
An Empirical Study on Retinex Methods for Low-Light Image Enhancement




Abstract
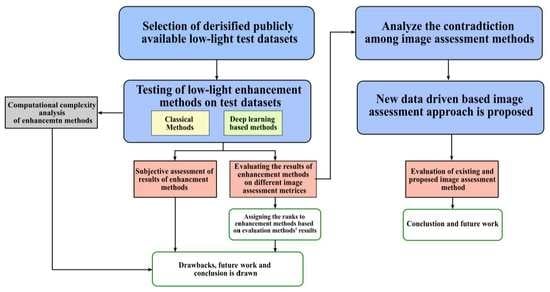
1. Introduction
- A comprehensive literature review is presented for Retinex-based and non-Retinex methods.
- A detailed experimental analysis is provided for a variety of Retinex-based and non-Retinex methods on a variety of publicly available test datasets using well-known image quality assessment metrics. Experimental results provide a holistic view of this field and provide readers with an understanding of the advantages and disadvantages of existing methodologies. In addition, the inconsistency of commonly used evaluation metrics is pointed out.
- An analysis of the computational effectiveness of enhancement methods is also conducted on images of different sizes. As a result of this computation cost, we can determine which enhancement methods are more suitable for real-time applications.
- Publicly available low-light test datasets were ranked based on experimental analysis. In developing more robust enhancement methods, the reader will benefit from this ranking of benchmarking test datasets.
2. Fundamentals
2.1. Retinex-Based Methods
2.2. Non-Retinex Methods
3. Objectives of Experimental Study
- 1.
- It has been noted that although there have been a large number of algorithms developed for low-light enhancement, Retinex theory-based models are gaining more attention due to their robustness. Retinex theory is even used in deep learning-based models. Specifically, this paper attempts to compare the performance of Retinex theory-based classical and deep learning low-light enhancement models with other state-of-the-art models.
- 2.
- Several low-light enhancement methods perform well on some test datasets but fail in real-world scenarios. An extensive range of real-world images should be used to test the robustness of the low-light enhancement models. As a means of assessing the robustness of enhancement methods in real-world scenarios, various test datasets spanning a wide range of lighting conditions and contents need to be selected, and the performance of Retinue-based models needs to be compared with that of other enhancement techniques on these test datasets.
- 3.
- The trend of real-time cellphone night photography is increasing day by day. Therefore, analyzing the computational costs associated with low-light enhancement methods is necessary. Comparison of not only the parameters of these methods but also the processing time for the images of four different sizes (i.e., , , and ) is required. A computational analysis of different sizes of images will enable the researchers to determine whether the computational cost increases linearly or exponentially as the image size increases.
- 4.
- The quality of low-light enhancement methods needs to be evaluated using a variety of image quality assessment (IQA) methods. Every metric aims to identify the particular quality of the predicted image. The LOE measures the naturalness of the image, whereas the information entropy measures the information contained in the image. What is the most effective method of comparing the robustness of low-light enhancement methods when comparing results based on these evaluation metrics?
4. Quantitative and Qualitative Analysis
4.1. Experimental Criteria for Enhancement Methods Comparison
4.2. Qualitative Evaluation of Enhancement Methods
4.3. Quantitative Comparison of Enhancement Methods
4.4. Computational Complexity Analysis of Enhancement Methods
4.5. Difficulty Analysis of Test Datasets
4.6. Evaluation IQA methods
5. Discussion
- i
- The enhancement methods are evaluated using four evaluation metrics. No method has emerged as the clear winner on all four metrics (LOE, entropy, NIQE, BRISQUE). This is due to the fact that each evaluation method measures a different aspect of enhancement methods (e.g., LOE measures naturalness, entropy measures information content, and NIQE measures distortion). A suggested average ranking system is found to be the most reliable method of comparing the overall performance of enactment methods.
- ii
- In the average ranking system, it has been observed that the three most successful enhancement methods (GLADNet, TBEFN, LLFlow) are based on supervised learning. Among the top ten methods, five are based on Retinex. In comparison to classical, advanced self-supervised, and zero-short learning methods, supervised learning is more effective. Denosing is the most challenging part in enhancement. Noise can be observed in the visual results of outperforming methods.
- iii
- There is no Retinex-based method among the top three fastest methods. As a result of the image decomposition, these methods are more time consuming. As the size of the image increases, the computational time of classical Retinex-based methods increases dramatically. Zero-DCE is the fastest learning-based method, taking approximately 0.017 s to process an image of size . However, it ranks 20th in terms of performance. GLADNet, on the other hand, is ranked first, but it takes approximately 2.772 s to process an image of the same size.
- iv
- The average ranking of all enhancement methods is observed in a broader sense. The results indicate that five methods in the top ten are based on Retinex theory (i.e., TBEFN, WV-SRIE, JieP, KinD, and PM-SIRE). The remaining five fall into different categories (i.e., HE, gamma correction, deep learning). When it comes to real-world scenarios, Retinex theory algorithms are more robust. In contrast, decomposing the image into illumination and reflectance makes them more computationally intensive and, therefore, slower. Computational complexity is the bottleneck for their development in real-world scenarios.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, J.; Wang, W.; Wang, R.; Gao, W. CSPS: An adaptive pooling method for image classification. IEEE Trans. Multimed. 2016, 18, 1000–1010. [Google Scholar] [CrossRef]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 8–12 October 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 850–865. [Google Scholar]
- He, A.; Luo, C.; Tian, X.; Zeng, W. A twofold siamese network for real-time object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4834–4843. [Google Scholar]
- Luo, W.; Sun, P.; Zhong, F.; Liu, W.; Zhang, T.; Wang, Y. End-to-end active object tracking via reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 3286–3295. [Google Scholar]
- Ristani, E.; Tomasi, C. Features for multi-target multi-camera tracking and re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6036–6046. [Google Scholar]
- Saini, M.; Wang, X.; Atrey, P.K.; Kankanhalli, M. Adaptive workload equalization in multi-camera surveillance systems. IEEE Trans. Multimed. 2012, 14, 555–562. [Google Scholar] [CrossRef]
- Feng, W.; Ji, D.; Wang, Y.; Chang, S.; Ren, H.; Gan, W. Challenges on large scale surveillance video analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 69–76. [Google Scholar]
- Ko, S.; Yu, S.; Kang, W.; Park, C.; Lee, S.; Paik, J. Artifact-free low-light video enhancement using temporal similarity and guide map. IEEE Trans. Ind. Electron. 2017, 64, 6392–6401. [Google Scholar] [CrossRef]
- Rasheed, M.T.; Shi, D. LSR: Lightening super-resolution deep network for low-light image enhancement. Neurocomputing 2022, 505, 263–275. [Google Scholar] [CrossRef]
- Khan, H.; Wang, X.; Liu, H. Handling missing data through deep convolutional neural network. Inf. Sci. 2022, 595, 278–293. [Google Scholar] [CrossRef]
- Khan, H.; Wang, X.; Liu, H. Missing value imputation through shorter interval selection driven by Fuzzy C-Means clustering. Comput. Electr. Eng. 2021, 93, 107230. [Google Scholar] [CrossRef]
- Khan, H.; Liu, H.; Liu, C. Missing label imputation through inception-based semi-supervised ensemble learning. Adv. Comput. Intell. 2022, 2, 1–11. [Google Scholar] [CrossRef]
- Ellrod, G.P. Advances in the detection and analysis of fog at night using GOES multispectral infrared imagery. Weather. Forecast. 1995, 10, 606–619. [Google Scholar] [CrossRef]
- Negru, M.; Nedevschi, S.; Peter, R.I. Exponential contrast restoration in fog conditions for driving assistance. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2257–2268. [Google Scholar] [CrossRef]
- Land, E.H. The retinex theory of color vision. Sci. Am. 1977, 237, 108–129. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.U.; Woodell, G.A. Properties and performance of a center/surround retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef] [PubMed]
- Jobson, D.J.; Rahman, Z.U.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Zeng, D.; Huang, Y.; Zhang, X.P.; Ding, X. A weighted variational model for simultaneous reflectance and illumination estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2782–2790. [Google Scholar]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 2016, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Lu, K.; Zhang, L. TBEFN: A two-branch exposure-fusion network for low-light image enhancement. IEEE Trans. Multimed. 2020, 23, 4093–4105. [Google Scholar] [CrossRef]
- Zhang, Y.; Di, X.; Zhang, B.; Li, Q.; Yan, S.; Wang, C. Self-supervised Low Light Image Enhancement and Denoising. arXiv 2021, arXiv:2103.00832. [Google Scholar]
- Zhu, A.; Zhang, L.; Shen, Y.; Ma, Y.; Zhao, S.; Zhou, Y. Zero-shot restoration of underexposed images via robust retinex decomposition. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Gonzalez, R.C. Digital Image Processing, 2nd ed.; Addison-Wesley: Boston, MA, USA, 1992. [Google Scholar]
- Abdullah-Al-Wadud, M.; Kabir, M.H.; Dewan, M.A.A.; Chae, O. A dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 2007, 53, 593–600. [Google Scholar] [CrossRef]
- Rahman, S.; Rahman, M.M.; Abdullah-Al-Wadud, M.; Al-Quaderi, G.D.; Shoyaib, M. An adaptive gamma correction for image enhancement. EURASIP J. Image Video Process 2016, 35, 2016. [Google Scholar] [CrossRef]
- Huang, S.C.; Cheng, F.C.; Chiu, Y.S. Efficient contrast enhancement using adaptive gamma correction with weighting distribution. IEEE Trans. Image Process. 2012, 22, 1032–1041. [Google Scholar] [CrossRef]
- Wang, Z.G.; Liang, Z.H.; Liu, C.L. A real-time image processor with combining dynamic contrast ratio enhancement and inverse gamma correction for PDP. Displays 2009, 30, 133–139. [Google Scholar] [CrossRef]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to see in the dark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3291–3300. [Google Scholar]
- Cai, J.; Gu, S.; Zhang, L. Learning a deep single image contrast enhancer from multi-exposure images. IEEE Trans. Image Process. 2018, 27, 2049–2062. [Google Scholar] [CrossRef] [PubMed]
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A Visible-infrared Paired Dataset for Low-light Vision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3496–3504. [Google Scholar]
- Park, J.; Lee, J.Y.; Yoo, D.; Kweon, I.S. Distort-and-recover: Color enhancement using deep reinforcement learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5928–5936. [Google Scholar]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Zheng, C.; Shi, D.; Shi, W. Adaptive Unfolding Total Variation Network for Low-Light Image Enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4439–4448. [Google Scholar]
- Wang, Y.; Wan, R.; Yang, W.; Li, H.; Chau, L.P.; Kot, A.C. Low-Light Image Enhancement with Normalizing Flow. arXiv 2021, arXiv:2109.05923. [Google Scholar] [CrossRef]
- Wang, W.; Wu, X.; Yuan, X.; Gao, Z. An experiment-based review of low-light image enhancement methods. IEEE Access 2020, 8, 87884–87917. [Google Scholar] [CrossRef]
- Qi, Y.; Yang, Z.; Sun, W.; Lou, M.; Lian, J.; Zhao, W.; Deng, X.; Ma, Y. A Comprehensive Overview of Image Enhancement Techniques. Arch. Comput. Methods Eng. 2021, 29, 583–607. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Han, L.H.; Jiang, J.; Cheng, M.M.; Gu, J.; Loy, C.C. Low-light image and video enhancement using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1. [Google Scholar] [CrossRef]
- Land, E.H.; McCann, J.J. Lightness and retinex theory. Josa 1971, 61, 1–11. [Google Scholar] [CrossRef]
- Land, E.H. Recent advances in retinex theory and some implications for cortical computations: Color vision and the natural image. Proc. Natl. Acad. Sci. USA 1983, 80, 5163. [Google Scholar] [CrossRef]
- Provenzi, E.; De Carli, L.; Rizzi, A.; Marini, D. Mathematical definition and analysis of the Retinex algorithm. JOSA A 2005, 22, 2613–2621. [Google Scholar] [CrossRef]
- Marini, D.; Rizzi, A. A computational approach to color adaptation effects. Image Vis. Comput. 2000, 18, 1005–1014. [Google Scholar] [CrossRef]
- Land, E.H. An alternative technique for the computation of the designator in the retinex theory of color vision. Proc. Natl. Acad. Sci. USA 1986, 83, 3078–3080. [Google Scholar] [CrossRef] [PubMed]
- Cooper, T.J.; Baqai, F.A. Analysis and extensions of the Frankle-McCann Retinex algorithm. J. Electron. Imaging 2004, 13, 85–92. [Google Scholar] [CrossRef]
- Provenzi, E.; Fierro, M.; Rizzi, A.; De Carli, L.; Gadia, D.; Marini, D. Random spray Retinex: A new Retinex implementation to investigate the local properties of the model. IEEE Trans. Image Process. 2006, 16, 162–171. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Liao, Y.; Zeng, D.; Huang, Y.; Zhang, X.P.; Ding, X. A probabilistic method for image enhancement with simultaneous illumination and reflectance estimation. IEEE Trans. Image Process. 2015, 24, 4965–4977. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Zheng, J.; Hu, H.M.; Li, B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans. Image Process. 2013, 22, 3538–3548. [Google Scholar] [CrossRef] [PubMed]
- Zosso, D.; Tran, G.; Osher, S.J. Non-Local Retinex—A Unifying Framework and Beyond. SIAM J. Imaging Sci. 2015, 8, 787–826. [Google Scholar] [CrossRef]
- Kimmel, R.; Elad, M.; Shaked, D.; Keshet, R.; Sobel, I. A variational framework for retinex. Int. J. Comput. Vis. 2003, 52, 7–23. [Google Scholar] [CrossRef]
- Ma, W.; Osher, S. A TV Bregman iterative model of Retinex theory. Inverse Probl. Imaging 2012, 6, 697. [Google Scholar] [CrossRef]
- Ma, W.; Morel, J.M.; Osher, S.; Chien, A. An L 1-based variational model for Retinex theory and its application to medical images. In Proceedings of the CVPR, Colorado Springs, CO, USA, 20–25 June 2011; pp. 153–160. [Google Scholar]
- Fu, X.; Zeng, D.; Huang, Y.; Ding, X.; Zhang, X.P. A variational framework for single low light image enhancement using bright channel prior. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; pp. 1085–1088. [Google Scholar]
- Ng, M.K.; Wang, W. A total variation model for Retinex. SIAM J. Imaging Sci. 2011, 4, 345–365. [Google Scholar] [CrossRef]
- Fu, X.; Zeng, D.; Huang, Y.; Liao, Y.; Ding, X.; Paisley, J. A fusion-based enhancing method for weakly illuminated images. Signal Process. 2016, 129, 82–96. [Google Scholar] [CrossRef]
- Cai, B.; Xu, X.; Guo, K.; Jia, K.; Hu, B.; Tao, D. A joint intrinsic-extrinsic prior model for retinex. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4000–4009. [Google Scholar]
- Ying, Z.; Li, G.; Ren, Y.; Wang, R.; Wang, W. A new low-light image enhancement algorithm using camera response model. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 3015–3022. [Google Scholar]
- Zhang, Y.; Guo, X.; Ma, J.; Liu, W.; Zhang, J. Beyond brightening low-light images. Int. J. Comput. Vis. 2021, 129, 1013–1037. [Google Scholar] [CrossRef]
- Hai, J.; Xuan, Z.; Yang, R.; Hao, Y.; Zou, F.; Lin, F.; Han, S. R2RNet: Low-light Image Enhancement via Real-low to Real-normal Network. arXiv 2021, arXiv:2106.14501. [Google Scholar]
- Liu, R.; Ma, L.; Zhang, J.; Fan, X.; Luo, Z. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10561–10570. [Google Scholar]
- Wang, R.; Xu, X.; Fu, C.W.; Lu, J.; Yu, B.; Jia, J. Seeing Dynamic Scene in the Dark: A High-Quality Video Dataset With Mechatronic Alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9700–9709. [Google Scholar]
- Zhao, Z.; Xiong, B.; Wang, L.; Ou, Q.; Yu, L.; Kuang, F. RetinexDIP: A Unified Deep Framework for Low-light Image Enhancement. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1076–1088. [Google Scholar] [CrossRef]
- Yu, R.; Liu, W.; Zhang, Y.; Qu, Z.; Zhao, D.; Zhang, B. Deepexposure: Learning to expose photos with asynchronously reinforced adversarial learning. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 2153–2163. [Google Scholar]
- Cheng, H.; Shi, X. A simple and effective histogram equalization approach to image enhancement. Digit. Signal Process. 2004, 14, 158–170. [Google Scholar] [CrossRef]
- Kim, Y.T. Contrast enhancement using brightness preserving bi-histogram equalization. IEEE Trans. Consum. Electron. 1997, 43, 1–8. [Google Scholar]
- Ibrahim, H.; Kong, N.S.P. Brightness preserving dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 2007, 53, 1752–1758. [Google Scholar] [CrossRef]
- Guan, X.; Jian, S.; Hongda, P.; Zhiguo, Z.; Haibin, G. An image enhancement method based on gamma correction. In Proceedings of the 2009 Second International Symposium on Computational Intelligence and Design, Changsha, China, 12–14 December 2009; Volume 1, pp. 60–63. [Google Scholar]
- Tao, L.; Zhu, C.; Xiang, G.; Li, Y.; Jia, H.; Xie, X. LLCNN: A convolutional neural network for low-light image enhancement. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-Light Image/Video Enhancement Using CNNs. In Proceedings of the BMVC, Newcastle, UK, 3–6 September 2018; p. 220. [Google Scholar]
- Wang, W.; Wei, C.; Yang, W.; Liu, J. GLADNet: Low-light enhancement network with global awareness. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Jodhpur, India, 15–18 December 2018; pp. 751–755. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Xiong, W.; Liu, D.; Shen, X.; Fang, C.; Luo, J. Unsupervised real-world low-light image enhancement with decoupled networks. arXiv 2020, arXiv:2005.02818. [Google Scholar]
- Xia, Z.; Gharbi, M.; Perazzi, F.; Sunkavalli, K.; Chakrabarti, A. Deep Denoising of Flash and No-Flash Pairs for Photography in Low-Light Environments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2063–2072. [Google Scholar]
- Le, H.A.; Kakadiaris, I.A. SeLENet: A semi-supervised low light face enhancement method for mobile face unlock. In Proceedings of the 2019 International Conference on Biometrics (ICB), Crete, Greece, 4–7 June 2019; pp. 1–8. [Google Scholar]
- Yang, W.; Wang, S.; Fang, Y.; Wang, Y.; Liu, J. From fidelity to perceptual quality: A semi-supervised approach for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3063–3072. [Google Scholar]
- Qiao, Z.; Xu, W.; Sun, L.; Qiu, S.; Guo, H. Deep Semi-Supervised Learning for Low-Light Image Enhancement. In Proceedings of the 2021 14th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Online. 23–25 October 2021; pp. 1–6. [Google Scholar]
- Wu, W.; Wang, W.; Jiang, K.; Xu, X.; Hu, R. Self-Supervised Learning on A Lightweight Low-Light Image Enhancement Model with Curve Refinement. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 1890–1894. [Google Scholar]
- Guo, C.G.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Wang, L.W.; Liu, Z.S.; Siu, W.C.; Lun, D.P. Lightening network for low-light image enhancement. IEEE Trans. Image Process. 2020, 29, 7984–7996. [Google Scholar] [CrossRef]
- Lee, C.; Lee, C.; Kim, C.S. Contrast enhancement based on layered difference representation of 2D histograms. IEEE Trans. Image Process. 2013, 22, 5372–5384. [Google Scholar] [CrossRef]
- Ma, K.; Zeng, K.; Wang, Z. Perceptual quality assessment for multi-exposure image fusion. IEEE Trans. Image Process. 2015, 24, 3345–3356. [Google Scholar] [CrossRef] [PubMed]
- Lv, F.; Li, Y.; Lu, F. Attention guided low-light image enhancement with a large scale low-light simulation dataset. arXiv 2019, arXiv:1908.00682. [Google Scholar] [CrossRef]
- Loh, Y.P.; Chan, C.S. Getting to know low-light images with the exclusively dark dataset. Comput. Vis. Image Underst. 2019, 178, 30–42. [Google Scholar] [CrossRef]
- Gonzalez, R.C. Digital Image Processing; Pearson Education India: Noida, India, 2009. [Google Scholar]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Papasaika-Hanusch, H. Digital image PROCESSING Using Matlab; Institute of Geodesy and Photogrammetry, ETH Zurich: Zurich, Switzerland, 1967; Volume 63. [Google Scholar]
- Celik, T.; Tjahjadi, T. Contextual and variational contrast enhancement. IEEE Trans. Image Process. 2011, 20, 3431–3441. [Google Scholar] [CrossRef]
- Pizer, S.M. Contrast-limited adaptive histogram equalization: Speed and effectiveness stephen m. pizer, r. eugene johnston, james p. ericksen, bonnie c. yankaskas, keith e. muller medical image display research group. In Proceedings of the First Conference on Visualization in Biomedical Computing, Atlanta, GA, USA, 22–25 May 1990; Volume 337. [Google Scholar]
- Cao, G.; Huang, L.; Tian, H.; Huang, X.; Wang, Y.; Zhi, R. Contrast enhancement of brightness-distorted images by improved adaptive gamma correction. Comput. Electr. Eng. 2018, 66, 569–582. [Google Scholar] [CrossRef]
- Ying, Z.; Li, G.; Gao, W. A bio-inspired multi-exposure fusion framework for low-light image enhancement. arXiv 2017, arXiv:1711.00591. [Google Scholar]
- Afifi, M.; Derpanis, K.G.; Ommer, B.; Brown, M.S. Learning Multi-Scale Photo Exposure Correction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9157–9167. [Google Scholar]
- Zhang, F.; Li, Y.; You, S.; Fu, Y. Learning Temporal Consistency for Low Light Video Enhancement From Single Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4967–4976. [Google Scholar]
- Li, C.; Guo, J.; Porikli, F.; Pang, Y. LightenNet: A convolutional neural network for weakly illuminated image enhancement. Pattern Recognit. Lett. 2018, 104, 15–22. [Google Scholar] [CrossRef]
- Hu, Y.; He, H.; Xu, C.; Wang, B.; Lin, S. Exposure: A white-box photo post-processing framework. ACM Trans. Graph. (TOG) 2018, 37, 1–17. [Google Scholar] [CrossRef]
- Ying, Z.; Li, G.; Ren, Y.; Wang, R.; Wang, W. A new image contrast enhancement algorithm using exposure fusion framework. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Ystad, Sweden, 22–24 August 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 36–46. [Google Scholar]
- Pu, T.; Wang, S. Perceptually motivated enhancement method for non-uniformly illuminated images. IET Comput. Vis. 2018, 12, 424–433. [Google Scholar] [CrossRef]
- Al-Ameen, Z. Nighttime image enhancement using a new illumination boost algorithm. IET Image Process. 2019, 13, 1314–1320. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | LIME | LOL | DICM | VV | MEF | NPE | LSRW | SLL | ExDark | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Methods | |||||||||||
| Non-Retinex Methods | HE [89] | 290.280 | 423.910 | 283.980 | 280.750 | 406.930 | 184.590 | 122.84 | 753.990 | 408.76 | 358.222 |
| DHE [27] | 7.663 | 22.227 | 75.608 | 21.013 | 7.852 | 23.974 | 13.930 | 10.177 | 138.049 | 35.610 | |
| BPDHE [68] | 6.960 | 125.046 | 14.936 | 4.110 | 5.480 | 7.643 | 5.985 | 382.146 | 134.774 | 76.342 | |
| CVC [90] | 99.386 | 286.840 | 135.324 | 91.217 | 97.464 | 131.478 | 124.946 | 324.260 | 189.896 | 164.534 | |
| CLAHE [91] | 183.094 | 397.432 | 386.183 | 209.867 | 224.280 | 379.588 | 242.572 | 504.013 | 252.236 | 308.807 | |
| AGCWD [29] | 10.075 | 0.1325 | 57.482 | 14.777 | 6.046 | 31.432 | 1.463 | 6.132 | 137.990 | 31.932 | |
| IAGC [92] | 63.028 | 170.190 | 53.502 | 55.943 | 66.710 | 41.488 | 77.123 | 278.054 | 165.790 | 113.600 | |
| BIMEF [93] | 136.898 | 141.159 | 239.271 | 102.891 | 155.616 | 225.588 | 117.777 | 480.848 | 237.563 | 212.589 | |
| MBLLEN [71] | 122.188 | 302.577 | 176.580 | 79.013 | 131.243 | 123.871 | 168.128 | 484.809 | 190.384 | 207.076 | |
| GLADNet [72] | 123.603 | 349.720 | 285.239 | 145.034 | 199.632 | 203.488 | 204.887 | 518.189 | 262.524 | 254.702 | |
| DLN [81] | 132.594 | 264.065 | 404.673 | 325.572 | 189.831 | - | 176.527 | 528.411 | 212.723 | - | |
| Zero-DCE [80] | 135.032 | 209.426 | 340.803 | 145.435 | 164.262 | 312.392 | 219.127 | 539.673 | 315.084 | 280.775 | |
| Exposure Correction [94] | 242.461 | 438.420 | 362.552 | 220.876 | 275.476 | 314.833 | 288.659 | 588.132 | 307.881 | 349.604 | |
| StableLLVE [95] | 134.130 | 267.686 | 476.374 | 192.262 | 198.069 | 394.811 | 179.101 | 344.573 | 248.400 | 287.660 | |
| LightenNet [96] | 681.834 | 387.204 | 772.380 | 328.510 | 896.201 | 714.390 | 930.978 | 924.638 | 636.000 | 698.788 | |
| White-box [97] | 90.876 | 125.682 | 195.516 | 124.115 | 96.704 | 120.687 | 84.279 | 370.972 | 135.606 | 156.695 | |
| LLFlow [38] | 365.530 | 367.153 | 563.765 | 300.058 | 430.534 | 538.078 | 685.344 | 764.261 | 445.274 | 511.808 | |
| Retinex-based Methods | LIME [21] | 559.618 | 404.114 | 818.660 | 460.440 | 618.480 | 870.215 | 434.485 | 1103.98 | 575.987 | 649.553 |
| NPE [50] | 300.505 | 317.399 | 264.604 | 352.294 | 344.953 | 257.010 | 435.676 | 293.158 | 358.018 | 327.889 | |
| JieP [58] | 249.137 | 314.798 | 287.305 | 137.026 | 292.798 | 305.435 | 216.597 | 690.829 | 345.754 | 323.818 | |
| PM-SIRE [49] | 113.631 | 73.558 | 152.779 | 113.031 | 166.640 | 104.945 | 143.945 | 189.09 | 193.194 | 142.148 | |
| WV-SRIE [20] | 106.308 | 83.806 | 162.224 | 69.480 | 210.261 | 155.683 | 131.724 | 236.846 | 220.823 | 158.856 | |
| MSRCR [19] | 842.029 | 1450.95 | 1185.11 | 1280.68 | 973.893 | 1252.07 | 893.216 | 1211.11 | 676.415 | 1115.43 | |
| CRM [59] | 271.652 | 21.818 | 450.102 | 174.751 | 285.250 | 534.275 | 119.712 | 619.537 | 352.672 | 314.419 | |
| EFF [98] | 136.898 | 141.159 | 239.271 | 102.891 | 155.616 | 255.588 | 117.777 | 480.848 | 237.563 | 207.512 | |
| pmea [99] | 491.663 | 725.647 | 477.792 | 318.569 | 679.002 | 610.183 | 418.046 | 1005.66 | 529.189 | 595.511 | |
| RetinexNet [22] | 472.189 | 770.105 | 636.160 | 391.745 | 708.250 | 838.310 | 591.278 | 950.895 | 548.905 | 679.456 | |
| KinD [36] | 214.893 | 434.595 | 261.771 | 134.844 | 275.474 | 241.221 | 379.899 | 479.139 | 308.869 | 303.412 | |
| RetinexDIP [64] | 767.042 | 1084.35 | 852.782 | 396.417 | 926.948 | 1099.39 | 572.429 | 1283.77 | 633.489 | 856.197 | |
| RRDNet [25] | 72.917 | 21.438 | 261.429 | 168.601 | 100.735 | - | 136.011 | 380.747 | 1.100 | - | |
| KinD++ [60] | 573.877 | 720.025 | 493.882 | 258.744 | 629.841 | - | 727.695 | 555.363 | 484.989 | - | |
| IBA [100] | 14.657 | 0.1616 | 445.574 | 169.714 | 12.823 | 364.810 | 137.727 | 21.758 | 284.333 | 179.613 | |
| Self-supervised Network [24] | 241.639 | 322.628 | 737.847 | 282.273 | 311.342 | 581.691 | 261.280 | 467.892 | 333.842 | 412.349 | |
| TBEFN [23] | 289.754 | 464.947 | 617.100 | 271.871 | 419.666 | 527.675 | 386.583 | 859.878 | 389.558 | 492.160 | |
| Average | 178.196 | 342.070 | 387.311 | 227.201 | 313.656 | 378.930 | 286.698 | 548.053 | 320.401 | - |
| Datasets | LIME | LOL | DICM | VV | MEF | NPE | LSRW | SLL | ExDark | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Methods | |||||||||||
| Non-Retinex Methods | Input | 4.357 | 6.748 | 4.274 | 3.524 | 4.263 | 3.717 | 5.391 | 5.358 | 5.128 | 4.800 |
| HE [89] | 3.884 | 8.413 | 3.850 | 2.662 | 3.870 | 3.535 | 3.963 | 6.438 | 4.752 | 4.685 | |
| DHE [27] | 3.914 | 8.987 | 3.780 | 2.648 | 3.518 | 3.510 | 3.626 | 6.292 | 4.518 | 4.610 | |
| BPDHE [68] | 3.827 | NaN | 3.786 | 2.857 | 3.902 | 3.531 | 3.935 | NaN | 4.727 | - | |
| CVC [90] | 4.029 | 8.014 | 3.823 | 2.692 | 3.636 | 3.498 | 4.127 | 5.828 | 4.662 | 4.535 | |
| CLAHE [91] | 3.907 | 7.268 | 3.792 | 2.784 | 3.606 | 3.461 | 4.581 | 5.756 | 4.734 | 4.490 | |
| AGCWD [29] | 4.032 | 7.528 | 3.868 | 2.970 | 3.629 | 3.544 | 3.733 | 5.660 | 4.582 | 4.434 | |
| IAGC [92] | 3.951 | 7.418 | 4.015 | 3.012 | 3.652 | 3.598 | 3.963 | 5.740 | 4.557 | 4.494 | |
| BIMEF [93] | 3.859 | 7.515 | 3.845 | 2.807 | 3.329 | 3.540 | 3.879 | 5.747 | 4.514 | 4.397 | |
| MBLLEN [71] | 4.513 | 4.357 | 4.230 | 4.179 | 4.739 | 3.948 | 4.722 | 3.979 | 4.478 | 4.329 | |
| GLADNet [72] | 4.128 | 6.475 | 3.681 | 2.790 | 3.360 | 3.522 | 3.397 | 5.066 | 3.767 | 4.009 | |
| DLN [81] | 4.341 | 4.883 | 3.789 | 3.228 | 4.022 | - | 4.419 | 4.376 | 4.415 | - | |
| Zero-DCE [80] | 3.769 | 7.767 | 3.567 | 3.216 | 3.283 | 3.582 | 3.720 | 5.998 | 3.917 | 4.381 | |
| Exposure Correction [94] | 4.215 | 7.886 | 3.588 | 3.078 | 4.456 | 3.414 | 3.820 | 4.942 | 4.357 | 4.443 | |
| StableLLVE [95] | 4.234 | 4.372 | 4.061 | 3.420 | 3.924 | 3.486 | 4.367 | 4.185 | 4.053 | 3.984 | |
| LightenNet [96] | 3.731 | 7.323 | 3.539 | 2.995 | 3.350 | 3.407 | 3.583 | 5.453 | 4.025 | 4.209 | |
| White-box [97] | 4.598 | 7.819 | 4.630 | 3.558 | 4.622 | 4.004 | 4.314 | 7.138 | 5.534 | 5.202 | |
| LLFlow [38] | 3.956 | 5.445 | 3.765 | 3.026 | 3.441 | 3.498 | 3.564 | 4.722 | 4.094 | 3.944 | |
| Retinex-based Methods | LIME [21] | 4.109 | 8.129 | 3.860 | 2.494 | 3.576 | 3.658 | 3.655 | 6.372 | 4.588 | 4.542 |
| NPE [50] | 3.578 | 8.158 | 3.736 | 2.471 | 3.337 | 3.426 | 3.576 | 5.771 | 4.220 | 4.337 | |
| JieP [58] | 3.719 | 6.872 | 3.678 | 2.765 | 3.390 | 3.522 | 4.015 | 5.622 | 4.215 | 4.260 | |
| PM-SIRE [49] | 4.050 | 7.506 | 3.978 | 3.010 | 3.450 | 3.531 | 3.984 | 5.435 | 4.383 | 4.410 | |
| WV-SRIE [20] | 3.786 | 7.286 | 3.898 | 2.849 | 3.474 | 3.450 | 3.826 | 5.453 | 4.241 | 4.310 | |
| MSRCR [19] | 3.939 | 8.006 | 3.948 | 2.814 | 3.688 | 3.780 | 3.872 | 5.574 | 4.904 | 4.573 | |
| CRM [59] | 3.854 | 7.686 | 3.801 | 2.617 | 3.264 | 3.562 | 3.721 | 6.008 | 4.525 | 4.391 | |
| EFF [98] | 3.859 | 7.515 | 3.845 | 2.807 | 3.329 | 3.540 | 3.879 | 5.747 | 4.514 | 4.390 | |
| pmea [99] | 3.843 | 8.281 | 3.836 | 2.573 | 3.431 | 3.598 | 3.694 | 6.237 | 4.296 | 4.493 | |
| RetinexNet [22] | 4.597 | 8.879 | 4.415 | 2.695 | 4.410 | 4.464 | 4.150 | 7.573 | 4.551 | 5.142 | |
| KinD [36] | 4.763 | 4.709 | 4.150 | 3.026 | 3.876 | 3.557 | 3.543 | 4.450 | 4.340 | 3.956 | |
| RetinexDIP [64] | 3.735 | 7.096 | 3.705 | 2.496 | 3.245 | 3.638 | 4.081 | 5.8828 | 4.234 | 4.297 | |
| RRDNet [25] | 3.936 | 7.436 | 3.637 | 2.814 | 3.508 | - | 4.126 | 5.524 | 4.010 | - | |
| KinD++ [60] | 4.385 | 4.616 | 3.804 | 2.660 | 3.738 | - | 3.354 | 5.090 | 4.343 | - | |
| IBA [100] | 4.062 | 7.884 | 3.723 | 3.310 | 3.536 | 3.630 | 3.728 | 5.837 | 4.273 | 4.490 | |
| Self-supervised Network [24] | 4.819 | 3.753 | 4.717 | 3.548 | 4.351 | 4.602 | 4.061 | 5.400 | 4.048 | 4.310 | |
| TBEFN [23] | 3.954 | 3.436 | 3.503 | 2.884 | 3.227 | 3.292 | 3.478 | 4.648 | 3.621 | 3.511 | |
| Average | 3.935 | 6.728 | 3.889 | 2.956 | 3.698 | 3.626 | 3.933 | 5.409 | 4.403 | - |
| Datasets | LIME | LOL | DICM | VV | MEF | NPE | LSRW | SLL | ExDark | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Methods | |||||||||||
| Non-Retinex Methods | Input | 6.148 | 4.915 | 6.686 | 6.715 | 6.075 | 7.017 | 5.415 | 5.616 | 5.744 | 6.023 |
| HE [89] | 7.342 | 7.184 | 7.221 | 7.383 | 7.118 | 7.756 | 6.874 | 6.662 | 6.708 | 7.113 | |
| DHE [27] | 7.097 | 6.749 | 7.141 | 7.225 | 6.913 | 7.512 | 6.531 | 6.741 | 6.613 | 6.930 | |
| BPDHE [68] | 6.610 | 5.932 | 6.968 | 6.977 | 6.420 | 7.348 | 6.260 | 5.191 | 6.188 | 6.413 | |
| CVC [90] | 6.875 | 6.409 | 7.055 | 7.216 | 6.755 | 7.402 | 6.318 | 6.549 | 6.465 | 6.772 | |
| CLAHE [91] | 6.764 | 5.679 | 7.088 | 7.056 | 6.583 | 7.408 | 6.033 | 6.591 | 6.302 | 6.595 | |
| AGCWD [29] | 6.792 | 6.415 | 6.925 | 7.021 | 6.648 | 7.398 | 6.394 | 6.278 | 6.248 | 6.666 | |
| IAGC [92] | 6.991 | 6.247 | 7.015 | 7.193 | 6.878 | 7.351 | 6.318 | 6.698 | 6.554 | 6.782 | |
| BIMEF [93] | 7.006 | 6.145 | 7.029 | 7.243 | 6.898 | 7.311 | 6.516 | 6.452 | 6.464 | 6.760 | |
| MBLLEN [71] | 7.164 | 7.303 | 7.255 | 7.333 | 7.081 | 7.386 | 7.236 | 7.197 | 7.132 | 7.240 | |
| GLADNet [72] | 7.502 | 7.356 | 7.404 | 7.447 | 7.408 | 7.452 | 7.393 | 7.581 | 7.250 | 7.412 | |
| DLN [81] | 7.121 | 7.277 | 7.250 | 7.535 | 7.255 | - | 7.202 | 7.576 | 7.129 | - | |
| Zero-DCE [80] | 7.166 | 6.531 | 7.224 | 7.572 | 7.093 | 7.402 | 7.035 | 6.545 | 6.932 | 7.042 | |
| Exposure Correction [94] | 7.112 | 7.244 | 7.256 | 6.962 | 6.955 | 7.531 | 7.039 | 7.247 | 6.907 | 7.142 | |
| StableLLVE [95] | 7.227 | 6.625 | 7.010 | 7.385 | 7.241 | 7.042 | 6.846 | 7.439 | 7.129 | 7.090 | |
| LightenNet [96] | 7.234 | 6.119 | 7.263 | 7.411 | 7.308 | 7.398 | 7.599 | 6.130 | 6.688 | 6.990 | |
| White-box [97] | 5.984 | 5.925 | 6.051 | 5.475 | 5.391 | 7.380 | 6.352 | 5.460 | 5.275 | 5.914 | |
| LLFlow [38] | 7.468 | 7.462 | 7.425 | 7.565 | 7.366 | 7.564 | 7.343 | 7.304 | 7.125 | 7.394 | |
| Retinex-based Methods | LIME [21] | 7.315 | 7.129 | 6.946 | 7.395 | 7.139 | 7.332 | 7.279 | 6.418 | 6.582 | 7.031 |
| NPE [50] | 7.368 | 6.971 | 7.208 | 7.550 | 7.405 | 7.446 | 7.318 | 6.418 | 6.772 | 7.139 | |
| JieP [58] | 7.087 | 6.443 | 7.218 | 7.457 | 7.104 | 7.427 | 6.794 | 6.473 | 6.631 | 6.943 | |
| PM-SIRE [49] | 7.006 | 6.322 | 7.084 | 7.309 | 6.894 | 7.404 | 6.696 | 6.325 | 6.441 | 6.812 | |
| WV-SRIE [20] | 6.999 | 6.348 | 7.088 | 7.401 | 6.942 | 7.386 | 6.663 | 6.190 | 6.463 | 6.812 | |
| MSRCR [19] | 6.563 | 6.841 | 6.677 | 6.957 | 6.455 | 6.762 | 6.895 | 5.936 | 6.319 | 6.605 | |
| CRM [59] | 6.487 | 4.971 | 6.640 | 6.559 | 6.203 | 7.026 | 5.494 | 6.068 | 5.921 | 6.115 | |
| EFF [98] | 7.006 | 6.145 | 7.029 | 7.243 | 6.898 | 7.311 | 6.516 | 6.452 | 6.464 | 6.760 | |
| pmea [99] | 7.284 | 6.824 | 7.220 | 7.479 | 7.273 | 7.449 | 7.074 | 6.638 | 6.725 | 7.088 | |
| RetinexNet [22] | 7.489 | 7.233 | 7.413 | 7.575 | 7.448 | 7.463 | 7.243 | 7.385 | 7.273 | 7.379 | |
| KinD [36] | 7.388 | 7.017 | 7.211 | 7.498 | 7.328 | 7.435 | 7.209 | 7.408 | 6.905 | 7.251 | |
| RetinexDIP [64] | 6.974 | 5.375 | 7.214 | 7.557 | 6.661 | 7.381 | 6.352 | 6.213 | 6.668 | 6.678 | |
| RRDNet [25] | 6.646 | 5.457 | 7.142 | 7.275 | 6.453 | - | 6.775 | 6.077 | 6.426 | - | |
| KinD++ [60] | 7.486 | 7.065 | 7.332 | 7.627 | 7.463 | - | 7.316 | 7.452 | 7.034 | - | |
| IBA [100] | 5.905 | 4.913 | 6.826 | 7.255 | 5.749 | 7.035 | 7.146 | 5.465 | 6.971 | 6.420 | |
| Self-supervised Network [24] | 7.497 | 7.404 | 6.675 | 7.298 | 7.469 | 6.997 | 7.397 | 7.484 | 7.296 | 7.253 | |
| TBEFN [23] | 7.436 | 6.875 | 7.328 | 7.507 | 7.383 | 7.366 | 7.047 | 7.519 | 7.313 | 7.292 | |
| Average | 7.000 | 6.481 | 7.072 | 7.247 | 6.904 | 7.340 | 6.798 | 6.605 | 6.659 | - |
| Datasets | LIME | LOL | DICM | VV | MEF | NPE | LSRW | SLL | ExDark | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Methods | |||||||||||
| Non-Retinex Methods | Input | 25.142 | 21.929 | 28.115 | 29.380 | 29.066 | 26.673 | 32.726 | 25.304 | 34.015 | 28.401 |
| HE [89] | 21.411 | 39.559 | 25.359 | 18.937 | 25.313 | 25.444 | 28.219 | 40.015 | 29.034 | 28.985 | |
| DHE [27] | 22.336 | 37.866 | 25.993 | 24.380 | 21.466 | 27.008 | 26.477 | 38.248 | 28.951 | 28.719 | |
| BPDHE [68] | 21.728 | NaN | 25.0972 | 25.183 | 22.345 | 26.425 | 25.129 | NaN | 27.417 | - | |
| CVC [90] | 22.589 | 27.101 | 24.620 | 21.766 | 19.285 | 25.693 | 26.808 | 29.007 | 26.979 | 25.126 | |
| CLAHE [91] | 23.274 | 29.463 | 24.248 | 23.480 | 22.701 | 25.368 | 29.570 | 31.579 | 28.543 | 26.825 | |
| AGCWD [29] | 21.964 | 28.421 | 24.725 | 23.961 | 19.420 | 26.4117 | 23.367 | 29.740 | 26.161 | 25.276 | |
| IAGC [92] | 24.314 | 24.058 | 27.026 | 26.617 | 21.843 | 26.044 | 23.854 | 32.813 | 27.429 | 26.211 | |
| BIMEF [93] | 23.135 | 27.651 | 26.811 | 22.542 | 20.220 | 25.504 | 24.077 | 34.982 | 27.910 | 26.174 | |
| MBLLEN [71] | 30.386 | 23.078 | 31.603 | 35.076 | 32.389 | 29.423 | 30.328 | 22.103 | 29.012 | 29.127 | |
| GLADNet [72] | 22.286 | 26.073 | 26.253 | 24.068 | 22.908 | 24.969 | 22.802 | 33.754 | 24.765 | 25.657 | |
| DLN [81] | 27.715 | 28.985 | 26.914 | 29.782 | 28.378 | - | 33.597 | 26.798 | 31.187 | - | |
| Zero-DCE [80] | 23.334 | 30.305 | 30.653 | 30.786 | 25.484 | 30.159 | 25.827 | 36.572 | 26.761 | 29.568 | |
| Exposure Correction [94] | 27.483 | 28.357 | 29.847 | 31.694 | 29.597 | 26.768 | 26.391 | 28.632 | 32.520 | 29.204 | |
| StableLLVE [95] | 28.885 | 32.194 | 28.150 | 28.295 | 28.475 | 25.662 | 30.563 | 25.850 | 27.749 | 28.367 | |
| LightenNet [96] | 19.523 | 28.062 | 28.791 | 23.502 | 21.469 | 27.667 | 25.144 | 28.055 | 25.924 | 26.077 | |
| White-box [97] | 28.807 | 31.721 | 33.212 | 35.733 | 33.599 | 26.671 | 25.081 | 39.450 | 37.429 | 32.862 | |
| LLFlow [38] | 22.856 | 29.709 | 25.072 | 23.157 | 25.673 | 25.392 | 22.011 | 28.041 | 26.133 | 25.649 | |
| Retinex-based Methods | LIME [21] | 23.572 | 33.973 | 27.137 | 25.394 | 25.158 | 28.576 | 27.658 | 35.829 | 28.704 | 28.986 |
| NPE [50] | 22.506 | 33.858 | 25.493 | 24.654 | 22.320 | 24.986 | 27.195 | 33.861 | 28.452 | 27.539 | |
| JieP [58] | 22.193 | 27.087 | 23.633 | 22.941 | 21.214 | 25.498 | 23.421 | 30.207 | 25.309 | 24.914 | |
| PM-SIRE [49] | 24.659 | 27.694 | 27.597 | 24.287 | 24.321 | 27.342 | 25.345 | 30.014 | 26.676 | 26.635 | |
| WV-SRIE [20] | 24.181 | 27.611 | 27.698 | 24.434 | 22.088 | 25.760 | 24.700 | 28.281 | 26.750 | 25.894 | |
| MSRCR [19] | 19.384 | 30.345 | 25.799 | 19.282 | 19.091 | 24.189 | 25.789 | 30.300 | 25.415 | 24.957 | |
| CRM [59] | 23.477 | 29.599 | 26.601 | 22.368 | 20.716 | 25.726 | 24.396 | 37.723 | 28.733 | 26.939 | |
| EFF [98] | 23.135 | 27.651 | 26.811 | 22.542 | 20.220 | 25.504 | 24.077 | 34.982 | 27.910 | 26.174 | |
| pmea [99] | 21.390 | 32.913 | 25.832 | 24.972 | 21.756 | 26.358 | 25.358 | 38.132 | 28.321 | 27.874 | |
| RetinexNet [22] | 26.101 | 39.586 | 26.656 | 22.459 | 26.036 | 29.086 | 29.021 | 41.506 | 30.170 | 30.565 | |
| KinD [36] | 26.773 | 26.645 | 30.696 | 28.887 | 30.438 | 27.753 | 26.763 | 30.539 | 29.256 | 28.872 | |
| RetinexDIP [64] | 21.723 | 19.679 | 25.199 | 25.338 | 23.605 | 26.671 | 25.081 | 32.618 | 32.175 | 26.296 | |
| RRDNet [25] | 24.499 | 26.834 | 29.621 | 23.396 | 17.750 | - | 27.100 | 29.205 | 27.606 | - | |
| KinD++ [60] | 20.025 | 25.086 | 27.852 | 28.164 | 30.024 | - | 26.973 | 34.978 | 31.775 | - | |
| IBA [100] | 24.336 | 31.117 | 32.103 | 34.646 | 23.748 | 29.933 | 25.826 | 32.537 | 26.639 | 29.569 | |
| Self-supervised Network [24] | 30.192 | 19.768 | 29.529 | 30.183 | 28.355 | 29.159 | 26.205 | 32.016 | 27.990 | 27.901 | |
| TBEFN [23] | 25.720 | 17.346 | 23.606 | 23.651 | 24.435 | 24.0355 | 22.929 | 30.676 | 25.064 | 23.968 | |
| Average | 23.009 | 27.752 | 27.267 | 25.841 | 24.312 | 26.621 | 26.280 | 31.267 | 28.425 | - |
| Image Size | 400 × 600 × 3 | 640 × 960 × 3 | 2304 × 1728 × 3 | 2848 × 4256 × 3 | Avg. | |
|---|---|---|---|---|---|---|
| Methods | ||||||
| Non-Retinex Methods | HE [89] | 0.00079 | 0.0014 | 0.0071 | 0.0203 | 0.00742 |
| DHE [27] | 23.590 | 59.625 | 409.628 | 1253.897 | 436.685 | |
| BPDHE [68] | 0.078 | 0.338 | 1.630 | 3.318 | 1.341 | |
| CVC [90] | 0.086 | 0.230 | 1.150 | 3.533 | 1.250 | |
| CLAHE [91] | 0.00033 | 0.00099 | 0.0058 | 0.0226 | 0.00743 | |
| AGCWD [29] | 0.031 | 0.053 | 0.344 | 1.079 | 0.377 | |
| IAGC [92] | 0.038 | 0.155 | 1.025 | 2.253 | 0.867 | |
| BIMEF [93] | 0.123 | 0.359 | 1.811 | 5.101 | 1.848 | |
| Exposure Correction [94] | 0.721 | 0.778 | 0.903 | 18.501 | 5.226 | |
| LightenNet [96] | 3.091 | 7.126 | 45.990 | 137.835 | 48.510 | |
| LLFlow [38] | 24.740 | 60.022 | 363.281 | 1403.92 | 462.991 | |
| Retinex-based Methods | LIME [21] | 0.090 | 0.296 | 1.506 | 4.650 | 1.635 |
| NPE [50] | 13.061 | 31.025 | 213.168 | 648.832 | 226.522 | |
| JieP [58] | 0.646 | 0.874 | 2.307 | 6.597 | 2.606 | |
| PM-SIRE [49] | 0.402 | 1.340 | 28.948 | 28.423 | 14.778 | |
| WV-SRIE [20] | 0.915 | 3.136 | 40.701 | 182.267 | 56.755 | |
| MSRCR [19] | 0.322 | 0.704 | 2.787 | 8.531 | 3.086 | |
| CRM [59] | 0.166 | 0.436 | 2.626 | 8.134 | 2.840 | |
| EFF [98] | 0.136 | 0.407 | 1.973 | 5.422 | 1.984 | |
| pmea [99] | 0.646 | 0.874 | 2.307 | 6.597 | 2.606 | |
| IBA [100] | 0.032 | 0.0829 | 0.512 | 1.385 | 0.503 |
| Image Size | 400 × 600 × 3 | 640 × 960 × 3 | 2304 × 1728 × 3 | 2848 × 4256 × 3 | Avg. | Parameters. | |
|---|---|---|---|---|---|---|---|
| Methods | |||||||
| Non-Retinex | StableLLVE [95] | 0.0047 | 0.005 | 0.0076 | 0.097 | 0.028 | 4.310 M |
| MBLLEN [71] | 0.240 | 0.327 | 1.601 | 8.133 | 2.575 | 0.450 M | |
| GLADNet [72] | 0.147 | 0.161 | 0.676 | 2.772 | 0.939 | 0.930 M | |
| White-box [97] | 6.040 | 6.483 | 9.833 | 15.200 | 9.389 | 8.560 M | |
| DLN [81] | 0.009 | 0.015 | 0.058 | 0.197 | 0.070 | 0.700 M | |
| Zero-DCE [80] | 0.0025 | 0.0026 | 0.021 | 0.043 | 0.017 | 0.079 M | |
| Retinex | RetinexNet [22] | 0.155 | 0.162 | 0.591 | 1.289 | 0.549 | 0.440 M |
| KinD [36] | 0.334 | 0.604 | 3.539 | 5.213 | 2.423 | 0.255 M | |
| RetinexDIP [64] | 33.924 | 37.015 | 63.443 | 112.545 | 61.732 | 0.707 M | |
| RRDNet [25] | 59.479 | 128.217 | 893.0 | 3003.5 | 1021.1 | 0.128 M | |
| KinD++ [60] | 0.337 | 0.857 | 5.408 | 19.746 | 6.587 | 8.275 M | |
| Self-supervised Net [24] | 0.022 | 0.054 | 0.366 | 1.212 | 0.414 | 0.485 M | |
| TBEFN [23] | 0.171 | 0.166 | 0.550 | 0.887 | 0.444 | 0.490 M |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rasheed, M.T.; Guo, G.; Shi, D.; Khan, H.; Cheng, X. An Empirical Study on Retinex Methods for Low-Light Image Enhancement. Remote Sens. 2022, 14, 4608. https://doi.org/10.3390/rs14184608
Rasheed MT, Guo G, Shi D, Khan H, Cheng X. An Empirical Study on Retinex Methods for Low-Light Image Enhancement. Remote Sensing. 2022; 14(18):4608. https://doi.org/10.3390/rs14184608
Chicago/Turabian StyleRasheed, Muhammad Tahir, Guiyu Guo, Daming Shi, Hufsa Khan, and Xiaochun Cheng. 2022. "An Empirical Study on Retinex Methods for Low-Light Image Enhancement" Remote Sensing 14, no. 18: 4608. https://doi.org/10.3390/rs14184608
APA StyleRasheed, M. T., Guo, G., Shi, D., Khan, H., & Cheng, X. (2022). An Empirical Study on Retinex Methods for Low-Light Image Enhancement. Remote Sensing, 14(18), 4608. https://doi.org/10.3390/rs14184608