1. Introduction
Marine object detection is one of the important fields of marine technology research [
1,
2,
3]. In the past, underwater object detection relied on divers, but the long-term underwater operations and complex underwater environment place a serious impact on their bodies. Underwater robots can help humans in underwater operations, which have the ability to identify and locate objects quickly and accurately [
4,
5,
6,
7]. Therefore, real-time detection of underwater object has a great research value and considerable application prospects. The objective of this paper is to study the object detection algorithm based on marine organisms, which can provide technical support for the monitoring, protection and sustainable development of marine fish and other biological resources.
The existing object detection methods fall into traditional methods and deep learning-based methods. The traditional methods generally fall into three relatively independent parts: region selection, feature extraction and classification by classifier. The accuracy and speed of its detection are not ideal.
As the artificial intelligence develops continuously, deep learning is widely used in speech recognition, natural speech processing, signal modulation and recognition, image analysis, optical communication and other fields [
8,
9,
10,
11,
12]. Object detection algorithms grounded on deep learning have become a new research focus. Convolutional neural network (CNN) is the main method of deep learning applications, which improves the quality of learning by increasing the amounts of convolutional layers. CNN uses the backpropagation algorithm for feedback learning, which minimizes human intervention and improves learning ability by automating feature extraction and multi-layer convolutional learning [
13]. Therefore, compared with the traditional detection methods with manual feature extraction, the learning effect of deep learning-based detection methods is better.
Object detection algorithms grounded on deep learning are roughly classified into two kinds: one is the two-stage algorithms based on classification, for example, R-CNN, Fast R-CNN, and Faster R-CNN [
14,
15,
16]; the other one is the one-stage algorithms based on regression, for example, YOLO [
17] and SSD [
18]. Many researchers have also applied these deep learning algorithms to underwater object detection. Lingcai Zeng added the adversarial network to the Faster R-CNN for training [
19], which improved the detection ability, but can only perform static detection. Yong Liu embedded a convolution kernel adaptive selection unit in the backbone of the Faster R-CNN [
20], which further increased the detection accuracy, but its FPS is 6.4, which also fails to satisfy the needs of real-time detection. YOLO is characterized by fast detection speed and it has good detection ability in the environment with clear field of view and obvious object characteristics, but it is not effective when used in underwater environment. Yan Li improved the in situ detection performance of plankton by embedding DenseNet in YOLOv3 [
21]. The backbone network structure of SSD is deep and has more parameters. It is not conducive to deployment on hardware and the ability to detect small objects is poor. Jun Yue improved SSD by the MobileNet to obtain higher detection accuracy [
22]. Kai Hu used feature enhancement approach to highlight the learning of detailed characteristics of echinus. And ResNet50 is used instead of VGG16 to expand the field of view for object detection. However, the complex network structure has not improved yet [
23]. Ellen M. Ditria from Australia uses Mask R-CNN to detect fish abundances inhabiting the east coast of Australia and achieves better results than Human Marine Experts. It is advantageous for monitoring fish biodiversity in their natural habitats [
24]. To overcome the challenges present in underwater videos due to a range of factors, Ahsan Jalal propose a hybrid solution to combine optical flow and Gaussian mixture models with YOLO deep neural network, which achieves the best fish detection results in a dataset collected by The University of Western Australia (UWA) [
25]. Two researchers from the UK have also conducted related research. Sophie Armitage from University of Exeter uses the YOLOv5 framework to detect underwater plastic litter in the southwest of England and achieves a very high accuracy of 95.23%. However, for images with accumulations of multiple plastics, the model often failed to identify some objects and misidentified others due to YOLO operates in a single pass over the image, reducing the capacity of the model to detect multiple small objects in close proximity [
26]. Ranjith Dinakaran from Northumbria University proposes a cascaded framework by combining the deep convolutional generative adversarial network (DCGAN) with SSD, named DCGAN + SSD, for the detection of various underwater objects. Though the detection accuracy of the model is higher than the original SSD, it is not fast enough to achieve real-time detection on automated underwater vehicles (AUVs) [
27]. Therefore, how to balance the speed and accuracy of detection to improve the efficiency of object detection is still a challenge that needs to be tackled for marine organism object detection.
The object detection framework called EfficientDet was invented in 2020 [
28], and the authors innovatively proposed compound scaling and Bidirectional Feature Pyramid Network (BiFPN), a feature fusion network that adds contextual information weights to the original feature pyramid network and performs top-down and bottom-up fusion. The excellent network structure balances the speed and accuracy of detection well. However, the Depthwise convolution (DWConv) in MBConvBlock will split the information between different channels, which is not conducive to information exchange between different channels. The ability of a single feature pyramid network to extract the characteristics of the object in depth still needs to be improved due to the complex environment of the seafloor, uneven distribution of brightness, poor differentiation between marine organisms and their living environment and organisms being obscured or semi-obscured and so on.
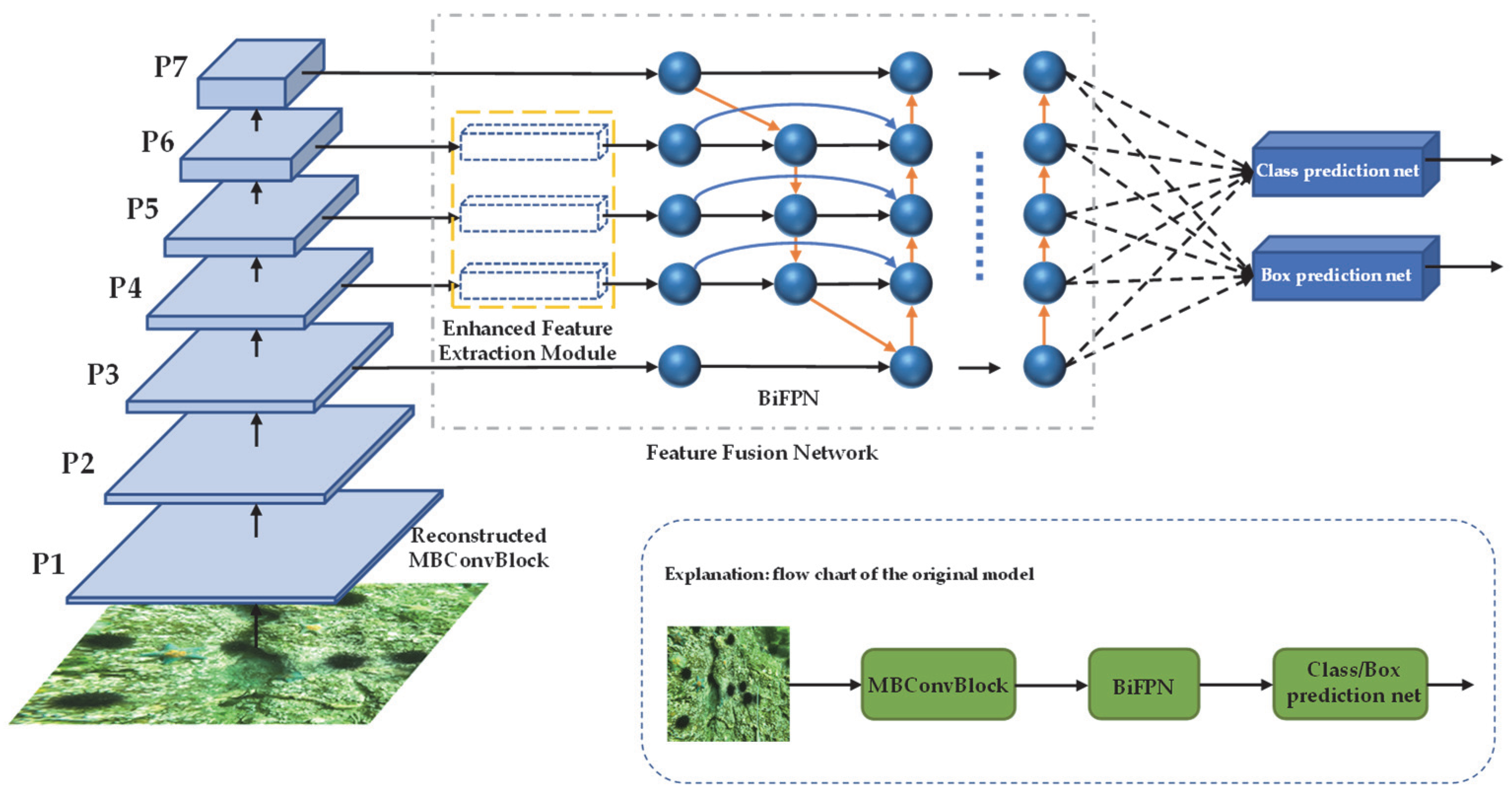
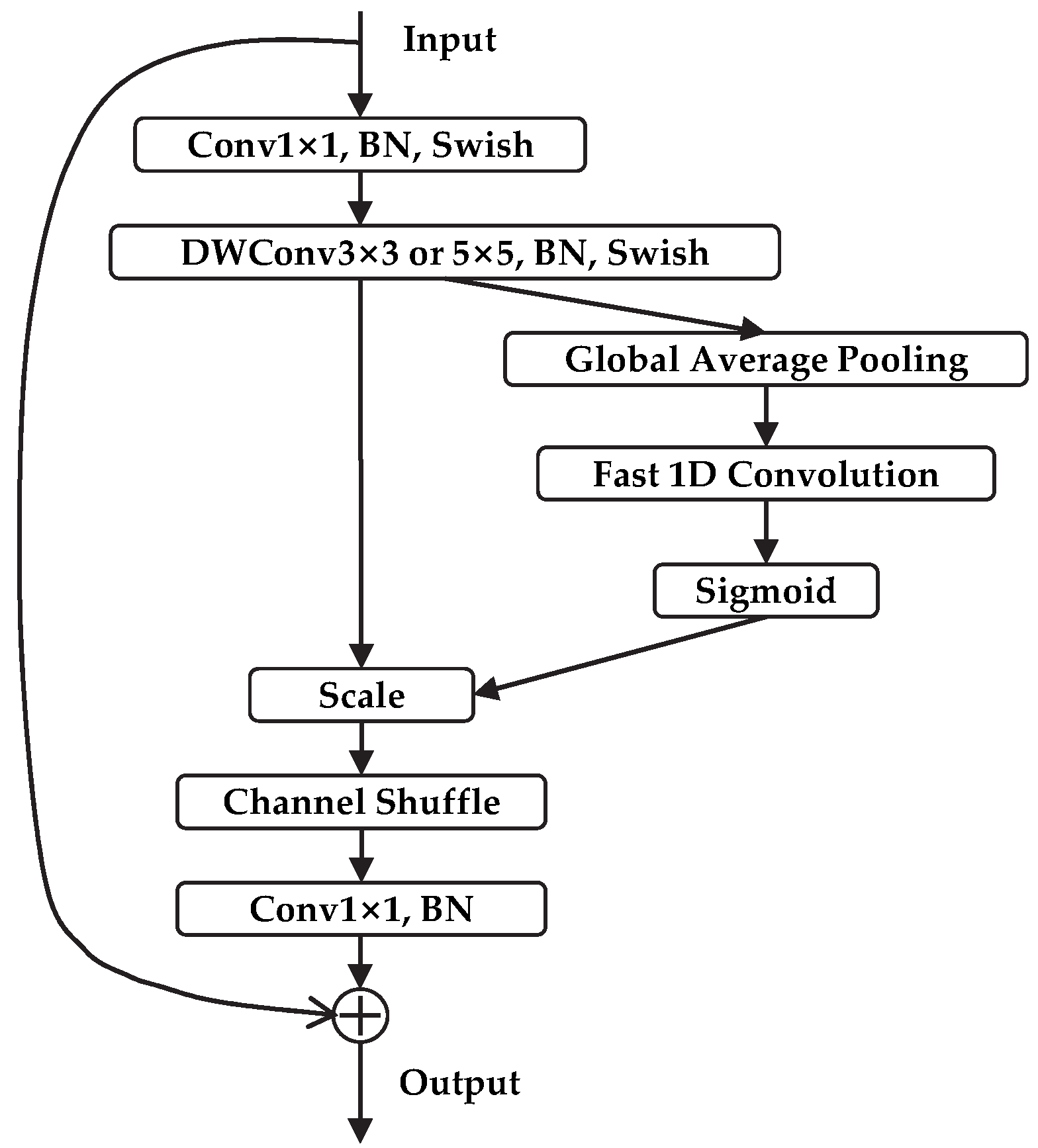
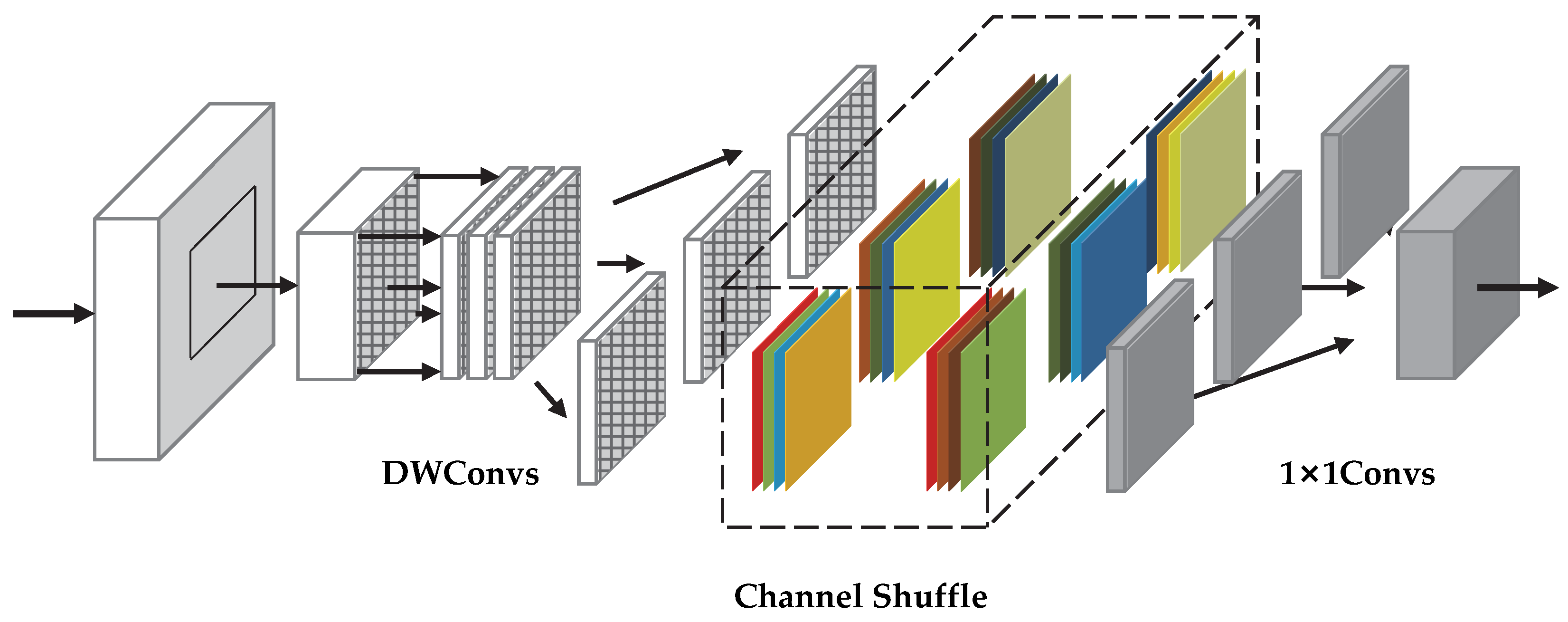
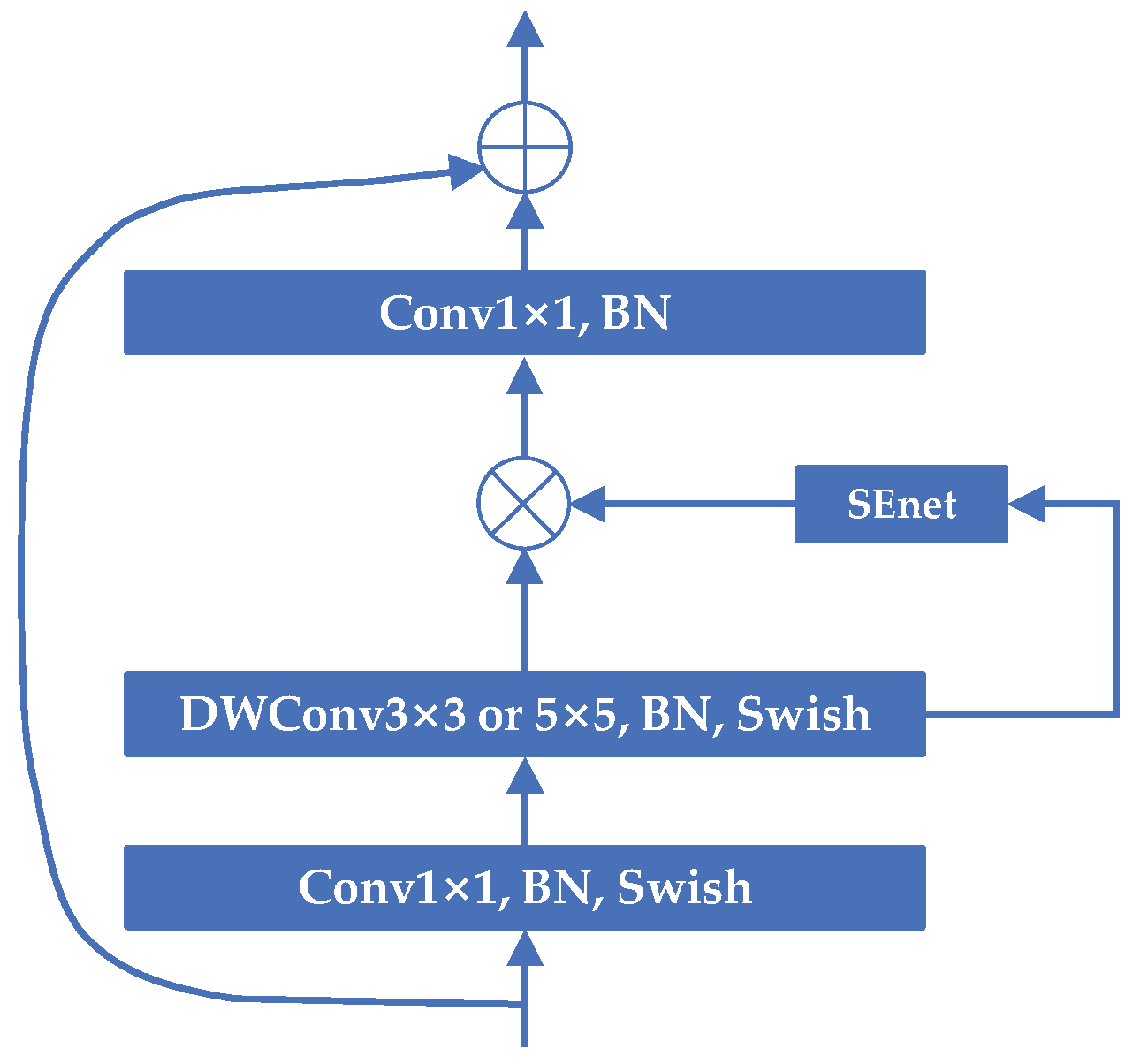
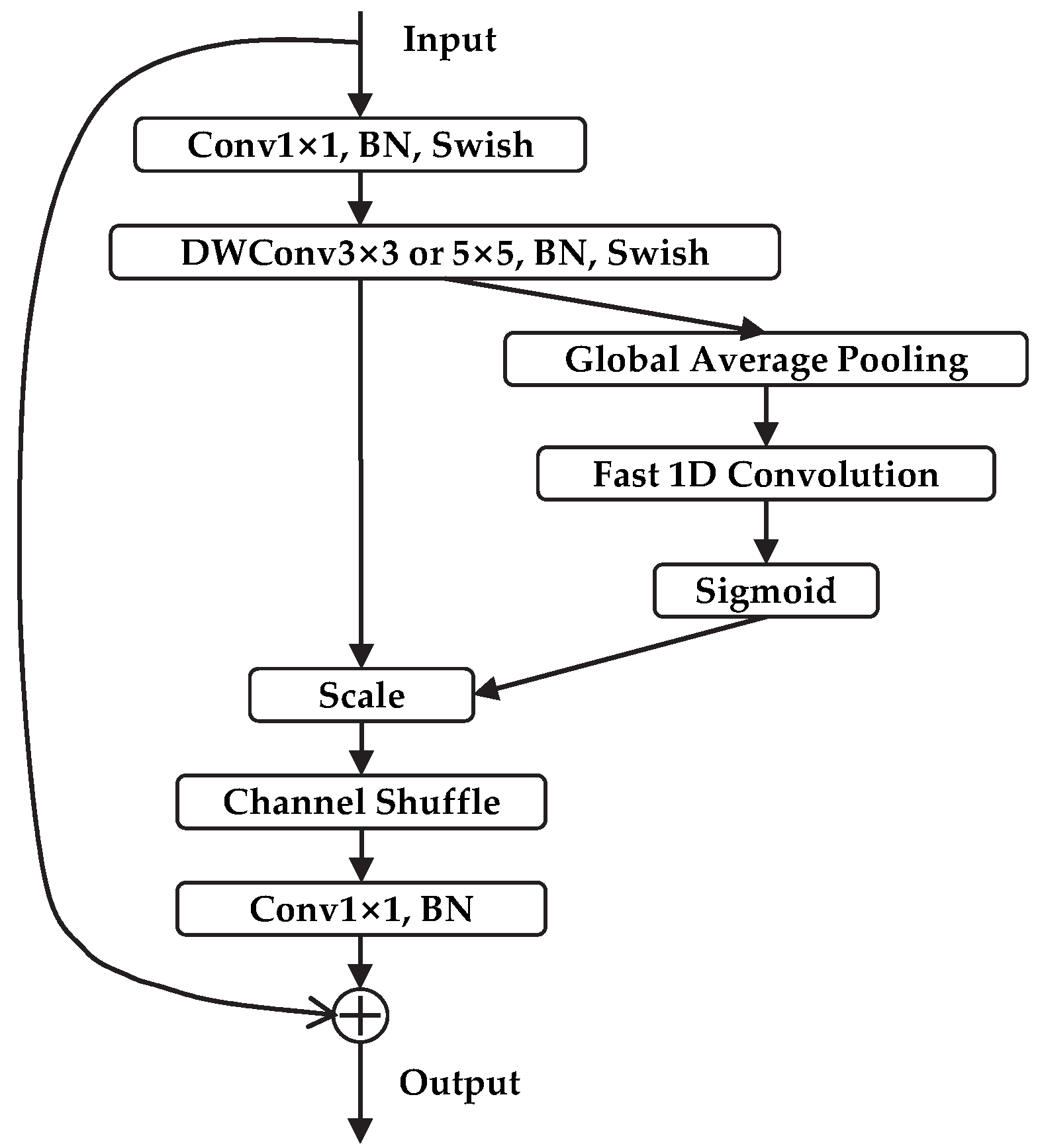
To address these shortcomings, a marine organism object detection model is proposed in this paper, which is called EfficientDet-Revised (EDR). It is based on the improved EfficientDet network. The chief achievements are as follows: (1) the Block of the model is improved by adding the channel shuffle module [
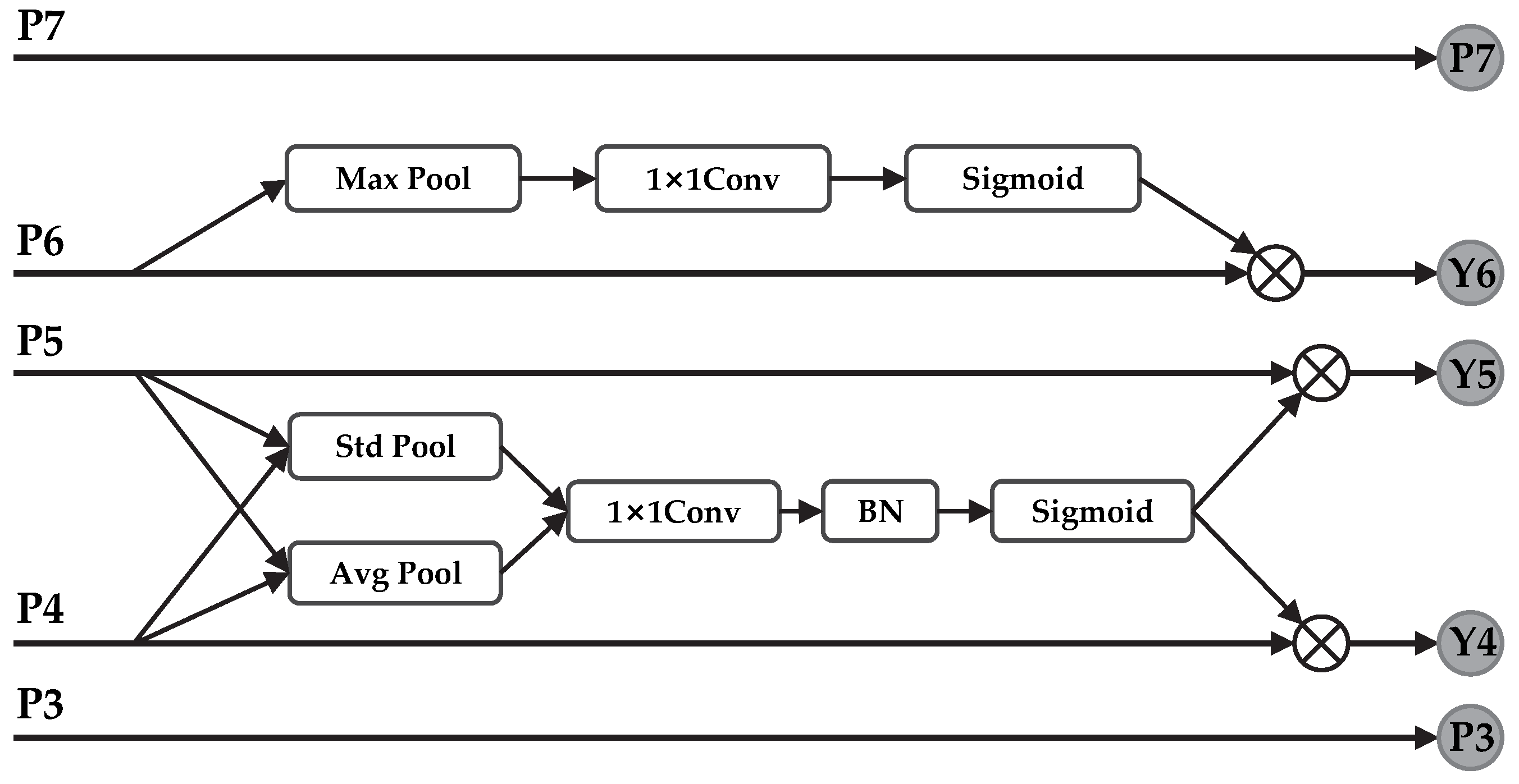
29] after the DWConv (3 × 3 or 5 × 5), which makes information between the channels in the feature layer can be fused to enhance the feature extraction capability of the network. (2) Removing the fully connected layer of the attention module in Block and using 1D convolution for learning can effectively capture cross-channel interactions, and cut down the complexity of the network to improve the detection efficiency. (3) In view of the complex characteristics of underwater objects and the shortcomings of EfficientNet in this aspect, this paper constructs Enhanced Feature Extraction module for multi-scale feature fusion after layers P4, P5, and P6 (corresponding to low-layer, middle-layer, and high-level feature maps, respectively). It adopts the thought of feature cross-layer fusion to complete the connection of different network layers, which enhances the contextual information. In the meantime, it improves the capability of the CNN to express the objects with different scales and strengthen the semantic information.
The contents of this paper are as follows:
Section 2 presents EefficientDet;
Section 3 introduces the improved network algorithm in detail;
Section 4 describes the experimental process, and gives and discusses the experimental results; and
Section 5 gives a summary of the full text.
2. EfficientDet
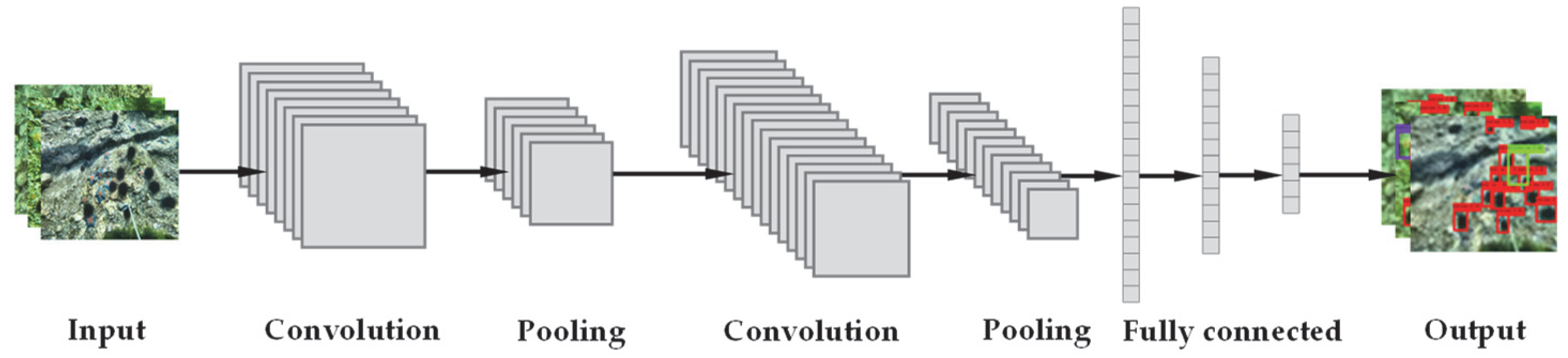
The CNN contains convolutional computation and have a deep structure. It includes convolutional layers, pooling layers and fully connected layers. The connections between the convolutional layers are called sparse connection which is used to reduce the connections between the network layers and the amounts of parameters and make the operation easy and efficient. The nature of weight sharing in CNN improves the stability and generalization ability of the network structure, avoids overfitting and enhances the learning effect [
30,
31]. The structure of model is shown in
Figure 1.
EfficientDet is one of the most advanced object detection algorithms, which has a simple structure and excellent performance. It is available in seven versions from D0 to D6. And the resolution, depth and width of the model can be scaled simultaneously by it according to resource constraints to meet the detection requirements under different conditions. By using the EfficientNet as the backbone network, BiFPN as the feature network, and the shared class/box prediction network, EfficientDet balances the speed and accuracy in the object detection task well.
2.1. Backbone Network
Enhancing the depth of the neural network, adding the width of the feature layer, and increasing the resolution of the input image can improve the detection accuracy of the network [
32,
33,
34], but also lead to more network parameters and higher computational costs.
To improve the detection efficiency, balancing the dimensions of network width, depth and resolution is crucial during CNN scaling. EfficientNet combines these three characteristics and puts forward a new model scaling method that uses an efficient composite coefficient to simultaneously adjust the depth, width, and resolution of the network. Grounded on the neural structure search technology [
35], the optimal composite coefficient can be obtained. As shown in equations.
where
represent the weight of depth, width and resolution, respectively, and are constants that can be determined by small network search, and
is a user-specified factor that controls the number of resources used for model scaling.
Under this constraint, , and are obtained. When , an optimal base model EfficientNet-B0 is obtained; when the is increased, it is equivalent to expanding the three dimensions of the base model at the same time, and the model becomes larger, the performance also improves, and the resource consumption also becomes larger.
The structure of EfficientNet is shown in
Figure 2.
The general structure of Block is shown in
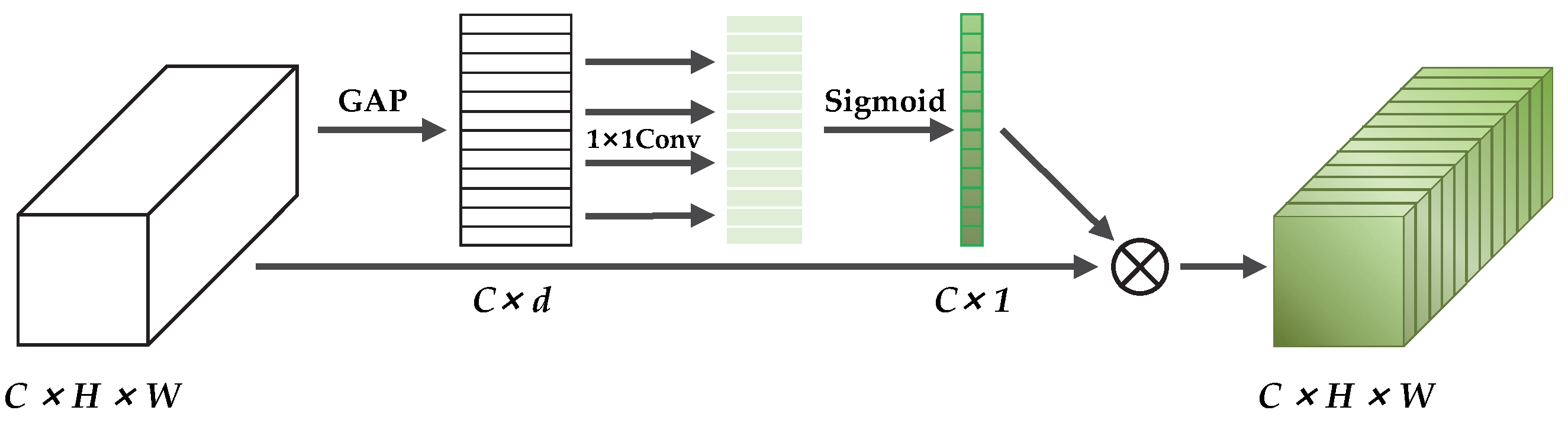
Figure 3, and its design idea is Inverted Residuals, using 1 × 1 convolution to up-dimension before the 3 × 3 or 5 × 5 DWConv, adding a channel attention mechanism after the DWConv, and finally adding a large residual edge after using 1 × 1 convolution to down-dimension. BN is the BatchNorm.
2.2. BIFPN
The top feature map has rich semantic information but low resolution, while the bottom feature map has low-level semantic information but higher resolution. Multi-scale feature fusion is the aggregation of features with different resolution semantic information, so that the network has the ability to detect features of different scales.
FPN, NAS-FPN, PANet, etc., [
36,
37,
38] have been widely used in multi-scale feature fusion. However, their direct combinations of the feature maps in different layers and ignores the contribution of different resolution features to the output features. The authors proposed BiFPN, which is simple and efficient. As shown in the formula, the importance of different input features to feature fusion is expressed by calculating the weights of different layers.
where
is the learnable weight, which can be a scalar, a vector, or a multidimensional tensor. The output weight can be controlled to be in the 0–1 by Relu and simple regularization.
4. Experiments
This experiment aims to illustrate the effectiveness of EDR algorithm in marine organism object detection. All experiments are conducted on Linux system. The GPU version required for the experiment is NVIDIA GTX 1080 (16G RAM). The software environments are Pytorch 1.2.0 on Python 3.6, Anaconda 3, CUDA 10.0 and CUDNN 7.3.0. The training epochs are set to 200. The batch size is set to 16 based on the performance of the graphics card. The learning rate is initially 0.01 and then is reduced by 10 times when epoch is 100 and 150.
The dataset is supplied by the National Natural Science Foundation for Underwater Robotics Professional Competition (URPC). It is labeled by labelImg, and the image format is PASCAL VOC, which includes four species: echinus, holothurian, scallop, and starfish. As shown in
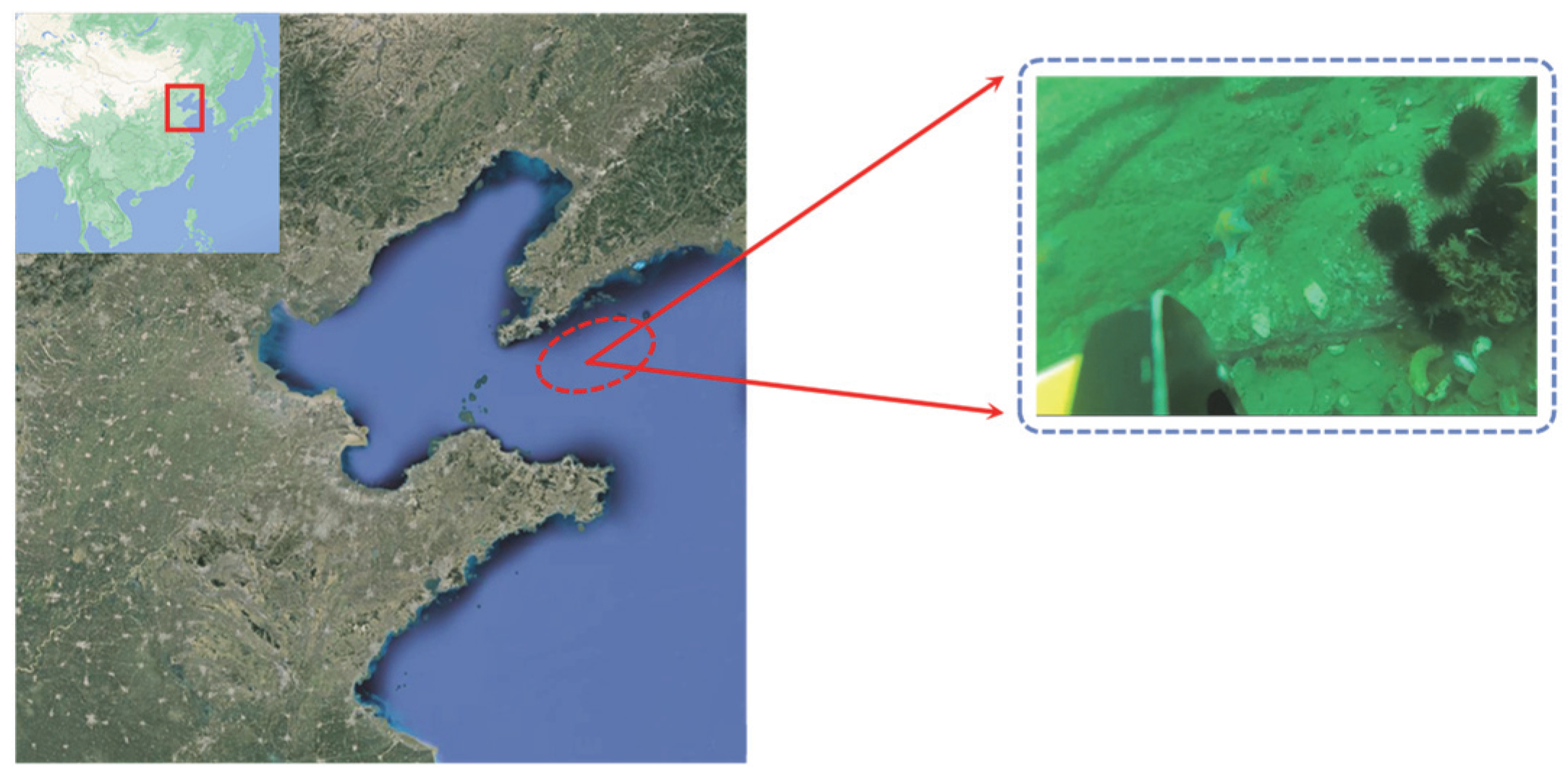
Figure 9, these data are collected by Remotely Operated Vehicle (ROV) in the sea off Dalian City, Liaoning Province, China, and are common marine organisms near the coast of China. There are 5543 images in the dataset, fall into training sets, validation sets, and test sets in the ratio of 7:2:1.
Figure 10 shows the proportional distribution of the size of each object to the size of the image. From the figure, it can be seen that the size proportion distribution of objects is relatively scattered, but most of them are concentrated in 0.1 to 0.3, which requires the model to have a good ability of multi-scale feature fusion.
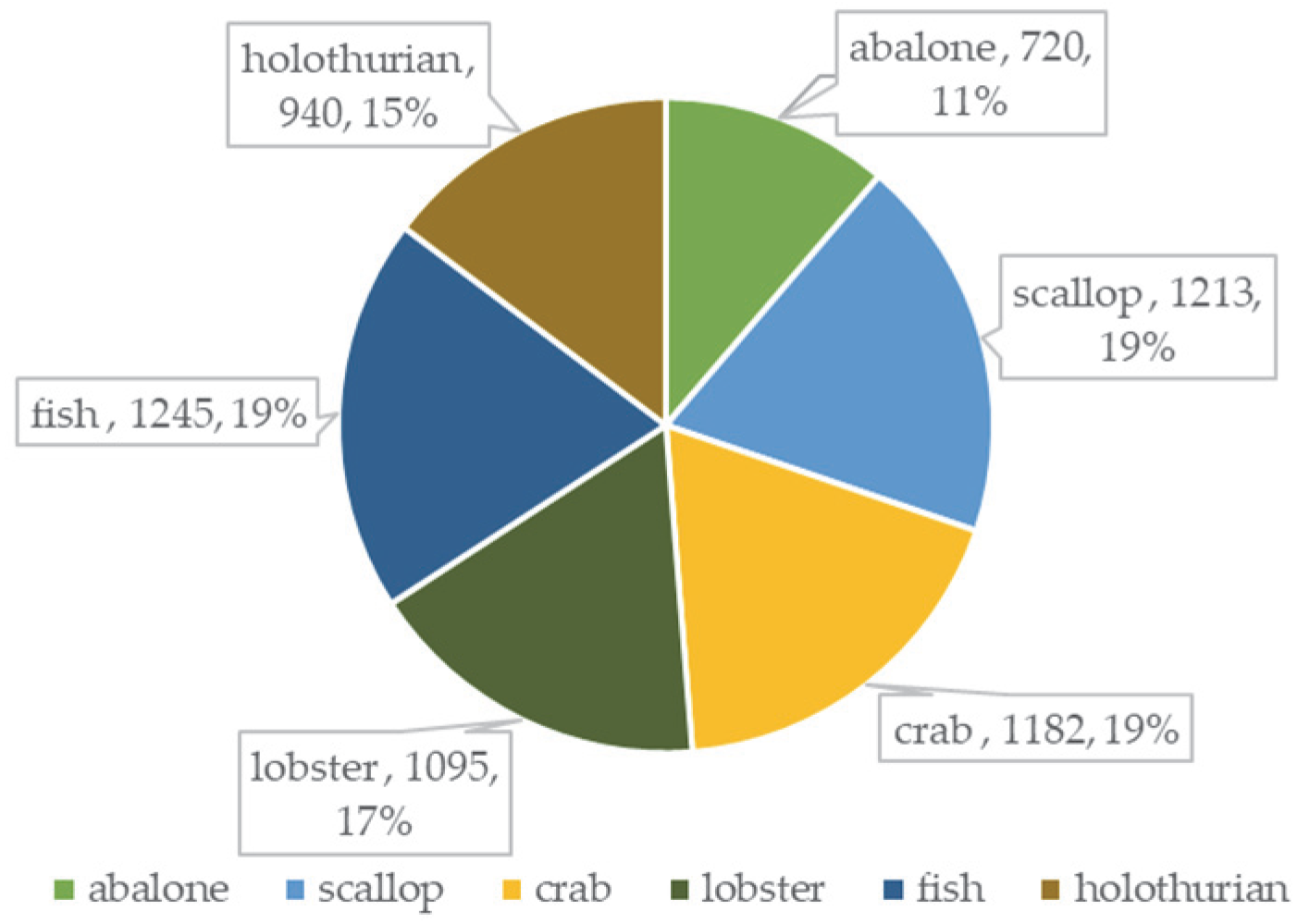
In order to verify the robustness of the model, some images of marine organisms are collected at Kaggle and make into a dataset in the same format. The dataset includes six species: abalone, crab, fish, holothurian, lobster and scallop. There are 6396 images in total.
Figure 11 shows the number of each species in this dataset, and the distribution of category samples in this dataset is relatively balanced.
4.1. Evaluation Indicators
The Intersect Over Union (IOU) threshold parameter needs to be set for the model prediction. When the IOU > 0.5, the detection is successful. In this paper, the mean Average Precision (mAP), Frames Per Second (FPS), and model size are used as evaluation indicators. First, it introduces Precision and Recall. The Precision is the ratio of correctly predicted positive classes to all predicted positive classes, and the Recall is the ratio of correctly predicted positive classes to all actual positive classes. The formulas are shown as follows.
where
is the number of positive classes that are correctly predicted,
is the number of negative classes that are predicted as positive classes, and
is the number of positive classes that are predicted as negative classes. To measure the true level of detection, the value of
AP was used to represent it as follows.
mAP is the mean of the
AP values of all categories, and the larger the mAP is, the higher the object detection accuracy of the algorithm has. The formula for mAP is as follows.
where
represents the number of categories detected.
Frames Per Second (FPS) indicates the number of images the algorithm can process per second, which is used to assess the detection speed of the algorithm. The minimum fluency of human eye recognition can be met when the frame rate >24 fps.
4.2. Results and Analysis of Experiments
First, the preliminary experiments with EfficientDet are conducted on the URPC public dataset. The versions of D0, D1 and D2 are trained due to resource limitation. The results are shown in
Table 1. As the compound scaling deepens, the mAP gets higher. At the same time, the size of the model is increasing and the FPS is getting smaller.
Even though EfficientDet-D2 has the highest accuracy, it consumes a lot of computational resources and is comparatively not easy to train. EfficientDet-D0, as the lightest model, is smaller and faster. EfficientDet-D0 is selected as the baseline and ablation experiments are conducted to verify the impact of different improvements on model performance.
Table 2 shows the results of the ablation studies performed on D0. ‘*’is the model that adds Channel Shuffle (CS) to the backbone. ‘**’is the model in which the Enhanced Feature Extraction module (EFEM) is added to ‘*’.
The results indicate that the model size and mAP of model ‘*’ increase by 8% and 0.56% respectively, while the FPS decrease by 4.6 compared with the original model. The addition of Channel Shuffle has resulted in some improvement in the accuracy of the model. The construction of the Enhanced Feature Extraction module result in a further 32% and 1.6% increase in model size and mAP for model ‘**’, respectively, while the FPS is only 28.3. As can be seen, the Enhanced Feature Extraction module contributes significantly to the accuracy improvement, but also leads to a large drop in the performance of other metrics. After replacing the fully connected layer with 1D convolution, the model size and FPS of the EDR are somewhat improved.
The further experiments are carried out on the URPC public dataset to compare the model proposed in this paper with other commonly used object detection models. The results of the experiment are shown in
Table 3.
As can be seen from
Table 3, in longitudinal comparison, the highest mAP of the algorithm put forward in this paper reaches 91.67%, which is 2.3% higher than the original detection algorithm. The improvement of mAP is mainly due to the construction of the multi-scale feature fusion network, which makes the model’s ability to grasp the object information enhanced. For underwater study, people focus more on the characteristics of the object to improve the detection capability. In horizontal comparison, it can be seen that the mAP of the EDR algorithm is higher than the other algorithms. Despite its poor performance in terms of speed, the EDR can also meet the requirements of real-time detection. Furthermore, the model size of EDR is much lower than the other methods, which can facilitate its deployment in ROV, so that ROV can have more memory space to expand and enrich the functions. These advantages stem from the good network design of EDR algorithm. The two-stage object detection algorithm represented by Faster R-CNN has good detection accuracy, but its detection speed is only 7.4 frames per second, which cannot meet the real-time requirement. Even though the addition of Feature Pyramid Network increases its detection accuracy by 2.83%, it can only do static detection. YOLOv4 is the representative of one-stage object detection algorithm, which has a good speed performance but poor detection accuracy performance. SSD perform well in both speed and accuracy, but its model size is not conducive to deployment on mobile devices. Mobile-SSD solves this problem very well, but mAP and FPS are greatly reduced. CenterNet and RetinaNet also perform mediocrely on various metrics. In general, in terms of marine organism object detection, EDR achieves a balance between speed and accuracy at a smaller cost.
Figure 12 shows the
AP comparison of different models, covering various categories of the dataset. For each category of objects, the detection accuracy of EDR is significantly better compared with the other methods.
To verify the validity of the model, the parallel experiments are conducted on Kaggle dataset.
Table 4 shows the detailed detection results of each category of object between different models. Bolded text indicates the best result. It is obvious that the method in this paper achieves the highest
AP on all kinds of objects, and the mAP reaches a maximum of 92.39%. The experimental results show that the proposed method can meet the detection requirements of different situations.
The visual detection results are shown in
Figure 13. Two images are selected at random, the images in the first row contain single-category objects, and the images in the second row contain multi-category objects. From the test results, it can be seen that the method in this paper is more effective than other methods whether objects are single-category or multi-category.
As shown in
Figure 14, to understand the detection results more realistically, the experiments are conducted in the four scenes, which are close-range clear, close-range blur, long-range clear, and long-range blur. From the results, it can be seen that each method can accurately detect the object in the close-range clear scenes. However, for the other scenes, all of the other methods have low accuracy and missed detection whether it is a long distance or a blurry image. While the method in this paper has higher accuracy and lower rate of missed detection for objects, and it has a good detection effect on small objects, obscured objects and objects with incomplete information.
In summary, the EDR algorithm put forward in this paper has better detection effect on objects in different underwater environments. An excellent object detection model of marine organism is very important. The great detection performance of EDR can provide favorable reference and basis for marine aquaculture and marine fishing and accelerate the development of the ocean economy towards intelligent and unmanned.
5. Conclusions
In this paper, a marine organism object detection model called EDR is proposed, which is based on the improved EfficientDet. Channel Shuffle is added to the backbone feature network to help information flow between feature channels and improve the feature extraction capability of the network. Replacing the fully connected layer with convolution to handle the problem of information redundancy in the network effectively reduces the amounts of parameters of the network. The Enhanced Feature Extraction module is constructed and used for multi-scale feature fusion to enhance the correlation among feature layers of different scales. Results show that the detection efficiency of the method put forward in this paper is higher compared with other algorithms.
Although the method in this paper has received good results, it is undeniable that the method still has some shortcomings. The addition of Channel Shuffle and the Enhanced Feature Extraction module has led to an increase in computing time. Accuracy has been improved at the expense of speed. On the server used for the experiments, the speed can reach the requirements for real-time detection. However, when tested on a laptop, there is some delay. It has caused us more trouble in performing experiments on mobile devices. In addition, the details of some dense objects and stacked objects are not obvious, there are still inevitable false detections and missed detections in the detection. We speculate that this is due to the lack of image pre-processing. It would be improved if the latest underwater image enhancement techniques could be applied to the data. In future research, we will address the above issues for improvement. Not only that, the following work still needs to be conducted: firstly, EDR relies heavily on the hardware system. It has only achieved D2 due to the equipment limitation. In the future, other versions of the algorithm can be obtained according to the application requirements; secondly, applying the model to the detection of other underwater targets, such as marine litter, is also one of our next tasks. Last, but not least, as for practical engineering applications, more research will be conducted on object localization and underwater picking technology to make the detection content of underwater objects more abundant.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}