1. Introduction
Land use and cover change, which are closely related to human development and ecological changes, have long been core areas of global environmental change. A large number of land use research projects have provided knowledge and service support for global and regional land resource surveys [
1,
2], territorial spatial planning [
3], ecological and environmental assessments [
4,
5], and other governmental decision-making processes and scientific research. Accurate classification is the basis for conducting land cover change research. With the development of industrialization, traditional classification methods based on two-dimensional images can no longer meet the needs of researchers. There is an urgent need for more spatial information to allow for the development of detailed strategies. Therefore, Light Detection and Ranging (LiDAR) data, which can efficiently sense surface and terrain information, are widely used for land cover classification. LiDAR point clouds are a form of data storage.
Compared with two-dimensional images, airborne single-wavelength LiDAR systems can acquire surface information, but they cannot obtain fine classification results. Numerous studies have shown that the performance of single-wavelength LiDAR point clouds can be further improved by combining image information [
6,
7]. However, determining how to achieve the full fusion of information remains an important issue.
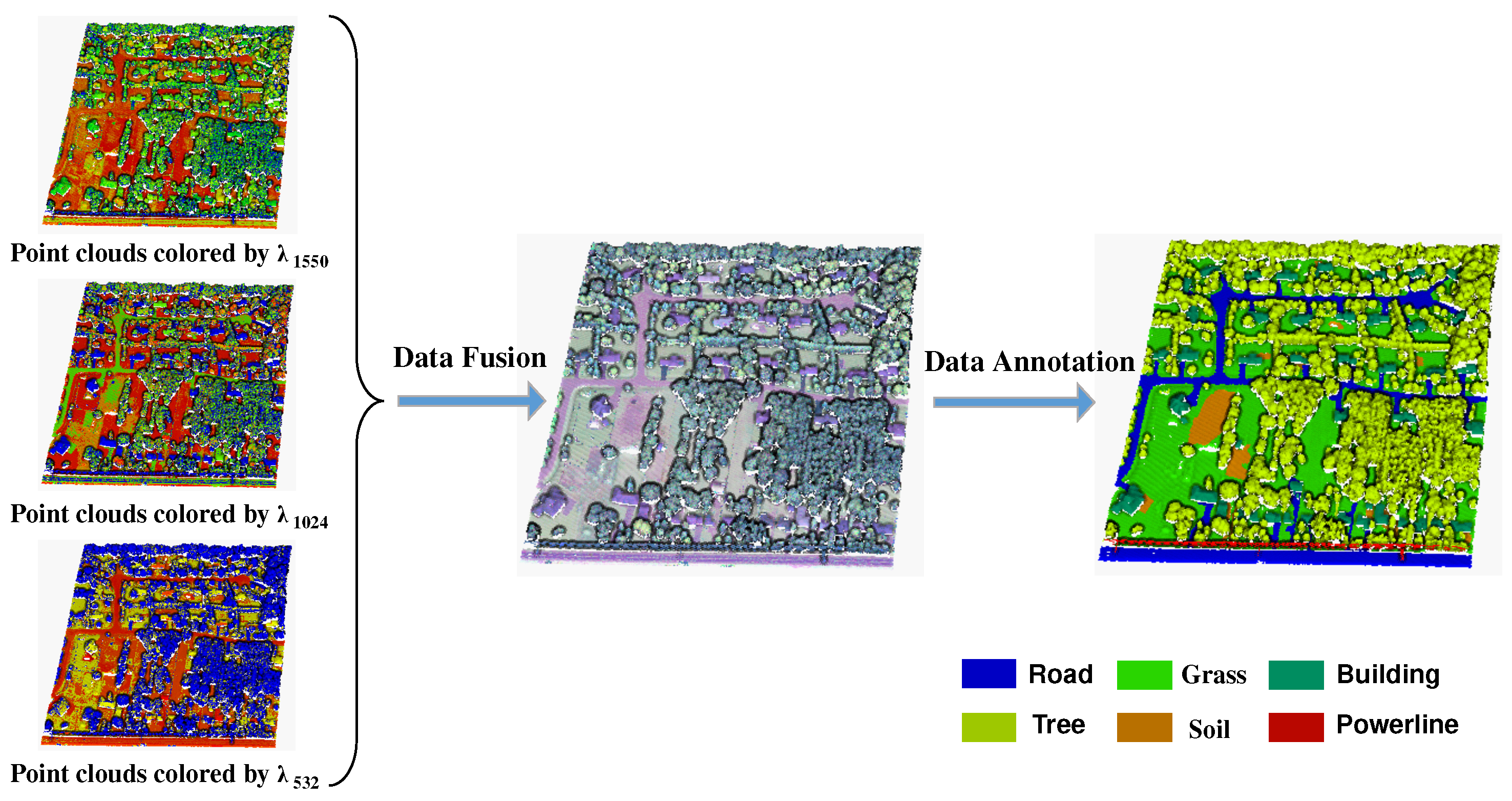
With the development of remote sensing technology, researchers have invented multispectral LiDAR systems that can collect multi-wavelength intensity information simultaneously, provide rich feature information about the target object, and avoid problems associated with data fusion. In 2014, Teledyne Optech developed the first multispectral three-wavelength airborne LiDAR system available for industrial and scientific use. In 2015, Wuhan University developed a four-wavelength LiDAR system. In recent years, multispectral point clouds have been widely used for land cover classification. Wichmann et al. [
8] explored the possibility of using multispectral LiDAR point clouds for land cover classification. Bakula et al. [
9] further evaluated the performance of multispectral LiDAR point clouds in classification tasks.
Determining how to make full use of multispectral LiDAR point clouds is an important issue. Classical machine learning algorithms are widely used as classifiers for land cover classification [
10], for example, through the maximum likelihood method [
9,
11,
12], support vector machine [
13,
14,
15], and random forest [
16,
17,
18] method. With the development of deep learning techniques, convolutional neural network-based algorithms [
19,
20,
21,
22,
23] have also been successfully applied to multispectral LiDAR point cloud classification. However, due to the disorder of point clouds, the original point clouds need to be transformed into structured data by voxelization or projection. This process inevitably increases the computational burden and leads to a loss of spatial information in some categories, which causes problems of large time consumption and inaccuracy. In 2017, Qi et al. proposed PointNet [
24] for the direct processing of conventional point clouds. Inspired by PointNet, researchers have proposed point-based deep learning methods for multispectral LiDAR point clouds. To obtain different channel weights, Jing et al. added the Squeeze-and-Excitation block to PointNet++ [
25], and SE-Pointnet++ [
26] was developed for the classification of multispectral LiDAR point clouds.
The successful application of Transformer [
27] in natural language processing and image processing has attracted researchers to explore its application in 3D point cloud analysis and its ability to achieve state-of-the-art performances in shape classification, part segmentation, semantic segmentation, and normal estimation. Although Transformer-based models can perform well with general point cloud datasets, optimal results are not always achieved with multispectral LiDAR data due to domain gaps [
28]. Therefore, we designed Transformer-based networks for multispectral LiDAR point cloud analysis. Our contributions are summarized as follows:
- (1)
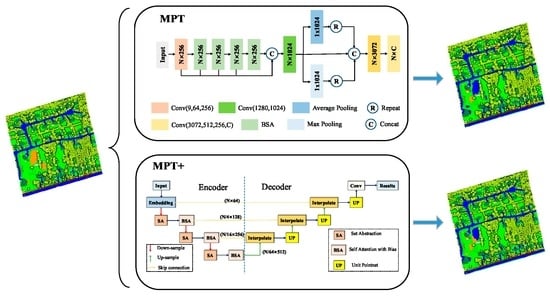
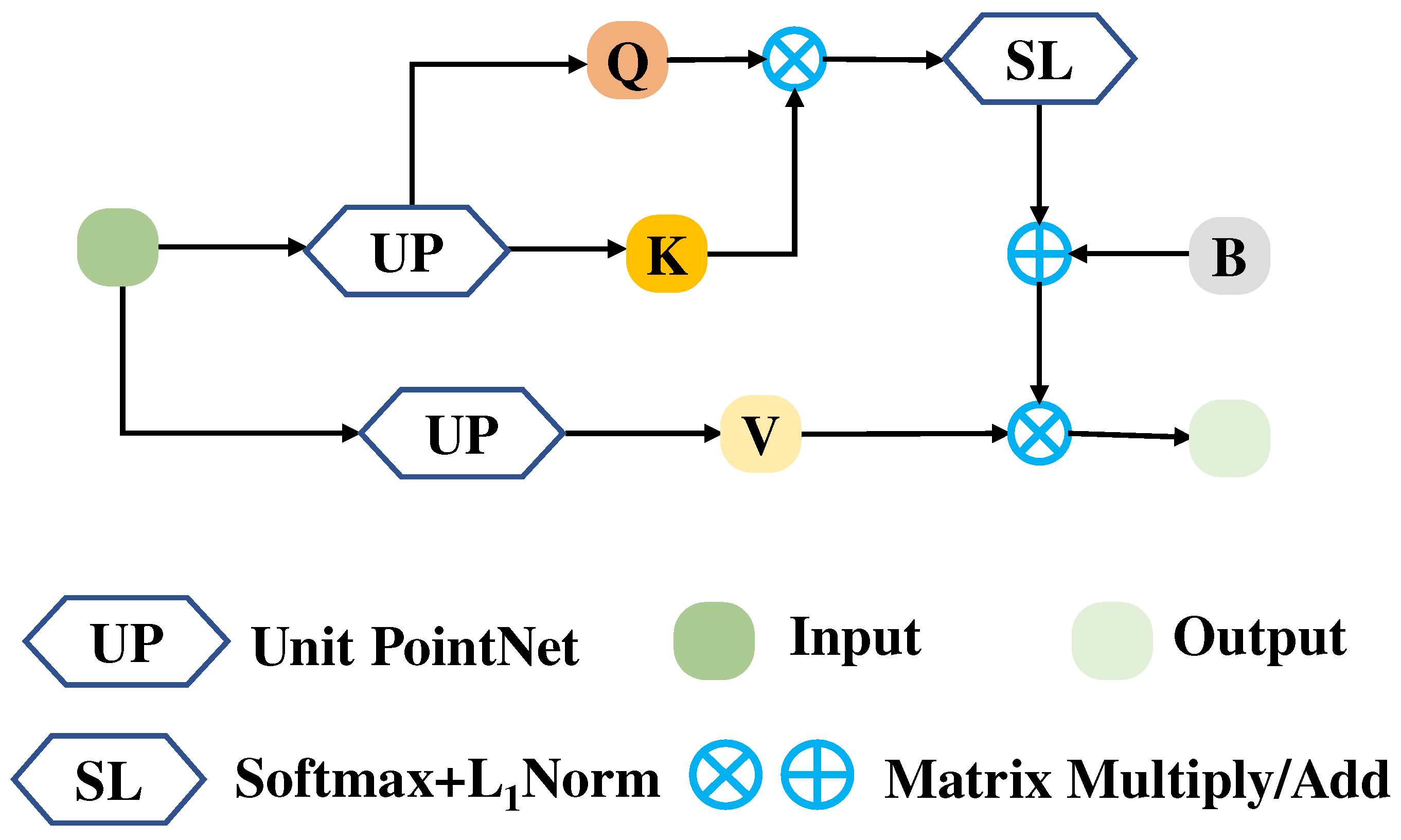
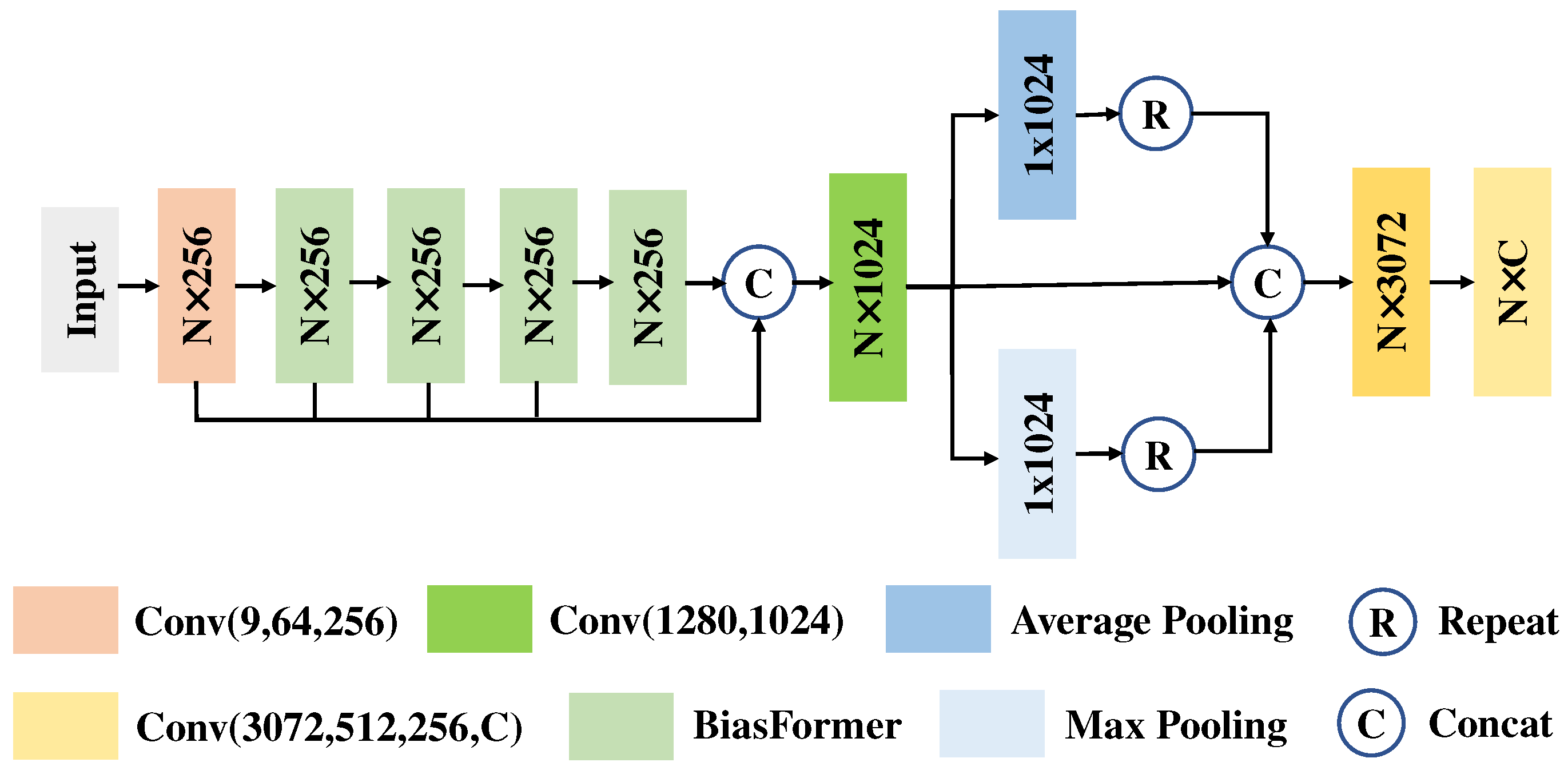
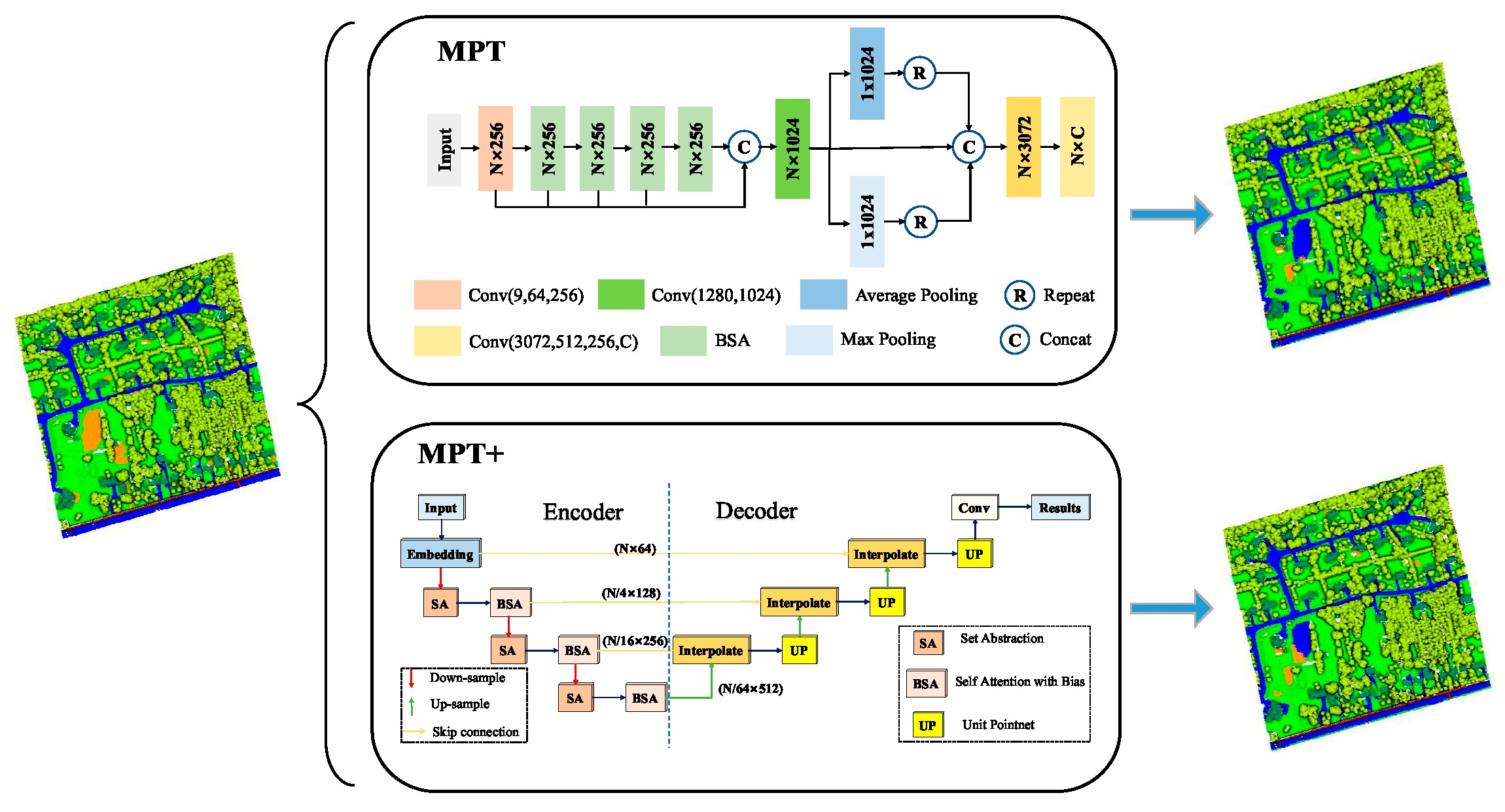
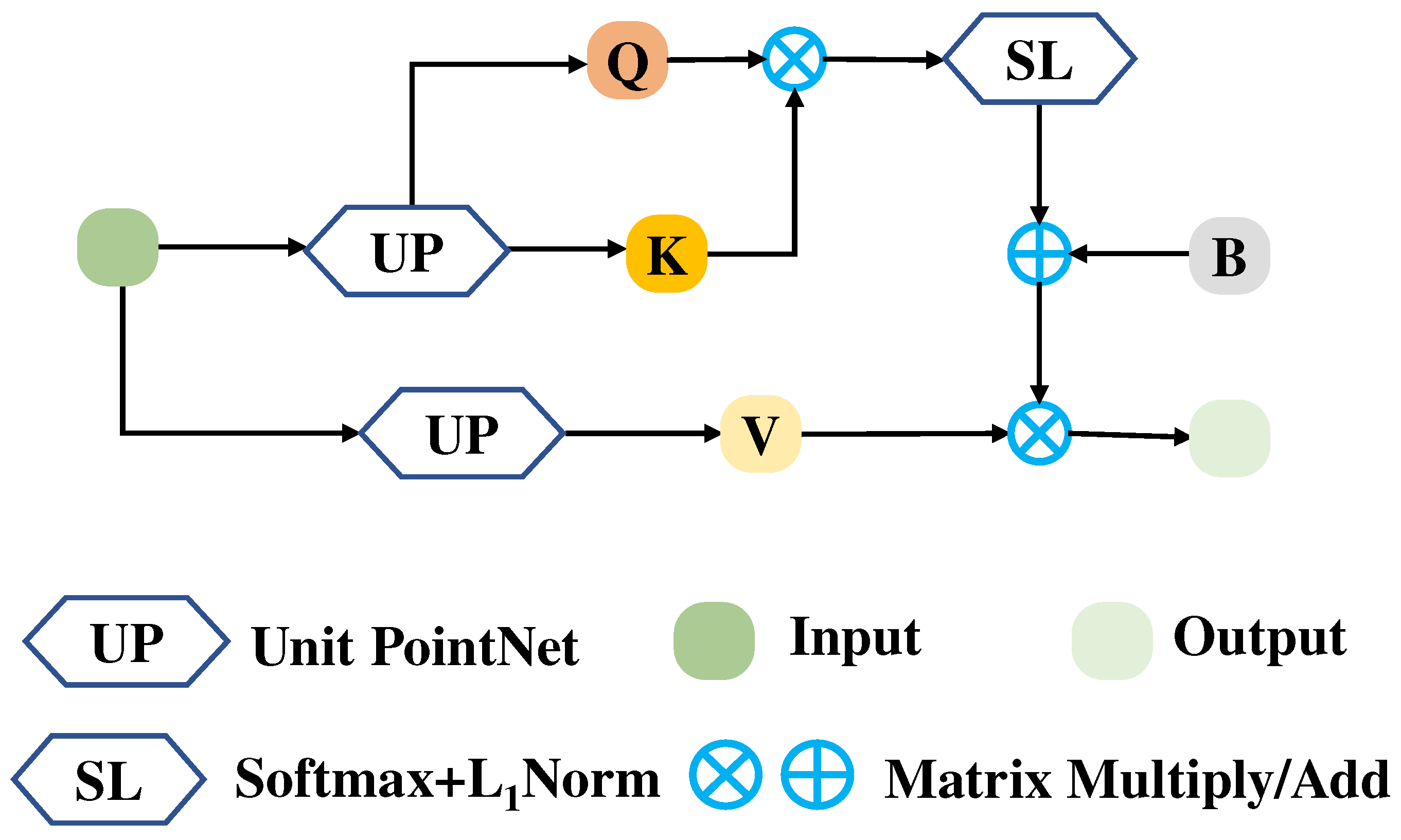
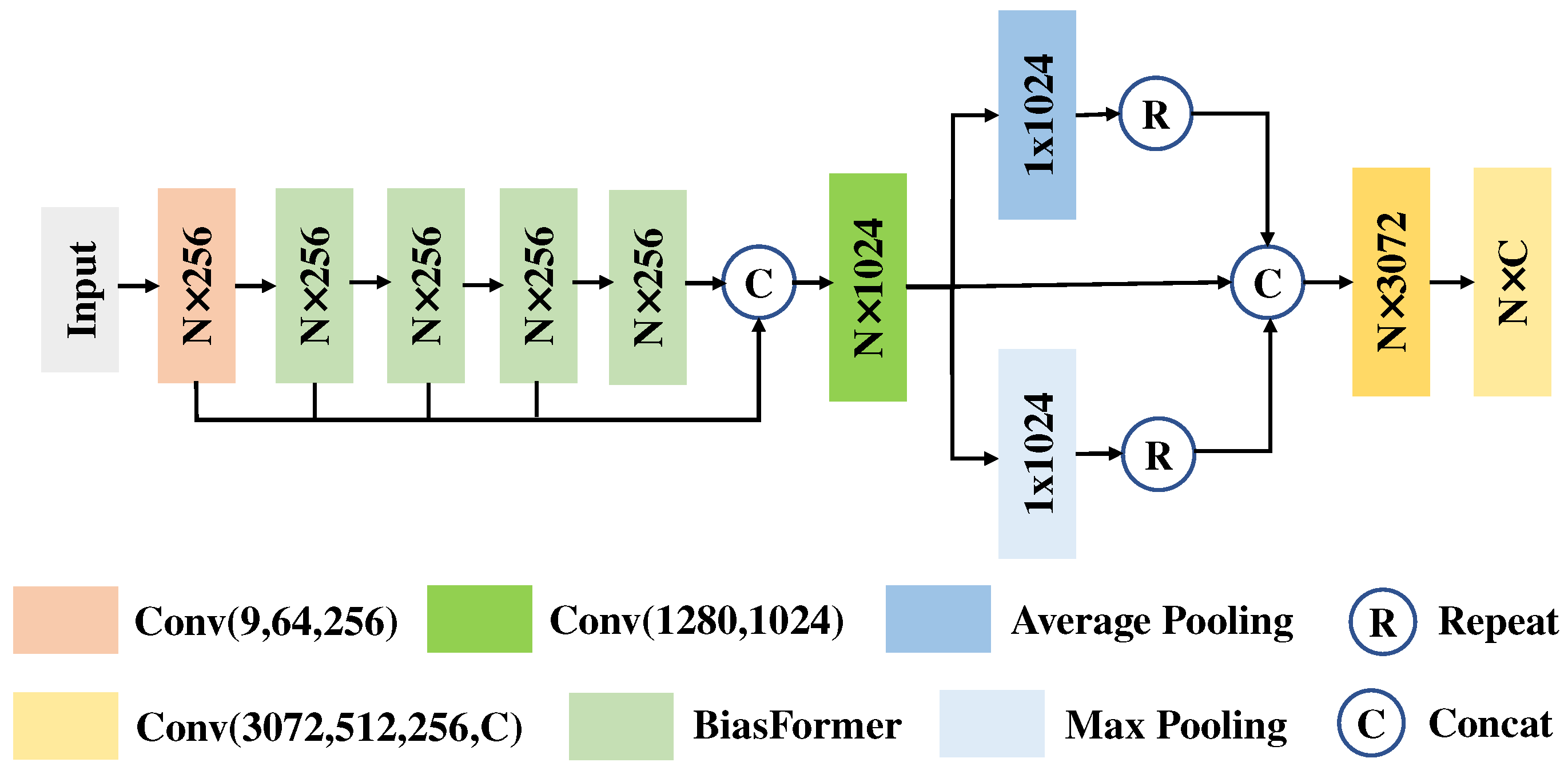
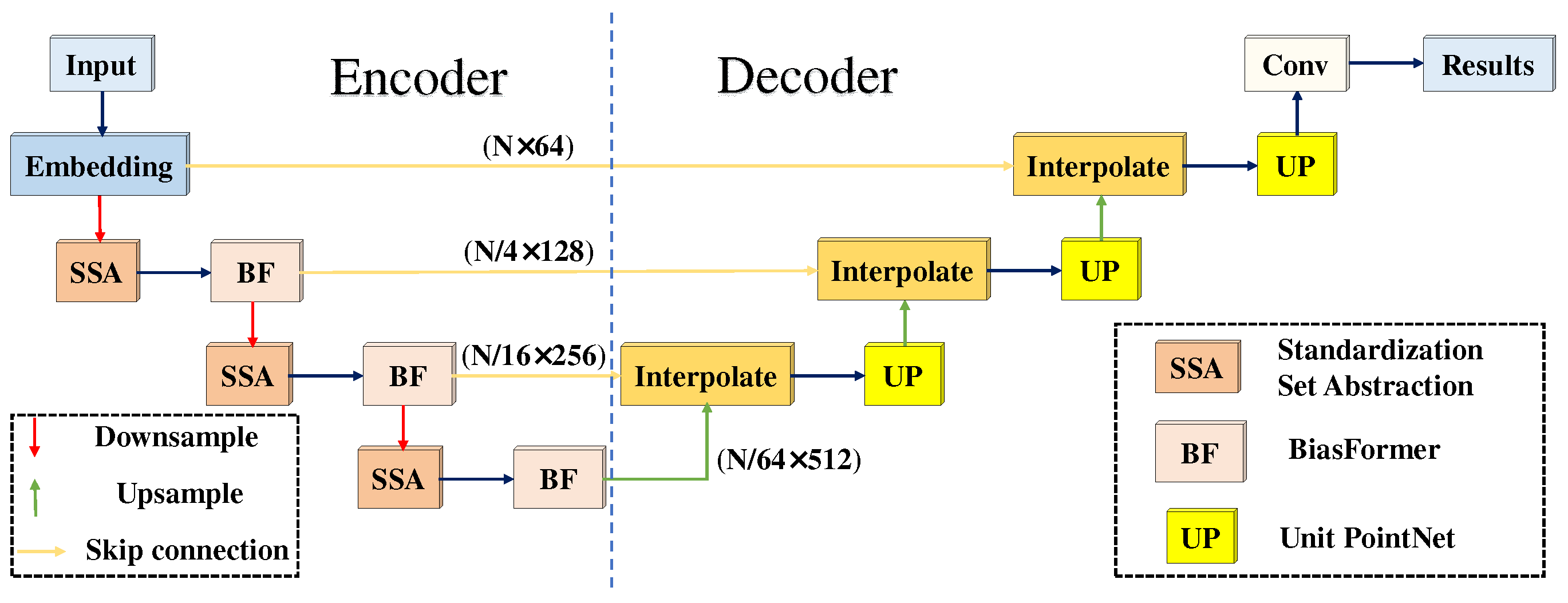
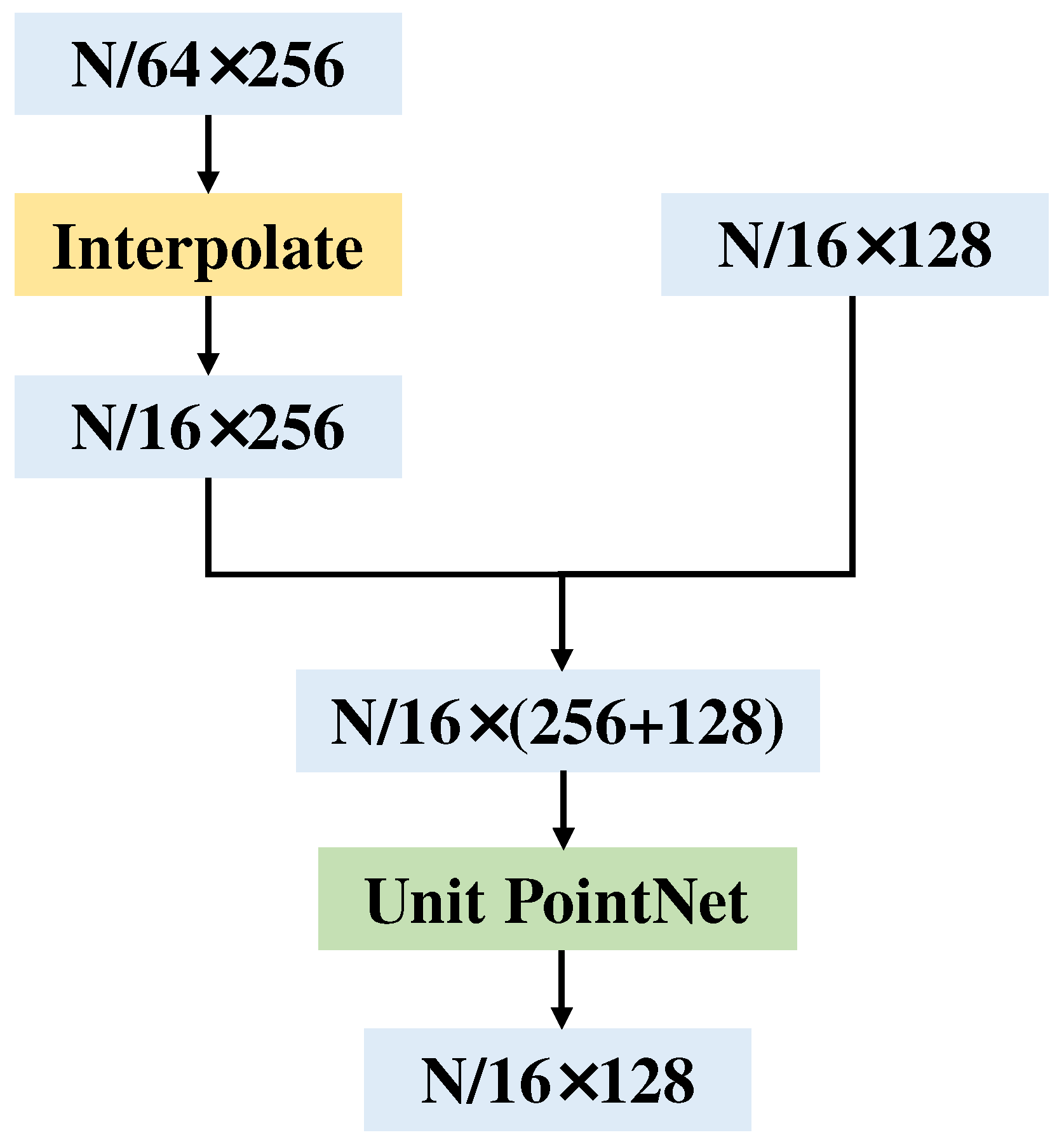
We designed a new Transformer structure to adapt to the sparseness of local regions of the LiDAR point cloud. Specifically, we added a bias to the Transformer, which is named BiasFormer, and changed the normalization methods of the feature maps. Based on BiasFormer, we propose a new multispectral LiDAR point cloud (MPT) classification network, which cascades BiasFormer to capture the deep information in multispectral LiDAR point clouds and uses multilayer perceptrons (MLPs) to accomplish the point-by-point prediction task.
- (2)
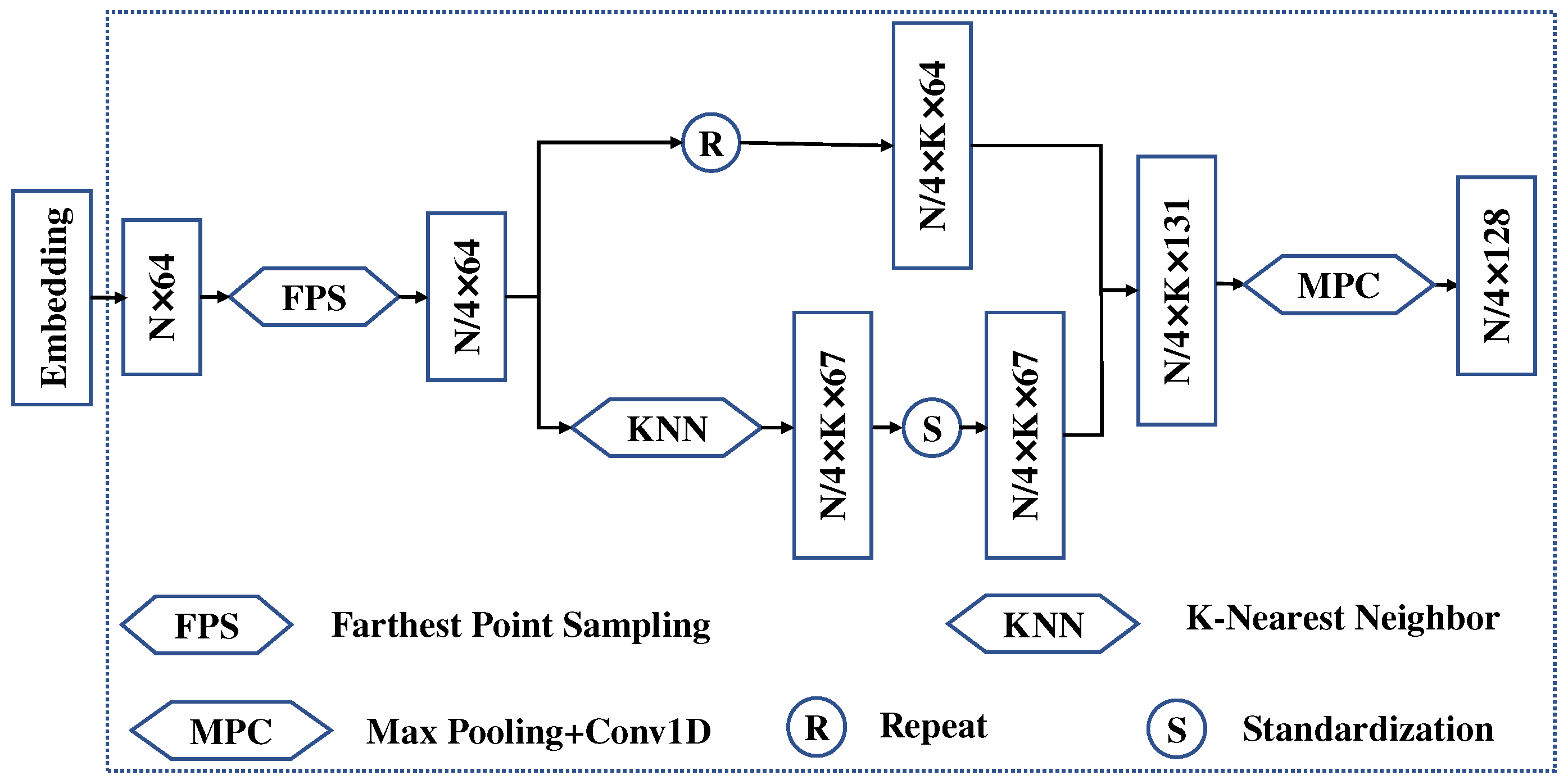
To further capture the topological relationships between points, we propose the SSA module. Specifically, the local contextual information is captured at different scales by iterative farthest point sampling (FPS) and K-nearest neighbor (KNN) algorithms. In each iteration, the point cloud distributions are transformed into normal distributions using the global information from the point clouds and the neighboring information of the centroid points in KNN algorithms to emphasize the influence of neighbor points at different distances to the centroid points. An improved version named MPT+ is proposed for multispectral LiDAR point cloud classification by combining the BiasFormer and SSA modules.
- (3)
We adopted a weighted cross-entropy loss function to deal with the imbalance among classes and compare the performance of the proposed MPT and MPT+ with seven classical models, thereby confirming the superiority of the proposed networks.
The remainder of this paper is organized as follows:
Section 2 introduces the processing methods for general point clouds and the applications of Transformer.
Section 3 describes the multispectral LiDAR point clouds and the proposed BiasFormer-based point-by-point classification networks.
Section 4 qualitatively and quantitatively analyzes the performance of the MPT and MPT+ networks and compares them with other classical models.
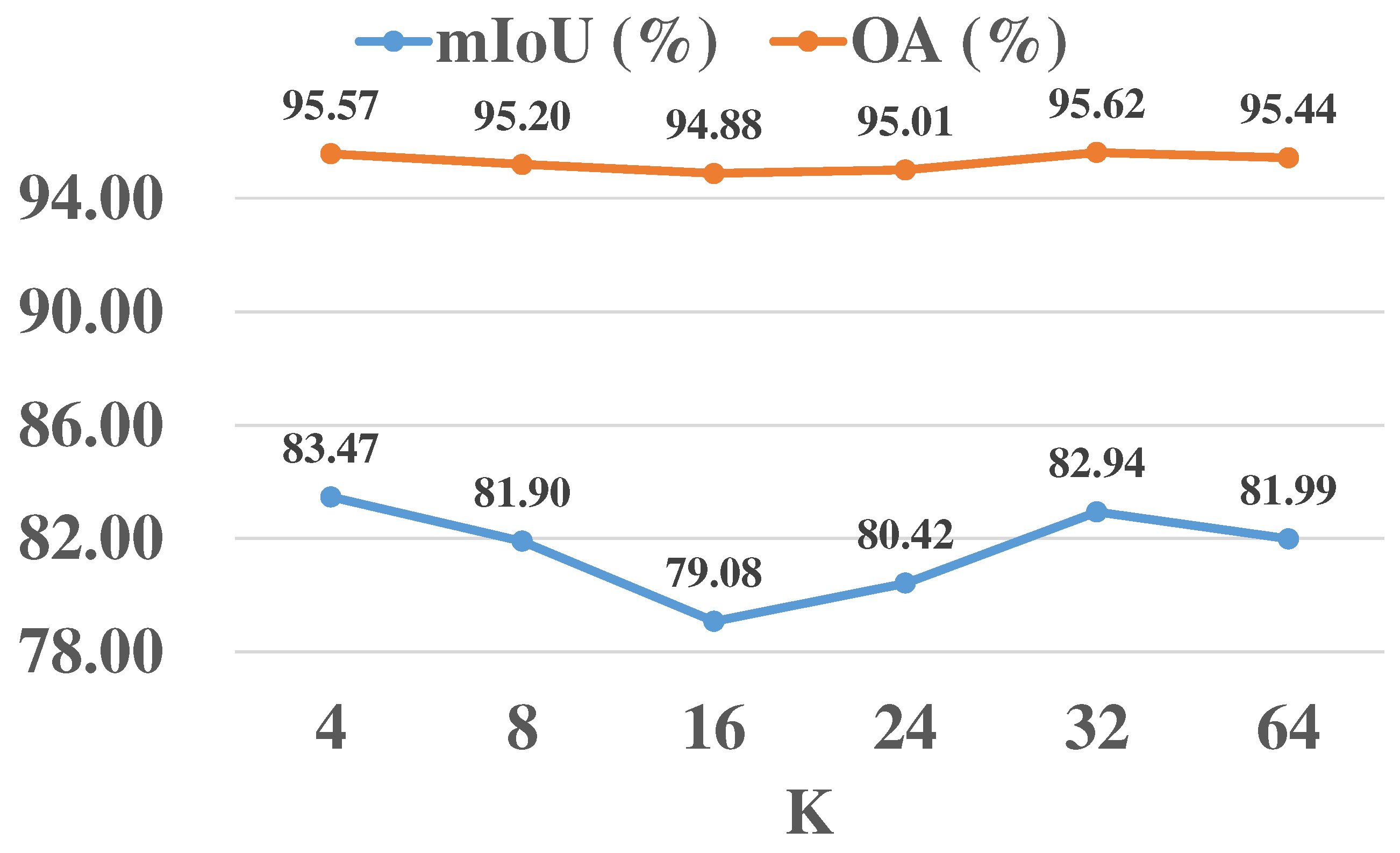
Section 5 surveys the effects of different parameters and the weighted cross-entropy loss function on the experimental results.
Section 6 concludes the whole paper and presents ideas for further work.
4. Experiments Settings and Results
In this section, we present the experiments conducted on multispectral LiDAR point clouds to validate and evaluate the performance of the proposed models. First, we elaborate on the software, hardware settings, and metrics used to evaluate the algorithms. Then, we analyze the performance of MPT and MPT+ with the confusion matrix. Finally, we further verify the superiority of the proposed models by comparing them with other popular point-based algorithms.
4.1. Parameter Settings and Evaluation Indicators
All experiments were performed on the Pytorch 1.10.2 platform using an RTX Titan GPU. The key parameter settings of MPT and MPT+ are shown in
Table 3.
The following evaluation criteria were used to quantitatively analyze the classification performance of multispectral LiDAR point clouds: the overall accuracy (
), Kappa coefficient (
), precision (
), recall (
),
(
), and Intersection over Union (
). Their calculation formulas are as follows:
where
represents the number of positive samples predicted by models to be positive,
represents the number of negative samples predicted by models to be negative,
represents the number of negative samples predicted by models to be positive,
represents the number of positive samples predicted by models to be negative, and
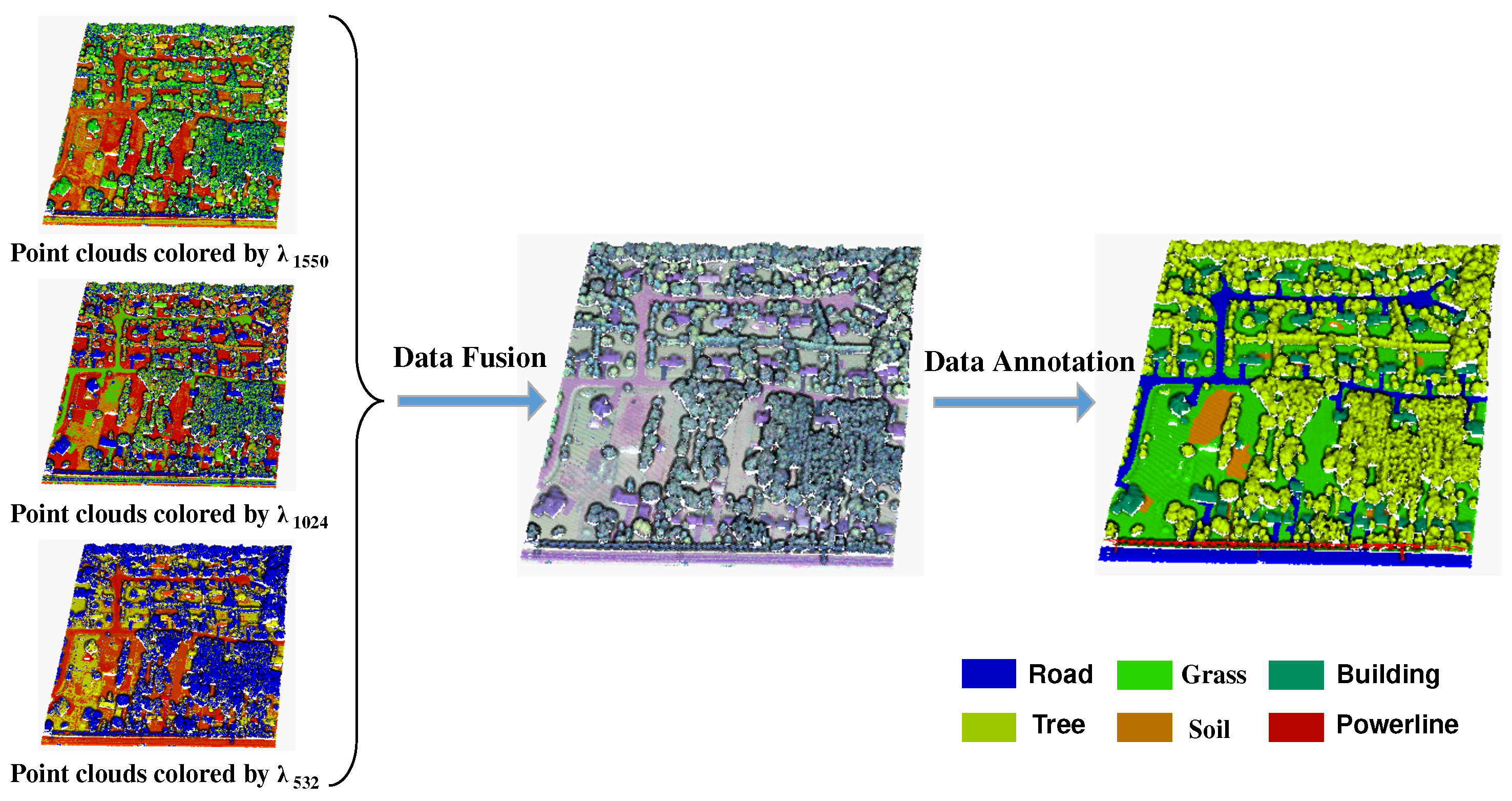
N represents the total number of labeled samples in the training dataset. Furthermore, according to the elevation information from different classes, we roughly classified the objects into two classes: high elevation and low elevation. High-elevation classes include roads, grass, and soil; whereas low-elevation classes include buildings, trees, and powerlines.
4.2. Performance of MPT and MPT+
In this section, we present the qualitative and quantitative evaluations of the classification performance of the MPT and MPT+ networks on multispectral LiDAR point clouds.
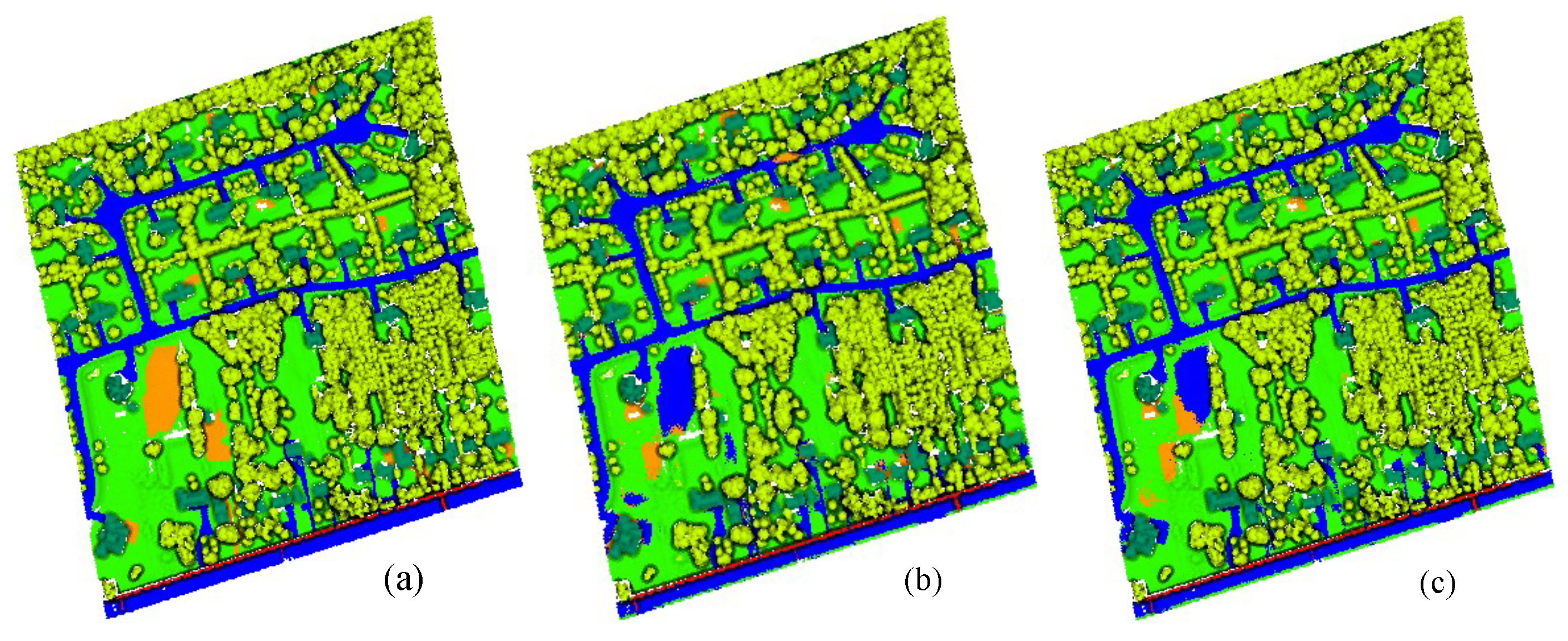
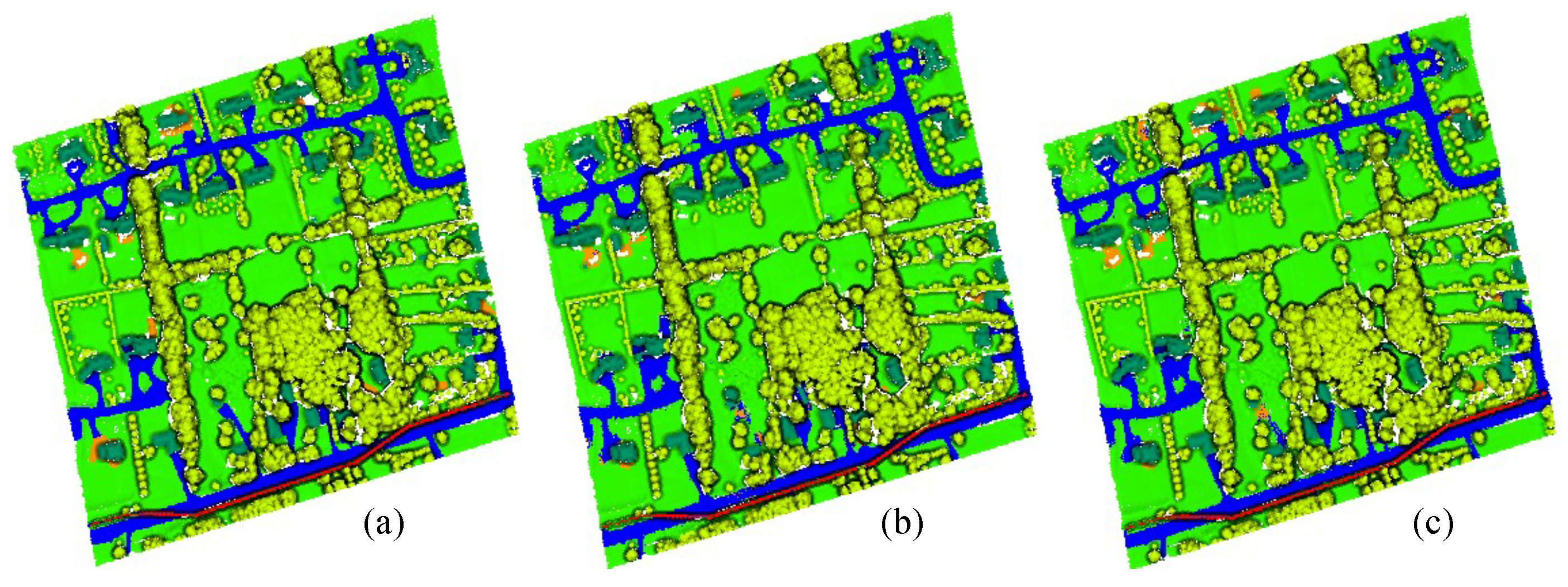
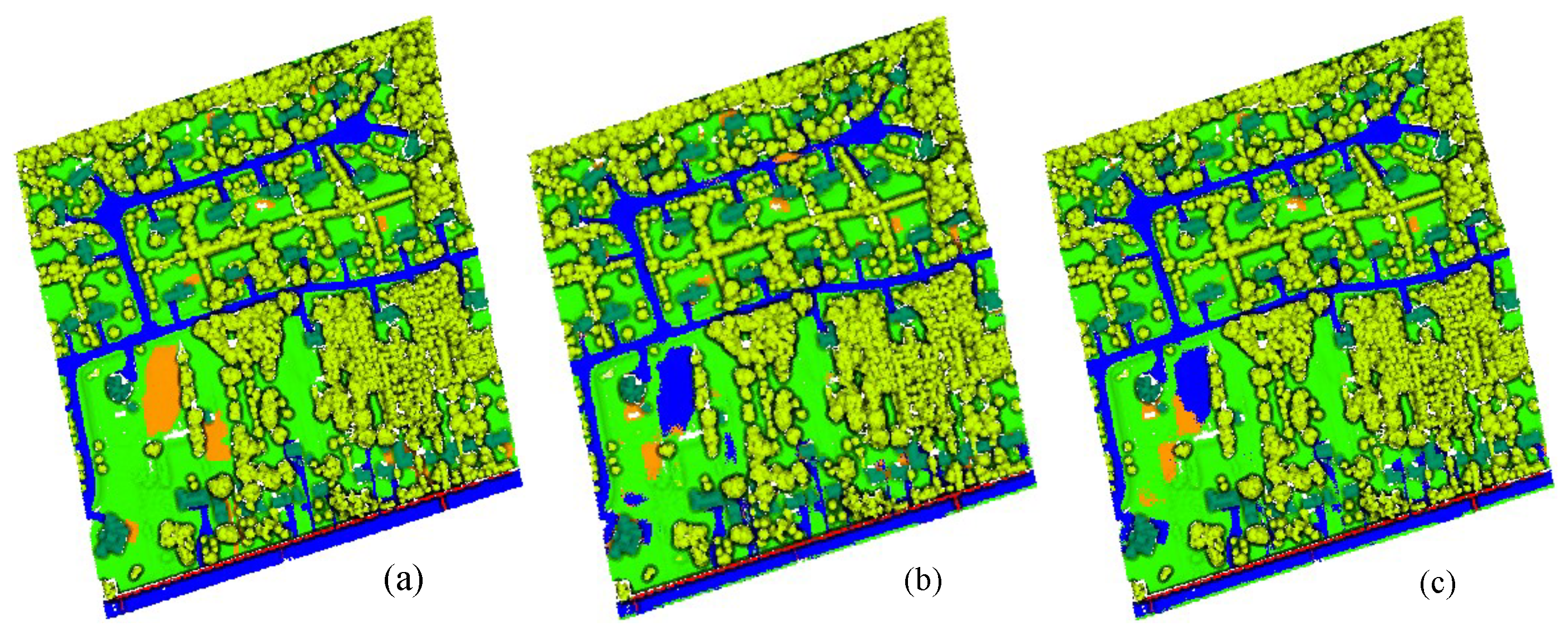
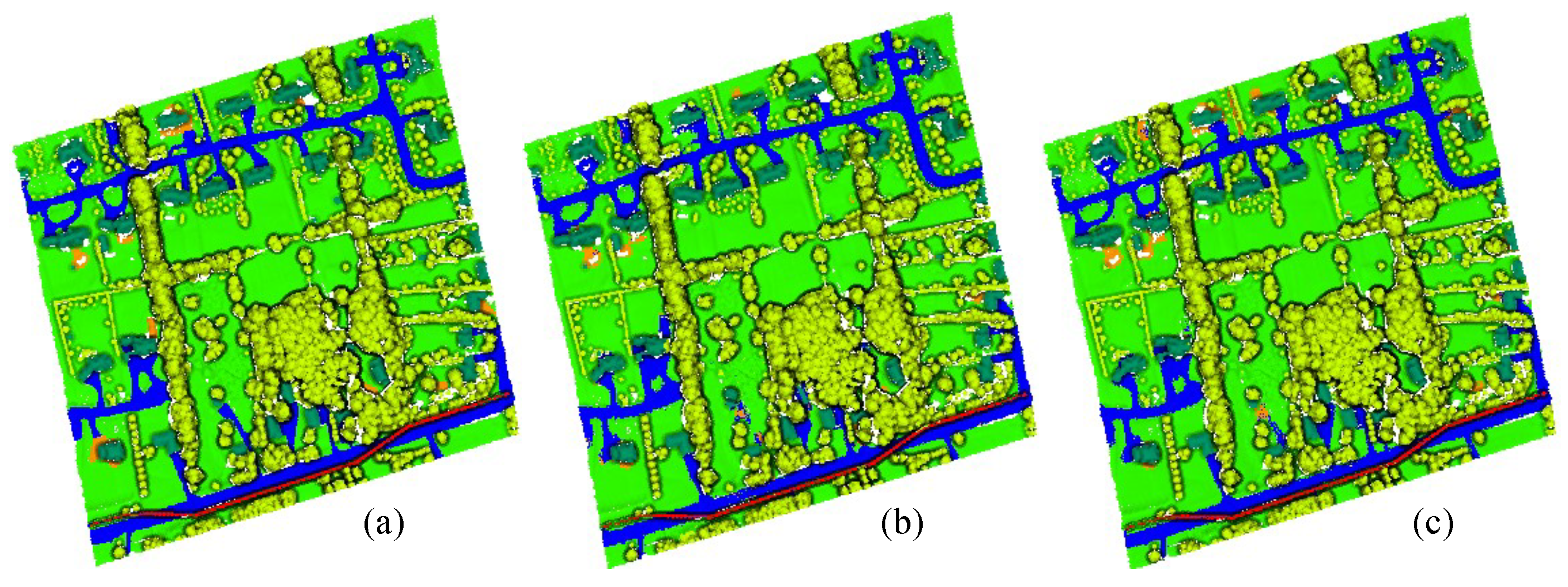
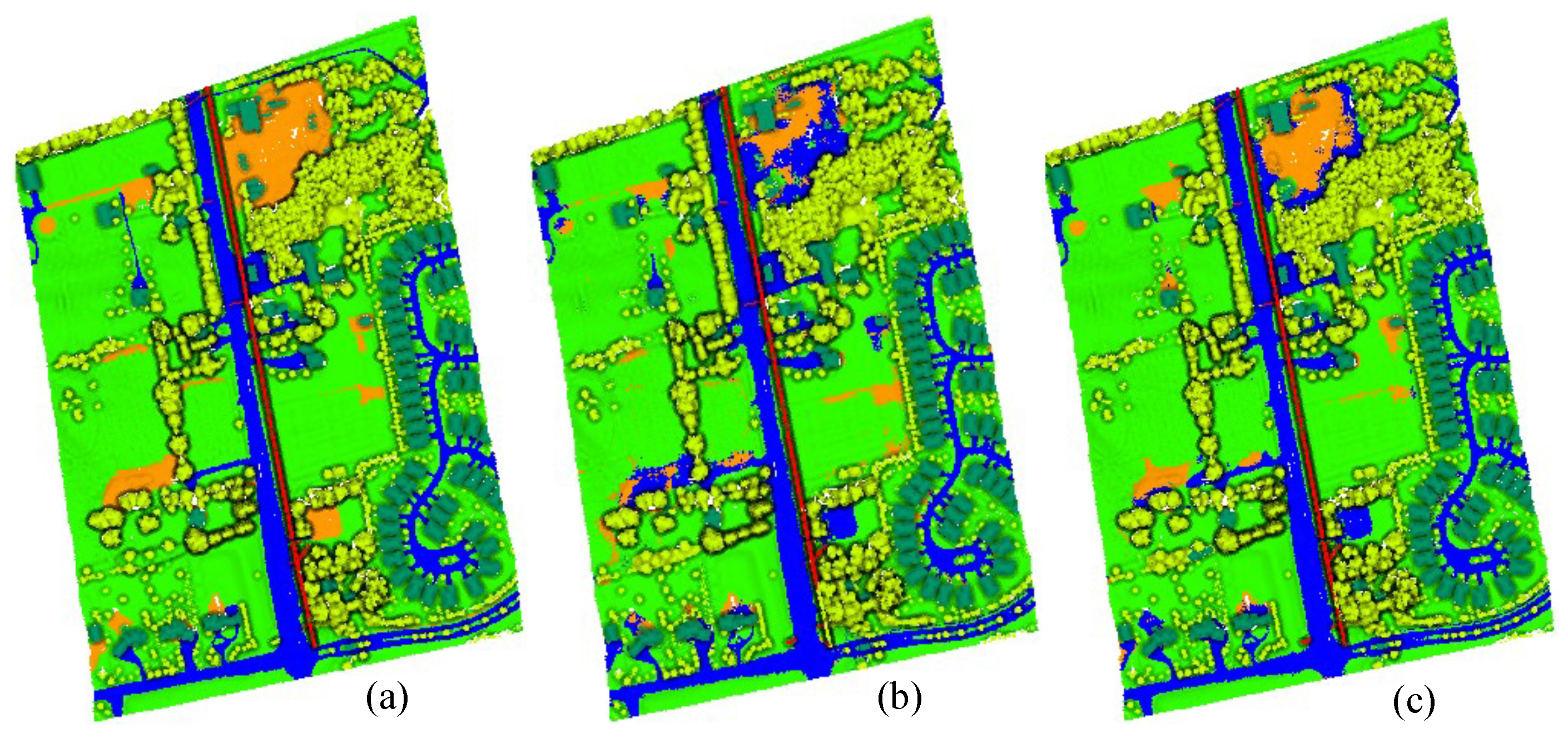
Figure 7,
Figure 8 and
Figure 9 show the ground truths and prediction results of areas 11–13. As shown in the figures, the classification results for the roads, buildings, grass, trees, and powerlines are satisfactory compared with the ground truths. However, the soil is misclassified as road, which is obvious in Area_11 and Area_13. Furthermore, we can observe that the MPT+ algorithm has fewer misclassified points for soil than the MPT algorithm. However, in small areas, grass, roads, and soil are still easily confused. We speculate that this is because roads, grass, and soil belong to the low-elevation classes. Misclassification points are not easily observed between buildings, trees, and powerlines. Although all three are high-elevation classes, the altitude gaps between the different classes are larger compared to low-elevation classes and are easier to distinguish.
We further quantitatively analyzed the performance of the MPT algorithm and the MPT+ algorithm in
Section 4.2.1 and
Section 4.2.2 through the confusion matrices of the ground truths and predicted labels.
4.2.1. Results Analysis of the MPT Network
It can be seen from the confusion matrix (
Table 4) of the prediction results obtained by the MPT algorithm that roads, buildings, grass, trees, and soil are confused with one another, while the powerlines (strips) only are mistakenly divided into buildings and trees, from which 2705 points are misclassified as buildings and 705 points are misclassified as trees. Additionally, there is more confusion between classes with similar elevations, such as roads, grass, and soil and buildings, trees, and powerlines. It can be seen from the evaluation criteria that trees have the best results with 98.38%
, 99.26%
, 99.10%
, and 99.18%
. The soil has the worst results with 20.27%
, 44.08%
, 27.28%
, and 33.70%
. In the remaining classes, four evaluation metrics exceed 70%. Furthermore, it is noted that the number of annotated samples for each class in the dataset varies greatly, which has a large impact on the results. Classes with a large number of labeled samples achieve better classification performances, and classes with a small number of labeled samples achieve poor classification performances.
4.2.2. Results Analysis of the MPT+ Network
Table 5 shows the confusion matrix for the prediction results of the MPT+ algorithm. It can be seen from the confusion matrix that the high-elevation classes and the low-elevation classes can be better distinguished. For example, only one road point is mistakenly classified as a building. In classes with similar elevation, the performance of MPT+ is also noteworthy. In the high-elevation classes, MPT+ can fully distinguish buildings from powerlines, and only a small number of buildings (1593 points) are misclassified as trees. Powerlines and trees are also clearly discriminative, with only 88 tree points misclassified as powerlines, and 226 powerline points misclassified as trees. The features of the low-elevation classes are more similar and have more misclassification points. It can be seen from the evaluation indicators that the
of roads, grass, and soil reach 78.58%, 93.30%, and 33.03%, respectively. In addition, it can be seen from the classification of each class that the performance of the MPT+ network is better than that of the MPT network. The
of roads, buildings, grass, trees, soil, and powerlines increased by 3.78%, 2.21%, 0.76%, 0.67%, 12.76%, and 6.52%, respectively. Among them, the classification results of soil improved most obviously, with 12.76%
, 20.65%
, 13%
, and 15.96%
. The classification results confirm the effectiveness of the MPT+ network.
4.3. Comparative Experiments
To the best of our knowledge, there are currently few algorithms that can be applied to multispectral LiDAR point clouds. To demonstrate the effectiveness of our proposed MPT and MPT+ networks, we selected an extensive number of representative point-based deep learning algorithms, including PointNet, PointNet++, DGCNN, GACNet, RSCNN, SE-PointNet++, and PCT. PointNet was the first to attempt to process point clouds directly; Pointnet++, based on PointNet, was proposed to focus on local structures; DGCNN, GACNet, and RSCNN are classic algorithms for processing point clouds; SE-PointNet++ was designed based on the characteristics of spectral LiDAR point clouds; and PCT was one of the earliest algorithms to apply Transformer to point cloud analysis.
Table 6 lists the comparison results with the other seven algorithms for the four evaluation indicators.
As can be seen from
Table 6, PointNet had the worst performance with 83.79%
, 44.28%
, 46.68%
, and 0.73
. PointNet directly classifies the entire scene point by point, cannot capture the geometric relationships between points, and cannot extract local features. Due to this shortcoming of PointNet, researchers have conducted further investigations. PointNet++ designs a set abstraction module, which captures local context information at different scales by iterating the set abstraction module. DGCNN considers the distances between point coordinates and neighbor points. The relative relationship in the feature space contains semantic features. GACNet establishes the graph structures of each point and neighbor points and calculates the edge weights of the center point and each adjacent point by attention mechanisms so that the network can achieve better results for the edge parts of the segmentation. RSCNN encodes the geometric relationship between points, which expands the application of CNN, and the weights of the CNN are also constrained by the geometric relationship. SE-PointNet++, based on PointNet++, introduces the Squeeze-and-Excitation module to distinguish the influences of different channels on the prediction results. The above algorithms, which do not include PointNet, achieve approximate results (about 90% OA). The Transformer naturally has permutation invariance when dealing with point sequences, making it suitable for disordered point cloud learning tasks. Inspired by Transformer, researchers proposed PCT. It can be seen that, compared with the previous best algorithm, the SE-PointNet++, the
,
,
, and
of the PCT network increase by 2.39%, 15.72%, 9.89%, and 0.04, respectively. For the same reason, we improved Transformer. For different point cloud densities in different regions, we added a bias to the Transformer to improve the robustness of the model. The evaluation results of the four indicators show that this method is better than PCT. Based on MPT, we proposed the hierarchical feature extraction network MPT+, which achieved the best results in terms of the four evaluation criteria with 95.62%
, 82.94%
, 88.42%
, and 0.94
.
6. Conclusions
In this work, we applied a Transformer to multispectral LiDAR point cloud classification research. Specifically, we proposed BiasFormer, which adds a bias to adapt to the density of different regions of the point cloud and changes the method of normalization.
Based on BiasFormer, we proposed an easy-to-implement multispectral LiDAR point cloud classification network which inputs the encoded point cloud into cascaded BiasFormers and predicts the classes by MLPs. To further differentiate the influences of local regions, we built an SSA module and proposed an improved Multispectral LiDAR point cloud classification (MPT+) network. The MPT+ network gradually expands the receptive field through recursive sampling to allow a wider range of information to be perceived. Qualitative and quantitative analyses were used to demonstrate the feasibility of the use of the MPT and MPT+ networks for carrying out multispectral LiDAR point cloud classification. In addition, we explored the influences of the spectra of different wavelengths, the number of neighbor points, and the number of sampling points on the performance of the control variable method; we obtained the best classification results based on optimal parameters. Furthermore, to deal with the class imbalance problem, we adopted a weighted cross-entropy loss function and improved the IoU by 4.59% on soil points. Finally, we compared the computational resources of the three best-performing networks and verified the superiority of our proposed models in terms of computational resource requirements and performance.
However, there is still a lot of room for improvement in soil points. In future work, we will explore the handling of sample imbalance, enhance the robustness and uniqueness of output features, and improve the accuracy of multispectral LiDAR point cloud classification.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}