
Assessing the Predictive Power of Democratic Republic of Congo’s National Spaceborne Biomass Map over Independent Test Samples


Abstract
:1. Introduction
2. Materials and Methods
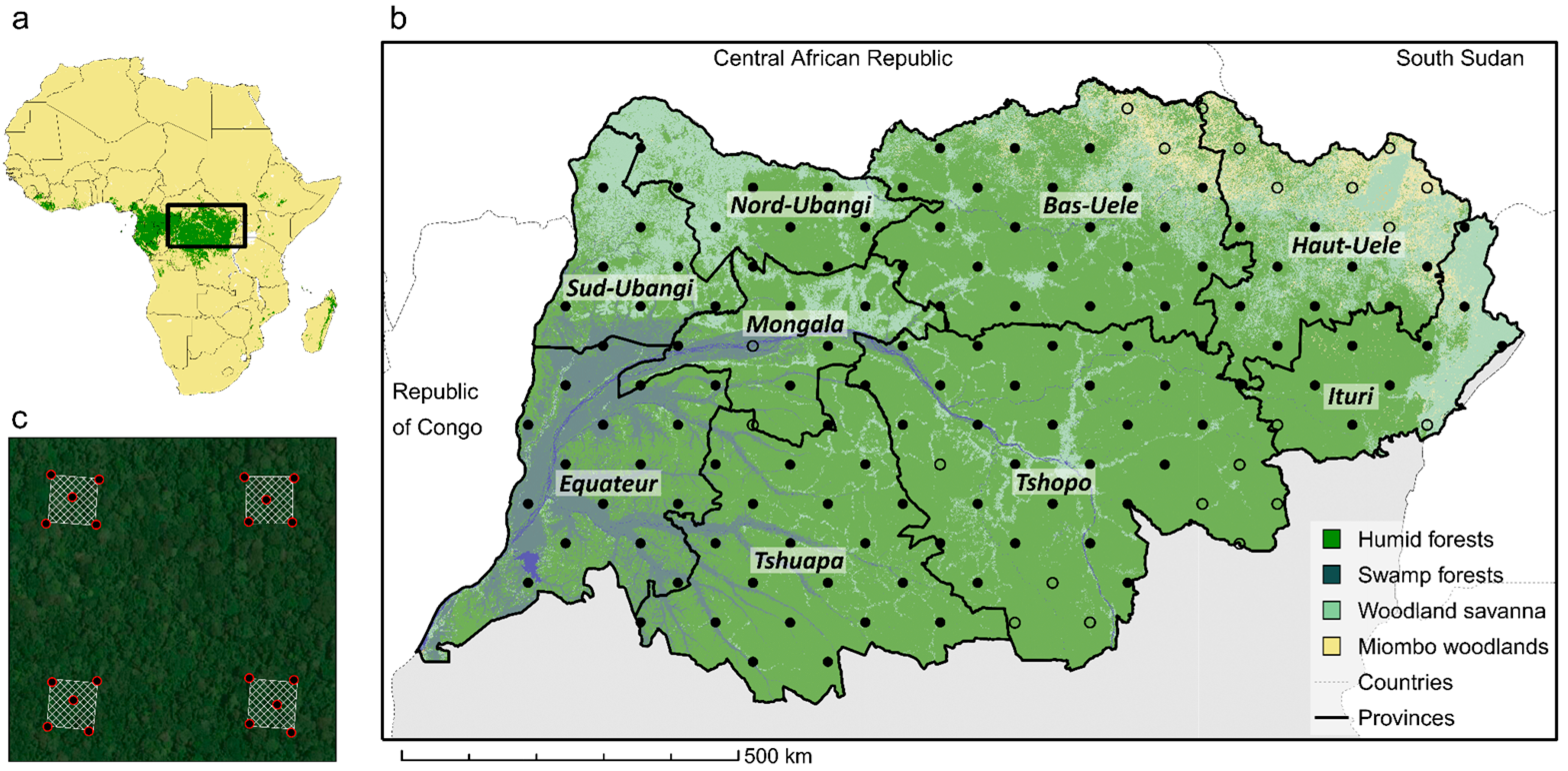
2.1. Study Area
2.2. Workflow of the Analysis
2.3. DRC’s National Spaceborne Map
2.4. National Forest Inventory Data
2.4.1. Sampling Design
2.4.2. Field Data
2.4.3. Aboveground Biomass Prediction from Inventory Data
2.4.4. Linking Field Plots to the National Spaceborne Biomass and Land Cover Maps
2.5. Statistical Analyses
2.5.1. Assessment of Map Predictive Power at Plot Locations
2.5.2. Design-Based Inference from the Field Sample Plots and Error Propagation
2.5.3. Model-Based Inference from the Biomass Map
3. Results
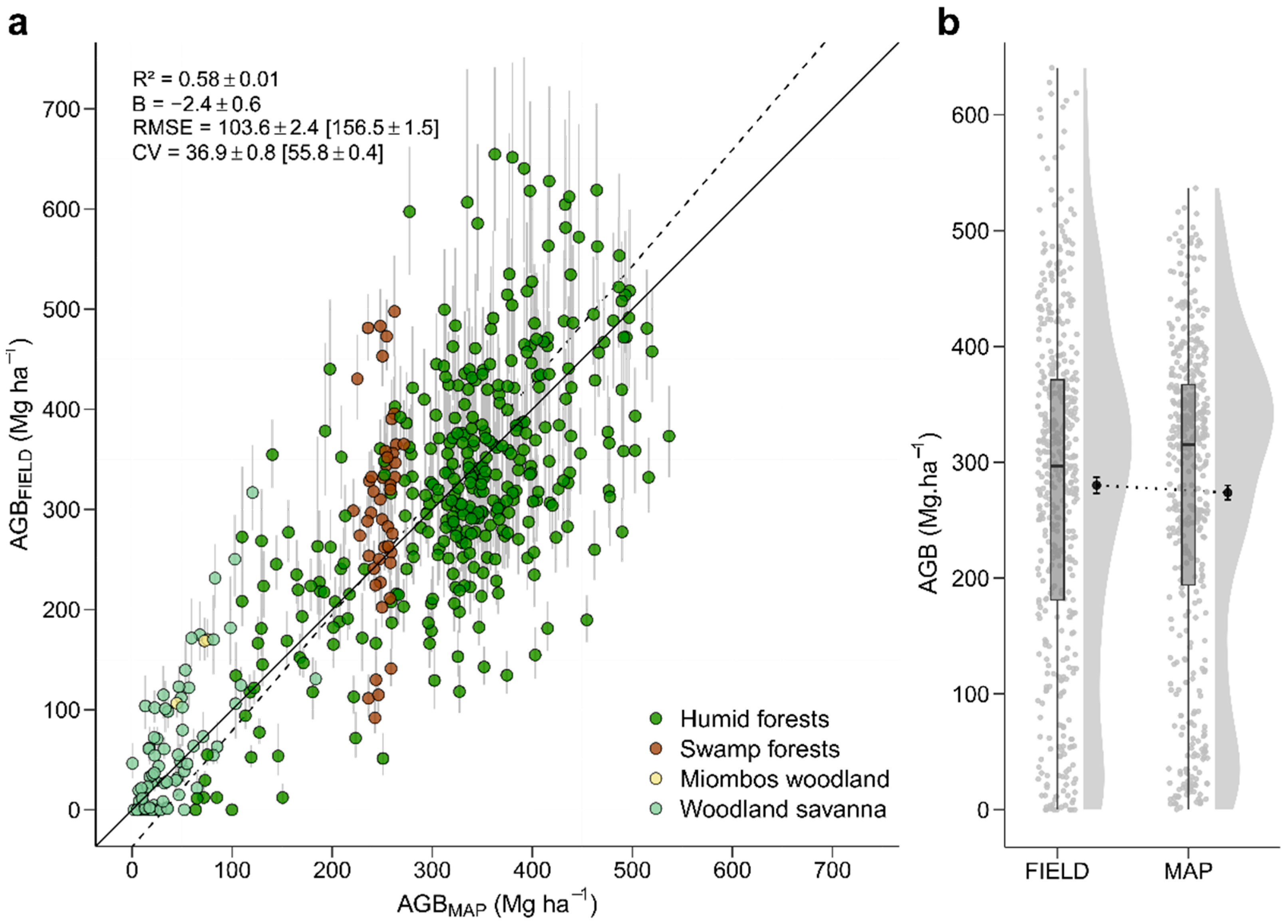
3.1. Predictions of Plot-to-Plot Biomass Variation
3.1.1. Relationship between AGBMAP and AGBFIELD across All Plots
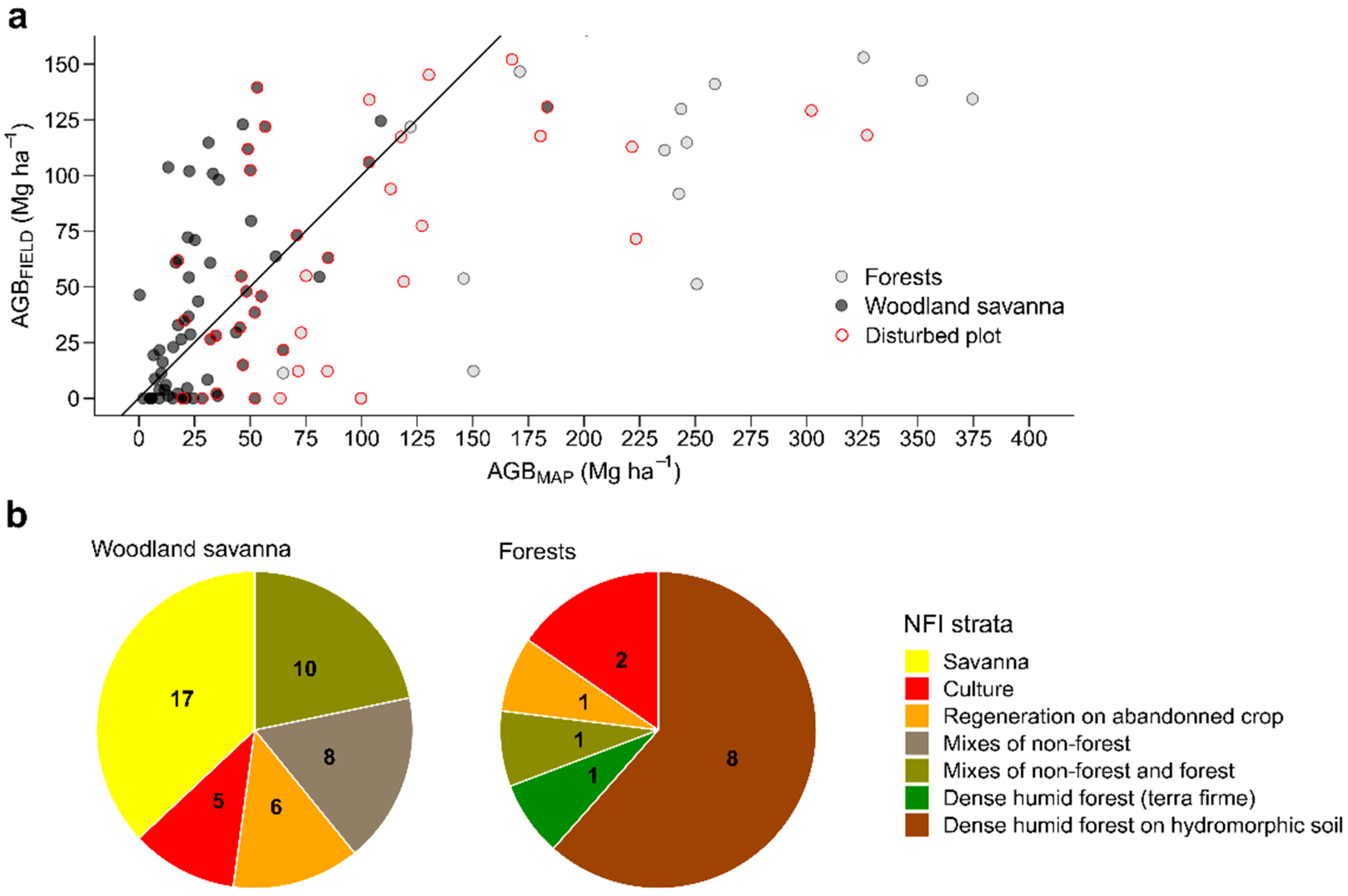
3.1.2. Mapping Error by Classes of AGBFIELD
3.1.3. Relationship between AGBMAP and AGBFIELD per Landcover Classes
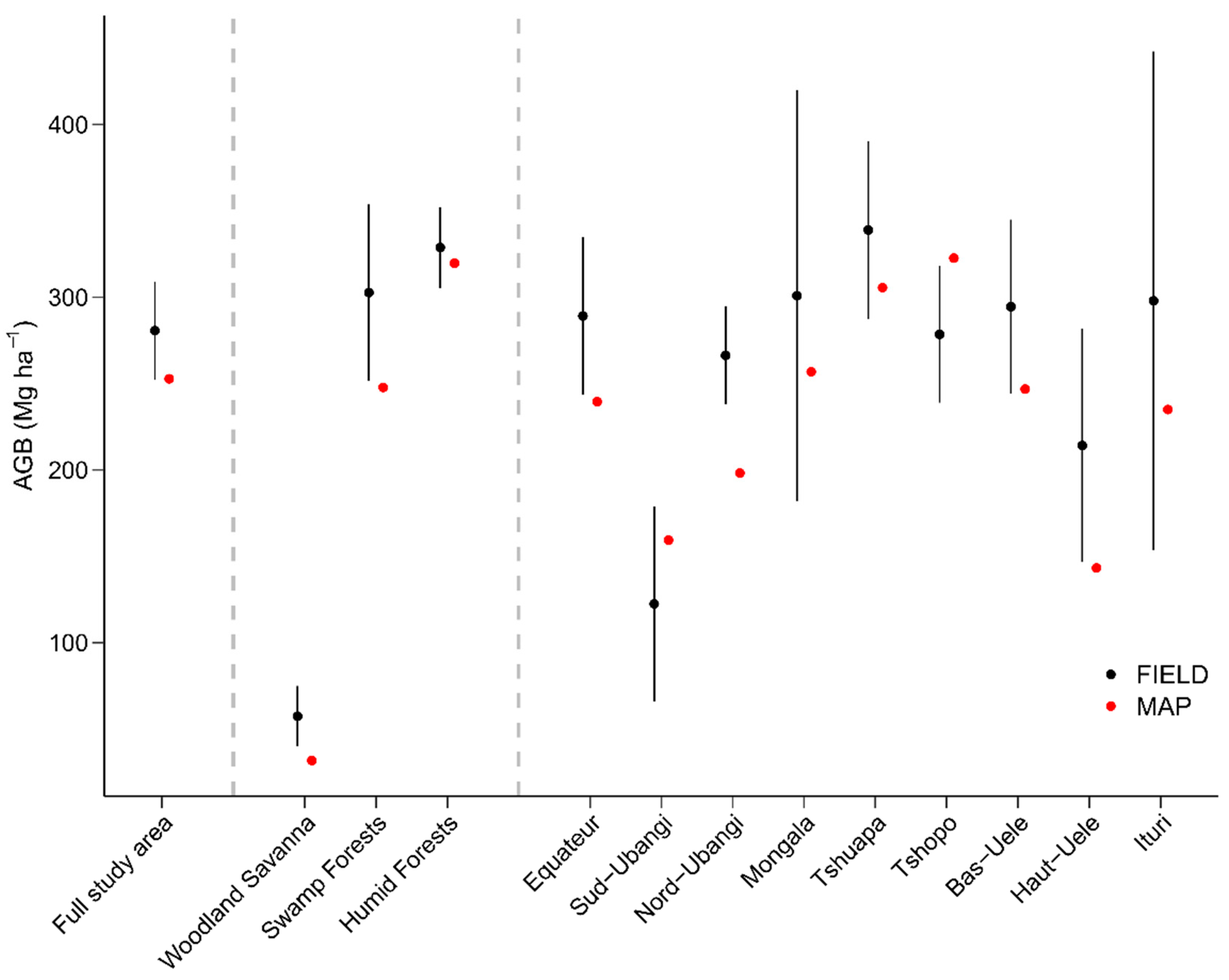
3.1.4. Predictions of Mean Biomass at Population Level
4. Discussion
4.1. The Overall Relationship between RS- and Field-Derived AGB Predictions Is Coherent
4.2. The RS Signal Saturates on Dense Forests—But at Relatively Large AGB Levels
4.3. The Map Shows Contrasted Performances within Landcover Classes
4.4. Implications for DRC’s Carbon Emissions Reporting and Outlooks
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mitchard, E.T.A. The Tropical Forest Carbon Cycle and Climate Change. Nature 2018, 559, 527–534. [Google Scholar] [CrossRef] [PubMed]
- Tyukavina, A.; Hansen, M.C.; Potapov, P.; Parker, D.; Okpa, C.; Stehman, S.V.; Kommareddy, I.; Turubanova, S. Congo Basin Forest Loss Dominated by Increasing Smallholder Clearing. Sci. Adv. 2018, 4, eaat2993. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ministère de l’Environnement et Développement Durable. Niveau d’Emissions de Référence Des Forêts; Ministère de l’Environnement et Développement Durable: Kinshasa, Democratic Republic of the Congo, 2018.
- United Nations. World Population Prospects: The 2017 Revision, Key Findings and Advance Tables; UN: New York, NY, USA, 2017. [Google Scholar]
- Kengoum Djiegni, F.; Pham, T.T.; Sonwa, D.J. Dix Ans de REDD+ Dans Un Contexte Politique Changeant En République Démocratique Du Congo; CIFOR Infobrief: Bogor, Indonesia, 2020. [Google Scholar]
- Sandker, M.; Crete, P.; Lee, D.; Sanz-Sanchez, M. Considérations Techniques Relatives à l’établissement de Niveaux d’émissions de Référence Pour Les Forêts et/Ou Niveaux de Référence Pour Les Forêts Dans Le Contexte de La REDD+ Au Titre de La CCNUCC; FAO: Rome, Italy, 2016; ISBN 978-92-5-208841-7. [Google Scholar]
- Nesha, M.K.; Herold, M.; Sy, V.D.; Duchelle, A.E.; Martius, C.; Branthomme, A.; Garzuglia, M.; Jonsson, O.; Pekkarinen, A. An Assessment of Data Sources, Data Quality and Changes in National Forest Monitoring Capacities in the Global Forest Resources Assessment 2005–2020. Environ. Res. Lett. 2021, 16, 054029. [Google Scholar] [CrossRef]
- Herold, M.; Carter, S.; Avitabile, V.; Espejo, A.B.; Jonckheere, I.; Lucas, R.; McRoberts, R.E.; Næsset, E.; Nightingale, J.; Petersen, R.; et al. The Role and Need for Space-Based Forest Biomass-Related Measurements in Environmental Management and Policy. Surv. Geophys. 2019, 40, 757–778. [Google Scholar] [CrossRef] [Green Version]
- McRoberts, R.E.; Tomppo, E.O.; Næsset, E. Advances and Emerging Issues in National Forest Inventories. Scand. J. For. Res. 2010, 25, 368–381. [Google Scholar] [CrossRef]
- Réjou-Méchain, M.; Barbier, N.; Couteron, P.; Ploton, P.; Vincent, G.; Herold, M.; Mermoz, S.; Saatchi, S.; Chave, J.; de Boissieu, F. Upscaling Forest Biomass from Field to Satellite Measurements: Sources of Errors and Ways to Reduce Them. Surv. Geophys. 2019, 40, 881–911. [Google Scholar] [CrossRef]
- Rejou-Mechain, M.; Muller-Landau, H.C.; Detto, M.; Thomas, S.C.; Le Toan, T.; Saatchi, S.S.; Barreto-Silva, J.S.; Bourg, N.A.; Bunyavejchewin, S.; Butt, N.; et al. Local Spatial Structure of Forest Biomass and Its Consequences for Remote Sensing of Carbon Stocks. Biogeosciences 2014, 11, 6827–6840. [Google Scholar] [CrossRef] [Green Version]
- Knapp, N.; Huth, A.; Fischer, R. Tree Crowns Cause Border Effects in Area-Based Biomass Estimations from Remote Sensing. Remote Sens. 2021, 13, 1592. [Google Scholar] [CrossRef]
- Duncanson, L.; Armston, J.; Disney, M.; Avitabile, V.; Barbier, N.; Calders, K.; Carter, S.; Chave, J.; Herold, M.; Macbean, N. Aboveground Woody Biomass Product Validation Good Practices Protocol. Version 1.0; CEOS Working Group on Calibration and Validation; Lanf Product Validation, 2021. Available online: https://lpvs.gsfc.nasa.gov/PDF/CEOS_WGCV_LPV_Biomass_Protocol_2021_V1.0.pdf (accessed on 16 June 2022).
- Jha, N.; Tripathi, N.K.; Barbier, N.; Virdis, S.G.P.; Chanthorn, W.; Viennois, G.; Brockelman, W.Y.; Nathalang, A.; Tongsima, S.; Sasaki, N.; et al. The Real Potential of Current Passive Satellite Data to Map Aboveground Biomass in Tropical Forests. Remote Sens. Ecol. Conserv. 2021, 7, 504–520. [Google Scholar] [CrossRef]
- Xu, L.; Saatchi, S.S.; Yang, Y.; Yu, Y.; White, L. Performance of Non-Parametric Algorithms for Spatial Mapping of Tropical Forest Structure. Carbon Balance Manag. 2016, 11, 18. [Google Scholar] [CrossRef] [Green Version]
- Mitchard, E.T.; Saatchi, S.S.; Baccini, A.; Asner, G.P.; Goetz, S.J.; Harris, N.L.; Brown, S. Uncertainty in the Spatial Distribution of Tropical Forest Biomass: A Comparison of Pan-Tropical Maps. Carbon Balance Manag. 2013, 8, 10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Langner, A.; Achard, F.; Grassi, G. Can Recent Pan-Tropical Biomass Maps Be Used to Derive Alternative Tier 1 Values for Reporting REDD+ Activities under UNFCCC? Environ. Res. Lett. 2014, 9, 124008. [Google Scholar] [CrossRef] [Green Version]
- Xu, L.; Saatchi, S.S.; Shapiro, A.; Meyer, V.; Ferraz, A.; Yang, Y.; Bastin, J.-F.; Banks, N.; Boeckx, P.; Verbeeck, H.; et al. Spatial Distribution of Carbon Stored in Forests of the Democratic Republic of Congo. Sci. Rep. 2017, 7, 15030. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saatchi, S.; Mascaro, J.; Xu, L.; Keller, M.; Yang, Y.; Duffy, P.; Espírito-Santo, F.; Baccini, A.; Chambers, J.; Schimel, D. Seeing the Forest beyond the Trees. Glob. Ecol. Biogeogr. 2015, 24, 606–610. [Google Scholar] [CrossRef] [Green Version]
- Réjou-Méchain, M.; Tanguy, A.; Piponiot, C.; Chave, J.; Hérault, B. Biomass: An r Package for Estimating above-Ground Biomass and Its Uncertainty in Tropical Forests. Methods Ecol. Evol. 2017, 8, 1163–1167. [Google Scholar] [CrossRef]
- Chave, J.; Coomes, D.; Jansen, S.; Lewis, S.L.; Swenson, N.G.; Zanne, A.E. Towards a Worldwide Wood Economics Spectrum. Ecol. Lett. 2009, 12, 351–366. [Google Scholar] [CrossRef]
- Zanne, A.E.; Lopez-Gonzalez, G.; Coomes, D.A.; Ilic, J.; Jansen, S.; Lewis, S.L.; Miller, R.B.; Swenson, N.G.; Wiemann, M.C.; Chave, J. Data from: Towards a Worldwide Wood Economics Spectrum. Ecol. Lett. 2009, 12, 351–366. [Google Scholar]
- Lamulamu, A.; Ploton, P.; Birigazzi, L.; Xu, L.; Saatchi, S.S.; Kibambe Lubamba, J.P. Genus and Species Level Mean Wood Density of DRC Tree Species. Figshare 2022. [Google Scholar] [CrossRef]
- Beirne, C.; Miao, Z.; Nuñez, C.L.; Medjibe, V.P.; Saatchi, S.; White, L.J.T.; Poulsen, J.R. Landscape-level Validation of Allometric Relationships for Carbon Stock Estimation Reveals Bias Driven by Soil Type. Ecol. Appl. 2019, 29, e01987. [Google Scholar] [CrossRef]
- Feldpausch, T.R.; Lloyd, J.; Lewis, S.L.; Brienen, R.J.; Gloor, M.; Monteagudo, M.A.; Lopez-Gonzalez, G.; Banin, L.; Abu, S.K.; Affum-Baffoe, K.; et al. Tree Height Integrated into Pan-Tropical Forest Biomass Estimates. Biogeosciences 2012, 9, 3381–3403. [Google Scholar] [CrossRef] [Green Version]
- Ploton, P.; Mortier, F.; Barbier, N.; Cornu, G.; Réjou-Méchain, M.; Rossi, V.; Alonso, A.; Bastin, J.-F.; Bayol, N.; Bénédet, F.; et al. A Map of African Humid Tropical Forest Aboveground Biomass Derived from Management Inventories. Sci. Data 2020, 7, 221. [Google Scholar] [CrossRef] [PubMed]
- Chave, J.; Réjou-Méchain, M.; Búrquez, A.; Chidumayo, E.; Colgan, M.S.; Delitti, W.B.; Duque, A.; Eid, T.; Fearnside, P.M.; Goodman, R.C.; et al. Improved Allometric Models to Estimate the Aboveground Biomass of Tropical Trees. Glob. Chang. Biol. 2014, 20, 3177–3190. [Google Scholar] [CrossRef] [PubMed]
- Johnson, C.E.; Barton, C.C. Where in the World Are My Field Plots? Using GPS Effectively in Environmental Field Studies. Front. Ecol. Environ. 2004, 2, 475–482. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Næsset, E.; Liknes, G.C.; Chen, Q.; Walters, B.F.; Saatchi, S.; Herold, M. Using a Finer Resolution Biomass Map to Assess the Accuracy of a Regional, Map-Based Estimate of Forest Biomass. Surv. Geophys. 2019, 40, 1001–1015. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [Green Version]
- Sarndal, C.; Särndal, C.-E.; Swensson, B.; Wretman, J. Model Assisted Survey Sampling; Springer: New York, NY, USA, 1992; p. S4900. ISBN 0-387-97528-4. [Google Scholar]
- Cochran, W.G. Sampling Techniques; John Weily and Sons Inc.: New York, NY, USA, 1977; p. 135. [Google Scholar]
- Scott, C.T.; Bechtold, W.A.; Reams, G.A.; Smith, W.D.; Hansen, M.H.; Moisen, G.G. Sample-Based Estimators Utilized by the Forest Inventory and Analysis National Information Management System; Gen. Tech. Rep. SRS-80; U.S. Department of Agriculture, Forest Service, Southern Research Station: Asheville, NC, USA, 2005; pp. 53–77.
- Tomppo, E. The Finnish National Forest Inventory. In Proceedings of the Eighth Annual Forest Inventory and Analysis Symposium, Monterey, CA, USA, 16–19 October 2006; McRoberts, R.E., Reams, G.A., Van Deusen, P.C., McWilliams, W.H., Eds.; Gen. Tech. Report WO-79. U.S. Department of Agriculture, Forest Service: Washington, DC, USA, 2009; pp. 39–46. [Google Scholar]
- Thompson, S.K. Sampling, 3rd ed.; John Wiley & Sons Inc: Hoboken, NJ, USA, 2012. [Google Scholar]
- Korhonen, K.T.; Salmensuu, O. Formulas for Estimators and Their Variances in NFI; Internal Report; United States Department of Agriculture: Washington, DC, USA, 2014. [Google Scholar]
- Henry, M.; Iqbal, Z.; Johnson, K.; Akhter, M.; Costello, L.; Scott, C.; Jalal, R.; Hossain, M.A.; Chakma, N.; Kuegler, O. A Multi-Purpose National Forest Inventory in Bangladesh: Design, Operationalisation and Key Results. For. Ecosyst. 2021, 8, 1–22. [Google Scholar] [CrossRef]
- Espejo, A.; Federici, S.; Green, C.; Amuchastegui, N.; d’Annunzio, R.; Balzter, H.; Bholanath, P.; Brack, C.; Brewer, C.; Birigazzi, L. Integration of Remote-Sensing and Ground-Based Observations for Estimation of Emissions and Removals of Greenhouse Gases in Forests: Methods and Guidance from the Global Forest Observations Initiative, Edition 3.0; UN Food and Agriculcure Organ: Rome, Italy, 2020; 300p. [Google Scholar]
- Birigazzi, L.; Gamarra, J.G.P.; Gregoire, T.G. Unbiased Emission Factor Estimators for Large-Area Forest Inventories: Domain Assessment Techniques. Environ. Ecol. Stat. 2018, 25, 199–219. [Google Scholar] [CrossRef]
- Scott, C.T. Estimation Using Ratio-to-Size Estimator across Strata and Subpopulations. 2018. Available online: https://www.scribd.com/document/388141246/Estimation-Using-Ratio-To-Size-Estimator-Across-Strata-and-Subpopulations-2018-04-18 (accessed on 15 December 2021).
- Rubin, D.B. Multiple Imputation for Survey Nonresponse; Wiley: New York, NY, USA, 1987. [Google Scholar]
- Hossain, M.A.; Aziz, A.; Chakma, N.; Johnson, K.; Henry, M.; Jalal, R.; Carrillo, O.; Scott, C.; Birigazzi, L.; Akhter, M.; et al. Estimation Procedures of Indicators and Variables of the Bangladesh Forest Inventory; Forest Department and Food and Agricultural Organization of the United Nations: Dhaka, Bangladesh, 2019. [Google Scholar]
- McRoberts, R.E.; Westfall, J.A. Propagating Uncertainty through Individual Tree Volume Model Predictions to Large-Area Volume Estimates. Ann. For. Sci. 2016, 73, 625–633. [Google Scholar] [CrossRef] [Green Version]
- Perugini, L.; Pellis, G.; Grassi, G.; Ciais, P.; Dolman, H.; House, J.I.; Peters, G.P.; Smith, P.; Günther, D.; Peylin, P. Emerging Reporting and Verification Needs under the Paris Agreement: How Can the Research Community Effectively Contribute? Environ. Sci. Policy 2021, 122, 116–126. [Google Scholar] [CrossRef]
- Marvin, D.C.; Asner, G.P.; Knapp, D.E.; Anderson, C.B.; Martin, R.E.; Sinca, F.; Tupayachi, R. Amazonian Landscapes and the Bias in Field Studies of Forest Structure and Biomass. Proc. Natl. Acad. Sci. USA 2014, 111, E5224–E5232. [Google Scholar] [CrossRef] [Green Version]
- Csillik, O.; Kumar, P.; Mascaro, J.; O’Shea, T.; Asner, G.P. Monitoring Tropical Forest Carbon Stocks and Emissions Using Planet Satellite Data. Sci. Rep. 2019, 9, 17831. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sagang, L.B.T.; Ploton, P.; Sonké, B.; Poilvé, H.; Couteron, P.; Barbier, N. Airborne Lidar Sampling Pivotal for Accurate Regional AGB Predictions from Multispectral Images in Forest-Savanna Landscapes. Remote Sens. 2020, 12, 1637. [Google Scholar] [CrossRef]
- Lu, D.; Chen, Q.; Wang, G.; Liu, L.; Li, G.; Moran, E. A Survey of Remote Sensing-Based Aboveground Biomass Estimation Methods in Forest Ecosystems. Int. J. Digit. Earth 2016, 9, 63–105. [Google Scholar] [CrossRef]
- Mermoz, S.; Réjou-Méchain, M.; Villard, L.; Le Toan, T.; Rossi, V.; Gourlet-Fleury, S. Decrease of L-Band SAR Backscatter with Biomass of Dense Forests. Remote Sens. Environ. 2015, 159, 307–317. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.V.; Goetz, S.J.; Turubanova, S.; Tyukavina, A.; Krylov, A.; Kommareddy, A.; Egorov, A. Mapping Tree Height Distributions in Sub-Saharan Africa Using Landsat 7 and 8 Data. Remote Sens. Environ. 2016, 185, 221–232. [Google Scholar] [CrossRef] [Green Version]
- Phillips, O.L.; Sullivan, M.J.; Baker, T.R.; Mendoza, A.M.; Vargas, P.N.; Vásquez, R. Species Matter: Wood Density Influences Tropical Forest Biomass at Multiple Scales. Surv. Geophys. 2019, 40, 913–935. [Google Scholar] [CrossRef] [Green Version]
- Næsset, E.; McRoberts, R.E.; Pekkarinen, A.; Saatchi, S.; Santoro, M.; Trier, Ø.D.; Zahabu, E.; Gobakken, T. Use of Local and Global Maps of Forest Canopy Height and Aboveground Biomass to Enhance Local Estimates of Biomass in Miombo Woodlands in Tanzania. Int. J. Appl. Earth Obs. Geoinf. 2020, 89, 102109. [Google Scholar]
- McRoberts, R.E. Compensating for Missing Plot Observations in Forest Inventory Estimation. Can. J. For. Res. 2003, 33, 1990–1997. [Google Scholar] [CrossRef]
- Dubayah, R.O.; Armston, J.; Kellner, J.R.; Duncanson, L.; Healey, S.P.; Patterson, P.L.; Hancock, S.; Tang, H.; Bruening, J.; Hofton, M.A. GEDI L4A Footprint Level Aboveground Biomass Density, Version 2; ORNL DAAC: Oak Ridge, TN, USA, 2021. [Google Scholar]
- Meyer, H.; Reudenbach, C.; Wöllauer, S.; Nauss, T. Importance of Spatial Predictor Variable Selection in Machine Learning Applications–Moving from Data Reproduction to Spatial Prediction. Ecol. Model. 2019, 411, 108815. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Landcover | N | R2 | B | RMSE | CV |
|---|---|---|---|---|---|
| Woodland Savanna | 77 | 0.41 ± 0.07 | −33.3 ± 3.1 | 54.4 ± 3.2 | 94.9 ± 5.1 |
| Swamp Forests | 46 | 0.02 ± 0.03 | −17.6 ± 1.4 | 113.3 ± 4.4 | 37.4 ± 1.3 |
| Humid Forests | 344 | 0.33 ± 0.02 | 0.8 ± 0.7 | 110.5 ± 2.9 | 33.6 ± 0.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lamulamu, A.; Ploton, P.; Birigazzi, L.; Xu, L.; Saatchi, S.; Kibambe Lubamba, J.-P. Assessing the Predictive Power of Democratic Republic of Congo’s National Spaceborne Biomass Map over Independent Test Samples. Remote Sens. 2022, 14, 4126. https://doi.org/10.3390/rs14164126
Lamulamu A, Ploton P, Birigazzi L, Xu L, Saatchi S, Kibambe Lubamba J-P. Assessing the Predictive Power of Democratic Republic of Congo’s National Spaceborne Biomass Map over Independent Test Samples. Remote Sensing. 2022; 14(16):4126. https://doi.org/10.3390/rs14164126
Chicago/Turabian StyleLamulamu, Augustin, Pierre Ploton, Luca Birigazzi, Liang Xu, Sassan Saatchi, and Jean-Paul Kibambe Lubamba. 2022. "Assessing the Predictive Power of Democratic Republic of Congo’s National Spaceborne Biomass Map over Independent Test Samples" Remote Sensing 14, no. 16: 4126. https://doi.org/10.3390/rs14164126
APA StyleLamulamu, A., Ploton, P., Birigazzi, L., Xu, L., Saatchi, S., & Kibambe Lubamba, J.-P. (2022). Assessing the Predictive Power of Democratic Republic of Congo’s National Spaceborne Biomass Map over Independent Test Samples. Remote Sensing, 14(16), 4126. https://doi.org/10.3390/rs14164126