
MSPR-Net: A Multi-Scale Features Based Point Cloud Registration Network


Abstract
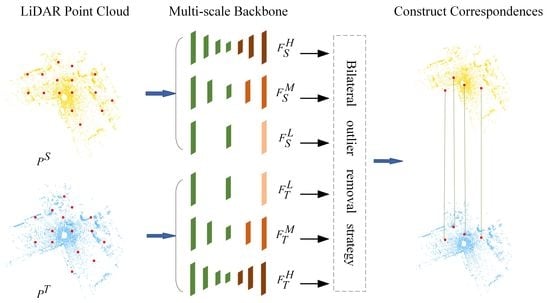
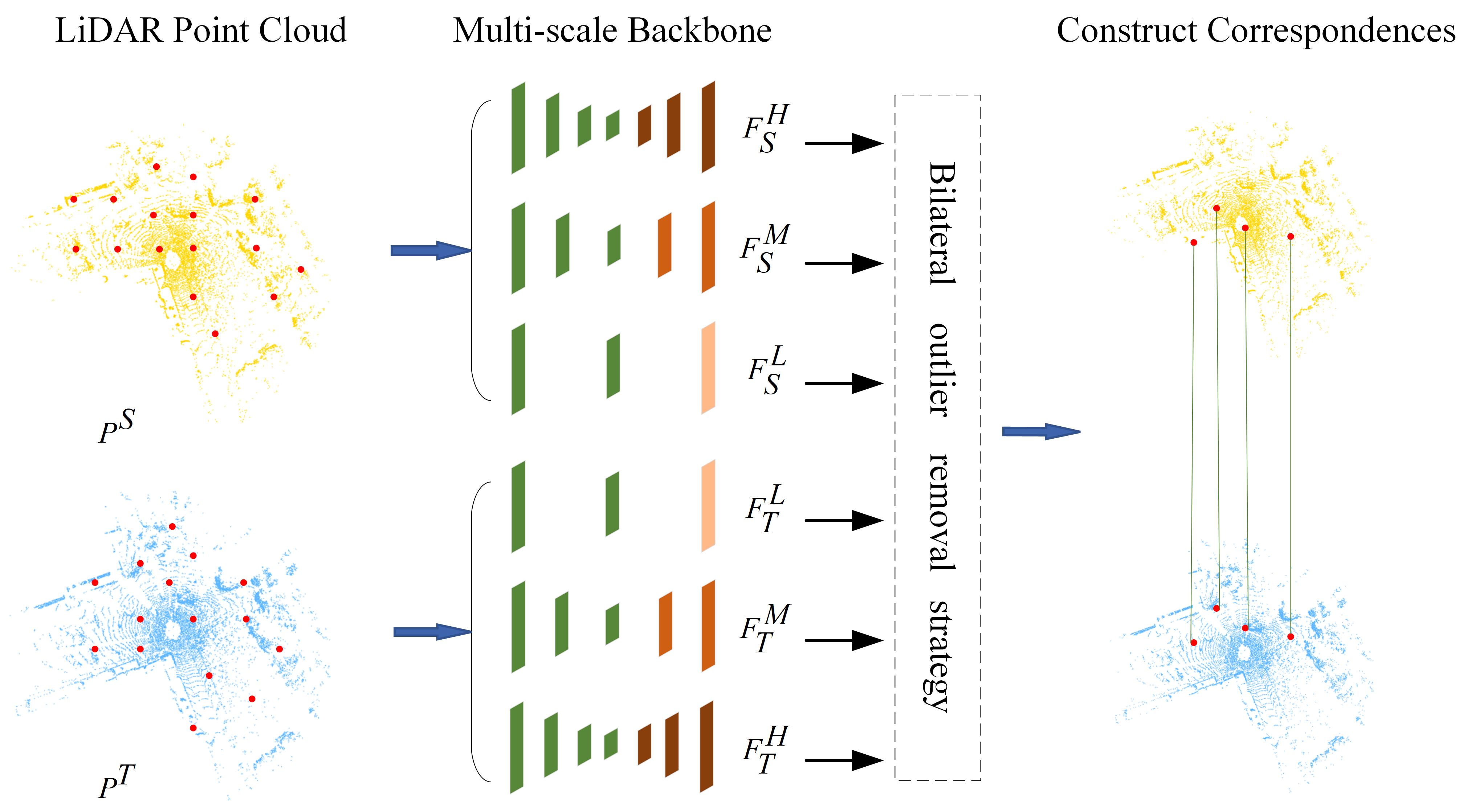
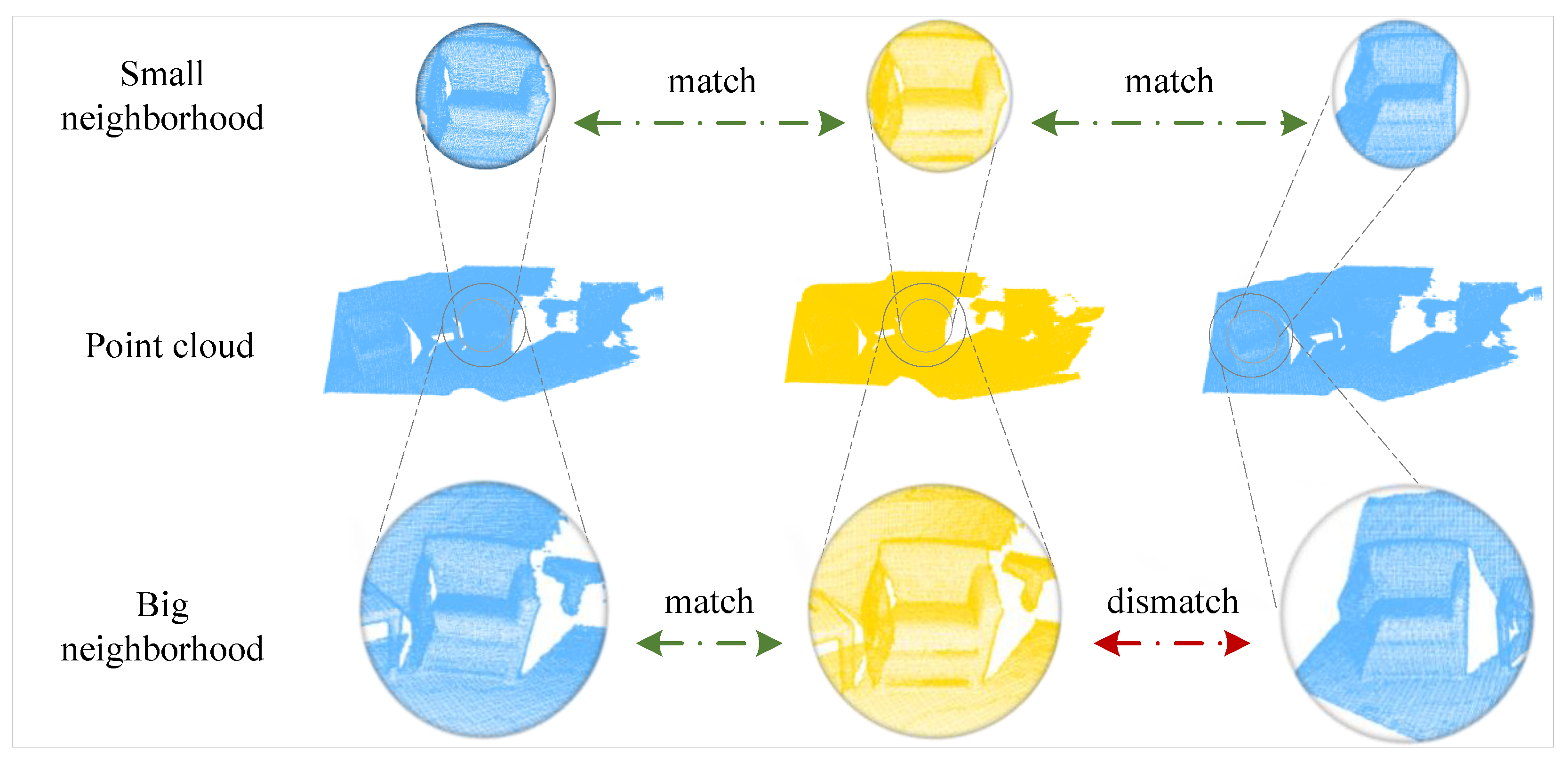
1. Introduction
- We propose a novel point cloud registration network named MSPR-Net, which achieves state-of-the-art performance in outdoor LiDAR datasets.
- We propose a local similarity estimation module and a global similarity estimation module to eliminate the instability of random samples so that the matched keypoints and their descriptors can have more consensus.
- We design a novel bilateral outlier removal strategy, which removes outliers from the source point cloud and target point cloud, respectively.
2. Related Works
2.1. Correspondence-Based Methods
2.2. Global Feature-Based Methods
2.3. Multi-Scale Network
3. Methods
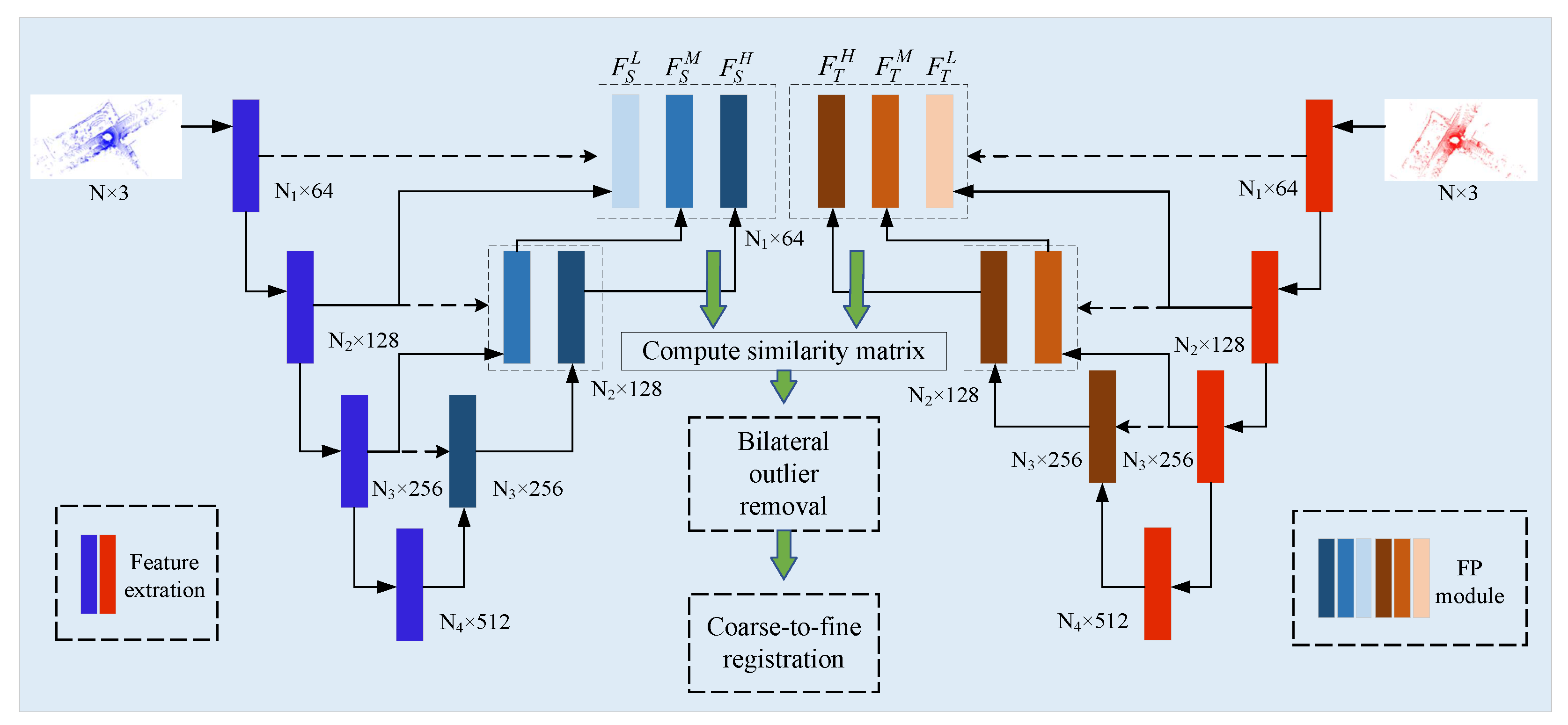
3.1. Network Architecture
3.1.1. Siamese Multi-Scale Backbone
3.1.2. Detector and Descriptor
- LSEM As shown in Figure 3, the input of LSEM is the cluster features. To simplify the formulation, the subscripts l are omitted. Firstly, is inputted into a 3-layer of Shared MLP to generate a feature map . After that, a max pooling operation is followed to get the global feature of the neighboring region. Finally, we compute the similarity of each point’s feature with the region feature, followed by a softmax function for normalization. For a local region center on , the local saliency can be calculated aswhere denotes the dot product. is the region feature and is the neighboring point’s feature. The sampled point will be relocated by the saliency weight aswhere is the coordinate of the neighborhood. We also update by the weighted sum of neighboring features to .
- GSEM LSEM only can refine the coordinate of the downsampled keypoints in a local region, no matter whether the point is in the overlapping area or not. To enhance the overlap awareness, we propose that GSEM make the network gradually pay attention to the overlap region as hierarchically downsampled. Different from PREDATOR, [49] which predicts overlap scores by a linear function, we use a more intuitive method to express the overlap scores of the keypoints. As every keypoint has aggregated the local region information, we calculate the similarity of each keypoint’s feature in the source point cloud with the global feature of the target point cloud. Intuitively, the features of the overlap region keypoints would be more similar to the corresponding global features than other points.
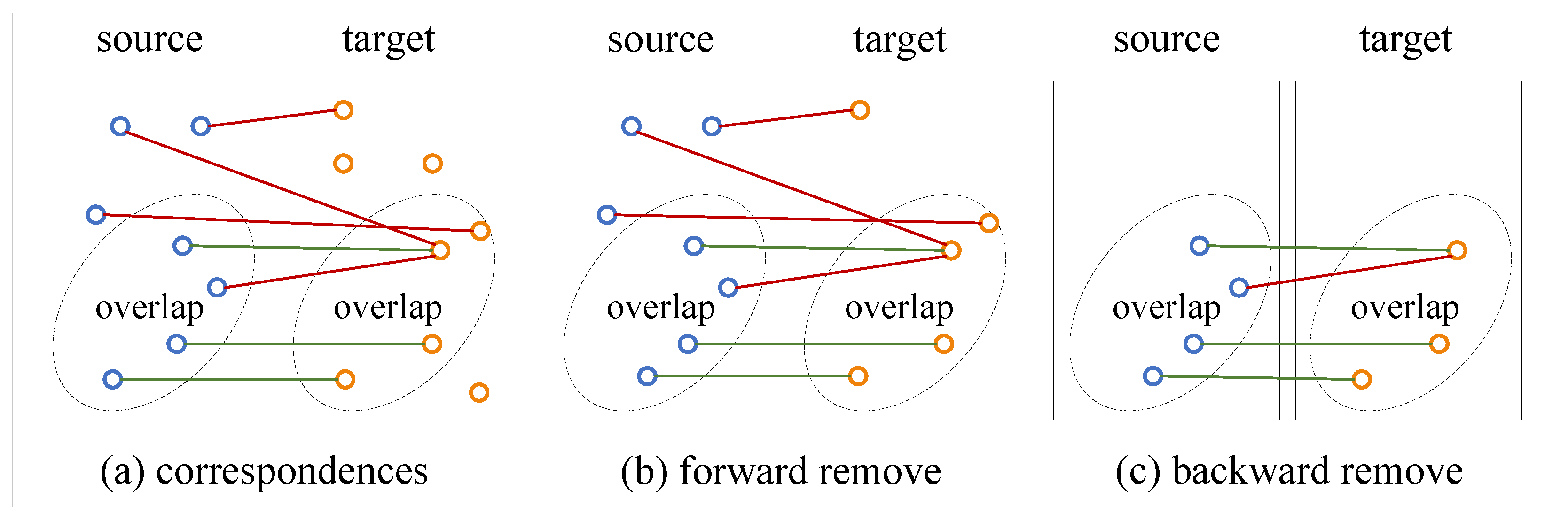
3.2. Bilateral Outlier Removal
3.3. Coarse-to-Fine Registration
3.4. Loss Function
4. Results
4.1. Implementation Details
4.2. Evaluation Metrics
4.3. KITTI Dataset
4.3.1. Performance
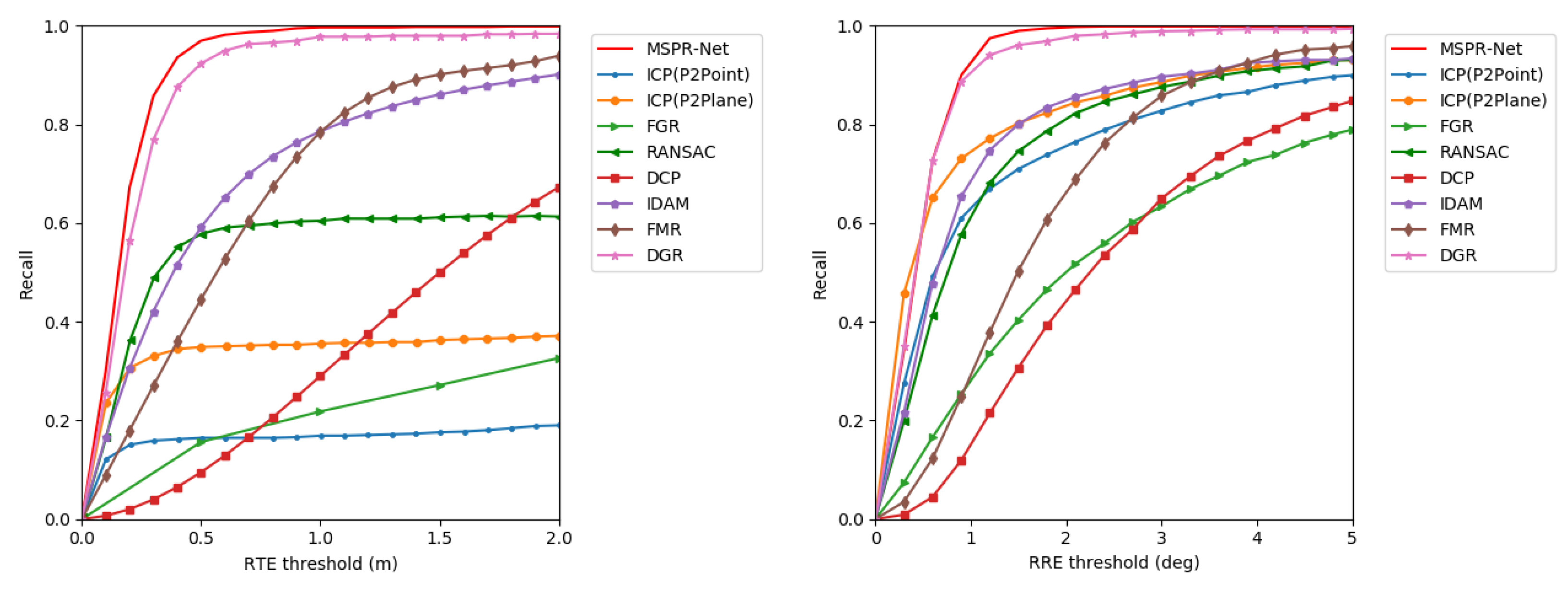
- Comparison with the traditional methods. MSPR-Net is compared with point-to-point and point-to-plane ICP, RANSAC, and FGR. According to the results in Table 1, the ICP algorithm achieves the best RRE and RTE on the KITTI dataset. However, they are both in a very low recall due to the imprecise initial transformation between point cloud pairs in most cases. FGR performs slightly better than ICP, but the result is still not good. Taking advantage of the multiple iterations and outlier rejection strategy, RANSAC obtains reasonable results. Our method achieves significantly higher recall, RTE, and RRE compared to RANSAC.
- Comparison with the learning-based methods. We compare our approach with learning-based point cloud registration methods, including IDAM, DGR, CoFiNet, and PREDATOR. As shown in Table 1, the recall of IDAM is about 70% and the average RTE and RRE are more than 1.0, which indicates the poor applicability of the object-level point cloud registration methods to complex, large-scale LiDAR point clouds. DGR performs much better than IDAM thanks to the powerful outlier rejection mechanism based on the 6D convolutional network. However, the voxel-based representation of point clouds limits the precision of registration. CoFiNet achieves the highest recall by using a coarse-to-fine registration strategy, but it gets a relatively larger RRE and RTE due to the position error caused by the sparsity of keypoints in the deep layer. PREDATOR achieves the best registration performance among all the learning-based baseline methods. We show that our approach achieves the best RRE (0.24°). For RTE and recall, our method only has a slight margin with PREDATOR. Moreover, our method achieves almost faster speed than PREDATOR.
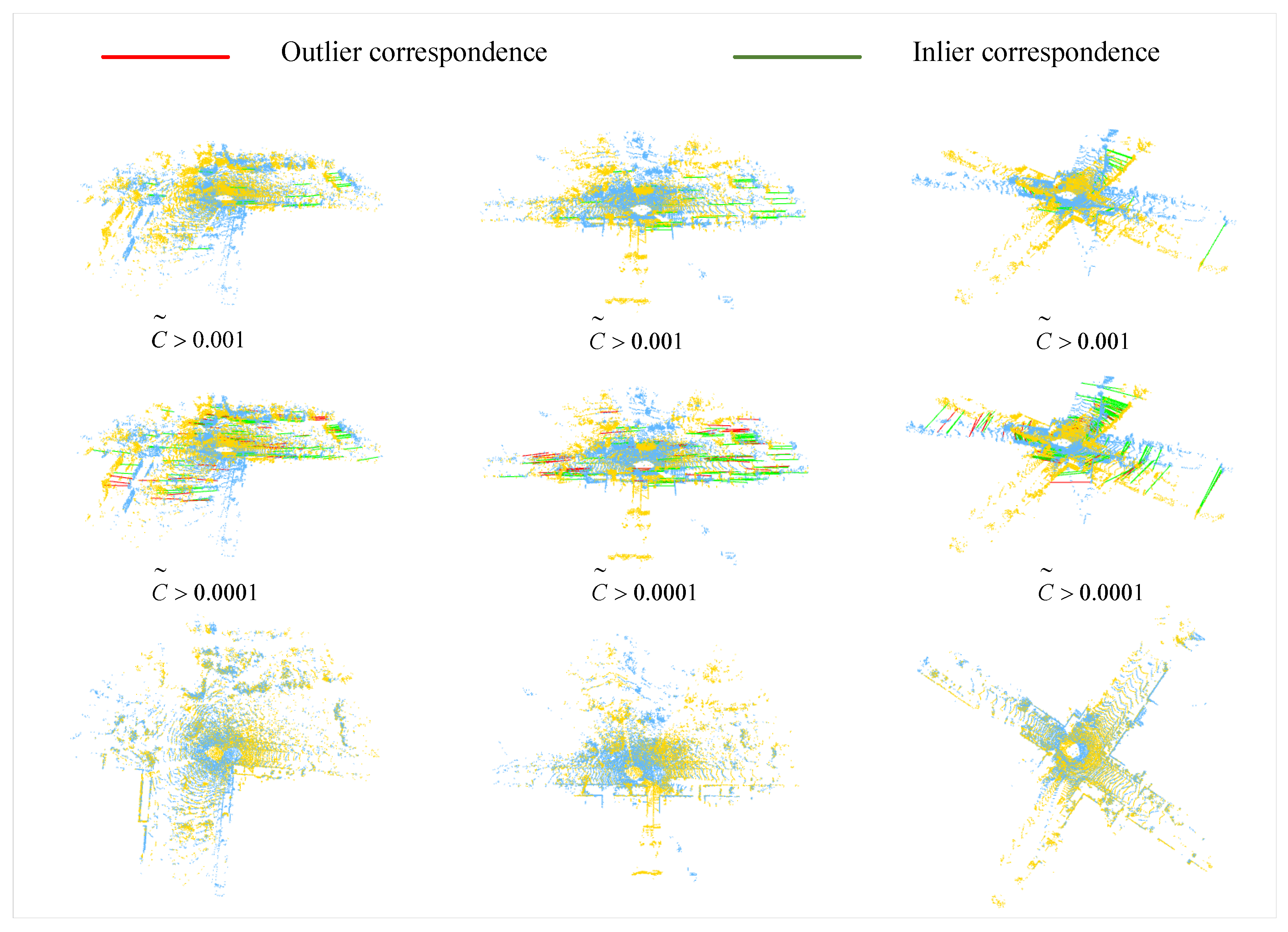
4.3.2. Qualitative Visualization
4.4. NuScenes Dataset
Performance
4.5. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Blais, G.; Levine, M.D. Registering multiview range data to create 3D computer objects. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 820–824. [Google Scholar] [CrossRef]
- Choi, S.; Zhou, Q.Y.; Koltun, V. Robust reconstruction of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5556–5565. [Google Scholar]
- Merickel, M. 3D reconstruction: The registration problem. Comput. Vision Graph. Image Process. 1988, 42, 206–219. [Google Scholar] [CrossRef]
- Sun, K.; Tao, W. A center-driven image set partition algorithm for efficient structure from motion. Inf. Sci. 2019, 479, 101–115. [Google Scholar] [CrossRef]
- Lu, W.; Zhou, Y.; Wan, G.; Hou, S.; Song, S. L3-net: Towards learning based lidar localization for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 6389–6398. [Google Scholar]
- Wan, G.; Yang, X.; Cai, R.; Li, H.; Zhou, Y.; Wang, H.; Song, S. Robust and precise vehicle localization based on multi-sensor fusion in diverse city scenes. In Proceedings of the 2018 IEEE international conference on robotics and automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 4670–4677. [Google Scholar]
- Wong, J.M.; Kee, V.; Le, T.; Wagner, S.; Mariottini, G.L.; Schneider, A.; Hamilton, L.; Chipalkatty, R.; Hebert, M.; Johnson, D.M.; et al. Segicp: Integrated deep semantic segmentation and pose estimation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5784–5789. [Google Scholar]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Proceedings of the Sensor fusion IV: Control Paradigms and Data Structures. SPIE, Boston, MA, USA, 12–15 November 1992; Volume 1611, pp. 586–606. [Google Scholar]
- Rusinkiewicz, S.; Levoy, M. Efficient variants of the ICP algorithm. In Proceedings Third International Conference on 3-D Digital Imaging and Modeling. Quebec City, QC, Canada, 28 May–1 June 2001; pp. 145–152. [Google Scholar]
- Fitzgibbon, A.W. Robust registration of 2D and 3D point sets. Image Vis. Comput. 2003, 21, 1145–1153. [Google Scholar] [CrossRef]
- Segal, A.; Haehnel, D.; Thrun, S. Generalized-icp. In Robotics: Science and Systems; University of Washington: Seattle, WA, USA, 2009; Volume 2, p. 435. [Google Scholar]
- Aoki, Y.; Goforth, H.; Srivatsan, R.A.; Lucey, S. Pointnetlk: Robust & efficient point cloud registration using pointnet. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7163–7172. [Google Scholar]
- Huang, X.; Mei, G.; Zhang, J. Feature-metric registration: A fast semi-supervised approach for robust point cloud registration without correspondences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11366–11374. [Google Scholar]
- Xu, H.; Liu, S.; Wang, G.; Liu, G.; Zeng, B. Omnet: Learning overlapping mask for partial-to-partial point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11 October 2021; pp. 3132–3141. [Google Scholar]
- Deng, H.; Birdal, T.; Ilic, S. Ppfnet: Global context aware local features for robust 3d point matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 195–205. [Google Scholar]
- Sarode, V.; Li, X.; Goforth, H.; Aoki, Y.; Srivatsan, R.A.; Lucey, S.; Choset, H. Pcrnet: Point cloud registration network using pointnet encoding. arXiv 2019, arXiv:1908.07906. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Wang, Y.; Solomon, J.M. Deep closest point: Learning representations for point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3523–3532. [Google Scholar]
- Yew, Z.J.; Lee, G.H. Rpm-net: Robust point matching using learned features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11824–11833. [Google Scholar]
- Fu, K.; Liu, S.; Luo, X.; Wang, M. Robust point cloud registration framework based on deep graph matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8893–8902. [Google Scholar]
- Choy, C.; Dong, W.; Koltun, V. Deep global registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2514–2523. [Google Scholar]
- Lee, J.; Kim, S.; Cho, M.; Park, J. Deep hough voting for robust global registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11 October 2021; pp. 15994–16003. [Google Scholar]
- Zhu, L.; Guan, H.; Lin, C.; Han, R. Neighborhood-aware Geometric Encoding Network for Point Cloud Registration. arXiv 2022, arXiv:2201.12094. [Google Scholar]
- Lu, F.; Chen, G.; Liu, Y.; Zhang, L.; Qu, S.; Liu, S.; Gu, R. Hregnet: A hierarchical network for large-scale outdoor lidar point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11 October 2021; pp. 16014–16023. [Google Scholar]
- Horache, S.; Deschaud, J.E.; Goulette, F. 3d point cloud registration with multi-scale architecture and self-supervised fine-tuning. arXiv 2021, arXiv:2103.14533. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Yang, J.; Li, H.; Campbell, D.; Jia, Y. Go-ICP: A globally optimal solution to 3D ICP point-set registration. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2241–2254. [Google Scholar] [CrossRef]
- Rosen, D.M.; Carlone, L.; Bandeira, A.S.; Leonard, J.J. SE-Sync: A certifiably correct algorithm for synchronization over the special Euclidean group. Int. J. Robot. Res. 2019, 38, 95–125. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Shen, Y.; Hui, L.; Jiang, H.; Xie, J.; Yang, J. Reliable Inlier Evaluation for Unsupervised Point Cloud Registration. arXiv 2022, arXiv:2202.11292. [Google Scholar] [CrossRef]
- Li, Y.; Harada, T. Lepard: Learning partial point cloud matching in rigid and deformable scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Orleans, LA, USA, 19–20 June 2022; pp. 5554–5564. [Google Scholar]
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with an Application to Stereo Vision; Morgan Kaufmann Publishers Inc.: Vancouver, BC, Canada, 1981; Volume 81. [Google Scholar]
- Cheng, R.; Razani, R.; Taghavi, E.; Li, E.; Liu, B. 2-s3net: Attentive feature fusion with adaptive feature selection for sparse semantic segmentation network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12547–12556. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Qiu, S.; Anwar, S.; Barnes, N. Semantic segmentation for real point cloud scenes via bilateral augmentation and adaptive fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1757–1767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef] [PubMed]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. How far are we from solving the 2d & 3d face alignment problem? (and a dataset of 230,000 3d facial landmarks). In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1021–1030. [Google Scholar]
- Najibi, M.; Samangouei, P.; Chellappa, R.; Davis, L.S. Ssh: Single stage headless face detector. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4875–4884. [Google Scholar]
- Liu, Y.; Cheng, M.M.; Hu, X.; Wang, K.; Bai, X. Richer convolutional features for edge detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3000–3009. [Google Scholar]
- Sun, K.; Tao, W.; Qian, Y. Guide to Match: Multi-Layer Feature Matching With a Hybrid Gaussian Mixture Model. IEEE Trans. Multimed. 2020, 22, 2246–2261. [Google Scholar] [CrossRef]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature verification using a "siamese" time delay neural network. Adv. Neural Inf. Process. Syst. 1993, 6, 737–744. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5105–5114. [Google Scholar]
- Zhou, Y.; Wan, G.; Hou, S.; Yu, L.; Wang, G.; Rui, X.; Song, S. Da4ad: End-to-end deep attention-based visual localization for autonomous driving. In European Conference on Computer Vision; Springer: Berlin, Germany, 2020; pp. 271–289. [Google Scholar]
- Huang, S.; Gojcic, Z.; Usvyatsov, M.; Wieser, A.; Schindler, K. Predator: Registration of 3d point clouds with low overlap. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4267–4276. [Google Scholar]
- Kabsch, W. A solution for the best rotation to relate two sets of vectors. Acta Crystallogr. Sect. A Cryst. Physics, Diffraction, Theor. Gen. Crystallogr. 1976, 32, 922–923. [Google Scholar] [CrossRef]
- Li, J.; Lee, G.H. Usip: Unsupervised stable interest point detection from 3d point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 361–370. [Google Scholar]
- Lu, F.; Chen, G.; Liu, Y.; Qu, Z.; Knoll, A. Rskdd-net: Random sample-based keypoint detector and descriptor. Adv. Neural Inf. Process. Syst. 2020, 33, 21297–21308. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Zhou, Q.Y.; Park, J.; Koltun, V. Fast global registration. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016; pp. 766–782. [Google Scholar]
- Li, J.; Zhang, C.; Xu, Z.; Zhou, H.; Zhang, C. Iterative distance-aware similarity matrix convolution with mutual-supervised point elimination for efficient point cloud registration. In European Conference on Computer Vision; Springer: Berlin, Germany, 2020; pp. 378–394. [Google Scholar]
- Yu, H.; Li, F.; Saleh, M.; Busam, B.; Ilic, S. Cofinet: Reliable coarse-to-fine correspondences for robust pointcloud registration. Adv. Neural Inf. Process. Syst. 2021, 34, 23872–23884. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | RTE (m) | RRE (deg) | Recall | Time (ms) |
|---|---|---|---|---|
| ICP (P2Point) [8] | 0.04 ± 0.05 | 0.11 ± 0.05 | 14.3% | 477.3 |
| ICP (P2Pane) [8] | 0.04 ± 0.04 | 0.14 ± 0.15 | 33.5% | 465.1 |
| FGR [54] | 0.93 ± 0.59 | 0.96 ± 0.81 | 39.4% | 508.9 |
| RANSAC [45] | 0.13 ± 0.07 | 0.54 ± 0.40 | 91.9% | 552.9 |
| IDAM [55] | 0.66 ± 0.48 | 1.06 ± 0.94 | 70.9% | 40.4 |
| DGR [21] | 0.32 ± 0.32 | 0.37 ± 0.30 | 98.7% | 1357.6 |
| CoFiNet [56] | 0.08 ± 0.06 | 0.36 ± 0.33 | 99.8% | 574.1 |
| PREDATOR [49] | 0.06 ± 0.06 | 0.28 ± 0.25 | 99.8% | 450.4 |
| MSPR-Net | 0.07 ± 0.12 | 0.24 ± 0.34 | 99.6% | 226.0 |
| Method | RTE (m) | RRE (deg) | Recall | Time (ms) |
|---|---|---|---|---|
| ICP (P2Point) [8] | 0.25 ± 0.51 | 0.25 ± 0.50 | 18.8% | 83.0 |
| ICP (P2Pane) [8] | 0.15 ± 0.30 | 0.21 ± 0.31 | 36.8% | 46.7 |
| FGR [54] | 0.71 ± 0.62 | 1.01 ± 0.92 | 32.2% | 288.4 |
| RANSAC [45] | 0.21 ± 0.19 | 0.74 ± 0.70 | 60.9% | 270.1 |
| DCP [18] | 1.09 ± 0.49 | 2.07 ± 0.14 | 58.6% | 46.3 |
| IDAM [55] | 0.47 ± 0.41 | 0.79 ± 0.78 | 88.0% | 36.6 |
| FMR [13] | 0.60 ± 0.39 | 1.61 ± 0.97 | 92.1% | 65.2 |
| DGR [21] | 0.21 ± 0.18 | 0.48 ± 0.43 | 98.4% | 518.4 |
| MSPR-Net | 0.12 ± 0.13 | 0.28 ± 0.24 | 99.9% | 208.7 |
| Base | MS | BOR | Coarse-to-Fine | RTE (m) | RRE (deg) | Recall |
|---|---|---|---|---|---|---|
| ✓ | 0.18 | 0.56 | 99.7% | |||
| ✓ | ✓ | 0.15 | 0.45 | 99.8% | ||
| ✓ | ✓ | ✓ | 0.14 | 0.40 | 99.9% | |
| ✓ | ✓ | ✓ | ✓ | 0.12 | 0.28 | 99.9% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, J.; Zhang, F.; Chen, Z.; Liu, L. MSPR-Net: A Multi-Scale Features Based Point Cloud Registration Network. Remote Sens. 2022, 14, 4874. https://doi.org/10.3390/rs14194874
Yu J, Zhang F, Chen Z, Liu L. MSPR-Net: A Multi-Scale Features Based Point Cloud Registration Network. Remote Sensing. 2022; 14(19):4874. https://doi.org/10.3390/rs14194874
Chicago/Turabian StyleYu, Jinjin, Fenghao Zhang, Zhi Chen, and Liman Liu. 2022. "MSPR-Net: A Multi-Scale Features Based Point Cloud Registration Network" Remote Sensing 14, no. 19: 4874. https://doi.org/10.3390/rs14194874
APA StyleYu, J., Zhang, F., Chen, Z., & Liu, L. (2022). MSPR-Net: A Multi-Scale Features Based Point Cloud Registration Network. Remote Sensing, 14(19), 4874. https://doi.org/10.3390/rs14194874