1. Introduction
Corn (
Zea mays L.) production in Mexico for the year 2020 exceeded 27.4 million tons [
1]. Corn is one of the most important crops in the country from a food, political, economic and social perspective [
2]. Cereals form a crucial part of the human diet and livestock feed, so achieving self-sufficiency in their production is an effective way to promote food security [
3].
Knowing the number of plants and monitoring their growth status are important for estimating yield [
4,
5]. Manual counting after plant emergence is not practical in large-scale production fields due to the amount of labor required, in addition to which it is inherently inaccurate [
3,
4,
6]. One approach that has been applied in recent years is the use of remotely piloted aerial systems (RPAS) equipped with optical sensors for agricultural remote sensing [
7]. Several studies have reported on the use of RPAS to determine planting densities in different crops; for example, in [
8], they reported on its use for the detection of cotton plants, based on machine learning with convolutional neural networks (CNNs), in [
9], they used CNNs for the detection and counting of tobacco plants, in [
10], they propose a CNN (WheatNet) based on MobileNetV2 with two outputs for the localization and counting of wheat ears from images; similarly, in [
11], they propose an integrated image pre-processing method (Excess Green Index and Otsu’s method) and CNNs for identifying and counting spinach plants.
Three methods for counting and classifying corn plants have been reported in the literature:
(1) Classical image processing techniques. In [
12], RGB cameras mounted on RPAS were compared using templates and normalized cross-correlation, obtaining
coefficients of 0.98, 0.90 and 0.16 for vegetative stages V2, V5 and V9, respectively. Gnädinger and Schmidhalter [
13], using the decorrstrech contrast enhancement procedure with thresholding, obtained
coefficients of 0.89 for vegetative stages V3 and V5. Shuai et al. [
14] employed the excess green (ExG) vegetation index, achieving a precision of 95% and recall of 100% for plant counts at vegetative stage V2.
(2) Classical image processing techniques plus machine learning procedures. In [
15], they used principal component analysis (PCA) and Otsu’s thresholding method to extract features as input to Naive Bayes neural network and Random Forest classifiers to classify corn plants and weeds in images captured with mobile devices. Varela et al. [
6] used color indices, geometric descriptors and decision tree classifiers for corn counting, achieving accuracies of 96% for stages V2 and V3. Pang et al. [
16] combined geometric descriptors and convolutional neural networks to count corn plants, achieving accuracies of 95.8% for vegetative stages V5 and V4.
(3) Machine learning with CNNs. In [
17], they compared color indices with CNN architectures, specifically “You Only Look Once” (YOLO) in its YOLOv3 and YOLOv3-tiny versions, to evaluate the detection of corn plants in images captured at a height of 0.3 m from the ground, achieving a 77% intersection over union (IoU). Wan et al. [
18] used a robot-mounted camera for real-time plant detection and counting, employing YOLOv3 and a Kalman filter, and achieved accuracies of 98% at stages V2 and V3. Vong et al. [
19] performed semantic segmentation with the U-NET architecture, obtaining
coefficients of 0.95 at the V2 stage. Velumani et al. [
20] evaluated the performance of Faster-RCNN for corn plant counting at different spatial resolutions, achieving an rRMSE value of 8% with a ground sampling distance (GSD) of 0.3 cm/pixel. Osco et al. [
5] proposed a CNN-based architecture for segmenting and counting corn plants, achieving F1-Scores of 0.87 for stage V3. Etienne et al. [
21] compared classical methods for image processing and Faster-RCNN in counting corn, sugar beet and sunflower plants.
In general, the best results were obtained when using CNNs with deep learning methods. Although there are some works that analyze the effects of weeds on the detection and counting of corn plants in aerial images [
5,
15,
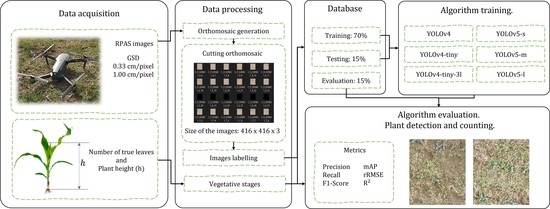
21], given the complexity of possible scenarios and the conditions of corn fields in Mexico, labeled databases are still required to assess the robustness of state-of-the-art object detection algorithms. Therefore, the following contributions are made in this paper: (i) a database with 11,191 aerial images of dimension 416 × 416 × 3 labeled, (ii) a comparison of the results obtained by YOLOv4, YOLOv4-tiny, YOLOv4-tiny-3l, YOLOv5-s, YOLOv5-m and YOLOv5-l models in the detection and counting of corn plants in weed-infested fields, considering the value of the intersection over union and confidence and (iii) the optimization of the confidence level and the intersection over union that maximize the F1-Score metric in the evaluation of the models.
The paper is organized as follows.
Section 2.1 describes the conditions and the process used for the acquisition of aerial images, as well as the labeling process for the formation of the database;
Section 2.2 and
Section 2.3 describes the algorithms used and the evaluation metrics. The results and discussion are provided in
Section 3 and
Section 4, respectively. Finally,
Section 5 provides conclusions and offers ideas for future research.
4. Discussion
The confidence value for the evaluation was chosen with the mode. When the models reached the maximum F1-Score, this value of 0.3 is lower than that of [
20], who report a confidence of 0.5 when evaluating the Faster-RCNN architecture, indicating better results in terms of plant classification. YOLOv4-based models with confidence values higher than 0.35 maintain a higher F1-Score value than YOLOv5 versions, indicating that YOLOv4 models are more reliable in terms of classifying corn plants.
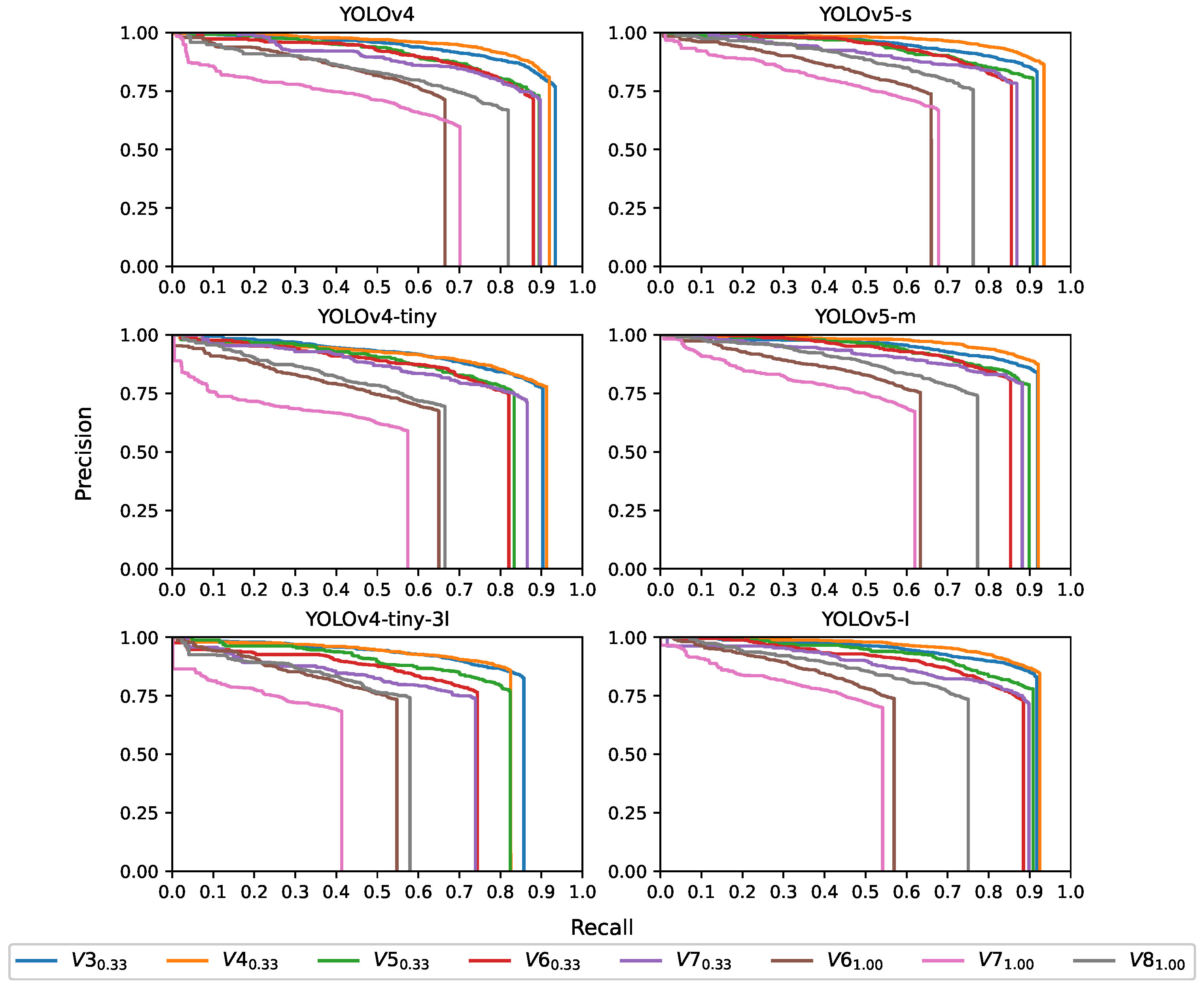
Most of the works on object detection in large datasets evaluate CNN models at IoU thresholds higher than 0.5 [
35]. By analyzing the graphs in
Figure 9, considering IoU thresholds greater than 0.5, a decrease can be seen in the F1-Score metric, indicating that the models lose precision in estimating the size of the corn plant. This can be seen in
Figure 14a, where it is observed that, in some cases, the label prediction does not include the plant leaves, and since the IoU threshold of 0.5 is not exceeded, they would be considered FP predictions. As in [
20], the F1-Score metric was evaluated at an IoU threshold of 0.25. An average increase of 4.92% was achieved for all YOLO models from an IoU threshold of 0.50. For the purposes of plant counting and detection, accurate estimation of plant dimensions is not considered critical [
20]. Consequently, the IoU threshold value of 0.25 and a confidence of 0.3 were used to better account for the smaller size of the detected bounding boxes and the classification of corn plants, as was done in [
20].
With respect to the plant count, YOLOv4 has a higher number of TPs, so it correlates better with the actual number of plants, with
= 0.81 and rRMSE = 39.55%, followed by the YOLOv5-s model, with
= 0.78 and rRMSE = 42.06%. Although there is a high correlation with the actual number of plants in both models, according to [
21], they would still be considered very poor results as they have rRMSE values greater than 20%.
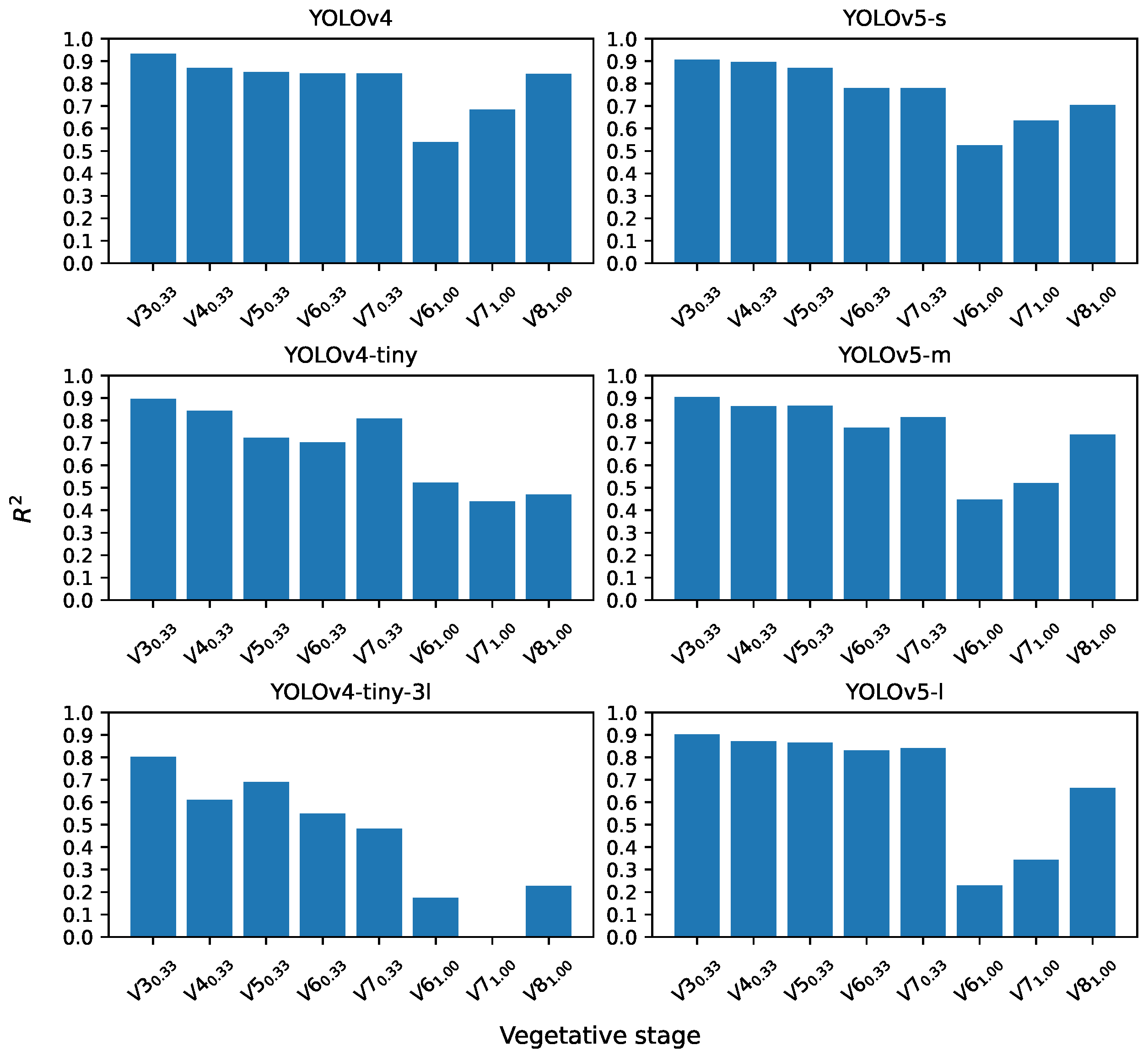
For a better analysis of the data, the models were evaluated for each plant growth stage and their spatial resolution. For the evaluation of the models at stages
and
, with the exception of YOLOv4-tiny-3l, the performance results are consistent with the findings reported in the literature. Similar results were found in [
21], who reported 10% < rRMSE < 20% for stages V3 and V4 under moderately weedy conditions. In [
13] a coefficient
= 0.89 is reported for stages V3 and V5, while in [
12]
= 0.98 is reported for stage V2.
For the YOLOv4-tiny and YOLOv4-tiny-3l models, the results considerably decay from the , stage, which is understandable since they reduce the number of convolutional layers. In addition, the idea that YOLOv4-tiny-3l performs better than YOLOv4-tiny by having one more output was rejected.
The YOLOv4 models and the YOLOv5 versions evaluated at stages
,
and
maintain the results of 70% < Pr < 80% and 85% < Rc < 90%, with the best scores at
followed by
. As the rRMSE values for
and
exceed 20%, the results are considered very poor and poor for
. These results are consistent with the limitation mentioned by [
6], where plants are prone to leaf overlap, which reduces the overall performance of the YOLO architecture evaluated in this work.
A visual inspection of the detections made by each YOLO model helped to understand that FPs at stages lower than V5 with GSD of 0.33 cm/pixel are due to detections made at the edges of the images and in isolated cases due to confusion with weeds. In these cases, the FP count can be lowered by filtering the results with confidence values greater than 0.30. For stages
,
,
and
, the FPs are mostly due to predictions made for unlabeled plants. Although partial labeling is not recommended in tasks addressed with supervised learning, in this case.=, full labeling was extremely complicated due to various errors in the image. Even so, the robustness of the YOLOv5-s model for detecting corn plants under highly complex weed conditions can be seen in
Figure 14b.
Although in [
20], the effect of spatial resolution on the detection of corn plants was evaluated, obtaining better results with a GSD of 0.3 cm/pixel in stages between V3 and V5, in this work it was observed that, for stages higher than V5, a GSD greater than 0.3 but lower than 1.00 cm/pixel should be considered because the images become difficult to visually interpret for labeling.
Finally, due to the characteristics of the camera mounted on the drone used in this research work, the flight height at which the best results were obtained was 10 m (GSD = 0.33 cm/pixel), which makes large-scale deployment unfeasible due to the limited data acquisition capability. Better cameras that allow for the acquisition of sharper images with plant-level detail at higher flight heights are required for better results when detecting corn plants and to make the application feasible. Another limitation of this study is that a range of GSD was not explored to determine an optimum for the detection of corn plants at vegetative stages above V5.
5. Conclusions
In this research work, a database of aerial images of corn crops with different levels of weed infestation and ground sampling distance was created. The detection and counting of corn plants were evaluated using YOLOv4, YOLOv4-tiny, YOLOv4-tiny-3l, YOLOv5-s, YOLOv5-m and YOLOv5-l architectures. It was shown that YOLOv5 and YOLOv4 architectures are robust in detecting and counting corn plants at stages below V5 in high-resolution images (GSD = 0.33 cm/pixel) even under weed infestation conditions, obtaining Pr results between 77 and 85%, an Rc above 90% and rRMSE between 10 and 20%.
However, in case of stages after V5 with GSD of 1.00 cm/pixel, the results were not favorable, due to the low quality of the images, which did not even allow for the complete labeling of the corn plants. High-resolution images are crucial to improve the results in plant detection; therefore, it is recommended to determine an optimal GSD for the acquisition of aerial images in stages after V5.
The effect of considering different confidence values and IoU thresholds as evaluating detection models was also observed. In this case, YOLOv4 has higher confidence levels than the YOLOv5 versions, although the YOLOv5 versions are more accurate in determining plant location and size. The largest errors in plant counts were obtained in case of the tiny versions of YOLOv4 due to the reduced number of convolutional layers.
Finally, to make plant detection feasible on a larger scale, one direction for future work would be to explore the use of super-resolution architectures coupled to an end-to-end trainable detector, solving the problem of acquiring low-resolution images.




 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}