
A Novel GAN-Based Anomaly Detection and Localization Method for Aerial Video Surveillance at Low Altitude

 ,
,  ,
, 

 , , , ,
, , , , 

Abstract
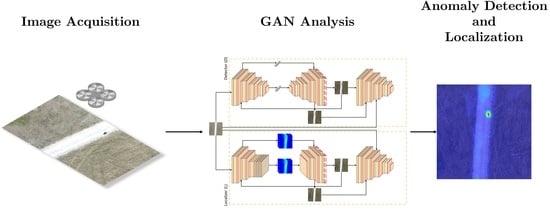
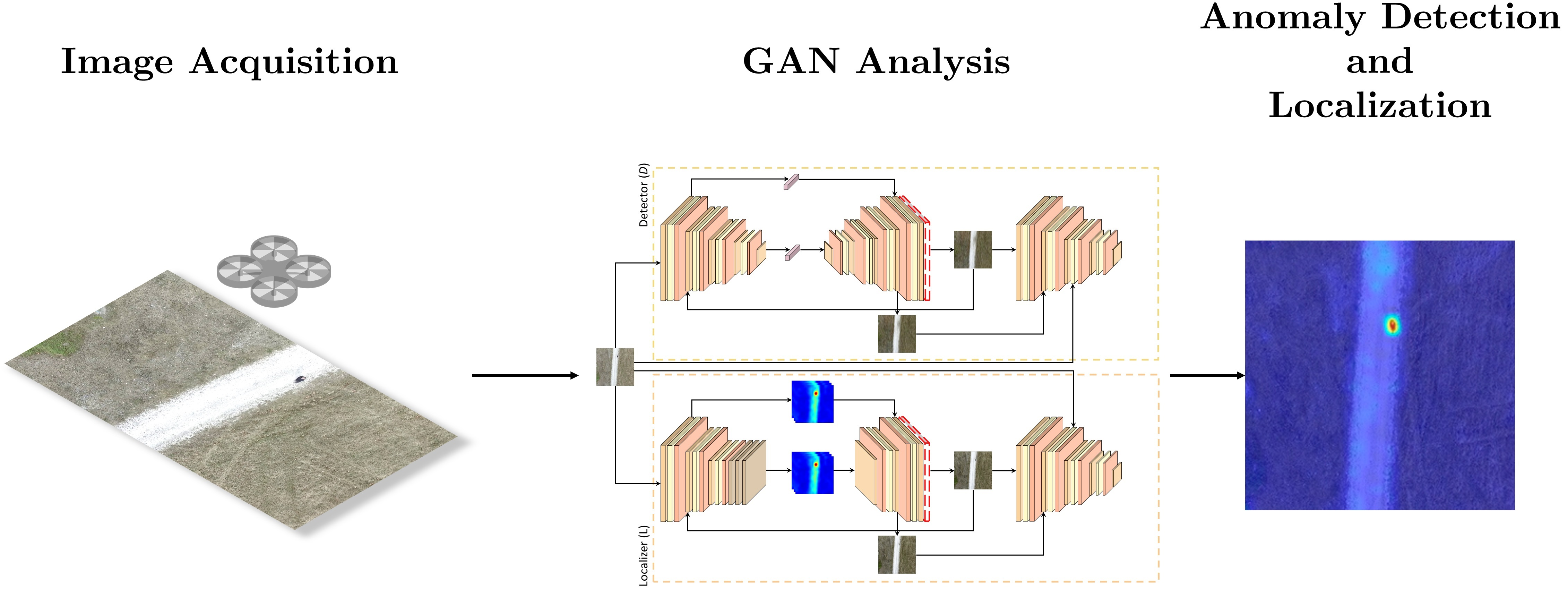
:
1. Introduction
- Designing a network architecture based on two GANs organized on parallel branches and intended for the modeling and learning of robust normal class data manifolds, which are crucial for increasing the performance and precision of detection and localization of eventually anomalous conditions;
- Detecting and localizing any anomalous element of interest in aerial videos at very low altitude (from 6 to 15 m), spanning from common items, e.g., cars or people, to undefined and challenging objects, e.g., IEDs, independently from their properties such as color, size, position, or shape, including elements never seen before;
- Presenting quantitative and qualitative experiments for the anomaly detection and localization tasks on the UMCD dataset, reaching outstanding results.
2. Related Work
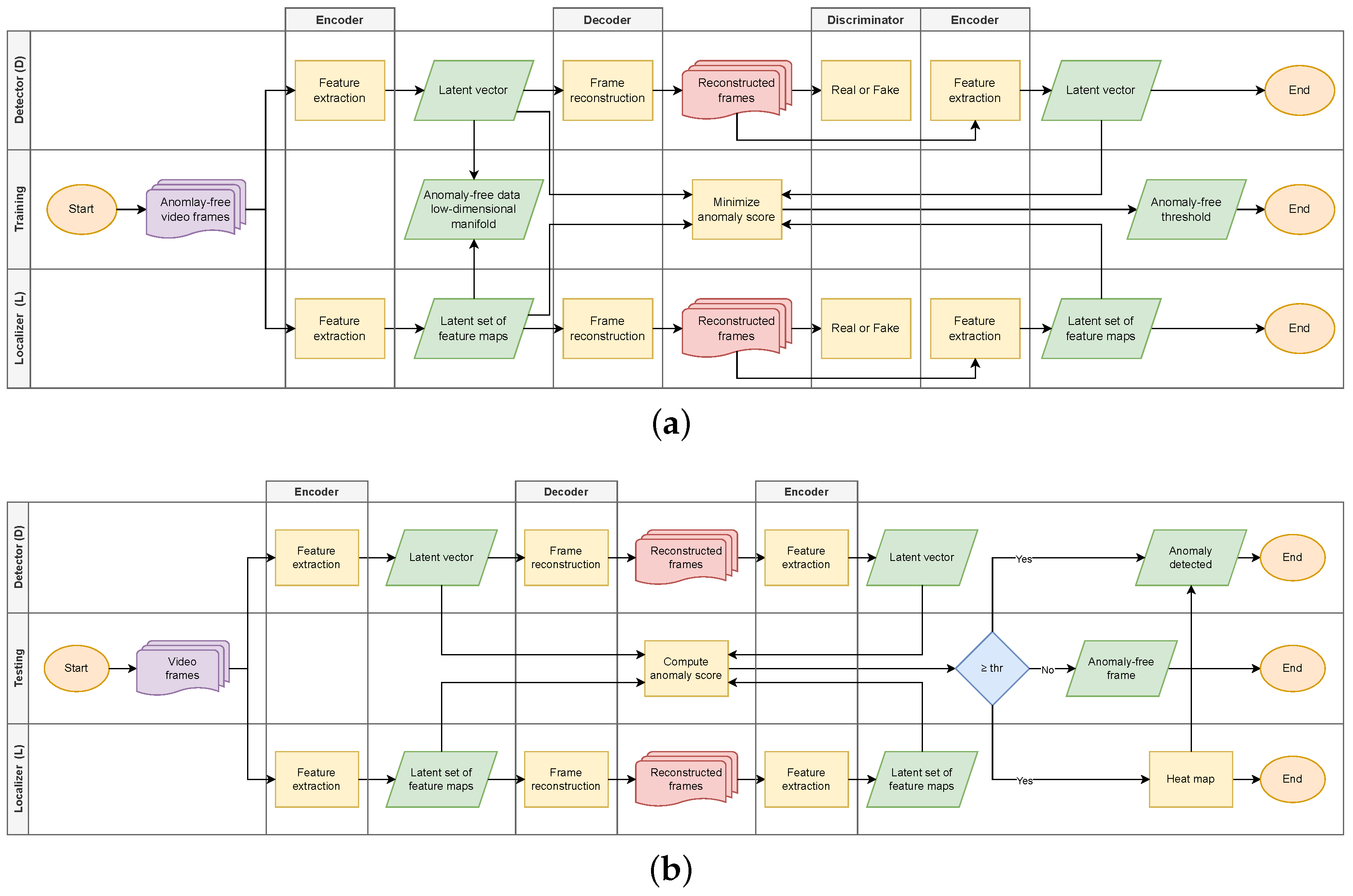
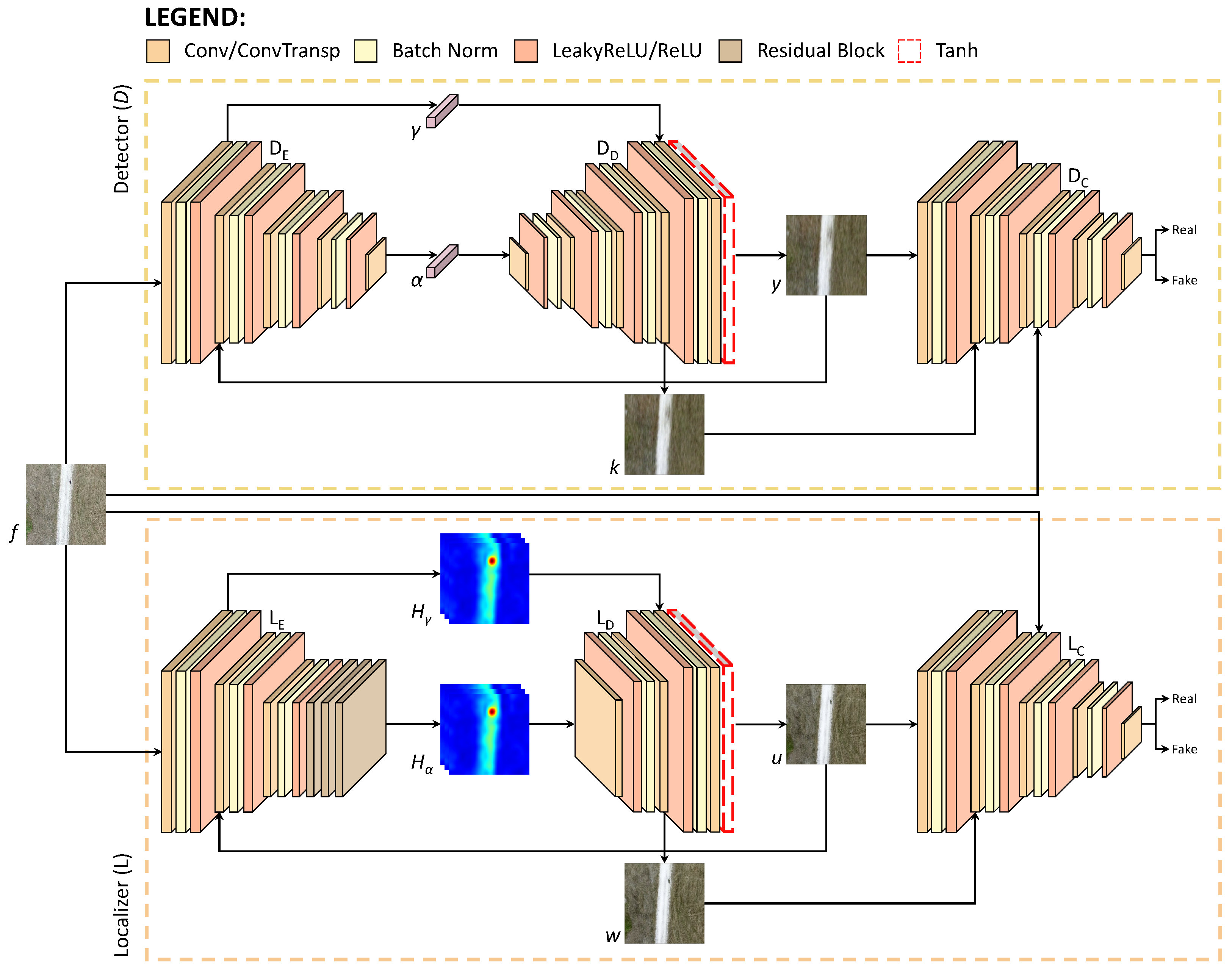
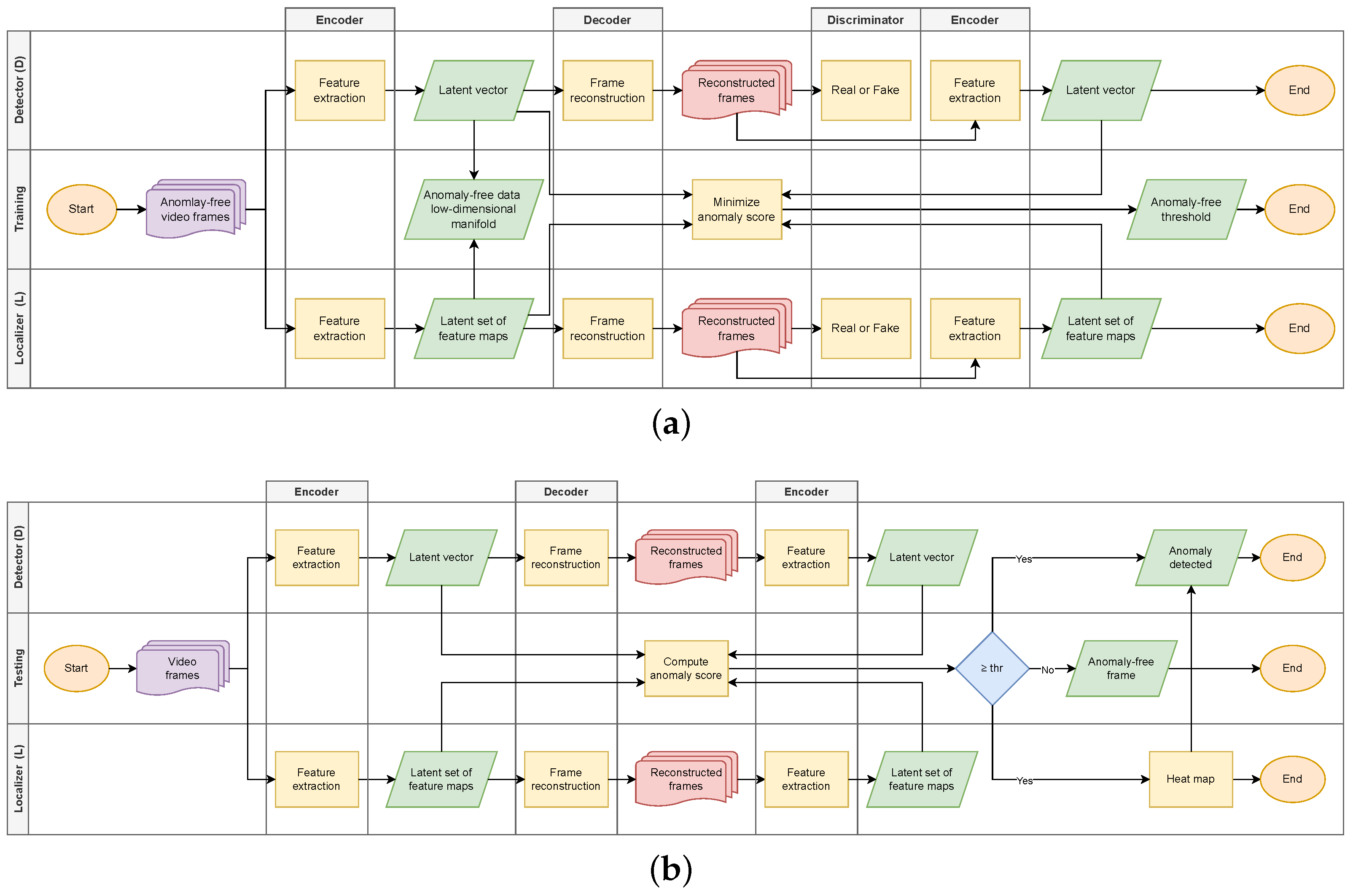
3. Methodology
3.1. Anomaly Detection
3.2. Anomaly Localization
4. Results
4.1. Dataset
4.2. Implementation Details
4.3. Anomaly Detection Results
4.4. Anomaly Localization Results
5. Discussion
5.1. Dataset
5.2. Implementation Details
5.3. Performance Evaluation
5.3.1. Single-Branch Architecture
5.3.2. Anomaly Detection
5.3.3. Anomaly Localization
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Huang, C.R.; Huang, W.Y.; Liao, Y.S.; Lee, C.C.; Yeh, Y.W. A Content-Adaptive Resizing Framework for Boosting Computation Speed of Background Modeling Methods. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 1192–1204. [Google Scholar] [CrossRef]
- Wang, H.; Lv, X.; Zhang, K.; Guo, B. Building Change Detection Based on 3D Co-Segmentation Using Satellite Stereo Imagery. Remote Sens. 2022, 14, 628. [Google Scholar] [CrossRef]
- Avola, D.; Bernardi, M.; Cinque, L.; Foresti, G.L.; Massaroni, C. Adaptive Bootstrapping Management by Keypoint Clustering for Background Initialization. Pattern Recognit. Lett. 2017, 100, 110–116. [Google Scholar] [CrossRef]
- Yang, L.; Cheng, H.; Su, J.; Li, X. Pixel-to-Model Distance for Robust Background Reconstruction. IEEE Trans. Circ. Syst. Video Technol. 2016, 26, 903–916. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, T.; Tian, Y.; Gao, W. Background-Modeling-Based Adaptive Prediction for Surveillance Video Coding. IEEE Trans. Image Process. 2014, 23, 769–784. [Google Scholar] [CrossRef]
- Jing, W.; Zhu, S.; Kang, P.; Wang, J.; Cui, S.; Chen, G.; Song, H. Remote Sensing Change Detection Based on Unsupervised Multi-Attention Slow Feature Analysis. Remote Sens. 2022, 14, 2834. [Google Scholar] [CrossRef]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, W.; Han, F.; Tuniyazi, A.; Li, H.; et al. Swin-Transformer-Enabled YOLOv5 with Attention Mechanism for Small Object Detection on Satellite Images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Avola, D.; Foresti, G.L.; Cinque, L.; Massaroni, C.; Vitale, G.; Lombardi, L. A Multipurpose Autonomous Robot for Target Recognition in Unknown Environments. In Proceedings of the 14th IEEE International Conference on Industrial Informatics (INDIN), Poitiers, France, 19–21 July 2016; pp. 766–771. [Google Scholar]
- Pan, X.; Tang, F.; Dong, W.; Gu, Y.; Song, Z.; Meng, Y.; Xu, P.; Deussen, O.; Xu, C. Self-Supervised Feature Augmentation for Large Image Object Detection. IEEE Trans. Image Process. 2020, 29, 6745–6758. [Google Scholar] [CrossRef]
- del Blanco, C.R.; Jaureguizar, F.; Garcia, N. An Efficient Multiple Object Detection and Tracking Framework for Automatic Counting and Video Surveillance Applications. IEEE Trans. Consum. Electron. 2012, 58, 857–862. [Google Scholar] [CrossRef] [Green Version]
- He, C.; Zhang, J.; Yao, J.; Zhuo, L.; Tian, Q. Meta-Learning Paradigm and CosAttn for Streamer Action Recognition in Live Video. IEEE Signal Process. Lett. 2022, 29, 1097–1101. [Google Scholar] [CrossRef]
- Liu, T.; Ma, Y.; Yang, W.; Ji, W.; Wang, R.; Jiang, P. Spatial-Temporal Interaction Learning Based Two-Stream Network for Action Recognition. Inf. Sci. 2022, 606, 864–876. [Google Scholar] [CrossRef]
- Meng, Q.; Zhu, H.; Zhang, W.; Piao, X.; Zhang, A. Action Recognition Using Form and Motion Modalities. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 1–16. [Google Scholar] [CrossRef]
- Avola, D.; Cinque, L.; Foresti, G.L.; Pannone, D. Automatic Deception Detection in RGB Videos Using Facial Action Units. In Proceedings of the 13th International Conference on Distributed Smart Cameras (ICDSC), Trento, Italy, 9–11 September 2019; pp. 1–6. [Google Scholar]
- Zhao, Q.; Zhang, B.; Lyu, S.; Zhang, H.; Sun, D.; Li, G.; Feng, W. A CNN-SIFT Hybrid Pedestrian Navigation Method Based on First-Person Vision. Remote Sens. 2018, 10, 1229. [Google Scholar] [CrossRef] [Green Version]
- Maji, B.; Swain, M.; Mustaqeem. Advanced Fusion-Based Speech Emotion Recognition System Using a Dual-Attention Mechanism with Conv-Caps and Bi-GRU Features. Electronics 2022, 11, 1328. [Google Scholar] [CrossRef]
- Liao, Y.; Vakanski, A.; Xian, M. A Deep Learning Framework for Assessing Physical Rehabilitation Exercises. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 468–477. [Google Scholar] [CrossRef] [PubMed]
- Vamsikrishna, K.M.; Dogra, D.P.; Desarkar, M.S. Computer-Vision-Assisted Palm Rehabilitation With Supervised Learning. IEEE Trans. Biomed. Eng. 2016, 63, 991–1001. [Google Scholar] [CrossRef]
- Petracca, A.; Carrieri, M.; Avola, D.; Basso Moro, S.; Brigadoi, S.; Lancia, S.; Spezialetti, M.; Ferrari, M.; Quaresima, V.; Placidi, G. A Virtual Ball Task Driven by Forearm Movements for Neuro-Rehabilitation. In Proceedings of the International Conference on Virtual Rehabilitation (ICVR), Valencia, Spain, 9–12 June 2015; pp. 162–163. [Google Scholar]
- Du, D.; Han, X.; Fu, H.; Wu, F.; Yu, Y.; Cui, S.; Liu, L. SAniHead: Sketching Animal-Like 3D Character Heads Using a View-Surface Collaborative Mesh Generative Network. IEEE Trans. Vis. Comput. Graph. 2022, 28, 2415–2429. [Google Scholar] [CrossRef] [PubMed]
- Jackson, B.; Keefe, D.F. Lift-Off: Using Reference Imagery and Freehand Sketching to Create 3D Models in VR. IEEE Trans. Vis. Comput. Graph. 2016, 22, 1442–1451. [Google Scholar] [CrossRef] [PubMed]
- Avola, D.; Caschera, M.C.; Ferri, F.; Grifoni, P. Ambiguities in Sketch-Based Interfaces. In Proceedings of the 40th Annual Hawaii International Conference on System Sciences (HICSS), Waikoloa, HI, USA, 3–6 January 2007; p. 290b. [Google Scholar]
- Messina, G.; Modica, G. Applications of UAV Thermal Imagery in Precision Agriculture: State of the Art and Future Research Outlook. Remote Sens. 2020, 12, 1491. [Google Scholar] [CrossRef]
- Adão, T.; Hruška, J.; Pádua, L.; Bessa, J.; Peres, E.; Morais, R.; Sousa, J.J. Hyperspectral Imaging: A Review on UAV-Based Sensors, Data Processing and Applications for Agriculture and Forestry. Remote Sens. 2017, 9, 1110. [Google Scholar] [CrossRef] [Green Version]
- Marusic, Z.; Zelenika, D.; Marusic, T.; Gotovac, S. Visual Search on Aerial Imagery as Support for Finding Lost Persons. In Proceedings of the 8th Mediterranean Conference on Embedded Computing (MECO), Budva, Montenegro, 10–14 June 2019; pp. 1–4. [Google Scholar]
- Scherer, J.; Yahyanejad, S.; Hayat, S.; Yanmaz, E.; Andre, T.; Khan, A.; Vukadinovic, V.; Bettstetter, C.; Hellwagner, H.; Rinner, B. An Autonomous Multi-UAV System for Search and Rescue. In Proceedings of the Workshop on Micro Aerial Vehicle Networks, Systems, and Applications for Civilian Use (DroNet), Florence, Italy, 18 May 2015; pp. 33–38. [Google Scholar]
- Ul Ain Tahir, H.; Waqar, A.; Khalid, S.; Usman, S.M. Wildfire Detection in Aerial Images Using Deep Learning. In Proceedings of the 2nd International Conference on Digital Futures and Transformative Technologies (ICoDT2), Rawalpindi, Pakistan, 24–26 May 2022; pp. 1–7. [Google Scholar]
- Jiao, Z.; Zhang, Y.; Mu, L.; Xin, J.; Jiao, S.; Liu, H.; Liu, D. A YOLOv3-based Learning Strategy for Real-time UAV-based Forest Fire Detection. In Proceedings of the Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 4963–4967. [Google Scholar]
- Xiao, J.; Zhang, S.; Dai, Y.; Jiang, Z.; Yi, B.; Xu, C. Multiclass Object Detection in UAV Images Based on Rotation Region Network. IEEE J. Miniat. Air Space Syst. 2020, 1, 188–196. [Google Scholar] [CrossRef]
- Zhang, R.; Shao, Z.; Huang, X.; Wang, J.; Li, D. Object Detection in UAV Images via Global Density Fused Convolutional Network. Remote Sens. 2020, 12, 3140. [Google Scholar] [CrossRef]
- Wang, S.; Han, Y.; Chen, J.; Zhang, Z.; Wang, G.; Du, N. A Deep-Learning-Based Sea Search and Rescue Algorithm by UAV Remote Sensing. In Proceedings of the IEEE CSAA Guidance, Navigation and Control Conference (CGNCC), Xiamen, China, 10–12 August 2018; pp. 1–5. [Google Scholar]
- Avola, D.; Cinque, L.; Di Mambro, A.; Diko, A.; Fagioli, A.; Foresti, G.L.; Marini, M.R.; Mecca, A.; Pannone, D. Low-Altitude Aerial Video Surveillance via One-Class SVM Anomaly Detection from Textural Features in UAV Images. Information 2022, 13, 2. [Google Scholar] [CrossRef]
- Avola, D.; Pannone, D. MAGI: Multistream Aerial Segmentation of Ground Images with Small-Scale Drones. Drones 2021, 5, 111. [Google Scholar] [CrossRef]
- Avola, D.; Cinque, L.; Fagioli, A.; Foresti, G.L.; Pannone, D.; Piciarelli, C. Automatic Estimation of Optimal UAV Flight Parameters for Real-Time Wide Areas Monitoring. Multimed. Tools Appl. 2021, 80, 25009–25031. [Google Scholar] [CrossRef]
- Avola, D.; Cinque, L.; Diko, A.; Fagioli, A.; Foresti, G.L.; Mecca, A.; Pannone, D.; Piciarelli, C. MS-Faster R-CNN: Multi-Stream Backbone for Improved Faster R-CNN Object Detection and Aerial Tracking from UAV Images. Remote Sens. 2021, 13, 1670. [Google Scholar] [CrossRef]
- Avola, D.; Foresti, G.L.; Martinel, N.; Micheloni, C.; Pannone, D.; Piciarelli, C. Real-Time Incremental and Geo-Referenced Mosaicking by Small-Scale UAVs. In Proceedings of the International Conference on Image Analysis and Processing (ICIAP), Catania, Italy, 11–15 September 2017; pp. 694–705. [Google Scholar]
- Avola, D.; Cinque, L.; Fagioli, A.; Foresti, G.L.; Massaroni, C.; Pannone, D. Feature-Based SLAM Algorithm for Small Scale UAV with Nadir View. In Proceedings of the International Conference on Image Analysis and Processing (ICIAP), Trento, Italy, 9–13 September 2019; pp. 457–467. [Google Scholar]
- Diez, Y.; Kentsch, S.; Fukuda, M.; Caceres, M.L.L.; Moritake, K.; Cabezas, M. Deep Learning in Forestry Using UAV-Acquired RGB Data: A Practical Review. Remote Sens. 2021, 13, 2837. [Google Scholar] [CrossRef]
- Bozcan, I.; Kayacan, E. UAV-AdNet: Unsupervised Anomaly Detection using Deep Neural Networks for Aerial Surveillance. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 1158–1164. [Google Scholar]
- Chriki, A.; Touati, H.; Snoussi, H.; Kamoun, F. UAV-based Surveillance System: An Anomaly Detection Approach. In Proceedings of the IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020; pp. 1–6. [Google Scholar]
- Martin, R.A.; Blackburn, L.; Pulsipher, J.; Franke, K.; Hedengren, J.D. Potential Benefits of Combining Anomaly Detection with View Planning for UAV Infrastructure Modeling. Remote Sens. 2017, 9, 434. [Google Scholar] [CrossRef] [Green Version]
- Avola, D.; Cinque, L.; Foresti, G.L.; Martinel, N.; Pannone, D.; Piciarelli, C. A UAV Video Dataset for Mosaicking and Change Detection From Low-Altitude Flights. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 2139–2149. [Google Scholar] [CrossRef] [Green Version]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Ramachandra, B.; Jones, M.J.; Vatsavai, R.R. A Survey of Single-Scene Video Anomaly Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 2293–2312. [Google Scholar] [CrossRef] [PubMed]
- Nayak, R.; Pati, U.C.; Das, S.K. A Comprehensive Review on Deep Learning-Based Methods for Video Anomaly Detection. Image Vis. Comput. 2021, 106, 1–19. [Google Scholar] [CrossRef]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep Learning for Anomaly Detection: A Review. ACM Comput. Surv. 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Hamdi, S.; Bouindour, S.; Snoussi, H.; Wang, T.; Abid, M. End-to-End Deep One-Class Learning for Anomaly Detection in UAV Video Stream. J. Imaging 2021, 7, 90. [Google Scholar] [CrossRef]
- Chan, A.; Vasconcelos, N. UCSD Pedestrian Dataset. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 909–926. [Google Scholar] [CrossRef] [Green Version]
- Bonetto, M.; Korshunov, P.; Ramponi, G.; Ebrahimi, T. Privacy in Mini-Drone Based Video Surveillance. In Proceedings of the 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; pp. 1–6. [Google Scholar]
- Chriki, A.; Touati, H.; Snoussi, H.; Kamoun, F. Deep Learning and Handcrafted Features for One-Class Anomaly Detection in UAV Video. Multimed. Tools Appl. 2021, 80, 2599–2620. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 886–893. [Google Scholar]
- Pearson, K. LIII. On Lines and Planes of Closest Fit to Systems of Points in Space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef] [Green Version]
- Klaser, A.; Marszałek, M.; Schmid, C. A Spatio-Temporal Descriptor Based on 3D-Gradients. In Proceedings of the 19th British Machine Vision Conference (BMVC), Leeds, UK, 1–4 September 2008; pp. 1–10. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A Training Algorithm for Optimal Margin Classifiers. In Proceedings of the 5th Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Jin, P.; Mou, L.; Xia, G.S.; Zhu, X.X. Anomaly Detection in Aerial Videos Via Future Frame Prediction Networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Brussels, Belgium, 11–16 July 2021; pp. 8237–8240. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Haralick, R.M. Statistical and Structural Approaches to Texture. Proc. IEEE 1979, 67, 786–804. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–11 December 2014; pp. 2672–2680. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:abs/1411.1784. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016; pp. 1–20. [Google Scholar]
- Avola, D.; Cascio, M.; Cinque, L.; Fagioli, A.; Foresti, G.L. Human Silhouette and Skeleton Video Synthesis Through Wi-Fi Signals. Int. J. Neural Syst. 2022, 32, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Akcay, S.; Atapour-Abarghouei, A.; Breckon, T.P. Ganomaly: Semi-Supervised Anomaly Detection via Adversarial Training. In Proceedings of the Asian Conference on Computer Vision (ACCV), Perth, Australia, 2–6 December 2018; pp. 622–637. [Google Scholar]
- Chen, D.; Yue, L.; Chang, X.; Xu, M.; Jia, T. NM-GAN: Noise-Modulated Generative Adversarial Network for Video Anomaly Detection. Pattern Recognit. 2021, 116, 107969. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Maas, A.; Hannun, A.; Ng, A. Rectifier Nonlinearities Improve Neural Network Acoustic Models. In Proceedings of the International Conference on Machine Learning (ICML), Atlanta, GA, USA, 16–21 June 2013; pp. 1–6. [Google Scholar]
- Youden, W.J. Index for Rating Diagnostic Tests. Cancer 1950, 3, 32–35. [Google Scholar] [CrossRef]
- Carrara, F.; Amato, G.; Brombin, L.; Falchi, F.; Gennaro, C. Combining GANs and AutoEncoders for Efficient Anomaly Detection. In Proceedings of the International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3939–3946. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Langs, G.; Schmidt-Erfurth, U. f-AnoGAN: Fast Unsupervised Anomaly Detection with Generative Adversarial Networks. Med. Image Anal. 2019, 54, 30–44. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dong, L.F.; Gan, Y.Z.; Mao, X.L.; Yang, Y.B.; Shen, C. Learning Deep Representations Using Convolutional Auto-Encoders with Symmetric Skip Connections. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 3006–3010. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019; pp. 1–19. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Avola, D.; Cascio, M.; Cinque, L.; Fagioli, A.; Foresti, G.L.; Marini, M.R.; Rossi, F. Real-time deep learning method for automated detection and localization of structural defects in manufactured products. Comput. Ind. Eng. 2022, 172, 108512. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Path Seq. # | 3-Layers | 4-Layers | 5-Layers | |
|---|---|---|---|---|
| CS | Path #1 | 0.839 | 0.856 | 0.847 |
| Path #2 | 0.831 | 0.825 | 0.827 | |
| Dirt | Path #1 | 0.871 | 0.875 | 0.879 |
| Path #2 | 0.852 | 0.850 | 0.873 | |
| Path #3 | 0.788 | 0.765 | 0.770 | |
| Path #4 | 0.798 | 0.763 | 0.783 | |
| Urban | Path #1 | 0.796 | 0.779 | 0.784 |
| Path #2 | 0.870 | 0.876 | 0.880 | |
| Path #3 | 0.739 | 0.720 | 0.730 | |
| Path #4 | 0.873 | 0.870 | 0.860 | |
| Avg AUROC | 0.826 | 0.818 | 0.823 |
| Path Seq. # | 3-Layers | 4-Layers | 5-Layers | |
|---|---|---|---|---|
| CS | Path #1 | 0.979 | 0.976 | 0.959 |
| Path #2 | 0.966 | 0.969 | 0.970 | |
| Dirt | Path #1 | 0.968 | 0.974 | 0.977 |
| Path #2 | 0.980 | 0.976 | 0.973 | |
| Path #3 | 0.977 | 0.965 | 0.949 | |
| Path #4 | 0.952 | 0.968 | 0.957 | |
| Urban | Path #1 | 0.973 | 0.984 | 0.952 |
| Path #2 | 0.976 | 0.982 | 0.987 | |
| Path #3 | 0.936 | 0.945 | 0.938 | |
| Path #4 | 0.983 | 0.979 | 0.980 | |
| Avg AUROC | 0.969 | 0.972 | 0.964 |
| Path Seq. # | Threshold | |
|---|---|---|
| CS | Path #1 | 0.079 |
| Path #2 | 0.031 | |
| Dirt | Path #1 | 0.039 |
| Path #2 | 0.125 | |
| Path #3 | 0.330 | |
| Path #4 | 0.362 | |
| Urban | Path #1 | 0.332 |
| Path #2 | 0.275 | |
| Path #3 | 0.219 | |
| Path #4 | 0.011 |
| Path Seq. # | 3-Layers | 4-Layers | 5-Layers | |
|---|---|---|---|---|
| CS | Path #1 | 0.956 | 0.948 | 0.951 |
| Path #2 | 0.947 | 0.950 | 0.946 | |
| Dirt | Path #1 | 0.955 | 0.960 | 0.959 |
| Path #2 | 0.962 | 0.949 | 0.953 | |
| Path #3 | 0.960 | 0.968 | 0.963 | |
| Path #4 | 0.956 | 0.952 | 0.944 | |
| Urban | Path #1 | 0.954 | 0.958 | 0.945 |
| Path #2 | 0.946 | 0.937 | 0.931 | |
| Path #3 | 0.965 | 0.962 | 0.954 | |
| Path #4 | 0.968 | 0.974 | 0.970 | |
| Avg SSIM | 0.957 | 0.956 | 0.952 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Avola, D.; Cannistraci, I.; Cascio, M.; Cinque, L.; Diko, A.; Fagioli, A.; Foresti, G.L.; Lanzino, R.; Mancini, M.; Mecca, A.; et al. A Novel GAN-Based Anomaly Detection and Localization Method for Aerial Video Surveillance at Low Altitude. Remote Sens. 2022, 14, 4110. https://doi.org/10.3390/rs14164110
Avola D, Cannistraci I, Cascio M, Cinque L, Diko A, Fagioli A, Foresti GL, Lanzino R, Mancini M, Mecca A, et al. A Novel GAN-Based Anomaly Detection and Localization Method for Aerial Video Surveillance at Low Altitude. Remote Sensing. 2022; 14(16):4110. https://doi.org/10.3390/rs14164110
Chicago/Turabian StyleAvola, Danilo, Irene Cannistraci, Marco Cascio, Luigi Cinque, Anxhelo Diko, Alessio Fagioli, Gian Luca Foresti, Romeo Lanzino, Maurizio Mancini, Alessio Mecca, and et al. 2022. "A Novel GAN-Based Anomaly Detection and Localization Method for Aerial Video Surveillance at Low Altitude" Remote Sensing 14, no. 16: 4110. https://doi.org/10.3390/rs14164110
APA StyleAvola, D., Cannistraci, I., Cascio, M., Cinque, L., Diko, A., Fagioli, A., Foresti, G. L., Lanzino, R., Mancini, M., Mecca, A., & Pannone, D. (2022). A Novel GAN-Based Anomaly Detection and Localization Method for Aerial Video Surveillance at Low Altitude. Remote Sensing, 14(16), 4110. https://doi.org/10.3390/rs14164110