
Embedded Feature Selection and Machine Learning Methods for Flash Flood Susceptibility-Mapping in the Mainstream Songhua River Basin, China



Abstract
1. Introduction
2. Study Area
3. Data Preparation
3.1. Flash Flood Inventory
3.2. Flash Flood Conditioning Factors
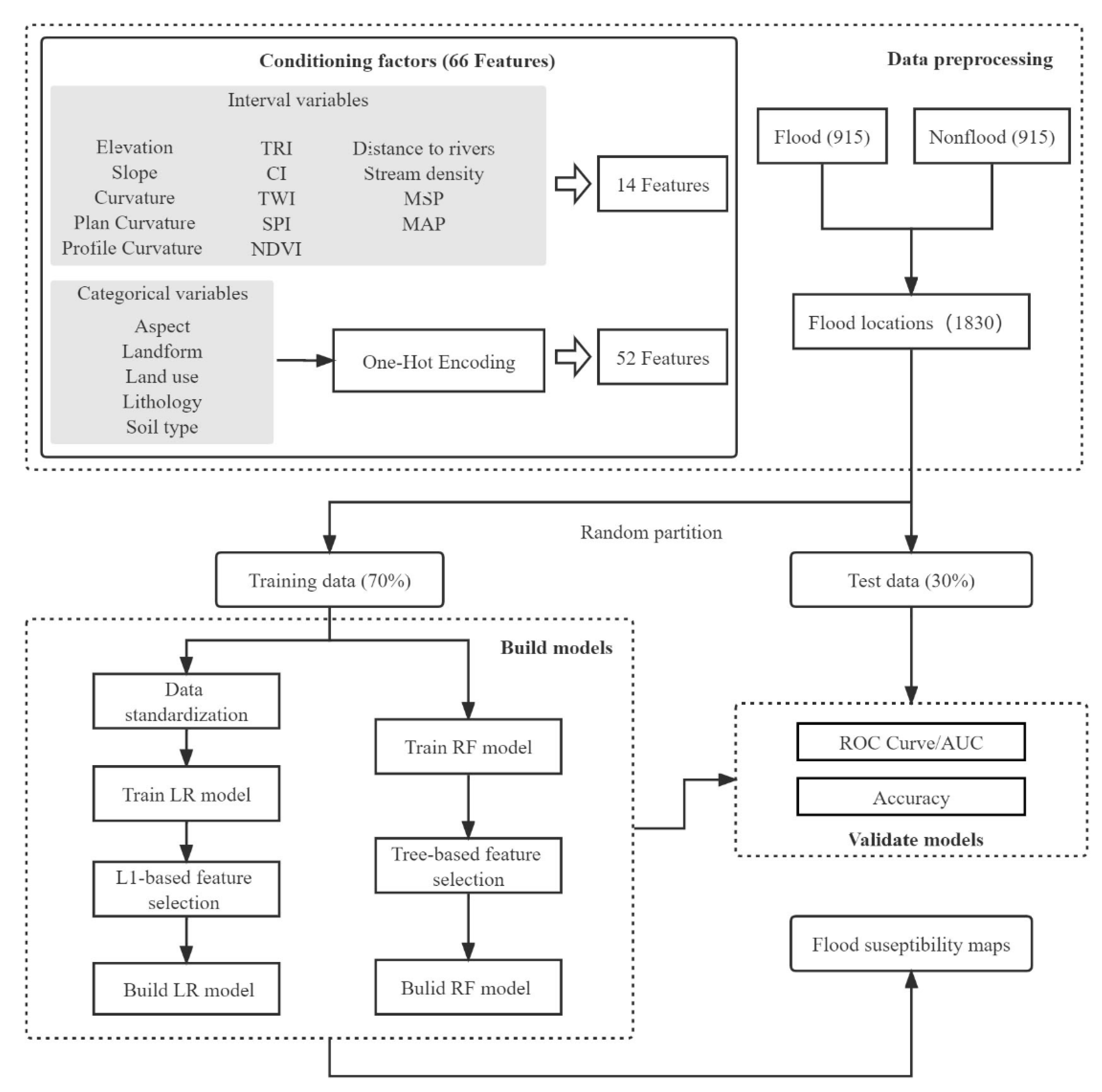
4. Methods
4.1. Machine Learning Algorithms
4.1.1. Logistic Regression (LR)
4.1.2. Random Forest (RF)
4.2. Embedded Feature Selection (EFS)
4.2.1. L1-Based Feature Selection for LR
4.2.2. Tree-Based Feature Selection for RF
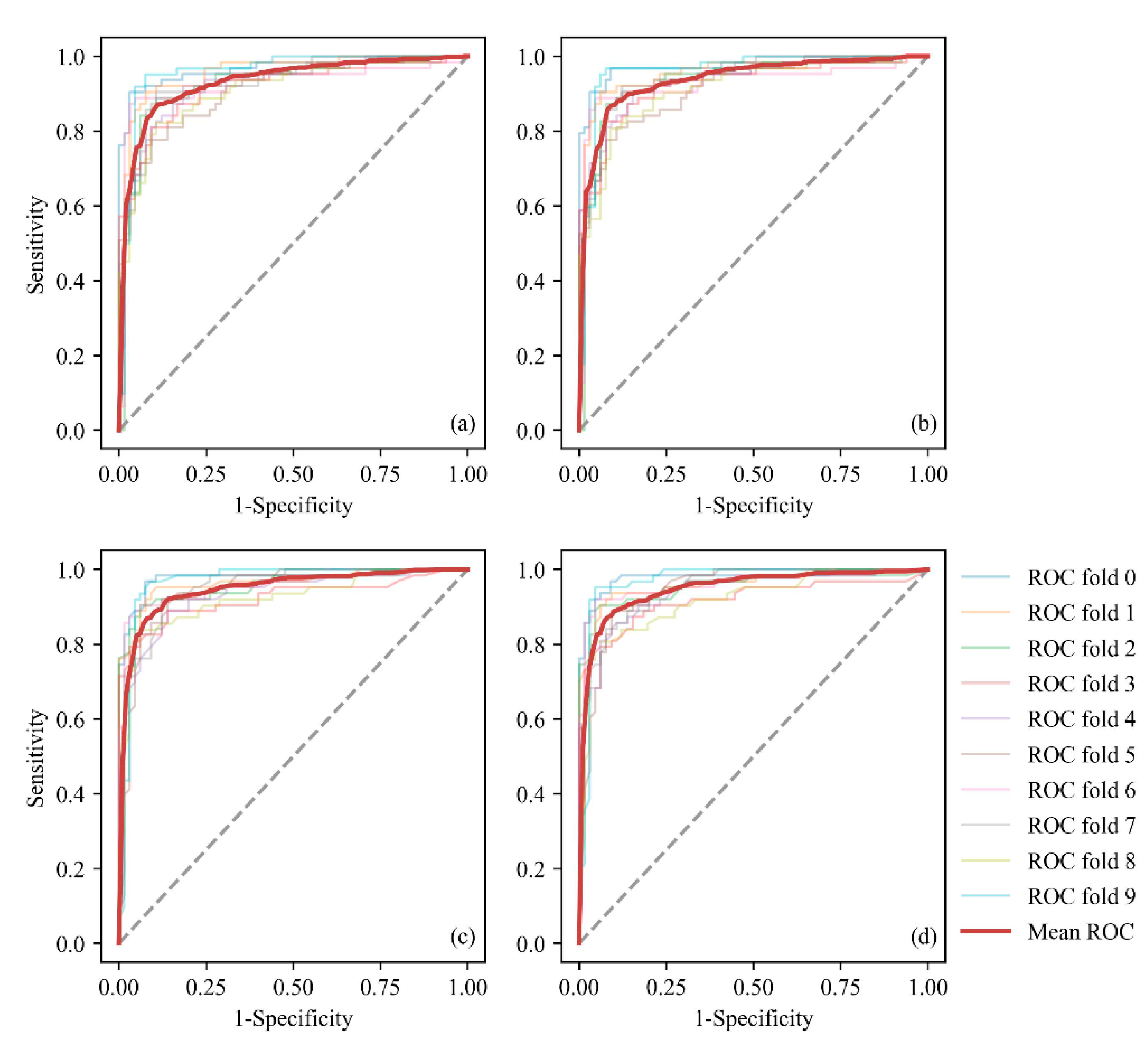
4.3. Model Evaluation
5. Results
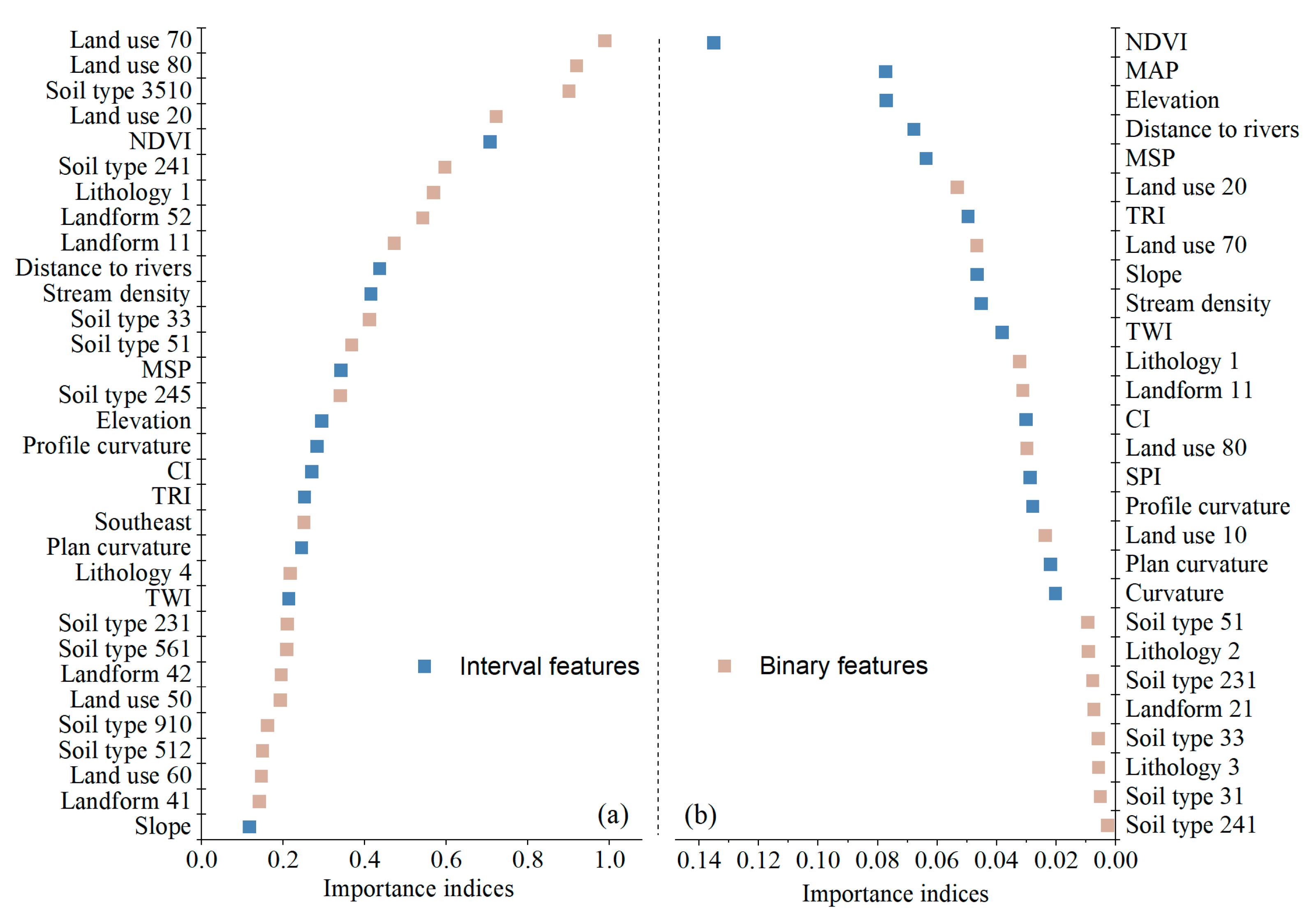
5.1. Selection of Conditioning Factors Based on the Embedded Method
5.2. Model Validation and Comparison
5.3. Generating FFSMs
6. Discussion
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fang, Z.C.; Wang, Y.; Peng, L.; Hong, H.Y. Predicting flood susceptibility using LSTM neural networks. J. Hydrol. 2020, 594, 125734. [Google Scholar] [CrossRef]
- Milly, P.C.D.; Wetherald, R.T.; Dunne, K.A.; Delworth, T.L. Increasing risk of great floods in a changing climate. Nature 2002, 415, 514–517. [Google Scholar] [CrossRef] [PubMed]
- Schiermeier, Q. Increased flood risk linked to global warming. Nature 2011, 470, 315. [Google Scholar] [CrossRef] [PubMed]
- Destro, E.; Amponsah, W.; Nikolopoulos, E.I.; Marchi, L.; Marra, F.; Zoccatelli, D.; Borga, M. Coupled prediction of flash flood response and debris flow occurrence: Application on an alpine extreme flood event. J. Hydrol. 2018, 558, 225–237. [Google Scholar] [CrossRef]
- Bui, D.T.; Ngo, P.T.T.; Pham, T.D.; Jaafari, A.; Minh, N.Q.; Hoa, P.V.; Samui, P. A novel hybrid approach based on a swarm intelligence optimized extreme learning machine for flash flood susceptibility mapping. Catena 2019, 179, 184–196. [Google Scholar] [CrossRef]
- Costache, R.; Pham, Q.B.; Sharifi, E.; Linh, N.T.T.; Abba, S.I.; Vojtek, M.; Vojtekova, J.; Nhi, P.T.T.; Khoi, D.N. Flash-Flood Susceptibility Assessment Using Multi-Criteria Decision Making and Machine Learning Supported by Remote Sensing and GIS Techniques. Remote Sens. 2019, 12, 106. [Google Scholar] [CrossRef]
- Ahmadalipour, A.; Moradkhani, H. A data-driven analysis of flash flood hazard, fatalities, and damages over the CONUS during 1996–2017. J. Hydrol. 2019, 578, 124106. [Google Scholar] [CrossRef]
- Costache, R.; Bui, D.T. Identification of areas prone to flash-flood phenomena using multiple-criteria decision-making, bivariate statistics, machine learning and their ensembles. Sci. Total Environ. 2020, 712, 136492. [Google Scholar] [CrossRef]
- Arabameri, A.; Saha, S.; Chen, W.; Roy, J.; Pradhan, B.; Bui, D.T. Flash flood susceptibility modelling using functional tree and hybrid ensemble techniques. J. Hydrol. 2020, 587, 125007. [Google Scholar] [CrossRef]
- Costache, R.; Pham, Q.B.; Avand, M.; Linh, N.T.T.; Vojtek, M.; Vojtekova, J.; Lee, S.; Khoi, D.N.; Nhi, P.T.T.; Dung, T.D. Novel hybrid models between bivariate statistics, artificial neural networks and boosting algorithms for flood susceptibility assessment. J. Environ. Manag. 2020, 265, 110485. [Google Scholar] [CrossRef]
- Bui, D.T.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar] [CrossRef]
- Trigila, A.; Iadanza, C.; Esposito, C.; Scarascia-Mugnozza, G. Comparison of Logistic Regression and Random Forests techniques for shallow landslide susceptibility assessment in Giampilieri (NE Sicily, Italy). Geomorphology 2015, 249, 119–136. [Google Scholar] [CrossRef]
- Rahmati, O.; Pourghasemi, H.R.; Zeinivand, H. Flood susceptibility mapping using frequency ratio and weights-of-evidence models in the Golastan Province, Iran. Geocarto Int. 2016, 31, 42–70. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Mansor, S.; Ahmad, N. Flood susceptibility assessment using GIS-based support vector machine model with different kernel types. Catena 2015, 125, 91–101. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Spatial prediction of flood susceptible areas using rule based decision tree (DT) and a novel ensemble bivariate and multivariate statistical models in GIS. J. Hydrol. 2013, 504, 69–79. [Google Scholar] [CrossRef]
- Khosravi, K.; Pham, B.T.; Chapi, K.; Shirzadi, A.; Shahabi, H.; Revhaug, I.; Prakash, I.; Bui, D.T. A comparative assessment of decision trees algorithms for flash flood susceptibility modeling at Haraz watershed, northern Iran. Sci. Total Environ. 2018, 627, 744–755. [Google Scholar] [CrossRef]
- Choubin, B.; Moradi, E.; Golshan, M.; Adamowski, J.; Sajedi-Hosseini, F.; Mosavi, A. An ensemble prediction of flood susceptibility using multivariate discriminant analysis, classification and regression trees, and support vector machines. Sci. Total Environ. 2019, 651, 2087–2096. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.S.; Wang, J.L.; Pradhan, B.; Hong, H.Y.; Bui, D.T.; Duan, Z.; Ma, J.Q. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. Catena 2017, 151, 147–160. [Google Scholar] [CrossRef]
- Bui, D.T.; Hoang, N.D.; Martinez-Alvarez, F.; Ngo, P.T.T.; Hoa, P.V.; Pham, T.D.; Samui, P.; Costache, R. A novel deep learning neural network approach for predicting flash flood susceptibility: A case study at a high frequency tropical storm area. Sci. Total Environ. 2019, 701, 134413. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.X.; Yue, J.J.; Tu, T.B. Mapping flood susceptibility in mountainous areas on a national scale in China. Sci. Total Environ. 2018, 615, 1133–1142. [Google Scholar] [CrossRef]
- Hong, H.Y.; Tsangaratos, P.; Ilia, I.; Liu, J.Z.; Zhu, A.X.; Chen, W. Application of fuzzy weight of evidence and data mining techniques in construction of flood susceptibility map of Poyang County, China. Sci. Total Environ. 2018, 625, 575–588. [Google Scholar] [CrossRef] [PubMed]
- Panahi, M.; Dodangeh, E.; Rezaie, F.; Khosravi, K.; Le, H.V.; Lee, M.J.; Lee, S.; Pham, B.T. Flood spatial prediction modeling using a hybrid of meta-optimization and support vector regression modeling. Catena 2021, 199, 105114. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar] [CrossRef][Green Version]
- Bui, D.T.; Tsangaratos, P.; Ngo, P.T.T.; Pham, T.D.; Pham, B.T. Flash flood susceptibility modeling using an optimized fuzzy rule based feature selection technique and tree based ensemble methods. Sci. Total Environ. 2019, 668, 1038–1054. [Google Scholar] [CrossRef] [PubMed]
- Zheng, A.; Casari, A. Feature Engineering for Machine Learning; Roumeliotis, R., Bleiel, J., Eds.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2018. [Google Scholar]
- Chen, C.; Tsai, Y.; Chang, F.; Lin, W. Ensemble feature selection in medical datasets: Combining filter, wrapper, and embedded feature selection results. Expert Syst. 2020, 37, e12553. [Google Scholar] [CrossRef]
- Yu, L.; Liu, H. Efficient Feature Selection via Analysis of Relevance and Redundancy. J. Mach. Learn. Res. 2004, 5, 1205–1224. [Google Scholar] [CrossRef]
- Saeys, Y.; Inza, I.; Larrañaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Luque-Espinar, J.A.; Chica-Olmo, M.; Mendes, M.P. Feature selection approaches for predictive modelling of groundwater nitrate pollution: An evaluation of filters, embedded and wrapper methods. Sci. Total Environ. 2018, 624, 661–672. [Google Scholar] [CrossRef]
- Liang, P.; Qin, C.Z.; Zhu, A.X.; Hou, Z.W.; Fan, N.Q.; Wang, Y.J. A case-based method of selecting covariates for digital soil mapping. J. Integr. Agric. 2020, 19, 2127–2136. [Google Scholar] [CrossRef]
- Lark, R.M.; Bishop, T.F.A.; Webster, R. Using expert knowledge with control of false discovery rate to select regressors for prediction of soil properties. Geoderma 2007, 138, 65–78. [Google Scholar] [CrossRef]
- Derksen, S.; Keselman, H.J. Backward, forward and stepwise automated subset selection algorithms: Frequency of obtaining authentic and noise variables. Br. J. Math. Stat. Psychol. 1992, 45, 265–282. [Google Scholar] [CrossRef]
- Lal, T.N.; Chapelle, O.; Weston, J.; Elisseeff, A. Embedded Methods. In Feature Extraction: Foundations and Applications; Guyon, I., Nikravesh, M., Gunn, S., Zadeh, L.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 137–165. [Google Scholar]
- Liu, C.J.; Guo, L.; Ye, L.; Zhang, S.F.; Zhao, Y.Z.; Song, T.Y. A review of advances in China’s flash flood early-warning system. Nat. Hazards 2018, 92, 619–634. [Google Scholar] [CrossRef]
- Songliao Water Conservancy Commission. Summary of “Songhua River Basin Comprehensive Planning (2012–2030)”; Songliao Water Conservancy Commission: Changchun, China, 2013. [Google Scholar]
- Liu, Y.; Huang, Y.; Wan, J.; Yang, Z.; Zhang, X. Analysis of Human Activity Impact on Flash Floods in China from 1950 to 2015. Sustainability 2021, 13, 217. [Google Scholar] [CrossRef]
- Hapuarachchi, H.A.P.; Wang, Q.J.; Pagano, T.C. A review of advances in flash flood forecasting. Hydrol. Process. 2011, 25, 2771–2784. [Google Scholar] [CrossRef]
- Bui, D.T.; Pradhan, B.; Nampak, H.; Bui, Q.T.; Tran, Q.A.; Nguyen, Q.P. Hybrid artificial intelligence approach based on neural fuzzy inference model and metaheuristic optimization for flood susceptibilitgy modeling in a high-frequency tropical cyclone area using GIS. J. Hydrol. 2016, 540, 317–330. [Google Scholar] [CrossRef]
- Pham, B.T.; Avand, M.; Janizadeh, S.; Phong, T.V.; Al-Ansari, N.; Ho, L.S.; Das, S.; Le, H.V.; Amini, A.; Bozchaloei, S.K.; et al. GIS Based Hybrid Computational Approaches for Flash Flood Susceptibility Assessment. Water 2020, 12, 683. [Google Scholar] [CrossRef]
- Khosravi, K.; Shahabi, H.; Pham, B.T.; Adamowski, J.; Shirzadi, A.; Pradhan, B.; Dou, J.; Ly, H.B.; Grof, G.; Ho, H.L.; et al. A comparative assessment of flood susceptibility modeling using Multi-Criteria Decision-Making Analysis and Machine Learning Methods. J. Hydrol. 2019, 573, 311–323. [Google Scholar] [CrossRef]
- Riley, S.J.; DeGloria, S.D.; Elliot, R. A terrain ruggedness index that quantifies topographic heterogeneity. Intermt. J. Sci. 1999, 5, 23–27. [Google Scholar]
- Costache, R. Flash-Flood Potential assessment in the upper and middle sector of Prahova river catchment (Romania). A comparative approach between four hybrid models. Sci. Total Environ. 2019, 659, 1115–1134. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood susceptibility mapping using a novel ensemble weights-of-evidence and support vector machine models in GIS. J. Hydrol. 2014, 512, 332–343. [Google Scholar] [CrossRef]
- Shahabi, H.; Shirzadi, A.; Ghaderi, K.; Omidvar, E.; Al-Ansari, N.; Clague, J.J.; Geertsema, M.; Khosravi, K.; Amini, A.; Bahrami, S.; et al. Flood Detection and Susceptibility Mapping Using Sentinel-1 Remote Sensing Data and a Machine Learning Approach: Hybrid Intelligence of Bagging Ensemble Based on K-Nearest Neighbor Classifier. Remote Sens. 2020, 12, 266. [Google Scholar] [CrossRef]
- Lee, M.J.; Kang, J.E.; Jeon, S. Application of frequency ratio model and validation for predictive flooded area susceptibility mapping using GIS. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 895–898. [Google Scholar]
- Razavi Termeh, S.V.; Kornejady, A.; Pourghasemi, H.R.; Keesstra, S. Flood susceptibility mapping using novel ensembles of adaptive neuro fuzzy inference system and metaheuristic algorithms. Sci. Total Environ. 2018, 615, 438–451. [Google Scholar] [CrossRef] [PubMed]
- Moore, I.D.; Grayson, R.B.; Ladson, A.R. Digital terrain modelling: A review of hydrological, geomorphological, and biological applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Pan, X.Z.; Pan, K. National 1:4 Million Soil Type Distribution Map (China Soil System Classification System) (2000); National Earth System Science Data Center-Soil Data Center: Nanjing, China, 2015. [CrossRef]
- Waqas, H.; Lu, L.; Tariq, A.; Li, Q.; Baqa, M.F.; Xing, J.; Sajjad, A. Flash Flood Susceptibility Assessment and Zonation Using an Integrating Analytic Hierarchy Process and Frequency Ratio Model for the Chitral District, Khyber Pakhtunkhwa, Pakistan. Water 2021, 13, 1650. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar] [CrossRef]
- Jaafari, A.; Mafi-Gholami, D.; Pham, B.T.; Bui, D.T. Wildfire Probability Mapping: Bivariate vs. Multivariate Statistics. Remote Sens. 2019, 11, 618. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M.C. Classification and Regression by RandomForest. R News 2002, 2, 18–22. [Google Scholar]
- Louppe, G. Understanding Random Forests: From Theory to Practice. Ph.D. thesis, University of Liège, Liège, Belgium, 2014. [Google Scholar]
- Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Bui, D.T.; Pham, B.T.; Khosravi, K. A novel hybrid artificial intelligence approach for flood susceptibility assessment. Environ. Modell. Softw. 2017, 95, 229–245. [Google Scholar] [CrossRef]
- Tang, X.Z.; Li, J.F.; Liu, M.N.; Liu, W.; Hong, H.Y. Flood susceptibility assessment based on a novel random Naive Bayes method: A comparison between different factor discretization methods. Catena 2020, 190, 104536. [Google Scholar] [CrossRef]
- Chen, W.; Hong, H.Y.; Li, S.J.; Shahabi, H.; Wang, Y.; Wang, X.J.; Bin Ahmad, B. Flood susceptibility modelling using novel hybrid approach of reduced-error pruning trees with bagging and random subspace ensembles. J. Hydrol. 2019, 575, 864–873. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y.; Xue, W.F.; Shahabi, H.; Li, S.J.; Hong, H.Y.; Wang, X.J.; Bian, H.Y.; Zhang, S.; Pradhan, B.; et al. Modeling flood susceptibility using data-driven approaches of naive Bayes tree, alternating decision tree, and random forest methods. Sci. Total Environ. 2019, 701, 134979. [Google Scholar] [CrossRef]
- Pahlavan-Rad, M.R.; Dahmardeh, K.; Hadizadeh, M.; Keykha, G.; Mohammadnia, N.; Gangali, M.; Keikha, M.; Davatgar, N.; Brungard, C. Prediction of soil water infiltration using multiple linear regression and random forest in a dry flood plain, eastern Iran. Catena 2020, 194, 104715. [Google Scholar] [CrossRef]
- Guo, F.T.; Wang, G.Y.; Su, Z.W.; Liang, H.L.; Wang, W.H.; Lin, F.F.; Liu, A.Q. What drives forest fire in Fujian, China? Evidence from logistic regression and Random Forests. Int. J. Wildland Fire 2016, 25, 505–519. [Google Scholar] [CrossRef]
- Prasad, A.M.; Iverson, L.R.; Liaw, A. Newer classification and regression tree techniques: Bagging and random forests for ecological prediction. Ecosystems 2006, 9, 181–199. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards, T.C.; Beard, K.H.; Cutler, A.; Hess, K.T. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef] [PubMed]
- Borga, M.; Anagnostou, E.N.; Bloschl, G.; Creutin, J.D. Flash flood forecasting, warning and risk management: The HYDRATE project. Environ. Sci. Policy 2011, 14, 834–844. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LR | RF | ||||
|---|---|---|---|---|---|
| Accuracy | AUC | Accuracy | AUC | ||
| Train data | Fold 1 | 0.9147 | 0.9726 | 0.9302 | 0.9790 |
| Fold 2 | 0.9140 | 0.9604 | 0.9218 | 0.9614 | |
| Fold 3 | 0.8828 | 0.9304 | 0.8906 | 0.9552 | |
| Fold 4 | 0.8593 | 0.9270 | 0.8593 | 0.9181 | |
| Fold 5 | 0.8671 | 0.9372 | 0.8593 | 0.9407 | |
| Fold 6 | 0.8437 | 0.9131 | 0.8984 | 0.9471 | |
| Fold 7 | 0.9062 | 0.9270 | 0.9218 | 0.9603 | |
| Fold 8 | 0.8828 | 0.9433 | 0.875 | 0.9501 | |
| Fold 9 | 0.8281 | 0.9140 | 0.8515 | 0.9162 | |
| Fold 10 | 0.9453 | 0.9626 | 0.9531 | 0.9698 | |
| Mean | 0.8844 | 0.9366 | 0.8961 | 0.9474 | |
| Test data | 0.8634 | 0.9277 | 0.8834 | 0.9486 | |
| Susceptibility Classes | LR | RF | ||
|---|---|---|---|---|
| Quantile | Nature Breaks | Quantile | Nature Breaks | |
| Very low | 3 | 3 | 3 | 5 |
| Low | 8 | 11 | 2 | 3 |
| Moderate | 21 | 23 | 1 | 16 |
| High | 52 | 50 | 11 | 63 |
| Very high | 831 | 828 | 898 | 828 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Zhang, H.; Zhao, J.; Guo, X.; Rihan, W.; Deng, G. Embedded Feature Selection and Machine Learning Methods for Flash Flood Susceptibility-Mapping in the Mainstream Songhua River Basin, China. Remote Sens. 2022, 14, 5523. https://doi.org/10.3390/rs14215523
Li J, Zhang H, Zhao J, Guo X, Rihan W, Deng G. Embedded Feature Selection and Machine Learning Methods for Flash Flood Susceptibility-Mapping in the Mainstream Songhua River Basin, China. Remote Sensing. 2022; 14(21):5523. https://doi.org/10.3390/rs14215523
Chicago/Turabian StyleLi, Jianuo, Hongyan Zhang, Jianjun Zhao, Xiaoyi Guo, Wu Rihan, and Guorong Deng. 2022. "Embedded Feature Selection and Machine Learning Methods for Flash Flood Susceptibility-Mapping in the Mainstream Songhua River Basin, China" Remote Sensing 14, no. 21: 5523. https://doi.org/10.3390/rs14215523
APA StyleLi, J., Zhang, H., Zhao, J., Guo, X., Rihan, W., & Deng, G. (2022). Embedded Feature Selection and Machine Learning Methods for Flash Flood Susceptibility-Mapping in the Mainstream Songhua River Basin, China. Remote Sensing, 14(21), 5523. https://doi.org/10.3390/rs14215523