1. Introduction
Agriculture is a key sector from an economic, social, and environmental point of view. Because of its high demand for water and nutrient inputs for increasing the yield, agriculture places high pressure on the surface and groundwater resources. This is an important issue for governments, policymakers, farmers, and other organizations, as estimations predict that, in order to cover the food demand by 2050, a 60% increment production will be needed [
1]. Policies from the international to local scale are facing the challenge of providing natural resource managers with the tools required for the sustainability of food supply sectors and resilience to climate change [
2,
3,
4]. In particular, the European and national authorities estimate the number of subsidies on the farm scale by considering farmers’ reports about their practices for crop management, such as water use, fertilizers, and energy, which are properly supervised by experts who help to encourage sustainable use. In this scenario, precise crop and land use classification (LUC) are necessary for assisting in the management of sustainable natural resources [
5] and also facing the consequences of climate change [
6]. LUC is the basic information required for the sustainable use of land, water, energy management, and the environment [
7]. Nevertheless, even gathering information about the harvested crops and their management has a high cost when it requires fieldwork.
Remote sensing is one of the main sources of information in this context. It can be applied to large areas and provides classification maps at a lower cost. The plot scale in remote sensing is limited by the pixel size of the images acquired by the sensors. However, due to the increase in both the spatiotemporal resolution of the data and processing power, improvements are becoming important in recent years [
8]. Hence, Sentinel and Landsat constellations provide data to monitor plots below 0.3 ha, which is adequate for most agricultural areas [
9].
Traditionally, the generation of an LUC map has consisted of the examination of multi-spectral and temporal sensor data at single positions and their surrounding areas. Therefore, a long time series of images at a high temporal frequency provides data that can be used to identify vegetation types with a high confidence level [
10]. Those algorithms are based on biophysical variables that vary over time according to the specific phenology of each crop, the agronomic management, and the environmental conditions. Regarding the importance of such temporal signatures, sensors with a high temporal resolution, such as MODIS, have been used for this purpose despite their low resolution (from 250 m to 1 km depending on the data) [
11,
12], providing good results, since they gather the sequential information of a specific location over time [
13]. The scenario is even more favorable nowadays, as there is an availability of multi-spectral remote sensing data of a relatively fine resolution (from 10 m to 60 m), provided by the Sentinel 2 constellation with a reasonable revisit frequency of 5 days [
14].
The first generation of procedures for LUC maps relied on experts who built models based on indexes calculated from the bands of the satellite images, such as the temporal evolution of NDVI, which is calculated as the near-infrared (NIR) minus red reflectance, divided by the near-infrared plus red reflectance [
15]. NDVI can be used to identify the land use of a single point with a reasonable computational cost [
16]. The attempts and the progress in efforts to automate the process of land use classification are moving towards the use of machine learning, an area of artificial intelligence. Machine learning models use features to identify patterns in datasets. When such patterns involve a target variable, these can be used to perform tasks such as classification. Gilabert et al. showed that temporal information can be extracted from the spectral bands [
17]. Experts manually fine-tuned the rules of those interpretable models based on simpler variables, according to their expertise regarding how features determine the type of crop and the knowledge about a concrete region [
18]. Foerster et al. [
13] and Hao et al. [
19] proposed solutions based on NDVI that use decision trees and random forest models, respectively, with a pixel-based approach. J. Inglada et al. tested random forests and support vector machines in crop classification using feature extractions, such as derived indices [
9]. Immitzer et al. proved that the most important bands of the Sentinel-2 images are the blue, red-edge, and shortwave infrared for crop classification in a study applying a random forest model [
20]. Additionally, authors such as Hao et al. indicated that it is possible to merge datasets with a similar spatial resolution in order to enrich the time series [
21]. Zhou et al. reported that optimizing the required number of images, resulting in a reduction in the time series length, had almost no impact on the accuracy of the classification [
22].
On the other hand, deep learning is a recently adopted technique based on neural networks that infer those characteristics directly from data, comprising fewer pre-processing steps and improving the results, as compared to machine learning models [
23]. There are many neural network types, but the convolutional (CNNs) and recurrent (RNNs) neural networks are the most useful in LUC. CNNs are mainly employed to process visual imagery, whereas RNNs are related to tasks whose input is sequential data [
24,
25]. As explained previously, deep learning algorithms represent a step forward, as they open the way to automatically apply models to time series of images collected from satellites throughout a crop cycle, classifying herbaceous and orchards crops and distinguishing between irrigated and non-irrigated lands. Consequently, despite not obtaining a fully automatic method of classification that is valid for all the land use cases, the use of deep learning models results in a reduction in the workload. Lyu et al. proposed an LSTM (long short-term memory, a kind of RNN) to extract spectral and temporal characteristics for change detection [
26]. This work was continued by Mou et al. with the use of Conv2D layers to extract spatial features to be inputted to LSTM layers. This network, which enhanced the detection of the temporal dependency, achieved better results than detection algorithms based on spatial features alone [
27]. The efficiency and the ability to ignore the shift in data so as to recognize patterns mean that the learning process of CNNs is the most suitable for image recognition [
28]. Rußwurm and Körner extracted temporal features from image sequences to identify crop types with LSTMs [
29]. They enhanced this model by using Conv2D layers to extract spatial features and an RNN with a bidirectional sequential encoder to introduce a sequence in a bidirectional manner [
30]. Zhong et al. showed that models based on one-dimension convolutional layers (Conv1D) achieved better results than models which rely on long short-term memory layers, which achieved worse results despite being useful for analyzing sequential data. The Conv1D-based model achieved the best result among the tested classifiers [
23]. Campos-Taberner et al. proposed a deep learning solution based on a recurrent neural network model with 2 Bi-LSTM layers and a fully connected layer to classify 10 crops using Sentinel-2 images and their bands, in addition to NDVI and enhanced NDVI [
31]. Portalés-Julià et al. assessed Sentinel-2’s capabilities in identifying abandoned crops, achieving the best results with the Bi-LSTM neural networks and random forest by classifying two major classes: active or abandoned crops and eight subclasses [
32]. Ruiz et al. presented a classification model using CNNs with very-high-resolution aerial orthoimages from the Spanish plan of aircraft orthophotography (PNOA) and calculated the NDVI from a Sentinel-2 level 2A image time series to determine the type of soil, according to six different classes and whether they were abandoned or not [
33]. Amani et al. showed that models firstly trained offline can be used on cloud platforms and applied to classify available online data, taking advantage of their satellite imagery and geospatial datasets on the planetary scale [
34].
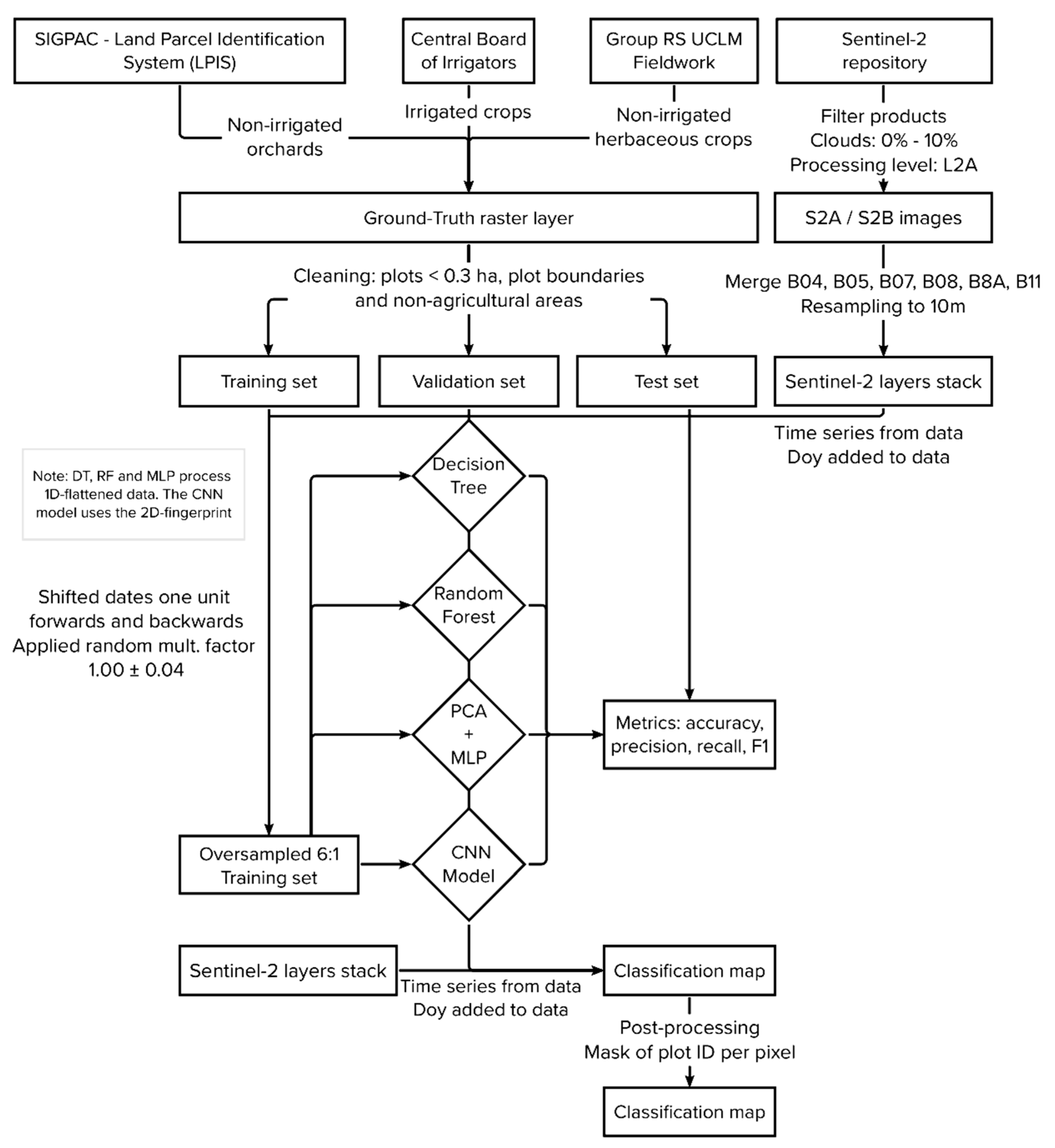
In this article, we propose a model for land use classification that requires few images and offers good results in the area of our focus. While some previous models work at the image level, carrying out segmentation and requiring large datasets, we consider that: (i) a pixel can contain enough information to successfully perform classification; (ii) part of this information lies in multispectral temporal patterns; and (iii) although such patterns are not especially complex, existing works based on random forest might not capture them, whereas others models, such as LTSM, are unnecessarily complex and require larger sequences. Based on these assumptions, we propose an approach that arranges the information corresponding to a pixel as a 2D yearly fingerprint and uses a convolution-based model (CNN) for the prediction. This approach can render multispectral temporal patterns more explicit and improve the classification. In fact, the state-of-the-art algorithms for time series classification are based on convolutions [
35,
36]. We also added a problem-specific process of oversampling, trying to deal with variations in phenology. We used this approach to perform (i) the classification of the main crop classes, focusing on herbaceous and woody crops, and (ii) discrimination between irrigated and non-irrigated areas.
Therefore, a relevant contribution of this work is the consequent improvement in pixel-based land use classification with a small number of images by representing data as a 2D fingerprint and using a CNN model. We tested our proposal in a well-known agricultural area in the Mancha Oriental aquifer in Spain. Improvement regarding these issues is of great interest, as land use information is a basic input for water accounting [
37], water footprint estimations for environmental management [
38], and yield prediction modelling [
39].
4. Discussion
The core information for the crop classification comes from the Sentinel 2A and 2B constellations of the Copernicus program, which, nowadays, provide a high temporal and spatial resolution. A total of 24 images gathered on different dates from March to October were used. Despite observing a considerable time gap between May and June in this application, such a situation did not affect the performance of the model, as shown by the results. Additional data from different sources could be added, such as Landsat or national orthophotography program images and local sensors, so as to provide biophysical variables. For operational purposes, according to the computational resources, and to ensure the future scalability to other areas, Sentinel-2 sensors provide enough information for a successful classification for the purpose of pursuing an automatic process.
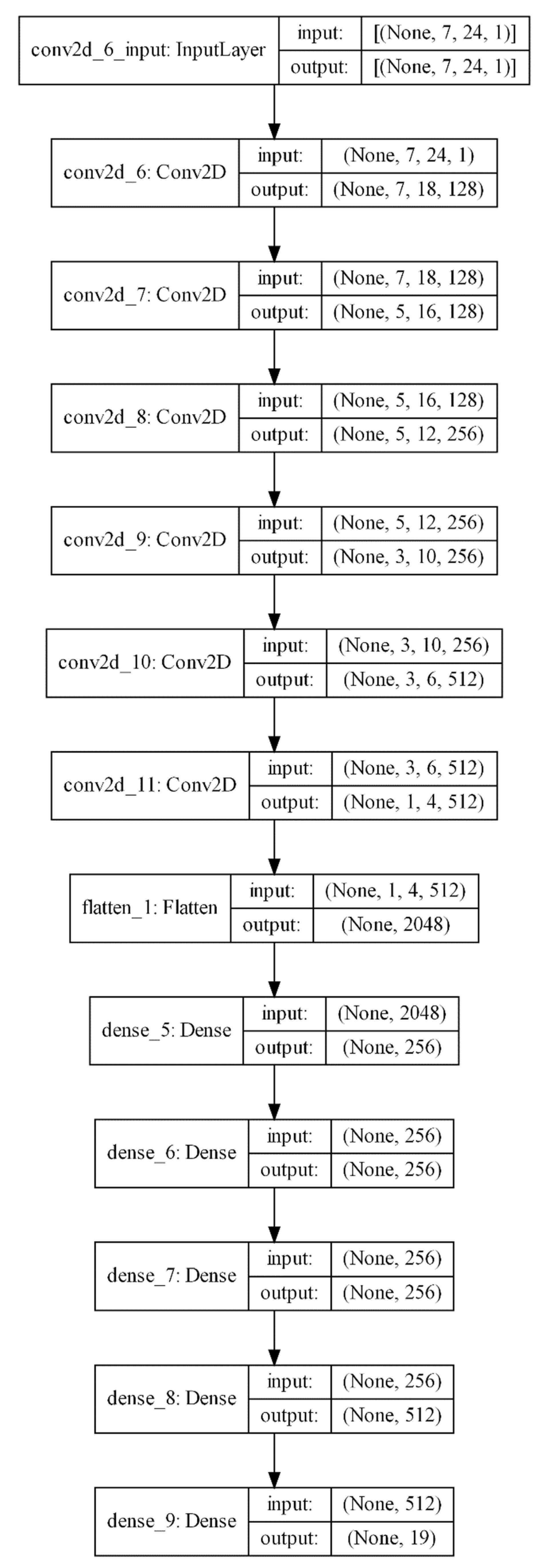
Our main objective was to represent the sequential data as a 2D spectro-temporal fingerprint of each pixel, which is particularly interesting with respect to its processing with machine learning. Therefore, it was tested using several algorithms, including CNNs, reducing the number of parameters for the fully connected layers and thus obtaining an enhancement of the speed and a reduction in the complexity of the model used to train and evaluate the data. The process of classification, designed to generate a land use cover, considers only the multispectral and temporal dimensions of the information at the pixel level.
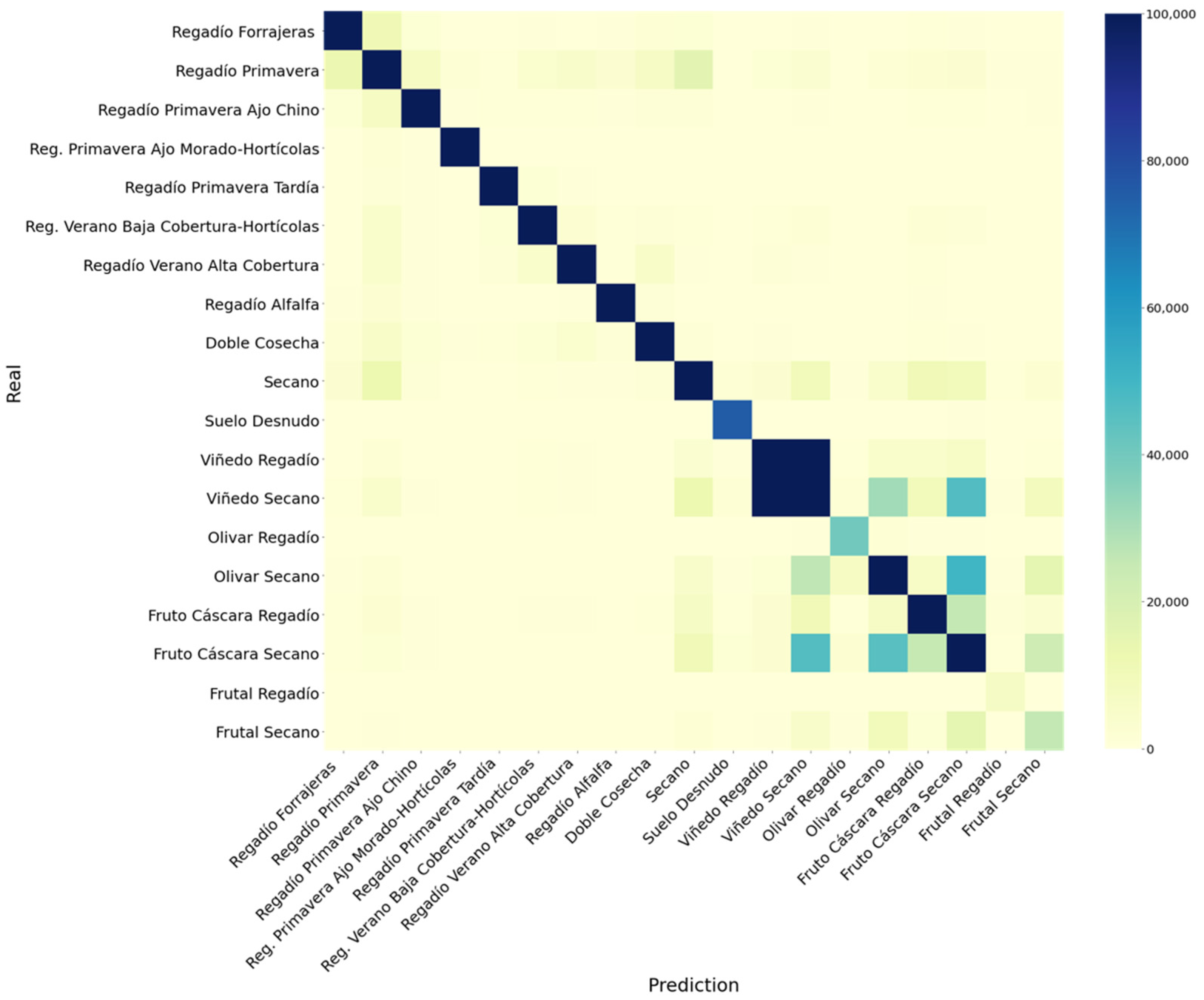
The convolutional neural network output was compared to those generated using other, simpler algorithms in global terms (
Table 12) and compared by considering each separate class (
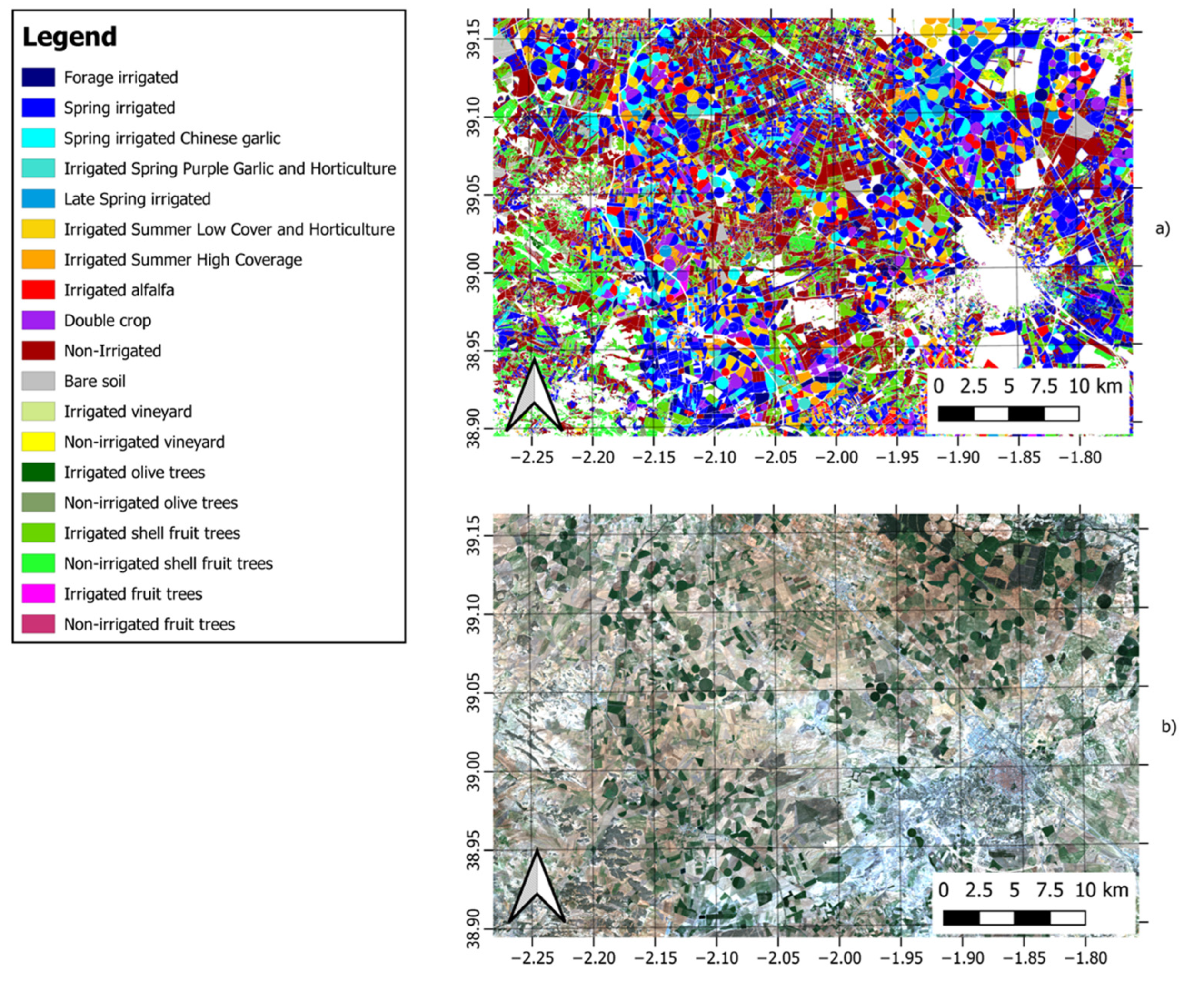
Table 13). CNNs were proved to outperform any other model applied to the experimental data considered in this study with a similar prediction time. Since the training phase can only take place once the model has been updated, the improvement in global accuracy highly compensates for the training time, which is important for generating reliable land use classification maps. Both the overall accuracy and weighted average F1 are affected by all the results achieved for every class. In general, the performance of all the models considered is high. However, considering the resolution of the satellite images, we expected this to result in a slightly lower performance in the case of orchards. The mismatches between these classes correspond mainly to the same aggregated categories distinguishing between irrigated and non-irrigated crops. Considering the importance of identifying irrigated crops, a specific model for this purpose was considered, using the same architecture, to identify the irrigated land use, showing a 95% accuracy and a 95% F1, whereas it increased to 97% for both metrics when post-processing was applied.
According to the proposals shown in
Table 14, different types of models can be used in land use classification. These include traditional models based on decision trees and random forests, which constitute one of the most successful machine learning methods and deep learning models based on the use of recurrent neural networks, such as long short-term memory and convolutional neural networks.
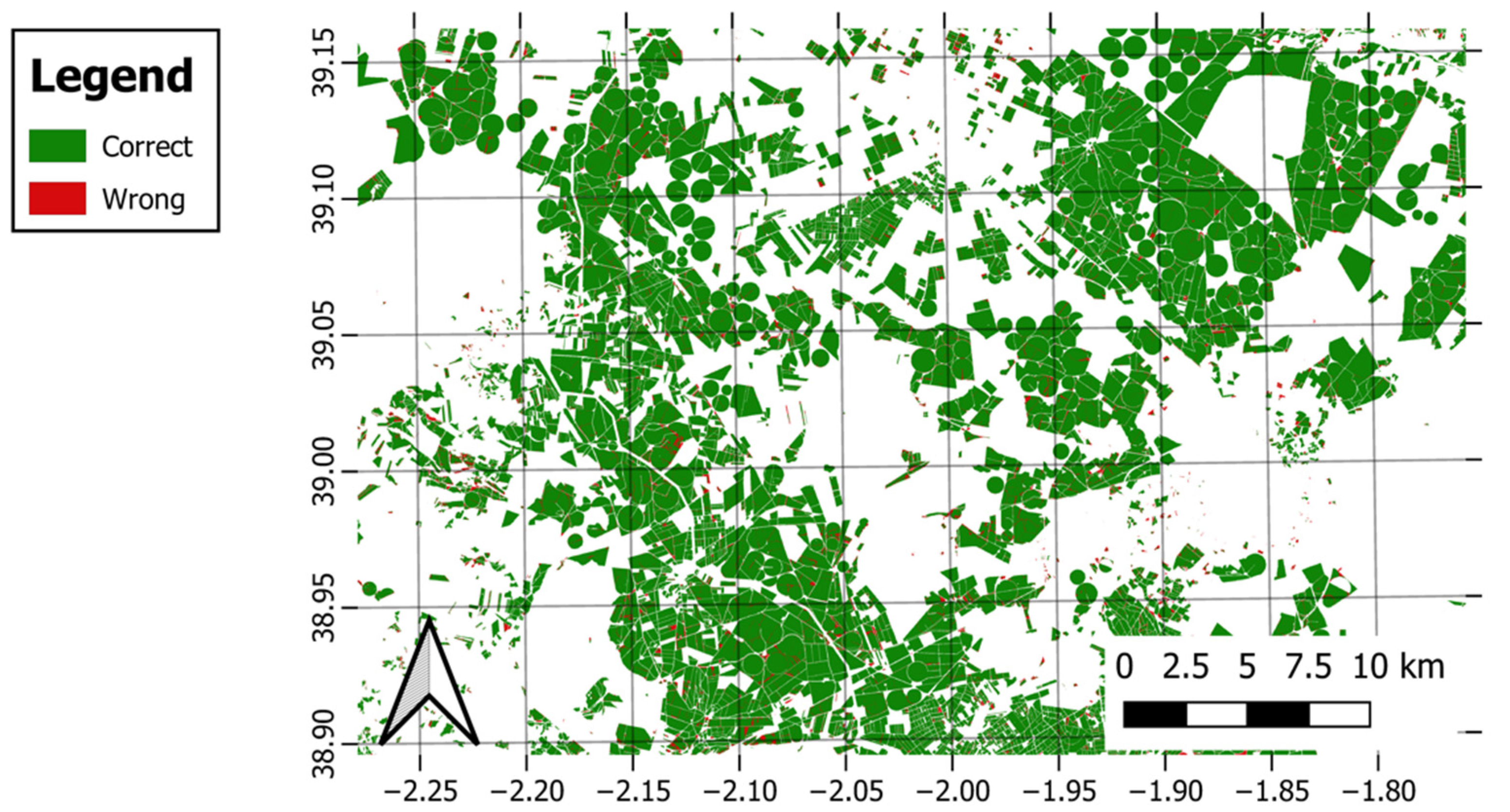
Similar works applied to a set of images with pixel sizes larger than the plot showed a low accuracy of 50% in crop classification in some areas because of the presence of trees in the fields and the lack of resolution [
9]. In light of this, the input information was filtered with a minimum threshold of 0.3 ha per plot, as explained in the methodology.
Hao et al. proposed a model which employs the phenological features obtained from a MODIS time series, whose resolution is lower than that of Landsat and Sentinel-2 images. They aimed to classify a reduced group of six classes, achieving an overall accuracy of 89% with a model based on random forest [
19].
As Fan et al. demonstrated [
58], the data volume of the Sentinel 2 images is large compared to the data provided by other satellites because of the medium-high resolution of the sensors. Therefore, we considered a similar solution, optimizing the volume of the training, while obtaining data to enable the model to learn without making the training set too large to be processed. Their model consists of a random forest that classifies the land use among nine classes. In this respect, it is necessary to point out that, when comparing algorithms, a smaller number of classes leads to simpler and more accurate models. In our proposal, we used CNNs inspired by Zhong et al.’s work [
23], consisting of Conv1D layers that can be used to extract temporal patterns from an enhanced vegetation index (EVI) time series for 14 classes, whereas our model used Conv2D layers to extract temporal and multispectral patterns from the 2D fingerprint so as to classify 19 classes.
Rußwurm and Körner proposed a model whose input is derived from a Sentinel-2 top-of-atmosphere (TOA) time series and a maximum cloud level of 80%. They employed a Bi-ConvLSTM model, which obtained an 89.6% global accuracy in classifying 17 herbaceous crops, considering the spatial and temporal distribution [
30]. In contrast, our proposal establishes a threshold of 10% for the presence of clouds in the image in order to consider it acceptable and employs a bottom-of-atmosphere (BOA) time series to perform the classification of both herbaceous crops and orchards, considering only the temporal distribution per pixel.
Campos-Taberner et al. presented a study which aimed to explain deep learning, in which they employed a bidirectional LSTM model [
31]. Portalés-Julià et al. made improvements on their previous work, in which they continued using Bi-LSTM models [
32], obtaining a 94.3% accuracy using random forests and an over 98% accuracy in their study area using Bi-LSTM networks. This may be the result of both the fact that the model did not discriminate irrigated areas and classified fewer classes. The use of LSTMs leads to higher computational costs in terms of time and resources compared to CNNs, which we used in our proposal with the aim of achieving an efficient model with a reduced number of parameters and a similar performance [
36].



 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}