
Smart Count System Based on Object Detection Using Deep Learning



Abstract
1. Introduction
- 1.
- We propose a novel object-counting method by applying our new object-counting technique (DBC-NMS) to an existing state-of-the-art deep learning object-detection model (CenterNet2) and hyper-parameter tuning.
- 2.
- Our cloud-based deep learning software server showcases consistent performance regardless of hardware device specifications. This means that many clients can handle our server at a low cost, and the more that clients use our server, the more our server becomes specialized for a specific domain through staged fine-tuning processes.
- 3.
- We demonstrate the potential of our smart counting system as a general-purpose counting device by realizing a pipeline of all the processes to the hardware system that can operate in conjunction with the cloud-based deep learning software server. Additionally, we propose a semi-automated object-collecting process to assist in the rapid removal of excessive objects.
2. Related Works
2.1. Deep-Learning-Based Counting
2.2. Object Detectors
3. The Proposed Smart Counting System
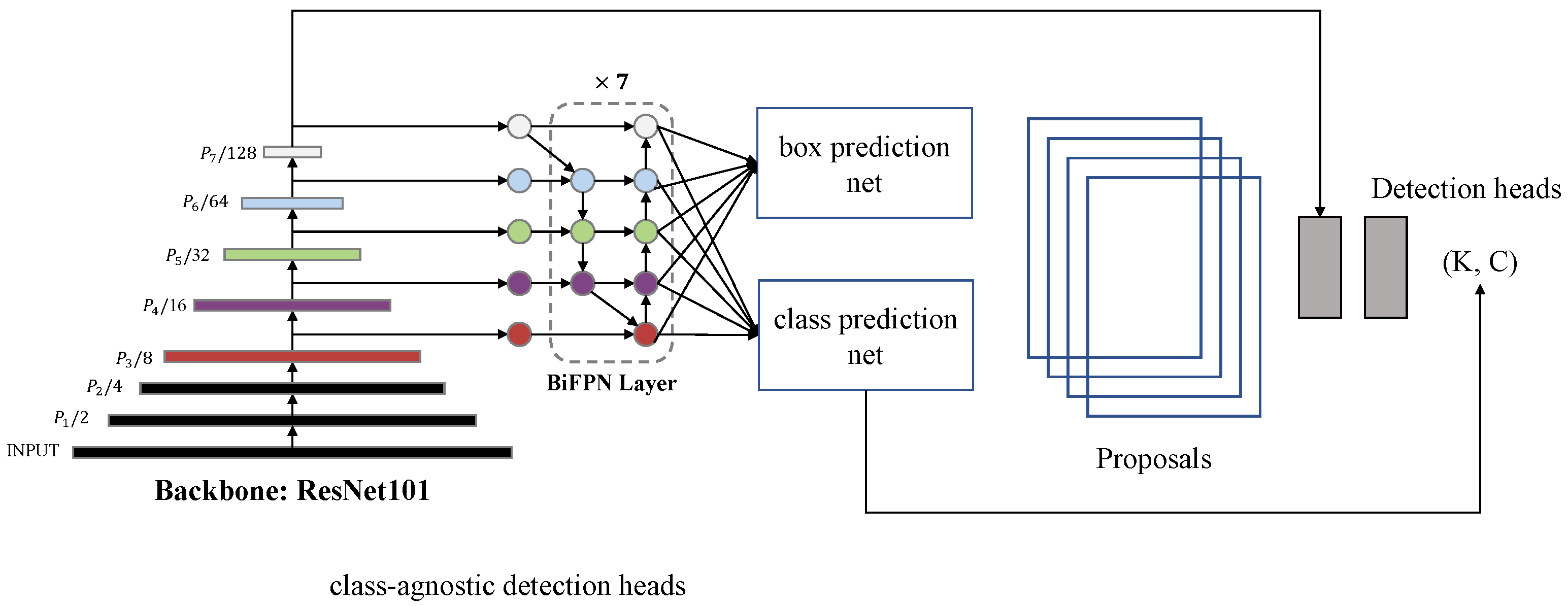
3.1. Object-Detection Configurations for the Object-Counting Task
3.1.1. Analysis of the Object Detectors
3.1.2. DBC-NMS (Distance between Circles—NMS)
| Algorithm 1 Pseudo code of DBC-NMS | |
| Input: | |
| ▹ is the list of initial detection boxes | |
| ▹ contains corresponding detection scores | |
| ▹ is the DBC-NMS threshold | |
| |
3.2. Cloud-Based Software Server
3.2.1. Architecture
3.2.2. Staged Fine-Tuning
3.3. Local Hardware Device
3.4. Web-Based UI
| Algorithm 2 Smart count system-UI algorithm |
|
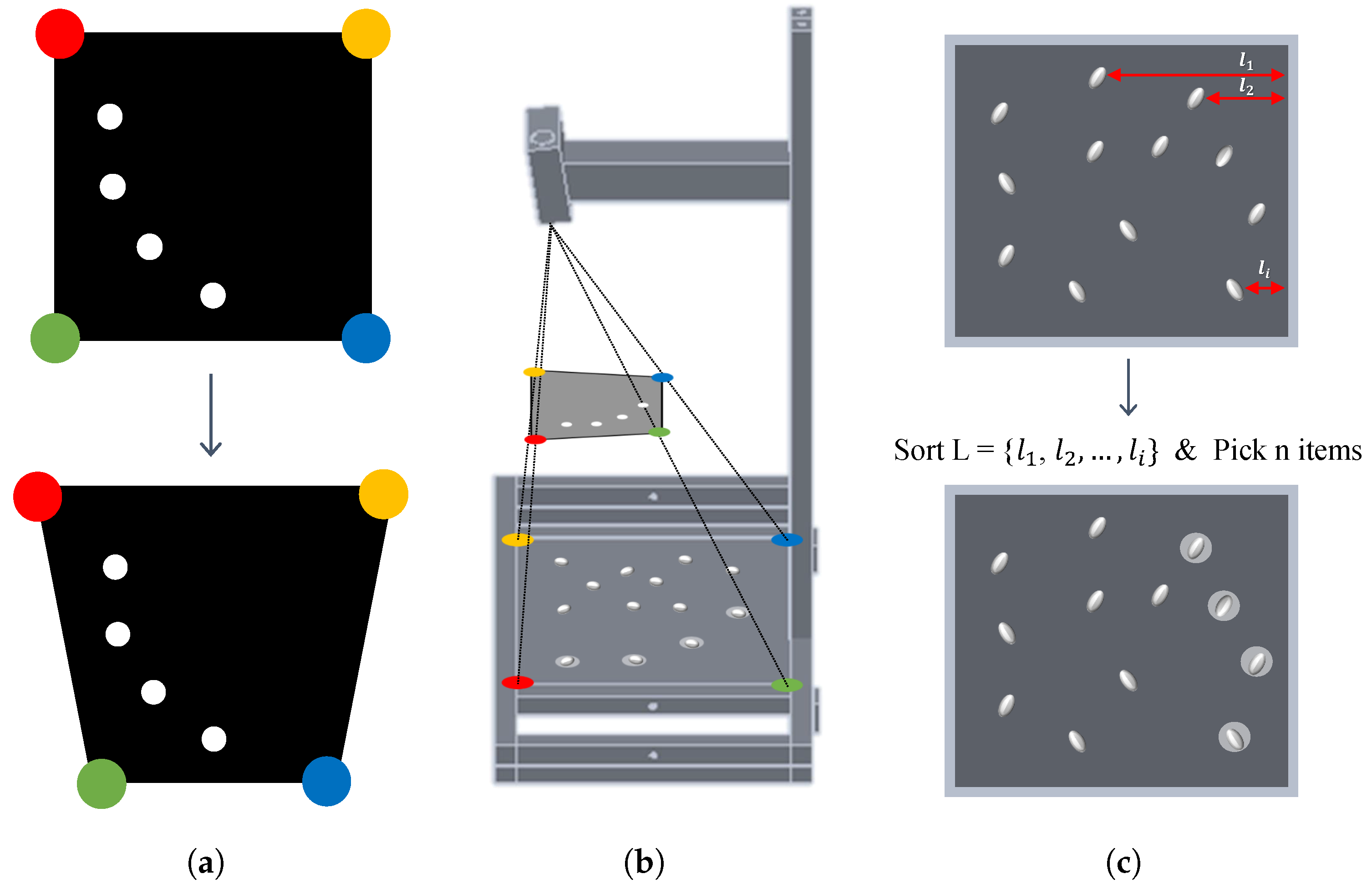
3.5. Beam Projector Transformation
3.6. Semi-Automated Counting and Collecting Process
4. Experimental Results and Analysis
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Comparison with Existing Works
4.5. The Effectiveness of the DBC-NMS
4.6. Sensitivity Analysis of Parameter for DBC-NMS
4.7. Staged Fine-Tuning
4.8. Scenario
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Phromlikhit, C.; Cheevasuvit, F.; Yimman, S. Tablet counting machine base on image processing. In Proceedings of the 5th 2012 Biomedical Engineering International Conference, Muang, Thailand, 5–7 December 2012; pp. 1–5. [Google Scholar]
- Furferi, R.; Governi, L.; Puggelli, L.; Servi, M.; Volpe, Y. Machine vision system for counting small metal parts in electro-deposition industry. Appl. Sci. 2019, 9, 2418. [Google Scholar] [CrossRef]
- Nudol, C. Automatic jewel counting using template matching. In Proceedings of the IEEE International Symposium on Communications and Information Technology, 2004, ISCIT 2004, Sapporo, Japan, 26–29 October 2004; Volume 2, pp. 654–658. [Google Scholar]
- Sun, F.J.; Li, S.; Xu, H.H.; Cai, J.D. Design of counting-machine based on CCD sensor and DSP. Transducer Microsyst. Technol. 2008, 4, 103–104. [Google Scholar]
- Venkatalakshmi, B.; Thilagavathi, K. Automatic red blood cell counting using hough transform. In Proceedings of the 2013 IEEE Conference on Information & Communication Technologies, Thuckalay, India, 11–12 April 2013; pp. 267–271. [Google Scholar]
- Gu, Y.; Li, L.; Fang, F.; Rice, M.; Ng, J.; Xiong, W.; Lim, J.H. An Adaptive Fitting Approach for the Visual Detection and Counting of Small Circular Objects in Manufacturing Applications. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2946–2950. [Google Scholar]
- Baygin, M.; Karakose, M.; Sarimaden, A.; Akin, E. An image processing based object counting approach for machine vision application. arXiv 2018, arXiv:1802.05911. [Google Scholar]
- Wang, C.; Zhang, H.; Yang, L.; Liu, S.; Cao, X. Deep people counting in extremely dense crowds. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1299–1302. [Google Scholar]
- Xue, Y.; Ray, N.; Hugh, J.; Bigras, G. Cell counting by regression using convolutional neural network. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 274–290. [Google Scholar]
- Lempitsky, V.; Zisserman, A. Learning to count objects in images. Adv. Neural Inf. Process. Syst. 2010, 23, 1324–1332. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 589–597. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Cnn-based cascaded multi-task learning of high-level prior and density estimation for crowd counting. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Gao, G.; Liu, Q.; Wang, Y. Counting From Sky: A Large-Scale Data Set for Remote Sensing Object Counting and a Benchmark Method. IEEE Trans. Geosci. Remote Sens. 2020, 59, 3642–3655. [Google Scholar] [CrossRef]
- Kilic, E.; Ozturk, S. An accurate car counting in aerial images based on convolutional neural networks. J. Ambient. Intell. Humaniz. Comput. 2021, 1–10. [Google Scholar] [CrossRef]
- Hsieh, M.R.; Lin, Y.L.; Hsu, W.H. Drone-based object counting by spatially regularized regional proposal network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4145–4153. [Google Scholar]
- Goldman, E.; Herzig, R.; Eisenschtat, A.; Goldberger, J.; Hassner, T. Precise detection in densely packed scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5227–5236. [Google Scholar]
- Cai, Y.; Du, D.; Zhang, L.; Wen, L.; Wang, W.; Wu, Y.; Lyu, S. Guided attention network for object detection and counting on drones. arXiv 2019, arXiv:1909.11307. [Google Scholar]
- Wang, Y.; Hou, J.; Hou, X.; Chau, L.P. A self-training approach for point-supervised object detection and counting in crowds. IEEE Trans. Image Process. 2021, 30, 2876–2887. [Google Scholar] [CrossRef]
- Mazzia, V.; Khaliq, A.; Salvetti, F.; Chiaberge, M. Real-time apple detection system using embedded systems with hardware accelerators: An edge AI application. IEEE Access 2020, 8, 9102–9114. [Google Scholar] [CrossRef]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO v3-Tiny: Object Detection and Recognition using one stage improved model. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 687–694. [Google Scholar]
- Horng, G.J.; Liu, M.X.; Chen, C.C. The smart image recognition mechanism for crop harvesting system in intelligent agriculture. IEEE Sensors J. 2019, 20, 2766–2781. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Li, W.; Li, H.; Wu, Q.; Chen, X.; Ngan, K.N. Simultaneously detecting and counting dense vehicles from drone images. IEEE Trans. Ind. Electron. 2019, 66, 9651–9662. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 14 March–1 July 2018; pp. 734–750. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. You Only Learn One Representation: Unified Network for Multiple Tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Probabilistic two-stage detection. arXiv 2021, arXiv:2103.07461. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Lo, R.C.; Tsai, W.H. Perspective-transformation-invariant generalized Hough transform for perspective planar shape detection and matching. Pattern Recognit. 1997, 30, 383–396. [Google Scholar] [CrossRef]
- Aich, S.; Stavness, I. Improving object counting with heatmap regulation. arXiv 2018, arXiv:1803.05494. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Detector | mAP | FPS |
|---|---|---|
| (Mean Average Precision) | (Frames per Second) | |
| Faster RCNN [24] | 39.8 | 9.4 |
| Tiny YOLO [25] | 23.7 | 33.6 |
| YOLO9000 [26] | 21.9 | 9.5 |
| RetinaNet (ResNet101-FPN) [29] | 40.8 | 5.4 |
| YOLOv3 (Darknet-53) [27] | 33.0 | 20 |
| CornerNet (Hourglass-104) [43] | 42.1 | 4.1 |
| CenterNet (Hourglass-104) [30] | 45.1 | 7.8 |
| YOLOv4 (CSPDarknet-53) [28] | 43.5 | 33 |
| CenterNet2 (ResNet101-BiFPN) [45] | 56.4 | 33 |
| Swin-T (cascade mask RCNN) [48] | 50.5 | 5.3 |
| YOLOR [44] | 52.6 | 47.5 |
| Method | CARPK | SKU110k | Pill | |||
|---|---|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | MAE | RMSE | |
| Goldman et al. [16] | 6.77 | 8.52 | 14.52 | 24.00 | 11.01 | 19.29 |
| Wang et al. [18] | 4.95 | 7.09 | 26.78 | 40.66 | 1.32 | 2.09 |
| Kilic et al. [14] | 2.12 | 3.02 | 14.74 | 27.54 | 6.70 | 13.37 |
| CenterNet2 [45] + DBC-NMS (ours) | 3.53 | 4.77 | 12.72 | 21.59 | 1.03 | 1.20 |
| Method | CARPK | SKU110k | Pill | |||
|---|---|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | MAE | RMSE | |
| Goldman et al. [16] + NMS | 6.77 | 12.00 | 14.52 | 24.00 | 11.01 | 19.29 |
| Wang et al. [18] + NMS | 7.28 | 9.30 | 27.85 | 49.96 | 1.32 | 2.09 |
| CenterNet2 [45] + NMS | 3.72 | 4.81 | 13.27 | 21.99 | 1.08 | 1.25 |
| Goldman et al. + Soft-NMS | 6.52 | 10.93 | 14.28 | 24.02 | 6.81 | 12.10 |
| Wang et al. + Soft-NMS | 4.95 | 7.09 | 26.78 | 40.66 | 1.32 | 2.09 |
| CenterNet2 + Soft-NMS | 3.60 | 4.78 | 13.05 | 21.83 | 1.04 | 1.23 |
| Goldman et al. + DBC-NMS | 6.22 | 10.93 | 14.24 | 24.00 | 6.79 | 12.07 |
| Wang et al. + DBC-NMS | 5.64 | 7.14 | 22.97 | 34.19 | 1.24 | 1.98 |
| CenterNet2 + DBC-NMS (ours) | 3.53 | 4.77 | 12.72 | 21.59 | 1.03 | 1.20 |
| Scenario | |
|---|---|
| 1. Place object on tray. | (a) |
| 2. Write your target quantity and press “Count!” button. | |
| 3. Check the current quantity and remove excess items. | |
| (Excess objects are marked with white circles.) | (b) |
| 4. Although 11 objects need to be removed, we removed 13 for example. | |
| 5. Press “Collect” button. | |
| 6. User Warning for target quantity mismatch. | |
| 7. Check the current quantity and add insufficient items. | (c) |
| 8. Press “Collect” button and collect items through motor control. | (d) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moon, J.; Lim, S.; Lee, H.; Yu, S.; Lee, K.-B. Smart Count System Based on Object Detection Using Deep Learning. Remote Sens. 2022, 14, 3761. https://doi.org/10.3390/rs14153761
Moon J, Lim S, Lee H, Yu S, Lee K-B. Smart Count System Based on Object Detection Using Deep Learning. Remote Sensing. 2022; 14(15):3761. https://doi.org/10.3390/rs14153761
Chicago/Turabian StyleMoon, Jiwon, Sangkyu Lim, Hakjun Lee, Seungbum Yu, and Ki-Baek Lee. 2022. "Smart Count System Based on Object Detection Using Deep Learning" Remote Sensing 14, no. 15: 3761. https://doi.org/10.3390/rs14153761
APA StyleMoon, J., Lim, S., Lee, H., Yu, S., & Lee, K.-B. (2022). Smart Count System Based on Object Detection Using Deep Learning. Remote Sensing, 14(15), 3761. https://doi.org/10.3390/rs14153761