1. Introduction
Freshwater resources are being depleted daily due to climate change and the increasing world population. Hence, the effective use of available water is of the utmost importance, which makes its monitoring vital for water savings, mitigation, and adaptation to climate change. In the last decade, soil moisture (SM) monitoring has been investigated with its different aspects, covering drought monitoring [
1,
2], flood prediction [
3], and agricultural applications [
4,
5]. In particular, in agriculture, SM significantly impacts planning, seeding, fertilization, and irrigation activities. In addition, its close relationship with crop productivity makes SM monitoring an essential factor for optimizing the use of available water resources [
6,
7].
The dynamics of SM are influenced by the physical properties of topography and soil as well as temporal changes in atmospheric conditions. The impact of these parameters on the variability of SM has been studied in depth concerning topographic data [
8,
9,
10,
11], soil texture [
11,
12,
13], and climate variables [
14,
15,
16]. In general, the prediction of SM in local studies (e.g., station-based SM forecasting) does not require static parameters, such as topography and soil texture, because these data vary insignificantly. However, the variability of SM in time depends on climate data in both local, regional, or global scale studies.
In the literature, researchers focused on minimizing the prediction uncertainties to estimate SM by using in situ measurements [
17,
18,
19,
20,
21]. Including the meteorological parameters in estimating SM enhances the prediction accuracy significantly. The study conducted in [
18] predicted the SM values of five stations located in Shandong Province of China by using varying depth measurements of SM together with meteorological variables. A similar study was performed in [
19], extending the spatial distribution of stations worldwide, to forecast the SM values. In this study, however, the time series of each station were trained and validated separately. Another study carried out by [
20] used the SM values of globally distributed stations of the International Soil Moisture Network (ISMN) coupled with climate, topography, and soil texture data to create a model for the daily prediction of SM in different depth layers. By spatially interpolating SM values of stations to form
grid cells, the trained model can predict SM in a quasi-global way. Although the sensor measurements provide more reliable estimations of SM values, the dependency of the model on SM sensors limits the use of the model within specific regions where in situ measurements exist. The lack of measurements in high latitudes resulted in poorer forecasts of SM values, specifically in arid regions.
Even though in situ measurements play a crucial role in understanding SM, their spatial coverage and network-related problems make them limited in global studies. Recent developments in satellite-based remote sensing allowed continuous monitoring of the Earth’s surface. In order to overcome the problems encountered in SM predictions when using in situ measurements, satellite data from microwave remote sensing has been used excessively [
22,
23]. In this context, satellite images are the key to breaking free from the dependency of SM prediction from in situ sensors. The data from the NASA soil moisture active passive (SMAP) [
24] and ESA soil moisture and ocean salinity (SMOS) [
25] missions are a valuable asset for the global SM monitoring with their 2–3 days temporal resolution. In 2020, ref. [
26] expanded the near real-time SM predictions by integrating time series data from SMAP and SMOS missions by using a statistical approach to overcome the inconsistencies between the different SM retrieval algorithms.
Although SMAP and SMOS SM products enable the monitoring of Earth’s surface moisture in high temporal resolution, their applications are constrained due to their coarse spatial resolution. To overcome this limitation, researchers [
27,
28] used downscaling methods by merging higher-resolution satellite images with lower-resolution SMAP/SMOS data to achieve improved spatial resolution SM predictions. Even though these downscaling efforts are applicable in predicting SM, the generated maps still have an insufficient spatial resolution (∼5.6 km) for applications such as agricultural monitoring. In this regard, the launch of the Sentinel SAR satellites by ESA under the Copernicus Programme paved the way for accurate SM retrieval in smaller scale by acquiring higher spatial resolution microwave remote sensing images [
29,
30,
31,
32,
33].
SM retrieval from remote sensing images has been improved by the state-of-art machine learning-based regression techniques owing to their ability to learn the relationship between predictors and SM from data [
34,
35,
36,
37]. An extensive review on the use of machine learning algorithms for predicting SM can be found in [
38]. As computers have improved in performance, deep learning (DL) algorithms have become increasingly popular, as they can handle nonlinear and complex relationships between input and output [
39].The SM forecasting studies that use remote sensing images exploited the ability of DL models to capture the spatial and temporal dynamics of SM at the expense of large datasets and high computational costs [
5,
40,
41,
42,
43,
44,
45].
Among the different DL methods, artificial neural networks (ANNs) have been proposed to estimate SM from microwave remote sensing images integrated with some auxiliary data [
46]. For example, although [
47] coupled S1 images with soil texture information, ref. [
44] used soil texture and soil temperature data to improve the prediction accuracy of SM retrieval. As an alternative to soil texture data, ref. [
48] include climate and topography data to the ANN model. Furthermore, in [
42], the combination of soil texture, topography, and climate data was utilized to improve the artificial neural network (ANN) model’s performance.
The recurrent neural network (RNN) is a DL technique that considers the sequential relationships between input data and their effects on the output data. Therefore, such DL models are more appropriate when the sequence modeling tasks are needed, such as SM prediction. However, RNN struggles to learn interdependency between input and output data when the sequence span gets longer [
49]. In order to overcome the limitation of this DL technique, a special kind of RNN, long short-term memory (LSTM) is proposed by [
50]. With the LSTM, information from a sequence can be carried along the consecutive sequences, and the model can learn the relationship between sequential data and output data.
The study conducted by [
51] applied LSTM architecture for the first time in SM studies by using the SMAP L3_SM_P product with climate and soil texture data to improve the design accuracy of SMAP SM data. In 2018, ref. [
52] presented a model for the long-term SM forecast on both surface and different depths over the continental US, aiming to exploit the SMAP data together with the land surface models. The model can predict long-term SM values in the same region by using the SMAP SM time series data. In [
53], the LSTM model trained with the same data classes used in [
51] to nowcast the SM data, when the SMAP L3_SM_P product became available. Another study [
54] downscaled the SMAP SM data in (∼1 km) with the help of climate, soil texture, and topography data by implementing LSTM.
This research aims to improve short-term SM prediction by combining the high temporal resolution SMAP SM product and high spatial resolution S1 backscatter coefficients integrated with the auxiliary data to assist the agricultural activities in the field scale. In this context, we used the SM data of the ground stations from ISMN, distributed around the world, to train an LSTM model with two microwave radar data products (SMAP and S1) together with soil texture, climate, and topographical data that are considered as the predictors of SM. The short-term forecast of SM on a field scale was successfully achieved by utilizing an approach dependent on microwave remote sensing, satellite-based observations. The model used in this study predict accurate SM values of the next day with high spatial resolution in regions with different geophysical properties and climate classes.
The manuscript is structured as follows:
Section 2 explains the materials and methods.
Section 4 describes the experimental research with data processing, model optimization, and our findings by focusing on the accuracy assessments of utilized methods.
Section 5 presents the interpretation of the results and focuses on the effects of land cover, especially in the presence of vegetation, soil texture, and climate, on SM estimation. We finalized the paper by highlighting the important outcomes of this study in
Section 6.
3. Methods
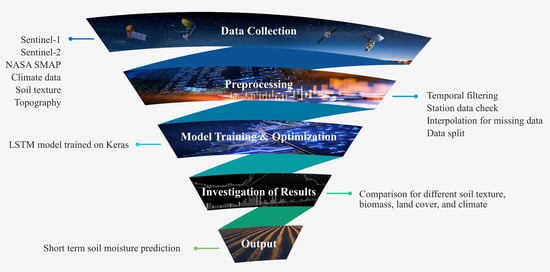
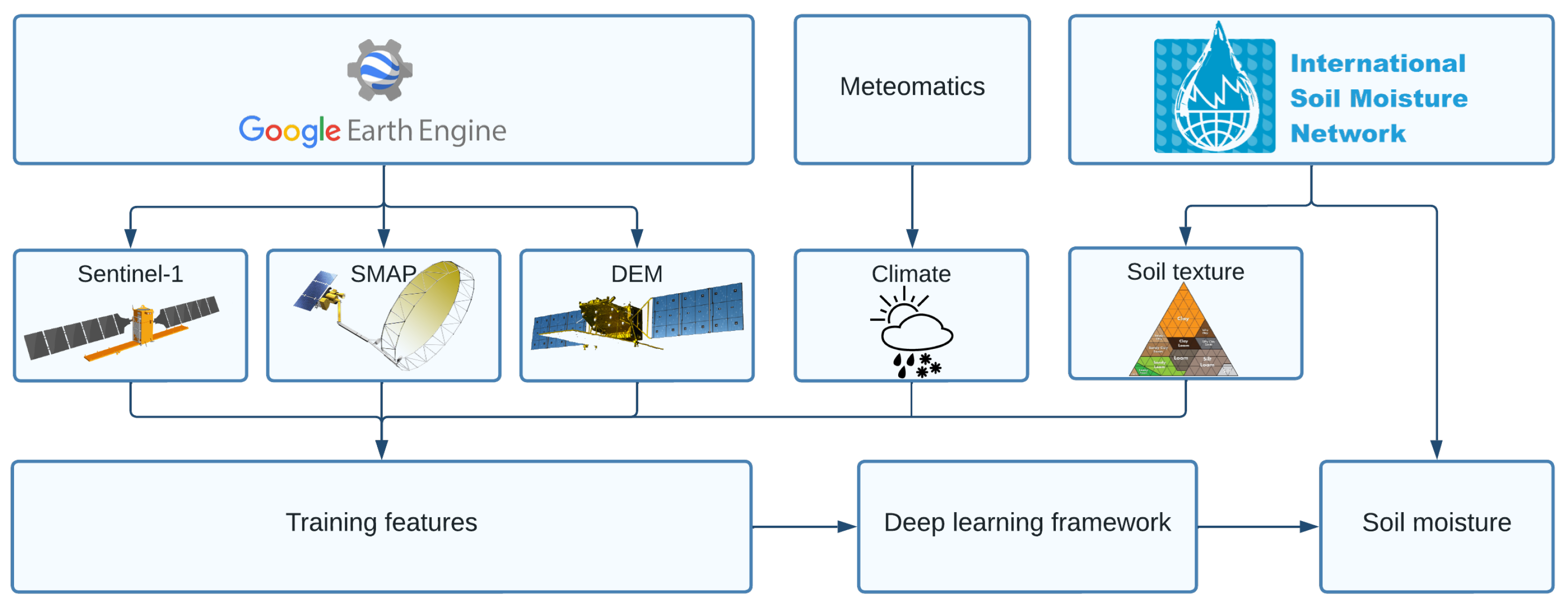
We employed the satellite data, soil texture, climate, and topography features mentioned above to forecast the SM by using the following process chart shown in
Figure 3. The process starts with the first row and ends with the accuracy assessment and prediction of SM.
3.1. Long Short-Term Memory
As a descendent of RNN, [
50] proposed an approach called long short-term memory (LSTM) to overcome the vanishing gradient problem in RNN. In LSTM, the ordinary unit cell repeats the input–output sequence; in RNN, this is replaced by a memory cell. LSTM contains three gates: the input gate
, forget gate
, and output gate
. In addition to these gates, there are two different parts: cell state
, which keeps information from previous states and transfers it to the next, and the hidden state
, which is the output of the LSTM cell. The equation of input gate, forget gate, and output gate is defined as
where
,
, and
are the weight matrix,
is input,
is the hidden state from previous time step,
,
and
are bias vector and
is the sigmoid activation function for the gates. The activation functions introduce nonlinearity by transforming inputs to targeted outputs with a nonlinear regression procedure, making the model capable of learning and performing more complex tasks. After the calculation of gates, the cell state and hidden state can be defined as
where
is the weight matrix,
is the cell state from the previous time step,
is the bias vector,
is the hyperbolic tangent activation function and ⊙ is the element-wise multiplication. The size of the weight matrix is determined according to the unit size and hidden layer size of the LSTM model, feature vector dimension, and feature sequence length. It should be noted here that the weight matrix of LSTM does not change through timesteps. For detailed information please refer to [
69].
3.2. Accuracy Assessment
Four accuracy metrics, namely, coefficient of determination (
), root mean square error (RMSE), unbiased root mean square error (ubRMSE), and mean absolute error (MAE) were used to evaluate the performance of the implemented model for the SM prediction. We have
In the above equations, , , and indicates actual SM, predicted SM, and mean value of the actual SM, at ith time step, respectively. Out of these four metrics, we use , RMSE, and ubRMSE to evaluate the performance and MAE for station-based assessments of the trained model.
3.3. Implementation of the LSTM Framework
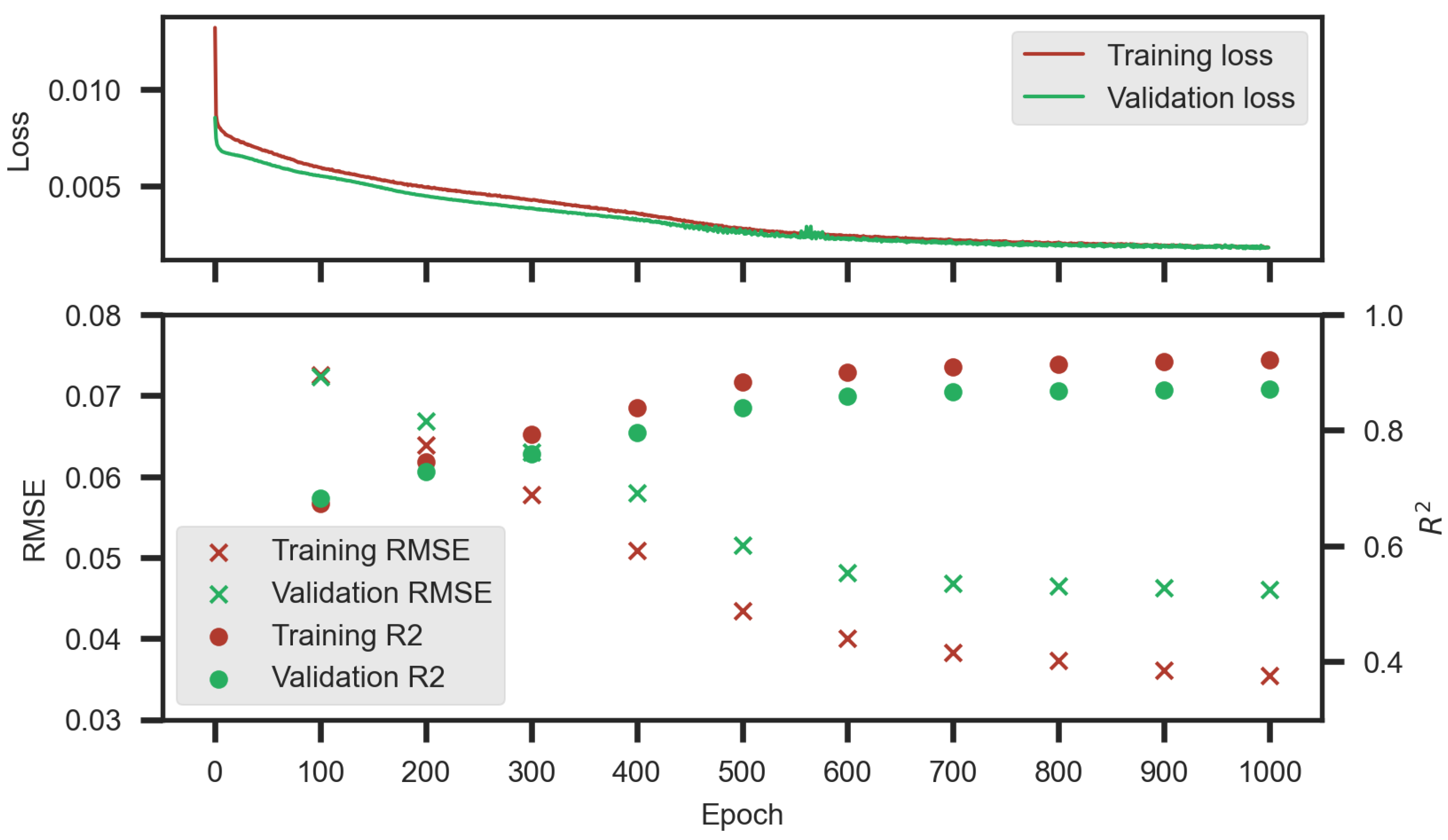
The SM value at time t () was predicted by using n number of input features with previous w sequential days (window size) as . After preparing the dataset, we divided it temporally into 60% for training, 10% for validation, and 30% for testing purposes. The temporal split corresponds to 658 days used to train the model starting from 31 December 2017 until 20 October 2019, 109 days used to validate the model training between 21 October 2019 and 6 February 2020, and 330 days used to evaluate the trained model from 7 February 2020 until 1 January 2021. Whereas the LSTM model was built with training data, the hyperparameter tuning was carried out by using a validation dataset. After the optimum hyperpamater set was determined, independent evaluation of the model was conducted based on testing data.
Before starting the training, we normalized all the input features via the MinMaxScaler function of the sklearn Python package to ensure numerical stability. For the normalization, we followed different strategies for static and dynamic features. By their nature, the static features have global minimum and maximum values; therefore, we normalized them together. On the other hand, dynamic features have local variations that change each station’s minimum and maximum values, leading to a station-based normalization.
One of the primary flexibility features involved in the use of time series data is the varying length of past data to make future predictions. In such a structure, the number of previous timesteps is called the window size. The window size parameter must be selected carefully because it impacts forecast accuracy. For its determination in the SM forecast, we reformed the original dataset according to different window sizes: last one day, five days, ten days, and thirty days.
The LSTM networks were created by using TensorFlow back-end with GPU processing integration in the conda environment. We used the the gridSearchCV function of the sklearn Python library, to determine the LSTM model’s hyperparameters. In addition, in the LSTM architecture, all models started with an LSTM layer, followed by a one-dimensional dense layer as an output.
5. Discussion
The LSTM-based SM forecast model relies on satellite-driven data, soil texture, topography, and climate. Therefore, as the predictions are conducted for different conditions, we investigated the prediction performances for land cover classes, biomass variations based on the NDVI calculated from the Sentinel-2 satellite, climate classes, and soil texture.
5.1. Relationship between Model Performance and Land Cover
The physical characteristics of the land cover affect the prediction accuracy of the developed LSTM model. This effect originates from the physical heterogeneity of the observed area.
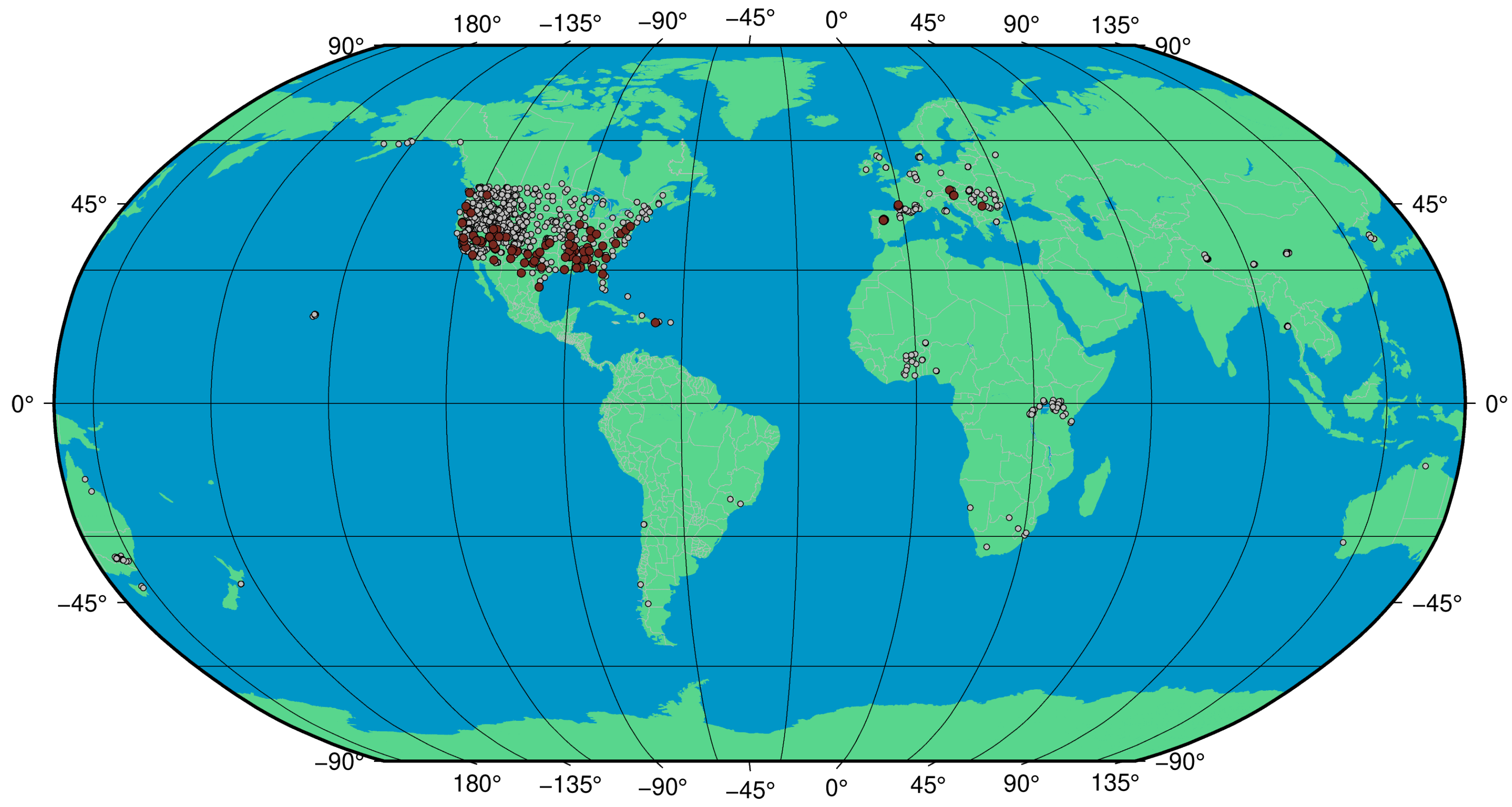
In the ISMN, every station is provided with its land cover type. The corresponding land covers are based on the ESA CCI land cover product [
58]. In a total of 103 stations, 34 croplands, 20 grasslands, 18 shrublands, 23 trees/forests, and 6 mosaics (mixture of trees, shrubs, herbaceous, and cropland), and two urban sites exist. However, we did not investigate the urban sites due to the insufficient number of samples.
Figure 6 presents the model’s prediction capability for different land covers. The smallest MAE (∼0.02) was achieved for shrubland class. The model shows similar performance for cropland, grassland, and tree covers with a mean MAE of approximately ∼0.03. However, the variance of MAE for the cropland cover is higher than the others. The worst MAE, (∼
), is obtained for the mosaic cover due to the complexity of the surface. This can be explained by the scattering mechanism of SAR imagery in the presence of vegetation and forest. Because the shrubland land cover class is sparsely vegetated area, radar signals can interact with the soil more than vegetation or forest canopy.
5.2. Relationship between Model Performance and NDVI
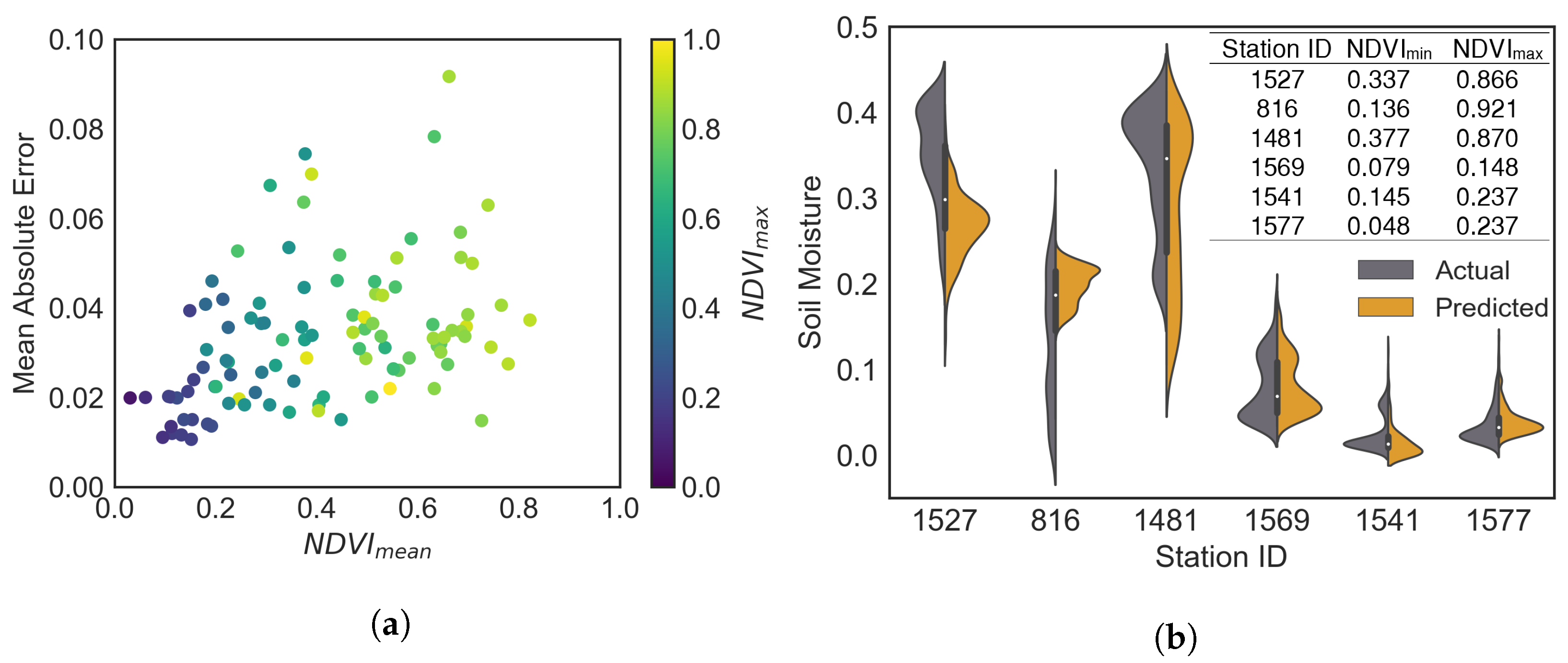
The presence of biomass over soil may affect the model’s prediction capability because the satellite data also carries information regarding the vegetation. To see the effect of the biomass, we calculated the NDVI from the S2 surface reflectance image during the testing periods and compared it with the MAE values of the model for the prediction dates.
Figure 7a visualizes the distribution of MAE values for all available stations together with the NDVI
and NDVI
values. The figure shows the correlation between the mean NDVI
and MAE values. MAE values tend to increase with increasing NDVI
values.
The violin plot given in
Figure 7b shows the distribution of the actual vs. predicted SM values at stations whose MAE values are lower (Station ID: 1569, 1541, 1577) with low soil moisture and higher (Station ID: 1527, 816, 1481) with high soil moisture. Here, we focused on finding out the origins of the variations in MAE values among these stations. For this purpose, the variation of the NDVI values were used. This analysis showed that the NDVI variation is one of the reasons for the deterioration of the SM prediction.
The backscattered signals obtained from SAR data were strongly affected by high biomass due to the interaction between electromagnetic radiation, plants, and soil. Therefore, these findings show that the model’s estimation performance is prone to uncertainties from the existing biomass. Similar findings also exist in previous studies [
35,
71,
72,
73]. These studies found that the SM content in bare or low-density vegetation areas is more predictable than in high-density vegetation areas.
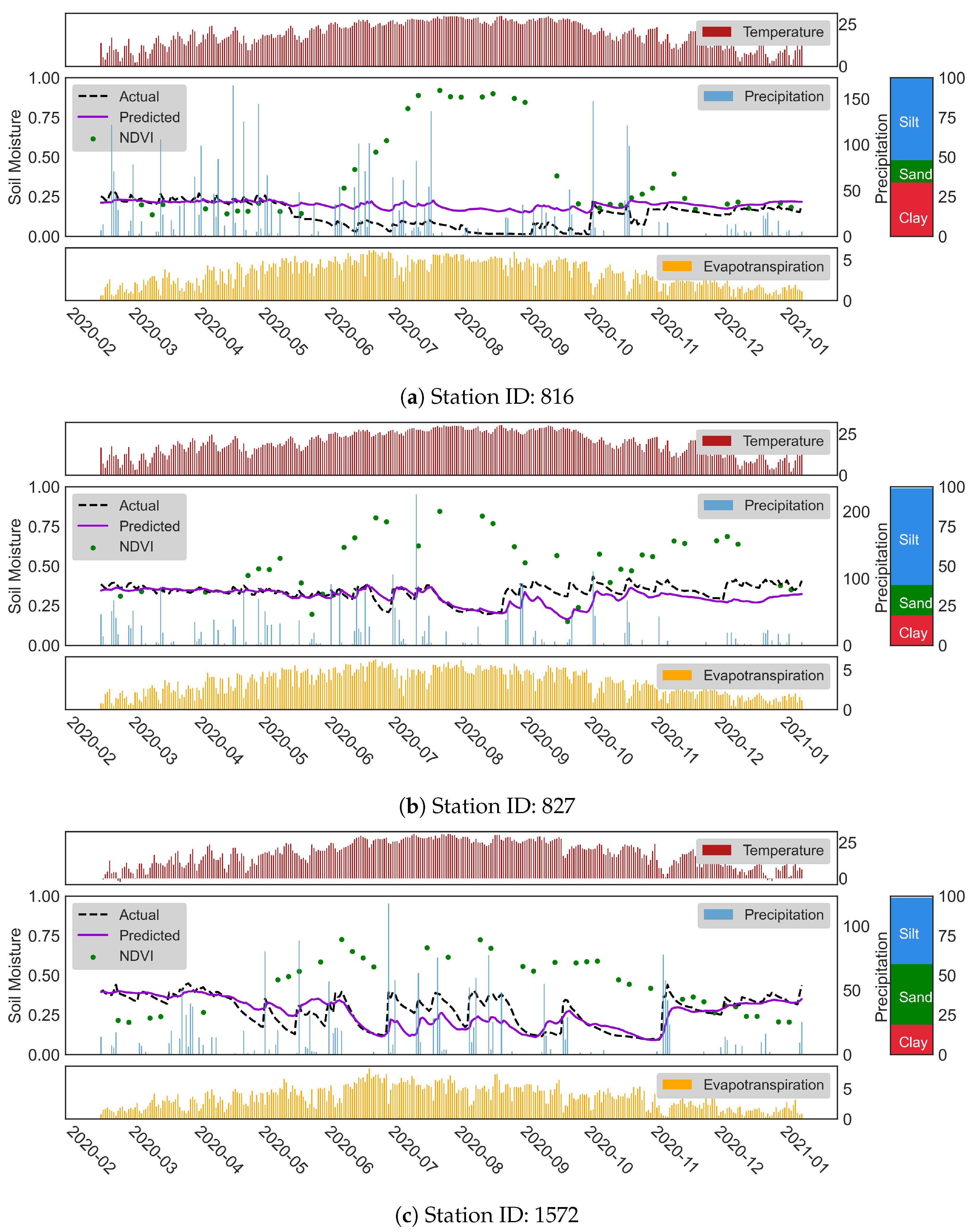
Another investigation that we conducted on the impact of NDVI variation was using station-based time series. For this purpose, we focused on some stations that show a variation in NDVI over the years. We see that the growth cycle of NDVI values before seeding and after harvest is lower than crops’ vegetative and reproductive phases. We believe that the prediction capability of the model thoughout the growth cycle is an important detail that needs to be investigated. Hence, we prepared the
Figure 8a to show the model’s performance in time. According to
Figure 8a, the model’s performance on the SM forecasting dropped approximately between May 2020 to October 2020 due to very low SM values. During this period, we can see an increase in the NDVI values from ∼0.2 to ∼0.9. We observed a similar situation in the other stations as well. In the time series of stations 827 and 1572, given in
Figure 8b,c, the station has higher NDVI values from June to the end of December and from mid-April to the beginning of November, respectively. These three stations and the others with similar behavior have MAE values less than
.
5.3. Relationship between Model Performance and Soil Texture
The variation in the soil texture is a driving factor for the spatial and temporal changes in the SM. Soils with high clay or silt fraction are associated with high water-holding capacity, resulting in a generally higher SM value. On the other hand, such soils lose their moisture slower than the others. From an agricultural point of view, clay soils have the highest soil moisture content in general; however, silty soils are more favorable for plants.
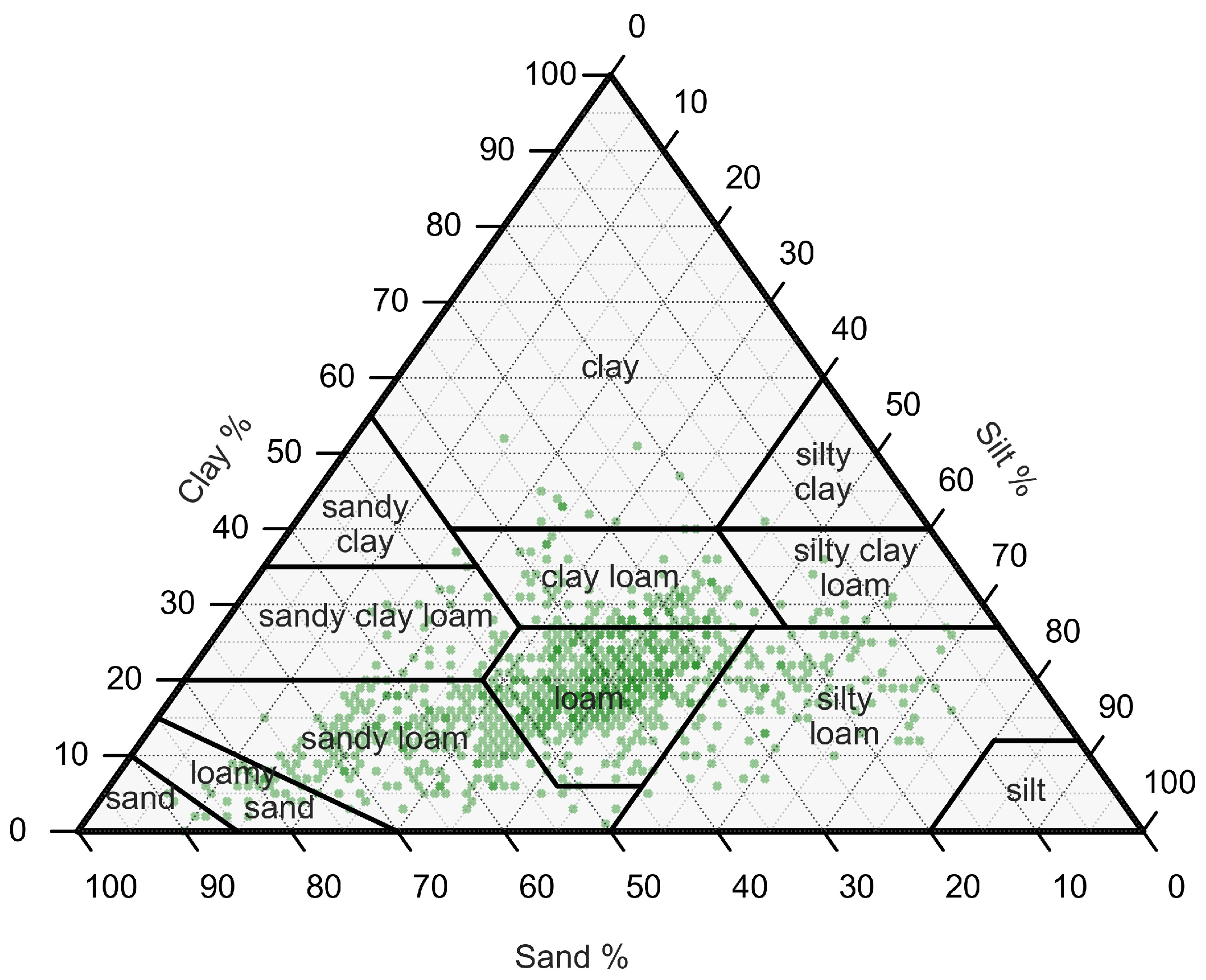
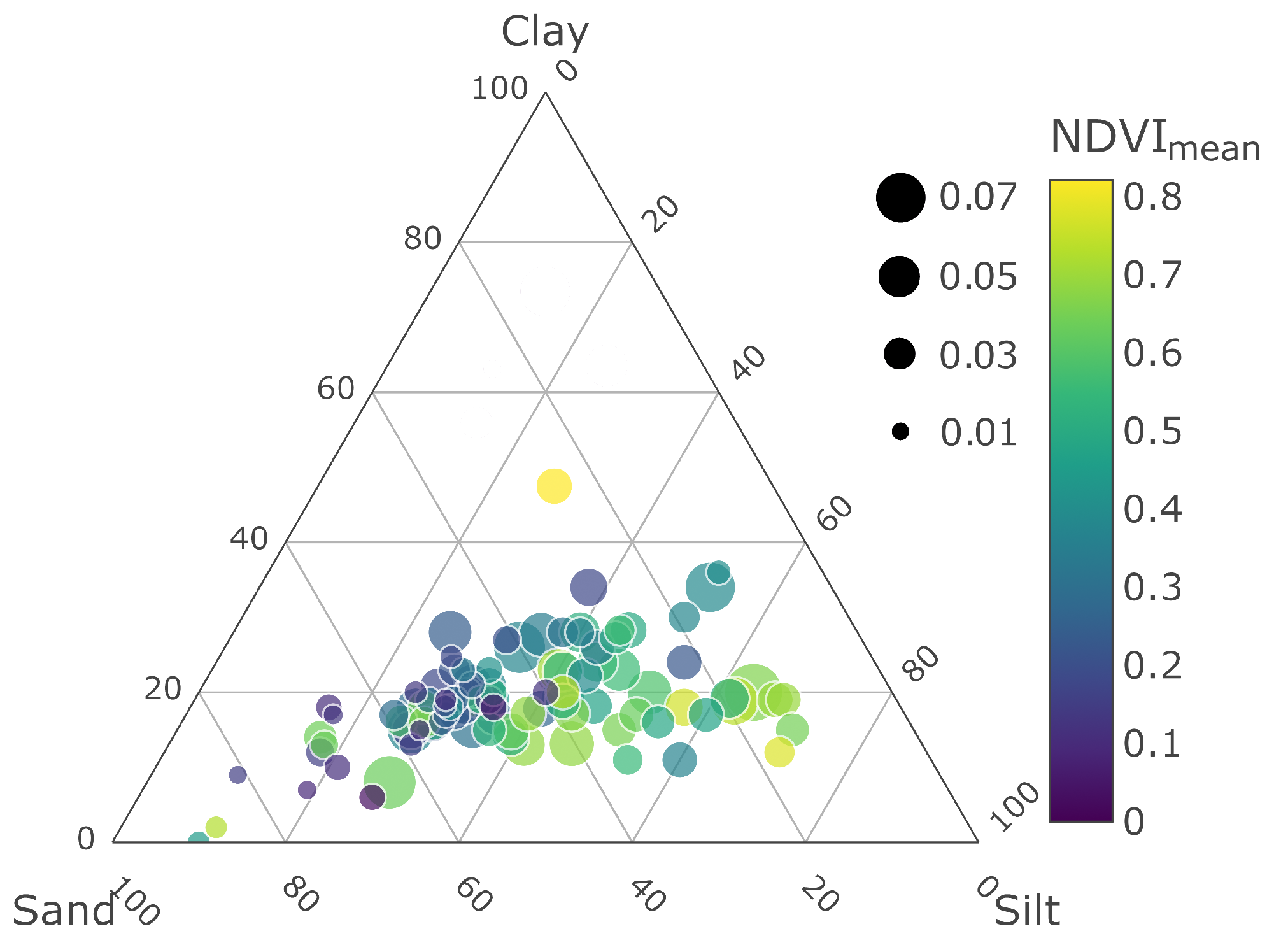
We provide a ternary plot in
Figure 9 to show the MAE values of stations, which are scattered based on their soil texture contents. In the same figure, we also included each station’s NDVI
values in a color map. The combination of soil texture and NDVI
allows us to observe the relationship between the amount of silt and clay in the soil and vegetation activity.
The size of each circle, representing a station, is proportional to its MAE value. We observe that the smaller circles generally accumulate in areas where the sand fraction is high. Among all the stations, 61% have sandy soil with an average MAE of , and 38% of them are silty soils with average MAE.
As we focus on particular stations for an in-depth investigation, it was observed that the silt content of the stations, having cropland cover, given in
Figure 8 are 52%, 61%, and 42% for stations 816, 827, and 1572, respectively. In the corresponding stations, we have similar findings that justify the performance of the model w.r.t. the change in the NDVI values.
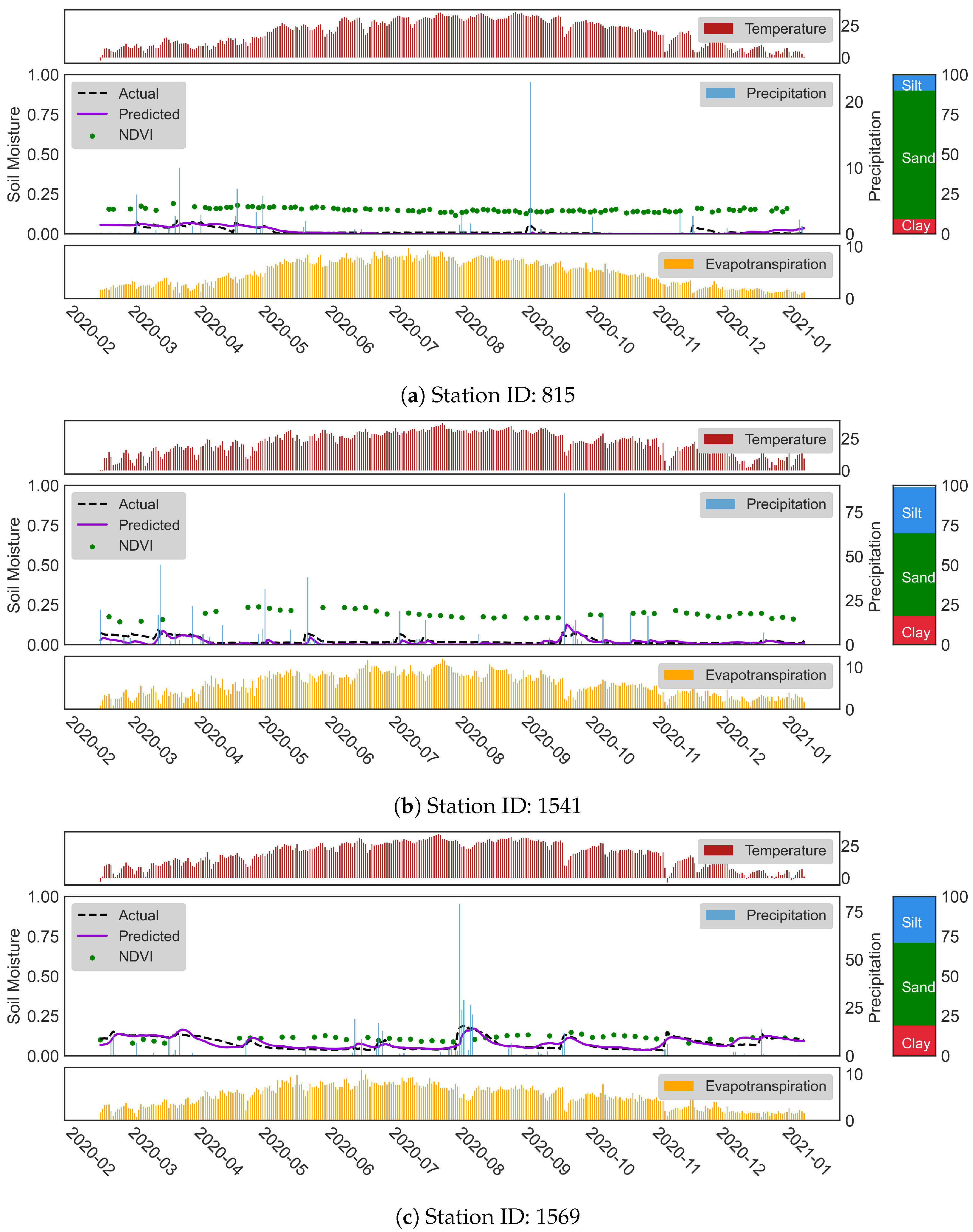
In addition to silt and clay-dominated soils, the soil types in which the sand proportion is higher generally have a lower trend in SM values because the sandy soil has low water-holding capacity. This property makes them less suitable for agricultural applications. In order to investigate the sand effect, we present the time series of SM predictions at stations 815, 1541, and 1569 in
Figure 10. The typical features of these stations are the high percentage of sand fraction in soil content (81%, 52%, and 52% for stations 815, 1541, and 1569) and lower NDVI values along the time series. The mean NDVI value for these stations is 0.15, 0.19, and 0.11, respectively. Unlike the findings from
Figure 8, we saw that in
Figure 10a, the higher sand fraction leads to lower and less fluctuated SM values. Thus, the highest accuracy was obtained at stations with sandy soils having low NDVI values.
5.4. Relationship between Model Performance and Climate Classes
Lastly, we investigated the effect of climate classes. To this aim, we used [
59], which defines four classes in total: tropical (A), dry (B), temperate (C), and continental (D). Our selected stations are distributed as
in class B and
in class C. The remaining
belongs to classes A and D, with one station for each.
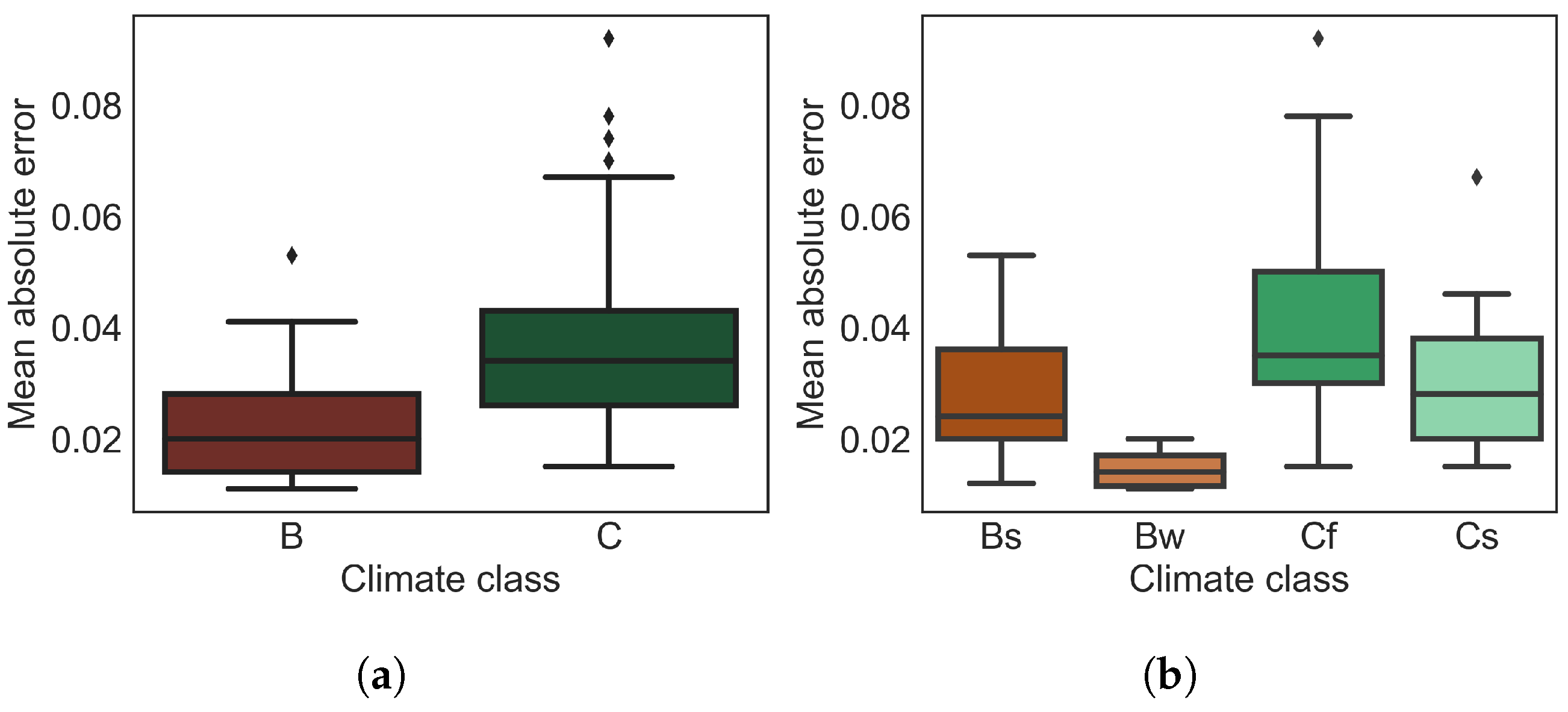
In
Figure 11, we present the model’s prediction performance under different climate conditions as a boxplot. The stations in class B shows lower MAE values compared to those in class C (see
Figure 11a). Considering the climate class properties, the rapid changes in the moisture affect the dielectric properties of the target [
32,
74]; at the same time, precipitation is a significant factor that negatively impacts the SM prediction due to the change in the interaction between SAR signals and land surface.
We obtained better soil moisture predictions in arid climates (Bw) than those in semi-arid climates (Bs) regions due to less precipitation and more evapotranspiration. We also observed a similar behavior between no-dry-season climate (Cf) and dry summer (Cs) temperate climate classes (see
Figure 11b). The no-dry-season climate, as inferred by its name, has a high precipitation rate compared to a dry summer climate, which makes the stations located in this climate region challenging for SM prediction.
6. Conclusions
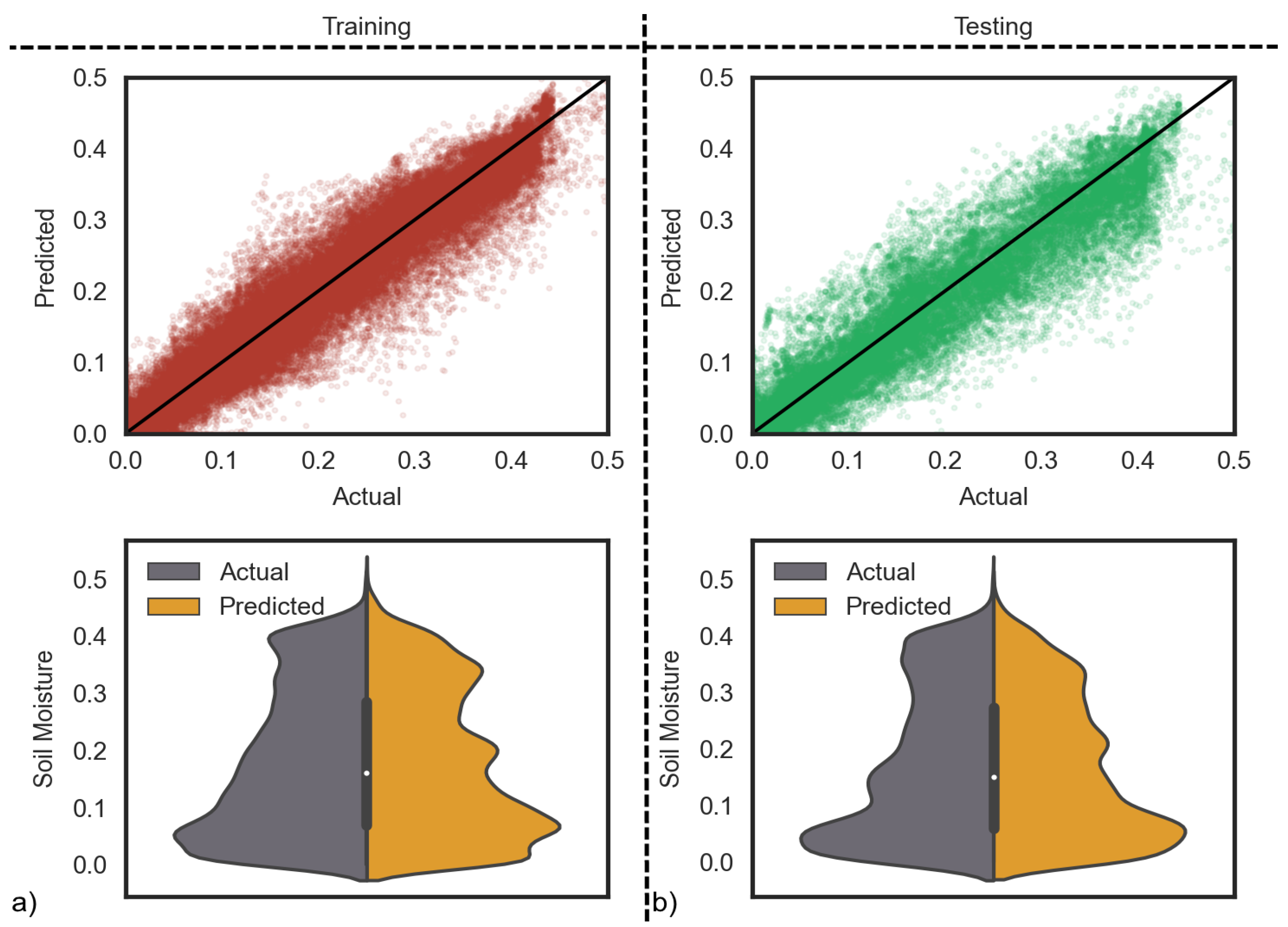
In this study, we investigated the short-term SM prediction based on satellite-derived data with LSTM. For this purpose, the static and dynamic features were combined to create sequential input data and used in situ SM measurements of 103 stations from ISMN as an output to train an LSTM model. Our approach uses soil texture and topographical data as static features and satellite (S1 and SMAP) and climate data as dynamic features. As SM monitoring is crucial for water resource management, we employed the SAR data due to its lower sensitivity to atmospheric conditions than optical data. To optimize the LSTM models’ hyperparameters, we used the gridSearchCV algorithm. After the optimization, the overall testing accuracy of the model was calculated as
,
, and
. The values obtained from different stations are summarized in
Appendix A, including the station ID, network and station name, soil texture, NDVI mean and max values, climate, land cover classes, and the corresponding MAE values.
During our investigations, it was observed that the model’s prediction performance is affected by the soil texture, vegetation status, and climate conditions. Variations in soil texture change the soil water-holding capacity. In the case in which the amount of sand was dominant, the SM values were easier to model than in the case of silt and clay dominance due to the low SM values and fewer fluctuations in sandy soils. We also observed that vegetation affects the interaction between the SAR signal and the soil. Thus, the model’s prediction ability was lowered in vegetated areas with high NDVI values. Moreover, the model can predict better under dry climate conditions, such as arid and semi-arid climates in relatively low precipitation.
This study used satellite-based products to create a model to forecast SM values. For operational purposes, we know that obtaining soil texture data on the pixel level is challenging. However, we can overcome this by conducting an intensive sampling campaign for soil texture, or existing models can be used [
75], which employs S1 and S2 multi-temporal data.
In the future, we plan to combine the LSTM model with the attention mechanism to study the contribution of each variable to SM prediction. The LSTM model combined with the attention mechanism can determine the importance of each feature and its temporal relationship with SM phenomena. Thus, we can increase the accuracy of the model predictions and explain the physical behavior of the black-box model.




 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










