
Few-Shot Object Detection in Remote Sensing Image Interpretation: Opportunities and Challenges



Abstract
:1. Introduction
1.1. Motivation
- (1)
- The actual number of targets is large but restricted by weather, illustration, viewing angle, resolution, and other factors, it is difficult to collect samples with high quality in diverse remote sensing images;
- (2)
- The number of high-value targets is rare and it is difficult to obtain enough images;
- (3)
- Low-value targets own a few historical images with the not-rich feature.
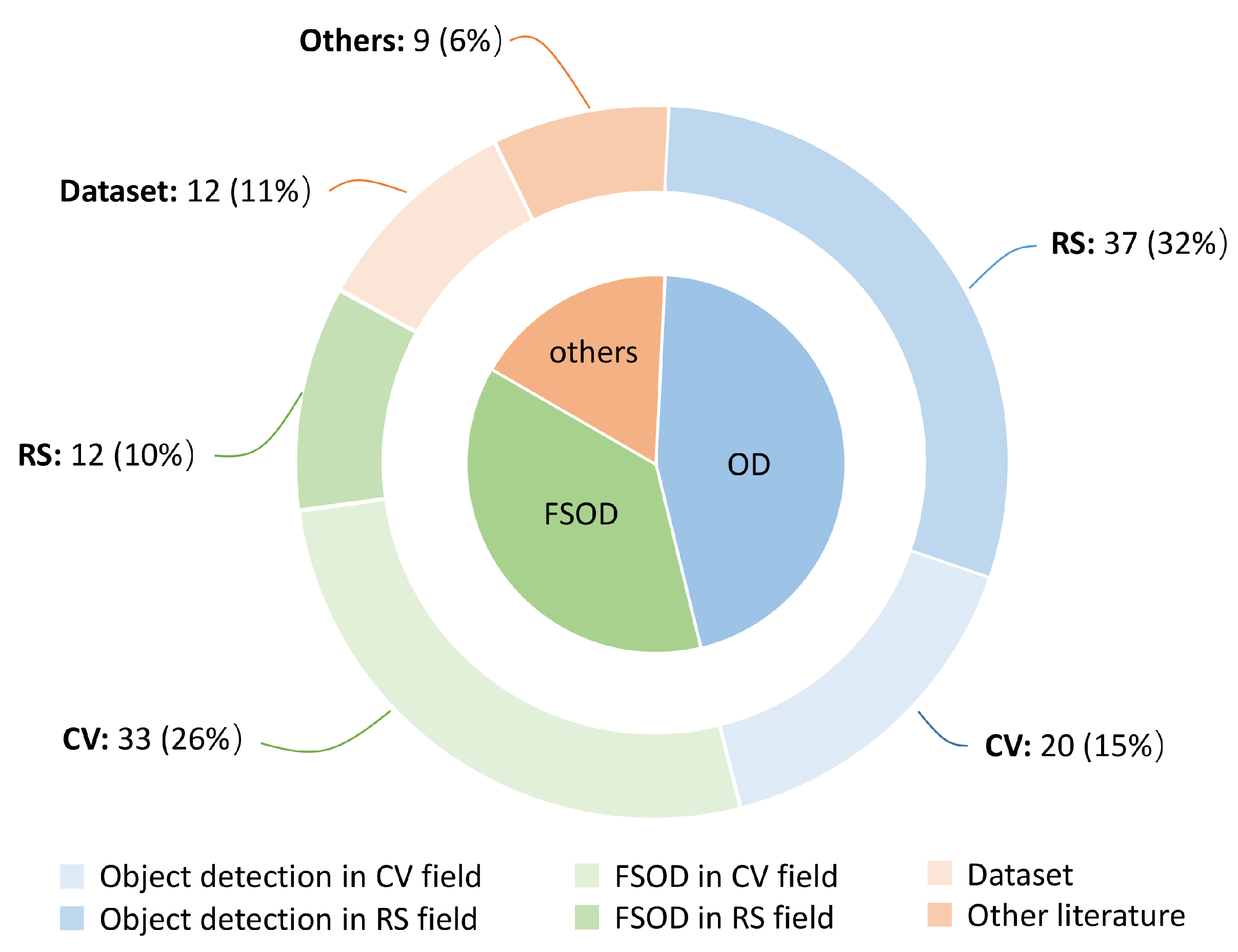
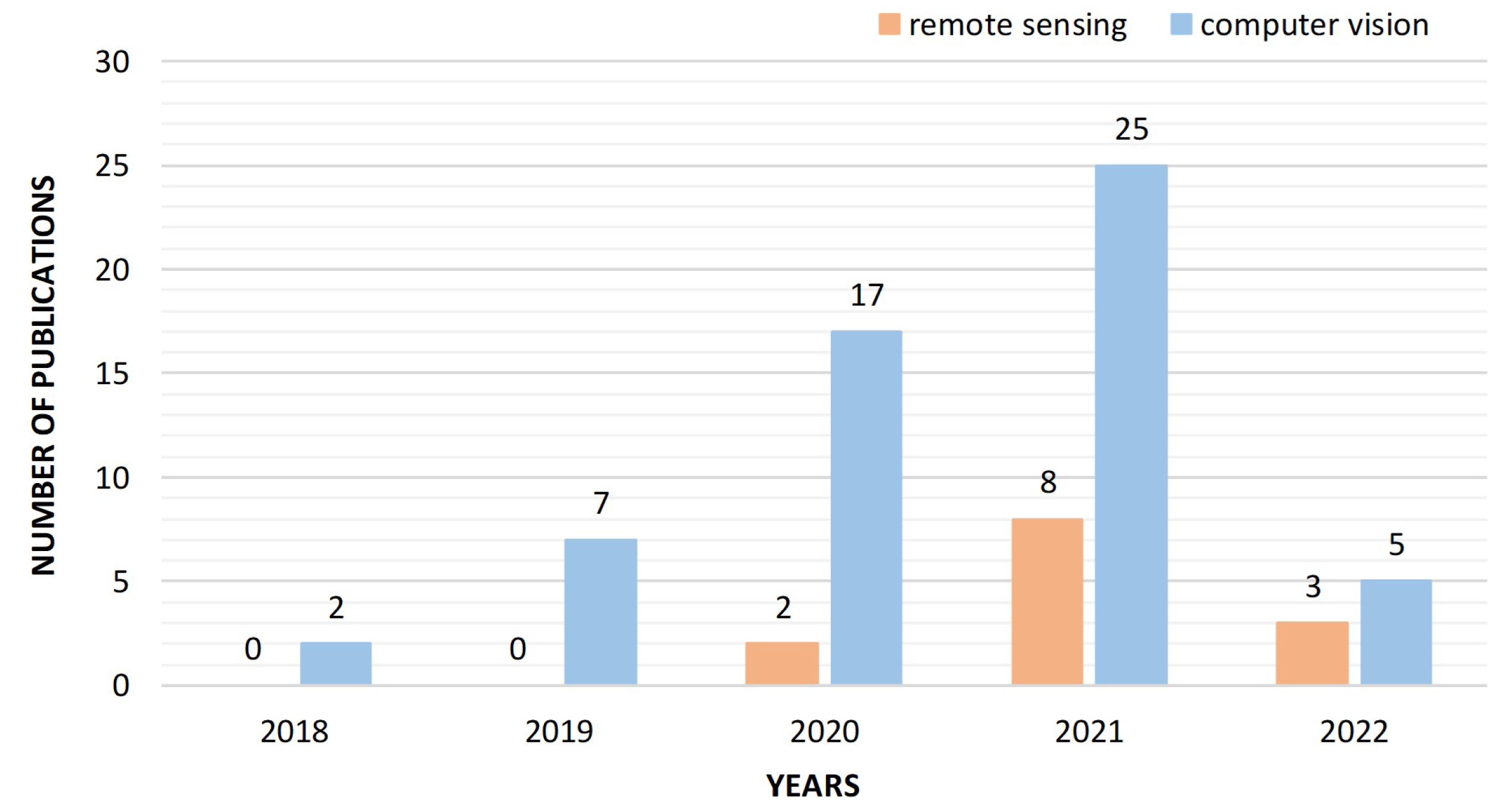
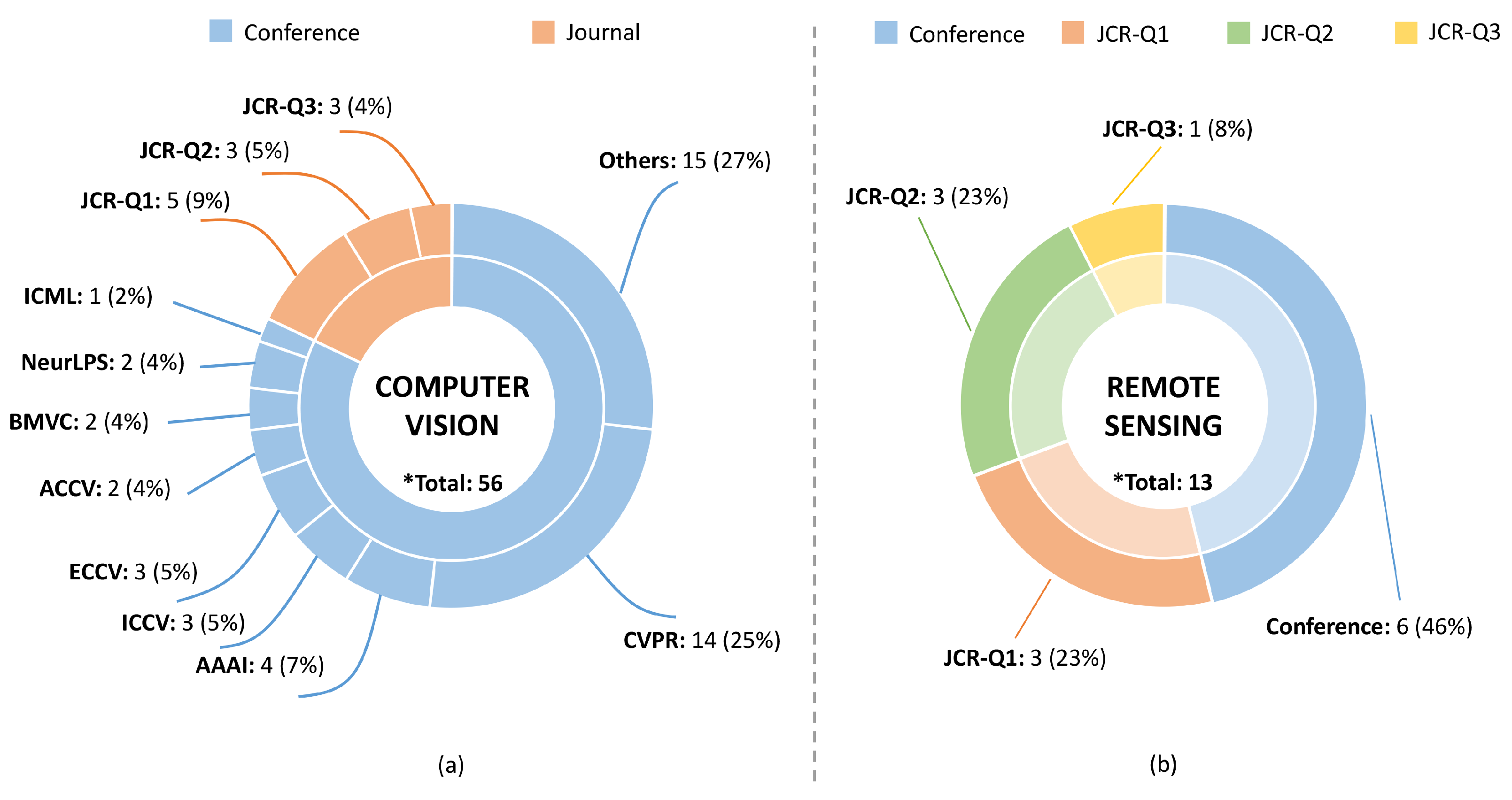
1.2. Literature Retrieval and Analysis
1.3. Problem Definition
- (1)
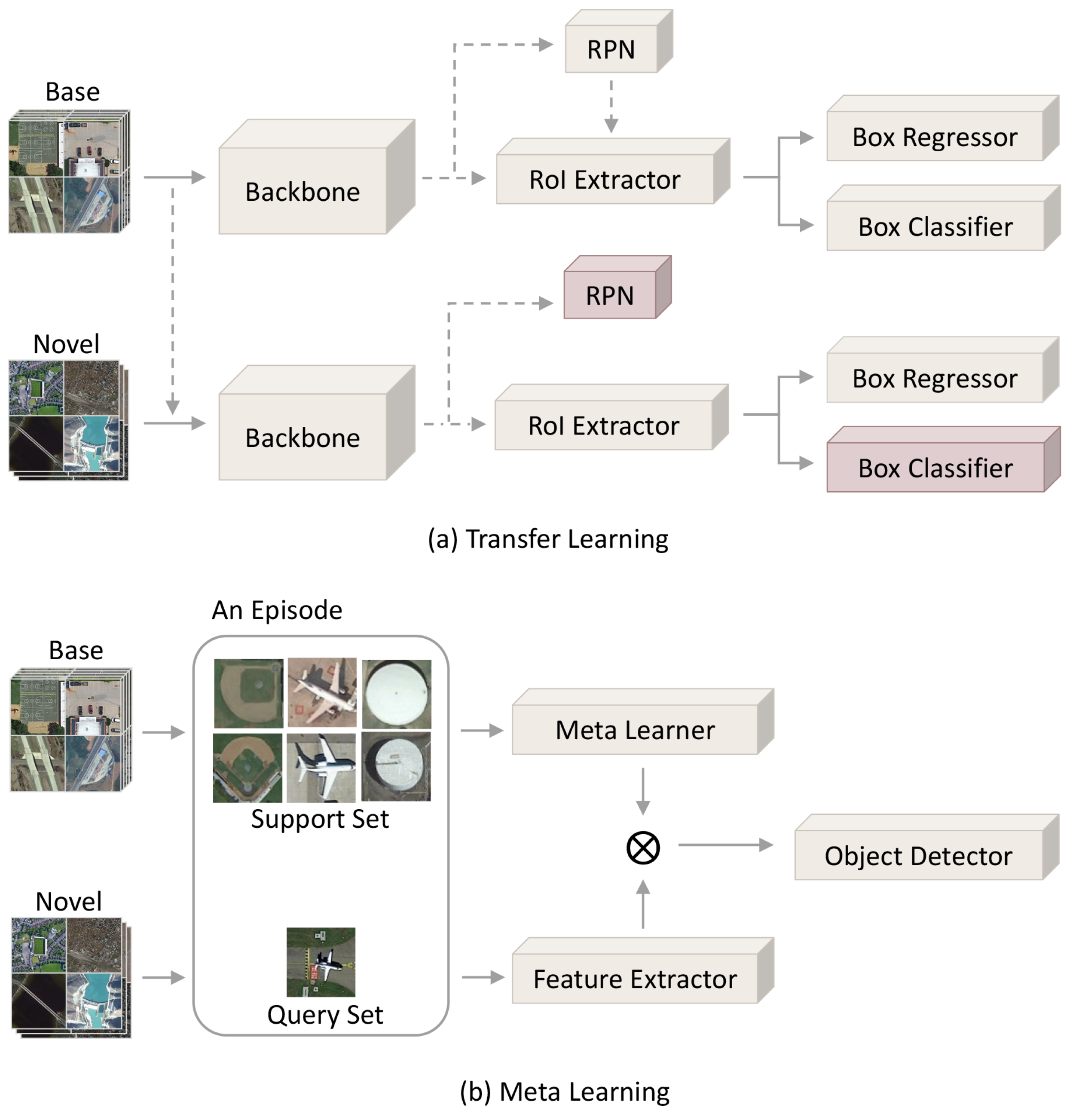
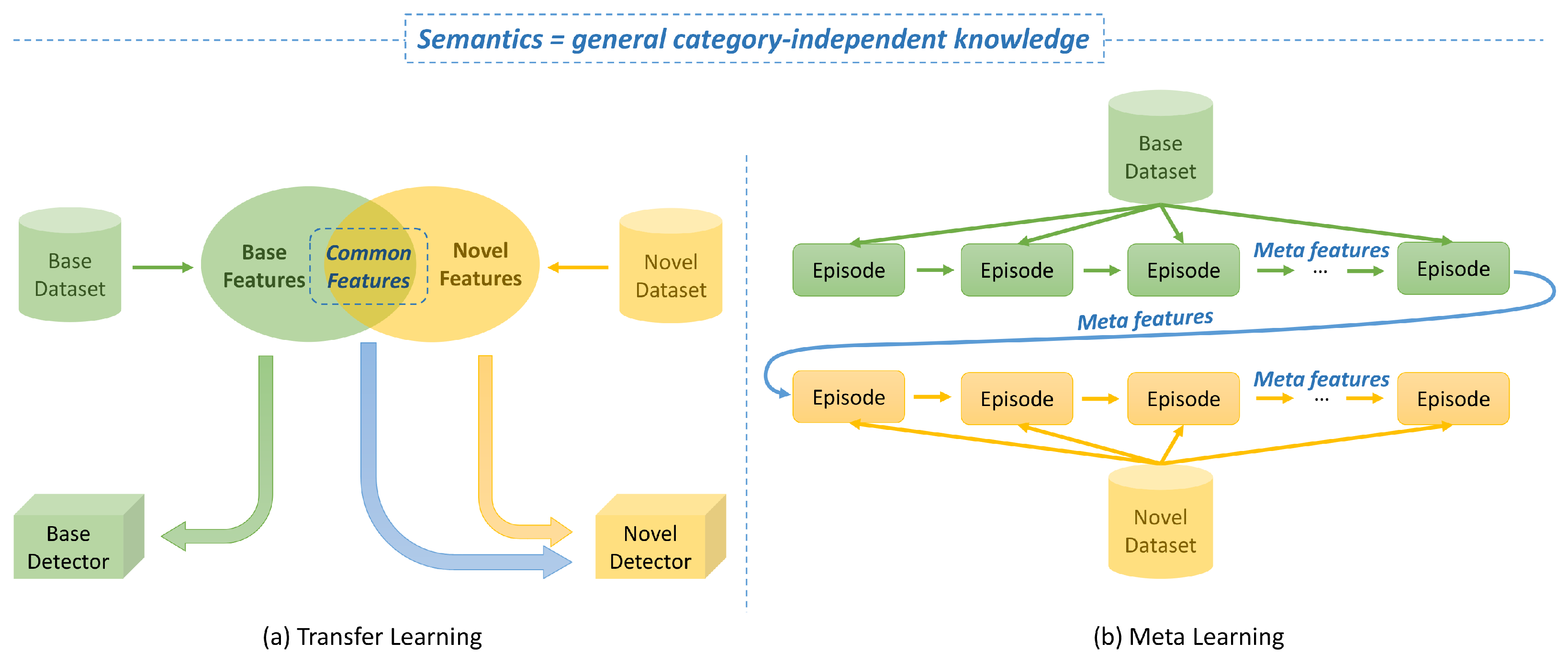
- Transfer learning-based FSOD learns from the source domain by supervised learning to obtain prior knowledge about targets, and the detector transfers from the source domain to the target domain. Thus, the training has two stages: pre-training on base classes and fine-tuning on novel classes in the target domain. These methods consider localization as category-irrelevant and classification as category-specific. The localization ability inherits from the training results of base classes in the source domain. So, when fine-tuning, nearly the entire trained parameters are frozen except the classifier.
- (2)
- Meta learning-based FSOD regards a set of learning patterns found in the source domain by meta learning as the meta (prior) knowledge, which is going to be embedded into the detection of novel classes. It trains and tests with a series of episodes, consisting of support sets and query sets, to simulate few-shot situations, as shown in Figure 5. The aim of training with these changeable episodes is to force the model to find out parameters that are adaptable after a few episodes from novel classes.
2. Object Detection Review
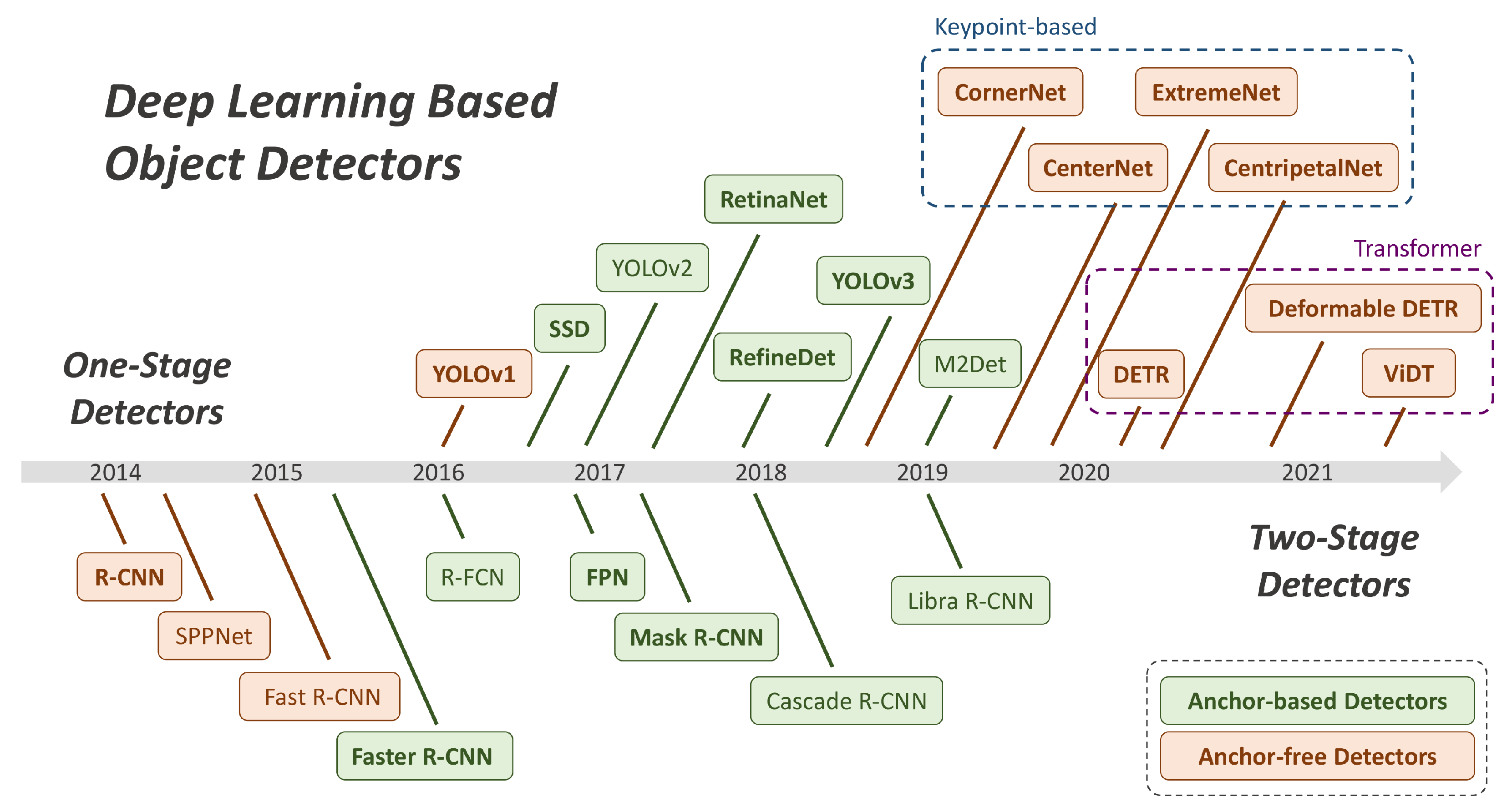
2.1. Classical Deep Learning Object Detection
2.2. Remote Sensing Object Detection
- (1)
- Complicated background: RS images own rich ground information, while the categories of interest are limited, so the background area occupies the majority, leading to the possible foreground-background misjudgment. Therefore, the solutions tend to suppress background information and highlight the target region features, where the attention mechanism [34,35,36,37,38] is effective. Moreover, our previous work [39] tried to divide the RS images into the target and non-target regions. The complex background information of non-target is extracted and suppressed by introducing a semantic segmentation task, which can effectively guide the correct selection of candidate regions. Similar ideas also appear in vehicle detection [40,41,42,43].
- (2)
- Multiple target directions: In RS images, specific targets, such as ships and aircraft, are usually distributed in diversified angles on a single image. However, only certain rotation invariance of CNN makes extracted features sensitive to target directions. The intuitive solution is to rotate and expand the samples [44,45,46,47,48], but with limited effect. Thus, various rotation-insensitive modules are proposed for feature extraction, such as regularization before and after rotation [49], multi-angle anchors in RPN [50], rotation-invariance in frequency domain [51], target position coordination redefinition in complex domain [52]. Direction prediction modules [44,47,53,54] in ship detection can also deal with the angle issue.
- (3)
- Densely small targets: Targets in RS images are too densely distributed in some specific situations, such as vehicles in a parking lot, airplanes in an airport, ships in a harbor, etc. Dense distribution and small-scale targets are two considerations. The improvements on the former mainly focus on feature enhancement to improve the discrimination of a single target [44,53,55], while the latter depends on increasing the size of the feature maps [56] or introducing shallow layer feature maps to provide more information [44,47,57,58,59].
- (4)
- Huge scale variance: As shown in Figure 7, scale variance occurs not only inter-class but also intra-class. Simultaneously keeping satisfactory detection accuracy on large- and small-scale targets is a hard issue. The current solution is to introduce a multi-scale mechanism, such as simply detecting on different scales [34,60], importing a feature pyramid network (FPN) [44,61], and designing or refining feature fusion networks [36,37,62,63,64,65,66,67]. However, the existing methods are still not effective for extreme scales, such as targets that only have a few pixels or almost occupy the whole image.
3. FSOD Design for Sample, Model and Strategy
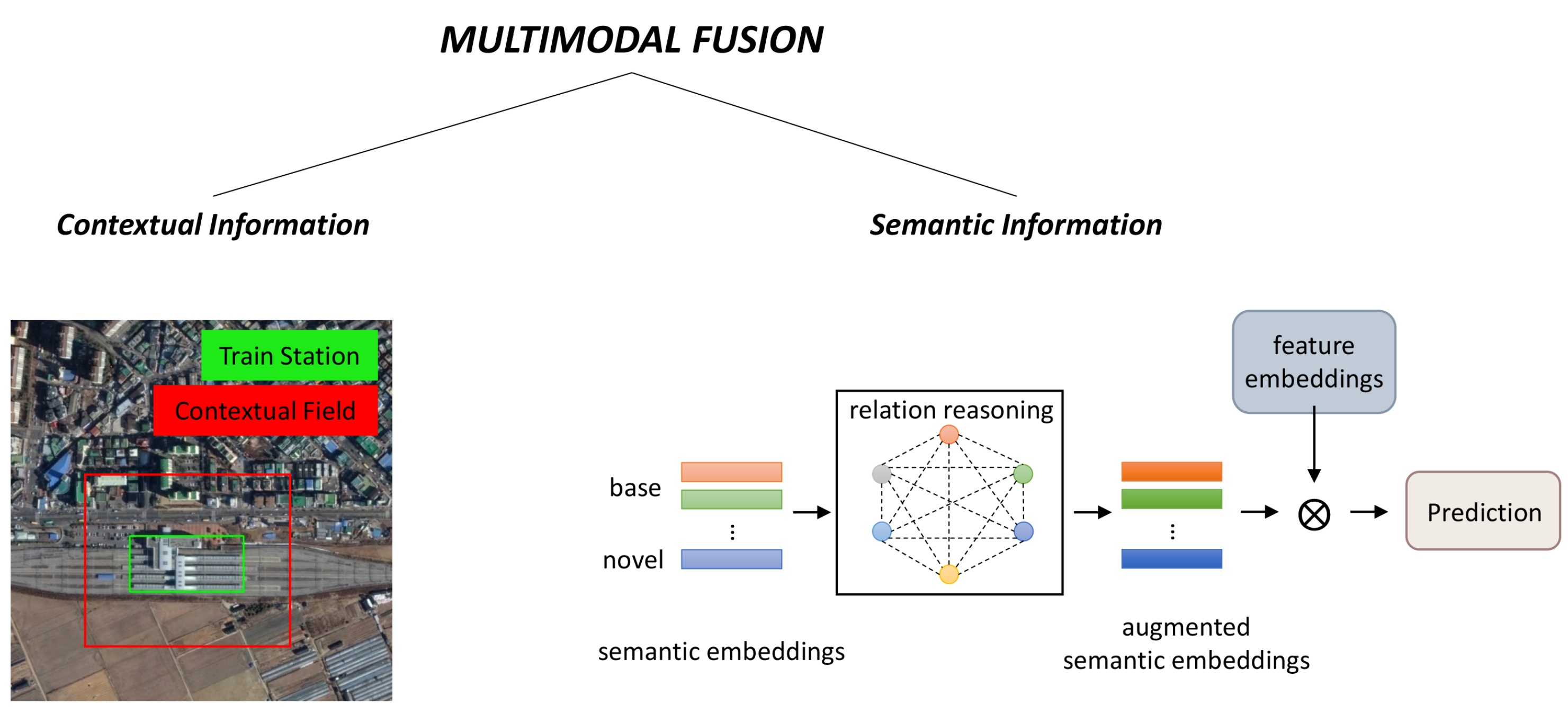
3.1. Sample: Feature Enhancement and Multimodal Fusion
3.2. Model: Semantics Extraction and Cross-Domain Mapping
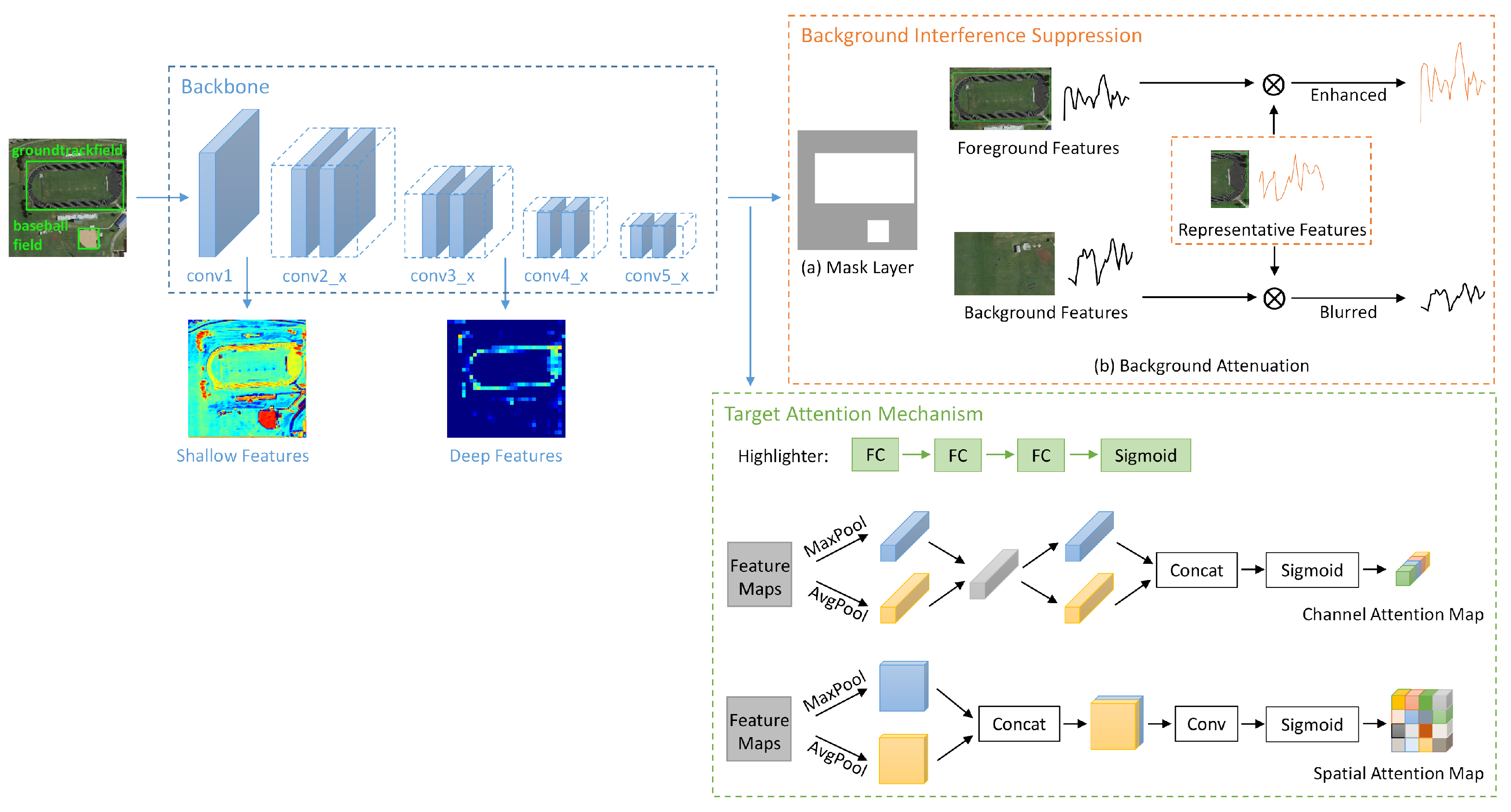
3.2.1. Target Information Extraction
- (1)
- High- and Low-Level Semantic Feature Extraction:
- (2)
- Background Interference Suppression:
- (3)
- Target Attention Mechanism:
3.2.2. Target Semantics Sharing
3.2.3. Cross-Domain Mapping of Shared Semantics
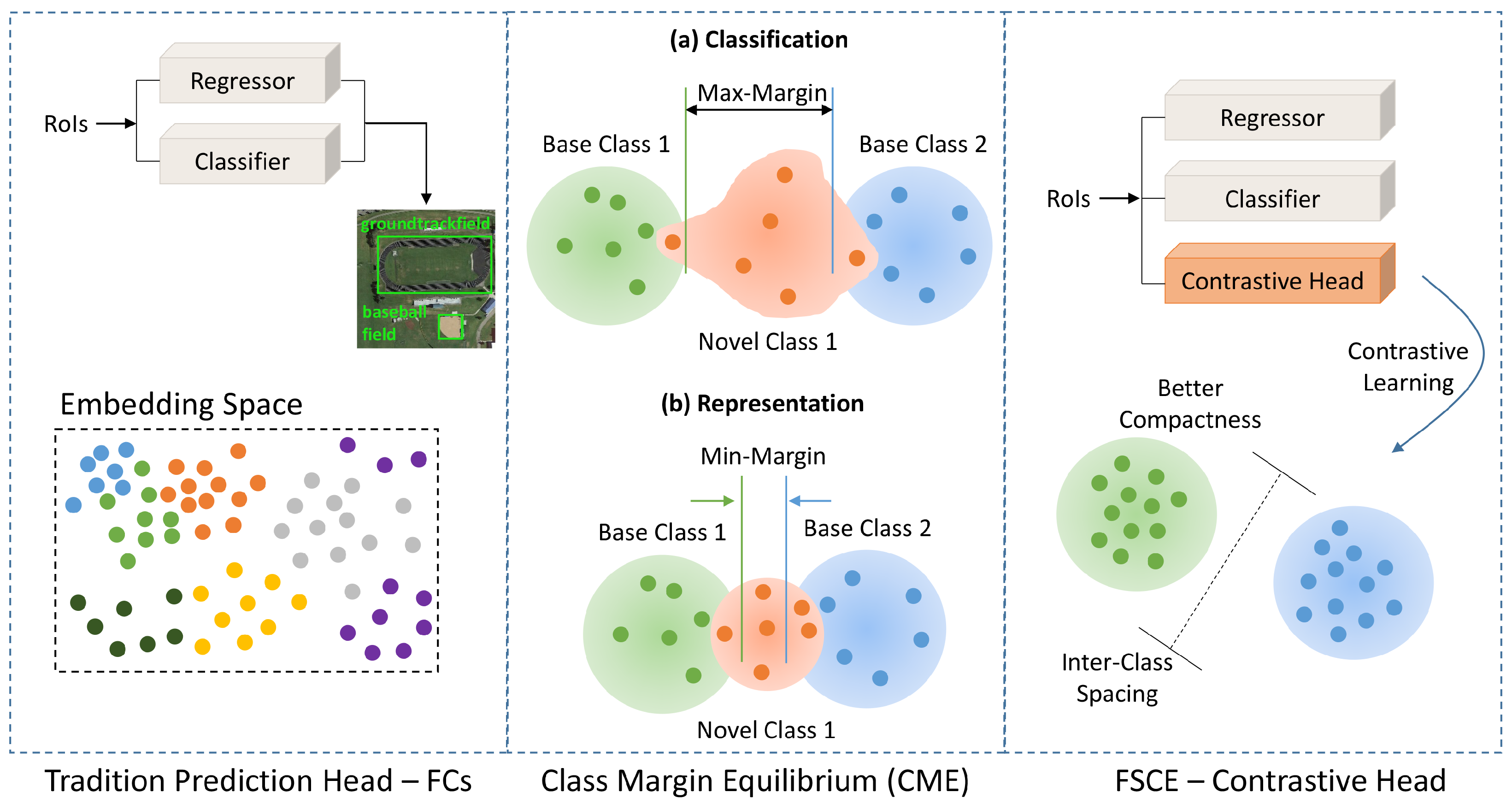
3.3. Few-Shot Prediction Head
3.4. Strategy: Fine-Tuning and Learning to Learn
4. Performance Evaluation
4.1. Experimental Datasets
- (1)
- NWPU VHR-10 [69]: With 10 annotated categories, the works [10,17,97,98] share the same partition, where three classes are chosen as novel classes and the rest as base ones. All the images that do not contain any novel object are selected for base-training and a very small set that contains both base and novel classes with only k annotated boxes for each are constructed for fine-tuning, where k equals 1, 2, 3, 5, and 10. Then, the test set includes all the images containing at least one novel object except those for training, whose quantity is about 300. Xiao et al. [11] excluded storage tank and harbor because the number of these objects in an image is much larger than 10, which violates few-shot settings. In addition, the other designs are the same as it does on RSOD [112].
- (2)
- DIOR [1]: As a large-scale publicly available dataset, DIOR has 20 categories with more than 23K images and 190K instances, in which five categories are selected to be novel classes while keeping the remaining 15 classes as the base ones. The authors of [17,97,98] followed the few-shot setting of [10], which takes all the images of base classes in training set for base-training and extracts k annotated boxes for each novel class in training set for fine-tuning, where k belongs to 5, 10, and 20. Then, the performance is tested on the entire DIOR’s validation set. When training, Cheng et al. [84] had k object instances for each novel class randomly from training set and validation set, where k equals to 3, 5, 10, 20, and 30, and performed evaluation on a testing set with both base and novel classes.
- (3)
- RSOD [112]: There are four categories in RSOD. In [83], one class is randomly selected as the novel class and the remaining three are base classes. Four different base/novel splits are separately evaluated for objectivity. In the base training phase, for each base class, of the samples are for training, and the rest for testing. In addition, in the novel fine-tuning phase, only k annotated boxes are selected in novel classes, where k equals to 1, 2, 3, 5, and 10.
- (4)
- iSAID [113]: Instead of selecting a fixed number of novel classes, the authors of [16] designed three base/novel splits with a different number of categories according to data characteristics, as shown in Table 1. The novel categories in the first split mainly contain small-sized objects with a large variation in appearance, while the second split holds objects with relatively large dimensions and small variances in appearance. In addition, the third split takes the top-6 categories with the fewest instances as novel ones, which are regarded as the lowest occurrence. The base training phase takes all objects from base classes. When fine-tuning, the number of annotated boxes per class is respectively set to 10, 50, and 100.
- (5)
- DOTA [3,68]: As an open source and constantly updated dataset, DOTA now has released versions 1.0, 1.5, and 2.0, whose number of categories increased from 15 to 18, and the number of instances expands nearly tenfold to 1.79 million. Jeune et al. [78] took DOTAv1.5 as the experimental dataset, and randomly chose two base/novel classes splits, 3 for novel and the remaining 13 for base. When constructing episodes, the number of shots for novel classes is 1, 3, 5, and 10.
- (6)
- DAN: To enrich the samples, Gao et al. [105] constructed a dataset named DAN as a collection of DOTA and NWPU VHR-10, which consists of 15 representative categories. In addition, three categories are chosen to be novel ones, keeping the rest as base classes. The number of shots used for evaluation is not stated.
- (1)
- PASCAL VOC: This is initially a large-scale well-annotated dataset for competition with two versions, VOC 2007 and VOC 2012. Following the common practice in classical object detection works [20,22], the VOC 07 test set is used for testing while VOC 07 and 12 train/val sets are for training. A total of 5 classes are randomly selected as novel ones, while keeping the remaining 15 ones as the base. In addition, 3 different base/novel splits are evaluated for objectiveness. When base-training, only annotations of base classes are available. In the novel fine-tuning phase, a very small set is constructed that includes k annotated boxes for each base and novel category, where .
- (2)
- MS-COCO: COCO is a much larger dataset than VOC, which contains 80 categories with 1.5 million object instances. A total of 5000 images from the validation set are used for evaluation and the remaining images in train/val set are for training. The 20 categories overlapped with VOC are selected as novel classes, and the remaining 60 categories are used as base classes, so as to perform the cross-dataset learning problem, that is, from COCO to PASCAL. Here, the number of annotated boxes with fine-tuning is 10 and 30.
- (3)
- FSOD: In [92], it is indicated that the key to FSL is the generalization ability of the model when facing new categories. Thus, it proposes a highly-diverse dataset specifically designed for the FSOD task with a large number of object categories, called FSOD, which contains 1000 categories, 800 base classes for training, and 200 novel classes for testing. The average number of images per category is far less than that of the datasets designed for generic object detection, while the number of categories is far more than them, as shown in Table 2. Here, .
4.2. Evaluation Criteria
4.3. Accuracy Performance
- (1)
- Experimental results on NWPU VHR-10. As shown in Table 3, in terms of predictive performance on novel classes, the transfer detector [17] achieves to be state-of-the-art (SOTA) due to its shared attention module and the balanced fine-tuning strategy. The former calculates multi-attention maps from the rich base samples to share with the novel fine-tuning stage as prior knowledge, while the latter alleviates the training imbalance problem caused by sample sizes between base and novel classes. Meanwhile, migrating the detection capability to the target domain often sacrifices the performance on base classes, in which respect, transfer learning also impacts less. A different base/novel splitting is adopted in Table 4. After discarding the categories that violate the few-shot scenario, in each experimental setting, the remaining classes are respectively treated to be the novel ones. These results demonstrate that the difficulty of detecting novel classes is distinct from class to class. For baseball, diamond, and ground track field, 10 shots are adequate to achieve satisfactory results, while for airplane or vehicle, it is just not enough. Thus, [11] came to the conclusion that the number of objects that are defined as few shots should vary among categories.
- (2)
- Experiments results on DIOR. In Table 5, the SOTA on DIOR when 5, 10, and 20 shots is illustrated to be the transfer detector [17], which is also the SOTA on NWPU VHR-10; it profited from its two proposed attention modules and training mechanism. Hence, when the sample size of novel objects is relatively large, the effect of the transfer detector is better. In addition, when only very few shots are provided, i.e., under a 2-shot or 3-shot setting, the meta detector [97] owns higher precision, which benefits from the meta-learning mechanism that can quickly learn from limited samples by training with a series of few-shot episodes. For the base accuracy attenuation problem, the new transfer-learning attempt PAMS-Det [98] is more able to handle it than the classical meta-learning approach FSODM [10], which also confirms the aforementioned conclusion that fine-tuning-based methods sacrifice less performance on the base classes than meta-based ones. Table 6 shows a different dataset reorganization thinking. The novel classes of the four splittings are non-overlapped. It is obvious that different base/novel splits own different detection accuracies. The reason is that, limited by the insufficient categories, the base training phase may not be able to extract totally category-irrelevant features. When there is a category-insufficient situation on both base and novel classes, the meta knowledge extraction from source domain and matching in target domain may result in contingency, thus influencing detection accuracy.
- (3)
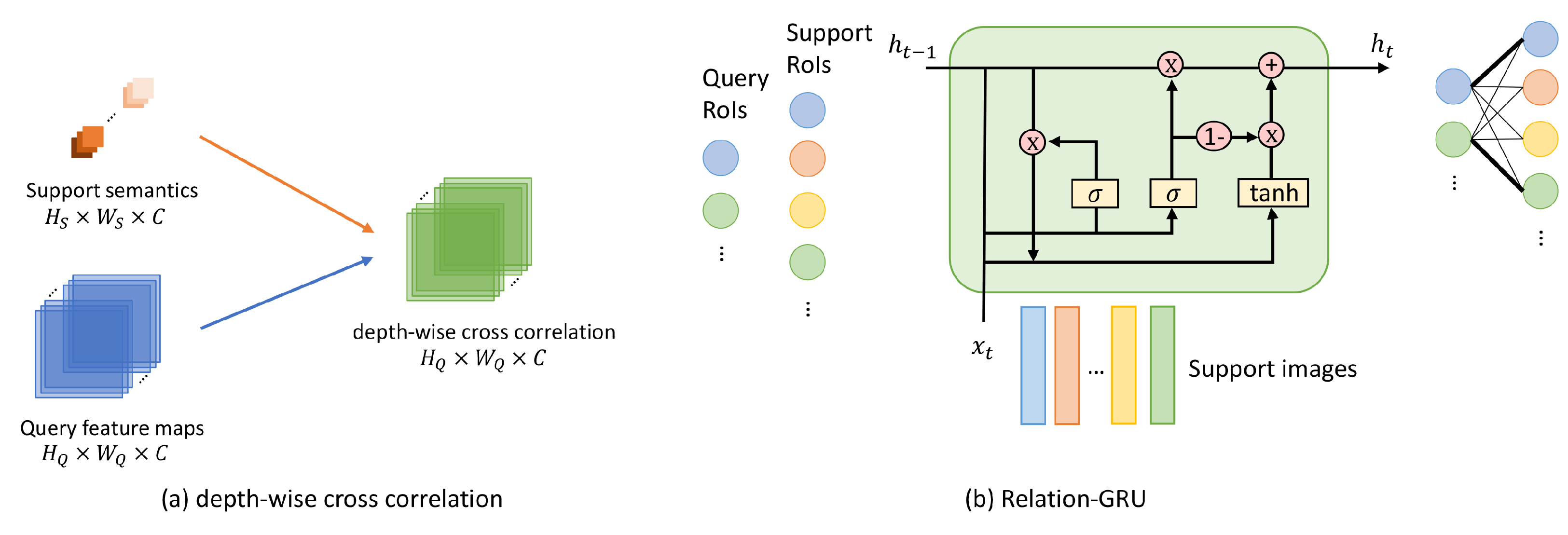
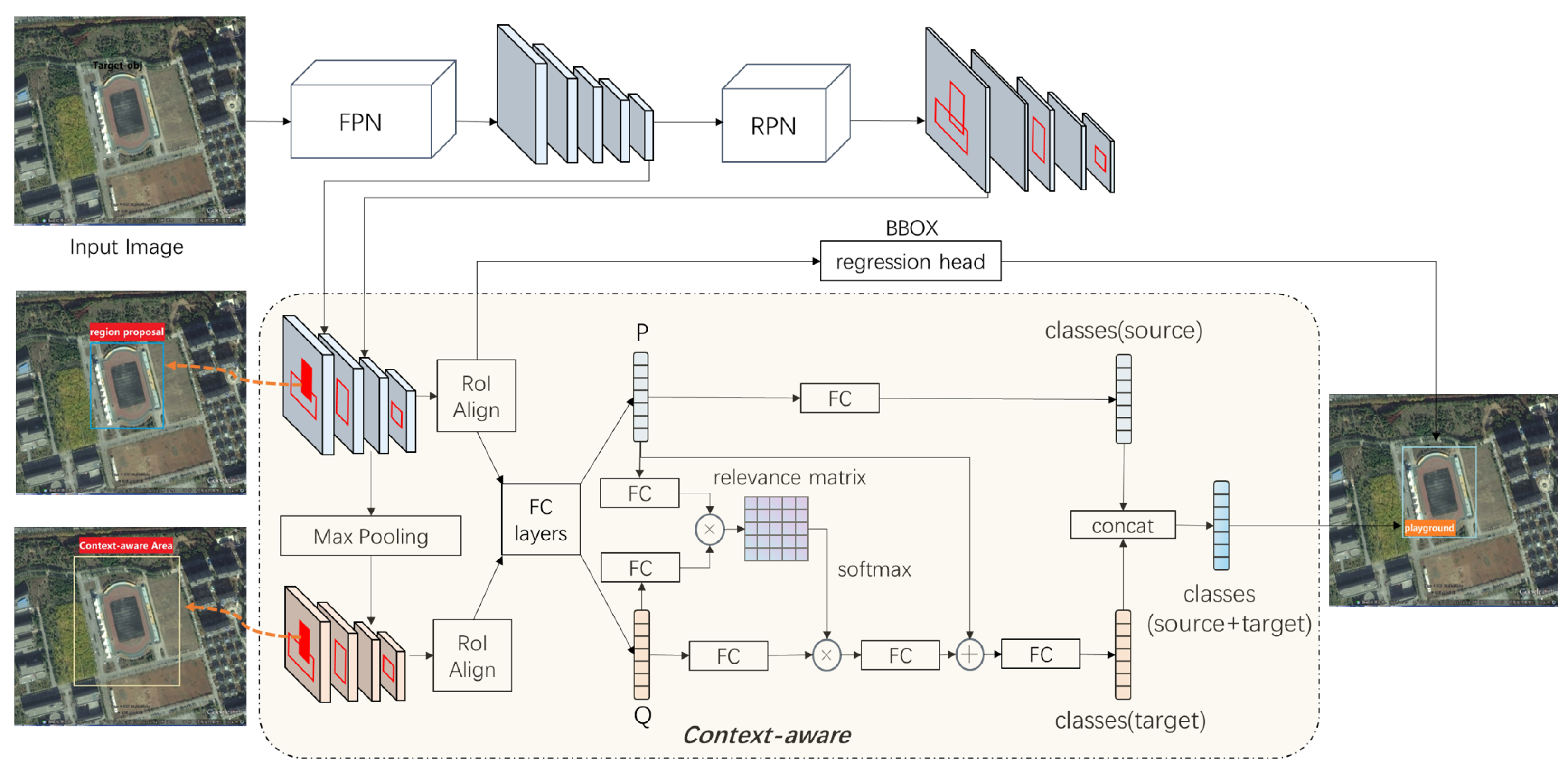
- Experiments on RSOD. As shown in Table 7, our two-stage multi-scale context-aware method has significantly better performance in most cases, which proves the effectiveness of our method in introducing the context mechanism into the two-stage multi-scale detection framework. The authors of [83] reached SOTA in the rest of the cases, which proposed a feature highlight module that can extract meta knowledge from coarse to fine. The creativity of the slightly inferior method [11] is a relation GRU for the matching between support knowledge and query instances. Thus, the accuracy comparison manifests that the import of contextual information does help and the extraction of meta knowledge is even more important than the matching procedure. Only the discriminative and representative features are founded, and the similarity measurement between support and query is meaningful.
- (4)
- Experiments on iSAID. As stated before, the dataset splits in [16] are carefully designed, instead of random selection. The first split contains objects with large variations in appearance, while the second split is on the contrary. The accuracy comparison between the two in Table 8 confirms an assumption that 10 shots may be not enough for diversified objects. Although the third split also varies less in appearance, it detects worse than the second one, which indicates that considering more novel classes impedes the few-shot learning procedure. Contrasting between the second and third splits, an assumption that fewer base classes and more novel classes yield worse performance is made and verified by another set of experiments. Hence, we can conclude that higher diversity of classes and instances can generate less class-specific features that can benefit the novel fine-tuning phase, and considering more novel classes has the opposite effect.
- (5)
- Experiments on DOTA. Generally speaking, more samples can bring better performance. However, this is not always observed in [78]. For instance, in the second split, the accuracy is stable with respect to the number of shots. In addition, Table 9 also shows that the accuracy gain is not as significant from 5 to 10 shots as that between 1, 3, and 5 shots. A relatively low number of samples may correctly approximate the class prototype and increasing the number might do damage. These are all because few samples lead to unsatisfactory representative space construction.
5. Opportunities and Challenges
5.1. High-Diversity FSOD Dataset of RS Images
5.2. Few-Shot Sample Acquisition Principle
5.3. Representation Abilities of Context Information
5.4. Effective and Reliable Training Strategy
5.5. Model Ensemble for Industrial Application
6. Conclusions
- (i)
- Design few-shot data acquisition rules for remote sensing images.Through the analysis of existing remote sensing object detection datasets, we find that, on the one hand, these datasets do not control the number of instances of the same category in one image. When the number is far more than the few-shot condition, such as 1, 3, or 5-shot, and thus, the data cannot be used for few-shot detectors. On the other hand, current annotations do not consider contextual information. However, some work suggests that the characteristics of the target’s environment benefit few-shot tasks. Therefore, how to screen, supplement and label datasets that meet the requirement of few-shot object detection is the primary problem to be solved.
- (ii)
- Build a deep neural network model close to the essence of human cognition.The existing few-shot detectors focus on extracting information or detection abilities from base classes and how to apply these into novel classes, which follow our stated research route. The semantics shared between source and target domains need to obey the cognition of “visual-semantic-semantic-visual”, and mining-shared features are the key to network model design.
- (iii)
- Establish a learning strategy that can aggregate multi-modal knowledge and improve network efficiency.Although there is still a performance gap between few-shot detectors and deep learning detectors, related studies show that the few-shot ones have shown acceptable detection ability for some kinds of targets with a limited number of shots. So, it is necessary to further focus on the integration and training methods, which can drive and build the practical application capabilities of few-shot detectors in these categories.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| FSOD | Few-Shot Object Detection |
| FSL | Few-shot learning |
| FSC | Few-shot Classification |
Appendix A. mAP Calculation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Average Precision (AP): | Average Recall (AR): | ||
|---|---|---|---|
| AP | AP at IoU = :50 : :05 : :95 | AR1 | AR given 1 detection per image |
| AP50 | AP at IoU = :50 | AR10 | AR given 10 detections per image |
| AP75 | AP at IoU = :75 | AR100 | AR given 100 detections per image |
| AP Across Scales: | AR Across Scales: | ||
| APS | AP for small objects: area < 322 | ARS | AR for small objects: area < 322 |
| APM | AP for medium objects: 322 < area < 962 | ARM | AR for medium objects: 322 < area < 962 |
| APL | AP for large objects: area > 962 | ARL | AR for large objects: area > 962 |
Appendix B. FSOD Performance in Natural Image Datasets
| Method/Shot | Novel Set 1 | Novel Set 2 | Novel Set 3 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 5 | 10 | 1 | 2 | 3 | 5 | 10 | 1 | 2 | 3 | 5 | 10 | |
| LSTD(YOLO) [85] | 8.2 | 1 | 12.4 | 29.1 | 38.5 | 11.4 | 3.8 | 5 | 15.7 | 31 | 12.6 | 8.5 | 15 | 27.3 | 36.3 |
| RepMet [77] | 26.1 | 32.9 | 34.4 | 38.6 | 41.3 | 17.2 | 22.1 | 23.4 | 28.3 | 35.8 | 27.5 | 31.1 | 31.5 | 34.4 | 37.2 |
| TFA w/ fc [86] | 36.8 | 29.1 | 43.6 | 55.7 | 57 | 18.2 | 29 | 33.4 | 35.5 | 39 | 27.7 | 33.6 | 42.5 | 48.7 | 50.2 |
| TFA w/ cos [86] | 39.8 | 36.1 | 44.7 | 55.7 | 56 | 23.5 | 26.9 | 34.1 | 35.1 | 39.1 | 30.8 | 34.8 | 42.8 | 49.5 | 49.8 |
| HOSENet [87] | 32.9 | - | 47.4 | 52.6 | 54.9 | - | - | - | - | - | - | - | - | - | - |
| LSCN [119] | 30.7 | 43.1 | 43.7 | 53.4 | 59.1 | 22.3 | 25.7 | 34.8 | 41.6 | 50.3 | 21.9 | 23.4 | 30.7 | 43.1 | 55.6 |
| Retentive RCNN [89] | 42.4 | 45.8 | 45.9 | 53.7 | 56.1 | 21.7 | 27.8 | 35.2 | 37 | 40.3 | 30.2 | 37.6 | 43 | 49.7 | 50.1 |
| FSSP [74] | 41.6 | - | 49.1 | 54.2 | 56.5 | 30.5 | - | 39.5 | 41.4 | 45.1 | 36.7 | - | 45.3 | 49.4 | 51.3 |
| MPSR [73] | 41.7 | 43.1 | 51.4 | 55.2 | 61.8 | 24.4 | 29.5 | 39.2 | 39.9 | 47.8 | 35.6 | 40.6 | 42.3 | 48 | 49.7 |
| TFA + Halluc [120] | 45.1 | 44 | 44.7 | 55 | 55.9 | 23.2 | 27.5 | 35.1 | 34.9 | 39 | 30.5 | 35.1 | 41.4 | 49 | 49.3 |
| CoRPNs+ Halluc [120] | 47 | 44.9 | 46.5 | 54.7 | 54.7 | 26.3 | 31.8 | 37.4 | 37.4 | 41.2 | 40.4 | 42.1 | 43.3 | 51.4 | 49.6 |
| FSCE [88] | 44.2 | 43.8 | 51.4 | 61.9 | 63.4 | 27.3 | 29.5 | 43.5 | 44.2 | 50.2 | 37.2 | 41.9 | 47.5 | 54.6 | 58.5 |
| SRR-FSD [81] | 47.8 | 50.5 | 51.3 | 55.2 | 56.8 | 32.5 | 35.3 | 39.1 | 40.8 | 43.8 | 40.1 | 41.5 | 44.3 | 46.9 | 46.4 |
| FSOD-SR [75] | 50.1 | 54.4 | 56.2 | 60 | 62.4 | 29.5 | 39.9 | 43.5 | 44.6 | 48.1 | 43.6 | 46.6 | 53.4 | 53.4 | 59.5 |
| DeFRCN [121] | 53.6 | 57.5 | 61.5 | 64.1 | 60.8 | 30.1 | 38.1 | 47 | 53.3 | 47.9 | 48.4 | 50.9 | 52.3 | 54.9 | 57.4 |
| FSRW [99] | 14.8 | 15.5 | 26.7 | 33.9 | 47.2 | 15.7 | 15.3 | 22.7 | 30.1 | 40.5 | 21.3 | 25.6 | 28.4 | 42.8 | 45.9 |
| MetaDet(YOLO) [90] | 17.1 | 19.1 | 28.9 | 35 | 48.8 | 18.2 | 20.6 | 25.9 | 30.6 | 41.5 | 20.1 | 22.3 | 27.9 | 41.9 | 42.9 |
| MetaDet(FRCN) [90] | 18.9 | 20.6 | 30.2 | 36.8 | 49.6 | 21.8 | 23.1 | 27.8 | 31.7 | 43 | 20.6 | 23.9 | 29.4 | 43.9 | 44.1 |
| Meta R-CNN [91] | 19.9 | 25.5 | 35 | 45.7 | 51.5 | 10.4 | 19.4 | 29.6 | 34.8 | 45.4 | 14.3 | 18.2 | 27.5 | 41.2 | 48.1 |
| FsDetView [122] | 24.2 | 35.3 | 42.2 | 49.1 | 57.4 | 21.6 | 24.6 | 31.9 | 37 | 45.7 | 21.2 | 30 | 37.2 | 43.8 | 49.6 |
| TIP [123] | 27.7 | 36.5 | 43.3 | 50.2 | 59.6 | 22.7 | 30.1 | 33.8 | 40.9 | 46.9 | 21.7 | 30.6 | 38.1 | 44.5 | 50.9 |
| DCNet [95] | 33.9 | 37.4 | 43.7 | 51.1 | 59.6 | 23.2 | 24.8 | 30.6 | 36.7 | 46.6 | 32.3 | 34.9 | 39.7 | 42.6 | 50.7 |
| NP-RepMet [76] | 37.8 | 40.3 | 41.7 | 47.3 | 49.4 | 41.6 | 43 | 43.3 | 47.4 | 49.1 | 33.3 | 38 | 39.8 | 41.5 | 44.8 |
| GenDet [94] | 38.5 | 47.1 | 52.2 | 57.7 | 63.5 | 26.8 | 34 | 37.3 | 42.8 | 48.3 | 33.4 | 40 | 44.3 | 51.2 | 56.5 |
| Meta-DETR [102] | 40.6 | 51.4 | 58 | 59.2 | 63.6 | 37 | 36.6 | 43.7 | 49.1 | 54.6 | 41.6 | 45.9 | 52.7 | 58.9 | 60.6 |
| CME [79] | 41.5 | 47.5 | 50.4 | 58.2 | 60.9 | 27.2 | 30.2 | 41.4 | 42.5 | 46.8 | 34.3 | 39.6 | 45.1 | 48.3 | 51.5 |
| #Shots | Method | Average Precision | Average Recall | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP | AP50 | AP75 | APS | APM | APL | AR1 | AR10 | AR100 | ARS | ARM | APL | ||
| 10 | LSTD(YOLO) [85] | 3.2 | 8.1 | 2.1 | 0.9 | 2 | 6.5 | 7.8 | 10.4 | 10.4 | 1.1 | 5.6 | 19.6 |
| TFA w/ fc [86] | 9.1 | 17.3 | 8.5 | - | - | - | - | - | - | - | - | - | |
| TFA w/ cos [86] | 9.1 | 17.1 | 8.8 | - | - | - | - | - | - | - | - | - | |
| HOSENet [87] | 10 | - | 9.1 | - | - | - | - | - | - | - | - | - | |
| MPSR [73] | 9.8 | 17.9 | 9.7 | 3.3 | 9.2 | 16.1 | 15.7 | 21.2 | 21.2 | 4.6 | 19.6 | 34.3 | |
| FSOD-SR [75] | 11.6 | 12.7 | 10.4 | 4.6 | 10.5 | 17.2 | 16.4 | 23.9 | 24.1 | 9.3 | 21.8 | 37.7 | |
| FSCE [88] | 11.9 | - | 10.5 | - | - | - | - | - | - | - | - | - | |
| FSSP [74] | 9.9 | 20.4 | 9.6 | - | - | - | - | - | - | - | - | - | |
| SRR-FSD [81] | 11.3 | 23 | 9.8 | - | - | - | - | - | - | - | - | ||
| LSCN [119] | 12.4 | 26.3 | 7.57 | - | - | - | - | - | - | - | - | ||
| FSRW [99] | 5.6 | 12.3 | 4.6 | 0.9 | 3.5 | 10.5 | 10.1 | 14.3 | 14.4 | 1.5 | 8.4 | 28.2 | |
| MetaDet [90] | 7.1 | 14.6 | 6.1 | 1 | 4.1 | 12.2 | 11.9 | 15.1 | 15.5 | 1.7 | 9.7 | 30.1 | |
| Meta R-CNN [91] | 8.7 | 19.1 | 6.6 | 2.3 | 7.7 | 14 | 12.6 | 17.8 | 17.9 | 7.8 | 15.6 | 27.2 | |
| GenDet [94] | 9.9 | 18.8 | 9.6 | 3.6 | 8.4 | 15.4 | - | - | - | - | - | - | |
| FsDetView [122] | 12.5 | 27.3 | 9.8 | 2.5 | 13.8 | 19.9 | 20 | 25.5 | 25.7 | 7.5 | 27.6 | 38.9 | |
| DCNet [95] | 12.8 | 23.4 | 11.2 | 4.3 | 13.8 | 21 | 18.1 | 26.7 | 25.6 | 7.9 | 24.5 | 36.7 | |
| CME [79] | 15.1 | 24.6 | 16.4 | 4.6 | 16.6 | 26 | 16.3 | 22.6 | 22.8 | 6.6 | 24.7 | 39.7 | |
| Meta-DETR [102] | 19 | 30.5 | 19.7 | - | - | - | - | - | - | - | - | - | |
| #Shots | Method | Average Precision | Average Recall | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP | AP50 | AP75 | APS | APM | APL | AR1 | AR10 | AR100 | ARS | ARM | APL | ||
| 30 | LSTD(YOLO) [85] | 6.7 | 15.8 | 5.1 | 0.4 | 2.9 | 12.3 | 10.9 | 14.3 | 14.3 | 0.9 | 7.1 | 27 |
| TFA w/ fc [86] | 12 | 22.2 | 11.8 | - | - | - | - | - | - | - | - | - | |
| TFA w/ cos [86] | 12.1 | 22 | 12 | - | - | - | - | - | - | - | - | - | |
| HOSENet [87] | 14 | - | 14 | - | - | - | - | - | - | - | - | - | |
| MPSR [73] | 14.1 | 25.4 | 14.2 | 4 | 12.9 | 23 | 17.7 | 24.2 | 24.3 | 5.5 | 21 | 39.3 | |
| FSOD-SR [75] | 15.2 | 27.5 | 14.6 | 6.1 | 14.5 | 24.7 | 18.4 | 27.1 | 27.3 | 9.8 | 25.1 | 42.6 | |
| FSCE [88] | 16.4 | - | 16.2 | - | - | - | - | - | - | - | - | ||
| FSSP [74] | 14.2 | 25 | 13.9 | - | - | - | - | - | - | - | - | - | |
| SRR-FSD [81] | 14.7 | 29.2 | 13.5 | - | - | - | - | - | - | - | - | ||
| LSCN [119] | 13.9 | 30.9 | 9.96 | - | - | - | - | - | - | - | - | ||
| FSRW [99] | 9.1 | 19 | 7.6 | 0.8 | 4.9 | 16.8 | 13.2 | 17.7 | 17.8 | 1.5 | 10.4 | 33.5 | |
| MetaDet [90] | 11.3 | 21.7 | 8.1 | 1.1 | 6.2 | 17.3 | 14.5 | 18.9 | 19.2 | 1.8 | 11.1 | 34.4 | |
| Meta RCNN [91] | 12.4 | 25.3 | 10.8 | 2.8 | 11.6 | 19 | 15 | 21.4 | 21.7 | 8.6 | 20 | 32.1 | |
| GenDet [94] | 14.3 | 27.5 | 13.8 | 4.8 | 13 | 24.2 | - | - | - | - | - | - | |
| FsDetView [122] | 14.7 | 30.6 | 12.2 | 3.2 | 15.2 | 23.8 | 22 | 28.2 | 28.4 | 8.3 | 30.3 | 42.1 | |
| DCNet [95] | 18.6 | 32.6 | 17.5 | 6.9 | 16.5 | 27.4 | 22.8 | 27.6 | 28.6 | 8.4 | 25.6 | 43.4 | |
| CME [79] | 16.9 | 28 | 17.8 | 4.6 | 18 | 29.2 | 17.5 | 23.8 | 24 | 6 | 24.6 | 42.5 | |
| Meta-DETR [102] | 22.2 | 35 | 22.8 | - | - | - | - | - | - | - | - | - | |
| Method | Base AP50 | Novel AP50 | ||||
|---|---|---|---|---|---|---|
| 1 | 3 | 5 | 1 | 3 | 5 | |
| FSRW [99] | 62.9 | 61.2 | 60.7 | 14.2 | 29.8 | 36.5 |
| TFA w/ fc [86] | 77.1 | 76 | 75.1 | 22.9 | 40.4 | 46.7 |
| TFA w/ cos [86] | 77.6 | 77.3 | 77.4 | 25.3 | 42.1 | 47.9 |
| MPSR [73] | 59.4 | 66.2 | 67.9 | 25.5 | 41.1 | 49.6 |
| HOSENet [87] | 79.2 | 77.9 | 77.8 | 32.9 | 47.4 | 52.9 |
| FSCE [88] | 78.9 | 74.1 | 76.6 | 44.2 | 51.4 | 61.9 |
| FSSP [74] | - | 73.5 | - | - | 49.1 | - |
| FSOD-SR [75] | - | 77.4 | - | - | 56.2 | - |
References
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Lam, D.; Kuzma, R.; McGee, K.; Dooley, S.; Laielli, M.; Klaric, M.; Bulatov, Y.; McCord, B. xview: Objects in context in overhead imagery. arXiv 2018, arXiv:1802.07856. [Google Scholar]
- Fei-Fei, L.; Fergus, R.; Perona, P. One-shot learning of object categories. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 594–611. [Google Scholar] [CrossRef]
- Fink, M. Object classification from a single example utilizing class relevance metrics. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2004; Volume 17. [Google Scholar]
- Shi, J.; Jiang, Z.; Zhang, H. Few-shot ship classification in optical remote sensing images using nearest neighbor prototype representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3581–3590. [Google Scholar] [CrossRef]
- Yao, X.; Yang, L.; Cheng, G.; Han, J.; Guo, L. Scene classification of high resolution remote sensing images via self-paced deep learning. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 521–524. [Google Scholar]
- Kim, J.; Chi, M. SAFFNet: Self-attention-based feature fusion network for remote sensing few-shot scene classification. Remote Sens. 2021, 13, 2532. [Google Scholar] [CrossRef]
- Li, X.; Deng, J.; Fang, Y. Few-Shot Object Detection on Remote Sensing Images. IEEE Trans. Geosci. Remote. Sens. 2021, 60, 1–14. [Google Scholar]
- Xiao, Z.; Qi, J.; Xue, W.; Zhong, P. Few-Shot Object Detection With Self-Adaptive Attention Network for Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4854–4865. [Google Scholar] [CrossRef]
- Huang, G.; Laradji, I.; Vazquez, D.; Lacoste-Julien, S.; Rodriguez, P. A survey of self-supervised and few-shot object detection. arXiv 2021, arXiv:2110.14711. [Google Scholar] [CrossRef]
- Antonelli, S.; Avola, D.; Cinque, L.; Crisostomi, D.; Foresti, G.L.; Galasso, F.; Marini, M.R.; Mecca, A.; Pannone, D. Few-shot object detection: A survey. ACM Comput. Surv. (CSUR) 2021. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. (CSUR) 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Sun, X.; Wang, B.; Wang, Z.; Li, H.; Li, H.; Fu, K. Research progress on few-shot learning for remote sensing image interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2387–2402. [Google Scholar] [CrossRef]
- Wolf, S.; Meier, J.; Sommer, L.; Beyerer, J. Double Head Predictor based Few-Shot Object Detection for Aerial Imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 721–731. [Google Scholar]
- Huang, X.; He, B.; Tong, M.; Wang, D.; He, C. Few-Shot Object Detection on Remote Sensing Images via Shared Attention Module and Balanced Fine-Tuning Strategy. Remote Sens. 2021, 13, 3816. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Dong, Z.; Li, G.; Liao, Y.; Wang, F.; Ren, P.; Qian, C. Centripetalnet: Pursuing high-quality keypoint pairs for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10519–10528. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 850–859. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Wang, C.; Bai, X.; Wang, S.; Zhou, J.; Ren, P. Multiscale visual attention networks for object detection in VHR remote sensing images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 310–314. [Google Scholar] [CrossRef]
- Li, Q.; Mou, L.; Jiang, K.; Liu, Q.; Wang, Y.; Zhu, X.X. Hierarchical region based convolution neural network for multiscale object detection in remote sensing images. In Proceedings of the IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4355–4358. [Google Scholar]
- Li, C.; Xu, C.; Cui, Z.; Wang, D.; Zhang, T.; Yang, J. Feature-attentioned object detection in remote sensing imagery. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3886–3890. [Google Scholar]
- Wang, J.; Ding, J.; Guo, H.; Cheng, W.; Pan, T.; Yang, W. Mask OBB: A semantic attention-based mask oriented bounding box representation for multi-category object detection in aerial images. Remote Sens. 2019, 11, 2930. [Google Scholar] [CrossRef]
- Yang, F.; Li, W.; Hu, H.; Li, W.; Wang, P. Multi-scale feature integrated attention-based rotation network for object detection in VHR aerial images. Sensors 2020, 20, 1686. [Google Scholar] [CrossRef] [PubMed]
- You, Y.; Cao, J.; Zhang, Y.; Liu, F.; Zhou, W. Nearshore ship detection on high-resolution remote sensing image via scene-mask R-CNN. IEEE Access 2019, 7, 128431–128444. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Zou, H. Toward fast and accurate vehicle detection in aerial images using coupled region-based convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3652–3664. [Google Scholar] [CrossRef]
- Mou, L.; Zhu, X.X. Vehicle instance segmentation from aerial image and video using a multitask learning residual fully convolutional network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6699–6711. [Google Scholar] [CrossRef]
- Li, Q.; Mou, L.; Xu, Q.; Zhang, Y.; Zhu, X.X. R3-net: A deep network for multi-oriented vehicle detection in aerial images and videos. arXiv 2018, arXiv:1808.05560. [Google Scholar]
- Li, X.; Men, F.; Lv, S.; Jiang, X.; Pan, M.; Ma, Q.; Yu, H. Vehicle Detection in Very-High-Resolution Remote Sensing Images Based on an Anchor-Free Detection Model with a More Precise Foveal Area. ISPRS Int. J. Geo-Inf. 2021, 10, 549. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Sun, X.; Yan, M.; Guo, Z.; Fu, K. Position detection and direction prediction for arbitrary-oriented ships via multitask rotation region convolutional neural network. IEEE Access 2018, 6, 50839–50849. [Google Scholar] [CrossRef]
- He, Y.; Sun, X.; Gao, L.; Zhang, B. Ship detection without sea-land segmentation for large-scale high-resolution optical satellite images. In Proceedings of the IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 717–720. [Google Scholar]
- Fu, Y.; Wu, F.; Zhao, J. Context-aware and depthwise-based detection on orbit for remote sensing image. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1725–1730. [Google Scholar]
- Li, M.; Guo, W.; Zhang, Z.; Yu, W.; Zhang, T. Rotated region based fully convolutional network for ship detection. In Proceedings of the IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 673–676. [Google Scholar]
- Schilling, H.; Bulatov, D.; Niessner, R.; Middelmann, W.; Soergel, U. Detection of vehicles in multisensor data via multibranch convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4299–4316. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-insensitive and context-augmented object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2337–2348. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.; Tian, J.; Chanussot, J.; Li, W.; Tao, R. ORSIm detector: A novel object detection framework in optical remote sensing imagery using spatial-frequency channel features. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5146–5158. [Google Scholar] [CrossRef]
- You, Y.; Ran, B.; Meng, G.; Li, Z.; Liu, F.; Li, Z. OPD-Net: Prow detection based on feature enhancement and improved regression model in optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6121–6137. [Google Scholar] [CrossRef]
- Liu, Z.; Hu, J.; Weng, L.; Yang, Y. Rotated region based CNN for ship detection. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 900–904. [Google Scholar]
- Liu, W.; Ma, L.; Chen, H. Arbitrary-oriented ship detection framework in optical remote-sensing images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 937–941. [Google Scholar] [CrossRef]
- Zhao, W.; Ma, W.; Jiao, L.; Chen, P.; Yang, S.; Hou, B. Multi-scale image block-level F-CNN for remote sensing images object detection. IEEE Access 2019, 7, 43607–43621. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, S.; Thachan, S.; Chen, J.; Qian, Y. Deconv R-CNN for small object detection on remote sensing images. In Proceedings of the IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2483–2486. [Google Scholar]
- Van Etten, A. You only look twice: Rapid multi-scale object detection in satellite imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Ma, Y.; Wei, J.; Zhou, F.; Zhu, Y.; Liu, J.; Lei, M. Balanced learning-based method for remote sensing aircraft detection. In Proceedings of the 2019 IEEE International Conference on Signal, Information and Data Processing (ICSIDP), Chongqing, China, 11–13 December 2019; pp. 1–4. [Google Scholar]
- Yu, L.; Hu, H.; Zhong, Z.; Wu, H.; Deng, Q. GLF-Net: A Target Detection Method Based on Global and Local Multiscale Feature Fusion of Remote Sensing Aircraft Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4021505. [Google Scholar] [CrossRef]
- Zhang, S.; He, G.; Chen, H.B.; Jing, N.; Wang, Q. Scale adaptive proposal network for object detection in remote sensing images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 864–868. [Google Scholar] [CrossRef]
- Zou, F.; Xiao, W.; Ji, W.; He, K.; Yang, Z.; Song, J.; Zhou, H.; Li, K. Arbitrary-oriented object detection via dense feature fusion and attention model for remote sensing super-resolution image. Neural Comput. Appl. 2020, 32, 14549–14562. [Google Scholar] [CrossRef]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-aware and multi-scale convolutional neural network for object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; Körner, M.; Reinartz, P. Towards multi-class object detection in unconstrained remote sensing imagery. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 150–165. [Google Scholar]
- Fu, K.; Chen, Z.; Zhang, Y.; Sun, X. Enhanced feature representation in detection for optical remote sensing images. Remote Sens. 2019, 11, 2095. [Google Scholar] [CrossRef]
- Li, Y.; Huang, Q.; Pei, X.; Jiao, L.; Shang, R. RADet: Refine feature pyramid network and multi-layer attention network for arbitrary-oriented object detection of remote sensing images. Remote Sens. 2020, 12, 389. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A context-aware detection network for objects in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef]
- Xu, C.; Li, C.; Cui, Z.; Zhang, T.; Yang, J. Hierarchical semantic propagation for object detection in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4353–4364. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Xia, G.S.; Bai, X.; Yang, W.; Yang, M.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; et al. Object detection in aerial images: A large-scale benchmark and challenges. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Li, X.; Wang, S. Object detection using convolutional neural networks in a coarse-to-fine manner. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2037–2041. [Google Scholar] [CrossRef]
- Chen, G.; Liu, L.; Hu, W.; Pan, Z. Semi-supervised object detection in remote sensing images using generative adversarial networks. In Proceedings of the IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2503–2506. [Google Scholar]
- Wang, T.; Zhang, X.; Yuan, L.; Feng, J. Few-shot adaptive faster r-cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7173–7182. [Google Scholar]
- Wu, J.; Liu, S.; Huang, D.; Wang, Y. Multi-scale positive sample refinement for few-shot object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 456–472. [Google Scholar]
- Xu, H.; Wang, X.; Shao, F.; Duan, B.; Zhang, P. Few-shot object detection via sample processing. IEEE Access 2021, 9, 29207–29221. [Google Scholar] [CrossRef]
- Kim, G.; Jung, H.G.; Lee, S.W. Spatial reasoning for few-shot object detection. Pattern Recognit. 2021, 120, 108118. [Google Scholar] [CrossRef]
- Yang, Y.; Wei, F.; Shi, M.; Li, G. Restoring negative information in few-shot object detection. arXiv 2020, arXiv:2010.11714. [Google Scholar]
- Karlinsky, L.; Shtok, J.; Harary, S.; Schwartz, E.; Aides, A.; Feris, R.; Giryes, R.; Bronstein, A.M. Repmet: Representative-based metric learning for classification and few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5197–5206. [Google Scholar]
- Jeune, P.L.; Lebbah, M.; Mokraoui, A.; Azzag, H. Experience feedback using Representation Learning for Few-Shot Object Detection on Aerial Images. arXiv 2021, arXiv:2109.13027. [Google Scholar]
- Li, B.; Yang, B.; Liu, C.; Liu, F.; Ji, R.; Ye, Q. Beyond Max-Margin: Class Margin Equilibrium for Few-shot Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7363–7372. [Google Scholar]
- Yang, Z.; Wang, Y.; Chen, X.; Liu, J.; Qiao, Y. Context-transformer: Tackling object confusion for few-shot detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12653–12660. [Google Scholar]
- Zhu, C.; Chen, F.; Ahmed, U.; Shen, Z.; Savvides, M. Semantic relation reasoning for shot-stable few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8782–8791. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2013; Volume 26. [Google Scholar]
- Xiao, Z.; Zhong, P.; Quan, Y.; Yin, X.; Xue, W. Few-shot object detection with feature attention highlight module in remote sensing images. In International Society for Optics and Photonics, Proceedings of the 2020 International Conference on Image, Video Processing and Artificial Intelligence, Shanghai, China, 21–23 August 2020; International Society for Optics and Photonics: Bellingham, WA, USA, 2020; Volume 11584, p. 115840Z. [Google Scholar]
- Cheng, G.; Yan, B.; Shi, P.; Li, K.; Yao, X.; Guo, L.; Han, J. Prototype-cnn for few-shot object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5604610. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Y.; Wang, G.; Qiao, Y. Lstd: A low-shot transfer detector for object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly simple few-shot object detection. arXiv 2020, arXiv:2003.06957. [Google Scholar]
- Zhang, L.; Chen, K.J.; Zhou, X. HOSENet: Higher-Order Semantic Enhancement for Few-Shot Object Detection. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Seattle, WA, USA, 13–19 June 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 175–186. [Google Scholar]
- Sun, B.; Li, B.; Cai, S.; Yuan, Y.; Zhang, C. FSCE: Few-shot object detection via contrastive proposal encoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7352–7362. [Google Scholar]
- Fan, Z.; Ma, Y.; Li, Z.; Sun, J. Generalized Few-Shot Object Detection without Forgetting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4527–4536. [Google Scholar]
- Wang, Y.X.; Ramanan, D.; Hebert, M. Meta-learning to detect rare objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9925–9934. [Google Scholar]
- Yan, X.; Chen, Z.; Xu, A.; Wang, X.; Liang, X.; Lin, L. Meta r-cnn: Towards general solver for instance-level low-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9577–9586. [Google Scholar]
- Fan, Q.; Zhuo, W.; Tang, C.K.; Tai, Y.W. Few-shot object detection with attention-RPN and multi-relation detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4013–4022. [Google Scholar]
- Zhang, S.; Luo, D.; Wang, L.; Koniusz, P. Few-shot object detection by second-order pooling. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Liu, L.; Wang, B.; Kuang, Z.; Xue, J.H.; Chen, Y.; Yang, W.; Liao, Q.; Zhang, W. GenDet: Meta Learning to Generate Detectors From Few Shots. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 3448–3460. [Google Scholar] [CrossRef]
- Hu, H.; Bai, S.; Li, A.; Cui, J.; Wang, L. Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10185–10194. [Google Scholar]
- Karlinsky, L.; Shtok, J.; Alfassy, A.; Lichtenstein, M.; Harary, S.; Schwartz, E.; Doveh, S.; Sattigeri, P.; Feris, R.; Bronstein, A.; et al. StarNet: Towards Weakly Supervised Few-Shot Object Detection. arXiv 2020, arXiv:2003.06798. [Google Scholar]
- Zhang, Z.; Hao, J.; Pan, C.; Ji, G. Oriented Feature Augmentation for Few-Shot Object Detection in Remote Sensing Images. In Proceedings of the 2021 IEEE International Conference on Computer Science, Electronic Information Engineering and Intelligent Control Technology (CEI), Fuzhou, China, 24–26 September 2021; pp. 359–366. [Google Scholar]
- Zhao, Z.; Tang, P.; Zhao, L.; Zhang, Z. Few-Shot Object Detection of Remote Sensing Images via Two-Stage Fine-Tuning. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-shot object detection via feature reweighting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8420–8429. [Google Scholar]
- Perez-Rua, J.M.; Zhu, X.; Hospedales, T.M.; Xiang, T. Incremental few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13846–13855. [Google Scholar]
- Li, F.; Yuan, J.; Feng, S.; Cai, X.; Gao, H. Center heatmap attention for few-shot object detection. In Proceedings of the International Symposium on Artificial Intelligence and Robotics 2021, Pretoria, South Africa, 10–11 November 2021; Springer: Berlin/Heidelberg, Germany, 2021; Volume 11884, pp. 230–241. [Google Scholar]
- Zhang, G.; Luo, Z.; Cui, K.; Lu, S. Meta-detr: Few-shot object detection via unified image-level meta-learning. arXiv 2021, arXiv:2103.11731. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Gao, Y.; Hou, R.; Gao, Q.; Hou, Y. A Fast and Accurate Few-Shot Detector for Objects with Fewer Pixels in Drone Image. Electronics 2021, 10, 783. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Q.; Yuan, Y.; Du, Q.; Wang, Q. ABNet: Adaptive Balanced Network for Multiscale Object Detection in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Chen, T.I.; Liu, Y.C.; Su, H.T.; Chang, Y.C.; Lin, Y.H.; Yeh, J.F.; Chen, W.C.; Hsu, W. Dual-awareness attention for few-shot object detection. IEEE Trans. Multimed. arXiv 2021, arXiv:2102.12152. [Google Scholar] [CrossRef]
- Xiao, Z.; Liu, Q.; Tang, G.; Zhai, X. Elliptic Fourier transformation-based histograms of oriented gradients for rotationally invariant object detection in remote-sensing images. Int. J. Remote Sens. 2015, 36, 618–644. [Google Scholar] [CrossRef]
- Shi, Z. Chapter 14—Brain-like intelligence. In Intelligence Science; Shi, Z., Ed.; Elsevier: Amsterdam, The Netherlands, 2021; pp. 537–593. [Google Scholar] [CrossRef]
- Girshick, R.; Radosavovic, I.; Gkioxari, G.; Dollár, P.; He, K. Detectron. 2018. Available online: https://github.com/facebookresearch/detectron (accessed on 23 August 2022).
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Waqas Zamir, S.; Arora, A.; Gupta, A.; Khan, S.; Sun, G.; Shahbaz Khan, F.; Zhu, F.; Shao, L.; Xia, G.S.; Bai, X. isaid: A large-scale dataset for instance segmentation in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 28–37. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Zhang, X.; Zhang, H.; Jiang, Z. Few shot object detection in remote sensing images. In International Society for Optics and Photonics, Proceedings of the Image and Signal Processing for Remote Sensing XXVII, Online, 13–17 September 2021; Bruzzone, L., Bovolo, F., Eds.; SPIE: Bellingham, WA, USA, 2021; Volume 11862, pp. 76–81. [Google Scholar] [CrossRef]
- Allen-Zhu, Z.; Li, Y. Towards understanding ensemble, knowledge distillation and self-distillation in deep learning. arXiv 2020, arXiv:2012.09816. [Google Scholar]
- Li, Y.; Cheng, Y.; Liu, L.; Tian, S.; Zhu, H.; Xiang, C.; Vadakkepat, P.; Teo, C.; Lee, T. Low-shot Object Detection via Classification Refinement. arXiv 2020, arXiv:2005.02641. [Google Scholar]
- Zhang, W.; Wang, Y.X. Hallucination improves few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13008–13017. [Google Scholar]
- Qiao, L.; Zhao, Y.; Li, Z.; Qiu, X.; Wu, J.; Zhang, C. Defrcn: Decoupled faster r-cnn for few-shot object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 8681–8690. [Google Scholar]
- Xiao, Y.; Marlet, R. Few-shot object detection and viewpoint estimation for objects in the wild. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 192–210. [Google Scholar]
- Li, A.; Li, Z. Transformation invariant few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3094–3102. [Google Scholar]







| Dataset | # cls | Base Classes | Novel Classes | Papers |
|---|---|---|---|---|
| NWPU VHR-10 | 10 | Remaining classes | 3 classes: airplane, baseball diamond, and tennis court | [10,17,97,98] |
| Remaining classes | Random 1 class except for storage tank and harbor | [11] | ||
| DIOR | 20 | Remaining classes | 5 classes: airplane, baseball field, tennis court, train station, windmill | [10,17,97,98] |
| Remaining classes | Split 1: baseball field, basketball court, bridge, chimney, ship | [84] | ||
| Split 2: airplane, airport, expressway toll station, harbor, ground track field | ||||
| Split 3: dam, golf course, storage tank, tennis court, vehicle | ||||
| Split 4: expressway service area, overpass, stadium, train station, windmill | ||||
| RSOD | 4 | Remaining classes | Random 1 class | [11,83] |
| iSAID | 15 | Remaining classes | Split 1: Helicopter, Ship, Plane, Large Vehicle | [16] |
| Split 2: Baseball Diamond, Soccer Ball Field, Roundabout | ||||
| Split 3: Ground Track Field, Helicopter, Baseball Diamond Roundabout, Soccer Ball Field, Basketball Court | ||||
| DOTAv1.5 | 16 | Remaining classes | Split 1: plane, ship, tennis court | [78] |
| Split 2: harbor, helicopter, soccer ball field | ||||
| DAN | 15 | Remaining classes | 3 classes: vehicle, storage tank, plane | [105] |
| Dataset | # Class | # Image | # Instance | Avg. # Img/Cls |
|---|---|---|---|---|
| PASCAL VOC 07+12 | 20 | 21,493 | 52,090 | 2604.5 |
| MS-COCO | 80 | 330 K | 1.5 million | 4125 |
| FSOD | 1000 | 66,502 | 182,951 | 182.951 |
| Method | Type | Novel mAP | Base mAP | ||||
|---|---|---|---|---|---|---|---|
| 1-Shot | 2-Shot | 3-Shot | 5-Shot | 10-Shot | |||
| FSODM [10] | Meta learning | - | - | 32 | 53 | 65 | 78 |
| SAM&BFS [17] | Transfer learning | 16.4 | 36.3 | 47 | 61.6 | 74.9 | - |
| OFA [97] | Meta learning | - | 34 | 43.2 | 60.4 | 66.7 | - |
| PAMS-Det [98] | Transfer learning | - | - | 37 | 55 | 66 | 88 |
| Method | Novel Class | 1-Shot | 2-Shot | 3-Shot | 5-Shot | 10-Shot |
|---|---|---|---|---|---|---|
| SAAN [11] | Airplane | 9.09 | 15.72 | 25.71 | 34.68 | 38.78 |
| Ship | 28.77 | 52.78 | 57.95 | 78.05 | 81.14 | |
| Baseball diamond | 32.6 | 63.41 | 80.26 | 81.2 | 89.75 | |
| Tennis court | 18.32 | 23.73 | 29.45 | 47.68 | 54.11 | |
| Basketball court | 21.33 | 37.74 | 42.43 | 54.78 | 80.16 | |
| Ground track field | 31.29 | 42.24 | 52.12 | 78.88 | 89.57 | |
| Bridge | 3.08 | 9.31 | 16.94 | 18.68 | 43.94 | |
| Vehicle | 9.37 | 13.15 | 22.77 | 29.6 | 36.24 |
| Method | Type | Novel mAP | Base mAP | ||||
|---|---|---|---|---|---|---|---|
| 2-Shot | 3-Shot | 5-Shot | 10-Shot | 20-Shot | |||
| FSODM [10] | Meta learning | - | - | 25 | 32 | 36 | 54 |
| SAM&BFS [17] | Transfer learning | - | - | 38.3 | 47.3 | 50.9 | - |
| OFA [97] | Meta learning | 27.6 | 32.8 | 37.9 | 40.7 | - | - |
| PAMS-Det [98] | Transfer learning | - | 28 | 33 | 38 | - | 65 |
| Novel mAP | Base mAP | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | 3-Shot | 5-Shot | 10-Shot | 20-Shot | 30-Shot | 3-Shot | 5-Shot | 10-Shot | 20-Shot | 30-Shot | |
| P-CNN [84] | Split 1 | 18 | 22.8 | 27.6 | 29.6 | 32.6 | 47 | 48.4 | 50.9 | 52.2 | 53.3 |
| Split 2 | 14.5 | 14.9 | 18.9 | 22.8 | 25.7 | 48.9 | 49.1 | 52.5 | 51.6 | 53 | |
| Split 3 | 16.5 | 18.8 | 23.3 | 28.8 | 32.1 | 49.5 | 49.9 | 52.1 | 53.1 | 53.6 | |
| Split 4 | 15.2 | 17.5 | 18.9 | 25.7 | 28.7 | 49.8 | 49.9 | 51.7 | 52.3 | 53.6 | |
| Method/Shot | Split 1 | Split 2 | Split 3 | Split 4 | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 5 | 10 | 1 | 2 | 3 | 5 | 10 | 1 | 2 | 3 | 5 | 10 | 1 | 2 | 3 | 5 | 10 | |
| SAAN [11] | 9.09 | 4.79 | 8.02 | 10.15 | 17.54 | 4.44 | 17.69 | 21.8 | 38.91 | 41.95 | 1.14 | 2.9 | 2.31 | 4.55 | 11.54 | 20.21 | 27.3 | 41.16 | 38.9 | 64.72 |
| FAHM [83] | 9.1 | 10.6 | 15 | 20.2 | 43.5 | 16.54 | 34.8 | 51.6 | 60.92 | 71.27 | 9.09 | 11.36 | 21.01 | 41.4 | 59.63 | 33.54 | 50.5 | 61.6 | 77.1 | 88.98 |
| Ours | 12.9 | 16.2 | 22.5 | 27.7 | 32.1 | 9.09 | 15.5 | 37.4 | 58.4 | 63.2 | 11.5 | 15.2 | 20.8 | 42.7 | 66.9 | 37.6 | 68.1 | 84.8 | 90.3 | 96.6 |
| Method | Novel mAP | Base mAP | |||||
|---|---|---|---|---|---|---|---|
| 10-Shot | 50-Shot | 100-Shot | 10-Shot | 50-Shot | 100-Shot | ||
| DH-FsDet [16] | Split 1 | 5.2 ± 0.8 | 12.8 ± 0.8 | 16.7 ± 1.7 | 65.0 ± 0.2 | 65.1 ± 0.1 | 65.2 ± 0.1 |
| Split 2 | 14.5 ± 1.7 | 28.9 ± 3.4 | 36.0 ± 1.7 | 64.5 ± 0.1 | 64.7 ± 0.1 | 64.8 ± 0.1 | |
| Split 3 | 9.7 ± 2.2 | 19.6 ± 2.4 | 23.1 ± 0.9 | 67.8 ± 0.1 | 68.0 ± 0.1 | 68.1 ± 0.1 | |
| Method | Novel mAP | Base mAP | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1-Shot | 2-Shot | 5-Shot | 10-Shot | 1-Shot | 2-Shot | 5-Shot | 10-Shot | ||
| prototypical FRCN [78] | Split 1 | 0.047 ± 0.02 | 0.024 ± 0.01 | 0.038 ± 0.01 | 0.041 ± 0.01 | 0.275 ± 0.01 | 0.352 ± 0.02 | 0.390 ± 0.01 | 0.384 ± 0.02 |
| Split 2 | 0.08 ± 0.01 | 0.101 ± 0.02 | 0.121 ± 0.01 | 0.101 ± 0.02 | 0.415 ± 0.03 | 0.392 ± 0.03 | 0.434 ± 0.02 | 0.414 ± 0.03 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; You, Y.; Su, H.; Meng, G.; Yang, W.; Liu, F. Few-Shot Object Detection in Remote Sensing Image Interpretation: Opportunities and Challenges. Remote Sens. 2022, 14, 4435. https://doi.org/10.3390/rs14184435
Liu S, You Y, Su H, Meng G, Yang W, Liu F. Few-Shot Object Detection in Remote Sensing Image Interpretation: Opportunities and Challenges. Remote Sensing. 2022; 14(18):4435. https://doi.org/10.3390/rs14184435
Chicago/Turabian StyleLiu, Sixu, Yanan You, Haozheng Su, Gang Meng, Wei Yang, and Fang Liu. 2022. "Few-Shot Object Detection in Remote Sensing Image Interpretation: Opportunities and Challenges" Remote Sensing 14, no. 18: 4435. https://doi.org/10.3390/rs14184435
APA StyleLiu, S., You, Y., Su, H., Meng, G., Yang, W., & Liu, F. (2022). Few-Shot Object Detection in Remote Sensing Image Interpretation: Opportunities and Challenges. Remote Sensing, 14(18), 4435. https://doi.org/10.3390/rs14184435