Abstract
Detecting objects from images captured by Unmanned Aerial Vehicles (UAVs) is a highly demanding task. It is also considered a very challenging task due to the typically cluttered background and diverse dimensions of the foreground targets, especially small object areas that contain only very limited information. Multi-scale representation learning presents a remarkable approach to recognizing small objects. However, this strategy ignores the combination of the sub-parts in an object and also suffers from the background interference in the feature fusion process. To this end, we propose a Fine-grained Target Focusing Network (FiFoNet) which can effectively select a combination of multi-scale features for an object and block background interference, which further revitalizes the differentiability of the multi-scale feature representation. Furthermore, we propose a Global–Local Context Collector (GLCC) to extract global and local contextual information and enhance low-quality representations of small objects. We evaluate the performance of the proposed FiFoNet on the challenging task of object detection in UAV images. A comparison of the experiment results on three datasets, namely VisDrone2019, UAVDT, and our VisDrone_Foggy, demonstrates the effectiveness of FiFoNet, which outperforms the ten baseline and state-of-the-art models with remarkable performance improvements. When deployed on an edge device NVIDIA JETSON XAVIER NX, our FiFoNet only takes about 80 milliseconds to process an drone-captured image.
1. Introduction
Unmanned Aerial Vehicles (UAVs) equipped with cameras have received a lot of attention in recent years [,,]. UAVs can be deployed rapidly with a wide range of new applications, including aerial photography and video surveillance, at a relatively low cost. Therefore, automatic understanding of visual data captured by UAVs is highly demanding, bringing computer vision and UAVs together more and more closely. In the field of computer vision, significant progress has been achieved in object detection. Existing detectors such as the YOLO family [,] and Faster RCNN [] can achieve satisfying performance on natural images. The targets to be recognized in natural scenes generally consist of a large number of pixels. These detectors usually demand a huge amount of computing resources to ensure their capability and performance. However, the existing detectors perform poorly in situ because UAV images contain quite small objects with very limited numbers of pixels, and the UAVs’ airborne computational resources are very limited [,,].
The difficulty of UAV object detection lies in building robust features to distinguish foreground targets with limited pixels from background clutter [,,]. Existing methods can be roughly grouped into three major streams, i.e., super-resolution-based (SR-based) methods, context-based methods and multi-scale representation-based (MR-based) methods.
(1) The SR-based methods attempt to super-resolve the whole image or the Regions of Interest (RoIs) [,,], and then, they perform object detection with a general-purpose object detector [,]. The newly generated details of RoIs can boost the detector’s performance to a higher degree. Efficiently selecting regions to be reconstructed is critical to the efficiency of the algorithm. While foreground reconstruction can effectively improve the detection accuracy, background reconstruction just increases the calculation burden of the algorithm []. However, it is difficult to locate foreground regions containing objects of interest while excluding any background.
(2) The context-based methods leverage the relationship between the object and its surrounding environment to infer the original region of the small object [,,]. However, due to the complexity and diversity of UAV background scenes, it is often difficult to build such contextual relationships. SR-based and context-based methods generally explicitly design a module specifically used for super-resolving RoIs or encoding context information, respectively, which can significantly increase the computation cost. Therefore, these algorithms are difficult to be deployed on UAVs.
(3) The MR-based methods first use different level features to represent objects [,,] and then recognize these objects in separate feature levels. Specifically, a high-level feature with a low resolution treats an object as a whole, and a low-level feature with a high resolution focuses on the object’s parts, such as its boundaries, as shown in Figure 1a. These methods build the coarse-grained features, which treat each object as a whole region and process them separately. However, this strategy neglects the fine-grained features in an object (as shown in Figure 1b), which has been demonstrated to improve object detection performance [,]. Furthermore, there is severe background interference in the combination of low-level and high-level features. In Figure 2a, for example, the red area covers parts of the background in the original image but misses the small targets in the far distance. In Figure 2b, the feature map focuses more accurately on the small objects. The background interference, in turn, adversely affects the learning in the subsequent layers, resulting in misclassifications in the final predictions, especially for recognizing small objects.
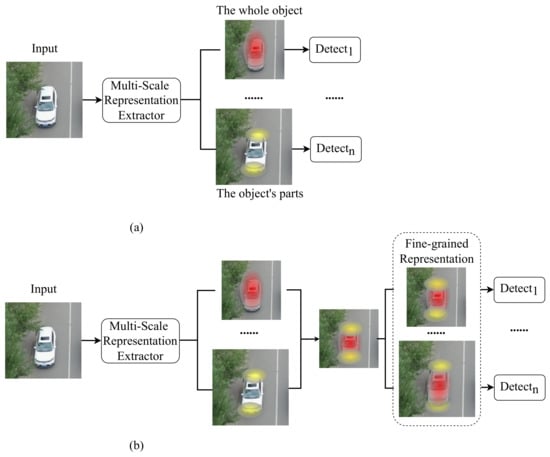
Figure 1.
Comparisons between the conventional coarse-grained representation (a) and our fine-grained representation (b).
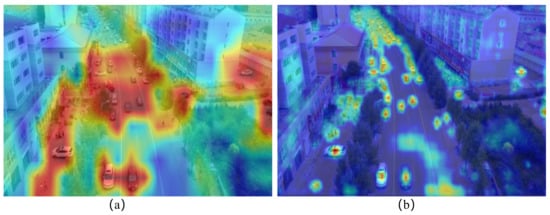
Figure 2.
The heatmap visualization of the high-level (a) and low-level (b) features. The features visualized in (a) appear to be noisy, covering more background but missing the small targets (the cars) in the far distance region. The features visualized in (b) focus more accurately on the objects, especially on small targets.
In this paper, we propose a Fine-grained Target Focusing Network (FiFoNet) to improve the performance of object detection in UAV images through aggregating fine-grained objects’ sub-parts with a special focus on foreground target areas. Compared with existing detectors, FiFoNet is distinctive in two significant aspects: (1) FiFoNet aggregates sub-part features in an object from different levels of features to provide a finer-grained object representation. (2) The fine-grained object representation can focus more on the foreground targets by blocking background interference with an object mask under the guidance of the object position label. We design a Global-Local Context Collector (GLCC) to further improve the accuracy of small object detection. Our GLCC module utilizes several convolution filters with different kernel sizes to collect both global and local context information surrounding the objects.
In summary, our main contributions are as follows:
First, we propose a novel conceptual feature representation, called Fine-grained Target Focusing (FiFo) Representation, which aggregates sub-regions from multi-scale features and blocks background interference.
Second, we propose FiFoNet, which effectively detects objects in UAVs’ images with our proposed FiFo representation.
Third, we propose GLCC, which utilizes a Global Average Pooling operation to encode global context information and dilated convolutional layers to extract local context information to enhance the low-quality representations of small objects.
Extensive experiments, including overall and ablation studies, are conducted on two widely used datasets VisDrone2019 [] and UAVDT [], as well as our VisDrone_Foggy dataset. Ablation studies show that with the proposed FiFA, TFB and GLCC modules, our FiFoNet unleashes the ability of multi-scale feature representations and has improved the detection accuracy by , , and , respectively, on the VisDrone2019 dataset. Moreover, we compare our FiFoNet with ten state-of-the-art (SOTA) and baseline detectors to verify its effectiveness. On the VisDrone2019 dataset, the result of FiFoNet is , which outperforms the SOTA detector SAIC-FPN [] by . On the UAVDT dataset, our FiFoNet’s result is , outperforming the SOTA detector GLSAN [] by . Last but not least, we deployed the proposed FiFoNet on an embedded computing board, NVIDIA Jetson Xavier NX, and tested it on the VisDrone2019 dataset. We have achieved an of and an average processing speed of 79.5 milliseconds per image on the edge device.
2. Related Work
Images captured by UAVs represent a special object detection scene. UAV images usually contain a large number of small targets. Small objects, whose feature representations usually are low quality, are the main reason for the poor detection performance. Some high-performing algorithms for small object detection have expanded the application field of UAVs. We will review three research directions for UAV object detection. The related work of the three research directions is summarized in Table 1.

Table 1.
Summary of the advantages and drawbacks of object detectors for drone-captured images.
2.1. SR-Based UAV Object Detection
SR-based UAV object detection methods [,,,,,,] have attempted to adopt super-resolution techniques to reconstruct the low-quality RoIs or their corresponding features into high-quality counterparts. Hu et al. [] utilized a simple bilinear interpolation for better target localization. However, super-resolving the whole image is inefficient because the processed background can be irrelevant to the detection task, and this can increase the inference time substantially. Instead of super-resolving whole images, Bai et al. [] firstly obtained RoIs by using a high-recall detector and then super-resolved those RoIs only. On the other hand, since image features contain rich contextual information, Noh et al. [] and Li et al. [] reconstructed the features, instead of the image patches, of RoIs to further improve detection performance. However, it is difficult to accurately estimate the positions of RoIs or the corresponding RoIs’ features prior to object detection, which is a chicken-and-egg problem. The above-mentioned methods all ignored the uneven distribution of objects with various dimensions in UAV images. Critical crowded regions should be examined by a detector in fine detail even if it requires a heavy computational burden, whereas sparse regions should be given less attention or even ignored. Following this idea, Deng et al. [] and Yang et al. [] firstly zoomed in the crowded regions that contained a large number of objects and then super-resolved the proposed regions for final detection. Aiming at real-world applications, Mukhiddinov [] developed a smart glass system for blind and visually impaired (BVI) people. The system can recognize objects in low-quality images and help BVI people navigate in dark–light or foggy environments. However, these methods generally consist of three stages, namely crowded region proposal, low-quality image enhancement and object detection, which are inefficient and cannot be trained in an end-to-end fashion.
2.2. Context-Based UAV Object Detection
Context-based UAV object detection methods [,,,,,,] have attempted to embed the relationship between an object and its surrounding environments into its original RoI’s features. Bell et al. [] adopted a spatial recurrent neural network to capture the contextual information outside the RoIs. Tang et al. [] proposed the Pyramidbox to learn features from contextual parts around small targets and leveraged the joint fusion of high-level and low-level features. A hierarchical contextual information extracting module [] was proposed to integrate segmentation features into object detection features. Peng et al. [] provided context information in high-level layers to supply low-level features to improve their semantic discriminativity. However, due to the complexity and diversity of the UAV images’ backgrounds, it is difficult to build such contextual relationships. Integrating contextual information can also lead to increase background noise, which may result in degraded performance.
2.3. MR-Based UAV Object Detection
Most of the early object detectors [,,,,,] failed to detect small objects. We argue the main reason is that features used for recognizing objects are typically extracted in the last layer, and when image feature maps are down-sampled with pooling operations in the feature extraction process, repeated down-sampling operations can degrade the quality of the small objects’ features. Specifically, the hierarchical structure of neural networks allows them to extract feature maps with different spatial resolutions. Features extracted by convolutional filers with large kernel sizes in high-level layers contain much semantic information but lose detailed information due to their low resolution. Whereas features extracted in lower-level layers with convolutional filters of smaller kernels are in a higher resolution but lack semantic information. Therefore, MR techniques are introduced to aggregation to improve small object detection accuracy.
MR-based UAV object detection methods [,,,,] use a strategy of combining the rich semantic information in high-level features for target classification and the detailed spatial information in low-level features for determining targets’ positions. PANet [] proposed adding a bottom–up path to supply the object spatial information in low-level features to the high-level features, which shortens the information path between the lower-layer and topmost-layer features. A Balanced Feature Pyramid [] was proposed, which consisted of four stages, i.e., rescaling, integrating, refining and strengthening. The same deeply integrated balanced semantic features were used to enhance the multi-scale features. NAS [] provided a new exploration direction for vision tasks. NAS-FPN [] and Bi-FPN [] utilized neural architecture searches to search Feature Pyramid Networks (FPN) and Path Aggregation Feature Pyramid Networks, respectively, for a better cross-scale feature network topology. However, the search processes required a huge amount of GPU resources and computation time.
In our work, we build a fine-grained object representation from different layers and introduce object position information and context information into the process of feature fusion to obtain multi-scale features with more expressive ability.
3. Methodology
3.1. Overview
The overview of the pipeline of FiFoNet is illustrated in Figure 3. It consists of four modules: (1) A CNN-based backbone for feature extraction; (2) A top–down pathway extracting multi-scale feature representations via capturing the detailed position information and semantic information; (3) A fine-grained target-focusing module for further refining the multi-scale feature representations extracted by the second module; (4) A head for estimating the position and classification score of the resultant bounding box.
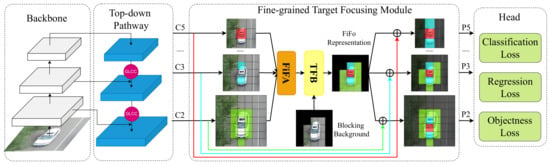
Figure 3.
The pipeline of the proposed FiFoNet, which consists of four modules. The first module is a backbone for feature extraction. The second module, which includes our proposed GLCC, is a top–down pathway for extracting multi-scale features. The third module is the newly proposed fine-grained target-focusing module for fine-grained feature aggregation and background noise suppression at the feature level. The last module is a head for predicting classification scores and bounding box positions. These four modules are merged into a unified network for an end-to-end training.
Our key idea is to build a fine-grained target focusing representation to further unleash the ability of the multi-scale feature representations. Toward this end, a fine-grained feature aggregation (FiFA) block is proposed to select a combination of sub-regions from multi-scale features. Moreover, a Target-Focusing Block (TFB) is proposed to focus the attention on the RoIs so as to suppress background noise.
3.2. Fine-Grained Feature Aggregation (FiFA)
The MR-based detectors lay more emphasis on object-level coarse-grained approaches and consider each object as a whole or a large part. However, the coarse-grained features tend to miss those fine details critical for detecting small objects and hence leave small objects in a disadvantaged situation. Different from the coarse-grained approaches, our FiFA is performed on the adaptive combination of multi-scale features to obtain fine-grained object representation for both large and small objects without significantly increasing the computational complexity.
Figure 4 illustrates the details of FiFA. We utilize the feature activation output from each stage’s last residual block. The outputs of these last residual blocks are defined as = for outputs of Conv2, Conv3, Conv4, and Conv5. We do not use Conv1 in the pyramid due to its large memory footprint. The input of FiFA is , and its output is R. The detailed fusion process is described as follows.
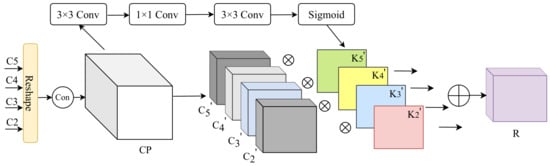
Figure 4.
The proposed fine-grained feature aggregation (FiFA) Block.
Firstly, we resize the features to the size of to integrate multi-level features. A convolution layer is used to reduce the number of channel dimensions of , and we then perform bilinear interpolation on the three feature maps to up-sample them. After the above operations, we obtain the reshaped features with the same size as . Secondly, we concatenate the reshaped features to obtain the integrated feature . A convolution layer is used to extract local context information. Then, a convolution layer is used to transform the channel dimension to the number of elements in . A convolution layer is adopted to further extract local information, and we use a sigmoid activation function to generate a weight map , where is the i-th weight map for the shape , the value of elements in ranges in . The i-th weight map is obtained by a broadcasting operation in which the original i-th weight map is stretched to become an array of same shape as . Finally, the weight map = is multiplied with the features to obtain R as follows:
The pseudo-code for aggregating the fine-grained features with our FiFA module is illustrated in Algorithm 1.
| Algorithm 1 The pseudo-code for aggregating fine-grained features with our FiFA module. |
| Input: Features extracted from different convolution layers . |
| Output: Features aggregated by our FiFA module . |
| 1: Reshape |
| 2: Concatenate |
| 3: Conv() → = |
| 4: Broadcast() → = |
| 5: Aggregate R with Equation (1). |
3.3. Target Focusing Block (TFB)
As shown in Figure 2, the fine-grained object representation generated by our FiFA block tends to contain some background noise, instead of focusing on the targets. We propose a Target-Focusing Block (TFB) to focus the fine features more on the target area and less on the background area. Then, representation learning is performed under the constraint of the object position.
Figure 5 presents the details of our TFB. The input of TFB is the feature R, whose output is denoted as . We design a mask-guided mechanism to refine the fused feature R to suppress background noise and highlight the foreground objects. Specifically, R first passes through a convolutional layer to encode the local context information, which then goes through a convolution layer to learn a one-channel feature map. The value of the one-channel feature map indicates the likelihood of a pixel in the foreground or background. Finally, a new enhanced feature map is obtained by multiplying the fused feature R and the one-channel feature map passing through a sigmoid function.
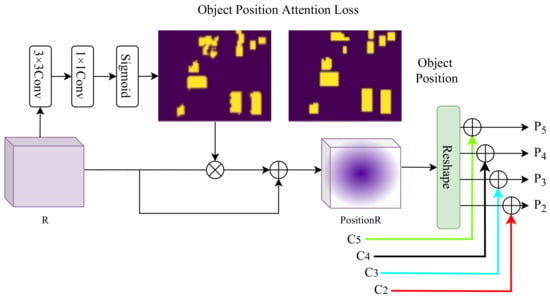
Figure 5.
The Target-Focusing Block (TFB).
For supervised training, the cross-entropy loss between the one-channel feature map and the binary mask is utilized to compute the object position attention loss. Due to the lack of mask annotation for high-precision object positions in UAV images, we assign the value of 1 to all the pixels inside the ground-truth bounding box and 0 for all other pixels to obtain the object position mask, as shown in Figure 5. Regardless of annotations for objects’ categories, all the value of the pixels inside the ground-truth bounding boxes in an image have the value of 1 to highlight the foreground regions.
Thus, the refined feature map is defined as:
and
where represents convolutional layers, denotes a sigmoid function, and M is the object mask map.
We use to improve the original multi-scale representations. ’s shape is the same as , which is different from and . We first reshape it to the size of and then add to the corresponding to obtain the final enhanced multi-scale representations for final detection, which is expressed as:
Here, denotes the operation of convolutional layers and up-sampling layers to reshape to the size of .
The pseudo-code of refining features with our TFB module is summarized in Algorithm 2.
| Algorithm 2 The pseudo-code for refining features with the proposed Target-Focusing Block (TFB). |
| Input: Features aggregated by FiFA ; |
| the ground truth of objects’ position . |
| Output: The final enhanced multi-scale features , |
| the object position loss . |
| 1: Estimate an object mask map, |
| 2: Compute object position attention loss, |
| 3: Obtain the refined feature map, |
| 4: Resize |
| 5: Output the final : |
| 6: |
| 7: |
| 8: |
| 9: |
3.4. Global-Local Context Collector
As shown in Figure 3, the lateral connection in the original top–down pathway is a convolutional kernel, which is utilized to reduce or increase the number of the feature channel. The features extracted with the convolutional kernel generally lack contextual information due to the small and fixed size of the convolutional kernel. We propose to collect both global and local contextual information in our proposed detector so as to improve small object detection performance.
Our proposed Global–Local Context Collector, denoted as GLCC, consists of three components, i.e., a global average pooling layer followed by a convolutional layer, several dilated convolutions with different kernels and atrous rates and a convolutional layer. The global average pooling layer is used to collect the global context information, and several dilated convolutions are used to collect the local context information. Figure 6 illustrates the details of GLCC. In the top branch, a convolutional layer is used to embed the input feature . In the bottom branch, a global average pooling layer is adopted to collect the global contextual information at the image level. In the middle branch, several convolution filters with the atrous rate are utilized to encode local context information. Finally, these features extracted through the above three branches are concatenated together. In particular, we formulate this procedure as follows:
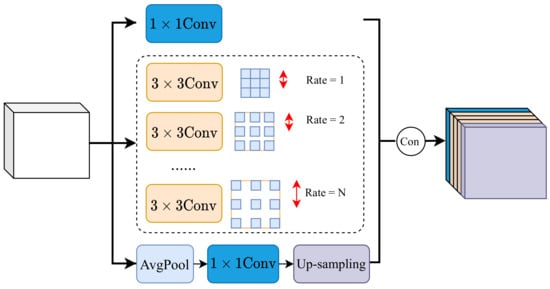
Figure 6.
The details of the proposed Global–Local Context Collector.
The proposed GLCC mainly consists of several convolution filters with different kernel sizes. Our GLCC captures contextual information surrounding targets to improve the expressive power of target representations. Especially, this strategy is very effective for enhancing small objects’ representations.
4. Experiments
In order to demonstrate that our FiFoNet method can effectively recognize small objects in UAV images, we conducted experiments on the UAV benchmark datasets VisDrone2019 [], UAVDT [], and our synthetic VisDrone_Foggy. In the following sub-sections, we first describe the three datasets and then use them to verify the effectiveness of our FiFoNet for UAV object detection.
4.1. Datasets and Models
In this work, VisDrone2019 [] and UAVDT [] are used to verify the effectiveness of our FiFoNet because these two datasets contain a large number of small size objects. We will give the details of the datasets and models as follows.
(1) VisDrone2019 []: The VisDrone2019 benchmark includes 6471 images for training, 548 images for validation, and 3190 testing images captured by UAVs. The captured images’ resolution is about pixels. These images are labeled with bounding boxes and ten categories: bicycle, awning-tricycle, tricycle, van, bus, truck, motor, pedestrian, person and car.
(2) VisDrone_Foggy: Our synthetic VisDrone_Foggy dataset is built upon the VisDrone2019 benchmark dataset. According to the atmospheric scattering model [], we transform images in the VisDrone2019 dataset to foggy images for our VisDrone_Foggy. We generate images with thin, medium thick, and thick fog by setting different parameters of the atmospheric scattering model, as shown in Figure 7. Our VisDrone_Foggy adopts the same annotations in the original VisDrone2019.

Figure 7.
Examples of images from our Visdrone_Foggy dataset. (a) The original image; (b) The estimated depth map; (c) The image with thin fog; (d) The image with medium thick fog; (e) The image with thick fog.
Specifically, the formation of foggy images can be formulated as follows:
where is the observed foggy image, is the corresponding clean images, A is the global atmospheric light, and t is the transmission describing the portion of the light.
The transmission t can be described as follows:
where is the scattering coefficient of the atmosphere, and is the depth map. We use ViTDepthNet [] for image depth estimation.
(3) UAVDT []: The UAVDT benchmark includes 23,258 images for training and 15,069 images for testing. The captured images’ resolution is about pixels. These images are labeled with bounding boxes and three predefined categories: bus, truck and car.
(4) Models: We have implemented several object detection models as the baselines, including SSD [], FPN [], YOLO [], and FRCNN []. We also compare our method with the state-of-the-art (SOTA) methods, such as mSODANet [], DSHNet [], CRENET [], GLSAN [], ClustDet [], SAIC-FPN [], and HRDNet [], which are designed specifically for UAV object detection.
4.2. Implementation and Evaluation Metrics
(1) Implementation: We implement our FiFoNet with PyTorch 1.8.1. The proposed model is run on a server with an NVIDIA RTX3090 GPU and an edge device with a NVIDIA JETSON XAVIER NX. During the training stage, we use part of the pre-trained model YOLOv5 (https://github.com/ultralytics/yolov5, accessed on 1 August 2022), which saves a lot of training time. We use the Adam optimizer for training and use as the initial learning rate with the cosine learning rate schedule. The learning rate of the last epoch decays to of the initial learning rate. The size of the input image of our model is very large, with the long side of the image being 1536 pixels, which is the same configuration as in TPH-YOLOv5 [].
(2) Evaluation Metrics: The same evaluation metrics as in PASCAL VOC [] are adopted to evaluate the detection performance of our FiFoNet. The metrics are defined as follows, including mean Average Precision (mAP) and Average Precision (AP):
Here, P stands for Precision, measuring how accurate the prediction is, i.e., the fraction of correct positive instances among all the positive instances. R represents Recall, measuring how good the classifier estimates the positives, i.e., the fraction of true positive instances among all the positive instances. is the curve composed of P and R. Then, , where N is the number of categories. is averaged on ten Intersection over Union (IoU) values of , and are computed at the single IoU of and , respectively. P and R are defined as:
and
where , and indicate the number of false negative predictions, false positive predictions and true positive predictions.
4.3. Ablation Studies
In order to analyze the impact of our method and validate the contributions of each component of our approach, we conducted seven experiments on the VisDrone2019 dataset. YOLOv5 [] is used as the baseline for the ablation studies.
(1) The Effectiveness of FiFA: We evaluate three methods to fuse the information of low-level features with high-level features. The three methods are Element-wise Sum and Average, Concatenation, and our FiFA. To compare their effectiveness, we apply different strategies on the same baseline. Table 2 presents that the detection accuracy of FiFA outperforms that of the Sum-and-Average approach by %. The result matches the intuition that the fine-grain feature fusion strategy of our FiFA module can release the advantages of the multi-scale feature representations more effectively. Therefore, we performed the remaining experiments with our FiFA module.
Table 2.
Comparison of Average Precision obtained with different fusion strategies on VisDrone2019.
(2) The effectiveness of TFB: The TFB is used to make the network suppress background noise and focus on foreground objects. Table 3 shows that the TFB obtain a 1.00% improvement compared with the baseline model.
Table 3.
Comparison of Average Precision obtained with our method with/without each module for small object detection on VisDrone2019-Val.
We verify the effectiveness of the generated objects’ mask for future refinement with the supervised information of object location. Specifically, the input feature map (Figure 8a) passes through a convolutional layer and then a convolution operation to estimate a one-channel mask (as shown in Figure 8d). The mask indicates the likelihood of the background and foreground. Finally, a new refined feature map is obtained, as shown in Figure 8c.

Figure 8.
Visualization of the results obtained with our TFB module. (a) The feature map input to TFB. (b) The output feature map without TFB. (c) The output features to TFB. (d) The object mask generated by BFR. (e) The ground-truth object position without their category. (f) The original images.
The comparison between the estimated attention mask (Figure 8d) and object position generated by ground truth without categories (Figure 8e) indicates that our TFB module can effectively estimate the target objects’ positions and scales. We compare the original feature maps (Figure 8b) and feature maps generated by TFB (Figure 8c). The comparison suggests that the proposed TFB module can suppress the interference of background noise effectively.
(3) The Effectiveness of GLCC: Table 4 presents that GLCC can significantly improve the detection performance by collecting contextual information. As we gradually aggregate more features from different convolutional layers, the detection performance of the algorithm continues to improve. Firstly, we follow the architecture of FPN and demonstrate its performance in the setting of , , where k is the kernel size and d denotes the dilation rate. We add a convolution in each lateral connection, which leads to , , and gain in and .
Table 4.
Ablation study of GLCC.
Furthermore, we add more convolutions with different dilation rates to collect more contextual information. It can be observed that the addition of convolutions with a dilation rate of 2, 3, 4 and 5 improves the detection accuracy. The method in the last row benefits from all kinds of convolutions and achieves the best results, which leads to a , , and gain in and . To this end, the convolutional layers in our GLCC module finally adopt the following configuration: kernel size = , dilation rate = . We denote GLCC with this configuration as GLCC.
We further visualize some features generated by GLCC as shown in Figure 9. The first and second columns are the input images and their feature maps are generated by the feature extractor of the baseline. The last column is the feature maps enhanced by our GLCC. It can be observed that the enhanced feature maps are better than the originally extracted feature maps, especially in the red-circled area. The visualization result demonstrates that our GLCC can effectively collect contextual information by convolutional filters with different dilation rates and thus generate high-quality representations for final object detection.

Figure 9.
Visualization of the feature maps obtained with GLCC. (a) The input image. (b) Features obtained without GLCC. (c) Features obtained with GLCC.
(4) Complexity Comparison: Table 5 compares the model complexity of our FiFoNet with that of the baseline. The evaluation metrics of the experiment include FLOPs (Floating Point Operations, the calculation amount of a model), Parameters (the number of model parameters), and Times (in milliseconds) on a server and edge device. The evaluation metric Times is calculated by the average of processing all of the images from the validation set. The total time includes the image pre-processing time, inference time and post-processing time. Table 5 shows that the of the model with our modules has increased by 1∼2%, while the number of model parameters and processing time only increase slightly.
Table 5.
Comparison of model complexity between our model and the baseline.
(5) Visual Comparison of the Detection Results: We also visually compare the detection results obtained with and without the proposed components in Figure 10. Comparing Figure 10b with Figure 10d, it can be seen that smaller objects can be well detected by our method. This is because our method converts the position-semantic inconsistency issue into one that makes the RoIs’ (located by tiny objects) multi-scale feature simultaneously contain detailed spatial information and strong semantic information.

Figure 10.
Visualization of the detection performance of our method. (a) Baseline detection results. (b) Zoomed-in baseline detection results on the sub-area. (c) Our detection results. (d) Our detection results on the corresponding sub-area.
(6) Effect of the low-level representation: We also conducted experiments to verify the effectiveness of low-level feature maps for UAV object detection. Table 3 shows that the tinyHead modification has boosted the performance by 3.7%. The tinyHead represents the baseline model with a lower-level representation extracted from the Backbone module. Figure 11 shows the comparison between the heatmaps of the last and second last layers. The red areas in the right column are darker and smaller than those in the middle column. The results show that the feature maps in the right column focus more accurately on the object spatial locations, indicating that our tinyHead can help make the network focus more precisely on objects. This is because the lower-level features are generated by the convolutional filter with a smaller kernel size, which is beneficial for extracting small objects’ features.

Figure 11.
Heatmap comparison between our newly added head for lower-level features. The raw image (left), heatmap from the last second layer (middle), heatmap from the last layer (right).
(7) Detection Results of Our FiFoNet on VisDrone_Foggy: We evaluate our FiFoNet on the VisDrone_Foggy dataset. We synthesize thin, medium thick and thick fog with the parameters in Equation (7). Table 6 shows the results. FiFoNet improves the baseline by , , and on the thin foggy, medium thick foggy, and thick foggy images, respectively. Figure 12 shows FiFoNet’s detection results on the VisDrone_Foggy dataset. It can be observed that most of the objects are correctly recognized, in spite of a small number of false positive and false negative samples as the fog grows. The detection results demonstrates its effectiveness in object detection in foggy scene.
Table 6.
Detection results of our FiFoNet with synthetic images on our VisDrone_Foggy dataset.
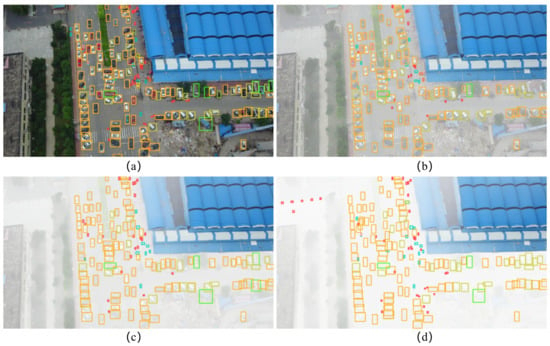
Figure 12.
Visualization of the results obtained with our FiFoNet on the clean image (a), the thin (b), medium thick (c), and thick (d) fog scenes.
4.4. Comparison with State-of-the-Art Methods
We compare our proposed FiFoNet with the SOTA algorithms on two datasets.
(1) Detection Results on VisDrone2019 Dataset: We compare the detection results with representative detectors’ results on VisDrone2019 in Table 7, including two-stage detectors, i.e., FRCNN [], FPN [], and one-stage detectors, i.e., SSD [] and YOLOv5 []. We achieve an of , of and of . The performance comparison with the SOTA methods, namely mSODANet [], DSHNet [], CRENet [], GLSAN [], ClustDet [] SAIC-FPN [], and HRDNet [], is also summarized in Table 7. Compared to the SOTA drone-view detector (SAIC-FPN), the is increased by and is increased by , suggesting that our FiFoNet outperforms these SOTA methods. To make a fair comparison, we do not use overlays of various tricks, oversized backbones, or model ensembles, which are often used in existing methods dealing with UAV data. Figure 13 shows the object detection results on aerial images of large or low-light scenes. It is worthy mentioning that FiFoNet can detect people in night-time images.
Table 7.
Comparison of our method with the baseline and SOTAs on VisDrone2019-Val and UAVDT. ’-’ means that the statistics are not available. The top two results are highlighted in red and green fonts.

Figure 13.
Visualization of the results obtained with our FiFoNet on large or low-light scenes. Note the zoomed-in views of the crowded areas highlighted in green boxes.
(2) Detection Results on UAVDT Dataset: The performance comparison of our FiFoNet and SOTA detectors on the VisDrone dataset including FRCNN [], ClusDet [], GLSAN [], and YOLOv5 [] is presented in Table 7. It can be seen from the table that the proposed approach achieves an of , an of and an of , outperforming the SOTA methods.
5. Limitation and Discussion
In addition to the above success, our FiFoNet has certain limitations. FiFoNet trained on high-quality drone-captured images would fail to obtain satisfactory detection performance under adverse weather conditions, including foggy or raining scenarios. The main reason for the poor detection performance of FiFoNet is considerable inconsistency in data distribution between high-quality images under sunny weather and low-quality images under adverse weather. Therefore, one of the main limitations of FiFoNet is poor detection performance under adverse weather.
Our VisDrone_Foggy dataset is synthetic and not collected from the real world, while we have achieved preliminary detection results under foggy weather conditions. There is still a significant difference between synthetic and real-world data. The degradation process of the real-world dataset is very complicated. We need to comprehensively collect real-world fog drone-captured images to verify the effectiveness of FiFoNet in adverse weather.
6. Conclusions
In this paper, we have proposed our FiFoNet to effectively detect objects in UAV images. The proposed FiFoNet first builds a FiFo representation, which contains strong semantic information and detailed spatial positions. Then, the FiFoNet refines the multi-scale features to focus them on the foreground against the noisy background. Finally, the GLCC collects the global and local context information surrounding small objects to further improve object detection accuracy. Extensive experiments on benchmark datasets have shown the effectiveness of our proposed method in terms of both quantitative and visual results. Our core components, FiFA, TFB and GLCC, can be easily plugged into existing MR-based detectors. Our FiFoNet has been deployed on an embedded computing board running on a real drone.
Author Contributions
Conceptualization, Y.X. and W.J.; methodology, Y.X. and W.J.; validation, Y.X.; formal analysis, Y.X.; writing—original draft preparation, Y.X.; writing—review and editing, W.J., X.L., X.F. and H.L.; visualization, Y.X.; supervision, Q.M.; funding acquisition, X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Fundamental Research Funds for the Central Universities (No. 20101216855) and the Key R&D Projects of Qingdao Science and Technology Plan (No. 21-1-2-18-xx).
Data Availability Statement
Not applicable.
Acknowledgments
We sincerely thank the authors of Yolov5 and Faster RCNN for providing their algorithm codes to facilitate the comparative experiments.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Avola, D.; Cinque, L.; Diko, A.; Fagioli, A.; Foresti, G.L.; Mecca, A.; Pannone, D.; Piciarelli, C. MS-Faster R-CNN: Multi-stream backbone for improved Faster R-CNN object detection and aerial tracking from UAV images. Remote Sens. 2021, 13, 1670. [Google Scholar] [CrossRef]
- Stojnić, V.; Risojević, V.; Muštra, M.; Jovanović, V.; Filipi, J.; Kezić, N.; Babić, Z. A method for detection of small moving objects in UAV videos. Remote Sens. 2021, 13, 653. [Google Scholar] [CrossRef]
- Ma, Y.; Li, Q.; Chu, L.; Zhou, Y.; Xu, C. Real-time detection and spatial localization of insulators for UAV inspection based on binocular stereo vision. Remote Sens. 2021, 13, 230. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Paradise, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13029–13038. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and Tracking Meet Drones Challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Wen, L.; Du, D.; Zhu, P.; Hu, Q.; Wang, Q.; Bo, L.; Lyu, S. Detection, tracking, and counting meets drones in crowds: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 7812–7821. [Google Scholar]
- Deng, S.; Li, S.; Xie, K.; Song, W.; Liao, X.; Hao, A.; Qin, H. A global-local self-adaptive network for drone-view object detection. IEEE Trans. Image Process. 2020, 30, 1556–1569. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Yan, J.; Liao, W.; Yang, X.; Tang, J.; He, T. Scrdet++: Detecting small, cluttered and rotated objects via instance-level feature denoising and rotation loss smoothing. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8232–8241. [Google Scholar]
- Deng, C.; Wang, M.; Liu, L.; Liu, Y.; Jiang, Y. Extended feature pyramid network for small object detection. IEEE Trans. Multimed. 2021, 24, 1968–1979. [Google Scholar] [CrossRef]
- Noh, J.; Bae, W.; Lee, W.; Seo, J.; Kim, G. Better to follow, follow to be better: Towards precise supervision of feature super-resolution for small object detection. In Proceedings of the the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9725–9734. [Google Scholar]
- Bashir, S.M.A.; Wang, Y. Small object detection in remote sensing images with residual feature aggregation-based super-resolution and object detector network. Remote Sens. 2021, 13, 1854. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Peng, J.; Wang, H.; Yue, S.; Zhang, Z. Context-aware co-supervision for accurate object detection. Pattern Recognit. 2022, 121, 108199. [Google Scholar] [CrossRef]
- Tang, X.; Du, D.K.; He, Z.; Liu, J. Pyramidbox: A context-assisted single shot face detector. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 797–813. [Google Scholar]
- Kong, Y.; Feng, M.; Li, X.; Lu, H.; Liu, X.; Yin, B. Spatial context-aware network for salient object detection. Pattern Recognit. 2021, 114, 107867. [Google Scholar] [CrossRef]
- Jiao, L.; Gao, J.; Liu, X.; Liu, F.; Yang, S.; Hou, B. Multi-Scale Representation Learning for Image Classification: A Survey. IEEE Trans. Artif. Intell. 2021. [Google Scholar] [CrossRef]
- Qiao, S.; Chen, L.C.; Yuille, A. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 10213–10224. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 7373–7382. [Google Scholar]
- Han, J.; Yao, X.; Cheng, G.; Feng, X.; Xu, D. P-CNN: Part-Based Convolutional Neural Networks for Fine-Grained Visual Categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 579–590. [Google Scholar] [CrossRef]
- Song, L.; Li, Y.; Jiang, Z.; Li, Z.; Sun, H.; Sun, J.; Zheng, N. Fine-grained dynamic head for object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 11131–11141. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
- Zhou, J.; Vong, C.M.; Liu, Q.; Wang, Z. Scale adaptive image cropping for UAV object detection. Neurocomputing 2019, 366, 305–313. [Google Scholar] [CrossRef]
- Xi, Y.; Jia, W.; Zheng, J.; Fan, X.; Xie, Y.; Ren, J.; He, X. DRL-GAN: Dual-stream representation learning GAN for low-resolution image classification in UAV applications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1705–1716. [Google Scholar] [CrossRef]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered object detection in aerial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8311–8320. [Google Scholar]
- Li, J.; Liang, X.; Wei, Y.; Xu, T.; Feng, J.; Yan, S. Perceptual generative adversarial networks for small object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1222–1230. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Paradise, NV, USA, 26 June–1 July 2016; pp. 2874–2883. [Google Scholar]
- Qiu, H.; Li, H.; Wu, Q.; Meng, F.; Xu, L.; Ngan, K.N.; Shi, H. Hierarchical context features embedding for object detection. IEEE Trans. Multimed. 2020, 22, 3039–3050. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6054–6063. [Google Scholar]
- Zou, Z.; Shi, Z. Random access memories: A new paradigm for target detection in high resolution aerial remote sensing images. IEEE Trans. Image Process. 2017, 27, 1100–1111. [Google Scholar] [CrossRef]
- Bai, Y.; Zhang, Y.; Ding, M.; Ghanem, B. Sod-mtgan: Small object detection via multi-task generative adversarial network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 206–221. [Google Scholar]
- Hu, P.; Ramanan, D. Finding tiny faces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 951–959. [Google Scholar]
- Mukhiddinov, M.; Cho, J. Smart glass system using deep learning for the blind and visually impaired. Electronics 2021, 10, 2756. [Google Scholar] [CrossRef]
- Yuan, Y.; Xiong, Z.; Wang, Q. VSSA-NET: Vertical spatial sequence attention network for traffic sign detection. IEEE Trans. Image Process. 2019, 28, 3423–3434. [Google Scholar] [CrossRef]
- Liu, Y.; Cao, S.; Lasang, P.; Shen, S. Modular lightweight network for road object detection using a feature fusion approach. IEEE Trans. Syst. Man Cybern. Syst. 2019, 51, 4716–4728. [Google Scholar] [CrossRef]
- Xiang, W.; Zhang, D.Q.; Yu, H.; Athitsos, V. Context-aware single-shot detector. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1784–1793. [Google Scholar]
- Ouyang, W.; Wang, K.; Zhu, X.; Wang, X. Chained cascade network for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1938–1946. [Google Scholar]
- Singh, B.; Davis, L.S. An analysis of scale invariance in object detection snip. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3578–3587. [Google Scholar]
- Lyu, P.; Yao, C.; Wu, W.; Yan, S.; Bai, X. Multi-oriented scene text detection via corner localization and region segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7553–7563. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 821–830. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. Int. Conf. Learn. Represent. 2017, 1–16. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7036–7045. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Vision and the atmosphere. Int. J. Comput. Vis. 2002, 48, 233–254. [Google Scholar] [CrossRef]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision transformers for dense prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 12179–12188. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Chalavadi, V.; Jeripothula, P.; Datla, R.; Ch, S.B. mSODANet: A Network for Multi-Scale Object Detection in Aerial Images using Hierarchical Dilated Convolutions. Pattern Recognit. 2022, 126, 108548. [Google Scholar] [CrossRef]
- Yu, W.; Yang, T.; Chen, C. Towards resolving the challenge of long-tail distribution in UAV images for object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3258–3267. [Google Scholar]
- Wang, Y.; Yang, Y.; Zhao, X. Object detection using clustering algorithm adaptive searching regions in aerial images. In Proceedings of the ECCV, Glasgow, UK, 23–28 August 2020; pp. 651–664. [Google Scholar]
- Liu, Z.; Gao, G.; Sun, L.; Fang, Z. HRDNet: High-resolution detection network for small objects. In Proceedings of the ICME, Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios. In Proceedings of the ICCVW, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Everingham, M.; Eslami, S.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Jocher, G. YOLOv5. 2021. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 August 2022).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).