1. Introduction
As the volume of data (texts, images, audios and videos) generated around the world continues to increase rapidly, the processing and storage of data have become a challenging issue in recent times and will continue well into the foreseeable future [
1,
2,
3,
4]. To overcome such difficulties, big data platforms based on distributed clusters have emerged and applied in multiple domains to handle various types of massive data [
5,
6,
7,
8]. Specifically, the Apache Hadoop [
9], the Apache Spark [
10] and the Apache Flink [
11] have been developed for massive data processing under a distributed cluster environment. Furthermore, these frameworks have been widely used by companies and research institutes around the world [
12,
13] with remarkable performance. As a result, it is becoming easier to mine valuable knowledge from massive databases using these tools [
14]. However, the complexity of scheduling tasks is increasing compared with that for a single machine with sequential algorithms [
15,
16,
17], despite the fact that the distributed clusters possess greater computational power. Therefore, how to schedule tasks for optimal performance and efficiency is critical for distributed platforms [
18].
To schedule tasks efficiently, several data stream partition methods have been developed for the distributed platforms, most of which have a similar implementation mechanism [
19]. The input data stream is always loaded and split into multiple parts according to the specific partition method, then various computing nodes are employed to process each part simultaneously to achieve distributed data processing [
20]. The partition methods are critical for distributed systems, as they can regulate the workload of each computing node scientifically and effectively improve the work efficiency [
21]. There have been two main types of partition methods in use up to now, the static method and the dynamic method [
22]. The static methods, such as the hash, range, and grid partition methods, are typically provided officially and readily applied to a variety of data types, but they are not easily adaptable to specific data stream tasks. The dynamic methods are usually designed by the users and can be applied to specific data stream tasks. They predict and guide partitions in the future by sampling and estimating the past data streams in a dynamic way, but their construction steps are complicated. In general, different types of data streams and distributed algorithms require different partition methods [
23]. Hence, how to select the appropriate partition method suitable for the task in hand is of great importance.
As is well known, improper partition can cause data skew issues, which could influence the execution efficiency directly in many tasks implemented over distributed clusters. Skewed partitions usually work harder, take longer and need more computational resources to complete the tasks [
24]. This can result not only in a serious waste of computing resources but also a significant decrease in execution efficiency, and may create computing bottlenecks and even result in failure of the computing task [
25]. Remote sensing images are an important category of big data given their volume characteristics [
26,
27]. Hence, how to select a proper partition method to efficiently process the large number of massive images under distributed clusters remains a challenge [
28]. Although the partition methods are less studied than the distributed image processing methods, the improper partition could bring up tough issues. Research on the partition method mainly focus on the task scheduling. Both Costa and Bentes [
29], and Sun and Zhang [
30] adopted the directed acyclic graph (DAG) and the partitionable tasks to exploit the task parallelism to sufficiently utilize the available computing resources and further improve the execution efficiency. The above two methods assumed that the images were loaded evenly into each partition. However, the load balancing of partitions for image tiles remains a problem in the beginning of the processing job. Specifically, the partition methods which handle the image tiles generated by the decomposition of large-scale images over distributed clusters are still not available, and this limits the performance of image processing applications. Therefore, how to divide the image tiles into appropriate partitions is a key point that needs to be addressed to further improve the performance of distributed image processing.
To solve the data skew problem, research over the last decade has designed and developed related data partition methods. Bertolucci and Carlini [
22] evaluated the impact of static and dynamic partition methods on efficiency using several graph algorithms, and demonstrated that the partition method adopted with respect to the data and algorithm characteristics could improve the task efficiency. Yu and Chen [
31] repartitioned the unprocessed blocks of straggling tasks to other idle tasks according to the constructed active task list to fully utilize the computing nodes when a new task is registered. Tang and Zhang [
32] evaluated the data stream distribution, sorted the partitions and split the large partition into various partitions to realize a uniform distribution. Liu and Zhu [
33] generated the partition lookup table to predict and guide future partitions based on the hypothesis that the characteristics of multi-batch data would not change frequently. Tang and Lv [
34] used rejection sampling to evaluate data distribution in parallel, then improved the hash or range partition methods, respectively, according to the actual application scenarios. However, the proposed algorithm was more suitable for the case where the computing power of each node was the same. Xiujin and Yueqin [
35] improved the aforementioned method by adding a dynamic evaluation method for the computing resource capability to more accurately evaluate the state of each computing node and more scientifically allocate the data stream to partitions with different resource allocations. Wang and Khan [
36] predicted automatically the potential problems a priori based on limited execution data and recommended the use of a locality setting and partitions. Fu and Tang [
37] evaluated the characteristics of a previous data stream, strengthened the capability of the computing nodes to allocate appropriately the computing tasks and achieved an even distribution by a series of optimization measures. Huang and Wei [
38] leveraged the skew detection algorithm to identify the skew partition and adjusted the task resource allocation according to the fine-grained resource allocation algorithm. Guoand Huang [
39] took into account the differences in computational capabilities among the computing nodes and assigned each task to the computing nodes with the highest performance factor according to the greedy strategy. Li and Zhang [
40] established a virtual partition for data partition with a huge amount of data, then used the hash partition method to further partition the data to alleviate the calculation pressure. Shen and Xiong [
41] also subdivided the partition into sub partitions, adjusting the data skew and scheduled the tasks on the basis of the granularity of the sub partition. Wang and Jia [
42] evaluated the data distribution according to the frequency of each data type, which was then analyzed to guide further merging or split operations of the partitions. However, the above partition methods are complex and suitable for different specialty applications, and application directly to image tiles can cause data skew problems. Moreover, there are no partition methods suitable for the remote sensing image tiles indexed by row and column numbers. Hence, an appropriate partition method for massive image tiles is needed urgently.
In this paper, the design of a new partition method is proposed to solve the data skew problem of image tiles, especially over distributed clusters. This partition method transforms the tile partitioning problem into a pixel clustering problem, and consists of three main steps, that is, seed point planning, the vertical direction adjustment and the horizontal direction adjustment. First, the seed point planning decides the initial location of the total partitions according to the image layout, and the initial seed points aggregate the surrounding image tiles into initial partitions. Second, the tuning operations are carried out along the vertical direction from top to bottom over the image layout. Finally, the bottom image tiles are tuned along the horizontal direction from left to right over the image layout. Hence, the final partition for the current image layout is generated, thus guiding the partitions of the image tile. Two traditional partition methods (the hash and range partition methods) were also employed to evaluate the elapsed time for the methods in terms of the image segmentation testing, data shuffle testing and image clipping testing. These experiments were carried out for four different types of image layouts with five kinds of partitions to reveal the performance in terms of the execution efficiency.
The main objectives of research were to:
Transform the partitioning problem into a uniform and compact clustering problem by regarding the image tiles as image pixels without spectral and texture information;
Propose a strategy for seed point generation of partitions based on the equal area conversion principle and tune the image tiles dynamically among the adjacent partitions to achieve an even distribution;
Solve the data skew problem existing in the distributed image processing tasks of the hash partition method and achieve an approximate linear relationship between the elapsed time and parallelism.
The organization of this paper is as follows.
Section 2 outlines the methods.
Section 3 describes the experimental design.
Section 4 presents the results, and this is followed by the discussion in
Section 5. Concluding remarks are given in the last section.
2. Methods
We first define three clustering principles of the image tile partitioning for the efficient parallel computation of the application tasks: (1) the number of partitions should be an integer multiple to the number of available nodes (the efficient use of resources); (2) the image tiles should be divided into partitions as uniformly as possible (even distribution); and (3) each partition should form a regular shape as possible such that the communications among nodes would be decreased (the equal area conversion).
This paper describes a novel static partition method—the raster partition method—that satisfies these clustering principles. The raster partition method is designed to leverage the row and column indexed characteristics of image tiles. In the method, massive image tiles are regarded as general image pixels which are missing the attributes of the spectrum response and texture. The proposed partition method consists mainly of three parts–the seed point planning, the vertical direction adjustment and the horizontal direction adjustment. Seed point planning is used to select the initial seed points and aggregate the image tiles to generate the initial partition. Then, the vertical direction adjustment is performed to fine tune the image tiles of the initial partition from top to bottom in terms of the vertical direction. Further, the horizontal direction adjustment is adopted to fine tune the image tiles of the remaining partition from left to right with respect to the horizontal direction. After performing these three steps, the massive image tiles would be distributed uniformly among each partition, and the data skew problem would also be solved. These three parts are explained in detail in the next section.
2.1. Seed Point Planning
In general image segmentation, the image pixels are clustered into meaningful objects according to its location, spectrum and textures information. However, the massive image tiles are regarded as image pixels with only location (column and row) information, which makes its clustering different from that of general ones. In addition, the partitioning process requires the seed points distributed evenly as possible to form regular shapes and solve the data skew problem. Therefore, we design a new initialization method for the image tile partitioning.
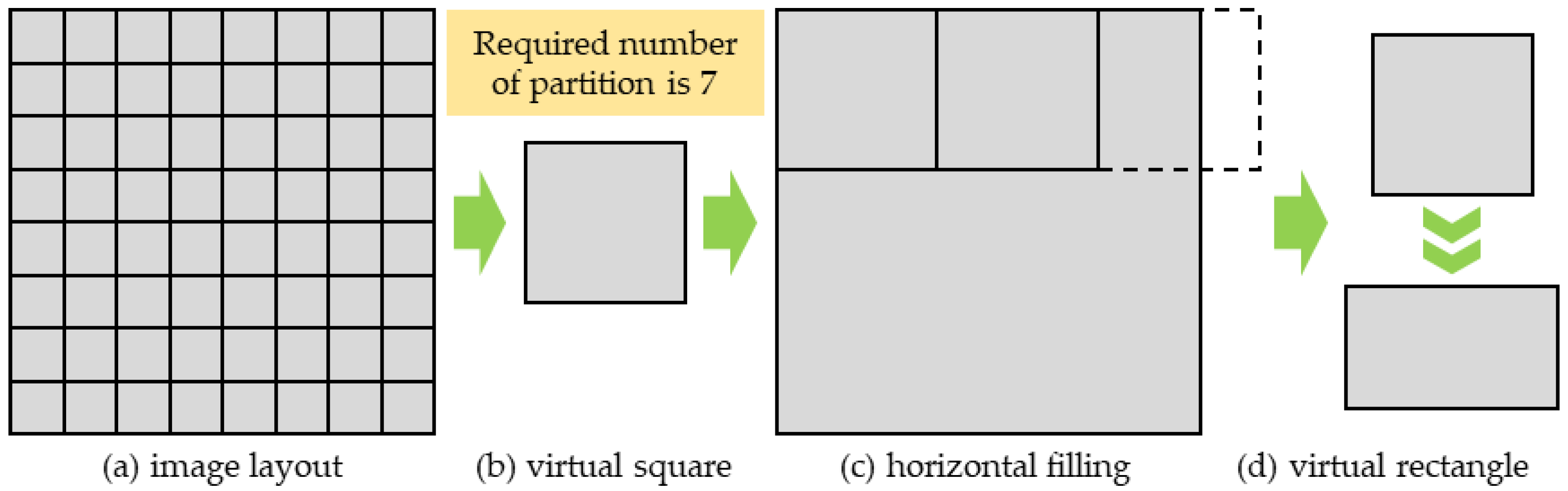
Seed point planning is the initial step of the image tile partition process, and it has a significant impact on the subsequent processing. In general, the number of seed points is determined by the number of partitions required by the application task (the number of partitions is set to 7 in all examples). Furthermore, the number of image tiles and the required number of partitions do not always have an integer division relationship, which makes it difficult to allocate evenly the total image tiles to each partition. Therefore, this section introduces the area factor of the image tile and achieves the initial uniform planning of seed points through the equal area conversion principle.
The area of each image tile is first defined as one unit, and the image area is the sum of all image tiles. The required number of partitions depends on the user’s actual demands and is used as the input parameter of the partition method. Then, the average area of the image tiles contained in each partition is calculated according to the number of partitions. A virtual square is then obtained by calculating the square root of the average partition area, as shown in
Figure 1b. The virtual squares are put side by side into an image layout, as shown in
Figure 1c. The maximum number (integer) of complete virtual squares that can be placed in the horizontal direction is recorded, and this is used as the number of filled virtual squares in the horizontal direction. Then, the horizontal length of the image layout is divided by the maximum number of virtual squares (integer) to get a virtual rectangle with the same area as the virtual square, as shown in
Figure 1d.
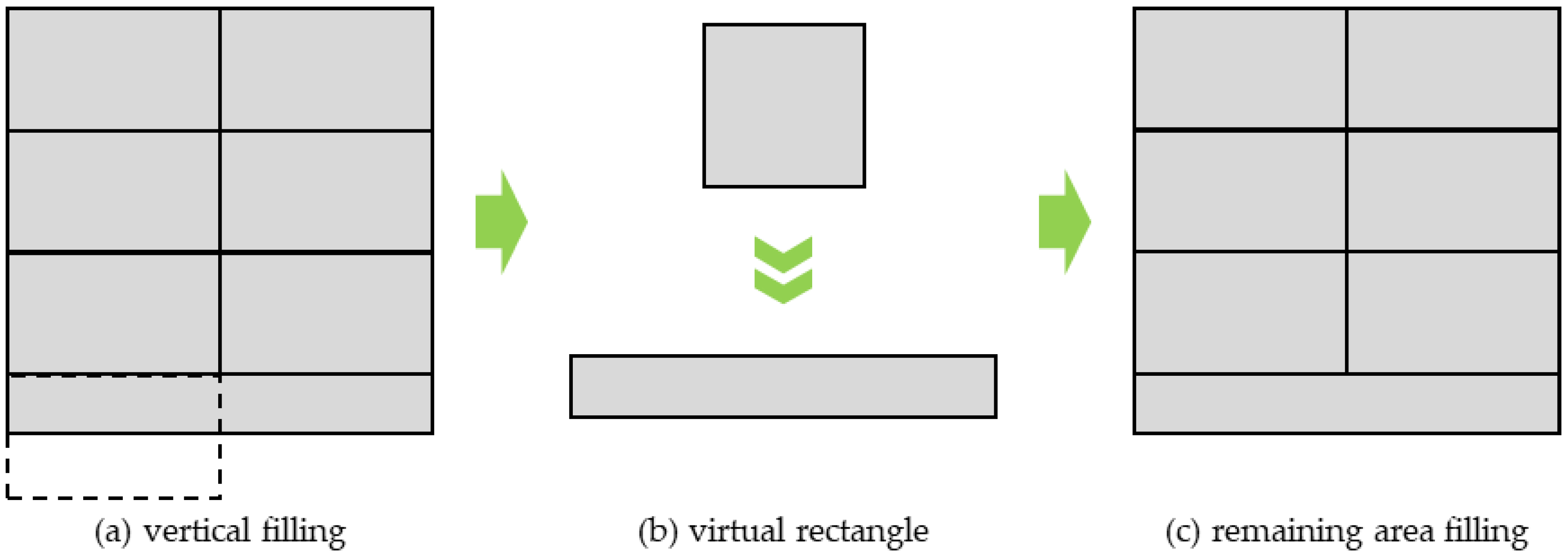
The virtual rectangle obtained by equal area conversion is used to fill the image layout in the order from left to right and from top to bottom. The maximum number (integer) of complete rectangles that can be placed in the vertical direction is recorded and taken as the number of filled virtual rectangles in the vertical direction, as shown in
Figure 2a. Most areas of the image layout have been filled with regular equal area virtual rectangles, and the length and height of the remaining space of the image layout cannot meet the demands of placing virtual squares or equal area virtual rectangles at the same time. At this time, the height of the remaining space in the image layout is taken as the height, and we calculate the new virtual rectangle according to the area of the virtual square, as shown in
Figure 2b. Next, the virtual square is converted into a new virtual rectangle according to the equal area conversion principle and used to fill completely the remaining space of image layout, as shown in
Figure 2c. In addition, the number of new rectangles that can be placed completely in the horizontal direction is also recorded.
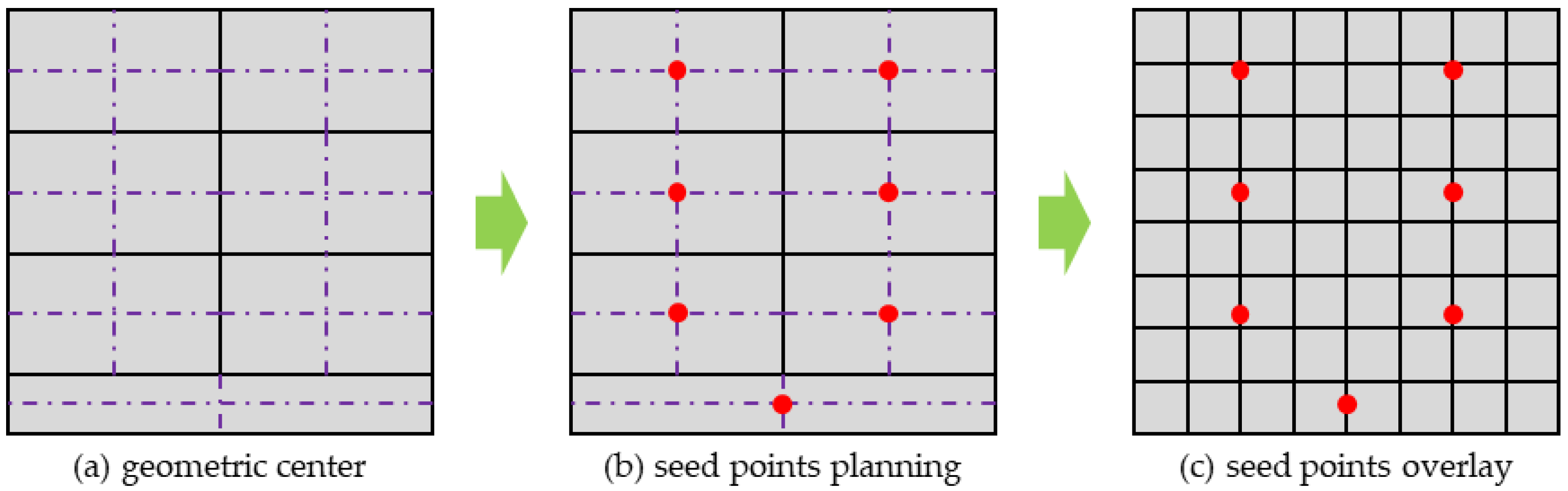
After completing the above steps, all the spaces in the image layout have been filled by two types of regular virtual rectangles according to the equal area conversion principle. In addition, the total number of each type of regular virtual rectangle is the same as that of the seed points or required partitions. The virtual square and the two types of regular virtual rectangle are both symmetrical, and the geometric center is just the center of the shape, as shown in
Figure 3a. Therefore, as illustrated in
Figure 3b, the geometric center of each equal area virtual rectangle in the image layout is extracted, and the corresponding horizontal and vertical coordinates are adopted as the seed point positions of the initial partition. Additionally, the category index corresponding to the partition encoding is established for each seed point. In the image layout, the image tiles are clustered according to the distance attribute with respect to the position of the initially planned seed points. All image tiles are allocated to the seed points having the closest distance, and the attribute tag information is also established to achieve the initialization of the image tiles, as shown in
Figure 4a.
2.2. Vertical Direction Adjustment
Seed point planning mainly uses the clustering principle to initialize the multiple image tiles into various partitions. Although the seed points are generated according to the geometric center of the shapes of equal area, the number of image tiles in each partition still varies significantly after initialization. Hence, more optimization operations are required to modify the distribution of image tiles. The vertical direction adjustment aims to further optimize the data skew problem of image tile partition in the vertical direction.
The number of image tiles is not always an integer multiple of the number of partitions required by the application of the user. Although it is not possible to achieve an absolute average of the number of image tiles in each partition, it should be ensured that the maximum difference of the number of image tiles among each partition is one image tile, in order to effectively limit the data skew problem. Therefore, the histogram of the number of image tiles in each partition is obtained to support the adjustment process in both directions.
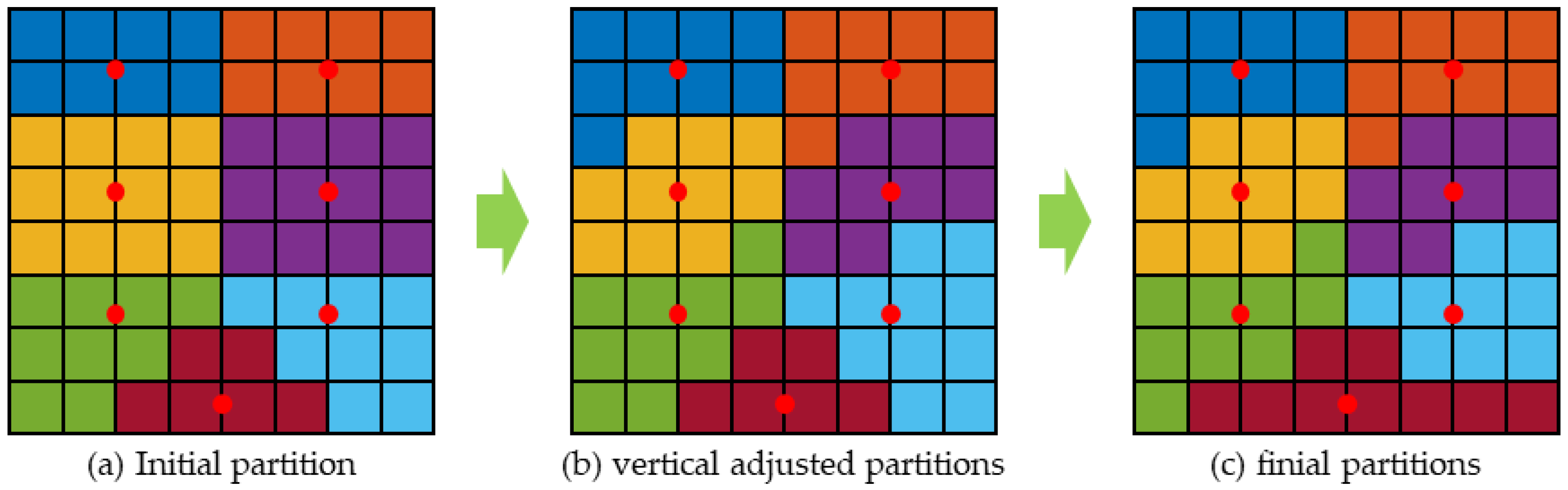
The initialization results of the image tiles are shown in
Figure 4a, where most partitions have the same width in their respective vertical directions. The vertical direction adjustment will continue to maintain the equal width characteristic of these zones in their respective vertical directions. The overall order of the adjustment calculation over the image layout is from left to right in the horizontal direction and from top to bottom in the vertical direction. Each seed point and its image tile are regarded as the basic processing unit. According to the partition histogram and the average number of image tiles for each partition, another two number thresholds are set for each partition, representing the minimum and maximum number standard for the image tiles in each partition, respectively. The minimum and maximum thresholds are acquired by applying the floor and ceil functions on the average number of image tiles, respectively.
For a partition having more image tiles than the maximum threshold, the number of redundant image tiles is calculated according to the maximum threshold, which is usually the actual number of image tiles in the current partition minus the maximum threshold. All image tiles of the current partition are scanned in the vertical direction to look for its neighbor partitions in its bottom of the image layout. The processing list is established by sorting the image tiles in the current partition according to the row and column index in descending order. Then, the image tiles with the highest ranking, according to the number of redundant image tiles, are transferred to the adjacent partition, and the related tags of partitions and image tiles are also updated. The transferred image tiles will join the adjacent partition below the current partition.
For a partition with less image tiles than the minimum threshold, the number of missing image tiles is calculated according to the minimum threshold, which is usually the minimum threshold minus the actual number of image tiles in the current partition. All image tiles of the adjacent partition at the bottom of the vertical direction are interrogated. The current and the adjacent partitions are scanned at the same time. The processing list is established by sorting the image tiles in the adjacent partition according to the row and column index in ascending order. Then, the image tiles with the highest ranking in the adjacent partition, according to the number of missing image tiles, are transferred to the current partition, and the related tags of partitions and image tiles are also updated. The transferred image tiles will join the current partition from the below adjacent partition.
As shown in
Figure 4b, the above adjustment process in the vertical direction will cover all but the bottom partitions which will remain stable. Therefore, the data skew problem of most partitions is solved, and the remaining data skew problem will be solved by the adjustment process for the horizontal direction.
2.3. Horizontal Direction Adjustment
After vertical direction adjustment, the data skew problem of image tiles in most partitions has been solved, but there remains a data skew problem in a small number of bottom partitions. This section is mainly concerned with how to optimize the bottom partitions in the image layout. In general, when the number of partitions can be exactly divided by the total number of image tiles, the horizontal direction adjustment would not be required.
Connected component analysis is used to scan and analyze the image tiles in the remaining bottom partitions, and the image tiles of all the data skew partitions are added to the same connected component. In the connected component, the image tiles are processed in each partition in the order from left to right along the horizontal direction according to the predefined number of partitions and the threshold values. Due to the irregular shape of the bottom connected component, it is inefficient to continue to use the simple image tile transfer as in the vertical direction adjustment. Therefore, the region growing algorithm may be adopted to process the target partitions based on four neighborhood directions (top, right, bottom and left), in order to obtain the partitions in which the number of image tiles meets the partition threshold well and all remaining image tiles in the image layout are evenly distributed.
After the bottom partitions are adjusted, the partitions in the connected component, and the corresponding mark and attribute information of the image tiles are updated. As shown in
Figure 4c, through the vertical and horizontal direction adjustment, all the image tiles located in the image layout are evenly distributed in predefined partitions, which solves the data skew problem with respect to the partitioning of image tiles during the distributed processing of remote sensing images.
5. Discussion
In this research, the raster partition method is proposed to solve the improper partition problem of image tiles decomposed from large-scale images. This method focused on the unevenly divided image tiles among partitions which occurs in the loading or dividing stages and leads to the data skew problem. The researches of [
29,
30] focused on the task parallelism problem, which profiled the applications in remote sensing field and incorporated them with DAG to realize the further optimization the execution time. They usually find the partitionable tasks and build the task parallelism based on the analysis of the dependencies among tasks, while the load balancing in the beginning of the task were not discussed. The load balancing and the task parallelism concentrate on the partition problems occurring in different computing stages, but both of them could promote the further improvement of the execution efficiency. Additionally, the task parallelism method would be the further study point in our research.
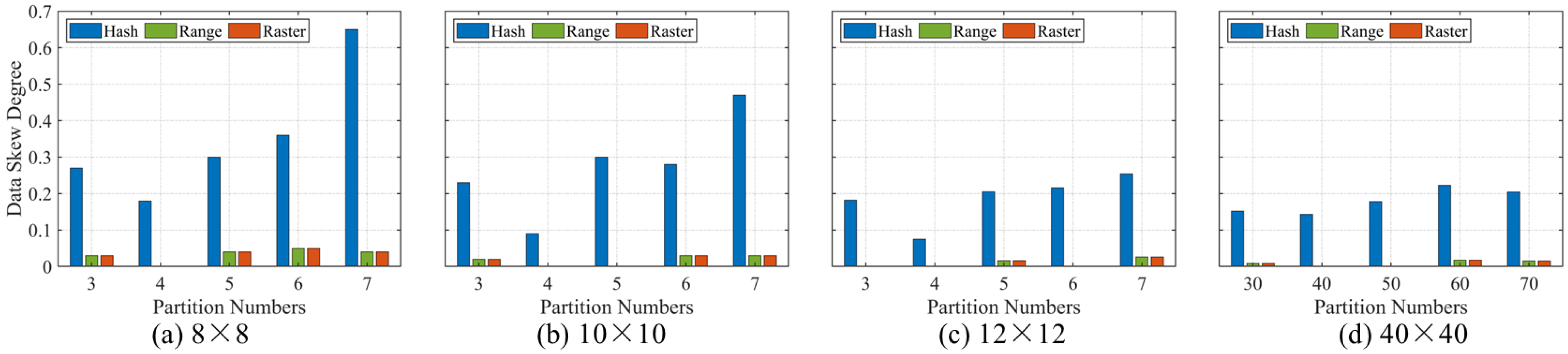
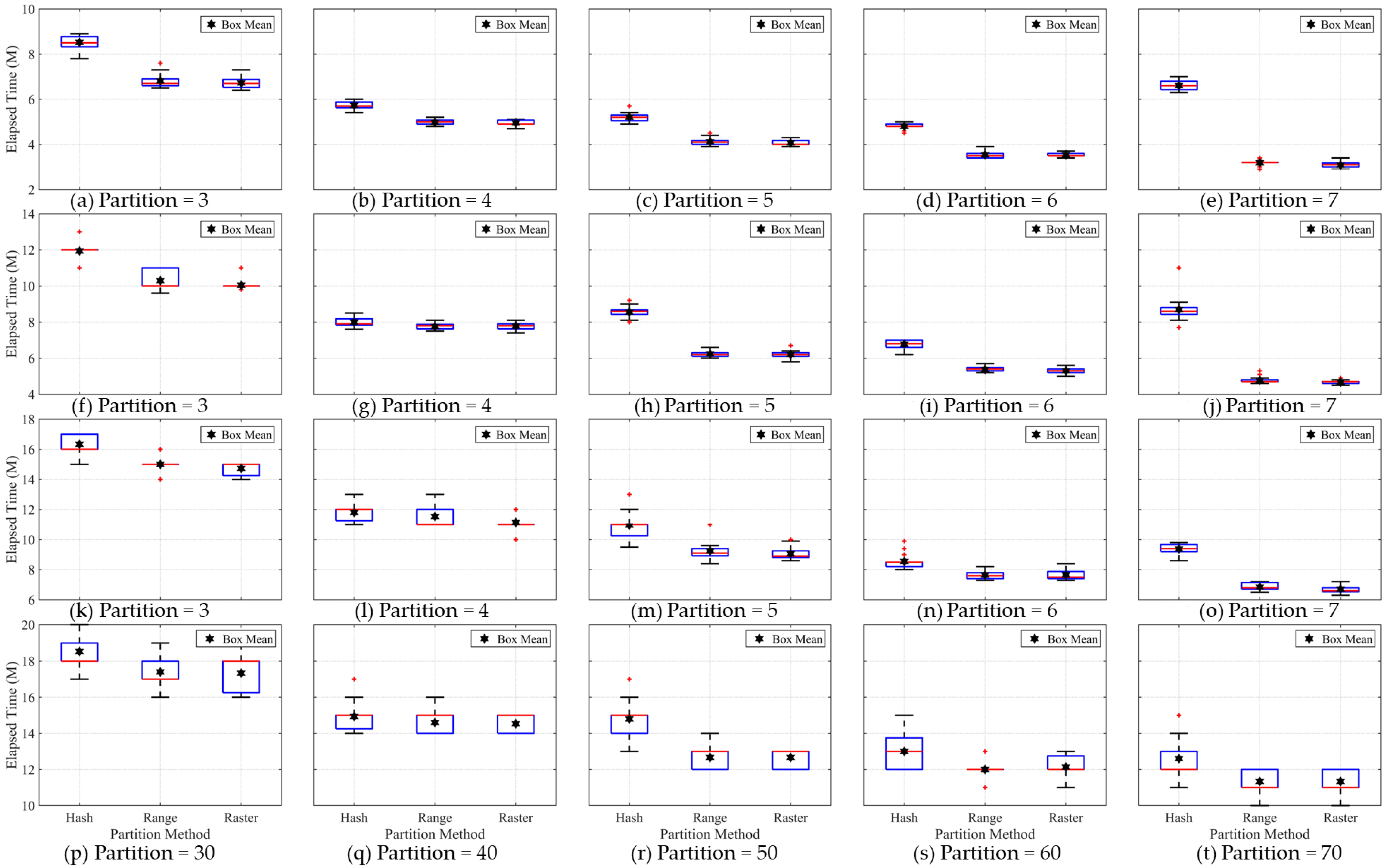
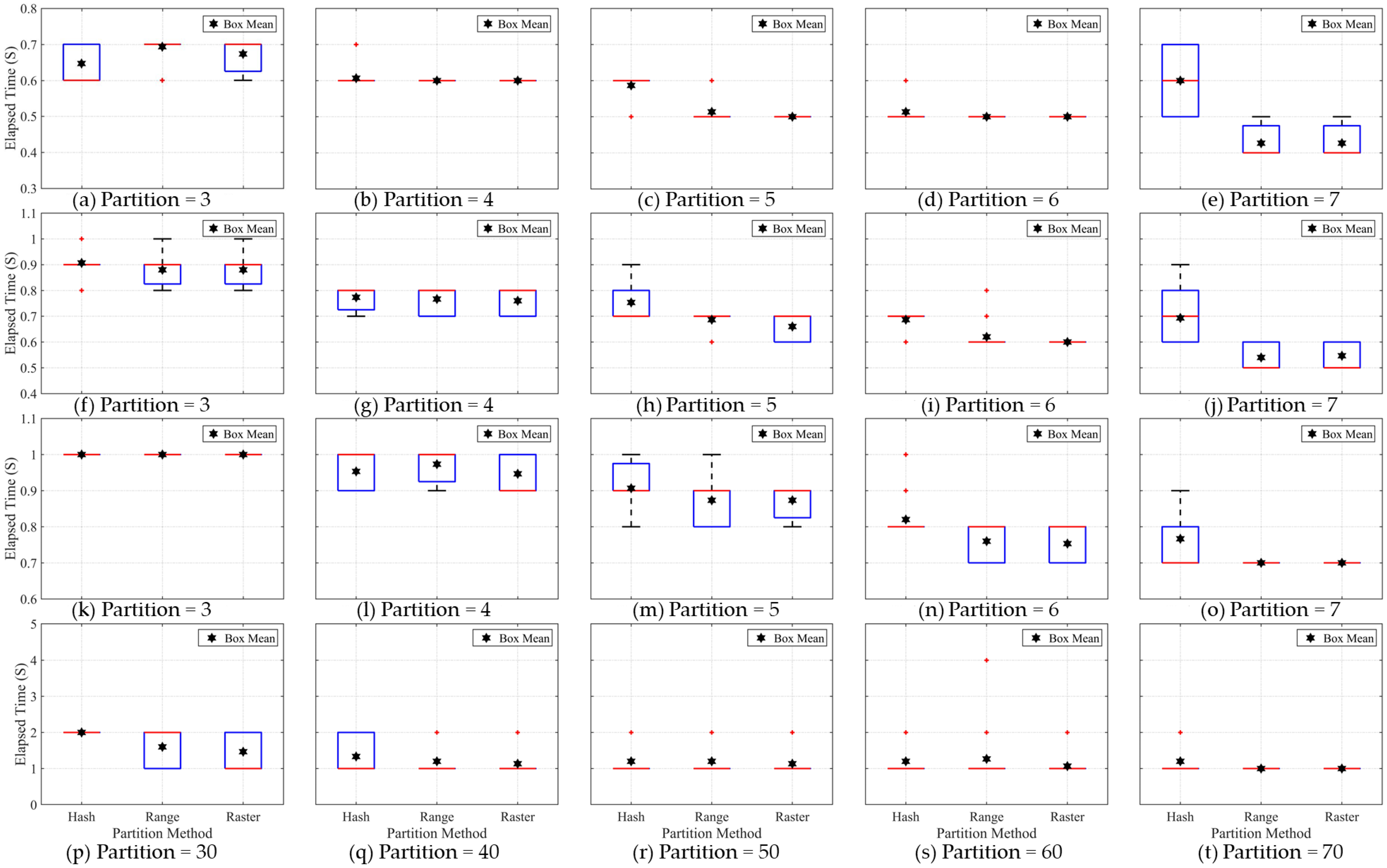
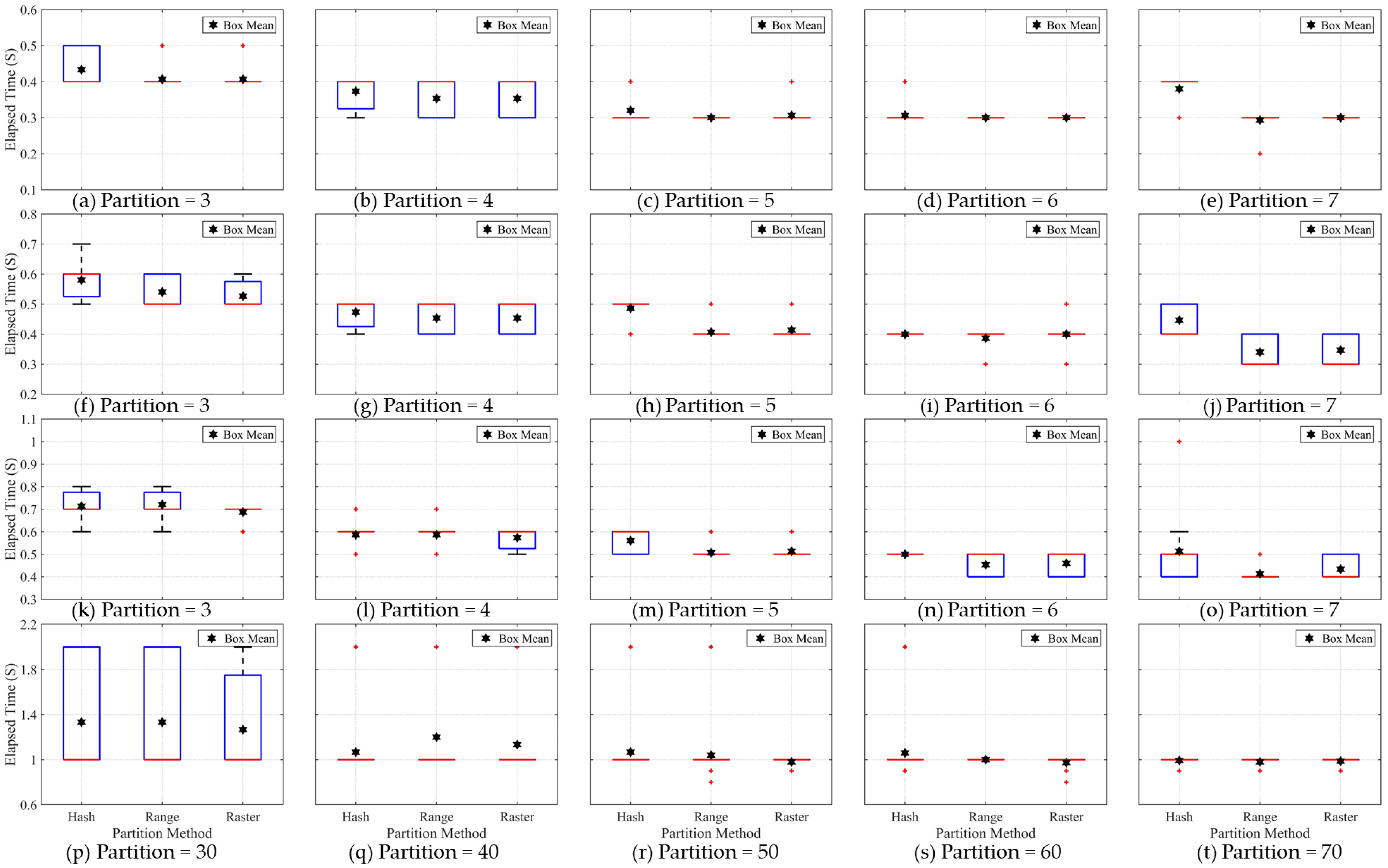
In terms of testing the image segmentation stage, the box graph is used to represent the elapsed time for all the repeat tests. The elapsed time recorded in each group changes within a certain range rather than having a fixed value, which is mainly caused by the operating condition of the distributed cluster and each computing node. When performing each round of calculation with a fixed number of computing nodes, the combination among these computing nodes is not unique, hence this will affect the execution efficiency of the same application task. The hash partition method requires more operational time than the range and raster partition methods in the image segmentation stage. The elapsed time for the hash partition method is affected by the degree of data skew and will rise with increase in the number of partitions, while the other two partition methods solve the problem of data skew. Although the elapsed time difference between the range and raster partition method is usually small, the elapsed time of the raster partition method is slightly lower than that of the range partition method.
In terms of testing the data shuffle stage, the two highest degrees of data skew for the hash partition method will clearly lead to the highest data shuffle time (as shown in
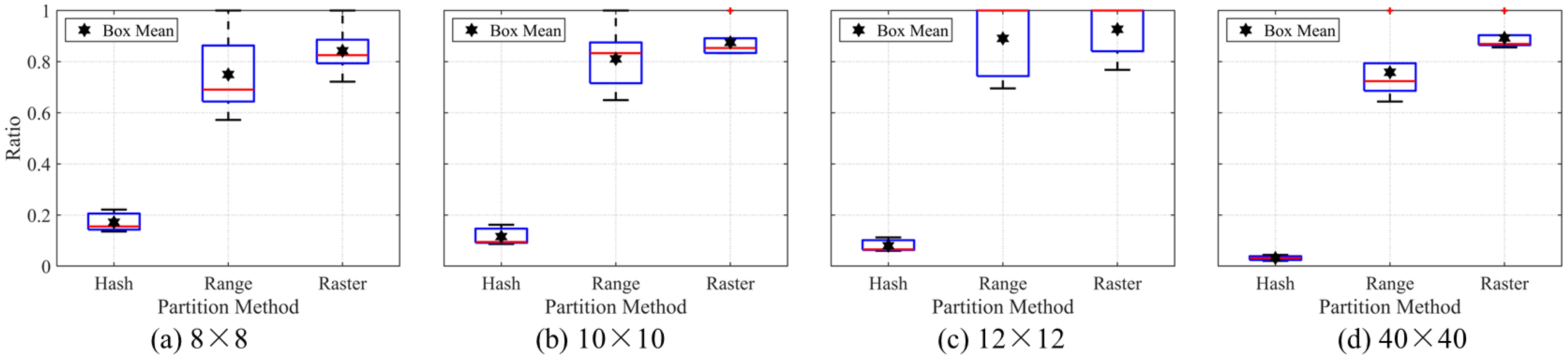
Figure 9). The higher the degree of data skew, the more the image tiles are contained in a small number of partitions. As is well known, the data shuffle process needs to obtain the image pixels of the image tiles located in the surrounding neighborhood, therefore, the partition needs to communicate using an internal network with more partitions (computing nodes) during the data shuffling stage. Compared with the internal network communication of the distributed cluster, the amount of image tiles is relatively small, therefore, a very high degree of data skew can lead to significant changes in the data shuffle time. In addition, the data shuffle time for the range partition method is slightly more than that for the raster partition method according to the average elapsed time for the data shuffle. The verification results show that the proposed raster partition method has a more compact partition structure and better efficiency performance among the three partition methods. On the one hand, due to the limitation of the Apache Spark platform management components, the elapsed time for all experiments can only be accurate to 0.1 s, which leads to a lack of accuracy in the recording of the elapsed time to a certain extent. On the other hand, other applications or service programs may occupy the internal network for communication when the test task is run in this experiment.
In terms of the testing of the image clipping stage, the image clipping process is a built-in function of the Geo trellis framework and is used to evaluate the impact of the variation in the number of partitions on the elapsed time. The elapsed time difference of image clipping stage can further verify the results generated by the former two test experiments. The elapsed times for the hash, range and raster partition methods were very close where the degree of data skew for the hash partition method was relatively low. In contrast, the elapsed time for the hash partition method can be clearly distinguished from that of the range and raster partition methods when the degree of data skew for the hash partition method was relatively high. This is because the image clipping function in the Geo trellis framework is very simple and requires very little operating time to complete. Therefore, only a huge difference of image tiles in each partition can lead to the relatively clear change in the operating time. The experimental testing shows that the data skew problem will indeed affect the efficiency of the distributed applications.
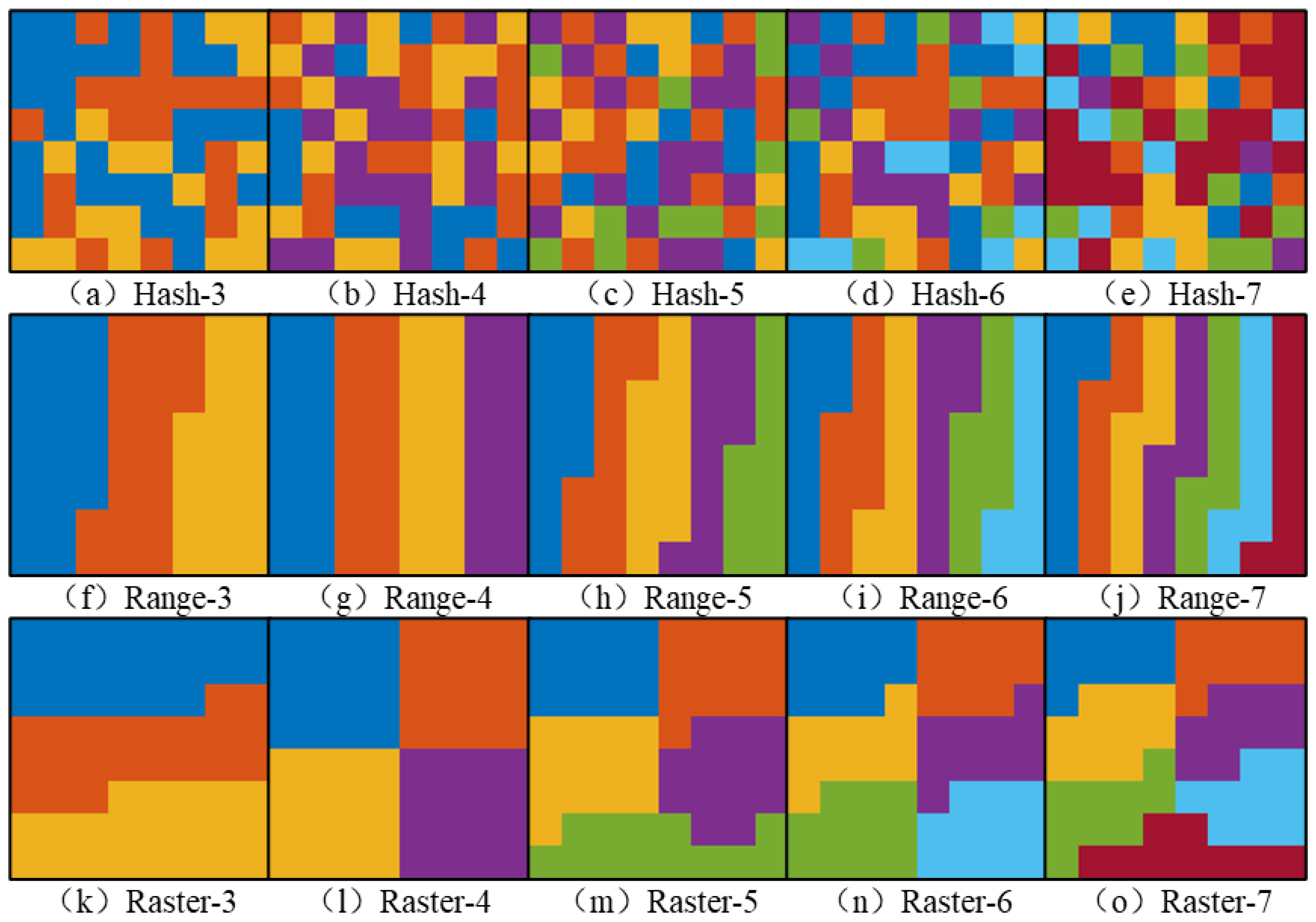
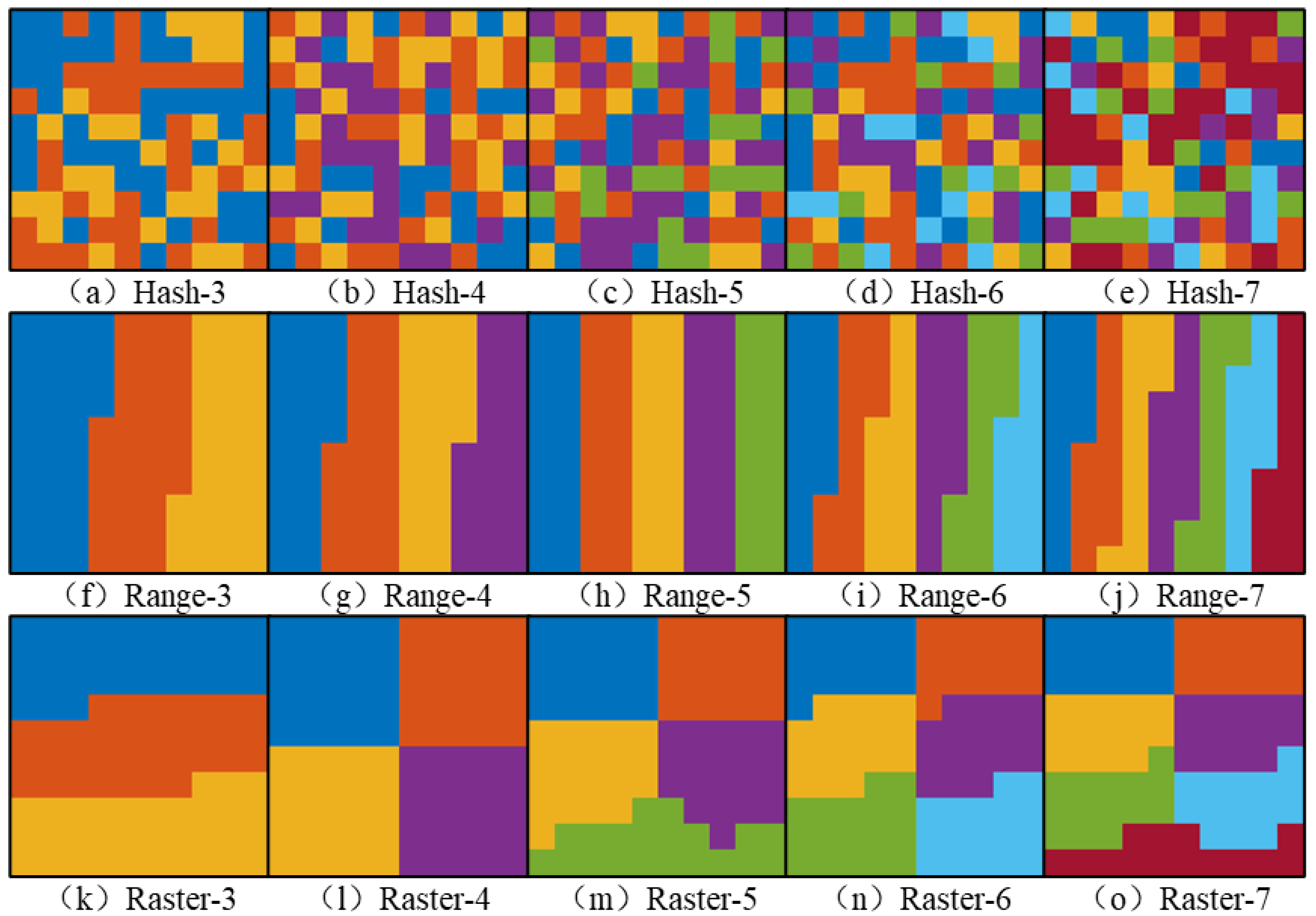
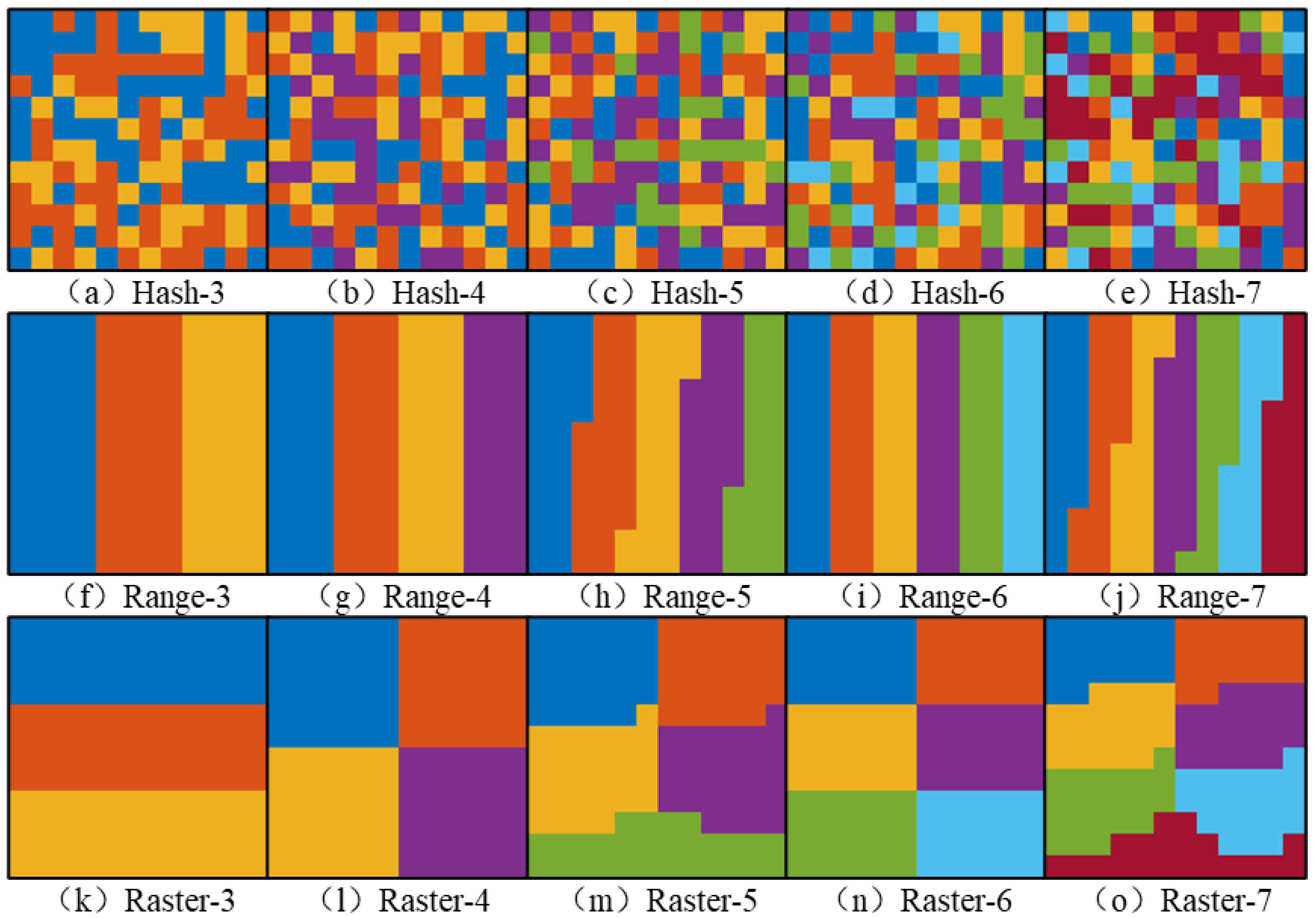
In terms of the several types of partition layout, the partition results for the hash, range and raster partition methods show, respectively, the randomness, the strip characteristic, and the aggregation feature in all types of image layouts and number of partitions. The hash partition method calculates the hash value of the column and row index corresponding to each decomposed image tile, and the manner of generation of the hash partition method determines the partition results. This usually generates random partition results, which leads to an extremely uneven number of image tiles in each partition. Therefore, more partitions will not improve the efficiency of the task but may lead to a longer task operating time or performance bottleneck. The processing order of the raster partition method is from top to bottom and from left to right, and the partitions located at the bottom of the image layout sometimes can have an abnormal shape and are not compact enough. A similar situation occurs in the results of the raster partition method when the number of partitions is 5 or 7, which is one deficiency in the current design scheme of the raster partition method.
6. Conclusions
As is well known, the data skew problem can influence the execution efficiency directly in many application tasks implemented over distributed clusters and even lead to performance bottlenecks. In addition, a partition method suitable for image tiles organized by row and column index characteristics is still not available. To solve the aforementioned data skew issues, this study proposed a novel partition method based on the clustering idea and the equal area conversion principle. The approach could specifically distribute the decomposed large-scale remote sensing image tiles uniformly to each computing node. Our proposed partition method consists of three main parts: the seed point planning, vertical direction adjustment and horizontal direction adjustment. In the method, image tiles are regarded as image pixels lacking spectrum and texture attributes, and the image tile partitioning problem is transformed into an image pixel clustering problem. First, the seed points are planned based on the equal area conversion principle and the image tiles are aggregated by taking the uniformity and compactness criteria into account to generate an initial partition. Second, the initial partition is fine tuned in terms of the vertical and horizontal directions to achieve a uniform distribution, which solves the data skew problem of image tiles. Two traditional partition methods (the hash and range partition methods) were employed to evaluate and verify the proposed partition method from three aspects: the elapsed time for the image segmentation stage, the data shuffle stage, and the image clipping stage. The results showed that the proposed partition method can solve the data skew problem by distributing image tiles evenly to each partition (computing node), and reduced the computational time by 21.5%, 7.7% and 8.5% on average in the three stages. Meanwhile, the elapsed time decreased monotonically as the number of partitions increased.
In future work, the proposed raster partition method could be further optimized in terms of the computational complexity and the compactness of the total partitions in the image layouts. In addition, the initial seed points should be selected and initialized in a more balanced distribution, which would maintain the adjacent image tiles within the same computing node as much as is feasibly possible. Furthermore, the task parallelism would be considered to further improve the execution efficiency in our research.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}