
The Prediction of the Tibetan Plateau Thermal Condition with Machine Learning and Shapley Additive Explanation



Abstract
: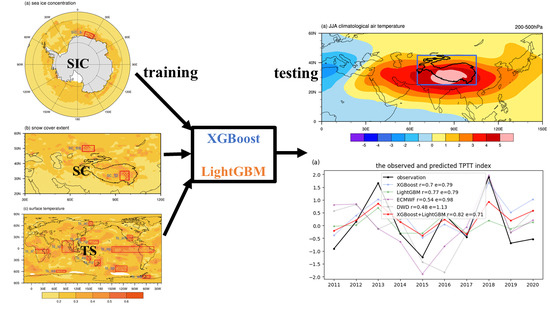
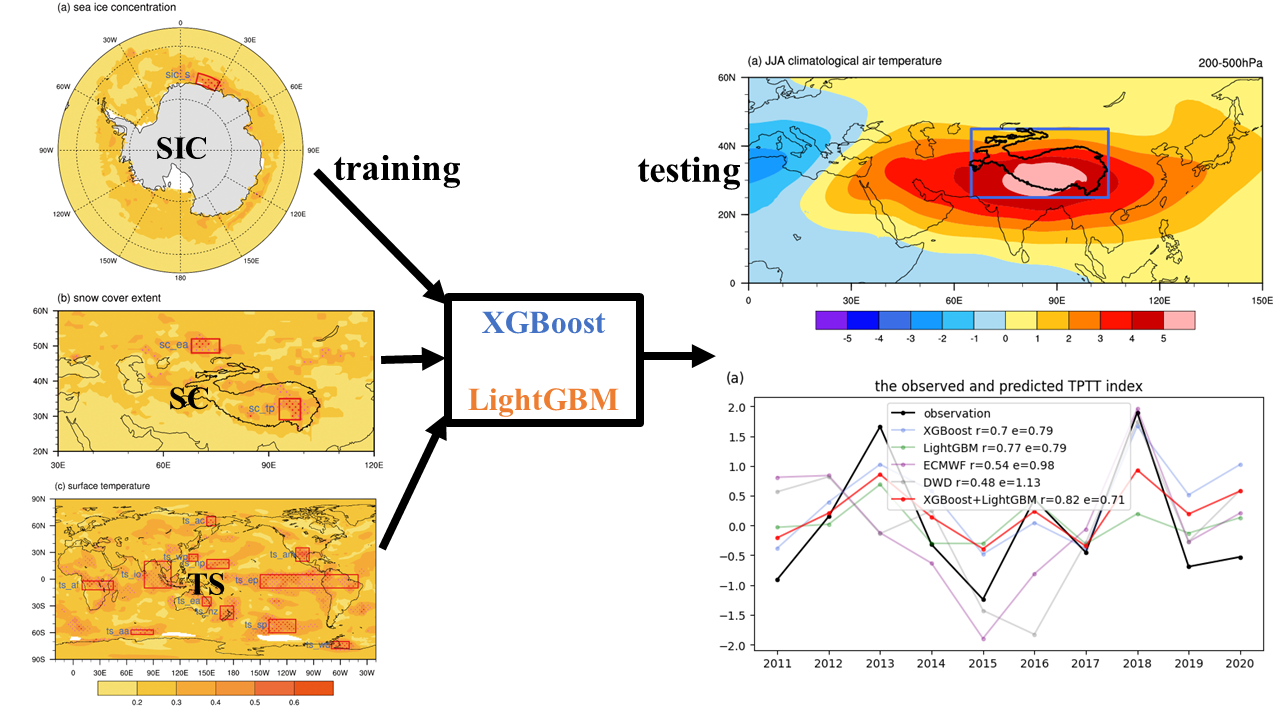{kind=link}
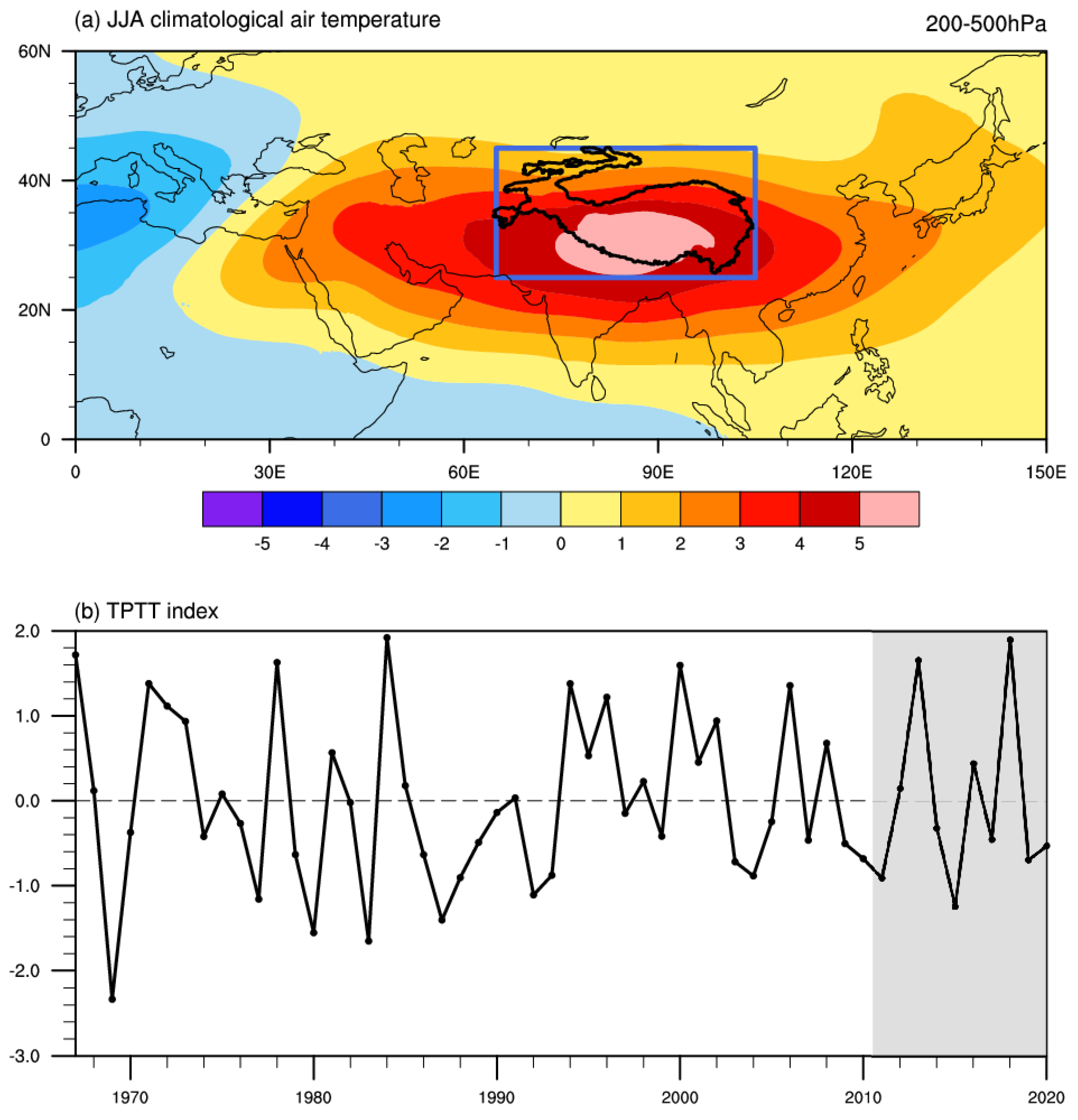{kind=link}
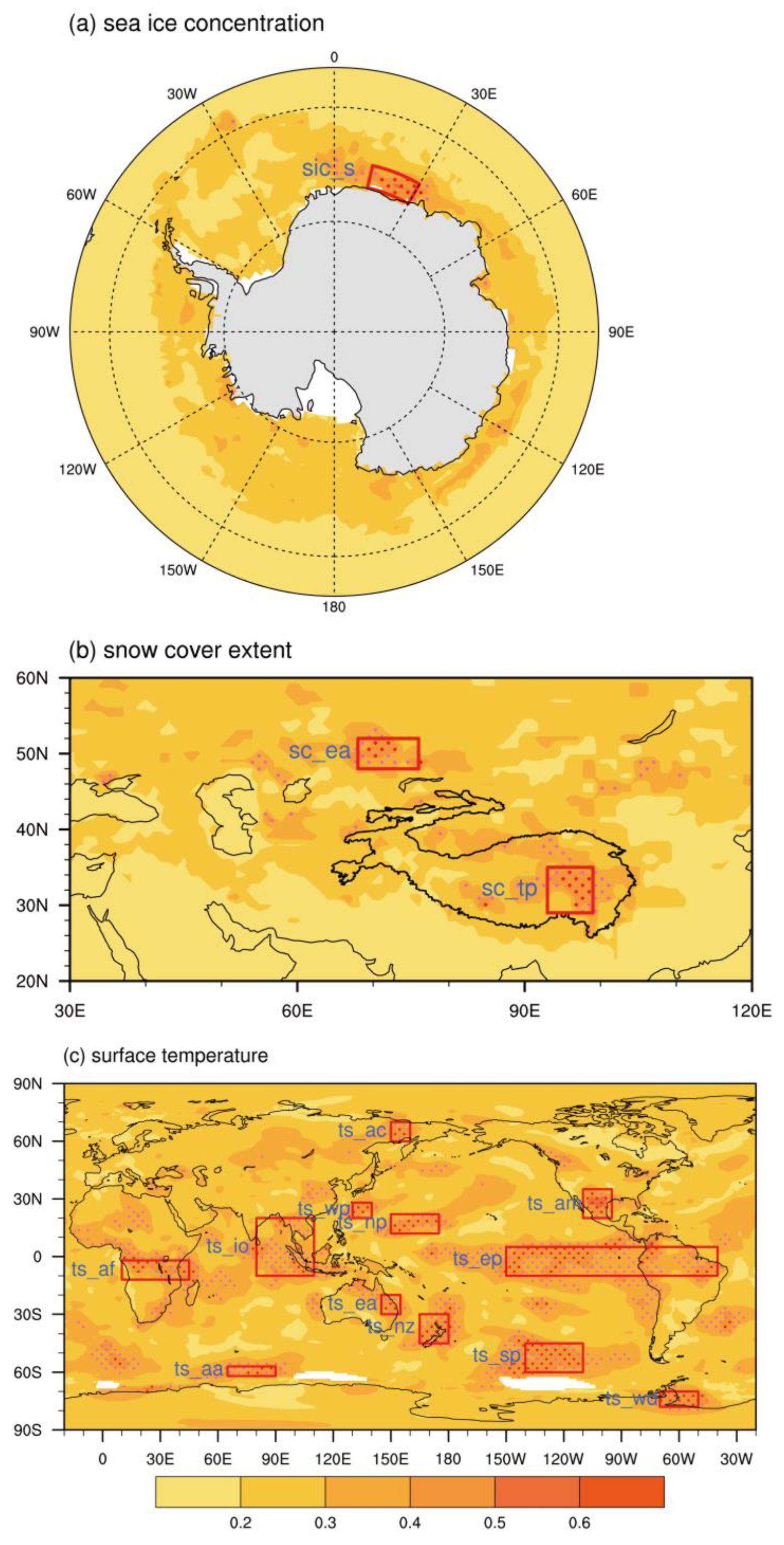{kind=link}
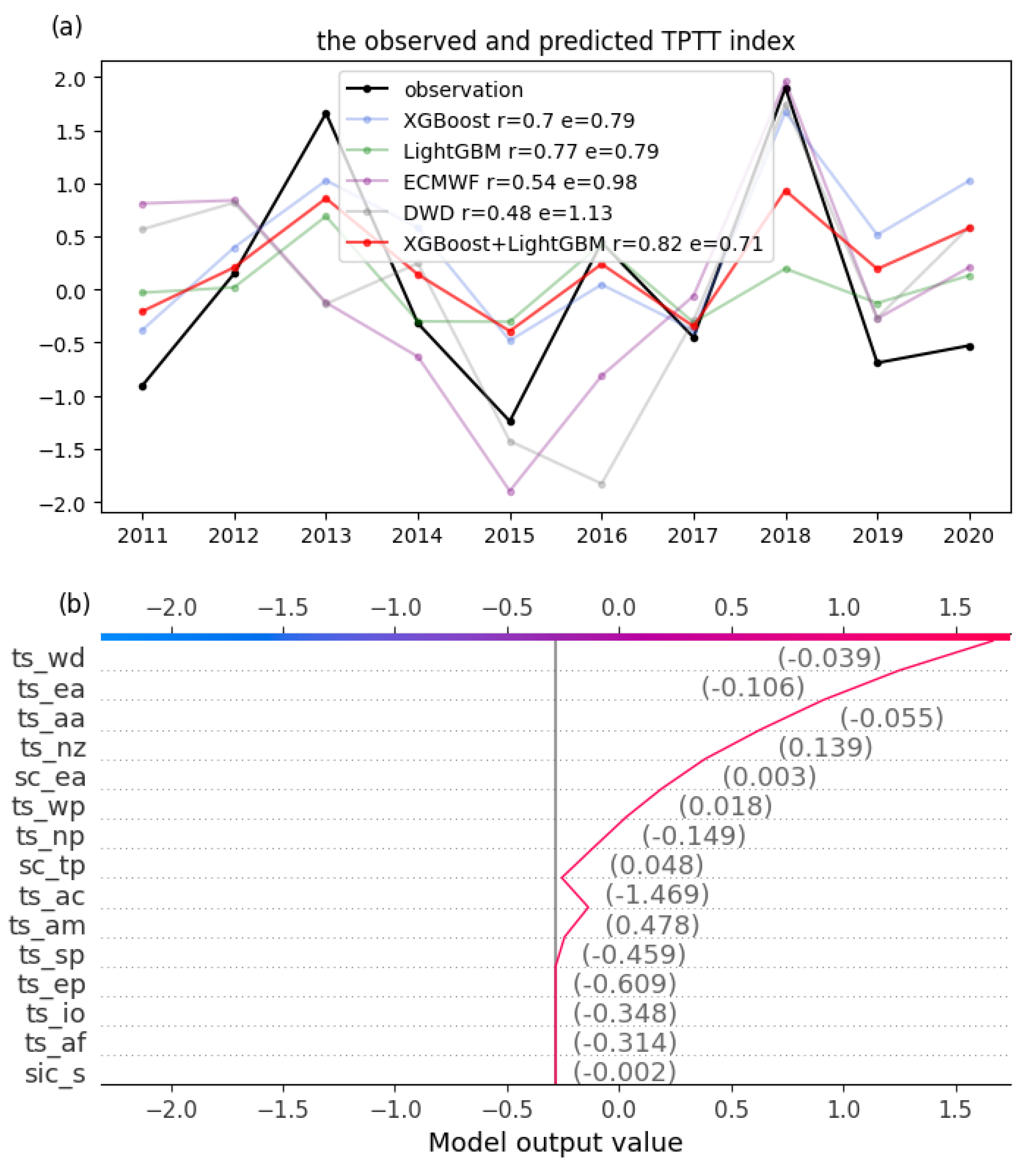{kind=link}
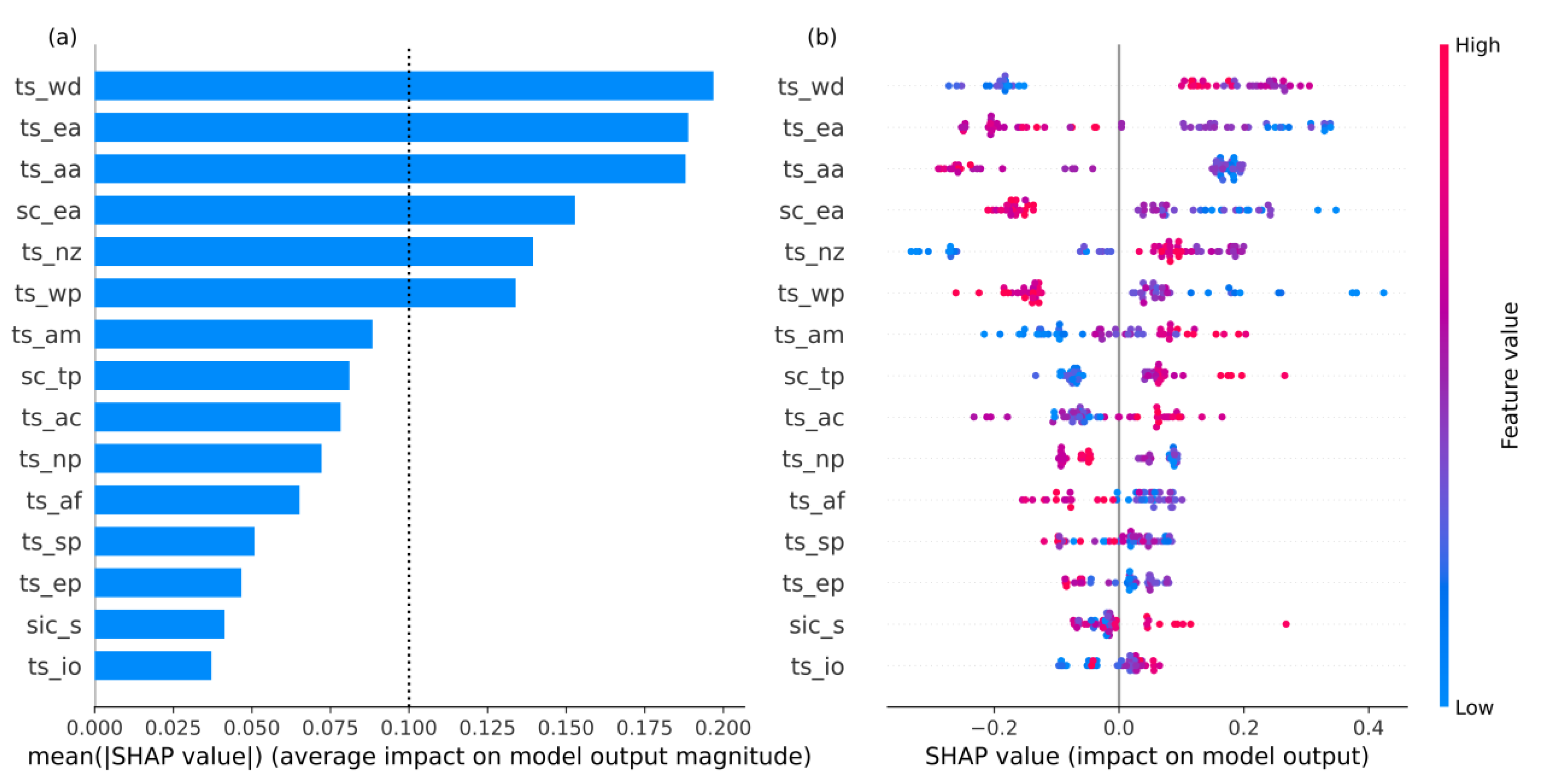{kind=link}
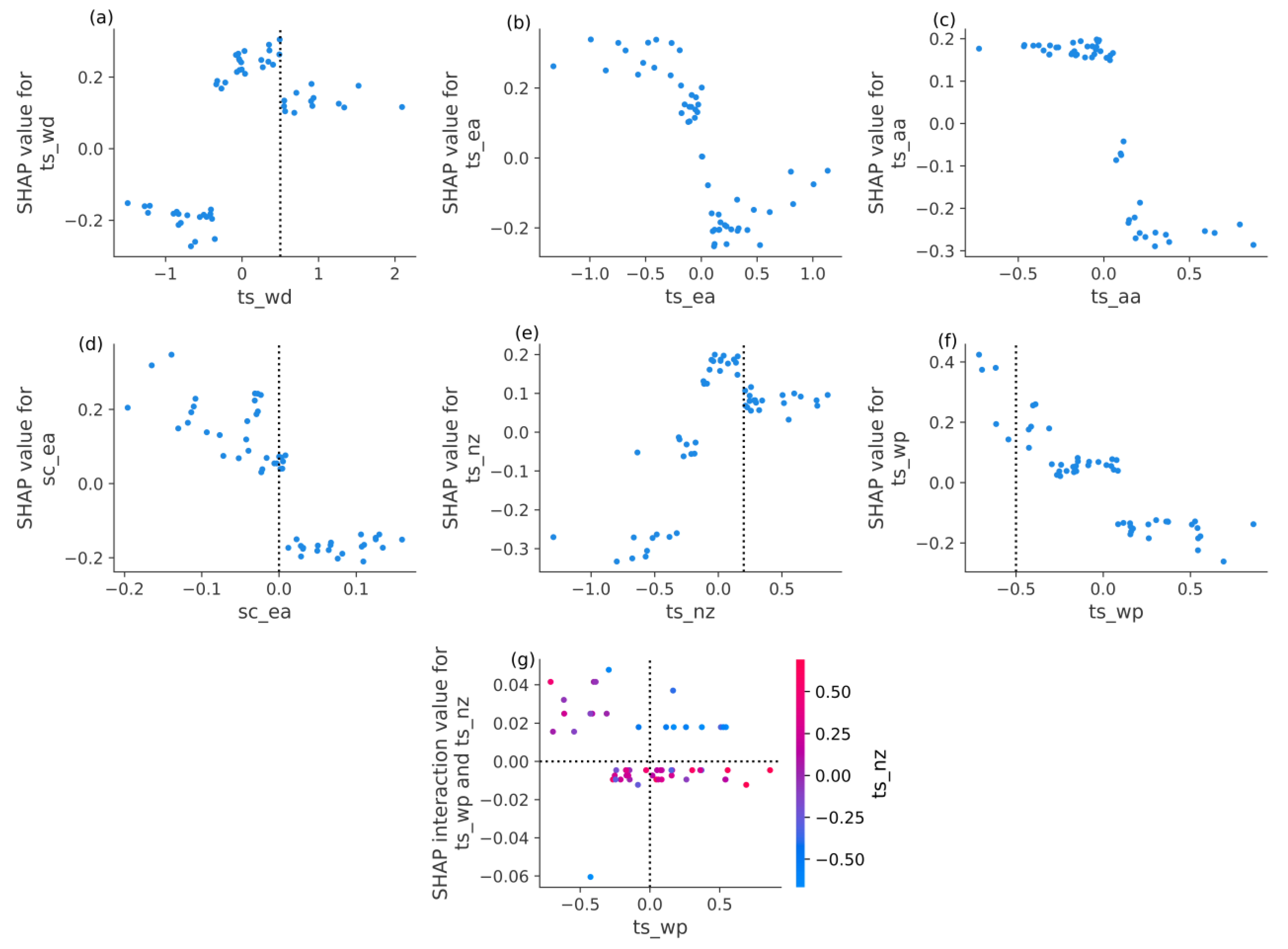{kind=link}
1. Introduction
2. Materials and Methods
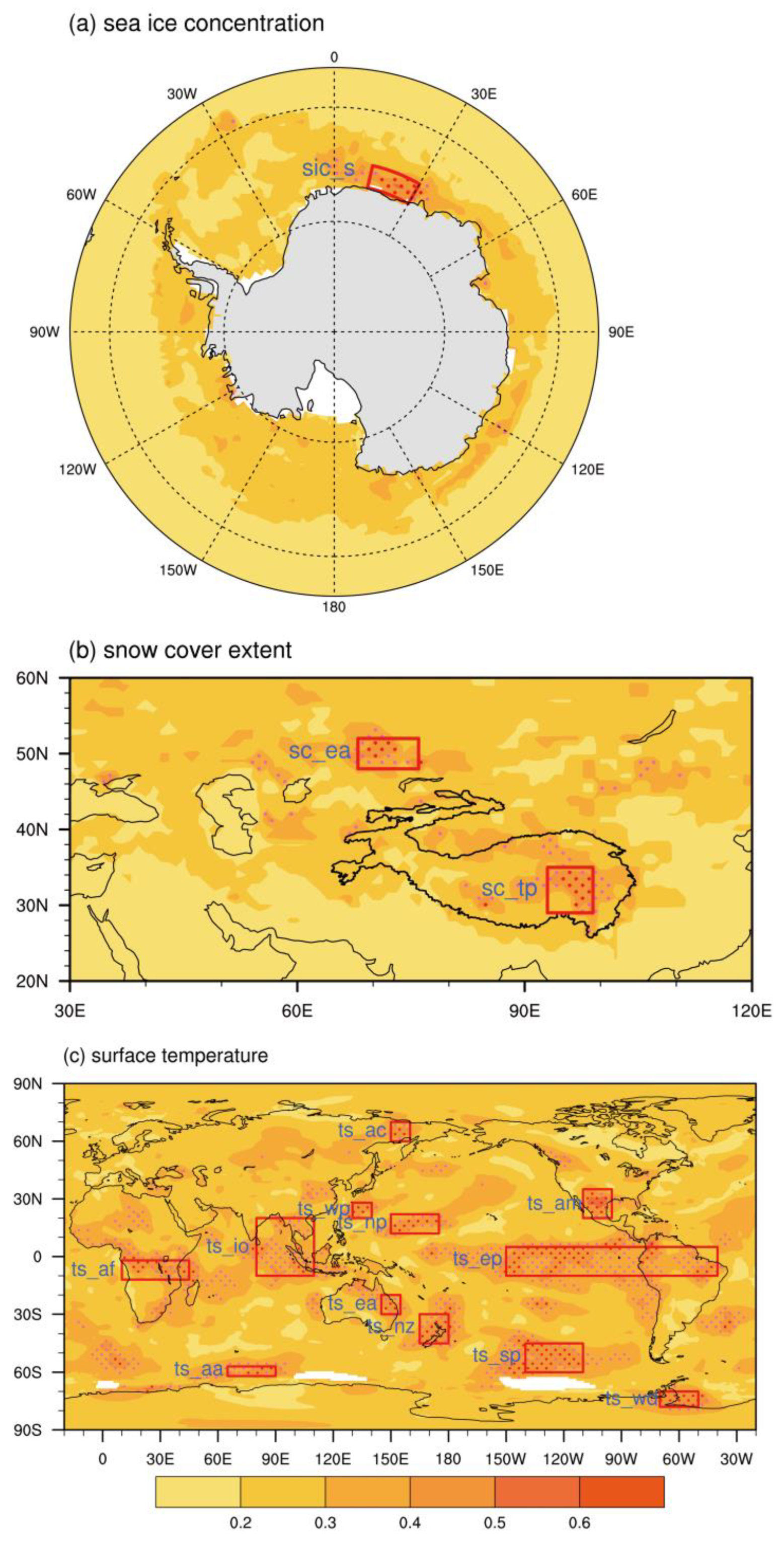
2.1. Data
2.2. Prediction Models
2.3. SHAP Method
2.4. Evaluation Metrics
3. Results
4. Discussion
4.1. Uncertainty
4.2. Comparison, Limitations and Contributions
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ye, D.; Gao, Y. Meteorology of the Qinghai-Xizang (Tibet) Plateau; Science Press: Beijing, China, 1979; p. 316. (In Chinese) [Google Scholar]
- Wu, G.; Duan, A.; Liu, Y.; Mao, J.; Ren, R.; Bao, Q.; He, B.; Liu, B.; Hu, W. Tibetan Plateau climate dynamics: Recent research progress and outlook. Natl. Sci. Rev. 2014, 2, 100–116. [Google Scholar] [CrossRef]
- Wu, G.; Liu, Y.; He, B.; Bao, Q.; Duan, A.; Jin, F.-F. Thermal Controls on the Asian Summer Monsoon. Sci. Rep. 2012, 2, 404. [Google Scholar] [CrossRef]
- Liu, Y.; Lu, M.; Yang, H.; Duan, A.; He, B.; Yang, S.; Wu, G. Land–atmosphere–ocean coupling associated with the Tibetan Plateau and its climate impacts. Natl. Sci. Rev. 2020, 7, 534–552. [Google Scholar] [CrossRef]
- Lai, X.; Gong, Y. Relationship between atmospheric heat source over the Tibetan Plateau and precipitation in the Sichuan–Chongqing region during summer. J. Meteorol. Res. 2017, 31, 555–566. [Google Scholar] [CrossRef]
- Zhao, P.; Chen, L. Interannual variability of atmospheric heat source/sink over the Qinghai—Xizang (Tibetan) Plateau and its relation to circulation. Adv. Atmos. Sci. 2001, 18, 106–116. [Google Scholar] [CrossRef]
- Ye, D.; Luo, S.; Zhu, B. The wind structure and heat balance in the lower troposphere over Tibetan Plateau and its surrounding. Acta Meteorol. Sin. 1957, 28, 108–121. (In Chinese) [Google Scholar]
- Wu, G.; Zhang, Y. Tibetan Plateau Forcing and the Timing of the Monsoon Onset over South Asia and the South China Sea. Mon. Weather Rev. 1998, 126, 913–927. [Google Scholar] [CrossRef]
- Wu, G.; He, B.; Liu, Y.; Bao, Q.; Ren, R. Location and variation of the summertime upper-troposphere temperature maximum over South Asia. Clim. Dyn. 2015, 45, 2757–2774. [Google Scholar] [CrossRef]
- Nan, S.; Zhao, P.; Chen, J. Variability of summertime Tibetan tropospheric temperature and associated precipitation anomalies over the central-eastern Sahel. Clim. Dyn. 2019, 52, 1819–1835. [Google Scholar] [CrossRef]
- Nan, S.; Zhao, P.; Chen, J.; Liu, G. Links between the thermal condition of the Tibetan Plateau in summer and atmospheric circulation and climate anomalies over the Eurasian continent. Atmos. Res. 2021, 247, 105212. [Google Scholar] [CrossRef]
- Zhu, Y.-Y.; Yang, S. Evaluation of CMIP6 for historical temperature and precipitation over the Tibetan Plateau and its comparison with CMIP5. Adv. Clim. Chang. Res. 2020, 11, 239–251. [Google Scholar] [CrossRef]
- Zhao, Y.; Duan, A.; Wu, G. Interannual Variability of Late-spring Circulation and Diabatic Heating over the Tibetan Plateau Associated with Indian Ocean Forcing. Adv. Atmos. Sci. 2018, 35, 927–941. [Google Scholar] [CrossRef]
- Jin, R.; Wu, Z.; Zhang, P. Tibetan Plateau capacitor effect during the summer preceding ENSO: From the Yellow River climate perspective. Clim. Dyn. 2018, 51, 57–71. [Google Scholar] [CrossRef]
- Cui, Y.; Duan, A.; Liu, Y.; Wu, G. Interannual variability of the spring atmospheric heat source over the Tibetan Plateau forced by the North Atlantic SSTA. Clim. Dyn. 2015, 45, 1617–1634. [Google Scholar] [CrossRef]
- Chen, Y.; Duan, A.; Li, D. Connection between winter Arctic sea ice and west Tibetan Plateau snow depth through the NAO. Int. J. Climatol. 2021, 41, 846–861. [Google Scholar] [CrossRef]
- Li, F.; Wan, X.; Wang, H.; Orsolini, Y.J.; Cong, Z.; Gao, Y.; Kang, S. Arctic sea-ice loss intensifies aerosol transport to the Tibetan Plateau. Nat. Clim. Chang. 2020, 10, 1037–1044. [Google Scholar] [CrossRef]
- Shaman, J.; Tziperman, E. The Effect of ENSO on Tibetan Plateau Snow Depth: A Stationary Wave Teleconnection Mechanism and Implications for the South Asian Monsoons. J. Clim. 2005, 18, 2067–2079. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, H.; Li, H.; Wang, H. The Impact of Preceding Spring Antarctic Oscillation on the Variations of Lake Ice Phenology over the Tibetan Plateau. J. Clim. 2020, 33, 639–656. [Google Scholar] [CrossRef]
- Dou, J.; Wu, Z. Southern Hemisphere Origins for Interannual Variations of Snow Cover over the Western Tibetan Plateau in Boreal Summer. J. Clim. 2018, 31, 7701–7718. [Google Scholar] [CrossRef]
- Ham, Y.G.; Kim, J.H.; Luo, J.J. Deep learning for multi-year ENSO forecasts. Nature 2019, 573, 568–572. [Google Scholar] [CrossRef]
- Davenport, F.V.; Diffenbaugh, N.S. Using machine learning to analyze physical causes of climate change: A case study of US Midwest extreme precipitation. Geophys. Res. Lett. 2021, 48, e2021GL093787. [Google Scholar] [CrossRef]
- Jones, N. How machine learning could help to improve climate forecasts. Nature 2017, 548, 379. [Google Scholar] [CrossRef] [PubMed]
- Rasp, S.; Pritchard, M.S.; Gentine, P. Deep learning to represent subgrid processes in climate models. Proc. Natl. Acad. Sci. USA 2018, 115, 9684–9689. [Google Scholar] [CrossRef] [PubMed]
- Qian, Q.; Jia, X.; Lin, H.; Zhang, R. Seasonal Forecast of Non-monsoonal Winter Precipitation over the Eurasian Continent using Machine Learning Models. J. Clim. 2021, 34, 7113–7129. [Google Scholar] [CrossRef]
- Tang, Y.; Duan, A. Using deep learning to predict the East Asian summer monsoon. Environ. Res. Lett. 2021, 16, 124006. [Google Scholar] [CrossRef]
- Xue, M.; Hang, R.; Liu, Q.; Yuan, X.-T.; Lu, X. CNN-based near-real-time precipitation estimation from Fengyun-2 satellite over Xinjiang, China. Atmos. Res. 2020, 250, 105337. [Google Scholar] [CrossRef]
- Li, H.; Yu, C.; Xia, J.; Wang, Y.; Zhu, J.; Zhang, P. A Model Output Machine Learning Method for Grid Temperature Forecasts in the Beijing Area. Adv. Atmos. Sci. 2019, 36, 1156–1170. [Google Scholar] [CrossRef]
- Abdi, A.M. Land cover and land use classification performance of machine learning algorithms in a boreal landscape using Sentinel-2 data. GISci. Remote Sens. 2020, 57, 1–20. [Google Scholar] [CrossRef]
- Wagle, N.; Acharya, T.D.; Kolluru, V.; Huang, H.; Lee, D.H. Multi-Temporal Land Cover Change Mapping Using Google Earth Engine and Ensemble Learning Methods. Appl. Sci. 2020, 10, 8083. [Google Scholar] [CrossRef]
- Talukdar, S.; Singha, P.; Mahato, S.; Shahfahad; Pal, S.; Liou, Y.-A.; Rahman, A. Land-Use Land-Cover Classification by Machine Learning Classifiers for Satellite Observations—A Review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef]
- Kang, Y.; Ozdogan, M.; Zhu, X.; Ye, Z.; Hain, C.; Anderson, M. Comparative assessment of environmental variables and machine learning algorithms for maize yield prediction in the US Midwest. Environ. Res. Lett. 2020, 15, 064005. [Google Scholar] [CrossRef]
- Zhong, J.; Zhang, X.; Gui, K.; Wang, Y.; Che, H.; Shen, X.; Zhang, L.; Zhang, Y.; Sun, J.; Zhang, W. Robust prediction of hourly PM2.5 from meteorological data using LightGBM. Natl. Sci. Rev. 2021, 8, nwaa307. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.; Han, D.; Ahn, M.-H.; Im, J.; Lee, S.J. Retrieval of Total Precipitable Water from Himawari-8 AHI Data: A Comparison of Random Forest, Extreme Gradient Boosting, and Deep Neural Network. Remote Sens. 2019, 11, 1741. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; Volume 30, pp. 4768–4777. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Yang, Y.; Yuan, Y.; Han, Z.; Liu, G. Interpretability analysis for thermal sensation machine learning models: An exploration based on the SHAP approach. Indoor Air 2022, 32, e12984. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Su, Q.; Wang, L.; Yang, R.; Cao, J. Response of the South Asian High in May to the early spring North Pacific Victoria Mode. J. Clim. 2022, 35, 3979–3993. [Google Scholar] [CrossRef]
- Vernekar, A.D.; Zhou, J.; Shukla, J. The Effect of Eurasian Snow Cover on the Indian Monsoon. J. Clim. 1995, 8, 248–266. [Google Scholar] [CrossRef]
- Titchner, H.A.; Rayner, N.A. The Met Office Hadley Centre sea ice and sea surface temperature data set, version 2: 1. Sea ice concentrations. J. Geophys. Res.-Atmos. 2014, 119, 2864–2889. [Google Scholar] [CrossRef]
- Robinson, D.A.; Estilow, T.W.; Program, N.C. NOAA Climate Data Record (CDR) of Northern Hemisphere (NH) Snow Cover Extent (SCE) Version 1. 2012. Available online: https://www.ncei.noaa.gov/ (accessed on 30 December 2021). [CrossRef]
- Rohde, R.A.; Hausfather, Z. The Berkeley Earth land/ocean temperature record. Earth Syst. Sci. Data 2020, 12, 3469–3479. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2022; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 3147–3155. [Google Scholar]
- Huang, L.; Kang, J.; Wan, M.; Fang, L.; Zhang, C.; Zeng, Z. Solar radiation prediction using different machine learning algorithms and implications for extreme climate events. Front. Earth Sci. 2021, 9, 202. [Google Scholar] [CrossRef]
- Shahhosseini, M.; Hu, G.; Huber, I.; Archontoulis, S.V. Coupling machine learning and crop modeling improves crop yield prediction in the US Corn Belt. Sci. Rep. 2021, 11, 1606. [Google Scholar] [CrossRef] [PubMed]
- Ding, C.; Cao, X.; Næss, P. Applying gradient boosting decision trees to examine non-linear effects of the built environment on driving distance in Oslo. Transp. Res. Part A Policy Pract. 2018, 110, 107–117. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar]
- Chang, I.; Park, H.; Hong, E.; Lee, J.; Kwon, N. Predicting effects of built environment on fatal pedestrian accidents at location-specific level: Application of XGBoost and SHAP. Accid. Anal. Prev. 2022, 166, 106545. [Google Scholar] [CrossRef]
- Barda, N.; Riesel, D.; Akriv, A.; Levy, J.; Finkel, U.; Yona, G.; Greenfeld, D.; Sheiba, S.; Somer, J.; Bachmat, E.; et al. Developing a COVID-19 mortality risk prediction model when individual-level data are not available. Nat. Commun. 2020, 11, 4439. [Google Scholar] [CrossRef] [PubMed]
- Székely, G.J.; Rizzo, M.L.; Bakirov, N.K. Measuring and testing dependence by correlation of distances. Ann. Stat. 2007, 35, 2769–2794. [Google Scholar] [CrossRef]
- Li, R.; Zhong, W.; Zhu, L. Feature Screening via Distance Correlation Learning. J. Am. Stat. Assoc. 2012, 107, 1129–1139. [Google Scholar] [CrossRef]
- Li, C.; Yanai, M. The Onset and Interannual Variability of the Asian Summer Monsoon in Relation to Land–Sea Thermal Contrast. J. Clim. 1996, 9, 358–375. [Google Scholar] [CrossRef]
- You, Q.; Cai, Z.; Pepin, N.; Chen, D.; Ahrens, B.; Jiang, Z.; Wu, F.; Kang, S.; Zhang, R.; Wu, T.; et al. Warming amplification over the Arctic Pole and Third Pole: Trends, mechanisms and consequences. Earth-Sci. Rev. 2021, 217, 103625. [Google Scholar] [CrossRef]
- Johnson, S.J.; Stockdale, T.N.; Ferranti, L.; Balmaseda, M.A.; Molteni, F.; Magnusson, L.; Tietsche, S.; Decremer, D.; Weisheimer, A.; Balsamo, G.; et al. SEAS5: The new ECMWF seasonal forecast system. Geosci. Model Dev. 2019, 12, 1087–1117. [Google Scholar] [CrossRef]
- Fröhlich, K.; Dobrynin, M.; Isensee, K.; Gessner, C.; Paxian, A.; Pohlmann, H.; Haak, H.; Brune, S.; Früh, B.; Baehr, J. The German climate forecast system: GCFS. J. Adv. Model. Earth Syst. 2021, 13, e2020MS002101. [Google Scholar] [CrossRef]
- Wu, Z.; Dou, J.; Lin, H. Potential influence of the November–December Southern Hemisphere annular mode on the East Asian winter precipitation: A new mechanism. Clim. Dyn. 2015, 44, 1215–1226. [Google Scholar] [CrossRef]
- Ding, R.; Li, J.; Tseng, Y.-h. The impact of South Pacific extratropical forcing on ENSO and comparisons with the North Pacific. Clim. Dyn. 2015, 44, 2017–2034. [Google Scholar] [CrossRef]
- Liu, G.; Zhang, Q.; Sun, S. The Relationship between Circulation and SST Anomaly East of Australia and the Summer Rainfall in the Middle and Lower Reaches of the Yangtze River. Chin. J. Atmos. Sci. 2008, 32, 231–241. (In Chinese) [Google Scholar]
- Hsu, H.-H.; Chen, Y.-L. Decadal to bi-decadal rainfall variation in the western Pacific: A footprint of South Pacific decadal variability? Geophys. Res. Lett. 2011, 38, L03703. [Google Scholar] [CrossRef]
- Wang, B.; Wu, R.; Fu, X. Pacific-East Asian Teleconnection: How Does ENSO Affect East Asian Climate? J. Clim. 2000, 13, 1517–1536. [Google Scholar] [CrossRef]
- Xue, X.; Chen, W.; Chen, S.; Feng, J. PDO modulation of the ENSO impact on the summer South Asian high. Clim. Dyn. 2018, 50, 1393–1411. [Google Scholar] [CrossRef]
- Wang, L.; Sharp, M.; Brown, R.; Derksen, C.; Rivard, B. Evaluation of spring snow covered area depletion in the Canadian Arctic from NOAA snow charts. Remote Sens. Environ. 2005, 95, 453–463. [Google Scholar] [CrossRef]
- Brown, R.; Derksen, C.; Wang, L. Assessment of spring snow cover duration variability over northern Canada from satellite datasets. Remote Sens. Environ. 2007, 111, 367–381. [Google Scholar] [CrossRef]
- Déry, S.J.; Brown, R.D. Recent Northern Hemisphere snow cover extent trends and implications for the snow-albedo feedback. Geophys. Res. Lett. 2007, 34, 22. [Google Scholar] [CrossRef]
- Brown, R.; Derksen, C.; Wang, L. A multi-data set analysis of variability and change in Arctic spring snow cover extent, 1967–2008. J. Geophys. Res.-Atmos. 2010, 115, D16. [Google Scholar] [CrossRef]
- Ravuri, S.; Lenc, K.; Willson, M.; Kangin, D.; Lam, R.; Mirowski, P.; Fitzsimons, M.; Athanassiadou, M.; Kashem, S.; Madge, S.; et al. Skilful precipitation nowcasting using deep generative models of radar. Nature 2021, 597, 672–677. [Google Scholar] [CrossRef] [PubMed]
- Lima, C.H.R.; Lall, U.; Jebara, T.; Barnston, A.G. Statistical Prediction of ENSO from Subsurface Sea Temperature Using a Nonlinear Dimensionality Reduction. J. Clim. 2009, 22, 4501–4519. [Google Scholar] [CrossRef]
- Zhao, H.; Lu, Y.; Jiang, X.; Klotzbach, P.J.; Wu, L.; Cao, J. A Statistical Intraseasonal Prediction Model of Extended Boreal Summer Western North Pacific Tropical Cyclone Genesis. J. Clim. 2022, 35, 2459–2478. [Google Scholar] [CrossRef]
- Domeisen, D.I.V.; Butler, A.H.; Charlton-Perez, A.J.; Ayarzagüena, B.; Baldwin, M.P.; Dunn-Sigouin, E.; Furtado, J.C.; Garfinkel, C.I.; Hitchcock, P.; Karpechko, A.Y.; et al. The Role of the Stratosphere in Subseasonal to Seasonal Prediction: 2. Predictability Arising From Stratosphere-Troposphere Coupling. J. Geophys. Res.-Atmos. 2020, 125, e2019JD030923. [Google Scholar] [CrossRef]
- Bibi, S.; Wang, L.; Li, X.; Zhou, J.; Chen, D.; Yao, T. Climatic and associated cryospheric, biospheric, and hydrological changes on the Tibetan Plateau: A review. Int. J. Climatol. 2018, 38, e1–e17. [Google Scholar] [CrossRef]
- Xie, S.-P.; Hu, K.; Hafner, J.; Tokinaga, H.; Du, Y.; Huang, G.; Sampe, T. Indian Ocean Capacitor Effect on Indo–Western Pacific Climate during the Summer following El Niño. J. Clim. 2009, 22, 730–747. [Google Scholar] [CrossRef]
- Xue, X.; Chen, W. Distinguishing interannual variations and possible impacted factors for the northern and southern mode of South Asia High. Clim. Dyn. 2019, 53, 4937–4959. [Google Scholar] [CrossRef]
- Liu, B.; Zhu, C.; Yuan, Y. Two interannual dominant modes of the South Asian High in May and their linkage to the tropical SST anomalies. Clim. Dyn. 2017, 49, 2705–2720. [Google Scholar] [CrossRef]
- Huang, G.; Qu, X.; Hu, K. The impact of the tropical Indian Ocean on South Asian High in boreal summer. Adv. Atmos. Sci. 2011, 28, 421–432. [Google Scholar] [CrossRef]
- Wang, B.; Fan, Z. Choice of South Asian Summer Monsoon Indices. Bull. Amer. Meteorol. Soc. 1999, 80, 629–638. [Google Scholar] [CrossRef]
- Gang, H.; Guijie, Z. The East Asian Summer Monsoon Index (1851–2021); National Tibetan Plateau Data Center: Tibet, China, 2019. [Google Scholar]
- Zhao, G.; Huang, G.; Wu, R.; Tao, W.; Gong, H.; Qu, X.; Hu, K. A New Upper-Level Circulation Index for the East Asian Summer Monsoon Variability. J. Clim. 2015, 28, 9977–9996. [Google Scholar] [CrossRef] [Green Version]

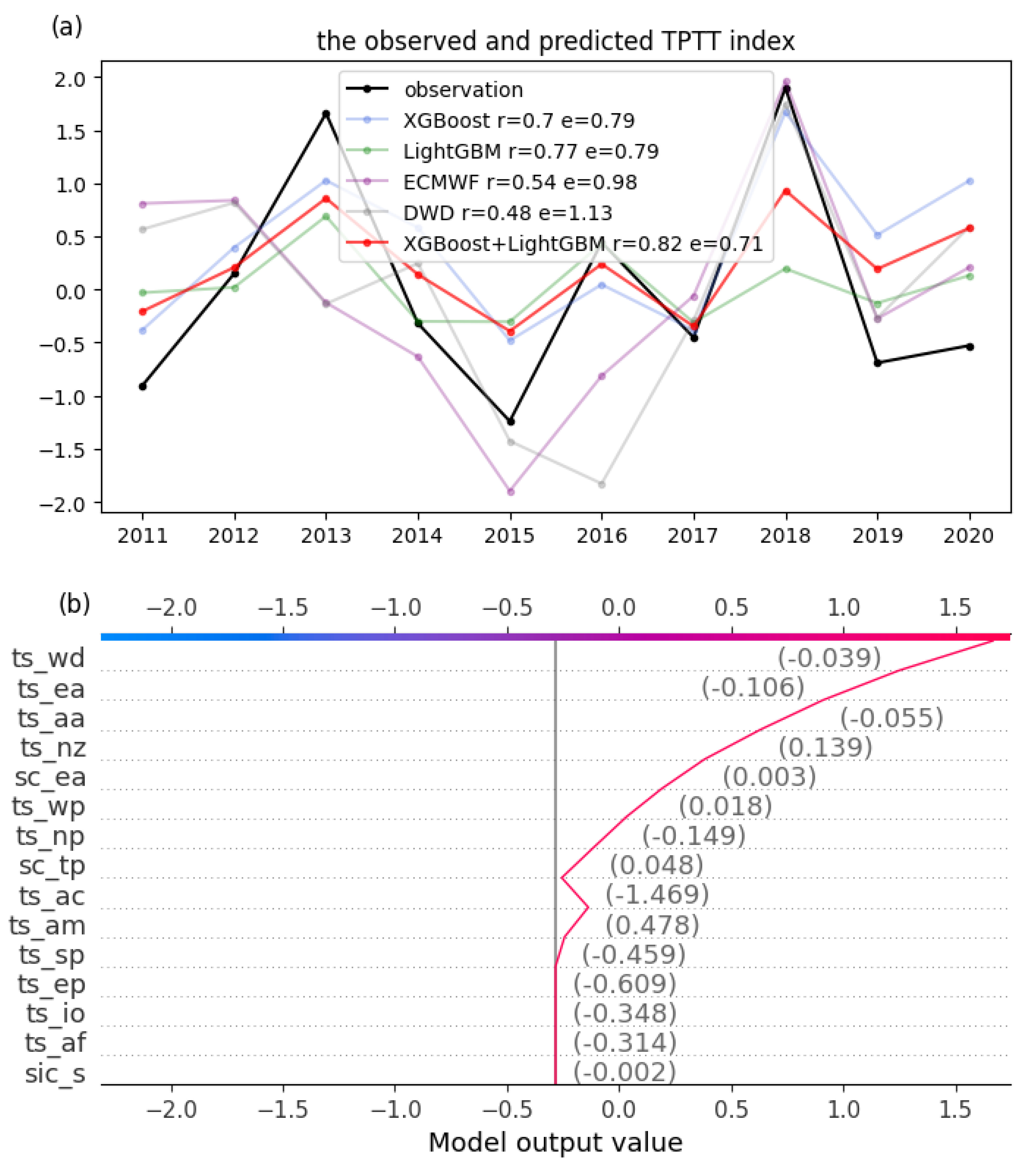
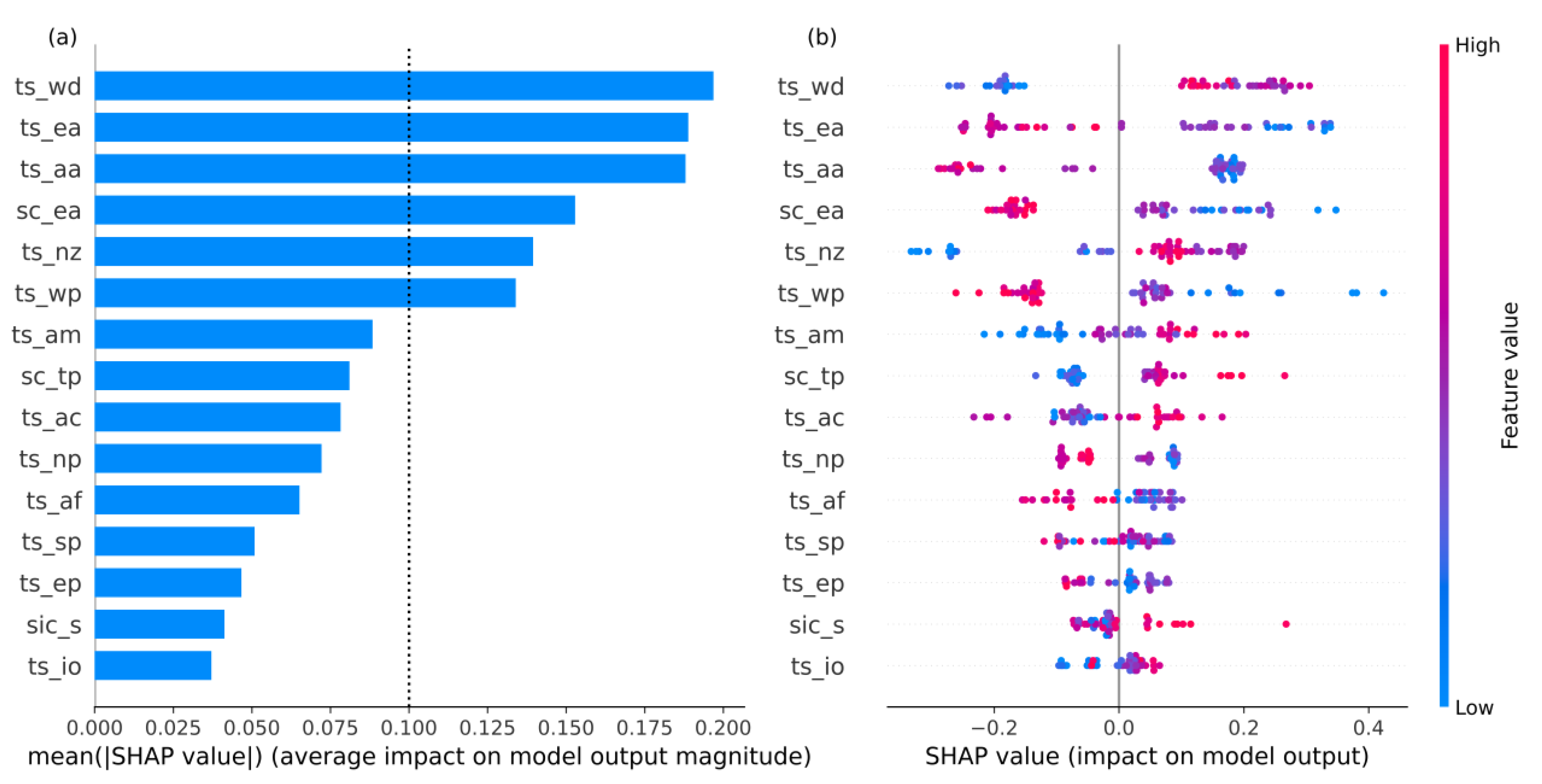
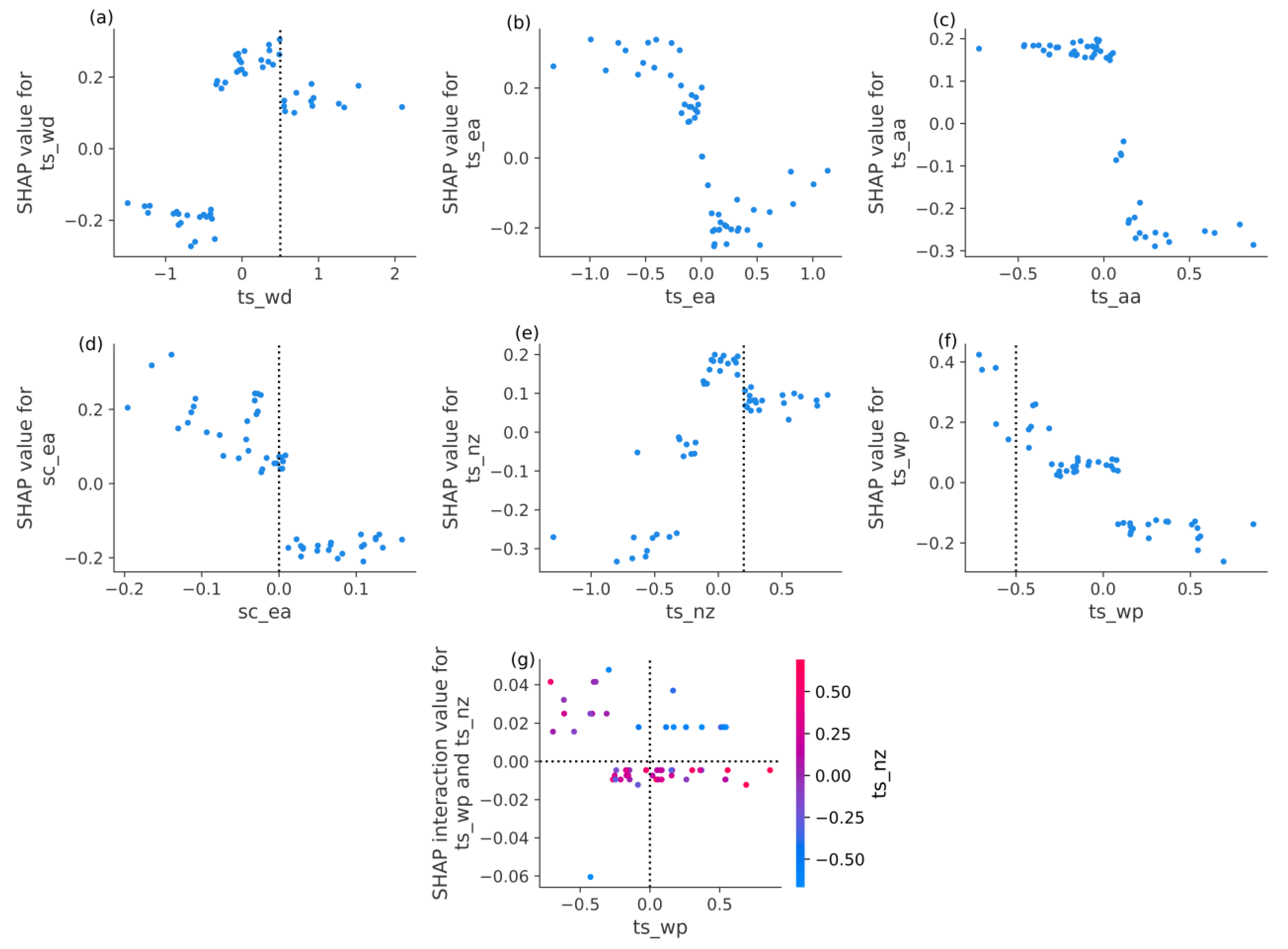
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, Y.; Duan, A.; Xiao, C.; Xin, Y. The Prediction of the Tibetan Plateau Thermal Condition with Machine Learning and Shapley Additive Explanation. Remote Sens. 2022, 14, 4169. https://doi.org/10.3390/rs14174169
Tang Y, Duan A, Xiao C, Xin Y. The Prediction of the Tibetan Plateau Thermal Condition with Machine Learning and Shapley Additive Explanation. Remote Sensing. 2022; 14(17):4169. https://doi.org/10.3390/rs14174169
Chicago/Turabian StyleTang, Yuheng, Anmin Duan, Chunyan Xiao, and Yue Xin. 2022. "The Prediction of the Tibetan Plateau Thermal Condition with Machine Learning and Shapley Additive Explanation" Remote Sensing 14, no. 17: 4169. https://doi.org/10.3390/rs14174169
APA StyleTang, Y., Duan, A., Xiao, C., & Xin, Y. (2022). The Prediction of the Tibetan Plateau Thermal Condition with Machine Learning and Shapley Additive Explanation. Remote Sensing, 14(17), 4169. https://doi.org/10.3390/rs14174169