

Local Matrix Feature-Based Kernel Joint Sparse Representation for Hyperspectral Image Classification


Abstract
:1. Introduction
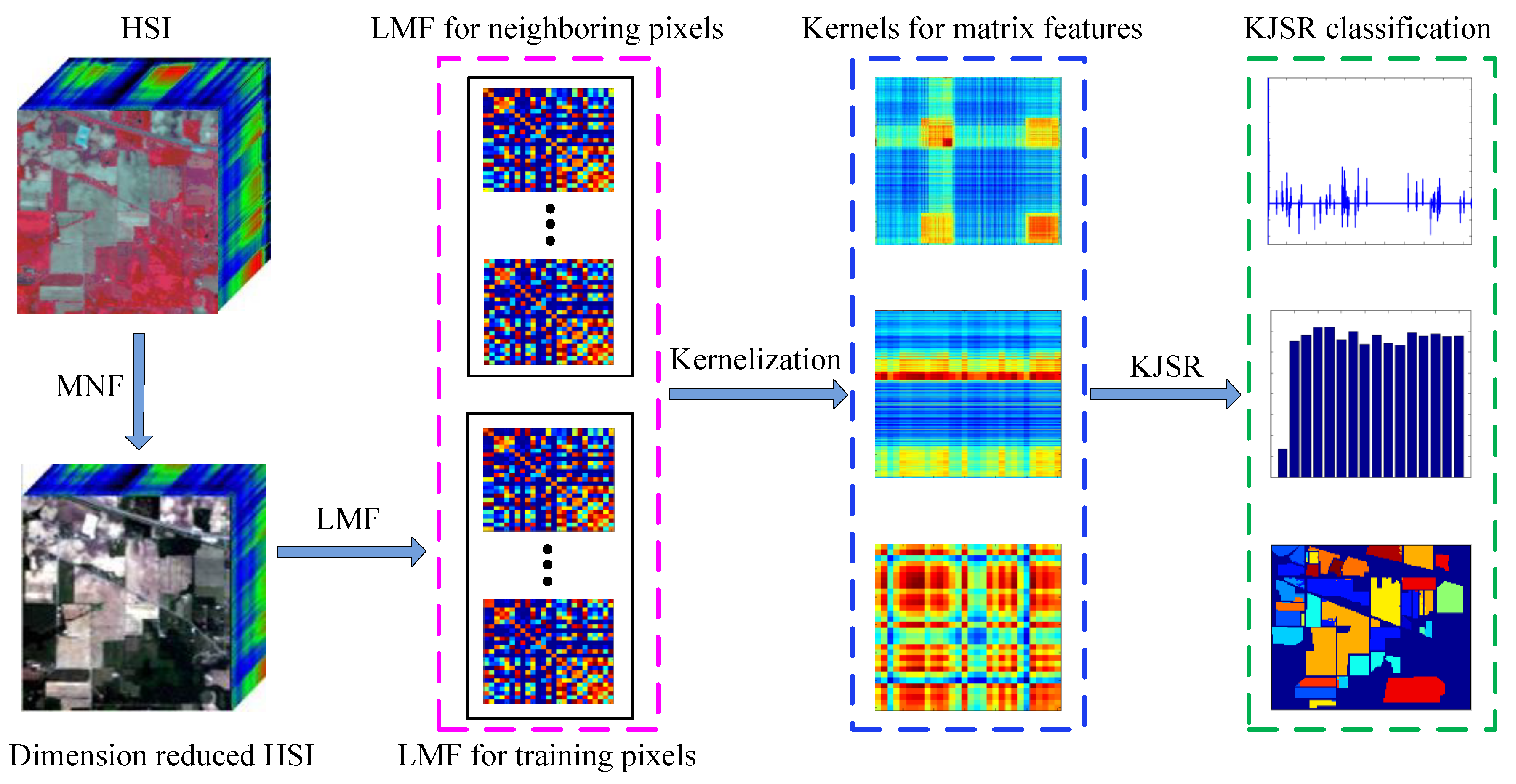
2. The Proposed Method
2.1. Maximum Noise Fraction
2.2. Local Neighborhood Construction
2.3. Local Matrix Representation
2.3.1. Local Covariance Matrix Representation
2.3.2. Local Correntropy Matrix Representation
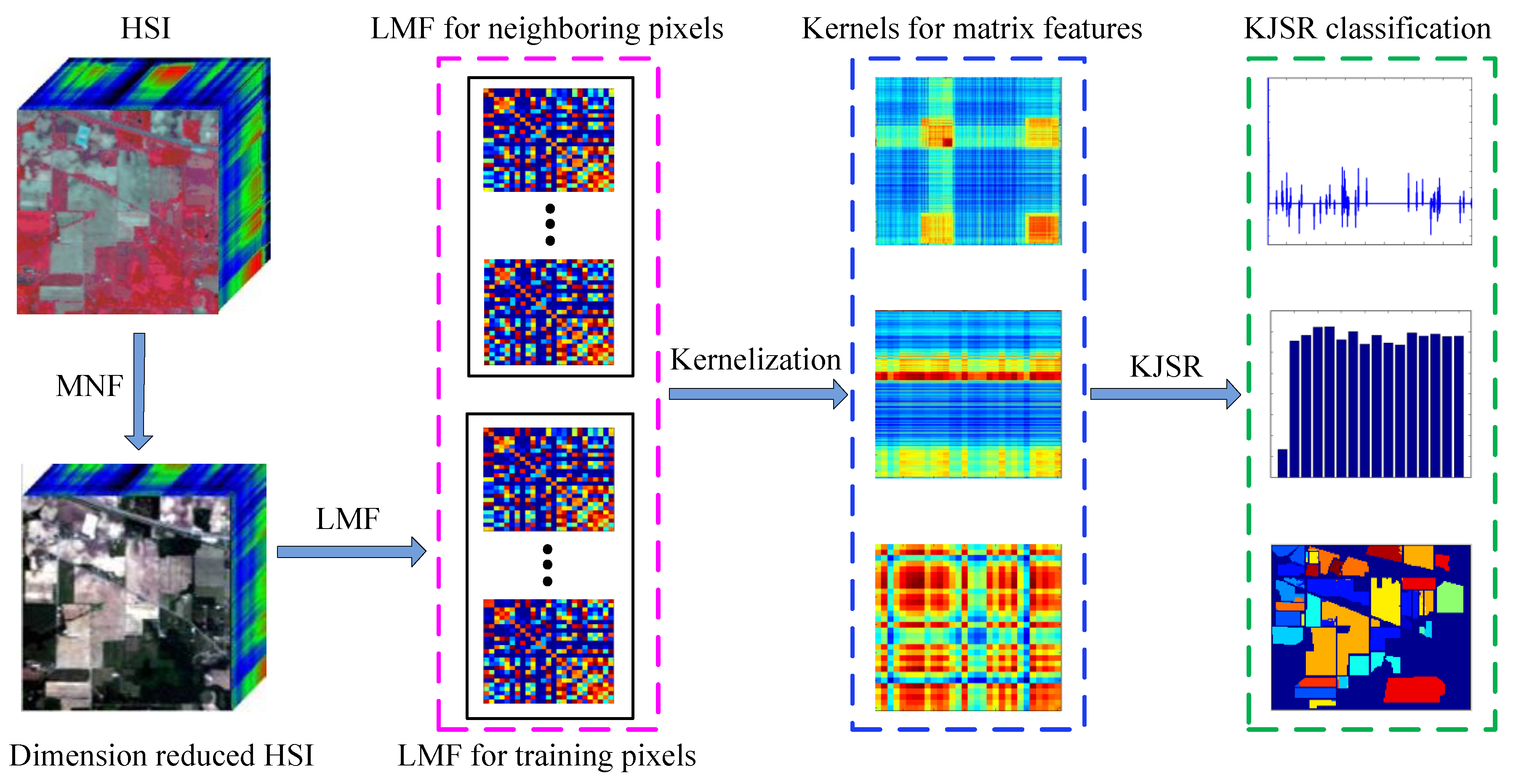
2.3.3. Local Matrix Feature
2.4. Local Matrix Feature Based Kernel Joint Sparse Representation
2.4.1. Joint Sparse Representation (JSR)
2.4.2. Kernel Joint Sparse Representation (KJSR)
2.4.3. Local Matrix Feature Based Kernel Joint Sparse Representation (LMFKJSR)
| Algorithm 1 LMFKJSR. |
Input: Dictionary , parameter K Output: The label of all testing pixels.
|
3. Experiments
3.1. Data Sets
- (1)
- Indian Pines (IP) (ftp://ftp.ecn.purdue.edu/biehl/MultiSpec/92AV3C.tif.zip, accessed on 8 October 2015): These data have a size of pixels and 220 spectral bands. After 20 bad bands are removed, the remaining 200 bands are used. The IP data contain 16 land cover classes. The false color composite image and ground-truth map are shown in Figure 2.
- (2)
- University of Pavia (UP) (https://www.ehu.eus/ccwintco/index.php?title=Hyperspectral_Remote_Sensing_Scenes, accessed on 8 June 2013): The UP data has the size of pixels and 115 spectral bands. After 12 bad bands are discared, 103 bands are retained. The data contain nine ground-truth classes. The false color composition image and the ground-truth map are shown in Figure 3.
- (3)
- Salinas (SA) (https://www.ehu.eus/ccwintco/index.php?title=Hyperspectral_Remote_Sensing_Scenes, accessed on 8 June 2013): The SA data have a size of pixels and 204 spectral bands. The data contain 16 ground-truth classes. The false color composite image and the ground-truth map are shown in Figure 4.
3.2. Experimental Setting
3.3. Classification Results
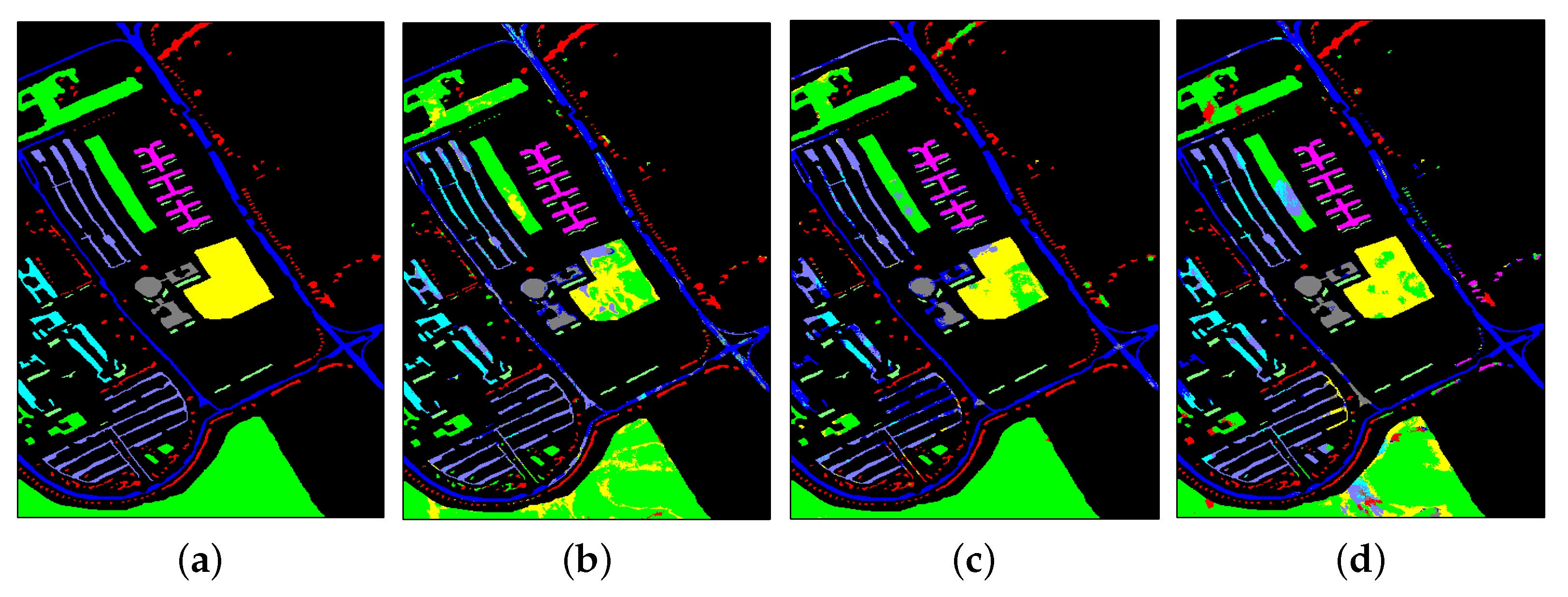
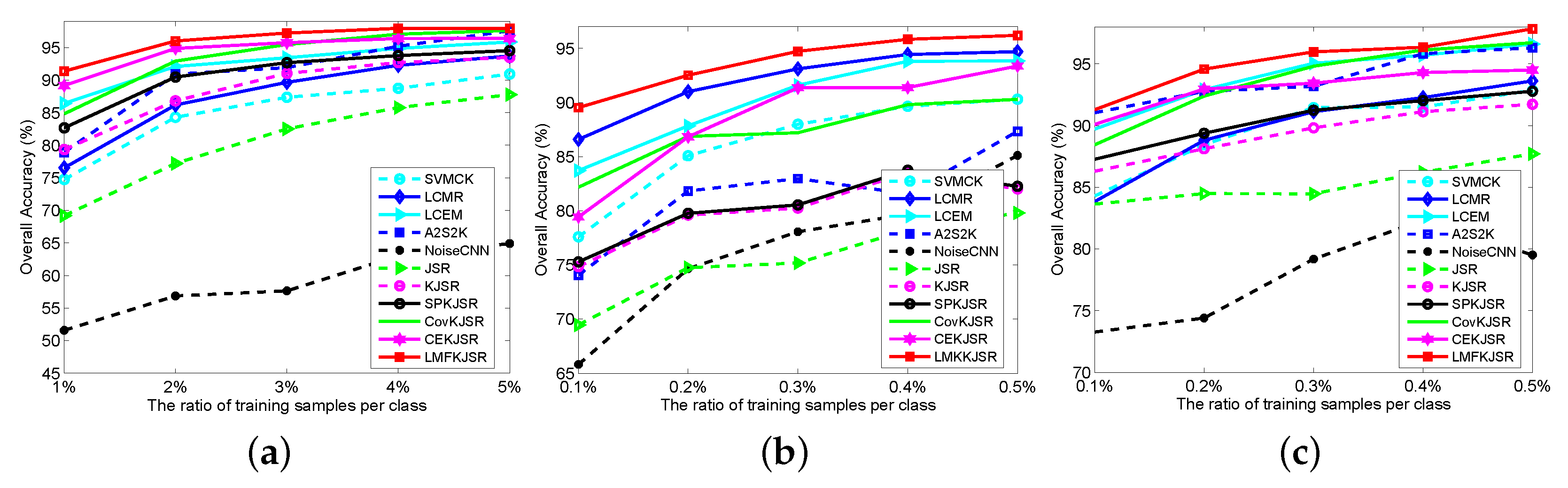
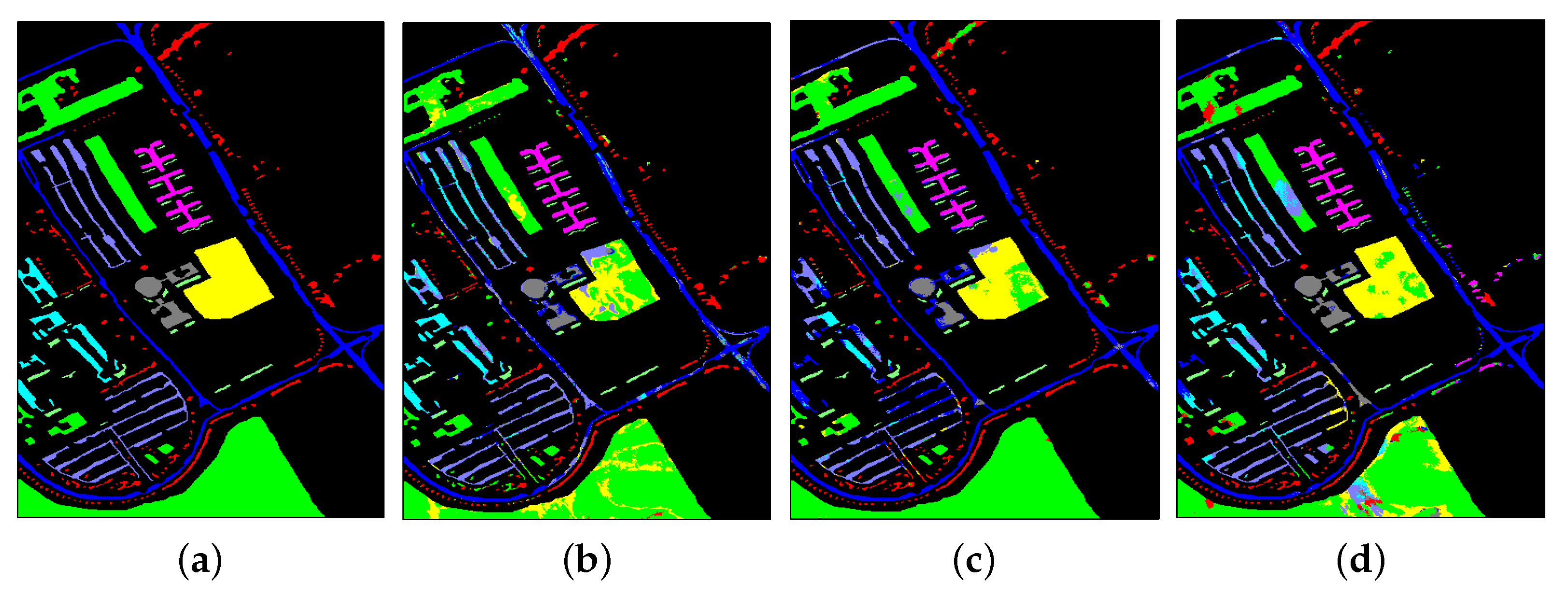
3.3.1. Results from IP
- (1)
- Among the three SVM-based classifiers, the matrix-feature-based classifiers (LCMR and LCEM) show much better results than the vector-feature-based SVM-CK. This demonstrates that the local covariance or correntropy matrix feature representation is more effective than the vector feature representation. In addition, due to the strong nonlinearity similarity representation ability, LCEM shows much better results than LCMR.
- (2)
- The recently proposed deep HSI classification methods (A2S2K and NoiseCNN) show poor results due to the limited number of training samples. In particular, for Classes 7 and 9 with only three training samples, the OA of each method is lower than 50%. To achieve satisfactory results, deep learning methods usually need a large number of training samples.
- (3)
- By mining nonlinear relations between pixels, KJSR improves JSR. By further selecting similar pixels in the spatial neighborhood based on self-paced learning, SPKJSR improves KJSR. By exploiting matrix representations, CovKJSR and CEKJSR improve the traditional vector-feature-based KJSRs. CEKJSR shows better results than CovKJSR.
- (4)
- Comparing CovKJSR with LCMR (or CEKJSR with LCEM), it can be seen that the KJSR methods show better results than SVM-based methods on these data. For IP data, there are many large homogeneous regions and region-based characteristics that can be used to improve the classification performance. Different from LCMR and LCEM, which only use the region-based matrix features, CovKJSR and CEKJSR use region-based characteristics in both the feature and classification parts. Therefore, KJSR methods show relatively better results.
- (5)
- By combining the local covariance and correntropy matrix features, the proposed LMFKJSR improves both methods and provides the best results. It demonstrates that the local covariance and correntropy features are complementary.
- (6)
- On the subclasses of “Corn” (Classes 2, 3, 4) and “Soybean” (Classes 10, 11, 12), the proposed LMFKJSR provides overall better results than the other methods (i.e., the best results on Classes 2, 10, and 11, the second best results on Classes 3 and 4). The results demonstrate that the local matrix feature representations exploiting both spectral correlation with covariance features and band similarity with correntropy features are more effective in distinguishing the subtle differences between similar materials.
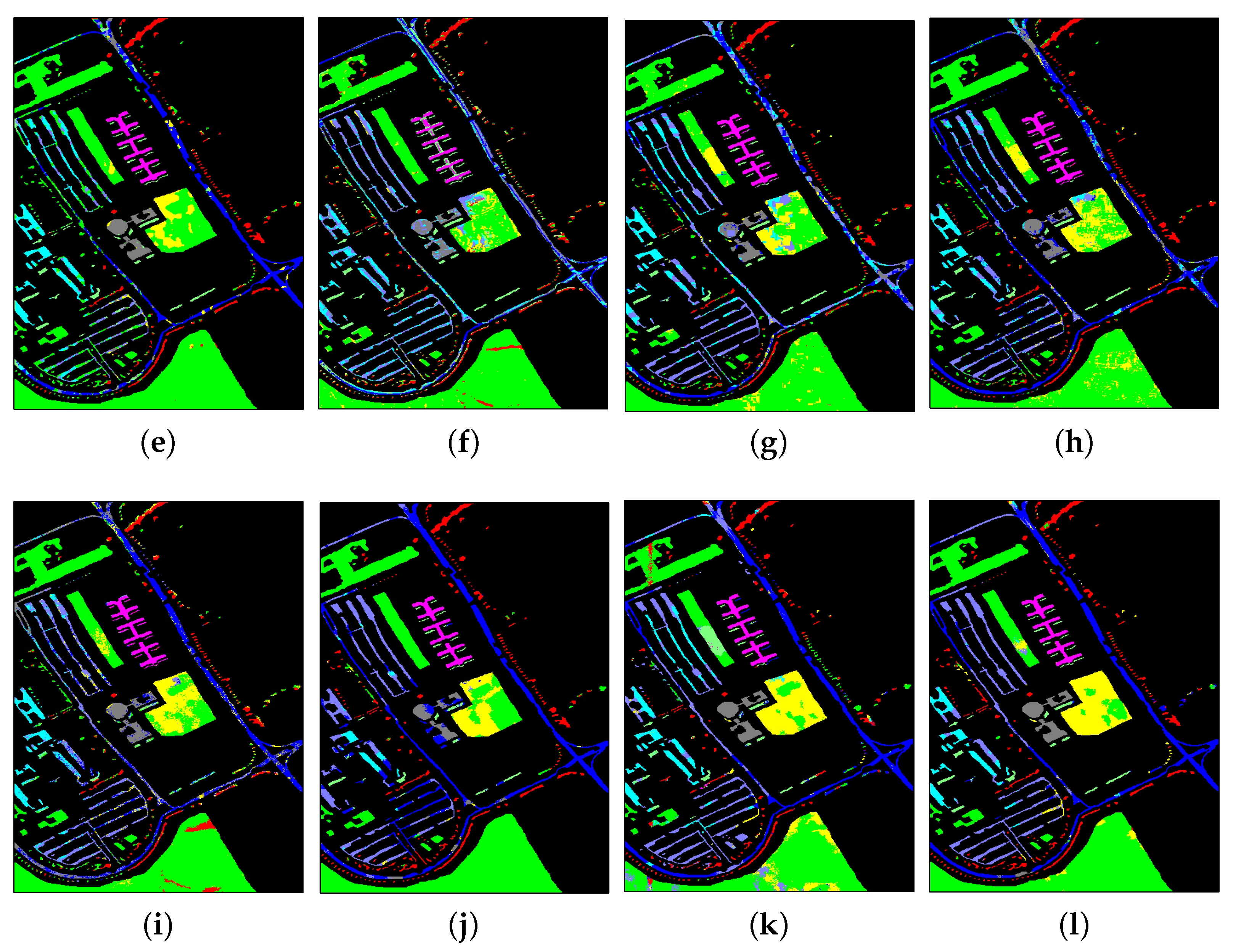
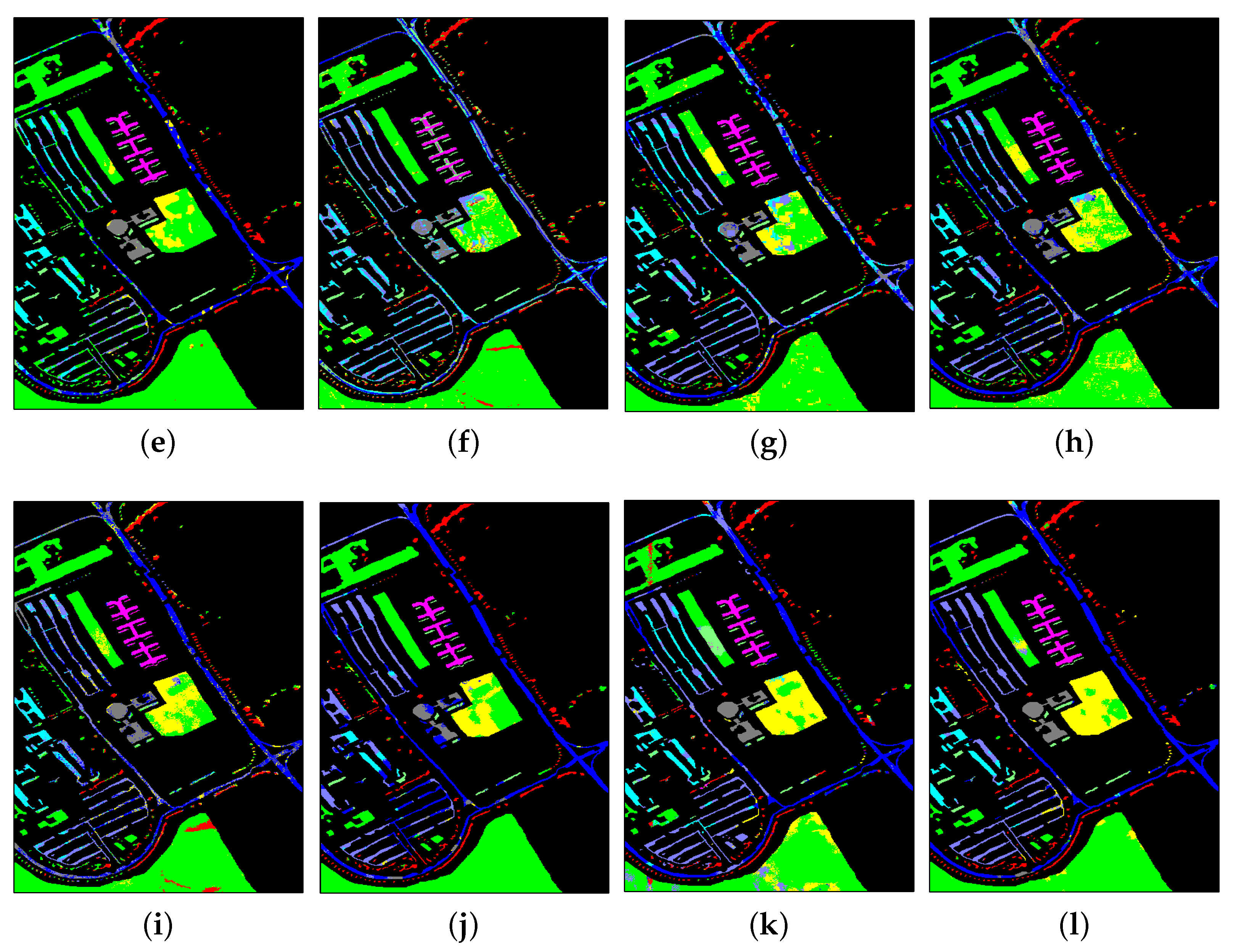
3.3.2. Results from UP
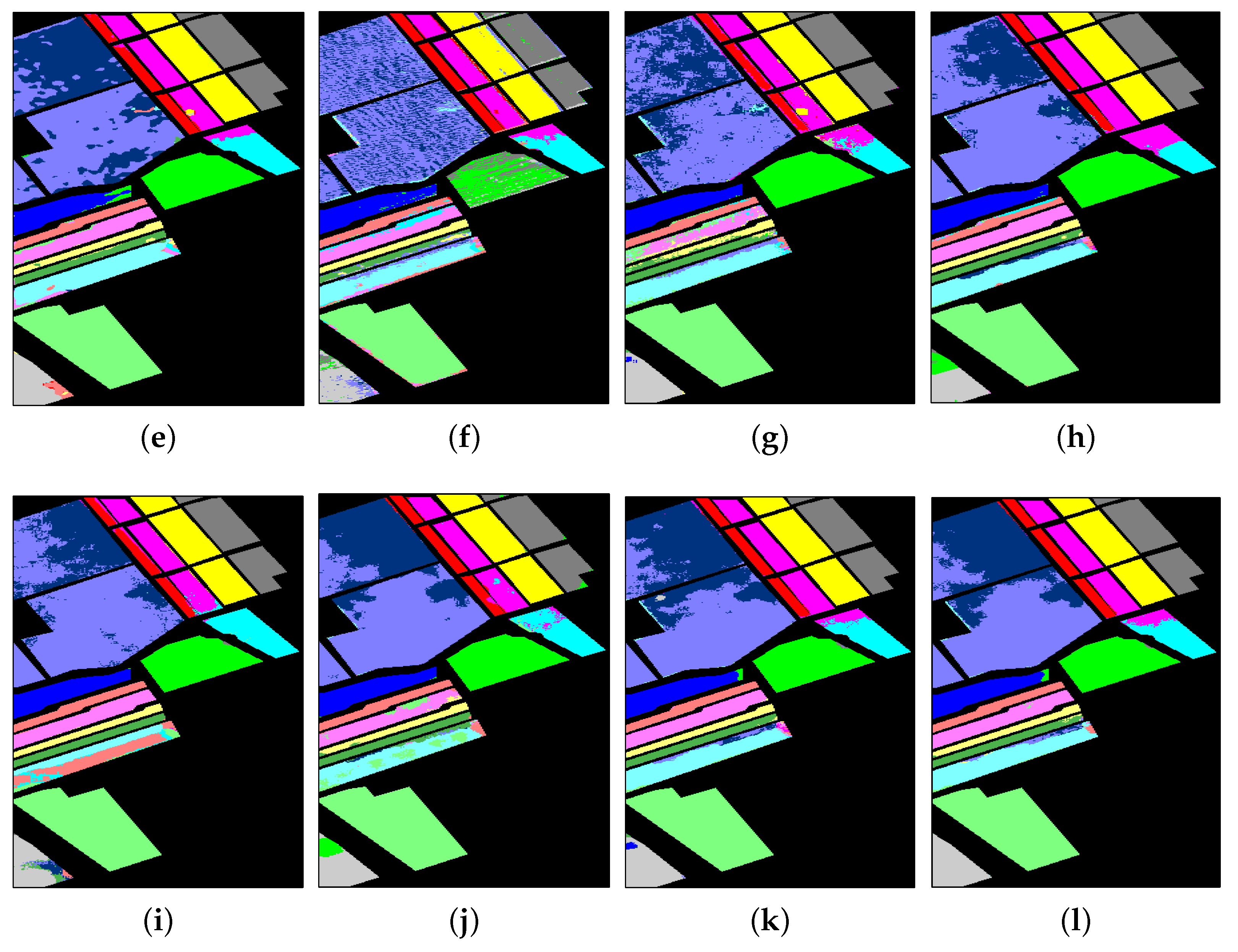
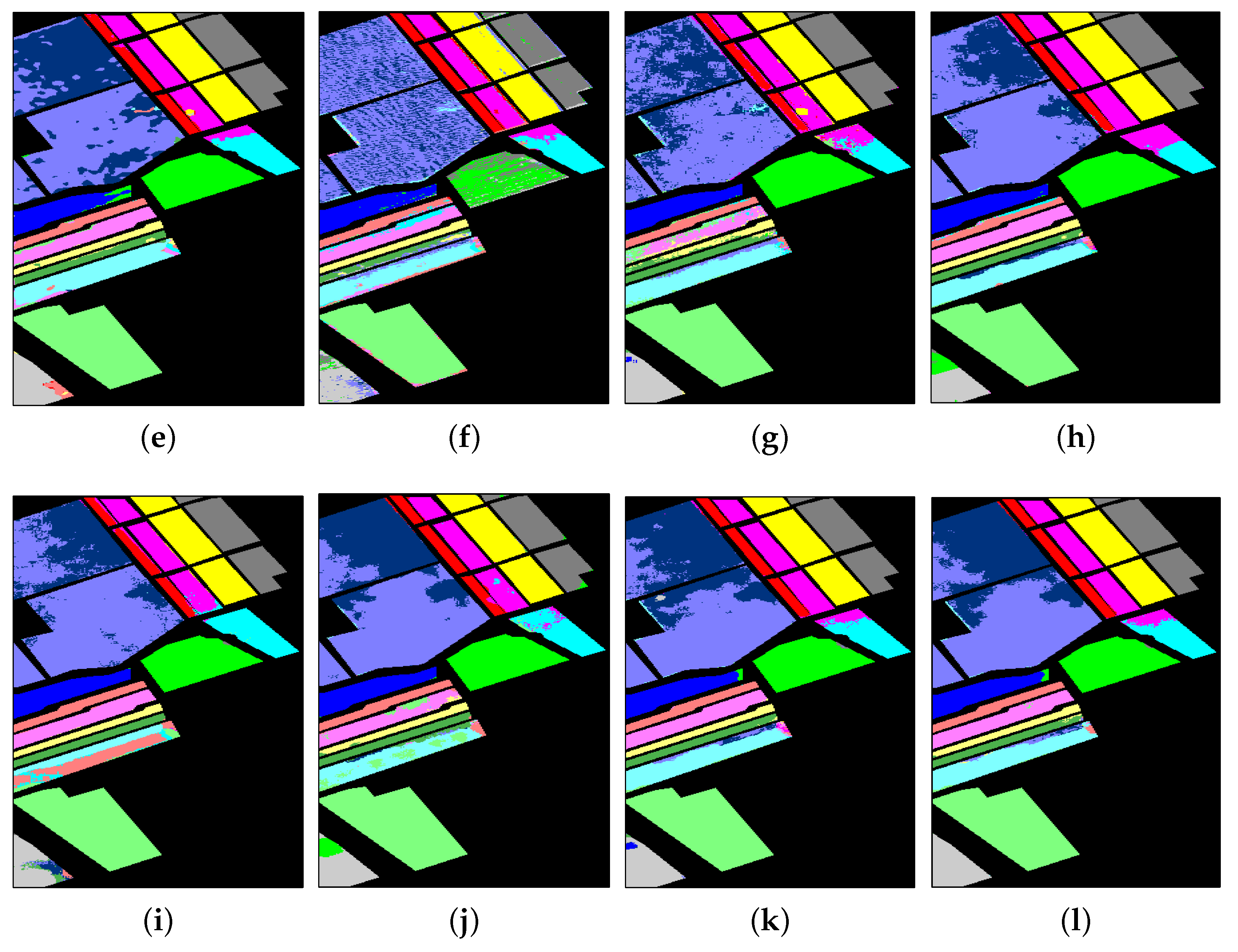
3.3.3. Results from SA
4. Discussions
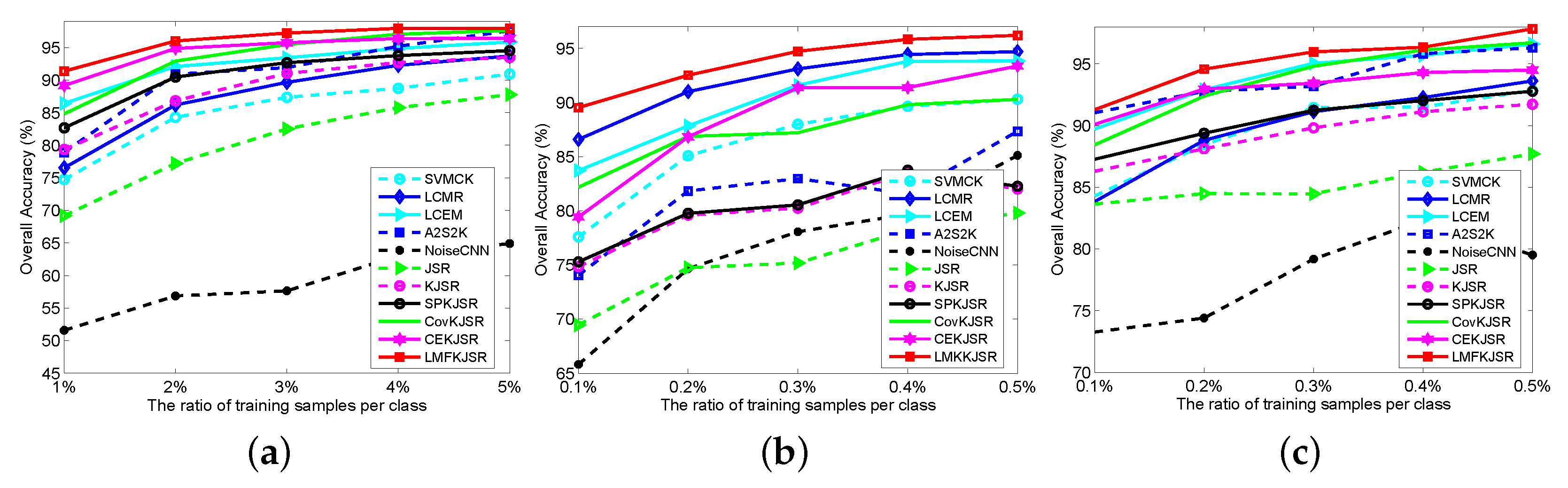
4.1. The Effect of the Number of Training Samples
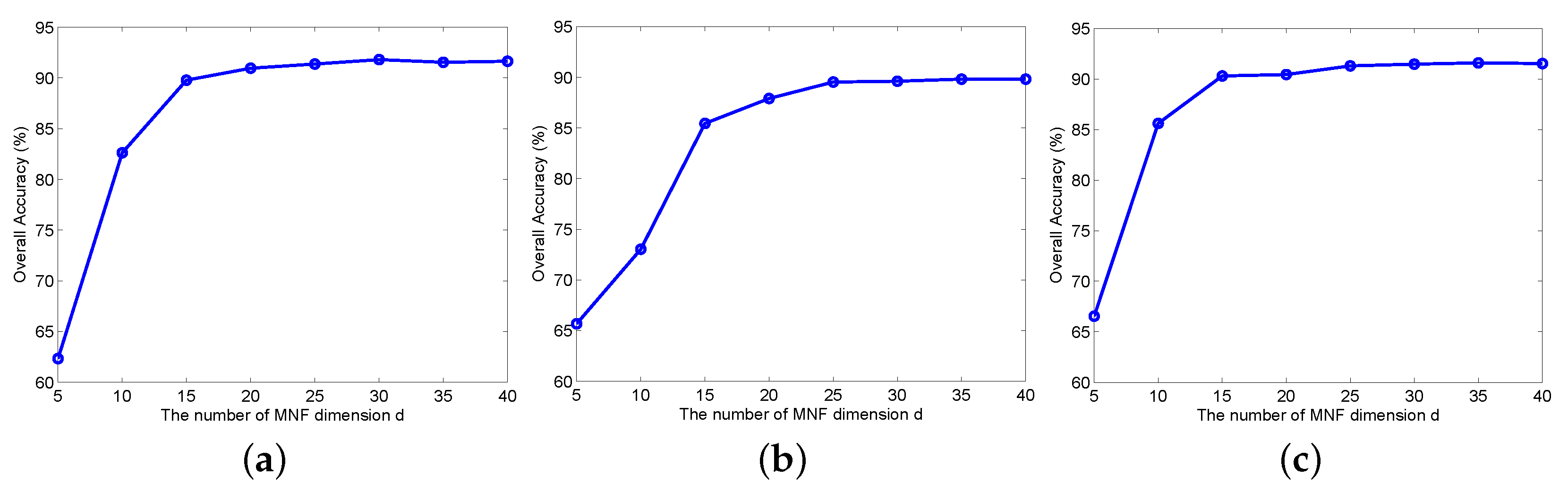
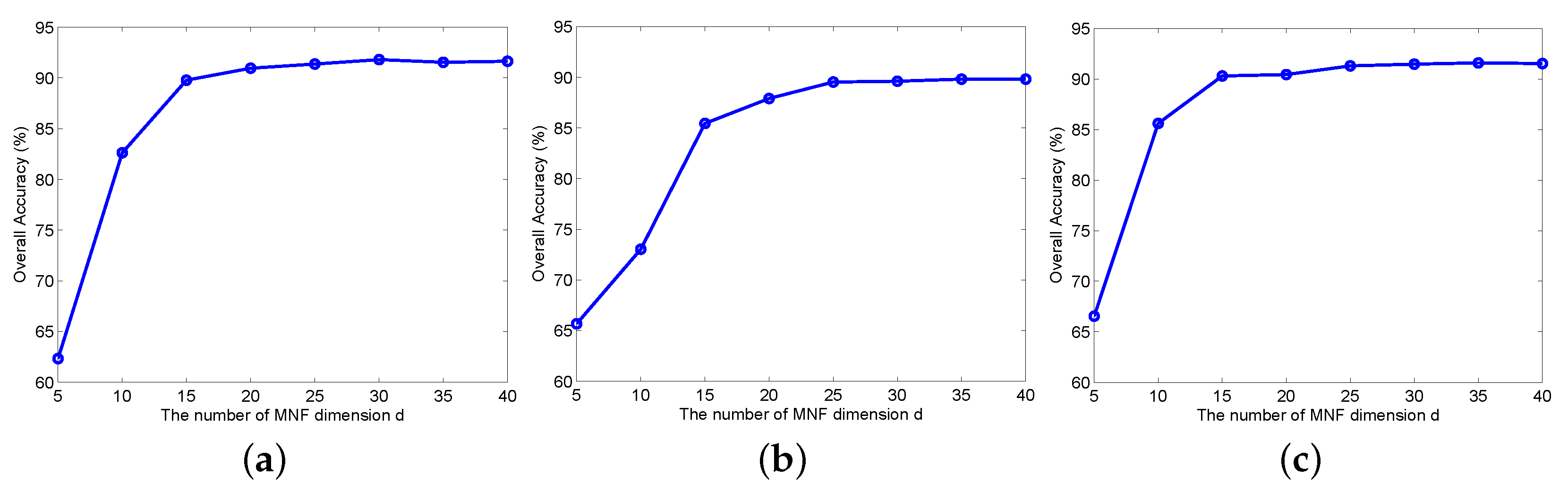
4.2. The Effect of the MNF Dimension
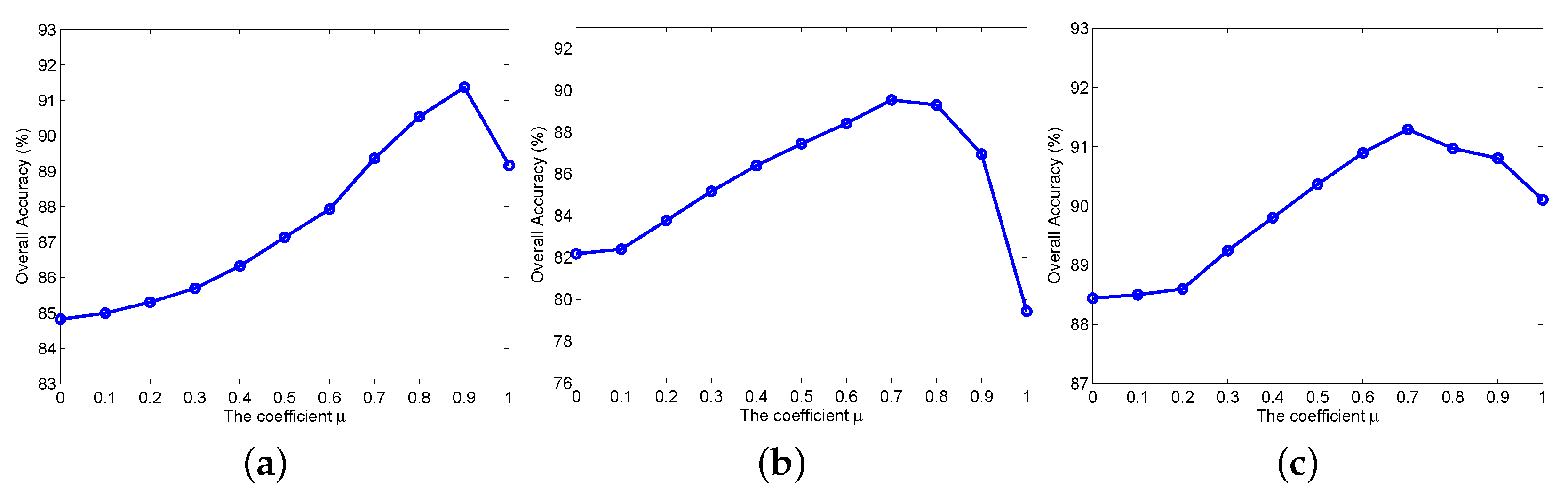
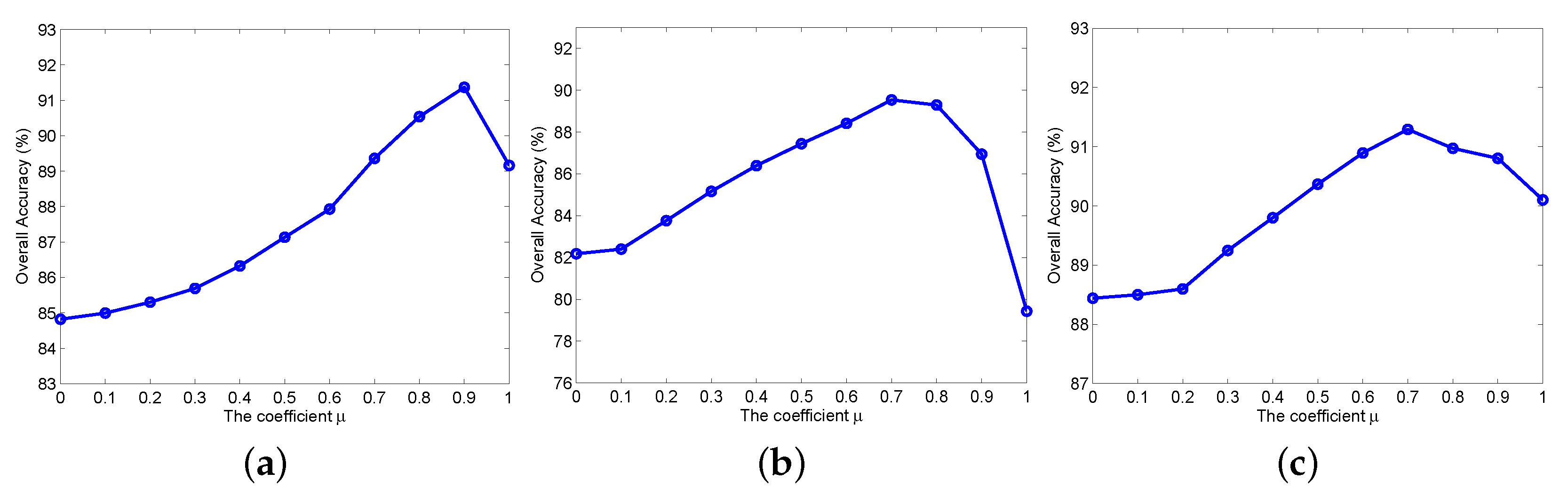
4.3. The Effect of the Weighting Coefficient
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral remote sensing data analysis and future challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef]
- He, L.; Li, J.; Liu, C.; Li, S. Recent advances on spectral-spatial hyperspectral image classification: An overview and new guidelines. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1579–1597. [Google Scholar]
- Peng, J.; Sun, W.; Li, H.; Li, W.; Meng, X.; Ge, C.; Du, Q. Low-rank and sparse representation for hyperspectral image processing: A review. IEEE Geosci. Remote Sens. Mag. 2022, 10, 10–43. [Google Scholar]
- Benediktsson, J.A.; Pesaresi, M.; Arnason, K. Classification and feature extraction for remote sensing images from urban areas based on morphological transformations. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1940–1949. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. An SVM ensemble approach combining spectral, structural, and semantic features for the classification of high-resolution remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2013, 51, 257–272. [Google Scholar] [CrossRef]
- Zhou, Y.; Peng, J.; Chen, C.L.P. Dimension reduction using spatial and spectral regularized local discriminant embedding for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1082–1095. [Google Scholar]
- Fang, L.; He, N.; Li, S.; Plaza, A.; Plaza, J. A new spatial-spectral feature extraction method for hyperspectral images using local covariance matrix representation. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3534–3546. [Google Scholar] [CrossRef]
- Rasti, B.; Hong, D.; Hang, R.; Ghamisi, P.; Kang, X.; Chanussot, J.; Benediktsson, J.A. Feature extraction for hyperspectral imagery: The evolution from shallow to deep: Overview and toolbox. IEEE Geosci. Remote Sens. Mag. 2020, 8, 60–88. [Google Scholar] [CrossRef]
- Jia, S.; Zhan, Z.; Zhang, M.; Xu, M.; Huang, Q.; Zhou, J.; Jia, X. Multiple feature-based superpixel-level decision fusion for hyperspectral and LiDAR data classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1437–1452. [Google Scholar]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Bruzzone, L. Kernel-based methods for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1351–1362. [Google Scholar] [CrossRef]
- Shen, L.; Jia, S. Three-dimensional Gabor wavelets for pixel-based hyperspectral imagery classification. IEEE Trans. Geosci. Remote Sens. 2011, 49, 5039–5046. [Google Scholar] [CrossRef]
- Li, W.; Chen, C.; Su, H.; Du, Q. Local binary patterns and extreme learning machine for hyperspectral imagery classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3681–3693. [Google Scholar] [CrossRef]
- Borzov, S.; Potaturkin, O. Increasing the classification efficiency of hyperspectral images due to multi-scale spatial processing. Comput. Opt. 2020, 44, 937–943. [Google Scholar]
- Camps-Valls, G.; Gomez-Chova, L.; Munoz-Mare, J.; Vila-Frances, J.; Calpe-Maravilla, J. Composite kernels for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2006, 3, 93–97. [Google Scholar] [CrossRef]
- Peng, J.; Zhou, Y.; Chen, C.L.P. Region-kernel-based support vector machines for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4810–4824. [Google Scholar]
- Zhou, Y.; Peng, J.; Chen, C.L.P. Extreme learning machine with composite kernels for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2351–2360. [Google Scholar]
- Gu, Y.; Chanussot, J.; Jia, X.; Benediktsson, J.A. Multiple kernel learning for hyperspectral image classification: A review. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6547–6565. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.; Tran, T. Hyperspectral image classification using dictionary-based sparse representation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3973–3985. [Google Scholar]
- Peng, J.; Du, Q. Robust joint sparse representation based on maximum correntropy criterion for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7152–7164. [Google Scholar]
- Peng, J.; Sun, W.; Du, Q. Self-paced joint sparse representation for the classification of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1183–1194. [Google Scholar] [CrossRef]
- Li, W.; Du, Q. Joint within-class collaborative representation for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2200–2208. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Roy, S.; Manna, S.; Song, T.; Bruzzone, L. Attention-based adaptive spectral–spatial kernel ResNet for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7831–7843. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Gong, Z.; Zhong, P.; Qi, J.; Hu, P. A CNN with noise inclined module and denoise framework for hyperspectral image classification. arXiv 2022, arXiv:2205.12459. [Google Scholar]
- Yang, W.; Peng, J.; Sun, W.; Du, Q. Log-Euclidean kernel-based joint sparse representation for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 5023–5034. [Google Scholar] [CrossRef]
- Tabia, H.; Laga, H. Covariance-based descriptors for efficient 3D shape matching, retrieval, and classification. IEEE Trans. Multimed. 2015, 17, 1591–1603. [Google Scholar] [CrossRef]
- Tuzel, O.; Porikli, F.; Meer, P. Region covariance: A fast descriptor for detection and classification. In Proceedings of the European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006; pp. 589–600. [Google Scholar]
- Zhang, X.; Wei, Y.; Cao, W.; Yao, H.; Peng, J.; Zhou, Y. Local correntropy matrix representation for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5525813. [Google Scholar] [CrossRef]
- Liu, W.; Pokharel, P.P.; Príncipe, J.C. Correntropy: Properties and applications in non-Gaussian signal processing. IEEE Trans. Signal Process. 2007, 55, 5286–5298. [Google Scholar] [CrossRef]
- Peng, J.; Li, L.; Tang, Y. Maximum likelihood estimation based joint sparse representation for the classification of hyperspectral remote sensing images. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1790–1802. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Nasrabadi, N.; Tran, T. Hyperspectral image classification via kernel sparse representation. IEEE Trans. Geosci. Remote Sens. 2013, 51, 217–231. [Google Scholar] [CrossRef]
- Green, A.; Berman, M.; Switzer, P.; Craig, M.D. A transformation for ordering multispectral data in terms of image quality with implications for noise removal. IEEE Trans. Geosci. Remote Sens. 1998, 26, 65–74. [Google Scholar] [CrossRef]
- Zhang, H.; Li, J.; Huang, Y.; Zhang, L. A nonlocal weighted joint sparse representation classification method for hyperspectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2057–2066. [Google Scholar] [CrossRef]
- Fang, L.; Li, S.; Duan, W.; Ren, J.; Benediktsson, J.A. Classification of hyperspectral images by exploiting spectral–spatial information of superpixel via multiple kernels. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6663–6674. [Google Scholar] [CrossRef]
- Li, P.; Wang, Q.; Zeng, H.; Zhang, L. Local Log-Euclidean multivariate Gaussian descriptor and its application to image classification. IEEE Trans. Pattern Anal. Machiche Intell. 2017, 39, 803–817. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Wang, Q.; Zuo, W.; Zhang, L. Log-Euclidean kernels for sparse representation and dictionary learningn. In Proceedings of the International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 1601–1608. [Google Scholar]
- Hu, S.; Peng, J.; Fu, Y.; Li, L. Kernel joint sparse representation based on self-paced learning for hyperspectral image classification. Remote Sens. 2019, 11, 1114. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Train | Test | SVMCK | LCMR | LCEM | A2S2K | NoiseCNN | JSR | KJSR | SPKJSR | CovKJSR | CEKJSR | LMFKJSR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3 | 51 | 64.12 | 99.22 | 93.94 | 86.67 | 46.15 | 77.84 | 88.04 | 96.67 | 97.06 | 92.16 | 95.69 |
| 2 | 14 | 1420 | 75.45 | 75.68 | 89.66 | 68.12 | 48.86 | 58.40 | 70.57 | 78.11 | 83.68 | 90.80 | 94.05 |
| 3 | 8 | 826 | 61.11 | 57.03 | 71.44 | 88.32 | 37.07 | 40.11 | 58.68 | 66.23 | 69.62 | 76.27 | 83.00 |
| 4 | 3 | 231 | 56.02 | 73.85 | 78.92 | 89.26 | 72.09 | 36.36 | 58.70 | 77.19 | 82.90 | 80.65 | 84.11 |
| 5 | 5 | 492 | 70.87 | 71.69 | 83.46 | 86.96 | 58.33 | 68.72 | 75.22 | 77.76 | 80.77 | 83.44 | 84.59 |
| 6 | 7 | 740 | 85.54 | 78.12 | 95.28 | 92.08 | 57.58 | 96.95 | 95.18 | 87.58 | 85.20 | 95.42 | 97.43 |
| 7 | 3 | 23 | 93.04 | 100.0 | 100.0 | 49.02 | 8.54 | 58.70 | 85.65 | 100.0 | 100.0 | 100.0 | 100.0 |
| 8 | 5 | 484 | 88.59 | 94.36 | 97.12 | 97.42 | 82.99 | 89.67 | 97.91 | 98.31 | 98.51 | 98.12 | 99.79 |
| 9 | 3 | 17 | 89.41 | 100.0 | 100.0 | 34.69 | 22.22 | 31.18 | 51.18 | 90.00 | 100.0 | 100.0 | 100.0 |
| 10 | 10 | 958 | 62.46 | 57.39 | 76.81 | 80.52 | 31.46 | 40.45 | 76.82 | 80.04 | 71.36 | 86.10 | 88.80 |
| 11 | 25 | 2443 | 79.78 | 83.98 | 88.69 | 71.05 | 49.26 | 78.70 | 86.39 | 88.26 | 89.82 | 89.83 | 91.47 |
| 12 | 6 | 608 | 45.76 | 51.89 | 71.93 | 90.83 | 26.69 | 42.48 | 56.81 | 66.60 | 70.54 | 83.11 | 82.68 |
| 13 | 3 | 209 | 83.21 | 84.88 | 98.42 | 87.07 | 42.36 | 98.95 | 99.95 | 84.40 | 84.55 | 99.38 | 99.86 |
| 14 | 13 | 1281 | 92.45 | 94.04 | 94.36 | 86.89 | 79.27 | 98.51 | 99.02 | 98.09 | 98.75 | 95.15 | 96.66 |
| 15 | 4 | 376 | 54.39 | 70.45 | 79.34 | 70.70 | 46.51 | 46.52 | 37.26 | 54.76 | 76.99 | 83.22 | 83.80 |
| 16 | 3 | 92 | 96.52 | 93.80 | 95.76 | 75.86 | 47.62 | 94.13 | 87.07 | 84.46 | 94.57 | 99.35 | 99.24 |
| Overall accuracy | 74.75 | 76.53 | 86.43 | 78.90 | 51.58 | 69.18 | 79.34 | 82.66 | 84.82 | 89.16 | 91.36 | ||
| Average accuracy | 74.92 | 80.40 | 88.44 | 78.47 | 47.33 | 66.10 | 76.53 | 83.03 | 87.15 | 90.81 | 92.57 | ||
| Coefficient | 0.712 | 0.730 | 0.845 | 0.757 | 0.439 | 0.644 | 0.762 | 0.801 | 0.826 | 0.876 | 0.902 | ||
| Class | Train | Test | SVMCK | LCMR | LCEM | A2S2K | NoiseCNN | JSR | KJSR | SPKJSR | CovKJSR | CEKJSR | LMFKJSR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 7 | 6624 | 74.54 | 83.47 | 84.67 | 76.78 | 64.24 | 31.01 | 68.13 | 73.91 | 80.91 | 77.72 | 83.38 |
| 2 | 19 | 18630 | 88.81 | 99.14 | 89.71 | 73.86 | 83.82 | 90.03 | 90.48 | 89.89 | 99.64 | 84.26 | 97.92 |
| 3 | 3 | 2096 | 63.19 | 66.82 | 68.76 | 56.74 | 29.10 | 67.56 | 65.84 | 67.29 | 51.57 | 73.78 | 79.90 |
| 4 | 3 | 3061 | 74.93 | 86.23 | 63.76 | 97.61 | 82.98 | 75.26 | 74.01 | 64.40 | 85.47 | 61.00 | 80.00 |
| 5 | 3 | 1342 | 99.61 | 89.52 | 97.76 | 98.82 | 97.27 | 99.69 | 99.84 | 99.33 | 99.30 | 99.52 | 99.57 |
| 6 | 5 | 5024 | 50.63 | 69.77 | 83.35 | 74.85 | 61.61 | 31.69 | 44.96 | 50.59 | 55.55 | 77.59 | 82.95 |
| 7 | 3 | 1327 | 79.16 | 77.12 | 96.67 | 73.24 | 13.20 | 80.78 | 66.44 | 74.15 | 74.62 | 100.0 | 99.01 |
| 8 | 4 | 3678 | 62.78 | 62.49 | 64.85 | 57.24 | 48.68 | 64.83 | 47.61 | 49.93 | 46.81 | 66.53 | 73.13 |
| 9 | 3 | 944 | 86.29 | 98.55 | 93.81 | 55.55 | 31.19 | 78.88 | 77.78 | 12.03 | 69.41 | 71.04 | 90.91 |
| Overall accuracy | 77.60 | 86.59 | 83.71 | 74.05 | 65.81 | 69.46 | 74.85 | 75.29 | 82.17 | 79.43 | 89.53 | ||
| Average accuracy | 75.55 | 81.46 | 82.59 | 73.85 | 56.89 | 68.86 | 73.71 | 64.61 | 73.70 | 79.05 | 87.42 | ||
| Coefficient | 0.702 | 0.819 | 0.786 | 0.633 | 0.541 | 0.590 | 0.661 | 0.667 | 0.755 | 0.733 | 0.860 | ||
| Class | Train | Test | SVMCK | LCMR | LCEM | A2S2K | NoiseCNN | JSR | KJSR | SPKJSR | CovKJSR | CEKJSR | LCCKJSR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3 | 2006 | 89.82 | 98.84 | 99.40 | 99.97 | 88.63 | 99.79 | 99.86 | 99.91 | 99.91 | 99.27 | 99.21 |
| 2 | 4 | 3722 | 94.34 | 90.74 | 98.76 | 98.32 | 92.16 | 99.01 | 99.81 | 99.27 | 93.59 | 99.24 | 99.86 |
| 3 | 3 | 1973 | 74.35 | 96.15 | 93.58 | 97.17 | 74.27 | 78.86 | 76.90 | 83.02 | 95.39 | 95.97 | 95.48 |
| 4 | 3 | 1391 | 92.58 | 93.90 | 97.28 | 91.40 | 83.05 | 98.07 | 94.28 | 86.24 | 97.04 | 98.27 | 98.68 |
| 5 | 3 | 2675 | 79.97 | 64.85 | 99.19 | 86.71 | 84.22 | 85.76 | 94.05 | 95.90 | 73.79 | 99.27 | 98.37 |
| 6 | 4 | 3955 | 96.93 | 95.63 | 99.90 | 99.80 | 99.18 | 99.87 | 100.0 | 99.86 | 99.81 | 99.90 | 99.89 |
| 7 | 4 | 3575 | 94.95 | 92.58 | 100.0 | 99.50 | 73.89 | 99.93 | 99.68 | 100.0 | 98.88 | 99.99 | 99.94 |
| 8 | 11 | 11260 | 81.95 | 87.48 | 77.89 | 81.61 | 54.79 | 90.76 | 87.07 | 89.96 | 88.09 | 82.24 | 89.09 |
| 9 | 6 | 6197 | 94.07 | 98.48 | 99.91 | 98.92 | 99.11 | 99.95 | 99.78 | 99.97 | 99.85 | 99.97 | 100.0 |
| 10 | 3 | 3275 | 52.67 | 53.95 | 72.23 | 97.70 | 85.30 | 92.48 | 59.95 | 63.76 | 64.65 | 70.56 | 70.36 |
| 11 | 3 | 1065 | 90.01 | 80.45 | 96.85 | 90.78 | 65.57 | 94.42 | 87.19 | 99.59 | 98.57 | 99.25 | 99.66 |
| 12 | 3 | 1924 | 85.47 | 71.83 | 91.49 | 95.89 | 81.43 | 79.07 | 97.42 | 94.45 | 83.85 | 94.10 | 93.79 |
| 13 | 3 | 913 | 97.02 | 94.66 | 99.12 | 93.40 | 88.25 | 79.89 | 99.67 | 96.90 | 95.49 | 97.83 | 99.19 |
| 14 | 3 | 1067 | 93.87 | 85.81 | 97.23 | 92.33 | 98.02 | 95.49 | 98.86 | 99.76 | 87.67 | 97.96 | 95.91 |
| 15 | 7 | 7261 | 78.02 | 65.75 | 78.89 | 78.57 | 37.78 | 54.31 | 53.66 | 52.04 | 73.56 | 74.73 | 73.13 |
| 16 | 3 | 1804 | 66.46 | 79.00 | 92.21 | 97.96 | 69.14 | 99.05 | 81.01 | 85.10 | 88.87 | 87.88 | 88.65 |
| Overall accuracy | 84.29 | 83.84 | 89.71 | 90.95 | 73.27 | 83.64 | 86.30 | 87.27 | 88.44 | 90.10 | 91.29 | ||
| Average accuracy | 85.16 | 84.38 | 93.37 | 93.75 | 79.67 | 84.74 | 89.32 | 90.36 | 89.94 | 93.53 | 93.83 | ||
| Coefficient | 0.825 | 0.819 | 0.885 | 0.899 | 0.701 | 0.817 | 0.847 | 0.858 | 0.871 | 0.890 | 0.903 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Chen, N.; Peng, J.; Sun, W. Local Matrix Feature-Based Kernel Joint Sparse Representation for Hyperspectral Image Classification. Remote Sens. 2022, 14, 4363. https://doi.org/10.3390/rs14174363
Chen X, Chen N, Peng J, Sun W. Local Matrix Feature-Based Kernel Joint Sparse Representation for Hyperspectral Image Classification. Remote Sensing. 2022; 14(17):4363. https://doi.org/10.3390/rs14174363
Chicago/Turabian StyleChen, Xiang, Na Chen, Jiangtao Peng, and Weiwei Sun. 2022. "Local Matrix Feature-Based Kernel Joint Sparse Representation for Hyperspectral Image Classification" Remote Sensing 14, no. 17: 4363. https://doi.org/10.3390/rs14174363
APA StyleChen, X., Chen, N., Peng, J., & Sun, W. (2022). Local Matrix Feature-Based Kernel Joint Sparse Representation for Hyperspectral Image Classification. Remote Sensing, 14(17), 4363. https://doi.org/10.3390/rs14174363