1. Introduction
In recent years, deep learning has been playing a major role in the field of hyperspectral imaging (HSI) [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11]. Various deep neural networks (DNNs) have been proposed to classify spectra features and segmentation [
3,
5] and use band selection for better classification [
10,
11]. Recently, DNNs have been used for the reconstruction of high-dimensional spectra from a few bands of the spectrum. These spectra are acquired by compressive sensing HSI (CS HSI) techniques, which reduce the storage capacity occupied by the huge HS cubes [
4,
6,
7] and reduce the effort associated with their acquisition.
Over the last decades, spectral imaging [
12,
13,
14,
15] has become progressively utilized in airborne and spaceborne remote sensing tasks [
16,
17], among many others. Today, it is used in many fields, such as vegetation science [
18], urban mapping [
19], geology [
20], mineralogy [
21], mine detection [
22], and more. Most such spectral imagers take advantage of the platform’s motion and may acquire the spectral data from the visible to the infrared wavelength ranges, by performing along-track spatial scanning of the imaged object [
14,
23]. The spectral information can then be measured directly, that is, by first splitting it into spectral components using dispersive or diffractive optical elements, followed by direct measurement of each component. Another approach is to acquire the spectral information indirectly, incorporating multiplexed and coded spectral measurements. This allows the benefit from Fellgett’s multiplex advantage [
24,
25] and, therefore, provides a significant gain in optical throughput, at the cost of less intuitive system design and the need for post-processing. A well-known example of indirect spectral acquisition is Fourier transform spectroscopy, which is used both for spectrometry [
26] and spectral imaging [
27,
28]. As conventional Fourier transform spectroscopy systems are based on mechanically scanned Michelson of Mach–Zehnder interferometers, they demand strict stability and precision requirements. Thus, in harsh aerial and space environments, significant sophistication in their mechanical construction is required, and high-cost translational stages are incorporated to preserve the interferometric stability [
29,
30]. The indirect spectral acquisition can also be achieved by utilizing voltage-driven liquid crystal phase retarders [
31,
32,
33,
34,
35,
36], evading the need for incorporating moving parts, which results in these strict stability requirements. One such system is the compressive sensing miniature ultra-spectral imaging (CS-MUSI) system presented in [
32,
33,
35]. It performs spectral multiplexing by applying a variable voltage to a thick liquid crystal cell (LCC), thus achieving distinctive wideband spectral encodings.
Our group took the idea of CS-MUSI a step further to the remote sensing area by introducing a design that can be used with push-broom type scanning. In [
37], we presented a wedge-shaped LCC that exploits a satellite’s motion along an orbit. Pixels of columns of the sensor behind the LCC capture the cross-track strips of the ground, each with a specific spectral modulation according to the height of the nematic liquid in front of the columns. The height of the nematic liquid changes linearly with the columns due to the geometric shape of the wedge (
Figure 1b). Unlike CS-MUSI, wedge-shaped LCC passively changes the modulation of the light according to its geometrical shape; therefore, there is no need to apply different voltages to generate spectral modulations. Among the distinct properties of the wedge-shaped LCC-based spectral imager in [
37] are its outstanding optical throughput (about two orders of magnitude higher than conventional HSI) and the ability to switch to panchromatic imaging mode.
With the wedge-shaped LCC (
Figure 1b), the different modulations obtained by the continuously changed nematic liquid depth in front of various sensor’s columns determine the spectral linear sensing process that produces the spectral cube according to Equation (1).
where
is the compressed spectrum,
is the number of measurements,
is the spectral sensing matrix,
is the number of spectral bands in the incoming signal, and
is the observed spectrum. On the other hand, the wedge-shaped LCC spectral modulation has a huge disadvantage, because the captured spectrum measurements are redundant, and thus, its acquired HS cube requires large memory storage and huge bandwidth capacity.
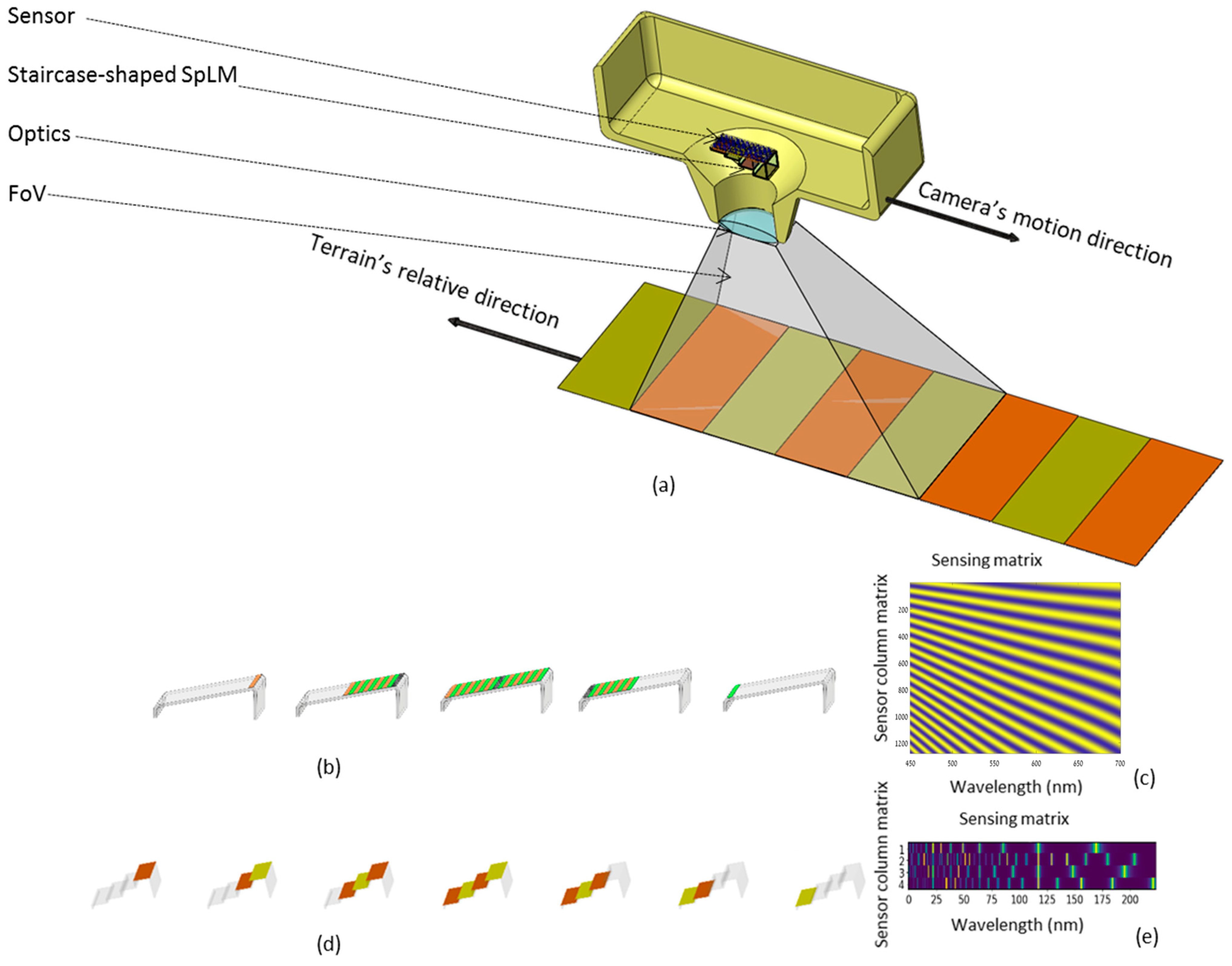
Figure 1a depicts the acquisition of the HS cube from the satellite. It describes the scanning along-track of an airborne or a spaceborne moving platform (in this case, a satellite camera equipped with an SpLM holding a staircase set of mFPR etalons [
38]) scanning the earth terrain with a field of view (FoV) consisting of a sequence of the cross-track slices from the various stairs of the SpLM. The imager’s optics projects the scene on the mFPR etalons, and each etalon is placed in front of a sensor column, thus capturing the spectrally encoded spectrum of a cross-track strip on the ground. The stair may occupy multiple sensor columns so that upon appropriate processing (e.g., registration and averaging) it improves the robustness of the measurements.
Figure 1b,d illustrates the difference between scanning the earth terrain with a wedge-shaped LCC and scanning the earth terrain with a staircase-shaped SpLM. In
Figure 1b a continuous slant of the wedge-shaped LCC in front of the sensor’s columns dictates that each column should participate in the sampling with its own modulation and the resulting sensing matrix is overcomplete (e.g., taking 1250 measurements for 224 spectral bands).
In this paper, we keep evolving from the wedge-shaped LCC concept (based on CS-MUSI) [
32,
35], by using a set of mFPR etalons for SpLM (
Figure 1d). In the staircase design, the width of the stairs is equal among all the stairs, so the image can be acquired continuously with the motion of the satellite in its orbit. The staircase design yields a novel CS HSI that:
- (1)
Compresses the spectral information of the scene from spectral bands to measurements respective to stairs in the SpLM,
- (2)
Considers mFPR technology for the SpLM, which is applicable in a much broader spectral regime than the wedge-shaped LCC. Thus, instead of the wedge-shaped LCC (
Figure 1b), here, we use a staircase-shaped set of mFPR etalons (see
Figure 1d). The advantage of mFPR is that it can be used for a wider spectral range, including visible light and the SWIR (
).
The staircase shape of the SpLM allows it to sample the terrain with an undercomplete spectral sensing matrix; that is, to compress the signal to a few measurements only, while each stair occupies a few pixel columns. In this way, each measurement can be averaged from a few pixels in its corresponding row for the robustness of the measurement. Together, they determine the compressive spectral sensing matrix for each row
under each stair
, which is used to compress the input signal. Similar to Equation (1), the sensing model is now described by Equation (2):
where
is the compressed spectrum,
is the number of stairs (measurements), and
is the compressive spectral sensing matrix.
In this paper, the optimal set of stairs height is learned by the PyCAE in an end-to-end fashion, from samples of remote-sensing HS cubes (i.e., Pavia center and Salinas valley [
39]). A detailed description of the PyCAE will be given in the next section. After optimizing the height of the stairs, the encoder of the PyCAE can be replaced by a staircase-shaped set of mFPRs, and measurements from this SpLM are reconstructed by the PyCAE decoder.
Our contribution is as follows:
We introduce a novel approach for learning the design and optimization of physical parameters of a system, by using a physics-constrained autoencoder (PyCAE).
We introduce a new concept of a compressive sensing hyperspectral imager for remote sensing with high throughput and an extremely high compressive ratio of the spectral dimension.
2. Materials and Methods
2.1. Physics-Constrained Autoencoder (PyCAE)
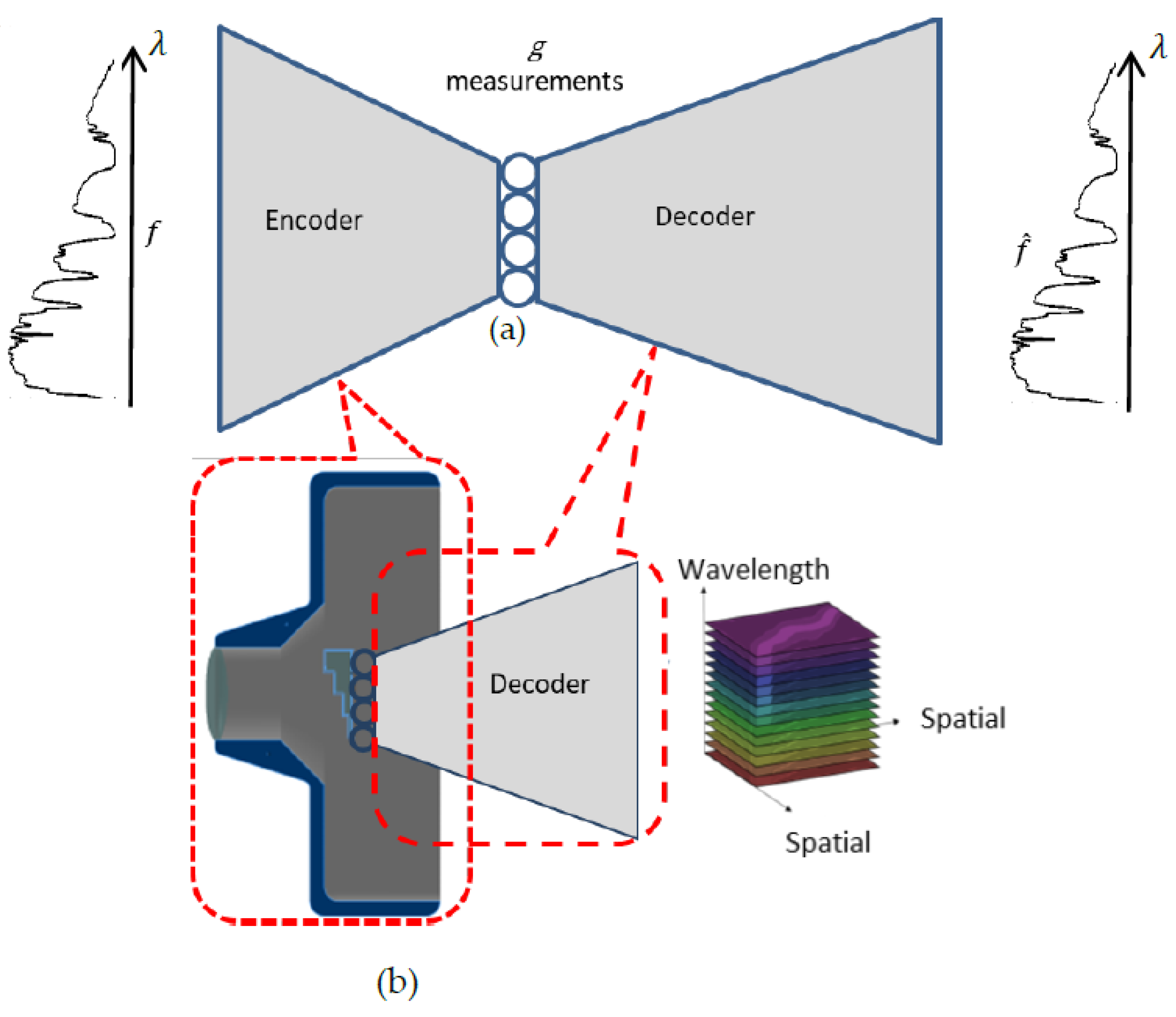
The proposed system consists of an encoder that emulates hardware with relay optics that images the light from the scene through the SpLM onto the sensor and software, which is a reconstruction DNN. The hardware can be modeled as a “sensing layer” and serves as the encoder of the PyCAE, while the reconstruction DNN serves as a decoder (
Figure 2). The coupling between them holds the compressed measurements while serving as the bottleneck of the autoencoder. Unlike encoders of conventional deep learning autoencoders, in our model, the encoder is constrained to comply with the physics of our optical sensing hardware.
Figure 2 depicts the general scheme of the system, including the deep learning model and respective sensing and reconstruction system.
PyCAE jointly optimizes the physical parameters that determine the values of the sensing matrix with the weights of the reconstruction DNN. Through its training process, we solve the following optimization problem:
where
is the PyCAE DNN consisting of the encoder
, which models the sensing matrix
, which depends on the physical parameters
, and of the decoder DNN
with the trained weights
W.
denotes the loss function (
Section 2.6), and
denotes the expectation operator, practically evaluated as an average over the training set of spectra
.
denotes a constrained set, in our case, dictated by the physics of the spectral modulation (see
Section 2.2).
After training the autoencoder, the encoder “sensing layer” is detached from the decoder and replaced by the real physical device, which feeds its measurements into the reconstruction DNN,
, where
holds the measurements in the bottleneck of the PyCAE. In our case, the sensing layer is mathematically modeled by
, which represents the transmission of the SpLM, depending on the parameters of the mFPR (see
Section 2.2).
For training purposes, we feed a high-dimensional spectrum with spectral dimensions as an input of the encoder and feed the same spectrum to the autoencoder’s output, while the bottleneck holds compressed measurements, .
2.2. The SpLM and Its Model
In [
38], we introduced the modified Fabry–Pérot Resonator (mFPR) for compressive hyperspectral imaging [
36]. To obtain different spectral modulations for different measurements, refs. [
38,
40] modified the classical etalons in two fundamental ways. First, a wide range of gaps between the mirrors of the etalons is used to obtain more than a single spectral transmission peak, as in the case of classical FP-etalon. Second, the reflectivity of the mirrors is reduced by about
to obtain multiple and wider spectral peaks. The array of the stairs set of the staircase-shaped mFPR is particularly adequate for this task, because it has good modulation, high throughput, and supports the visible and SWIR spectrum.
Here, we implement these etalons in the shape of stairs, so they can be used for compressive scanning imaging in the vertical direction of the stairs. We also model a BK7 glass as a substance to fill the etalons gaps, because it has good transparency to all the spectrum ranges we work on.
The spectral transmission of an ideal FP resonator is given by Equations (4) and (5) [
38,
40]:
where
is the optical thickness, and
is the finesse coefficients that are equal to
where
is the wavelength,
is the refractive index of the material between the two FP mirrors, and
is the incident angle of light.
is the reflectivity of both mirrors that defines the full width at half-maximum (FWHM) of the spectral peaks.
is the gap between the mirrors, which is responsible for the spectral modulation shape. As the gap grows, the number of the orders grows as well (i.e., the number of the spectral peaks). The gaps between the mirrors
are the parameters that need to be optimized by the PyCAE to give a series of optimized modulations to construct an efficient sensing matrix. The spectral transmission
is then the modulation of each stair of the SpLM, which is one line of the spectral sensing matrix
.
2.3. Encoder—Sensing Layer
Central to the PyCAE is the encoder, which models the sensing layer and reflects the spectral sensing matrix
. It represents a set of mFPR etalons forming the staircase shape (
Figure 1d). Each stair in the staircase is an mFPR etalon whose height determines the gap
between the mirrors of the etalon. By establishing each etalon’s gap
, the respective modulation of the spectral transmittance
(given by Equation (4)) determines a row of the sensing matrix
. The bottleneck of the PyCAE,
, is the output of the encoder, and it holds the measurements according to Equation (6):
where
is the
wavelength transmittance of the mFPR at the
stair (i.e.,
), and
is the intensity of the
element of the spectrum of the incident light.
The encoder is used to optimize the SpLM’s parameters (e.g., the height of the stair-shaped mFPR’s etalons, ). It implements the physical model (Equation (4)) as its activation function, while the layer’s weights which reflect the height of the stairs are optimized parameters that are improved together with the reconstruction network’s weights at each iteration.
The optimized PyCAE’s encoder reflects the SpLM’s set of mFPR etalons (
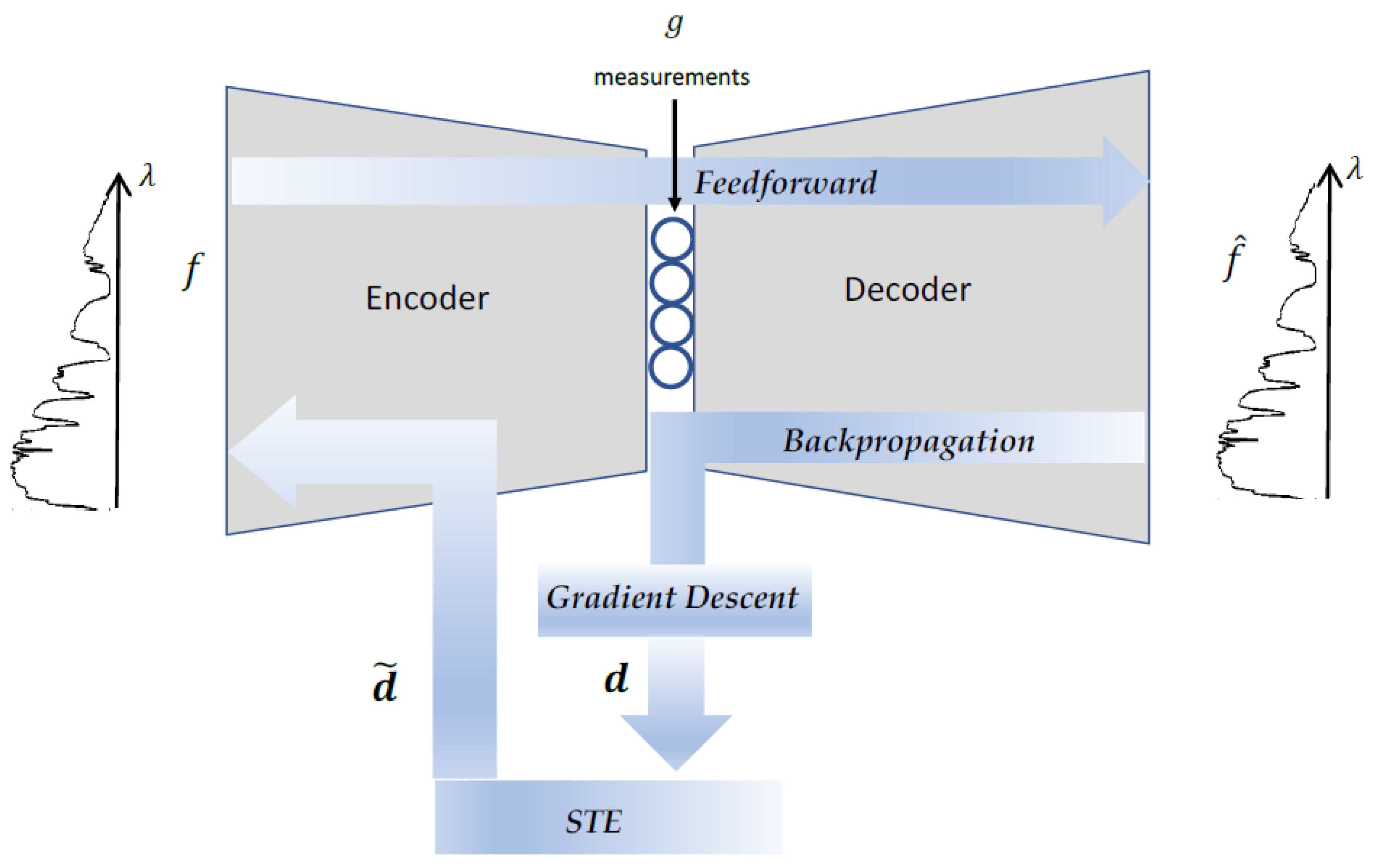
Figure 2); hence, the optimization process must consider the stairs’ physical constraints and the production limitations. To do so, we use the straight-through estimator (STE) technique, which was originally proposed by [
41] for binary neural networks.
2.4. Straight-Through Estimator (STE)
To constrain the weights that represent the height of the stairs of the SpLM that are parametrized in the encoder, such as to be in a certain range of height and to have a minimum step of height between consecutive stairs, we use the STE algorithm.
According to the STE, at the feedforward phase, the input of the layer flows through the layer’s weights to the activation function of the layer, as if it had been the identity function [
42]. But in the backpropagation phase, the flow of the gradients does not directly update the weights that represent the stairs’ heights
. Instead, the gradients update the weights according to Equations (7)–(9):
Equation (7) determines the range of depths for all the mFPR stairs between
and
, and Equation (8) constrains the smallest step between consecutive stairs to be
. In Equation (9),
of the encoder is the
weight, which represents a gap
of the
mFPR etalon to be updated;
is the learning rate; and
is the gradient, which backpropagates through the set of constraint functions as if it had been the identity of the activation function
(the function that represents the action of the mFPR etalons with respect to
).
is calculated by the chain rule from the loss function at the output of the decoder, as shown in Equation (10):
where
is the number of layers in the decoder,
are the weights of the
layer of the decoder, and
is the activation of the
layer of the decoder.
Equation (11) shows the gradient of the mFPR etalons transmittance (Equations (4) and (5)) with respect to the depth
of the etalons for an incident angle of light
:
Figure 3 and Algorithm 1 depict the STE mechanism:
| Algorithm 1. Straight-Through Estimator (STE) |
Initialization: Initialize weights due to model design constraints. (e.g., all weights value are between the minimum and maximum boundaries)
Feedforward: Use current weights to flow information straight through the physical formula of the model.
Backpropagation:Update weights by gradients flow through all layers from the output layer to the input layer (sensing layer). Deploy constraints on the updated weights to fit model requirements. (e.g., clip values between minimum and maximum boundaries).
|
In the case of a set of mFPR stairs of our SpLM, we constrain the range of the stair heights in the range of by clipping the weights in each iteration and limiting the minimum step between two stairs to , by binning the weights in bins of .
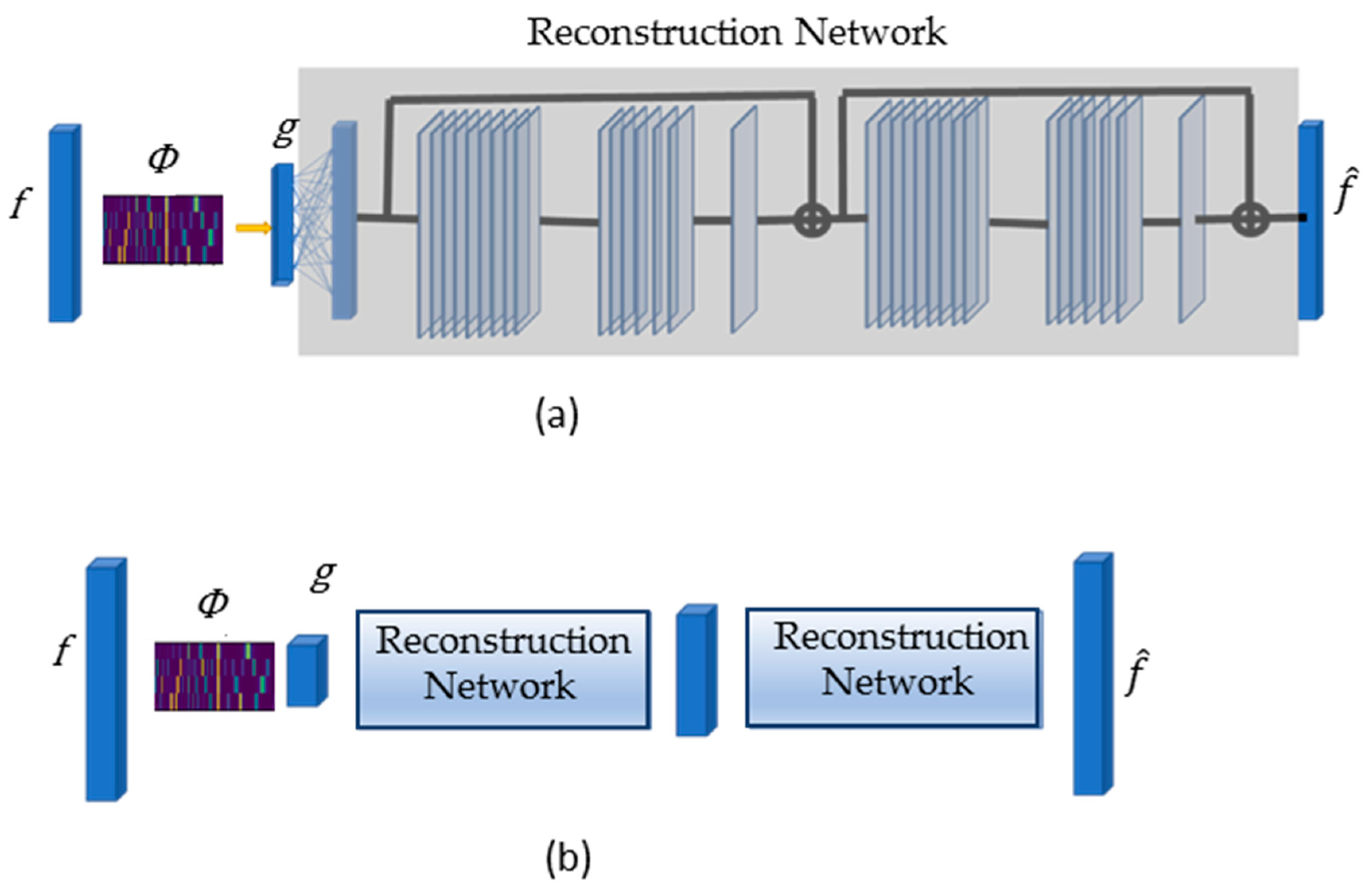
2.5. Decoder—Reconstruction DNN
The decoder of PyCAE serves as a reconstruction DNN. We designed it as a residual DNN following the general scheme of the DR2-net [
43]. DR2-net was developed initially to reconstruct 2D images from compressed images; therefore, we adapted it to accept 1-dimensional (1D) spectra, as we successfully did in [
6]. We modified the kernel sizes for each layer in a residual block (as they are hyperparameters of the network) to a 1D kernel.
Figure 4a schemes the basic structure of the reconstruction DNN. The first layer of the reconstruction DNN is a fully connected layer that has
nodes as the
spectral bands in the label of the spectrum. This layer is followed by batch normalization and a ‘Relu’ activation function. The layer provides a first approximation of the spectrum. The first approximation is followed by a train of residual blocks, where each block consists of 3 convolutional layers and a skip connection, as shown in
Figure 4a. The first layer has 64 kernels of size 9, the second layer has 32 kernels of size 1, and the third layer has 1 filter with a kernel consisting of 7 elements. Each layer is followed by batch normalization and a ‘Relu’ activation function. The last layer of the reconstruction DNN is a convolutional layer with 1 filter, which has 1 element and no activation function. Because the task of the reconstruction network is to reconstruct a high-dimensional space from a very small dimensional space, this task is challenging. The transformation of a compressed spectrum
to a fully high-dimensional spectrum
is hard because it is an ill-posed problem, where the compressed signal
is transformed from a narrow subspace to a wider subspace. To mitigate this, we employ a progressive reconstruction approach inspired by the progressive upsampling super-resolution algorithms [
44]. Our network upsamples the signal in 4 steps to intermediate sizes and upsamples it again to the final size of the original spectrum, where each step has a train of 5 residual blocks. The number of subnetworks is a hyperparameter of the system.
Figure 4b shows 2 steps of a progressive upsampling network.
2.6. Loss Function and Metrics for the PyCAE
We use the mean-square-error (MSE) as the loss function of the PyCAE to reduce the differences between sample pairs (input–label) from the training set in the training phase. The MSE is defined as follows:
where
is the number of spectral bands in the signal
, and
is the estimation of signal
.
To evaluate the reconstruction performance, we use two widely used metrics:
- (1)
Structural similarity index measure (SSIM) [
45] to assess the similarity between the structure of the estimated signal to the label as follows:
where
are the estimated and original spectrum, respectively;
are the averages of the estimated and original spectrum, respectively;
are the variances of the estimated and original spectrum, respectively; and
is the covariance of the estimated and original spectrum.
are two variables to stabilize the division with a weak denominator, is the dynamic range of the spectral bands, and are constants where and by default.
- (2)
Spectral angle mapper (SAM) [
46] evaluates the spectral information preservation degree between the label to the reconstructed spectrum:
where
are the estimated and original spectrum, respectively.
3. Results
3.1. Training Details
To train the PyCAE for spectra reconstruction, we need to initialize the etalon gaps parameters for the activation function according to Equations (4) and (5) The reflectivity of the mirrors is ; hence, the finesse is . We take the incident angle to be , and the refraction index is taken to be the BK7 refractive index for each band, depending on the HS cube dataset under analysis.
We used the ADAM optimizer with a learning rate of 0.001 and a learning rate scheduler that reduces the learning rate by a factor of after the 3 first epochs.
We trained the PyCAE on two common remote sensing HS cube datasets, Pavia center, and Salinas valley from [
39], and evaluated the model on their validation set. We also evaluated its generalization on another HS cube; we evaluated the performance on the Pavia University dataset with the model trained on the Pavia center dataset.
3.1.1. Datasets—Pavia Center and Salinas Valley
The Pavia center HS cube from [
39], consists of two concatenated images of scenes that were acquired by the ROSIS sensor over Pavia center, Italy, with 102 spectral bands from
to
and with
spatial pixels as shown in
Figure 5. The spectra intensity was normalized to be between 0 and 1. The dataset was augmented by injecting Gaussian noise with standard deviation (STD)
. Then, the HS cube was divided into a training set, which includes the spectra at 70% of the pixels, and a test set, which includes 30% of the pixels.
The Salinas scene from [
39], was acquired by the AVIRIS sensor over Salinas Valley, California, with 224 spectral bands from
to
and with
spatial pixels. The spectra intensity was normalized to be between 0 to 1. The dataset was augmented by injecting Gaussian noise with standard deviation (STD)
. Then, the HS cube was divided into a training set, which includes the spectra of 70% of the spatial pixels, and a test set, which includes 30% of the pixels.
The data of the Pavia center dataset has a wider variance than that of the Salinas valley dataset. In
Section 3.3,
Section 3.4 and
Section 3.5, it can be seen that very few spectra in the dataset are needed to reconstruct the Salinas valley dataset (only 111,104 spectra in the HS cube) with better reconstructions than in the Pavia center and Pavia University (
Section 3.2.) datasets (Pavia center includes 1,201,216 spectra in its HS cube), even though its compression ratio is twice smaller. This is due to the tight variance of its data compared to the variance of spectra in the Pavia center and Pavia University datasets.
3.1.2. Pavia University—Generalization Evaluation
In
Section 3.1.1, we trained the PyCAE on 70% spectra of one dataset (Pavia center or Salinas valley) and validated and tested it on the remaining 30% spectra. Because many of the spectra are from the same materials under evaluation, they are almost the same, with small deviations inside each group of materials. For this reason, they show a particularly good reconstruction performance.
To evaluate the generalization of the PyCAE on a complete unseen dataset, we used the Pavia University dataset from [
39] (
Figure 6) and consists of a spatial resolution of
pixels as a test set that didn’t participate in the training phase. Since the Pavia University HS cube was acquired in the same spectral range
as the Pavia center HS cube, we evaluated the PyCAE that was trained on the Pavia center dataset with the Pavia University dataset.
3.2. The Optimized SpLMs
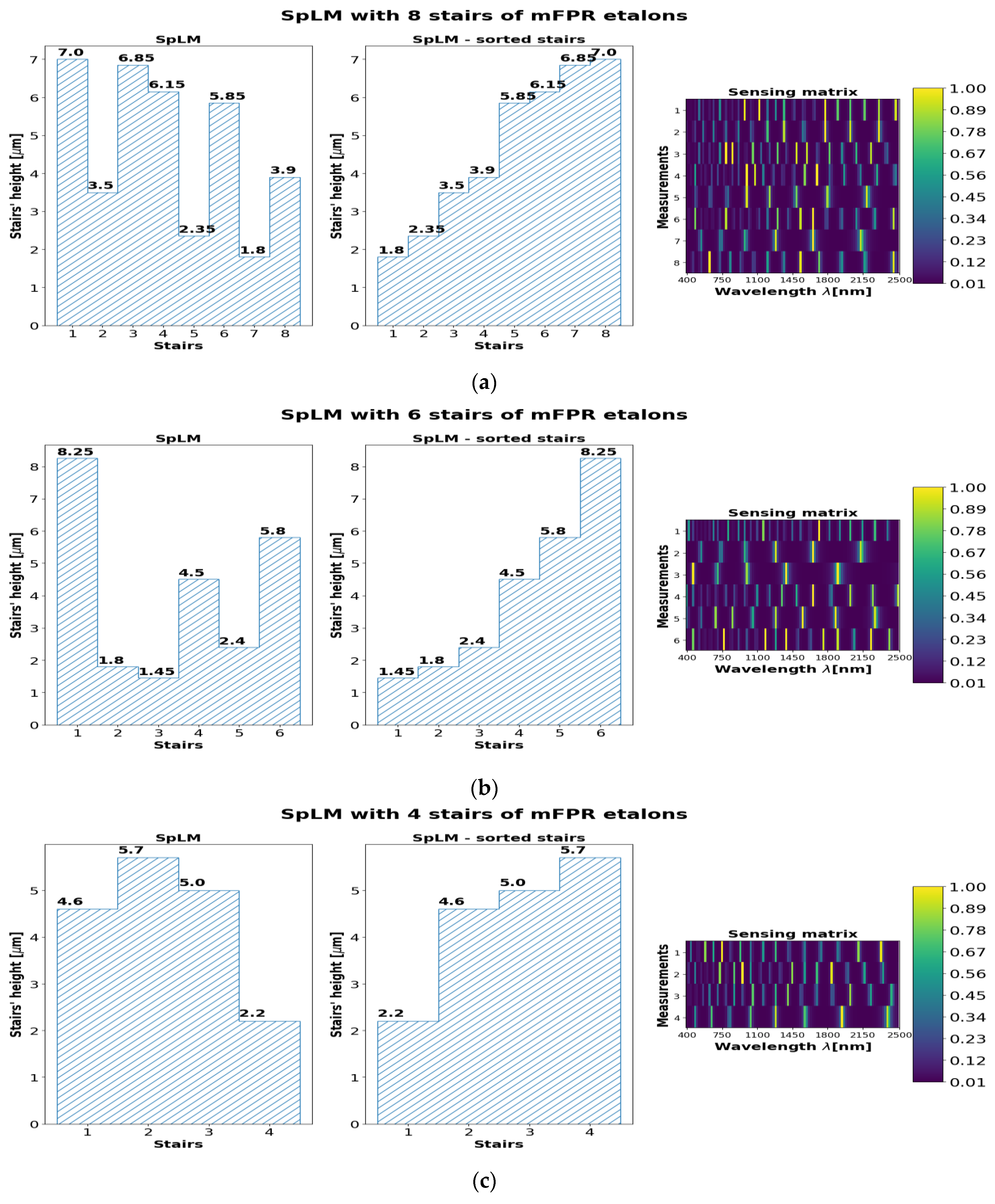
During the training, the SpLM’s geometries were optimized for each dataset and specifically for each version of the PyCAE, where each version has a different number of mFPR stairs. Accordingly, the compatible sensing matrices were optimized. After the optimization, the order of the stairs of the SpLM can be sorted in an increasing order of heights to mitigate the manufacturing process. Then, the resulting measures from the sensor must be registered to the decoder (reconstruction DNN) in the same order it was optimized. As an example,
Figure 7 shows the height profile of the learned SpLMs and their respective sensing matrices of the Pavia center for each configuration. The learned profiles of the SpLMs with eight, six, and four staircases are shown on the left-hand side. The SpLMs with the sorted staircase are shown in the center. On the right-hand side of
Figure 7, the respective sensing matrix,
, is shown. Each row in the sensing matrix represents the spectral transmission of the mFPR realized in each stair. It can be seen that shallow stairs have low-frequency modulation, while deep stairs have high-frequency modulation. The number of stairs determines the number of rows in the sensing matrix,
M, and thus the number of different modulated measurements.
3.3. The Reconstruction DNN
The decoder of the PyCAE (
Figure 4) is the software part used for HSI reconstruction, and as such, we report here its running speed on a GPU and its number of parameters. The runtime of the reconstruction DNN implemented by the Tensorflow 2 framework on Nvidia
® RTX 3090 TI GPU is 32 msec., both for PyCAE that was trained on the Pavia center dataset and for the PyCAE that was trained on the Salinas valley dataset. It can be seen that the run time is much shorter than that of common iterative algorithms [
7].
The reconstruction DNN (i.e., the decoder of PyCAE), which was trained on the Pavia center dataset, has 672,201 trainable parameters and 4508 nontrainable parameters (total of 676,709 parameters) for PyCAE with 4 measurement configurations, 689,519 trainable parameters and 4516 nontrainable parameters (total of 694,035 parameters) for PyCAE with 6 measurement configurations, and 706,827 trainable parameters and 4524 nontrainable parameters (total of 711,351 parameters) for PyCAE with 8 measurement configurations.
The decoder of PyCAE, which was trained on the Salinas valley dataset, has 1,402,809 trainable parameters and 5240 nontrainable parameters (total of 1,408,049 parameters) for PyCAE with 4 measurement configurations, 1,420,635 trainable parameters and 5248 nontrainable parameters (total of 1,425,883 parameters) for PyCAE with 6 measurement configurations, and 1,438,425 trainable parameters and 5256 nontrainable parameters (total of 1,443,681 parameters) for PyCAE with 8 measurement configurations.
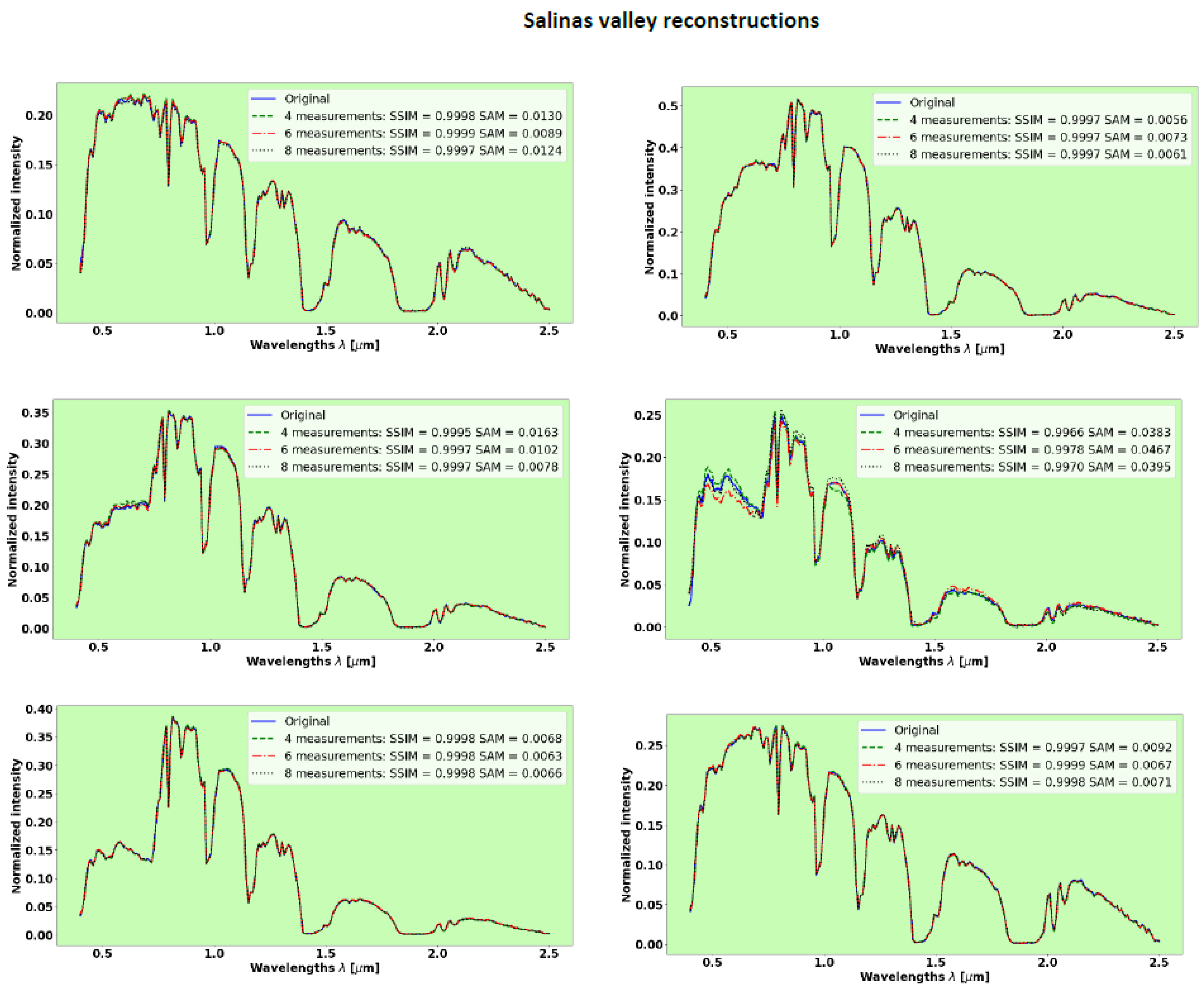
3.4. Salinas Valley
Figure 8 shows the results of spectra reconstruction with 224 spectral bands in the visible-light and SWIR domains evaluated with 8, 6, and 4 measurements. The reconstructions of the Salinas valley show excellent performance.
Table 1 shows the SSIM and SAM metrics evaluated over the entire test set.
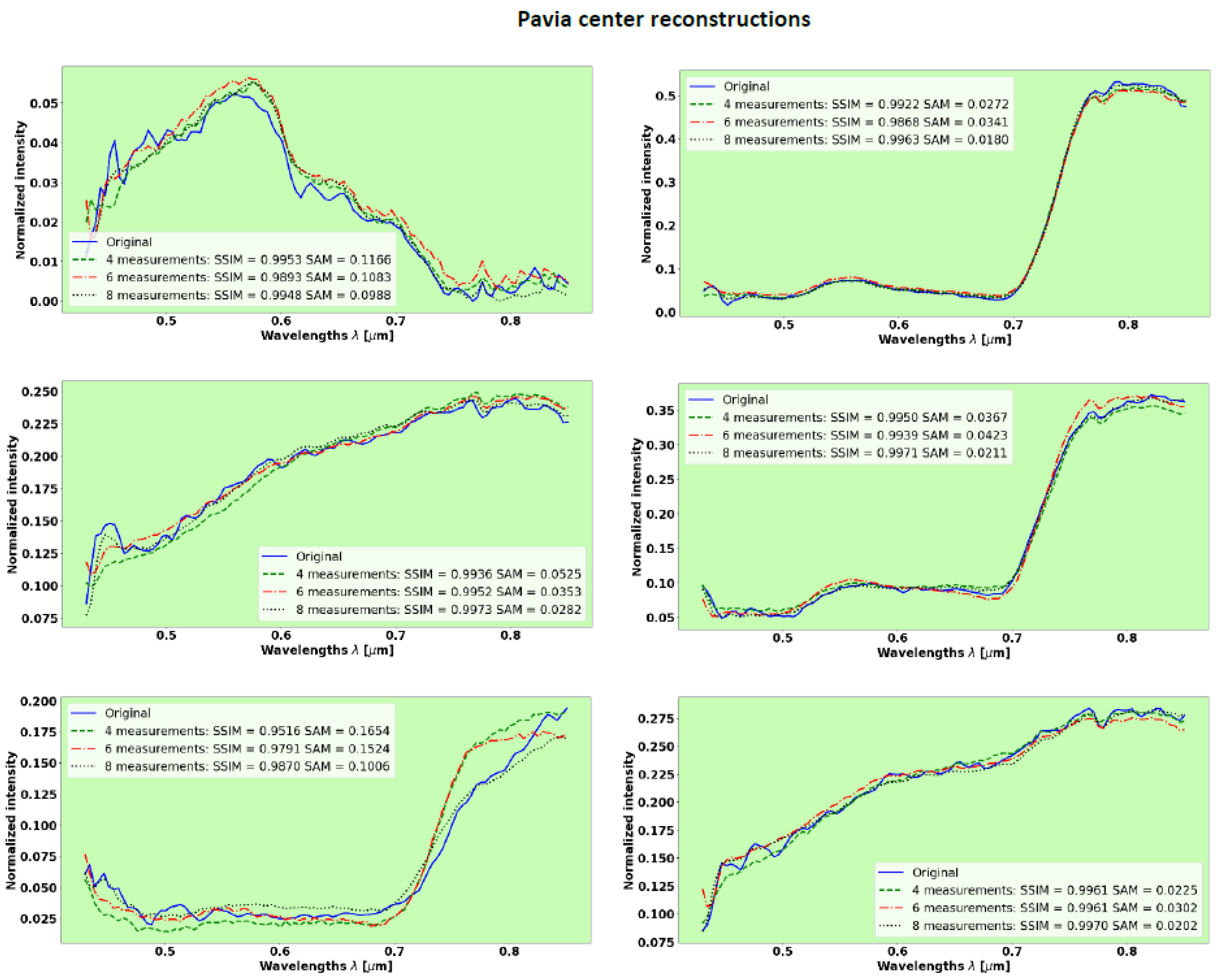
3.5. Pavia Center
Figure 9 shows representative results of spectra reconstruction with 102 spectral bands, evaluated with 8, 6, and 4 measurements.
Table 2 summarizes the results of the mean values for SSIM and SAM over the validation/test set.
3.6. Generalization—Pavia University
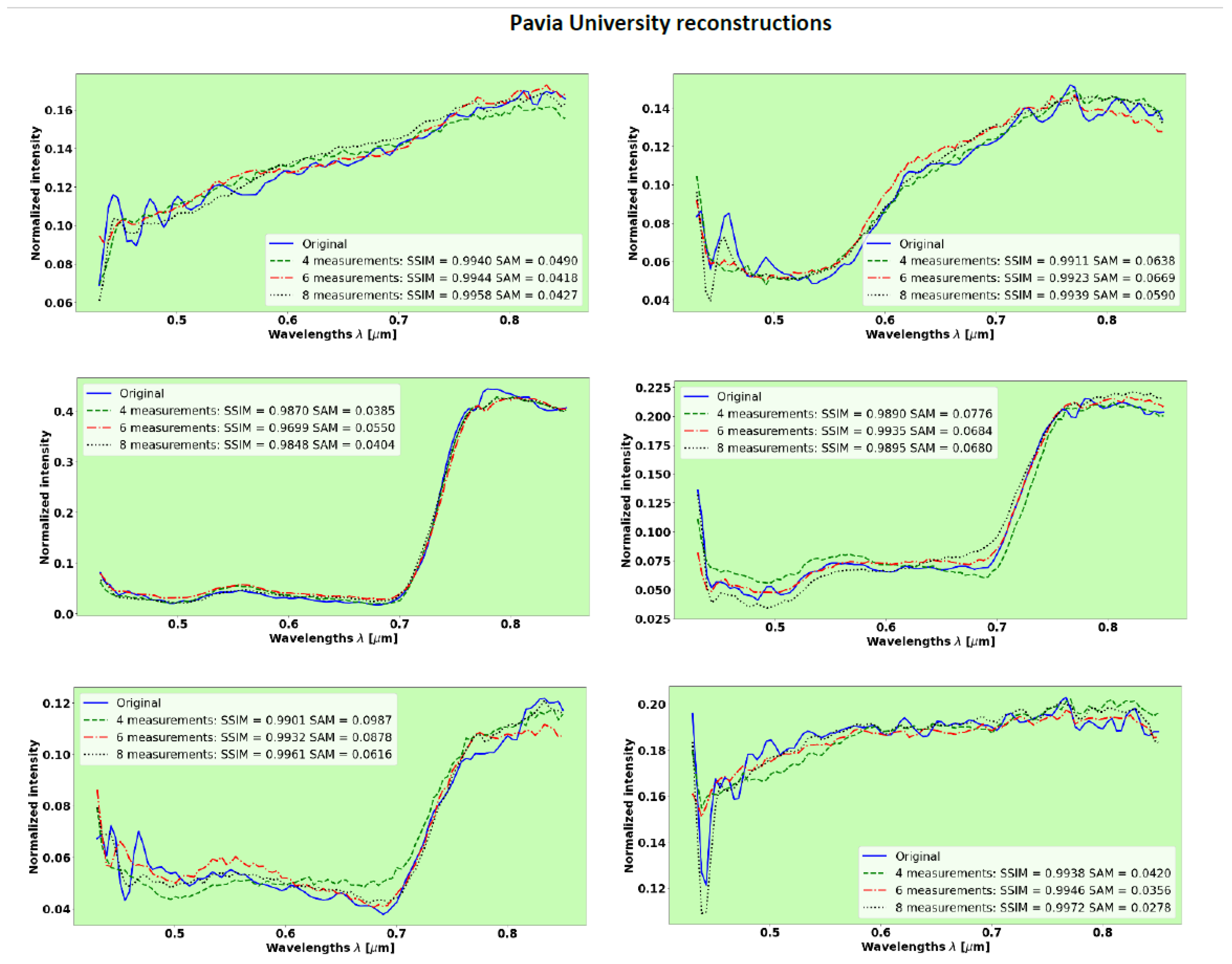
The Pavia center dataset was augmented by adding noise to let the PyCAE evade overfitting. Also, it was divided into 70% for the training set and 30% for the validation/test set. In this section, we evaluate the PyCAE trained on the Pavia center dataset to predict spectra from the Pavia University dataset, which was acquired by the same spectral imaging system on a different scene (
Figure 6).
Figure 10 shows the results of spectra reconstruction with 103 spectral bands, evaluated with 8, 6, and 4 measurements.
Table 3 summarizes the results of the mean values for SSIM and SAM over the Pavia University test set. This test set was not introduced to the PyCAE during the training process, which was performed on the Pavia center dataset. It can be seen in
Figure 10 and
Table 3 that the reconstructions of unseen spectra from the Pavia University test set exhibit similar performance obtained with the validation set from the Pavia center.
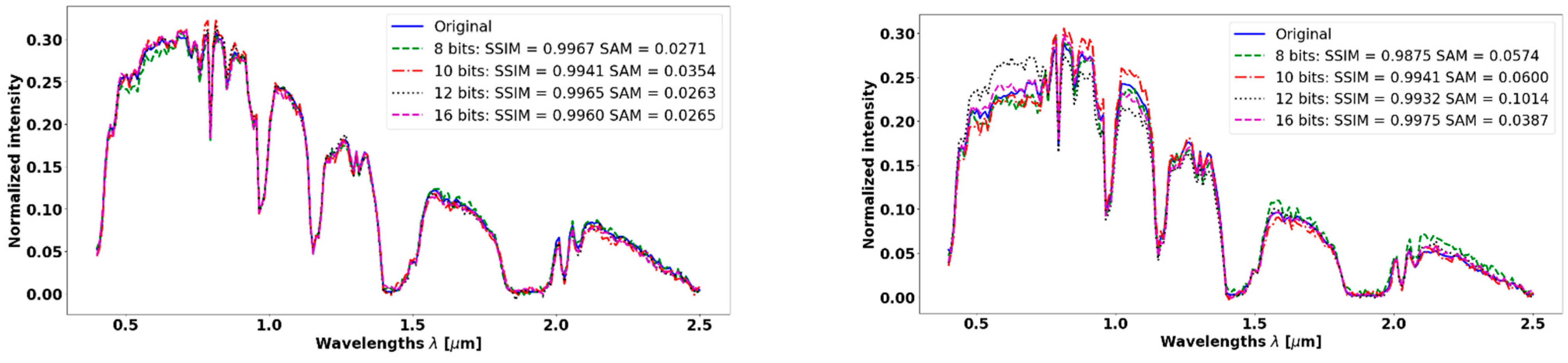
3.7. Robustness to Quantization Noise
The SpLM modulates the incident light reaching the sensor, but the sensor adds various kinds of noise. Quantization noise is inherently part of the sensing process, and it depends on the number of bits per pixel. It can distort the compressed measurements, which the reconstruction of the spectrum relies on. Here, we evaluate the impact of quantization noise that cannot be avoided in any digital sampling process of a continuous signal.
We normalized the intensity of spectra in both the Pavia center and Salinas valley datasets in the range of . To evaluate the impact of quantization noise on the reconstruction, we evaluate the quantization impact on sensors that have pixels with , and 8 bits, so the number of quantization levels , is 65,536, 4096, 2048, and 256, respectively.
The quantization noise (QN) of the compressed spectrum
is:
where
is the number of bits in a pixel,
are the compressed measurements and
is the uniform distribution [
47].
Figure 11 demonstrates the robustness of the PyCAE to these levels of quantization noise and
Table 4 summarizes the mean SSIM and the mean of SAM over the Salinas Valley dataset.
4. Conclusions
The PyCAE was trained on the Pavia center dataset with , and compression ratios. It was also trained on the Salinas valley dataset with , and compression ratios. The PyCAE generalization was evaluated on 100% of the Pavia University dataset, by a PyCAE that was trained on 70% of the Pavia center dataset. We found that even at such high compression ratios, our method exhibited excellent reconstructions with an average SSIM above 0.99 and average SAM below 0.07. A similar performance was also obtained on the generalization test on the Pavia University dataset.
Augmenting the datasets by adding exceedingly small normal noise with variation mitigates overfitting and gives much better results.
The robustness to quantization noise of PyCAE was evaluated on the Salinas valley dataset. The evaluation was performed on typical sensor quantization depths (16 bits, 12 bits, 10 bits, and 8 bits), yet we see excellent results with an average SSIM greater than 0.98 and SAM smaller than 0.071.
PyCAE has proved to be a very efficient optimizer for the design and optimization of SpLM made of a set of mFPRs with different depths for a compressive HSI platform. Moreover, PyCAE can be used as a concept for the optimization of many other signal sensors when the physics model of the sensor is mathematically well defined.
We also presented a new compressive HSI for airborne and spaceborne platforms that benefit from high optical throughput together with reduced bandwidth and storage requirements. This HSI platform, optimized by the PyCAE, is superior to the HSI with wedge-shaped LCC as its SpLM, because it compresses the HS cube by a factor of up to 56:1.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}