
Automatic Detection of Pothole Distress in Asphalt Pavement Using Improved Convolutional Neural Networks



Abstract
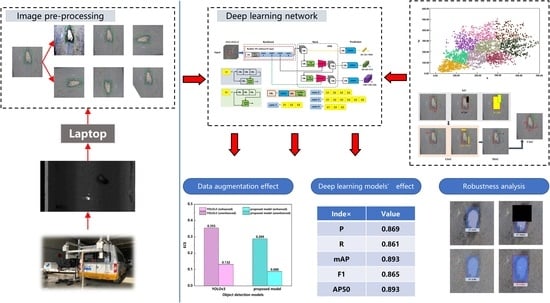
1. Introduction
- (1)
- The pothole dataset was contrast-enhanced by color adjustment, and geometric transformation was adopted to expand the number of samples. A data augmentation strategy suitable for potholes was proposed to train DL models.
- (2)
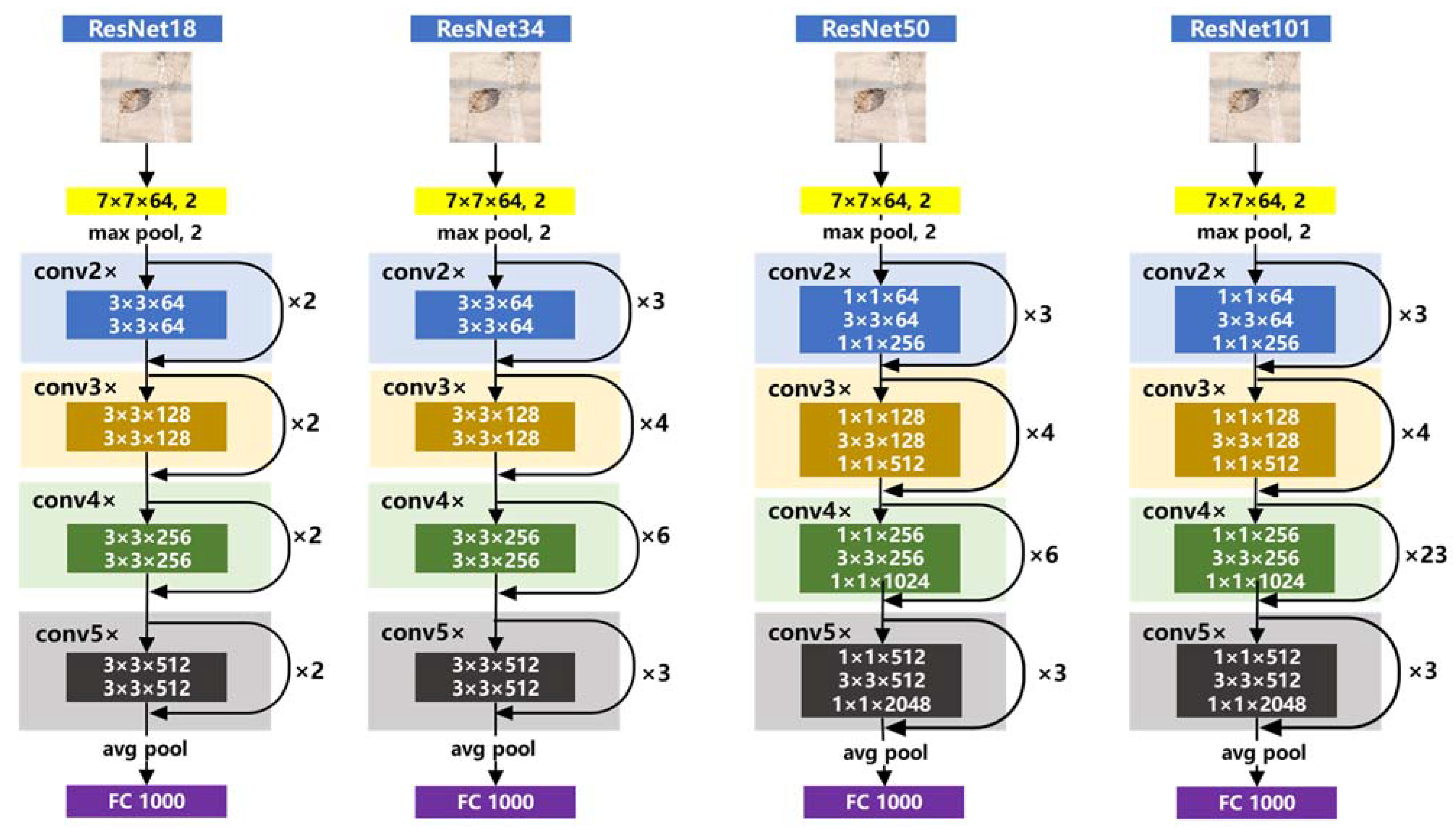
- The ResNet101 network was used to improve the feature extraction network of YOLOv3. Complete intersection over union (CIoU) was applied to measure the loss of the proposed model. The anchor sizes were modified by the K-Means++ algorithm. An object detection model applicable for potholes was established.
- (3)
- Adversarial samples of potholes were generated by random occlusion and adding noise before testing, which verified the robustness of this model.
2. Methodology
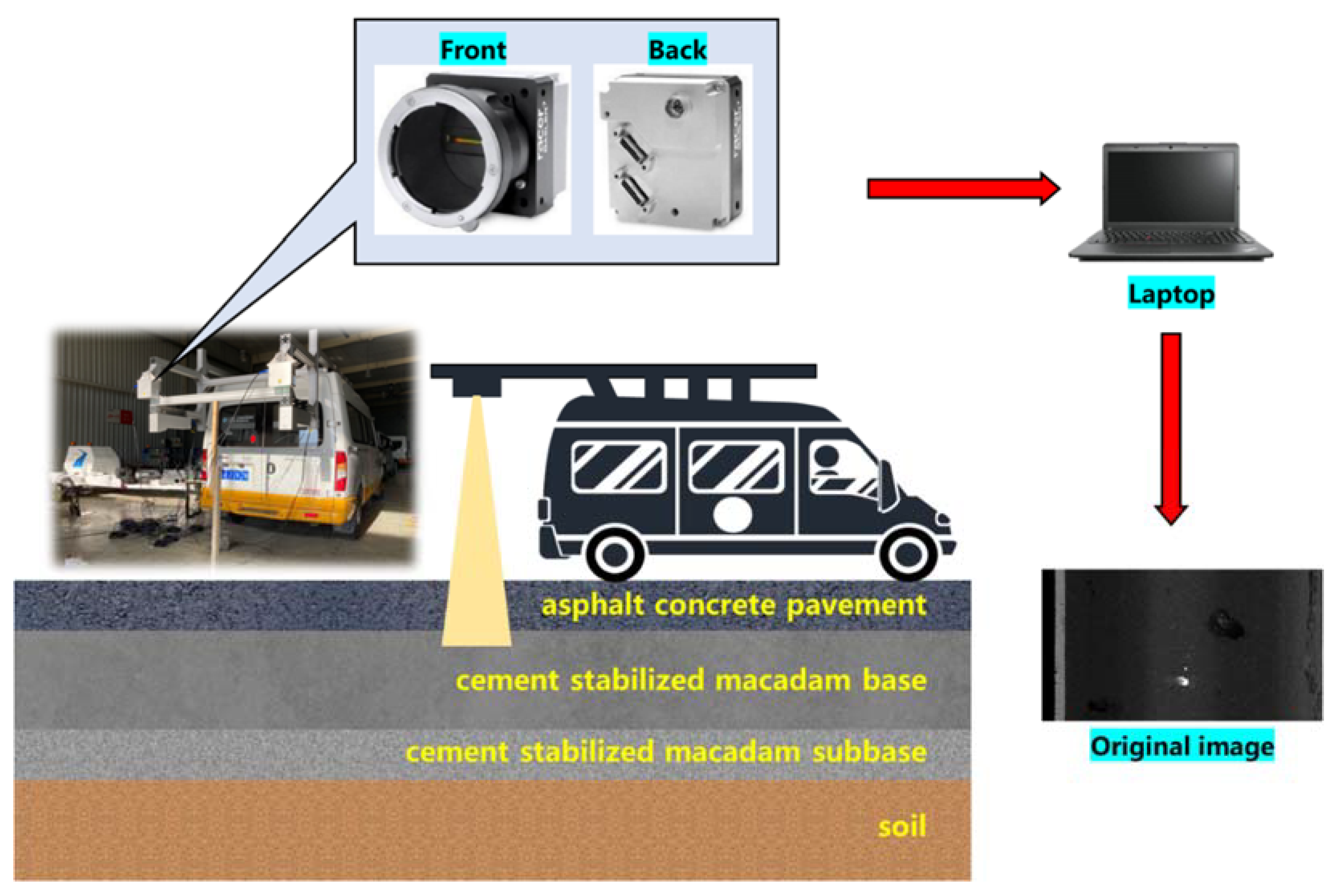
2.1. Pavement Pothole Dataset
2.2. Pothole Data Pre-Processing
2.2.1. Color Adjustment
2.2.2. Geometric Transformation
2.3. Object Detection
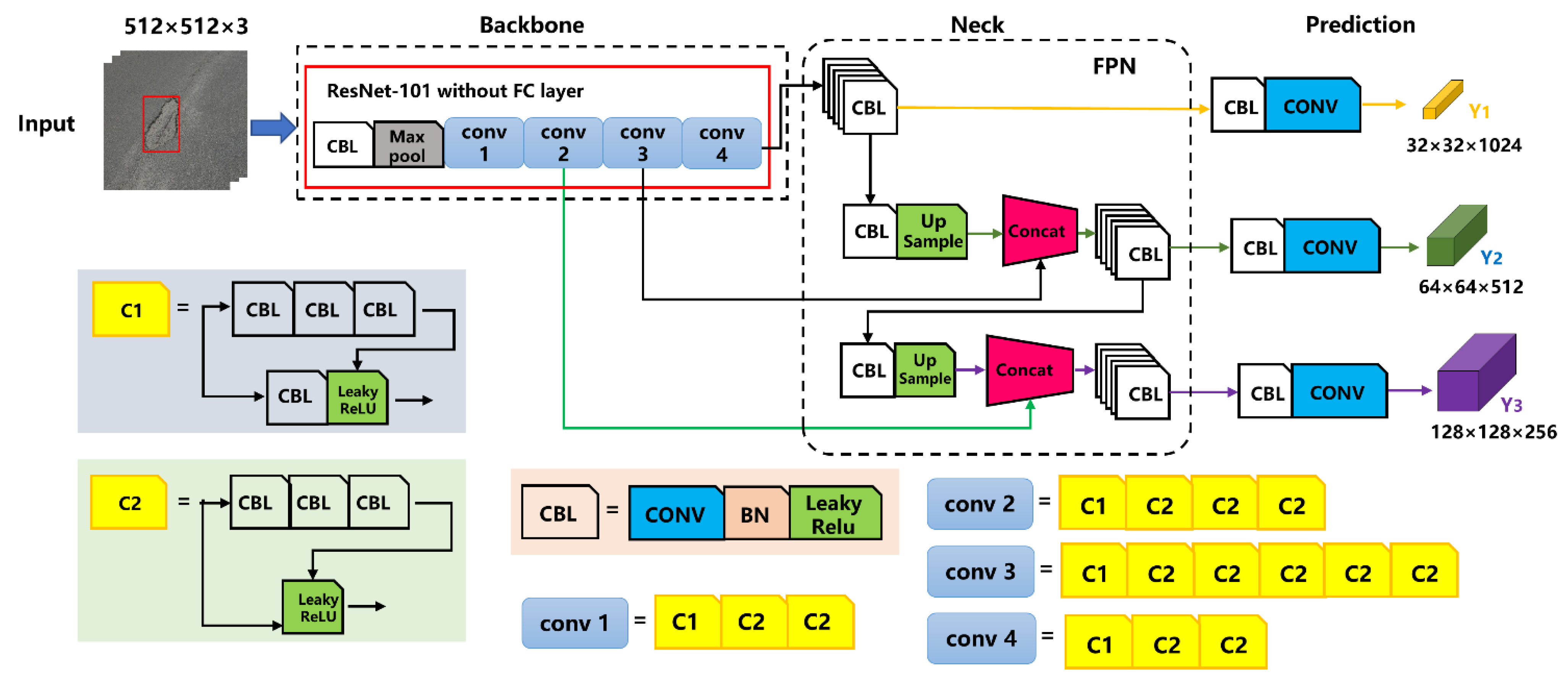
2.3.1. YOLOv3–ResNet101 Structure
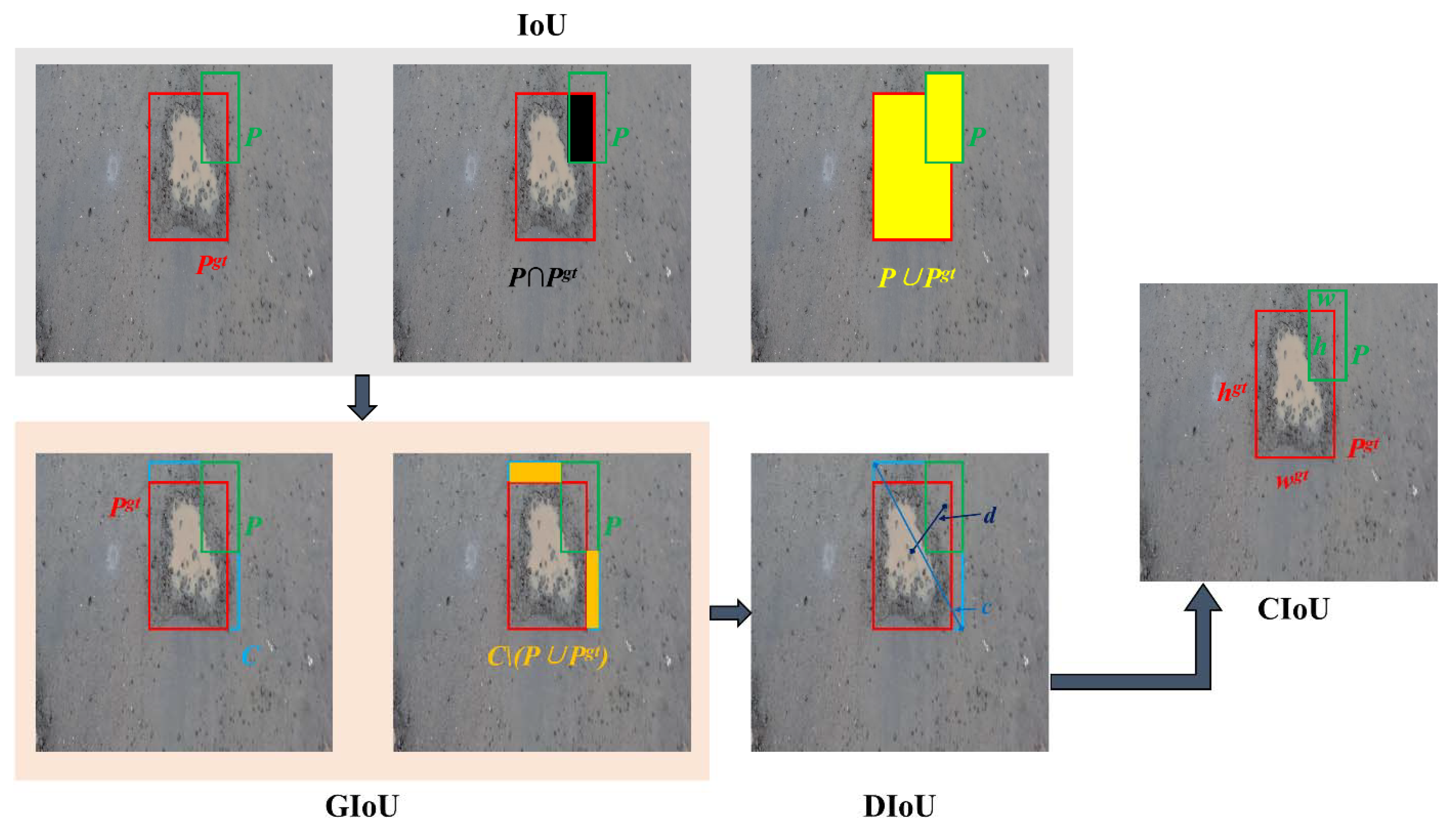
2.3.2. Loss Function
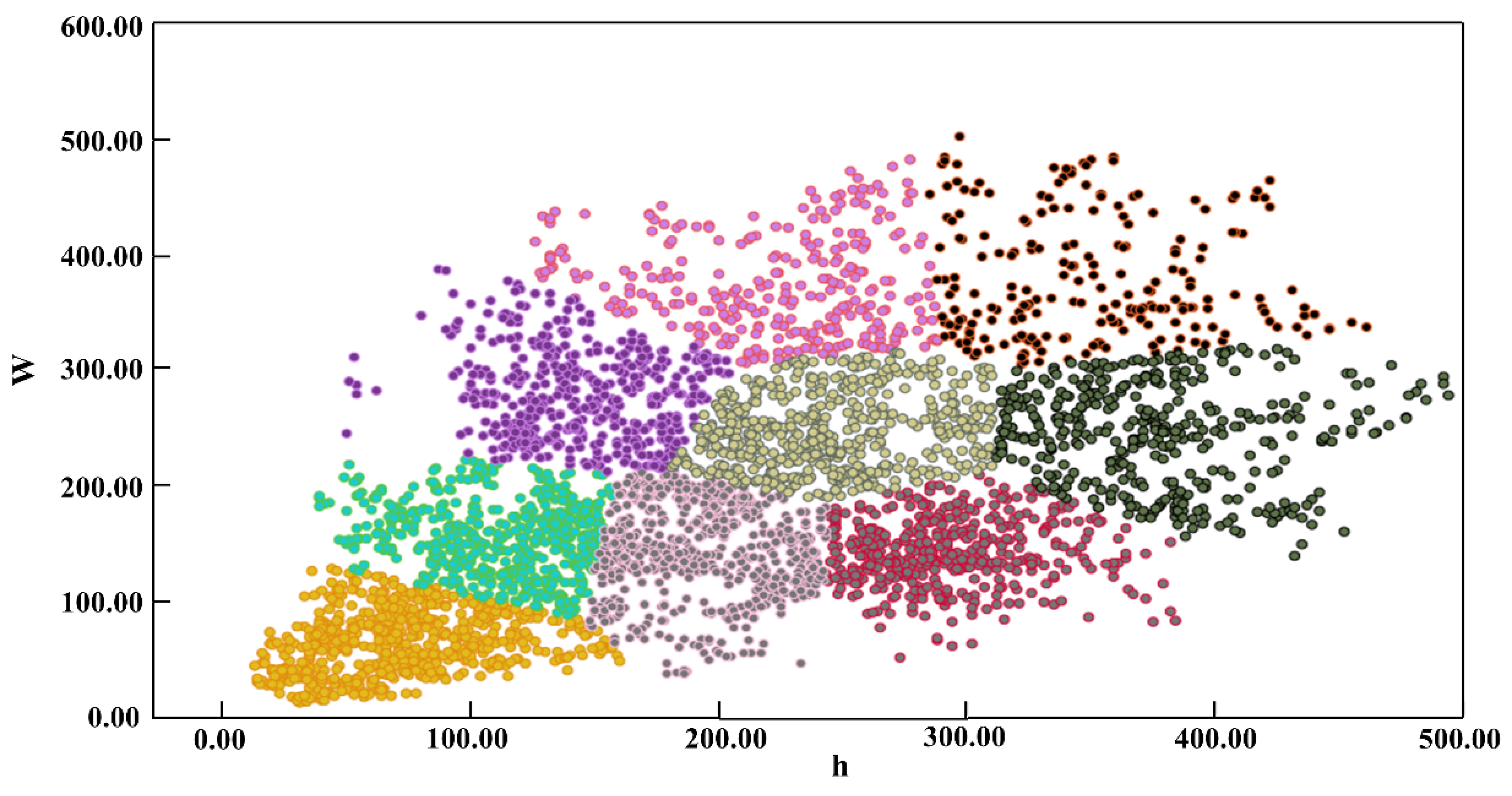
2.3.3. Anchor Size
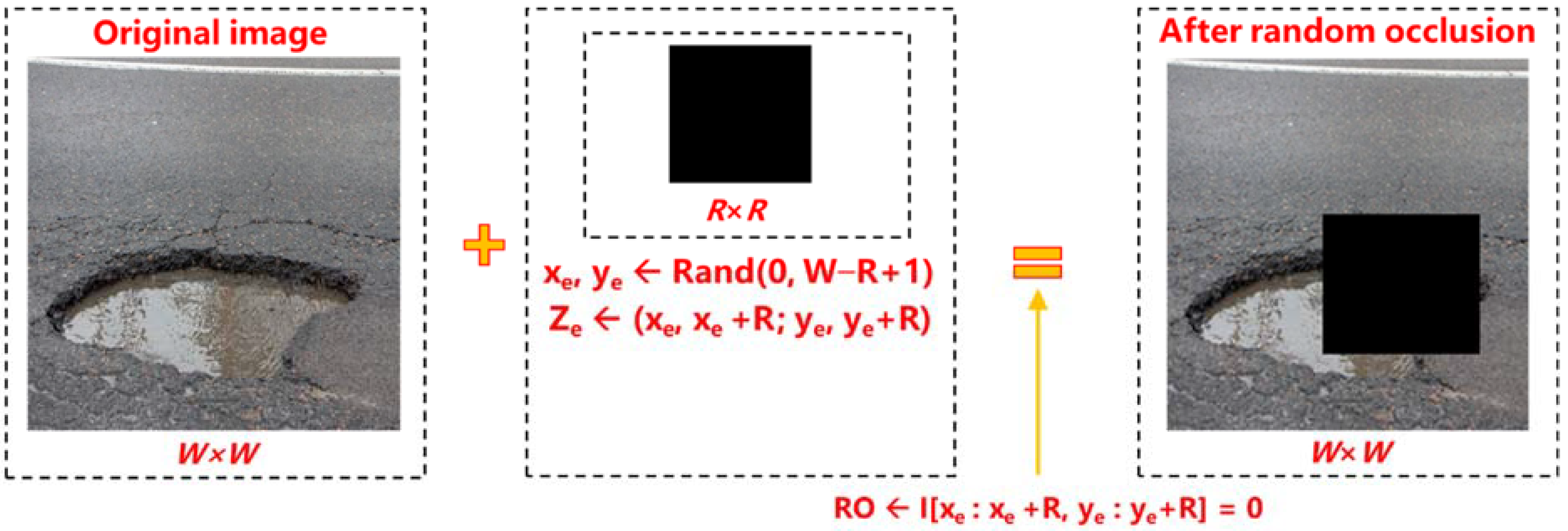
2.3.4. Robustness Verification
2.3.5. Evaluation Index
3. Results and Discussion
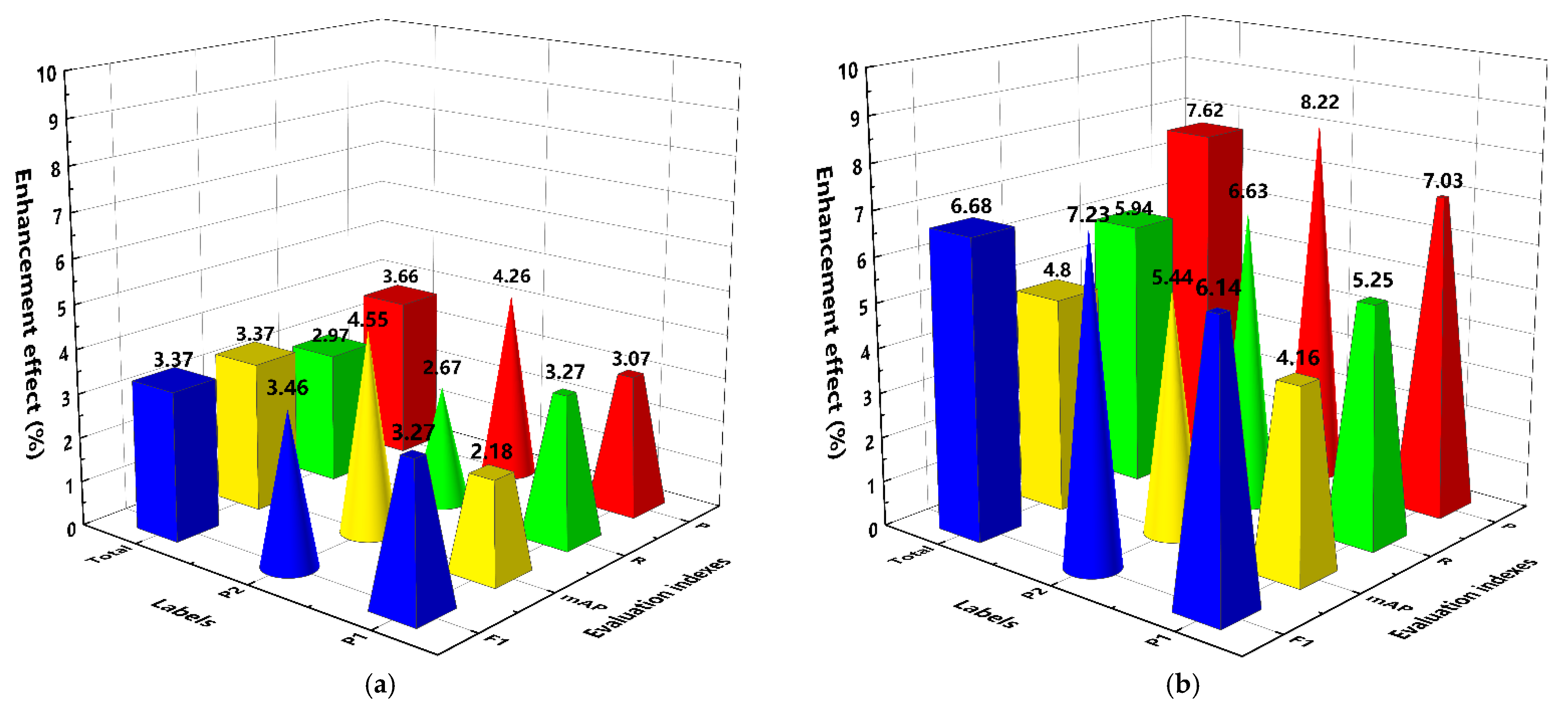
3.1. Results of Data Augmentation
3.2. Evaluation of Different DL Models
3.3. Robustness Analysis
3.4. Generalization Performance Analysis
4. Conclusions
- (1)
- An effective image preprocessing strategy for improving and expanding the pothole dataset was proposed using the methods of color adjustment and geometric transformation, which ensured the detection stability of the proposed model.
- (2)
- The potholes were further subdivided according to whether there was water. The detection results could preliminarily judge the surface state of the pothole and weather conditions.
- (3)
- The ResNet101 network was adopted to extract features in the YOLOv3 model, which obtained abundant information on potholes. The modified anchor sizes based on the K-Means++ method were more in line with the shapes and sizes of the pothole, which improved the accuracy of the identification and location. The loss function defined by CIoU was of great help for accurate pothole detection.
- (4)
- The robustness of the proposed model was verified by generating adversarial attack samples through random occlusion and adding noise. Results showed that the overall robustness was good. Specifically, the proposed model was more robust to Gaussian noise under the interference intensity.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, S.; Tu, X.; Xu, C.; Chen, L.; Lin, S.; Li, R. An Optimized Deep Neural Network for Overhead Contact System Recognition from LiDAR Point Clouds. Remote Sens. 2021, 13, 4110. [Google Scholar] [CrossRef]
- Liu, Z.; Gu, X.; Wu, C.; Ren, H.; Zhou, Z.; Tang, S. Studies on the validity of strain sensors for pavement monitoring: A case study for a fiber Bragg grating sensor and resistive sensor. Constr. Build. Mater. 2022, 321, 126085. [Google Scholar] [CrossRef]
- Luo, Q.; Ge, B.; Tian, Q. A fast adaptive crack detection algorithm based on a double-edge extraction operator of FSM. Constr. Build. Mater. 2019, 204, 244–254. [Google Scholar] [CrossRef]
- Chen, Y.; Liang, J.; Gu, X.; Zhang, Q.; Deng, H.; Li, S. An improved minimal path selection approach with new strategies for pavement crack segmentation. Measurement 2021, 184, 109877. [Google Scholar] [CrossRef]
- Liang, J.; Gu, X.; Chen, Y. Fast and robust pavement crack distress segmentation utilizing steerable filtering and local order energy. Constr. Build. Mater. 2020, 262, 120084. [Google Scholar] [CrossRef]
- Wang, L.; Gu, X.; Liu, Z.; Wu, W.; Wang, D. Automatic detection of asphalt pavement thickness: A method combining GPR images and improved Canny algorithm. Measurement 2022, 196, 111248. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, Y.; Gu, X.; Yeoh, J.K.; Zhang, Q. Visibility classification and influencing-factors analysis of airport: A deep learning approach. Atmos. Environ. 2022, 278, 119085. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Cha, Y.-J.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Xiong, Y.; Zhou, Y.; Wang, F.; Wang, S.; Wang, Z.; Ji, J.; Wang, J.; Zou, W.; You, D.; Qin, G. A Novel Intelligent Method Based on the Gaussian Heatmap Sampling Technique and Convolutional Neural Network for Landslide Susceptibility Mapping. Remote Sens. 2022, 14, 2866. [Google Scholar] [CrossRef]
- Puttagunta, M.; Ravi, S. Medical image analysis based on deep learning approach. Multimedia Tools Appl. 2021, 80, 24365–24398. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Wu, W.; Gu, X.; Li, S.; Wang, L.; Zhang, T. Application of Combining YOLO Models and 3D GPR Images in Road Detection and Maintenance. Remote Sens. 2021, 13, 1081. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, J.; Sun, W. Recognition of the Typical Distress in Concrete Pavement Based on GPR and 1D-CNN. Remote Sens. 2021, 13, 2375. [Google Scholar] [CrossRef]
- Deng, T.; Zhou, Z.; Fang, F.; Wang, L. Research on Improved YOLOv3 Traffic Sign Detection Method. Comput. Eng. Appl. 2020, 56, 28–35. [Google Scholar]
- Liu, Z.; Gu, X.; Dong, Q.; Tu, S.; Li, S. 3D Visualization of Airport Pavement Quality Based on BIM and WebGL Integration. J. Transp. Eng. Part B Pavements 2021, 147, 04021024. [Google Scholar] [CrossRef]
- Zhou, W.N.; Sun, L.H. A Real-time Detection Method for Multi-scale Pedestrians in Complex Environment. J. Electron. Inf. Technol. 2021, 43, 2063–2070. [Google Scholar]
- Liu, T.; Wang, Y.; Niu, X.; Chang, L.; Zhang, T.; Liu, J. LiDAR Odometry by Deep Learning-Based Feature Points with Two-Step Pose Estimation. Remote Sens. 2022, 14, 2764. [Google Scholar] [CrossRef]
- Miao, P.; Srimahachota, T. Cost-effective system for detection and quantification of concrete surface cracks by combination of convolutional neural network and image processing techniques. Constr. Build. Mater. 2021, 293, 123549. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Nie, M.; Wang, K. Pavement Distress Detection Based on Transfer Learning. In Proceedings of the 2018 5th International Conference on Systems and Informatics (ICSAI), Nanjing, China, 10–12 November 2018; pp. 435–439. [Google Scholar]
- Pei, L.; Shi, L.; Sun, Z.; Li, W.; Gao, Y.; Chen, Y. Detecting potholes in asphalt pavement under small-sample conditions based on improved faster region-based convolution neural networks. Can. J. Civ. Eng. 2022, 49, 265–273. [Google Scholar] [CrossRef]
- Song, L.; Wang, X. Faster region convolutional neural network for automated pavement distress detection. Road Mater. Pavement Des. 2021, 22, 23–41. [Google Scholar] [CrossRef]
- Cao, X.G.; Gu, Y.F.; Bai, X.Z. Detecting of foreign object debris on airfield pavement using convolution neural network. In Proceedings of the LIDAR Imaging Detection and Target Recognition 2017, Changchun, China, 23–25 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhu, J.; Zhong, J.; Ma, T.; Huang, X.; Zhang, W.; Zhou, Y. Pavement distress detection using convolutional neural networks with images captured via UAV. Autom. Constr. 2022, 133, 103991. [Google Scholar] [CrossRef]
- Liu, Z.; Gu, X.; Yang, H.; Wang, L.; Chen, Y.; Wang, D. Novel YOLOv3 Model With Structure and Hyperparameter Optimization for Detection of Pavement Concealed Cracks in GPR Images. IEEE Trans. Intell. Transp. Syst. 2022, 1–11. [Google Scholar] [CrossRef]
- Liu, Z.; Yuan, L.; Zhu, M.; Ma, S.; Chen, L. YOLOv3 Traffic sign Detection based on SPP and Improved FPN. Comput. Eng. Appl. 2021, 57, 164–170. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Tan, Y.; Cai, R.; Li, J.; Chen, P.; Wang, M. Automatic detection of sewer defects based on improved you only look once algorithm. Autom. Constr. 2021, 131, 103912. [Google Scholar] [CrossRef]
- Cao, Y.; Zhou, Y. Multi-Channel Fusion Leakage Detection. J. Cyber Secur. 2020, 5, 40–52. [Google Scholar]
- Guo, T.W.; Lu, K.; Chai, X.; Zhong, Y. Wool and Cashmere Images Identification Based on Deep Learning. In Proceedings of the Textile Bioengi-neering and Informatics Symposium (TBIS), Manchester, UK, 25–28 July 2018; pp. 950–956. [Google Scholar]
- Tzutalin. LabelImg. Git Code. 2015. Available online: https://github.com/tzutalin/labelImg (accessed on 5 October 2015).
- Xue, J.; Xu, H.; Yang, H.; Wang, B.; Wu, P.; Choi, J.; Cai, L.; Wu, Y. Multi-Feature Enhanced Building Change Detection Based on Semantic Information Guidance. Remote Sens. 2021, 13, 4171. [Google Scholar] [CrossRef]
- Du, Z.; Yuan, J.; Xiao, F.; Hettiarachchi, C. Application of image technology on pavement distress detection: A review. Measurement 2021, 184, 109900. [Google Scholar] [CrossRef]
- Liu, Z.; Gu, X.; Wu, W.; Zou, X.; Dong, Q.; Wang, L. GPR-based detection of internal cracks in asphalt pavement: A combination method of DeepAugment data and object detection. Measurement 2022, 197, 111281. [Google Scholar] [CrossRef]
- Lae, S.; Narasimhadhan, A.V.; Kumar, R. Automatic Method for Contrast Enhancement of Natural Color Images. J. Electr. Eng. Technol. 2015, 10, 1233–1243. [Google Scholar] [CrossRef][Green Version]
- Xie, Y.; Wu, Y.; Wang, Y.; Zhao, X.; Wang, A. Light field all-in-focus image fusion based on wavelet domain sharpness evaluation. J. Beijing Univ. Aeronaut. Astronaut. 2019, 45, 1848–1854. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Huang, Z.; Zhao, H.; Zhan, J.; Li, H. A multivariate intersection over union of SiamRPN network for visual tracking. Vis. Comput. 2021, 38, 2739–2750. [Google Scholar] [CrossRef]
- Ji, S.; Du, T.; Deng, S.; Cheng, P.; Shi, J.; Yang, M.; Li, B. Robustness Certification Research on Deep Learning Models: A Survey. Chin. J. Comput. 2022, 45, 190–206. [Google Scholar]
- Hou, J.; Zeng, H.; Cai, L.; Zhu, J.; Chen, J. Random occlusion assisted deep representation learning for vehicle re-identification. Control. Theory Appl. 2018, 35, 1725–1730. [Google Scholar]
- Wang, W.; Gao, S.; Zhou, J.; Yan, Y. Research on Denoising Algorithm for Salt and Pepper Noise. J. Data Acquis. Processing 2015, 30, 1091–1098. [Google Scholar]
- Kindler, G.; Kirshner, N.; O’Donnell, R. Gaussian noise sensitivity and Fourier tails. Isr. J. Math. 2018, 225, 71–109. [Google Scholar] [CrossRef]
- Tong, Z.; Xu, P.; Denœux, T. Evidential fully convolutional network for semantic segmentation. Appl. Intell. 2021, 51, 6376–6399. [Google Scholar] [CrossRef]
- Guo, C.; Pleiss, G.; Sun, Y.; Weinberger, K.Q. On Calibration of Modern Neural Networks. arXiv 2017, arXiv:1706.04599. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2015, arXiv:1512.02325. [Google Scholar]
- Maeda, H.; Kashiyama, T.; Sekimoto, Y.; Seto, T.; Omata, H. Generative adversarial network for road damage detection. Comput. Aided Civ. Infrastruct. Eng. 2021, 36, 47–60. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Camera Features | Details | Camera Features | Details |
|---|---|---|---|
| Type | Basler raL2048-80km | Power supply requirements (typical value) | 3 W |
| Interface | Camera Link | Type of light-sensitive chips | CMOS |
| Resolution ratio | 3854 px × 2065 px | Size of light-sensitive chips | 14.3 mm |
| Dataset | Training Dataset | Validation Dataset | Testing Dataset |
|---|---|---|---|
| Image with potholes | 480 | 160 | 160 |
| Image without potholes | 720 | 240 | 240 |
| Total | 1200 | 400 | 400 |
| Pre-Processing Steps | Original Image | Color Transformation (Contrast Adjustment) | Geometric Transformation (Data Augmentation) | ||||
|---|---|---|---|---|---|---|---|
| Contrast | Sharpness | Rotating 90° Anticlockwise | Rotating 90° Clockwise | Rotating 180° | Random Crop | ||
| Potholes with water |  |  |  |  |  |  |  |
| Potholes without water |  |  |  |  |  |  |  |
| Network | Layer Name | Output Size | Parameters |
|---|---|---|---|
| ResNet101 | conv1 | 512 × 512 × 3 | conv, 7 × 7 × 64, stride 2 |
| conv2 | 256 × 256 × 64 | >max pool, 3 × 3, stride 2 bottleneck: 1 × 1 | |
| conv3 | 128 × 128 × 256 | bottleneck: 1 × 1 | |
| conv4 | 64 × 64 × 512 | bottleneck: 1 × 1 | |
| conv5 | 32 × 32 × 1024 | bottleneck: 1 × 1 | |
| YOLOv3 | Y1 | 32 × 32 × 1024 | 3 anchors |
| Y2 | 64 × 64 × 512 | 3 anchors | |
| Y3 | 128 × 128 × 256 | 3 anchors |
| Detection Scale | Anchor Size | ||
|---|---|---|---|
| Scale 1: 32 × 32 | (176, 312) | (335, 247) | (285, 362) |
| Scale 2: 64 × 64 | (126, 236) | (285.5, 132) | (213, 201) |
| Scale 3: 128 × 128 | (34, 35) | (72, 79) | (149, 126) |
| Hyperparameters | Value |
|---|---|
| Batch size | 2 |
| Epochs | 100 |
| Learning rate | 0.00125 |
| Weight decay | L2 |
| Optimizer | Momentum |
| Momentum | 0.9 |
| Evaluation Indices | P | R | mAP | F1 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P1 | P2 | Total | P1 | P2 | Total | P1 | P2 | Total | P1 | P2 | Total | |
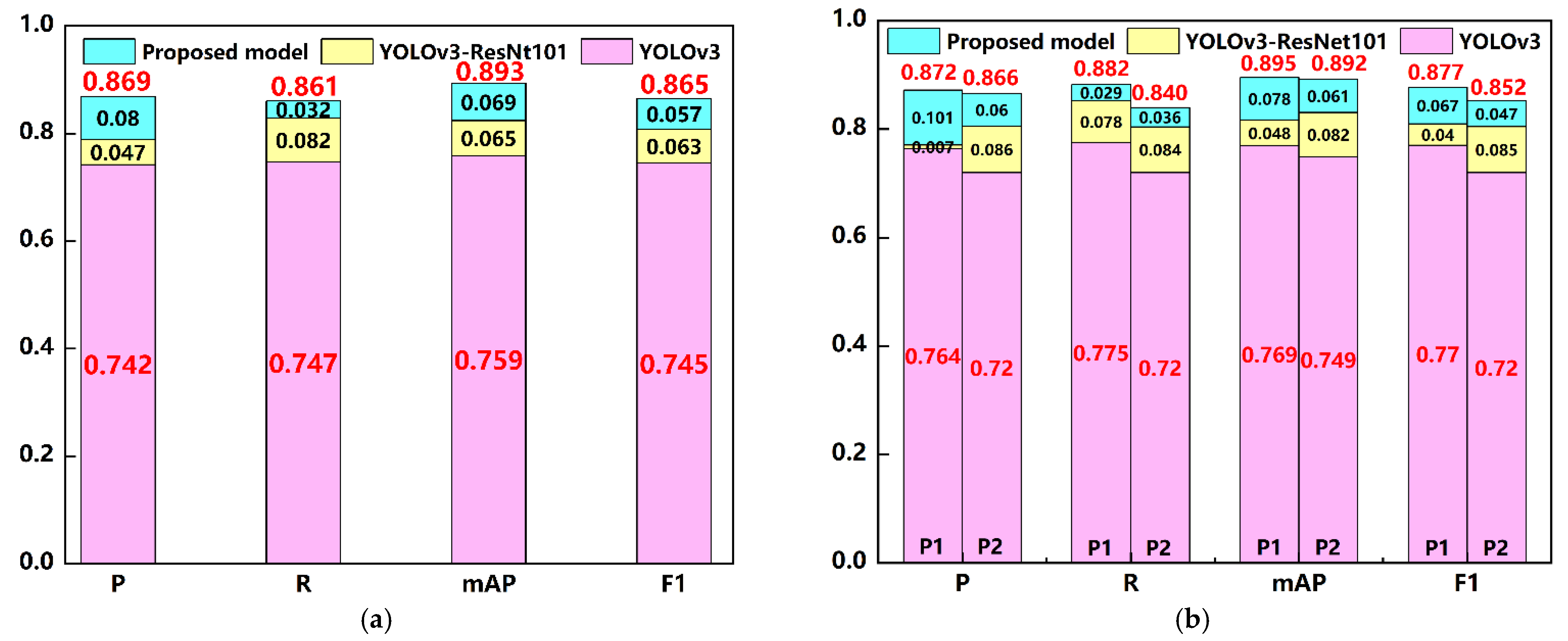
| YOLOv3 | 0.734 | 0.677 | 0.705 | 0.742 | 0.693 | 0.718 | 0.749 | 0.704 | 0.727 | 0.737 | 0.685 | 0.711 |
| YOLOv3 (aug) | 0.764 | 0.720 | 0.742 | 0.775 | 0.720 | 0.747 | 0.771 | 0.749 | 0.760 | 0.769 | 0.720 | 0.744 |
| Proposed model | 0.802 | 0.784 | 0.793 | 0.830 | 0.773 | 0.801 | 0.853 | 0.838 | 0.845 | 0.816 | 0.780 | 0.798 |
| Proposed model (aug) | 0.872 | 0.866 | 0.869 | 0.882 | 0.840 | 0.861 | 0.895 | 0.892 | 0.893 | 0.877 | 0.852 | 0.865 |
| Evaluation Indices | Faster R-CNN [49] | Cascade R-CNN [50] | SSD [51] | YOLOv3–DarkNet53 [26] | YOLOv3–ResNet101 | Proposed Model | |
|---|---|---|---|---|---|---|---|
| P | P1 | 0.807 | 0.800 | 0.747 | 0.764 | 0.771 | 0.872 |
| P2 | 0.817 | 0.804 | 0.751 | 0.720 | 0.806 | 0.866 | |
| Total | 0.812 | 0.802 | 0.749 | 0.742 | 0.789 | 0.869 | |
| R | P1 | 0.793 | 0.794 | 0.733 | 0.775 | 0.853 | 0.882 |
| P2 | 0.822 | 0.810 | 0.738 | 0.720 | 0.804 | 0.840 | |
| Total | 0.807 | 0.802 | 0.736 | 0.747 | 0.829 | 0.861 | |
| mAP | P1 | 0.825 | 0.797 | 0.798 | 0.769 | 0.817 | 0.895 |
| P2 | 0.814 | 0.805 | 0.751 | 0.749 | 0.831 | 0.892 | |
| Total | 0.819 | 0.801 | 0.775 | 0.759 | 0.824 | 0.893 | |
| F1 | P1 | 0.798 | 0.831 | 0.742 | 0.770 | 0.810 | 0.877 |
| P2 | 0.800 | 0.803 | 0.744 | 0.720 | 0.805 | 0.852 | |
| Total | 0.799 | 0.817 | 0.743 | 0.745 | 0.808 | 0.865 | |
| AP50 | 0.819 | 0.801 | 0.775 | 0.759 | 0.824 | 0.893 | |
| AP75 | 0.744 | 0.763 | 0.685 | 0.625 | 0.750 | 0.841 | |
| AP90 | 0.782 | 0.783 | 0.730 | 0.692 | 0.784 | 0.867 | |
| Evaluation Indices | IoU50 | IoU75 | IoU90 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P1 | P2 | Total | P1 | P2 | Total | P1 | P2 | Total | |
| P | 0.788 | 0.793 | 0.790 | 0.733 | 0.738 | 0.736 | 0.275 | 0.277 | 0.276 |
| R | 0.763 | 0.802 | 0.783 | 0.718 | 0.746 | 0.732 | 0.266 | 0.248 | 0.257 |
| mAP | 0.810 | 0.814 | 0.812 | 0.764 | 0.773 | 0.769 | 0.211 | 0.325 | 0.268 |
| F1 | 0.775 | 0.797 | 0.786 | 0.737 | 0.743 | 0.740 | 0.240 | 0.238 | 0.239 |
| Labels | Original Images | Proposed Model | Proposed Model (Random Occlusion) | Proposed Model (Salt-and-Pepper Noise Attacked) | Proposed Model (Gaussian Noise Attacked) |
|---|---|---|---|---|---|
| P1 (pothole with water) |  |  |  |  |  |
 |  |  |  |  | |
| P2 (pothole without water) |  |  |  |  |  |
 |  |  |  |  |
| Original image |  |  |  |  |  |
| Detection results of the proposed model |  |  |  |  |  |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.; Liu, Z.; Gu, X.; Wu, W.; Chen, Y.; Wang, L. Automatic Detection of Pothole Distress in Asphalt Pavement Using Improved Convolutional Neural Networks. Remote Sens. 2022, 14, 3892. https://doi.org/10.3390/rs14163892
Wang D, Liu Z, Gu X, Wu W, Chen Y, Wang L. Automatic Detection of Pothole Distress in Asphalt Pavement Using Improved Convolutional Neural Networks. Remote Sensing. 2022; 14(16):3892. https://doi.org/10.3390/rs14163892
Chicago/Turabian StyleWang, Danyu, Zhen Liu, Xingyu Gu, Wenxiu Wu, Yihan Chen, and Lutai Wang. 2022. "Automatic Detection of Pothole Distress in Asphalt Pavement Using Improved Convolutional Neural Networks" Remote Sensing 14, no. 16: 3892. https://doi.org/10.3390/rs14163892
APA StyleWang, D., Liu, Z., Gu, X., Wu, W., Chen, Y., & Wang, L. (2022). Automatic Detection of Pothole Distress in Asphalt Pavement Using Improved Convolutional Neural Networks. Remote Sensing, 14(16), 3892. https://doi.org/10.3390/rs14163892