
MSL-Net: An Efficient Network for Building Extraction from Aerial Imagery




Abstract
:1. Introduction
- (1)
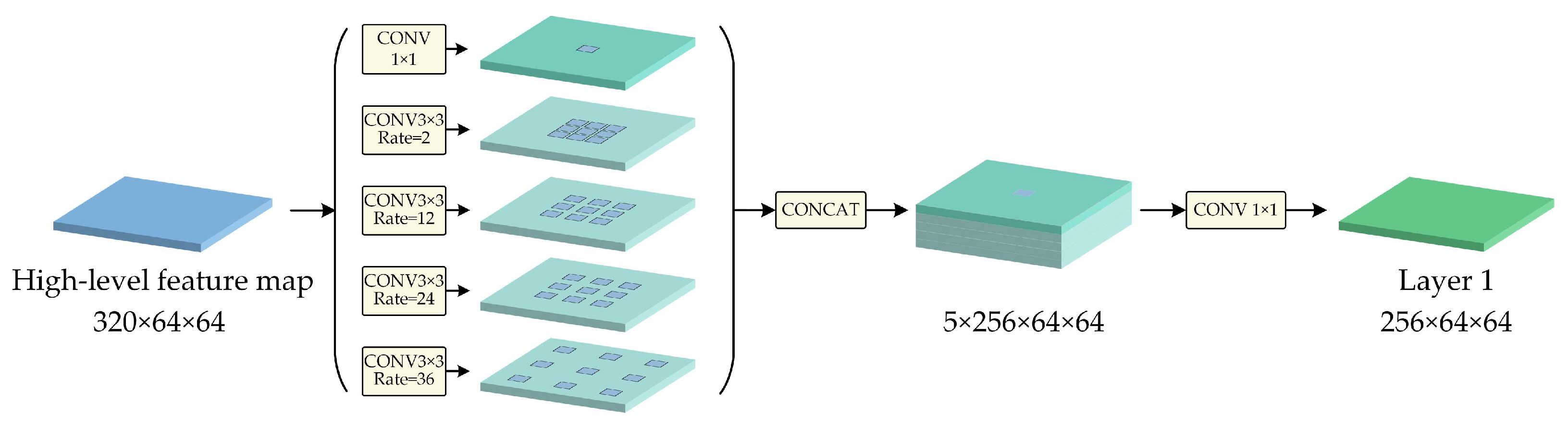
- For feature maps, feature pyramids can be applied to enlarge their receptive fields and obtain multiscale target features. The pyramid scene parsing network (PSPNet) [23] fuses four different scales of feature maps in parallel via a pyramid pooling module, improving the network’s ability to obtain multiscale information. In DeepLabv3 [24], an atrous spatial pyramid pooling (ASPP) structure is adopted to enlarge the receptive fields and, thus, has a significant advantage in large object segmentation. To restore more building contour information, Xu [25] enhanced the combination of an encoder and a decoder based on a DeepLabv3+ [26] network embedded with an ASPP module.
- (2)
- For input images, skip connections are applied to fuse different levels of feature maps to obtain multilevel image features. The level of image features increases as the network layers deepen. Low-level features provide the basis for object category detection, and high-level features facilitate accurate segmentation and positioning. U-Net [27] uses long skip connections to integrate low-level features with high-level features and has high performance in medical image segmentation. Improved from U-Net, networks such as IEU-Net [28], HA U-Net [29] and EMU-CNN [30] have performed well. The MPRSU-Net [31] was constructed by combining long and short skip connections, alleviating the holes and fragmentary edges in the segmentation results obtained when extracting large buildings.
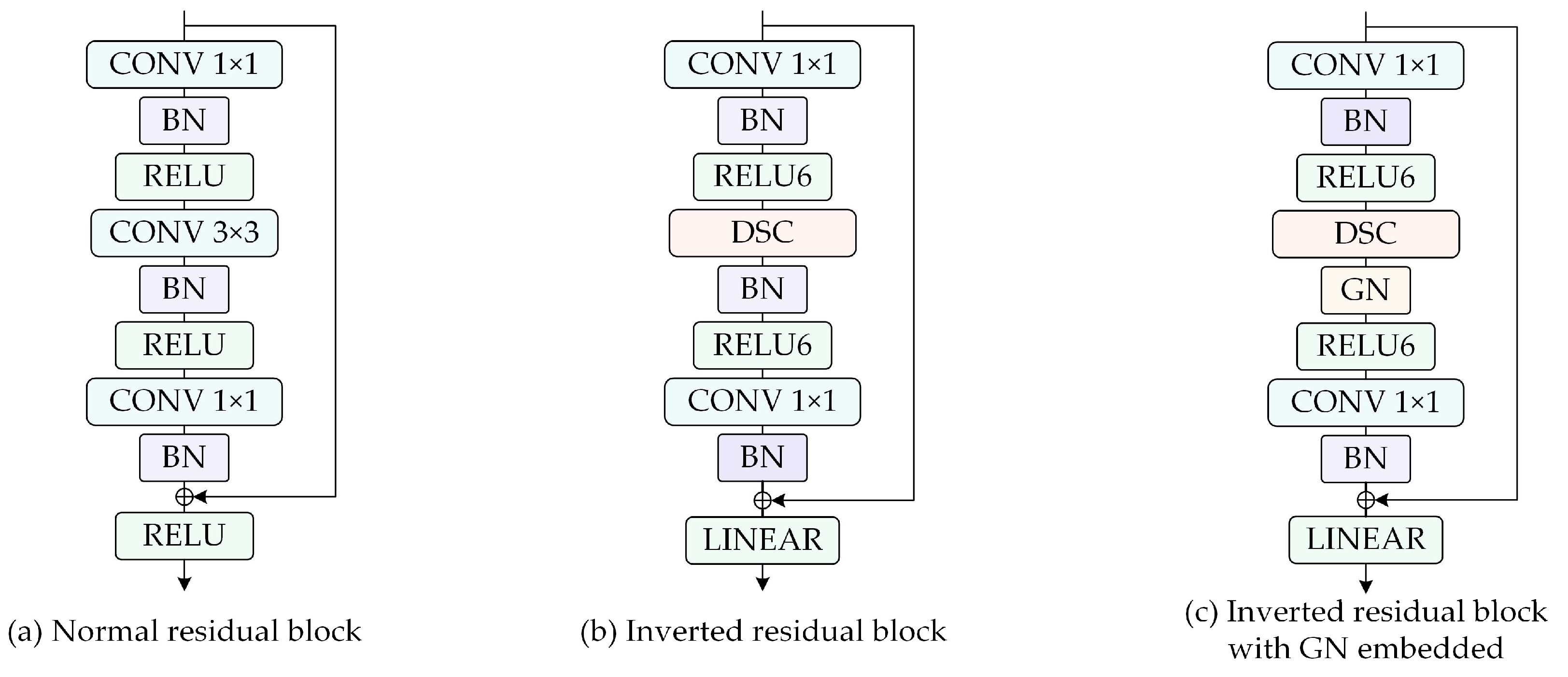
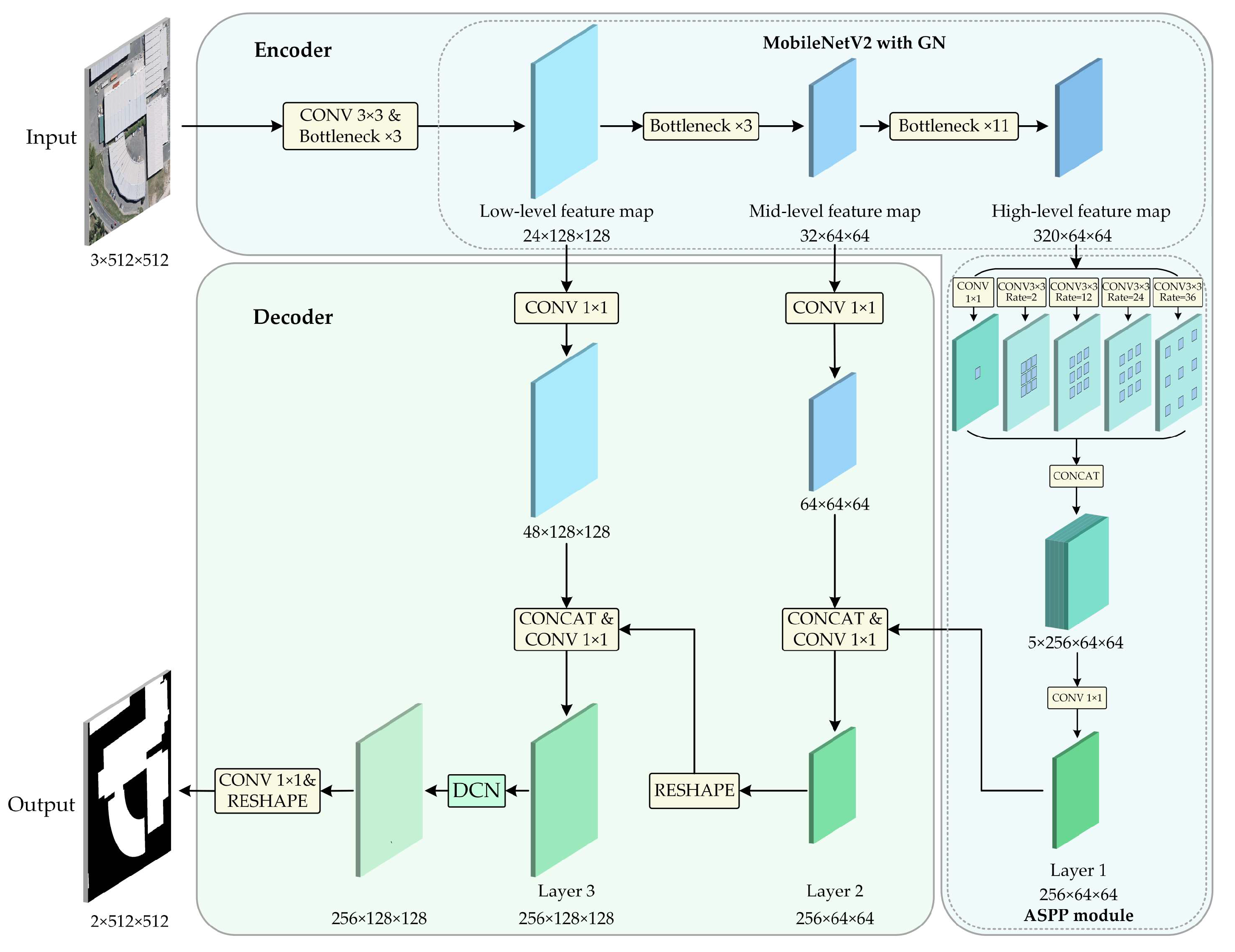
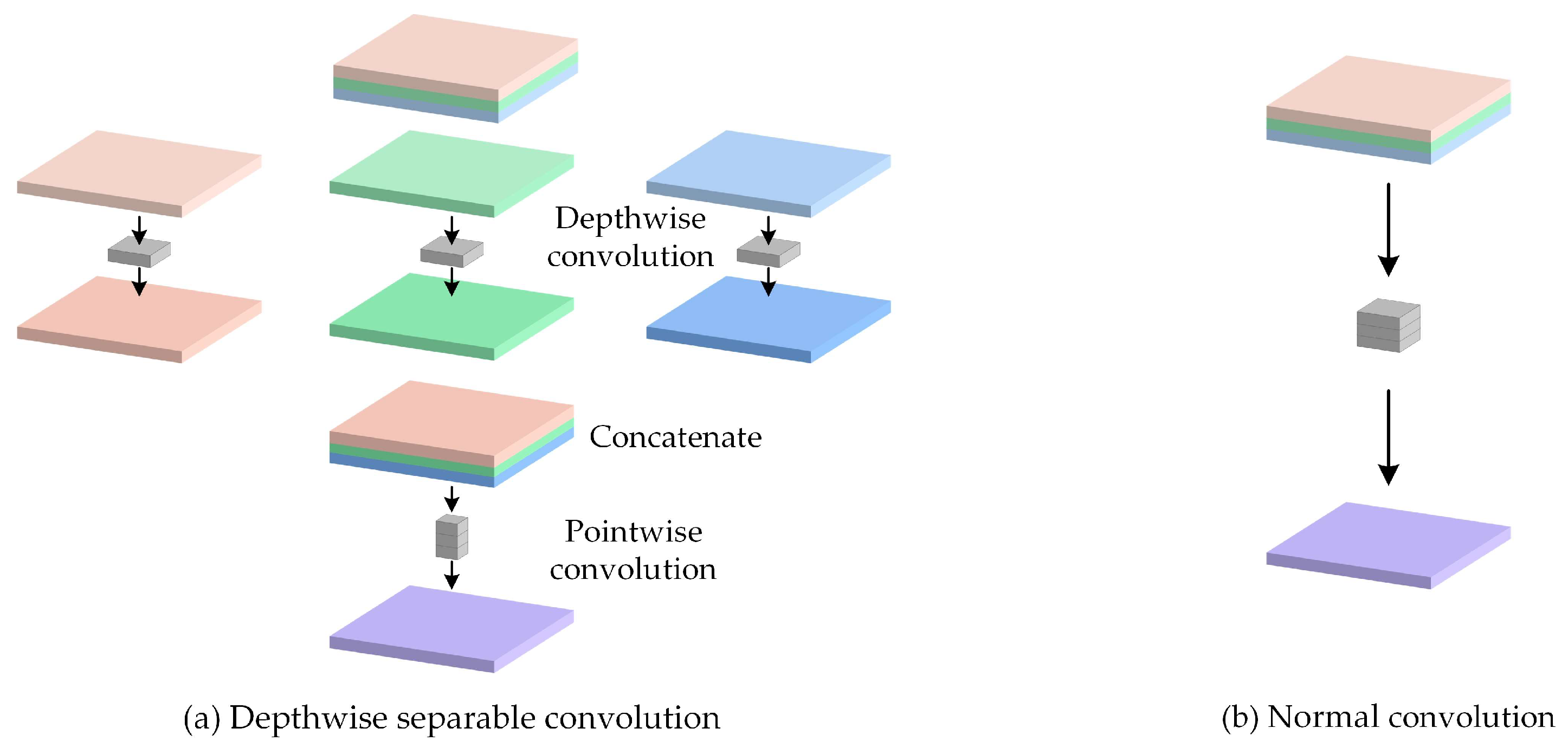
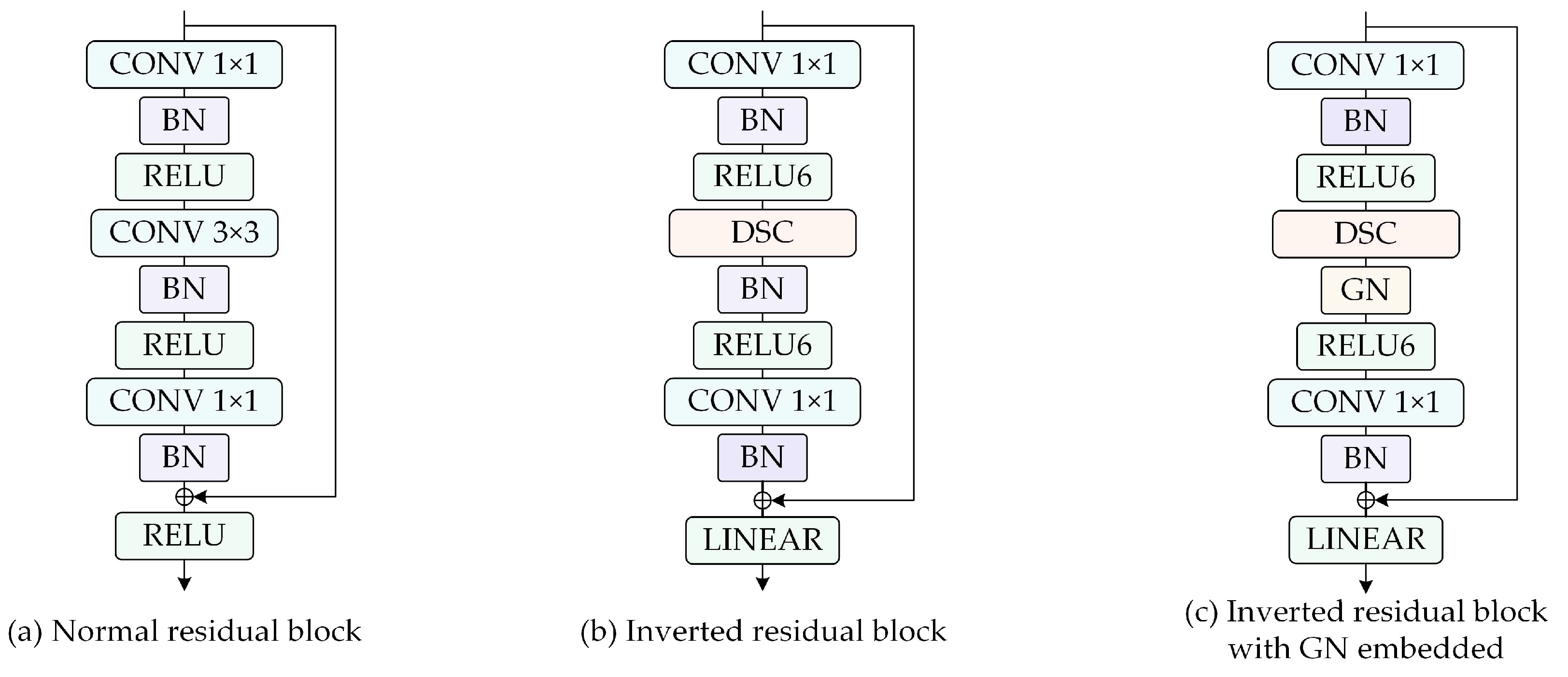
- In the encoding stage of MSL-Net, we introduce the MobileNetV2 [39] architecture to extract multilevel features. The inverted residual blocks in MobileNetV2 are constructed as bottlenecks using depthwise separable convolution (DSC) [40] and group normalization (GN) operations [41], which noticeably reduce the model complexity while improving its training and inference speeds. The multiscale features are extracted by an ASPP module to enhance the ability of the model to recognize multiscale buildings.
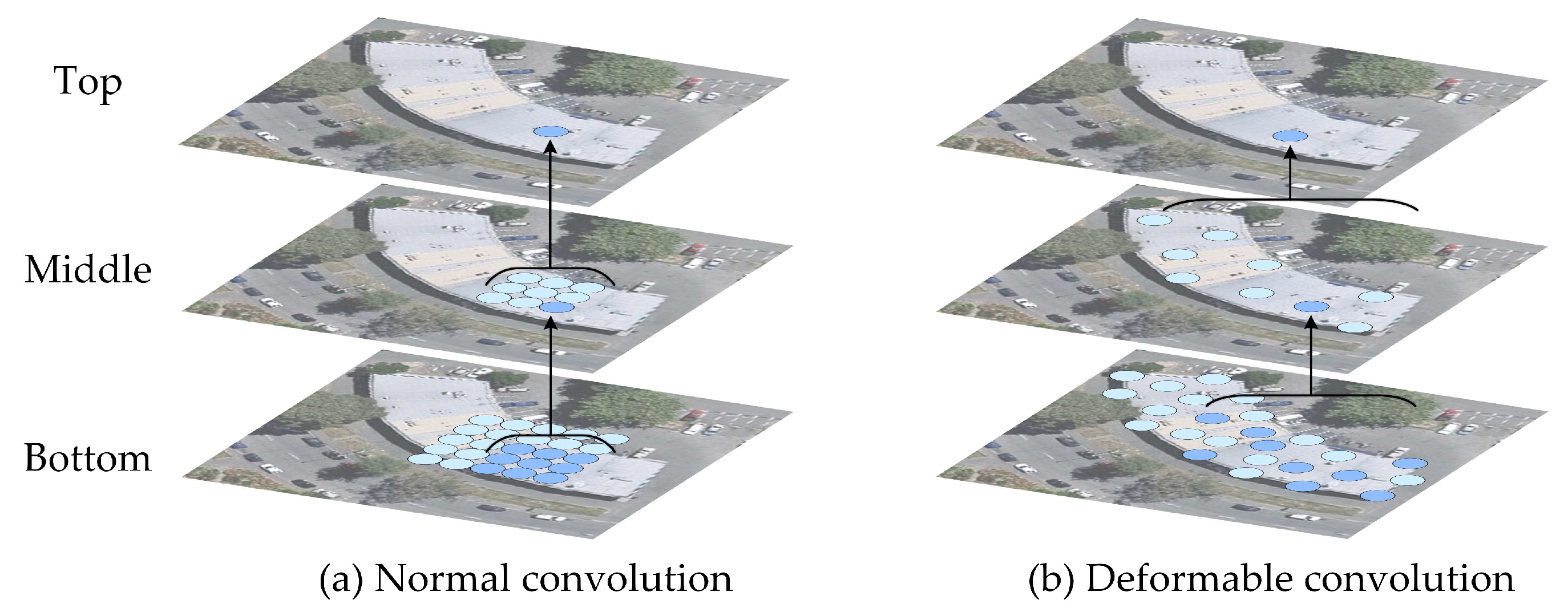
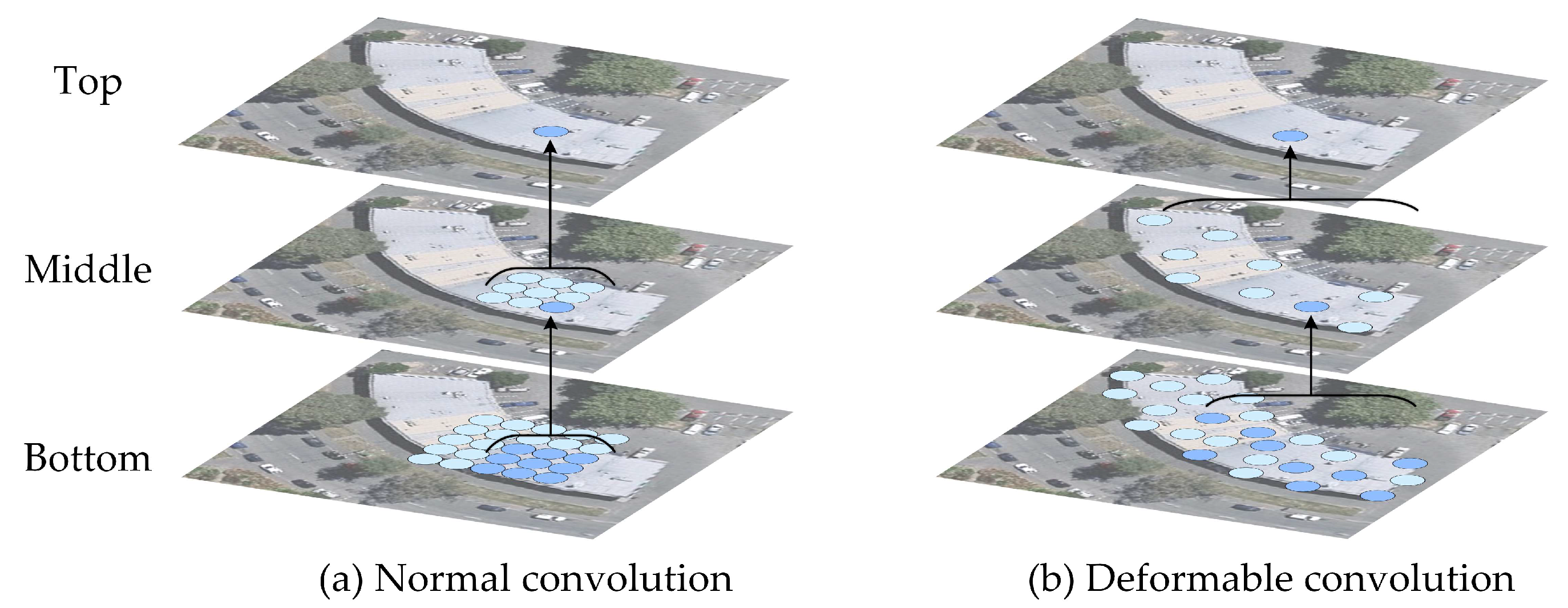
- In the decoding stage of MSL-Net, long skip connections [42] are applied to establish a long-distance dependence between the feature encoding and feature decoding layers. This long-distance dependence is beneficial for obtaining the rich hierarchical features of an image and effectively preventing holes in the segmentation results [31]. Before performing pixel classification, a deformable convolution network (DCN) layer [43] is added to ensure strong model robustness even when extracting buildings with irregular shapes.
2. Materials and Methods
2.1. MSL-Net Architecture
2.2. Feature Extraction Backbone in the Encoder
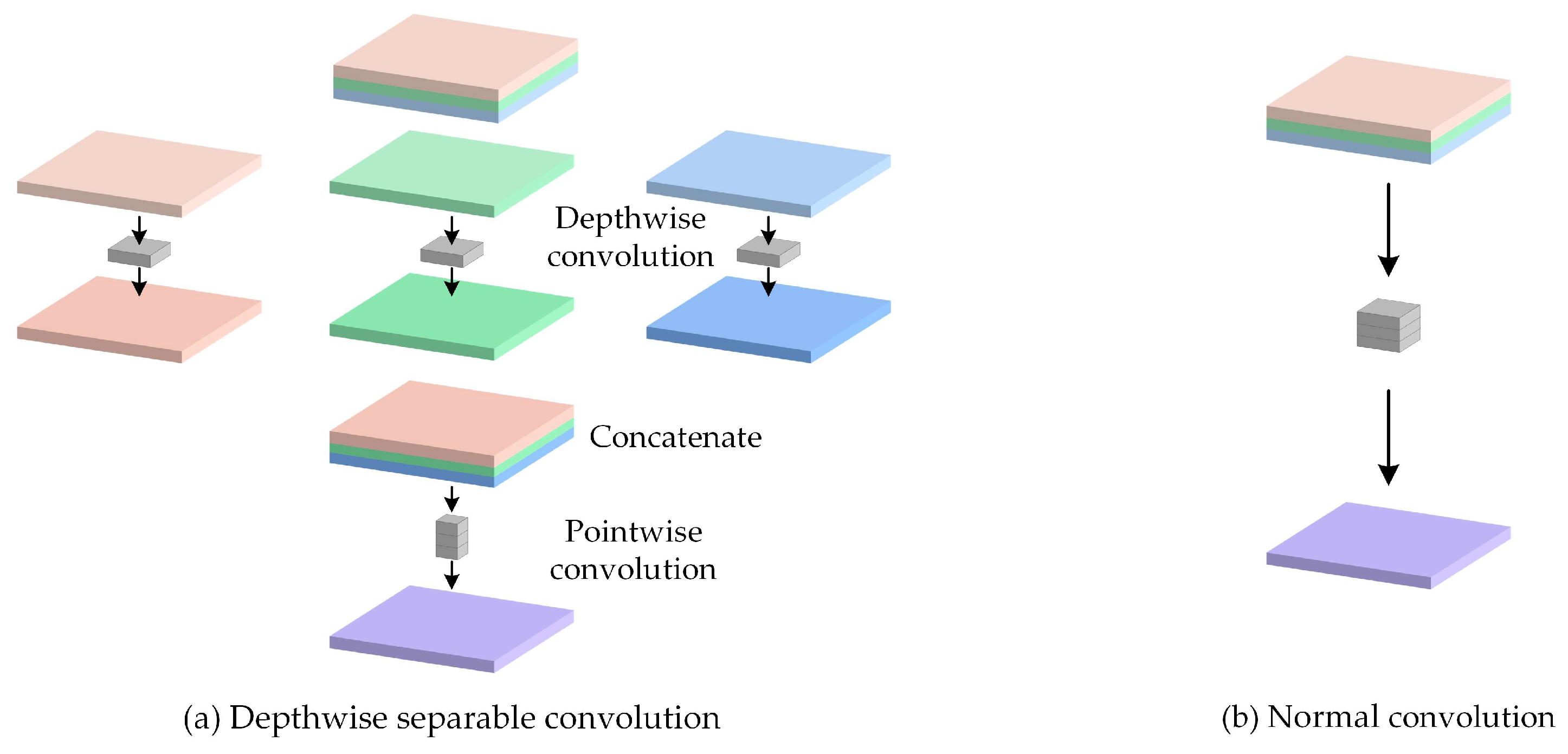
2.2.1. DSC in the Backbone
2.2.2. GN in the Backbone
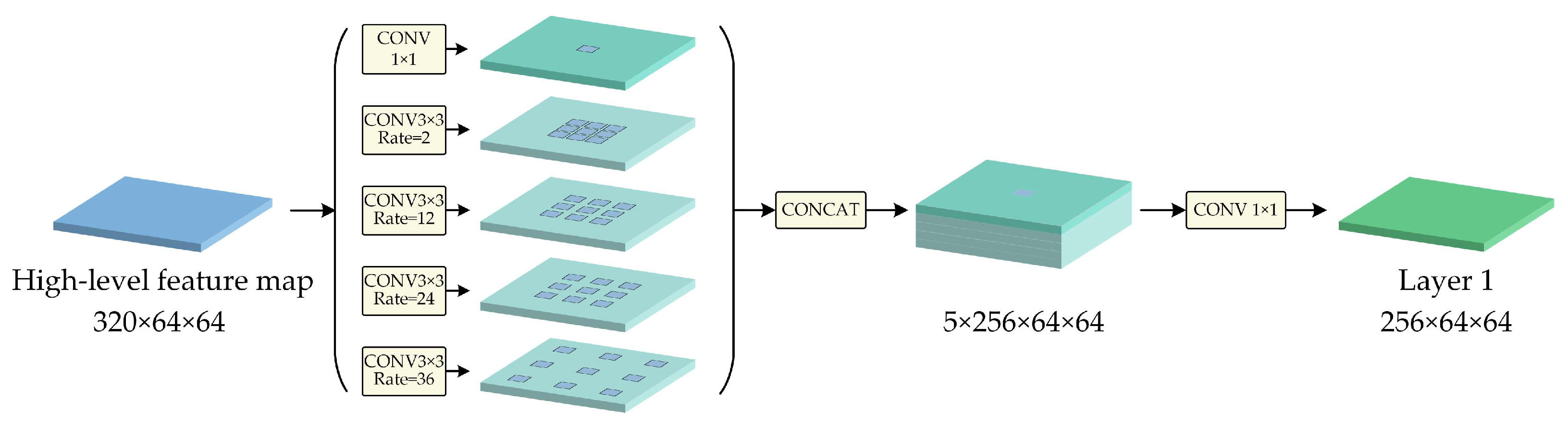
2.3. ASPP in the Encoder
2.4. Deformable Convolution in the Decoder
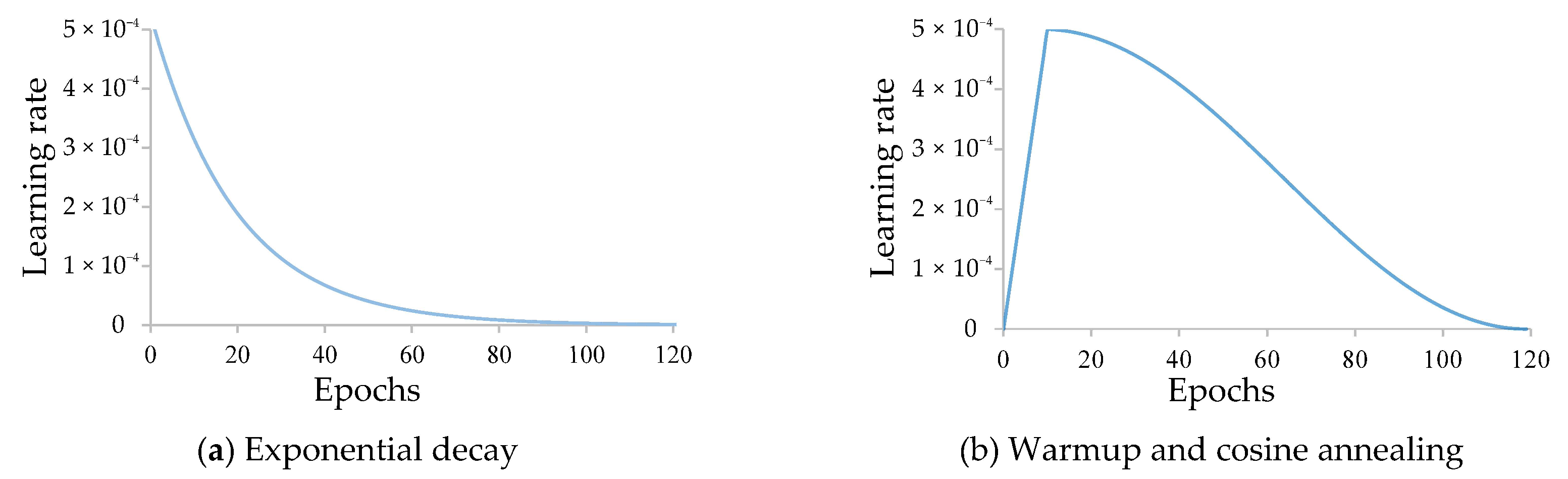
2.5. Warmup and Cosine Annealing Learning Rate Policy
3. Experiments and Results
3.1. Descriptions of the Datasets
3.2. Experimental Settings
3.3. Evaluation Metrics
4. Discussion
4.1. Comparisons on Each Dataset
4.1.1. Comparison on the WHU Dataset
4.1.2. Comparison on the Inria Dataset
4.1.3. Comparison on the Massachusetts Dataset
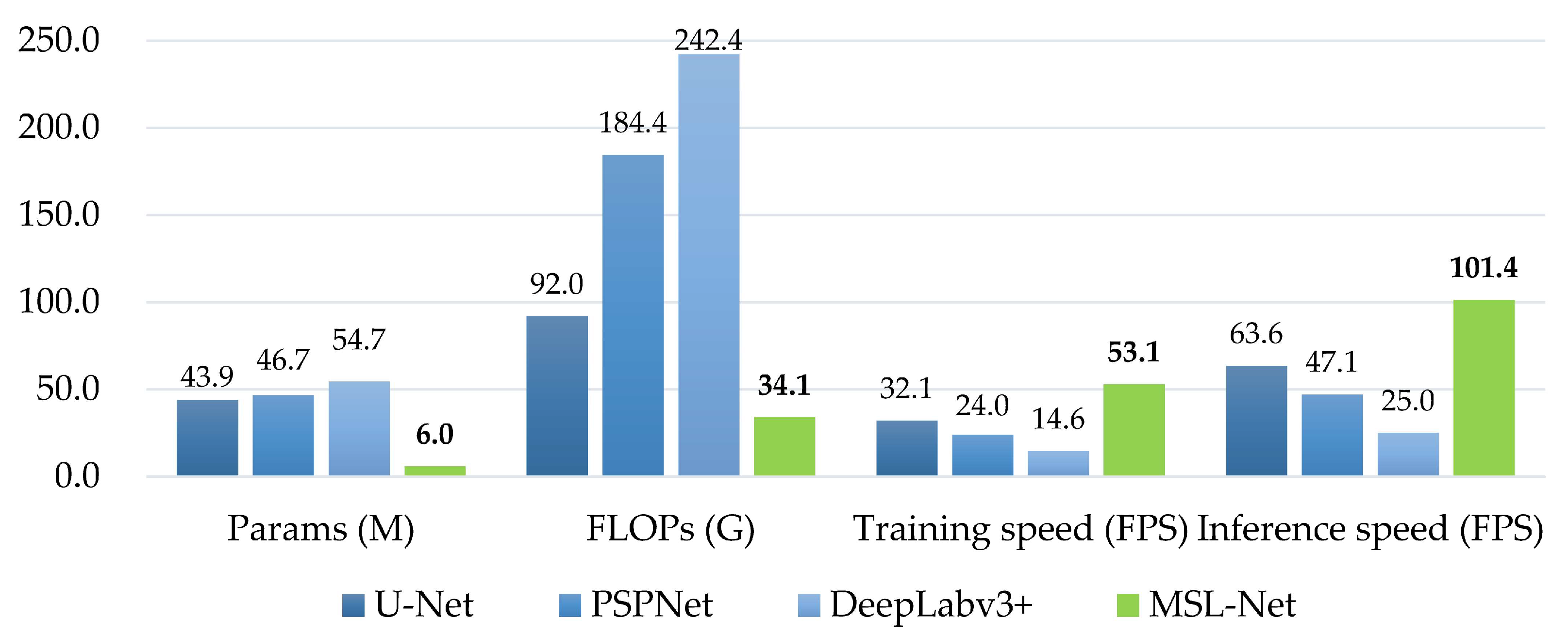
4.2. Complexity Comparison
4.3. Comparison with State-of-the-Art Methods
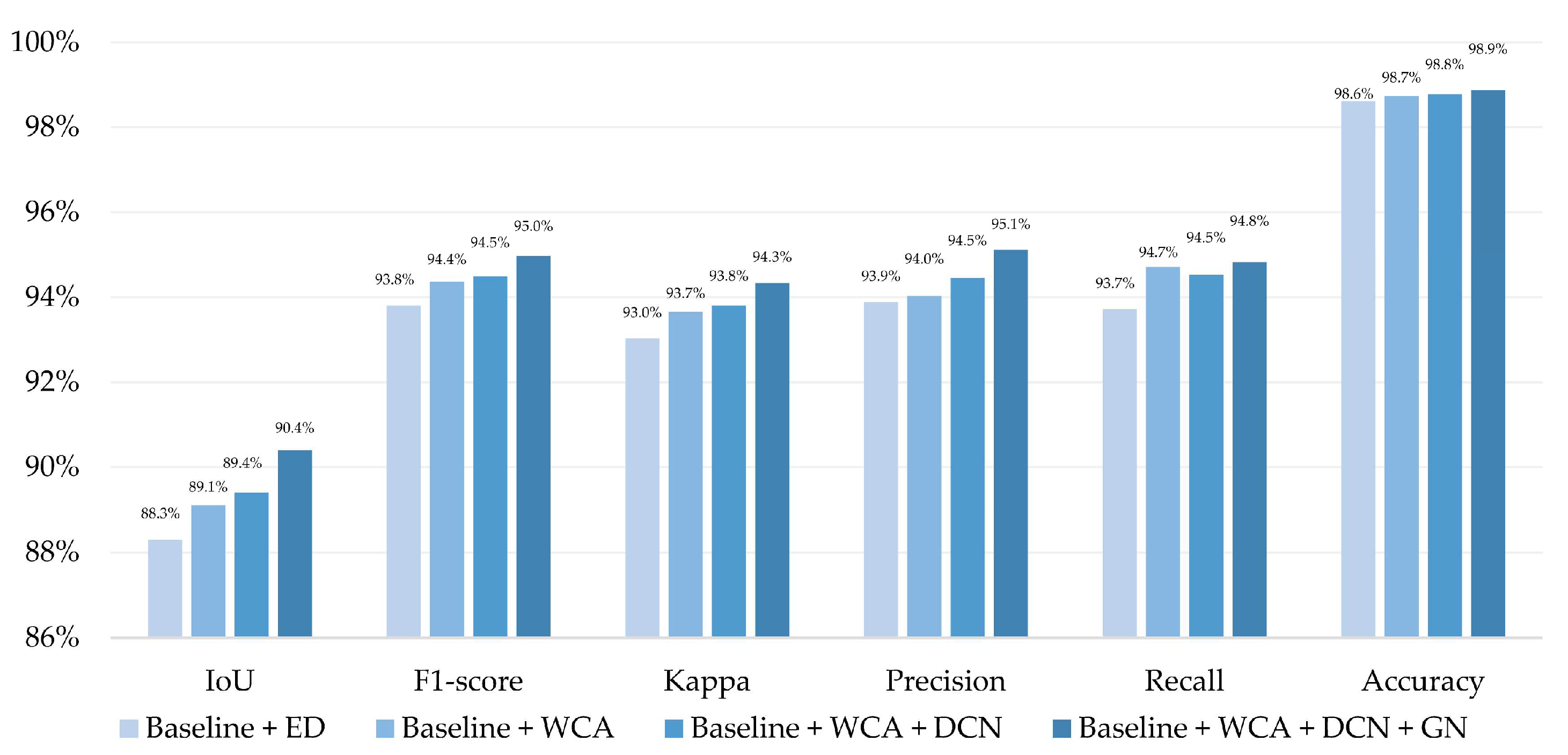
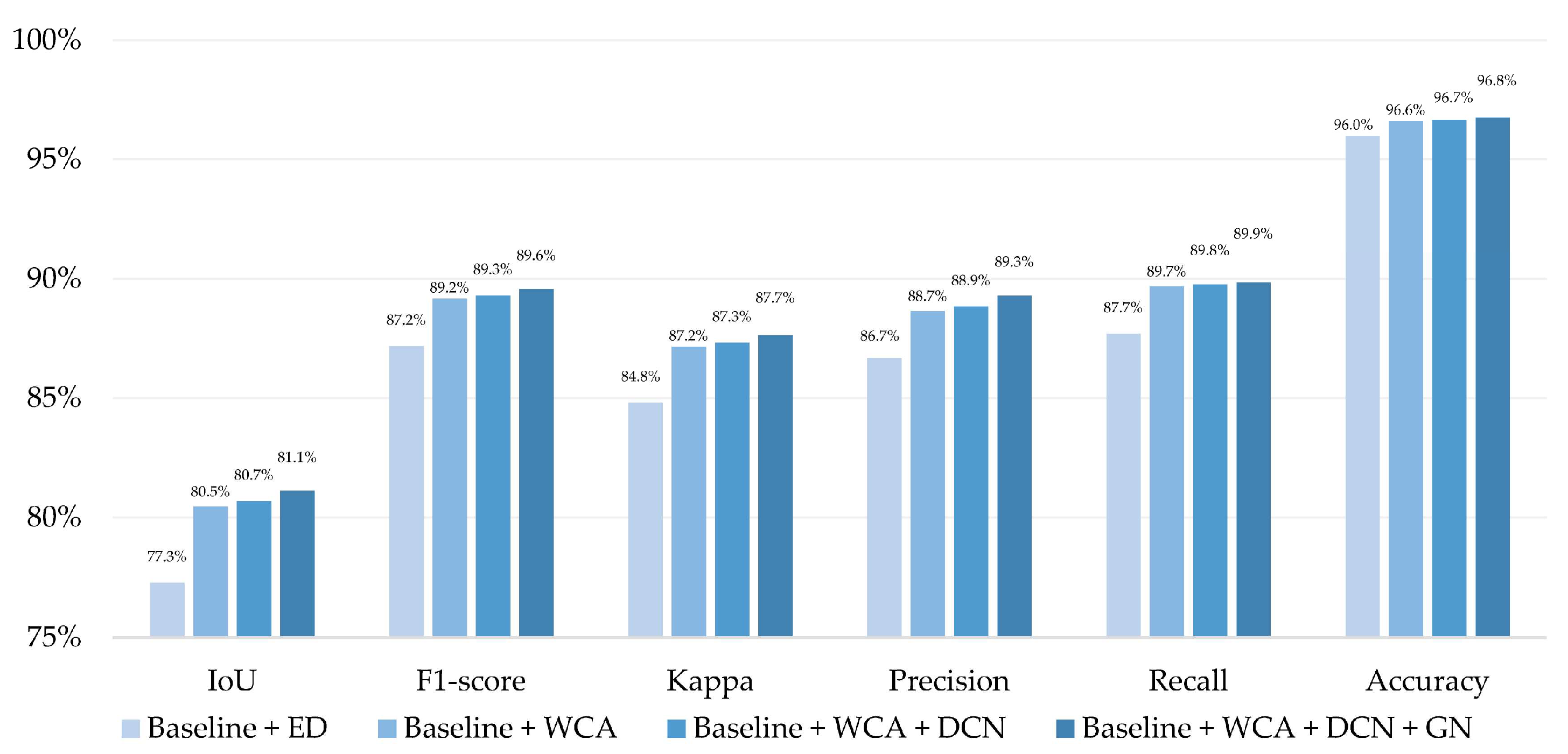
4.4. Ablation Experiments
4.5. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ASPP | Atrous spatial pyramid pooling |
| BN | Batch normalization |
| CPU | Central processing unit |
| DCN | Deformable convolution network |
| DSC | Depthwise separable convolution |
| FCN | Fully convolutional network |
| FLOPs | Floating-point operations |
| FN | False negative |
| FP | False positive |
| FPS | Frames per second |
| GN | Group normalization |
| GPU | Graphics processing unit |
| IoU | Intersection over union |
| OS | Operating system |
| TP | True positive |
| TN | True negative |
References
- Zeng, Y.; Guo, Y.; Li, J. Recognition and Extraction of High-Resolution Satellite Remote Sensing Image Buildings Based on Deep Learning. Neural. Comput. Appl. 2022, 34, 2691–2706. [Google Scholar] [CrossRef]
- Ghanea, M.; Moallem, P.; Momeni, M. Building Extraction from High-Resolution Satellite Images in Urban Areas: Recent Methods and Strategies Against Significant Challenges. Int. J. Remote Sens. 2016, 37, 5234–5248. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Chen, Q.; Wang, L.; Waslander, S.L.; Liu, X. An End-to-End Shape Modeling Framework for Vectorized Building Outline Generation from Aerial Images. ISPRS J. Photogramm. Remote Sens. 2020, 170, 114–126. [Google Scholar] [CrossRef]
- Katartzis, A.; Sahli, H.; Nyssen, E.; Cornelis, J. Detection of Buildings from a Single Airborne Image Using a Markov Random Field Model. In Proceedings of the IGARSS 2001, Scanning the Present and Resolving the Future, IEEE 2001 International Geoscience and Remote Sensing Symposium (Cat. No.01CH37217), Sydney, Australia, 9–13 July 2001; Volume 6, pp. 2832–2834. [Google Scholar]
- Simonetto, E.; Oriot, H.; Garello, R. Rectangular Building Extraction from Stereoscopic Airborne Radar Images. IEEE Trans. Geosci. Remote Sens. 2005, 43, 2386–2395. [Google Scholar] [CrossRef]
- Jung, C.R.; Schramm, R. Rectangle Detection Based on a Windowed Hough Transform. In Proceedings of the 17th Brazilian Symposium on Computer Graphics and Image Processing, Curitiba, Brazil, 20–20 October 2004; pp. 113–120. [Google Scholar]
- Li, L. Research on Shadow-Based Building Extraction from High Resolution Remote Sensing Images. Master’s Thesis, Hunan University of Science and Technology, Xiangtan, China, 2011. [Google Scholar]
- Zhao, Z.; Zhang, Y. Building Extraction from Airborne Laser Point Cloud Using NDVI Constrained Watershed Algorithm. Acta Optica Sin. 2016, 36, 503–511. [Google Scholar]
- Zhou, S.; Liang, D.; Wang, H.; Kong, J. Remote Sensing Image Segmentation Approach Based on Quarter-Tree and Graph Cut. Comput. Eng. 2010, 36, 224–226. [Google Scholar]
- Wei, D. Research on Buildings Extraction Technology on High Resolution Remote Sensing Images. Master’s Thesis, Information Engineering University, Zhengzhou, China, 2013. [Google Scholar]
- Tournaire, O.; Brédif, M.; Boldo, D.; Durupt, M. An Efficient Stochastic Approach for Building Footprint Extraction from Digital Elevation Models. ISPRS J. Photogramm. Remote Sens. 2010, 65, 317–327. [Google Scholar] [CrossRef]
- Parsian, S.; Amani, M. Building Extraction from Fused LiDAR and Hyperspectral Data Using Random Forest Algorithm. Geomatica 2017, 71, 185–193. [Google Scholar] [CrossRef]
- Ferro, A.; Brunner, D.; Bruzzone, L. Automatic Detection and Reconstruction of Building Radar Footprints from Single VHR SAR Images. IEEE Trans. Geosci. Remote Sens. 2013, 51, 935–952. [Google Scholar] [CrossRef]
- Wei, Y.; Zhao, Z.; Song, J. Urban Building Extraction from High-Resolution Satellite Panchromatic Image Using Clustering and Edge Detection. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004; IEEE: Anchorage, AK, USA, 2004; Volume 3, pp. 2008–2010. [Google Scholar]
- Huang, X.; Zhang, L. Morphological Building/Shadow Index for Building Extraction from High-Resolution Imagery Over Urban Areas. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 161–172. [Google Scholar] [CrossRef]
- Gao, X.; Wang, M.; Yang, Y.; Li, G. Building Extraction from RGB VHR Images Using Shifted Shadow Algorithm. IEEE Access 2018, 6, 22034–22045. [Google Scholar] [CrossRef]
- Maruyama, Y.; Tashiro, A.; Yamazaki, F. Use of Digital Surface Model Constructed from Digital Aerial Images to Detect Collapsed Buildings during Earthquake. Procedia Eng. 2011, 14, 552–558. [Google Scholar] [CrossRef]
- Guo, H.; Du, B.; Zhang, L.; Su, X. A Coarse-to-Fine Boundary Refinement Network for Building Footprint Extraction from Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2022, 183, 240–252. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Yuan, J. Learning Building Extraction in Aerial Scenes with Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2793–2798. [Google Scholar] [CrossRef] [PubMed]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. High-Resolution Aerial Image Labeling with Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7092–7103. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Xu, Z.; Shen, Z.; Li, Y.; Zhao, L.; Ke, Y.; Li, L.; Wen, Q. Classification of High-Resolution Remote Sensing Images Based on Enhanced DeepLab Algorithm and Adaptive Loss Function. Nat. Remote Sens. Bull. 2022, 26, 406–415. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Wang, Z.; Zhou, Y.; Wang, S.; Wang, F.; Xu, Z. House Building Extraction from High-Resolution Remote Sensing Images based on IEU-Net. Nat. Remote Sens. Bull. 2021, 25, 2245–2254. [Google Scholar]
- Xu, L.; Liu, Y.; Yang, P.; Chen, H.; Zhang, H.; Wang, D.; Zhang, X. HA U-Net: Improved Model for Building Extraction from High Resolution Remote Sensing Imagery. IEEE Access 2021, 9, 101972–101984. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, D.; Ma, A.; Zhong, Y.; Fang, F.; Xu, K. Multiscale U-Shaped CNN Building Instance Extraction Framework with Edge Constraint for High-Spatial-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6106–6120. [Google Scholar] [CrossRef]
- Zhang, Y.; Yan, Q.; Deng, F. Multi-Path RSU Network Method for High-Resolution Remote Sensing Image Building Extraction. Acta Geod. Cartogr. Sin. 2022, 51, 135–144. [Google Scholar]
- Xu, J.; Liu, W.; Shan, H.; Shi, J.; Li, E.; Zhang, L.; Li, H. High-Resolution Remote Sensing Image Building Extraction Based on PRCUnet. J. Geo-inf. Sci. 2021, 23, 1838–1849. [Google Scholar]
- He, Z.; Ding, H.; An, B. E-Unet: A Atrous Convolution-Based Neural Network for Building Extraction from High-Resolution Remote Sensing Images. Acta Geod. Cartogr. Sin. 2022, 51, 457–467. [Google Scholar]
- Zhang, C.; Liu, H.; Ge, Y.; Shi, S.; Zhang, M. Multi-Scale Dilated Convolutional Pyramid Network for Building Extraction. J. Xi’an Univ. Sci. Technol. 2021, 41, 490–497, 574. [Google Scholar]
- Rashidian, V.; Baise, L.G.; Koch, M. Detecting Collapsed Buildings After a Natural Hazard on VHR Optical Satellite Imagery Using U-Net Convolutional Neural Networks. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 9394–9397. [Google Scholar]
- Xiong, C.; Li, Q.; Lu, X. Automated Regional Seismic Damage Assessment of Buildings Using an Unmanned Aerial Vehicle and a Convolutional Neural Network. Autom. Constr. 2020, 109, 102994. [Google Scholar] [CrossRef]
- Cooner, A.J.; Shao, Y.; Campbell, J.B. Detection of Urban Damage Using Remote Sensing and Machine Learning Algorithms: Revisiting the 2010 Haiti Earthquake. Remote Sens. 2016, 8, 868. [Google Scholar] [CrossRef]
- Shimoni, M.; Haelterman, R.; Perneel, C. Hypersectral Imaging for Military and Security Applications: Combining Myriad Processing and Sensing Techniques. IEEE Geosci. Remote Sens. Mag. 2019, 7, 101–117. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Sifre, L. Rigid-Motion Scattering for Image Classification. Ph.D. Thesis, École Polytechnique, Paris, France, 2014. [Google Scholar]
- Wu, Y.; He, K. Group Normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway Networks. arXiv 2015, arXiv:1505.00387. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets V2: More Deformable, Better Results. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9300–9308. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Huang, L.; Zhou, Y.; Wang, T.; Luo, J.; Liu, X. Delving into the Estimation Shift of Batch Normalization in a Network. arXiv 2022, arXiv:2203.10778. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2017, arXiv:1608.03983. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can Semantic Labeling Methods Generalize to Any City? The Inria Aerial Image Labeling Benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.M.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Sun, X.; Meng, Y.; Liang, J.; Wu, F.; Li, J. Dice Loss for Data-imbalanced NLP Tasks. arXiv 2020, arXiv:1911.02855. [Google Scholar]
- Ji, S.; Wei, S. Building Extraction via Convolutional Neural Networks from an Open Remote Sensing Building Dataset. Acta Geod. Cartogr. Sin. 2019, 48, 448–459. [Google Scholar]
- Yu, M.; Chen, X.; Zhang, W.; Liu, Y. AGs-Unet: Building Extraction Model for High Resolution Remote Sensing Images Based on Attention Gates U Network. Sensors 2022, 22, 2932. [Google Scholar] [CrossRef]
- Zhou, D.; Wang, G.; He, G.; Long, T.; Yin, R.; Zhang, Z.; Chen, S.; Luo, B. Robust Building Extraction for High Spatial Resolution Remote Sensing Images with Self-Attention Network. Sensors 2020, 20, 7241. [Google Scholar] [CrossRef]
- Chen, M.; Wu, J.; Liu, L.; Zhao, W.; Tian, F.; Shen, Q.; Zhao, B.; Du, R. DR-Net: An Improved Network for Building Extraction from High Resolution Remote Sensing Image. Remote Sens. 2021, 13, 294. [Google Scholar] [CrossRef]
- Huang, H.; Chen, Y.; Wang, R. A Lightweight Network for Building Extraction from Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. BRRNet: A Fully Convolutional Neural Network for Automatic Building Extraction from High-Resolution Remote Sensing Images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef]
- Liu, P.; Liu, X.; Liu, M.; Shi, Q.; Yang, J.; Xu, X.; Zhang, Y. Building Footprint Extraction from High-Resolution Images via Spatial Residual Inception Convolutional Neural Network. Remote Sens. 2019, 11, 830. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Spatial Resolution (m) | Pixels | Area (km2) | Tiles |
|---|---|---|---|---|
| WHU dataset | 0.3 | 512 × 512 | 450 | 8189 |
| Inria dataset | 0.3 | 5000 × 5000 | 810 | 180 |
| Massachusetts dataset | 1.0 | 1500 × 1500 | 240 | 151 |
| Dataset | Training Set | Validation Set | Test Set |
|---|---|---|---|
| WHU dataset | 4737 | 1036 | 2416 |
| Inria dataset | 14418 | 1782 | 1800 |
| Massachusetts dataset | 1233 | 36 | 90 |
| Item | Details |
|---|---|
| CPU | Intel i7-12700K @ 3.61 GHz |
| GPU | GeForce RTX 3090 (24 GB) |
| OS | Windows 10 x64 |
| Language | Python 3.8 |
| Framework | PyTorch 1.8.1 |
| Prediction | Building | Background | |
|---|---|---|---|
| Ground Truth | |||
| Building | TP | FN | |
| Background | FP | TN | |
| Method | IoU (%) | Accuracy (%) | F1-Score (%) | Kappa (%) | Precision (%) | Recall (%) |
|---|---|---|---|---|---|---|
| U-Net | 84.9 | 98.2 | 91.9 | 90.8 | 90.0 | 93.8 |
| PSPNet | 87.6 | 98.5 | 93.4 | 92.6 | 92.6 | 94.3 |
| DeepLabv3+ | 88.0 | 98.6 | 93.6 | 92.8 | 94.4 | 92.9 |
| MSL-Net | 90.4 | 98.9 | 95.0 | 94.3 | 95.1 | 94.8 |
| Method | IoU (%) | Accuracy (%) | F1-Score (%) | Kappa (%) | Precision (%) | Recall (%) |
|---|---|---|---|---|---|---|
| U-Net | 78.2 | 96.2 | 87.8 | 85.5 | 88.5 | 87.0 |
| PSPNet | 80.9 | 96.7 | 89.4 | 87.5 | 88.9 | 89.9 |
| DeepLabv3+ | 78.1 | 96.2 | 87.7 | 85.4 | 88.2 | 87.1 |
| MSL-Net | 81.1 | 96.8 | 89.6 | 87.7 | 89.3 | 89.9 |
| Method | IoU (%) | Accuracy (%) | F1-Score (%) | Kappa (%) | Precision (%) | Recall (%) |
|---|---|---|---|---|---|---|
| U-Net | 67.6 | 92.6 | 80.7 | 76.1 | 78.5 | 83.0 |
| PSPNet | 67.2 | 92.6 | 80.4 | 75.8 | 79.3 | 81.5 |
| DeepLabv3+ | 63.3 | 91.3 | 77.5 | 74.5 | 74.9 | 80.4 |
| MSL-Net | 70.9 | 93.6 | 83.0 | 79.0 | 81.9 | 84.1 |
| Method | IoU (%) | F1-Score (%) | Params (M) |
|---|---|---|---|
| AGs-Unet | 85.5 | – | 34.9 |
| PISANet | 88.0 | 93.6 | – |
| DR-Net | 88.3 | 93.8 | 9.0 |
| RSR-Net | 88.3 | – | 2.9 |
| BRRNet | 89.0 | 94.1 | 17.3 |
| SRI-Net | 89.1 | 94.2 | – |
| MSL-Net | 90.4 | 95.0 | 6.0 |
| Method | WHU | Inria | Massachusetts | |||
|---|---|---|---|---|---|---|
| IoU | F1-Score | IoU | F1-Score | IoU | F1-Score | |
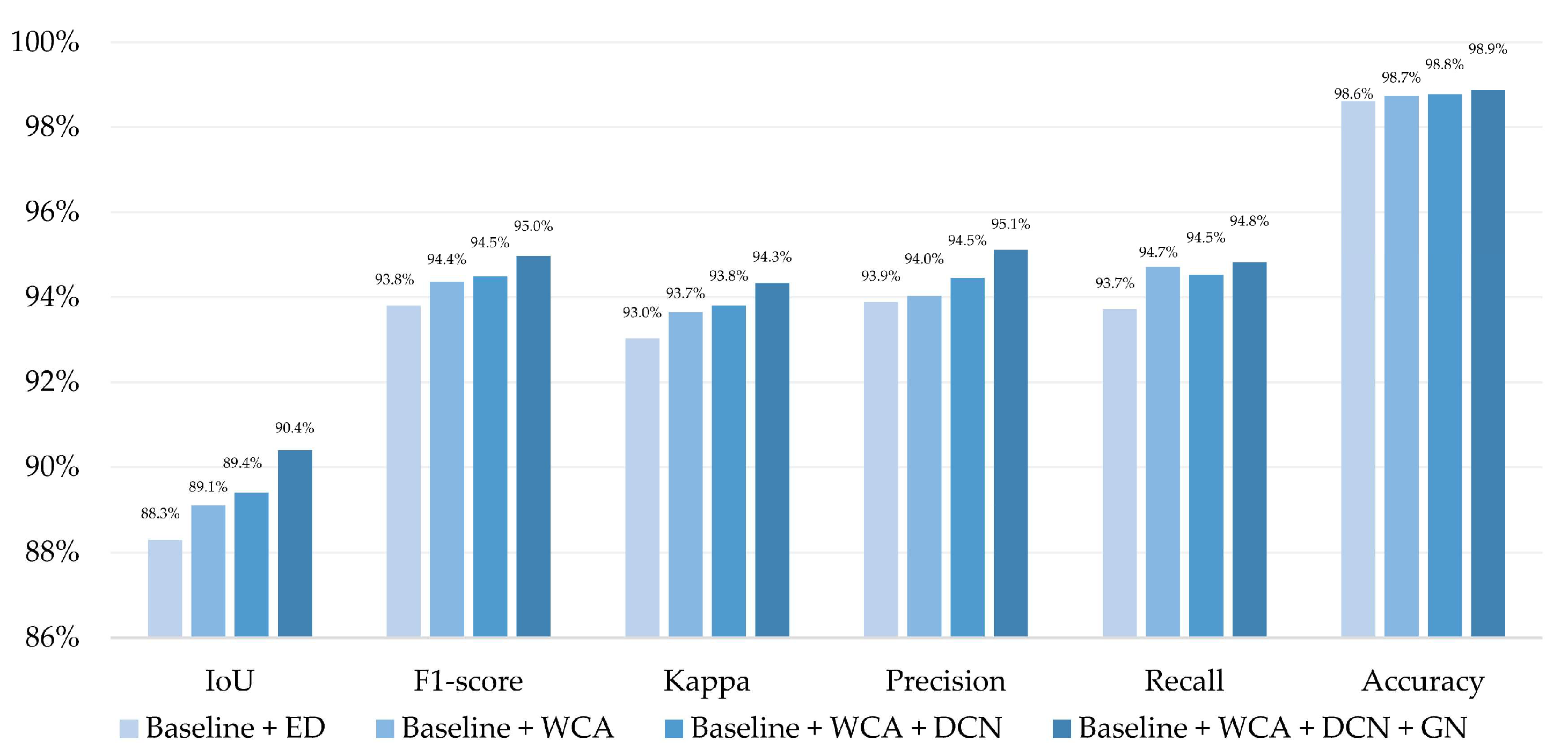
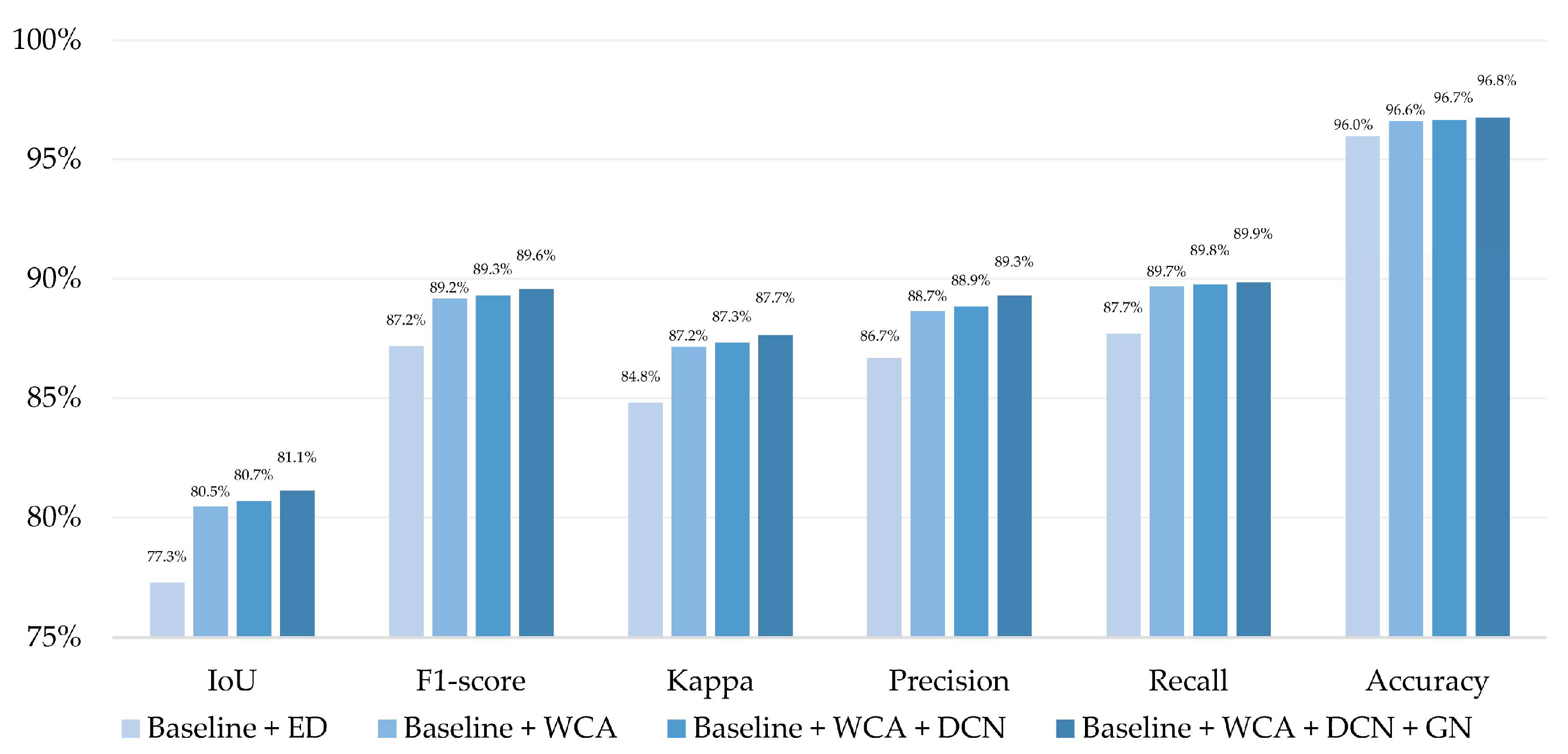
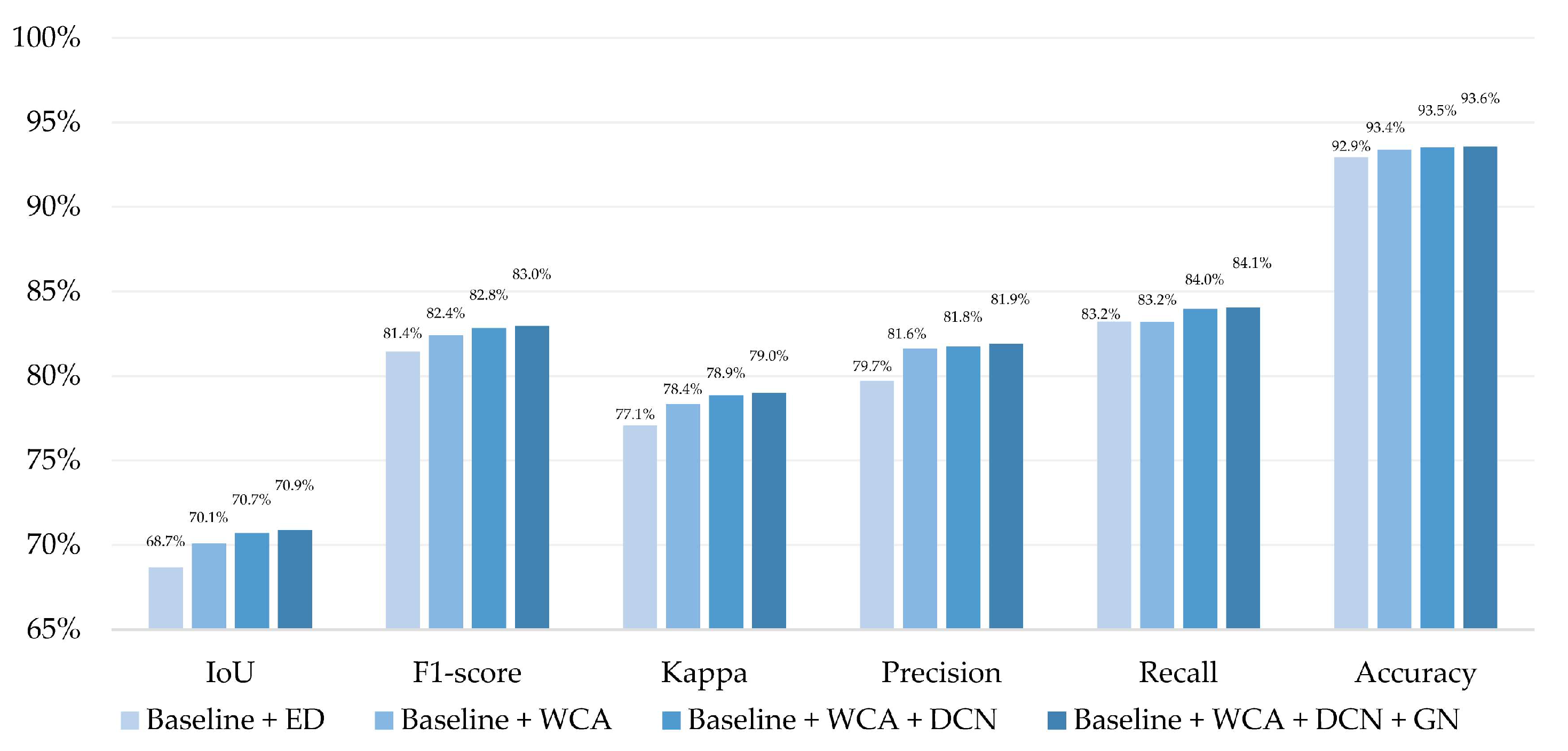
| Baseline + ED | 88.3% | 93.9% | 77.3% | 87.2% | 68.7% | 81.4% |
| Baseline + WCA | 89.1% | 94.6% | 80.5% | 89.2% | 70.1% | 82.4% |
| Baseline + WCA + DCN | 89.4% | 94.9% | 80.7% | 89.3% | 70.7% | 82.8% |
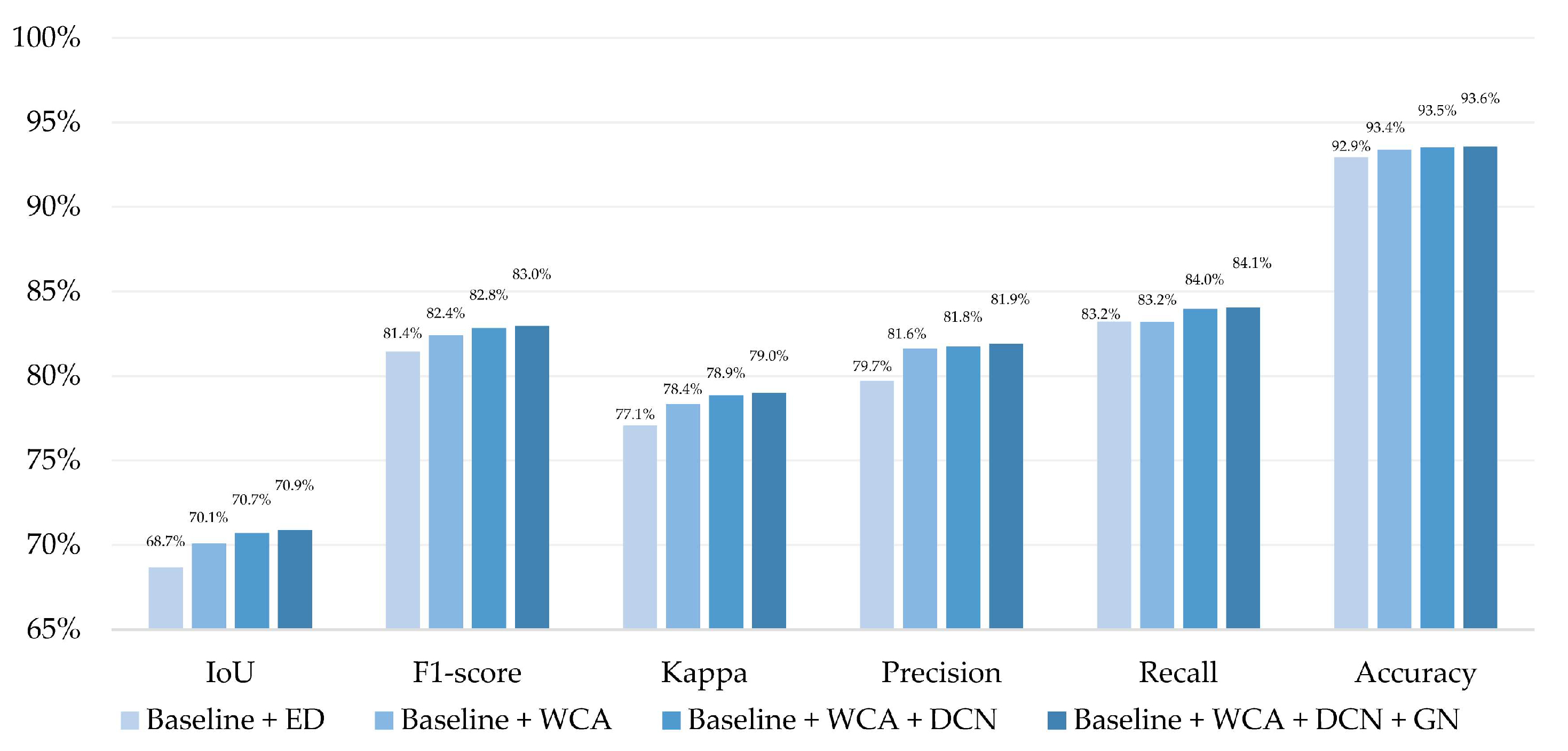
| Baseline + WCA + DCN + GN | 90.4% | 95.0% | 81.1% | 89.6% | 70.9% | 83.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, Y.; Wu, F.; Yin, J.; Liu, C.; Gong, X.; Wang, A. MSL-Net: An Efficient Network for Building Extraction from Aerial Imagery. Remote Sens. 2022, 14, 3914. https://doi.org/10.3390/rs14163914
Qiu Y, Wu F, Yin J, Liu C, Gong X, Wang A. MSL-Net: An Efficient Network for Building Extraction from Aerial Imagery. Remote Sensing. 2022; 14(16):3914. https://doi.org/10.3390/rs14163914
Chicago/Turabian StyleQiu, Yue, Fang Wu, Jichong Yin, Chengyi Liu, Xianyong Gong, and Andong Wang. 2022. "MSL-Net: An Efficient Network for Building Extraction from Aerial Imagery" Remote Sensing 14, no. 16: 3914. https://doi.org/10.3390/rs14163914
APA StyleQiu, Y., Wu, F., Yin, J., Liu, C., Gong, X., & Wang, A. (2022). MSL-Net: An Efficient Network for Building Extraction from Aerial Imagery. Remote Sensing, 14(16), 3914. https://doi.org/10.3390/rs14163914