1. Introduction
Light detection and ranging (LiDAR) technologies can produce highly precise three-dimensional (3D) topographic data by emitting lasers and measuring their return time [
1]. These technologies have the capability to quantify structural changes on the surface, such as erosion and deposition, without surface disturbance and detailed field measurement. When operated from aircraft, LiDAR sensors can measure 3D data with a point density of sub meters to meters and on scales from a single kilometer to over a hundred kilometers [
2,
3,
4]. In comparison, ground-based laser scanners can acquire the data with a significantly higher point density but on a much smaller spatial extent. In a typical use-case of LiDAR technologies in quantifying soil erosion and surface denudation, a high density and fine spatial resolution are necessary to estimate micro-topographic changes, such as hillslope and streambank erosion [
5,
6,
7]. In particular, when erosion is dispersed across space as sheet or interrill erosion, an unsustainable level of erosion can result from millimeter-scale topographic changes. Ground-based LiDAR can be implemented from stationary-fixed laser scanners on tripods or from personal wearable, movable laser scanners. The laser scanner operated from tripods is commonly known as Terrestrial Laser Scanning (TLS). TLS has been used in various settings where accurately measuring surface changes necessitates high point density and precision, such as hillslopes [
5,
6,
7], tilled soils [
8,
9,
10], badlands [
11], erosion plots [
12], gullies [
13,
14,
15,
16,
17], bluffs [
18], and channels [
19].
When measuring surface changes from 3D point clouds at fine scales where TLS is frequently used, special care is needed to mitigate the effect of erroneous non-ground points [
5,
6]. Non-ground or off-terrain (OT) points can be produced by many sources, such as scanner error, noise, vegetation, or ground litter. Any point obscuring the accurate representation of the ground surface reduces the accuracy of subsequent analysis. Therefore, most uses of TLS data are accompanied by a 3D point cloud filtering process to isolate ground points. Filtering can substantially increase the accuracy of a surface represented by a 3D point cloud at fine resolutions [
20,
21].
Many approaches have been used in filtering 3D point clouds. TLS point clouds can be manually examined to remove OT points [
22,
23]. Although it is a straightforward approach, manually filtering points can be labor-intensive, and the results are not easily replicated. Automatic filtering approaches that are repeatable with minimal user input are beneficial when data quantity is relatively high, particularly in multitemporal TLS datasets [
24]. Several automatic filtering algorithms have been developed and deployed in TLS-based topographic change studies, such as a cloth simulation filter (CSF) [
25], a modified slope-based filter (MSBF) [
26], and a random forest (RF) classifier filter [
27]. Additional research is needed to choose and implement an automatic filtering algorithm for a given surface.
In an initial study of ground filtering algorithms applied to TLS data, Roberts et al. [
28] found that no single algorithm was adequate for every variety of surface based on the comparison with a manually classified reference dataset. However, the reference datasets in their study were of a lower point density than would be expected when measuring fine surface changes related to erosion. Further research is necessary to evaluate the effect of point filtering algorithms on high-density TLS point clouds.
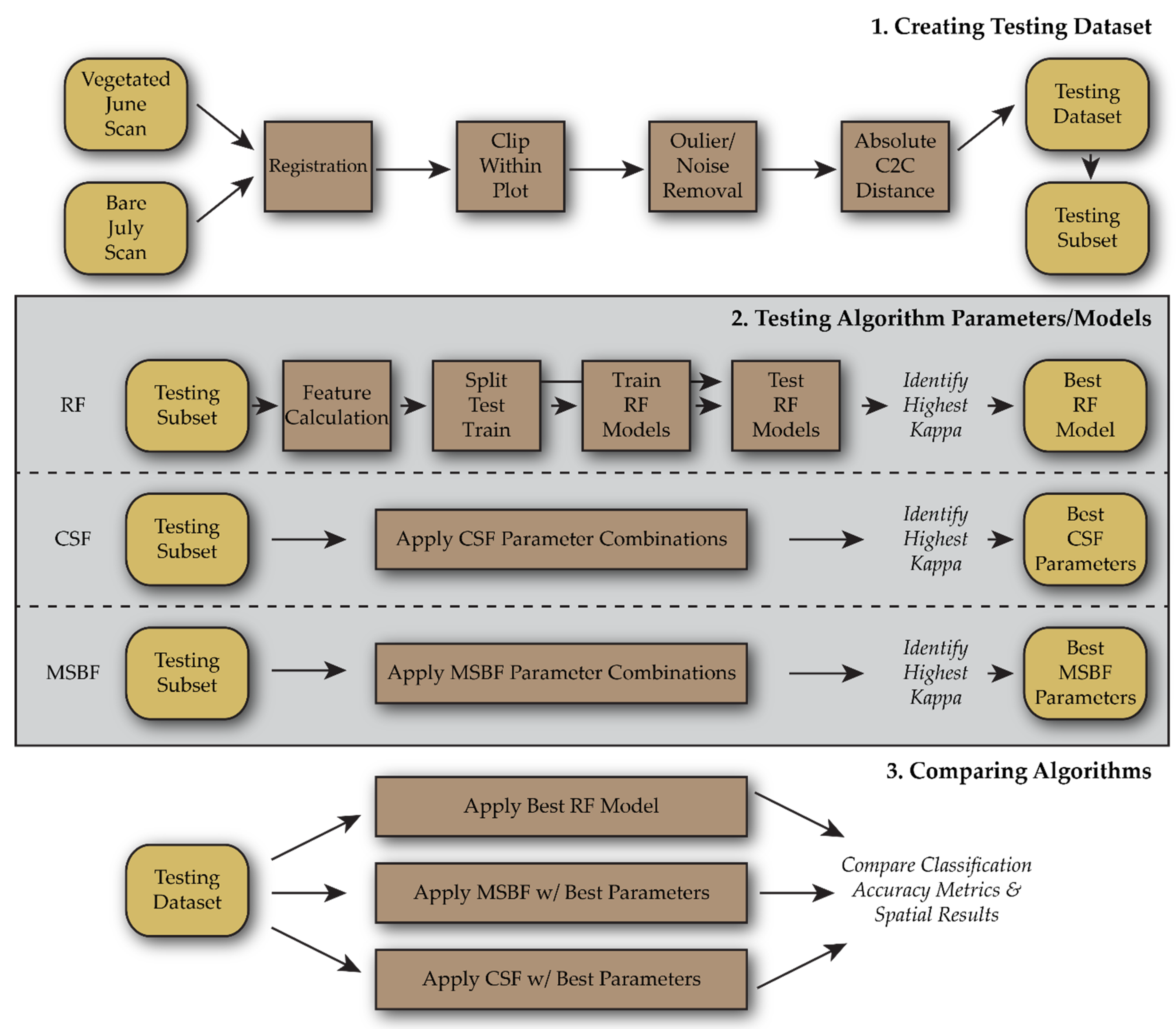
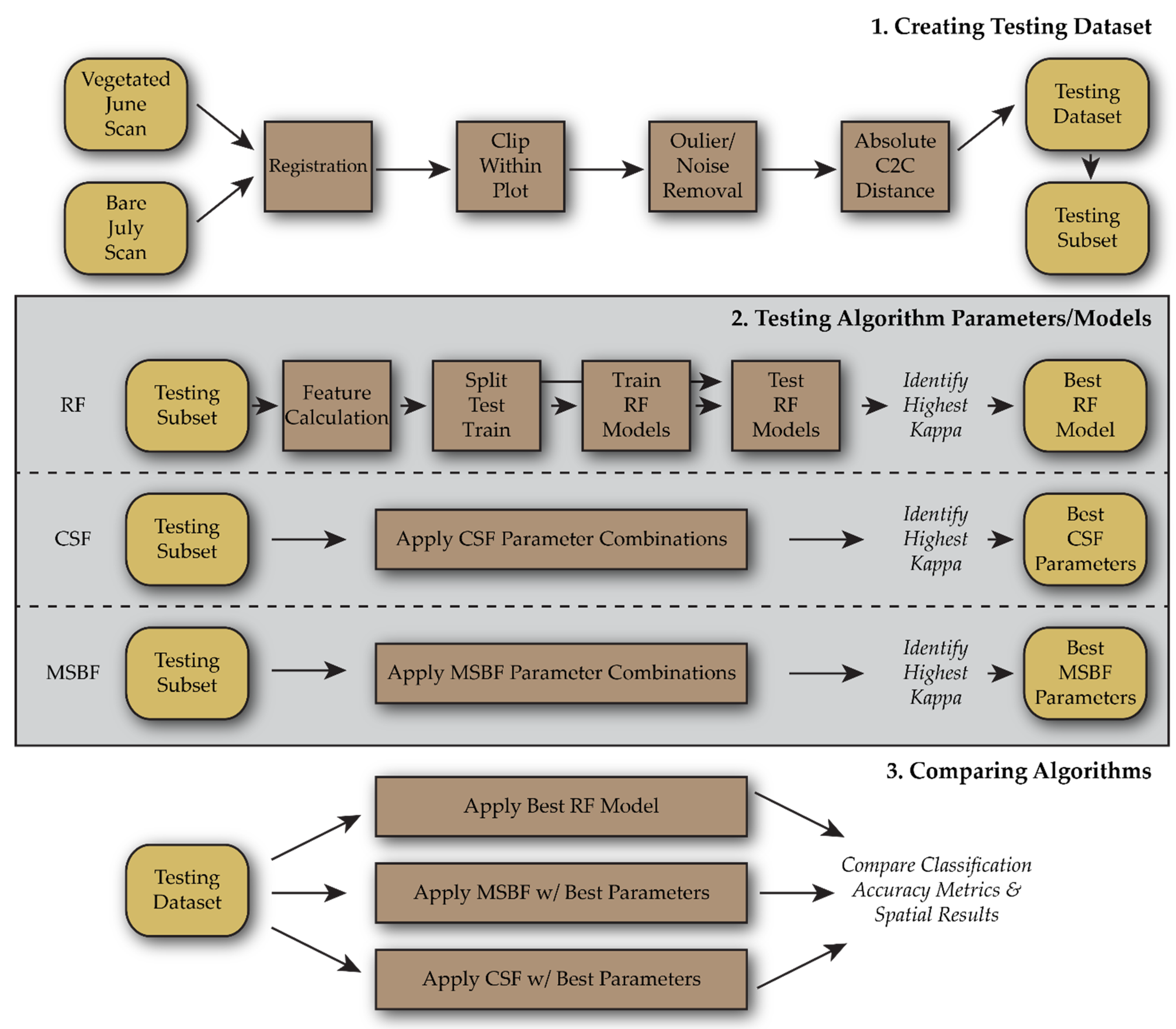
This study assesses the performance of three filtering algorithms: CSF, MSBF, and RF, in identifying ground points from a high-density TLS dataset. Successive TLS scans, one scan under highly vegetated conditions and a second under bare conditions, were collected from a controlled erosion plot to produce a testing dataset of classified ground and OT points. This testing dataset was used to tune the algorithm parameters and measure the performance of each filtering algorithm. The following questions are addressed using these results: (1) Can any of the filtering algorithms effectively remove the vegetation points at fine resolutions?; (2) What is the impact of parameter tuning on the performance of each algorithm?; and (3) Which algorithm provides the best performance with the optimized/tunned parameters? This study provides critical insight into the ground point filtering process, which is essential in using TLS to quantify fine-scale topographic changes.
3. Results
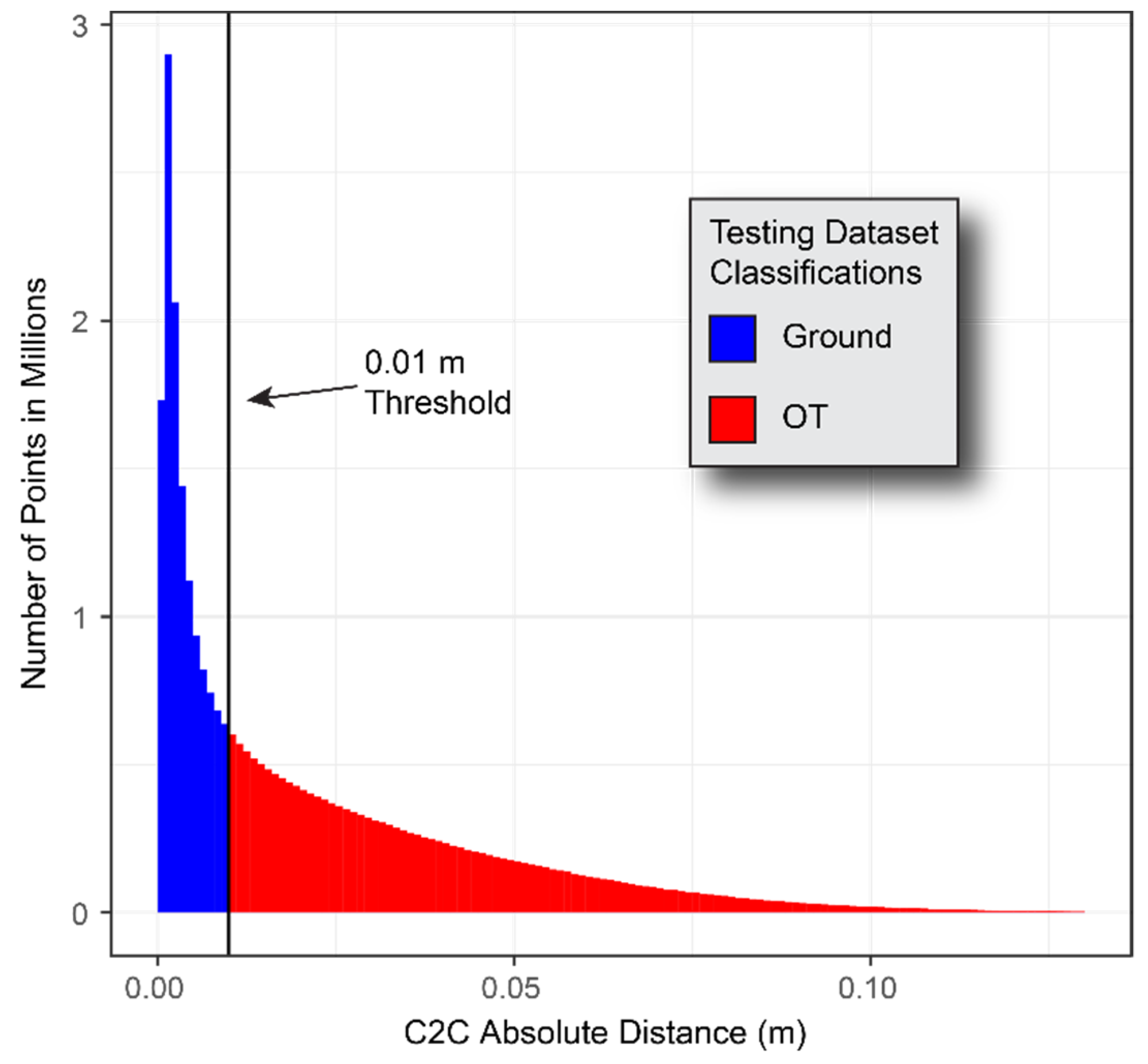
Of the over 30 million points, approximately 13 million points had a C2C absolute distance of <0.01 m between the vegetated June and bare July scans, and 17 million points had a C2C absolute distance of >0.01 m. These points are classified as ground and OT points, respectively.
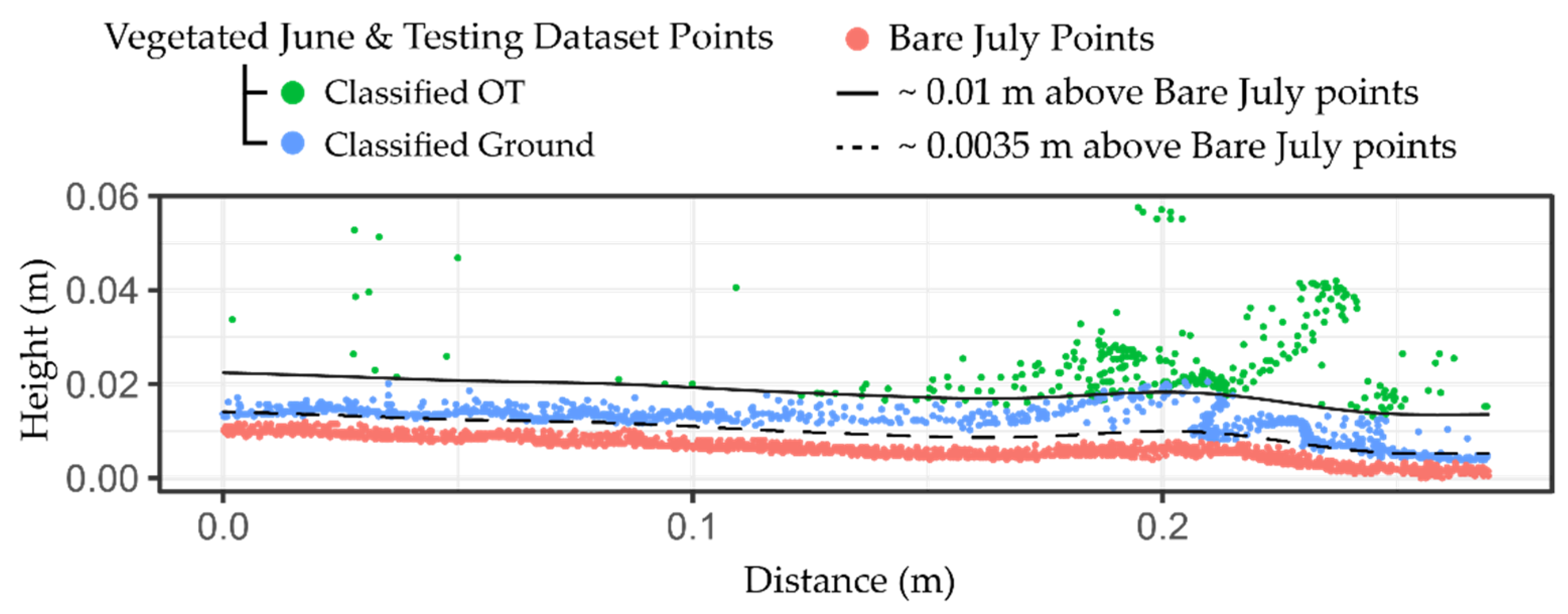
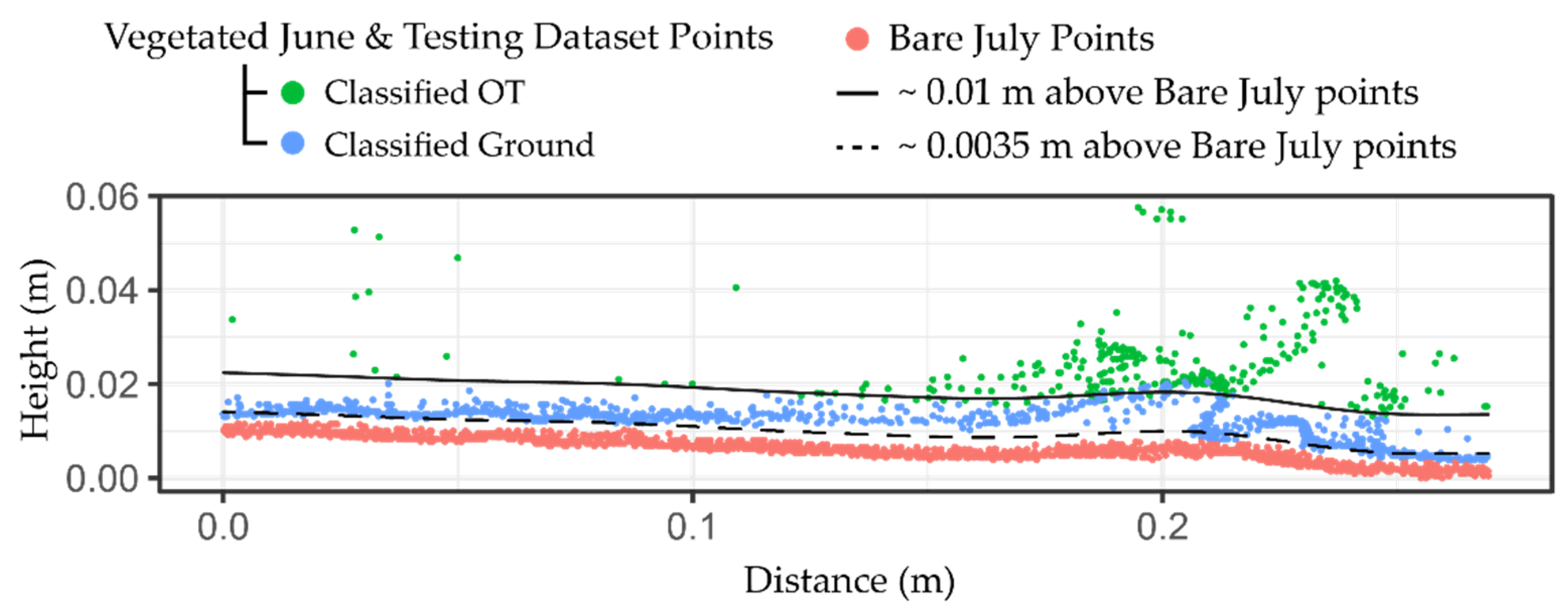
Figure 6 shows the histogram of the C2C absolute distances and classifications. Cross sections of the testing dataset overlaying the bare July 3D point cloud reveal a close agreement between the ground classified points and the points from the bare scan where vegetation is sparse (
Figure 7). In highly vegetated areas, fewer points fall under the 0.01 m threshold, and ground-classified points occur much more infrequently.
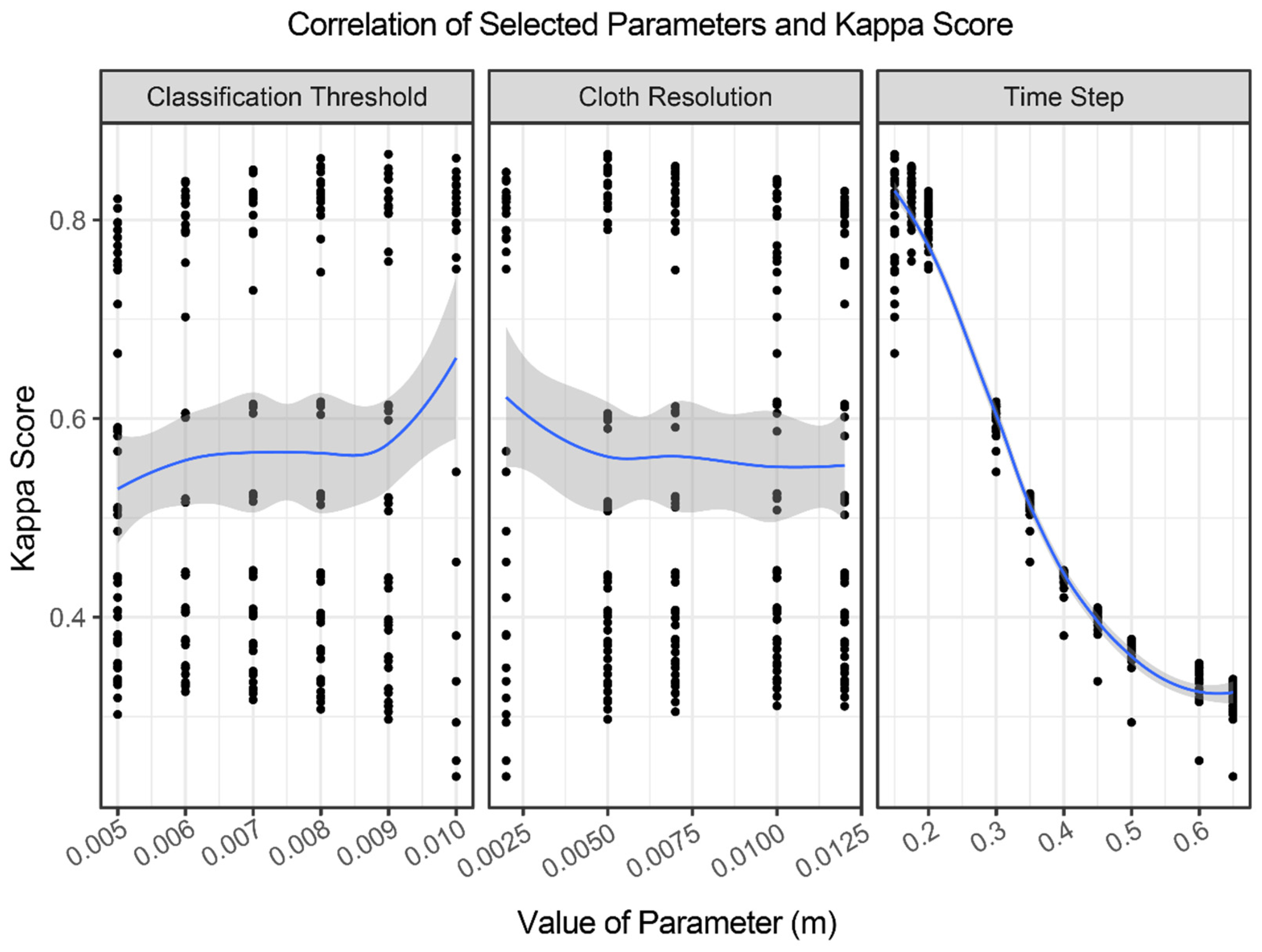
The adjustable parameters of the CSF algorithm are ‘smoothing’, ‘cloth resolution’, ‘rigidness’, ‘time step’, ‘classification threshold’, and ‘iterations’. Of these parameters, only ‘cloth resolution’, ‘time step’, and ‘classification threshold’ were found to substantially affect the classification. The parameters that did not affect classification were set to the recommended default values of ‘smoothing = false’, ‘rigidness = 3’, and ‘iterations = 500’. For the parameters affecting the classification, combinations of the following value ranges were used: ‘cloth resolution’ from 0.002 m to 0.012 m; ‘time step’ from 0.1 m to 0.65 m; and ‘classification threshold’ from 0.005 m to 0.01 m. This resulted in 277 combinations of parameters being applied to a subset of the testing dataset. These values were selected considering the point density of the dataset and the expected scale of changes.
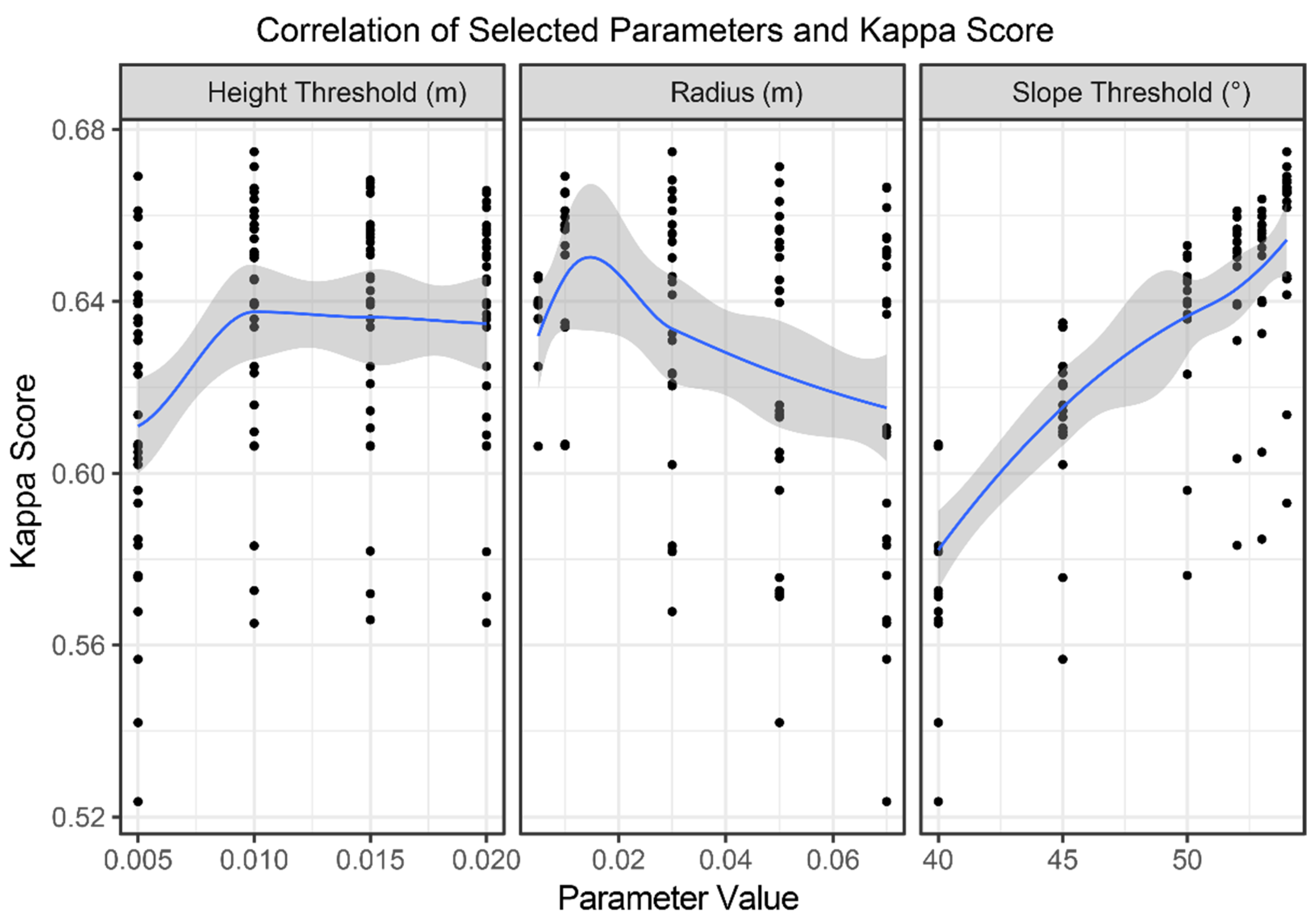
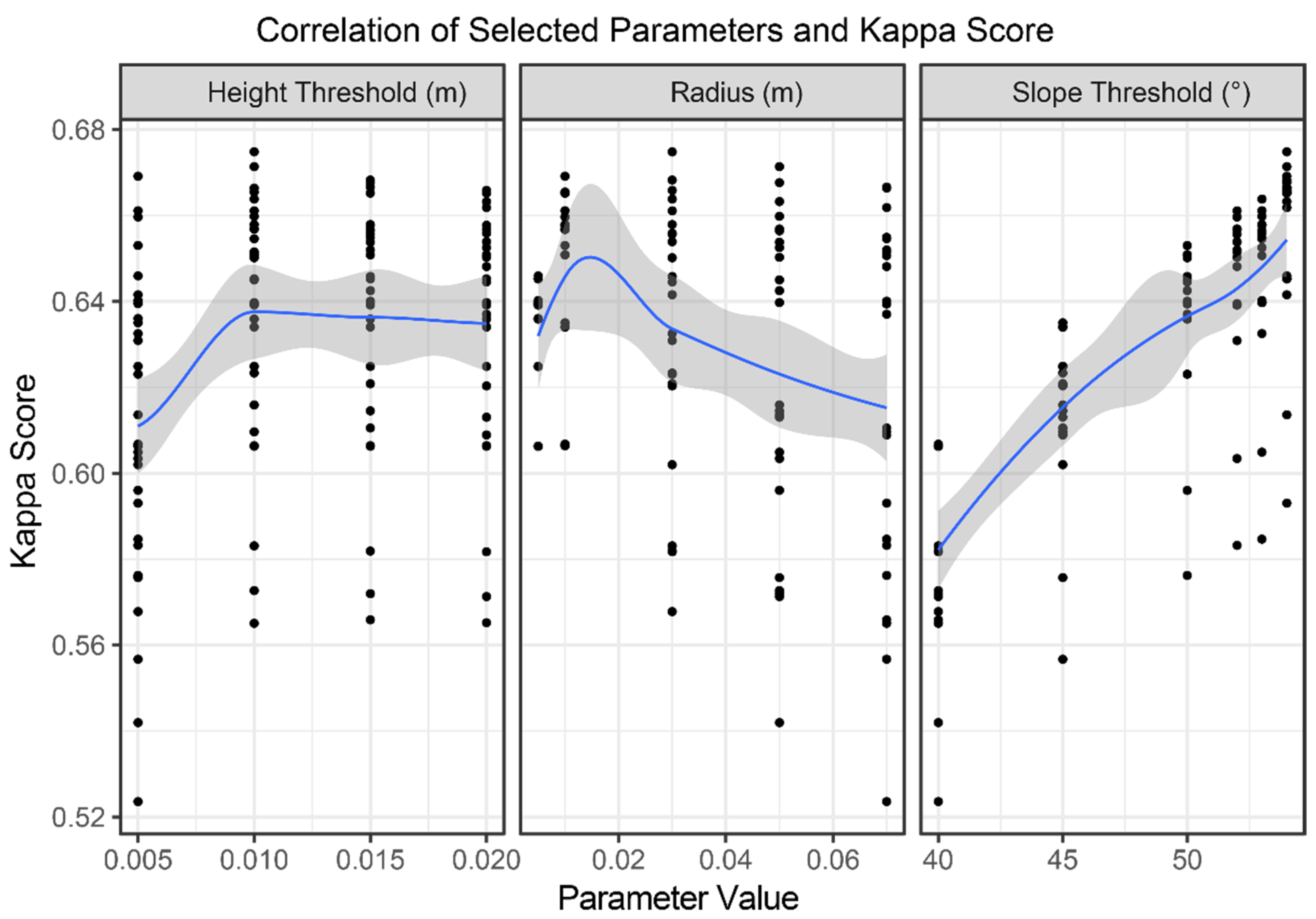
For the MSBF algorithm, combinations of input parameters of the following value ranges were used: ‘radius’ from 0.005 m to 0.07 m; ‘minimum neighbors’ from 10 to 75; ‘slope threshold’ from 40° to 54°; ‘height threshold’ from 0.005 m to 0.02 m; and ‘slope normalization’ at True or False. This total of 721 combinations were applied to a subset of the testing dataset. Like CSF, considering point density and surface topography, these values were selected as reasonable inputs.
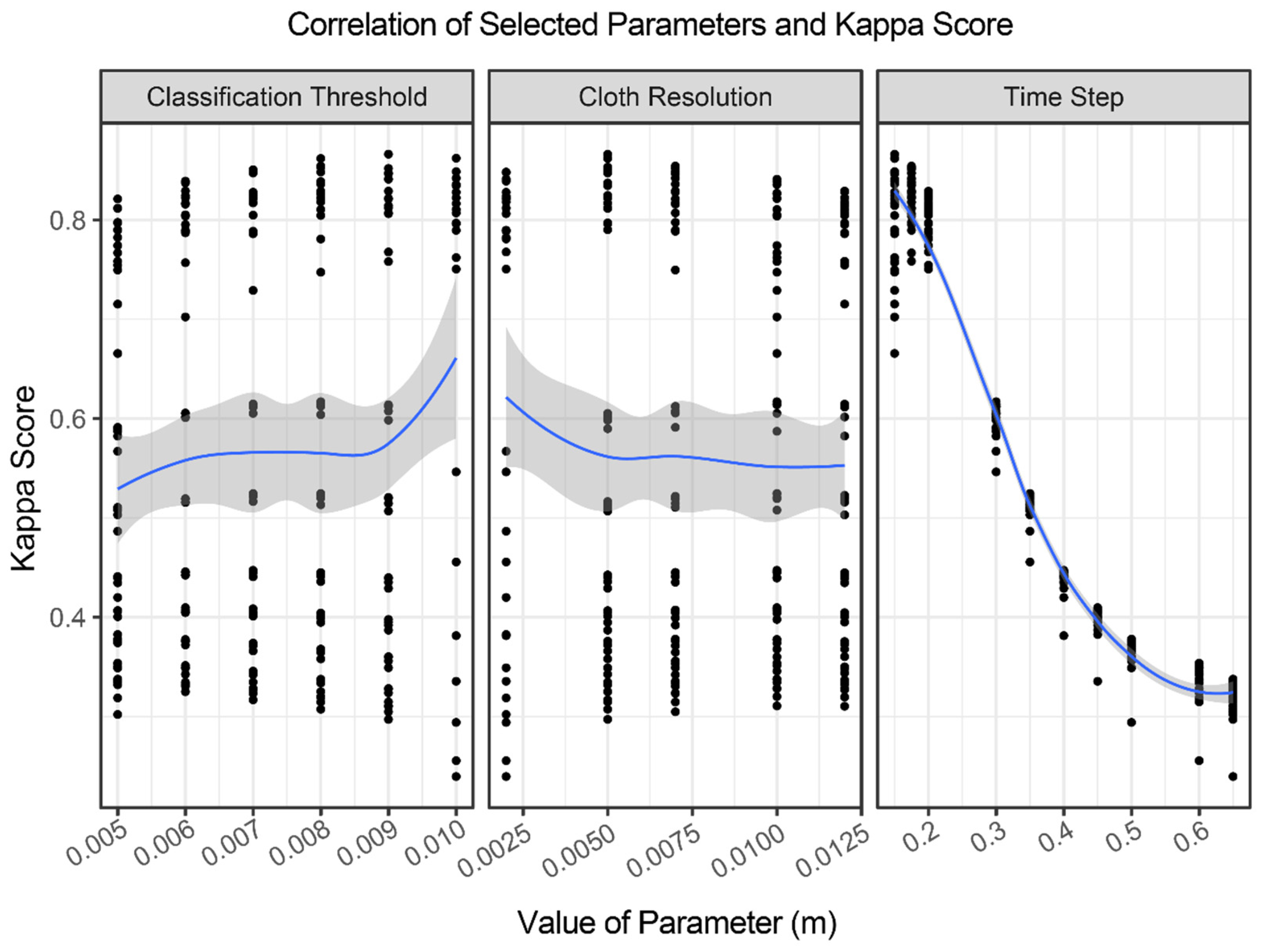
Nearly 1000 iterations of input parameters for the CSF, MSBF algorithms, and two variations of RF models are applied to the subset of the testing dataset. The highest performing CSF parameter iteration resulted in a Kappa value of 0.86, with the lowest iteration resulting in a Kappa score of 0.24. Iterations of the CSF parameters where the ‘time step’ parameter was below 0.15 m resulted in a failed classification. Of the impactful CSF parameters, the ‘time step’ parameter was most strongly correlated with the Kappa score and appears to be the primary driver of algorithm performance (
Figure 8). The sets of input parameters that produced the highest Kappa value are given in
Table 1 and are further applied to the entire dataset.
The parameter iterations of the MSBF algorithm applied to the subset dataset produced a tighter range of Kappa values from 0.67 to 0.52. For this dataset, the ‘Slope Threshold’ parameter had the closest correlation with algorithm performance (
Figure 9). The parameters producing the highest Kappa value are listed in
Table 1, and these parameters were applied to the entire testing dataset.
The performances of the two RF models were compared for the subset dataset using a randomly generated 75% and 25% of points for model training and testing, respectively. Relative to the 25% of points from the subset, the RF model built considering the eigenvalues of five neighborhood scales outperformed the model built on three scales in all metrics. The inclusion of two additional neighborhood scales, 0.0075 m and 0.025 m, into the model’s base training dataset of 0.005 m, 0.01 m, and 0.015 m increased the Kappa value from 0.63 to 0.72. The RF model built using the full range of neighborhood scales was then applied to the entire dataset (including all points within the subset).
Only the optimal parameters/models were used for the whole testing dataset to evaluate the performances of CSF, MSBF, and RF approaches (
Table 2). The CSF algorithm outperforms the other algorithms in most metrics except the ground precision and OT recall, for which MSBF narrowly outperformed CSF. The accuracy metrics for CSF and RF are balanced between the ground and OT classes, with CSF scoring slightly higher in every category.
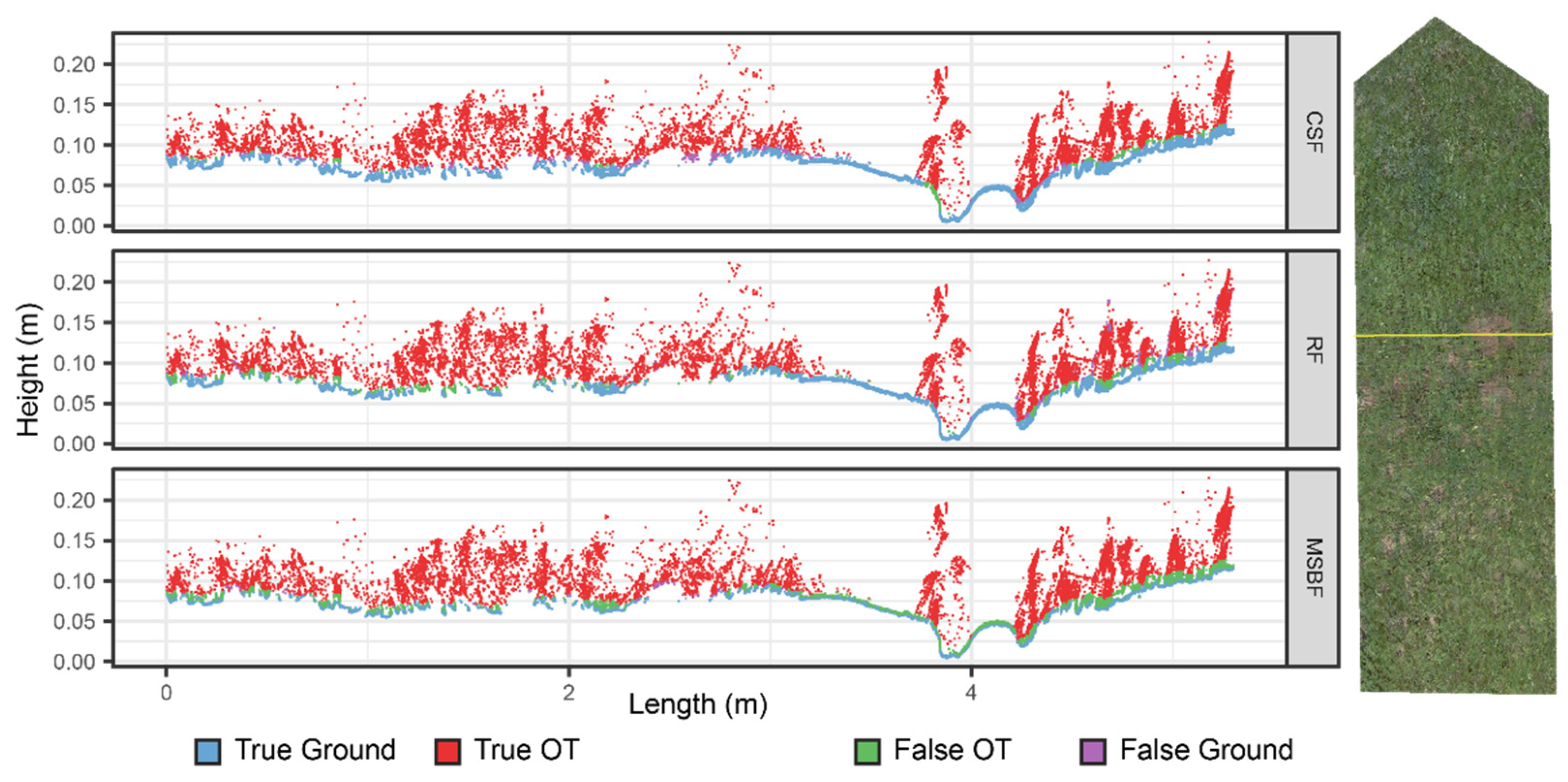
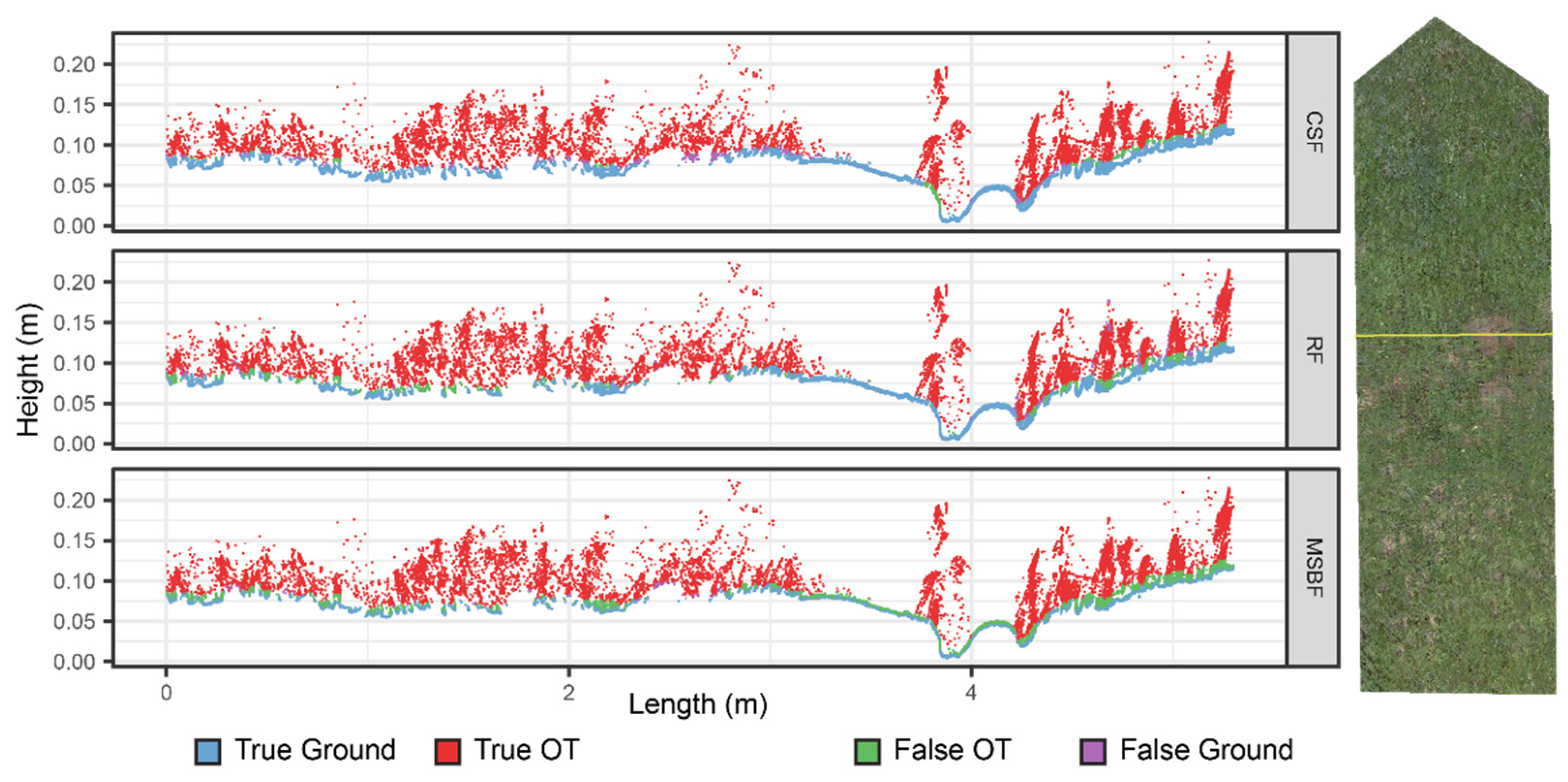
Figure 10 shows a portion of the plot free of vegetation. At this location, the few OT points of the testing dataset result from noise reflections and portions of a small pebble that moved into the area between scans. All algorithms easily identify these OT points. The only noticeable difference is with the MSBF, which consistently falsely classifies OT points over most of the surface. The cross-section results also show this pattern for MSBF (
Figure 11): along the correctly classified ground points, there is a layer of falsely classified OT points that is not present for the other algorithms.
Figure 12 shows a portion of the plot dominated by vegetation. At this site, CSF is remarkably accurate relative to the other algorithms. CSF falsely classifies some OT points as ground on the left portions of the site where the vegetation is thicker but to a lesser degree than RF. The RF classifier misclassifies points more frequently than the other algorithms in densely vegetated areas. The MSBF’s high OT recall score suggests that the MSBF excels in this vegetated area, although the same pattern of disqualifying many ground points is still evident on the right portion of the area.
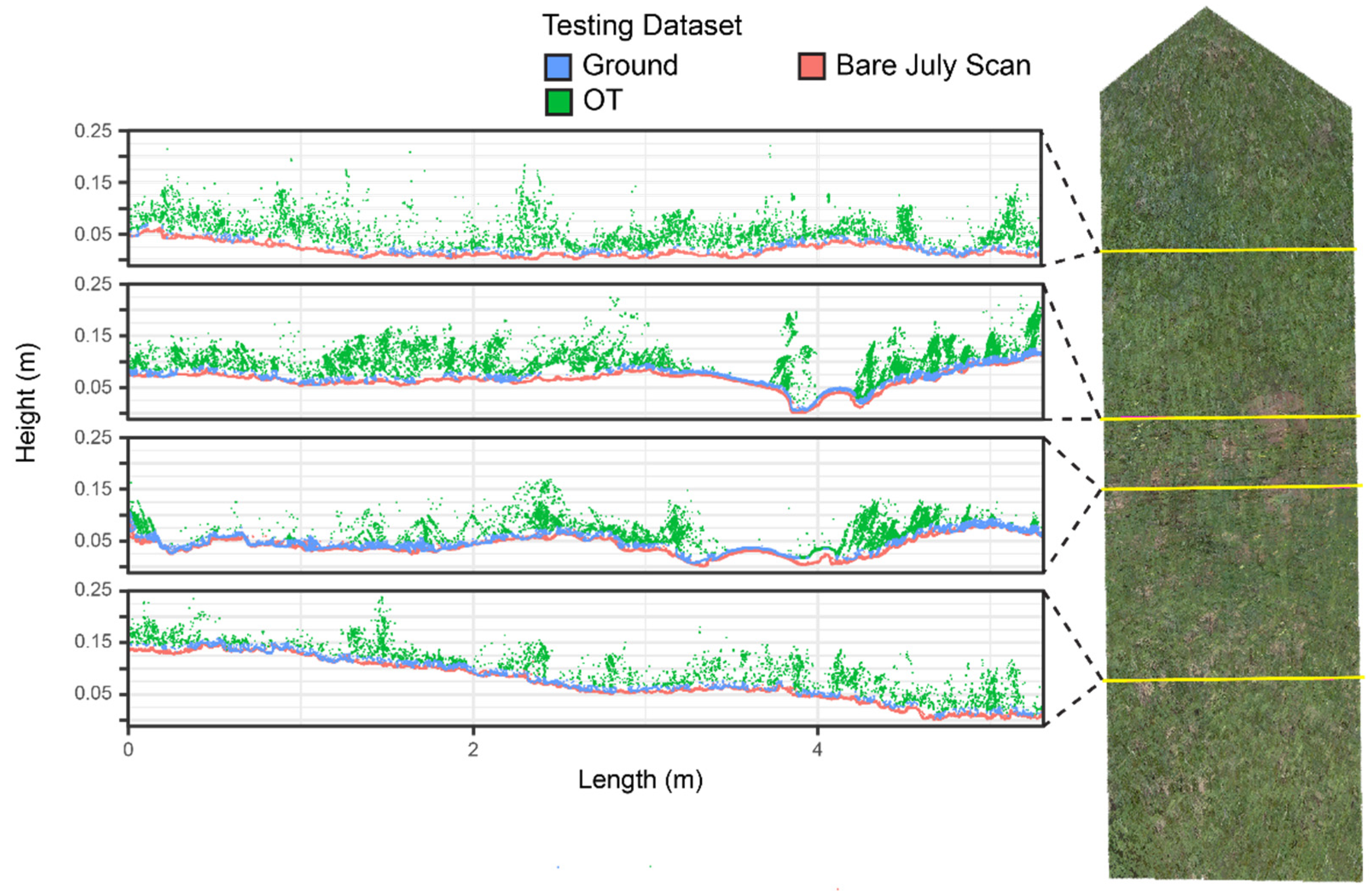
The area shown in
Figure 13 contains a variety of conditions: taller, denser vegetation on the left, a single plant surrounded by flat ground in the center, and short vegetation close to ground on the right. The CSF and RF algorithms classify most ground and densely vegetated areas correctly. The MSBF algorithm again shows the pattern of excessively excluding ground points.
4. Discussion
4.1. Testing Dataset
A test dataset is needed to assess the performance of the point filtering algorithms. Studies have generated the testing dataset by manual classification of ground and OT points, which is time consuming and labor intensive [
28]. It is also difficult to generate a large and high-density testing dataset using the manual classification approach. The 3D point clouds obtained by terrestrial LiDAR include millions of points, and the point spacing is in millimeters to centimeters.
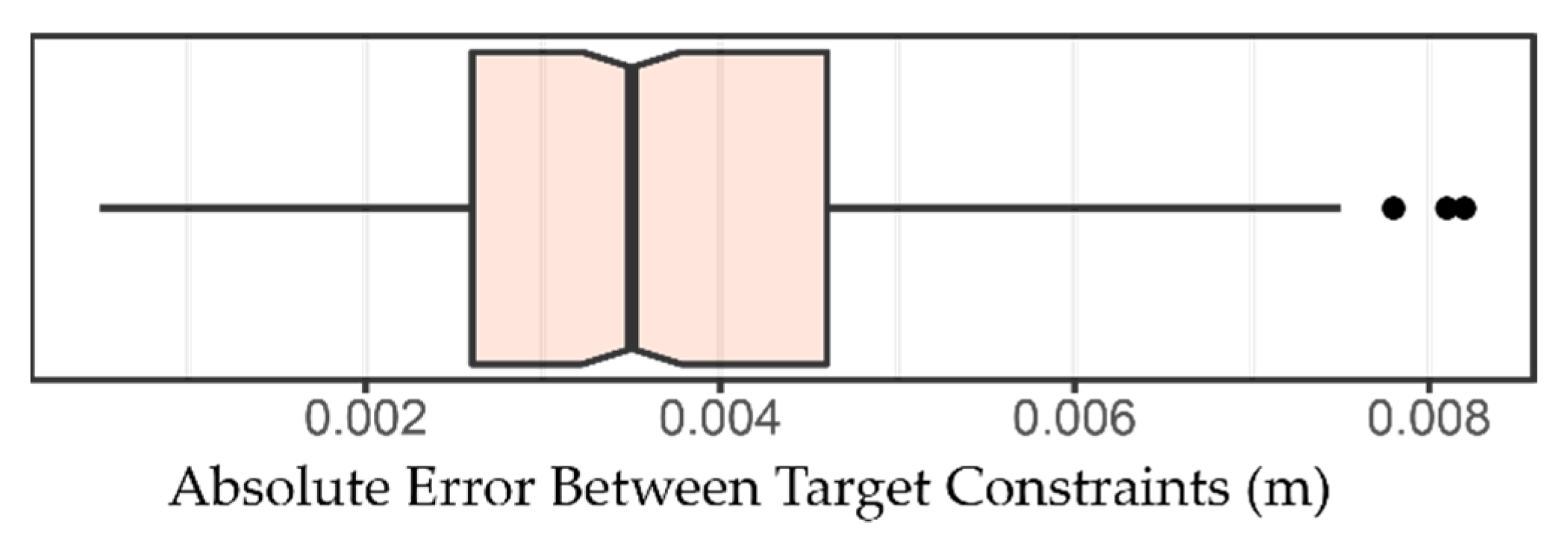
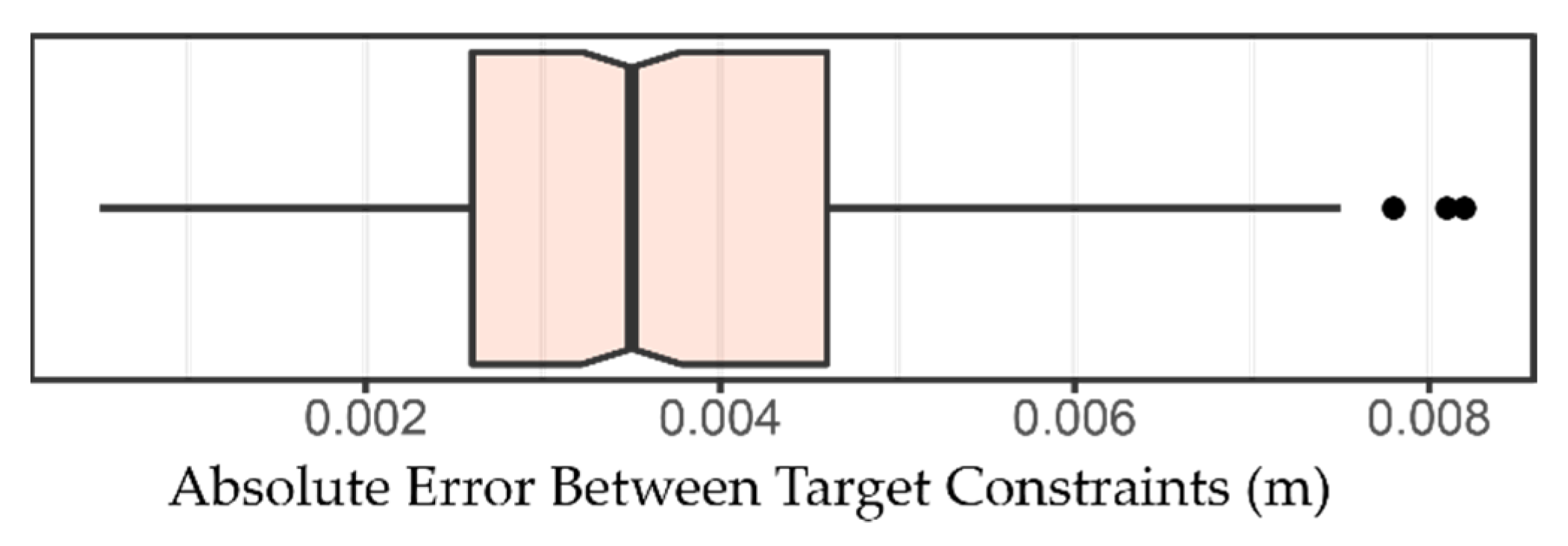
In this paper, we used a novel approach to generate the testing dataset by the comparison of the two successive scans before and after removing vegetation. Assuming no ground surface changes occur during vegetation removal, the C2C absolute distancing between two ground points at the same location would be within two registration errors (0.007 m) of the two 3D point clouds (99% confidence level). However, we did observe some ground surface changes during the one-month period between the two scans. To account for this potential impact, we used a much larger distance of 0.01 m as the C2C absolute distance threshold to classify the testing dataset into ground and OT points (about three registration errors, 99.9% confidence level). This method is fast and efficient, and the created dataset is also large enough for the performance assessment of the filtering algorithms.
However, despite the use of a much larger distance threshold of 0.01 m between the two scans for the point classification, misclassified OT points still exist within the testing dataset. These misclassified OT points are from true ground surfaces that experienced erosion between the two scans.
Figure 14 shows an example of the misclassified OT points in the testing dataset. Another example can be seen in the second cross sectional profile from the bottom at the 4 m length mark in
Figure 7. It is possible to manually identify and remove errors in the testing dataset. However, it is time consuming and requires a significant effort to check and fix these errors on a complex dataset of many millions of points. In future studies, these errors may be mitigated by either shortening the time between conducting vegetated and bare scans or preventing the experimental plot from being exposed to rainfall between scans. Overall, this misclassification appears rare and is considered an acceptable trade-off to enable the automated classification of the ground and OT points from the 3D point cloud of >30 million points.
4.2. The Impacts of Various Parameters on the Performance of Different Algorithms
Each filtering algorithm uses various parameters for 3D point cloud filtering or classification. However, few studies have examined the impacts of these parameters on the performance of varied types of 3D point clouds. In this study, we identified the most sensitive and the best performance parameters of each filtering algorithm by the comparison of a set of classification results using different combinations of parameters. Our results based on the CSF algorithm directly contrast with the original study of this algorithm for airborne LiDAR, which suggested that a ‘time step’ parameter of 0.65 m was suitable for most situations [
25]. For our TLS data, the use of 0.65 m for the ‘time step’ parameter produces the least accurate results, whereas the use of a much smaller ‘time step’ value of 0.15 m achieves the highest Kappa score. It seems that TLS and airborne LiDAR data have dramatically different scales in terms of the ‘time step’ parameter. In addition to the challenges associated with applying CSF to TLS, the simulated cloth used by CSF may ‘stick’ to true OT points whose elevation profile transitions gradually away from the true ground, resulting in a false ground classification. Our results suggest that the CSF algorithm can produce excellent classifications on dense TLS datasets if the input parameters are carefully considered, as the default parameter settings do not seem to apply to high-density TLS point clouds.
Our initial observation of the correlations between individual parameters and the Kappa values for MSBF suggested that the impacts of different parameters are somewhat obfuscated by the interactions between parameters. Future research is needed for a more detailed sensitivity analysis on the impact of the MSBF parameters.
In terms of the RF classifier, the inclusion of additional scales improved the classification results, although a trade-off exists between the benefit of additional scales and increased computation time and complexity. For our test dataset, it appears that the improvement of the Kappa value by 0.09 is worth the computational cost of moving from a 3-neighborhood scale (9 features) to a 5-neighborhood scale (15 features).
4.3. The Comparison of Different Algorithms on 3D Point Cloud Classification
The results based on our testing dataset indicate that CSF outperformed RF and MSBF for the ground and OT point classification of TLS-generated point clouds. CSF scored higher in most metrics, including a Kappa score of 0.86 compared to 0.75 for RF and 0.62 for MSBF when using the best performance parameters. Although CSF was originally designed for airborne LiDAR data, it can produce a highly accurate classification of TLS data when the parameters are carefully considered.
Even with the lowest Kappa score, MSBF produced the highest ground precision and OT recall score, suggesting that it may be advantageous when it is critical to capture only ground points at the cost of excluding some ground points. A closer observation of the MSBF classification results suggests that many falsely classified OT points are slightly above the other ground points in relatively flat areas. This distribution pattern indicates that these points may originate from an individual scanning view farther away from the site. Because these points are less than 0.01 m from the bare surface, they are classified as ground points in the testing dataset. However, MSBF likely classified these points as OT points based on the slope threshold. The application of MSBF to varied surface conditions within a single site may be limited as only a single set of slope and height thresholds are used. Additionally, if OT points are clustered together to create a relatively large and smooth enough surface, the measured neighborhood slope and height may fall below the thresholds, resulting in the misclassification of these OT points to the ground points.
In an area illustrated in
Figure 13, both CSF and RF classify most flat ground and densely vegetated areas correctly, whereas MSBF again shows the pattern of excessively excluding ground points. However, this site also contains portions of the testing dataset that are incorrectly classified as OT points because of >0.01 m surface erosion between the two scans. Detailed examination of the classification results suggests that CSF and MSBF classify the ground points more accurately at this site because both methods classify the eroded portions as ground. Interestingly, the RF classifier agrees with the misclassified testing data because of the use of these misclassified points as the training data, suggesting that the RF implementation is sensitive to the training data selection, and even the relatively few errors in our testing dataset may be inappropriate for training RF models. However, our study is only a case study. More work is needed in the future to examine if there are more appropriate surface features that may be used to generate RF models or if the selected features are applicable to a site with different surface characteristics.
5. Conclusions
This study used successive high-density TLS scans of a hillslope plot before and after removing vegetation to generate an automatically classified testing dataset to assess the performance of three point filtering algorithms: CSF, MSBF, and RF. Our results indicate that the performance of each algorithm is affected by the selection of input parameters. The ‘time step’ parameter was highly influential over classification accuracy for the CSF algorithm. The default value recommended by the algorithm in processing airborne LiDAR data leads to the least accurate classifications for these 3D point clouds, whereas a much smaller ‘time step’ value produces the highest classification for TLS data. The variations of parameters for the MSBF algorithm produced a tighter—though less accurate—range of classification accuracies. The ‘slope threshold’ parameter showed the closest correlation with classification accuracy. Two RF models were tested, considering 3 and 5 neighborhoods of eigenvalues, and RF classification accuracy increased with increasing numbers of neighborhoods.
In terms of classification accuracy, CSF outperformed both RF and MSBF. CSF scored higher in most metrics, including a Kappa score of 0.86 compared to 0.75 for RF and 0.62 for MSBF. It is evident that although designed for airborne LiDAR data, CSF can produce a highly accurate classification of TLS data if the parameters are carefully considered. Even with the lowest Kappa score, MSBF produced the highest ground precision and OT recall score, suggesting that it may be advantageous when it is critical to capture only ground points at the cost of excluding some ground points. In addition, a detailed examination of MSBF-classified results displayed a pattern of falsely identifying ground points as OT in locations where the points were slightly above relatively flat areas. RF produced moderate classifications despite being trained using only fifteen features.
This study suggests that the performance of filtering algorithms varies depending on parameter settings. An in-depth sensitivity analysis for different parameter settings may further extend the applications of these filtering algorithms in TLS data. It should be noted that the testing dataset developed in this study is not perfect because the plot experienced some erosion between the two scans. To mitigate the effects of erosion, this study used a larger threshold (0.01 m) than the registration error (0.0035 m) to classify the testing dataset. Despite this, misclassified points can be observed in some sites, and these affected the performance assessment of the filtering algorithms. Future studies may consider applying the filtering algorithms to other well-classified testing datasets obtained by TLS. In addition, the surface characteristics of the experimental plot in this study are fairly homogenous, and the best parameters derived for these filtering algorithms require further testing before being applied to other surfaces where TLS data may require filtering.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}