
Comparative Study of Convolutional Neural Network and Conventional Machine Learning Methods for Landslide Susceptibility Mapping



Abstract
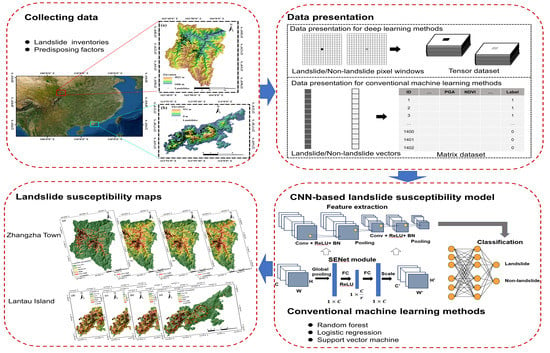
1. Introduction
2. Study Areas and Data
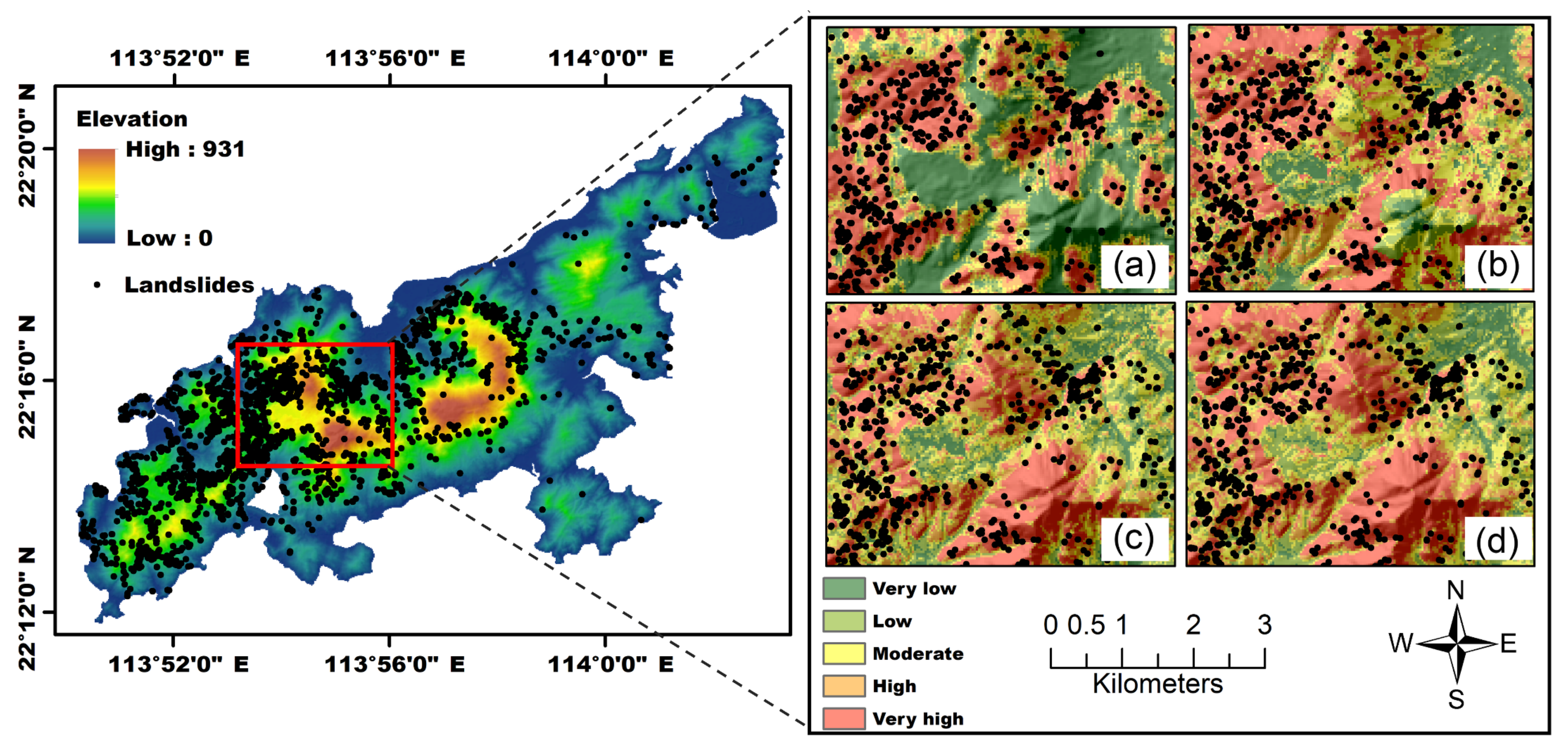
2.1. Study Areas
2.2. Landslide Inventories
2.3. Landslide Predisposing Factors
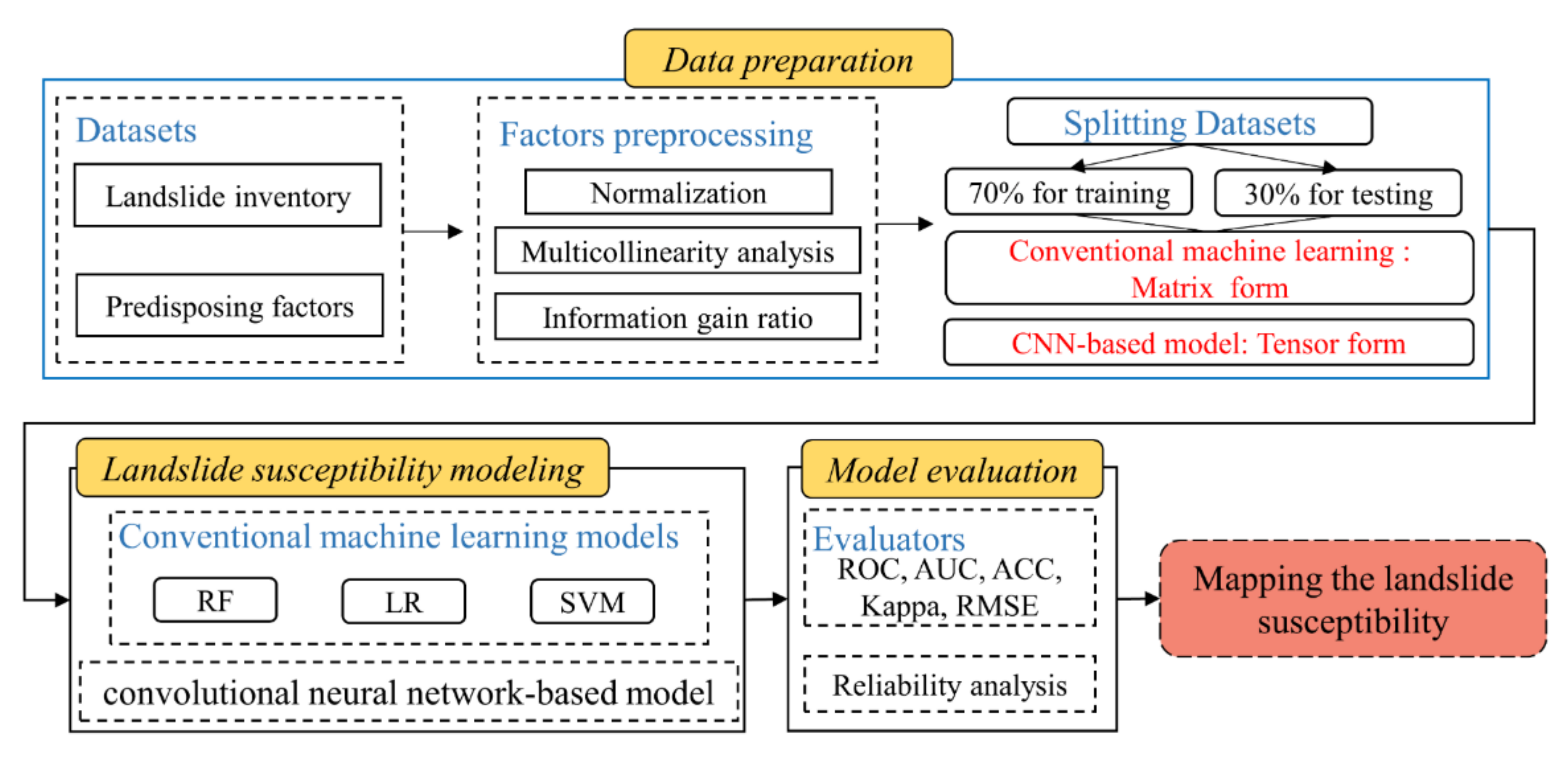
3. Methodology
3.1. Information Gain Ratio
3.2. Establishment of Spatial Datasets
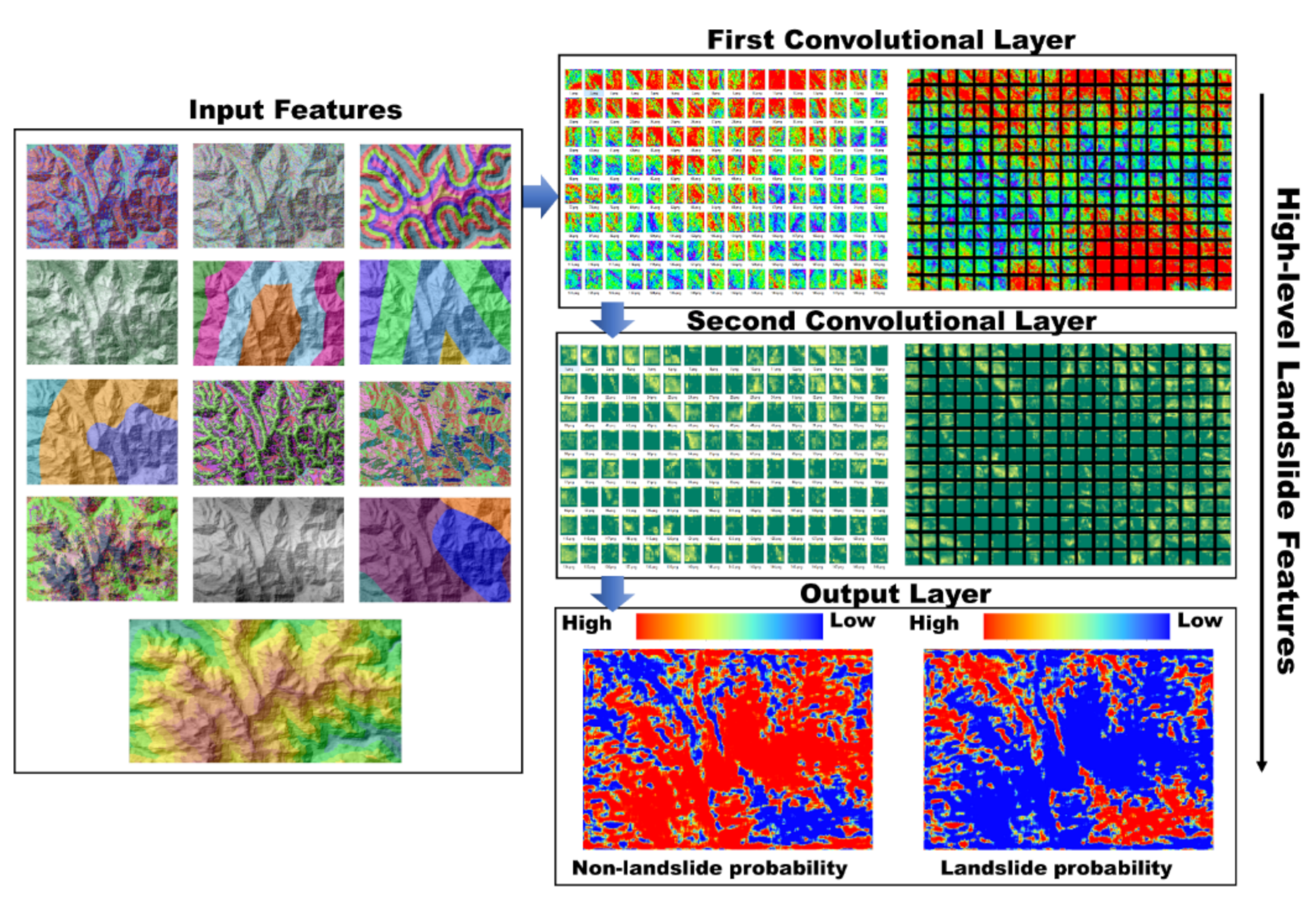
3.3. Convolutional Neural Network (CNN)
3.4. Conventional Machine Learning Methods
3.4.1. Random Forest
3.4.2. Logistics Regression
3.4.3. Support Vector Machine
3.5. Generation of Landslide Susceptibility Maps
3.6. Model Performance Evaluation
4. Results
4.1. Selection of Predisposing Factors
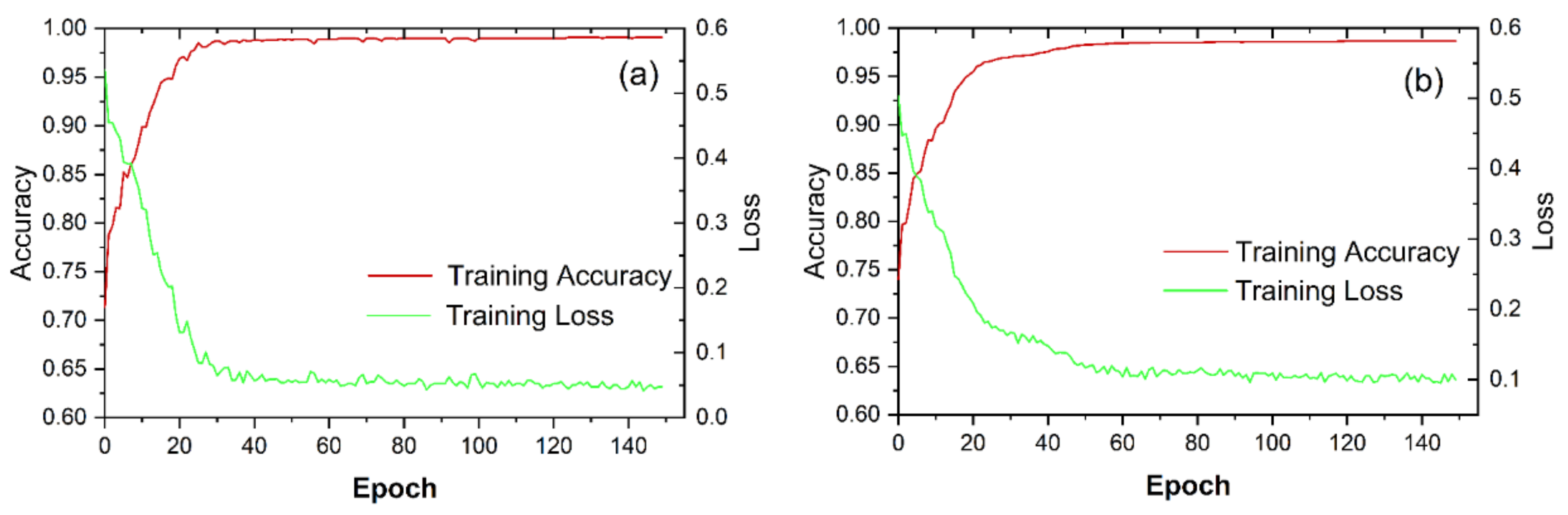
4.2. Construction of Models
4.3. Model Comparison
4.4. Landslide Susceptibility Mapping
5. Discussion
5.1. Model Parameter Analysis
5.2. Computational Efficiency
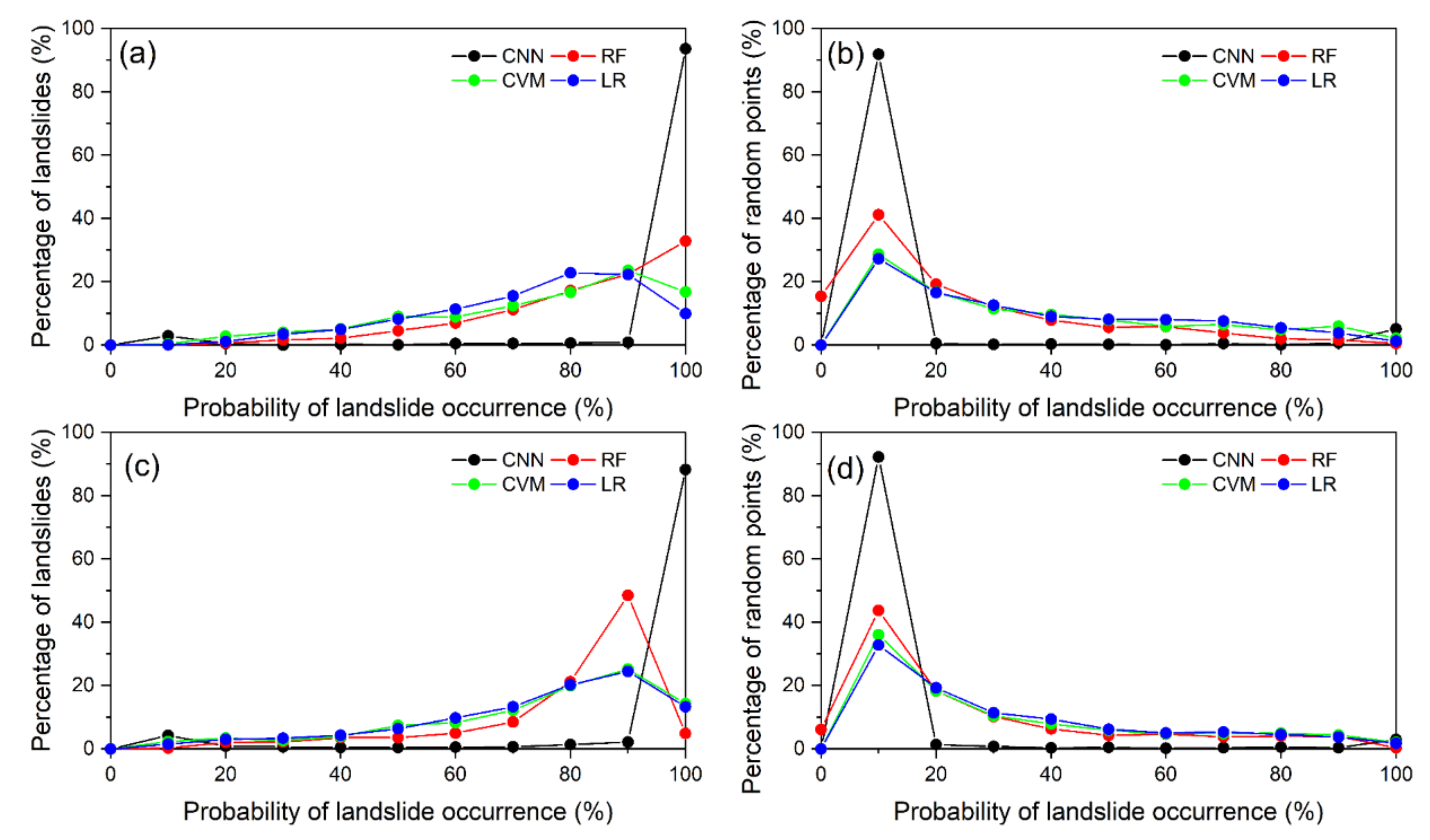
5.3. Reliability Analysis of the Modeling Results
5.4. Analysis of the Salt-and-Pepper Effect in LSM
5.5. Limitations and Future Research
6. Conclusions
- Among four landslide susceptibility models (i.e., CNN, RF, LR, and SVM), the CNN-based model exhibits the best predictive capability for LSM on the testing datasets.
- Different from the datasets of conventional ML methods, the 3D dataset allows more spatial information to be considered and learned by CNN-based models. The LSM generated by the CNN-based model is not only sensitive to the high-risk landslide zone but also significantly reduces the salt-and-pepper effect, which guarantees the consistency of susceptibility assessment.
- Although the CNN-based model achieved significant results, it consumed more time than conventional ML models in both the training and prediction phase. When assessing landslide susceptibility for large areas, time efficiency is an issue that must be considered. Therefore, the choice of the LSM model should be a trade-off between time efficiency and performance.
- The results of the LSM would assist in disaster management and policy making in the Jiuzhaigou region. Also, this study adds value to the literature of landslide susceptibility mapping through a comparative study of CNN-based and conventional ML models.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| LSM | landslide susceptibility mapping |
| CNN | convolutional neural network |
| ML | machine learning |
| AUC | area under the curve |
| LULC | land use and land cover |
| GIS | geographic information system |
| RF | random forest |
| ANN | artificial neural network |
| SVM | support vector machine |
| 1/2/3D | 1/2/3 dimension |
| GEE | Google Earth Engine |
| IGR | information gain ratio |
| SENet | squeeze-and-excitation network |
| ReLU | rectified linear unit |
| SRM | structure risk minimization |
| IDW | inverse distance weighted |
| ROC | receiver operating characteristic |
| RMSE | root mean square error |
| LSI | landslide susceptibility index |
| M.D. | mean deviation |
Appendix A





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predisposing Factors | Data Type | Source | Resolution |
|---|---|---|---|
| Elevation | Raster | Esri China (HK) | 30 × 30 m |
| Slope aspect | |||
| Slope angle | |||
| TRI | |||
| TWI | |||
| NDVI | Raster | Derived from Sentinel-2A on the Google Earth Engine | 10 × 10 m |
| Land use | Raster | Derived from the GLC_FCS30 datasets (https://doi.org/10.5194/essd-13-2753-2021) (accessed on 6 November 2021) | 30 × 30 m |
| Distance to faults | Lines | Derived from the geological map supported by the Civil Engineering and Development Department, HKSAR | 1:100,000 |
| Lithology | Polygon | ||
| Yearly precipitation | Raster | PDIR-Now satellite precipitation product | 4 × 4 km |
| Symbol | Geological Age | Main Lithology |
|---|---|---|
| KG | Cretaceous | Granitic rocks |
| JG | Jurassic | Granitic rocks |
| JS | Jurassic | Sandstone, siltstone, and mudstone |
| JT | Jurassic | Tuff and lava |
| KT | Cretaceous | Tuff and lava |
| QS | Quaternary | Superficial deposits (silt, sand, and gravel) |
| RE | - | Fill |
References
- Jaafari, A.; Panahi, M.; Pham, B.T.; Shahabi, H.; Bui, D.T.; Rezaie, F.; Lee, S. Meta optimization of an adaptive neuro-fuzzy inference system with grey wolf optimizer and biogeography-based optimization algorithms for spatial prediction of landslide susceptibility. Catena 2019, 175, 430–445. [Google Scholar] [CrossRef]
- Ali, R.; Kuriqi, A.; Kisi, O. Human–Environment Natural Disasters Interconnection in China: A Review. Climate 2020, 8, 48. [Google Scholar] [CrossRef]
- Reichenbach, P.; Rossi, M.; Malamud, B.D.; Mihir, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth-Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Jones, J.N.; Boulton, S.J.; Bennett, G.L.; Stokes, M.; Whitworth, M.R.Z. Temporal Variations in Landslide Distributions Following Extreme Events: Implications for Landslide Susceptibility Modeling. J. Geophys. Res. Earth Surf. 2021, 126, e2021JF006067. [Google Scholar] [CrossRef]
- Sidle, R.C.; Bogaard, T.A. Dynamic earth system and ecological controls of rainfall-initiated landslides. Earth-Sci. Rev. 2016, 159, 275–291. [Google Scholar] [CrossRef]
- Youssef, A.M.; Al-Kathery, M.; Pradhan, B. Landslide susceptibility mapping at Al-Hasher area, Jizan (Saudi Arabia) using GIS-based frequency ratio and index of entropy models. Geosci. J. 2014, 19, 113–134. [Google Scholar] [CrossRef]
- Yu, X.; Zhang, K.; Song, Y.; Jiang, W.; Zhou, J. Study on landslide susceptibility mapping based on rock-soil characteristic factors. Sci. Rep. 2021, 11, 15476. [Google Scholar] [CrossRef]
- Lucà, F.; Conforti, M.; Robustelli, G. Comparison of GIS-based gullying susceptibility mapping using bivariate and multivariate statistics: Northern Calabria, South Italy. Geomorphology 2011, 134, 297–308. [Google Scholar] [CrossRef]
- Tien Bui, D.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2015, 13, 361–378. [Google Scholar] [CrossRef]
- Muceku, Y.; Korini, O.; Kuriqi, A. Geotechnical Analysis of Hill’s Slopes Areas in Heritage Town of Berati, Albania. Period. Polytech. Civ. Eng. 2016, 60, 61–73. [Google Scholar] [CrossRef]
- Abedini, M.; Tulabi, S. Assessing LNRF, FR, and AHP models in landslide susceptibility mapping index: A comparative study of Nojian watershed in Lorestan province, Iran. Environ. Earth Sci. 2018, 77, 405. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Rossi, M. Landslide susceptibility modeling in a landslide prone area in Mazandarn Province, north of Iran: A comparison between GLM, GAM, MARS, and M-AHP methods. Theor. Appl. Climatol. 2016, 130, 609–633. [Google Scholar] [CrossRef]
- Dahal, R.K.; Hasegawa, S.; Nonomura, A.; Yamanaka, M.; Masuda, T.; Nishino, K. GIS-based weights-of-evidence modelling of rainfall-induced landslides in small catchments for landslide susceptibility mapping. Environ. Geol. 2007, 54, 311–324. [Google Scholar] [CrossRef]
- Hasekioğulları, G.D.; Ercanoglu, M. A new approach to use AHP in landslide susceptibility mapping: A case study at Yenice (Karabuk, NW Turkey). Nat. Hazards 2012, 63, 1157–1179. [Google Scholar] [CrossRef]
- Dong, J.-J.; Tung, Y.-H.; Chen, C.-C.; Liao, J.-J.; Pan, Y.-W. Discriminant analysis of the geomorphic characteristics and stability of landslide dams. Geomorphology 2009, 110, 162–171. [Google Scholar] [CrossRef]
- He, S.; Pan, P.; Dai, L.; Wang, H.; Liu, J. Application of kernel-based Fisher discriminant analysis to map landslide susceptibility in the Qinggan River delta, Three Gorges, China. Geomorphology 2012, 171, 30–41. [Google Scholar] [CrossRef]
- Lee, S.; Lee, M.-J.; Jung, H.-S.; Lee, S. Landslide susceptibility mapping using Naïve Bayes and Bayesian network models in Umyeonsan, Korea. Geocarto Int. 2019, 35, 1665–1679. [Google Scholar] [CrossRef]
- Tsangaratos, P.; Ilia, I. Comparison of a logistic regression and Naïve Bayes classifier in landslide susceptibility assessments: The influence of models complexity and training dataset size. Catena 2016, 145, 164–179. [Google Scholar] [CrossRef]
- Jana, S.K.; Sekac, T.; Pal, D.K. Geo-spatial approach with frequency ratio method in landslide susceptibility mapping in the Busu River catchment, Papua New Guinea. Spat. Inf. Res. 2018, 27, 49–62. [Google Scholar] [CrossRef]
- Yilmaz, I. Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: A case study from Kat landslides (Tokat—Turkey). Comput. Geosci. 2009, 35, 1125–1138. [Google Scholar] [CrossRef]
- Constantin, M.; Bednarik, M.; Jurchescu, M.C.; Vlaicu, M. Landslide susceptibility assessment using the bivariate statistical analysis and the index of entropy in the Sibiciu Basin (Romania). Environ. Earth Sci. 2010, 63, 397–406. [Google Scholar] [CrossRef]
- Zhang, T.-y.; Han, L.; Zhang, H.; Zhao, Y.-h.; Li, X.-a.; Zhao, L. GIS-based landslide susceptibility mapping using hybrid integration approaches of fractal dimension with index of entropy and support vector machine. J. Mt. Sci. 2019, 16, 1275–1288. [Google Scholar] [CrossRef]
- Felicísimo, Á.M.; Cuartero, A.; Remondo, J.; Quirós, E. Mapping landslide susceptibility with logistic regression, multiple adaptive regression splines, classification and regression trees, and maximum entropy methods: A comparative study. Landslides 2012, 10, 175–189. [Google Scholar] [CrossRef]
- Hong, H.; Pradhan, B.; Jebur, M.N.; Bui, D.T.; Xu, C.; Akgun, A. Spatial prediction of landslide hazard at the Luxi area (China) using support vector machines. Environ. Earth Sci. 2015, 75, 1–14. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Kornejady, A.; Kerle, N.; Shabani, F. Investigating the effects of different landslide positioning techniques, landslide partitioning approaches, and presence-absence balances on landslide susceptibility mapping. Catena 2020, 187, 104364. [Google Scholar] [CrossRef]
- Zare, M.; Pourghasemi, H.R.; Vafakhah, M.; Pradhan, B. Landslide susceptibility mapping at Vaz Watershed (Iran) using an artificial neural network model: A comparison between multilayer perceptron (MLP) and radial basic function (RBF) algorithms. Arab. J. Geosci. 2012, 6, 2873–2888. [Google Scholar] [CrossRef]
- Li, L.; Liu, R.; Pirasteh, S.; Chen, X.; He, L.; Li, J. A novel genetic algorithm for optimization of conditioning factors in shallow translational landslides and susceptibility mapping. Arab. J. Geosci. 2017, 10, 209. [Google Scholar] [CrossRef]
- Chen, W.; Peng, J.; Hong, H.; Shahabi, H.; Pradhan, B.; Liu, J.; Zhu, A.X.; Pei, X.; Duan, Z. Landslide susceptibility modelling using GIS-based machine learning techniques for Chongren County, Jiangxi Province, China. Sci. Total Environ. 2018, 626, 1121–1135. [Google Scholar] [CrossRef]
- Wei, X.; Zhang, L.; Luo, J.; Liu, D. A hybrid framework integrating physical model and convolutional neural network for regional landslide susceptibility mapping. Nat. Hazards 2021, 109, 471–497. [Google Scholar] [CrossRef]
- Yang, X.; Liu, R.; Yang, M.; Chen, J.; Liu, T.; Yang, Y.; Chen, W.; Wang, Y. Incorporating Landslide Spatial Information and Correlated Features among Conditioning Factors for Landslide Susceptibility Mapping. Remote Sens. 2021, 13, 2166. [Google Scholar] [CrossRef]
- Thi Ngo, P.T.; Panahi, M.; Khosravi, K.; Ghorbanzadeh, O.; Kariminejad, N.; Cerda, A.; Lee, S. Evaluation of deep learning algorithms for national scale landslide susceptibility mapping of Iran. Geosci. Front. 2021, 12, 505–519. [Google Scholar] [CrossRef]
- Sameen, M.I.; Pradhan, B.; Lee, S. Application of convolutional neural networks featuring Bayesian optimization for landslide susceptibility assessment. Catena 2020, 186, 104249. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Hong, H. Comparison of convolutional neural networks for landslide susceptibility mapping in Yanshan County, China. Sci. Total Environ. 2019, 666, 975–993. [Google Scholar] [CrossRef]
- Yi, Y.; Zhang, Z.; Zhang, W.; Jia, H.; Zhang, J. Landslide susceptibility mapping using multiscale sampling strategy and convolutional neural network: A case study in Jiuzhaigou region. Catena 2020, 195, 104851. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S.; Emery, W.J. Object-Based Convolutional Neural Network for High-Resolution Imagery Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3386–3396. [Google Scholar] [CrossRef]
- Chen, T.; Zhu, L.; Niu, R.-q.; Trinder, C.J.; Peng, L.; Lei, T. Mapping landslide susceptibility at the Three Gorges Reservoir, China, using gradient boosting decision tree, random forest and information value models. J. Mt. Sci. 2020, 17, 670–685. [Google Scholar] [CrossRef]
- Chen, W.; Zhang, S. GIS-based comparative study of Bayes network, Hoeffding tree and logistic model tree for landslide susceptibility modeling. Catena 2021, 203, 105344. [Google Scholar] [CrossRef]
- Barella, C.F.; Sobreira, F.G.; Zêzere, J.L. A comparative analysis of statistical landslide susceptibility mapping in the southeast region of Minas Gerais state, Brazil. Bull. Eng. Geol. Environ. 2018, 78, 3205–3221. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Wang, M.; Peng, L.; Hong, H. Comparative study of landslide susceptibility mapping with different recurrent neural networks. Comput. Geosci. 2020, 138, 104445. [Google Scholar] [CrossRef]
- Huang, F.; Ye, Z.; Jiang, S.-H.; Huang, J.; Chang, Z.; Chen, J. Uncertainty study of landslide susceptibility prediction considering the different attribute interval numbers of environmental factors and different data-based models. Catena 2021, 202, 105250. [Google Scholar] [CrossRef]
- Liu, R.; Li, L.; Pirasteh, S.; Lai, Z.; Yang, X.; Shahabi, H. The performance quality of LR, SVM, and RF for earthquake-induced landslides susceptibility mapping incorporating remote sensing imagery. Arab. J. Geosci. 2021, 14, 1–15. [Google Scholar] [CrossRef]
- Lanxin, D.A.I.; Qiang, X.U.; Xuanmei, F.A.N.; Ming, C.H.A.N.G.; Qin, Y.A.N.G.; Fan, Y.A.N.G.; Jing, R.E.N. A preliminary study on spatial distribution patterns of landslides triggered by Jiuzhaigou earthquake in Sichuan on August 8th, 2017 and their susceptibility assessment. J. Eng. Geol. 2017, 25, 1151–1164. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, L.; Yin, K.; Luo, H.; Li, J. Landslide identification using machine learning. Geosci. Front. 2021, 12, 351–364. [Google Scholar] [CrossRef]
- Tian, Y.; Xu, C.; Ma, S.; Xu, X.; Wang, S.; Zhang, H. Inventory and Spatial Distribution of Landslides Triggered by the 8th August 2017 MW 6.5 Jiuzhaigou Earthquake, China. J. Earth Sci. 2018, 30, 206–217. [Google Scholar] [CrossRef]
- Chen, X.; Chen, W. GIS-based landslide susceptibility assessment using optimized hybrid machine learning methods. Catena 2021, 196, 104833. [Google Scholar] [CrossRef]
- Meunier, P.; Hovius, N.; Haines, A.J. Regional patterns of earthquake-triggered landslides and their relation to ground motion. Geophys. Res. Lett. 2007, 34, L20408. [Google Scholar] [CrossRef]
- Sørensen, R.; Zinko, U.; Seibert, J. On the calculation of the topographic wetness index: Evaluation of different methods based on field observations. Hydrol. Earth Syst. Sci. 2006, 10, 101–112. [Google Scholar] [CrossRef]
- Cevik, E.; Topal, T. GIS-based landslide susceptibility mapping for a problematic segment of the natural gas pipeline, Hendek (Turkey). Environ. Geol. 2003, 44, 949–962. [Google Scholar] [CrossRef]
- Saha, A.K.; Gupta, R.P.; Arora, M.K. GIS-based Landslide Hazard Zonation in the Bhagirathi (Ganga) Valley, Himalayas. Int. J. Remote Sens. 2010, 23, 357–369. [Google Scholar] [CrossRef]
- Ozdemir, A.; Altural, T. A comparative study of frequency ratio, weights of evidence and logistic regression methods for landslide susceptibility mapping: Sultan Mountains, SW Turkey. J. Asian Earth Sci. 2013, 64, 180–197. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013. [Google Scholar]
- Ye, C.-m.; Liu, X.; Xu, H.; Ren, S.-c.; Li, Y.; Li, J. Classification of hyperspectral images based on a convolutional neural network and spectral sensitivity. J. Zhejiang Univ.-Sci. A 2020, 21, 240–248. [Google Scholar] [CrossRef]
- Tang, P.; Du, P.; Xia, J.; Zhang, P.; Zhang, W. Channel Attention-Based Temporal Convolutional Network for Satellite Image Time Series Classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Al-Katheeri, M.M. Landslide susceptibility mapping using random forest, boosted regression tree, classification and regression tree, and general linear models and comparison of their performance at Wadi Tayyah Basin, Asir Region, Saudi Arabia. Landslides 2015, 13, 839–856. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Schneider, M.J.; Gorr, W.L. ROC-based model estimation for forecasting large changes in demand. Int. J. Forecast. 2015, 31, 253–262. [Google Scholar] [CrossRef][Green Version]
- Wu, Y.; Ke, Y.; Chen, Z.; Liang, S.; Zhao, H.; Hong, H. Application of alternating decision tree with AdaBoost and bagging ensembles for landslide susceptibility mapping. Catena 2020, 187, 104396. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Chen, H.X.; Zhang, L.M. A physically-based distributed cell model for predicting regional rainfall-induced shallow slope failures. Eng. Geol. 2014, 176, 79–92. [Google Scholar] [CrossRef]
- Meunier, P.; Hovius, N.; Haines, J.A. Topographic site effects and the location of earthquake induced landslides. Earth Planet. Sci. Lett. 2008, 275, 221–232. [Google Scholar] [CrossRef]
- Brain, M.J.; Rosser, N.J.; Tunstall, N. The control of earthquake sequences on hillslope stability. Geophys. Res. Lett. 2017, 44, 865–872. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Du, J.; Zhang, L.; Song, Y.; Sun, G. Multi-geohazards susceptibility mapping based on machine learning—A case study in Jiuzhaigou, China. Nat. Hazards 2020, 102, 851–871. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Fang, Z.; Wang, Y.; Peng, L.; Hong, H. Integration of convolutional neural network and conventional machine learning classifiers for landslide susceptibility mapping. Comput. Geosci. 2020, 139, 104470. [Google Scholar] [CrossRef]
- Cantarino, I.; Carrion, M.A.; Goerlich, F.; Martinez Ibañez, V. A ROC analysis-based classification method for landslide susceptibility maps. Landslides 2018, 16, 265–282. [Google Scholar] [CrossRef]
- Guo, Z.; Shi, Y.; Huang, F.; Fan, X.; Huang, J. Landslide susceptibility zonation method based on C5.0 decision tree and K-means cluster algorithms to improve the efficiency of risk management. Geosci. Front. 2021, 12, 101249. [Google Scholar] [CrossRef]
- Blaschke, T.; Lang, S.; Lorup, E.; Strobl, J.; Zeil, P. Object-Oriented Image Processing in an Integrated GIS/Remote Sensing Environment and Perspectives for Environmental Applications. Environ. Inf. Plan. Politics Public 2000, 2, 555–570. [Google Scholar]



















| Predisposing Factors | Data Type | Source | Resolution |
|---|---|---|---|
| Elevation | Raster | Derived from the ASTER Global DEM (http://earthexplorer.usgs.gov) acquired from the USGS (accessed on 6 November 2021) | 30 × 30 m |
| Slope aspect | |||
| Slope angle | |||
| TRI | |||
| TWI | |||
| Distance to roads | Lines | OpenStreetMap (https://www.openstreetmap.org/) (accessed on 6 November 2021) | - |
| Land use | Raster | Derived from the Sentinel-2A on the Google Earth Engine | 10 × 10 m |
| NDVI | |||
| PGA | Polygon | Downloaded from the USGS (https://earthquake.usgs.gov) (accessed on 6 November 2021) | - |
| Distance to rivers | Lines | Derived from the geological map supported by the China Geological Survey | 1:500,000 |
| Distance to faults | |||
| Lithology | Polygon | ||
| Yearly precipitation | Raster | PDIR-Now satellite precipitation product (http://chrsdata.eng.uci.edu/) (accessed on 6 November 2021) | 4 × 4 km |
| Training Set | Testing Set | ||
|---|---|---|---|
| Landslide pixels | Non-landslide pixels | Landslide pixels | Non-landslide pixels |
| i × 2 × s × s × 70% | i × 2 × s × s × 70% | i × 2 × s × s × 30% | i × 2 × s × s × 30% |
| Study Areas | Metrics | Landslide Susceptibility Models | |||
|---|---|---|---|---|---|
| CNN | RF | LR | SVM | ||
| Zhangzha Town | ACC | 0.83 * | 0.82 | 0.78 | 0.76 |
| RMSE | 0.41 * | 0.42 | 0.47 | 0.49 | |
| Kappa | 0.67 * | 0.64 | 0.56 | 0.53 | |
| Sensitivity | 0.81 | 0.85 * | 0.83 | 0.80 | |
| Specificity | 0.86 * | 0.80 | 0.73 | 0.73 | |
| Lantau Island | ACC | 0.86 * | 0.84 | 0.79 | 0.79 |
| RMSE | 0.38 * | 0.41 | 0.46 | 0.46 | |
| Kappa | 0.72 * | 0.67 | 0.58 | 0.58 | |
| Sensitivity | 0.85 | 0.86 * | 0.80 | 0.79 | |
| Specificity | 0.87 * | 0.81 | 0.78 | 0.79 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, R.; Yang, X.; Xu, C.; Wei, L.; Zeng, X. Comparative Study of Convolutional Neural Network and Conventional Machine Learning Methods for Landslide Susceptibility Mapping. Remote Sens. 2022, 14, 321. https://doi.org/10.3390/rs14020321
Liu R, Yang X, Xu C, Wei L, Zeng X. Comparative Study of Convolutional Neural Network and Conventional Machine Learning Methods for Landslide Susceptibility Mapping. Remote Sensing. 2022; 14(2):321. https://doi.org/10.3390/rs14020321
Chicago/Turabian StyleLiu, Rui, Xin Yang, Chong Xu, Liangshuai Wei, and Xiangqiang Zeng. 2022. "Comparative Study of Convolutional Neural Network and Conventional Machine Learning Methods for Landslide Susceptibility Mapping" Remote Sensing 14, no. 2: 321. https://doi.org/10.3390/rs14020321
APA StyleLiu, R., Yang, X., Xu, C., Wei, L., & Zeng, X. (2022). Comparative Study of Convolutional Neural Network and Conventional Machine Learning Methods for Landslide Susceptibility Mapping. Remote Sensing, 14(2), 321. https://doi.org/10.3390/rs14020321