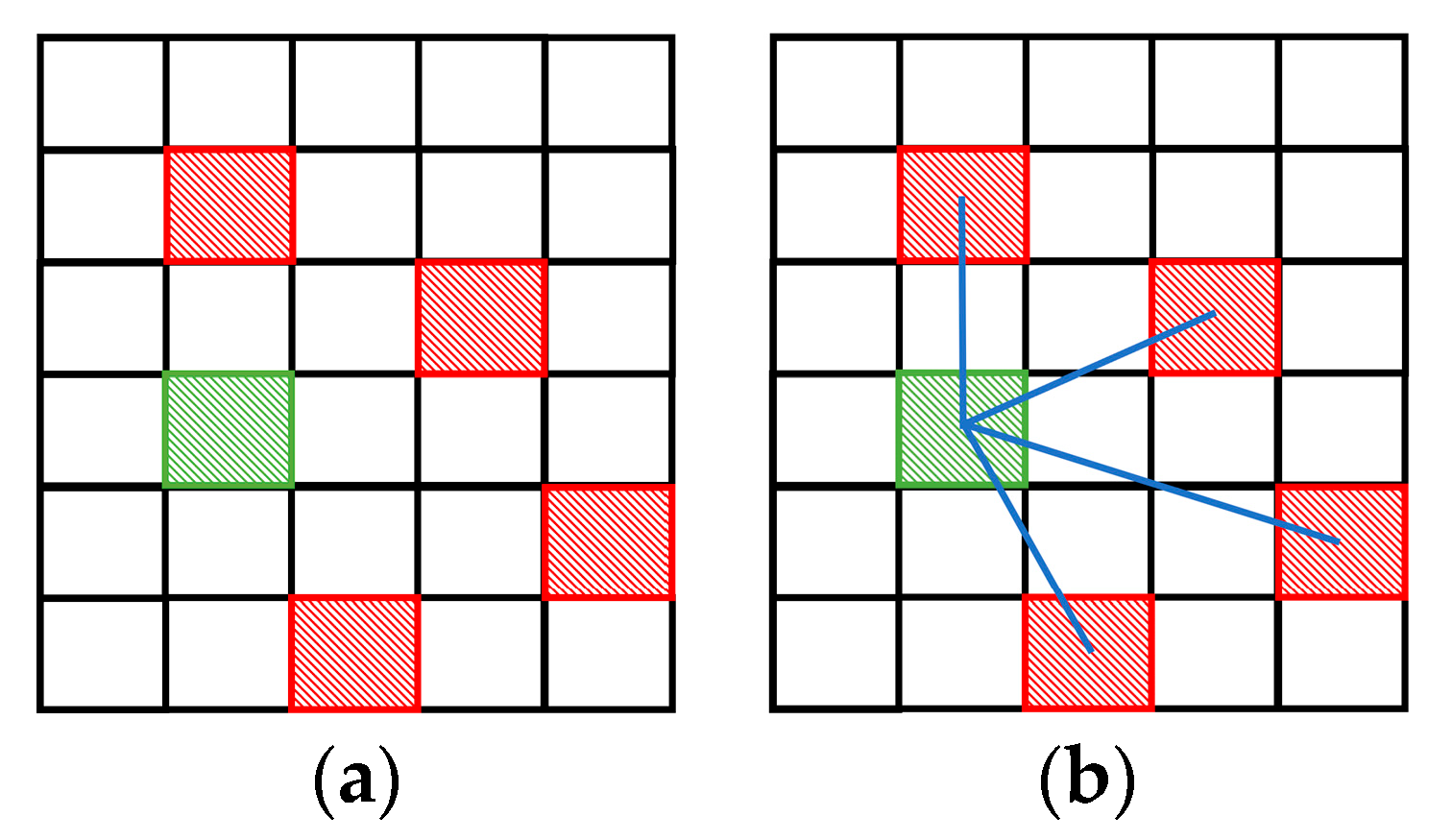
2.2.3. Regularization Term
2.3. Solution
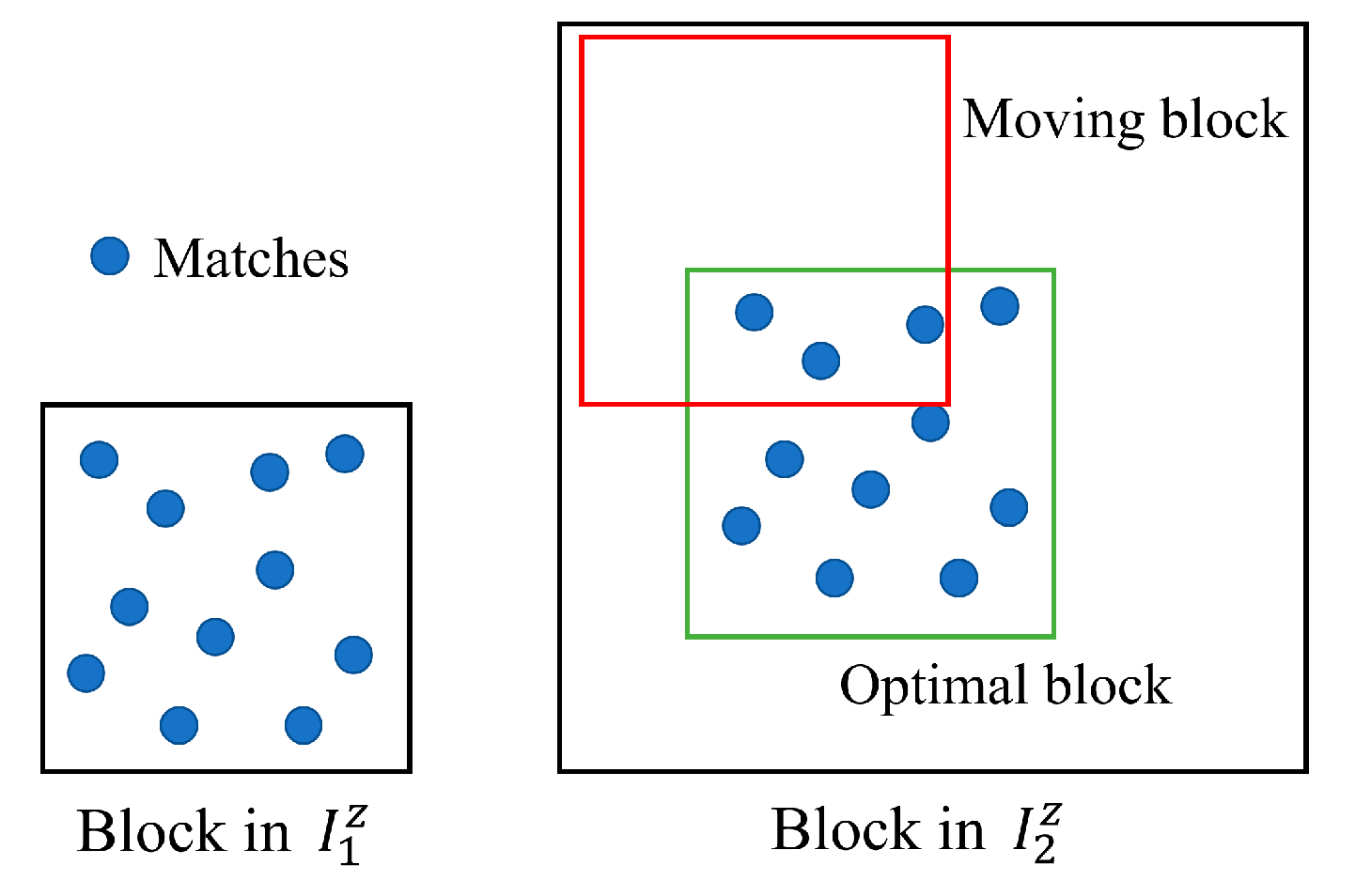
2.4. Post-Processing
3. Study Areas and Data
4. Results
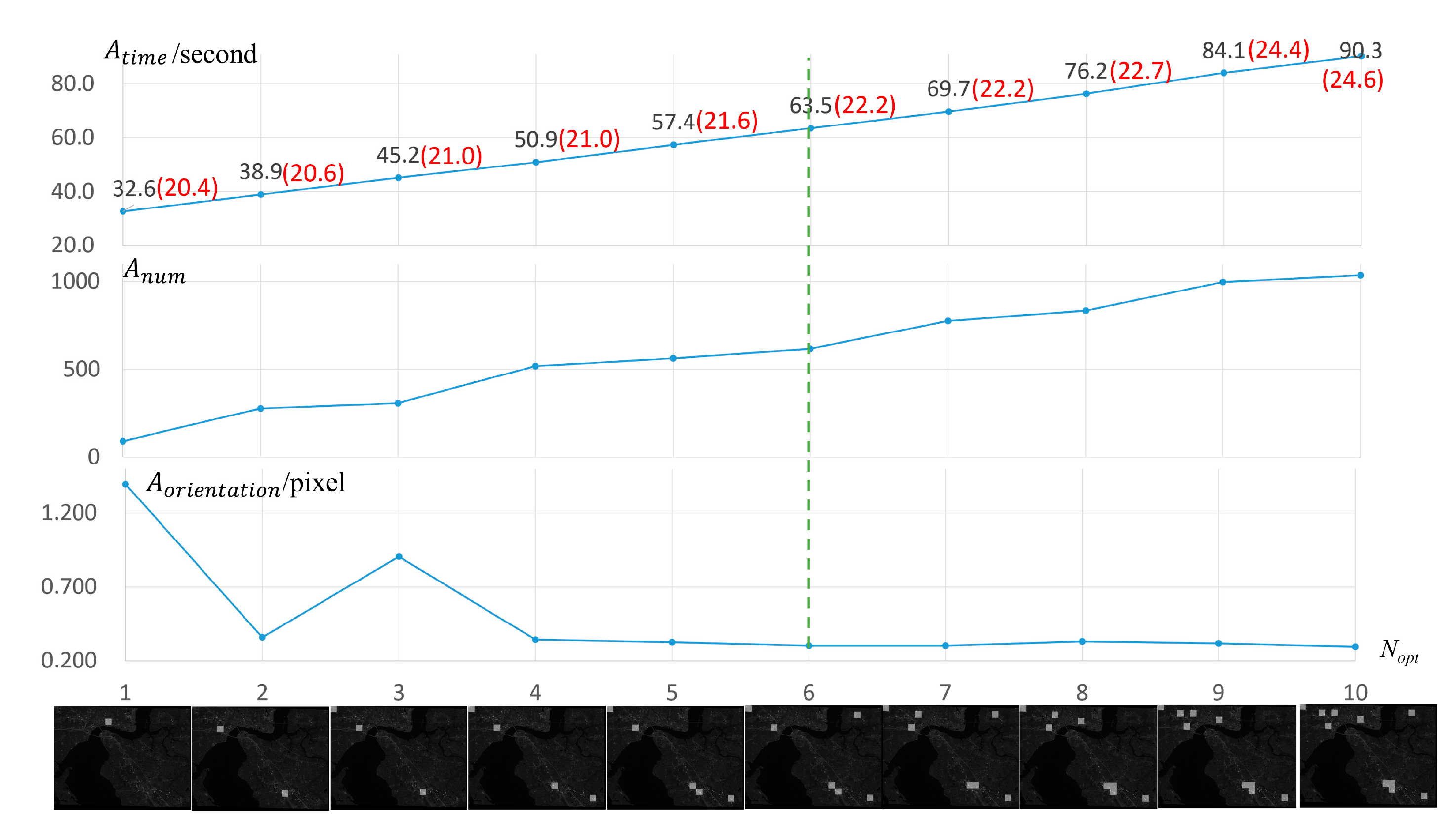
4.1. Analysis on Optimal Parameters of the Proposed Method
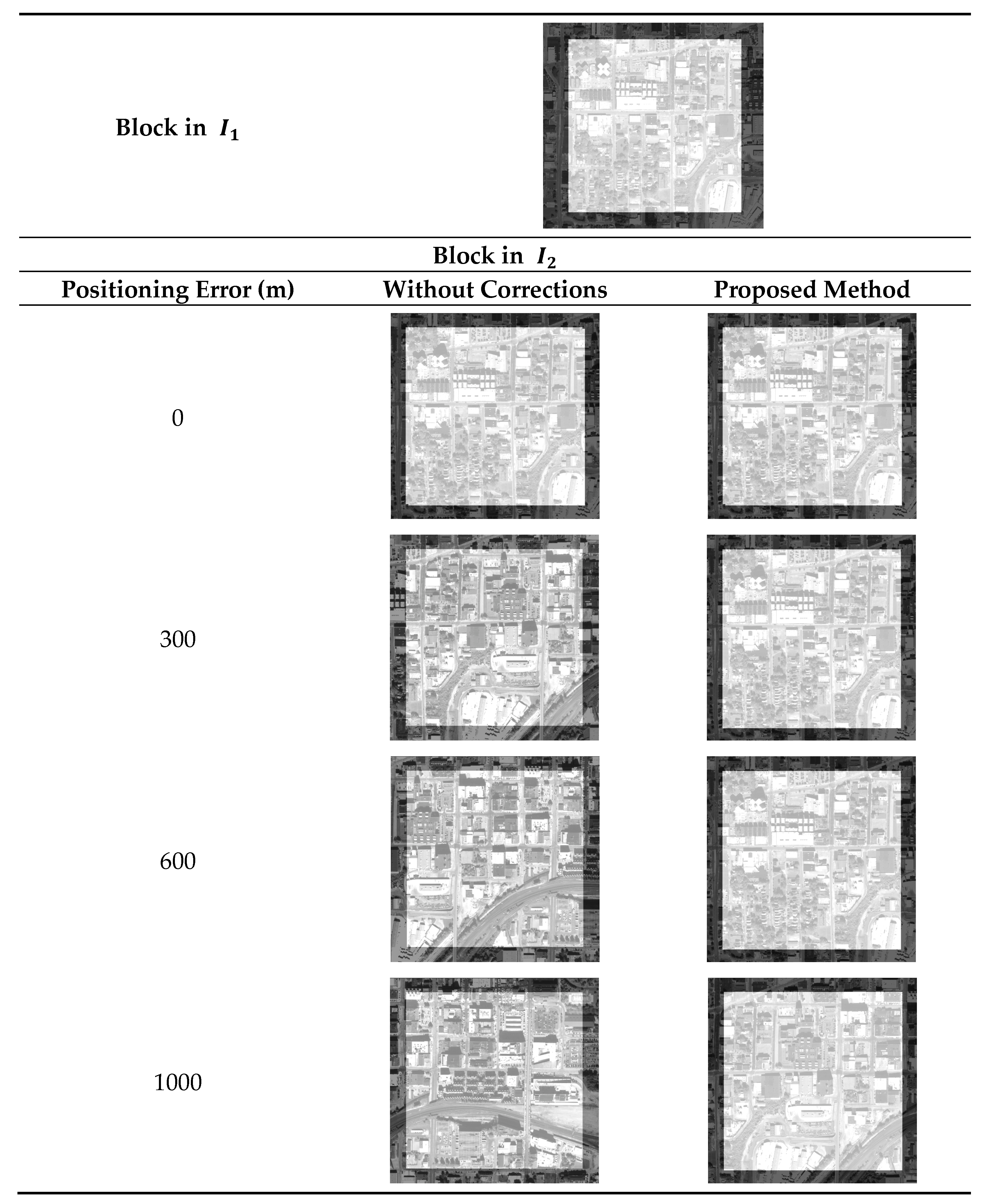
4.2. Analysis on Positioning Error Correction of the Proposed Method
4.3. Comparison of Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Prakash, P. Introduction to Satellite Photogrammetry, 1st ed.; OrangeBooks Publication: Bhilai, India, 2021. [Google Scholar]
- Kocanaogullari, A.; Ataer-Cansizoglu, E. Active Descriptor Learning for Feature Matching. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ling, X.; Zhang, Y.; Xiong, J.; Huang, X.; Chen, Z. An image matching algorithm integrating global SRTM and image segmentation for multi-source satellite imagery. Remote Sens. 2016, 8, 672. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, S.; Yuan, W.; Cai, Y. Poor textural image tie point matching via graph theory. ISPRS J. Photogramm. 2017, 129, 21–31. [Google Scholar] [CrossRef]
- Tahoun, M.; Shabayek, A.E.R.; Nassar, H.; Giovenco, M.M.; Reulke, R.; Emary, E.; Hassanien, A.E. Satellite Image Matching and Registration: A Comparative Study Using Invariant Local Features. In Image Feature Detectors and Descriptors: Foundations and Applications; Awad, A.I., Hassaballah, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 135–171. [Google Scholar]
- Luo, Q.-Y.; Zhang, J.-D.; Zhu, L.-C.; Huang, X. Research on Feature Matching of High-Resolution Optical Satellite Stereo Imagery under Difficult Conditions. In Proceedings of the 8th China Hight Resolution Earth Observation Conference (CHREOC); Springer: Singapore, 2022. [Google Scholar]
- Huang, X.; Wan, X.; Peng, D. Robust Feature Matching with Spatial Smoothness Constraints. Remote Sens. 2020, 12, 3158. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust Invariant Scalable Keypoints. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Alcantarilla, P.F.; Solutions, T. Fast explicit diffusion for accelerated features in nonlinear scale spaces. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1281–1298. [Google Scholar]
- Kuriakose, E.; Viswan, A. Remote sensing image matching using sift and affine transformation. Int. J. Comput. Appl. 2013, 80, 22–27. [Google Scholar] [CrossRef]
- Tahoun, M.; Shabayayek, A.E.R.; Hassanien, A.E. Matching and co-registration of satellite images using local features. In Proceedings of the International Conference on Space Optical Systems and Applications, Kobe, Japan, 7–9 May 2014. [Google Scholar]
- Zheng, M.; Wu, C.; Chen, D.; Meng, Z. Rotation and affine-invariant SIFT descriptor for matching UAV images with satellite images. In Proceedings of the 2014 IEEE Chinese Guidance, Navigation and Control Conference, Yantai, China, 8–10 August 2014; pp. 2624–2628. [Google Scholar]
- Li, X.-X.; Luo, X.; Wu, Y.-X.; Li, Z.-T.; Xu, W.-B. Research on Stereo Matching for Satellite Generalized Image Pair Based on Improved SURF and RFM. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 2739–2742. [Google Scholar]
- Karim, S.; Zhang, Y.; Brohi, A.A.; Asif, M.R. Feature Matching Improvement through Merging Features for Remote Sensing Imagery. 3D Res. 2018, 9, 52. [Google Scholar] [CrossRef]
- Cheng, L.; Li, M.; Liu, Y.; Cai, W.; Chen, Y.; Yang, K. Remote sensing image matching by integrating affine invariant feature extraction and RANSAC. Comput. Electr. Eng. 2012, 38, 1023–1032. [Google Scholar] [CrossRef]
- Sedaghat, A.; Ebadi, H. Remote Sensing Image Matching Based on Adaptive Binning SIFT Descriptor. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5283–5293. [Google Scholar] [CrossRef]
- Yao, Y.; Zhang, Y.; Wan, Y.; Liu, X.; Guo, H. Heterologous Images Matching Considering Anisotropic Weighted Moment and Absolute Phase Orientation. Geomat. Inf. Sci. Wuhan Univ. 2021, 46, 1727–1736. [Google Scholar]
- Xiang, Y.; Wang, F.; You, H. OS-SIFT: A robust SIFT-like algorithm for high-resolution optical-to-SAR image registration in suburban areas. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3078–3090. [Google Scholar] [CrossRef]
- Chen, J.; Yang, M.; Peng, C.; Luo, L.; Gong, W. Robust Feature Matching via Local Consensus. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Li, J.; Hu, Q.; Ai, M. 4FP-Structure: A Robust Local Region Feature Descriptor. Photogramm. Eng. Remote Sens. 2017, 83, 813–826. [Google Scholar] [CrossRef]
- Liu, Y.-X.; Mo, F.; Tao, P.-J. Matching Multi-Source Optical Satellite Imagery Exploiting a Multi-Stage Approach. Remote Sens. 2017, 9, 1249. [Google Scholar] [CrossRef]
- De Tone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 224–236. [Google Scholar]
- He, H.; Chen, M.; Chen, T.; Li, D. Matching of remote Sensing Images with Complex Background Variations via Siamese Convolutional Neural Network. Remote Sens. 2018, 10, 355. [Google Scholar] [CrossRef]
- Yang, Z.; Dan, T.; Yang, Y. Multi-Temporal Remote Sensing Image Registration Using Deep Convolutional Features. IEEE Access 2018, 6, 38544–38555. [Google Scholar] [CrossRef]
- Fan, D.; Dong, Y.; Zhang, Y. Satellite image matching method based on deep convolution neural network. Acta Geod. Cartogr. Sin. 2018, 47, 844–853. [Google Scholar]
- Dong, Y.; Jiao, W.; Long, T.; Liu, L.; He, G.; Gong, C.; Guo, Y. Local Deep Descriptor for Remote Sensing Image Feature Matching. Remote Sens. 2019, 11, 430. [Google Scholar] [CrossRef]
- Xu, C.; Liu, C.; Li, H.; Ye, Z.; Sui, H.; Yang, W. Multiview Image Matching of Optical Satellite and UAV Based on a Joint Description Neural Network. Remote Sens. 2022, 14, 838. [Google Scholar] [CrossRef]
- Xiong, J.-X.; Zhang, Y.-J.; Zheng, M.-T.; Ye, Y.-X. An SRTM assisted image matching algorithm for long-strip satellite imagery. J. Remote. Sens. 2013, 17, 1103–1117. [Google Scholar]
- Du, W.-L.; Li, X.-Y.; Ye, B.; Tian, X.-L. A fast dense feature-matching model for cross-track pushbroom satellite imagery. Sensors 2018, 18, 4182. [Google Scholar] [CrossRef] [PubMed]
- Ling, X.; Huang, X.; Zhang, Y.; Zhou, G. Matching Confidence Constrained Bundle Adjustment for Multi-View High-Resolution Satellite Images. Remote Sens. 2020, 12, 20. [Google Scholar] [CrossRef]
- Brown, M.; Goldberg, H.; Foster, K.; Leichtman, A.; Wang, S.; Hagstrom, S.; Bosch, M.; Almes, S. Large-Scale Public Lidar and Satellite Image Data Set for Urban Semantic Labeling. In Proceedings of the SPIE Defense + Security, Orlando, FL, USA, 15–19 April 2018. [Google Scholar]
- SpaceNet on Amazon Web Services (AWS). Available online: https://spacenetchallenge.github.io/datasets/datasetHomePage.html (accessed on 15 October 2018).
- Dataset Was Created for the IARPA CORE3D Program. Available online: https://www.iarpa.gov/index.php/research-programs/core3d (accessed on 24 April 2022).
- Sarlin, P.E.; De Tone, D.; Malisiewicz, T.; Rabinovich, A. SuperGlue: Learning Feature Matching with Graph Neural Networks. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4937–4946. [Google Scholar]












Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, D.; Huang, X.; Zhang, J.; Yao, Y.; Han, Y. Efficient and Robust Feature Matching for High-Resolution Satellite Stereos. Remote Sens. 2022, 14, 5617. https://doi.org/10.3390/rs14215617
Gong D, Huang X, Zhang J, Yao Y, Han Y. Efficient and Robust Feature Matching for High-Resolution Satellite Stereos. Remote Sensing. 2022; 14(21):5617. https://doi.org/10.3390/rs14215617
Chicago/Turabian StyleGong, Danchao, Xu Huang, Jidan Zhang, Yongxiang Yao, and Yilong Han. 2022. "Efficient and Robust Feature Matching for High-Resolution Satellite Stereos" Remote Sensing 14, no. 21: 5617. https://doi.org/10.3390/rs14215617
APA StyleGong, D., Huang, X., Zhang, J., Yao, Y., & Han, Y. (2022). Efficient and Robust Feature Matching for High-Resolution Satellite Stereos. Remote Sensing, 14(21), 5617. https://doi.org/10.3390/rs14215617