
Image-Based Obstacle Detection Methods for the Safe Navigation of Unmanned Vehicles: A Review




Abstract
1. Introduction
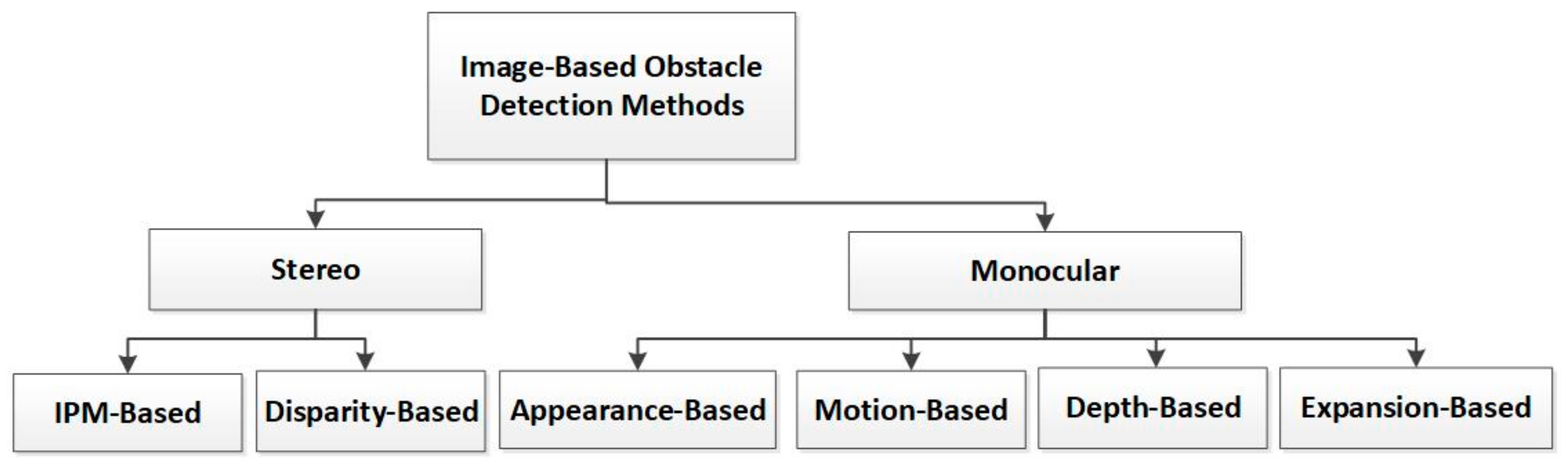
2. Classification of Obstacle Detection Techniques
- (a)
- Narrow and small obstacle detection
- (b)
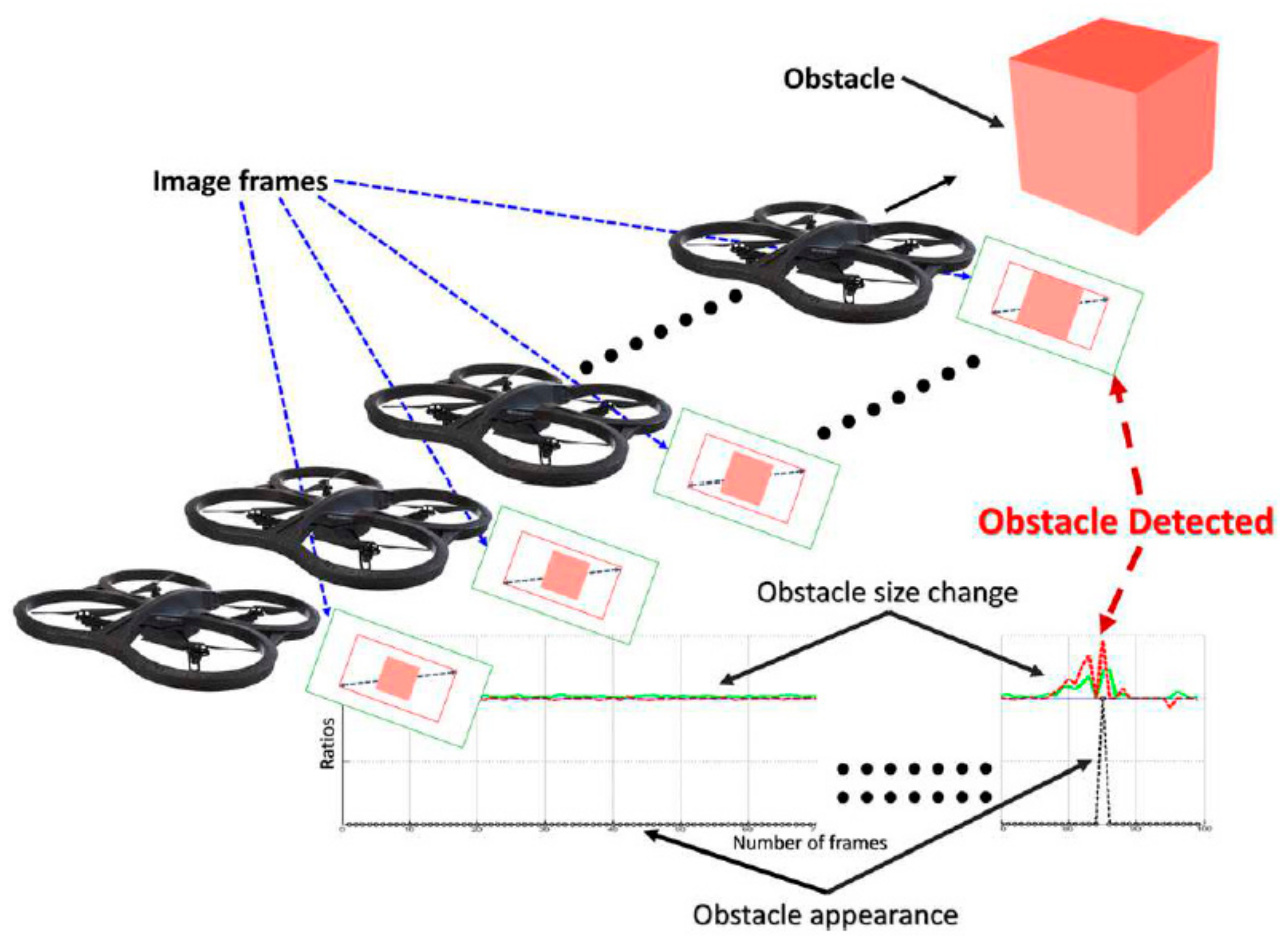
- Moving obstacle detection
- (c)
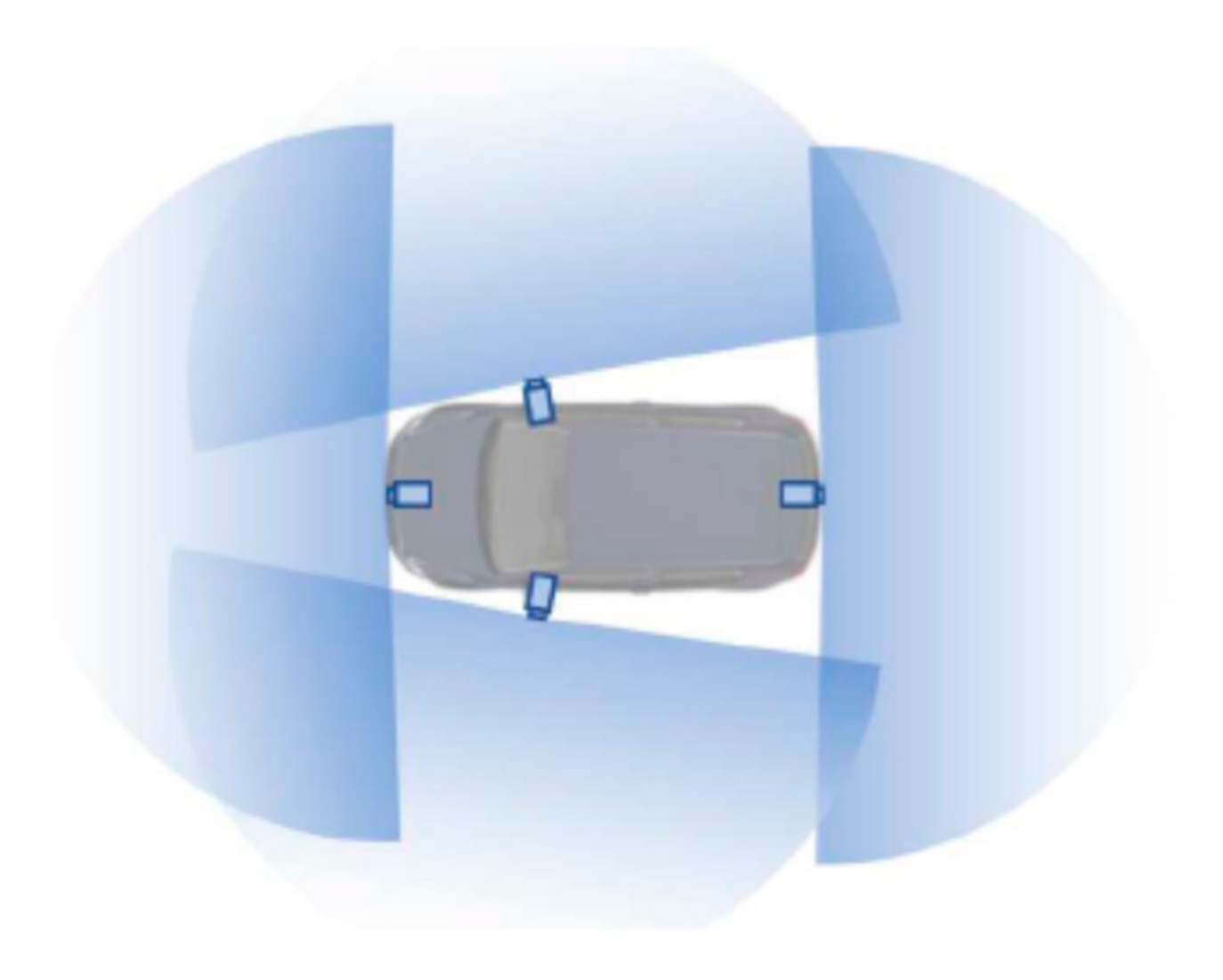
- Obstacle detection in all directions
- (d)
- Fast/real-time obstacle detection
3. Monocular Obstacle Detection Techniques
3.1. Appearance-Based
3.2. Motion-Based
3.3. Depth-Based
3.4. Expansion–Based
3.5. Summary
4. Stereo-Based Obstacle Detection Techniques
4.1. IPM–Based Method
4.2. Disparity Histogram-Based
4.2.1. Disparity Histogram-Based Obstacle Detection for Terrestrial Robots
4.2.2. Disparity Histogram-Based Obstacle Detection for Aerial Robots
4.3. Summary
5. Discussion and Prospects
6. Conclusions and Suggestions for Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Colomina, I.; Molina, P. Unmanned aerial systems for photogrammetry and remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2014, 92, 79–97. [Google Scholar] [CrossRef]
- Reinoso, J.; Gonçalves, J.; Pereira, C.; Bleninger, T. Cartography for Civil Engineering Projects: Photogrammetry Supported by Unmanned Aerial Vehicles. Iran. J. Sci. Technol. Trans. Civ. Eng. 2018, 42, 91–96. [Google Scholar] [CrossRef]
- Janoušek, J.; Jambor, V.; Marcoň, P.; Dohnal, P.; Synková, H.; Fiala, P. Using UAV-Based Photogrammetry to Obtain Correlation between the Vegetation Indices and Chemical Analysis of Agricultural Crops. Remote Sens. 2021, 13, 1878. [Google Scholar] [CrossRef]
- Barry, A.J.; Florence, P.R.; Tedrake, R. High-speed autonomous obstacle avoidance with pushbroom stereo. J. Field Robot. 2018, 35, 52–68. [Google Scholar] [CrossRef]
- Lee, H.; Ho, H.; Zhou, Y. Deep Learning-based Monocular Obstacle Avoidance for Unmanned Aerial Vehicle Navigation in Tree Plantations. J. Intell. Robot. Syst. 2021, 101, 5. [Google Scholar] [CrossRef]
- Toth, C.; Jóźków, G. Remote sensing platforms and sensors: A survey. ISPRS J. Photogramm. Remote Sens. 2016, 115, 22–36. [Google Scholar] [CrossRef]
- Goodin, C.; Carrillo, J.; Monroe, J.G.; Carruth, D.W.; Hudson, C.R. An Analytic Model for Negative Obstacle Detection with Lidar and Numerical Validation Using Physics-Based Simulation. Sensors 2021, 21, 3211. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.-w.; Zheng, B.-y.; Wang, C.; Zhao, C.-h.; Hou, X.-l.; Pan, Q.; Xu, Z. A survey on multi-sensor fusion based obstacle detection for intelligent ground vehicles in off-road environments. Front. Inf. Technol. Electron. Eng. 2020, 21, 675–692. [Google Scholar] [CrossRef]
- John, V.; Mita, S. Deep Feature-Level Sensor Fusion Using Skip Connections for Real-Time Object Detection in Autonomous Driving. Electronics 2021, 10, 424. [Google Scholar] [CrossRef]
- Serna, A.; Marcotegui, B. Urban accessibility diagnosis from mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2013, 84, 23–32. [Google Scholar] [CrossRef]
- Díaz-Vilariño, L.; Boguslawski, P.; Khoshelham, K.; Lorenzo, H.; Mahdjoubi, L. INDOOR NAVIGATION FROM POINT CLOUDS: 3D MODELLING AND OBSTACLE DETECTION. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 275–281. [Google Scholar] [CrossRef]
- Li, F.; Wang, H.; Akwensi, P.H.; Kang, Z. Construction of Obstacle Element Map Based on Indoor Scene Recognition. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W13, 819–825. [Google Scholar] [CrossRef]
- Keramatian, A.; Gulisano, V.; Papatriantafilou, M.; Tsigas, P. Mad-c: Multi-stage approximate distributed cluster-combining for obstacle detection and localization. J. Parallel Distrib. Comput. 2021, 147, 248–267. [Google Scholar] [CrossRef]
- Giannì, C.; Balsi, M.; Esposito, S.; Fallavollita, P. Obstacle Detection System Involving Fusion of Multiple Sensor Technologies. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 127–134. [Google Scholar] [CrossRef]
- Xie, G.; Zhang, J.; Tang, J.; Zhao, H.; Sun, N.; Hu, M. Obstacle detection based on depth fusion of lidar and radar in challenging conditions. In Industrial Robot: The International Journal of Robotics Research and Application; Emerald Group Publishing Limited: Bradford, UK, 2021. [Google Scholar] [CrossRef]
- Qin, R.; Zhao, X.; Zhu, W.; Yang, Q.; He, B.; Li, G.; Yan, T. Multiple Receptive Field Network (MRF-Net) for Autonomous Underwater Vehicle Fishing Net Detection Using Forward-Looking Sonar Images. Sensors 2021, 21, 1933. [Google Scholar] [CrossRef]
- Yılmaz, E.; Özyer, S.T. Remote and Autonomous Controlled Robotic Car based on Arduino with Real Time Obstacle Detection and Avoidance. Univers. J. Eng. Sci. 2019, 7, 1–7. [Google Scholar] [CrossRef][Green Version]
- Singh, B.; Kapoor, M. A Framework for the Generation of Obstacle Data for the Study of Obstacle Detection by Ultrasonic Sensors. IEEE Sens. J. 2021, 21, 9475–9483. [Google Scholar] [CrossRef]
- Kucukyildiz, G.; Ocak, H.; Karakaya, S.; Sayli, O. Design and implementation of a multi sensor based brain computer interface for a robotic wheelchair. J. Intell. Robot. Syst. 2017, 87, 247–263. [Google Scholar] [CrossRef]
- Quaglia, G.; Visconte, C.; Scimmi, L.S.; Melchiorre, M.; Cavallone, P.; Pastorelli, S. Design of a UGV powered by solar energy for precision agriculture. Robotics 2020, 9, 13. [Google Scholar] [CrossRef]
- Pirasteh, S.; Shamsipour, G.; Liu, G.; Zhu, Q.; Chengming, Y. A new algorithm for landslide geometric and deformation analysis supported by digital elevation models. Earth Sci. Inform. 2020, 13, 361–375. [Google Scholar] [CrossRef]
- Ye, C.; Li, H.; Wei, R.; Wang, L.; Sui, T.; Bai, W.; Saied, P. Double Adaptive Intensity-Threshold Method for Uneven Lidar Data to Extract Road Markings. Photogramm. Eng. Remote Sens. 2021, 87, 639–648. [Google Scholar] [CrossRef]
- Li, H.; Ye, W.; Liu, J.; Tan, W.; Pirasteh, S.; Fatholahi, S.N.; Li, J. High-Resolution Terrain Modeling Using Airborne LiDAR Data with Transfer Learning. Remote Sens. 2021, 13, 3448. [Google Scholar] [CrossRef]
- Ghasemi, M.; Varshosaz, M.; Pirasteh, S.; Shamsipour, G. Optimizing Sector Ring Histogram of Oriented Gradients for human injured detection from drone images. Geomat. Nat. Hazards Risk 2021, 12, 581–604. [Google Scholar] [CrossRef]
- Yazdan, R.; Varshosaz, M.; Pirasteh, S.; Remondino, F. Using geometric constraints to improve performance of image classifiers for automatic segmentation of traffic signs. Geomatica 2021, 75, 28–50. [Google Scholar] [CrossRef]
- Al-Obaidi, A.S.M.; Al-Qassar, A.; Nasser, A.R.; Alkhayyat, A.; Humaidi, A.J.; Ibraheem, I.K. Embedded design and implementation of mobile robot for surveillance applications. Indones. J. Sci. Technol. 2021, 6, 427–440. [Google Scholar] [CrossRef]
- Foroutan, M.; Tian, W.; Goodin, C.T. Assessing impact of understory vegetation density on solid obstacle detection for off-road autonomous ground vehicles. ASME Lett. Dyn. Syst. Control. 2021, 1, 021008. [Google Scholar] [CrossRef]
- Han, S.; Jiang, Y.; Bai, Y. Fast-PGMED: Fast and Dense Elevation Determination for Earthwork Using Drone and Deep Learning. J. Constr. Eng. Manag. 2022, 148, 04022008. [Google Scholar] [CrossRef]
- Tondin Ferreira Dias, E.; Vieira Neto, H.; Schneider, F.K. A Compressed Sensing Approach for Multiple Obstacle Localisation Using Sonar Sensors in Air. Sensors 2020, 20, 5511. [Google Scholar] [CrossRef]
- Huh, S.; Cho, S.; Jung, Y.; Shim, D.H. Vision-based sense-and-avoid framework for unmanned aerial vehicles. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 3427–3439. [Google Scholar] [CrossRef]
- Aswini, N.; Krishna Kumar, E.; Uma, S. UAV and obstacle sensing techniques–a perspective. Int. J. Intell. Unmanned Syst. 2018, 6, 32–46. [Google Scholar] [CrossRef]
- Lee, T.-J.; Yi, D.-H.; Cho, D.-I. A monocular vision sensor-based obstacle detection algorithm for autonomous robots. Sensors 2016, 16, 311. [Google Scholar] [CrossRef] [PubMed]
- Zahran, S.; Moussa, A.M.; Sesay, A.B.; El-Sheimy, N. A new velocity meter based on Hall effect sensors for UAV indoor navigation. IEEE Sens. J. 2018, 19, 3067–3076. [Google Scholar] [CrossRef]
- Mashaly, A.S.; Wang, Y.; Liu, Q. Efficient sky segmentation approach for small UAV autonomous obstacles avoidance in cluttered environment. In Proceedings of the Geoscience and Remote Sensing Symposium (IGARSS), 2016 IEEE International, Beijing, China, 10–15 July 2016; pp. 6710–6713. [Google Scholar]
- Al-Kaff, A.; García, F.; Martín, D.; De La Escalera, A.; Armingol, J.M. Obstacle detection and avoidance system based on monocular camera and size expansion algorithm for UAVs. Sensors 2017, 17, 1061. [Google Scholar] [CrossRef]
- Huh, K.; Park, J.; Hwang, J.; Hong, D. A stereo vision-based obstacle detection system in vehicles. Opt. Lasers Eng. 2008, 46, 168–178. [Google Scholar] [CrossRef]
- Padhy, R.P.; Choudhury, S.K.; Sa, P.K.; Bakshi, S. Obstacle Avoidance for Unmanned Aerial Vehicles: Using Visual Features in Unknown Environments. IEEE Consum. Electron. Mag. 2019, 8, 74–80. [Google Scholar] [CrossRef]
- McGuire, K.; de Croon, G.; De Wagter, C.; Tuyls, K.; Kappen, H.J. Efficient Optical Flow and Stereo Vision for Velocity Estimation and Obstacle Avoidance on an Autonomous Pocket Drone. IEEE Robot. Autom. Lett. 2017, 2, 1070–1076. [Google Scholar] [CrossRef]
- Sun, B.; Li, W.; Liu, H.; Yan, J.; Gao, S.; Feng, P. Obstacle Detection of Intelligent Vehicle Based on Fusion of Lidar and Machine Vision. Eng. Lett. 2021, 29, EL_29_2_41. [Google Scholar]
- Ristić-Durrant, D.; Franke, M.; Michels, K. A Review of Vision-Based On-Board Obstacle Detection and Distance Estimation in Railways. Sensors 2021, 21, 3452. [Google Scholar] [CrossRef]
- Nobile, L.; Randazzo, M.; Colledanchise, M.; Monorchio, L.; Villa, W.; Puja, F.; Natale, L. Active Exploration for Obstacle Detection on a Mobile Humanoid Robot. Actuators 2021, 10, 205. [Google Scholar] [CrossRef]
- Yu, X.; Marinov, M. A study on recent developments and issues with obstacle detection systems for automated vehicles. Sustainability 2020, 12, 3281. [Google Scholar] [CrossRef]
- Yeong, D.J.; Velasco-Hernandez, G.; Barry, J.; Walsh, J. Sensor and sensor fusion technology in autonomous vehicles: A review. Sensors 2021, 21, 2140. [Google Scholar] [CrossRef] [PubMed]
- Nieuwenhuisen, M.; Droeschel, D.; Schneider, J.; Holz, D.; Labe, T.; Behnke, S. Multimodal obstacle detection and collision avoidance for micro aerial vehicles. In Proceedings of the Mobile Robots (ECMR), 2013 European Conference on Mobile Robots, Residència d’Investigadors, Barcelona, Spain, 25 September 2013; pp. 7–12. [Google Scholar]
- Droeschel, D.; Nieuwenhuisen, M.; Beul, M.; Holz, D.; Stückler, J.; Behnke, S. Multilayered mapping and navigation for autonomous micro aerial vehicles. J. Field Robot. 2016, 33, 451–475. [Google Scholar] [CrossRef]
- D’souza, M.M.; Agrawal, A.; Tina, V.; HR, V.; Navya, T. Autonomous Walking with Guiding Stick for the Blind Using Echolocation and Image Processing. Methodology 2019, 7, 66–71. [Google Scholar] [CrossRef]
- Carrio, A.; Lin, Y.; Saripalli, S.; Campoy, P. Obstacle detection system for small UAVs using ADS-B and thermal imaging. J. Intell. Robot. Syst. 2017, 88, 583–595. [Google Scholar] [CrossRef]
- Beul, M.; Krombach, N.; Nieuwenhuisen, M.; Droeschel, D.; Behnke, S. Autonomous navigation in a warehouse with a cognitive micro aerial vehicle. In Robot Operating System (ROS); Springer: Berlin/Heidelberg, Germany, 2017; pp. 487–524. [Google Scholar]
- John, V.; Nithilan, M.; Mita, S.; Tehrani, H.; Sudheesh, R.; Lalu, P. So-net: Joint semantic segmentation and obstacle detection using deep fusion of monocular camera and radar. In Proceedings of the Pacific-Rim Symposium on Image and Video Technology, Sydney, NSW, Australia, 18–22 November 2019; pp. 138–148. [Google Scholar]
- Kragh, M.; Underwood, J. Multi-Modal Obstacle Detection in Unstructured Environments with Conditional Random Fields. J. Field Robot. 2017, 37, 53–72. [Google Scholar] [CrossRef]
- Singh, Y.; Kaur, L. Obstacle Detection Techniques in Outdoor Environment: Process, Study and Analysis. Int. J. Image Graph. Signal Processing 2017, 9, 35–53. [Google Scholar] [CrossRef][Green Version]
- Qiu, Z.; Zhao, N.; Zhou, L.; Wang, M.; Yang, L.; Fang, H.; He, Y.; Liu, Y. Vision-based moving obstacle detection and tracking in paddy field using improved yolov3 and deep SORT. Sensors 2020, 20, 4082. [Google Scholar] [CrossRef]
- Gharani, P.; Karimi, H.A. Context-aware obstacle detection for navigation by visually impaired. Image Vis. Comput. 2017, 64, 103–115. [Google Scholar] [CrossRef]
- Hatch, K.; Mern, J.M.; Kochenderfer, M.J. Obstacle Avoidance Using a Monocular Camera. In Proceedings of the AIAA Scitech 2021 Forum, Virtual Event, 11–22 January 2021; p. 0269. [Google Scholar]
- Badrloo, S.; Varshosaz, M. Monocular vision based obstacle detection. Earth Obs. Geomat. Eng. 2017, 1, 122–130. [Google Scholar] [CrossRef]
- Ulrich, I.; Nourbakhsh, I. Appearance-based obstacle detection with monocular color vision. In Proceedings of the AAAI/IAAI, Austin, TX, USA, 30 July 2000; pp. 866–871. [Google Scholar]
- Liu, J.; Li, H.; Liu, J.; Xie, S.; Luo, J. Real-Time Monocular Obstacle Detection Based on Horizon Line and Saliency Estimation for Unmanned Surface Vehicles. Mob. Netw. Appl. 2021, 26, 1372–1385. [Google Scholar] [CrossRef]
- Shih An, L.; Chou, L.-H.; Chang, T.-H.; Yang, C.-H.; Chang, Y.-C. Obstacle Avoidance of Mobile Robot Based on HyperOmni Vision. Sens. Mater. 2019, 31, 1021. [Google Scholar] [CrossRef]
- Wang, S.-H.; Li, X.-X. A Real-Time Monocular Vision-Based Obstacle Detection. In Proceedings of the 2020 6th International Conference on Control, Automation and Robotics (ICCAR), Singapore, 20–23 April 2020; pp. 695–699. [Google Scholar]
- Talele, A.; Patil, A.; Barse, B. Detection of real time objects using TensorFlow and OpenCV. Asian J. Converg. Technol. (AJCT) 2019, 5. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M. {TensorFlow}: A System for {Large-Scale} Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Bradski, G. The openCV library. In Dr. Dobb’s Journal: Software Tools for the Professional Programmer; M & T Pub., the University of Michigan: Ann Arbor, MI, USA, 2000; Volume 25, pp. 120–123. [Google Scholar]
- Rane, M.; Patil, A.; Barse, B. Real object detection using TensorFlow. In ICCCE 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 39–45. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, D.; Zou, Z.; Chen, Y.; Liu, B.; Yao, X.; Shan, S. Obstacle detection of rail transit based on deep learning. Measurement 2021, 176, 109241. [Google Scholar] [CrossRef]
- He, Y.; Liu, Z. A Feature Fusion Method to Improve the Driving Obstacle Detection under Foggy Weather. IEEE Trans. Transp. Electrif. 2021, 7, 2505–2515. [Google Scholar] [CrossRef]
- Liu, J.; Li, H.; Luo, J.; Xie, S.; Sun, Y. Efficient obstacle detection based on prior estimation network and spatially constrained mixture model for unmanned surface vehicles. J. Field Robot. 2021, 38, 212–228. [Google Scholar] [CrossRef]
- de Croon, G.; De Wagter, C. Learning what is above and what is below: Horizon approach to monocular obstacle detection. arXiv 2018, arXiv:1806.08007. [Google Scholar]
- Zeng, Y.; Zhao, F.; Wang, G.; Zhang, L.; Xu, B. Brain-Inspired Obstacle Detection Based on the Biological Visual Pathway. In Proceedings of the International Conference on Brain and Health Informatics, Omaha, NE, USA, 13–16 October 2016; pp. 355–364. [Google Scholar]
- Jia, B.; Liu, R.; Zhu, M. Real-time obstacle detection with motion features using monocular vision. Vis. Comput. 2015, 31, 281–293. [Google Scholar] [CrossRef]
- Ohnishi, N.; Imiya, A. Appearance-based navigation and homing for autonomous mobile robot. Image Vis. Comput. 2013, 31, 511–532. [Google Scholar] [CrossRef]
- Tsai, C.-C.; Chang, C.-W.; Tao, C.-W. Vision-Based Obstacle Detection for Mobile Robot in Outdoor Environment. J. Inf. Sci. Eng. 2018, 34, 21–34. [Google Scholar]
- Gunn, S.R. Support vector machines for classification and regression. ISIS Tech. Rep. 1998, 14, 5–16. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- de Croon, G.; De Wagter, C.; Seidl, T. Enhancing optical-flow-based control by learning visual appearance cues for flying robots. Nat. Mach. Intell. 2021, 3, 33–41. [Google Scholar] [CrossRef]
- Urban, D.; Caplier, A. Time- and Resource-Efficient Time-to-Collision Forecasting for Indoor Pedestrian Obstacles Avoidance. J. Imaging 2021, 7, 61. [Google Scholar] [CrossRef] [PubMed]
- Nalpantidis, L.; Gasteratos, A. Stereo vision depth estimation methods for robotic applications. In Depth Map and 3D Imaging Applications: Algorithms and Technologies; IGI Global: Hershey/Derry/Dauphin, PA, USA, 2012; pp. 397–417. [Google Scholar]
- Lee, J.; Jeong, J.; Cho, J.; Yoo, D.; Lee, B.; Lee, B. Deep neural network for multi-depth hologram generation and its training strategy. Opt. Express 2020, 28, 27137–27154. [Google Scholar] [CrossRef] [PubMed]
- Almalioglu, Y.; Saputra, M.R.U.; De Gusmao, P.P.; Markham, A.; Trigoni, N. GANVO: Unsupervised deep monocular visual odometry and depth estimation with generative adversarial networks. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Colombo, Sri Lanka, 9–10 May 2019; pp. 5474–5480. [Google Scholar]
- Kim, D.; Ga, W.; Ahn, P.; Joo, D.; Chun, S.; Kim, J. Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth. arXiv 2022, arXiv:2201.07436. [Google Scholar]
- Gao, W.; Wang, K.; Ding, W.; Gao, F.; Qin, T.; Shen, S. Autonomous aerial robot using dual-fisheye cameras. J. Field Robot. 2020, 37, 497–514. [Google Scholar] [CrossRef]
- Silva, A.; Mendonça, R.; Santana, P. Monocular Trail Detection and Tracking Aided by Visual SLAM for Small Unmanned Aerial Vehicles. J. Intell. Robot. Syst. 2020, 97, 531–551. [Google Scholar] [CrossRef]
- Häne, C.; Heng, L.; Lee, G.H.; Fraundorfer, F.; Furgale, P.; Sattler, T.; Pollefeys, M. 3D visual perception for self-driving cars using a multi-camera system: Calibration, mapping, localization, and obstacle detection. Image Vis. Comput. 2017, 68, 14–27. [Google Scholar] [CrossRef]
- Lin, Y.; Gao, F.; Qin, T.; Gao, W.; Liu, T.; Wu, W.; Yang, Z.; Shen, S. Autonomous aerial navigation using monocular visual-inertial fusion. J. Field Robot. 2018, 35, 23–51. [Google Scholar] [CrossRef]
- Zhao, C.; Sun, Q.; Zhang, C.; Tang, Y.; Qian, F. Monocular depth estimation based on deep learning: An overview. Sci. China Technol. Sci. 2020, 63, 1612–1627. [Google Scholar] [CrossRef]
- Kumar, V.R.; Milz, S.; Simon, M.; Witt, C.; Amende, K.; Petzold, J.; Yogamani, S. Monocular Fisheye Camera Depth Estimation Using Semi-supervised Sparse Velodyne Data. arXiv 2018, arXiv:1803.06192. [Google Scholar] [CrossRef]
- Mancini, M.; Costante, G.; Valigi, P.; Ciarfuglia, T.A. J-MOD 2: Joint Monocular Obstacle Detection and Depth Estimation. IEEE Robot. Autom. Lett. 2018, 3, 1490–1497. [Google Scholar] [CrossRef]
- Haseeb, M.A.; Guan, J.; Ristic-Durrant, D.; Gräser, A. DisNet: A novel method for distance estimation from monocular camera. In Proceedings of the 10th Planning, Perception and Navigation for Intelligent Vehicles (PPNIV18), IROS, Madrid, Spain, 1 October 2018. [Google Scholar]
- Máttyus, G.; Luo, W.; Urtasun, R. Deeproadmapper: Extracting road topology from aerial images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3438–3446. [Google Scholar]
- Homayounfar, N.; Ma, W.-C.; Liang, J.; Wu, X.; Fan, J.; Urtasun, R. Dagmapper: Learning to map by discovering lane topology. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 16–17 June 2019; pp. 2911–2920. [Google Scholar]
- Maturana, D.; Chou, P.-W.; Uenoyama, M.; Scherer, S. Real-time semantic mapping for autonomous off-road navigation. In Proceedings of the Field and Service Robotics, Toronto, ON, Canada, 25 April 2018; pp. 335–350. [Google Scholar]
- Sengupta, S.; Sturgess, P.; Ladický, L.u.; Torr, P.H. Automatic dense visual semantic mapping from street-level imagery. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Algarve, Portugal, 7–12 October 2012; pp. 857–862. [Google Scholar]
- Gerke, M.; Xiao, J. Fusion of airborne laserscanning point clouds and images for supervised and unsupervised scene classification. ISPRS J. Photogramm. Remote Sens. 2014, 87, 78–92. [Google Scholar] [CrossRef]
- Seif, H.G.; Hu, X. Autonomous driving in the iCity—HD maps as a key challenge of the automotive industry. Engineering 2016, 2, 159–162. [Google Scholar] [CrossRef]
- Jiao, J. Machine learning assisted high-definition map creation. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; pp. 367–373. [Google Scholar]
- Ye, C.; Zhao, H.; Ma, L.; Jiang, H.; Li, H.; Wang, R.; Chapman, M.A.; Junior, J.M.; Li, J. Robust lane extraction from MLS point clouds towards HD maps especially in curve road. IEEE Trans. Intell. Transp. Syst. 2020, 23, 1505–1518. [Google Scholar] [CrossRef]
- Ming, Y.; Meng, X.; Fan, C.; Yu, H. Deep learning for monocular depth estimation: A review. Neurocomputing 2021, 438, 14–33. [Google Scholar] [CrossRef]
- Mori, T.; Scherer, S. First results in detecting and avoiding frontal obstacles from a monocular camera for micro unmanned aerial vehicles. In Proceedings of the Robotics and Automation (Icra), 2013 IEEE International Conference on, Karlsruhe, Germany, 6–10 May 2013; pp. 1750–1757. [Google Scholar]
- Aguilar, W.G.; Casaliglla, V.P.; Pólit, J.L. Obstacle avoidance based-visual navigation for micro aerial vehicles. Electronics 2017, 6, 10. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Escobar-Alvarez, H.D.; Johnson, N.; Hebble, T.; Klingebiel, K.; Quintero, S.A.; Regenstein, J.; Browning, N.A. R-ADVANCE: Rapid Adaptive Prediction for Vision-based Autonomous Navigation, Control, and Evasion. J. Field Robot. 2018, 35, 91–100. [Google Scholar] [CrossRef]
- Badrloo, S.; Varshosaz, M.; Pirasteh, S.; Li, J. A novel region-based expansion rate obstacle detection method for MAVs using a fisheye camera. Int. J. Appl. Earth Obs. Geoinf. 2022, 108, 102739. [Google Scholar] [CrossRef]
- Jung, H.; Lee, Y.; Kim, B.; Yoon, P.; Kim, J. Stereo vision-based forward obstacle detection. Int. J. Automot. Technol. 2007, 8, 493–504. [Google Scholar]
- Parmar, M.M.; Rawlo, R.R.; Shirke, J.L.; Sangam, S. Self-Driving Car. Int. J. Res. Appl. Sci. Eng. Technol. (IJRASET). 2022, 10, 2305–2309. [Google Scholar] [CrossRef]
- Wang, C.; Shi, Z.-k. A novel traffic stream detection method based on inverse perspective mapping. Procedia Eng. 2012, 29, 1938–1943. [Google Scholar] [CrossRef]
- Muad, A.M.; Hussain, A.; Samad, S.A.; Mustaffa, M.M.; Majlis, B.Y. Implementation of inverse perspective mapping algorithm for the development of an automatic lane tracking system. In Proceedings of the 2004 IEEE Region 10 Conference TENCON, Chiang Mai, Thailand, 21–24 November 2004; pp. 207–210. [Google Scholar]
- Kuo, L.-C.; Tai, C.-C. Robust Image-Based Water-Level Estimation Using Single-Camera Monitoring. IEEE Trans. Instrum. Meas. 2022, 71, 1–11. [Google Scholar] [CrossRef]
- Hu, Z.; Xiao, H.; Zhou, Z.; Li, N. Detection of parking slots occupation by temporal difference of inverse perspective mapping from vehicle-borne monocular camera. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2021, 235, 3119–3126. [Google Scholar] [CrossRef]
- Lin, C.-T.; Shen, T.-K.; Shou, Y.-W. Construction of fisheye lens inverse perspective mapping model and its applications of obstacle detection. EURASIP J. Adv. Signal Processing 2010, 2010, 296598. [Google Scholar] [CrossRef]
- Bertozzi, M.; Broggi, A. GOLD: A parallel real-time stereo vision system for generic obstacle and lane detection. IEEE Trans. Image Processing 1998, 7, 62–81. [Google Scholar] [CrossRef] [PubMed]
- Kim, C.-h.; Lee, T.-j. An application of stereo camera with two different FoVs for SLAM and obstacle detection. IFAC-PapersOnLine 2018, 51, 148–153. [Google Scholar] [CrossRef]
- Wang, H.; Yuan, K.; Zou, W.; Peng, Y. Real-time region-based obstacle detection with monocular vision. In Proceedings of the 2005 IEEE International Conference on Robotics and Biomimetics-ROBIO, Hong Kong, China, 5–9 July 2005; pp. 615–619. [Google Scholar]
- Fazl-Ersi, E.; Tsotsos, J.K. Region classification for robust floor detection in indoor environments. In Proceedings of the International Conference Image Analysis and Recognition, Halifax, NS, Canada, 6–8 July 2009; pp. 717–726. [Google Scholar]
- Cucchiara, R.; Perini, E.; Pistoni, G. Efficient Stereo Vision for Obstacle Detection and AGV Navigation. In Proceedings of the ICIAP, Modena, Italy, 10–14 September 2007; pp. 291–296. [Google Scholar]
- Tanveer, M.H.; Sgorbissa, A. An Inverse Perspective Mapping Approach using Monocular Camera of Pepper Humanoid Robot to Determine the Position of Other Moving Robot in Plane. In Proceedings of the ICINCO (2), Porto, Portugal, 29–31 July 2018; pp. 229–235. [Google Scholar]
- Song, W.; Xiong, G.; Cao, L.; Jiang, Y. Depth calculation and object detection using stereo vision with subpixel disparity and hog feature. In Advances in Information Technology and Education; Springer: Berlin/Heidelberg, Germany, 2011; pp. 489–494. [Google Scholar]
- Kim, D.; Choi, J.; Yoo, H.; Yang, U.; Sohn, K. Rear obstacle detection system with fisheye stereo camera using HCT. Expert Syst. Appl. 2015, 42, 6295–6305. [Google Scholar] [CrossRef]
- Ball, D.; Ross, P.; English, A.; Milani, P.; Richards, D.; Bate, A.; Upcroft, B.; Wyeth, G.; Corke, P. Farm Workers of the Future: Vision-Based Robotics for Broad-Acre Agriculture. IEEE Robot. Autom. Mag. 2017, 24, 97–107. [Google Scholar] [CrossRef]
- Salhi, M.S.; Amiri, H. Design on FPGA of an obstacle detection module over stereo image for robotic learning. Indian J. Eng. 2022, 19, 72–84. [Google Scholar]
- Huang, H.-C.; Hsieh, C.-T.; Yeh, C.-H. An indoor obstacle detection system using depth information and region growth. Sensors 2015, 15, 27116–27141. [Google Scholar] [CrossRef] [PubMed]
- Muhovič, J.; Bovcon, B.; Kristan, M.; Perš, J. Obstacle tracking for unmanned surface vessels using 3-D point cloud. IEEE J. Ocean. Eng. 2019, 45, 786–798. [Google Scholar] [CrossRef]
- Murmu, N.; Nandi, D. Lane and Obstacle Detection System Based on Single Camera-Based Stereo Vision System. In Applications of Advanced Computing in Systems; Springer: Berlin/Heidelberg, Germany, 2021; pp. 259–266. [Google Scholar]
- Sun, T.; Pan, W.; Wang, Y.; Liu, Y. Region of Interest Constrained Negative Obstacle Detection and Tracking With a Stereo Camera. IEEE Sens. J. 2022, 22, 3616–3625. [Google Scholar] [CrossRef]
- Dairi, A.; Harrou, F.; Senouci, M.; Sun, Y. Unsupervised obstacle detection in driving environments using deep-learning-based stereovision. Robot. Auton. Syst. 2018, 100, 287–301. [Google Scholar] [CrossRef]
- Zhang, J.; Hu, S.; Shi, H. Deep learning based object distance measurement method for binocular stereo vision blind area. Methods 2018, 9, 606–613. [Google Scholar] [CrossRef]
- Zhang, Y.; Song, J.; Ding, Y.; Yuan, Y.; Wei, H.-L. FSD-BRIEF: A Distorted BRIEF Descriptor for Fisheye Image Based on Spherical Perspective Model. Sensors 2021, 21, 1839. [Google Scholar] [CrossRef]
- Choe, J.; Joo, K.; Rameau, F.; Kweon, I.S. Stereo object matching network. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xian, China, 30 May–5 June 2021; pp. 12918–12924. [Google Scholar]
- Luo, W.; Schwing, A.G.; Urtasun, R. Efficient deep learning for stereo matching. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June 2016; pp. 5695–5703.
- Song, W.; Yang, Y.; Fu, M.; Li, Y.; Wang, M. Lane detection and classification for forward collision warning system based on stereo vision. IEEE Sens. J. 2018, 18, 5151–5163. [Google Scholar] [CrossRef]
- Haris, M.; Hou, J. Obstacle Detection and Safely Navigate the Autonomous Vehicle from Unexpected Obstacles on the Driving Lane. Sensors 2020, 20, 4719. [Google Scholar] [CrossRef]
- Mukherjee, A.; Adarsh, S.; Ramachandran, K. ROS-Based Pedestrian Detection and Distance Estimation Algorithm Using Stereo Vision, Leddar and CNN. In Intelligent System Design; Springer: Berlin/Heidelberg, Germany, 2021; pp. 117–127. [Google Scholar]
- Tijmons, S.; de Croon, G.C.; Remes, B.D.; De Wagter, C.; Mulder, M. Obstacle avoidance strategy using onboard stereo vision on a flapping wing mav. IEEE Trans. Robot. 2017, 33, 858–874. [Google Scholar] [CrossRef]
- Lin, J.; Zhu, H.; Alonso-Mora, J. Robust vision-based obstacle avoidance for micro aerial vehicles in dynamic environments. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 2682–2688. [Google Scholar]
- Grinberg, M.; Ruf, B. UAV Use Case: Real-Time Obstacle Avoidance System for Unmanned Aerial Vehicles Based on Stereo Vision. In Towards Ubiquitous Low-Power Image Processing Platforms; Springer: Berlin/Heidelberg, Germany, 2021; pp. 139–149. [Google Scholar]
- Rateke, T.; von Wangenheim, A. Passive vision road obstacle detection: A literature mapping. Int. J. Comput. Appl. 2020, 44, 376–395. [Google Scholar] [CrossRef]
- Wang, W.; Wang, S.; Guo, Y.; Zhao, Y. Obstacle detection method of unmanned electric locomotive in coal mine based on YOLOv3-4L. J. Electron. Imaging 2022, 31, 023032. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title | Ref | Applications |
|---|---|---|
| Design of a UGV powered by solar energy for precision agriculture | [20] | Agriculture |
| A new algorithm for landslide geometric and deformation analysis supported by digital elevation models | [21] | Automated derivation of landslide geometry |
| Double adaptive intensity-threshold method for uneven lidar data to extract road markings | [22] | Autonomous driving |
| High-resolution terrain modelling using airborne LiDAR data with transfer learning | [23] | Terrain modelling |
| Optimising sector ring histogram of oriented gradients for human injured detection from drone images | [24] | Finding injured people |
| Using geometric constraints to improve the performance of image classifiers for automatic segmentation of traffic signs | [25] | Autonomous driving |
| Embedded design and implementation of a mobile robot for surveillance applications | [26] | Surveillance |
| Assessing the impact of understory vegetation density on solid obstacle detection for off-road autonomous ground vehicles | [27] | Autonomous driving |
| Fast-PGMED: Fast and Dense Elevation Determination for Earthwork Using Drone and Deep Learning | [28] | Elevation determination |
| Title | Ref | Content |
|---|---|---|
| Multimodal obstacle detection and collision avoidance for micro aerial vehicles | [44] | Developing a lightweight 3D laser scanner and visual obstacle detection using wide-angle stereo cameras |
| Multilayered mapping and navigation for autonomous micro aerial vehicles | [45] | Integrating a three-dimensional (3D) laser scanner, two stereo camera pairs, and ultrasonic distance sensors |
| Autonomous walking with a guiding stick for the blind using echolocation and image processing | [46] | Using ultrasonic sensors, image sensors and a Smartphone app to navigate the user to the destination |
| Obstacle detection system for small UAVs using ads-b and thermal imaging. | [47] | Integrating a TIR camera and an Automatic Dependent SurveillanceBroadcast (ADS-B) receiver |
| Autonomous navigation in a warehouse with a cognitive micro aerial vehicle | [48] | Integrating a dual 3D laser scanner, three stereo camera pairs, an IMU, an RFID reader, and a powerful onboard computer running the ROS middleware |
| So-net: joint semantic segmentation and obstacle detection using a deep fusion of monocular camera and radar | [49] | Using radar and vision-based deep learning perception framework |
| Multimodal obstacle detection in unstructured environments with conditional random fields | [50] | Fusing lidar and camera |
| Deep feature-level sensor fusion using skip connections for real-time object detection in autonomous driving | [9] | Sensor fusion of the visible camera with the millimetre-wave radar and the thermal camera |
| Ref | Used for: | Principle | Strength(s) | Weakness(es) | NSOD | MOD | ODAD | FOD |
|---|---|---|---|---|---|---|---|---|
| [30] | UAV | Detection and tracking airborne obstacles in a complex background | Moving obstacle detection | Inability to detect stationary obstacles | - | ✓ | - | - |
| [34] | UAV | Sky segmentation | Efficiency in complex environments | Not separating far and near obstacles | - | - | - | - |
| [32] | Car | Inverse perspective mapping is used to obtain geometric cues for obstacle detection obstacle detection | Small and narrow obstacle detection | Camera installation at a little distance from the ground. Inefficiency for UAVs and cars | ✓ | - | - | - |
| [68] | Mobile robot | Self-supervised learning to find the horizon line | Efficiency in different environments | Unsuccessful in office environments | - | - | - | - |
| [58] | Mobile robot | Combining an improved dynamic window approach (IDWA) and an artificial potential field to avoid obstacles |
| Insufficient in real-world environments | - | - | ✓ | - |
| ||||||||
| [60] | Mobile robot | Use of TensorFlow and OpenCV | Real-time | The resolution of the camera is very poor, which affects the accuracy of obstacle detection | - | - | - | ✓ |
| [63] | Mobile robot | Use of TensorFlow | Real-time | Low-resolution images | - | - | - | ✓ |
| [52] | Agriculture machine | Use of improved YOLOv3 and Deep SORT | Moving obstacle detection Real-time | Requiring enriched training data is | - | ✓ | - | ✓ |
| [59] | Dual-lens camera sensor robot | Use of a local object background subtraction method |
| Incomplete obstacle detection | - | ✓ | - | ✓ |
| [65] | Train | Use of the improved-YOLOv4 network | High accuracy and real-time obstacle detection | The environment, the amount and type of data impact | - | - | - | ✓ |
| [57] | USV | Horizon line detection to detect obstacles below the estimated horizon line | Real-time | Inefficiency for cars and UAVs | - | - | - | ✓ |
| [66] | Car | Feature fusion to improve the performance of the camera sensor in obstacle detection under misty weather | Obstacle detection under foggy weather Real-time | Low accuracy | - | - | - | ✓ |
| [67] | USV | Semantic segmentation for real-time obstacle detection | Real-time | Weak navigation when there is a strong reflection and confusing obstacles | - | - | - | ✓ |
| Ref | Used for: | Principle | Strength(s) | Weakness(es) | NSOD | MOD | ODAD | FOD |
|---|---|---|---|---|---|---|---|---|
| [70] | Car | Use of motion features | Real-time performance by utilising feature points rather than all pixels | Algorithm failure occurs if there are too many miss detections or mismatched feature points | - | - | - | ✓ |
| [53] | Blind people | Computing optical flow and tracking certain points | Both moving and stationary obstacle detection | Incorrect detection of some points on lamps, floors, and reflective surfaces | - | - | - | - |
| [72] | Mobile robot | Combining obstacle points and salience map | Effective obstacle detection in outdoor environments | May not be used on UAVs that usually fly at high altitudes | - | - | - | - |
| Ref | Used for: | Principle | Strength(s) | Weakness(es) | NSOD | MOD | ODAD | FOD |
|---|---|---|---|---|---|---|---|---|
| [83] | Car | Depth map generation with motion stereo system | Obstacle detection in all directions | Inability to identify moving obstacles | - | - | ✓ | - |
| [84] | MAV | Depth estimation based on keyframes | Obstacle detection with wide FOV |
| - | - | ✓ | - |
| ||||||||
| [86] | Car | Use of CNN network | Obstacle detection in all directions | Need for appropriate training data | - | - | ✓ | - |
| [87] | UAV | Use of image features obtained via fine-tuning the VGG19 network | Fast obstacle detection | The need for adequate initial training | - | - | - | ✓ |
| [88] | - | Use of Multi Hidden-Layer Neural Network, named DisNet | Reliable estimation of distances in static railway scenes | Extraction of inaccurate object bounding boxes that limit obstacle detection | - | - | - | - |
| [54] | UAV | Use of hybrid neural network | Efficiency in a complex outdoor environment at comparatively high speeds | Poor performance due to noise | - | - | - | - |
| [76] | visually impaired | Focus on the Time-to-Collision network’s ability | Time-efficient | Inability to correctly detect different types of obstacles | - | - | - | ✓ |
| Ref | Used for: | Principle | Strength(s) | Weakness(es) | NSOD | MOD | ODAD | FOD |
|---|---|---|---|---|---|---|---|---|
| [69] | UAV | Brain-inspired rasterisation | Efficiency for both fixed and mobile cameras in a simple background | In the complex background, this approach does not apply to mobile robots | - | ✓ | - | - |
| [99] | compact MAV | Use of SURF | Reduced computational complexity | Weak in the identification of other obstacles such as trees | - | - | - | - |
| [35] | MAV | Use of keypoints scale ratio and convex hull area ratio | Can be used in complex environments |
| - | - | - | - |
| ||||||||
| [55] | UAV | Use of distance ratio | Ability to distinguish near-far obstacles | Moving the camera loses its effectiveness | - | - | - | - |
| [101] | MAV | Use of optical flow | Navigation in complex environments | Problems with the use of optical flow | - | - | - | - |
| [37] | UAV | Use of Euclidean distance expansion | Depth estimation from a single camera |
| - | - | - | - |
| ||||||||
| [5] | UAV | Use of Faster R-CNN and image heights of trees | Ability to detect trees | Unable to detect objects other than trees (e.g., people, cars) | - | - | - | ✓ |
| [102] | MAV | Use of regions expansion rate | Accurate and complete obstacle detection | Time-consuming | - | - | ✓ | - |
| Ref | Used for: | Principle | Strength(s) | Weakness(es) | NSOD | MOD | ODAD | FOD |
|---|---|---|---|---|---|---|---|---|
| [110] | Car | Use of the difference between the left and right IPM | Highly accurate |
| - | - | - | - |
| ||||||||
| [111] | Mobile robot | Use of stereo cameras with two distinct FOVs | low-cost | Low-resolution images | - | - | - | - |
| Ref | Used for: | Principle | Strength(s) | Weakness(es) | NSOD | MOD | ODAD | FOD | |
|---|---|---|---|---|---|---|---|---|---|
| [120] | Blind people | Remove the surface and solve the problems of over-segmentation | Effective in a low light environment | Cannot be used outdoors | - | - | - | ✓ | |
| [117] | Car | Presenting the HCT-based stereo matching method, | Real-time obstacle detection under a variety of lighting conditions |
| - | ✓ | ✓ | - | |
| |||||||||
| [118] | Agricultural cars | Describes a vision-based obstacle detection system that continually adapts to environmental and illumination variations | Obstacles are detected in a variety of lighting conditions | Unable to detect obstacles that have been disguised in their appearance or structure | - | - | - | - | |
| [119] | Car | Use of FPGA | Real-time | The communication between the modules is still to be optimised | - | - | - | ✓ | |
| [121] | USV | Use of 3-D Point Cloud | Real-time | Problem of detecting large objects (e.g., coast and piers) | - | - | - | ✓ | |
| [124] | Car | Use of unsupervised, deep-learning approaches | Real-time | Negative effect of high image noise on the method’s performance | - | - | - | ✓ | |
| [129] | Car | Use of convolutional neural network | lightweight stereo vision-based driving lane detection | Need appropriate training | - | - | - | ✓ | |
| [125] | Car | Use of deep learning and binocular vision | Real-time and effective | Detecting pedestrians and ignoring other obstacles such as cars, trees, etc. | - | - | - | ✓ | |
| [130] | Autonomous vehicle | Use of MRF | Small obstacle detection | Need to train the model on multiple training dataset | ✓ | - | - | ✓ | |
| [122] | Self-driving car | Generating a disparity map | Real-time | low-resolution camera | - | - | - | ✓ | |
| [131] | Car | Combining CNN and sensor fusion algorithms | Fast and credible results | Need appropriate training | - | - | - | ✓ | |
| [123] | Car | Use of 3D point cloud candidates and a variant of RANSAC | Road obstacle detection such as potholes and cracks | Incomplete obstacle detection due to 3D point cloud candidates selection | - | - | - | ✓ | |
| Ref | Used for: | Principle | Strength(s) | Weakness(es) | NSOD | MOD | ODAD | FOD |
|---|---|---|---|---|---|---|---|---|
| [38] | UAV | Computationally efficient optical flow and stereo algorithm | Reducing computational complexity to increase navigational efficiency |
| - | - | - | ✓ |
| ||||||||
| [132] | MAV | Use of only strong matched points and reduction of images resolution | Fast |
| - | - | - | ✓ |
| ||||||||
| [4] | UAV | Detecting only obstacles at a certain depth | Real-time | Instability due to the need for very exact camera calibration | - | - | - | ✓ |
| [133] | MAV | Depth estimation | Moving obstacle detection | The obstacle’s velocity estimation may be very noisy | - | ✓ | - | - |
| [134] | UAV | Computation of the U-disparity and V-disparity maps | Real-time | FPGAs have limited memory capacity | - | - | - | ✓ |
| Criteria | NSOD | MOD | ODAD | FOD | |
|---|---|---|---|---|---|
| Methods | |||||
| Monocular | Appearance-based | [32] | [30,52,59] | [58] | [52,57,59,60,63,65,66,67,135,136] |
| Motion-based | - | - | - | [70] | |
| Depth-based | - | - | [83,84,86] | [76,87] | |
| Expansion-based | - | [69] | - | [5] | |
| Stereo | [4,130] | [117,133] | [118] | [4,38,119,120,121,122,123,124,125,129,131,132,134] | |
| Criteria | Accuracy | Speed | Cost | |
|---|---|---|---|---|
| Methods | ||||
| Monocular | Appearance-based | * | *** | ** |
| Motion-based | * | * | ** | |
| Depth-based | ** | * | ** | |
| Expansion-based | *** | *** | ** | |
| Stereo | *** | * | * | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Badrloo, S.; Varshosaz, M.; Pirasteh, S.; Li, J. Image-Based Obstacle Detection Methods for the Safe Navigation of Unmanned Vehicles: A Review. Remote Sens. 2022, 14, 3824. https://doi.org/10.3390/rs14153824
Badrloo S, Varshosaz M, Pirasteh S, Li J. Image-Based Obstacle Detection Methods for the Safe Navigation of Unmanned Vehicles: A Review. Remote Sensing. 2022; 14(15):3824. https://doi.org/10.3390/rs14153824
Chicago/Turabian StyleBadrloo, Samira, Masood Varshosaz, Saied Pirasteh, and Jonathan Li. 2022. "Image-Based Obstacle Detection Methods for the Safe Navigation of Unmanned Vehicles: A Review" Remote Sensing 14, no. 15: 3824. https://doi.org/10.3390/rs14153824
APA StyleBadrloo, S., Varshosaz, M., Pirasteh, S., & Li, J. (2022). Image-Based Obstacle Detection Methods for the Safe Navigation of Unmanned Vehicles: A Review. Remote Sensing, 14(15), 3824. https://doi.org/10.3390/rs14153824