
Research on Uncertainty of Landslide Susceptibility Prediction—Bibliometrics and Knowledge Graph Analysis

 ,
,  , , , ,
, , , ,  , ,
, , 
Abstract

1. Introduction
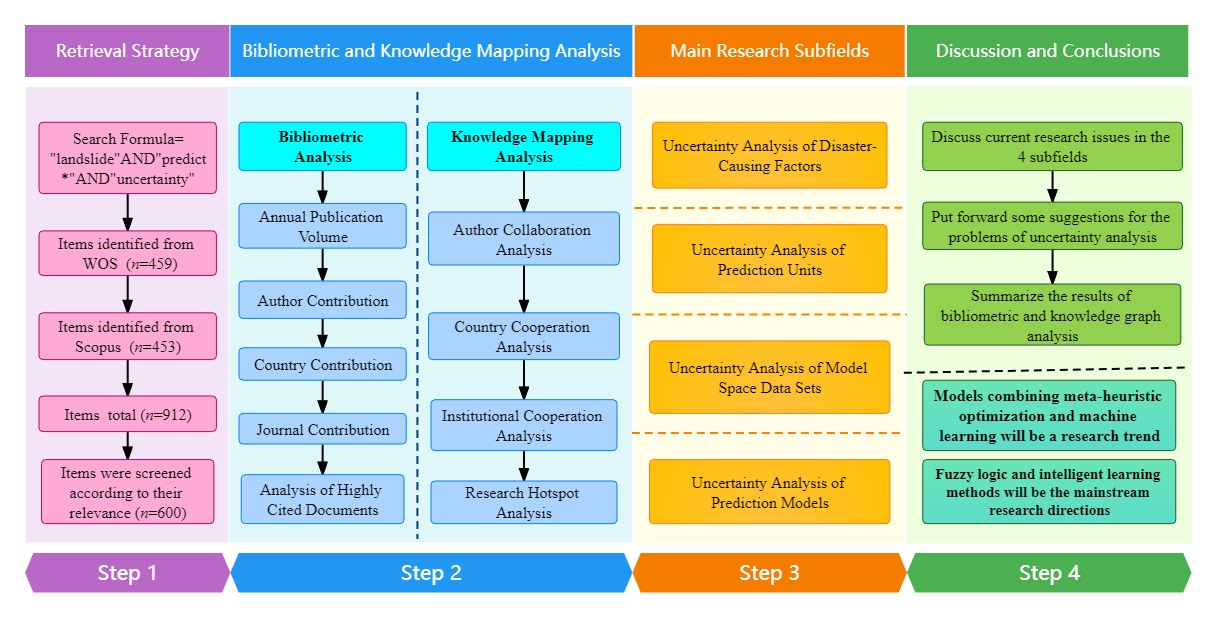
2. Data Sources and Analysis Methods
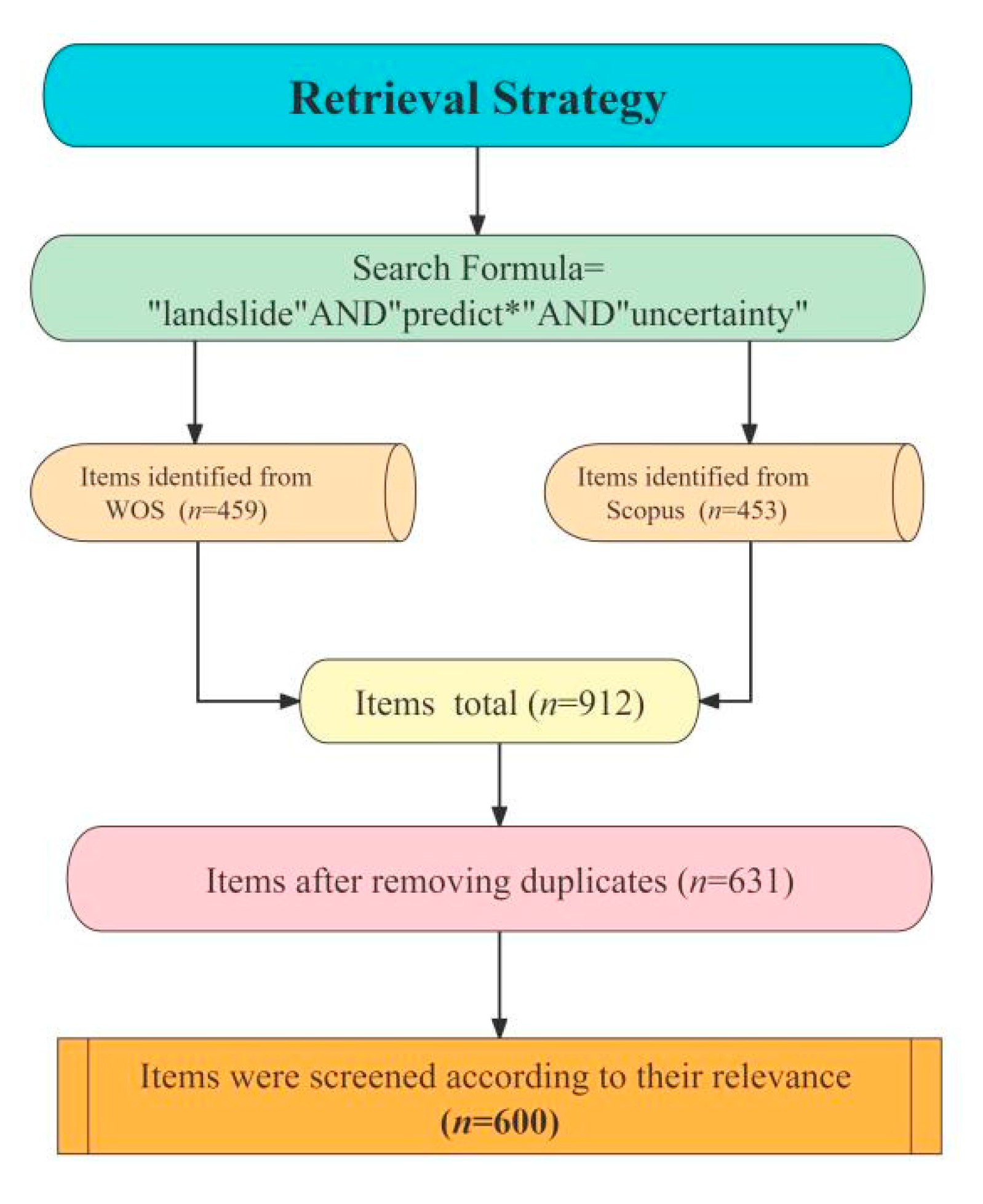
2.1. Retrieval Strategy and Data Collation
- Unified format: The text data format (*.ris, *.txt) and table data format (*.xls, *.csv) were adopted for download, respectively. Endnote mainly uses the data in *.ris format for document browsing and reference management, and it is also convenient for VOSviewer software to make bibliometric analyses and visual analyses. The files in *.txt format were named download_w459.txt (from WOS) and download_s453.txt (from Scopus). The synonyms were merged, and wrong words were corrected for knowledge mapping analysis by Citespace. The two data formats of *.xls and *.csv were unified as *.xls to prepare for the next step of data collation, de-duplication, and screening.
- Collation and de-duplication: In these two platforms, all original data were downloaded to the Excel spreadsheet in the way of the full record, were de-duplicated according to the title and DOI after being combined into a file, were extracted according to the year, author, title, publication type, journal source, number of citations, keywords, and other information, and then sorted by the publication type as the first column.
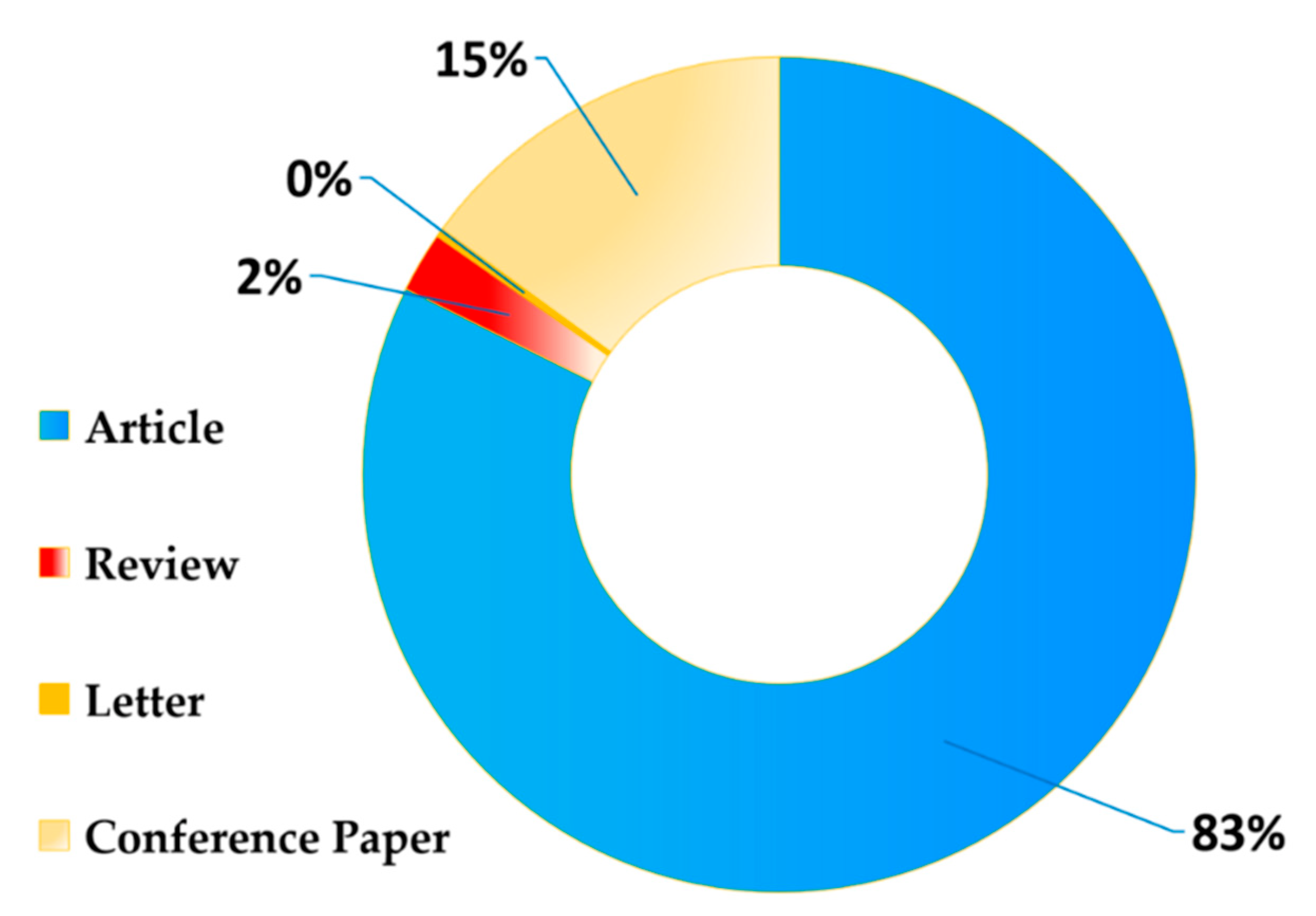
- Item-by-item screening: Manual screening was carried out item by item according to the publication type of the documents, and only the documents with peer review and editor’s supervision were retained. The types of these documents include articles, reviews, letters, and conference papers. The editorial material, book chapter, and other documents that were weakly correlated with this paper were removed. After identification and iteration, some wrong records were deleted to finally obtain 600 valid documents. The typical document characteristics are shown in Table 1.
2.2. Analysis Method
3. Results
3.1. Bibliometric Analysis
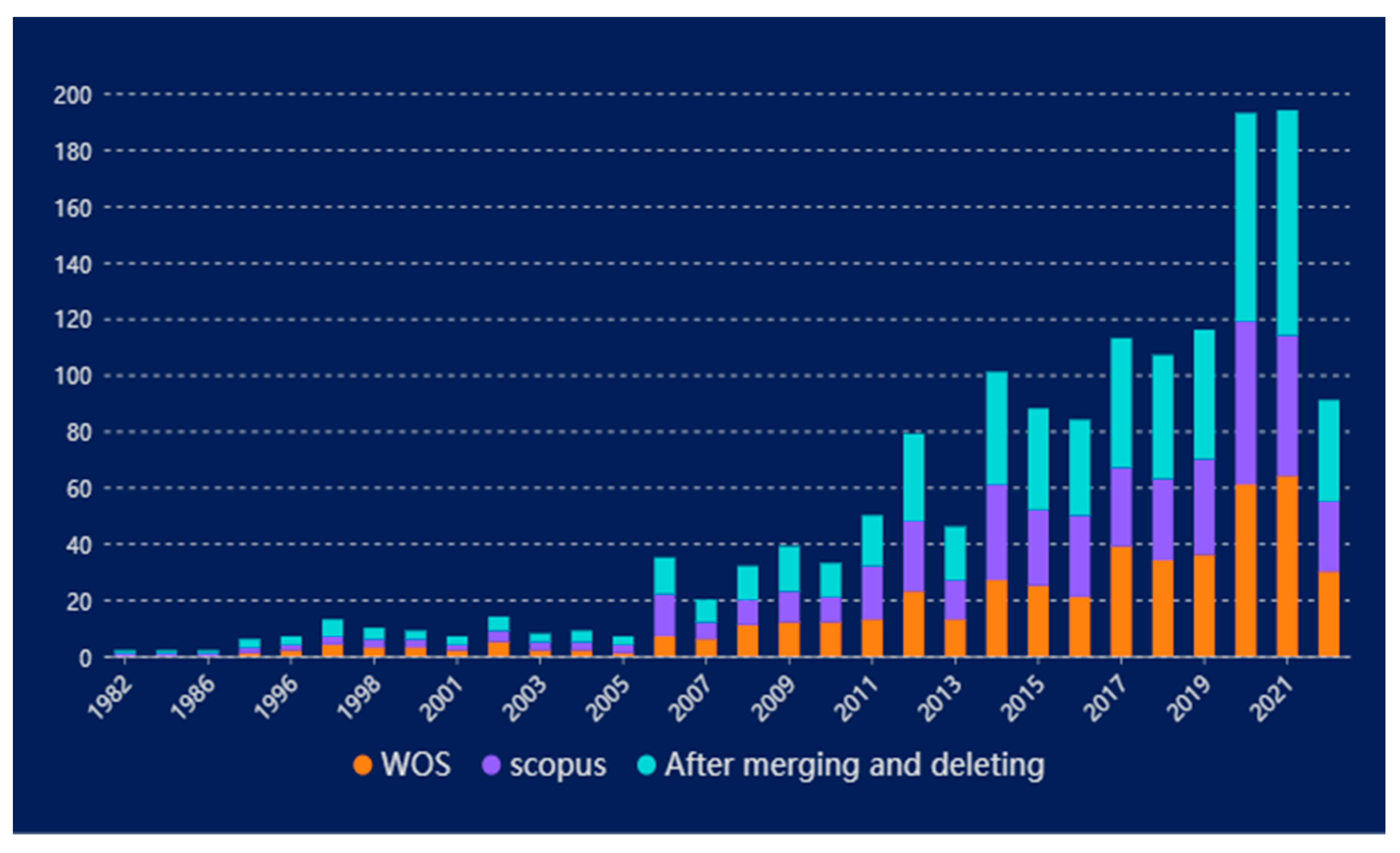
3.1.1. Statistics of Documents Publication Time
- (1)
- Different start times of tracking: Scopus collected the probability assessment published by Atkinson, G.M. et al. on modeling and predicting landslides due to the possibility of liquefaction and overstress caused by earthquakes from 1982 [53], while WOS collected the investigation of BUISSON, L. et al. on the application of artificial intelligence (AI) technology to environmental protection in France from 1992 [54]. This investigation first showed that landslide prevention data could be embedded into artificial intelligence systems.
- (2)
- Different distribution of the number of annual documents published: The years when the data on the WOS platform were more than those on the Scopus platform include 1997, 2002, 2008–2010, and 2017–2022. The years when the data on the Scopus platform were more than those on the WOS platform include 1982, 1985, 1986, 1992, 2003–2006, and 2011–2016. The two platforms have the same number of documents published in other years.
- (3)
- Different collection processes: The collection time of the Scopus platform is earlier than that of the WOS platform, and the number of documents published in most of the early years on the Scopus platform is more than that on the WOS platform. However, in recent years, WOS has focused more on this field and will continue to strengthen its tracking in this field in the future (seen from the trend of documents published). Therefore, the statistics of document publication time show that the research data in this field shall be downloaded from the two document platforms to make the data more comprehensive. The document sample database established based on this is more reasonable and effective.

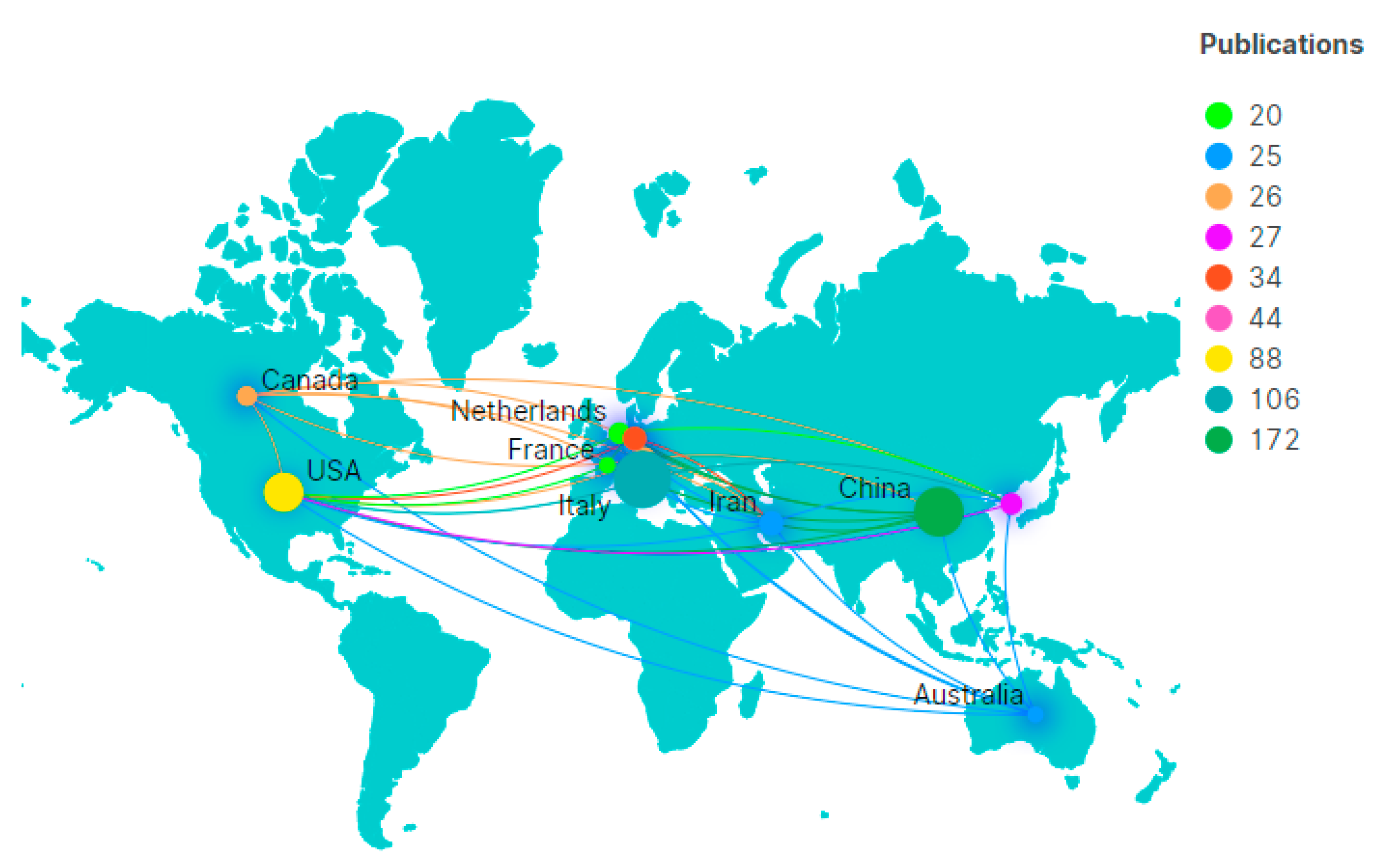
3.1.2. Contribution Analysis
3.1.3. Analysis of Highly Cited Documents
3.2. Knowledge Mapping Analysis
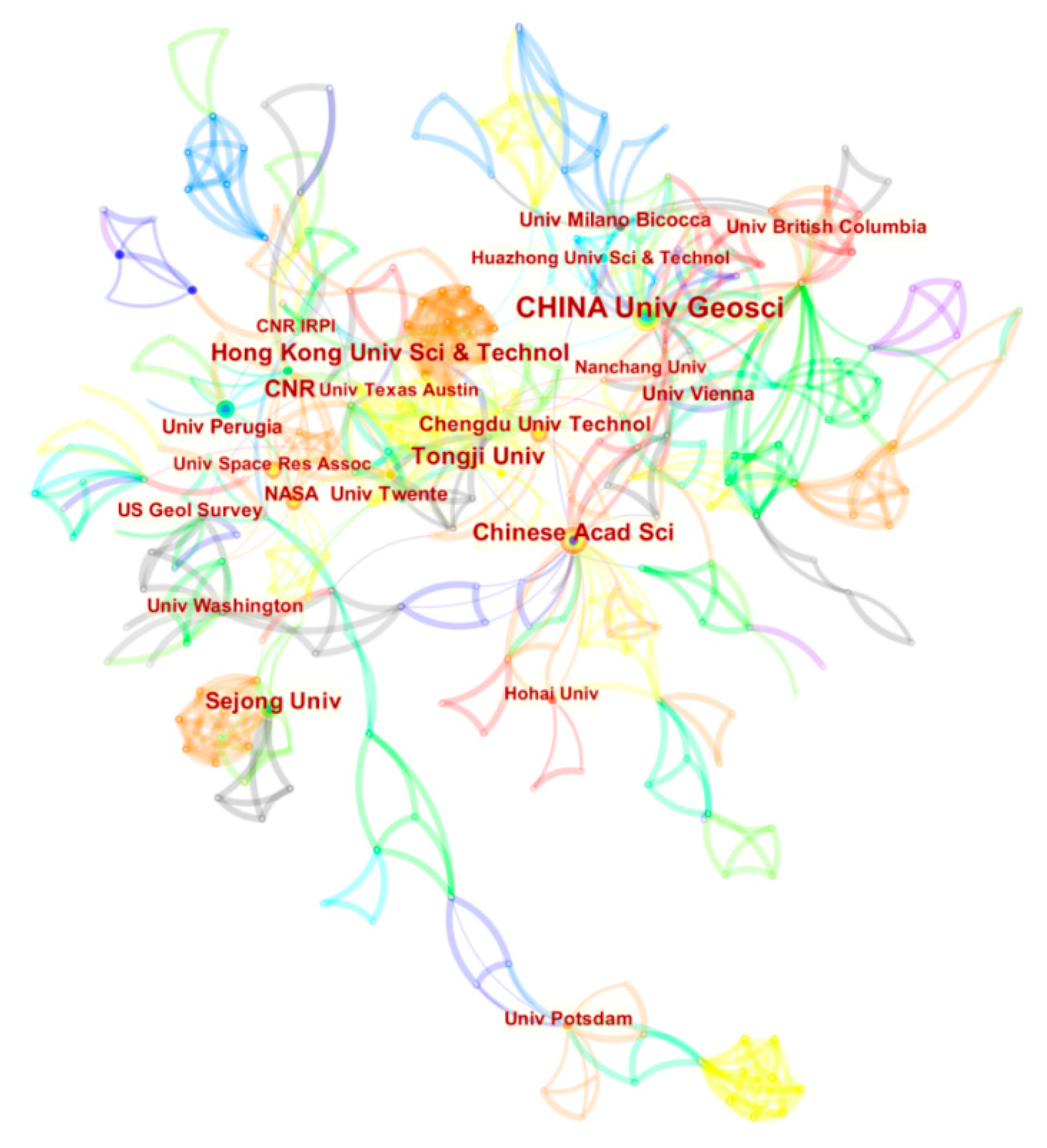
3.2.1. Analysis of Scientific Research Cooperation
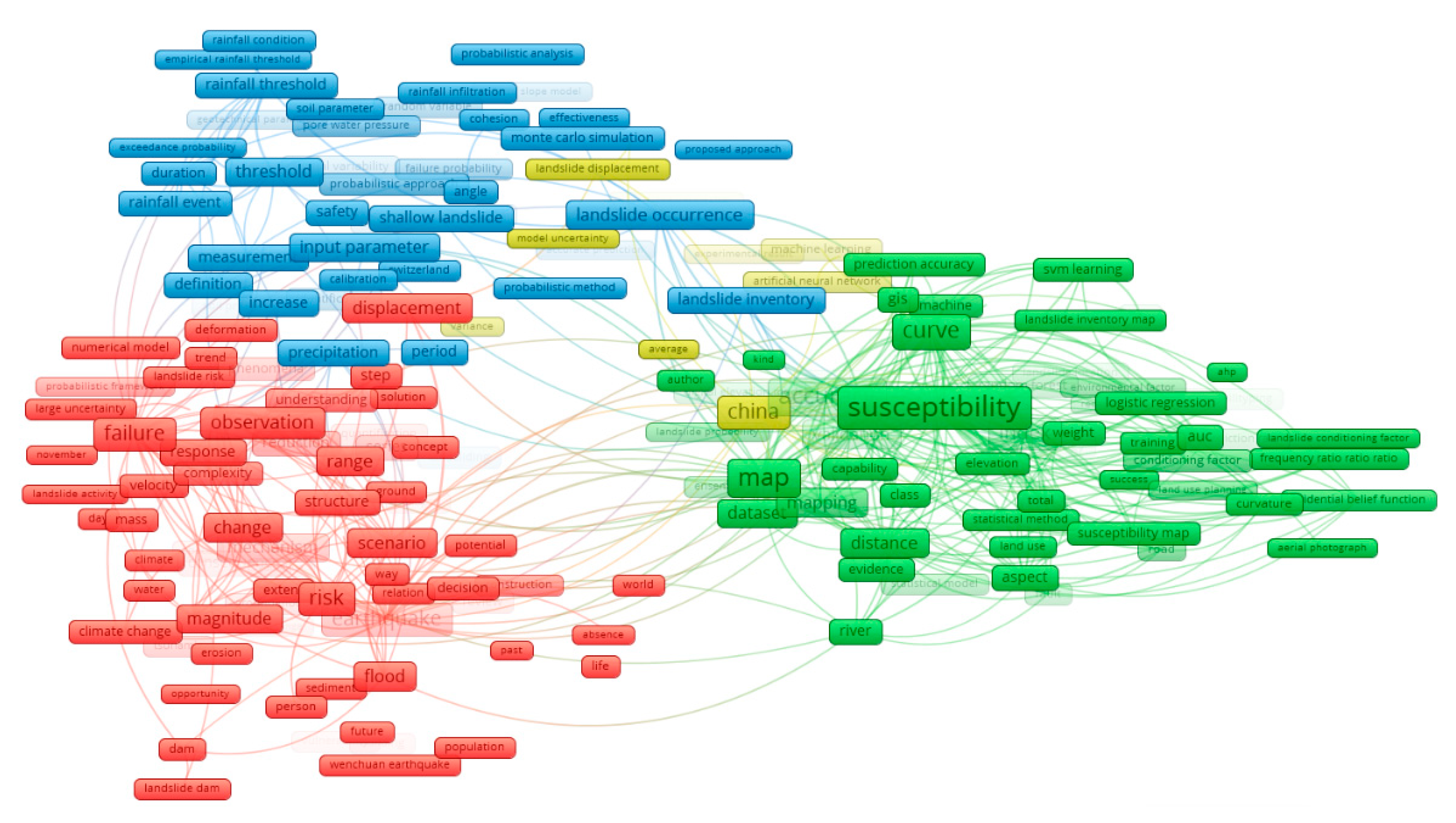
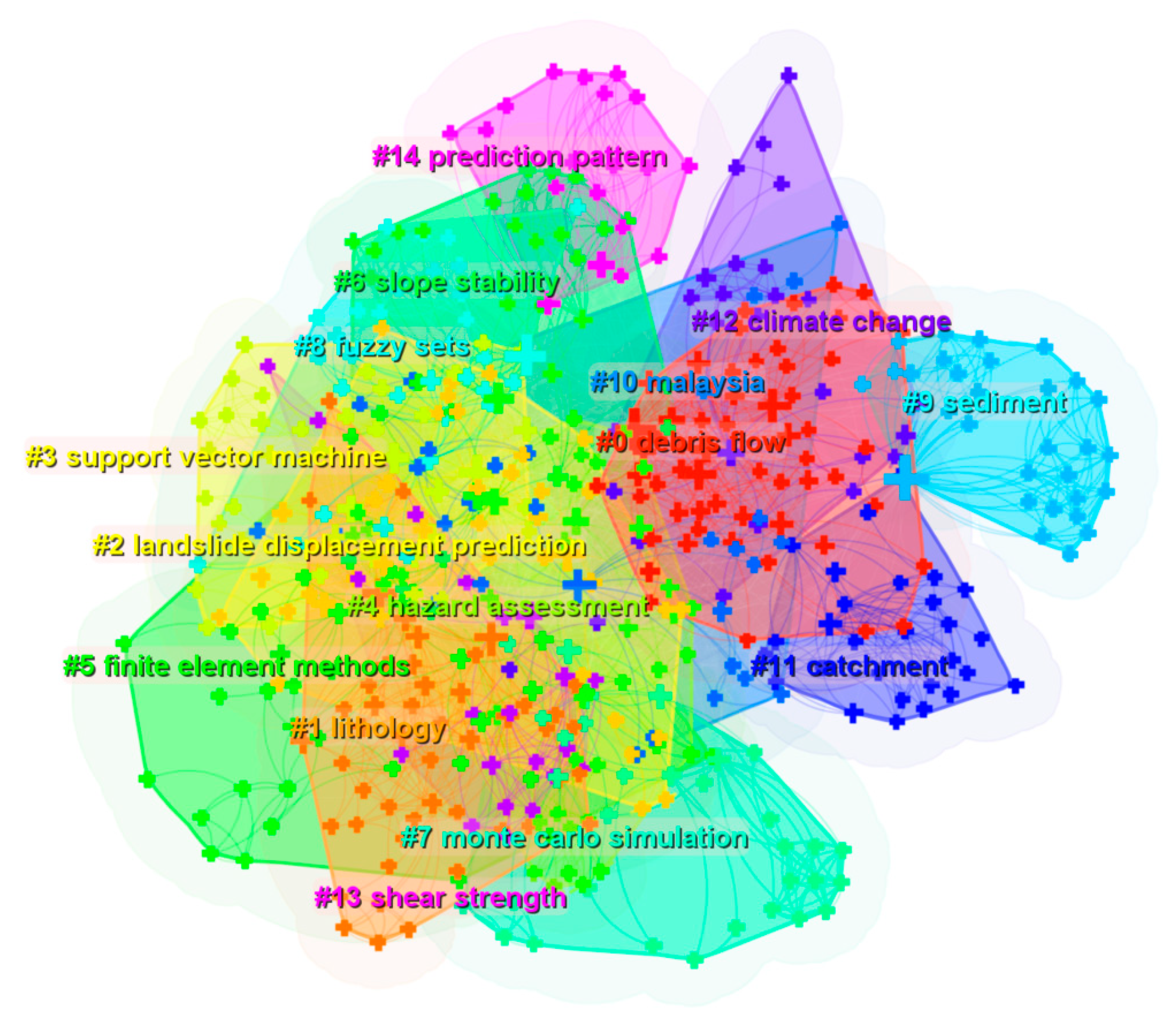
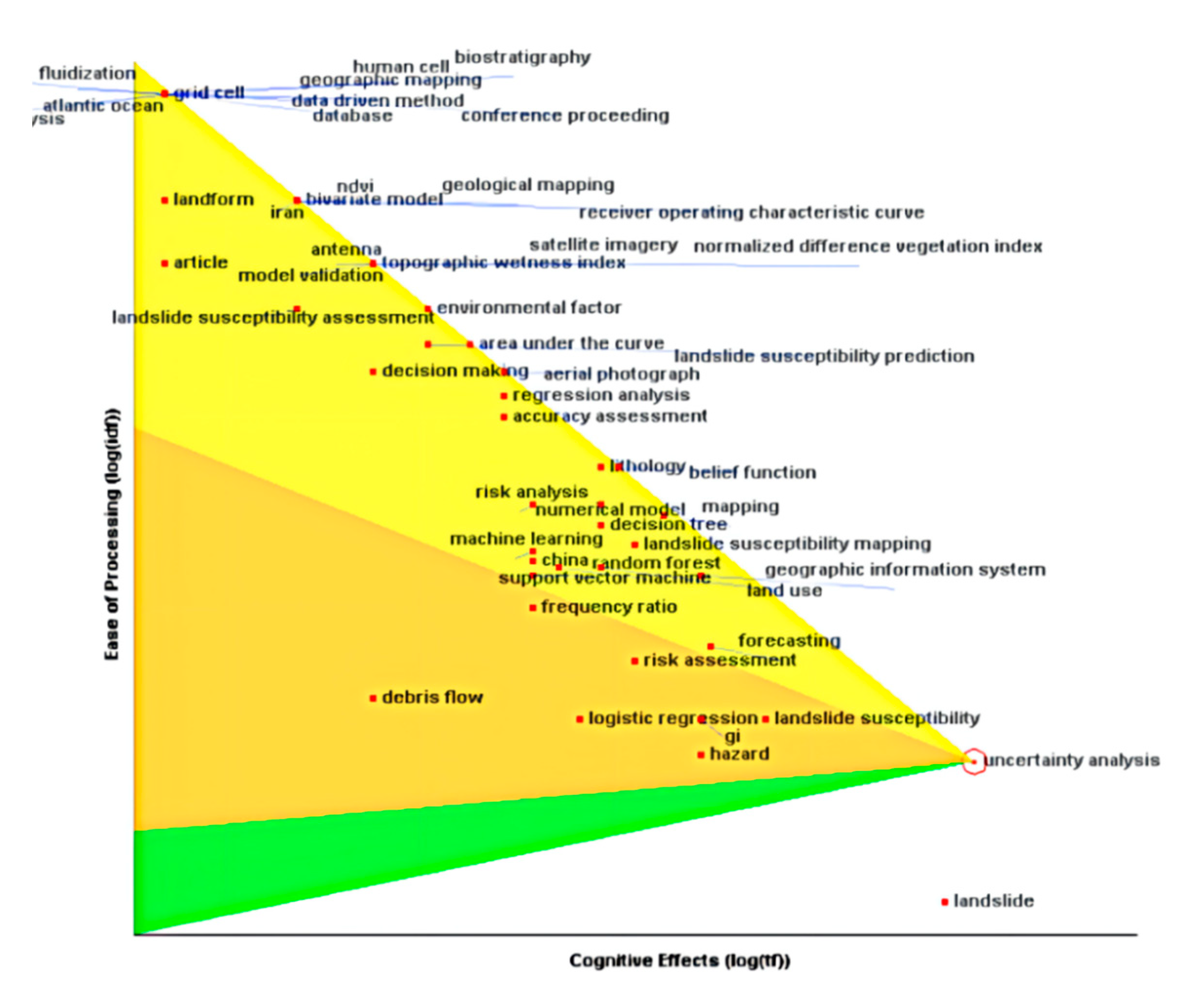
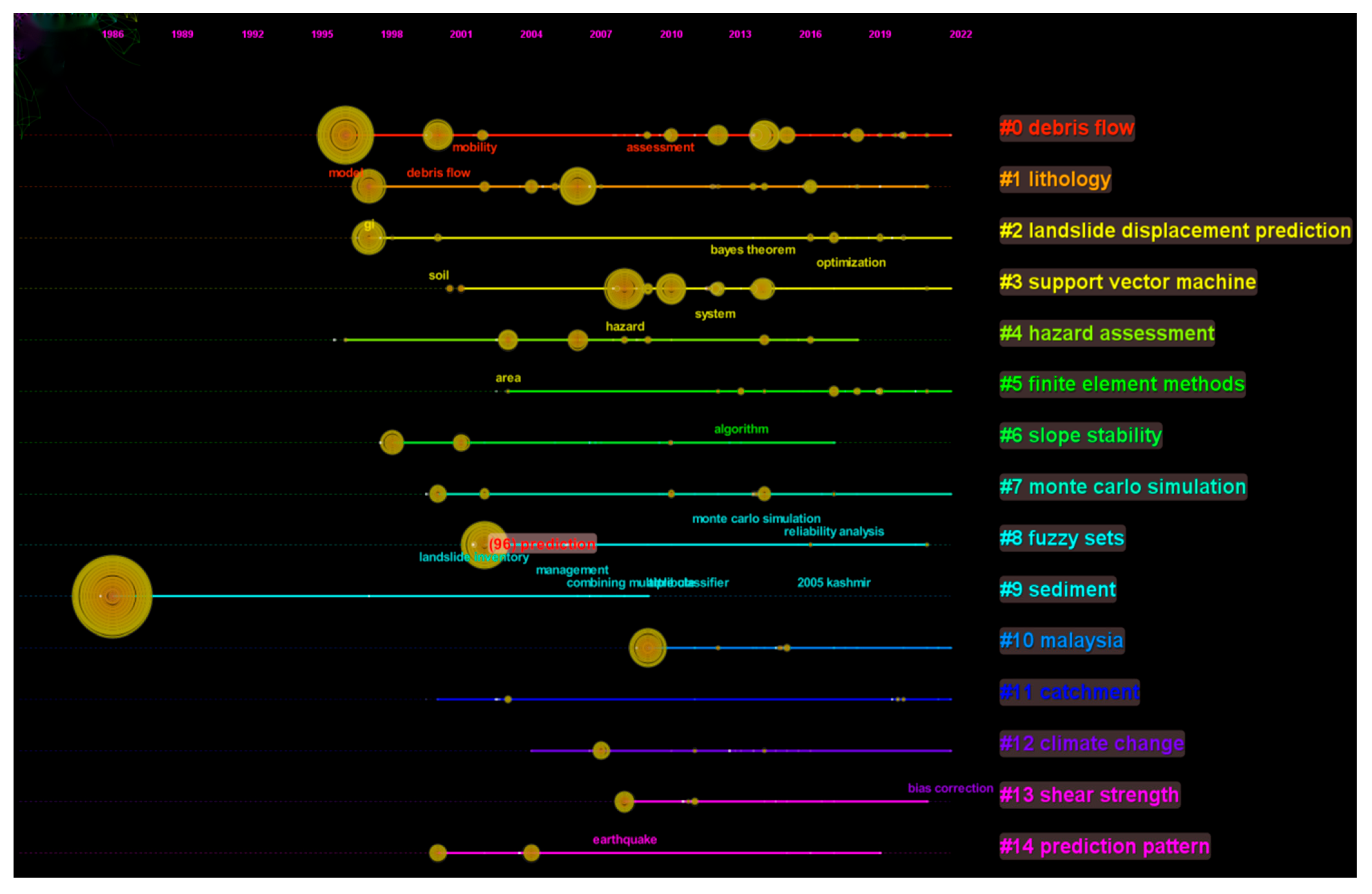
3.2.2. Analysis of Research Hotspots
- (1)
- Research on disaster-causing factors. It is composed of clusters #0 debris flow, #1 lithology, #6 slope stability, #9 sediment, #12 climate change, and #13 shear strength. Many factors cause landslides. The analysis results of the cluster map (Figure 10) show that the influencing factors of debris flow, underlying surface structure, and rainfall are the research hotspots.
- (2)
- Research on prediction units. It is composed of clusters #2 landslide displacement prediction, #10 malaysia, and #11 catchment. A representative document in cluster #2 landslide displacement prediction was published by Aydin, A. in 2006 [70], which suggests that landslide-prone slopes should be investigated on site to reduce the uncertainty of delimiting the boundary of the research zone. The three documents involving cluster #10 malaysia mainly introduce the slope failure data analysis [71] and modeling framework [72], and they reveal the uncertainty of probability prediction [73]. Although there are few documents related to this cluster, these documents were published in the past two years, indicating that this cluster’s research content is a current hot research topic. Furthermore, by retrieving the abstracts of documents in the document sample database, it was found that 43 records are directly related to cluster #11 catchment, which shows that catchment is undoubtedly a hot topic of current research.
- (3)
- Research on data sets. It comprises clusters #4 hazard assessment and #8 fuzzy sets. From the number of groups, it can be seen that there are few research contents related to data sets. However, this does not mean scholars do not care about the topic. On the contrary, it reflects the lack of landslide data.
- (4)
- Research on prediction models. It comprises clusters #3 support vector machine, #5 finite element methods, #7 Monte Carlo simulation, and #14 prediction pattern. In addition to the cluster #14 prediction pattern, the other three cluster numbers related to the prediction models are highly ranked. Figure 10 intuitively shows that the three cluster color blocks cover a large area, indicating that the landslide susceptibility prediction models have attracted much attention. There are many landslide prediction models that can be selected, but it can be found that the three models of support vector machine, finite element methods, and Monte Carlo simulation are the most popular uncertainty analysis models for landslide susceptibility prediction at present.

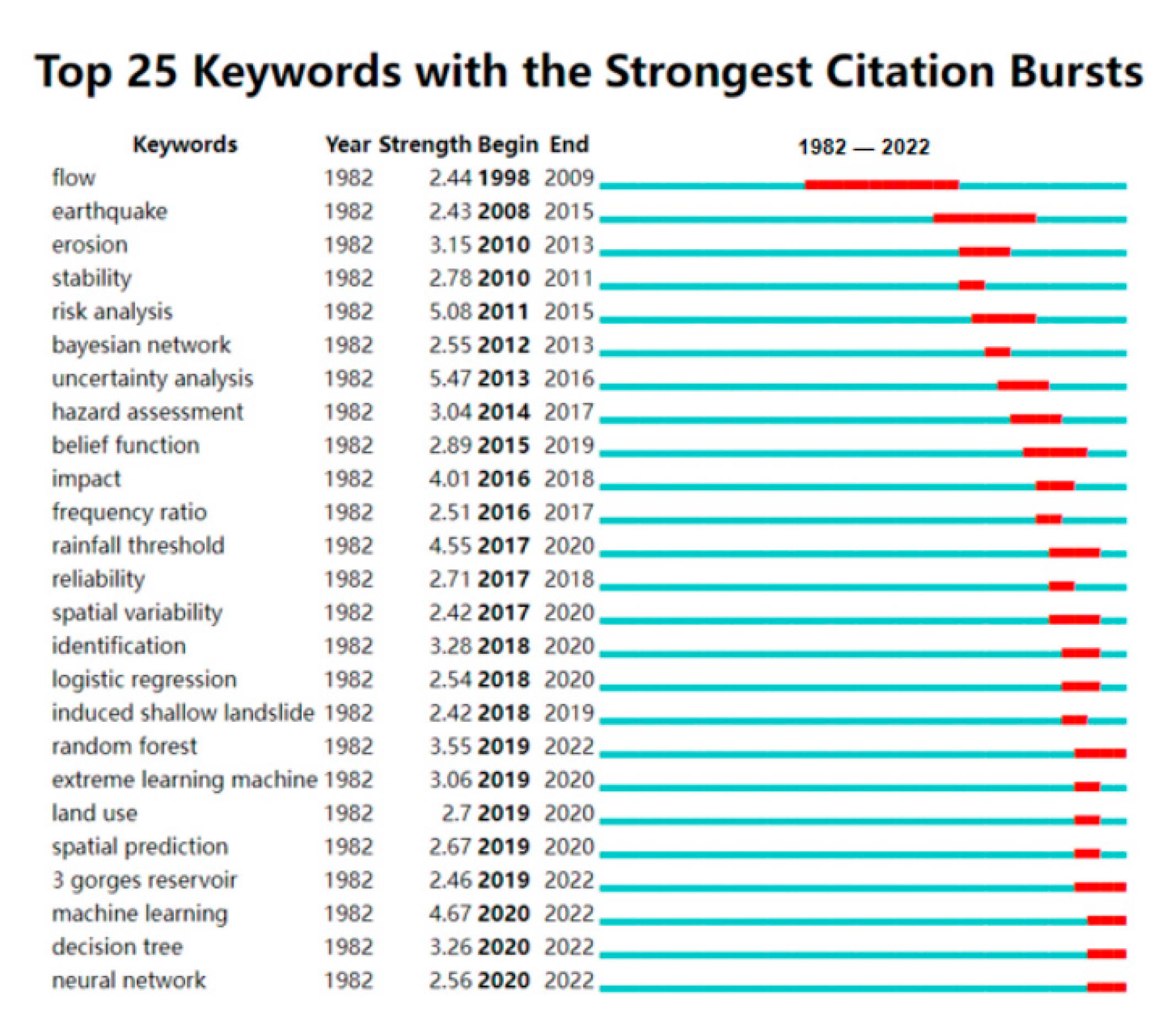
3.2.3. Analysis of Frontier Trend
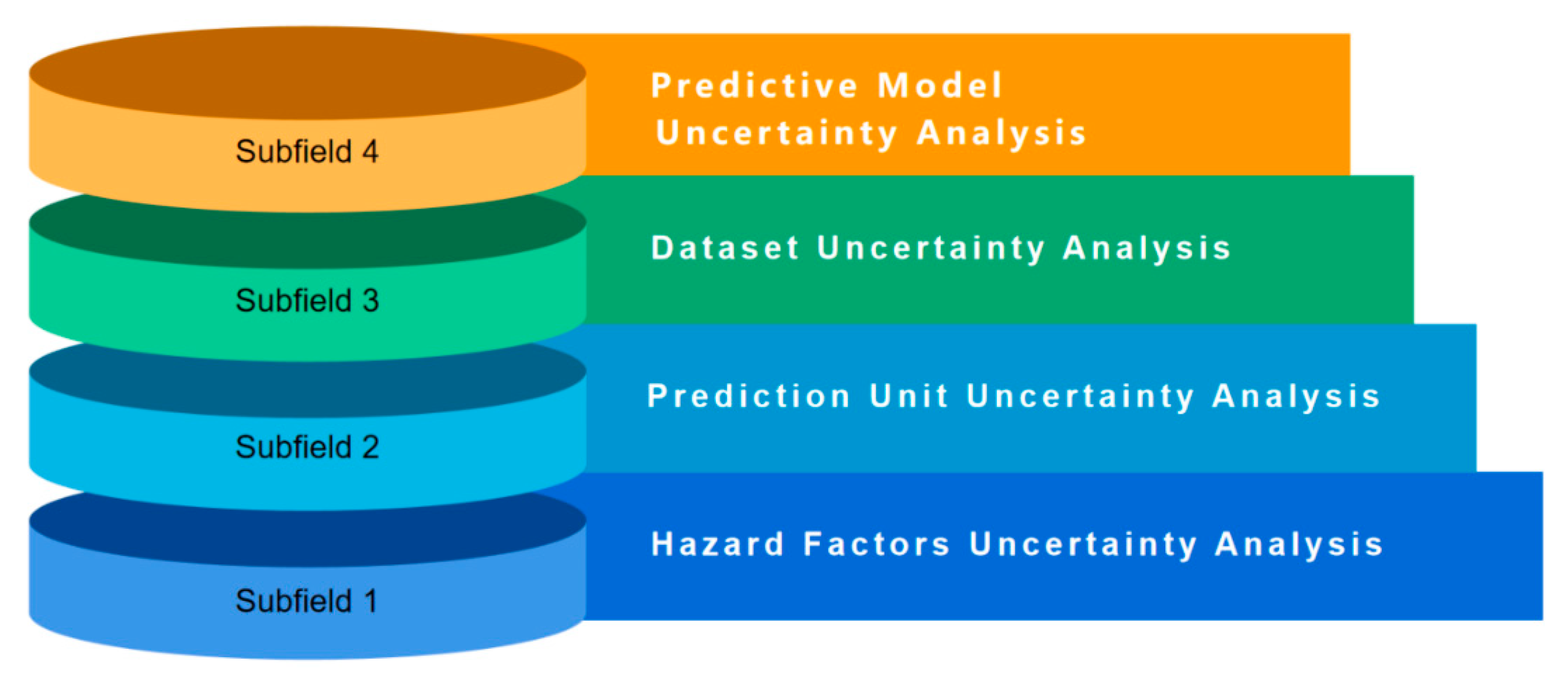
4. Main Research Subfields
- (1)
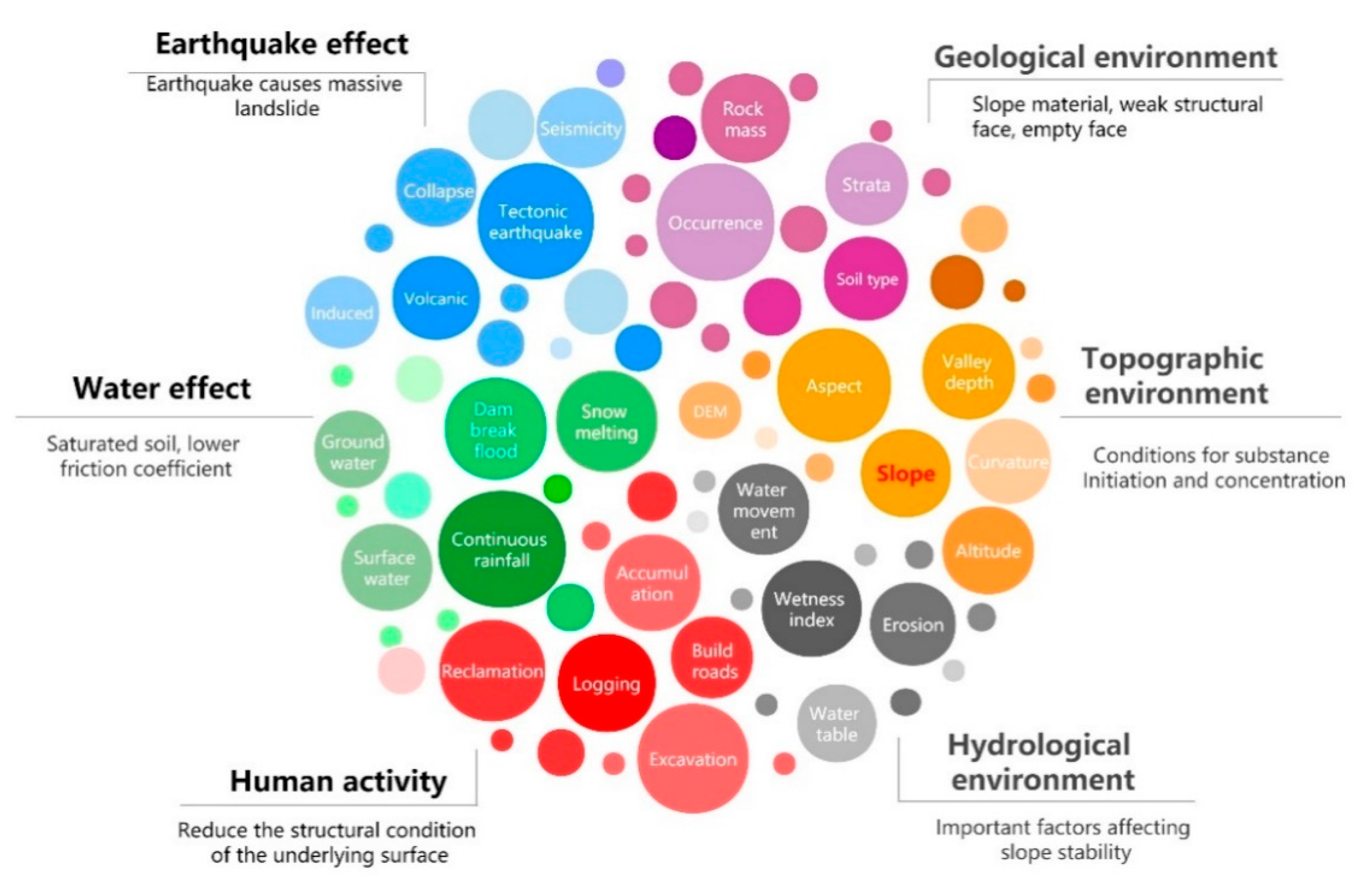
- Regarding objective factors, the landslide system is influenced by random conditions and processes. The internal conditions cause the influence, external factors, and the interaction of internal and external factors that constitute the landslide system. When the landslide disaster prediction models are built, the data used often come from a small number of the known and observable key influencing factors, but a large number of information that is unknown or difficult to obtain is not taken into account, which makes the landslide prediction model only approximate to the actual situation in essence and increases the uncertainty of the models [81].
- (2)
- In terms of the influence of subjective factors, the process of building landslide prediction models is easily influenced and interfered with by the subjective factor of the human cognitive level and the lack of accurate understanding of the prediction unit, data set selection, and model determination of landslide prediction models will inevitably greatly increase the uncertainty of the model [82].
4.1. Uncertainty Analysis of Disaster-Causing Factors
4.2. Uncertainty Analysis of Prediction Units
4.3. Uncertainty Analysis of Model Space Data Sets
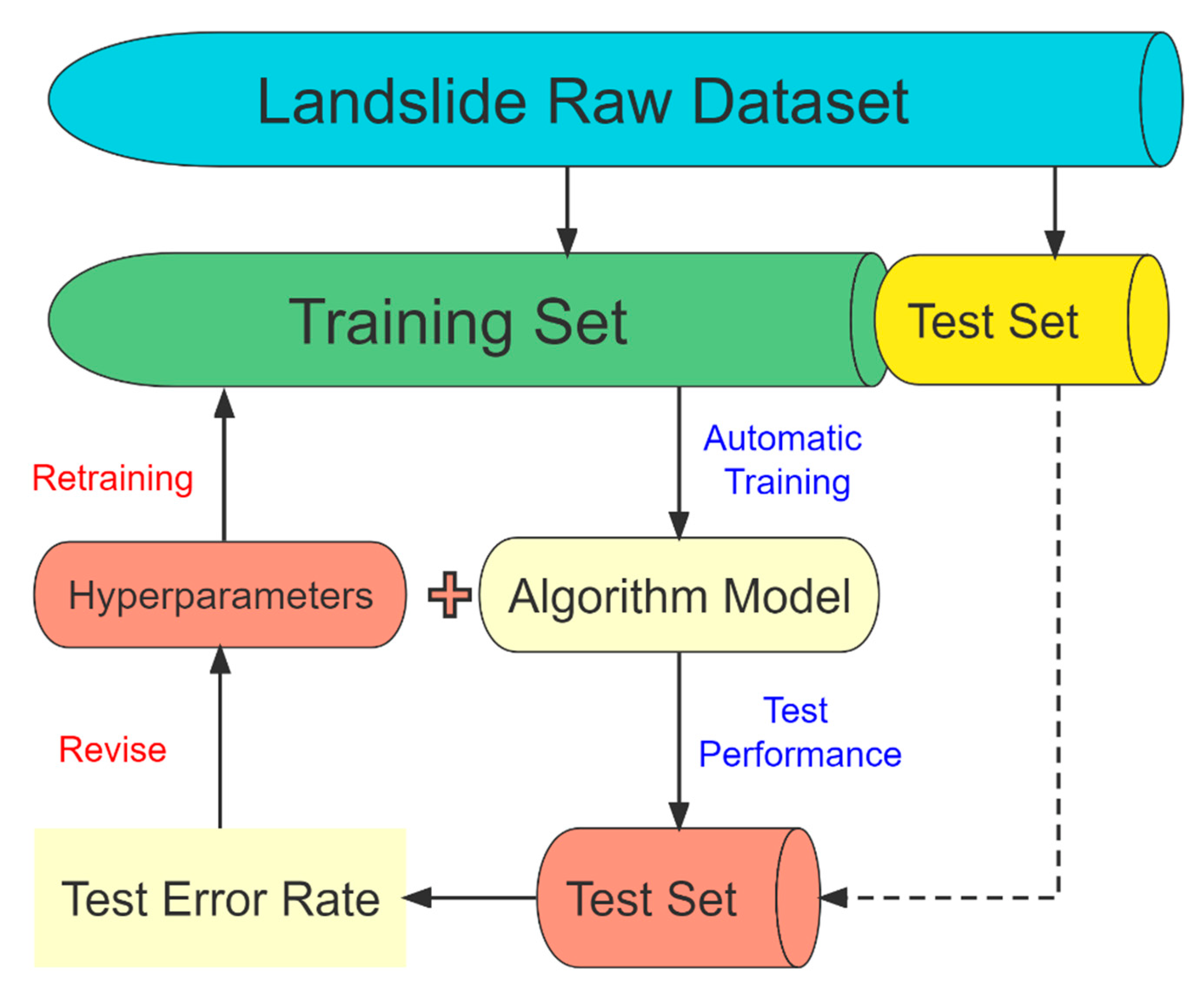
4.4. Uncertainty Analysis of Prediction Models
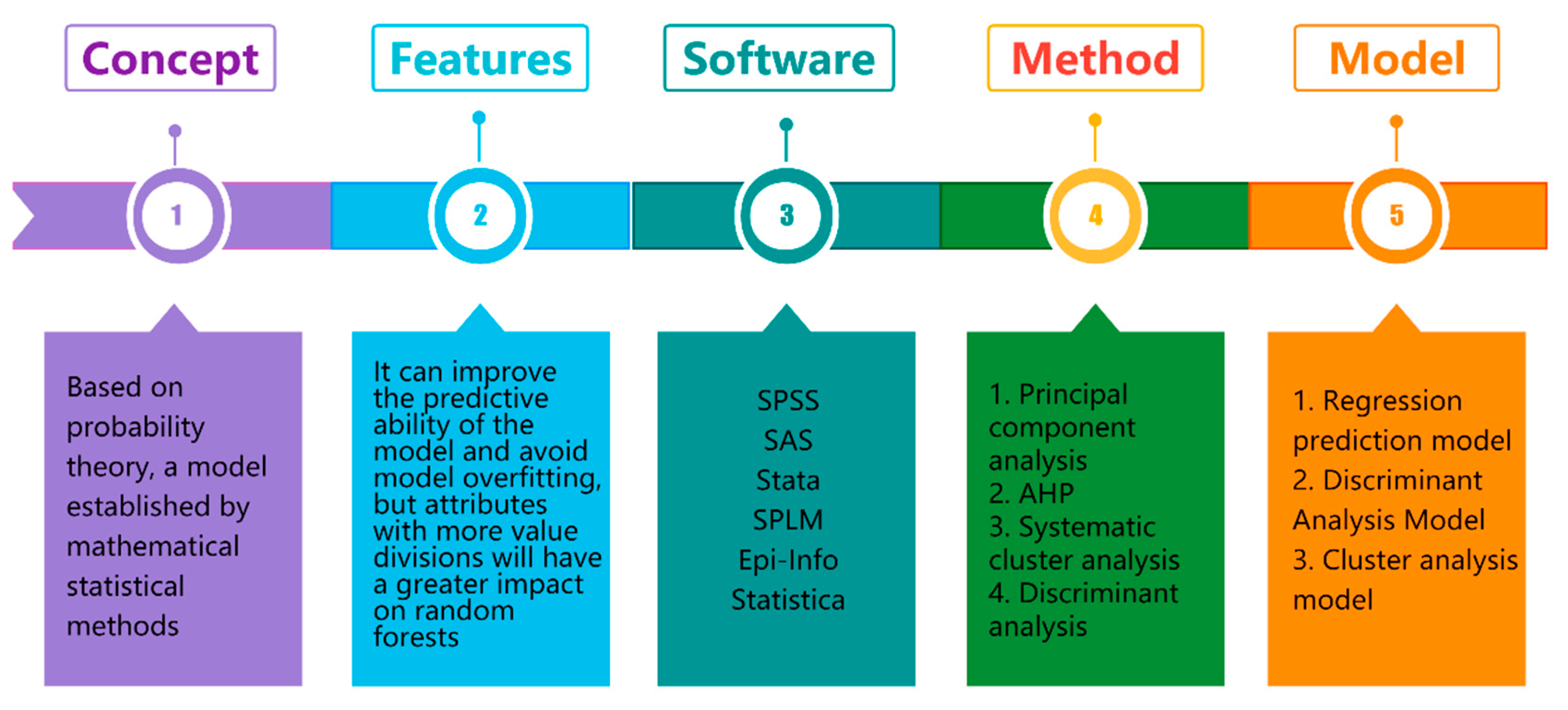
4.4.1. Statistical Model
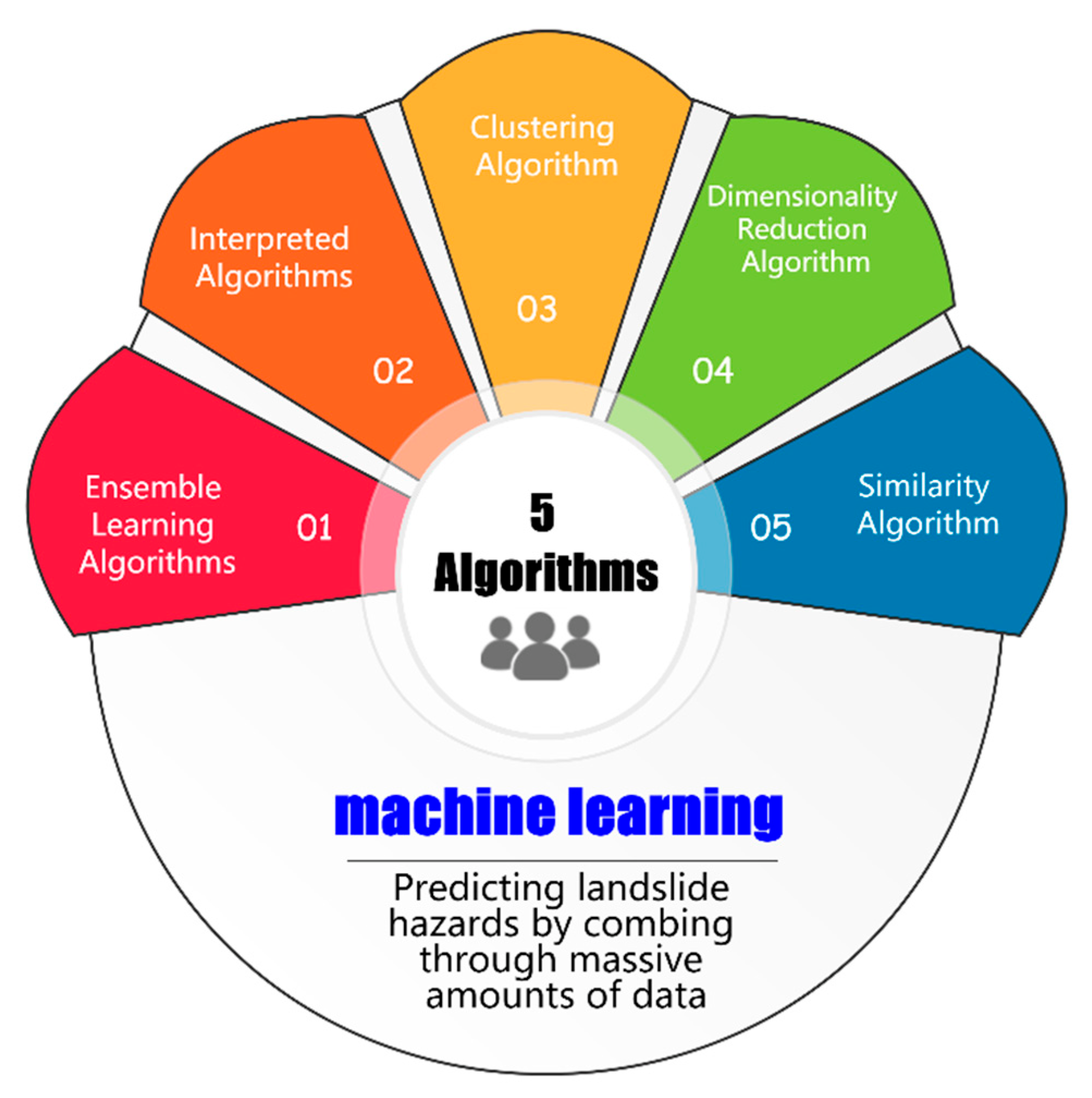
4.4.2. Pattern Recognition Model
- (1)
- The ensemble learning algorithm is mainly used in regression and classification or supervised learning problems. Due to its inherent properties, the ensemble learning algorithm is superior to all traditional machine learning algorithms, including Naïve Bayes, SVM, and decision tree.
- (2)
- Interpretation algorithm: It can identify and understand variables with statistically significant results. Therefore, instead of creating models to predict landslide disasters, it is better to develop interpretative models to understand the relationship between variables in the landslide disaster prediction models, including the SHAP algorithm and LIME algorithm.
- (3)
- Clustering algorithm: It is an unsupervised learning task used for clustering analysis, which usually groups the data into clusters. Unlike the known target variables of supervised learning, there are traditionally no target variables in a clustering analysis. A clustering algorithm can be used to find natural patterns and trends of landslide displacement data. It includes K-means clustering and hierarchical clustering.
- (4)
- Dimension reduction algorithm: It is a technology used to reduce the number of input variables (or characteristic variables) in the data set. With the increase in dimension (the number of input variables), the volume of spatial data of the landslide model increases exponentially, which eventually leads to the sparse data of main control factors for landslide prediction. It includes the principal component analysis (PCA) and linear discriminant analysis (LDA).
- (5)
- Similarity algorithm: It refers to those algorithms used to calculate the similarity of records/nodes/data points/text pairs and includes the similarity algorithm for comparing the distance between two data points (such as Euclidean distance) and the similarity algorithm for calculating text similarity (such as the Levenshtein algorithm).
5. Discussion
6. Conclusions
- (1)
- In terms of the number of a document published, the research on the uncertainty of landslide susceptibility prediction shows an increasing trend, which can be divided into the rise stage of research (1982–2005), the apparent growth stage (2006–2016), and the vigorous development stage (2017–2022) (Figure 2).
- (2)
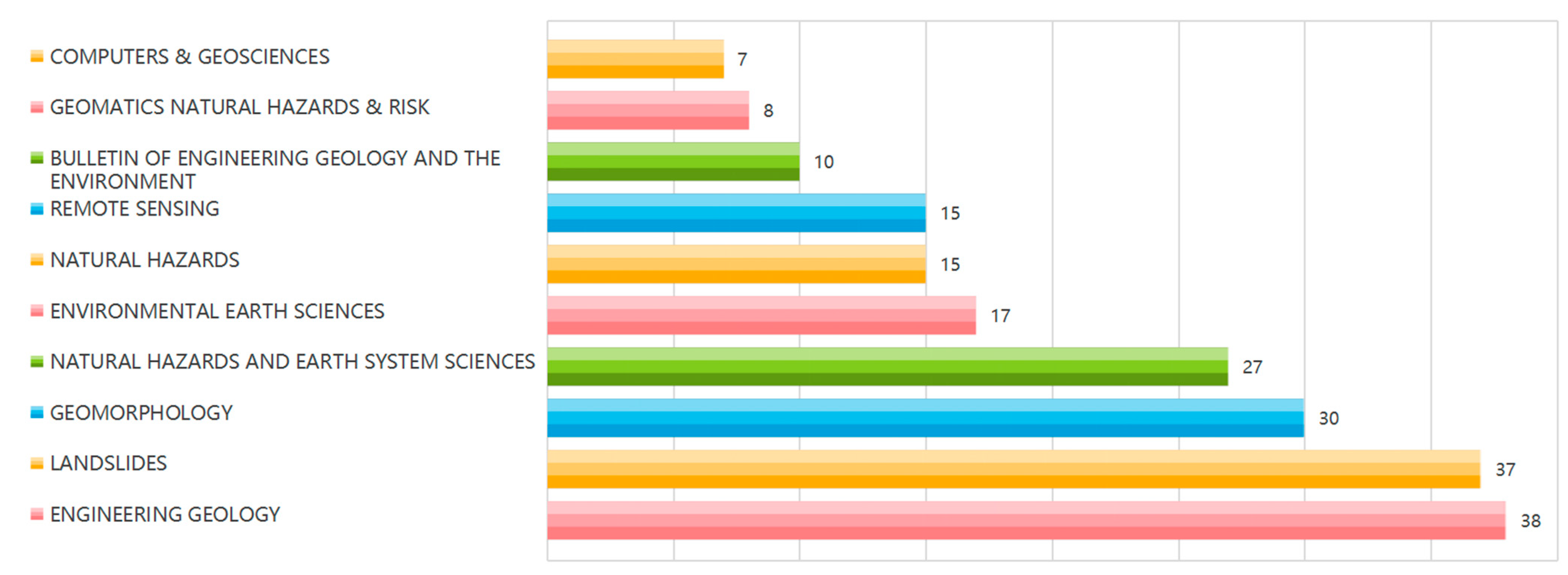
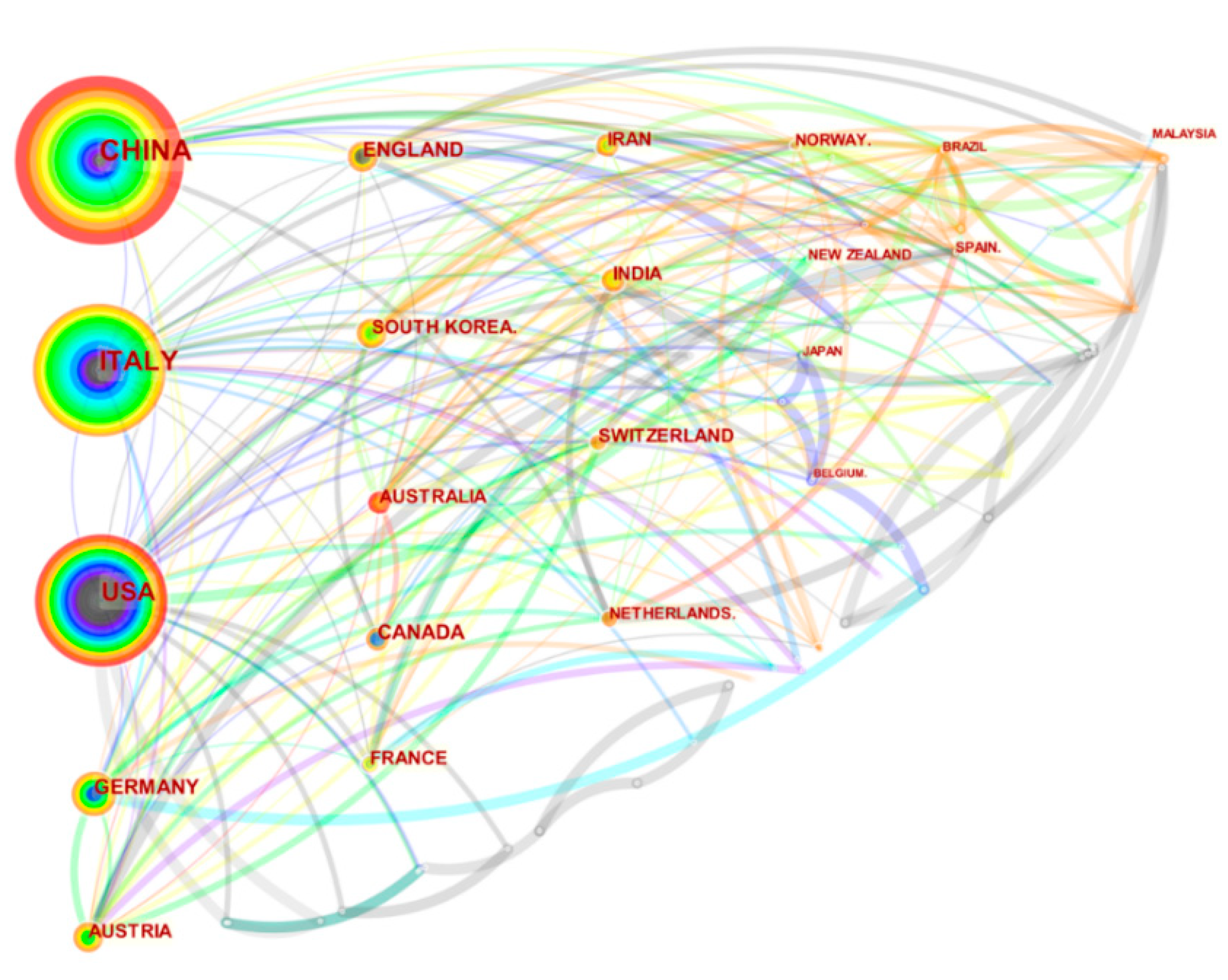
- From the contribution analysis, it was found that Guzzetti F team has the highest number of documents published, and the documents they published are the most authoritative (Table 2); the three most influential countries in this field are China, Italy, and the United States (Figure 3); documents and journals came from a variety of sources, among which ENGINEERING GEOLOGY, LANDSLIDES, and GEOMORPHOLOGY have the largest number of publications (Figure 4).
- (3)
- Through the analysis of research hotspots and development trends, the influencing factors of debris flow, underlying surface structure, and rainfall are the research hotspots, and random forest, machine learning, and neural networks are the frontier research trends in the future.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Basharat, M.; Riaz, M.T.; Jan, M.Q.; Xu, C.; Riaz, S. A review of landslides related to the 2005 Kashmir Earthquake: Implication and future challenges. Nat. Hazards 2021, 108, 1–30. [Google Scholar] [CrossRef]
- Culler, E.S.; Badger, A.M.; Minear, J.T.; Tiampo, K.F.; Zeigler, S.D.; Livneh, B. A multi-sensor evaluation of precipitation uncertainty for landslide-triggering storm events. Hydrol. Process. 2021, 35, e14260. [Google Scholar] [CrossRef] [PubMed]
- Salinas-Jasso, J.A.; Velasco-Tapia, F.; Navarro de León, I.; Salinas-Jasso, R.A.; Alva-Niño, E. Estimation of rainfall thresholds for shallow landslides in the Sierra Madre Oriental, northeastern Mexico. J. Mt. Sci. 2020, 17, 1565–1580. [Google Scholar] [CrossRef]
- Croissant, T.; Lague, D.; Davy, P.; Davies, T.; Steer, P. A precipiton-based approach to model hydro-sedimentary hazards induced by large sediment supplies in alluvial fans. Earth Surf. Processes Landf. 2017, 42, 2054–2067. [Google Scholar] [CrossRef]
- Li, B.V.; Jenkins, C.N.; Xu, W. Strategic protection of landslide vulnerable mountains for biodiversity conservation under land-cover and climate change impacts. Proc. Natl. Acad. Sci. USA 2022, 119, e2113416118. [Google Scholar] [CrossRef] [PubMed]
- Løvholt, F.; Pedersen, G.; Harbitz, C.B.; Glimsdal, S.; Kim, J. On the characteristics of landslide tsunamis. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2015, 373, 20140376. [Google Scholar] [CrossRef] [PubMed]
- Samia, J.; Temme, A.; Bregt, A.; Wallinga, J.; Guzzetti, F.; Ardizzone, F.; Rossi, M. Do landslides follow landslides? Insights in path dependency from a multi-temporal landslide inventory. Landslides 2017, 14, 547–558. [Google Scholar] [CrossRef]
- Lu, J.; Hu, S.; Niu, Z.; You, R. The Application of Fuzzy Comprehensive Evaluation Model in Landslide Prediction. In Proceedings of the 2010 3rd International Conference on Information Management, Innovation Management and Industrial Engineering, Kunming, China, 26-28 November 2010; Volume 4, pp. 612–615. [Google Scholar]
- Tonini, M.; Pecoraro, G.; Romailler, K.; Calvello, M. Spatio-temporal cluster analysis of recent Italian landslides. Georisk Assess. Manag. Risk Eng. Syst. Geohazards 2020, 1–19. [Google Scholar] [CrossRef]
- Tiwari, B.; Tran, D.; Ajmera, B.; Oli, H.; Stapleton, J. Effect of Pre-and Post-Earthquake Rainfall Events on the Deformation and Stability of Slopes. Geotech. Struct. Eng. Congr. 2016, 2016, 1540–1544. [Google Scholar]
- Chae, B.G.; Park, H.J.; Catani, F.; Simoni, A.; Matteo Berti, M. Landslide prediction, monitoring and early warning: A concise review of state-of-the-art. Geosci. J. 2017, 21, 1033–1070. [Google Scholar] [CrossRef]
- Chong, X.U. Detailed inventory of landslides triggered by the 2008 Wenchuan earthquake and its comparison with other earthquake events in the world. Sci. Technol. Rev. 2012, 30, 18–26. [Google Scholar]
- Zhang, S.; Li, C.; Zhang, L.; Peng, M.; Zhan, L.; Xu, Q. Quantification of human vulnerability to earthquake-induced landslides using Bayesian network. Eng. Geol. 2020, 265, 105436. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, L.M.; Xiang, B.; Yuan, Q. Travel distances of earthquake-induced landslides. In Geo-Congress 2013: Stability and Performance of Slopes and Embankments III; ASCE: Reston, VI, USA, 2013; pp. 991–1001. [Google Scholar]
- Froude, M.J.; Petley, D.N. Global fatal landslide occurrence from 2004 to 2016. Nat. Hazards Earth Syst. Sci. 2018, 18, 2161–2181. [Google Scholar] [CrossRef]
- Hong, Y.; Adler, R.; Huffman, G. Use of satellite remote sensing data in the mapping of global landslide susceptibility. Nat. Hazards 2007, 43, 245–256. [Google Scholar] [CrossRef]
- Orense, R.; Sapuay, S. Preliminary report on the 17 February 2006 Leyte, Philippines landslide. Soils Found. 2006, 46, 685–693. [Google Scholar] [CrossRef][Green Version]
- Montgomery, D.R.; Dietrich, W.E. A physically based model for the topographic control on shallow landsliding. Water Resour. Res. 1994, 30, 1153–1171. [Google Scholar] [CrossRef]
- Collison, A.; Wade, S.; Griffiths, J.; Dehn, M. Modelling the impact of predicted climate change on landslide frequency and magnitude in SE England. Eng. Geol. 2000, 55, 205–218. [Google Scholar] [CrossRef]
- Liu, Z.; Shao, J.; Xu, W.; Chen, H.; Shi, C. Comparison on landslide nonlinear displacement analysis and prediction with computational intelligence approaches. Landslides 2014, 11, 889–896. [Google Scholar] [CrossRef]
- Bregoli, F.; Medina, V.; Bateman, A. The energy transfer from granular landslides to water bodies explained by a data-driven, physics-based numerical model. Landslides 2021, 18, 1337–1348. [Google Scholar] [CrossRef]
- Brabb, E.E. Innovative approaches to landslide hazard mapping. In Proceedings of the 4th International Symposium on Landslides; Canadian Geotechnical Society: Calgary, AB, Canada, 1984; Volume 1, pp. 307–324. [Google Scholar]
- Fu, H.; Yang, J.L.; Zhang, J.H.; Liu, M.W. Comparative Study on Landslide Hazard Deformation Forecast Method. In Applied Mechanics and Materials; Trans Tech Publications Ltd.: Kapellweg, Switzerland, 2012; Volume 226, pp. 1318–1321. [Google Scholar]
- Abraham, M.T.; Pothuraju, D.; Satyam, N. Rainfall thresholds for prediction of landslides in Idukki, India: An empirical approach. Water 2019, 11, 2113. [Google Scholar] [CrossRef]
- He, K.Q.; Wang, S.Q.; Du, W.; Wang, S.J. Dynamic features and effects of rainfall on landslides in the Three Gorges Reservoir region, China: Using the Xintan landslide and the large Huangya landslide as the examples. Environ. Earth Sci. 2010, 59, 1267–1274. [Google Scholar]
- Xu, Q.; Peng, D.; Zhang, S.; Zhu, X.; He, C.Y.; Qi, X.; Zhao, K.Y.; Xiu, D.H.; Ju, N.P. Successful implementations of a real-time and intelligent early warning system for loess landslides on the Heifangtai terrace, China. Eng. Geol. 2020, 278, 105817. [Google Scholar] [CrossRef]
- Zhang, Y.; Meng, X.M.; Dijkstra, T.A.; Jordan, C.J.; Chen, G.; Zeng, R.Q.; Novellino, A. Forecasting the magnitude of potential landslides based on InSAR techniques. Remote Sens. Environ. 2020, 241, 111738. [Google Scholar] [CrossRef]
- Osanai, N.; Shimizu, T.; Kuramoto, K.; Kojima, S.; Noro, T. Japanese early-warning for debris flows and slope failures using rainfall indices with Radial Basis Function Network. Landslides 2010, 7, 325–338. [Google Scholar] [CrossRef]
- Sosio, R.; Crosta, G.B.; Chen, J.H.; Hung, O. Modelling rock avalanche propagation onto glaciers. Quat. Sci. Rev. 2012, 47, 23–40. [Google Scholar] [CrossRef]
- Gariano, S.L.; Guzzetti, F. Landslides in a changing climate. Earth-Sci. Rev. 2016, 162, 227–252. [Google Scholar] [CrossRef]
- Sala, G.; Lanfranconi, C.; Frattini, P.; Rusconi, G.; Crosta, G. Cost-sensitive rainfall thresholds for shallow landslides. Landslides 2021, 18, 2979–2992. [Google Scholar] [CrossRef]
- Yang, Z.; Yuan, X.; Liu, C.; Nie, R.; Liu, T.; Dai, X.; Ma, L.; Tang, M.; Xu, Y.; Lu, H. Meta-Analysis and Visualization of the Literature on Early Identification of Flash Floods. Remote Sens. 2022, 14, 3313. [Google Scholar] [CrossRef]
- Broeckx, J.; Rossi, M.; Lijnen, K.; Campforts, B.; Poesen, J.; Vanmaercke, M. Landslide mobilization rates: A global analysis and model. Earth-Sci. Rev. 2020, 201, 102972. [Google Scholar] [CrossRef]
- Fleuchaus, P.; Blum, P.; Wilde, M.; Terhorst, B.; Butscher, C. Retrospective evaluation of landslide susceptibility maps and review of validation practice. Environ. Earth Sci. 2021, 80, 485. [Google Scholar] [CrossRef]
- Ghahramani, N.; Chen, H.J.; Clohan, D.; Liu, S.; Llano-Serna, M.; Rana, N.M.; McDougall, S.; Evans, S.G.; Take, W.A. A benchmarking study of four numerical runout models for the simulation of tailings flows. Sci. Total Environ. 2022, 827, 154245. [Google Scholar] [CrossRef]
- Baghbani, A.; Choudhury, T.; Costa, S.; Reiner, J. Application of artificial intelligence in geotechnical engineering: A state-of-the-art review. Earth-Sci. Rev. 2022, 228, 103991. [Google Scholar] [CrossRef]
- Reichenbach, P.; Rossi, M.; Malamud, B.D.; Mihir, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth-Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Park, H.J.; Jang, J.Y.; Lee, J.H. Physically based susceptibility assessment of rainfall-induced shallow landslides using a fuzzy point estimate method. Remote Sens. 2017, 9, 487. [Google Scholar] [CrossRef]
- Johnston, A.C. Seismic moment assessment of earthquakes in stable continental regions—III. New Madrid 1811–1812, Charleston 1886 and Lisbon 1755. Geophys. J. Int. 1996, 126, 314–344. [Google Scholar] [CrossRef]
- Ho, J.Y.; Liu, C.H.; Chen, W.B.; Chang, C.H.; Lee, K.T. Using ensemble quantitative precipitation forecast for rainfall-induced shallow landslide predictions. Geosci. Lett. 2022, 9, 22. [Google Scholar] [CrossRef]
- Nuryanto, D.E.; Satyaningsih, R.; Nuraini, T.A.; Fajariana, Y.; Anggraeni, R.; Sopaheluwakan, A.; Yuliyanti, M.S. Prediction of soil moisture and rainfall induced landslides: A comparison of several PBL parameters in the WRF mode. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2021; Volume 893, p. 012025. [Google Scholar]
- Pritchard, A. Statistical Bibliography: An Interim Bibliography; Nort-Western Polytechnic School of Librarianship: London, UK, 1969. [Google Scholar]
- Isl Zupic, I.; Čater, T. Bibliometric methods in management and organization. Organ. Res. Methods 2015, 18, 429–472. [Google Scholar] [CrossRef]
- Van Eck, N.; Waltman, L. Software survey: VOSviewer, a computer program for bibliometric mapping. Scientometrics 2010, 84, 523–538. [Google Scholar] [CrossRef]
- Hassan-Montero, Y.; Guerrero-Bote, V.P.; De-Moya-Anegón, F. Graphical interface of the Scimago Journal and Country Rank: An interactive approach to accessing bibliometric information. Prof. Inf. 2014, 23, 272–278. [Google Scholar] [CrossRef]
- Mark, N.W. The who, what and why of knowledge mapping. J. Knowl. Manag. 2001, 5, 249–264. [Google Scholar]
- Hellström, T.; Husted, K. Mapping knowledge and intellectual capital in academic environments: A focus group study. J. Intellect. Cap. 2004, 5, 165–180. [Google Scholar] [CrossRef]
- Chen, C. Science mapping: A systematic review of the literature. J. Data Inf. Sci. 2017, 2, 1–40. [Google Scholar] [CrossRef]
- Chen, C.; Ibekwe-SanJuan, F.; Hou, J. The structure and dynamics of cocitation clusters: A multiple-perspective cocitation analysis. J. Am. Soc. Inf. Sci. Technol. 2010, 61, 1386–1409. [Google Scholar] [CrossRef]
- Chen, C. CiteSpace II: Detecting and visualizing emerging trends and transient patterns in scientific literature. J. Am. Soc. Inf. Sci. Technol. 2006, 57, 359–377. [Google Scholar] [CrossRef]
- Chen, C. Searching for intellectual turning points: Progressive knowledge domain visualization. Proc. Natl. Acad. Sci. USA 2004, 101 (Suppl. 1), 5303–5310. [Google Scholar] [CrossRef]
- Ding, L.; Ma, L.; Li, L.; Liu, C.; Li, N.; Yang, Z.; Yao, Y.; Lu, H. A Survey of Remote Sensing and Geographic Information System Applications for Flash Floods. Remote Sens. 2021, 13, 1818. [Google Scholar] [CrossRef]
- Atkinson, G.M.; Davenport, A.G.; Novak, M. Seismic risk to pipelines with application to Northern Canada. Can. J. Civ. Eng. 1982, 9, 248–264. [Google Scholar] [CrossRef]
- Buisson, L.; Martin Clouaire, R.; Vieu, L.; Wybo, J.L. Artificial intelligence and environmental protection: A survey of selected applications in France. In Proceedings of the IFIP 12th World Computer Congress, Mardid, Spain, 7–11 September 1992. [Google Scholar]
- Carrara, A.; Cardinali, M.; Guzzetti, F. Uncertainty in assessing landslide hazard and risk. ITC J. 1992, 2, 172–183. [Google Scholar]
- Wu, T.H.; Abdel-Latif, M.A. Prediction and mapping of landslide hazard. Can. Geotech. J. 2000, 37, 781–795. [Google Scholar] [CrossRef]
- Mendoza, C.H.; Gibbons, E.M.; Reinoso, P.A.; Bermeo, R.E. Evaluation and Zoning by Mass Removal Phenomena (MRP) Along the Ecuadorian Heavy Crude Oil Pipeline Route. International Pipeline Conference. Am. Soc. Mech. Eng. 2012, 45158, 459–467. [Google Scholar]
- Horton, P.; Jaboyedoff, M.; Rudaz, B.; Zimmermann, M. Flow-R, a model for susceptibility mapping of debris flows and other gravitational hazards at a regional scale. Nat. Hazards Earth Syst. Sci. 2013, 13, 869–885. [Google Scholar] [CrossRef]
- Feizizadeh, B.; Blaschke, T. An uncertainty and sensitivity analysis approach for GIS-based multicriteria landslide susceptibility mapping. Int. J. Geogr. Inf. Sci. 2014, 28, 610–638. [Google Scholar] [CrossRef] [PubMed]
- Feizizadeh, B.; Blaschke, T.; Nazmfar, H. GIS-based ordered weighted averaging and Dempster–Shafer methods for landslide susceptibility mapping in the Urmia Lake Basin, Iran. Int. J. Digit. Earth 2014, 7, 688–708. [Google Scholar] [CrossRef]
- Friedel, M.J. Modeling hydrologic and geomorphic hazards across post-fire landscapes using a self-organizing map approach. Environ. Model. Softw. 2011, 26, 1660–1674. [Google Scholar] [CrossRef]
- Ardizzone, F.; Cardinali, M.; Carrara, A.; Guzzetti, F.; Reichenbach, P. Impact of mapping errors on the reliability of landslide hazard maps. Nat. Hazards Earth Syst. Sci. 2002, 2, 3–14. [Google Scholar] [CrossRef]
- Guzzetti, F.; Reichenbach, P.; Ardizzone, F.; Cardinali, M.; Galli, M. Estimating the quality of landslide susceptibility models. Geomorphology 2006, 81, 166–184. [Google Scholar] [CrossRef]
- Tang, H.; Gong, W.; Li, C.; Wang, L.Q.; Juang, C.H. A new framework for characterizing landslide deformation: A case study of the Yu-Kai highway landslide in Guizhou, China. Bull. Eng. Geol. Environ. 2019, 78, 4291–4309. [Google Scholar] [CrossRef]
- Gariano, S.L.; Melillo, M.; Peruccacci, S.; Brunetti, M.T. How much does the rainfall temporal resolution affect rainfall thresholds for landslide triggering? Nat. Hazards 2020, 100, 655–670. [Google Scholar] [CrossRef]
- Peruccacci, S.; Brunetti, M.T.; Gariano, S.L.; Melillo, M.; Rossi, M.; Guzzetti, F. Rainfall thresholds for possible landslide occurrence in Italy. Geomorphology 2017, 290, 39–57. [Google Scholar] [CrossRef]
- Fabbri, A.G.; Komac, M.; Patera, A.; Chung, C.J. Favourability modelling of landslide hazard with spatial uncertainty of clab membership: A reapplication in central Slovenia. In Proceedings of the IAMG 2015—17th Annual Conference of the International Association for Mathematical Geosciences, Freiberg, Germany, 5–13 September 2015; pp. 848–856. [Google Scholar]
- Althuwaynee, O.F.; Pradhan, B.; Lee, S. Application of an evidential belief function model in landslide susceptibility mapping. Comput. Geosci. 2012, 44, 120–135. [Google Scholar] [CrossRef]
- Van den Eeckhaut, M.; Vanwalleghem, T.; Poesen, J.; Govers, G.; Verstraeten, G.; Vandekerckhove, L. Prediction of landslide susceptibility using rare events logistic regression: A case-study in the Flemish Ardennes (Belgium). Geomorphology 2006, 76, 392–410. [Google Scholar] [CrossRef]
- Aydin, A. Stability of saprolitic slopes: Nature and role of field scale heterogeneities. Nat. Hazards Earth Syst. Sci. 2006, 6, 89–96. [Google Scholar] [CrossRef]
- Lu, M.; Zhang, J.; Zhang, L.; Zhang, L. Assessing the annual risk of vehicles being hit by a rainfall-induced landslide: A case study on Kennedy Road in Wan Chai, Hong Kong. Nat. Hazards Earth Syst. Sci. 2020, 20, 1833–1846. [Google Scholar] [CrossRef]
- Diriba, T.A.; Debusho, L.K. Statistical Modelling of Extreme Rainfall Indices using Multivariate Extreme Value Distributions. Environ. Model. Assess. 2021, 26, 543–563. [Google Scholar] [CrossRef]
- Fischer, M.; Korup, O.; Veh, G.; Walz, A. Controls of outbursts of moraine-dammed lakes in the greater Himalayan region. Cryosphere 2021, 15, 4145–4163. [Google Scholar] [CrossRef]
- Thomas, M.A.; Mirus, B.B.; Collins, B.D.; Lu, N.; Godt, J.W. Variability in soil-water retention properties and implications for physics-based simulation of landslide early warning criteria. Landslides 2018, 15, 1265–1277. [Google Scholar] [CrossRef]
- Dunne, T. Critical data requirements for prediction of erosion and sedimentation in mountain drainage basins 1. J. Am. Water Resour. Assoc. 1998, 34, 795–808. [Google Scholar] [CrossRef]
- Faming, H.; Zhou, Y.E.; Chi, Y. Uncertainties of landslide susceptibility prediction: Different attribute interval divisions of environmental factors and different data-based models. Earth Sci. 2020, 45, 4535–4549. [Google Scholar]
- Borrelli, P.; Robinson, D.A.; Panagos, P.; Ballabio, C. Land use and climate change impacts on global soil erosion by water (2015–2070). Proc. Natl. Acad. Sci. USA 2020, 117, 21994–22001. [Google Scholar] [CrossRef]
- Fang, Z.; Wang, Y.; Niu, R.; Peng, L. Landslide susceptibility prediction based on positive unlabeled learning coupled with adaptive sampling. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11581–11592. [Google Scholar] [CrossRef]
- Fu, Z.; Long, J.; Chen, W.; Li, C.; Zhang, H.; Yao, W. Reliability of the prediction model for landslide displacement with step-like behavior. Stoch. Environ. Res. Risk Assess. 2021, 35, 2335–2353. [Google Scholar] [CrossRef]
- Volpe, E.; Ciabatta, L.; Salciarini, D.; Camici, S.; Cattoni, E.; Brocca, L. The impact of probability density functions assessment on model performance for slope stability analysis. Geosciences 2021, 11, 322. [Google Scholar] [CrossRef]
- Bathrellos, G.D.; Skilodimou, H.D.; Zygouri, V.; Koukouvelas, I.K. Landslide: A recurrent phenomenon? Landslide hazard assessment in mountainous areas of central Greece. Z. Geomorphol. 2021, 63, 95–114. [Google Scholar] [CrossRef]
- Juang, C.H.; Gong, W.; Martin, J.R., II; Chen, Q.S. Model selection in geological and geotechnical engineering in the face of uncertainty-does a complex model always outperform a simple model? Eng. Geol. 2018, 242, 184–196. [Google Scholar] [CrossRef]
- Wang, Y.; Tang, H.; Wen, T.; Ma, J. A hybrid intelligent approach for constructing landslide displacement prediction intervals. Appl. Soft Comput. 2019, 81, 105506. [Google Scholar] [CrossRef]
- Palazzolo, N.; Peres, D.J.; Bordoni, M.; Meisina, C.; Creaco, E.; Cancelliere, A. Improving spatial landslide prediction with 3d slope stability analysis and genetic algorithm optimization: Application to the oltrepò pavese. Water 2021, 13, 801. [Google Scholar] [CrossRef]
- Cardarilli, M.; Lombardi, M.; Corazza, A. Landslide risk management through spatial analysis and stochastic prediction for territorial resilience evaluation. Int. J. Saf. Secur. Eng. 2019, 9, 109–120. [Google Scholar] [CrossRef]
- Fu, X.; Zhu, Q.; Liu, C.; Li, N.; Zhuang, W.; Yang, Z.; Lu, H.; Tang, M. Estimation of Landslides and Road Capacity after August 8, 2017, MS7.0 Jiuzhaigou Earthquake Using High-Resolution Remote Sensing Images. Adv. Civ. Eng. 2020, 2020, 8828385. [Google Scholar] [CrossRef]
- Getirana, A.; Kirschbaum, D.; Mandarino, F.; Ottoni, M.; Khan, S.; Arsenault, K. Potential of GPM IMERG precipitation estimates to monitor natural disaster triggers in urban areas: The case of Rio de Janeiro, Brazil. Remote Sens. 2020, 12, 4095. [Google Scholar] [CrossRef]
- Li, Z.; Sun, J.; Gao, M.; Fu, G.; An, Z.; Zhao, Y.; Fang, L.; Guo, X. Evaluation of horizontal ground motion waveforms at Sedongpu Glacier during the 2017 M6. 9 Mainling earthquake based on the equivalent Green’s function. Eng. Geol. 2022, 306, 106743. [Google Scholar] [CrossRef]
- Liu, H.; Du, J.; Yi, Y. Reconceptualising flood risk assessment by incorporating sediment supply. CATENA 2022, 217, 106503. [Google Scholar] [CrossRef]
- Pedrozzi, G. Triggering of landslides in Canton Ticino (Switzerland) and prediction by the rainfall intensity and duration method. Bull. Eng. Geol. Environ. 2004, 63, 281–291. [Google Scholar] [CrossRef]
- Bicocchi, G.; D’Ambrosio, M.; Rossi, G.; Rosi, A.; Tacconi-Stefanelli, C.; Segoni, S.; Nocentini, M.; Vannocci, P.; Tofani, V.; Casagli, N.; et al. Geotechnical in situ measures to improve landslides forecasting models: A case study in Tuscany (Central Italy). In Landslides and Engineered Slopes Experience, Theory and Practice; CRC Press: Boca Raton, FL, USA, 2018; pp. 419–424. [Google Scholar]
- Cai, J.S.; Yan, E.C.; Yeh, T.C.J.; Zha, Y.Y. Sampling schemes for hillslope hydrologic processes and stability analysis based on cross-correlation analysis. Hydrol. Process. 2017, 31, 1301–1313. [Google Scholar] [CrossRef]
- Khasanov, S.; Juliev, M.; Uzbekov, U.; Sayidjakhon Khasanov, S.; Juliev, M.; Uzbekov, U.; Aslanov, I.; Agzamova, I.; Normatova, N.; Islamov, S.; et al. Landslides in Central Asia: A review of papers published in 2000–2020 with a particular focus on the importance of GIS and remote sensing techniques. GeoScape 2021, 15, 134–145. [Google Scholar] [CrossRef]
- Castelli, M.; Scavia, C. A multidisciplinary methodology for hazard and risk assessment of rock avalanches. Rock Mech. Rock Eng. 2008, 41, 3–36. [Google Scholar] [CrossRef]
- Regmi, N.R.; Giardino, J.R.; Vitek, J.D. Assessing susceptibility to landslides: Using models to understand observed changes in slopes. Geomorphology 2010, 122, 25–38. [Google Scholar] [CrossRef]
- Li, W.; Fan, X.; Huang, F.; Chen, W.; Hong, H.; Huang, J.; Guo, Z. Uncertainties analysis of collapse susceptibility prediction based on remote sensing and GIS: Influences of different data-based models and connections between collapses and environmental factors. Remote Sens. 2020, 12, 4134. [Google Scholar] [CrossRef]
- Tsai, F.; Lai, J.S.; Chen, W.W.; Lin, T.H. Analysis of topographic and vegetative factors with data mining for landslide verification. Ecol. Eng. 2013, 61, 669–677. [Google Scholar] [CrossRef]
- Tsai, T.L.; Tsai, P.Y.; Yang, P.J. Probabilistic modeling of rainfall-induced shallow landslide using a point-estimate method. Environ. Earth Sci. 2015, 73, 4109–4117. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, L.; Wang, S.; Lari, S. Regional landslide susceptibility zoning with considering the aggregation of landslide points and the weights of factors. Landslides 2014, 11, 399–409. [Google Scholar] [CrossRef]
- Oguz, E.A.; Depina, I.; Thakur, V. Effects of soil heterogeneity on susceptibility of shallow landslides. Landslides 2022, 19, 67–83. [Google Scholar] [CrossRef]
- Lian, C.; Zeng, Z.; Yao, W.; Tang, H. Ensemble of extreme learning machine for landslide displacement prediction based on time series analysis. Neural Comput. Appl. 2014, 24, 99–107. [Google Scholar] [CrossRef]
- Huang, F.; Ye, Z.; Jiang, S.H.; Huang, J.; Chang, Z.; Chen, J. Uncertainty study of landslide susceptibility prediction considering the different attribute interval numbers of environmental factors and different data-based models. Catena 2021, 202, 105250. [Google Scholar] [CrossRef]
- Gorsevski, P.V.; Gessler, P.E.; Boll, J.; Elliot, W.J.; Foltz, R.B. Spatially and temporally distributed modeling of landslide susceptibility. Geomorphology 2006, 80, 178–198. [Google Scholar] [CrossRef]
- Zhang, Z.; Yang, F.; Chen, H.; Wu, Y.; Li, T.; Li, W.; Wang, Q.; Liu, P. GIS-based landslide susceptibility analysis using frequency ratio and evidential belief function models. Environ. Earth Sci. 2016, 75, 948. [Google Scholar] [CrossRef]
- Nikolopoulos, E.I.; Crema, S.; Marchi, L.; Marra, F.; Guzzetti, F.; Borga, M. Impact of uncertainty in rainfall estimation on the identification of rainfall thresholds for debris flow occurrence. Geomorphology 2014, 221, 286–297. [Google Scholar] [CrossRef]
- Meena, S.R.; Mishra, B.K.; Tavakkoli, P.S. A hybrid spatial multi-criteria evaluation method for mapping landslide susceptible areas in kullu valley, himalayas. Geosciences 2019, 9, 156. [Google Scholar] [CrossRef]
- Van den Eeckhaut, M.; Reichenbach, P.; Guzzetti, F.; Rossi, M.; Poesen, J. Combined landslide inventory and susceptibility assessment based on different mapping units: An example from the Flemish Ardennes, Belgium. Nat. Hazards Earth Syst. Sci. 2009, 9, 507–521. [Google Scholar] [CrossRef]
- Strauch, R.; Istanbulluoglu, E.; Nudurupati, S.S.; Bandaragoda, C.; Gasparini, N.M.; Tucker, G.E. A hydroclimatological approach to predicting regional landslide probability using Landlab. Earth Surf. Dyn. 2018, 6, 49–75. [Google Scholar] [CrossRef]
- Burton, A.; Arkell, T.J.; Bathurst, J.C. Field variability of landslide model parameters. Environ. Geol. 1998, 35, 100–114. [Google Scholar] [CrossRef]
- Wu, C.Y.; Yeh, Y.C. A landslide probability model based on a long-term landslide inventory and rainfall factors. Water 2020, 12, 937. [Google Scholar] [CrossRef]
- Lombardo, L.; Tanyas, H.; Huser, R.; Guzzetti, F.; Castro-Camilo, D. Landslide size matters: A new data-driven, spatial prototype. Eng. Geol. 2021, 293, 106288. [Google Scholar] [CrossRef]
- Zêzere, J.L.; Pereira, S.; Melo, R.; Oliveira, S.C.; Garcia, R.A.C. Mapping landslide susceptibility using data-driven methods. Sci. Total Environ. 2017, 589, 250–267. [Google Scholar] [CrossRef] [PubMed]
- Kocaman, S.; Gokceoglu, C. CitSci as a New Approach for Landslide Researches. In GeoInformation for Disaster Management Conference; Springer: Cham, Switzerland, 2018; pp. 161–183. [Google Scholar]
- Kocaman, S.; Gokceoglu, C. A CitSci app for landslide data collection. Landslides 2019, 16, 611–615. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Mancini, F.; Capra, A.; Castagnetti, C.; Ceppi, C.; Bertacchini, E.; Rivola, R. Contribution of geomatics engineering and VGI within the landslide risk assessment procedures. In International Conference on Computational Science and Its Applications; Springer: Cham, Switzerland, 2015; pp. 635–647. [Google Scholar]
- Manfré, L.A.; Hirata, E.; Silva, J.B.; Shinohara, E.J.; Giannotti, M.A.; Larocca, A.P.C.; Quintanilha, J.A. An analysis of geospatial technologies for risk and natural disaster management. ISPRS Int. J. Geo-Inf. 2012, 1, 166–185. [Google Scholar] [CrossRef]
- Lombardo, L.; Tanyas, H. Chrono-validation of near-real-time landslide susceptibility models via plug-in statistical simulations. Eng. Geol. 2020, 278, 105818. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, L.; Wang, Y.; Jiang, Q.; Qi, D. Precipitation data and their uncertainty as input for rainfall-induced shallow landslide models. Front. Earth Sci. 2019, 13, 695–704. [Google Scholar] [CrossRef]
- Mantovani, F.; Soeters, R.; van Westen, C.J. Remote sensing techniques for landslide studies and hazard zonation in Europe. Geomorphology 1996, 15, 213–225. [Google Scholar] [CrossRef]
- Murillo, M.L.; Hunter, G.J. Assessing uncertainty due to elevation error in a landslide susceptibility model. Trans. GIS 1997, 2, 289–298. [Google Scholar] [CrossRef]
- Bernard, T.G.; Lague, D.; Steer, P. Beyond 2D landslide inventories and their rollover: Synoptic 3D inventories and volume from repeat lidar data. Earth Surf. Dyn. 2021, 9, 1013–1044. [Google Scholar] [CrossRef]
- Bezak, N.; Jemec Auflič, M.; Mikoš, M. Reanalysis of Soil Moisture Used for Rainfall Thresholds for Rainfall-Induced Landslides: The Italian Case Study. Water 2021, 13, 1977. [Google Scholar] [CrossRef]
- Leonarduzzi, E.; McArdell, B.W.; Molnar, P. Rainfall-induced shallow landslides and soil wetness: Comparison of physically based and probabilistic predictions. Hydrol. Earth Syst. Sci. 2021, 25, 5937–5950. [Google Scholar] [CrossRef]
- Anis, Z.; Wissem, G.; Vali, V.; Smida, H.; Essghaier, G.M. GIS-based landslide susceptibility mapping using bivariate statistical methods in North-western Tunisia. Open Geosci. 2019, 11, 708–726. [Google Scholar] [CrossRef]
- Mahalingam, R.; Olsen, M.J.; O’Banion, M.S. Evaluation of landslide susceptibility mapping techniques using lidar-derived conditioning factors (Oregon case study). Geomat. Nat. Hazards Risk 2016, 7, 1884–1907. [Google Scholar] [CrossRef]
- Lin, Q.; Wang, Y.; Liu, T.; Zhu, Y.; Sui, Q. The vulnerability of people to landslides: A case study on the relationship between the casualties and volume of landslides in China. Int. J. Environ. Res. Public Health 2017, 14, 212. [Google Scholar] [CrossRef]
- Du, J.; Glade, T.; Woldai, T.; Chai, B.; Zeng, B. Landslide susceptibility assessment based on an incomplete landslide inventory in the Jilong Valley, Tibet, Chinese Himalayas. Eng. Geol. 2020, 270, 105572. [Google Scholar] [CrossRef]
- Rohan, T.J.; Wondolowski, N.; Shelef, E. Landslide susceptibility analysis based on citizen reports. Earth Surf. Process. Landf. 2021, 46, 791–803. [Google Scholar] [CrossRef]
- Fell, R.; Corominas, J.; Bonnard, C.; Cascini, L.; Leroi, E. Guidelines for landslide susceptibility, hazard and risk zoning for land-use planning. Eng. Geol. 2008, 102, 99–111. [Google Scholar] [CrossRef]
- Hsu, P.H.; Su, W.R.; Chang, C.C. Hazards analysis and prediction from remote sensing and GIS using spatial data mining and knowledge discovery: A case study for landslide hazard zonation. Earth Resour. Environ. Remote Sens./GIS Appl. II 2011, 8181, 81810R. [Google Scholar]
- Kavzoglu, T.; Teke, A. Advanced hyperparameter optimization for improved spatial prediction of shallow landslides using extreme gradient boosting (XGBoost). Bull. Eng. Geol. Environ. 2022, 81, 201. [Google Scholar] [CrossRef]
- Sun, D.; Wen, H.; Wang, D.; Xu, J. A random forest model of landslide susceptibility mapping ased on hyperparameter optimization using Bayes algorithm. Geomorphology 2020, 362, 107201. [Google Scholar] [CrossRef]
- Wan, Z.; Dong, H.; Liu, B. On choice of hyper-parameters of support vector machines for time series regression and prediction with orthogonal design. Rock Soil Mech. 2010, 32, 503–508. [Google Scholar]
- Wang, X.; Huang, F.; Cheng, Y. Super-parameter selection for Gaussian-Kernel SVM based on outlier-resisting. Measurement 2014, 58, 147–153. [Google Scholar] [CrossRef]
- Park, H.J.; Jang, J.Y.; Lee, J.H. Assessment of rainfall-induced landslide susceptibility at the regional scale using a physically based model and fuzzy-based Monte Carlo simulation. Landslides 2019, 16, 695–713. [Google Scholar] [CrossRef]
- Marin, R.J.; García, E.F.; Aristizábal, E. Assessing the effectiveness of TRIGRS for predicting unstable areas in a tropical mountain basin (Colombian Andes). Geotech. Geol. Eng. 2021, 39, 2329–2346. [Google Scholar] [CrossRef]
- Thiery, Y.; Malet, J.P.; Sterlacchini, S.; Puissant, A.; Maquaire, O. Landslide susceptibility assessment by bivariate methods at large scales: Application to a complex mountainous environment. Geomorphology 2007, 92, 38–59. [Google Scholar] [CrossRef]
- Schicker, R.; Moon, V. Comparison of bivariate and multivariate statistical approaches in landslide susceptibility mapping at a regional scale. Geomorphology 2012, 161, 40–57. [Google Scholar] [CrossRef]
- Rossi, M.; Reichenbach, P. LAND-SE: A software for statistically based landslide susceptibility zonation, version 1.0. Geosci. Model Dev. 2016, 9, 3533–3543. [Google Scholar] [CrossRef]
- Shepheard, C.J.; Vardanega, P.J.; Holcombe, E.A.; Hen-Jones, R.; Luca, F.D. Minding the geotechnical data gap: Appraisal of the variability of key soil parameters for slope stability modelling in Saint Lucia. Bull. Eng. Geol. Environ. 2019, 78, 4851–4864. [Google Scholar] [CrossRef]
- Lu, H.; Ma, L.; Fu, X.; Liu, C.; Wang, Z.; Tang, M.; Li, N.W. Landslides information extraction using object-oriented image analysis paradigm based on deep learning and transfer learning. Remote Sens. 2020, 12, 752. [Google Scholar] [CrossRef]
- Li, W.; Shi, Y.; Huang, F.; Hong, H.; Song, G. Uncertainties of collapse susceptibility prediction based on remote sensing and GIS: Effects of different machine learning models. Front. Earth Sci. 2021, 9, 635. [Google Scholar] [CrossRef]
- Yuan, X.; Liu, C.; Nie, R.; Yang, Z.; Li, W.; Dai, X.; Cheng, J.; Zhang, J.; Ma, L.; Fu, X.; et al. A Comparative Analysis of Certainty Factor-Based Machine Learning Methods for Collapse and Landslide Susceptibility Mapping in Wenchuan County, China. Remote Sens. 2022, 14, 3259. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood susceptibility analysis and its verification using a novel ensemble support vector machine and frequency ratio method. Stoch. Environ. Res. Risk Assess. 2015, 29, 1149–1165. [Google Scholar] [CrossRef]
- Huang, L.; Xiang, L. Method for meteorological early warning of precipitation-induced landslides based on deep neural network. Neural Process. Lett. 2018, 48, 1243–1260. [Google Scholar] [CrossRef]
- Luo, X.; Lin, F.; Chen, Y.; Zhu, S.; Xu, Z.; Huo, Z.; Yu, M.; Peng, J. Coupling logistic model tree and random subspace to predict the landslide susceptibility areas with considering the uncertainty of environmental features. Sci. Rep. 2019, 9, 15369. [Google Scholar] [CrossRef]
- Sahin, E.K. Assessing the predictive capability of ensemble tree methods for landslide susceptibility mapping using XGBoost, gradient boosting machine, and random forest. SN Appl. Sci. 2020, 2, 1308. [Google Scholar] [CrossRef]
- Di Napoli, M.; Carotenuto, F.; Cevasco, A.; Confuorto, P.; Di Martire, D.; Firpo, M.; Pepe, G.; Raso, E.; Calcaterra, D. Machine learning ensemble modelling as a tool to improve landslide susceptibility mapping reliability. Landslides 2020, 17, 1897–1914. [Google Scholar] [CrossRef]
- Valter, P.; Lindgren, P.; Prasad, R. The consequences of artificial intelligence and deep learning in a world of persuasive business models. IEEE Aerosp. Electron. Syst. Mag. 2018, 33, 80–88. [Google Scholar] [CrossRef]
- Mohan, A.; Singh, A.K.; Kumar, B.; Dwivedi, R. Review on remote sensing methods for landslide detection using machine and deep learning. Trans. Emerg. Telecommun. Technol. 2021, 32, e3998. [Google Scholar] [CrossRef]
- Bui, T.A.; Lee, P.J.; Lum, K.Y.; Loh, C.; Tan, K. Deep Learning for Landslide Recognition in Satellite Architecture. IEEE Access 2020, 8, 143665–143678. [Google Scholar] [CrossRef]
- Xu, G.; Zhu, X.; Fu, D.; Dong, J.; Xiao, X.M. Automatic land cover classification of geo-tagged field photos by deep learning. Environ. Model. Softw. 2017, 91, 127–134. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Publication Type | Year | Authors | Title | Publication/Source Titles | Cited Reference Count | Keywords |
|---|---|---|---|---|---|---|
| Article | 2017 | Park, H.J. et al. [38] | Physically based susceptibility assessment of rainfall-induced shallow landslides using a fuzzy point estimate method | Remote sensing | 141 (WOS) | Monte-carlo-simulation; differential sar interferometry; rock slope stability; li-shan landslide; modeling uncertainty; reliability-analysis; hazard assessment; satellite; risk; failure |
| Review | 1996 | Johnston, A.C. [39] | Seismic moment assessment of earthquakes in stable continental regions—III. New Madrid 1811-1812, Charleston 1886, and Lisbon 1755. | Geophysical Journal International | 352 (Scopus) | Earthquake intensity; earthquake-source mechanism; seismic moment |
| Letter | 2022 | Ho, J.Y. et al. [40] | Using ensemble quantitative precipitation forecast for rainfall-induced shallow landslide predictions | Geoscience letters | 23 (WOS) | Physically-based model |
| Conference Paper | 2021 | Nuryanto, D.E. et al. [41] | Prediction of soil moisture and rainfall induced landslides; a comparison of several PBL parameters in the WRF model | IOP Conference Series: Earth and Environmental Science | 1 (Scopus) | landslide; rainfall; soil moisture; WRF model |
| Authors | Post Volume | Masterpiece | Representative Contribution | Index (Source, Scopus) |
|---|---|---|---|---|
| Guzzetti, F. et al. [63] | 16 | Estimating the quality of landslide susceptibility models | A landslide susceptibility model for a region in central Italy is presented, and a framework for assessing model reliability and forecasting skills is presented. | 64 |
| Tang, H. et al. [64] | 12 | A new framework for characterizing landslide deformation: a case study of the Yu-Kai highway landslide in Guizhou, China | A new framework for characterizing landslide deformation is proposed, which can establish the evolution of landslide deformation in both the geometric and temporal domains, allowing the evaluation of the sliding mechanism of landslides. | 37 |
| Gariano, S.L. et al. [65] | 12 | How much does the rainfall temporal resolution affect rainfall thresholds for landslide triggering? | The impact of the temporal resolution of rainfall measurements on a landslide-triggered rainfall threshold calculation in a region of northern Italy was assessed and discussed. | 19 |
| Peruccacci, S. et al. [66] | 10 | Rainfall thresholds for possible landslide occurrence in Italy | Landslide information obtained from multiple sources and rainfall data captured by rain gauges to construct a catalog of rainfall events in Italy between 1996 and 2014. | 24 |
| Fabbri, A.G. et al. [67] | 9 | Favorability modeling of landslide hazard with spatial uncertainty of clab membership: a reapplication in central Slovenia | Shared the spatial database of landslide hazard prediction in central Slovenia and carried out spatial prediction experiments by verifying the technology, emphasizing the importance of the shared database. | 15 |
| References | Cite Frequency | Year | Title | Publication Type | Research Contents |
|---|---|---|---|---|---|
| Guzzetti, F. et al. [63] | 573 (Scopus) 549 (WOS) | 2006 | Estimating the Quality of Landslide Susceptibility Models | Article | The error associated with the susceptibility assessment for each mapping unit was determined by studying the variation in the model’s susceptibility estimates. |
| Reichenbach, P. et al. [37] | 569 (Scopus) 257 (WOS) | 2018 | A Review of Statistically-Based Landslide Susceptibility Models | Review | Provides a critical review of statistical approaches to landslide susceptibility modeling and associated terrain zoning, provides graphical visualizations, and reveals significant heterogeneity in subject data, modeling approaches, and model evaluation criteria. |
| Gariano, S.L. et al. [30] | 419 (Scopus) 270 (WOS) | 2016 | Landslides in a Changing Climate | Review | An initial global assessment of future landslide impacts and a global map of projected impacts of climate change on landslide activity and abundance are presented. |
| Althuwaynee, O.F. et al. [68] | 247 (Scopus) 230 (WOS) | 2012 | Application of an Evidential Belief Function Model in Landslide Susceptibility Mapping | Article | Exploring potential applications of evidence belief function models in landslide susceptibility mapping using GIS. |
| Van Den Eeckhaut, M. et al. [69] | 294 (Scopus) 203 (WOS) | 2006 | Prediction of Landslide Susceptibility Using Rare Events Logistic Regression: A Case-Study in the Flemish Ardennes (Belgium) | Article | Evaluate the statistical multivariate method of rare event logistic regression to create landslide susceptibility maps. |
| References | Purpose | Factors | Research Idea | Conclusion |
|---|---|---|---|---|
| Tsai, F. et al. [97] | Verify landslides caused by heavy rainfall in Taiwan | Topographic and vegetation factors | Used decision tree and Bayesian network data mining algorithm to extract landslide factors from the provided knowledge and develop a statistical-based mechanism to reduce data uncertainty. | Apply the model to landslide prediction directly, and the prediction results will be unreliable due to the spatial uncertainty of data. |
| Tsai, T.L. et al. [98] | Evaluate shallow landslides caused by rainfall | Soil parameters, slope conditions, and hydrological conditions | Compared the applicability of Rosenblueth point estimation method and Monte Carlo simulation method by using various soil parameters, slope conditions, and hydrological conditions. | The correlation of soil parameters reduces the safety standard deviation factor but does not affect the safety mean factor. The prediction error may occur if the correlation of soil parameters is ignored. |
| Wang, X. et al. [99] | Analyze the correlation between relevant factors and landslide | Lithology, relative relief, tectonic fault density, rainfall, and road density | Proposed using the CLSI and CLAI calculated based on the frequency ratio to express the correlation between various factors and landslide occurrences. | CLSI is helpful to reduce the uncertainty of sensitivity assessment when the landslide inventory with non-uniformity problems is used. |
| Oguz, E.A. et al. [100] | Quantify the impact of disaster-causing factors on prediction uncertainty | Geotechnical and hydrological parameters | Developed a three-dimensional slope stability model combined with random field model and Monte Carlo method to capture spatial variability and predict landslide susceptibility. | The new model has higher landslide prediction accuracy than the traditional model. |
| Lian, C. et al. [101] | Affect the interaction of different inducing factors of landslide evolution | Structure, rainfall, and reservoir water level fluctuation | Proposed a new neural network technology of extreme learning machine integration (E-ELM) and used the grey correlation analysis (GRA) method to screen out the inducing factors with great influence as the input factors in E-ELM. | The model can predict the trend component displacement and periodic component displacement, and the total predicted displacement is obtained by adding the predicted displacement values of each factor. |
| Huang, F. et al. [102] | Study the influence of environmental factor attribute interval division quantity on modeling | Topography and landform, formation lithology, hydrological environment, and surface coverage | Obtained the landslide inventory and its environmental factors in the research area and carried out frequency ratio analysis on continuous environmental factors under the condition of dividing quantitative values in different attribute intervals. | When the frequency ratio analysis is made, there is a critical point in the continuous environmental factor of the landslide that can effectively avoid too complex of a frequency ratio calculation, while ensuring the prediction accuracy. |
| Division Method | Research Content | Object to Be Divided | Method | Conclusion |
|---|---|---|---|---|
| Regular units | Obtain the optimal landslide sensitivity assessment [107] | Lithology and soil hydrological information in regional landslide inventory | Divide the research area into grid units and topographical units, subdivide the slope units according to the topographic gradient to obtain hydrological morphological units, and determine a single pixel as the representative of the landslide depletion area for grid units. | It minimized the inherent limitations of regional landslide inventory and sensitivity maps. |
| Influence of soil depth on the probability of occurrence of landslides [108] | Soil characteristics and vegetation classification | Develop a source tracking algorithm (STA), and use the spatial variable supplementary data from a hydrologic source domain (HSD) and the spatial distribution grid data of soil characteristics and vegetation classification to characterize the parameter estimation of the probability distribution of the model input uncertainty. | “Over-representation” areas that suffer from shallow landslides may be misleading. Locations with high landslide probability other than landslides can be used as the index for the additional investigation of missing areas. | |
| Evaluate the spatial variability and uncertainty of model parameters [109] | Slope, soil strength | Analyze the grid data, provide the estimated value of parameter area with relevant error range by the Kriging method and display the safety factor calculated at each point of the grid to identify the landslide. | This landslide prediction method can be improved by using the Kriging method. | |
| Irregular unit division | Number of landslide events when rainfall reaches its threshold [110] | Landslide inventory, daily rainfall, and effective cumulative rainfall | Divide the research area into multiple rain gauge control areas by the improved Thiessen Polygon method and divide the control area into slope units that reflect the topographic characteristics to improve the spatial resolution of the rain gauge. | The rainfall of at least one rainfall event in the slope unit exceeds the threshold. |
| Uncertainty of different landslide boundaries on modeling [76] | Slope, lithology, and other environmental factors | Establish the correlation between the landslide boundary and the frequency ratio of the landslide boundary and environmental factors based on landslide points, buffer circles, and polygonal surfaces, and then select multilayer perceptron and random forest to build the model. | Compare the method using a polygon surface with the method based on point and circle, and the boundary and spatial shape can significantly improve the accuracy of landslide sensitivity map LSM. | |
| Predict the scope of landslide [111] | Plane area of landslide | First introduce a statistic-based model, establish models on the slope triggered by the landslide in response to seismic vibration, and simulate the expected failure surface on the slope without landslide. | The model can estimate the plane area of the landslide aggregated by each slope unit. | |
| Evaluate the influence of topographic mapping unit on data-driven landslide sensitivity map [112] | Slope angle, aspect, slope area ratio, lithology, and land use / land cover | Calculate the landslide sensitivity model by using the same topographic mapping unit (slope topographic unit) and the complete landslide inventory represented by polygon features. | The accuracy of landslide spatial location is the key criterion for selecting the most suitable topographical unit for modeling; when the spatial accuracy is low, the grid topographic units should not be used, and the use of irregular units can help to reduce the adverse effects caused by location errors. |
| Location | Data | Application | Conclusion |
|---|---|---|---|
| Countries of the European Community [120] | Remote sensing landslide data | Emphasize the image types required for different analysis scales; monitor the activities of existing landslides by GPS, photogrammetric technology, and radar interferometry; spatio-temporal analysis and prediction of slope failure | Integrate remote sensing technology into the overall framework of landslide prediction uncertainty analysis technology. |
| The Cascade Range in western Oregon, USA [121] | DEM and geological data | Process the DEM to generate a series of slope stability maps and evaluate the uncertain impact of elevation error on landslide sensitivity | The evaluation of the ability of uncertainty may help to understand the advantages and disadvantages of digital data and spatial information system applications. |
| Kaikoura, New Zealand [122] | Multi-temporal airborne laser radar data set | Propose to use a new semi-automatic 3D point cloud difference method to detect the landform variations, filter the false landslide detection caused by laser radar elevation error, obtain a robust landslide list with uncertainty measurement, and directly measure the volume and geometric characteristics of the landslide. | The size dependence detection of the system is insufficient in the 2D list, while the 3D derived list can be used to detect various hillside movements that cannot be captured by 2D landslide surveying and mapping. |
| Italy [123] | FraneItalia database | Use thousands of landslide events for the reanalysis of uncertain data sets to obtain precipitation and volumetric soil moisture data | Compared with the reanalyzed soil moisture data, precipitation information is still a better prediction index to trigger landslides. |
| Switzerland [124] | Soil moisture and rainfall data | Propose a sequential threshold method, which first is divided into dry and wet preconditions through antecedent soil saturation threshold, and then estimate two threshold curves with different total rainfall duration. | The combination of soil moisture state estimation and infinite slope method can improve the separation between triggered and non-triggered rainfall events of landslides. |
| Northwestern Tunisia [125] | Data of landslide regulating factors such as elevation, slope, and aspect | Draw landslide sensitivity maps by two bivariate statistical models (evidence belief function (EBF) and weight of evidence (woe)), and landslide inventory maps by aerial photos, satellite images, and field surveys. | The landslide sensitivity maps of the two models are very similar, but the WoE model is more effective and can be used for the future planning of the research area. |
| Oregon [126] | Laser radar derived data set | Make use of the laser radar derived data set and set up the research area through several widely used statistical technologies to realize landslide sensitivity analysis | Only a few factors are needed to produce a satisfactory ability sensitivity map with high predictability. |
| References | Research Content | Model Used | Method | Conclusion |
|---|---|---|---|---|
| Thiery, Y. et al. [138] | Test of the performance of statistical evaluation method for landslide sensitivity | Weight of evidence (WOE) | Identify variables that represent the optimal response; test evaluate the simulation performance by the optimal combination of predictive variables and new predictive variables; evaluate the statistical model through expert judgment | The bivariate method can effectively evaluate the landslide sensitivity at the scale of 1:10,000. When RV and PV are complex or limited by an insufficient amount of information, expert knowledge needs to be introduced into the statistical model to generate a reliable landslide sensitivity map. |
| Schicker R. et al. [139] | Extraction of landslide inventory data from the original database | Logistic regression and weight of evidence | Use sensitivity maps that are predicted successfully and derived and evaluated by ROC curves for logistic regression and weight of evidence | The WOE method cannot successfully predict landslides other than the original data. |
| Rossi, M. et al. [140] | Evaluation of landslide sensitivity | Support vector machine, logistic regression | Describe the structure of software for landslide sensitivity evaluation, explain the input and output, and illustrate the specific applications with maps and graphics | Complete and comprehensive landslide sensitivity evaluation includes a model performance analysis, prediction skill evaluation, and error and uncertainty estimation. |
| Shepheard, C.J. et al. [141] | Variation of rock and soil parameters | Regression analysis | Determine the possible range of slope safety factor and the relative influence of other rock and soil parameters (such as topsoil depth and rainfall) through the statistical analysis combined with numerical simulation | A database of particle size distribution, in-situ moisture content, Atterberg, and direct shear box test results was set up. |
| References | Research Content | Model Used | Method | Conclusion |
|---|---|---|---|---|
| Tehrany, M.S. et al. [145] | Evaluation of flood sensitivity | Support vector machine (SVM) and frequency ratio (FR) | Propose a new integration method, in which the spatial modeling is established in the flood sensitivity evaluation by integrating support vector machine (SVM) and frequency ratio (FR) | The proposed integration method has fast, accurate, and reasonable effectiveness in the flood sensitivity evaluation. |
| Huang, L. et al. [146] | Weather early warning of precipitation-induced landslides | Deep learning | Propose deep belief network (DBN) method with Softmax classifier and Dropout mechanism, in which the Softmax classifier is added to the top of the DBN neural network to improve the prediction accuracy | Compared with the existing BP neural network algorithm and the BP algorithm based on particle swarm optimizer (PSO-BP) algorithm, the newly proposed method has higher accuracy and better technical performance. |
| Luo, X. et al. [147] | Generation of landslide sensitivity map | Random subspace (RS) and logistic model tree (LMT) | Propose a hybrid machine learning method RSLMT, in which the landslide sensitivity map (LSM) is generated by coupled random subspace (RS) and logistic model tree (LMT) | The uncertainty introduced by the characteristics is input, and the over-fitting problem is solved by dimension reduction to improve the prediction rate of landslide occurrence. |
| Sahin, E.K. et al. [148] | Landslide sensitivity map | Integration method based on regression tree | Draw landslide sensitivity maps by three integration methods based on regression tree such as gradient boosting machine (GBM), extreme gradient boosting (XGBoost), and random forest (RF) | The prediction ability of the model created by the optimal factor combination is the highest. |
| Di Napoli, M. et al. [149] | Statistics of landslide sensitivity map | ML algorithm of artificial neural network, generalized lifting model, and maximum entropy | A new methodology is proposed and tested in the study area, and the eliciting factor is selected for evaluation by a variance inflation factor | Integrated modeling based on artificial neural network, generalized boosting model, and maximum entropy ML algorithm, showing higher reliability. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Z.; Liu, C.; Nie, R.; Zhang, W.; Zhang, L.; Zhang, Z.; Li, W.; Liu, G.; Dai, X.; Zhang, D.; et al. Research on Uncertainty of Landslide Susceptibility Prediction—Bibliometrics and Knowledge Graph Analysis. Remote Sens. 2022, 14, 3879. https://doi.org/10.3390/rs14163879
Yang Z, Liu C, Nie R, Zhang W, Zhang L, Zhang Z, Li W, Liu G, Dai X, Zhang D, et al. Research on Uncertainty of Landslide Susceptibility Prediction—Bibliometrics and Knowledge Graph Analysis. Remote Sensing. 2022; 14(16):3879. https://doi.org/10.3390/rs14163879
Chicago/Turabian StyleYang, Zhengli, Chao Liu, Ruihua Nie, Wanchang Zhang, Leili Zhang, Zhijie Zhang, Weile Li, Gang Liu, Xiaoai Dai, Donghui Zhang, and et al. 2022. "Research on Uncertainty of Landslide Susceptibility Prediction—Bibliometrics and Knowledge Graph Analysis" Remote Sensing 14, no. 16: 3879. https://doi.org/10.3390/rs14163879
APA StyleYang, Z., Liu, C., Nie, R., Zhang, W., Zhang, L., Zhang, Z., Li, W., Liu, G., Dai, X., Zhang, D., Zhang, M., Miao, S., Fu, X., Ren, Z., & Lu, H. (2022). Research on Uncertainty of Landslide Susceptibility Prediction—Bibliometrics and Knowledge Graph Analysis. Remote Sensing, 14(16), 3879. https://doi.org/10.3390/rs14163879