
Multi-Feature Information Complementary Detector: A High-Precision Object Detection Model for Remote Sensing Images


Abstract
:
1. Introduction
- (1)
- Using feature enhancement methods, such as the attention mechanism, to improve the feature representation of the object, thus indirectly weakening the background information. This method is the current mainstream approach and offers a substantial improvement in accuracy. However, this approach requires a targeted design for the corresponding modules and is relatively computationally complex.
- (2)
- The relationship between the object and background selectively eliminates background features or enhances features of the object. This approach considers the features of the object and attends to background features. However, a better strategy is needed to distinguish the beneficial background from the interfering background; otherwise, this will lead to confusion between the object and the background.
- (3)
- Using prior information, the impact of complex background information on detector performance is reduced manually. This method is simple and easy to use but results in a limited improvement in accuracy and requires a considerable labor force to select data with a single background for pretraining, which increases the cost of training.
- (1)
- A global feature information complementary (GFIC) module which combines the advantages of pooling and dilated convolution to deeply fuse the primary features and enhance the semantic representation of the model. Aimed at the characteristics of remote sensing images with large-scale changes in objects, a dual multi-scale feature fusion strategy is used to solve the challenges posed by different scale objects in the same image.
- (2)
- A positive and negative feature guidance (PNFG) module. We define noise information in a complex background that is useless for object detection as negative features. In contrast, the features that provide valuable information for object detection are defined as positive features. Because positive and negative features are coupled with the features extracted by the backbone network, a PNFG strategy is designed to eliminate negative features while enhancing and refining positive features.
- (3)
- A highly accurate object detection model for remote sensing images that achieves state-of-the-art performance on publicly available remote sensing image object detection datasets.
2. Related Work
2.1. Object Detection for Complex Backgrounds
2.2. Object Detection of Multi-Scale Objects
2.3. One-Stage Remote Sensing Image Object Detection
3. Methodology
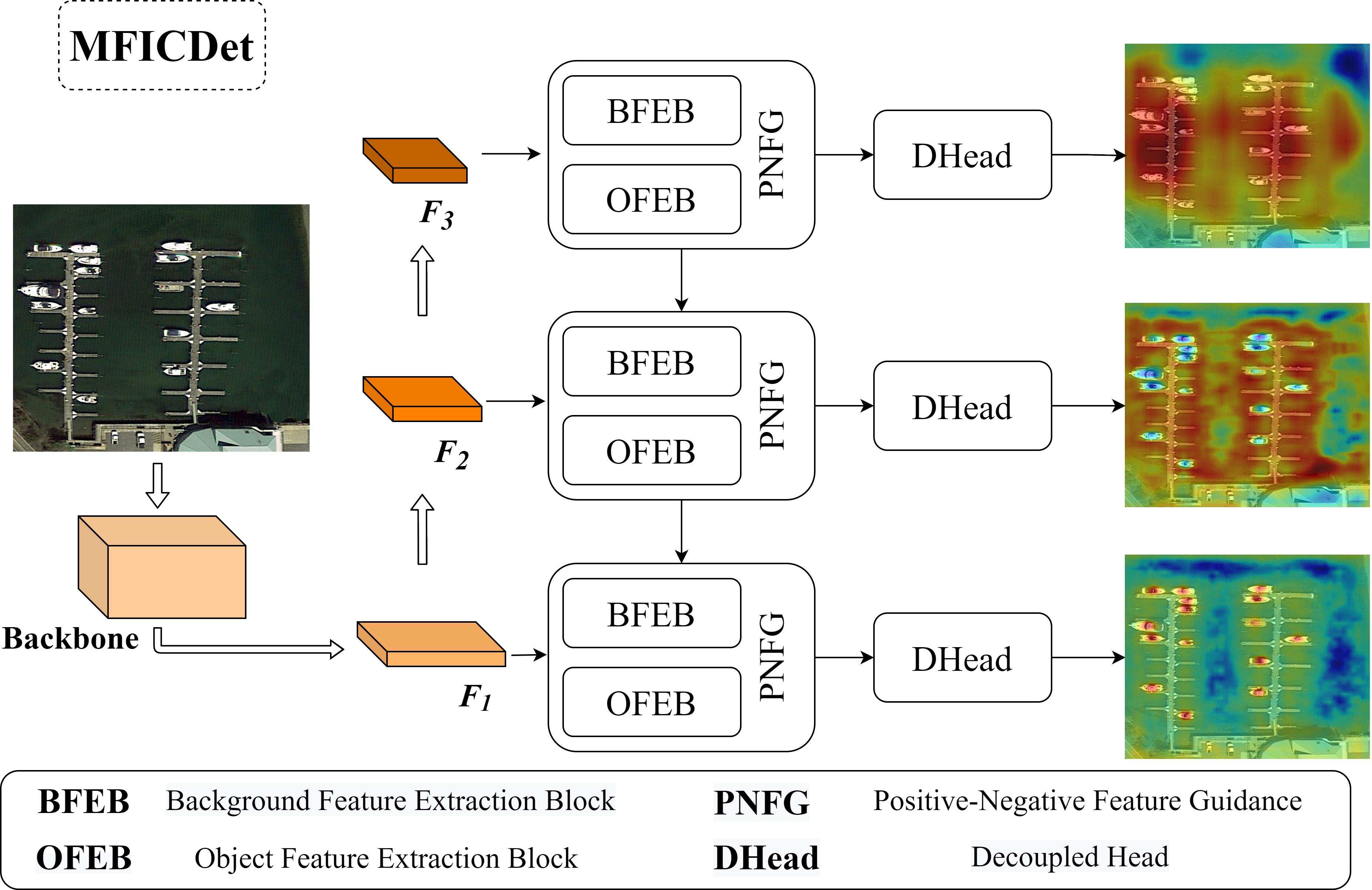
3.1. Network Architecture
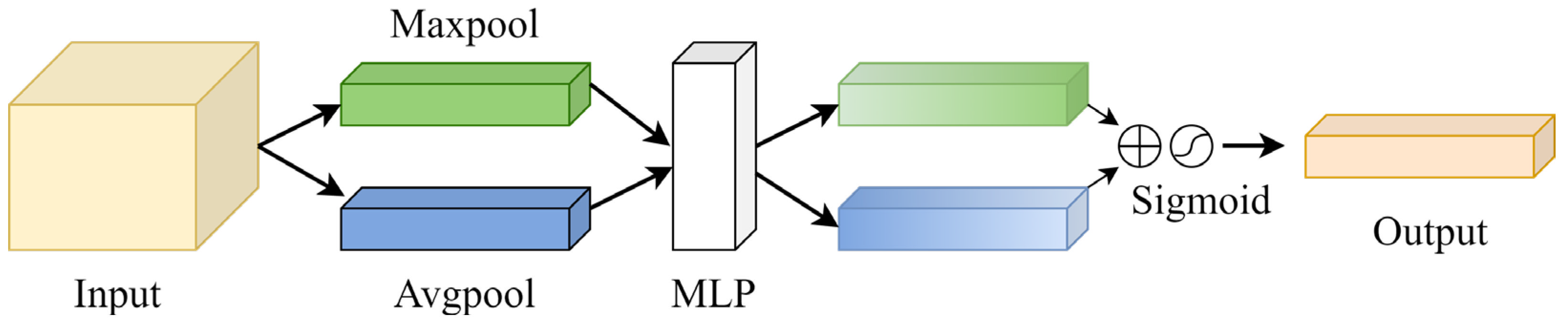
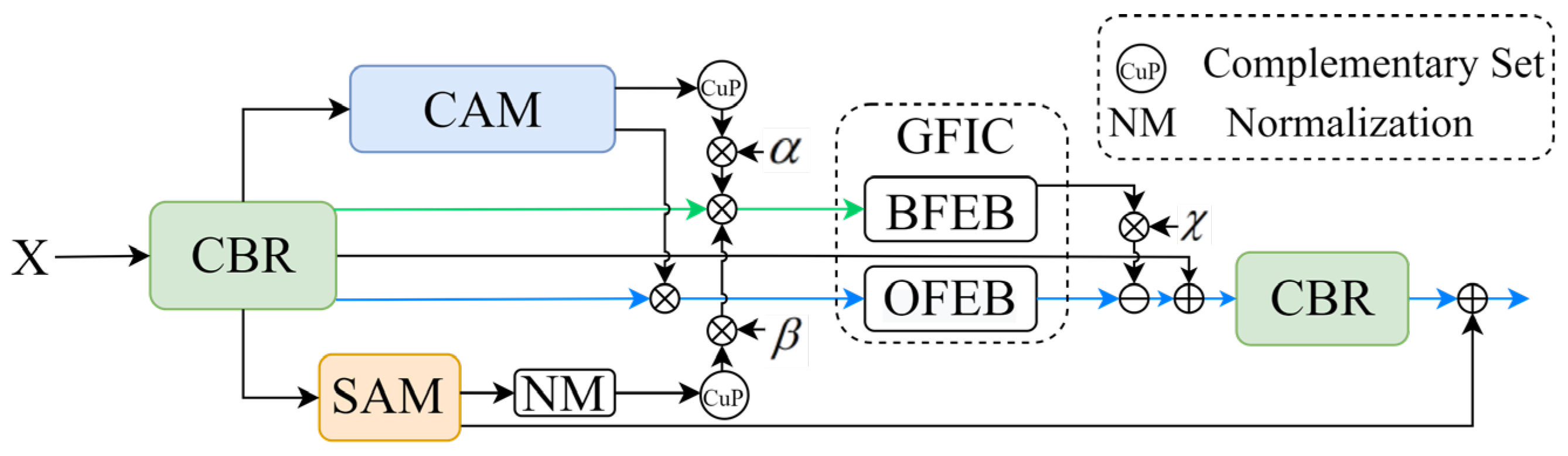
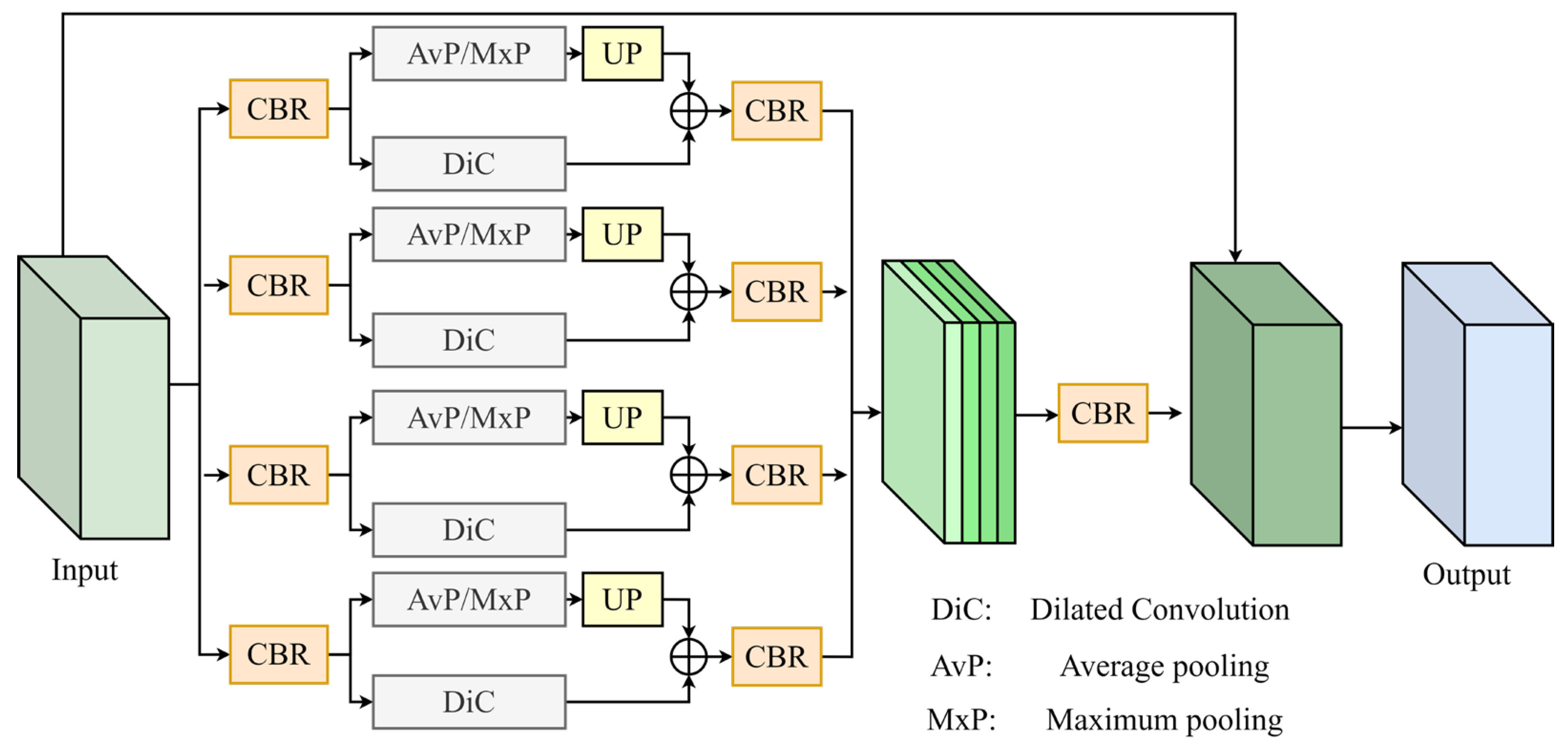
3.2. Global Feature Information Complementary Module
- (1)
- Object Feature Extraction Block
- (2)
- Background Feature Extraction Block
3.3. Positive and Negative Feature Guidance Module
- (1)
- Generation of Positive and Negative Features.
- (2)
- Positive and Negative Features Guidance
3.4. Decoupled Head
3.5. Loss Function
4. Experiments and Analysis
4.1. Data Introduction
4.2. Evaluation Metrics
4.3. Training Details
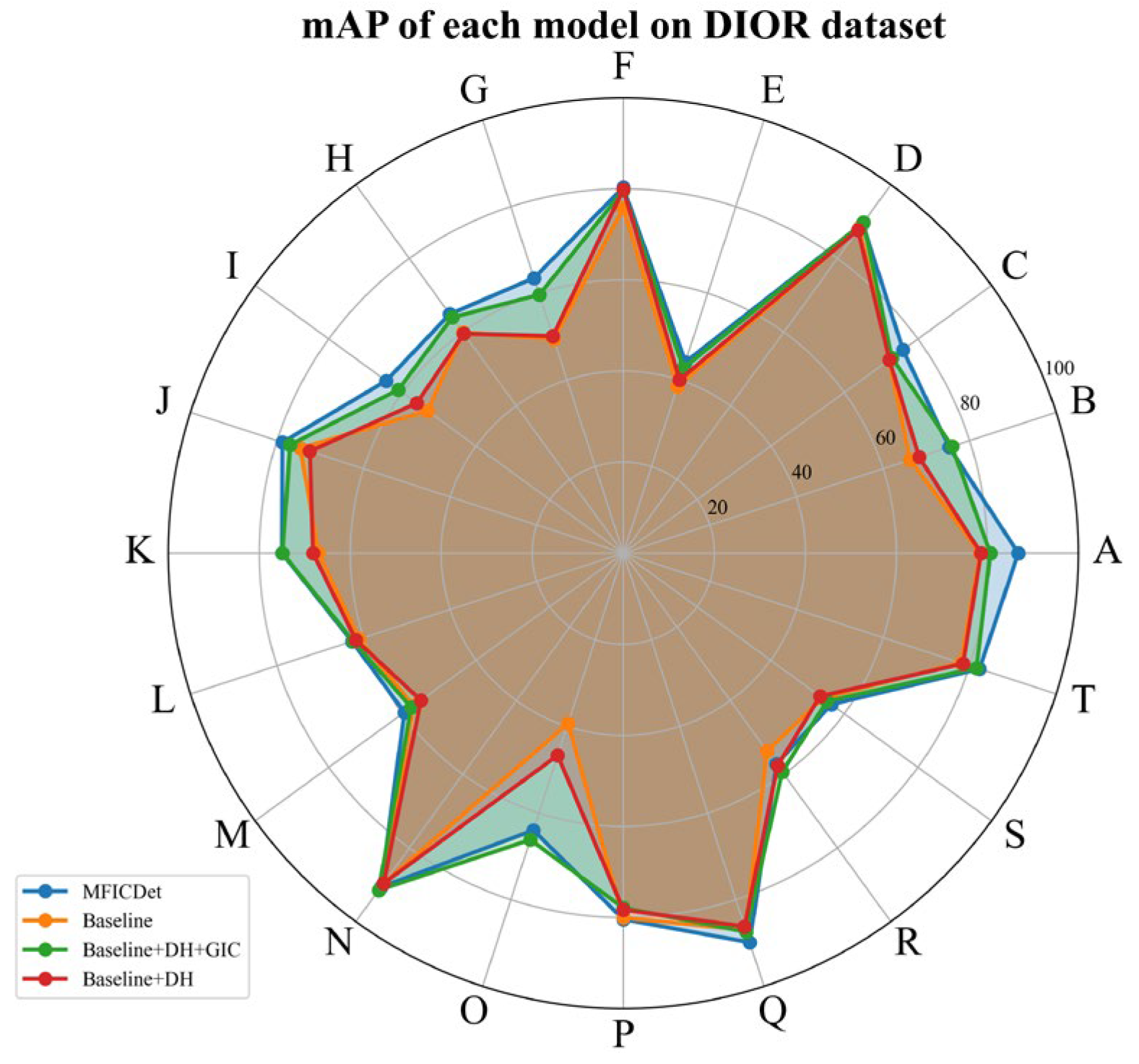
4.4. Ablation Experiments
- (1)
- Ablation Experiments on the DIOR Dataset
- (2)
- Ablation Experiments on the NWPU VHR-10 Dataset
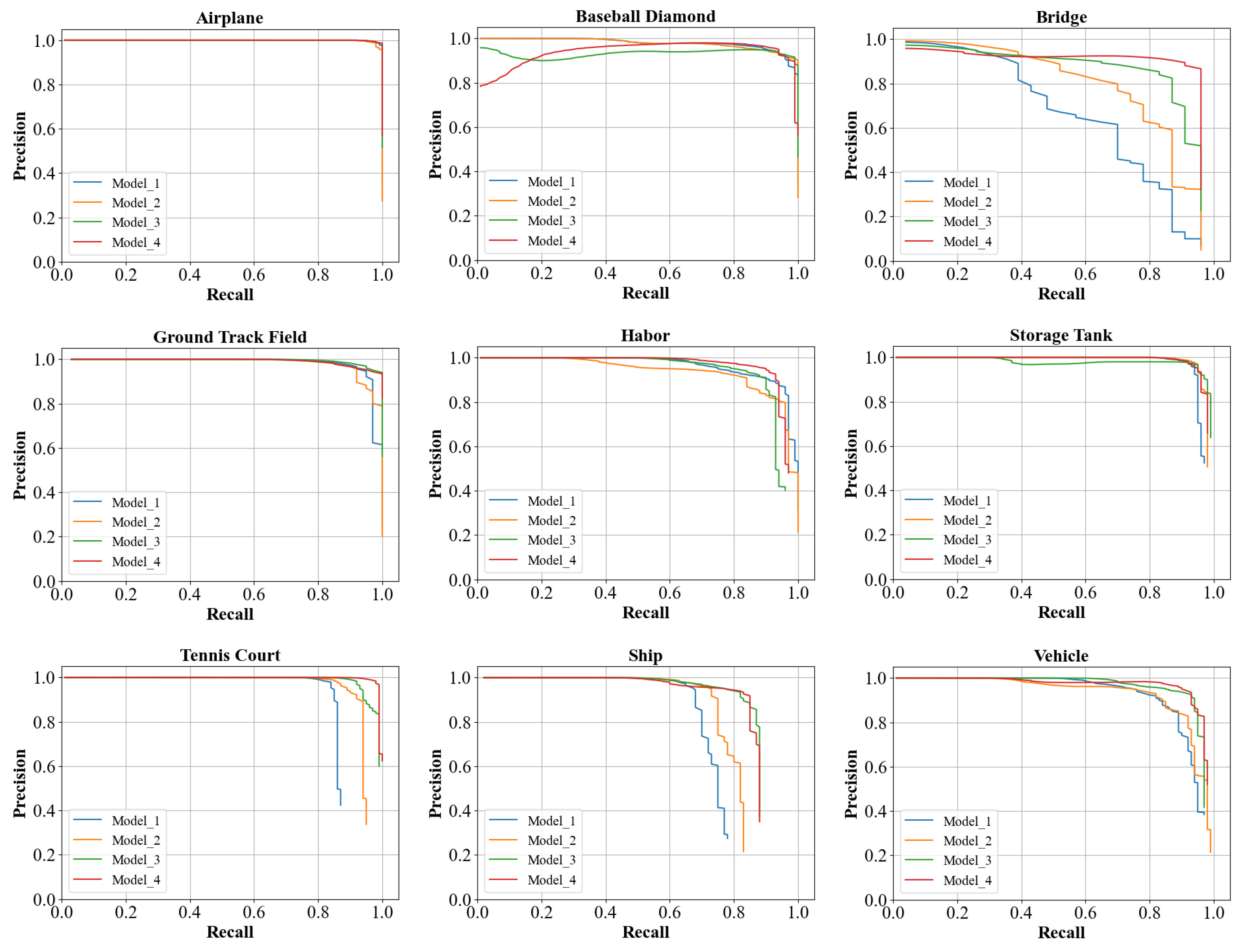
4.5. Quantitative Comparison and Analysis
- (1)
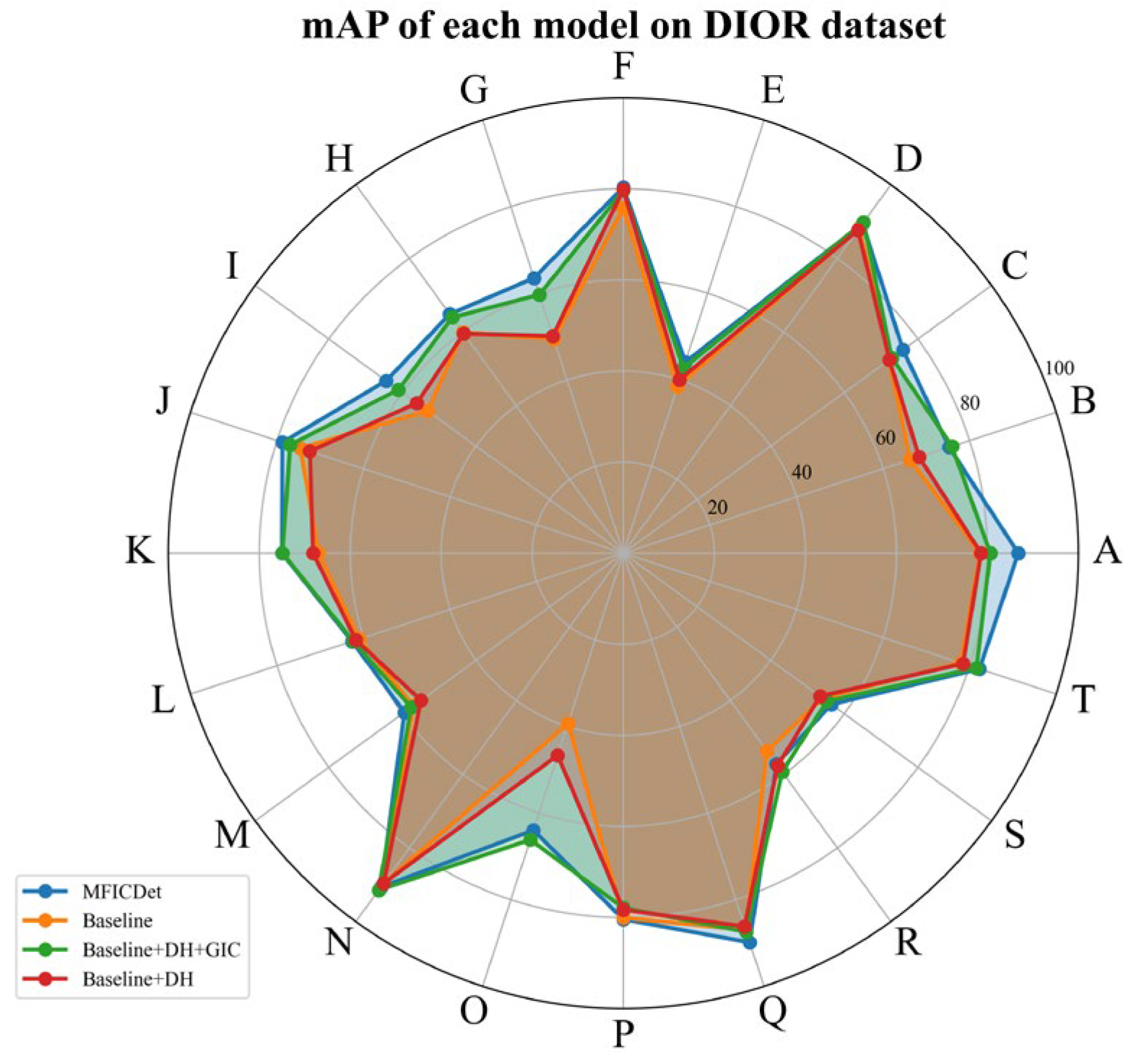
- Comparison and Analysis Using the DIOR Dataset

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | mAP | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN [3] | 63.10 | 54.10 | 71.40 | 63.30 | 81.00 | 42.60 | 72.50 | 57.50 | 68.70 | 62.10 | 73.10 | 76.50 | 42.80 | 56.00 | 71.80 | 57.00 | 63.50 | 81.20 | 53.00 | 43.10 | 80.90 |
| YOLOv4 [12] | 66.71 | 75.27 | 69.95 | 70.95 | 88.78 | 39.99 | 76.61 | 54.02 | 59.94 | 60.65 | 67.68 | 70.15 | 58.76 | 57.34 | 87.71 | 50.21 | 75.66 | 86.58 | 52.62 | 52.74 | 78.62 |
| SSD [5] | 58.60 | 59.50 | 72.70 | 72.40 | 75.70 | 29.70 | 65.80 | 56.60 | 63.50 | 53.10 | 65.30 | 68.60 | 49.40 | 48.10 | 59.20 | 61.00 | 46.60 | 76.30 | 55.10 | 27.40 | 65.70 |
| CF2PN [39] | 67.25 | 78.32 | 78.29 | 76.48 | 88.4 | 37.00 | 70.95 | 59.9 | 71.23 | 51.15 | 75.55 | 77.14 | 56.75 | 58.65 | 76.06 | 70.61 | 55.52 | 88.84 | 50.83 | 36.89 | 86.36 |
| FENet [55] | 68.30 | 54.10 | 78.20 | 71.60 | 81.00 | 46.50 | 79.00 | 65.20 | 76.50 | 69.60 | 79.10 | 82.20 | 52.00 | 57.60 | 71.90 | 71.80 | 62.30 | 81.20 | 61.20 | 43.30 | 81.20 |
| ASSD [35] | 71.10 | 85.60 | 82.40 | 75.80 | 89.50 | 40.70 | 77.60 | 64.70 | 67.10 | 61.70 | 80.80 | 78.60 | 62.00 | 58.00 | 84.90 | 65.30 | 65.30 | 87.90 | 62.40 | 44.50 | 76.30 |
| CSFF [56] | 68.00 | 57.20 | 79.60 | 70.10 | 87.40 | 46.10 | 76.60 | 62.70 | 82.60 | 73.20 | 78.20 | 81.60 | 50.70 | 59.50 | 73.30 | 63.40 | 58.50 | 85.90 | 61.90 | 42.90 | 86.90 |
| CornerNet [41] | 64.90 | 58.80 | 84.20 | 72.00 | 80.80 | 46.40 | 75.30 | 64.30 | 81.60 | 76.30 | 79.50 | 79.50 | 26.10 | 60.60 | 37.60 | 70.70 | 45.20 | 84.00 | 57.10 | 43.00 | 75.90 |
| AOPG [58] | 64.41 | 62.39 | 37.79 | 71.62 | 87.63 | 40.90 | 72.47 | 31.08 | 65.42 | 77.99 | 73.20 | 81.94 | 42.32 | 54.45 | 81.17 | 72.69 | 71.31 | 81.49 | 60.04 | 52.38 | 69.99 |
| O2-DNet [37] | 68.40 | 61.20 | 80.10 | 73.70 | 81.40 | 45.20 | 75.80 | 64.80 | 81.20 | 76.50 | 79.50 | 79.70 | 47.20 | 59.30 | 72.60 | 70.50 | 53.70 | 82.60 | 55.90 | 49.10 | 77.80 |
| MSFC [57] | 70.08 | 85.84 | 76.24 | 74.38 | 90.10 | 44.15 | 78.12 | 55.51 | 60.92 | 59.53 | 76.92 | 73.68 | 49.55 | 57.24 | 89.62 | 69.21 | 76.52 | 86.74 | 51.82 | 55.23 | 84.31 |
| Our | 72.08 | 86.78 | 75.28 | 75.96 | 89.46 | 44.13 | 80.33 | 63.53 | 64.88 | 64.40 | 78.76 | 75.01 | 62.67 | 59.45 | 90.65 | 63.97 | 80.41 | 89.86 | 57.22 | 56.49 | 82.30 |
- (2)
- Comparison and Analysis Using the NWPU VHR-10 Dataset
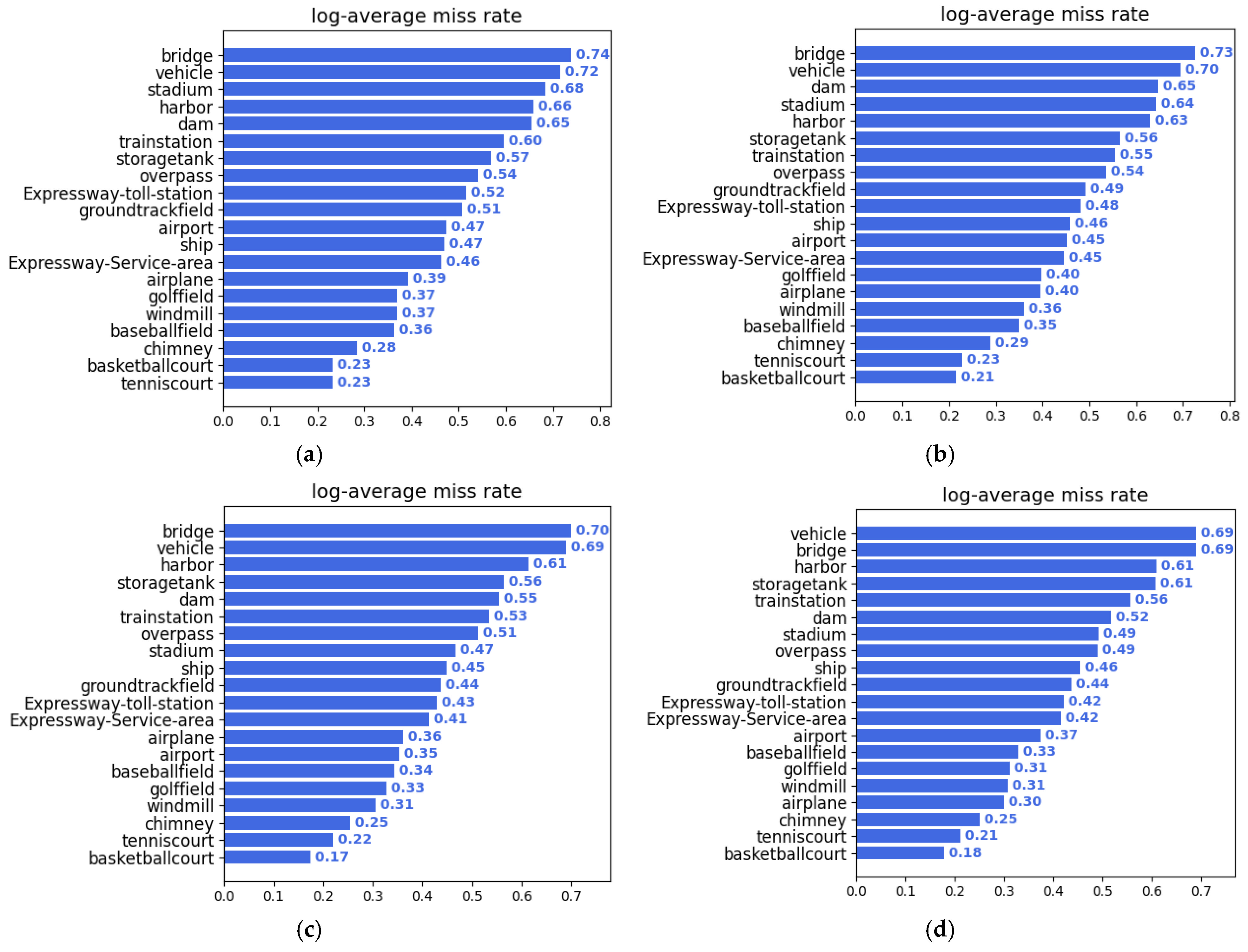
4.6. Visualization
5. Discussion
5.1. Limitations
5.2. Future Works
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, X.; Zhou, Y.N.; Luo, J. Deep learning for processing and analysis of remote sensing big data: A technical review. Big Earth Data. 2021, 1–34. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, USA, 7–12 December 2015; Volume 28. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Liu, J.; Yang, D.; Hu, F. Multiscale Object Detection in Remote Sensing Images Combined with Multi-Receptive-Field Features and Relation-Connected Attention. Remote Sens. 2022, 14, 427. [Google Scholar] [CrossRef]
- Bai, J.; Ren, J.; Yang, Y.; Xiao, Z.; Yu, W.; Havyarimana, V.; Jiao, L. Object Detection in Large-Scale Remote-Sensing Images Based on Time-Frequency Analysis and Feature Optimization. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Cheng, B.; Li, Z.; Xu, B.; Dang, C.; Deng, J. Target Detection in Remote Sensing Image Based on Object-and-Scene Context Constrained CNN. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Q.; Yuan, Y.; Du, Q.; Wang, Q. ABNet: Adaptive Balanced Network for Multiscale Object Detection in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, K.; Wang, J.; Wang, Y.; Wang, Q.; Li, X. GCWNet: A Global Context-Weaving Network for Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Ma, W.; Li, N.; Zhu, H.; Jiao, L.; Tang, X.; Guo, Y.; Hou, B. Feature Split–Merge–Enhancement Network for Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, Y.; Huang, Q.; Pei, X.; Jiao, L.; Shang, R. RADet: Refine Feature Pyramid Network and Multi-Layer Attention Network for Arbitrary-Oriented Object Detection of Remote Sensing Images. Remote Sens. 2020, 12, 389. [Google Scholar] [CrossRef]
- Shi, L.; Tang, Z.; Wang, T.; Xu, X.; Liu, J.; Zhang, J. Aircraft detection in remote sensing images based on deconvolution and position attention. Int. J. Remote Sens. 2021, 42, 4241–4260. [Google Scholar] [CrossRef]
- Cheng, B.; Li, Z.; Xu, B.; Yao, X.; Ding, Z.; Qin, T. Structured Object-Level Relational Reasoning CNN-Based Target Detection Algorithm in a Remote Sensing Image. Remote Sens. 2021, 13, 281. [Google Scholar] [CrossRef]
- Song, Z.; Sui, H.; Hua, L. A hierarchical object detection method in large-scale optical remote sensing satellite imagery using saliency detection and CNN. Int. J. Remote Sens. 2021, 42, 2827–2847. [Google Scholar] [CrossRef]
- Hou, L.; Lu, K.; Xue, J.; Hao, L. Cascade detector with feature fusion for arbitrary-oriented objects in remote sensing images. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Yang, F.; Li, W.; Hu, H.; Li, W.; Wang, P. Multi-Scale Feature Integrated Attention-Based Rotation Network for Object Detection in VHR Aerial Images. Sensors 2020, 20, 1686. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Yan, J.; Liao, W.; Yang, X.; Tang, J.; He, T. Scrdet++: Detecting small, cluttered and rotated objects via instance-level feature denoising and rotation loss smoothing. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar]
- Yu, D.; Ji, S. A New Spatial-Oriented Object Detection Framework for Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Zhu, P.; Chen, P.; Tang, X.; Li, C.; Jiao, L. Foreground Refinement Network for Rotated Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Wang, J.; He, X.; Faming, S.; Lu, G.; Jiang, Q.; Hu, R. Multi-Size Object Detection in Large Scene Remote Sensing Images Under Dual Attention Mechanism. IEEE Access 2022, 10, 8021–8035. [Google Scholar] [CrossRef]
- Zhu, D.; Xia, S.; Zhao, J.; Zhou, Y.; Niu, Q.; Yao, R.; Chen, Y. Spatial hierarchy perception and hard samples metric learning for high-resolution remote sensing image object detection. Appl. Intell. 2021, 52, 3193–3208. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Y.; Wu, Y.; Zhang, K.; Wang, Q. FRPNet: A Feature-Reflowing Pyramid Network for Object Detection of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2020. [Google Scholar] [CrossRef]
- Liu, N.; Celik, T.; Li, H.-C. Gated Ladder-Shaped Feature Pyramid Network for Object Detection in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Cheng, G.; He, M.; Hong, H.; Yao, X.; Qian, X.; Guo, L. Guiding Clean Features for Object Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zhou, X.; Shen, K.; Liu, Z.; Gong, C.; Zhang, J.; Yan, C. Edge-Aware Multiscale Feature Integration Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Cong, R.; Zhang, Y.; Fang, L.; Li, J.; Zhao, Y.; Kwong, S. RRNet: Relational Reasoning Network With Parallel Multiscale Attention for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Han, W.; Kuerban, A.; Yang, Y.; Huang, Z.; Liu, B.; Gao, J. Multi-Vision Network for Accurate and Real-Time Small Object Detection in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, K.; Wu, Y.; Wang, J.; Wang, Y.; Wang, Q. Semantic Context-Aware Network for Multiscale Object Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered object detection in aerial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8311–8320. [Google Scholar]
- Li, Y.; Kong, C.; Dai, L.; Chen, X. Single-Stage Detector with Dual Feature Alignment for Remote Sensing Object Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Hou, L.; Lu, K.; Xue, J. Refined One-Stage Oriented Object Detection Method for Remote Sensing Images. IEEE Trans. Image Process 2022, 31, 1545–1558. [Google Scholar] [CrossRef]
- Xu, T.; Sun, X.; Diao, W.; Zhao, L.; Fu, K.; Wang, H. ASSD: Feature Aligned Single-Shot Detection for Multiscale Objects in Aerial Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Huang, Z.; Li, W.; Xia, X.-G.; Wang, H.; Jie, F.; Tao, R. LO-Det: Lightweight Oriented Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Wei, H.; Zhang, Y.; Chang, Z.; Li, H.; Wang, H.; Sun, X. Oriented objects as pairs of middle lines. ISPRS J. Photogramm. Remote Sens. 2020, 169, 268–279. [Google Scholar] [CrossRef]
- Liu, N.; Celik, T.; Zhao, T.; Zhang, C.; Li, H.-C. AFDet: Toward More Accurate and Faster Object Detection in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 12557–12568. [Google Scholar] [CrossRef]
- Huang, W.; Li, G.; Chen, Q.; Ju, M.; Qu, J. CF2PN: A Cross-Scale Feature Fusion Pyramid Network Based Remote Sensing Target Detection. Remote Sens. 2021, 13, 847. [Google Scholar] [CrossRef]
- Shi, L.; Kuang, L.; Xu, X.; Pan, B.; Shi, Z. CANet: Centerness-Aware Network for Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2019, 128, 642–656. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Mei, H.; Ji, G.P.; Wei, Z.; Yang, X.; Wei, X.; Fan, D.-P. Camouflaged object segmentation with distraction mining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8772–8781. [Google Scholar]
- Zeiler, M.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
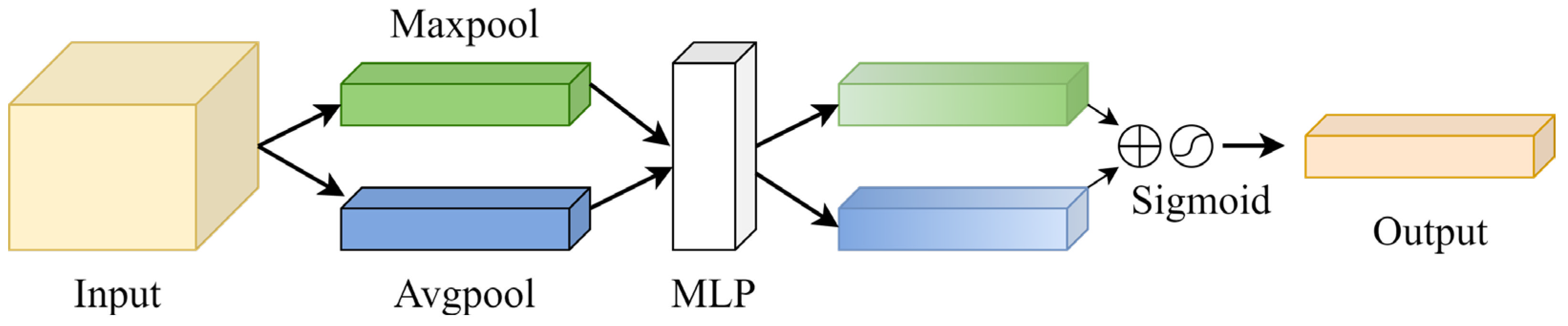
- Woo, S.; Park, J.; Lee, J.; Kweon, I. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of localization confidence for accurate object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 784–799. [Google Scholar]
- Song, G.; Liu, Y.; Wang, X. Revisiting the sibling head in object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11563–11572. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9627–9636. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Wu, Y.; Chen, Y.; Yuan, L.; Liu, Z.; Wang, L.; Li, H.; Fu, Y. Rethinking classification and localization for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Su, H.; Wei, S.; Yan, M.; Wang, C.; Shi, J.; Zhang, X. Object Detection and Instance Segmentation in Remote Sensing Imagery Based on Precise Mask R-CNN[C]. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1454–1457. [Google Scholar]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Cheng, G.; Lang, C.; Wu, M.; Xie, X.; Yao, X.; Han, J. Feature enhancement network for object detection in optical remote sensing images. J. Remote Sens. 2021, 2021, 9805389. [Google Scholar] [CrossRef]
- Cheng, G.; Si, Y.; Hong, H.; Yao, X.; Guo, L. Cross-scale feature fusion for object detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 431–435. [Google Scholar] [CrossRef]
- Zhang, T.; Zhuang, Y.; Wang, G.; Dong, S.; Chen, H.; Li, L. Multiscale Semantic Fusion-Guided Fractal Convolutional Object Detection Network for Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–20. [Google Scholar] [CrossRef]
- Cheng, G.; Wang, J.; Li, K.; Xie, X.; Lang, C.; Yao, Y.; Han, J. Anchor-free oriented proposal generator for object detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Zhu, S.; Zhang, J.; Liang, X.; Guo, Q. Multiscale Semantic Guidance Network for Object Detection in VHR Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Shamsolmoali, P.; Chanussot, J.; Zareapoor, M.; Zhou, H.; Yang, J. Multipatch Feature Pyramid Network for Weakly Supervised Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Li, W.T.; Li, L.W.; Li, S.Y.; Mou, J.C.; Hei, Y.Q. Efficient Vertex Coordinate Prediction-Based CSP-Hourglass Net for Object OBB Detection in Remote Sensing. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]






| Targeted Questions | Methods | Literatures | Advantages | Unresolved Issues |
|---|---|---|---|---|
| Complex backgrounds | Diminish background features and highlight object features | [7,11,13,14,16,20,22,23] |
|
|
| Explore the relationship between background and object | [6,8,15,21] |
|
| |
| Scale diversity | Feature pyramid network | [9,11,24,25,26,27] |
|
|
| Increase the receptive field of multi-scale features | [6,29,30] |
|
| |
| Refine multi-scale features | [10,24,28] |
|
| Model | Recall | Precision | mF1 | mAP |
|---|---|---|---|---|
| Baseline | 56.51 | 87.61 | 67.50 | 66.17 |
| Baseline + DHead | 57.33 | 89.98 | 68.45 | 66.77 |
| Baseline + GFIC + DHead | 63.18 | 87.58 | 72.70 | 70.87 |
| MFICDet | 62.77 | 88.55 | 72.65 | 72.08 |
| Model | Recall | Precision | mF1 | mAP |
|---|---|---|---|---|
| Baseline | 87.80 | 90.56 | 88.70 | 92.57 |
| Baseline + DHead | 90.26 | 89.42 | 89.60 | 93.60 |
| Baseline + GFIC + DHead | 93.66 | 91.03 | 92.30 | 95.35 |
| MFICDet | 95.47 | 90.59 | 92.60 | 96.41 |
| Model | mAP | Airplane | Basketball | Bridge | Ground | Harbor | Ship | Storage | Tennis | Vehicle | Baseball |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Yolov4 | 90.39 | 99.93 | 95.73 | 69.79 | 99.26 | 93.25 | 75.98 | 97.88 | 84.24 | 90.16 | 97.72 |
| ABNet [9] | 94.21 | 100 | 95.98 | 69.04 | 99.86 | 94.26 | 92.58 | 97.77 | 99.26 | 95.62 | 97.76 |
| SMENet [11] | 95.64 | 99.06 | 98.56 | 99.06 | 100 | 93.98 | 95.65 | 91.92 | 98.15 | 81.28 | 98.76 |
| MPFPNet [60] | 94.57 | 99.84 | 91.69 | 92.30 | 99.73 | 94.82 | 92.63 | 96.98 | 89.83 | 89.15 | 98.49 |
| MSGNet [59] | 95.53 | 98.93 | 92.02 | 91.07 | 99.98 | 99.09 | 93.68 | 97.90 | 91.82 | 92.22 | 98.60 |
| MRNet [28] | 92.50 | 99.50 | 95.40 | 82.20 | 99.20 | 98.60 | 88.40 | 90.20 | 89.20 | 92.90 | 98.70 |
| EVCP [61] | 94.10 | 98.80 | 91.60 | 87.80 | 99.70 | 91.80 | 92.50 | 99.80 | 91.10 | 88.60 | 99.80 |
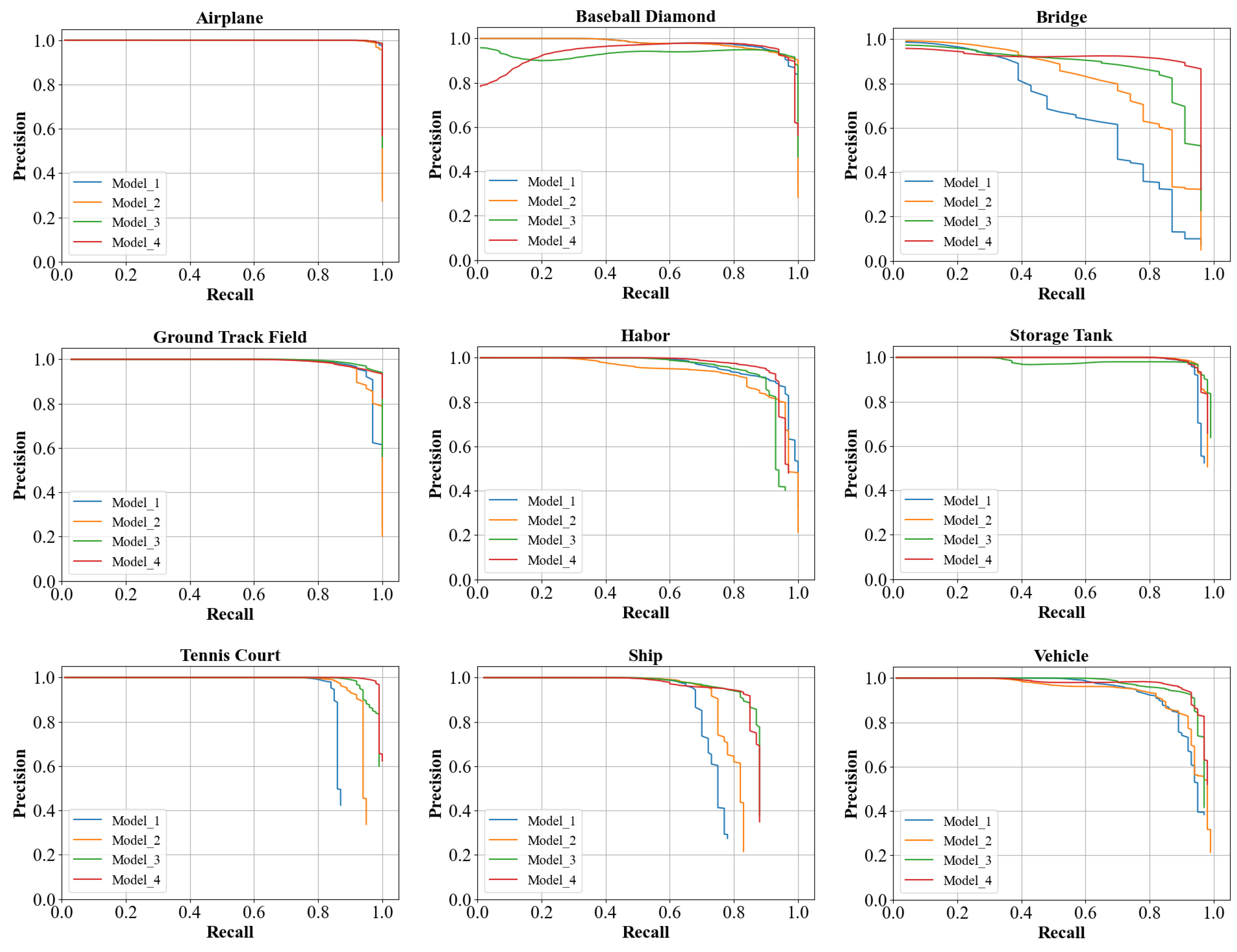
| Our | 96.41 | 99.99 | 99.99 | 92.13 | 99.62 | 95.17 | 86.43 | 97.86 | 99.62 | 95.90 | 97.42 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Gong, Z.; Liu, X.; Guo, H.; Lu, J.; Yu, D.; Lin, Y. Multi-Feature Information Complementary Detector: A High-Precision Object Detection Model for Remote Sensing Images. Remote Sens. 2022, 14, 4519. https://doi.org/10.3390/rs14184519
Wang J, Gong Z, Liu X, Guo H, Lu J, Yu D, Lin Y. Multi-Feature Information Complementary Detector: A High-Precision Object Detection Model for Remote Sensing Images. Remote Sensing. 2022; 14(18):4519. https://doi.org/10.3390/rs14184519
Chicago/Turabian StyleWang, Jiaqi, Zhihui Gong, Xiangyun Liu, Haitao Guo, Jun Lu, Donghang Yu, and Yuzhun Lin. 2022. "Multi-Feature Information Complementary Detector: A High-Precision Object Detection Model for Remote Sensing Images" Remote Sensing 14, no. 18: 4519. https://doi.org/10.3390/rs14184519
APA StyleWang, J., Gong, Z., Liu, X., Guo, H., Lu, J., Yu, D., & Lin, Y. (2022). Multi-Feature Information Complementary Detector: A High-Precision Object Detection Model for Remote Sensing Images. Remote Sensing, 14(18), 4519. https://doi.org/10.3390/rs14184519