
An Automatic Velocity Analysis Method for Seismic Data-Containing Multiples

Abstract
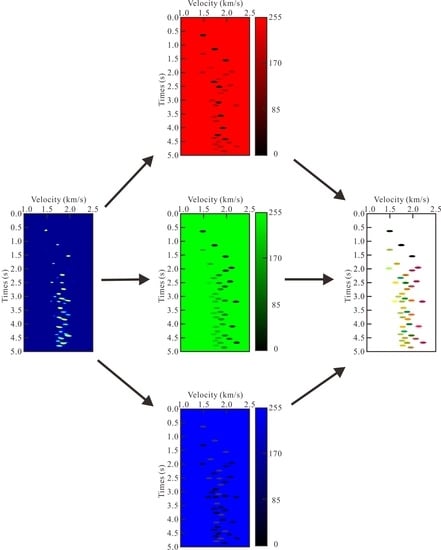
1. Introduction
2. Materials and Methods
2.1. Common Automatic Velocity Analysis
2.2. Multiple Independent Automatic Velocity Analysis
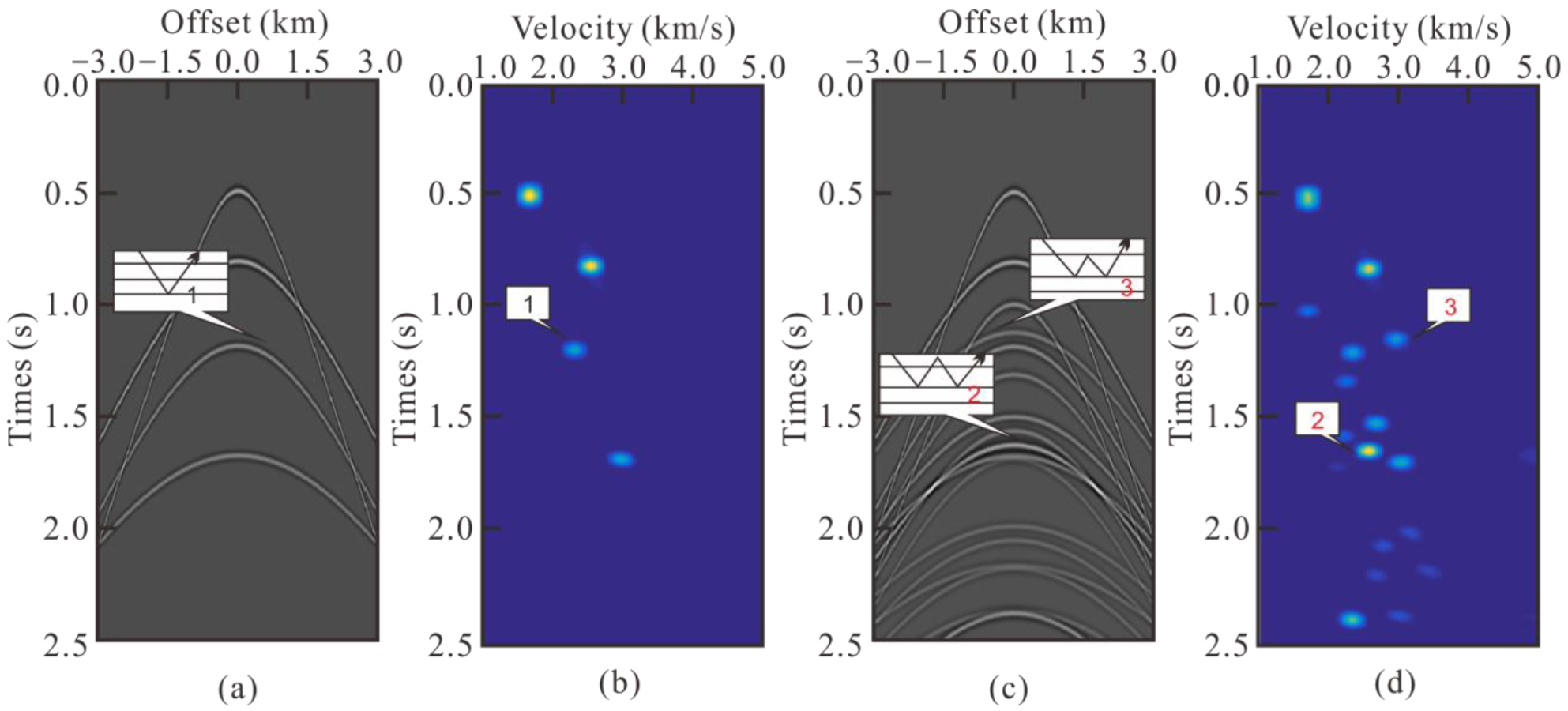
2.2.1. Peak Picking
2.2.2. Attribution of Predicted Multiples
2.2.3. Peaks Identification of Primary Reflection Based on the Multi-Attribute Analysis
- (1)
- Determine the optimal peak and the worst peak ;
- (2)
- Obtain the relative proximity between each peak and the optimal peak;
- (3)
- Determine the dividing point of primary and multiple reflections through the inflection point of evaluation results [65].
| Algorithm 1: Multiple Independent Automatic Velocity Analysis Algorithm |
| (1) Input: Original data containing multiples , Predicted multiple generated by modularization |
| (2) Calculate the velocity spectra for: , |
| (3) Peak picking in velocity spectra : |
| (4) Attribute predicted multiples: |
| (5) |
| (6) Main cycle: |
| (9) Acquire MS attribute: |
| (10) Acquire VVD attribute: |
| (11) Acquire AL attribute: |
| (12) |
| (13) Until |
| (14) Regularization: , , |
| (15) Determine primary based on Multi-attribute Analysis theory: Calculate relative proximity: , Determine the dividing point between primaries and multiples (Inflection point): |
| (16) RGB space mapping |
| (17) Output: Velocity curve, RGB velocity spectra |
3. Results
4. Discussion
4.1. Sensitivity to Multiple
4.2. Processing Detail
4.3. Usage Recommendation
- (1)
- Batch processing when the data size is too large. For instance, when processing three-dimensional data, automatic velocity analysis can reduce a lot of burden in the face of massive CMPs. The proposed method is fully automatic and multiple-independent, which is more suitable for adaptive batch processing.
- (2)
- Instead of the traditional semblance spectra, the RGB-based color spectra provide a more intuitive distinction between primaries and multiples. The color of each peak implies rich geophysical information, which can be used as a reference for manual picking. The relationship between seismic wavefield and color is shown in Table 3:
4.4. Potential Research Directions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Chen, Y. Automatic velocity analysis using high-resolution hyperbolic Radon transform. Geophysics 2018, 83, A53–A57. [Google Scholar] [CrossRef]
- Virieux, J.; Asnaashari, A.; Brossier, R.; Métivier, L.; Ribodetti, A.; Zhou, W. An introduction to full waveform inversion. In Encyclopedia of Exploration Geophysics; Society of Exploration Geophysicists: Houston, TX, USA, 2017; pp. R1-1–R1-40. [Google Scholar] [CrossRef]
- Verschuur, D.; Staal, X.; Berkhout, A. Joint migration inversion: Simultaneous determination of velocity fields and depth images using all orders of scattering. Lead. Edge 2016, 35, 1037–1046. [Google Scholar] [CrossRef]
- Tanis, M.C.; Shah, H.; Watson, P.A.; Harrison, M.; Yang, S.; Lu, L.; Carvill, C. Diving-wave refraction tomography and reflection tomography for velocity model building. In Proceedings of the 2006 SEG Annual Meeting, New Orleans, LA, USA, 1–6 October 2006. [Google Scholar] [CrossRef]
- Luo, S.; Hale, D. Velocity analysis using weighted semblance. Geophysics 2012, 77, U15–U22. [Google Scholar] [CrossRef]
- Kazei, V.; Ovcharenko, O.; Plotnitskii, P.; Peter, D.; Zhang, X.; Alkhalifah, T. Mapping full seismic waveforms to vertical velocity profiles by deep learning. Geophysics 2021, 86, R711–R721. [Google Scholar] [CrossRef]
- Khoshnavaz, M.J. High-resolution seismic velocity analysis by sign-based weighted semblance. Geophysics 2021, 86, U135–U143. [Google Scholar] [CrossRef]
- Wilson, H.; Gross, L. Reflection-constrained 2D and 3D non-hyperbolic moveout analysis using particle swarm optimization. Geophys. Prospect. 2019, 67, 550–571. [Google Scholar] [CrossRef]
- Taner, M.T.; Koehler, F. Velocity spectra—Digital computer derivation applications of velocity functions. Geophysics 1969, 34, 859–881. [Google Scholar] [CrossRef]
- Alkhalifah, T. Seismic data processing in vertically inhomogeneous TI media. Geophysics 1997, 62, 662–675. [Google Scholar] [CrossRef]
- Virieux, J.; Operto, S. An overview of full-waveform inversion in exploration geophysics. Geophysics 2009, 74, WCC1–WCC26. [Google Scholar] [CrossRef]
- Yilmaz, Ö. Seismic Data Analysis: Processing, Inversion, and Interpretation of Seismic Data; Society of Exploration Geophysicists: Houston, TX, USA, 2001. [Google Scholar] [CrossRef]
- Zhou, H.-W.; Hu, H.; Zou, Z.; Wo, Y.; Youn, O. Reverse time migration: A prospect of seismic imaging methodology. Earth-Sci. Rev. 2018, 179, 207–227. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, T.; Chen, X. Velocity analysis using similarity-weighted semblance. Geophysics 2015, 80, A75–A82. [Google Scholar] [CrossRef]
- Li, Y.; Zhao, D.; Yu, S. Status and trend on land seismic acquisition technique of SINOPEC. Geophys. Prospect. Pet. 2013, 52, 363–371. (In Chinese) [Google Scholar]
- Toldi, J.L. Velocity analysis without picking. Geophysics 1989, 54, 191–199. [Google Scholar] [CrossRef]
- Lumley, D.E. Monte Carlo automatic velocity picks. SEP Rep. 1997, 75, 1–25. [Google Scholar]
- Fomel, S. Velocity analysis using AB semblance. Geophys. Prospect. 2009, 57, 311–321. [Google Scholar] [CrossRef]
- Gan, S.; Wang, S.; Chen, Y.; Qu, S.; Zu, S. Velocity analysis of simultaneous-source data using high-resolution semblance-coping with the strong noise. Geophys. J. Int. 2016, 204, 768–779. [Google Scholar] [CrossRef]
- Gong, X.; Wang, S.; Zhang, T. Velocity analysis using high-resolution semblance based on sparse hyperbolic Radon transform. J. Appl. Geophys. 2016, 134, 146–152. [Google Scholar] [CrossRef]
- Ebrahimi, S.; Kahoo, A.R.; Chen, Y.; Porsani, M. A high-resolution weighted AB semblance for dealing with amplitude-variation-with-offset phenomenon. Geophysics 2017, 82, V85–V93. [Google Scholar] [CrossRef]
- Liu, G.; Li, C.; Liu, X.; Ge, Q.; Chen, X. Automatic stacking-velocity estimation using similarity-weighted clustering. Geophys. Prospect. 2018, 66, 649–663. [Google Scholar] [CrossRef]
- Velis, D. Simulated annealing velocity analysis: Automating the picking process. Geophysics 2021, 86, V119–V130. [Google Scholar] [CrossRef]
- Mulder, W.A.; ten Kroode, A.P.E. Automatic velocity analysis by differential semblance optimization. Geophysics 2002, 67, 1184–1191. [Google Scholar] [CrossRef]
- Shen, P.; Symes, W.W. Automatic velocity analysis via shot profile migration. Geophysics 2008, 73, VE49–VE59. [Google Scholar] [CrossRef]
- Li, J.; Symes, W.W. Interval velocity estimation via NMO-based differential semblance. Geophysics 2007, 72, U75–U88. [Google Scholar] [CrossRef]
- Zhang, Y.; Biondi, B. Moveout-based wave-equation migration velocity analysis. Geophysics 2013, 78, U31–U39. [Google Scholar] [CrossRef][Green Version]
- Weibull, W.W.; Arntsen, B. Automatic velocity analysis with reverse-time migration. Geophysics 2013, 78, S179–S192. [Google Scholar] [CrossRef]
- Sun, B.; Alkhalifah, T. Automatic wave-equation migration velocity analysis by focusing subsurface virtual sources. Geophysics 2018, 83, U1–U8. [Google Scholar] [CrossRef]
- Choi, H.; Byun, J.; Seol, S.J. Automatic velocity analysis using bootstrapped differential semblance and global search methods. Explor. Geophys. 2010, 41, 31–39. [Google Scholar] [CrossRef]
- Zuberi, A.; Alkhalifah, T. Imaging by forward propagating the data: Theory and application. Geophys. Prospect. 2013, 61, 248–267. [Google Scholar] [CrossRef]
- Zuberi, M.A.H.; Alkhalifah, T. Generalized internal multiple imaging (GIMI) using Feynman-like diagrams. Geophys. J. Int. 2014, 197, 1582–1592. [Google Scholar] [CrossRef][Green Version]
- Singh, S.; Snieder, R.; Behura, J.; van der Neut, J.; Wapenaar, K.; Slob, E. Marchenko imaging: Imaging with primaries, internal multiples, and free-surface multiples. Geophysics 2015, 80, S165–S174. [Google Scholar] [CrossRef]
- Leite, L.W.B.; Vieira, W.W.S. Automatic seismic velocity analysis based on nonlinear optimization of the semblance function. J. Appl. Geophys. 2019, 161, 182–192. [Google Scholar] [CrossRef]
- Weglein, A.B.; Hsu, S.-Y.; Terenghi, P.; Li, X.; Stolt, R.H. Multiple attenuation: Recent advances and the road ahead. Lead. Edge 2011, 30, 864–875. [Google Scholar] [CrossRef]
- Wang, Y.H. Multiple attenuation: Coping with the spatial truncation effect in the Radon transform domain. Geophys. Prospect. 2003, 51, 75–87. [Google Scholar] [CrossRef]
- Herrmann, F.J.; Boeniger, U.; Verschuur, D.J. Non-linear primary-multiple separation with directional curvelet frames. Geophys. J. Int. 2007, 170, 781–799. [Google Scholar] [CrossRef]
- de Souza, M.S.; Porsani, M.J. Automatic velocity analysis using complex seismic traces. In Proceedings of the 14th International Congress of the Brazilian Geophysical Society & EXPOGEF, Rio de Janeiro, Brazil, 3–6 August 2015; pp. 1337–1341. [Google Scholar] [CrossRef]
- He, W.; Geng, J. Elimination of free-surface-related multiples by combining Marchenko scheme and seismic interferometry. Geophysics 2022, 87, Q1–Q14. [Google Scholar] [CrossRef]
- Wiggins, J.W. Attenuation of complex water-bottom multiples by wave-equation-based prediction and subtraction. Geophysics 1988, 53, 1527–1539. [Google Scholar] [CrossRef]
- Verschuur, D.J.; Berkhout, A.; Wapenaar, C. Adaptive surface-related multiple elimination. Geophysics 1992, 57, 1166–1177. [Google Scholar] [CrossRef]
- Verschuur, D.J.; Berkhout, A.J. Removal of internal multiples with the common-focus-point (CFP) approach: Part 2—Application strategies and data examples. Geophysics 2005, 70, V61–V72. [Google Scholar] [CrossRef]
- Guitton, A.; Verschuur, D. Adaptive subtraction of multiples using the L1-norm. Geophys. Prospect. 2004, 52, 27–38. [Google Scholar] [CrossRef]
- Herrmann, F.J.; Wang, D.; Verschuur, D.J. Adaptive curvelet-domain primary-multiple separation. Geophysics 2008, 73, A17–A21. [Google Scholar] [CrossRef]
- Li, Z.-x. Adaptive multiple subtraction based on support vector regression. Geophysics 2020, 85, V57–V69. [Google Scholar] [CrossRef]
- Dragoset, B.; Verschuur, E.; Moore, I.; Bisley, R. A perspective on 3D surface-related multiple elimination. Geophysics 2010, 75, A245–A261. [Google Scholar] [CrossRef]
- Natan. Fast 2D Peak Finder. 2021. Available online: https://www.mathworks.com/matlabcentral/fileexchange/37388-fast-2d-peak-finder (accessed on 26 May 2021).
- Fomel, S. Local seismic attributes. Geophysics 2007, 72, A29–A33. [Google Scholar] [CrossRef]
- Hu, B.; Wang, D.; Wang, R. An Iterative Focal Denoising Strategy for Passive Seismic Data. Pure Appl. Geophys. 2020, 177, 4607–4622. [Google Scholar] [CrossRef]
- Claerbout, J.F.; Abma, R. Earth Soundings Analysis: Processing versus Inversion; Blackwell Scientific Publications: London, UK, 1992; Volume 6. [Google Scholar]
- Fomel, S.; Jin, L. Time-lapse image registration using the local similarity attribute. Geophysics 2009, 74, A7–A11. [Google Scholar] [CrossRef]
- Jiménez, A.; Ríos-Insua, S.; Mateos, A. A generic multi-attribute analysis system. Comput. Oper. Res. 2006, 33, 1081–1101. [Google Scholar] [CrossRef]
- Ríos-Insua, S.; Gallego, E.; Jiménez, A.; Mateos, A. A multi-attribute decision support system for selecting intervention strategies for radionuclide contaminated freshwater ecosystems. Ecol. Model. 2006, 196, 195–208. [Google Scholar] [CrossRef]
- Shevchenko, G.; Ustinovichius, L.; Andruškevičius, A. Multi-attribute analysis of investments risk alternatives in construction. Technol. Econ. Dev. Econ. 2008, 14, 428–443. [Google Scholar] [CrossRef]
- Zavadskas, E.K.; Turskis, Z.; Kildiene, S. State of art surveys of overviews on mcdm/madm methods. Technol. Econ. Dev. Econ. 2014, 20, 165–179. [Google Scholar] [CrossRef]
- Ferreira, R.S.; Oliveira, D.A.B.; Semin, D.G.; Zaytsev, S. Automatic Velocity Analysis Using a Hybrid Regression Approach With Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4464–4470. [Google Scholar] [CrossRef]
- Abbad, B.; Ursin, B.; Rappin, D. Automatic nonhyperbolic velocity analysis. Geophysics 2010, 75, Y3. [Google Scholar] [CrossRef]
- Van der Baan, M.; Kendall, J.M. Estimating anisotropy parameters and traveltimes in the τ-p domain. Geophysics 2002, 67, 1076–1086. [Google Scholar] [CrossRef]
- Sheriff, R.E.; Geldart, L.P. Exploration Seismology; Cambridge University Press: Cambridge, UK, 1995. [Google Scholar]
- Chen, C.-T. Extensions of the TOPSIS for group decision-making under fuzzy environment. Fuzzy Sets Syst. 2000, 114, 1–9. [Google Scholar] [CrossRef]
- Xu, Z. Uncertain Multi-Attribute Decision Making: Methods and Applications; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar] [CrossRef]
- Shih, H.-S.; Shyur, H.-J.; Lee, E.S. An extension of TOPSIS for group decision making. Math. Comput. Model. 2007, 45, 801–813. [Google Scholar] [CrossRef]
- Zavadskas, E.K.; Mardani, A.; Turskis, Z.; Jusoh, A.; Nor, K.M. Development of TOPSIS method to solve complicated decision-making problems—An overview on developments from 2000 to 2015. Int. J. Inf. Technol. Decis. Mak. 2016, 15, 645–682. [Google Scholar] [CrossRef]
- Yoon, K.P.; Kim, W.K. The behavioral TOPSIS. Expert Syst. Appl. 2017, 89, 266–272. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Shi, X.; Yang, C.; Wang, W.; Li, Y. Risk evaluation of coal spontaneous combustion on the basis of auto-ignition temperature. Fuel 2018, 233, 68–76. [Google Scholar] [CrossRef]
- Vega, A.; Aguaron, J.; Garcia-Alcaraz, J.; Mara Moreno-Jimenez, J. Notes on Dependent Attributes in TOPSIS. In Proceedings of the 2nd International Conference on Information Technology and Quantitative Management (ITQM), the National Research University Higher School of Economics, Moscow, Russia, 3–5 June 2014; pp. 308–317. [Google Scholar] [CrossRef]
- Papathanasiou, J.; Ploskas, N. Topsis. In Multiple Criteria Decision Aid; Springer: Berlin/Heidelberg, Germany, 2018; pp. 1–30. [Google Scholar] [CrossRef]
- Hua, Z.; Gong, B.; Xu, X. A DS-AHP approach for multi-attribute decision making problem with incomplete information. Expert Syst. Appl. 2008, 34, 2221–2227. [Google Scholar] [CrossRef]
- Abdalla, A.; Cen, H.; Abdel-Rahman, E.; Wan, L.; He, Y. Color Calibration of Proximal Sensing RGB Images of Oilseed Rape Canopy via Deep Learning Combined with K-Means Algorithm. Remote Sens. 2019, 11, 3001. [Google Scholar] [CrossRef]
- Verm, R.W.; Symes, W.W. Practice and pitfalls in NMO-based differential semblance velocity analysis. In SEG Technical Program Expanded Abstracts 2006; Society of Exploration Geophysicists: Houston, TX, USA, 2006; pp. 2112–2116. [Google Scholar] [CrossRef]
- Berkhout, A.J.; Verschuur, D.J. Removal of internal multiples with the common-focus-point (CFP) approach: Part 1—Explanation of the theory. Geophysics 2005, 70, V45–V60. [Google Scholar] [CrossRef]
- Ding, C.; Ma, J. Automatic migration velocity analysis via deep learning. Geophysics 2022, 87, U135–U153. [Google Scholar] [CrossRef]
- Park, M.J.; Sacchi, M.D. Automatic velocity analysis using convolutional neural network and transfer learning. Geophysics 2020, 85, V33–V43. [Google Scholar] [CrossRef]
- Crowe, T.J.; Noble, J.S.; Machimada, J.S. Multi-attribute analysis of ISO 9000 registration using AHP. Int. J. Qual. Reliab. Manag. 1998, 15, 205–222. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Maximum | Minimum | Average | Median | |
|---|---|---|---|---|
| Primary | 6.0 × 10−6 | 1.6 × 10−11 | 2.1 × 10−6 | 3.0 × 10−7 |
| Multiple | 2.1 × 10−1 | 4.2 × 10−3 | 9.7 × 10−2 | 7.8 × 10−2 |
| MB | RT | MS | MI | |
|---|---|---|---|---|
| 6.0% | 5.4% | 5.0% | 1.3% |
| Type | Features | Color |
|---|---|---|
| Primary | low similarity, high velocity and amplitude in common |  |
| Internal multiple | low amplitude, high similarity. velocity relates to the developed formation. |  |
| Surface-related multiple | high similarity, velocity relates to shallow formation, amplitude could be high. |  |
| Suspicious peak | the peak should be focused on |  |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Wang, D.; Hu, B.; Gong, X. An Automatic Velocity Analysis Method for Seismic Data-Containing Multiples. Remote Sens. 2022, 14, 5428. https://doi.org/10.3390/rs14215428
Zhang J, Wang D, Hu B, Gong X. An Automatic Velocity Analysis Method for Seismic Data-Containing Multiples. Remote Sensing. 2022; 14(21):5428. https://doi.org/10.3390/rs14215428
Chicago/Turabian StyleZhang, Junming, Deli Wang, Bin Hu, and Xiangbo Gong. 2022. "An Automatic Velocity Analysis Method for Seismic Data-Containing Multiples" Remote Sensing 14, no. 21: 5428. https://doi.org/10.3390/rs14215428
APA StyleZhang, J., Wang, D., Hu, B., & Gong, X. (2022). An Automatic Velocity Analysis Method for Seismic Data-Containing Multiples. Remote Sensing, 14(21), 5428. https://doi.org/10.3390/rs14215428